Anthropic veröffentlicht Claude Sonnet 5
01. Juli 2026 um 09:58
Anthropic hat mit Claude Sonnet 5 sein neuestes Sprachmodell veröffentlicht, das sich besonders für agentische Aufgaben empfiehlt.
Anthropic hat mit Claude Sonnet 5 sein neuestes Sprachmodell veröffentlicht, das sich besonders für agentische Aufgaben empfiehlt.
Auf OpenRouter, einer Plattform, die über eine einheitliche API Zugriff auf Dutzende Sprachmodelle erlaubt, rangierte in den letzten Wochen das anonyme Modell Owl Alpha in den Nutzungsstatistiken…
Die Europäische Kommission hat das Konsortium EUROPA unter Führung der italienischen KI-Firma Domyn zum Sieger des Wettbewerbs “Frontier AI Grand Challenge” gekürt.
Ein Kommentar von Michal Kohútek Ende April 2026 hat Jon Seager, Canonicals VP of Engineering, die Pläne für die kommenden Ubuntu-Releases vorgestellt, darunter auch zusätzliche KI-Funktionen und…
Das amerikanische Start-up Inception mit Sitz in Palo Alto hat mit Mercury 2 ein superschnelles Reasoning-Modell vorgestellt, das über 1000 Token in der Sekunde verarbeiten kann.
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt machte Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
Update 15.3.2026: Rechtschreibkontrolle deaktivieren
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Unter Fedora funktioniert es wie folgt:
sudo dnf install fuse-libs # FUSE-Bibliothek installieren
chmod +x Downloads/*.AppImage # execute-Bit setzen
Downloads/LM-Studio-<n.n>.AppImage # LM Studio ausführen
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
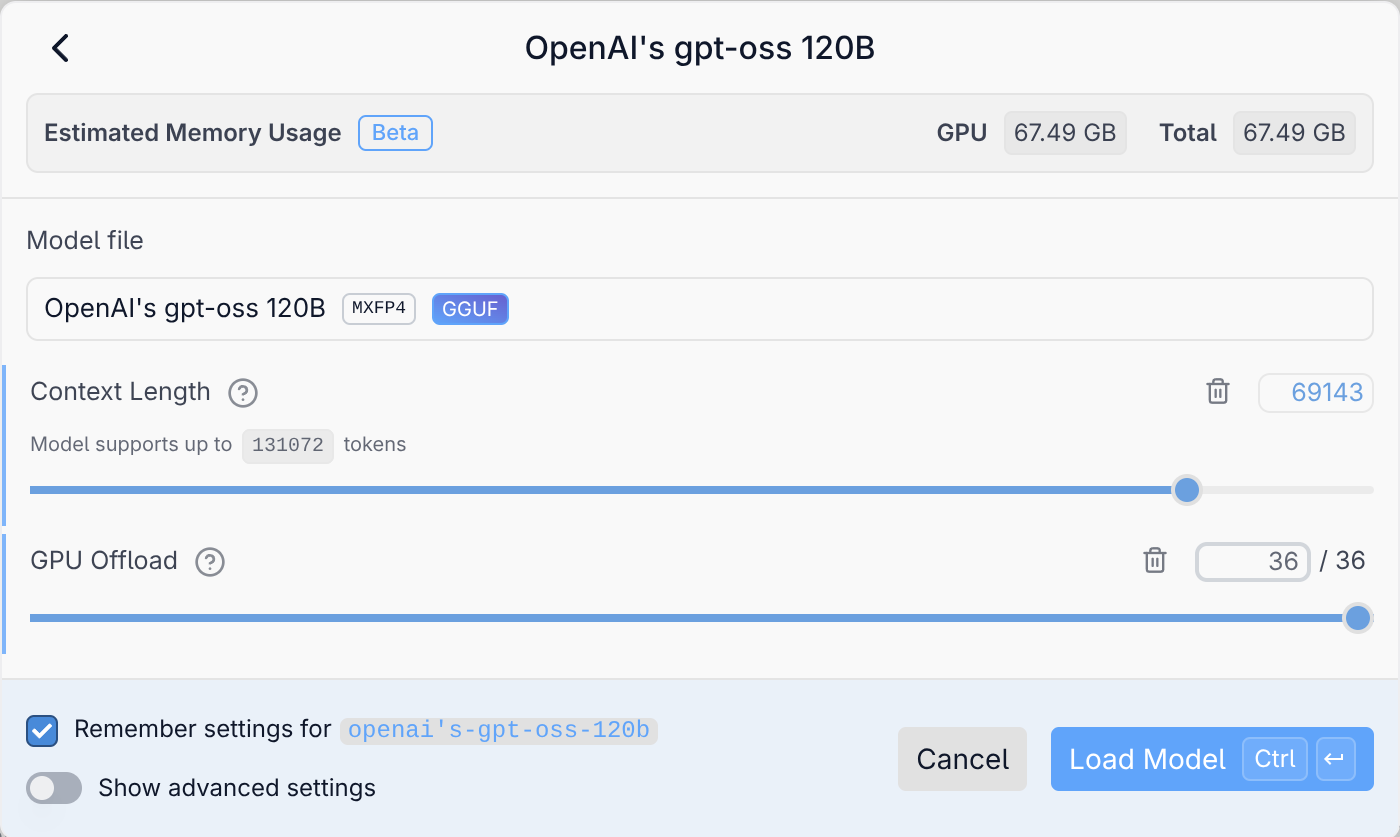
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
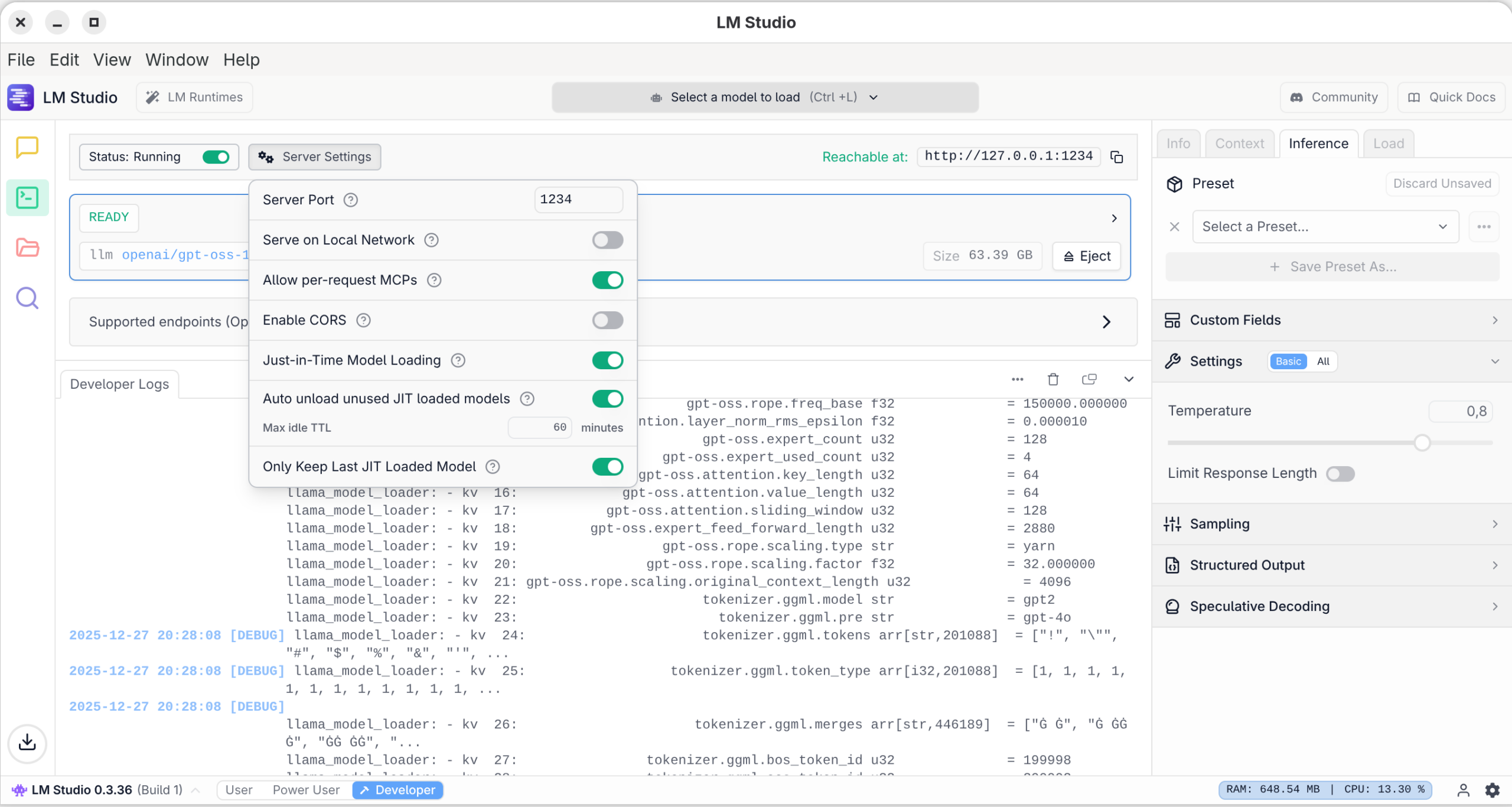
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Sprachmodell MoE Parameter Quant. Token/s
------------- ----- ---------- --------- --------
deepseek-r1-distill-qwen-14b nein 14 Mrd. Q4_K_S 22
devstral-small-2-2512 nein 25 Mrd. Q4_K_M 13
glm-4.5-air ja 110 Mrd. Q3_K_L 25
gpt-oss-20b ja 20 Mrd. MXFP4 65
gpt-oss-120b ja 120 Mrd. MXFP4 48
nouscoder-14b nein 14 Mrd. Q4_K_S 22
qwen3-30b-a3b ja 30 Mrd. Q4_K_M 70
qwen3-next-80b-83b ja 80 Mrd. Q4_K_XL 40
seed-oss-36b nein 36 Mrd. Q4_K_M 10
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Zu den größten Ärgernissen der LM-Studio-Oberfläche (intern realisiert auf Basis des Electron-Frameworks) zählt die stets aktive Rechtschreibkontrolle in allen Eingabefeldern. In den Einstellungsdialogen gibt es gefühlt eine Million Optionen, aber keine, um die Rechtschreibkontrolle zu deaktivieren :-( Wenn jetzt die Desktop-Sprache (deutsch) und die Sprache Ihrer Prompts (englisch) nicht übereinstimmt, wird praktisch der gesamte Text rot unterstrichen. Mühsam.
Abhilfe: Suchen Sie nach der Konfigurationsdatei, die unter Linux den Namen .config/LM Studio/Preferences hat. Dort löschen Sie alle vordefinierten dictionary-Zeichenketten für die Einstellung spellcheck. In meinem Fall sieht die neue Datei dann so aus:
{"migrated_user_scripts_toggle":true,
"spellcheck":{"dictionaries":[""],"dictionary":""}}
Tipps zur Suche der Konfigurationsdatei bei anderen Betriebssystemen finden Sie in diesem Issue.
Während multimodale LLMs heute Textaufgaben auf Doktorandenniveau lösen können, versagen sie bei visuellen Aufgaben, die Kleinkinder im Alter von drei bis fünf Jahren beherrschen.
Mit Open Responses gibt es nun erstmals einen Vorschlag für einen Open-Source-Standard für ein herstellerunabhängiges JSON-API, über das Clients mit LLMs kommunizieren können.
Clem Delangue, der Mitbegründer und CEO von Hugging Face, der bekannten Plattform für KI-Modelle, sieht die Gefahr, dass bereits im nächsten Jahr eine Blase platzt.
Große Sprachmodelle (LLMs) sind leistungsstark, aber statisch – ihnen fehlten bislang Mechanismen, um ihre Gewichte an neue Aufgaben, Kenntnisse oder Beispiele anzupassen.
Das 2022 gegründete chinesische KI-Startup MiniMax sorgt mit seinem Modell M2 für Aufsehen, das sich auf Anhieb unter die Top-5 aller Sprachmodelle einreiht und nur 8 Prozent dessen kosten soll,…
Anthropic hat sein neues Sprachmodell Claude Haiku 4.5 vorgestellt.
Die Open-Source-Plattform Ollama erlaubt die lokale Ausführung von LLMs. Mit Ollama 0.12.6 kommt experimentelle Unterstützung für Vulkan hinzu, womit sich der Kreis der unterstützten GPUs erweitert.
Mehr als ein Viertel aller kann sich eine Freundschaft mit einer KI vorstellen und bei den 16 – 29-Jährigen würde sogar mehr als die Hälfte bei bestimmten Themen lieber mit einer KI…
Eine neue, von Huawei entwickelte und unter Apache-2.0-Lizenz veröffentlichte Kompressionsmethode macht es möglich, dass große Sprachmodelle auf deutlich kleineren und billigeren Rechnern laufen.
Die EPFL (École polytechnique fédérale de Lausanne), die ETH Zürich und das Schweizerische Supercomputing-Zentrum CSCS haben ein von ihnen entwickeltes Sprachmodell namens Apertus vorgestellt.
Forscher der University of California San Diego und von Meta haben in einem Papier eine neue Methode vorgestellt, um schlussfolgernde Sprachmodelle so zu optimieren, dass sie bessere Antworten…
Forscher von Apple haben herausgefunden, dass einzelne unter den Milliarden Parametern eines LLM, sogenannte Super Weights, die Sprachfähigkeit des Modells entscheidend beeinflussen oder sogar…
Der TikTok-Mutterkonzern ByteDance hat mit Seed-OSS-36B ein weiteres chinesisches LLM als Open Source veröffentlicht. Es erschien unter der Apache-2.0-Lizenz.
Eine neue Studie von Google und dem University College London untersucht, warum große Sprachmodelle einerseits felsenfest von einer einmal gefundenen Antwort überzeugt sind, sich dann aber sehr…
KI ist aus unserem Leben nicht mehr wegzudenken. Ihren wahren Wert muss sie allerdings noch beweisen. Derzeit werden Open-Source-Entwickler vermehrt mit wertlosem KI-Müll überschüttet.
Heute berichte ich über meine Nutzung großer Sprachmodelle (engl. Large Language Model, kurz LLM) und freue mich, wenn ihr eure Erfahrungen in den Kommentaren oder vielleicht sogar einem eigenen Blog mit mir teilt.
Ich konzentriere mich in diesem Text auf Beispiele, in denen mich die Nutzung von LLMs in meiner Arbeit unterstützt. Dies soll nicht darüber hinwegtäuschen, dass LLMs halluzinieren und falsche Antworten produzieren können. Auch hierzu finden sich diverse Beispiele, die den Fokus des Artikels jedoch verschieben und den Umfang sprengen würden.
Ich nutze ChatGPT und Gemini, um Bilder für Präsentationen zu generieren. Dabei hat bis jetzt ChatGPT die Nase vorn.
Zuvor habe ich Bilder entweder selbst erstellt oder Stunden mit der Suche in Datenbanken mit lizenzfreien Bildern verbracht. Dies war für mich stets eine sehr frustrierende Erfahrung. Nun kann ich beschreiben, was ich in einem Bild sehen möchte und die Künstliche Intelligenz in Form eines LLM generiert mir entsprechende Bilder. Dies bringt für mich eine große Zeitersparnis und ich habe weniger Stress.
Damit ist jetzt nicht gemeint, dass ich mir E-Mails mit mehr als fünf Sätzen zusammenfassen lasse. Aber auf der Arbeit erlebe ich es häufig, dass ich mal kurz nicht in eine Google Group geschaut habe und plötzlich eine Diskussion mit 40-70 Beiträgen darin finde. Diesen Diskussionen zu folgen war in der Vergangenheit sehr zeitaufwendig bis hinzu unmöglich. Und wir haben sehr viele Maillinglisten.
Wir haben auf der Arbeit Google Workspace und ich gebe gerne zu, dass sich damit bereits ohne KI-Unterstützung super arbeiten lässt. Die nahtlose Integration von Gemini macht es allerdings noch besser.
Wenn ich eine E-Mail Diskussion öffne, kann ich mir mit einem Klick eine Zusammenfassung erstellen lassen. Folgender Prompt hat sich bisher als nützlich erwiesen, um mir einen Überblick zu verschaffen: „Erstelle eine kurze Zusammenfassung, die den Diskussionsgegenstand wiedergibt. Führe auf, wer welche Argumente vertritt. Falls es Lösungsvorschläge und Action Items gibt, liste diese stichpunktartig auf.“
Anhand der Zusammenfassung kann ich in kurzer Zeit beurteilen, ob eine Diskussion für mich von Relevanz ist oder nicht. Auch hier ist der Vorteil durch Nutzung der KI im Allgemeinen die Zeitersparnis und im Speziellen die gute Integration in die vorhandenen Werkzeuge. Ich würde mir nicht die Mühe machen, alle Nachrichten einer langen Diskussion in einen Prompt zu kopieren, um diese dann von einem LLM analysieren zu lassen.
Ich weiß, was ich sagen möchte und drücke mich gerne direkt aus. Das kommt in der Kommunikation mit internationalen Empfängern aus anderen Kulturkreisen nicht immer gut an. Ich schätze auch hier die gute Integration von Gemini in Google Mail, wo ich es manchmal als Formulierungshilfe nutze.
Gemini bietet 3-4 Antwortvarianten an, die in einer Vorschau im Nachrichtenfenster angezeigt werden. Manche sind fernab meiner Vorstellung, andere kommen erstaunlich nah heran. So kann ich die am besten zutreffende Antwort auswählen, kürze sie etwas ein, ergänze evtl. noch 1-2 Sätze und bin fertig.
Vorteile auch hier die Zeitersparnis und die etwas höflicher bzw. runder formulierten E-Mails.
Ihr ahnt vielleicht schon, wo es jetzt hingeht. Google Gemini integriert sich auch hervorragend in Google Meet. Und so haben wir in einer internen Besprechung mit Zustimmung aller Beteiligten die Funktion ausprobiert, ein Besprechungs-Protokoll zu erstellen. Wir waren positiv überrascht.
Die Besprechung wurde auf Deutsch durchgeführt. Gemini war für diese Sprache offiziell noch als Alpha markiert, was das Ergebnis umso beeindruckender macht. Nach der Besprechung wurde ein Google Doc mit einer deutschsprachigen Zusammenfassung erstellt und im Kalender in den Termin eingefügt, so dass alle Teilnehmer es finden und darauf zugreifen können.
Ich habe das Protokoll gelesen und musste lediglich einige Schreibfehler bei Namen und englischen Fachbegriffen korrigieren. Alle Teilnehmer waren sich einig, dass die wesentlichen Punkte korrekt zusammengefasst wurden. Bei englischsprachigen Meetings, welche aufgezeichnet werden, enthält die Zusammenfassung sogar die Zeitstempel, zu denen protokollierte Aussagen gemacht wurden.
Es muss nun also kein Protokollant mehr ausgelost werden und alle Teilnehmer:innen können sich auf die Besprechung konzentrieren.
Da sich die Zusammenfassung auf das Wesentliche konzentriert, finde ich diese noch besser als ein Transkript, welches auch die belanglosen Beiträge wiedergibt und viel Redundanz enthalten kann.
Als Organisator verlasse ich mich nicht blind auf die KI. Ich lese das Protokoll zeitnah nach der Besprechung und korrigiere es ggf. Es ist bei uns auch nicht unüblich, dass Teilnehmer:innen auch im Nachgang zu einer Besprechung Ergänzungen und Korrekturen zum gemeinsamen Dokument beitragen.
Google NotebookLM bietet eine Umgebung, in der mit KI-Unterstützung Inhalte von PDFs, Google Docs & Slides sowie Webseiten verarbeitet werden können. Ich möchte die Nutzung anhand eines konkreten Beispiels erläutern.
Leider habe ich mir die konkreten Prompts und detaillierten Antworten nicht gespeichert, so dass ich meine Erfahrung aus dem Gedächtnis aufschreibe.
Ich betreibe einen Server für Laborumgebungen aus der Hetzner-Serverbörse. Zu diesem gab es eine IPv4-Adresse und ein IPv6-Subnetz. Des Weiteren hat Hetzner eine Richtlinie zur Nutzung von MAC-Adressen. In meinem Fall darf nur die MAC der physischen Netzwerkkarte auf dem Switch im Rechenzentrum erscheinen, nicht jedoch die virtuellen MACs meiner virtuellen Maschinen (VM). Möchte ich meinen Server als Hypervisor-Host verwenden und die darauf laufenden VMs im Internet erreichbar machen, benötige ich dafür ein geroutetes Netzwerk auf dem Hypervisor.
Prinzipiell weiß ich, was zu tun ist. Es gibt bei Hetzner auch eine Anleitung, wie man Debian für Proxmox entsprechend konfiguriert, die ich auf RHEL mit Network Manager adaptieren kann. Deshalb schien mir diese Aufgabe geeignet, um zu testen, wie sich ChatGPT und NotebookLM dabei schlagen.
Ich habe beide Lösungen dabei angewiesen, mit folgenden Quellen zu arbeiten:
Bei ChatGPT sind die URLs zu den Quellen in den Prompt einzugeben. Bei NotebookLM kann zu Beginn konfiguriert werden, welche Quellen im aktuellen Notebook zu verwenden sind. Diese kann man flexibel selektieren oder abwählen, um zu steuern, mit welchen Quellen die KI arbeiten soll.
Beiden Werkzeugen habe ich über den Prompt mitgeteilt, welche IPv6-Adresse ich auf der physischen Netzwerkkarte des Hosts nutzen möchte. Anschließend habe ich via Prompt eine zu RHEL 9 passende Schritt-für-Schritt-Anleitung gefordert, mit der die gewünschte Netzwerkkonfiguration umgesetzt werden kann. Die angebotenen Lösungen wurden in beiden Fällen durch weitere Prompts verfeinert.
Die von ChatGPT generierte Lösung war komplex und falsch. Aufgrund meiner eigenen Erfahrung hatte ich direkt Zweifel und glaubte nicht, dass der vorgeschlagene wilde Mix aus Bridge und Teaming mit Master- und Slave-Interface auf der Bridge funktionieren würde.
Um meine Annahme zu verifizieren, habe ich die vorgeschlagene Lösung trotzdem umgesetzt und nach der Hetzner-MAC-Abuse-Meldung wieder zurückgebaut.
Ich hatte keine Lust, ChatGPT mit dem Ergebnis zu konfrontieren und weiter mit dem Bot zu chatten, da ich wenig Hoffnung hatte, dass ich noch zu einer funktionierenden Lösung komme.
Hier hat mir die Erfahrung deutlich besser gefallen. Gemini hat auf meinen Prompt mit einer Zusammenfassung reagiert, welche Informationen über die bereitgestellten Quellen zu meinem Prompt bieten. Dabei wurden auch Referenzen mit ausgegeben, um direkt zur Quelle springen zu können. Im Anschluss gab es eine Schritt-für-Schritt-Anleitung mit Code-Beispielen. Zu jedem Code-Beispiel erfolgte dazu eine Erklärung, was man dort sieht und was die einzelnen Parameter bedeuten. Dies hat mir gut gefallen.
Die ersten zwei Anleitungen waren noch etwas ungenau, ließen sich jedoch durch weitere Prompts soweit verfeinern, dass ich sie fast 1-zu-1 übernehmen konnte.
Warum nur fast? Ich habe mir die in der Schritt-für-Schritt-Anleitung referenzierten Quellen angeschaut und mit den dortigen Informationen die Code-Beispiele weiter optimiert, so dass sie besser zu meiner Umgebung passen. Evtl. hätte Gemini dies mit besseren Prompts ebenfalls hinbekommen.
Auch diese Lösung habe ich implementiert und sie läuft bis heute. Die KI hat mich auf dem Weg zur Lösung unterstützt und ich musste nicht die vier Quellen komplett und im Detail lesen, um mir die Lösung komplett selbst zu erarbeiten. Ich bin mit dem Ergebnis sehr zufrieden.
Künstliche Intelligenz und deren Nutzung ist nicht unumstritten. Der aktuelle Energiebedarf ist enorm und es ist zu befürchten, dass dies negative Umweltauswirkungen zur Folge hat. KI-Modelle können halluzinieren, was zu Fehlern führt, wenn man die Antworten der Modelle nicht verifiziert.
Die Weigerung, KI im Beruf zu benutzen und ihre Möglichkeiten zu erkunden, führt meiner Einschätzung nach jedoch nur dazu, dass man sich selbst benachteiligt. KI mag Arbeitsplätze nicht so schnell ersetzen. Aber Menschen, die KI effizient nutzen können, werden Menschen von Stellen verdrängen, die dies nicht können. Es erscheint mir daher sinnvoll, den Einsatz von KI im Beruf und Alltag zu erkunden.
Den größten Vorteil bietet mir die KI-Nutzung aktuell dort, wo sie gut in meine Anwendungen und Werkzeuge wie z.B. Mail, Videokonferenzen und Kalender integriert ist. Der Vorteil besteht überwiegend in Zeitersparnis. Ich habe die gewünschten Informationen schneller mit weniger eigenem Aufwand in ausreichender Qualität zur Verfügung, wobei die Qualität mit geringem Aufwand durch manuelle Überarbeitung schnell gesteigert werden kann, um ein gutes Ergebnis zu erzielen.
KI-Assistenten lassen sich nutzen, um die Zeit zur Lösung zu verkürzen. Ich hätte die Dokumentationen alle selbst lesen und mir die Lösung erarbeiten können. Ich bin mir jedoch sicher, dass ich dafür deutlich mehr Zeit hätte investieren müssen.
Im Endeffekt hilft mir KI dabei, mehr Aufgaben im gleichen Zeitintervall zu erledigen.
Die Forscher verschiedener führender Institute, darunter der Shanghai Jiao Tong University oder des Institute for Advanced Algorithms Research, Shanghai, konstatieren, dass das Fehlen einer gut…
Debian strebt nach vielen Diskussionen über KI ein Budget für freie Nutzung von LLMs für Entwickler an. Dabei geht es auch um KI-generierten Code.
Ein Sprachmodell unterstützt Programmierer besser, ein anderes ist ein Mathe-Ass, ein drittes läuft beim kreativen Schreiben zur Hochform auf – jedes hat seine Stärken und Schwächen.