Das KDE-Entwicklungsteam hat offiziell die finale stabile Version der neuen Plasma 6.0-Desktopumgebung angekündigt. Dies markiert einen bedeutenden Meilenstein in der Open-Source-Welt für das Jahr 2024, da Plasma zu den beiden führenden Desktop-Umgebungen gehört und eine große weltweite Nutzerbasis hat. Die neue Version bringt viele Verbesserungen und neue Funktionen mit sich, darunter die Nutzung von Qt...
Mit Kali Linux 2024.1 hat das Team die erste Version dieses Jahres veröffentlicht. Es gibt einige Neuerungen und auch visuell wurde die Security-Distribution aufgefrischt. Neu ist auch, dass es neue Spiegel-Server gibt, auf denen das Image gehostet ist. 2024 Theme-Änderungen und Desktop-Verbesserungen Es ist schon ein bisschen Tradition geworden, dass die 20**.1-Versionen immer ein neues Theme mit sich bringen. Das Team hat sowohl das Boot-Menü als auch den Anmeldebildschirm sowie die Wallpaper geändert. Es gibt auch einige Verbesserungen beim Xfce-Desktop. […]
Ab sofort ist die finale Version von Tails 6.0 verfügbar. Es ist die erste Version, die auf Debian 12 Bookworm basiert und GNOME 43 als Desktop-Umgebung mit sich bringt. Bei Tails 6.0 wurde die meiste Software aktualisiert. Zudem gibt es diverse Verbesserungen bezüglich Sicherheit und Benutzerfreundlichkeit. Zu den neuen Funktionen gehört eine Fehlererkennung beim permanenten Speicher. Tails 6.0 warnt Dich, wenn beim Lesen von Daten oder Schreiben auf den USB-Stick Fehler auftrete. Damit kannst Du mögliche Hardware-Fehler auf dem USB-Stick […]
Der Raspberry Pi wird sicherlich oftmals headless eingesetzt, das bedeutet, es sind keine Tastatur, Bildschirm oder Maus angeschlossen. Nach der anfänglichen Installation läuft der Winzling, möglicherweise in einer dunklen Ecke und verrichtet einfach seinen Job. Gut bei der Installation von Raspberry Pi OS via Imager ist, dass Du zwischenzeitlich auch gleich SSH-Zugang konfigurieren kannst. Nett wäre auch, wenn Du eine fixe IP-Adresse vergeben könntest. Das musst Du aber weiterhin manuell konfigurieren oder Du kennst die MAC-Adresse des Computers und vergibst […]
Du kannst ab sofort die neueste Version des FCM herunterladen. Im Full Circle Magazine findest Du die Üblichen Verdächtigen, aber auch eine Geschichte, wie jemand von OSX auf Linux Mint umgestiegen ist. Die Geschichte kommt mir bekannt vor, da ich selbst einige Zeit Macs benutzt habe, nachdem sie Intel-Prozessoren eingebaut haben. Die Reise des Users begann vor circa 20 Jahren. Der User war mit Windows NT unzufrieden und bekam daher von einem Bekannten eine CD von Ubuntu 4.10 Warty Warthog. […]
Mit einem Dualstack-Proxy Internet-Protokolle verbinden beschrieb eine Möglichkeit, um von Hosts, welche ausschließlich über IPv6-Adressen verfügen, auf Ziele zugreifen zu können, die ausschließlich über IPv4-Adressen verfügen. In diesem Beitrag betrachte ich die andere Richtung.
Zu diesem Beitrag motiviert hat mich der Kommentar von Matthias. Er schreibt, dass er für den bei einem Cloud-Provider gehosteten Jenkins Build Server IPv4 deaktivieren wollte, um Kosten zu sparen. Dies war jedoch nicht möglich, da Kollegen aus einem Co-Workingspace nur mit IPv4 angebunden sind und den Zugriff verloren hätten.
Doch wie kann man nun ein IPv6-Netzwerk für ausschließlich IPv4-fähige Clients erreichbar machen, ohne für jeden Host eine IPv4-Adresse zu buchen? Dazu möchte ich euch anhand eines einfachen Beispiels eine mögliche Lösung präsentieren.
Vorkenntnisse
Um diesem Text folgen zu können, ist ein grundsätzliches Verständnis von DNS, dessen Resource Records (RR) und des HTTP-Host-Header-Felds erforderlich. Die Kenntnis der verlinkten Wikipedia-Artikel sollte hierfür ausreichend sein.
Umgebung
Zu diesem Proof of Concept gehören:
Ein Dualstack-Reverse-Proxy-Server (HAProxy) mit den DNS-RR:
haproxy.example.com. IN A 203.0.113.1
haproxy.example.com IN AAAA 2001:DB8::1
Zwei HTTP-Backend-Server mit den DNS-RR:
www1.example.com IN AAAA 2001:DB8::2
www2.example.com IN AAAA 2001:DB8::3
Zwei DNS-RR:
www1.example.com IN A 203.0.113.1
www2.example.com IN A 203.0.113.1
Ein Client mit einer IPv4-Adresse
Ich habe mich für HAProxy als Reverse-Proxy-Server entschieden, da dieser in allen Linux- und BSD-Distributionen verfügbar sein sollte und mir die HAProxy Maps gefallen, welche ich hier ebenfalls vorstellen möchte.
Der Versuchsaufbau kann wie folgt skizziert werden:
Ein Dualstack-Reverse-Proxy-Server (B) verbindet IPv4-Clients mit IPv6-Backend-Servern
HAProxy-Konfiguration
Für dieses Minimal-Beispiel besteht die HAProxy-Konfiguration aus zwei Dateien, der HAProxy Map hosts.map und der Konfigurationsdatei poc.cfg.
Eine HAProxy Map besteht aus zwei Spalten. In der ersten Spalte stehen die FQDNs, welche vom HTTP-Client aufgerufen werden können. In der zweiten Spalte steht der Name des Backends aus der HAProxy-Konfiguration, welcher bestimmt, an welche Backend-Server eine eingehende Anfrage weitergeleitet wird. In obigem Beispiel werden Anfragen nach www1.example.com an das Backend serversa und Anfragen nach www2.example.com an das Backend serversb weitergeleitet.
Die HAProxy Maps lassen sich unabhängig von der HAProxy-Konfigurations-Datei pflegen und bereitstellen. Map-Dateien werden in ein Elastic Binary Tree-Format geladen, so dass ein Wert aus einer Map-Datei mit Millionen von Elementen ohne spürbare Leistungseinbußen nachgeschlagen werden kann.
Die HAProxy-Konfigurations-Datei poc.cfg für dieses Minimal-Beispiel ist ähnlich simpel:
~]$ cat /etc/haproxy/conf.d/poc.cfg
frontend fe_main
bind :80
use_backend %[req.hdr(host),lower,map(/etc/haproxy/conf.d/hosts.map)]
backend serversa
server server1 2001:DB8::1:80
backend serversb
server server1 2001:DB8::2:80
In der ersten Zeile wird ein Frontend mit Namen fe_main definiert. Zeile 2 bindet Port 80 für den entsprechenden Prozess und Zeile 3 bestimmt, welches Backend für eingehende HTTP-Anfragen zu nutzen ist. Dazu wird der HTTP-Host-Header ausgewertet, falls notwendig, in Kleinbuchstaben umgewandelt. Mithilfe der Datei hosts.map wird nun ermittelt, welches Backend zu verwenden ist.
Die weiteren Zeilen definieren zwei Backends bestehend aus jeweils einem Server, welcher auf Port 80 Anfragen entgegennimmt. In diesem Beispiel sind nur Server mit IPv6-Adressen eingetragen. IPv4-Adressen sind selbstverständlich auch zulässig und beide Versionen können in einem Backend auch gemischt auftreten.
Kann eine HTTP-Anfrage nicht über die hosts.map aufgelöst werden, läuft die Anfrage in diesem Beispiel in einen Fehler. Für diesen Fall kann ein Standard-Backend definiert werden. Siehe hierzu den englischsprachigen Artikel Introduction to HAProxy Maps von Chad Lavoie.
Der Kommunikationsablauf im Überblick und im Detail
Der Kommunikationsablauf im Überblick
Von einem IPv4-Client aus benutze ich curl, um die Seite www1.example.com abzurufen:
~]$ curl -4 -v http://www1.example.com
* processing: http://www1.example.com
* Trying 203.0.113.1:80...
* Connected to www1.example.com (203.0.113.1) port 80
> GET / HTTP/1.1
> Host: www1.example.com
> User-Agent: curl/8.2.1
> Accept: */*
>
< HTTP/1.1 200 OK
< server: nginx/1.20.1
< date: Sat, 06 Jan 2024 18:44:22 GMT
< content-type: text/html
< content-length: 5909
< last-modified: Mon, 09 Aug 2021 11:43:42 GMT
< etag: "611114ee-1715"
< accept-ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<title>Test Page for the HTTP Server on Red Hat Enterprise Linux</title>
Der FQDN www1.example.com wird mit der IPv4-Adresse 203.0.113.1 aufgelöst, welche dem Host haproxy.example.com gehört. Bei der Zeile Host: www1.example.com handelt es sich um den HTTP-Host-Header, welchen der HAProxy benötigt, um das richtige Backend auszuwählen.
Es ist zu sehen, dass wir eine Antwort von einem NGINX-HTTP-Server erhalten. Der HTML-Quelltext wurde gekürzt.
Damit ist es gelungen, von einem IPv4-Client eine Ressource abzurufen, die von einem IPv6-Server bereitgestellt wird.
Im Access-Log des Backend-Servers mit der IPv6-Adresse 2001:DB8::2 sieht man:
Die Anfrage erreicht den Backend-Server von der IPv6-Adresse des haproxy.example.com (2001:DB8::1). Die am Ende der Zeile zu sehende IPv4-Adresse (192.0.2.1) gehört dem IPv4-Client, von dem ich die Anfrage gesendet habe.
Gedanken zur Skalierung
In diesem Beispiel sind die Server www1.example.com und www2.example.com über ihre IPv6-Adressen direkt erreichbar. Nur die Client-Anfragen von IPv4-Clients laufen über den Reverse-Proxy. Wenn man es wünscht, kann man selbstverständlich sämtliche Anfragen (von IPv4- und IPv6-Clients) über den Reverse-Proxy laufen lassen.
In kleinen Umgebungen kann man einen Reverse-Proxy wie HAProxy zusammen mit Squid (vgl. Artikel Mit einem Dualstack-Proxy Internet-Protokolle verbinden) auf einem Host laufen lassen. Selbstverständlich kann man sie auch auf separate Hosts verteilen.
Hochverfügbarkeit lässt sich auch hier mit keepalived nachrüsten:
Die Internet-Protokolle IPv4 und IPv6 werden wohl noch eine ganze Zeit gemeinsam das Internet bestimmen und parallel existieren. Ich bin mir sogar sicher, dass ich das Ende von IPv4 nicht mehr miterleben werde. Dualstack-(Reverse)-Proxy-Server stellen eine solide und robuste Lösung dar, um beide Welten miteinander zu verbinden.
Sicher bleiben noch ausreichend Herausforderungen übrig. Ich denke da nur an Firewalls, Loadbalancer, NAT und Routing. Und es werden sich auch Fälle finden lassen, in denen Proxyserver nicht infrage kommen. Doch mit diesen Herausforderungen beschäftige ich mich dann in anderen Artikeln.
Unix und Linux, als feste Größen im Bereich der Betriebssysteme, stehen seit langem im Fokus von Vergleichen und Kontrasten. Dieser Bericht wird sich vertieft mit ihren Ursprüngen, Lizenzmodellen, Kernel-Architekturen, Entwicklungsparadigmen, Befehlszeilenumgebungen, Dateisystemstrukturen, Systeminitialisierung und Benutzeroberflächen auseinandersetzen. Das Ziel ist es, den komplexen Unterschied zwischen Unix und Linux zu entwirren und dabei eine umfassende Perspektive zu bieten.
Unix und Linux, als feste Größen im Bereich der Betriebssysteme, stehen seit langem im Fokus von Vergleichen und Kontrasten. Dieser Bericht wird sich vertieft mit ihren Ursprüngen, Lizenzmodellen, Kernel-Architekturen, Entwicklungsparadigmen, Befehlszeilenumgebungen, Dateisystemstrukturen, Systeminitialisierung und Benutzeroberflächen auseinandersetzen. Das Ziel ist es, den komplexen Unterschied zwischen Unix und Linux zu entwirren und dabei eine umfassende Perspektive zu...
LibreOffice 7.6.5 Community ist veröffentlicht und Du kannst es ab sofort für Linux, macOS und Windows herunterladen. Es ist die fünfte Wartungs-Version der 7.6.x-Reihe und sie ist gründlicher getestet als das nagelneue LibreOffice 24.2. Wer die Community-Edition in einer produktiven Umgebung einsetzen möchte, sollte am besten 7.6.5 nehmen. Insgesamt wurden über 90 Bugs ausgebessert. Für den Einsatz in Unternehmen empfiehlt TDF die LibreOffice-Enterprise-Familie durch entsprechende Partner. Du kannst LibreOffice 7.6.5 Community aus dem Download-Bereich der Projektseite herunterladen. Es gibt Versionen […]
Canonical hat im Zeitplan die Veröffentlichung von Ubuntu 22.04.4 LTS (Jammy Jellyfish) bekanntgegeben, die mit dem Linux-Kernel 6.5 und Mesa 23.2 ausgestattet ist. Diese Version markiert das vierte Punkt-Release der aktuellen Ubuntu 22.04 LTS (Jammy Jellyfish)-Serie und bringt eine Reihe von Aktualisierungen für die Kernkomponenten des Betriebssystems. Sechs Monate nach der Veröffentlichung von Ubuntu 22.04.3...
Das GIMP-Team hat die letzte Entwicklungsversion vor GIMP 3 veröffentlicht. Die Entwickler geben an, dass GIMP 2.99.18 etwas hinter dem Zeitplan zurückliegt. Allerdings gibt es diverse Neuerungen und Änderungen. Das Team erinnert daran, dass es sich um eine instabile Entwicklungsversion handelt. Es wird davon abgeraten, sie in einer produktiven Umgebung einzusetzen. Interessierte dürfen sich die Testversion aber gerne genauer ansehen und gefundene Fehler melden. Das Team warnt sogar davor, dass Version 2.99.18 eine der instabilsten Versionen der 2.99er-Reihe sein könnte. […]
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
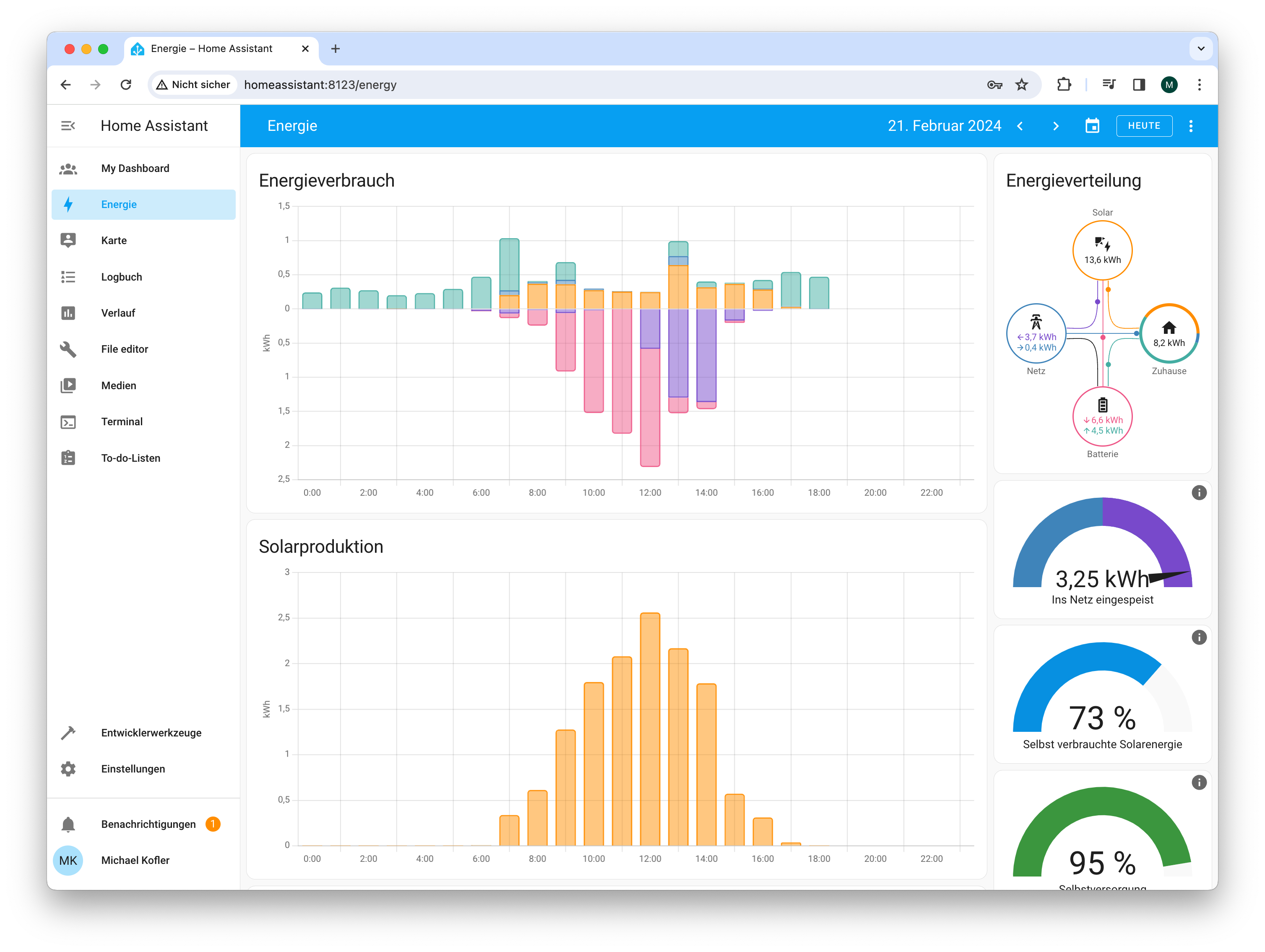
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
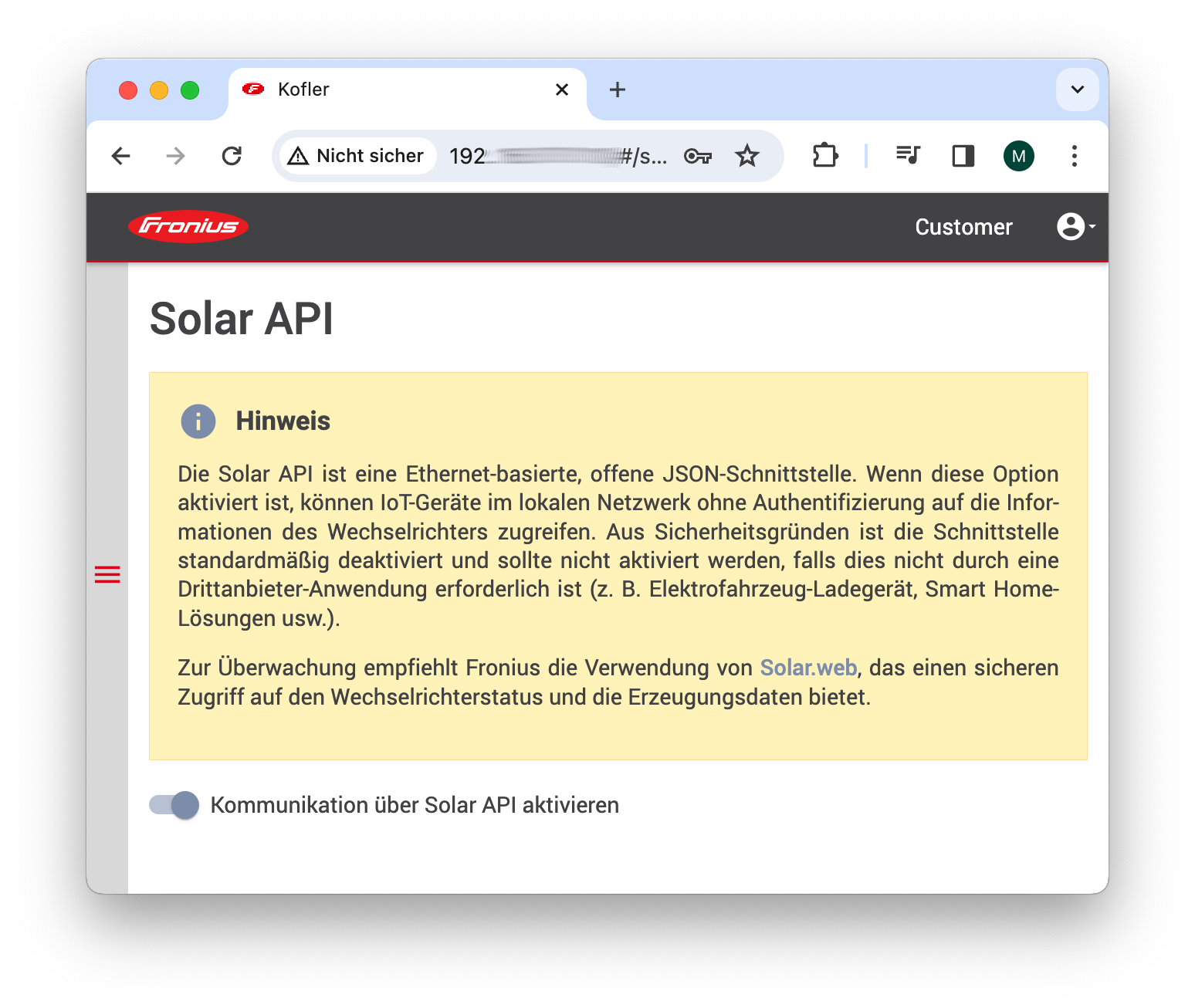
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
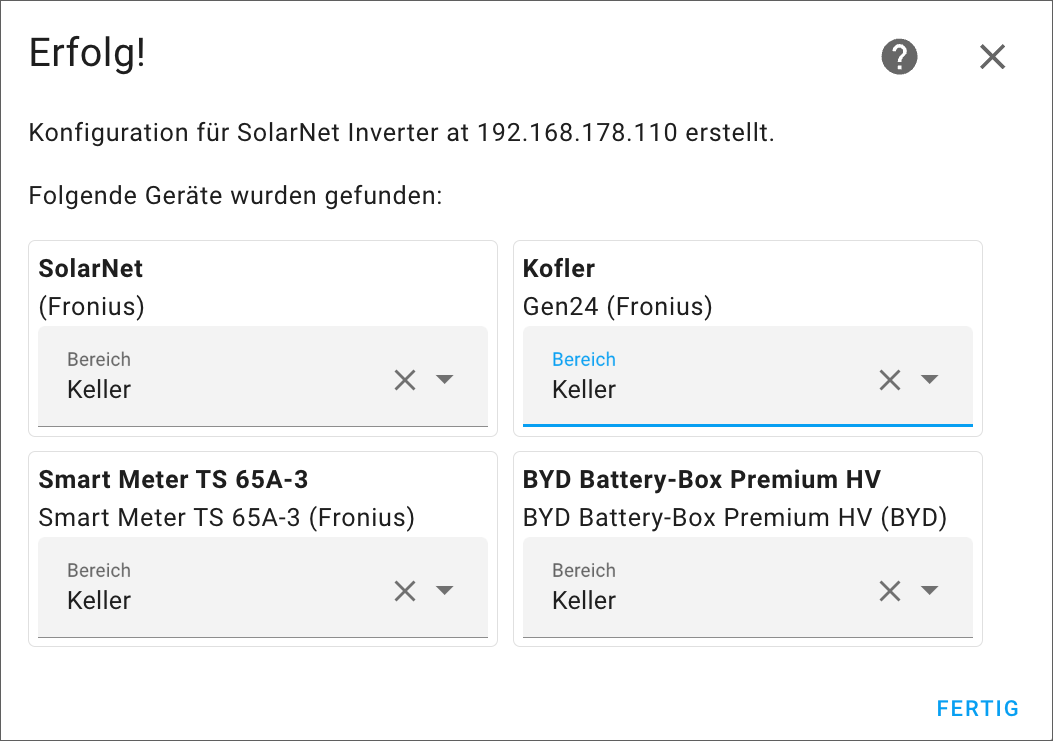
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
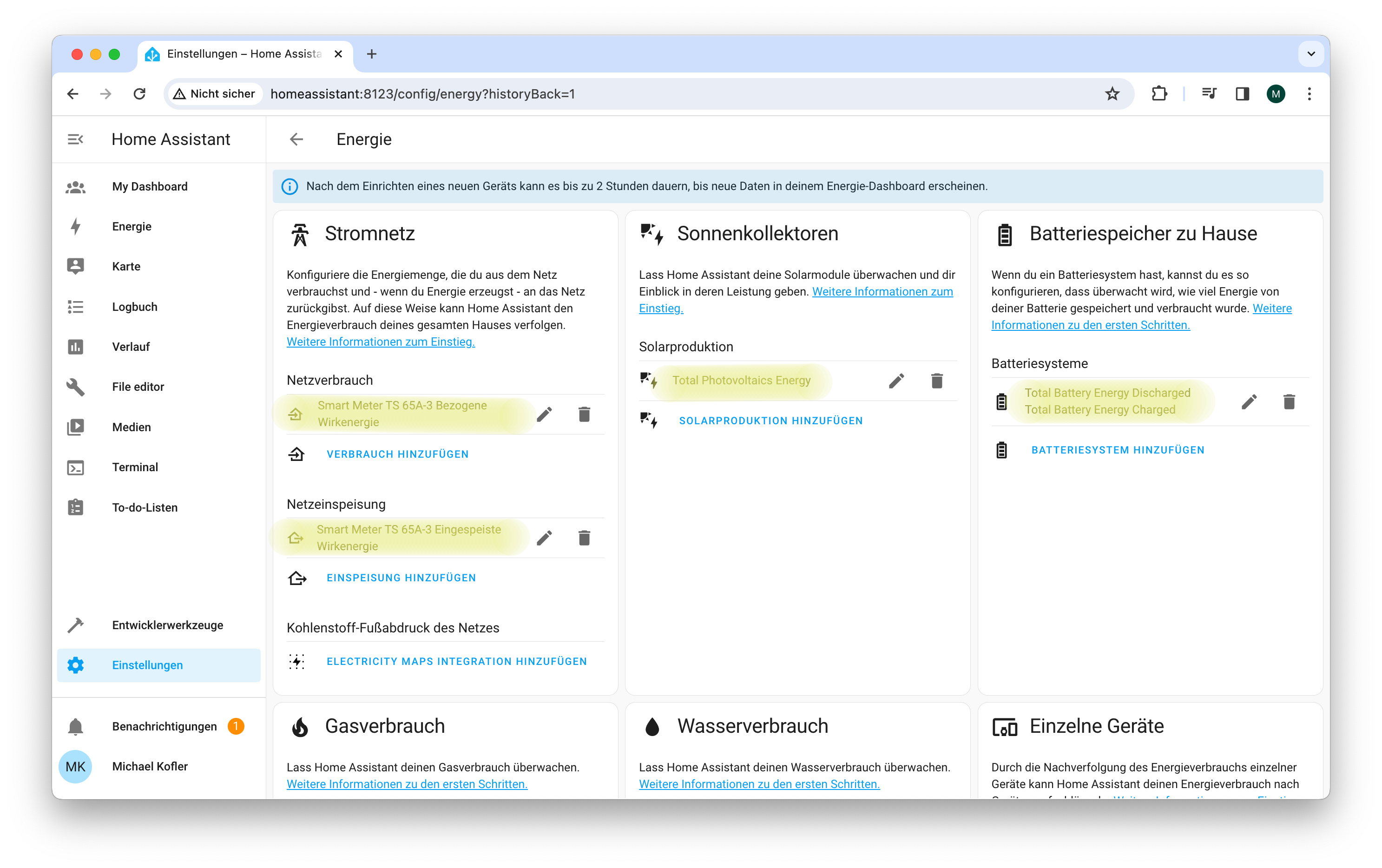
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
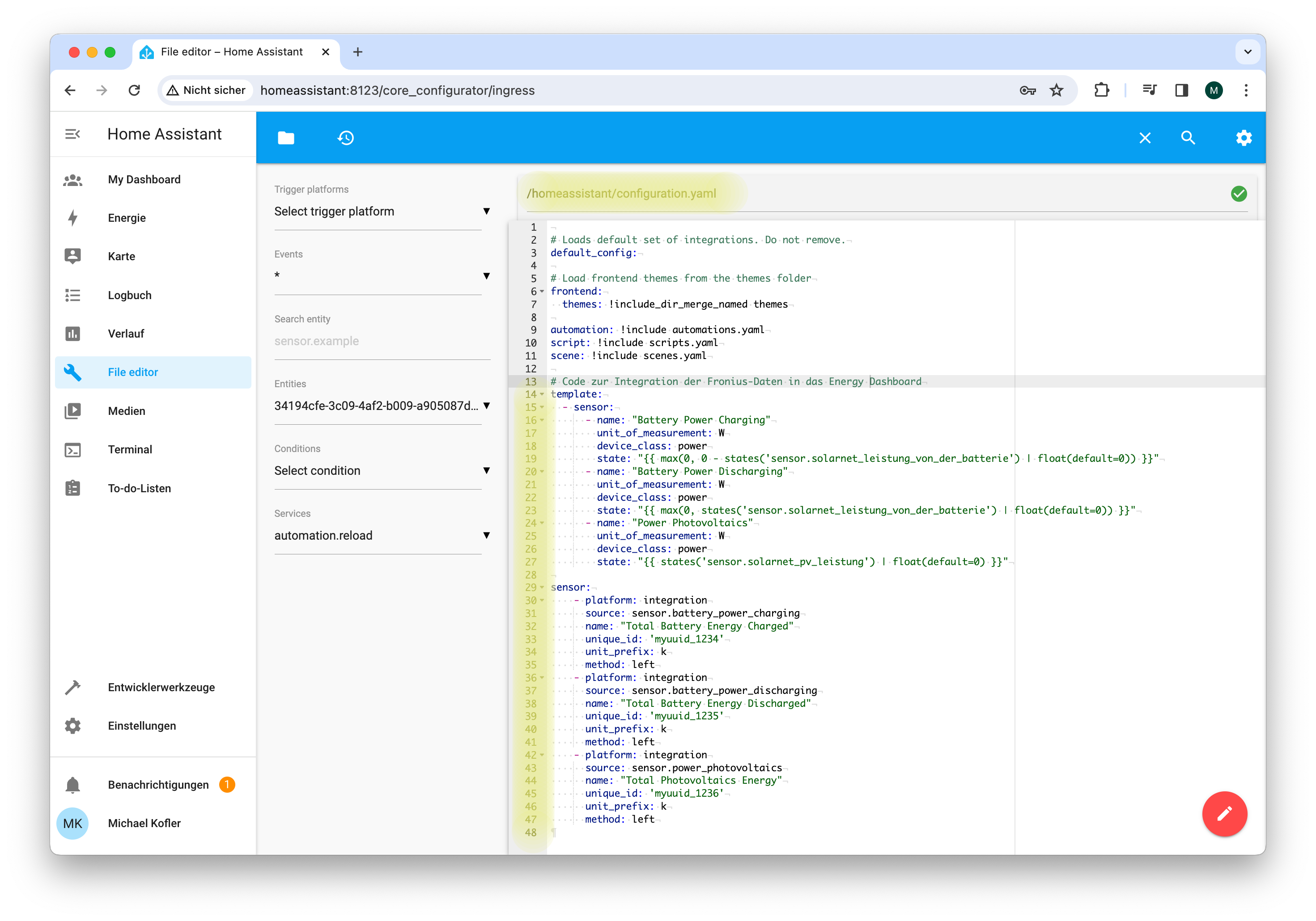
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
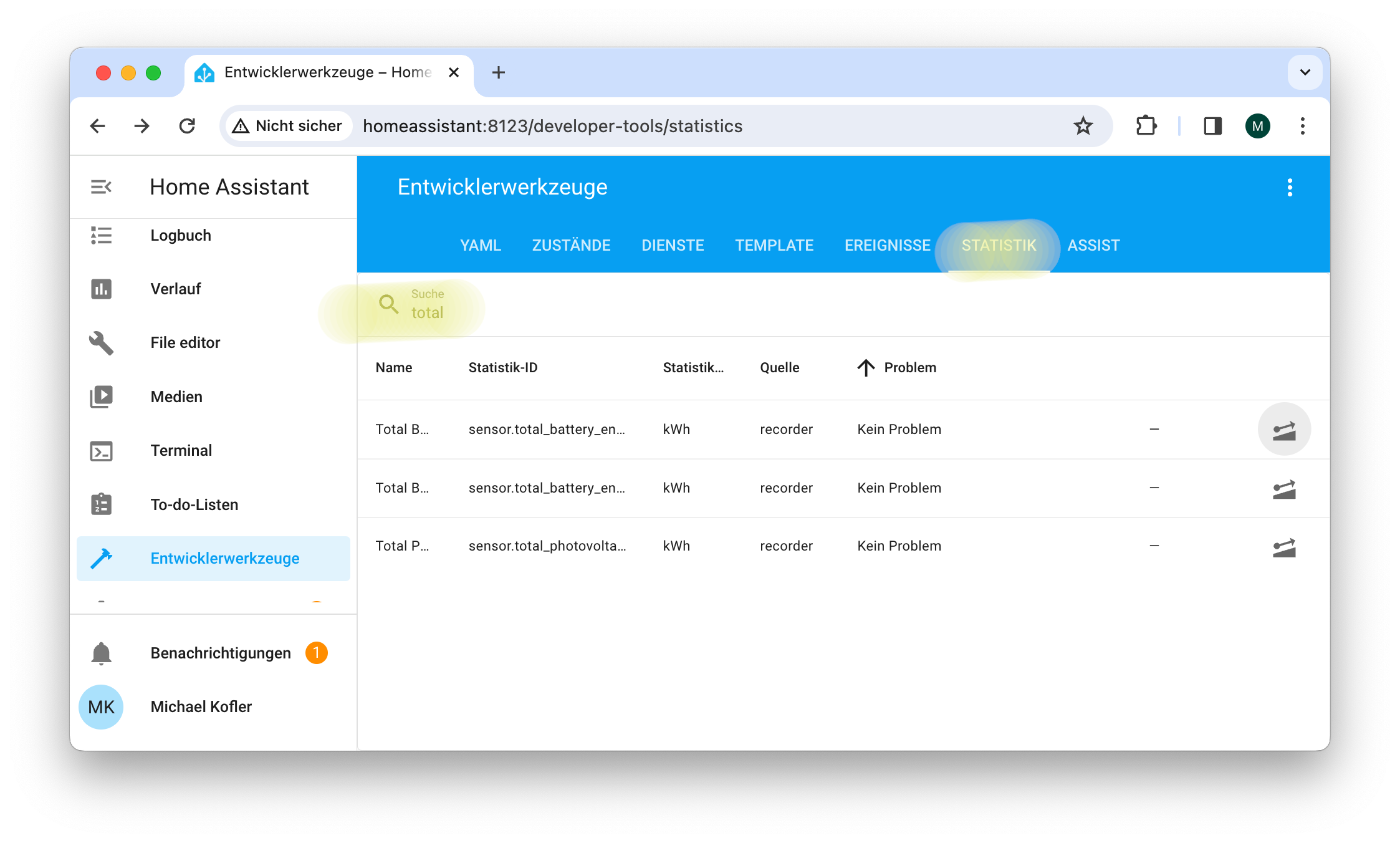
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
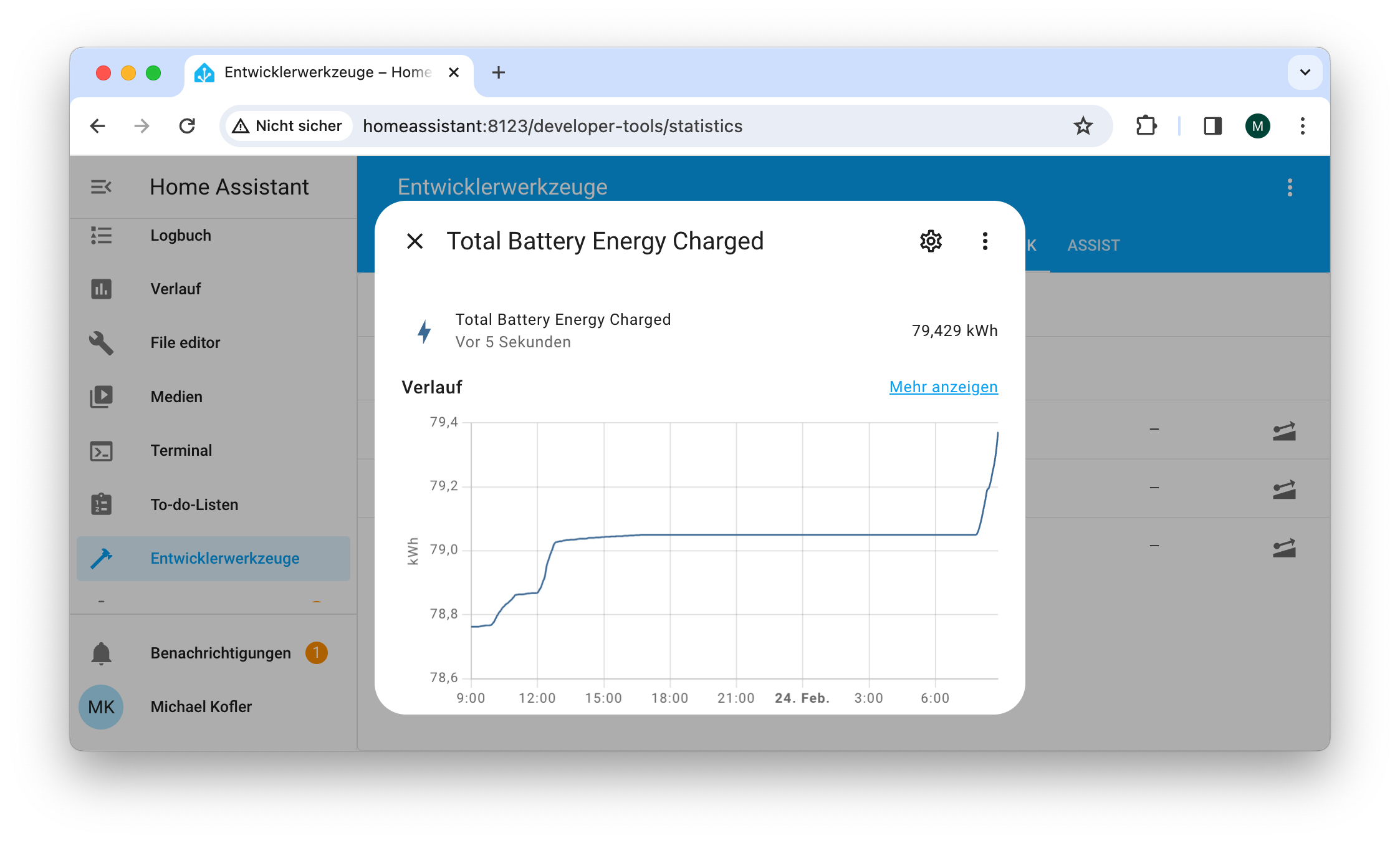
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
GNOME 45.4 markiert das vierte Wartungsupdate der aktuellen “Riga”-Serie und konzentriert sich auf die Behebung von Fehlern und Abstürzen um die Stabilität und Zuverlässigkeit der Desktop-Umgebung zu verbessern. Diese Version bringt eine Reihe von Verbesserungen und neuen Funktionen mit sich. Die offizielle Ankündigung gibt es hier. Folgende Verbesserungen werden angeboten: Darüber hinaus wurden auch Initial...
System76, das Unternehmen hinter der Linux Distribution Pop!_OS, entwickelt mit COSMIC eine Desktop-Umgebung, die derzeit im Alpha-Stadium ist. COSMIC entsteht als Alternative zu Gnome Shell, da man mit der Entwicklung von Gnome unzufrieden ist bzw. die Richtung der Entwicklung von Gnome nicht gefällt. Mit der in Rust neu geschriebenen COSMIC Lösung verspricht System76 eine Rückkehr...
Als hätten sich zwei meiner Lieblingsprogramme für die Bearbeitung von Fotos abgesprochen. Fast zeitgleich wurden darktable 4.6.1 und RawTherapee 5.10 veröffentlicht. Neuerungen in RawTherapee 5.10 Es gibt jede Menge Neuerungen und Verbesserungen in RawTherapee 5.10. Dazu gehören unter anderem: Zudem gibt es Unterstützung für mehr Kameras und / oder es wurden neue Raw-Formate unterstützt sowie Farbprofile hinzugefügt oder verbessert. Du findest alle Neuerungen und Änderungen im Changelog zu RawTherapee 5.10. Im Download-Bereich des Projekts kannst Du RawTherapee 5.10 für Linux, […]
Canonical hat sich für Ubuntu LTS Nutzer wieder etwas Neues einfallen lassen um auf Ubuntu Pro aufmerksam zu machen. Wer im Terminal das System aktualisiert, bekommt ständig eine Meldung, dass gewisse Pakete nur mit einem Ubuntu Pro Abo eingespielt werden können. Was Du dagegen tun kannst, zeige ich Dir in diesem Beitrag. Kurze Eckpunkte zu...
Ab sofort dürfen Fotografen, Künstler und Grafikdesigner am offiziellen Wallpaper-Wettbewerb für Ubuntu 24.04 LTS Noble Numbat teilnehmen. Du hast also die Chance, dass Dein Hintergrundbild in Canonicals nächstem Betriebssystem mit Langzeitunterstützung ist. Die geplante Veröffentlichung von Ubuntu 24.04 TLS ist am 25. April 2024. Das Betriebssystem wird 5 Jahre lang unterstützt, bei Ubuntu Pro sogar 10 Jahre. Canonical will bei diesem Wettbewerb einen etwas anderen Ansatz verfolgen, damit die Vielfalt an Hintergrundbildern davon profitiert. Ab sofort gibt es vier verschiedene […]
Nachdem unsere Community-Cloud das vorab letzte Software-Upgrade und eine neue SSD erhalten hatte, wurde es nun Zeit auch die Hardware auf eine neue Stufe zu heben. Da wir der Meinung waren, dass hierzu ein Raspberry P4 4 Modell B mit 8GB völlig ausreicht, haben wir uns bewusst für dieses Gerät entschieden. Eingepackt in ein passiv gekühltes Metallgehäuse wird uns diese Kombination, so hoffe ich, die nächste Zeit zuverlässig begleiten.
Da ein Upgrade der installierten Software vom Raspberry Pi 3 auf den Raspberry Pi 4 wenig sinnvoll und auch fast unmöglich umzusetzen ist, war die Idee, die Datenbank und das Datenverzeichnis der Nextcloud in eine Neuinstallation (64-Bit) einzubinden.
Für den Wechsel auf 64-Bit hätte eigentlich parallel zum bestehenden System eine Neuinstallation auf dem erwähnten Raspberry Pi durchgeführt werden müssen. Hier konnte ich mir die Arbeit aber ein wenig erleichtern, indem ich die MicroSD meiner eigenen Cloud klonen konnte. Auf dem geklonten System waren so nur einige Anpassungen vorzunehmen, bevor das neue Gerät an Stelle des 32-Bit-Systems in Betrieb genommen werden konnte.
Aufnahme mit Wärmebildkamera (Raspberry Pi 4 – passive Kühlung)
Die aus dem Raspberry Pi 3 gesicherte Datenbank wurde in den Raspberry Pi 4 eingelesen und die Daten-SSD in die /etc/fstab eingebunden. Danach wurde der ddclient mit der DynDNS neu konfiguriert. Ein neues Zertifikat wurde erstellt und die automatische Upgrade-Routine hierzu angepasst. Zum Schluss mussten nur noch die Ports im Speedport-Router für die neue Hardware freigegeben werden.
Fazit
Der Aufwand hat sich in dem Sinne gelohnt, da dieses nun mittlerweile über fünfeinhalb Jahre existierende Projekt, zukunftssicher weiterbetrieben werden kann.
Die UBports Foundation hat angekündigt, dass sie für zukünftige OTA (Over-the-Air)-Updates ihres mobilen Betriebssystems Ubuntu Touch auf ein Fixed-Release-Modell umstellen möchte, um Herausforderungen zu bewältigen, die durch die bisherigen Ansätze entstanden sind. Vor etwa einem Jahr veröffentlichte die UBports Foundation das erste Ubuntu Touch OTA-Update auf Basis von Ubuntu 20.04 LTS. Zuvor arbeitete Ubuntu Touch...
Nachdem nun unsere Community-Cloud endlich wieder lief, habe ich versucht innerhalb der Gemeinschaft unseren Cloud-Speicher etwas zu bewerben. Bei einigen Nutzern war dieser inzwischen etwas in Vergessenheit geraten, samt den nötigen Passwörtern.
Es kommt natürlich immer wieder vor, dass Zugangsdaten nicht richtig verwahrt werden oder gar ganze Passwörter nicht mehr auffindbar sind. Mehrfache fehlerhafte Eingaben können jedoch, wie im Fall der Nextcloud, dazu führen, dass Nutzer-IPs ausgesperrt bzw. blockiert werden. Diesen Schutz nennt man Bruteforce-Schutz.
Bruteforce-Schutz
Nextcloud bietet einen eingebauten Schutzmechanismus gegen Bruteforce-Angriffe, der dazu dient, das System vor potenziellen Angreifern zu sichern, die wiederholt verschiedene Passwörter ausprobieren. Diese Sicherheitsvorkehrung ist standardmäßig in Nextcloud aktiviert und trägt dazu bei, die Integrität der Daten zu wahren und unautorisierten Zugriff auf das System zu verhindern.
Wie es funktioniert
Die Funktionsweise des Bruteforce-Schutzes wird besonders deutlich, wenn man versucht, sich auf der Anmeldeseite mit einem ungültigen Benutzernamen und/oder Passwort anzumelden. Bei den ersten Versuchen mag es unauffällig erscheinen, doch nach mehreren wiederholten Fehlversuchen wird man feststellen, dass die Überprüfung des Logins mit zunehmender Häufigkeit länger dauert. An dieser Stelle tritt der Bruteforce-Schutz in Kraft, der eine maximale Verzögerung von 25 Sekunden für jeden Anmeldeversuch einführt. Nach erfolgreicher Anmeldung werden sämtliche fehlgeschlagenen Versuche automatisch gelöscht. Wichtig zu erwähnen ist, dass ein ordnungsgemäß authentifizierter Benutzer von dieser Verzögerung nicht mehr beeinträchtigt wird, was die Sicherheit des Systems und die Benutzerfreundlichkeit gleichermaßen gewährleistet.
Bruteforce-Schutz kurzzeitig aushebeln
Hat nun einmal die Falle zugeschnappt und ein Anwender wurde aus der Nextcloud ausgesperrt, so kann sich das Problem über die Zeit von selbst lösen. Es gibt aber auch die Möglichkeit die Datenbank entsprechend zurückzusetzen.
Zuerst wechselt man in das Nextcloud-Verzeichnis. Danach werden über den folgenden OCC-Befehl die Bruteforce-Einträge der Datenbank resetet.
cd /var/www/html/nextcloud/
sudo -u www-data php occ security:bruteforce:reset 0.0.0.0
Neue Bruteforce-Attacken werden natürlich danach wieder geloggt und verdächtige IPs ausgesperrt.
Das Debian-Projekt hat das Debian 12.5 Update veröffentlicht, das wichtige Sicherheits-Patches enthält. Diese Aktualisierung, die genau zwei Monate nach der vorherigen Version 12.4 erfolgt, ist die fünfte in der stabilen “Bookworm”-Serie. Hauptbestandteil dieses Updates sind Fehlerkorrekturen und Sicherheits-Patches, da Debian bei seinen kleineren Veröffentlichungen den Fokus auf die Stabilität des Systems legt ohne neue Funktionen...
Als Teil der Bemühungen, sein Angebot an Desktop-Umgebungen zu vereinheitlichen, hat Fedora eine neue Familie von Linux Spins namens „Fedora Atomic Desktops“ eingeführt. Diese umfassen vier Haupt-Spins: Dieser Rebranding-Prozess zielt darauf ab, die Klarheit und Kohärenz in Bezug auf Fedoras Verwendung der rpm-ostree-Technologie zu verbessern, die atomare Updates und Rollbacks ermöglicht, um die Systemstabilität und...
Die Entscheidung für die optimale Linux-Distribution für den täglichen Gebrauch ist von erheblicher Bedeutung und beeinflusst maßgeblich das gesamte Nutzungserlebnis. Angesichts einer Vielzahl von verfügbaren Optionen, die jeweils auf unterschiedliche Vorlieben und Bedürfnisse zugeschnitten sind, erfordert die Suche nach der besten Lösung sorgfältige Überlegungen. In diesem umfassenden Leitfaden werden wir vier der führenden Linux-Distributionen erkunden,...
Ab sofort gibt es eine neue Version von PeaZip. Das Archivierungs-Programm ist Open Source und für Linux, Windows und macOS verfügbar. Du kannst es kostenlos herunterladen. Eine besondere Neuerung bei PeaZip 9.7 ist, dass es nun eine native Version für AArch64/ARM64 Linux gibt. Das heißt, Du kannst PeaZip jetzt auch auf einem Raspberry Pi 5 oder Vorgängern nutzen, die 64-Bit unterstützen. Das gilt natürlich für alle anderen Plattformen mit einer entsprechenden Architektur. Es gab bereits experimentelle Versionen und auch die […]
Der Raspberry Pi 5 ist schon eine Weile auf dem Markt. Bisher hatte ich aber keine Gelegenheit, selbst einen zu testen. Nun ist es endlich so weit und ich habe ein ähnliches Experiment wie damals mit dem Raspberry Pi 400 durchgeführt. Der Pi 400 oder 4 eignet sich bedingt als Desktop-Ersatz. Die Sache kann ziemlich langsam werden, insbesondere, wenn viele Anwendungen offen sind oder Du Aufgaben durchführst, die zu viel Leistung erfordern. Der Pi 5 ist wesentlich schneller und ich […]