Am 16. September 2023 fanden in Halle am Institut für Informatik der Martin-Luther-Universität die Campus Medien Tage 2023 statt.
Hierzu wurde ich von der Studierendenzeitschrift hastuzeit angefragt, einen kleinen Workshop zum Thema WordPress durchzuführen. Da dies eine gute Plattform bot, die freie Software WordPress vorzustellen, habe ich nicht lange überlegt und ja gesagt. Ich wusste zu diesem Zeitpunkt nicht, in wie weit das Puplikum schon mit diesem Content-Management-System gearbeitet hat, deshalb habe ich mich kurzerhand dazu entschieden auf die Grundlagen von WordPress einzugehen und die Basics etwas näher zu beleuchten.
Instagram-Post cameta_halle
Campus Medien Tage 2023
Da tatsächlich nur ein Viertel der anwesenden Studierenden mit WordPress (aus administrativer Sicht) bisher in Berührung kam, lag ich mit meinem Gefühl hier durchaus richtig. Einige Fragen konnten in der anschließenden Diskussion noch beantwortet werden.
Neben meinem Vortrag gab es viele weitere interessante Themen, wie Grafikbearbeitung, die richtige Verwendung von Suchmaschinen, Künstliche Intelligenz, Fotografie, Tipps zum redaktionellen Schreiben und Rechtliches, in Form von Vorträgen und Workshops.
Workshop CaMeTa
Alles in allem war es eine sehr gute Veranstaltung, organisiert und durchgeführt von engagierten jungen und wissbegierigen Menschen.
pip ist das Paketverwaltungs-Tool von Python. Wenn Sie in einem Script ein Zusatzmodul benötigen, führen Sie einfach pip install xxx bzw. unter macOS und bei manchen Linux-Distributionen pip3 install xxx aus. pip lädt das erforderliche Modul sowie eventuelle Abhängigkeiten herunter und installiert die Pakete lokal (d.h., sie brauchen meine root-Rechte).
Meistens funktioniert pip gut — aber nicht immer. Die häufigste Fehlerquelle unter Windows ist die Parallelinstallation mehrerer Python-Versionen. Dann ist nicht immer klar, auf welche Python-Version sich pip bezieht. Nach meiner Erfahrung scheint pip zumeist die falsche Version zu nehmen. Daher mein Tipp: Vermeiden Sie unter Windows unbedingt die Mehrfachinstallation von Python!
Aber auch unter Linux kann es Probleme geben. Die Ursache hier besteht darin, dass viele Distributionen selbst eine riesige Sammlung von Paketen mit Python-Erweiterungen anbieten. Die Parallelinstallation eines Moduls, einmal mit apt oder dnf und ein zweites Mal mit pip, kann dann zu Konflikten führen — insbesondere dann, wenn nicht exakt dieselben Versionen zum Einsatz kommen. Die Python-Entwickler haben deswegen im Python Enhancement Proposals (PEP) 668 festgeschrieben, dass in solchen Fällen Pakete aus Linux-Repositories vorzuziehen sind. PEP 668 gilt grundsätzlich seit Python 3.11. Tatsächlich implementiert ist es momentan nur in aktuellen Linux-Distributionen:
Ubuntu ab Version 23.04
Debian ab Version 12
Raspberry Pi OS ab dem Bookworm-Release (Okt. 2023)
Arch Linux
Noch nicht implementiert ist PEP 668 dagegen unter RHEL und Fedora (auch nicht in Version 39 Beta).
pip-Fehlermeldung
Der Versuch, mit pip ein Modul zu installieren, führt bei aktuellen Debian-, Ubuntu- und Raspberry-Pi-OS-Versionen zur folgenden Fehlermeldung:
$ pip install matplotlib
error: externally-managed-environment
This environment is externally managed
To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.11/README.venv for more information.
note: If you believe this is a mistake, please contact your Python
installation or OS distribution provider. You can override this,
at the risk of breaking your Python installation or OS, by
passing --break-system-packages. Hint: See PEP 668 for the
detailed specification.
Lösung 1: Installation des äquivalenten Linux-Pakets
Die obige Fehlermeldung weist direkt auf die beste Lösung hin — nämlich die Installation des entsprechenden Linux-Pakets mit apt python3-xxx, wobei xxx der Paketname ist. Für die matplotlib führen Sie unter Debian, Ubuntu und Raspberry Pi OS das folgende Kommando aus:
sudo apt install python3-matplotlib
Diese Empfehlung ist mit zwei Einschränkungen verbunden: Sie erfordert, dass Sie root– oder sudo-Rechte haben, und sie setzt voraus, dass das gewünschte Modul tatsächlich im Repository Ihrer Linux-Distribution zur Verfügung steht. Letzteres ist oft der Fall, aber nicht immer. Auf pypi.org gibt es fast 500.000 Projekte, die Debian-Standard-Repositories enthalten dagegen »nur« gut 4000 (apt list | grep python3- | wc -l).
Lösung 2: Verwendung einer virtuellen Umgebung
Ein Virtual Environment im Kontext von Python ist ganz einfach ein Projektverzeichnis, in das die für das Projekt erforderlichen Module lokal und projektspezifisch installiert werden. Das hat mehrere Vorteile:
Es ist klar, welche Module ein bestimmtes Projekt benötigt. Das Projekt lässt sich später einfacher auf einen anderen Rechner übertragen.
Es kann keine Konflikte zwischen unterschiedlichen Projekten geben, die unterschiedliche Module erfordern.
Sie sind nicht auf die von Ihrer Linux-Distribution angebotenen Python-Module eingeschränkt und brauchen keine Administratorrechte zur Installation von Linux-Paketen.
Virtuelle Umgebungen werden von Python durch das Modul venv unterstützt. Dieses Modul muss vorweg installiert werden, entweder mit apt install python3-venv oder durch apt install python3-full. Anschließen richten Sie Ihr Projekt ein:
$ python3 -m venv my-project
Python erzeugt das Verzeichnis my-project, falls dieses noch nicht existiert, und richtet dort eine minimale Python-Umgebung ein. (»Minimal« bedeutet: ca. 1500 Dateien, Platzbedarf ca. 25 MByte. Nun ja.) Nun führen Sie in Ihrem Terminal-Fenster mit source das Shell-Script activate aus, um die Umgebung zu aktivieren:
$ cd my-project
$ source bin/activate
(my-project)$
In dieser Umgebung funktioniert pip wie gewohnt. In der Folge können Sie Ihr Script ausführen, das die lokal installierte Module nutzt:
Anstelle venv direkt zu nutzen, gibt es diverse Tools, um die Verwaltung Ihrer virtuellen Umgebungen zu vereinfachen. Am bekanntesten sind pipenv und virtualenv. Persönlich ist mir pipenv am liebsten. Das Tool muss vorweg installiert werden (apt install pipenv).
Lösung 3: Das Kommando pipx
pipx ist eine Variante zum klassischen pip-Kommando, das sich gleichzeitig um die Einrichtung einer virtuellen Umgebung kümmert (siehe auch die Dokumentation). pipx ist allerdings nicht zur Installation von Bibliotheken gedacht, sondern zur Installation fertiger Python-Programme. Diese werden in .local/bin gespeichert.
pipx ist nur dann eine attraktive Option, wenn Sie ein als Python-Modul verfügbares Programm unkompliziert installieren und ausführen wollen. Wenn Sie dagegen selbst Scripts entwickeln, die von anderen Modulen abhängig sind, ist pipx nicht das richtige Werkzeug.
Lösung 4: Option pip --break-system-packages
Ein vierter Lösungsweg besteht darin, an pip die Option --break-system-packages zu übergeben. Die Option ist weniger schlimm, als ihr Name vermuten lässt. Im Prinzip funktioniert pip jetzt so wie bisher und installiert das gewünschte Modul, ganz egal, ob es ein äquivalentes Paket Ihrer Distribution gibt oder nicht, und unabhängig davon, ob dieses Paket womöglich schon installiert ist.
Empfehlenswert ist der Einsatz dieser Option in CI-Scripts (Continuous Integration), z.B. in Test- oder Deploy-Scripts für git (siehe auch diesen Blog-Beitrag von Louis-Philippe Véronneau). Die Option --break-system-packages ist oft der schnellste und bequemste Weg, nicht mehr funktionierende Scripts wieder zum Laufen zu bringen.
Nachdem Hasskommentare in der ukrainischen Übersetzungsdateien entfernt wurden (siehe auch omgubuntu.co.uk), steht das ISO-Image von Ubuntu 23.10 »Mantic Minotaur« wieder zum Download zur Verfügung. Die neueste Version von Ubuntu ist das letzte Release vor der nächsten LTS-Version — und insofern besonders interessant: »Mantic Minotaur« vermittelt eine erste Vorstellung, wie Ubuntu LTS die nächsten Jahre prägen wird.
Updates: 14.11.2023, Netplan
Installation und App Center
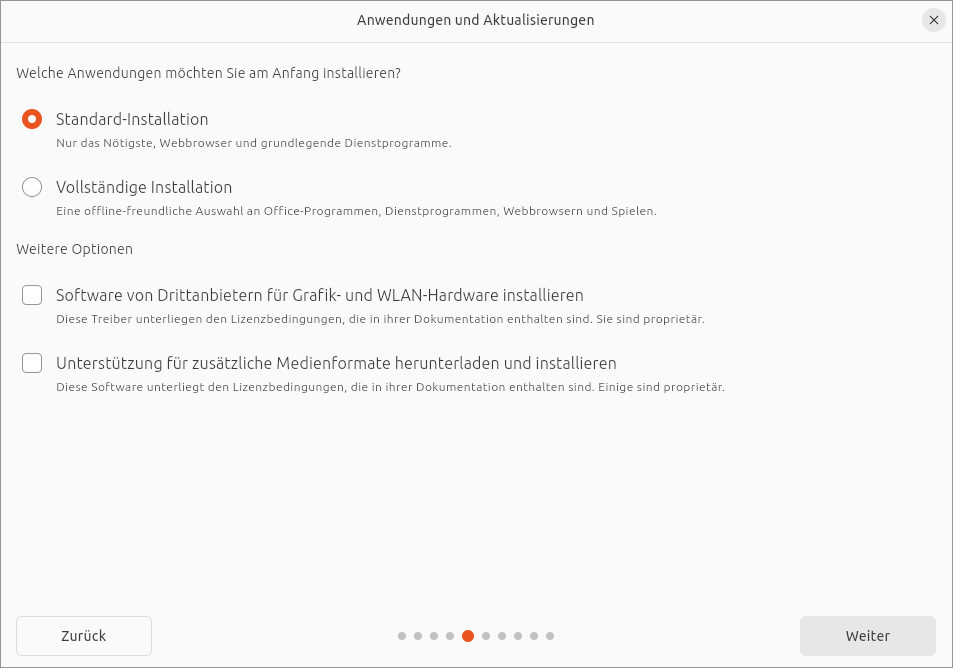
Ich habe die Installation diesmal nur in virtuellen Maschinen getestet. Zumindest dort hat das neue Installationsprogramm problemlos funktioniert — auf jeden Fall besser als in Version 23.04, in der das Installationsprogramm erstmalig zum Einsatz kam. Die für die meisten Nutzer wichtigste Neuerung besteht darin, dass nun standardmäßig eine »Minimalinstallation« durchgeführt wird — ohne LibreOffice, Thunderbird, Foto-Verwaltung, Audio-Player usw.
Standardmäßig wird eine Minimalinstallation ohne Office-Programme durchgeführt
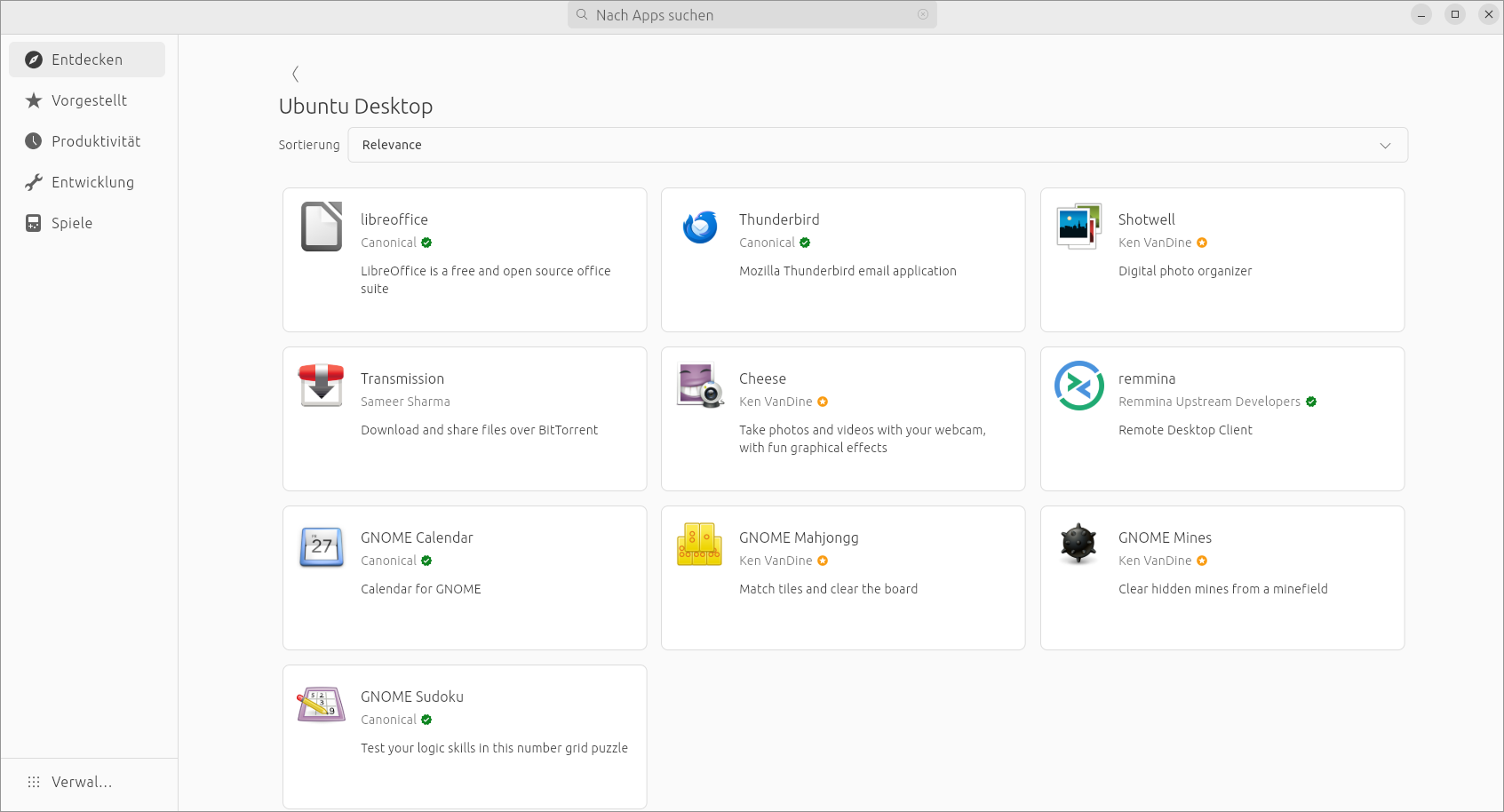
Grundsätzlich mag ich diesen Minimalismus. Bei der Installation der fehlenden Programme hilft das mit der Bibliothek Flutter neu implementierte »App Center«, dessen Versionsnummer 1.0.0-alpha lautet. 1.0.0 klingt an sich schon abschreckend, »alpha« macht es noch schlimmer. Bei meinen Tests sind aber erfreulicherweise keine Probleme aufgetreten. Im App Center führt Entdecken / Jump start your desktop in die Sammlung Ubuntu Desktop, die auf bisher vorinstallierte Pakete verweist.
Eine Rubrik im neuen App Center offeriert wichtige Office-Programme ausschließlich im Snap-Format
Eines sollte Ihnen aber klar sein: Anders als manche Tester von Ubuntu 23.10 geschrieben haben, werden mit dem App Center ausschließlich Snap-Pakete installiert. Ob das gewünschte Programm auch im Debian-Format zur Verfügung steht oder nicht, spielt keine Rolle. Für das App Center gilt Snap only. Falls Sie Debian-Pakete vorziehen, müssen Sie diese nun im Terminal mit apt suchen und installieren (also z.B. apt install gimp). In Ubuntu gibt es keine (vorinstallierte) grafischer Oberfläche mehr, um Debian-Pakete zu installieren.
Das App Center ist auch insofern ein Rückschritt, als es nicht in der Lage ist, heruntergeladene Debian-Pakete zu installieren. Wenn Sie im Webbrowser die gerade heruntergeladene *.deb-Datei anklicken, erhalten Sie die Fehlermeldung, dass es kein (grafisches) Programm zur Verarbeitung von *.deb-Dateien gibt. Sie müssen die Installation wie folgt durchführen:
sudo apt install ~/Downloads/name.deb
Platzbedarf
Ich habe in der Vergangenheit oft über den immensen Platzbedarf von Snap-Paketen geschimpft, sowohl auf der SSD als auch (nach dem Start) im Arbeitsspeicher. Für diesen Artikel wollte ich diese Aussagen mit neuem Zahlenmaterial untermauern, bin aber auf überraschende Ergebnisse gestoßen.
Die neue »Minimalinstallation« beansprucht 4,7 GByte Platz auf der SSD. Nicht mitgerechnet ist dabei die Swap-Datei /swap.img. Das Installationsprogramm richtet diese Datei je nach Hardware sehr großzügig ein (bei meinen Tests mit 3,9 GiB). Tipps, wie Sie die Swap-Datei bei Bedarf verkleinern können, folgen gleich.
Der Snap-Anteil nach einer Minimalinstallation beträgt ca. 1 GByte:
Ich habe nun alle Snaps aus der Rubrik Ubuntu Desktop installiert, also LibreOffice, Thunderbird, Shotwell usw., insgesamt 10 Pakete. Der Platzbedarf der Snaps steigt auf 2,8 GByte:
Der RAM-Bedarf des Ubuntu-Desktops im Leerlauf mit einem Terminal-Fenster und dem Programm Systemüberwachung beträgt laut free -h ca. 1,2 GByte. Nun habe ich Firefox (ca. 8 Sekunden), Shotwell (wieder 8 Sekunden) und LibreOffice Writer (20 Sekunden) gestartet, ohne darin aktiv zu arbeiten. Alle Tests habe ich in einer virtuellen Maschine mit 2 CPU-Cores und 4 GiB RAM durchgeführt. Auf echter Hardware sind schnellere Startzeiten zu erwarten.
Der Speicherbedarf im RAM steigt dann auf moderate 1,9 GByte an.
Kurz und gut: Der Platzbedarf von Snap-Paketen sowohl auf dem Datenträger als auch im Arbeitsspeicher ist beträchtlich, aber er ist nicht mehr so exorbitant hoch wie früher. Und je mehr Snap-Pakete parallel installiert werden, desto geringer ist der gemeinschaftliche Overhead durch die Parallelinstallation diverser Bibliotheken. (Unter Ubuntu 23.10 ist Gnome 45 installiert. Aber damit alle Snap-Pakete der Kategorie Ubuntu Desktop ausgeführt werden können, ist parallel dazu auch Gnome 42 und Gnome 3.38 erforderlich — siehe das obige Listing.)
Die Startzeiten von Programmen sind weiterhin etwas höher als bei einer gleichwertigen Installation durch Debian-Pakete, aber damit kann ich mich abfinden. Canonical hat seine Snap-Infrastruktur also in den vergangenen Jahren schrittweise verbessert. Sie funktioniert nun spürbar besser als in den ersten Versionen.
Als wichtigster Kritikpunkt bleibt der proprietäre Snap Store, der alleine durch Canonical verwaltet wird. Alternative Snap-Paketquellen sind nicht vorgesehen (ganz im Gegensatz zu Red Hats Flatpak-System).
Swap-Datei verkleinern
Sie können die Swap-Datei bei Bedarf Ihren eigenen Bedürfnissen entsprechend verkleinern:
Canonical wollte CUPS eigentlich in ein Snap-Paket umbauen (siehe openprinting.github.io) und in dieser Form in Ubuntu integrieren. Aufgrund technischer Probleme ist dieses Vorhaben nun voraussichtlich bis Version 24.10 verschoben. Die LTS-Version 24.04 ist für derartige Experimente nicht so gut geeignet.
TPM-Verschlüsselung
Technisch sehr interessant ist Canonicals Konzept, die Verschlüsselung des Datenträgers mittels TPM (Trusted Platform Modules, also in die CPU eingebaute Kryptografie-Funktionen) abzusichern. Unter Windows, macOS, iOS und Android ist dies längst eine Selbstverständlichkeit. Mangels geeigneter Hardware habe ich diese Funktionen allerdings nicht testen können.
Aktuell bezeichnet die Dokumentation dieses Feature zudem noch als experimentell. Es wird nur ausgewählte TPM-Hardware unterstützt. Die Implementierung basiert (natürlich) auf Snap-Paketen für den Bootloader und den Kernel. Proprietäre Kernel-Module (NVIDIA) können nicht verwendet werden. Soweit ich das Konzept verstanden habe, muss das Verschlüsselungspasswort weiterhin eingegeben werden, d.h. das Hochfahren und Authentifizieren nur per Fingerabdruck ist nicht möglich. Oder, anders formuliert: Das Boot-Konzept wird sicherer, aber nicht komfortabler.
Netplan
Ubuntu verwendet mit Netplan seit 2016 ein selbst entwickeltes System zur Administration der Netzwerkverbindungen. Netplan ist vor allem bei Server-Installationen wichtig, wo es eine zentrale Rolle einnimmt. Am Desktop delegiert Netplan die Kontrolle über die WLAN-Schnittstellen dagegen an den NetworkManager. Insofern haben Desktop-Anwender Netplan nie bemerkt.
Grundsätzlich ändert sich daran auch mit Version 23.10 nichts. Neu ist aber, dass die Kommunikation zwischen dem NetworkManager und Netplan nicht länger eine Einbahnstraße ist. Bisher wusste Netplan nichts von den durch den NetworkManager verwalteten Netzwerkverbindungen. Laut dem Ubuntu Blog hat sich das mit Version 23.10 geändert: Vom NetworkManager eingerichtete Verbindungen werden nun in /etc/netplan gespeichert (und nicht mehr in /etc/NetworkManager/system-connections/). Dabei kommt die Netplan-eigene Syntax für Konfigurationsdateien zum Einsatz. Bei einem Update von älteren Ubuntu-Versionen werden vorhandene WLAN-Verbindungen automatisch nach /etc/netplan migriert.
Desktop
Ubuntu 23.10 verwendet Gnome 45 als Desktop. Mehrere vorinstallierte Shell Extensions (Desktop Icons, Ubuntu AppIndicators, Ubuntu Dock und Ubuntu Tiling Assistand) stellen sinnvolle Zusatzfunktionen zur Verfügung:
Das Dock kann wahlweise links, rechts oder unten platziert werden.
Fenster können so verschoben werden, dass diese ein Bildschirmviertel ausfüllen (Quarter Tiling). Außerdem gibt es einige fortgeschrittene Tiling-Funktionen. (Gnome ohne Erweiterungen kennt bekanntermaßen nur Bildschirmhälften, was auf einem großen Monitor mager ist.)
Auf dem Desktop können Icons dargestellt werden.
Ältere Gnome-Programme können Indikator-Icons im Panel darstellen.
Ubuntu verwendet Gnome 45 als Desktop, angereichert um ein paar Extensions für das vertikale Dock, Quarter-Tiling und Desktop-Icons
Der Fokus auf Snap macht es nicht immer ganz klar, wo welches Paket zu suchen ist. Gimp, LibreOffice, aber auch Docker (!) können als Snap-Pakete installiert werden. Programmiersprachen wie C, Java, Python oder PHP (Ausnahme: Go, siehe Kommentare) sowie Server-Anwendungen wie Apache, MySQL oder Samba sind vorerst noch gewöhnliche Debian-Pakete.
Raspberry Pi
Ubuntu 23.10 läuft auch auf dem nagelneuen Raspberry Pi 5. Einen diesbezüglichen Test habe ich schon vor ein paar Tagen veröffentlicht.
Fazit
Aus meiner Sicht ist und bleibt Ubuntu die erste Anlaufstelle für Linux-Einsteiger. Der Desktop ist optisch ansprechend, Gnome Shell Extensions helfen dort nach, wo Gnome Defizite hat. In ganz vielen Fällen gilt: It just works.
Allerdings hat sich Canonical — allen Widerständen zum Trotz — dazu entschieden, voll auf das eigene Snap-Paketformat zu setzen. Grundsätzlich funktioniert das gut. Aus der Sicht von Canonical ist es natürlich toll, nur ein Paket für verschiedene Ubuntu-Releases warten zu müssen — und die Paket-Version losgelöst von der Ubuntu-Version auch aktualisieren zu können. Canonical kann also durch die Änderung eines Pakets ein LibreOffice-Update auf das nächste Major-Release für alle gerade aktiven Ubuntu-Versionen durchführen. Diesem Vorteil steht anwenderseitig ein — sagen wir mal — großzügiger Umgang mit Ressourcen gegenüber.
Bisher konnte man als erfahrener Ubuntu-Anwender Snap-Paketen aus dem Weg gehen, also snap deinstallieren und anstelle von Snap-Paketen gleichwertige Debian-Pakete installieren. Das wird zunehmend unmöglich, und das ist letztlich auch der falsche Denkansatz. Vielmehr gilt: Wer Ubuntu sagt, muss auch Snap sagen. Und wer das nicht will, muss sich von Ubuntu verabschieden.
Ich bin deswegen auf ArchLinux umgestiegen und habe es nicht bereut. Für Linux-Einsteiger, die dem Snap-Kosmos misstrauisch gegenüberstehen, sind Debian oder Linux Mint einfachere Alternativen. Wenn Sie dagegen keine ideologischen Einwände gegen Snap haben und einen ordentlichen Rechner besitzen, ist Ubuntu samt Snap eine runde Sache.
(Aktualisiert am 15.10.2023, Geekbench-Ergebnisse mit/ohne Lüfter)
Nach Raspberry Pi OS Bookworm habe ich mir heute auch Ubuntu 23.10 auf dem Raspberry Pi angesehen. In aller Kürze: Der Raspberry Pi 5 ist ein großartiger Desktop-Rechner, Ubuntu mit Gnome unter Wayland läuft absolut flüssig.
Ubuntu 23.04 mit Gnome-Desktop und Wayland auf einem Raspberry Pi 5
Systemvoraussetzungen
Die Desktop-Version von Ubuntu 23.10 läuft nur auf den Modellen 4B, 400 und 5 und beansprucht zumindest 4 GiB RAM. Bei meinem Test mit offenem Terminal, Firefox (zwei Tabs mit GitHub und orf.at) sowie dem neuen App Center waren erst gut 2 GiB RAM in Verwendung. Mit offenem Gimp, VS Code und App Center steigt der Speicherbedarf dann auf 4 GiB. Insofern sind für’s ernsthafte Arbeiten 8 GiB RAM sicher kein Schaden.
Installation
Zur Installation habe ich mit dem Raspberry Pi Imager Ubuntu 23.10 auf eine SD-Karte übertragen. Die Spracheinstellung in der Konfigurationsphase beim ersten Starts bleibt wirkungslos und muss später in den Systemeinstellungen nachgeholt werden. Außerdem müssen mit Installierte Sprachen verwalten alle erforderlichen Sprachdateien heruntergeladen werden.
Ein initiales Ubuntu-Desktop-System beansprucht etwa 6 GByte auf der SD-Karte. Mit Schuld am verhältnismäßig großem Speicherbedarf für ein Ubuntu-»Minimalsystem« ohne Anwendungsprogramme ist der unmäßige Speicherbedarf der vorinstallierten Snap-Paketen (App Center, Firefox plus alle dazu erforderlichen Basisbibliotheken).
Gnome
Gnome 45 mit Wayland läuft absolut flüssig. Nur der Start von Snap-Apps führt zu kleinen Verzögerungen — das kennt man ja auch von Ubuntu-Installationen auf hochwertiger Hardware. Bei meinem Testrechner (Pi 5 mit 8 GiB RAM) braucht Firefox beim ersten Start ca. 4 Sekunden, bis es am Bildschirm erscheint. Damit kann man wirklich leben ;-)
Screenshots funktionieren auf Anhieb.
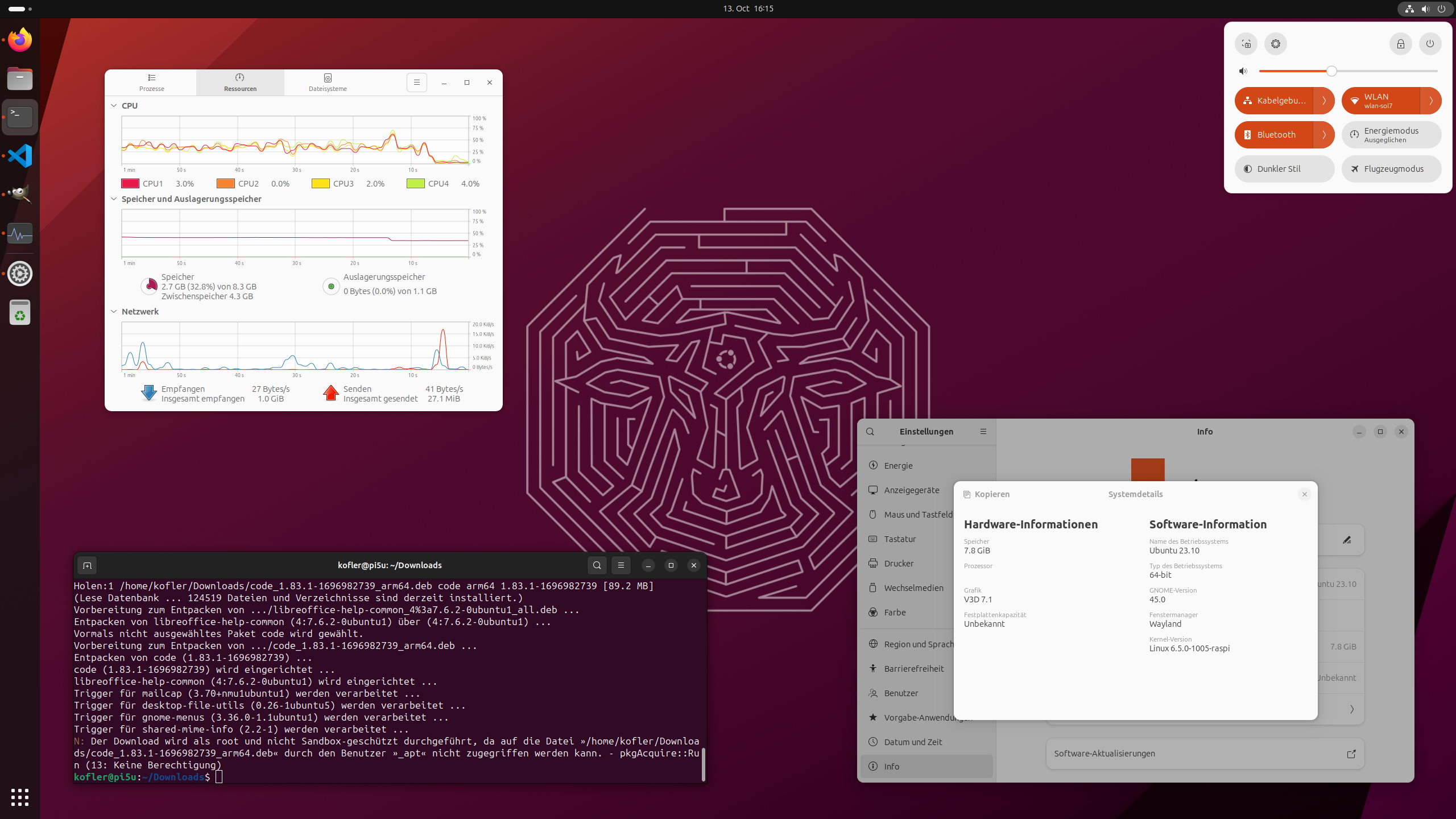
Bei der Erkennung der Systemdaten (also Info/Systemdetails in den Einstellungen) versagt Gnome aber und kann weder die CPU noch die Größe der SD-Karte erkennen (siehe die Abbildung oben). Aber das sind Kleinigkeiten.
Kernel
Ubuntu verwendet mit Version 6.5 einen neueren Kernel als Raspberry Pi OS. Im Gegensatz zu Raspberry Pi OS kommt die »normale« Pagesize von 4 kByte zum Einsatz:
pi5u$ uname -a
Linux pi5u 6.5.0-1005-raspi #7-Ubuntu SMP PREEMPT_DYNAMIC
Sun Oct 8 08:06:18 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
pi5u$ getconf PAGESIZE
4096
Visual Studio Code
Erstaunlicherweise fehlt in der Snap-Bibliothek Visual Studio Code. Ein Debian-Paket für ARM64 kann von https://code.visualstudio.com heruntergeladen werden. Es muss dann mit sudo apt install ./code_xxx.deb installiert werden. Die nachfolgende Fehlermeldung pkgAcquire::Run / Keine Berechtigung können Sie ignorieren. Vergessen Sie aber nicht, ./ bzw. einen gültigen Pfad voranzustellen, sonst glaubt apt, code_xxx.deb wäre der Paketname und verweigert die Installation der lokalen Datei.
Geekbench
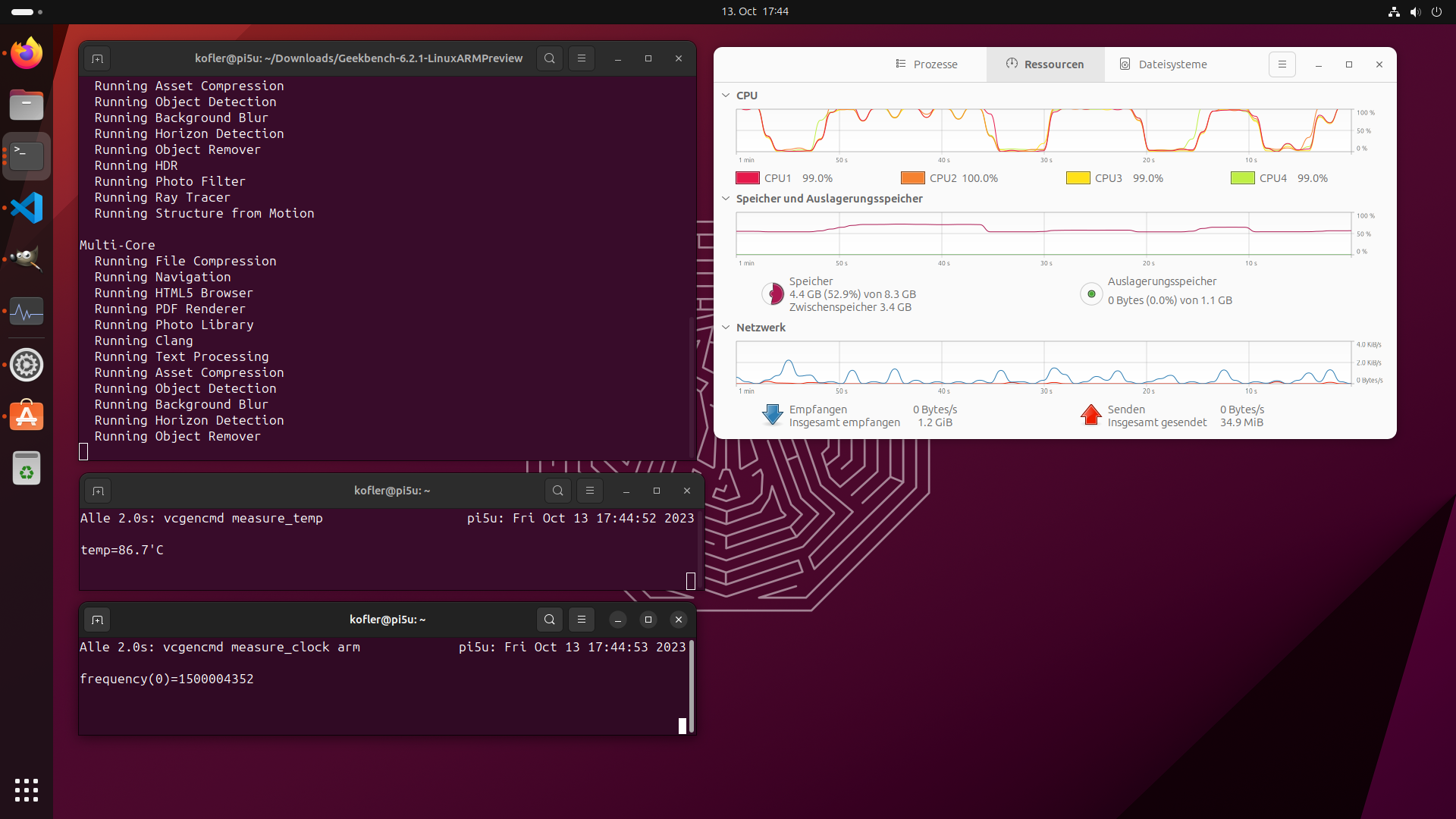
Unter https://www.geekbench.com/preview/ gibt es eine AArch64-Version von Geekbench, die ich heruntergeladen, ausgepackt und ausgeführt habe. Die Temperatur des SoC steigt während der Tests auf über 85 °C. Die CPU-Frequenz wird in der Folge auf 1,5 GHz gedrosselt. Ich habe keine Kühlung verwendet (weder aktiv noch passiv). Ergebnisse unter diesen Voraussetzungen: 657
Single-Core Score, 1233 Multi-Core Score. Mehr Details finden Sie hier: https://browser.geekbench.com/v6/cpu/3060411
Geekbench
Im Leerlauf unter Ubuntu 23.10 beträgt die CPU-Temperatur übrigens gut 70°C, also auch schon mehr als genug.
Ubuntu fehlt eine dynamische Lüftersteuerung. Sobald ein Lüfter angeschlossen wird, läuft dieser mit maximaler Leistung und produziert ein durchaus störendes Ausmaß an Lärm. Die CPU-Temperatur sinkt dann im Leerlauf auf gut 30°C. Selbst während der Ausführung von Geekbench steigt die Temperatur nur kurzzeitig über 45°C. Gleichzeitig fallen die Werte etwas besser aus (siehe auch https://browser.geekbench.com/v6/cpu/3095791).
Geekbench 6 Single-Core Multi-Core
-------------- ------------ ------------
Ohne Lüfter 657 1233
Mit Lüfter 737 1542
Eine letzte Anmerkung zu Geekbench: Die 64-Bit-Version von Raspberry Pi OS und Geekbench 6.2 sind wegen der 4-kByte-Pagesize inkompatibel zueinander.
Abstürze
Während meiner Tests kam es zweimal zu kapitalen Abstürzen (Bildschirm wurde schwarz, kein Netzwerkzugriff mehr etc.). Möglicherweise war das von mir eingesetzte Netzteil zu schwach. (Unter Raspberry Pi OS hatte ich mit demselben Netzteil allerdings keine Probleme.)
Ich bin dann auf das neue Original-Raspberry-Pi-Netzteil umgestiegen (27 W für einen Minirechner erscheinen wirklich mehr als üppig, aber sei’s drum). Die Komplett-Abstürze haben sich nicht wiederholt.
Allerdings ist in der Folge auch Gimp bei der Verwendung des Dateiauswahldialogs zweimal abgestürzt. Das kenne ich von meinem Notebook überhaupt nicht. Ich kann natürlich nicht sagen, ob dieses Problem ARM-, Ubuntu- oder Raspberry-Pi-spezifisch ist. Aber für zwei Stunden Betrieb waren das für meinen Geschmack recht viele Abstürze …
Seit gestern ist die neue Version von Raspberry Pi OS auf der Basis von Debian 12 (»Bookworm«) verfügbar. Diese Version ist Voraussetzung für den Raspberry Pi 5, läuft aber natürlich auch auf älteren Raspberry Pis. Ich habe meine Tests auf einem Pi 5 sowie einem Pi 400 durchgeführt.
Auf den ersten Blick sieht der Desktop auf der Basis von LXDE nahezu unverändert aus. Aber dieser Eindruck täuscht erheblich: Raspberry Pi OS verwendet jetzt Wayland, PipeWire und den NetworkManager.
Auf den Modellen Pi 4, Pi 400 und Pi 5 läuft der Pixel Desktop unter Wayland
Wayland für Pi 4 und 5, Abschied von X in Raten
Auf aktuellen Raspberry-Pi-Modellen (Pi 4, Pi 400, Pi 5) kommt nun standardmäßig Wayland statt xorg als Fundament für das Grafiksystem zum Einsatz.
pi5$ echo $XDG_SESSION_TYPE
wayland
Das ist ein großer Schritt, weil dafür viele Komponenten verändert bzw. hinzugefügt werden mussten:
Zusammen mit dem Panel mussten auch die diversen Plugins für das Menü, die Bluetooth- und WLAN-Konfiguration, Lautstärkeeinstellung usw. neu implementiert werden.
Das für Wayland neu implementierte Panel hat zwei Plugins, die die CPU-Auslastung und -Temperatur anzeigen
Der Wayland-Umstieg ist mit den von anderen Desktop-Systemen bekannten Einschränkungen bzw. Kinderkrankheiten verbunden: Fernwartung, Screenshots usw. zicken bzw. funktionieren gar nicht. Auf das Thema VNC und Remote Desktop gehe ich hier in einem eigenen Artikel ein. Zum Erstellen von Screenshots verwenden Sie am besten das Kommando grim (siehe Projektseite). Gimp und scrot liefern lediglich schwarze Bilder, shutter stürzt ab.
Ältere Raspberry-Pi-Modelle (Pi 3, Zero etc.) verwenden aufgrund von Performance-Problemen weiterhin xorg. Aber auch bei diesen Modellen ist in Zukunft der Wechsel zu Wayland geplant.
Audio-System PipeWire
Nach Fedora, Ubuntu & Co. verwendet nun auch Raspberry Pi OS das neue PipeWire-Audiosystem. Es ersetzt PulseAudio. Für die Desktop-Nutzung der Audio-Funktionen sollten sich dadurch nichts ändern. Wenn Sie Audio-Funktionen per Script steuern möchten, müssen Sie sich an die neuen pw-xxx-Kommandos gewöhnen (siehe https://docs.pipewire.org/page_tools.html).
Netzwerkkonfiguration mit dem NetworkManager
Ähnlich wie beim Audio-System passt sich Raspberry Pi OS auch bei der Netzwerkkonfiguration den anderen Distributionen an und verwendet nun den NetworkManager als Backend. dhcpcd hat ausgedient. Wiederum ist von der Änderung an der Oberfläche nicht viel zu sehen. Die Konfigurationswerkzeuge zur Herstellung einer WLAN-Verbindung sehen ähnlich aus wie bisher. Allerdings gibt es nun diverse neue Funktionen, z.B. zur Herstellung von VPN-Verbindungen. Änderung ergeben sich auch, wenn Sie die Netzwerkkonfiguration per Script verändern möchten. Das wichtigste neue Kommando ist nmcli. Die Konfigurationsdateien werden in /etc/NetworkManager gespeichert. WLAN-Passwörter landen in /etc/NetworkManager/system-connections/*.conf.
Bei meinen Tests traten im Zusammenspiel mit dem Raspberry Pi Imager bei der Vorweg-Konfiguration (z.B. für Headless-Systeme) noch Fehler auf. Es ist aber zu erwarten/hoffen, dass diese bald gelöst sein werden.
Webbrowser: Firefox oder Chromium?
In der Vergangenheit galt Chromium als Default-Webbrowser für Raspberry Pi OS. In Kooperation mit Mozilla wurde nun auch Firefox besser an die Hardware- und Software-Eigenheiten angepasst und wird nun als gleichwertige Alternative angeboten. Standardmäßig sind beide Programme installiert. Den Default-Webbrowser können Sie im Programm Raspberry-Pi-Konfiguration festlegen.
Mathematica
Aus nostalgischen Gründen bin ich ein großer Fan von Mathematica und finde es fantastisch, dass das Programm Raspberry-Pi-OS-Anwendern kostenlos zur Verfügung steht. Das gilt auch für die neue Version von Raspberry Pi OS — aber aktuell nicht auf dem Pi 5. Dort erscheint beim Start der Hinweis, dass ein Lizenzcode erforderlich ist. Anscheinend soll dieses Problem
noch behoben werden. Die Raspberry Pi Foundation wartet diesbezüglich auf ein Update von Wolfram (Quelle). Update 9.11.2023: Mit den neuesten Updates funktioniert nun auch Mathematica wieder — und zwar schneller denn je!
Versionsnummern
Dank des neuen Fundaments auf der Basis von Debian 12 haben sich viele Versionsnummern geändert:
Bisher war es unter Python gebräuchlich, Zusatzmodule einfach mit pip bzw. pip3 zu installieren. In aktuellen Python-Versionen ist das nicht mehr erwünscht und führt zu einem Fehler:
$ pip install --user matplotlib
error: externally-managed-environment
This environment is externally managed
To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
For more information visit http://rptl.io/venv
note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages.
hint: See PEP 668 for the detailed specification.
Es gibt zwei Auswege:
Einer besteht darin, das entsprechende Paket aus dem Raspberry Pi OS Repository zu installieren. Für das obige Beispiel würde das richtige Kommande sudo apt install python3-matplotlib lauten.
Der geänderte Umgang mit Python-Modulen hat übrigens nichts mit Raspberry Pi OS zu tun, sondern ist eine von der Python-Entwicklergemeinde vorgegebene Änderung, die alle modernen Linux-Distributionen betrifft.
Ich habe meine Tests dagegen mit der 64-Bit-Version durchgeführt, die für Pi-Modelle mit mehr als 2 GByte zweckmäßiger ist, einzelnen Prozessen mehr RAM zuordnen kann und etwas mehr Geschwindigkeit verspricht.
Interessanterweise kommt je nach Raspberry-Pi-Modell eine unterschiedliche Pagesize zum Einsatz: 16 kByte auf dem Raspberry Pi 5 aber wie bisher 4 kByte auf dem Raspberry Pi 400.
Die 16-kByte-Pagesize ist übrigens zu manchen Programmen inkompatibel. Unter anderem kann deswegen Geekbench 6.2 nicht in der 64-Bit-Version von Raspberry Pi OS ausgeführt werden.
Lüftersteuerung
Der Raspberry Pi 5 enthält eine Buchse zum Anschluss eines CPU-Lüfters. Raspberry Pi OS kümmert sich darum, den Lüfter nur nach Bedarf einzuschalten, und auch dann dynamisch (also nur in der erforderlichen Drehzahl). Im Leerlaufbetrieb bleibt der Raspberry Pi 5 lautlos.
Upgrade
Ein Upgrade eines bereits installierten Raspberry Pi OS »Bullseye« auf Version »Bookworm« ist theoretisch durch eine Veränderung der Paketquellen möglich (siehe z.B. hier im Raspberry-Pi-Forum). Diese Vorgehensweise wird aber explizit nicht unterstützt und führt nach meinen eigenen Erfahrungen oft zu massiven Problemen. Wenn Sie die aktuelle Version von Raspberry Pi OS nutzen möchten, müssen Sie also eine SD-Karte neu damit einrichten. Das hat natürlich den Nachteil, dass Sie alle Konfigurationsarbeiten wiederholen und ggfs. Ihre eigenen Projekte bzw. Ihren Code manuell übertragen und womöglich auch adaptieren müssen.
Ein neuer adminForge Service kann ab sofort genutzt werden. Ein quelloffener Lesezeichenmanager zum gemeinsamen sammeln, organisieren und archivieren von Webseiten. Linkwarden Bookmark Manager Ein quelloffener Lesezeichenmanager zum gemeinsamen sammeln, organisieren und archivieren von Webseiten....
Wer sich schon einmal mit MTAs (Mail Transfer Agent) auseinandergesetzt hat, dem wird Postfix sicherlich ein Begriff sein. Postfix zählt zu den bekanntesten Mailservern im Linuxbereich, ist schnell und recht einfach zu konfigurieren, eine gewisse Grundkenntnis vorausgesetzt. Für einen sicheren Mailverkehr möchte ich hier noch einmal auf das Crypto Handbuch verweisen.
Letzte Woche war ja ein wenig Exchange Server im Programm, heute soll es aber um eine Auswertung des Mailverkehrs, welcher täglich über einen Postfix Server rauscht, gehen.
Postfix Log Entry Summarizer
Hierfür gibt es sicherlich einige Monitoring Tools, eines davon ist Pflogsumm (Postfix Log Entry Summarizer), welches eine ausführliche Auswertung bietet, ohne, dass der Anwender viel konfigurieren muss.
Unter Ubuntu ist dieses Tool recht schnell konfiguriert und im Optimalfall erhaltet ihr am Ende eine Übersicht aller Nachrichten, egal ob gesendet, empfangen oder geblockt. Auch der Traffic, die Menge oder die Mailadressen werden ausgewertet. Bis zu dieser Statistik ist aber noch ein wenig Vorarbeit zu leisten.
Pflogsumm installieren (Ubuntu)
sudo apt-get install pflogsumm
Postfix Log Entry Summarizer konfigurieren
Ihr habt nun die Möglichkeit das Tool direkt aufzurufen und euch eine Liveauswertung geben zu lassen, um zu sehen was gerade auf dem Mailserver passiert. Pflogsumm macht nichts anderes, als auf die Logfiles des Postfix Server zurückzugreifen und diese auszuwerten. Mit einem Einzeiler lässt sich so eine Statistik in eine Datei schreiben oder per Mail versenden.
sudo pflogsumm -u 5 -h 5 --problems_first -d today /var/log/mail.log >> test oder
sudo pflogsumm -u 5 -h 5 --problems_first -d today /var/log/mail.log | mail -s "Postfix Mail Report" info@example.com
Vorarbeit zur regelmäßigen Postfix Analyse
Eine IST Auswertung mag zwar interessant sein, die regelmäßige Auswertung der letzten Tage ist jedoch um einiges interessanter. Realisierbar ist dies mit den Logs des Vortages, diese werden Mittels logrotate gepackt und können danach ausgewertet werden. Zunächst muss logrotate angepasst werden, damit täglich neue Logs geschrieben werden.
Wenn gewünscht ist, dass die Logrotation pünktlich zu einer gewissen Uhrzeit laufen soll, sagen wir um 2 Uhr Nachts , ist es nötig crontab zu editieren und dort die Laufzeit anzupassen.
Nun können wir unser eigenes Script zusammen stellen, welches am Schluss eine Auswertung versendet.
sudo nano mailstatistiken.sh
#!/bin/bash
#
###############
# mailstats #
###############
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
# Log Archive entpacken
gunzip /var/log/mail.log.1.gz
#Temporaere Datei anlegen
MAIL=/tmp/mailstats
#Etwas Text zum Anfang
echo "Taeglicher Mail Stats Report, erstellt am $(date "+%H:%M %d.%m.%y")" > $MAIL
echo "Mail Server Aktivitaeten der letzten 24h" >> $MAIL
#Pflogsumm aufrufen
/usr/sbin/pflogsumm --problems_first /var/log/mail.log.1 >> $MAIL
# Versenden der Auswertung
cat /tmp/mailstats | mail -s "Postfix Report $(date --date='yesterday')" stats@example.com
#Archiv wieder packen, damit alles seine Ordnung hat
gzip /var/log/mail.log.1
Insgesamt eine leichte Übung. Das fertige Skript noch mit "chmod +x" ausführbar machen und am besten via "crontab -e" zu einem gewünschten Zeitpunkt ausführen.
Am Ende solltet ihr jeden Tag per Mail eine ausführliche Zusammenfassung der E-Mails Statistiken erhalten.
Ein neuer adminForge Service kann ab sofort genutzt werden. Privatsphäre neu definiert: Der erste Messenger ohne Nutzerkennungen! SimpleX Chat Server Privatsphäre neu definiert: Der erste Messenger ohne Nutzerkennungen! simplex.adminforge.de Features: Es gibt keine Benutzerkennung...
Wer Exim4 als Mailserver einsetzt, wie es zum Beispiel in Debian-basierten Linux-Distributionen der Standard ist, sollte sich zeitnah um Updates bemühen oder - wenn der Dienst nicht zwangsläufig benötigt ist (bei manchen läuft Exim unbewusst) - spätestens jetzt gänzlich abschalten.
Es gibt zumindest eine schwere Remote-Code-Execution-Sicherheitslücke.
Bleeping Computer berichtete über die Lücke(n), denn es geht um bis zu 6 Schwachstellen unterschiedlicher Stärke.
Die genauen Details sind zum aktuellen Zeitpunkt noch nicht verfügbar, um Exploits nicht zu befördern.
Es reicht allerdings unauthentifizierter Zugriff auf Port 25.
Der Fund geht auf die Zero Day Initiative von Trend Micro zurück.
Sie hatte bereits im Juni letzten Jahres, also 2022, auf die Lücken aufmerksam gemacht.
Besonders pikant: bis vor kurzem waren noch keine Patches verfügbar, zumal die schwerwiegende Lücke ZDI-23-1469 bereits Mitte der Woche veröffentlicht wurde.
Laut einer E-Mail der Entwickler ist ein bedeutenden Teil der Lücken bereits geschlossen und die Updates an die Distributoren verteilt.
Dass die Lücke nicht schneller gefixt wurde, lag an Schwierigkeiten bei der Kommunikation.
Bei Ubuntu wird die Lücke als CVE-2023-42115 geführt, hier sind noch keine Updates verfügbar.
Exim4-Admins sollten dies im Auge behalten und sofort reagieren.
Mit ersten Exploits ist demnächst zu rechnen, wenn mehr über die Lücke bekannt wird.
Der Mailserver ist weit verbreitet, es gibt laut Bleeping Computer mehrere Millionen Instanzen im Internet.
Das Wettrennen um die Technologieführerschaft der Large Language Models lief größtenteils bisher auf dem amerikanischen Kontinent ab. OpenAI hat das Produkt populär gemacht und Meta AI veröffentlicht den Konkurrenten mit den freien Gewichten. Mit Falcon 40B und 180B gab es allerdings schon Konkurrenz aus Abu Dhabi, zumal mit der gewählten Apache-2.0-Lizenz ein deutlich offenerer Ansatz gewählt wurde.
Als kurz vor dem Sommer das Start-up Mistral aus Paris 105 Millionen Euro eingesammelt hat, waren die Medienberichte zumindest leicht kritisch, da nicht nur das Start-up mit einer gigantischen Finanzierungssumme aus der Taufe gehoben wurde, sondern das Produkt auch noch gar nicht fertig war.
Aus der LLM-Sicht ist dies allerdings verständlich, da solche großen Summen schlicht die Voraussetzung sind, um an den Start zu gehen.
Schließlich benötigt Training leistungsfähige GPUs und die sind teuer.
Mit dem veröffentlichten Modell Mistral 7B zeigt das Start-up, was es kann.
Dabei handelt es sich um ein LLM, das über 7 Mrd. Parameter verfügt und Llama 2 13B in allen und LLaMa 34B in vielen üblichen Benchmarks überbietet: Commonsense Reasoning, World Knowledge, Reading Comprehension, Math, Code, Popular aggregated results.
In Codingaufgaben kann die Leistung von CodeLlama 7B erreicht werden.
Das Beste am LLM ist, dass es unter der Apache-2.0-Lizenz steht.
Als klassische Open-Source-Lizenz gibt es nicht nur den Forschern und Entwicklern viele Freiheiten, sondern auch eine gewisse Lizenzsicherheit, dass das Modell in freier Software verwendet werden kann.
Ich hatte bereits vor Wochen geschrieben, dass freie Modelle eine gute Möglichkeit sind, um sich als neuer Player auf dem Markt zu profilieren.
Diesen Plan verfolgt nicht nur Falcon, sondern nun auch offenbar Mistral.
Es ist trotzdem davon auszugehen, dass die 105 Millionen Euro keine "Forschungsspende" waren und kommerzielle Produkte zeitnah folgen werden.
Für die Forscher und Entwickler von LLMs hat die aktuelle Veröffentlichung nichtsdestotrotz Vorteile.
Meta AI hat mit der Lizenzgebung von Llama 2 auf die Open-Source-Bewegung in der LLM-Welt reagiert und sein aktuelles Modell unter eine permissive, aber trotzdem proprietäre Lizenz gestellt.
Mistral geht allerdings noch einen Schritt weiter und setzt eine "klassische" Open-Source-Lizenz ein.
Das hat nicht nur Signalwirkung, sondern ermöglicht, dass Unternehmen ihre LLM-Lösungen zunehmend privat hosten können, da die Parameteranzahl mit 7 Mrd. so dimensioniert ist, dass auch kleinere Datacenter-GPUs für die Ausführung bzw. Inferenz ausreichen.
Es bleibt also weiterhin spannend im Umfeld der LLMs.
Ein neuer adminForge Service kann ab sofort genutzt werden. Mit Transfer.sh könnt ihr Dateien per cURL hochladen. Transfer.sh: cURL Dateiupload Einfache Freigabe von Dateien über die Befehlszeile. transfer.adminforge.de Features: Hergestellt für die Verwendung in...
Vor kurzem gab es das „WinRAR | 9GAG Special Offer!“ und ich bin einer von 5449 Personen, die bei diesem Angebot zugeschlagen haben. Der Key gilt nicht nur für WinRAR, sondern auch für die...
So stand es an einem Freitag auf Mastodon geschrieben. Nach einem Schmunzeln fragte ich mich: „Ja warum eigentlich nicht?“ Dieser Frage möchte ich heute nachgehen.
Der englischsprachige Satz aus dem Titel ist eine Aufforderung, an einem Freitag keine Änderungen an produktiven Systemen vorzunehmen, um das Wochenende nicht zu gefährden. Viele von euch kennen vermutlich berühmte letzte Worte wie:
Was soll schon schiefgehen?
Nur noch diese kleine Änderung, dann ist Feierabend.
Das wurde getestet, da kann nichts passieren.
Das geht ganz schnell, ich mache das noch eben.
Nicht selten hat sich der Feierabend oder das Wochenende nach diesen Sätzen erheblich verzögert oder sind ganz ausgefallen, weil eben doch etwas schiefgegangen ist. In der Folge waren wichtige Dienste nicht mehr verfügbar und Systemadministratoren haben das Abendessen mit ihrer Familie versäumt, weil sie den Klump wieder zum Laufen bringen mussten. Solche Erlebnisse führen zu Aussagen wie:
Never change a running system. Oder eben
Don’t push to production on Friday
Die Logik dahinter ist bestechend einfach. Wenn etwas funktioniert und man nichts daran ändert, wird wohl auch nichts kaputt gehen. Allerdings stehen diese Aussagen dem DevOps-Mantra von Continuous Integration and Continuous Delivery (CI/CD) entgegen, welches fordert, dass Änderungen zu jeder Zeit möglich sein müssen.
Und wer hat nun recht? Ich denke, die Wahrheit liegt wie so oft irgendwo in der Mitte.
Ob Änderungen durchgeführt werden können, hängt in meinen Augen nicht vom Wochentag ab, sondern vielmehr von den Antworten auf die folgenden Fragen:
Sind alle für die Abnahmetests erforderlichen Key-User nach der Änderungen verfügbar und können direkt im Anschluss testen?
Sind alle Verantwortlichen anwesend bzw. verfügbar, welche entscheiden, ob die Änderung bzw. das Deployment erfolgreich war oder nicht?
Liegt das Wartungsfenster in einem Zeitraum, in dem ggf. externe Supportdienstleister erreichbar und diese Zeiträume durch Service-Level-Agreements (SLA) abgedeckt sind?
Findet die Änderung in einem Zeitfenster statt, in dem Störungen toleriert werden können?
Sind zum Beispiel alle 37 Key-User, 8 Abteilungsleiterinnen und das 20-köpfige Betriebs-Team für die Personal- und Buchhaltungsanwendung Freitag nach 18:00 bis voraussichtlich 21:00 Uhr alle verfügbar und können im Fehlerfall mit offenem Ende verfügbar bleiben, steht einer Änderung bzw. einem Deployment nichts im Wege. Ist dies jedoch nicht der Fall und man stellt Fehler möglicherweise erst im Laufe des kommenden Montags fest, wo ein Rollback evtl. schon nicht mehr möglich ist, sollte man den Change vielleicht lieber Montagmorgen starten?
In einem anderen Fall ist das Team nicht sicher, ob sie das System im Fehlerfall ohne Hilfe des Herstellers wiederherstellen können. Der Support-Vertrag deckt jedoch nur die Zeiten Mo-Fr von jeweils 08:00-17:00 Uhr mit 4 Stunden Reaktionszeit ab. Hier ist es vielleicht ebenfalls besser, das Wartungsfenster in den frühen Morgen als in den Freitagabend zu legen.
Habe ich hingegen einen 24/7-Supportvertrag und meine IT-Betriebsabteilung darf auch am Wochenende arbeiten, bietet sich ein Change mit langer Dauer am Wochenende an, um die Betriebsabläufe möglichst wenig zu beeinträchtigen.
Sind Änderungen nur von kurzer Dauer und man möchte möglichst viele User verfügbar haben, die sofort testen und mögliche Fehler finden, ist vermutlich auch Dienstag Vormittag 10:00 Uhr eine gute Zeit.
Es hängt also nicht primär vom Wochentag, sondern vielmehr von einigen anderen Faktoren ab, wann Änderungen in Produktion ausgerollt werden sollten.
Wie seht ihr das? Nach welchen Kriterien werden bei euch Deployments geplant und durchgeführt?
PS: Ich finde jedoch absolut nichts Verwerfliches daran, wenn man sich den Freitag für die Pflege und Aktualisierung der Dokumentation reservieren kann und nicht mit aller Gewalt noch etwas kaputtfuckeln muss. ;-)
Egal, ob du einen Einstieg in Debian, Ubuntu und Co suchst, für ein LPIC Zertifikat Wissen aneignen willst oder schlicht und einfach nur ein Nachschlagewerk benötigst, die Linux Command Library ist ein guter Begleiter für Linux Menschen.
Die Sammlung umfasst ca. 5000 Handbuchseiten, mehr als 22 grundlegende Kategorien und eine Reihe allgemeiner Tipps für Terminals. Die passende App dazu funktioniert zu 100 % offline, benötigt keine Internetverbindung und hat keine Tracking-Software.
Simon Schubert hat die Online-Lernplattform für Linux Kommandos ins Leben gerufen. Neben der App kann das Nachschlagewerk klassisch im Browser genutzt werden.
Folgende Kategorien stehen dir zum Abrufen von zig Kommandos zur Verfügung:
One-liners
System Information
Systemkontrolle
Nutzer und Gruppen
Dateien und Nutzer
Input
Drucken
JSON
Netzwerk
Suchen und Finden
Git
SSH
Video & Audio
Paketmanager
Hacking Tools
Terminal Games
Kryptowährungen
VIM Texteditor
Emacs Texteditor
Nano Texteditor
Pico Texteditor
Micro Texteditor
Ein Cheatsheet mit praktischen Befehlen kannst du ebenfalls abrufen.
Die Linux Command Library ist Open Source und auf GitHub verfügbar. Die passende App dazu bekommst du auf im Play Store oder auf F-Droid.
Im siebten Teil meiner losen Reihe über die RHEL System Roles stelle ich die Rolle rhc vor, mit welcher sich RHEL-Systeme (Version >= 8.6) in der Hybrid Cloud Console, Insights und dem RHSM registrieren lassen.
Möchte man ein oder mehrere RHEL-Systeme in der Hybrid Cloud Console registrieren, kann man dazu die RHEL System Role rhc verwenden.
Die Rolle
Durch die Installation des Pakets rhel-system-roles existiert die Rolle rhc bereits auf meinem System und muss nur noch konfiguriert werden. Die Rolle selbst findet man im Pfad /usr/share/ansible/roles/rhel-system-roles.rhc/ und die Dokumentation in /usr/share/doc/rhel-system-roles/rhc/README.md.
Das Playbook
- name: Register systems
hosts: all
vars:
rhc_auth:
activation_keys:
keys: ["key-1", ...]
rhc_organization: "your-organization"
roles:
- rhel-system-roles.rhc
key-1 ist durch den eigenen Activation Key zu ersetzen
your-organization ist durch die eigene Org-ID zu ersetzen
Mit diesem Playbook werden die Hosts im RHSM und der Hybrid Cloud Console registriert
Die Systeme werden bei Insights registriert und laden regelmäßig aktuelle Daten hoch
Die Systeme werden für die Ausführung von Remediation Playbooks konfiguriert
Fazit
Mit dieser System Role ist es einfach möglich, eine große Anzahl Systeme in die Hybrid Cloud Console aufzunehmen. Dabei lässt sich konfigurieren, ob Funktionen wie Insights und Remediation Playbooks genutzt werden können.
Eine weitere tolle Rolle aus dem Paket rhel-system-roles, die sich einfach zur Anwendung bringen lässt.
Zwei neue adminForge Services können ab sofort genutzt werden. 1) Hat.sh ist eine Webanwendung, die eine sichere lokale Dateiverschlüsselung im Browser ermöglicht. Sie ist schnell, sicher und verwendet moderne kryptografische Algorithmen mit Chunked-AEAD-Stream-Verschlüsselung/Entschlüsselung. 2)...
Auf Mobiltelefonen, Tablets, Laptops, Netzwerkspeichern und in diversen Anwendungen in unserem Heimnetzwerk befinden sich Daten, welche wir schmerzlich vermissen würden, wenn sie dauerhaft verloren gingen.
Im Folgenden beschreibe ich, wie ich z.B. Fotos, Videos, Zeugnisse, Verträge, Urkunden, Versicherungspolicen, etc. vor Verlust schütze.
Sie sind unsere ständigen Begleiter, verfügen über große Speicher und beinhalten häufig jede Menge an Fotos und Videos. Diese werden mit DS-Apps auf eine Synology Diskstation im heimischen Netzwerk gesichert.
Für Threema benutze ich Threema Safe. Ein Datenbackup führe ich nicht durch. Der Inhalt der Nachrichten ist mir nicht so wichtig, als dass mich ein Verlust schmerzen würde.
E-Mails, Kalender und Kontakte werden zwischen Mailbox.org und diversen Geräten synchronisiert, jedoch nicht gesichert. Wenn jemand z.B. das Adressbuch löscht, müsste ich das Netzwerk vom PC trennen, um das Adressbuch ohne Netzwerkverbindung zu starten, um den letzten Stand von dort wiederherstellen zu können. Für mich ist das ausreichend, da ich bei einem GAU meine wichtigsten Kontakte auch ohne Adressbuch zu erreichen weiß und sich Kontaktinformationen von Handwerkern und sonstigen Unternehmen wieder recherchieren lassen.
Sollte ich Zugriff auf die App Aegis Authenticater verlieren, muss ich auf die Backup-Codes zurückgreifen, welche in einer KeePass-Datenbank lagern.
Falls ihr einfache Lösungen kennt, um sämtliche Apps samt deren Inhalte sichern und auf abweichenden Telefonen wiederherstellen zu können, freue ich mich, wenn ihr mir davon berichtet.
Network Attached Storage (NAS)
Meine Synology Diskstation ist:
Das Ziel für automatisierte Datensicherungen von Mobiltelefonen und Tablets
Datensicherungsziel für die Backups meiner virtuellen Server im LAN und in der Cloud
Primärer Speicherort für Fotos, Videos, eine Musiksammlung, Git-Repos
Primärspeicher für archivierte Daten, die ich vermutlich nie wieder benötige
Ausgewählte Daten werden wöchentlich mit Hyper Backup (Backup-Anwendung der Diskstation) auf eine angeschlossene USB-Festplatte gesichert. Darüber hinaus habe ich mir ein Offsite-Backup gebastelt, welches ich in diesem Artikel beschrieben habe.
Über Erfolg und Misserfolg der Sicherungen werde ich per E-Mail benachrichtigt.
Die größte Herausforderung für mich ist es, die Wiederherstellbarkeit der gesicherten Daten zu kontrollieren. Dies mache ich bisher sporadisch und manuell. Und vermutlich viel zu selten.
Darüber hinaus nutze ich Déjà Dup Backups für eine wöchentliche Datensicherung meines HOME-Verzeichnisses in die Nextcloud mit 180 Tagen Vorhaltezeit. Auch hier teste dich die Wiederherstellbarkeit sporadisch.
Das HOME-Verzeichnis meines Dienstlaptops wird täglich mit Déjà Dup in das Google Drive meines Arbeitgebers gesichert.
Urkunden, Verträge, Zeugnisse und weiterer Papierkram
Auch wir haben jede Menge totes Holz im Schrank stehen, dessen Wiederbeschaffung bei Verlust mit viel Zeit und Mühe verbunden ist.
Hier möchte ich die Wiederherstellung noch verbessern, indem ich auf meinem Laptop ein Ansible-Playbook ablege, welches die Paperless-NGX-Instanz auf meinem Laptop wiederherstellt. So teste ich die Wiederherstellbarkeit und habe immer eine relativ aktuelle Kopie auf der verschlüsselten Festplatte meines Laptops bei mir.
Auf einem virtuellen Server in der Cloud möchte ich diese Daten aktuell nicht so gerne hosten. Dazu muss ich mir zuvor in Ruhe Gedanken über mögliche Risiken für die Integrität und Vertraulichkeit der Daten machen.
Meine produktive Paperless-NGX-Instanz steht mit dem Papier im gleichen Haus. Das Backup beinhaltet alle PDF-Dateien und liegt verschlüsselt in der Cloud. Da die Dateinamen halbwegs sinnvoll benannt sind, scheint im Falle eines GAU die Suche im Heuhaufen nicht hoffnungslos.
Blog und Nextcloud
Für beide Dienste, welche auf einem virtuellen Server bei Contabo laufen, wird zur Datensicherung wöchentlich ein Datenbank-Dump und ein Archiv der Verzeichnisstruktur mit Ordnern und Dateien erstellt. Dieses Backup wird lokal auf dem Server abgelegt und für 30 Tage vorgehalten. Ich nutze dafür selbstgeschriebene Bash-Skripte, welche durch Cron ausgeführt werden.
Auf meinem NAS läuft ein Skript, welches die Backups vom Server auf das NAS synchronisiert.
Über Erfolg und Misserfolg der einzelnen Jobs werde ich per E-Mail benachrichtigt.
Die Wiederherstellbarkeit teste ich sporadisch und sollte dies mutmaßlich häufiger tun. Ein Automat dafür befindet sich aktuell in Arbeit. Den aktuellen Stand kann man in folgenden Artikeln nachlesen:
Ruhende Daten werden verschlüsselt, bevor sie in die Cloud hochgeladen werden. Das Restrisiko, dass der fremde Betreiber prinzipiell die Kontrolle über meinen virtuellen Server übernehmen kann, bleibt.
Betreibe ich Server oder Dienst nicht im eigenen Heimnetzwerk, nutze ich für den Betrieb deutsche Anbieter mit Standorten in Deutschland. Zu diesen habe ich einfach das größte Vertrauen, dass sie sich an geltende Gesetze halten, die Hoffnung, dass sie den Datenschutz ernst nehmen und meine Daten dort gut aufbewahrt sind.
Wie sichert ihr eure Daten außer Haus? Welche Dienste verwendet ihr dazu? Ich freue mich, wenn ihr eure Erfahrungen in den Kommentaren teilt.
Zusammenfassung
Ich habe mir zumindest mal Gedanken gemacht, welche Daten so wichtig sind, dass ich sie vor Verlust schützen möchte. Zum Schutz vor Verlust kommen verschiedene Verfahren zum Einsatz, die auf der Schaffung von Redundanz durch Synchronisierung oder der Datensicherung mit Versionierung beruhen.
Die Wiederherstellbarkeit wird zumindest sporadisch getestet. Dieser Punkt ist sicherlich ausbaufähig.
Wer die einzelnen Abschnitte gelesen hat, stellt jedoch auch fest, dass es schnell ein wenig unübersichtlich wird. Zumindest hilft dieser Artikel etwas, den Überblick zu behalten.
Für die Zukunft wünsche ich mir eine dedizierte Backup-Senke im Keller, in der sich ausschließlich Backups befinden und eine Offsite-Senke, auf welche die Daten der Backup-Senke gesichert werden. Bis ich da hinkomme, wird sicherlich noch etwas Zeit vergehen.
Ein neuer adminForge Service kann ab sofort genutzt werden. Mit Documenso habt ihr eine quelloffene Alternative zu DocuSign. Mit diesem Dienst kannst du PDF Dokumente von Personen unterzeichnen lassen. Documenso: DocuSign Alternative Mit Documenso...
30 Jahre Debian - 30 Jahre felsenfeste Entwicklung und noch kein Ende in Sicht.
An diesem Tag vor 30 Jahren, am 16.08.1993, erschien in der Newsgroup comp.os.linux.developmenteine Ankündigung, die den Anfang eines der größten und langlebigsten Projekte im Linux-Ökosystem markieren sollte. Lasst uns für einen kurzen Moment zurückblicken.
Es ist nicht nur ein gepimptes SLS, es ist das "Debian Linux Release". Ian Murdock, der selbst mit der vermutlich ersten Linux-Distribution unzufrieden war und beschlossen hat, die Sache selbst in die Hand zu nehmen, hätte sich womöglich nie erträumen können, dass sein "brand-new Linux release", wie er es damals nannte, irgendwann seinen 30. Geburtstag feiern würde.
Begründer eines Distributionszweiges
Im Laufe der Jahre hat Debian bewiesen, dass es mehr als nur ein übereifriger Rebell unter den Betriebssystemen ist. Es hat die Grundlage für viele andere Distributionen wie z. B. Ubuntu gelegt. Es hat die Freiheit und Offenheit verkörpert, die das Herzstück der Open-Source-Bewegung bilden. Es hat glaubhafte Alternativen zu proprietären Betriebssystemen aufgezeigt und Zweifler zum Schweigen gebracht. Auch, wenn der letzte Punkt in der öffentlichen Diskussion nicht ganz offensichtlich ist, sprechen die Zahlen für sich: Debian ist ein fester Bestandteil vieler produktiver Serversetups.
Mit der tief verwurzelten Philosophie, die sich im Debian-Gesellschaftsvertrag widerspiegelt, unterstreicht das Projekt seine kompromisslose Haltung zugunsten freier Software, auch wenn über die Jahre insgesamt eine gewisse Toleranz gegenüber nachinstallierbarer unfreier Software Einzug gehalten hat.
Debian ist heute wichtiger denn je, da die Distribution den Test of Time bestand und sich zu einer Alternative zu Enterprise-Distributionen gemausert hat. Stabilität und Kontinuität sind entscheidende Faktoren, denn Debian baut auf klassischen Releases auf, von denen - je nach Zählweise - bereits 20 erschienen sind. Die Release werden seit Version 1.1 nach Toy-Story-Charakteren bezeichnet. Debian ist ein Leuchtturm, ein einsamer Fels in der Brandung einer Welt, die zunehmend von Anbietern dominiert wird, welche Daten und Freiheiten der Nutzer nicht beachten und sie an ihre Plattformen binden.
In diesem Sinne, lasst uns auf 30 Jahre technologischer Alternativen anstoßen. Herzlichen Glückwunsch, Debian! Auf 30 weitere Jahre der Innovation und Unabhängigkeit.
Open-Source-Software nachhaltig zu entwickeln, wird immer schwieriger. Willkommen im Zeitalter von "Nur schauen, nicht anfassen" für kommerzielle Rivalen.
Das in San Francisco ansässige Softwareunternehmen HashiCorp, bekannt für seine Cloud-Tools wie Terraform, Vagrant oder Vault, ändert seine Lizenzbedingungen. In einer Ankündigung wird der Wechsel von der Mozilla Public License 2.0 zur Business Source License mit der Gewährleistung kontinuerlicher Investitionen des Unternehmens in seine Community begründet.
HashiCorp hält weiterhin daran fest, seinen Quellcode frei verfügbar zu machen. Allerdings gibt die BSL dem Unternehmen mehr Kontrolle darüber, wer den Code kommerziell nutzen darf. Mit anderen Worten, wer Software von HashiCorp produktiv nutzt und sie für ein Konkurrenzprodukt einsetzen möchte, ist von nun an nicht nur bösen Blicken, sondern auch rechtlichen Hürden ausgesetzt.
In guter Gesellschaft
Einige Unternehmen haben diesen Schritt bereits vollzogen und sind auf unfreie Lizenzmodelle umgestiegen. Couchbase, Sentry und MariaDB MaxScale sind einige Beispiele dafür. Dies wirft natürlich die Frage auf, ob wir uns von der Idee freier Open-Source-Software verabschieden müssen. Die Omnipräsenz der Cloud-Industrie, die seit den 2010er-Jahren sich großer Beliebtheit erfreut, droht ernsthaft, die FOSS-Welt zu destabilisieren.
Stellt dir vor, du hast einen reichen Obstgarten erschaffen, in dem jeder sich frei der Früchte bedienen kann. Größzügig lädst du alle ein, sich nach Belieben zu bedienen und empfiehlst ihnen, selber Bäume zu pflanzen oder die Saaten weiterzuverbreiten. Eines Tages bemerkt ihr jedoch, dass einige Gäste die Früchte einsacken, sie auf eigenen Märkten verkaufen und die Profite einsacken, ohne selbst an die Ursprungscommunity etwas zurückzugegeben. Klingt unfair? Genau das passiert momentan in der Open-Source-Welt.
Damit wird Open Source zwar nicht von Tisch gewischt, sondern in eine Richtung gelenkt, die den freien ungehinderten Austausch unabhängig von gewerblichen Interessen einschränkt. Konkret wackelt dabei das 6. Kriterium der Open-Source-Definition (OSD), das eine Unterscheidung nach Einsatzfeldern ausschließt.
HashiCorp betont, dass es sich weiterhin seiner Community, seinen Partnern und Kunden verpflichtet sieht. Nur die Zeit wird zeigen, ob diese Lizenzänderungen die richtigen Schritte auf dem Weg dorthin sind. Einerseits werden Möglichkeiten von Forks eingeschränkt, andererseits ist niemandem geholfen, wenn die Weiterentwicklung durch HashiCorp auf dem Spiel steht, nur, weil externe Akteure bezogen auf die Einnahmen sinnbildlich das Wasser abgraben. Die Leute, die Software entwickeln, müssen auch von etwas bezahlt werden.
Update (20:30 Uhr): Ggfs. werde ich mich mit der BSL noch einmal in einem gesonderten Artikel beschäftigen, aber ein kleines Detail ist hierbei vllt. noch erwähnenswert, um den Blick auf die Sache zu ändern. Die von HashiCorp verwendete Form der BSL setzt auf eine Art Embargozeit. Nach 4 Jahren der Veröffentlichung eines nach BSL lizenzierten Werkes in einer spezifischen Version, greift folgender Passus:
Effective on the Change Date, or the fourth anniversary of the first publicly available distribution of a specific version of the Licensed Work under this License, whichever comes first, the Licensor hereby grants you rights under the terms of the Change License, and the rights granted in the paragraph above terminate.
Auch in der Sommerpause gibt es vereinzelte Neuigkeiten aus der Welt der künstlichen Intelligenz. Heute möchte ich mich dabei wieder einmal den Agenten widmen.
MetaGPT
Beim Einsatz von ChatGPT und ähnlichen LLMs stellt sich schnell die Frage, ob da nicht auch mehr geht. Ob das System nicht zur Abbildung alltäglicher Arbeit herangezogen werden kann. Insbesondere mit Anfang des Jahres aus dem Winterschlaf erwachten Konzept der Agenten wurde die Zusammenarbeit unterschiedlicher KI-Instanzen wieder relevant und spannend. Umso interessanter ist es, diese Konzepte zusammenzuführen.
AutoGPT und Co. sind diesem Ziel gefolgt und konnten schon lustige Ergebnisse demonstrieren, wenn man die LLMs sinnbildlich an den eigenen Computer anschließt und z. B. die Ausgaben des LLMs als Eingabe für die eigene Shell verwendet (nicht nachmachen, ist eine dumme Idee). Doch auch hier gab es einige Schwächen, ganz rund lief alles bei weitem noch nicht.
Die Autoren hinter MetaGPT (hier im Bezug auf griechisch meta = über) haben systematisch verschiedene Rollen inkl. ihrer Interaktionen ausgearbeitet und stellen ihre Ergebnisse als Preprint und ihr Framework auf GitHub bereit. Dabei wird eine einzeilige Aufgabe, z. B. die Entwicklung eines Spiels, vom System eingelesen und dann auf ein hierarchisches Team aus Agenten verteilt. Diese Agenten haben verschiedene Rollen, die sich auf die System-Prompts abbilden, d. h. beispielhaft "Du bist ein Entwickler für Python..." oder "Du bist ein Requirements-Engineer...". Am Ende des Tages fällt ein Ergebnis raus, das dann ausprobiert werden kann.
Das Konzept sieht in meinen Augen sehr spannend aus und entwickelt sich stets weiter. Dabei wird deutlich, dass eine simple Prompt für hochwertiges Prompt-Engineering nicht reicht, vielmehr können Effekte ähnlich wie beim Ensemble-Learning genutzt werden, durch die mehrere Instanzen von LLMs, die gemeinsam ein Problem bearbeiten, deutlich effektiver arbeiten.
Was LLMs von Cyc lernen können
Irgendwie habe ich die ganzen letzten Monate schon darauf gewartet, dass sich die Autoren klassischer Expertensysteme beim LLM-Thema zu Wort melden. Immerhin prallen hier zwei komplett unterschiedliche Welten aufeinander, die beide versuchen, die Welt zu erklären.
Klassische Expertensysteme versuchen mit Logik die Welt in Regeln zu fassen. Das typische Beispiel ist "Wenn es regnet, dann wird die Straße nass". Eine klare Implikation, die in eine Richtung geht: ist das Kriterium auf der "wenn"-Seite erfüllt, gilt die Aussage auf der "dann"-Seite. Wird das System gefragt, was mit der Straße passiert, wenn es regnet, antwortet es immer, dass sie nass wird. Immer. Dass es nicht zwangsläufig der Regen sein muss, wenn die Straße nass ist, wird ebenfalls durch Logik ermöglicht, da die obige Regel eine Implikation ist und keine Äquivalenz, denn da würde es heißen "Immer wenn es regnet, dann wird die Straße nass".
Problematischer wird es zu modellieren, dass die Straße selbst bei Regen da nicht nass wird, wo gerade ein Auto parkt. Hieran erkennt man, dass es sich um ein schwieriges Unterfangen handelt, wenn Expertensysteme die echte Welt modellieren sollen. Das Cyc-Projekt hat die Mühe aber auf sich genommen und über die letzten knapp 40 Jahre über eine Million solcher Regeln zusammengetragen. Viele einfache Expertensysteme gelten grundsätzlich aber als veraltet und konnten die Erwartungen für "generelle Intelligenz" schon vor 30 Jahren nicht erfüllen.
Anders funktionieren LLMs, die nicht mit klassischer Logik, sondern Wahrscheinlichkeiten arbeiten, um das "am ehesten passende" nächste Wort für die Antwort zu finden. Zusammengefasst sind Expertensysteme für ihre Präzision zulasten der Vielseitigkeit bekannt und LLMs einfach anders herum.
Doug Lenat von Cyc und Gary Marcus von der NYU haben in ihrem Preprint nun 16 Anforderungen zusammengetragen, die eine "vertrauenswürdige KI" haben sollte, darunter Erklärung, Herleitung oder Kontext. Anschließend gehen die Autoren noch ein, wie ihr (kommerzielles) Cyc das umsetzen kann.
Ich bin tatsächlich überzeugt, dass man untersuchen sollte, wie sich diese beiden Ansätze verheiraten lassen. Dabei sprechen auch die Ergebnisse von AutoGPT, MetaGPT & Co. dafür, dass das Vorhaben auf neuronaler Ebene angegangen werden muss, da einfache Varianten wie System-Prompts á la "Du bist LogikGPT. Gib mir die Entscheidungsregeln in Prädikatenlogik aus." immer noch auf Token-/Wortvorhersagen basieren und zu viel Halluzination zulassen.
Dennoch bin ich sicher, dass es auch hier Fortschritte geben wird, die wir dann früher oder später in einem Wochenrückblick diskutieren können. Bis dahin!
Der Pinecil v2 kann, wie der Pinecil v1 und andere IronOS-kompatible Lötkolben, mit einem eigenen Bootlogo versehen werden. Hierfür müssen folgende Voraussetzungen erfüllt sein: Pinecil v2 mit IronOS 2.22-rc (oder neuer) Ich für diese...
Ich habe mir mit einem Odroid HC1 ein zusätzliches NAS aufgebaut, auf welchen mein Proxmox VE Server täglich sichern soll. Sofern ihr noch keinen freigegebenen Ordner, auf welchen der Proxmox VE Server am Ende...
In der heutigen Ausgabe des Wochenrückblicks blicken wir auf ein neues Modell von IBM und einen Ausblick auf neue Features in der ChatGPT-Oberfläche von OpenAI.
IBM und NASA veröffentlichen Foundation-Model für Geodaten
Wie ich an der einen und anderen Stelle im Wochenrückblick schon einmal erwähnt habe, beschränkt sich die Transformer-Architektur mittlerweile nicht mehr nur auf Textaufgaben. Mit Vision Transformers lässt sich dies auch auf die grafische Ebene erweitern.
In einer Kooperation zwischen IBM und der NASA wurden nun die Prithvi-Modelle auf Hugging Face veröffentlicht. Sie ermöglichen es, ein Satellitenbild einzugeben und z. B. vorhersagen zu lassen, welche Gebiete am ehesten Fluten ausgesetzt sein könnten.
Um diese Vorhersagen zu ermöglichen, hat IBM Daten aus dem Harmonized Landsat Sentinel-2-Projekt (HLS) herangezogen, um ein Foundation Modell zu trainieren. Im HLS-Datensatz befinden Satellitendaten, die mit je 30 Metern pro Pixel aufgelöst sind. Auf der technischen Seite wird ein Vision Transformer mit Masked Autoencoder eingesetzt. Das Foundation Modell kann nun von weiteren Forschern feingetuned werden, um die jeweiligen Vorhersagen weiter zu verbessern. Durch IBMs Arbeit sollen nun mehr als 250.000 TB an Missionsdaten von der NASA besser zugänglich gemacht werden. Weitere Details zum Projekt können im Blogartikel und in der Pressemitteilung von IBM abgerufen werden.
Neue ChatGPT-Features
Wie SimilarWeb schon vor wenigen Wochen beobachten konnte, ebbt der Hype um ChatGPT langsam ab. Auffällig beim Release von ChatGPT war auch, wie puristisch die ganze Oberfläche war. Dabei ist es vermutlich das Backend, was OpenAI gemeistert hat, denn sie haben es geschafft, das System in den ersten Wochen unter ziemlich hoher Last aufrecht zu erhalten.
Im Frontend wurden aber zwischenzeitlich auch Änderungen und Verbesserungen umgesetzt, insbesondere die Einführung des kostenpflichtigen Dienstes ChatGPT Plus hat einige Anpassungen erfordert. Logan Kilpatrick, zuständig für "Developer Relations" bei OpenAI, gab nun einen Ausblick, was demnächst zu erwarten ist.
So wird es unter anderem vorgeschlagene Einstiegs- und Folgefragen und die Möglichkeit des Uploads mehrerer Dateien im Code Interpreter geben. Zudem soll die Zwangsabmeldung nach 14 Tagen abgeschafft werden.
Während ein Teil der Änderungen hilfreiche Detailverbesserungen beisteuert, werden die "vorgeschlagenen Folgefragen" am lustigsten sein. Nun schreibt also ChatGPT nicht nur die Antworten, sondern auch die Fragen. Es bleibt spannend.