Das Entwickler-Team von Ubuntu hat sich dafür entschieden, beim kommenden Ubuntu 24.04 LTS Noble Numbat per Standard keine Spiele mehr zu installieren. Bisher wurden bei Ubuntu vier Spiele vorinstalliert: Das Team ist auch der Meinung, dass selbst diese wenigen ausgewählten Spiele immer weniger repräsentativ für Ubuntu sind. Natürlich sind diese Games nicht aus den Repos verschwunden. Wer sie nach der Installation des Betriebssystems wieder haben möchte, kann sie selbstverständlich nachinstallieren. Werde ich die Games vermissen? Nein … ich habe sie […]
Mit dem aktuellen Update auf Brave 1.63 (Desktop) können Nutzer der Brave-Wallet auch native Bitcoin-SegWit-Adressen erstellen. Damit steht Dir eine native BTC-Adresse zur Verfügung, die im Vergleich zu den anderen Bitcoin-Kontotypen niedrigere Transaktionsgebühren und eine bessere Fehlererkennung bietet. Über die Brave Wallet kannst Du jetzt auch von allen Arten von Bitcoin-Adressen Geldmittel senden und empfangen, inklusive Legacy, Nested SegWit, Native SegWit und Taproot. Das gewährleistet die Kompatibilität mit Wallets von Drittanbietern. Damit Du Bitcoin in Deine Brave-Wallet einzahlen kannst, musst […]
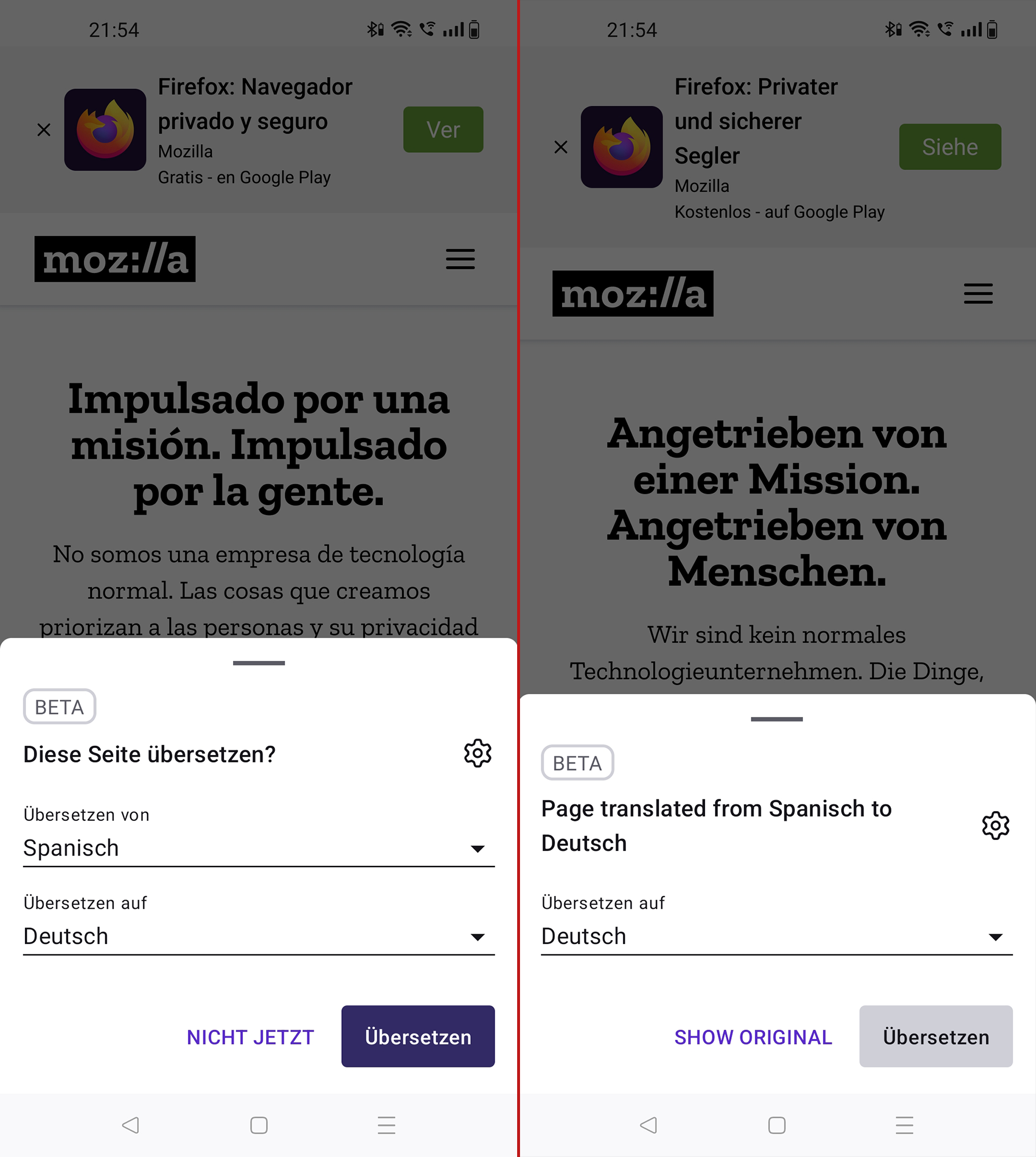
Firefox für den Desktop besitzt eine Funktion zur vollständigen Übersetzung von Websites, welche im Gegensatz zu Google Translate & Co. komplett im Browser arbeitet und nichts an einen Server sendet. Für Android befindet sich die Funktion noch in Entwicklung, kann aber bereits getestet werden.
Firefox für Windows, macOS und Linux wird seit Version 118 standardmäßig mit einer lokalen Funktion zur maschinellen Übersetzung von Websites für den Browser ausgeliefert. Das bedeutet, dass die Übersetzung vollständig im Browser geschieht und keine zu übersetzenden Inhalte an einen Datenriesen wie Google oder Microsoft übermittelt werden müssen.
Wer eine Nightly-Version von Firefox für Android nutzt, kann das Feature jetzt schon auf seinem Smartphone oder Tablet testen. Dazu muss auf der Seite Einstellungen → Über Firefox fünfmal auf das Firefox-Logo getippt werden. Anschließend gibt es einen neuen Punkt „Secret Settings“ in den Einstellungen, worüber die Übersetzungsfunktion aktiviert werden kann.
Nach der Aktivierung erscheint ein Übersetzungssymbol in der Adressleiste, sofern Firefox eine Übersetzung dieser Sprache unterstützt. Zwar sind noch nicht alle Optionen funktionsfähig, aber die Übersetzung und damit der wichtigste Teil des neuen Features funktioniert bereits.
Mit Kali Linux 2024.1 hat das Team die erste Version dieses Jahres veröffentlicht. Es gibt einige Neuerungen und auch visuell wurde die Security-Distribution aufgefrischt. Neu ist auch, dass es neue Spiegel-Server gibt, auf denen das Image gehostet ist. 2024 Theme-Änderungen und Desktop-Verbesserungen Es ist schon ein bisschen Tradition geworden, dass die 20**.1-Versionen immer ein neues Theme mit sich bringen. Das Team hat sowohl das Boot-Menü als auch den Anmeldebildschirm sowie die Wallpaper geändert. Es gibt auch einige Verbesserungen beim Xfce-Desktop. […]
Kurz notiert: heute wurde die Desktopumgebung Plasma 6 aus dem KDE-Projekt freigegeben. Mit dem Umstieg auf Qt 6 und den einhergehenden Arbeiten ist es nach knapp 10 Jahren der erste große Major-Release (KDE Plasma 5 wurde 2014 veröffentlicht). Eine weitere wegweisende Änderung ist, dass der Fokus nun klar auf dem Display-Server Wayland liegt, der auch nun zur Standardeinstellung wurde. X11 wird jedoch weiterhin unterstützt.
Eine Auswahl der weiteren Änderungen:
Es gibt einen neuen Overview-Effekt.
Durch Wayland wird nun auch HDR unterstützt.
Es gibt neue Filter zur Unterstützung bei Farbenblindheit.
Das Einstellungsprogramm wurde überarbeitet.
Der bekannte KDE Cube ist zurück.
Neue Standardeinstellungen:
Dateien/Verzeichnisse werden nun mit einem Klick ausgewählt und mit einem Doppelklick geöffnet.
Das Panel ist nun standardmäßig schwebend.
Thumbnail-Grid ist nun der Standard-Task-Switcher.
Scrollen auf dem Desktop führt nun nicht mehr zum Wechsel der virtuellen Desktops.
Auch die KDE-Anwendungen erfahren umfangreiche Updates. All diese Informationen können im Release Announcement nachvollzogen werden.
KDE Plasma 6 sollte nun sukzessive auch in die Distributionen Einzug halten. Arch Linux ist als Beispiel für einen Rolling Release da schon schnell dabei. Ob und inwiefern komplexe Setups des traditionell sehr einstellbaren Desktop-Systems umgezogen werden können, wird sich dann zeigen. Ein großer Vorteil des KDE-Ansatzes zeigt sich allerdings schon im Release-Announcement: viele der Funktionen können genutzt werden, müssen es aber nicht. Dem Endanwender wird die Wahl überlassen, welche Optionen er nutzen möchte.
Bislang ist Firefox für Android nicht im Speziellen für die großen Oberflächen von Tablets optimiert. Nutzer der Nightly-Version können ab sofort eine Tableiste aktivieren.
Firefox für Android war bisher nicht für Tablets optimiert. Das bedeutet, dass Firefox mehr oder weniger die gleiche Oberfläche wie für Smartphones verwendet. Tatsächlich zeigt Firefox auf Tablets neben der Adressleiste zumindest Schaltflächen für Zurück, Vorwärts und Neuladen an. Darüber hinaus gibt es aber keine weiteren Anpassungen. Vor allem eine Tableiste wie beim Desktop-Firefox wird von vielen Tablet-Nutzern vermisst. Darüber, dass Mozilla daran arbeitet, hatte ich im Januar berichtet.
Wer eine Nightly-Version von Firefox für Android auf einem Tablet nutzt, kann ab sofort eine erste Version der Tableiste aktivieren. Dazu muss auf der Seite Einstellungen → Über Firefox fünfmal auf das Firefox-Logo getippt werden. Anschließend gibt es einen neuen Punkt „Secret Settings“ in den Einstellungen, worüber die Tableiste aktiviert werden kann. Spätestens nach einem Neustart von Firefox steht diese dann zur Verfügung.
Es handelt sich zu diesem Zeitpunkt um keine fertige Implementierung. Unter anderem das Verschieben von Tabs via Drag and Drop ist eine Funktion, an der bereits gearbeitet wird und welche im Laufe der kommenden Tage Einzug erhalten wird. Wer die weitere Entwicklung der Tableiste verfolgen möchte, kann dies über die Abhängigkeiten des entsprechenden Meta-Tickets machen. Für eine verbesserte Tablet-Unterstützung generell gibt es ein eigenes Meta-Ticket.
Um auch einmal in die Welt des Arduino einzutauchen, habe ich mir ein paar Bauteile bestellt und etwas experimentiert. Da ich ein großer Uhren-Fan bin, hatte ich auch gleich eine adäquate Idee. Bei meiner Suche bin ich auf den Artikel „MAKING AN ARDUINO I2C-DIGITALUHR“ gestoßen. So war die Idee geboren, diese Uhr nachzubauen.
Nachdem alle Bauteile inkl. des Arduino Uno Rev. 3 bei mir eingetroffen waren, hieß es ein wenig löten. Die 7-Segmentanzeige HT16K33 sowie das Real Time Clock Modul DS1307 mussten mit Pins für das Steckboard versehen werden. Als das geschafft war, kämpfte ich damit den Code auf den Arduino zu übertragen.
Alte Arduino IDE Version
Hier begannen nun meine Probleme. Ich stellte mir das Vorhaben recht einfach vor. Ich musste doch einfach nur alle Bauteile verbinden, die benötigten Bibliotheken einbinden, den Code in die Software Arduino IDE hinein kopieren und diesen dann in den Arduino hochladen.
Leider funktionierte das aber nicht wie erwartet und ich als Arduino-Neuling war recht ratlos. Mein erster Gedanke war, dass vielleicht beim Löten etwas kaputtgegangen oder der Fehler bei der Verdrahtung zu suchen war. Meine Fehlersuche lief jedoch ins Leere. Da ich absoluter Neuling in der Programmierung dieses Mikrocontrollers war, musste ich mich zunächst einlesen, Videos anschauen, Arduino-Experten befragen und natürlich selbst ausprobieren und experimentieren.
Als ich mir den oben erwähnten Artikel nochmals etwas näher ansah, stellte ich fest, dass dieser Beitrag schon fast 12 Jahre alt ist. Also verwarf ich den Gedanken der Uhr erst und begann mit den Grundlagen.
Die von mir installierte Version von Arduino IDE war die 1.8.19. Hier gibt es etliche Beispiele etwas aus dem Gerät herauszuholen. Im Internet fand ich eine ähnliche Grafik, wie die hier abgebildete (Arduino Uno mit LED). Hier hat ein mutiger User eine LED in Pin 13 und GND gesteckt (hierfür sollte aber ein Vorwiderstand ca. 220 Ohm in Reihe geschaltet werden). Das schnörkellose Beispiel gefiel mir und ich konnte über „Blink“ dem Arduino das erste Lebenszeichen entlocken.
Arduino Uno mit LED
Da ich nun eigentlich das HT16K33 Display ansteuern wollte, suchte ich auch hierfür nach einem Beispiel. Ich fand so die gleichnamige Bibliothek und konnte auch hier einige Tests durchlaufen lassen. Das Display war also in Ordnung.
Einen selbigen Test führte ich mit der Real Time Clock DS1307 und der Bibliothek „RTClib“ durch. Hierbei bekam ich die Zeit im Monitor von Arduino IDE ausgegeben. Also war auch dieses Modul funktionstüchtig.
Nun war die Zuversicht sehr groß, dass ich nur noch alles zusammen stecken muss und ich die Uhr endlich zum Laufen bekomme. Leider klappte das aber nicht. Die in Arduino IDE 1.8.19 ausgegebene Fehlermeldung half mir an dieser Stelle nicht weiter.
Neue Arduino IDE Version
Obwohl ich der Meinung war, dass die verwendete Version mein Vorhaben realisieren kann, lud ich mir die aktuelle Version 2.3.2 herunter und entpackte diese im Downloads-Verzeichnis. Das Öffnen des Programms mit Rechtsklick auf Arduino-IDE -> Ausführen fand ich auf Dauer nicht so praktikabel, also baute ich mir ein Startup Icon mit folgendem Inhalt:
Dieses bekam den Namen Arduino und wurde erst einmal auf dem Desktop abgelegt. Dieser Starter wurde mit Rechtsklick -> Start erlauben aktiviert und danach in das Verzeichnis /usr/share/applications verschoben. So habe ich die aktuelle Version in mein System (Ubuntu 20.04 LTS) eingebunden.
Die Version 2.3.2 verriet mir nun beim Versuch den Code an den Arduino zu übertragen, wo der letzte und entscheidende Fehler lag. Es fehlte die Bibliothek „Adafruit_BusIO“.
Verdrahtung auf dem Steckboard
Nachdem diese nun eingebunden war, ließ sich der Code übertragen und das Herz der Uhr begann zu schlagen.
Ab sofort ist die finale Version von Tails 6.0 verfügbar. Es ist die erste Version, die auf Debian 12 Bookworm basiert und GNOME 43 als Desktop-Umgebung mit sich bringt. Bei Tails 6.0 wurde die meiste Software aktualisiert. Zudem gibt es diverse Verbesserungen bezüglich Sicherheit und Benutzerfreundlichkeit. Zu den neuen Funktionen gehört eine Fehlererkennung beim permanenten Speicher. Tails 6.0 warnt Dich, wenn beim Lesen von Daten oder Schreiben auf den USB-Stick Fehler auftrete. Damit kannst Du mögliche Hardware-Fehler auf dem USB-Stick […]
Wolvic, der Browser für Virtual und Mixed Reality, wurde in der Version 1.6 veröffentlicht. Neben einigen Neuerungen macht Wolvic 1.6 auch einen Sprung bei der verwendeten GeckoView-Engine von Mozilla.
Igalia hat Wolvic 1.6 veröffentlicht. Bei Wolvic handelt es sich um einen Browser für Virtual und Mixed Reality, welcher auf dem eingestellten Firefox Reality basiert.
Neuerungen von Wolvic 1.6
Wolvic 1.6 nutzt eine aktuellere Code-Basis von Mozilla. So wurden die Mozilla Android Components sowie die Gecko-Engine von Version 116 auf Version 121 aktualisiert. Nutzer profitieren vor allem durch eine verbesserte Webkompatibilität.
Auf Geräten, die nicht von Huawei sind, wurde die Telemetrie-Option entfernt, da der ursprünglich genutzte Telemetrie-Service von Mozilla deaktiviert ist. Auf Geräten von Huawei bleibt die Option bestehen, weil dort ein eigenes Telemetrie-System genutzt wird.
Mit dem Pico Neo3 wurde die Unterstützung für ein weiteres VR-Headset hinzugefügt.
Diverse Verbesserungen gab es beim Betrachten von Vollbild-Videos. Ebenfalls verbessert wurde die Reaktionsfähigkeit und Stabilität der Tastatur, außerdem kann für diese jetzt eine experimentelle Autovervollständigung aktiviert werden. Die entsprechenden Wörterbücher werden bei Bedarf heruntergeladen. Darüber hinaus wurden noch drei neue Umgebungen hinzugefügt.
Dies war nur eine Auswahl der größten Highlights. Dazu kommt wie immer eine Reihe weiterer Korrekturen und Verbesserungen unter der Haube.
Mein Lehrbuch Datenbanksysteme ist gerade in der 2. Auflage erschienen. Es richtet sich an Studierende, Entwickler und Datenbankanwender. Es erklärt, wie moderne Datenbankmanagementsysteme funktionieren. Es zeigt Ihnen, wie Sie Datenbanken korrekt und effizient entwerfen. Es erläutert den Umgang mit der Structured Query Language (SQL) und gibt einen Überblick über die Administration und Programmierung von Datenbanksystemen.
Unzählige Übungsaufgaben (mit Lösungen!) helfen Ihnen, das erlernte Wissen zu verfestigen und anzuwenden. Zusammen mit dem Buch erhalten Sie den Online-Zugriff auf mehrere Beispieldatenbanken, sodass Sie SQL-Kommandos ohne die langwierige Installation eines eigenen Datenbank-Servers ausprobieren können. Alternativ können Sie die zum Download angebotenen Beispieldatenbanken natürlich auch lokal installieren.
In das Buch fließt meine bald 30-jährige Erfahrung im Entwurf von Datenbanken, bei der Entwicklung von Datenbankanwendungen, bei der Administration von Datenbankmanagementsystemen (DBMS) sowie aus dem Unterricht ein. Ein besonderer Fokus des Buchs liegt im korrekten Datenbankdesign. Fehler, die in dieser Phase passieren, sind später praktisch nicht mehr zu korrigieren. Das Buch berücksichtigt auch neue Entwicklungen, von NoSQL bis hin zu modernen SQL-Features (Rekursion, Common Table Expressions, Window-Funktionen etc.).
Für die 2. Auflage habe ich den NoSQL-Teil des Buchs ausgebaut und um ein MongoDB-Kapitel ergänzt. Außerdem habe ich diverse Fehler korrigiert und da und dort kleine Ergänzungen und Verbesserungen vorgenommen.
Wenn Sie auf der Fachhochschule oder Universität eine Datenbank-Vorlesung oder -Übung abhalten: Kontaktieren Sie dozenten@rheinwerk-verlag.de und fordern Sie ein kostenloses Belegexemplar an!
Mozilla hat Firefox 123 für Apple iOS veröffentlicht. Dieser Artikel beschreibt die Neuerungen von Firefox 123.
Die Neuerungen von Firefox 123 für iOS
Mozilla hat Firefox 123 für das iPhone, iPad sowie iPod touch veröffentlicht. Die neue Version steht im Apple App Store zum Download bereit. Die neue Version bringt eine verbesserte Performance des Startbildschirms und Verbesserungen des Theme-Systems. Dazu kommen wie immer diverse Fehlerbehebungen sowie Verbesserungen unter der Haube.
Ubuntu Pro ist eine Updateerweiterung für bestimmte Pakete der bekannten Distribution.
Ubuntu LTS soll so 10 Jahre Abdeckung für über 25.000 Pakete erhalten. Zusätzlich erhältst du Kernel Livepatching, Telefonsupport und Pakete fürs Hardening (NIST-certified FIPS crypto-modules, USG hardening mit CIS and DISA-STIG Profilen und Common Criteria EAL2).
Leider wird für dieses kostenpflichtige Produkt Werbung gemacht, auf dem Terminal und im Ubuntu Update Manager.
Sollte dich das stören, kannst du diese Meldungen mit wenigen Befehlen abschalten.
Alternativ kannst du dich auch einfach für Ubuntu Pro anmelden, denn der Zugang ist für Privatanwender für bis zu fünf Installationen umsonst.
Ubuntu Pro Nachrichten abschalten
sudo pro config set apt_news=false
Das Abschalten der APT News reicht nicht ganz aus, um dir die Werbeeinblendung zu ersparen.
Du musst zusätzlich eine Datei editieren und deren Inhalt auskommentieren
nano /etc/apt/apt.conf.d/20apt-esm-hook.conf
Ubuntu Advantage deaktivieren oder deinstallieren
Optional kannst du das Ubuntu Advantage Paket entfernen, bzw. die Expanded SecurityMaintenance (ESM) abschalten, wenn du magst.
Ubuntu Advantage war der Vorgänger von Ubuntu Pro
Dieses beinhaltet wie die Pro-Variante Kernel Livepatching, Unterstützung für Landscape oder Zugriff auf eine Wissensdatenbank. Alles Dinge, die für Privatanwender nur bedingt interessant sind.
Solltest du nun maximal verwirrt sein, was zu welchem Supportmodell gehört und wie es unterstützt wird, hier ein Vergleich von endoflifedate. Ubuntu Pro (Infra-Only) steht in der Tabelle für das alte Ubuntu Advantage.
Mit einem Dualstack-Proxy Internet-Protokolle verbinden beschrieb eine Möglichkeit, um von Hosts, welche ausschließlich über IPv6-Adressen verfügen, auf Ziele zugreifen zu können, die ausschließlich über IPv4-Adressen verfügen. In diesem Beitrag betrachte ich die andere Richtung.
Zu diesem Beitrag motiviert hat mich der Kommentar von Matthias. Er schreibt, dass er für den bei einem Cloud-Provider gehosteten Jenkins Build Server IPv4 deaktivieren wollte, um Kosten zu sparen. Dies war jedoch nicht möglich, da Kollegen aus einem Co-Workingspace nur mit IPv4 angebunden sind und den Zugriff verloren hätten.
Doch wie kann man nun ein IPv6-Netzwerk für ausschließlich IPv4-fähige Clients erreichbar machen, ohne für jeden Host eine IPv4-Adresse zu buchen? Dazu möchte ich euch anhand eines einfachen Beispiels eine mögliche Lösung präsentieren.
Vorkenntnisse
Um diesem Text folgen zu können, ist ein grundsätzliches Verständnis von DNS, dessen Resource Records (RR) und des HTTP-Host-Header-Felds erforderlich. Die Kenntnis der verlinkten Wikipedia-Artikel sollte hierfür ausreichend sein.
Umgebung
Zu diesem Proof of Concept gehören:
Ein Dualstack-Reverse-Proxy-Server (HAProxy) mit den DNS-RR:
haproxy.example.com. IN A 203.0.113.1
haproxy.example.com IN AAAA 2001:DB8::1
Zwei HTTP-Backend-Server mit den DNS-RR:
www1.example.com IN AAAA 2001:DB8::2
www2.example.com IN AAAA 2001:DB8::3
Zwei DNS-RR:
www1.example.com IN A 203.0.113.1
www2.example.com IN A 203.0.113.1
Ein Client mit einer IPv4-Adresse
Ich habe mich für HAProxy als Reverse-Proxy-Server entschieden, da dieser in allen Linux- und BSD-Distributionen verfügbar sein sollte und mir die HAProxy Maps gefallen, welche ich hier ebenfalls vorstellen möchte.
Der Versuchsaufbau kann wie folgt skizziert werden:
Ein Dualstack-Reverse-Proxy-Server (B) verbindet IPv4-Clients mit IPv6-Backend-Servern
HAProxy-Konfiguration
Für dieses Minimal-Beispiel besteht die HAProxy-Konfiguration aus zwei Dateien, der HAProxy Map hosts.map und der Konfigurationsdatei poc.cfg.
Eine HAProxy Map besteht aus zwei Spalten. In der ersten Spalte stehen die FQDNs, welche vom HTTP-Client aufgerufen werden können. In der zweiten Spalte steht der Name des Backends aus der HAProxy-Konfiguration, welcher bestimmt, an welche Backend-Server eine eingehende Anfrage weitergeleitet wird. In obigem Beispiel werden Anfragen nach www1.example.com an das Backend serversa und Anfragen nach www2.example.com an das Backend serversb weitergeleitet.
Die HAProxy Maps lassen sich unabhängig von der HAProxy-Konfigurations-Datei pflegen und bereitstellen. Map-Dateien werden in ein Elastic Binary Tree-Format geladen, so dass ein Wert aus einer Map-Datei mit Millionen von Elementen ohne spürbare Leistungseinbußen nachgeschlagen werden kann.
Die HAProxy-Konfigurations-Datei poc.cfg für dieses Minimal-Beispiel ist ähnlich simpel:
~]$ cat /etc/haproxy/conf.d/poc.cfg
frontend fe_main
bind :80
use_backend %[req.hdr(host),lower,map(/etc/haproxy/conf.d/hosts.map)]
backend serversa
server server1 2001:DB8::1:80
backend serversb
server server1 2001:DB8::2:80
In der ersten Zeile wird ein Frontend mit Namen fe_main definiert. Zeile 2 bindet Port 80 für den entsprechenden Prozess und Zeile 3 bestimmt, welches Backend für eingehende HTTP-Anfragen zu nutzen ist. Dazu wird der HTTP-Host-Header ausgewertet, falls notwendig, in Kleinbuchstaben umgewandelt. Mithilfe der Datei hosts.map wird nun ermittelt, welches Backend zu verwenden ist.
Die weiteren Zeilen definieren zwei Backends bestehend aus jeweils einem Server, welcher auf Port 80 Anfragen entgegennimmt. In diesem Beispiel sind nur Server mit IPv6-Adressen eingetragen. IPv4-Adressen sind selbstverständlich auch zulässig und beide Versionen können in einem Backend auch gemischt auftreten.
Kann eine HTTP-Anfrage nicht über die hosts.map aufgelöst werden, läuft die Anfrage in diesem Beispiel in einen Fehler. Für diesen Fall kann ein Standard-Backend definiert werden. Siehe hierzu den englischsprachigen Artikel Introduction to HAProxy Maps von Chad Lavoie.
Der Kommunikationsablauf im Überblick und im Detail
Der Kommunikationsablauf im Überblick
Von einem IPv4-Client aus benutze ich curl, um die Seite www1.example.com abzurufen:
~]$ curl -4 -v http://www1.example.com
* processing: http://www1.example.com
* Trying 203.0.113.1:80...
* Connected to www1.example.com (203.0.113.1) port 80
> GET / HTTP/1.1
> Host: www1.example.com
> User-Agent: curl/8.2.1
> Accept: */*
>
< HTTP/1.1 200 OK
< server: nginx/1.20.1
< date: Sat, 06 Jan 2024 18:44:22 GMT
< content-type: text/html
< content-length: 5909
< last-modified: Mon, 09 Aug 2021 11:43:42 GMT
< etag: "611114ee-1715"
< accept-ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<title>Test Page for the HTTP Server on Red Hat Enterprise Linux</title>
Der FQDN www1.example.com wird mit der IPv4-Adresse 203.0.113.1 aufgelöst, welche dem Host haproxy.example.com gehört. Bei der Zeile Host: www1.example.com handelt es sich um den HTTP-Host-Header, welchen der HAProxy benötigt, um das richtige Backend auszuwählen.
Es ist zu sehen, dass wir eine Antwort von einem NGINX-HTTP-Server erhalten. Der HTML-Quelltext wurde gekürzt.
Damit ist es gelungen, von einem IPv4-Client eine Ressource abzurufen, die von einem IPv6-Server bereitgestellt wird.
Im Access-Log des Backend-Servers mit der IPv6-Adresse 2001:DB8::2 sieht man:
Die Anfrage erreicht den Backend-Server von der IPv6-Adresse des haproxy.example.com (2001:DB8::1). Die am Ende der Zeile zu sehende IPv4-Adresse (192.0.2.1) gehört dem IPv4-Client, von dem ich die Anfrage gesendet habe.
Gedanken zur Skalierung
In diesem Beispiel sind die Server www1.example.com und www2.example.com über ihre IPv6-Adressen direkt erreichbar. Nur die Client-Anfragen von IPv4-Clients laufen über den Reverse-Proxy. Wenn man es wünscht, kann man selbstverständlich sämtliche Anfragen (von IPv4- und IPv6-Clients) über den Reverse-Proxy laufen lassen.
In kleinen Umgebungen kann man einen Reverse-Proxy wie HAProxy zusammen mit Squid (vgl. Artikel Mit einem Dualstack-Proxy Internet-Protokolle verbinden) auf einem Host laufen lassen. Selbstverständlich kann man sie auch auf separate Hosts verteilen.
Hochverfügbarkeit lässt sich auch hier mit keepalived nachrüsten:
Die Internet-Protokolle IPv4 und IPv6 werden wohl noch eine ganze Zeit gemeinsam das Internet bestimmen und parallel existieren. Ich bin mir sogar sicher, dass ich das Ende von IPv4 nicht mehr miterleben werde. Dualstack-(Reverse)-Proxy-Server stellen eine solide und robuste Lösung dar, um beide Welten miteinander zu verbinden.
Sicher bleiben noch ausreichend Herausforderungen übrig. Ich denke da nur an Firewalls, Loadbalancer, NAT und Routing. Und es werden sich auch Fälle finden lassen, in denen Proxyserver nicht infrage kommen. Doch mit diesen Herausforderungen beschäftige ich mich dann in anderen Artikeln.
In drei Wochen beginnen die Chemnitzer Linux-Tage 2024 mit dem diesjährigen Motto „Zeichen setzen“. Am 16. und 17. März erwartet euch im Hörsaalgebäude an der Richenhainer Straße 90 ein vielfältiges Programm an Vorträgen und Workshops. Hier finden sich Vorträge für interessierte Neueinsteiger wie für alte Hasen.
So geht es am Samstag im Einsteigerforum beispielsweise um die Digitalisierung analoger Fotos, das Erstellen von Urlaubsvideos mit der Software OpenShot oder die Verschlüsselung von E-Mails. In der Rubrik „Schule“ gibt Arto Teräs einen Einblick in den Einsatz der Open-Source-Lösung Puavo an finnischen und deutschen Schulen. Zusätzlich stehen Vorträge aus den Bereichen Finanzen, Medien, Datensicherheit, KI oder Netzwerk auf dem Programm. Am Sonntag gibt das Organisationsteam der Chemnitzer Linux-Tage mit „make CLT“ Einblicke in die Planung und Strukturen der Veranstaltung selbst. In der Rubrik „Soft Skills” wird es um die Schätzung von Aufwänden oder notwendige Fähigkeiten von Software-Entwicklern gehen.
Eintrittskarten können online im Vorverkauf und an der Tageskasse erworben werden. Kinder bis 12 Jahren haben freien Eintritt.
Während viele Besucher bereits Stammgäste sind, werden auch neue Gesichter herzlich willkommen. Lasst euch gern von der hier herrschenden Atmosphäre voller Begeisterung für freie Software und Technik anstecken und begeistern.
Ich selbst freue mich, am Samstag um 10:00 Uhr in V6 den Vortrag mit dem obskuren Namen ::1 beisteuern zu dürfen. Update: Unverhofft kommt oft. Uns so freue ich mich am Sonntag um 10:00 Uhr in Raum V7 noch in einem zweiten Vortrag vertreten zu sein. Zusammen mit Michael Decker von der ASPICON GmbH erfahrt ihr, wie man „Mit Ansible Collections & Workflows gegen das Playbook-Chaos“ angehen kann.
Darüber hinaus beteilige ich mich als Sessionleiter für die folgenden drei Vorträge an der Veranstaltung:
So habe ich auf jeden Fall einen Platz im Raum sicher. ;-)
Wer ebenfalls helfen möchte, kann sich unter Mitmachen! informieren und melden.
Für mich ist dieses Jahr einiges im Programm dabei. Doch freue ich mich ebenso sehr auf ein Wiedersehen mit alten Bekannten aus der Gemeinschaft und darauf, neue Gesichter (Namen kann ich mir meist erst Jahre später merken) kennenzulernen.
Im Frontend ändert sich mein Blog nur noch marginal. Jedoch musste ich mich aufgrund von Änderungen im Sourcecode von WordPress für ein anderes Theme entscheiden. Zuvor hatte ich ein Theme von einem deutschen bekannten Entwicklerpaar gekauft, aber leider endet hier der Support doch recht schnell. Auch Bugfixes, welche ich einmal auf Github eingereicht hatte, wurden ... Weiterlesen
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
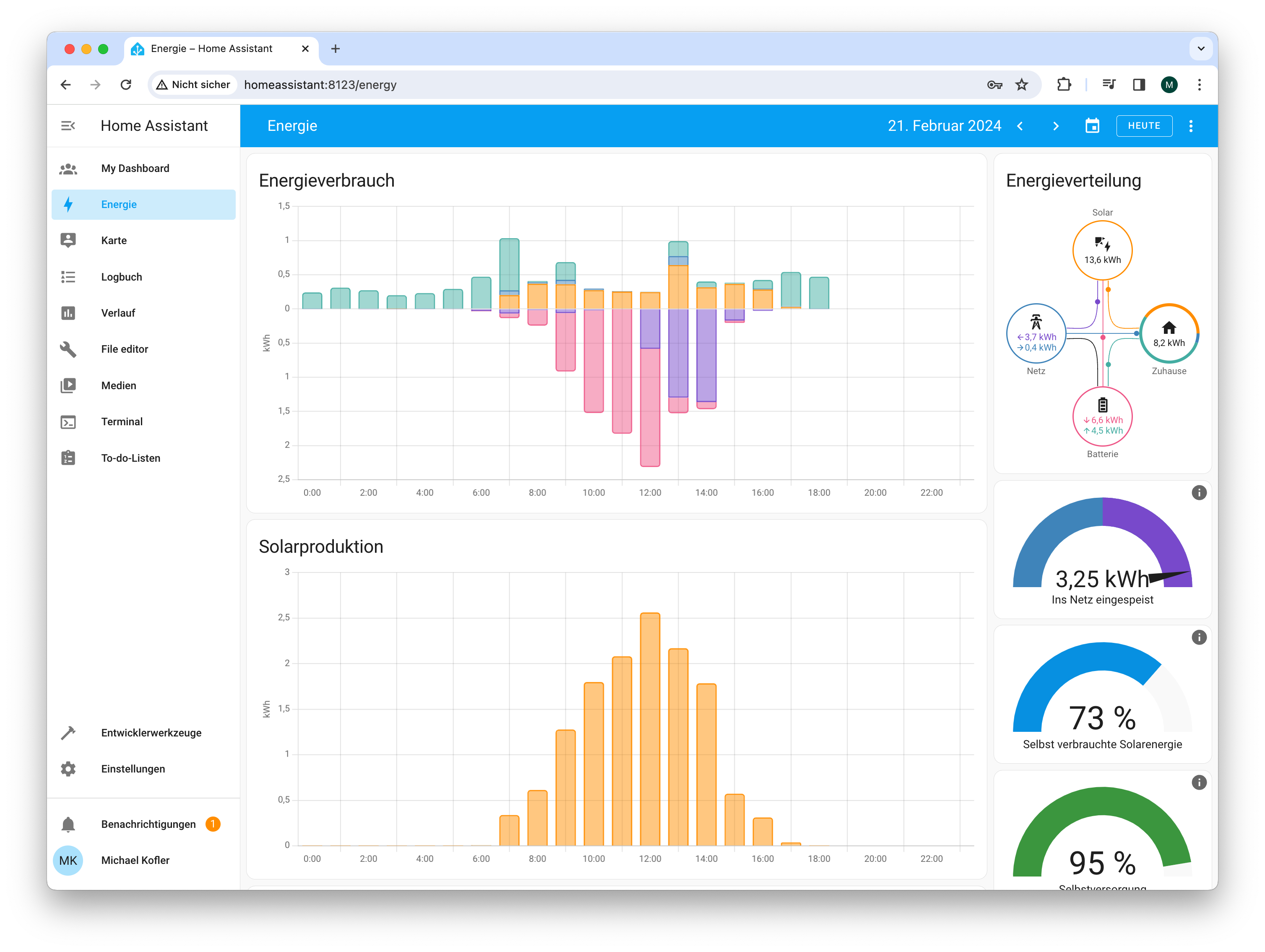
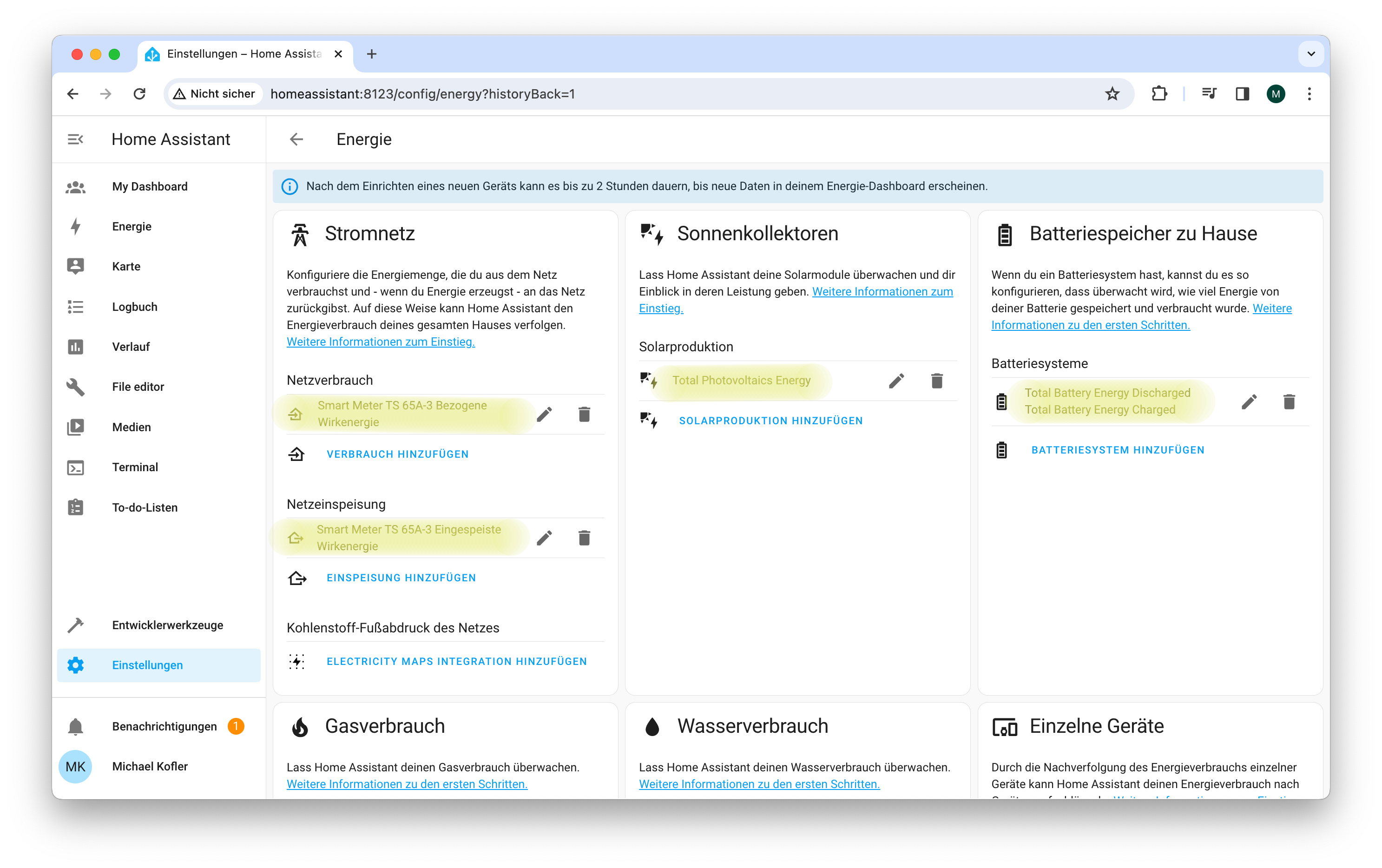
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
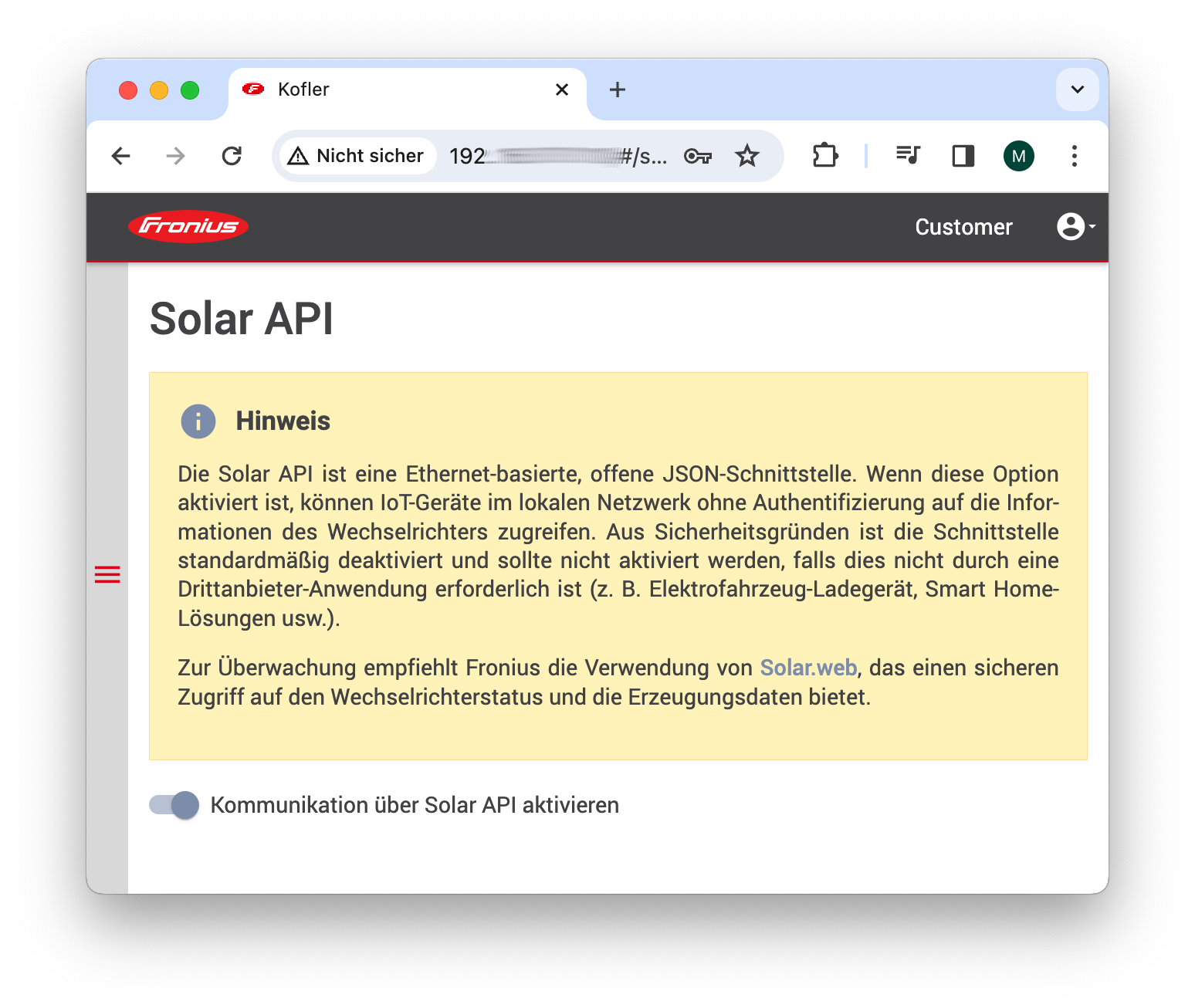
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
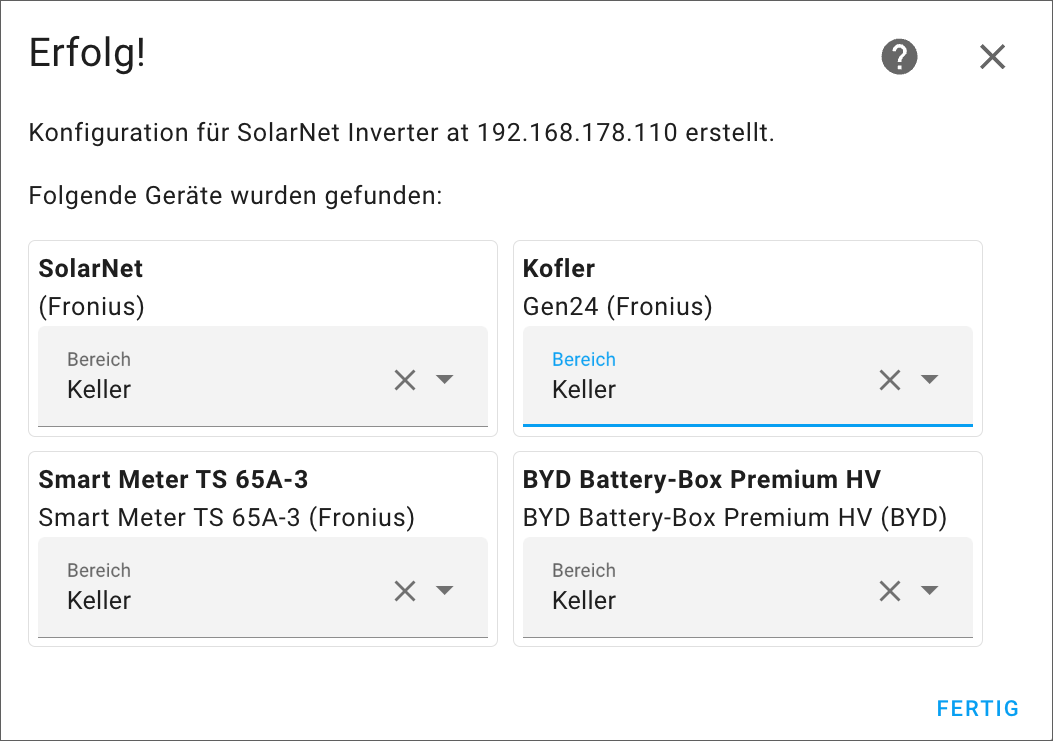
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
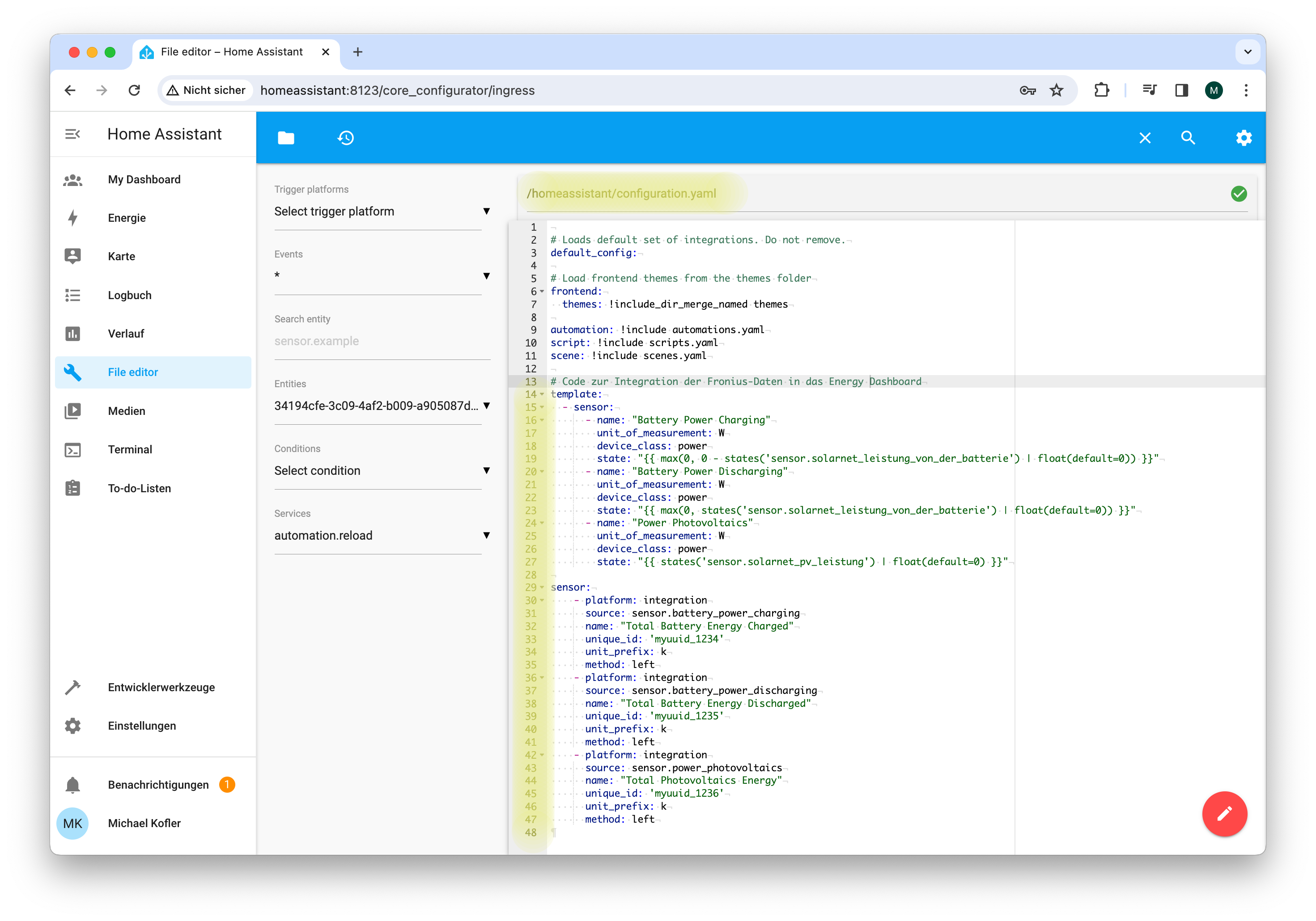
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
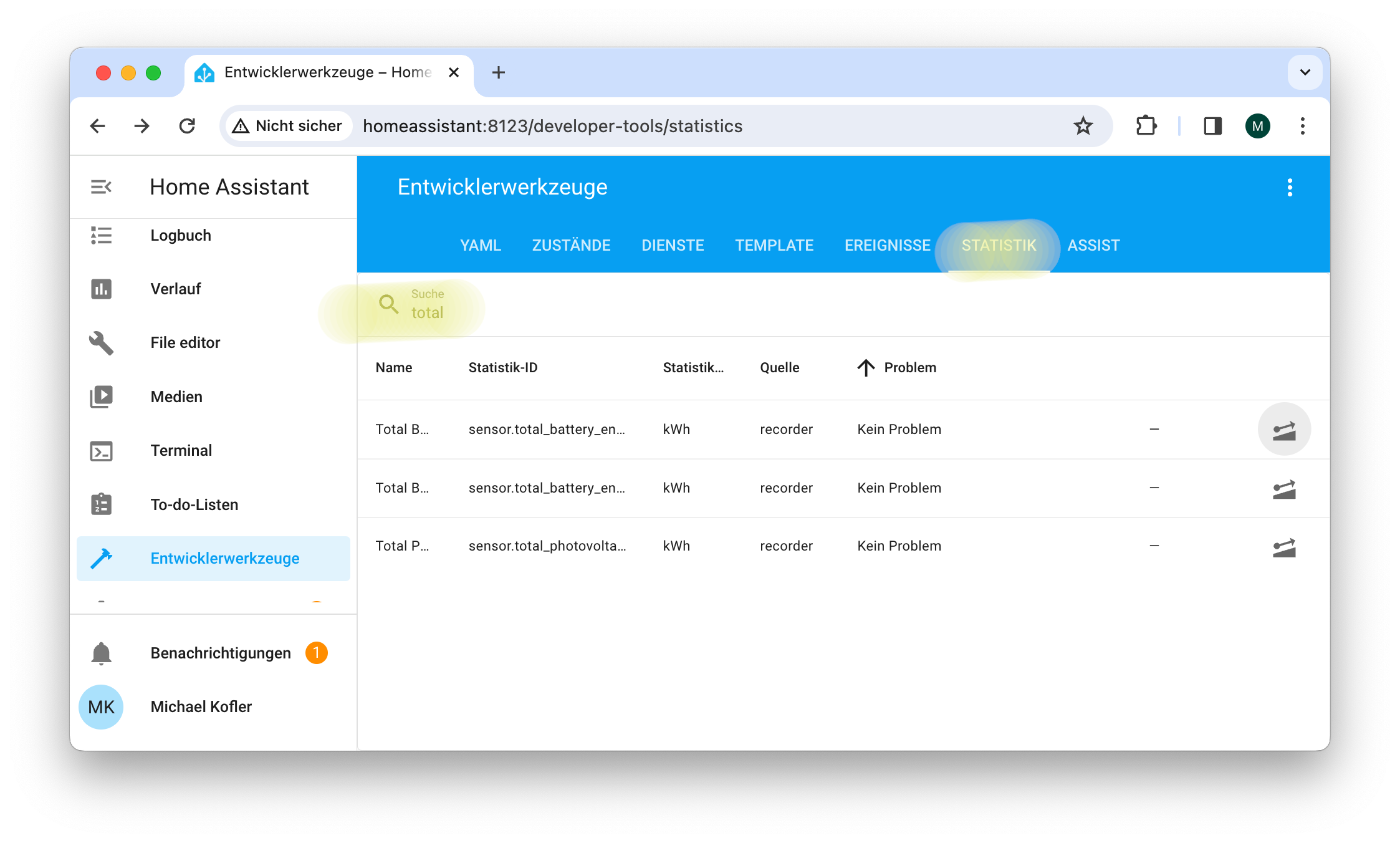
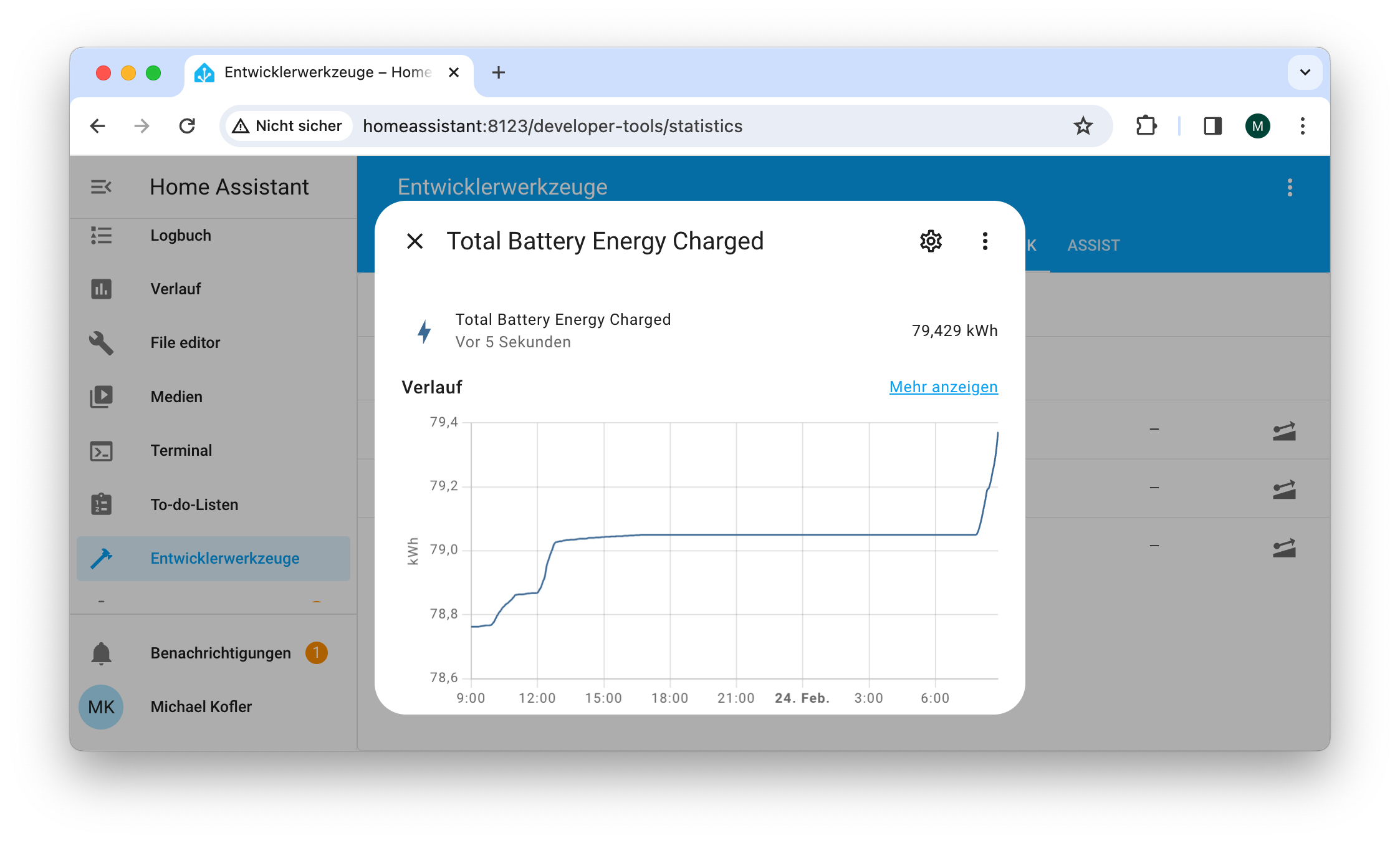
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
Ich habe nun das nächste Plugin aus WordPress entfernt. Auch habe ich mir nochmals Gedanken über dieses Plugin gemacht und es ist definitiv nicht Datenschutz konform, wenn ich Daten aus Github nachgeladen habe. Ich hatte zwar somit immer die neueste Version des Codes eingebunden, aber es war eigentlich eine Faulheit auf Kosten der Lesenden. Im ... Weiterlesen
Am 16. und 17. März 2024 werde ich euch auf den Chemnitzer Linux-Tagen um 10:00 Uhr in Raum V6 mit einem Vortrag über IPv6 unterhalten.
Dazu bin ich noch auf der Suche nach ein paar Beispielen aus dem echten Leben. Falls ihr mögt, teilt mir doch eure schönsten und schlimmsten Momente im Zusammenhang mit IPv6 mit und ich prüfe, ob ich sie in meinen Vortrag mit einbauen kann.
Wann und wie hat IPv6 euren Tag gerettet?
Wieso hat euch das Protokoll Alpträume beschehrt?
Was funktioniert wider Erwarten immer noch nicht mit IPv6?
Habt ihr lustige Geschichten, die ihr (anonym) mit der Welt teilen möchtet?
Ich freue mich über Einsendungen, Beiträge und Rückmeldungen:
Bitte schreibt dazu, ob ihr eine Namensnennung wünscht oder euer Beispiel anonym einfließen soll.
Um einen runden Vortrag zu erstellen, wird evtl. nicht jeder Beitrag einfließen können. Bitte habt Verständnis dafür und verzeiht, wenn ihr euch nicht im Vortrag wiederfindet. Ich werde eure Geschichten ggf. im Nachgang hier im Blog veröffentlichen.
Nachdem unsere Community-Cloud das vorab letzte Software-Upgrade und eine neue SSD erhalten hatte, wurde es nun Zeit auch die Hardware auf eine neue Stufe zu heben. Da wir der Meinung waren, dass hierzu ein Raspberry P4 4 Modell B mit 8GB völlig ausreicht, haben wir uns bewusst für dieses Gerät entschieden. Eingepackt in ein passiv gekühltes Metallgehäuse wird uns diese Kombination, so hoffe ich, die nächste Zeit zuverlässig begleiten.
Da ein Upgrade der installierten Software vom Raspberry Pi 3 auf den Raspberry Pi 4 wenig sinnvoll und auch fast unmöglich umzusetzen ist, war die Idee, die Datenbank und das Datenverzeichnis der Nextcloud in eine Neuinstallation (64-Bit) einzubinden.
Für den Wechsel auf 64-Bit hätte eigentlich parallel zum bestehenden System eine Neuinstallation auf dem erwähnten Raspberry Pi durchgeführt werden müssen. Hier konnte ich mir die Arbeit aber ein wenig erleichtern, indem ich die MicroSD meiner eigenen Cloud klonen konnte. Auf dem geklonten System waren so nur einige Anpassungen vorzunehmen, bevor das neue Gerät an Stelle des 32-Bit-Systems in Betrieb genommen werden konnte.
Aufnahme mit Wärmebildkamera (Raspberry Pi 4 – passive Kühlung)
Die aus dem Raspberry Pi 3 gesicherte Datenbank wurde in den Raspberry Pi 4 eingelesen und die Daten-SSD in die /etc/fstab eingebunden. Danach wurde der ddclient mit der DynDNS neu konfiguriert. Ein neues Zertifikat wurde erstellt und die automatische Upgrade-Routine hierzu angepasst. Zum Schluss mussten nur noch die Ports im Speedport-Router für die neue Hardware freigegeben werden.
Fazit
Der Aufwand hat sich in dem Sinne gelohnt, da dieses nun mittlerweile über fünfeinhalb Jahre existierende Projekt, zukunftssicher weiterbetrieben werden kann.
Nachdem nun unsere Community-Cloud endlich wieder lief, habe ich versucht innerhalb der Gemeinschaft unseren Cloud-Speicher etwas zu bewerben. Bei einigen Nutzern war dieser inzwischen etwas in Vergessenheit geraten, samt den nötigen Passwörtern.
Es kommt natürlich immer wieder vor, dass Zugangsdaten nicht richtig verwahrt werden oder gar ganze Passwörter nicht mehr auffindbar sind. Mehrfache fehlerhafte Eingaben können jedoch, wie im Fall der Nextcloud, dazu führen, dass Nutzer-IPs ausgesperrt bzw. blockiert werden. Diesen Schutz nennt man Bruteforce-Schutz.
Bruteforce-Schutz
Nextcloud bietet einen eingebauten Schutzmechanismus gegen Bruteforce-Angriffe, der dazu dient, das System vor potenziellen Angreifern zu sichern, die wiederholt verschiedene Passwörter ausprobieren. Diese Sicherheitsvorkehrung ist standardmäßig in Nextcloud aktiviert und trägt dazu bei, die Integrität der Daten zu wahren und unautorisierten Zugriff auf das System zu verhindern.
Wie es funktioniert
Die Funktionsweise des Bruteforce-Schutzes wird besonders deutlich, wenn man versucht, sich auf der Anmeldeseite mit einem ungültigen Benutzernamen und/oder Passwort anzumelden. Bei den ersten Versuchen mag es unauffällig erscheinen, doch nach mehreren wiederholten Fehlversuchen wird man feststellen, dass die Überprüfung des Logins mit zunehmender Häufigkeit länger dauert. An dieser Stelle tritt der Bruteforce-Schutz in Kraft, der eine maximale Verzögerung von 25 Sekunden für jeden Anmeldeversuch einführt. Nach erfolgreicher Anmeldung werden sämtliche fehlgeschlagenen Versuche automatisch gelöscht. Wichtig zu erwähnen ist, dass ein ordnungsgemäß authentifizierter Benutzer von dieser Verzögerung nicht mehr beeinträchtigt wird, was die Sicherheit des Systems und die Benutzerfreundlichkeit gleichermaßen gewährleistet.
Bruteforce-Schutz kurzzeitig aushebeln
Hat nun einmal die Falle zugeschnappt und ein Anwender wurde aus der Nextcloud ausgesperrt, so kann sich das Problem über die Zeit von selbst lösen. Es gibt aber auch die Möglichkeit die Datenbank entsprechend zurückzusetzen.
Zuerst wechselt man in das Nextcloud-Verzeichnis. Danach werden über den folgenden OCC-Befehl die Bruteforce-Einträge der Datenbank resetet.
cd /var/www/html/nextcloud/
sudo -u www-data php occ security:bruteforce:reset 0.0.0.0
Neue Bruteforce-Attacken werden natürlich danach wieder geloggt und verdächtige IPs ausgesperrt.
Stellt euch vor, ihr habt eine Menge von Servern, welche ausschließlich über IPv6-Adressen verfügen und deshalb keine Dienste nutzen können, welche nur über IPv4 bereitgestellt werden. Wer sich dies nicht vorstellen mag, findet in „IPv6… Kein Anschluss unter dieser Nummer“ ein paar Beispiele dafür.
Was kann man nun tun, damit diese IPv6-only-Hosts dennoch mit der IPv4-only-Welt kommunizieren können?
Eine mögliche Lösung ist die Nutzung eines Dualstack-Proxy-Servers. Das ist ein Server, welcher über Adressen beider Internet-Protokoll-Versionen verfügt und so stellvertretend für einen IPv6-Host mit einem IPv4-Host kommunizieren kann. Das folgende Bild veranschaulicht den Kommunikationsablauf:
Ablauf der Netzwerkkommunikation eines IPv6-Hosts mit einem IPv4-Host über einen Dualstack-Proxy-Server
Im Bild ist zu sehen:
Wie IPv6-Host A eine Verbindung über IPv6 zum Proxy-Server B aufbaut und diesem bspw. die gewünschte URL mitteilt
Der Proxy-Server B baut nun seinerseits eine IPv4-Verbindung zu IPv4-Host C auf, welcher die gewünschten Inhalte bereitstellt
IPv4-Host C sendet seine Antwort über IPv4 an den Proxy-Server
Der Proxy-Server sendet die gewünschten Inhalte anschließend via IPv6 an den IPv6-Host A zurück
Screencast zur Demonstration der Proxy-Nutzung
Das obige Video demonstriert die Nutzung eines Proxy-Servers durch den Abruf einer Demo-Seite mit curl:
Mit dem host-Kommando wird gezeigt, dass für die Demo-Seite kein AAAA-Record existiert; die Seite ist also nicht via IPv6 erreichbar
Mit dem ip-Kommando wird geprüft, dass der Host auf dem Interface ens18 ausschließlich über IPv6-Adressen verfügt
Ohne Proxy ist die Demo-Seite nicht abrufbar
Erst durch Nutzung des Proxys kann die Seite abgerufen werden
Funktioniert das auch von IPv4 nach IPv6?
Ja. Entscheidend ist, dass der verwendete Proxy beide IP-Versionen unterstützt.
Welcher Proxy ist empfehlenswert?
Der Proxy-Server muss beide IP-Versionen beherrschen. Ich persönlich bevorzuge Squid. Dieser ist in so gut wie allen Linux-Distributionen verfügbar, weit verbreitet, robust und selbstverständlich Freie Software.
Sind damit alle Herausforderungen bewältigt?
Für eine Virtualisierungs-Umgebung mit einer IPv4-Adresse und einem /64-IPv6-Netzsegment funktioniert diese Lösung gut. Sie funktioniert auch in jeder anderen Umgebung, wie gezeigt. Man beachte jedoch, dass man mit nur einem Proxy einen Single-Point-of-Failure hat. Um diesem zu begegnen, kann man Squid mit keepalived hochverfügbar gestalten.
Keepalived ist ebenfalls Freie Software. Sie kostet kein Geld, erhöht jedoch die Komplexität der Umgebung. Verfügbarkeit vs. Komplexität möge jeder Sysadmin selbst gegeneinander abwägen.
Wie mache ich meine IPv6-Dienste für IPv4-User erreichbar, die keinen Proxy haben?
Das Stichwort lautet Reverse-Proxy. Ein Artikel dazu erscheint in Kürze in diesem Blog. ;-)
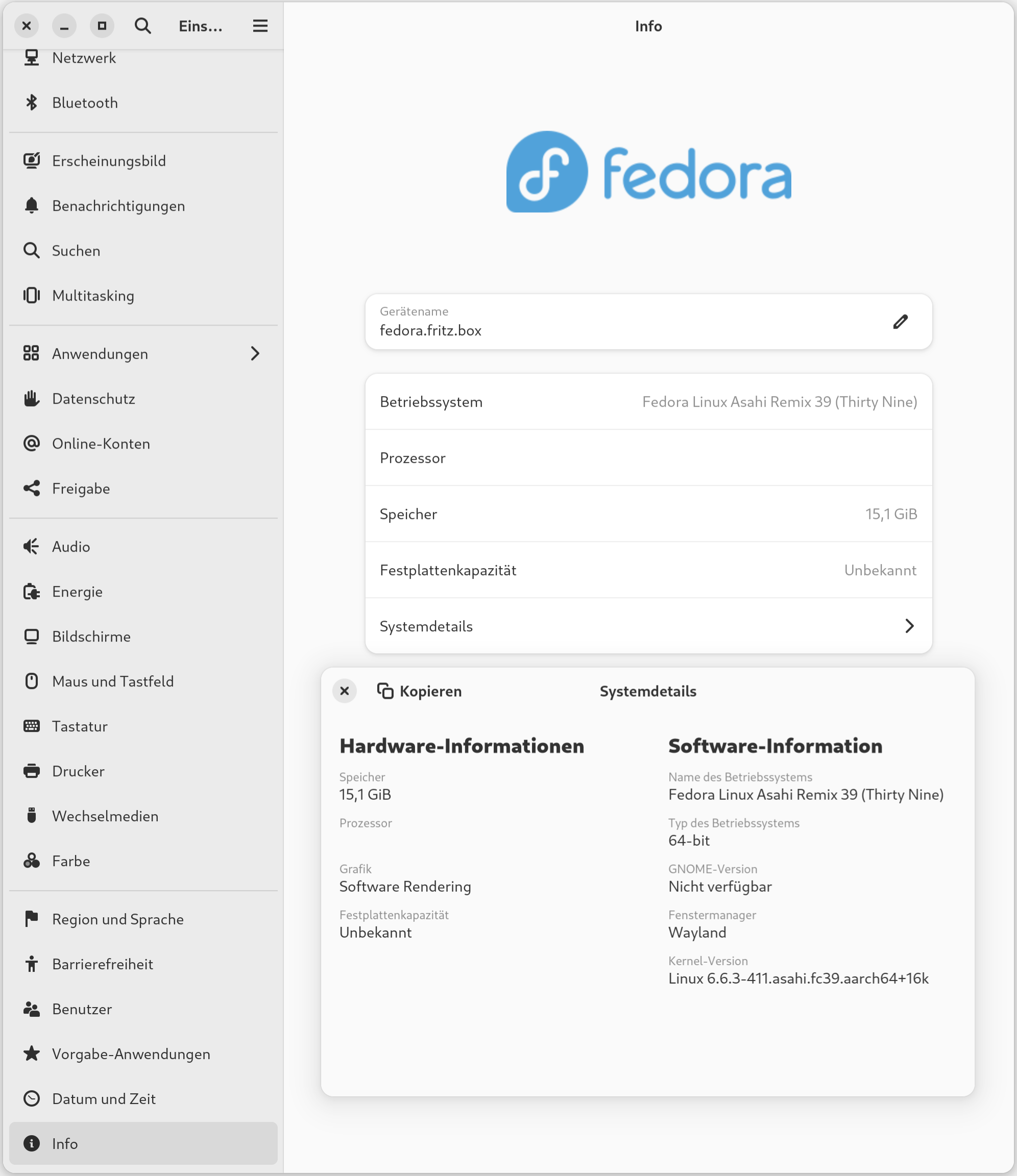
Nachdem ich mich vor ein paar Wochen ausführlich mit der Installation von Fedora Asahi Linux auseinandergesetzt habe, geht es jetzt um die praktischen Erfahrungen. Der Artikel ist ein wenig lang geworden und geht primär auf Tools ein, die ich in meinem beruflichen Umfeld oft brauche.
Ich habe mich für die Gnome-Variante von Fedora Asahi Linux entschieden, die grundsätzlich ausgezeichnet funktioniert. Dazu aber gleich eine Einschränkung: Der Asahi-Entwickler Hector Martin ist KDE-Fan; insofern ist die KDE-Variante besser getestet und sollte im Zweifelsfall als Desktop-System vorgezogen werden.
Gnome Systemeinstellungen
Hardware-Unterstützung
Asahi Linux unterstützt aktuell noch keine Macs mit M3-CPUs. Außerdem hapert es noch bei USB-C-Displays (HDMI funktioniert), einigen Thunderbolt-/USB4-Features und der Mikrofon-Unterstützung. (Die Audio-Ausgabe funktioniert, bei den Notebooks anscheinend sogar in sehr hoher Qualität. Aus eigener Erfahrung kann ich da beim Mac Mini nicht mitreden, dessen Lautsprecher ist ja nicht der Rede wert.) Auf die Authentifizierung mit TouchId müssen Sie auch verzichten. Einen guten Überblick über die Hardware-Unterstützung finden Sie am Ende der folgenden Seite:
Ich habe Fedora Asahi Linux nur auf einem Mac Mini M1 getestet (16 GB RAM). Damit habe ich sehr gute Erfahrungen gemacht. Das System ist genauso leise wie unter macOS (sprich: lautlos, auch wenn der Lüfter sich immer minimal dreht). Aber ich kann keine Aussagen zur Akku-Laufzeit machen, weil ich aktuell kein MacBook besitze. Wie gut Linux die Last zwischen Performance- und Efficiency-Cores verteilt, kann ich ebenfalls nicht sagen.
Der Ruhezustand funktioniert, auch das Aufwachen ;-) Dazu muss allerdings kurz die Power-Taste gedrückt werden. Ein Tastendruck oder ein Mausklick reicht nicht.
Tastatur
An meinem Mac Mini ist eine alte Apple-Alu-Tastatur angeschlossen. Grundsätzlich funktioniert sie auf Anhieb. Ein paar kleinere Optimierungen habe ich vor einiger Zeit hier beschrieben.
Konfiguration bei der Linux-Installation
Ich habe ja schon in meinem Blog-Beitrag zur Installation festgehalten: Während der Installation von Fedora gibt es praktisch keine Konfigurationsmöglichkeiten. Insbesondere können Sie weder die Partitionierung noch das Dateisystem beeinflussen (es gibt eine Partition für alles, das darin enthaltene Dateisystem verwendet btrfs ohne Verschlüsselung).
Wenn Sie davon abweichende Vorstellungen haben und technisch versiert sind, können Sie anfänglich nur einen Teil des freien Disk-Speichers für das Root-System von Fedora nutzen und später eine weitere Partition (z.B. für /home) nach eigenen Vorstellungen hinzuzufügen.
Swap-File
Während der Installation wurde auf meinem System die Swap-Datei /var/swap/swapfile in der Größe von 8 GiB eingerichtet (halbe RAM-Größe?). Außerdem verwendet Fedora standardmäßig Swap on ZRAM. Damit kann Fedora gerade ungenutzte Speicherseite in ein im RAM befindliches Device auslagern. Der Clou: Die Speicherseiten werden dabei komprimiert.
Beim meiner Konfiguration (16 GiB RAM, 8 GiB Swap-File, 8 GiB ZRAM-Swap) glaubt das System, dass es über fast 32 GiB Speicherplatz verfügen kann. (Etwas RAM wird für das Grafiksystem abgezwackt.) Ganz geht sich diese Rechnung natürlich nicht aus, weil ja das ZRAM-Swap selbst wieder Arbeitsspeicher kostet. Aber sagen wir 4 GB ZRAM entspricht mit Komprimierung 8 GB Speicherplatz + 11 GB restliches RAM + 8 GB Swapfile: das würde 27 GB Speicherplatz ergeben. Wenn nicht alle Programme zugleich aktiv sind, kann man damit schon arbeiten.
cat /proc/swaps
Filename Type Size Used Priority
/var/swap/swapfile file 8388576 0 -2
/dev/zram0 partition 8388592 0 100
free -m
total used free shared buff/cache available
Mem: 15444 8063 2842 1521 7112 7381
Swap: 16383 0 16383
Weil ich beim Einsatz virtueller Maschinen gescheitert bin (siehe unten), kann ich nicht beurteilen, ob diese Konfiguration mit der Arbeitsspeicherverwaltung von macOS mithalten kann. Die funktioniert nämlich richtig gut. Auch macOS komprimiert Teile des gerade nicht genutzten Speichers und kompensiert so (ein wenig) den unendlichen Apple-Geiz, was die Ausstattung mit RAM betrifft (oder die Geldgier, wenn mehr RAM gewünscht wird).
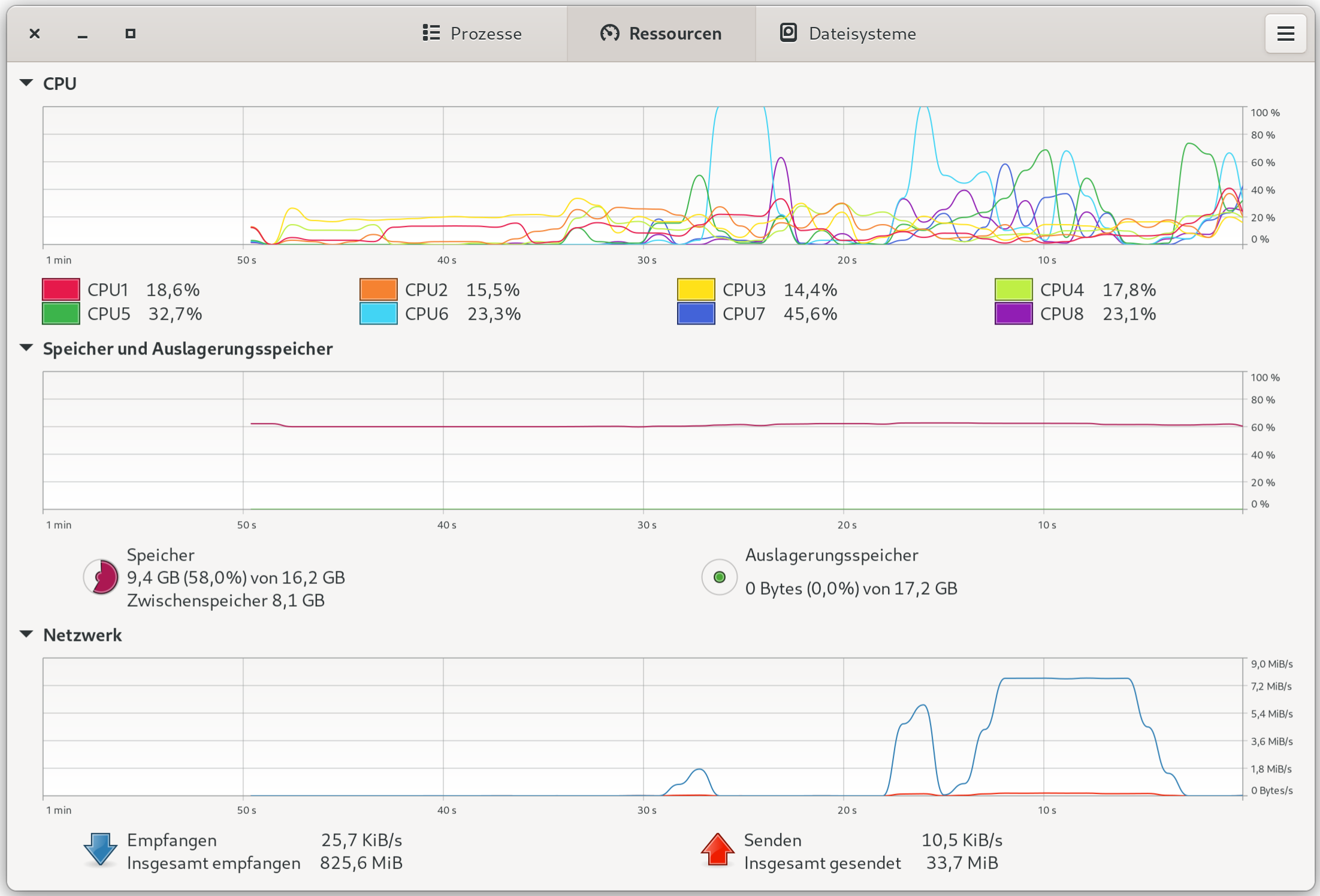
Gnome Systemüberwachung
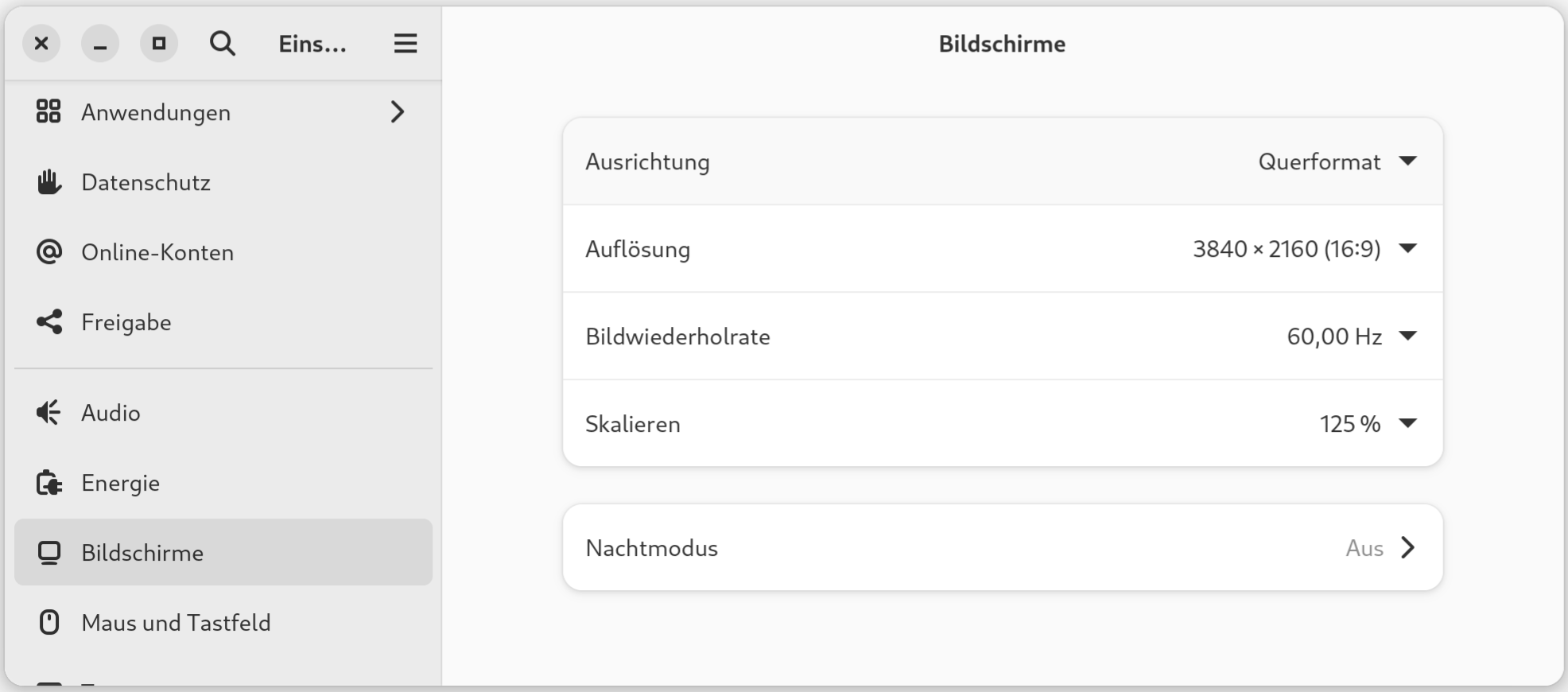
Gnome + Fractional Scaling: mühsam wie vor 10 Jahren
Ein altes Problem: Auf meinem 4k-Monitor (27 Zoll) ist der Bildschirminhalt bei einer Skalierung von 100 % arg klein, bei 200 % sinnlos groß. Seit Jahren wird gepredigt, wie toll Gnome + Wayland ist, aber Fractional Scaling funktioniert immer noch nicht standardmäßig?
Dieses Problem lässt sich zum Glück lösen:
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
Aus Gnome ausloggen, neu einloggen. Jetzt können in den Systemeinstellungen 125 % eingestellt, optimal für mich.
Die fraktionelle Skalierung funktioniert für Wayland-Programme gut, sie muss aber umständlich aktiviert werden
Die meisten Programme, die ich üblicherweise verwende, kommen mit 125 % gut zurecht. Wichtigste Ausnahme (für mich): Emacs. Die Textdarstellung ist ziemlich verschwommen. Angeblich gibt es eine Wayland-Version von Emacs (siehe hier), aber ich habe noch nicht versucht, sie zu installieren.
Webbrowser: kein Google Chrome
Als Webbrowser ist standardmäßig Firefox installiert und funktioniert ausgezeichnet. Chromium steht alternativ auch zur Verfügung (dnf install chromium). Ich bin allerdings, was den Webbrowser betrifft, in der Google-Welt zuhause. Ich habe mich vor über 10 Jahren für Google Chrome entschieden. Lesezeichen, Passwörter usw. — alles bei Google. (Bitte die Kommentare nicht für einen Browser-Glaubenskrieg nutzen, ich werde keine entsprechenden Kommentare freischalten.)
Insofern trifft es mich hart, dass es aktuell keine Linux-Version von Google Chrome für arm64 gibt. Ich habe also die Bookmarks + Passwörter nach Firefox importiert. Bookmarks sind easy, Passwörter müssen in Chrome in eine CSV-Datei exportiert und in Firefox wieder importiert werden. Mit etwas Webrecherche auch nicht schwierig, aber definitiv umständlich. Und natürlich ohne Synchronisation. (Für alle Firefox-Fans: Ja, auch Firefox funktioniert großartig, ich habe überhaupt keine Einwände. Wenn ich die Entscheidung heute treffen würde, wäre vielleicht Firefox der Gewinner. Google bekommt auch so genug von meinen Daten …)
Drag&Drop von Nautilus nach Firefox funktionierte bei meinen Tests nicht immer zuverlässig. Ich glaube, dass es sich dabei um ein Wayland-Problem handelt. Ähnliche Schwierigkeiten hatte ich auf meinen »normalen« Linux-Systemen (also x86) mit Google Chrome auch schon, wenn Wayland im Spiel war.
Nextcloud: perfekt
Zum Austausch meiner wichtigsten Dateien zwischen diversen Rechnern verwende ich Nextcloud. Ich habe nextcloud-client-nautilus installiert und eingerichtet, funktioniert wunderbar. Damit im Panel das Nextcloud-Icon angezeigt wird, ist die Gnome-Erweiterung AppIndicator and KStatusNotifierItem Support erforderlich.
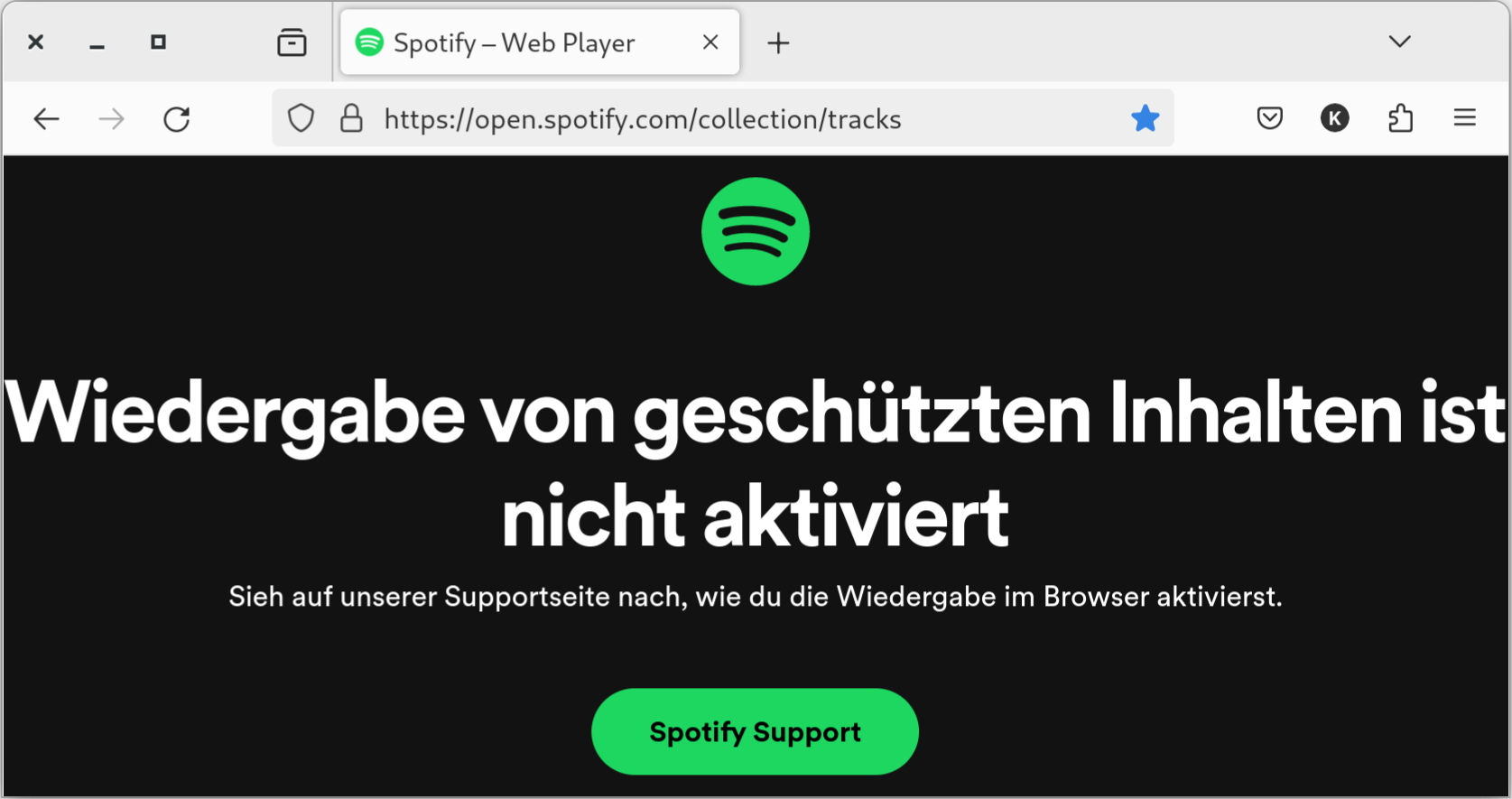
Spotify + Firefox: gescheitert
Ich höre beim Arbeiten gerne Musik. Die Spotify-App gibt es nicht für arm64. Kein Problem, ich habe mich schon lange daran gewöhnt, Spotify im Webbrowser auszuführen. Aber Spotify hält nichts von Firefox: Wiedergabe von geschützten Inhalten ist nicht aktiviert.
Spotify und Firefox vertragen sich nicht
Das Problem ist bekannt und gilt eigentlich als gelöst. Es muss das Widevine-Plugin installiert werden. Asahi greift dabei auf ein Paket der ChromeBooks zurück. Es kann mit widevine-installer installiert werden. (widevine-installer befindet sich im gleichnamigen Paket und ist standardmäßig installiert.) Gesagt, getan:
sudo widevine-installer
This script will download, adapt, and install a copy of the Widevine
Content Decryption Module for aarch64 systems.
Widevine is a proprietary DRM technology developed by Google.
This script uses ARM64 builds intended for ChromeOS images and is
not supported nor endorsed by Google. The Asahi Linux community
also cannot provide direct support for using this proprietary
software, nor any guarantees about its security, quality,
functionality, nor privacy. You assume all responsibility for
usage of this script and of the installed CDM.
This installer will only adapt the binary file format of the CDM
for interoperability purposes, to make it function on vanilla
ARM64 systems (instead of just ChromeOS). The CDM software
itself will not be modified in any way.
Widevine version to be installed: 4.10.2662.3
...
Installing...
Setting up plugin for Firefox and Chromium-based browsers...
Cleaning up...
Installation complete!
Please restart your browser for the changes to take effect.
Nach einem Firefox-Neustart ändert sich: nichts. Ein weiterer Blick in discussion.fedoraproject.org verrät: Es muss auch der User Agent geändert werden, d.h. Firefox muss als Betriebssystem ChromeOS angeben:
Es gibt zwei Möglichkeiten, den User Agent zu ändern. Die eine besteht darin, die Seite about:config zu öffnen, die Option general.useragent.override zu suchen und zu ändern. Das gilt dann aber für alle Webseiten, was mich nicht wirklich glücklich macht.
Die Alternative besteht darin, ein UserAgent-Plugin zu installieren. Ich habe mich für den User-Agent Switcher and Manager entschieden.
Langer Rede kurzer Sinn: Mit beiden Varianten ist es mir nicht gelungen, Spotify zur Zusammenarbeit zu überreden. An dieser Stelle habe ich nach rund einer Stunde Frickelei aufgegeben. Es gibt im Internet Berichte, wonach es funktionieren müsste. Vermutlich bin ich einfach zu blöd.
Spotify + Chromium: geht
Da wollte ich Firefox eine zweite Chance geben … Stattdessen Chromium installiert, damit funktioniert Spotify (widevine-installer vorausgesetzt) auf Anhieb. Sei’s drum.
Chromium läuft übrigens standardmäßig als X-Programm (nicht Wayland), aber nachdem ich den Browser aktuell nur als Spotify-Player benutze, habe ich mir nicht die Mühe gemacht, das zu ändern.
Wie Emacs und Chromium läuft auch Code vorerst als X-Programm. Entsprechend unscharf ist die Schrift bei 125% Scaling. Das ArchWiki verrät, dass beim Programmstart die Option --ozone-platform-hint=auto übergeben werden muss. Das funktioniert tatsächlich: Plötzlich gestochen scharfe Schrift auch in Code.
Ich habe mir eine Kopie von code.desktop erstellt und die gerade erwähnte Option in die Exec-Zeile eingebaut. Bingo!
qemu/libvirt/virt-manager: keine Grafik, keine Maus, keine Tastatur, kein Glück
Meine Arbeit spielt sich viel in virtuellen Maschinen und Containern ab. QEMU und die libvirt-Bibliotheken sind standardmäßig installiert, die grafische VM-Verwaltung gibt es mit dnf install virt-manager dazu.
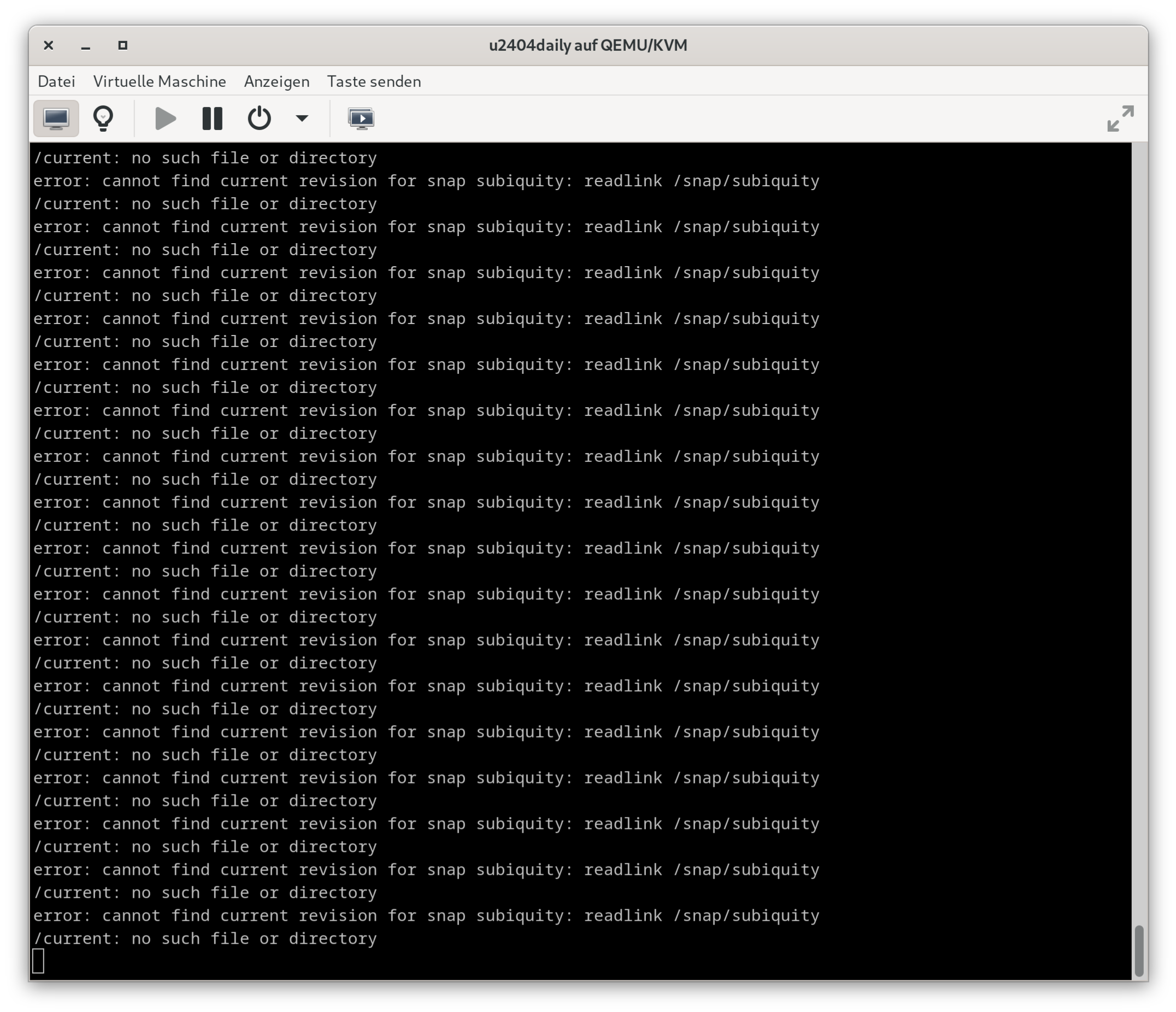
Als nächstes habe ich mir ein Daily-ISO-Image für Arm64 von Ubuntu 24.04 heruntergeladen und versucht, es in einer virtuellen Maschine zu installieren. Kurz nach dem Start stürzt der virt-manager ab. Die virtuelle Maschine läuft weiter, allerdings nur im Textmodus. Später bleibt die die Installation in einer snap-Endlosschleife hängen. Nun gut, es ist eine Entwicklerversion, die noch nicht einmal offiziellen Beta-Status hat.
Eine gescheiterte Installation von Ubuntu 24.04 daily
Nächster Versuch mit 23.10. Allerdings gibt es auf cdimage.ubuntu.com kein Desktop-Image für arm64!? Gut, ich nehme das Server-Image und baue dieses nach einer Minimalinstallation mit apt install ubuntu-desktop in ein Desktop-System um. Allerdings stellt sich heraus, dass aptsehr lange braucht (Größenordnung: eine Stunde, bei nur sporadischer CPU-Belastung; ich weiß nicht, was da schief läuft). Die Textkonsole im Viewer von virt-manager ist zudem ziemlich unbrauchbar. Installation fertig, Neustart der virtuellen Maschine. Es gelingt nicht, den Grafikmodus zu aktivieren.
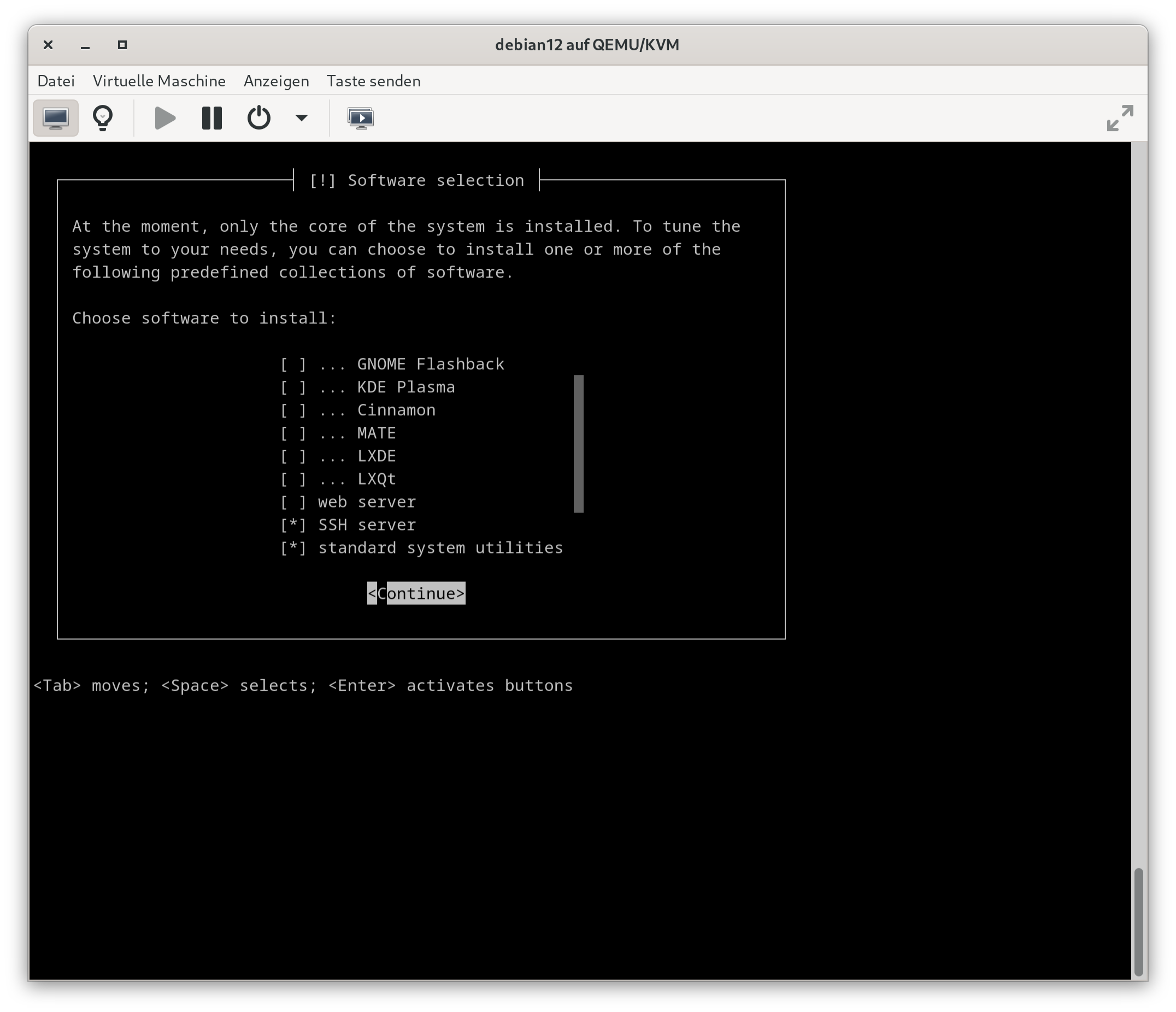
Dritter Versuch, Debian 12 für arm64. Obwohl ich mich für eine Installation im Grafikmodus entscheide, erscheinen die Setup-Dialoge in einem recht trostlosen Textmodus (so, als würde die Konsole keine Farben unterstützen).
Super-minimalistischer Textmodus in der VM
Schön langsam dämmert mir, dass mit dem Grafiksystem etwas nicht stimmt. Tatsächlich hat keine der virtuellen Maschinen ein Grafiksystem! (virt-manager unter x86 richtet das Grafiksystem automatisch ein, und es funktioniert — aber offenbar ist das unter arm64 anders.) Ich füge also das Grafiksystem manuell hinzu, aber wieder treten diverse Probleme auf: der VGA-Modus funktioniert nicht, beim Start der VM gibt es die Fehlermeldung failed to find romfile vgabios-stdvga.bin. QXL lässt sich nicht aktivieren: domain configuration does not support video model qxl. RAMfb führt zu einem EFI-Fehler während des Startups. Zuletzt habe ich mit virtio Glück. Allerdings funktioniert jetzt die Textkonsole nicht mehr, der Bootvorgang erfolgt im Blindflug.
Der Grafikmodus erscheint, aber die Maus bewegt sich nicht. Klar, weil der virt-manager auch das Mauseingabe-Modul nicht aktiviert hat. Ich füge auch diese Hardware-Komponente hinzu. Tatsächlich lässt sich der Mauscursor nach dem nächsten Neustart nutzen — aber die Tastatur geht nicht. Ja, die fehlt auch. Wieder ‚Gerät hinzufügen‘, ‚Eingabe/USB-Tastatur‘ führt zum Ziel. Vorübergehend habe ich jetzt ein Erfolgserlebnis, für ein paar Minuten kann ich Ubuntu 23.10 tatsächlich im Grafikmodus verwenden. Ich kann sogar eine angemessene Auflösung einstellen. Aber beim nächsten Neustart bleibt der Monitor schwarz: Display output is not active.
An dieser Stelle habe ich aufgegeben. Die nächste Auflage meines Linux-Buchs (die steht zum Glück erst 2025 an) könnte ich in dieser Umgebung nicht schreiben. Dazu brauche ich definitiv eine Linux-Installation auf x86-Hardware.
Docker, pardon, Podman: voll OK
Red Hat und Fedora meiden Docker wie der Teufel das Weihwasser. Dafür ist die Eigenentwicklung Podman standardmäßig installiert (Version 4.9). Das Programm ist weitestgehend kompatibel zu Docker und in der Regel ein guter Ersatz.
Ich setze in Docker normalerweise stark auf docker compose. Dieses Subkommando ist in Podman noch nicht integriert. Abhilfe schafft das (einigermaßen kompatible) Python-Script podman-compose, das mit dnf installiert wird und aktuell in Version 1.0.6 vorliegt.
Mein Versuch, mit Podman mein aus LaTeX und Pandoc bestehendes Build-System für meine Bücher zusammenzubauen, gelang damit überraschend problemlos. In compose.yaml musste ich die Services mit privileged: true kennzeichnen, um diversen Permission-denied-Fehlern aus dem Weg zu gehen. Auf jeden Fall sind hier keine unlösbaren Hürden aufgetreten.
Fazit
Soweit Asahi Linux mit Ihrem Mac kompatibel ist und Sie keine Features nutzen möchten, die noch nicht unterstützt werden (aus meiner Sicht am schmerzhaftesten: USB-C-Monitor, Mikrofon), funktioniert es großartig. Einerseits die Apple-Kombination aus hoher Performance und Stille, andererseits Linux mit all seinen Konfigurationsmöglichkeiten. Was will man mehr?
Leider sind die arm64-Plattform (genaugenommen aarch64) und Wayland noch immer nicht restlos Linux-Mainstream. Alle hier beschriebenen Ärgernisse hatten irgendwie damit zu tun — und nicht mit Asahi Linux! Der größte Stolperstein für mich: Mit virt-manager lässt sich nicht vernünftig arbeiten. Mag sein, dass sich diese Probleme umgehen lassen (Gnome Boxes?; Cockpit), aber ich befürchte, dass die Probleme tiefer gehen.
Eine gewisse Ironie an der Geschichte besteht darin, dass ich gerade am Raspberry-Pi-Buch arbeite: Raspberry Pi OS ist mittlerweile ebenfalls für die arm64-Architektur optimiert, es verwendet ebenfalls Wayland. Aber Fractional Scaling ist für den PIXEL Desktop sowieso nicht vorgesehen, damit entfallen alle damit verbundenen Probleme. So fällt es nicht auf, dass diverse Programme via XWayland laufen. Und um die arm64-Optimierungen hat sich die Raspberry Pi Foundation in den letzten Monaten gekümmert — zumindest, soweit es für den Raspberry Pi relevante Programme betrifft. Ich arbeite also momentan sowie schon in einer arm64-Welt, und es funktioniert verblüffend gut!
Wenn es also außer dem Raspberry Pi und den MacBooks noch ein paar »normale« Notebooks mit arm64-CPUs gäbe, würde das sowohl dem Markt als auch der Stabilität von Linux auf dieser Plattform gut tun.
Bleibt noch die Frage, ob Asahi Linux besser als macOS ist. Schwer zu sagen. Für hart-gesottene Linux-Fans sicher. Für meine alltägliche Arbeit ist der größte Linux-Pluspunkt absurderweise ein ganz winziges Detail: Ich verwende ununterbrochen die Linux-Funktion, dass ich Text mit der Maus markieren und dann sofort mit der mittleren Maustaste wieder einfügen kann. macOS kann das nicht. Für macOS spricht hingegen die naturgemäß bessere Unterstützung der Apple-Hardware.
Losgelöst davon funktionieren fast alle gängigen Open-Source-Tools auch unter macOS. Über den Desktop von macOS kann man denken, wie man will; ich kann damit leben. Hundertprozentig glücklich machen mich auch Gnome oder KDE nicht. In jedem Fall ist es unter macOS wie unter Linux mit etwas Arbeit verbunden, den Desktop so zu gestalten, wie ich ihn haben will.
PS: Ein persönliches Nachwort
Seit zwei Monaten verwende ich versuchsweise macOS auf einem Mac Mini (wie beschrieben, M1-CPU + 16 GB RAM) als Hauptdesktop. Ich schreibe/überarbeite dort meine Bücher, bereite den Unterricht vor, administriere Linux-Server, entwickle Code. Virtuelle Maschinen laufen mit UTM. Docker funktioniert gut, allerdings stört, dass der Speicher für Docker fix alloziert wird. (Docker unterstützt sogar Rosetta. Ich habe eine Docker-Umgebung, die ein x86-Binary enthält, zu dem es kein arm64-Äquivalent gibt. Und es läuft einfach, es ist schwer zu glauben …)
Ich verwende Chrome als Webbrowser, Thunderbird als E-Mail-Programm, LibreOffice für Office-Aufgaben, Gimp als Bitmap-Editor, draw.io als Zeichenprogramm, Emacs + Code als Editoren, Skim als PDF-Viewer. Im Terminal sind diverse SSH-Sessions aktiv, so dass ich den Raspberry Pi, meine Linux-Server usw. administrieren kann. Zusatzsoftware installiere ich mit brew so unkompliziert wie mit dnf oder apt. Im Prinzip bin ich auf keine unüberwindbaren Hindernisse gestoßen, um meine alltägliche Arbeit auszuführen.
Es gibt nur ganz wenige originale macOS-Programme, die ich regelmäßig ausführe: das Terminal, Preview + Fotos. Außerdem finde ich es praktisch, dass ich M$ Office nativ verwenden kann. Ich hasse Word zwar abgrundtief, muss aber beruflich doch hin und wieder damit arbeiten. Das habe ich bisher auf einem Windows-Rechner erledigt.
Letzten Endes ist der Grund für dieses Experiment banal: Mich nervt der Lüfter meines Linux-Notebooks (ein fünf Jahre alter Lenovo P1) immer mehr. Wenn ich die meiste Zeit Ruhe haben will, muss ich den Turbo-Modus der CPU deaktivieren. Ist es für Intel/AMD wirklich unmöglich, eine CPU zu bauen, die so energieeffizient ist wie die CPUs von Apple? Kann keiner der Mainstream-Notebook-Hersteller (Lenovo, Dell etc.) ein Notebook bauen, das ganz gezielt für den leisen Betrieb gedacht ist, OHNE die Performance gleich komplett auf 0 zu reduzieren?
Im Unterschied zum Lenovo P1 läuft mein Mac komplett lautlos und ist gleichzeitig um ein Mehrfaches schneller. Es ist nicht auszuschließen, dass mein nächstes Notebook keine CPU von Intel oder AMD haben wird, sondern eine M3- oder M4-CPU von Apple. Die Option, auf diesem zukünftigen MacBook evt. auch Linux ausführen zu können, ist ein Pluspunkt und der Grund, weswegen ich mich so intensiv mit Asahi Linux auseinandersetze.
Ich habe es nicht ausprobiert, aber Sie können auch Ubuntu auf M1/M2-Macs installieren. Canonical überlegt anscheinend sogar, das irgendwann offiziell zu unterstützen.
Des Öfteren erinnere ich Kollegen daran, doch bitte bei Upgrades in einer Remoteshell mit einem terminal mutliplexer zu arbeiten. Falls doch einmal die Verbindung abbricht, nicht ein halb installiertes, oder konfiguriertes Paket vorliegt. Das kann viel und sehr unangenehme Arbeit auslösen. Man glaubt es kaum, den Fakt habe ich bei meiner Firewall in meinem Homeoffice ... Weiterlesen
Das soziale Netzwerk Mastodon hat mit seinem web- und mobilen Anwendungen für mich einen wunderbaren Standard in das Leben gerufen und sogleich in dem Netzwerk etabliert. Die ausführliche Bildbeschreibung. Die Beschreibung wird, unterstützt durch künstliche Intelligenz, per Knopfdruck als ein Text generiert. Der Text wird nun noch an die eigenen Wünsche angepasst. Damit beschreibt der ... Weiterlesen
WP-Appbox ist ein wunderbares Plugin, welches vielfältige Darstellungsmöglichkeiten für die Verlinkung verschiedener Apps bietet. Das Plugin war bei mir seit 2013 in Benutzung. Ich habe es erstmals bei dem Blogbeitrag Ownstagram ein eigenes Instagram verwendet. Das Plugin bindet verschiedene Stores anhand eines Shortcodes ein und zieht sich hier die gewünschten Daten aus dem Shop. Ein ... Weiterlesen