In meinem Arbeitsalltag wimmelt es von virtuellen Linux-Maschinen, die ich primär mit zwei Programmen ausführe:
virtual-machine-manager alias virt-manager (KVM/QEMU) unter Linux
UTM (QEMU + Apple Virtualization) unter macOS
Dabei treten regelmäßig zwei Probleme auf:
Bei Neuinstallationen funktioniert der Datenaustausch über die Zwischenablage zwischen Host und VM (= Gast) funktioniert nicht.
Die Uhrzeit in der VM ist falsch, nachdem der Host eine Weile im Ruhestand war.
Diese Ärgernisse lassen sich leicht beheben …
Anmerkung: Ich beziehe mich hier explizit auf die Desktop-Virtualisierung. Ich habe auch VMs im Server-Betrieb — da brauche ich keine Zwischenablage (Text-only, SSH-Administration), und die Uhrzeit macht wegen des dauerhaften Internet-Zugangs auch keine Probleme.
Zwischenablage mit Spice als Grafik-Protokoll
Wenn das Virtualisierungssystem das Grafiksystem mittels Simple Protocol for Independent Computing Environments (SPICE) überträgt (gilt per Default im virtual-machine-manager und in UTM), funktioniert die Zwischenablage nur, wenn in der virtuellen Maschine das Paket spice-vdagent installiert ist. Wenn in der virtuellen Maschine Wayland läuft, was bei immer mehr Distributionen standardmäßig funktioniert, brauchen Sie außerdem wl-clipboard. Also:
Nach der Installation müssen Sie sich in der VM aus- und neu einloggen, damit die Programme auch gestartet werden. Manche, virtualisierungs-affine Distributionen installieren die beiden winzigen Pakete einfach per Default. Deswegen funktioniert die Zwischenablage bei manchen Linux-Gästen sofort, bei anderen aber nicht.
Synchronisierung der Uhrzeit
Grundsätzlich beziehen sowohl die virtuellen Maschine als auch der Virtualisierungs-Host die Uhrzeit via NTP aus dem Internet. Das klappt problemlos.
Probleme treten dann auf, wenn es sich beim Virtualisierungs-Host um ein Notebook oder einen Desktop-Rechner handelt, der hin- und wieder für ein paar Stunden inaktiv im Ruhezustand schläft. Nach der Reaktivierung wird die Zeit im Host automatisch gestellt, in den virtuellen Maschinen aber nicht.
Vielleicht denken Sie sich: Ist ja egal, so wichtig ist die Uhrzeit in den virtuellen Maschinen ja nicht. So einfach ist es aber nicht. Die Überprüfung von Zertifikaten setzt die korrekte Uhrzeit voraus. Ist diese Voraussetzung nicht gegeben, können alle möglichen Problem auftreten (bis hin zu Fehlern bei der Software-Installation bzw. bei Updates).
Für die lokale Uhrzeit in den virtuellen Maschinen ist das Programm chrony zuständig. Eigentlich sollte es in der Lage sein, die Zeit automatisch zu justieren — aber das versagt, wenn die Differenz zwischen lokaler und echter Zeit zu groß ist. Abhilfe: starten Sie chronyd neu:
sudo systemctl restart chronyd
Um die automatische Einstellung der Uhrzeit nach der Wiederherstellung eines Snapshots kümmert sich der qemu-guest-agent (z.B. im Zusammenspiel mit Proxmox). Soweit das Programm nicht automatisch installiert ist:
Im digitalen Arbeitsumfeld sind heterogene IT-Strukturen längst zur Realität geworden. Man arbeitet heute in Teams, die Geräte mit unterschiedlichen Betriebssystemen nutzen – Windows, Linux und macOS koexistieren zunehmend selbstverständlich. Dabei stellt sich weniger die Frage, welches System das beste ist, sondern vielmehr, wie man plattformübergreifend sichere Arbeitsbedingungen schafft. Denn jedes Betriebssystem bringt eigene Stärken mit, aber auch spezifische Schwachstellen. Besonders im Kontext verteilter Arbeitsplätze, hybrider Teams und cloudbasierter Prozesse ist es entscheidend, Sicherheitsmaßnahmen nicht isoliert, sondern systemübergreifend zu denken. Nur wenn man versteht, wie die jeweiligen Architekturen funktionieren und wie sie auf technischer wie organisatorischer Ebene zusammenspielen, kann man Risiken minimieren. Der Zugriff auf sensible Daten, Authentifizierungsmethoden oder der Einsatz von Monitoring-Tools – all diese Bereiche müssen strategisch aufeinander abgestimmt werden.
Unterschiedliche Sicherheitsmodelle verstehen – wie man systembedingte Schwächen ausgleicht
Jedes Betriebssystem folgt einer eigenen Sicherheitsphilosophie. Um ein sicheres Zusammenspiel zu gewährleisten, muss man diese zunächst durchdringen. Windows setzt traditionell auf eine zentrale Benutzerverwaltung über Active Directory und nutzt Gruppenrichtlinien zur Durchsetzung von Sicherheitsvorgaben. macOS orientiert sich stark am UNIX-Prinzip der Benutzertrennung und bringt mit Gatekeeper und System Integrity Protection eigene Schutzmechanismen mit. Linux hingegen ist durch seine Offenheit und Modularität geprägt, was eine hohe Anpassbarkeit ermöglicht – aber auch eine größere Verantwortung beim Anwender voraussetzt.
Man darf sich nicht auf die scheinbare „Stärke“ eines Systems verlassen, sondern muss die jeweiligen Lücken kennen. Während Windows anfällig für Malware über unsichere Dienste sein kann, sind bei Linux-Konfigurationen oft Fehlbedienungen ein Einfallstor. macOS wiederum schützt zuverlässig gegen viele Schadprogramme, ist aber nicht gegen Zero-Day-Exploits immun. Die Lösung liegt in der wechselseitigen Kompensation: Man etabliert Prozesse, die die Schwächen eines Systems durch die Stärken eines anderen abfedern. Etwa durch zentrale Netzwerksegmentierung oder rollenbasierte Zugriffskonzepte. Auch einfache Maßnahmen – wie das sichere Hinterlegen und regelmäßige Erneuern eines Windows 11 Keys – tragen ihren Teil dazu bei, potenzielle Angriffsflächen zu minimieren. Wer das Sicherheitsprofil jedes Systems im Detail kennt, kann systemübergreifend robuste Schutzmechanismen implementieren.
Gemeinsame Standards etablieren – wie man durchrichtlinienübergreifende Policies implementiert
In einer Umgebung mit mehreren Betriebssystemen stößt man schnell auf ein Problem: Sicherheitseinstellungen greifen oft nur innerhalb ihrer nativen Plattform. Um dennoch einheitliche Schutzkonzepte umzusetzen, ist es erforderlich, Richtlinienbetrieb systemübergreifend zu denken. Hier kommen sogenannte Cross-Platform-Policies ins Spiel. Diese Sicherheitsrichtlinien sind nicht an ein bestimmtes Betriebssystem gebunden, sondern basieren auf übergeordneten Prinzipien wie Zero Trust, Least Privilege oder Multi-Faktor-Authentifizierung.
Man beginnt mit einer Analyse aller eingesetzten Systeme und deren zentraler Sicherheitsfunktionen. Anschließend definiert man Kernanforderungen – etwa zur Passwortsicherheit, zum Patch-Zyklus oder zur Verschlüsselung von Daten – und setzt diese mithilfe von Tools wie Microsoft Intune, Jamf oder Open Source-Pendants auf allen Plattformen durch. Dabei ist darauf zu achten, dass die Auslegung der Richtlinien nicht zu rigide erfolgt, da gerade bei Linux-Systemen individuelle Konfigurationen notwendig sein können.
Ein praktisches Beispiel ist der Umgang mit Administratorrechten. Unter Windows nutzt man Gruppenrichtlinien, unter Linux sudo-Berechtigungen, unter macOS rollenbasierte Nutzerprofile. Einheitliche Richtlinien sorgen dafür, dass man die Kontrolle über Rechtevergabe und Systemzugriffe auch bei gemischten Umgebungen nicht verliert. Selbst die Lizenzverwaltung, etwa die Zuweisung eines Windows 11 Keys, kann zentral über Plattform-Managementlösungen erfolgen – sicher, nachvollziehbar und auditierbar.
Authentifizierung, Verschlüsselung, Rechtevergabe – worauf man in gemischten Umgebungen achten muss
Die Authentifizierung bildet die erste Sicherheitsbarriere jedes Systems – unabhängig vom Betriebssystem. In einem plattformübergreifenden Setup muss man sicherstellen, dass alle eingesetzten Mechanismen ein gleich hohes Sicherheitsniveau bieten. Single Sign-On (SSO) über Identity Provider wie Azure AD oder Okta hilft, zentrale Identitäten zu verwalten und Systemzugriffe nachvollziehbar zu gestalten. Entscheidend ist, dass man auch Geräte außerhalb der Windows-Welt – etwa unter Linux oder macOS – nahtlos einbindet.
Verschlüsselung ist der zweite Eckpfeiler. Während Windows mit BitLocker arbeitet, setzen viele Linux-Distributionen auf LUKS, und macOS verwendet FileVault. Diese Tools unterscheiden sich in Funktion und Konfiguration, verfolgen jedoch dasselbe Ziel: die Integrität sensibler Daten auf Systemebene zu gewährleisten. Ein ganzheitliches Verschlüsselungskonzept stellt sicher, dass Daten unabhängig vom Endgerät geschützt sind – selbst wenn der physische Zugriff durch Dritte erfolgt.
Rechtevergabe schließlich muss nicht nur sicher, sondern auch nachvollziehbar sein. Unter Windows spielt das Active Directory eine Schlüsselrolle, unter Linux helfen Access Control Lists (ACL), während macOS ebenfalls fein abgestufte Rollenmodelle erlaubt. Die Herausforderung liegt darin, diese Mechanismen so zu verzahnen, dass keine Lücken entstehen.
Endpoint Management und Monitoring – wie man mit zentralen Tools die Kontrolle behält
In modernen Arbeitsumgebungen verlässt man sich nicht mehr auf stationäre IT-Strukturen. Notebooks, Tablets und mobile Geräte bewegen sich außerhalb klassischer Unternehmensnetzwerke. Das macht effektives Endpoint Management zur unverzichtbaren Sicherheitskomponente. Dabei steht man vor der Aufgabe, unterschiedliche Betriebssysteme gleichzeitig zu verwalten – ohne dass die Kontrolle über Konfiguration, Updates oder Zugriffsrechte verloren geht.
Man setzt auf zentrale Managementlösungen wie Microsoft Endpoint Manager, VMware Workspace ONE oder plattformunabhängige Open-Source-Ansätze wie Munki oder Ansible. Diese Tools ermöglichen es, Sicherheitsrichtlinien über Systemgrenzen hinweg auszurollen, Patches zeitnah zu verteilen und Geräte bei Auffälligkeiten sofort zu isolieren. Auch das Monitoring wird damit skalierbar und konsistent. Man erkennt unautorisierte Zugriffe, veraltete Softwarestände oder kritische Konfigurationsabweichungen – unabhängig davon, ob es sich um ein Windows-Notebook, ein Linux-Server-Device oder ein macOS-Arbeitsgerät handelt.
Ein strukturierter Lifecycle-Ansatz gehört ebenfalls dazu. Vom ersten Boot bis zum Offboarding eines Geräts muss nachvollziehbar dokumentiert werden, welche Zugriffe gewährt, welche Daten gespeichert und welche Updates durchgeführt wurden. Selbst administrative Elemente wie das Einpflegen eines Windows 11 Keys lassen sich über diese Plattformen verwalten – revisionssicher, automatisiert und zuverlässig. So wahrt man in komplexen IT-Landschaften jederzeit die Übersicht und bleibt handlungsfähig.
Markdown ist eine leicht verständliche Auszeichnungssprache für Texte. Einige von Euch kennen jene aus Readme-Dateien aus Git Repositories, Dokumentationen und von statischen Bloggeneratoren wie Hugo, oder Jekyll. Markdown bietet für mich entscheidende Vorteile. Ein in Markdown formatierter und strukturierten Text ist für immer in der gewünschten Formatierung betrachtbar. Er ist nicht an ein bestimmtes Programm ... Weiterlesen
Einen Nextcloud-Kalender in Thunderbird einzubinden, ist nicht sehr schwer. Wie das Ganze funktioniert, zeige ich in diesem Artikel.
Vorbereitung in der Nextcloud
Zuerst meldet man sich über die Weboberfläche der Nextcloud an. Dort navigiert man zum Kalender und weiter unten links auf die Kalender-Einstellungen.
Nextcloud – Kalender-Einstellungen
Dort wird dann die Primäre CalDAV-Adresse, wie im Screenshot zu sehen, kopiert.
Nextcloud – CalDAV-Adresse
Vorbereitung in Thunderbird
In Thunderbird wählt man den Kalender aus, klickt auf Neuer Kalender, wählt Im Netzwerk und fügt den Benutzernamen des Nextcloud-Accounts sowie die zuvor kopierte CalDAV-Adresse ein.
Ist dies erledigt, wird der Kalender in Thunderbird angezeigt. Nach der automatischen Synchronisation, die eine Weile dauern kann, sind auch die ersten Einträge – wie im Screenshot zu sehen – sichtbar.
Viele Anwender haben lange darauf gewartet – GIMP ist nach fast sechs Jahren Entwicklungszeit in Version 3 erschienen. Dieses Release bringt einen komplett überarbeiteten Kern mit sich und setzt nun auf das GTK3-Toolkit. Das Buch „GIMP 3: Das umfassende Handbuch“ bietet – wie der Name schon verrät – ein umfassendes Nachschlagewerk zum GNU Image Manipulation Program, kurz: GIMP.
Das Buch ist in sieben Teile gegliedert.
Teil I – Grundlagen widmet sich, wie der Titel schon sagt, den grundlegenden Funktionen von GIMP. Der Autor erläutert die Oberfläche des Grafikprogramms und stellt dabei heraus, dass sich Nutzer auch in der neuen Version schnell zurechtfinden – ein Hinweis, der mögliche Bedenken beim Umstieg zerstreuen dürfte. Die Aussage „GIMP ist nicht Photoshop“ von Jürgen Wolf ist prägnant und unterstreicht, dass es sich bei GIMP um ein eigenständiges, leistungsfähiges Programm handelt, das keinen direkten Vergleich mit kommerzieller Software scheuen muss – oder sollte. Zahlreiche Workshops mit umfangreichem Zusatzmaterial begleiten die einzelnen Kapitel. Neben der Benutzeroberfläche werden in Teil I auch Werkzeuge und Dialoge ausführlich erklärt. Darüber hinaus wird beschrieben, wie RAW-Aufnahmen in GIMP importiert und weiterverarbeitet werden können. Ebenso finden sich Anleitungen zum Speichern und Exportieren fertiger Ergebnisse sowie Erläuterungen zu den Unterschieden zwischen Pixel- und Vektorgrafiken (siehe Grafik). Auch Themen wie Farben, Farbmodelle und Farbräume werden behandelt – Letzteres wird im dritten Teil des Buches noch einmal vertieft.
Vektorgrafik vs. Pixelgrafik
Teil II – Die Bildkorrektur behandelt schwerpunktmäßig die Anpassung von Helligkeit, Kontrast und anderen grundlegenden Bildeigenschaften. Ein wesentlicher Abschnitt widmet sich der Verarbeitung von RAW-Aufnahmen, wobei das Zusammenspiel von GIMP mit Darktable im Mittelpunkt steht. Zahlreiche Beispiele und praxisnahe Bearbeitungshinweise unterstützen den Leser bei der Umsetzung am eigenen Bildmaterial.
Teil III – Rund um Farbe und Schwarzweiß beschreibt den Umgang mit Farben und erläutert grundlegende Konzepte dieses Themenbereichs. Dabei wird auch der Einsatz von Werkzeugen wie Pinsel, Stift und Sprühpistole behandelt. Darüber hinaus zeigt das Kapitel, wie Farben verfremdet und Schwarzweißbilder erstellt werden können.
Teil IV – Auswahlen und Ebenen führt den Leser in die Arbeit mit Auswahlen und Ebenen ein. Besonders faszinierend ist dabei das Freistellen von Objekten und die anschließende Bildmanipulation – eine Disziplin, die GIMP hervorragend beherrscht. Auch hierzu bietet das Buch eine Schritt-für-Schritt-Anleitung in Form eines Workshops.
Teil V – Kreative Bildgestaltung und Retusche erklärt, was sich hinter Bildgröße und Auflösung verbirgt und wie sich diese gezielt anpassen lassen. Techniken wie der „Goldene Schnitt“ werden vorgestellt und angewendet, um Motive wirkungsvoll in Szene zu setzen. Außerdem zeigt das Kapitel, wie sich Objektivfehler – etwa tonnen- oder kissenförmige Verzeichnungen – sowie schräg aufgenommene Horizonte korrigieren lassen. Die Bildverbesserung und Retusche werden ausführlich behandelt. Vorgestellte Techniken wie die Warptransformation sind unter anderem in der Nachbearbeitung von Werbefotografie unverzichtbar.
Retusche – Warptransformation
Teil VI – Pfade, Text, Filter und Effekte beschäftigt sich mit den vielfältigen Möglichkeiten, die GIMP für die Arbeit mit Pixel- und Vektorgrafiken bietet. So lassen sich beispielsweise Pixelgrafiken nachzeichnen, um daraus Vektoren bzw. Pfade für die weitere Bearbeitung zu erzeugen. Eine weitere Übung, die sich mit der im Handbuch beschriebenen Methode leicht umsetzen lässt, ist der sogenannte Andy-Warhol-Effekt.
Andy-Warhol-Effekt
Teil VII – Ausgabe und Organisation zeigt, wie der Leser kleine Animationen im WebP- oder GIF-Format erstellen kann. Auch worauf beim Drucken und Scannen zu achten ist, wird in diesem Kapitel ausführlich erläutert. Jürgen Wolf geht zudem noch einmal umfassend auf die verschiedenen Einstellungen in GIMP ein. Besonders hilfreich ist die Auflistung sämtlicher Tastaturkürzel, die die Arbeit mit dem Grafikprogramm spürbar erleichtern.
Das Buch umfasst insgesamt 28 Kapitel und deckt damit alle wichtigen Bereiche der Bildbearbeitung mit GIMP 3 ab.
„GIMP 3: Das umfassende Handbuch“ von Jürgen Wolf überzeugt durch eine klare Struktur, verständliche Erklärungen und praxisnahe Workshops. Sowohl Einsteiger als auch fortgeschrittene Anwender finden hier ein zuverlässiges Nachschlagewerk rund um die Bildbearbeitung mit GIMP. Besonders hervorzuheben sind die zahlreichen Beispiele sowie die umfassende Behandlung aller relevanten Themenbereiche. Wer ernsthaft mit GIMP arbeiten möchte, findet in diesem Buch eine uneingeschränkte Kaufempfehlung.
Vor einem dreiviertel Jahr haben Bernd Öggl, Sebastian Springer und ich das Buch Coding mit KI geschrieben und uns während dieser Zeit intensiv mit diversen KI-Tools und Ihrer Anwendung beschäftigt.
Was hat sich seither geändert? Wie sieht die berufliche Praxis mit KI-Tools heute aus? Im folgenden Fragebogen teilen wir drei unsere Erfahrungen, Wünsche und Ärgernisse. Sie sind herzlich eingeladen, in den Kommentaren eigene Anmerkungen hinzuzufügen.
Bei welchen Projekten hast du KI-Tools im letzten Monat eingesetzt? Mit welchem Erfolg?
Bernd: KI-Tools haben in meine tägliche Programmierung Einzug gehalten und sparen mir Zeit. Oft traue ich der Ki zu wenig zu und stelle Fragen, die nicht weit genug gehen. Zum „vibe-coding“ bin ich noch nicht gekommen :-) Ich verwende KI-Tools in diesen Projekten:
ein großes Code Repo mit Angular und C#: Einsatz sowohl in VSCode (Angular) und Visual Studio (C#, die Unterstützung ist überraschend gut).
ein kleines Projekt (HTML, JS, MongoDB (ca. 20.000 MongoDocs)).
zwei verschiedene Flutter Apps für Android
für eine größere PHP/MariaDB Codebase
Sebastian: Ich setze mittlerweile verschiedene KI-Tools flächendeckend in den Projekten ein. Wir haben das mittlerweile auch in unsere Verträge mit aufgenommen, dass das explizit erlaubt ist.
Die letzten Projekte waren in JavaScript/TypeScript im Frontend React, im Backend Node.js, und es waren immer mittelgroße Projekte mit 2 – 4 Personen über mehrere Monate.
Die verschiedenen Tools sind mittlerweile zum Standard geworden und ich möchte nicht mehr darauf verzichten müssen, gerade bei den langweiligen Routineaufgaben helfen sie enorm.
Michael: Ich habe zuletzt einige Swift/SwiftUI-Beispielprogramme entwickelt. Weil Swift und insbesondere SwiftUI ja noch sehr dynamisch in der Weiterentwicklung ist, hatten die KI-Tools die Tendenz, veraltete Programmiertechniken vorzuschlagen. Aber mit entsprechenden Prompts (use modern features, use async/await etc.) waren die Ergebnisse überwiegend gut (wenn auch nicht sehr gut).
Ansonsten habe ich in den letzten Monaten immer wieder kleinere Mengen Code in PHP/MySQL, Python und der bash geschrieben bzw. erweitert. Mein Problem ist zunehmend, dass ich beim ständigen Wechsel die Syntaxeigenheiten der diversen Sprachen durcheinanderbringe. KI-Tools sind da meine Rettung! Der Code ist in der Regel trivial. Mit einem sorgfältig formulierten Prompt funktioniert KI-generierter Code oft im ersten oder zweiten Versuch. Ich kann derartige Routine-Aufgaben mit KI-Unterstützung viel schneller erledigen als früher, und die KI-Leistungen sind diesbezüglich ausgezeichnet (besser als bei Swift).
Welches KI-Tool verwendest du bevorzugt? In welchem Setup?
Michael: Ich habe in den vergangenen Monaten fast ausschließlich Claude Pro verwendet (über die Weboberfläche). Was die Code-Qualität betrifft, bin ich damit sehr zufrieden und empfand diese oft besser als bei ChatGPT.
In VSCode läuft bei mir Cody (Free Tier). Ich verwende es nur für Vervollständigungen. Es ist OK.
Ansonsten habe ich zuletzt den Großteil meiner Arbeitszeit in Xcode verbracht. Xcode ist im Vergleich zu anderen IDEs noch in der KI-Steinzeit, die aktuell ausgelieferten KI-Werkzeuge in Xcode sind unbrauchbar. Eine Integration von Claude in Xcode hätte mir viel Hin und Her zwischen Xcode und dem Webbrowser erspart. (Es gibt ein Github-Copilot-Plugin für Xcode, das ich aber noch nicht getestet habe. Apple hat außerdem vor fast einem Jahr Swift Code angekündigt, das bessere KI-Funktionen verspricht. Leider ist davon nichts zu sehen. Apple = Gute Hardware, schlechte Software, zumindest aus Entwicklerperspektive.)
Für lokale Modelle habe ich aktuell leider keine geeignete Hardware.
Sebastian: Ich habe über längere Zeit verschiedene IDE-Plugins mit lokalen Modellen ausprobiert, nutze aber seit einigen Monaten nur noch GitHub Copilot. Die Qualität und Performance ist deutlich besser als die von lokalen Modellen.
Für Konzeption und Ideenfindung nutze ich ebenfalls größere kommerzielle Werkzeuge. Aktuell stehen die Gemini-Modelle bei mir ganz hoch im Kurs. Die haben mit Abstand den größten Kontext (1 – 2 Millionen Tokens) und die Ergebnisse sind mindestens genauso gut wie bei ChatGPT, Claude & Co.
Lokale Modelle nutze ich eher punktuell oder für die Integration in Applikationen. Gerade wenn es um Übersetzung, RAG und ähnliches geht, wo es entweder um Standardaufgaben oder um Teilaufgaben geht, wo man mit weiteren Tools wie Vektordatenbanken die Qualität steuern kann. Bei den lokalen Modellen hänge ich nach wie vor bei Llama3 wobei sich auch die Ergebnisse von DeepSeek sehen lassen können.
Für eine kleine Applikation habe ich auch europäische Modelle (eurollm und teuken) ausprobiert, wobei ich da nochmal deutlich mehr Zeit investieren muss.
Für die Ausführung lokaler Modelle habe ich auf die Verfügbarkeit der 50er-Serie von NVIDIA gewartet, wobei mir die RTX 5090 deutlich zu teuer ist. Ich habe seit Jahresbeginn ein neues MacBook Pro (M4 Max) das bei der Ausführung lokaler Modelle echt beeindruckend ist. Mittlerweile nutze ich das MacBook deutlich mehr als meinen Windows PC mit der alten 3070er.
Bernd: Ich verwende aus Interesse vor allem lokale Modelle, die auf meinem MacBook Pro (M2/64GB) wunderbar schnell performen (aktuell gemma3:27b und deepseek-r1:32b, aber das ändert sich schnell). Am MacBook laufen die über ollama. Ich muss aber beruflich auch unter Windows arbeiten und arbeite eigentlich (noch) am liebsten unter Linux mit neovim.
Dazu ist das Macbook jetzt immer online und im lokalen Netz erreichbar. Unter Windows verwenden ich in VSCode das Continue Plugin mit dem Zugriff auf die lokalen Modelle am MacBook. In Visual Studio läuft CoPilot (die „Gratis“-Version). Unter Linux verwende ich sehr oft neovim (mit lazyvim) mit dem avante-Plugin. Während ich früher AI nur für code-completion verwendet habe, ist es inzwischen oft so, dass ich Code-Blöcke markiere und der AI dazu Fragen stelle. Avante macht dann wunderbare Antworten mit Code-Blöcken, die ich wie einen git conflict einbauen kann. Sie sagen es ist so wie cursor.ai, aber das habe ich noch nicht verwendet.
Daneben habe ich unter Linux natürlich auch VSCode mit Continue. Und wenn ich gerade einmal nicht im Büro arbeite (also das Macbook nicht im aktuellen Netz erreichbar ist), so wie gerade eben, dann habe ich Credits für Anthropic und verwende Claude (3.5 Sonnet aktuell) für AI support.
Wo haben dich KI-Tools in letzter Zeit überrascht bzw. enttäuscht?
Sebastian: Ich bin nach wie vor enttäuscht wie viel Zeit es braucht, um den Kontext aufzubauen, damit dir ein LLM wirklich bei der Arbeit hilft. Gerade wenn es um neuere Themen wie aktuelle Frameworks geht. Allerdings lohnt es sich bei größeren Projekten, hier Zeit zu investieren. Ich habe in ein Test-Setup für eine Applikation gleich mehrere Tage investiert und konnte am Ende qualitativ gute Tests generieren, indem ich den Testcase mit einem Satz beschrieben habe und alles weitere aus Beispielen und Templates kam.
Ich bin sehr positiv überrascht vom Leistungssprung den Apple bei der Hardware hingelegt hat. Gerade das Ausführen mittelgroßer lokaler LLMs merkt man das extrem. Ein llama3.2-vision, qwq:32b oder teuken-7b funktionieren echt gut.
Bernd: Überrascht hat mich vor allem der Qualitäts-Gewinn bei lokalen Modellen. Im Vergleich zu vor einem Jahr sind da Welten dazwischen. Ich mache nicht ständig Vergleiche, aber was die aktuellen Kauf-Modelle liefern ist nicht mehr so ganz weit weg von gemma3 und vergleichbaren Modellen.
Michael: Ich musste vor ein paar Wochen eine kleine REST-API in Python realisieren. Datenbank und API-Design hab‘ ich selbst gemacht, aber das Coding hat nahezu zu 100 Prozent die KI erledigt (Claude). Ich habe mich nach KI-Beratung für das FastAPI-Framework entschieden, das ich vorher noch nie verwendet habe. Insgesamt ist die (einzige) Python-Datei knapp 400 Zeilen lang. Acht Requests mit den dazugehörigen Datenstrukturen, Absicherung durch ein Time-based-Token, komplette, automatisch generierte OpenAPI-Dokumentation, Wahnsinn! Und ich habe wirklich nur einzelne Zeilen geändert. (Andererseits: Ich wusste wirklich ganz exakt, was ich wollte, und ich habe viel Datenbank- und Python-Basiswissen. Das hilft natürlich schon.)
So richtig enttäuscht haben mich KI-Tools in letzter Zeit selten. In meinem beruflichen Kontext ergeben sich die größten Probleme bei ganz neuen Frameworks, zu denen die KI zu wenig Trainingsmaterial hat. Das ist aber erwartbar und insofern keine Überraschung. Es ist vielmehr eine Bestätigung, dass KI-Tools keineswegs von sich aus ‚intelligent‘ sind, sondern zuerst genug Trainingsmaterial zum Lernen brauchen.
Was wäre dein größter Wunsch an KI-Coding-Tools?
Bernd: Gute Frage. Aktuell nerven mich ein bisschen die verschiedenen Plugins und die Konfigurationen für unterschiedliche Editoren. Wie gesagt, neovim ist für mich wichtig, da hast du, wie in OpenSource üblich, 23 verschiedene Plugins zur Auswahl :-) Zum Glück gibt es ollama, weil da können alle anbinden. Ich glaub M$ versucht das eh mit CoPilot, eine Lösung, die überall funktioniert, nur ich will halt lokale Modelle und nicht Micro$oft….
Sebastian: Im Moment komme ich mit dem Wünschen ehrlich gesagt gar nicht hinterher, so rasant wie sich alles entwickelt. Microsoft hat GitHub Copilot den Agent Mode spendiert, TypeScript wird “mehr copiloty” und bekommt APIs die eine engere Einbindung von LLMs in den Codingprozess erlauben. Wenn das alles in einer ausreichenden Qualität kommt, hab ich erstmal keine weiteren Wünsche.
Michael: Ich bin wie gesagt ein starker Nutzer der webbasierten KI-Tools. Was ich dabei über alles schätze ist die Möglichkeit, mir die gesamte Konversation zu merken (als Bookmark oder indem ich den Link als Kommentar in den Code einbaue). Ich finde es enorm praktisch, wenn ich mir später noch einmal anschauen kann, was meine Prompts waren und welche Antworten das damalige KI-Modell geliefert hat.
Eine vergleichbare Funktion würde ich mir für IDE-integrierte KI-Tools wünschen. Eine KI-Konversation in VSCode mit GitHub Copilot oder einem anderen Tool sowie die nachfolgenden Code-Umbauten sind später nicht mehr reproduzierbar — aus meiner Sicht ein großer Nachteil.
Beeinflusst die lokale Ausführbarkeit von KI-Tools deinen geplanten bzw. zuletzt durchgeführten Hardware-Kauf?
Bernd: zu 100%! Mein MacBook Pro (gebraucht gekauft, M2 Max mit 64GB) wurde ausschließlch aus diesem Grund gekauft und es war ein großer Gewinn.
Ich habe jetzt ein 2.100 EUR Thinkpad und ein 2.200 EUR MacBook. Rate mal was ich öfter verwende :-) . Die Hardware beim Mac (besonders das Touchpad) ist besser und ich habe quasi alle Linux-Tools auch am Mac (fish-shell, neovim, git, Browser, alle anderen UI-Programme). Wenn ich unter Linux arbeite, denke ich mir oft: »Ah, das kann ich jetzt nicht ollama fragen, weil das nur am MacBook läuft«. Natürlich könnte ich Claude verwenden, aber irgend etwas im Kopf ist dann doch so: »Das muss man jetzt nicht über den großen Teich schicken.«
4000 EUR für die Nvidia-Maschine, die ich zusätzlich zum Laptop mitnehmen muss, ist kein Ding für mich. Ich möchte einen Linux Laptop, der die LLMs so schnell wie der Mac auswerten kann (und noch ein gutes Touchpad hat). Das ist der Wunsch ans Christkind …
Michael: Ein ärgerliches Thema! Ich bin bei Hardware eher sparsam. Vor einem Jahr habe ich mir ein Apple-Notebook (M3 Pro mit 36 GB RAM) gegönnt und damit gerade mein Swift-Buch aktualisiert. Leider waren mir zum Zeitpunkt des Kaufs die Hardware-Anforderungen für lokale LLMs zu wenig klar. Das Notebook ist großartig, aber es hat zu wenig RAM. Den Speicher brauche ich für Docker, virtuelle Maschinen, IDEs, Webbrowser etc. weitgehend selbst, da ist kein Platz mehr für große LLMs.
Aus meiner Sicht sind 64 GB RAM aktuell das Minimum für einen Entwickler-PC mit lokalen LLMs. Im Apple-Universum ist das sündhaft teuer. Im Intel/AMD-Lager gibt es wiederum kein einziges Notebook, das — was die Hardware betrifft — auch nur ansatzweise mit Apple mithalten kann. Meine Linux- und Windows-Rechner kann ich zwar billig mit mehr RAM ausstatten, aber die GPU-Leistung + Speicher-Bandbreite sind vollkommen unzureichend. Deprimierend.
Ein externer Nvidia-Mini-PC (kein Notebook, siehe z.B. die diversen Ankündigungen auf notebookcheck.com) mit 128 GB RAM als LLM-Server wäre eine Verlockung, aber ich bin nicht bereit, dafür plus/minus 4000 EUR auszugeben. Da zahle ich lieber ca. 20 EUR/Monat für ein externes kommerzielles Tool. Aber derartige Rechner, wenn sie denn irgendwann lieferbar sind, wären sicher ein spannendes Angebot für Firmen, die einen lokalen LLM-Server einrichten möchten.
Generell bin ich überrascht, dass die LLM-Tauglichkeit bis jetzt kein großes Thema für Firmen-Rechner und -Notebooks zu sein scheint. Dass gerade Apple hier so gut performt, war ja vermutlich auch nicht so geplant, sondern hat sich mit den selbst entwickelten CPUs als eher zufälliger Nebeneffekt ergeben.
Sebastian: Ursprünglich war mein Plan auf die neuen NVIDIA-Karten zu warten. Nachdem ich aber im Moment eher auf kommerzielle Tools setze und sich mein neues MacBook zufällig als richtige KI-Maschine entpuppt, werde ich erstmal warten, wie sich die Preise entwickeln. Ich bin auch enttäuscht, dass NVIDIA den kleineren karten so wenig Speicher spendiert hat. Meine Hoffnung ist, dass nächstes Jahr die 5080 mit 24GB rauskommt, das wär dann genau meins.
In einer Zeit, in der immer mehr Daten digital gespeichert werden, ist es wichtiger denn je, sich Gedanken über die Sicherheit und den Schutz der eigenen Daten zu machen. Cloudspeicherung bietet eine bequeme Möglichkeit, Daten zu sichern und von überall aus darauf zuzugreifen. Doch viele Nutzer sind besorgt über die Sicherheit ihrer Daten in der Cloud und suchen nach einer Alternative, die ihnen mehr Kontrolle über ihre Daten gibt. Die Nextcloud ist eine solche Alternative, die Sicherheit, Flexibilität und Datenschutz bietet.
Was ist Nextcloud?
Nextcloud ist eine Open-Source-Plattform für die Speicherung und Synchronisierung von Daten. Sie wurde im Jahr 2016 als Abspaltung von OwnCloud ins Leben gerufen und wird von einer Community von Entwicklern und Benutzern ständig weiterentwickelt. Nextcloud bietet ähnliche Funktionen wie andere Cloudspeicherlösungen, darunter die Möglichkeit, Dateien hochzuladen, zu teilen und zu synchronisieren, Kalender und Kontakte zu verwalten und vieles mehr.
Sicherheit und Datenschutz
Einer der Hauptvorteile von Nextcloud ist die Sicherheit, die sie bietet. Da Nextcloud eine Self-Hosted-Lösung ist, haben Benutzer die volle Kontrolle über ihre Daten und können selbst entscheiden, wo sie gespeichert werden. Dies bedeutet, dass Benutzer ihre Daten auf ihren eigenen Servern speichern können, anstatt sie einem Drittanbieter anvertrauen zu müssen. Darüber hinaus bietet Nextcloud Verschlüsselungsoptionen, um die Sicherheit der Daten zu gewährleisten.
Nextcloud legt großen Wert auf Datenschutz. Die Plattform bietet Funktionen wie End-to-End-Verschlüsselung, um sicherzustellen, dass sowohl die Datenübertragung als auch die Speicherung der Daten sicher sind. Nextcloud ermöglicht es Benutzern auch, ihre eigenen Nutzungsbedingungen festzulegen und zu kontrollieren, wer Zugriff auf ihre Daten hat. Dies gibt Benutzern ein hohes Maß an Kontrolle und Privatsphäre über ihre Daten.
Flexibilität und Integration
Nextcloud zeichnet sich auch durch ihre Flexibilität aus. Die Plattform bietet eine Vielzahl von Apps und Erweiterungen, die es Benutzern ermöglichen, die Funktionalität von Nextcloud nach ihren individuellen Bedürfnissen anzupassen. Dies reicht von der Integration mit anderen Diensten und Anwendungen bis hin zur Anpassung des Benutzeroberfläche. Benutzer können auch Nextcloud mit verschiedenen Plugins erweitern, um zusätzliche Funktionen hinzuzufügen.
Nextcloud ist auch in der Lage, mit verschiedenen Geräten und Betriebssystemen zu interagieren. Benutzer können Nextcloud auf verschiedenen Geräten wie Desktop-Computern, Tablets und Smartphones verwenden und von überall aus auf ihre Daten zugreifen. Die Plattform bietet auch Unterstützung für verschiedene Betriebssysteme wie Windows, macOS und Linux.
Fazit
Die Nextcloud ist eine sichere und flexible Alternative zur Cloudspeicherung, die Benutzern mehr Kontrolle über ihre Daten bietet. Mit Funktionen wie Verschlüsselung, Datenschutz und flexiblen Erweiterungsmöglichkeiten ist Nextcloud die ideale Lösung für alle, die ihre Daten sicher und privat speichern möchten. Nextcloud ist eine Open-Source-Lösung, die von einer großen Community von Entwicklern und Benutzern unterstützt wird, so dass Benutzer sicher sein können, dass ihre Daten in guten Händen sind. Wenn man auf der Suche nach einer sicheren und flexiblen Cloudspeicherlösung ist, ist Nextcloud die richtige Wahl.
Invidious ist eineSoftware, die es ermöglicht, Videos von YouTube anzusehen, ohne direkt die offizielle YouTube-Website, oder App zu verwenden. Die selbstgehostete Software ermöglicht eine werbefreie Nutzung von Youtube und schützt die Privatsphäre der Nutzer, indem es Tracking durch Google verhindert. Invidious bietet die weiteren Funktionen wie das Herunterladen von Videos, das Ansehen ohne Anmeldung und ... Weiterlesen
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
Teil II: mit VirtualBox (Windows mit Intel/AMD-CPU)
Teil III (dieser Text): mit UTM (macOS ARM)
In diesem Artikel gehe ich davon aus, dass Sie einen Mac mit ARM-CPU (M1, M2 usw.) verwenden. Für ältere Modelle mit Intel-CPUs gelten z.T. andere Details, auf die ich hier nicht eingehe. Insbesondere müssen Sie dann eine ISO-Datei für x86-kompatible CPUs verwenden, anstatt, wie hier beschrieben, eine ARM-ISO-Datei!
Virtualisierungssysteme für macOS ARM
Sie haben die Wahl:
Parallels Desktop: gut, aber wegen jährlicher Update-Pflicht sehr teuer
VMWare Fusion: kostenlos (for personal use), aber gut versteckter Download (erfordert vorher Registrierung bei Broadcom, danach lange Suche), verwirrende Bedienung, unklare Zukunft
UTM: Open-Source-Programm, kostenloser Download oder 10 EUR über App Store (einziger Unterschied: automatische Updates)
VirtualBox: kostenlos, aber aktuell erst als Beta-Version verfügbar und extrem langsam
Ich konzentriere mich hier auf UTM, der aus meiner Sicht überzeugendsten Lösung.
UTM
UTM ist ein Open-Source-Programm, das nur als Schnittstelle zu zwei Virtualisierungssystemen dient: dem aus der Linux-Welt bekannten QEMU-System sowie dem Apple Hypervisor Virtualization Framework (integraler Bestandteil von macOS seit Version 13, also seit Herbst 2022). UTM ist also lediglich eine grafische Oberfläche und delegiert die eigentliche Virtualisierung an etablierte Frameworks.
Sie können UTM um ca. 10 EUR im App Store kaufen und so die UTM-Entwickler ein wenig unterstützen, oder das Programm kostenlos von https://mac.getutm.app/ herunterladen und (vollkommen unkompliziert!) selbst installieren.
Sodann können Sie mit UTM virtuelle Maschinen mit Linux, Windows und macOS ausführen. Ich behandle hier ausschließlich Linux.
QEMU oder Apple Virtualization?
Wenn Sie in UTM eine neue virtuelle Maschine für Linux einrichten, haben Sie die Wahl zwischen zwei Virtualisierungssystemen: QEMU und Apple Virtualization. Welches ist besser?
Die QEMU-Variante bietet viel mehr Konfigurationsmöglichkeiten rund um die Netzwerkeinbindung und das Grafiksystem. Allerdings braucht die virtuelle Maschine doppelt so viel RAM wie vorgesehen: Wenn Sie eine VM mit 4 GB RAM einrichten, gehen beim Betrieb 8 GB RAM im macOS-Arbeitsspeicher verloren! macOS ist gut dabei, ungenutzte RAM-Teile zu komprimieren oder auszulagern, dennoch ist diese RAM-Verschwendung Wahnsinn. (Das gleiche Problem habe ich übrigens auch bei Tests mit VMWare Fusion festgestellt.)
Bei Apple Virtualization funktioniert die Speicherverwaltung, d.h. eine virtuelle Maschine mit 4 GB RAM braucht tatsächlich nur 4 GB RAM. (Das sollte ja eigentlich selbstverständlich sein …) Dafür haben Sie bei der Netzwerkkonfiguration kaum Wahlmöglichkeiten. Die VMs werden immer über eine Netzwerkbrücke in das lokale Netzwerk integriert. Es gibt zwar zwei Optionen, Gemeinsames Netzwerk und Bridge-Modus. Soweit ich es nachvollziehen kann, reduziert Gemeinsames Netzwerk nur die Optionen für den Bridge-Modus, ändert aber daran nichts. Das Apple Virtualization Framework würde auch NAT unterstützen, aber UTM stellt diese Option nicht zur Wahl.
In der Oberfläche von UTM wird die Verwendung von Apple Virtualization als experimentell bezeichnet. Ich habe bei meinen Tests leider mit beiden Frameworks gelegentliche Abstürze von virtuellen Maschinen erlebt. Ich würde beide Frameworks als gleichermaßen stabil betrachten (oder auch instabil, je nach Sichtweise; unter Linux mit QEMU/KVM sind mir Abstürze unbekannt). Persönlich verwende ich, vor allem um RAM zu sparen, für neue VMs nur mehr die Apple Virtualization. Glücklicherweise passt der Bridge Modus gut zu meinen Netzwerkanforderungen.
Wenn Sie VMs mit macOS oder Windows erstellen, entfällt die Wahlmöglichkeit. Windows VMs können nur durch QEMU ausgeführt werden, macOS VMs nur mit dem Apple Virtualization Framework.
Ubuntu installieren
Die erste Hürde hin zur Ubuntu-Installation besteht darin, ein ARM-ISO-Image zu finden. Auf den üblichen Download-Seiten finden Sie nur die x86-Variante von Ubuntu Desktop. Es gibt aber sehr wohl ein ARM-Image! Es ist auf der Website cdimage.ubuntu.com versteckt (noble-desktop-arm64.iso):
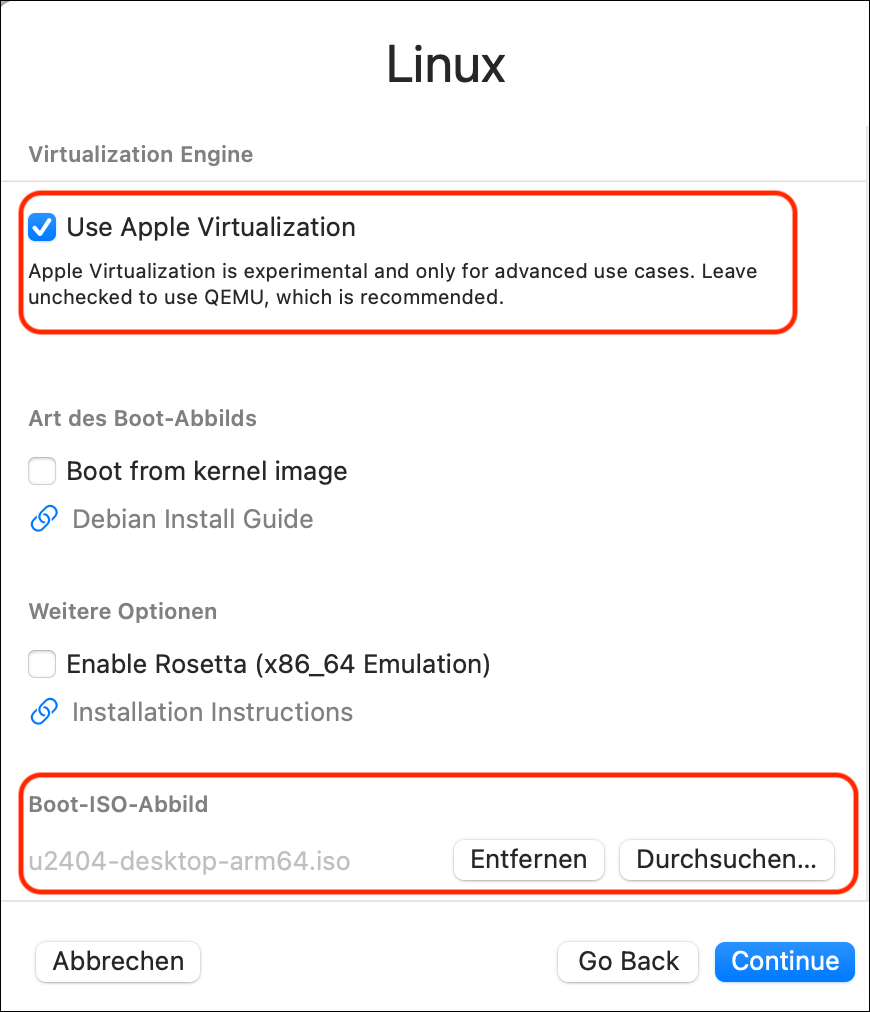
In UTM klicken Sie auf den Plus-Button, um eine neue virtuelle Maschine einzurichten. Danach wählen Sie die folgenden Optionen:
Virtualisieren
Linux
Option Use Apple Virtualiuation, Button Durchsuchen, um die ISO-Datei (das Boot-ISO-Abbild) auszuwählen
Speicher: 4 GB ist zumeist eine sinnvolle Einstellung
Prozessorkerne: ich verwende zumeist 2, die Einstellung Standard ist auch OK
Datenspeicher (Größe des Disk-Images): nach Bedarf, 25 GB sind in meiner Erfahrung das Minimum
Freigegebener Ordner: sollte die Nutzung eines macOS-Verzeichnisses innerhalb der virtuellen Maschine ermöglichen, funktioniert meines Wissens aber nur, wenn die virtuelle Maschine selbst macOS ist
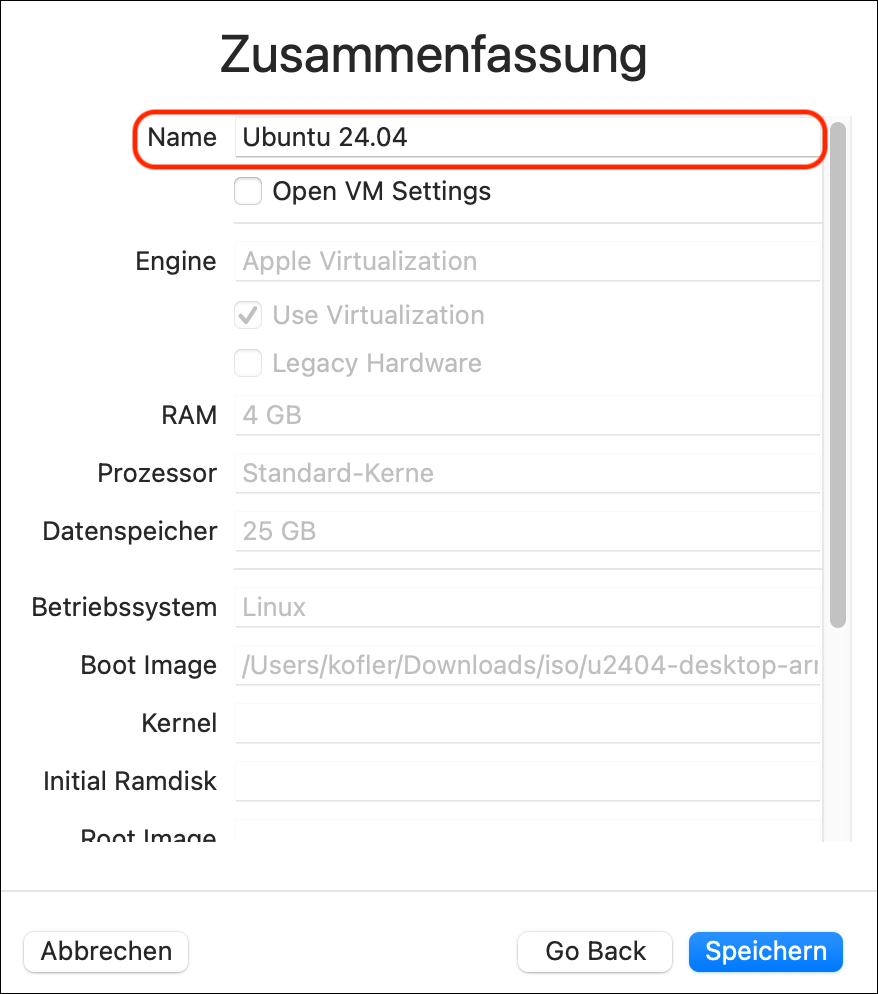
Zusammenfassung: hier geben Sie der virtuellen Maschine einen Namen
Setup der neuen virtuellen Maschine in UTMEinstellung des Namens der virtuellen Maschine
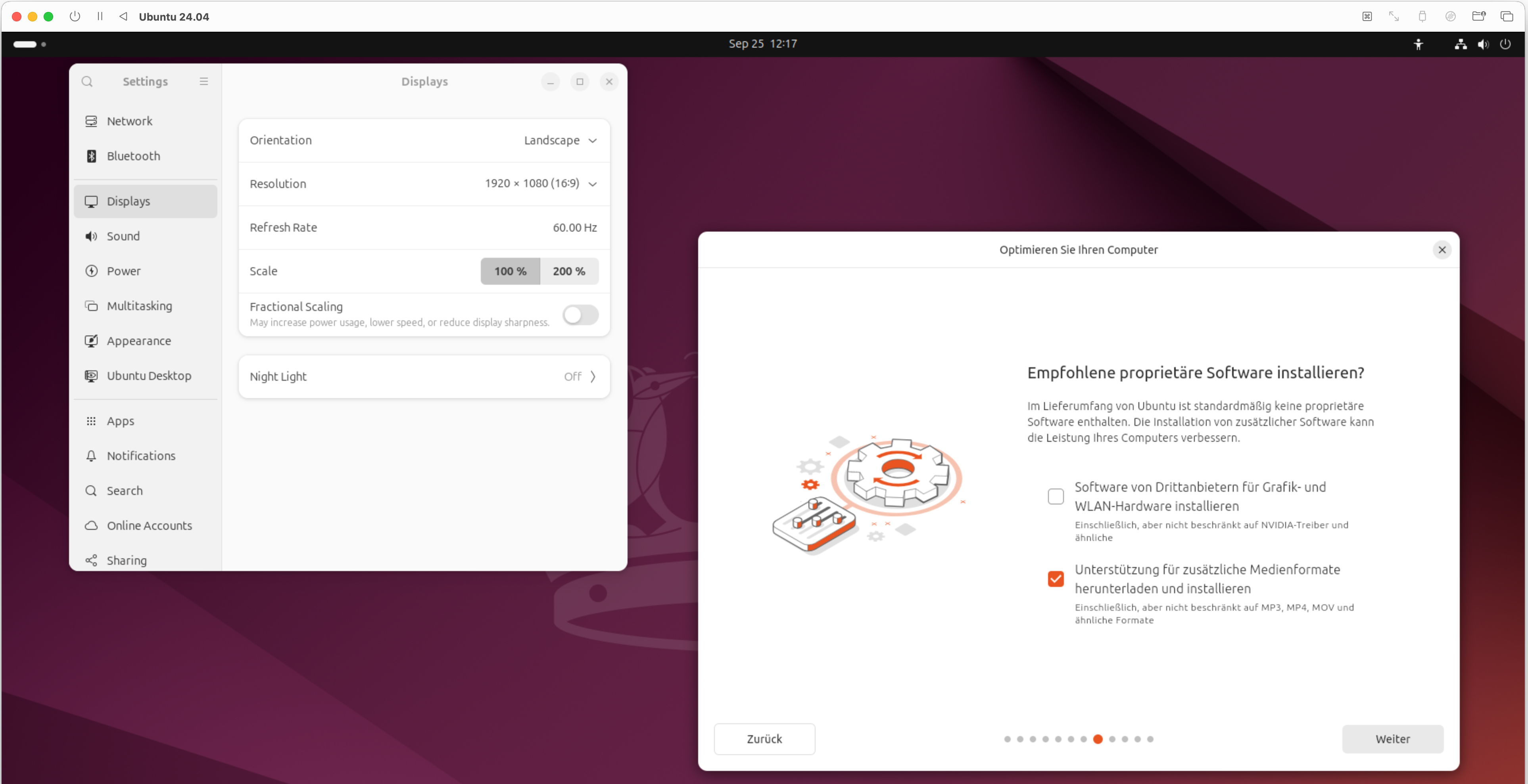
Nachdem Sie alle Einstellungen gespeichert haben, starten Sie die virtuelle Maschine. Nach ca. 30 Sekunden sollte der Desktop mit dem Installationsprogramm erscheinen (erster Dialog: Welcome to Ubuntu). Falls das Installationsprogramm je nach Monitor auf einem riesigen Desktop winzig dargestellt wird, öffnen Sie rechts oben über das Panel-Menü die Einstellungen (Zahnrad-Icon), suchen das Dialogblatt Displays und wählen eine kleinere Bildschirmauflösung aus.
Im Installationsprogramm stellen Sie nun die gewünschte Sprache ein. Bei der Einstellung des Tastaturlayouts wählen Sie Deutsch und die Tastaturvariante Deutsch Macintosh, damit die Mac-Tastatur unter Ubuntu richtig funktioniert. Alle weiteren Einstellungen erfolgen wie bei einer Installation unter VirtualBox, siehe Ubuntu 24.04 in VirtualBox ausführen. Sie brauchen keine Software von Drittanbietern, können aber die Option Unterstützung für zusätzliche Medieformate aktivieren.
Ausführung des Ubuntu-Installationsprogramms
Nach Abschluss aller Setup-Dialoge dauert die Installation ca. fünf Minuten. Da während der Installation manche Pakete aus dem Internet heruntergeladen werden, ist die Dauer der Installation auch von der Geschwindigkeit Ihres Internetzugangs abhängig.
Ubuntu nutzen
Nach dem ersten Neustart erscheint der Ubuntu-Desktop. Wieder kann es je nach Monitor passieren, dass die Grafikauflösung in der virtuellen Maschine zu groß ist. Öffnen Sie das Programm Einstellungen, dort das Dialogblatt Anzeigegeräte und stellen Sie eine passende Auflösung ein. Im Unterschied zu anderen Virtualisierungsprogramme ändert sich die Auflösung nicht automatisch, wenn Sie das UTM-Fenster verändern. Stattdessen wird der im Fenster angezeigte Inhalt skaliert.
Damit sich die Maus in der virtuellen Maschine wie unter macOS verhält, aktivieren Sie in Einstellungen/Maus und Tastfeld die Option Natürliche Rollrichtung.
Um Text zwischen macOS und Ubuntu auszutauschen, können Sie die Zwischenablage verwenden. Dazu muss weder zusätzliche Software installiert noch irgendeine Konfiguration verändert werden.
Zum Austausch von Dateien verwenden Sie am einfachsten scp.
Ubuntu 24.04 (ARM) läuft unter macOS
Speicherort der virtuellen Maschinen
UTM speichert die virtuellen Maschinen im Verzeichnis Library/Containers/com.utmapp.UTM. In der Regel ist es nicht zweckmäßig, die riesigen Image-Dateien in das TimeMachine-Backup mit aufzunehmen. Fügen Sie daher bei den TimeMachine-Einstellungen eine entsprechende Regel hinzu.
Einmal wollte ich faul sein und gleichzeitig einem FOSS-Projekt etwas Gutes tun. Anstelle mich immer selbst um ein Update von LibreOffice zu kümmern, wollte ich es aus dem Apple App Store installieren, via selbigen an das Projekt spenden und die Downloadzahlen im Store um eine Wertigkeit erhöhen. Automatische Updates im Hintergrund sollten hier die Wahl ... Weiterlesen
ChatGPT, Copilot & Co. verwenden Large Language Models (LLMs). Diese werden auf leistungsstarken Servern ausgeführt und als Cloud-Services angeboten. Das funktioniert wunderbar. Aber nicht jeder will Daten, Text und Code ständig in die Cloud hochladen. Kann man also — mit »gewöhnlicher« Hardware — LLMs auch lokal ausführen?
Tatsächlich ist das verblüffend einfach. Das Tool der Wahl heißt Ollama. Was Docker für Container ist, ist Ollama für LLMs!
Ollama kann ziemlich mühelos unter Linux, macOS und Windows installiert werden. Unter Windows und macOS starten Sie Ollama als Hintergrunddienst mit einer winzigen grafischen Oberfläche (im Prinzip nur ein Icon, das den Status anzeigt). Unter Linux richten Sie den Dienst mit systemctl ein:
systemctl enable --now ollama
Ollama läuft im Terminal, kann aber auch per API genutzt werden (z.B. zur Realisierung einer Web-Schnittstelle).
Ollama anwenden
Jetzt können Sie Ollama mit dem gleichnamigen Kommando im Terminal ausführen. Mit ollama run <llmname> installieren Sie eines der öffentlich verfügbaren Sprachmodelle (mehr dazu im nächsten Abschnitt) und können dann im Textmodus Kommandos ausführen:
ollama run llama2
>>> I need a regex to verify a date in US format. Can you help?
Of course! To match a date in the format of "MM/DD/YYYY" (month-day-year)
or "MM/DD/YYYY HH:MM AM/PM", you can use the following regular expression:
\b(\d{1,2}/\d{1,2}/\d{4})|(\d{1,2}/\d{1,2}/\d{4} \d{0,2})?\b
Here's a breakdown of how this regex works:
* \b: Matches a word boundary (the start or end of a word) to ensure
we're matching the entire date field.
* (\d{1,2}/\d{1,2}/\d{4}): Matches the month/day/year format. The
(\d{1,2}) captures the month and day as individual digits (0-2
digits for the month and 1-2 digits for the day). The / separates
the date components.
* |: Or, used to match the alternative format.
* (\d{1,2}/\d{1,2}/\d{4} \d{0,2})?: Matches the month/day/year with
time format. The (\d{1,2}) captures the month and day as individual
digits (0-2 digits for the month and 1-2 digits for the day). The /
separates the date components. The \d{0,2} matches the time component
(0-2 digits representing the hour and minute).
* \b: Matches a word boundary to ensure we're matching the entire date field again.
Note that this regex will match both US and international dates in the
"MM/DD/YYYY" format, as well as dates in the "MM/DD/YYYY HH:MM AM/PM"
format. If you need a more specific format (e.g., only US dates),
feel free to modify the regex accordingly.
Manche Sprachmodelle können auch Deutsch (nochmals llama2), wenngleich die sprachliche Qualität mitunter nur mittelmäßig ist.
>>> Was ist der Dopplereffekt?
Der Dopplereffekt ist ein physikalischer Effekt, der durch die Beugung von
Lichtwellen verursacht wird, wenn diese durch eine mediummässige Materie
passt. In einer bestimmten Umgebung oder Situation kann das Licht, das durch
eine bestimmte Fläche oder ein Objekt passt, sich "verlangsamen" und eine
Dopplereffekthelligkeit erzeugen.
Der Dopplereffekt ist ein spezifischer Effekt, der auf der Beugung von
Lichtwellen basiert. Wenn Licht durch ein Medium passt, wird es durch die Faser
des Mediums beugt und umgestaltet. Die Intensität des Lichts, das durch ein
Medium passt, kann sich durch den Dopplereffekt ändern.
Im Alltag können wir den Dopplereffekt beispielsweise bei der Anähnlichkeit von
Objekten in einer Ferne sehen. Wenn ein Auto oder eine andere Objekte in der
Ferne auf uns zukommt, wird es durch die Luft des Raumes beugt und erscheint
größer und weiter weg, als es tatsächlich ist.
Der Dopplereffekt kann auch in anderen Bereichen wie der Optik, Elektrotechnik
oder Medizin verwendet werden. Zum Beispiel können Dopplereffekte in der
Medizin verwendet werden, um die Blutungen in einem Körperteil zu bestimmen.
Es gibt verschiedene Arten von Dopplereffekten, darunter:
* LichtDopplereffekt: Der Effekt, den das Licht erzeugt, wenn es durch ein
Medium passt.
* ZeitDopplereffekt: Der Effekt, den die Zeit erzeugt, wenn sie durch ein
Objekt oder eine bestimmte Umgebung verändert wird.
* Räumliche Dopplereffekte: Der Effekt, den die räumliche Position von Objekten
oder der Standort eines Beobachters auf die Erscheinung des Dopplereffekts
ausübt.
Insgesamt ist der Dopplereffekt ein interessanter und wichtiger
physikalischerEffekt, der in vielen Bereichen der Wissenschaft und Technologie
Verwendung findet.
Ollama stellt seine Funktionen über eine REST-API zur Verfügung und kann somit lokal auch durch eigene Scripts und Editor-Plugins (z.B. Continue für VSCode) genutzt werden. Natürlich gibt es auch Module/Bibliotheken für diverse Sprachen, z.B. für Python.
Öffentliche Sprachmodelle
Die bekanntesten Sprachmodelle sind zur Zeit GPT-3.5 und GPT-4. Sie wurden von der Firma openAI entwickelt und sind die Basis für ChatGPT. Leider sind die aktellen GPT-Versionen nicht öffentlich erhältlich.
Zum Glück gibt es aber eine Menge anderer Sprachmodelle, die wie Open-Source-Software kostenlos heruntergeladen und von Ollama ausgeführt werden können. Gut geeignet für erste Experimente sind llama2, gemma und mistral. Einen Überblick über wichtige, Ollama-kompatible LLMs finden Sie hier:
Viele Sprachmodelle stehen in unterschiedlicher Größe zur Verfügung. Die Größe wird in der Anzahl der Parameter gemessen (7b = 7 billions = 7 Milliarden). Die Formel »größer ist besser« gilt dabei nur mit Einschränkungen. Mehr Parameter versprechen eine bessere Qualität, das Modell ist dann aber langsamer in der Ausführung und braucht mehr Platz im Arbeitsspeicher. Die folgende Tabelle gilt für llama2, einem frei verfügbaren Sprachmodell der Firma Meta (Facebook & Co.).
Wenn Sie llama2:70b ausführen wollen, sollte Ihr Rechner über 64 GB RAM verfügen.
Update: Quasi zugleich mit diesem Artikel wurde llama3 fertiggestellt (Details und noch mehr Details). Aktuell gibt es zwei Größen, 8b (5 GB) und 80b (40 GB).
ollama run llava:13b
>>> describe this image: raspap3.jpg
Added image 'raspap3.jpg'
The image shows a small, single-board computer like the Raspberry Pi 3, which is
known for its versatility and uses in various projects. It appears to be connected
to an external device via what looks like a USB cable with a small, rectangular
module on the end, possibly an adapter or expansion board. This connection
suggests that the device might be used for communication purposes, such as
connecting it to a network using an antenna. The antenna is visible in the
upper part of the image and is connected to the single-board computer by a
cable, indicating that this setup could be used for Wi-Fi or other wireless
connectivity.
The environment seems to be an indoor setting with wooden flooring, providing a
simple and clean background for the electronic components. There's also a label
on the antenna, though it's not clear enough to read in this image. The setup
is likely part of an electronics project or demonstration, given the simplicity
and focus on the connectivity equipment rather than any additional peripherals
or complex arrangements.
Eigentlich eine ganz passable Beschreibung für das folgende Bild!
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Praktische Erfahrungen, Qualität
Es ist erstaunlich, wie rasch die Qualität kommerzieller KI-Tools — gerade noch als IT-Wunder gefeiert — zur Selbstverständlichkeit wird. Lokale LLMs funktionieren auch gut, können aber in vielerlei Hinsicht (noch) nicht mit den kommerziellen Modellen mithalten. Dafür gibt es mehrere Gründe:
Bei kommerziellen Modellen fließt mehr Geld und Mühe in das Fine-Tuning.
Auch das Budget für das Trainingsmaterial ist größer.
Kommerzielle Modelle sind oft größer und laufen auf besserer Hardware. Das eigene Notebook ist mit der Ausführung (ganz) großer Sprachmodelle überfordert. (Siehe auch den folgenden Abschnitt.)
Wodurch zeichnet sich die geringere Qualität im Vergleich zu ChatGPT oder Copilot aus?
Die Antworten sind weniger schlüssig und sprachlich nicht so ausgefeilt.
Wenn Sie LLMs zum Coding verwenden, passt der produzierte Code oft weniger gut zur Fragestellung.
Die Antworten werden je nach Hardware viel langsamer generiert. Der Rechner läuft dabei heiß.
Die meisten von mir getesteten Modelle funktionieren nur dann zufriedenstellend, wenn ich in englischer Sprache mit ihnen kommuniziere.
Die optimale Hardware für Ollama
Als Minimal-Benchmark haben Bernd Öggl und ich das folgende Ollama-Kommando auf diversen Rechnern ausgeführt:
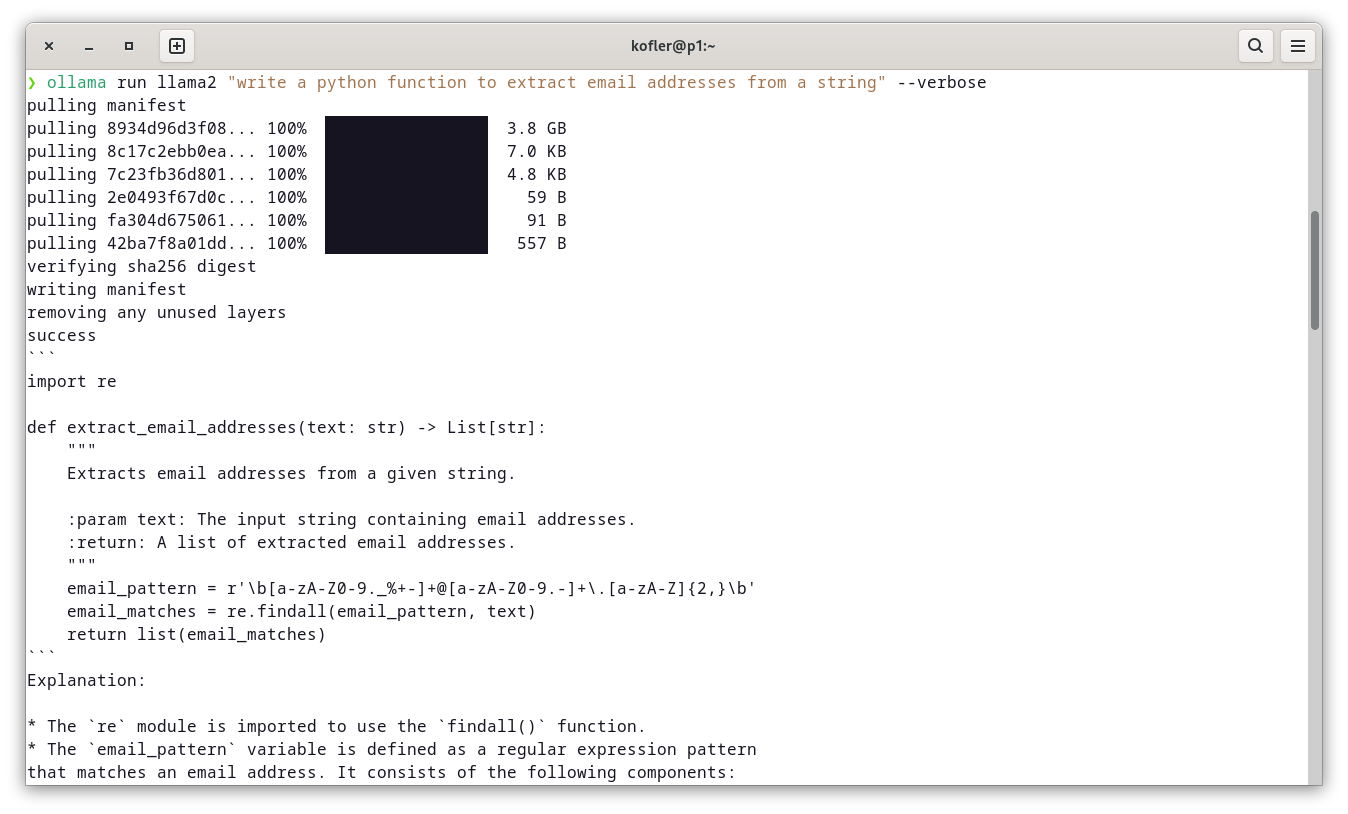
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
Die Ergebnisse dieses Kommandos sehen immer ziemlich ähnlich aus, aber die erforderliche Wartezeit variiert beträchtlich!
Grundsätzlich kann Ollama GPUs nutzen (siehe auch hier und hier). Im Detail hängt es wie immer vom spezifischen GPU-Modell, von den installierten Treibern usw. ab. Wenn Sie unter Linux mit einer NVIDIA-Grafikkarte arbeiten, müssen Sie CUDA-Treiber installieren und ollama-cuda ausführen. Beachten Sie auch, dass das Sprachmodell im Speicher der Grafikkarte Platz finden muss, damit die GPU genutzt werden kann.
Apple-Rechner mit M1/M2/M3-CPUs sind für Ollama aus zweierlei Gründen ideal: Es gibt keinen Ärger mit Treibern, und der gemeinsame Speicher für CPU/GPU ist vorteilhaft. Die GPUs verfügen über so viel RAM wie der Rechner. Außerdem bleibt der Rechner lautlos, wenn Sie Ollama nicht ununterbrochen mit neuen Abfragen beschäftigen. Allerdings verlangt Apple leider vollkommen absurde Preise für RAM-Erweiterungen.
Zum Schluss noch eine Bitte: Falls Sie Ollama auf Ihrem Rechner installiert haben, posten Sie bitte Ihre Ergebnisse des Kommandos ollama run llama2 "write a python function to extract email addresses from a string" --verbose im Forum!
Ab sofort kannst Du Tor Browser 13.0.14 herunterladen oder bestehende Installationen aktualisieren. Aktuelle Versionen des Browsers aktualisieren sich selbst. Hier siehst Du, wie das bei mir abläuft. Tor Browser 13.0.14 bringt wichtige Sicherheits-Updates bezüglich Firefox mit sich. Ein Bugfix beschäftigt sich mit Fingerprinting, beziehungsweise ist eine Schutzmaßnahme gegen Fingerprinting. Bei der neuesten Version wurde Tor auf 0.4.8.11 aktualisiert. Für Linux, macOS und Windows basiert Tor Browser 13.0.14 auf Firefox 115.10.0esr. Für Android wurde die Software auf GeckoView 115.10.0esr aktualisiert. Für […]
Nach einem kleinen Rücksetzer im Februar ist Steam auf Linux im März 2024 wieder knapp an die 2 % herangerückt. Nun muss man dazu sagen, dass diese Umfragen mit Vorsicht zu genießen sind, da nicht alle Steam-User gefragt werden und nicht alle, die gefragt werden, teilnehmen müssen. Dennoch sind die Steam-Statistiken ein guter Indikator, wie es um Linux und Spiele steht. Die Umfrage im März hat einen Marktanteil von 1,94 % ergeben (Februar 2024 1,76 %). Damit ist Steam unter […]
The Document Foundation hat gleich zwei Bugfix-Releases gemeinsam veröffentlicht. Das sind genauer gesagt LibreOffice 24.2.2 Community sowie LibreOffice 7.6.6 Community. Beides sind Wartungsversionen, die Bugs ausbessern, um die Qualität und Kompatibilität zu verbessern. Bei LibreOffice 24.2.2 wurden insgesamt 77 Bugs ausgebessert. Du findest beide Versionen ab sofort im Download-Bereich der Projektseite. TDF rät allen Usern, sobald wie möglich zu aktualisieren. Bezüglich Betriebssysteme benötigst Du mindestens Microsoft Windows 7 SP1 und Apple macOS 10.15. Bei Linux kommt es darauf an, ob […]
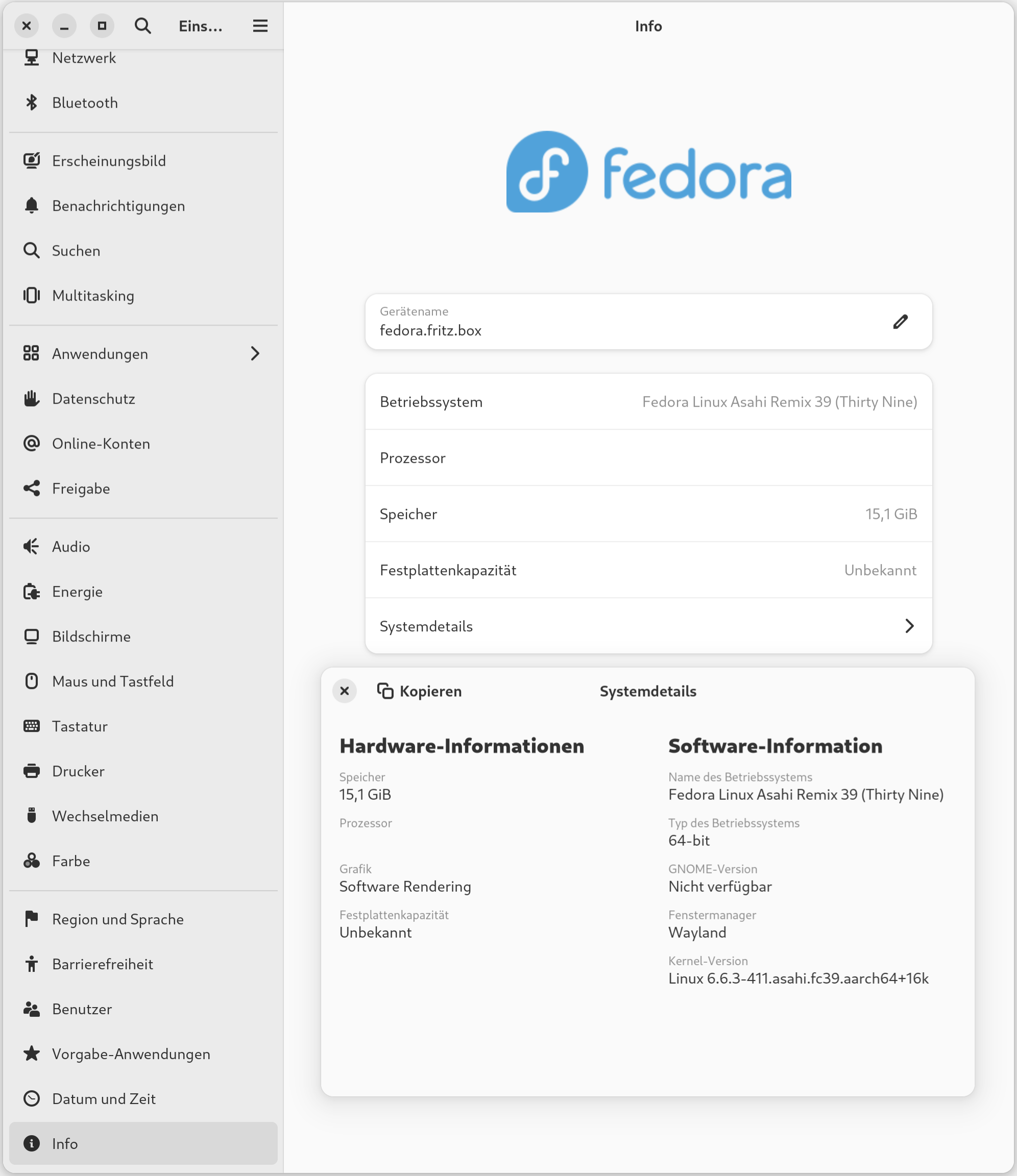
Nachdem ich mich vor ein paar Wochen ausführlich mit der Installation von Fedora Asahi Linux auseinandergesetzt habe, geht es jetzt um die praktischen Erfahrungen. Der Artikel ist ein wenig lang geworden und geht primär auf Tools ein, die ich in meinem beruflichen Umfeld oft brauche.
Ich habe mich für die Gnome-Variante von Fedora Asahi Linux entschieden, die grundsätzlich ausgezeichnet funktioniert. Dazu aber gleich eine Einschränkung: Der Asahi-Entwickler Hector Martin ist KDE-Fan; insofern ist die KDE-Variante besser getestet und sollte im Zweifelsfall als Desktop-System vorgezogen werden.
Gnome Systemeinstellungen
Hardware-Unterstützung
Asahi Linux unterstützt aktuell noch keine Macs mit M3-CPUs. Außerdem hapert es noch bei USB-C-Displays (HDMI funktioniert), einigen Thunderbolt-/USB4-Features und der Mikrofon-Unterstützung. (Die Audio-Ausgabe funktioniert, bei den Notebooks anscheinend sogar in sehr hoher Qualität. Aus eigener Erfahrung kann ich da beim Mac Mini nicht mitreden, dessen Lautsprecher ist ja nicht der Rede wert.) Auf die Authentifizierung mit TouchId müssen Sie auch verzichten. Einen guten Überblick über die Hardware-Unterstützung finden Sie am Ende der folgenden Seite:
Ich habe Fedora Asahi Linux nur auf einem Mac Mini M1 getestet (16 GB RAM). Damit habe ich sehr gute Erfahrungen gemacht. Das System ist genauso leise wie unter macOS (sprich: lautlos, auch wenn der Lüfter sich immer minimal dreht). Aber ich kann keine Aussagen zur Akku-Laufzeit machen, weil ich aktuell kein MacBook besitze. Wie gut Linux die Last zwischen Performance- und Efficiency-Cores verteilt, kann ich ebenfalls nicht sagen.
Der Ruhezustand funktioniert, auch das Aufwachen ;-) Dazu muss allerdings kurz die Power-Taste gedrückt werden. Ein Tastendruck oder ein Mausklick reicht nicht.
Tastatur
An meinem Mac Mini ist eine alte Apple-Alu-Tastatur angeschlossen. Grundsätzlich funktioniert sie auf Anhieb. Ein paar kleinere Optimierungen habe ich vor einiger Zeit hier beschrieben.
Konfiguration bei der Linux-Installation
Ich habe ja schon in meinem Blog-Beitrag zur Installation festgehalten: Während der Installation von Fedora gibt es praktisch keine Konfigurationsmöglichkeiten. Insbesondere können Sie weder die Partitionierung noch das Dateisystem beeinflussen (es gibt eine Partition für alles, das darin enthaltene Dateisystem verwendet btrfs ohne Verschlüsselung).
Wenn Sie davon abweichende Vorstellungen haben und technisch versiert sind, können Sie anfänglich nur einen Teil des freien Disk-Speichers für das Root-System von Fedora nutzen und später eine weitere Partition (z.B. für /home) nach eigenen Vorstellungen hinzuzufügen.
Swap-File
Während der Installation wurde auf meinem System die Swap-Datei /var/swap/swapfile in der Größe von 8 GiB eingerichtet (halbe RAM-Größe?). Außerdem verwendet Fedora standardmäßig Swap on ZRAM. Damit kann Fedora gerade ungenutzte Speicherseite in ein im RAM befindliches Device auslagern. Der Clou: Die Speicherseiten werden dabei komprimiert.
Beim meiner Konfiguration (16 GiB RAM, 8 GiB Swap-File, 8 GiB ZRAM-Swap) glaubt das System, dass es über fast 32 GiB Speicherplatz verfügen kann. (Etwas RAM wird für das Grafiksystem abgezwackt.) Ganz geht sich diese Rechnung natürlich nicht aus, weil ja das ZRAM-Swap selbst wieder Arbeitsspeicher kostet. Aber sagen wir 4 GB ZRAM entspricht mit Komprimierung 8 GB Speicherplatz + 11 GB restliches RAM + 8 GB Swapfile: das würde 27 GB Speicherplatz ergeben. Wenn nicht alle Programme zugleich aktiv sind, kann man damit schon arbeiten.
cat /proc/swaps
Filename Type Size Used Priority
/var/swap/swapfile file 8388576 0 -2
/dev/zram0 partition 8388592 0 100
free -m
total used free shared buff/cache available
Mem: 15444 8063 2842 1521 7112 7381
Swap: 16383 0 16383
Weil ich beim Einsatz virtueller Maschinen gescheitert bin (siehe unten), kann ich nicht beurteilen, ob diese Konfiguration mit der Arbeitsspeicherverwaltung von macOS mithalten kann. Die funktioniert nämlich richtig gut. Auch macOS komprimiert Teile des gerade nicht genutzten Speichers und kompensiert so (ein wenig) den unendlichen Apple-Geiz, was die Ausstattung mit RAM betrifft (oder die Geldgier, wenn mehr RAM gewünscht wird).
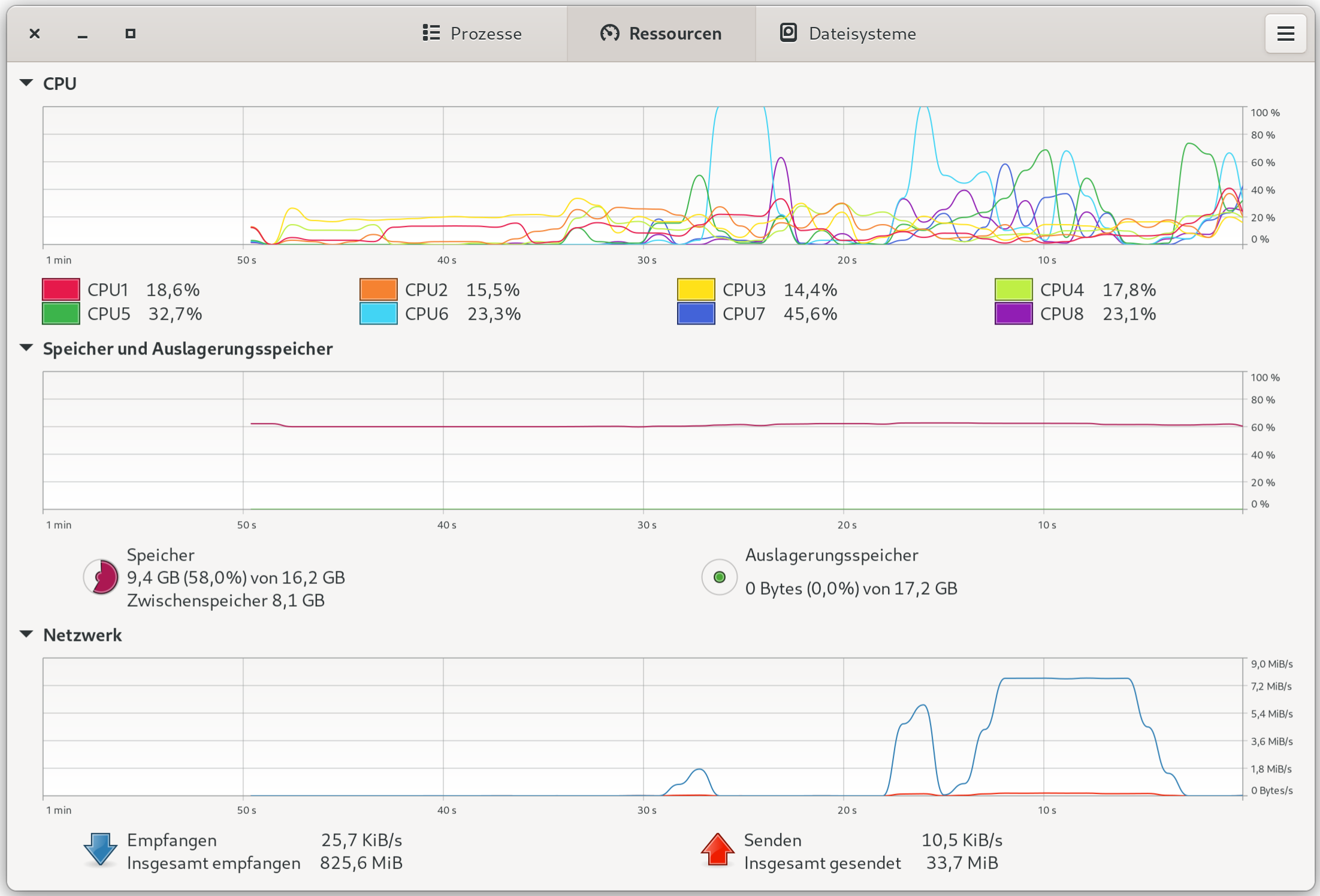
Gnome Systemüberwachung
Gnome + Fractional Scaling: mühsam wie vor 10 Jahren
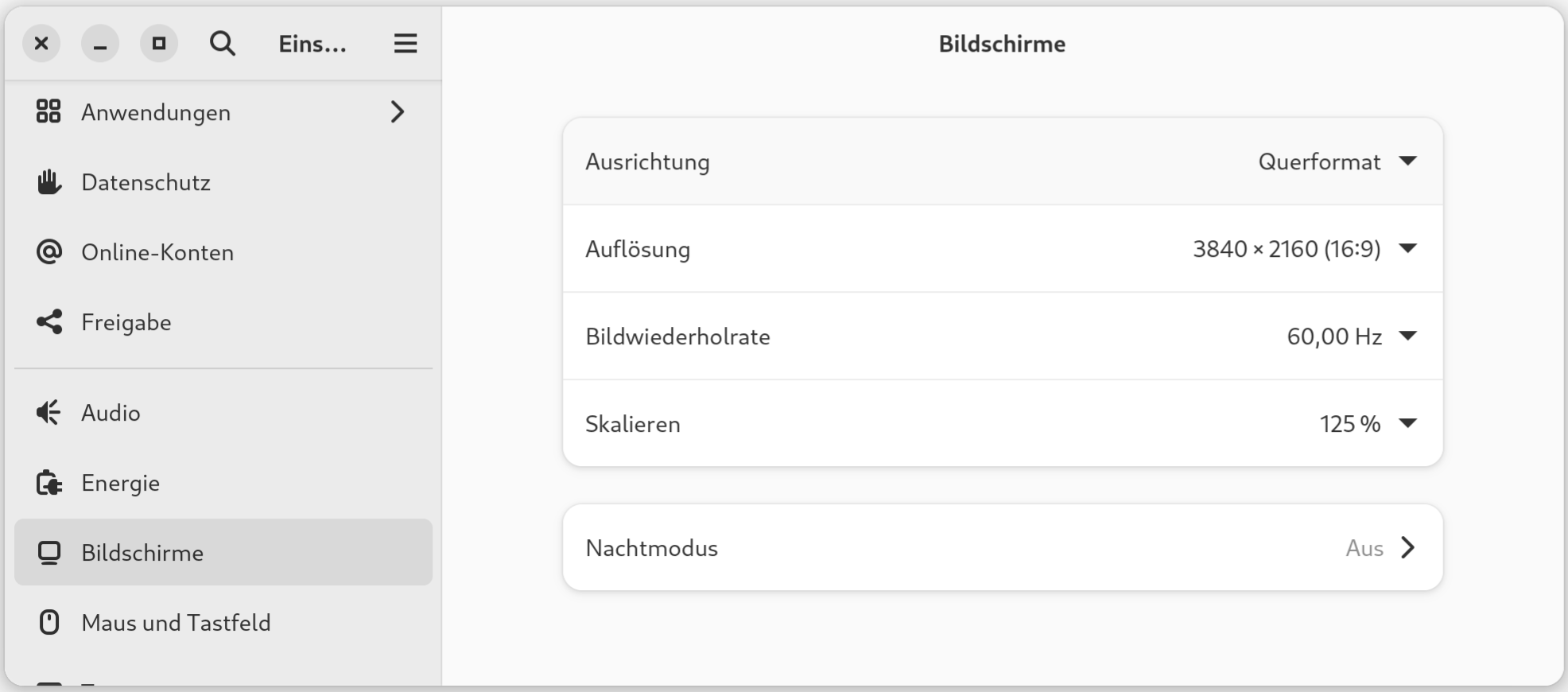
Ein altes Problem: Auf meinem 4k-Monitor (27 Zoll) ist der Bildschirminhalt bei einer Skalierung von 100 % arg klein, bei 200 % sinnlos groß. Seit Jahren wird gepredigt, wie toll Gnome + Wayland ist, aber Fractional Scaling funktioniert immer noch nicht standardmäßig?
Dieses Problem lässt sich zum Glück lösen:
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
Aus Gnome ausloggen, neu einloggen. Jetzt können in den Systemeinstellungen 125 % eingestellt, optimal für mich.
Die fraktionelle Skalierung funktioniert für Wayland-Programme gut, sie muss aber umständlich aktiviert werden
Die meisten Programme, die ich üblicherweise verwende, kommen mit 125 % gut zurecht. Wichtigste Ausnahme (für mich): Emacs. Die Textdarstellung ist ziemlich verschwommen. Angeblich gibt es eine Wayland-Version von Emacs (siehe hier), aber ich habe noch nicht versucht, sie zu installieren.
Webbrowser: kein Google Chrome
Als Webbrowser ist standardmäßig Firefox installiert und funktioniert ausgezeichnet. Chromium steht alternativ auch zur Verfügung (dnf install chromium). Ich bin allerdings, was den Webbrowser betrifft, in der Google-Welt zuhause. Ich habe mich vor über 10 Jahren für Google Chrome entschieden. Lesezeichen, Passwörter usw. — alles bei Google. (Bitte die Kommentare nicht für einen Browser-Glaubenskrieg nutzen, ich werde keine entsprechenden Kommentare freischalten.)
Insofern trifft es mich hart, dass es aktuell keine Linux-Version von Google Chrome für arm64 gibt. Ich habe also die Bookmarks + Passwörter nach Firefox importiert. Bookmarks sind easy, Passwörter müssen in Chrome in eine CSV-Datei exportiert und in Firefox wieder importiert werden. Mit etwas Webrecherche auch nicht schwierig, aber definitiv umständlich. Und natürlich ohne Synchronisation. (Für alle Firefox-Fans: Ja, auch Firefox funktioniert großartig, ich habe überhaupt keine Einwände. Wenn ich die Entscheidung heute treffen würde, wäre vielleicht Firefox der Gewinner. Google bekommt auch so genug von meinen Daten …)
Drag&Drop von Nautilus nach Firefox funktionierte bei meinen Tests nicht immer zuverlässig. Ich glaube, dass es sich dabei um ein Wayland-Problem handelt. Ähnliche Schwierigkeiten hatte ich auf meinen »normalen« Linux-Systemen (also x86) mit Google Chrome auch schon, wenn Wayland im Spiel war.
Nextcloud: perfekt
Zum Austausch meiner wichtigsten Dateien zwischen diversen Rechnern verwende ich Nextcloud. Ich habe nextcloud-client-nautilus installiert und eingerichtet, funktioniert wunderbar. Damit im Panel das Nextcloud-Icon angezeigt wird, ist die Gnome-Erweiterung AppIndicator and KStatusNotifierItem Support erforderlich.
Spotify + Firefox: gescheitert
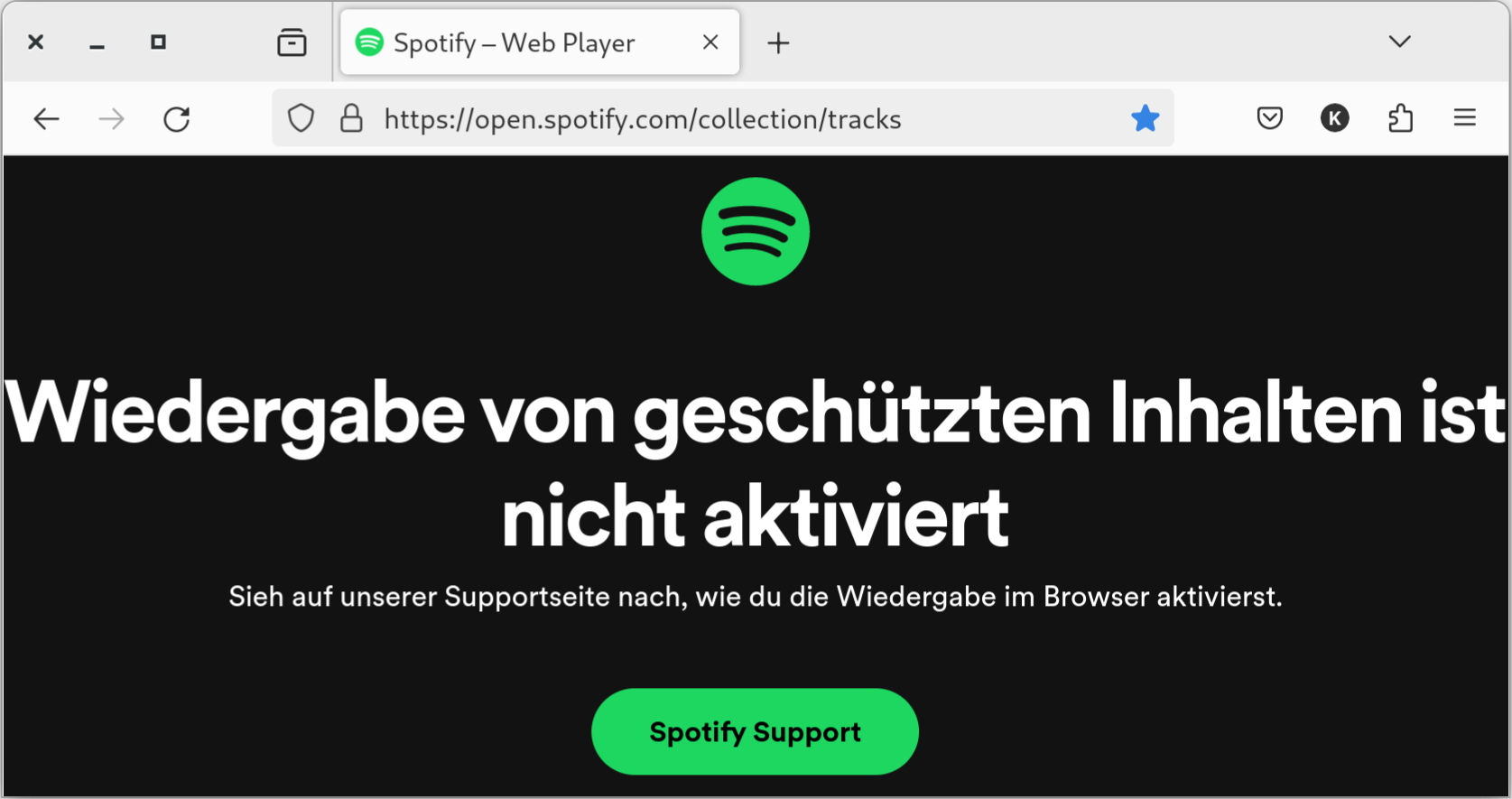
Ich höre beim Arbeiten gerne Musik. Die Spotify-App gibt es nicht für arm64. Kein Problem, ich habe mich schon lange daran gewöhnt, Spotify im Webbrowser auszuführen. Aber Spotify hält nichts von Firefox: Wiedergabe von geschützten Inhalten ist nicht aktiviert.
Spotify und Firefox vertragen sich nicht
Das Problem ist bekannt und gilt eigentlich als gelöst. Es muss das Widevine-Plugin installiert werden. Asahi greift dabei auf ein Paket der ChromeBooks zurück. Es kann mit widevine-installer installiert werden. (widevine-installer befindet sich im gleichnamigen Paket und ist standardmäßig installiert.) Gesagt, getan:
sudo widevine-installer
This script will download, adapt, and install a copy of the Widevine
Content Decryption Module for aarch64 systems.
Widevine is a proprietary DRM technology developed by Google.
This script uses ARM64 builds intended for ChromeOS images and is
not supported nor endorsed by Google. The Asahi Linux community
also cannot provide direct support for using this proprietary
software, nor any guarantees about its security, quality,
functionality, nor privacy. You assume all responsibility for
usage of this script and of the installed CDM.
This installer will only adapt the binary file format of the CDM
for interoperability purposes, to make it function on vanilla
ARM64 systems (instead of just ChromeOS). The CDM software
itself will not be modified in any way.
Widevine version to be installed: 4.10.2662.3
...
Installing...
Setting up plugin for Firefox and Chromium-based browsers...
Cleaning up...
Installation complete!
Please restart your browser for the changes to take effect.
Nach einem Firefox-Neustart ändert sich: nichts. Ein weiterer Blick in discussion.fedoraproject.org verrät: Es muss auch der User Agent geändert werden, d.h. Firefox muss als Betriebssystem ChromeOS angeben:
Es gibt zwei Möglichkeiten, den User Agent zu ändern. Die eine besteht darin, die Seite about:config zu öffnen, die Option general.useragent.override zu suchen und zu ändern. Das gilt dann aber für alle Webseiten, was mich nicht wirklich glücklich macht.
Die Alternative besteht darin, ein UserAgent-Plugin zu installieren. Ich habe mich für den User-Agent Switcher and Manager entschieden.
Langer Rede kurzer Sinn: Mit beiden Varianten ist es mir nicht gelungen, Spotify zur Zusammenarbeit zu überreden. An dieser Stelle habe ich nach rund einer Stunde Frickelei aufgegeben. Es gibt im Internet Berichte, wonach es funktionieren müsste. Vermutlich bin ich einfach zu blöd.
Spotify + Chromium: geht
Da wollte ich Firefox eine zweite Chance geben … Stattdessen Chromium installiert, damit funktioniert Spotify (widevine-installer vorausgesetzt) auf Anhieb. Sei’s drum.
Chromium läuft übrigens standardmäßig als X-Programm (nicht Wayland), aber nachdem ich den Browser aktuell nur als Spotify-Player benutze, habe ich mir nicht die Mühe gemacht, das zu ändern.
Wie Emacs und Chromium läuft auch Code vorerst als X-Programm. Entsprechend unscharf ist die Schrift bei 125% Scaling. Das ArchWiki verrät, dass beim Programmstart die Option --ozone-platform-hint=auto übergeben werden muss. Das funktioniert tatsächlich: Plötzlich gestochen scharfe Schrift auch in Code.
Ich habe mir eine Kopie von code.desktop erstellt und die gerade erwähnte Option in die Exec-Zeile eingebaut. Bingo!
qemu/libvirt/virt-manager: keine Grafik, keine Maus, keine Tastatur, kein Glück
Meine Arbeit spielt sich viel in virtuellen Maschinen und Containern ab. QEMU und die libvirt-Bibliotheken sind standardmäßig installiert, die grafische VM-Verwaltung gibt es mit dnf install virt-manager dazu.
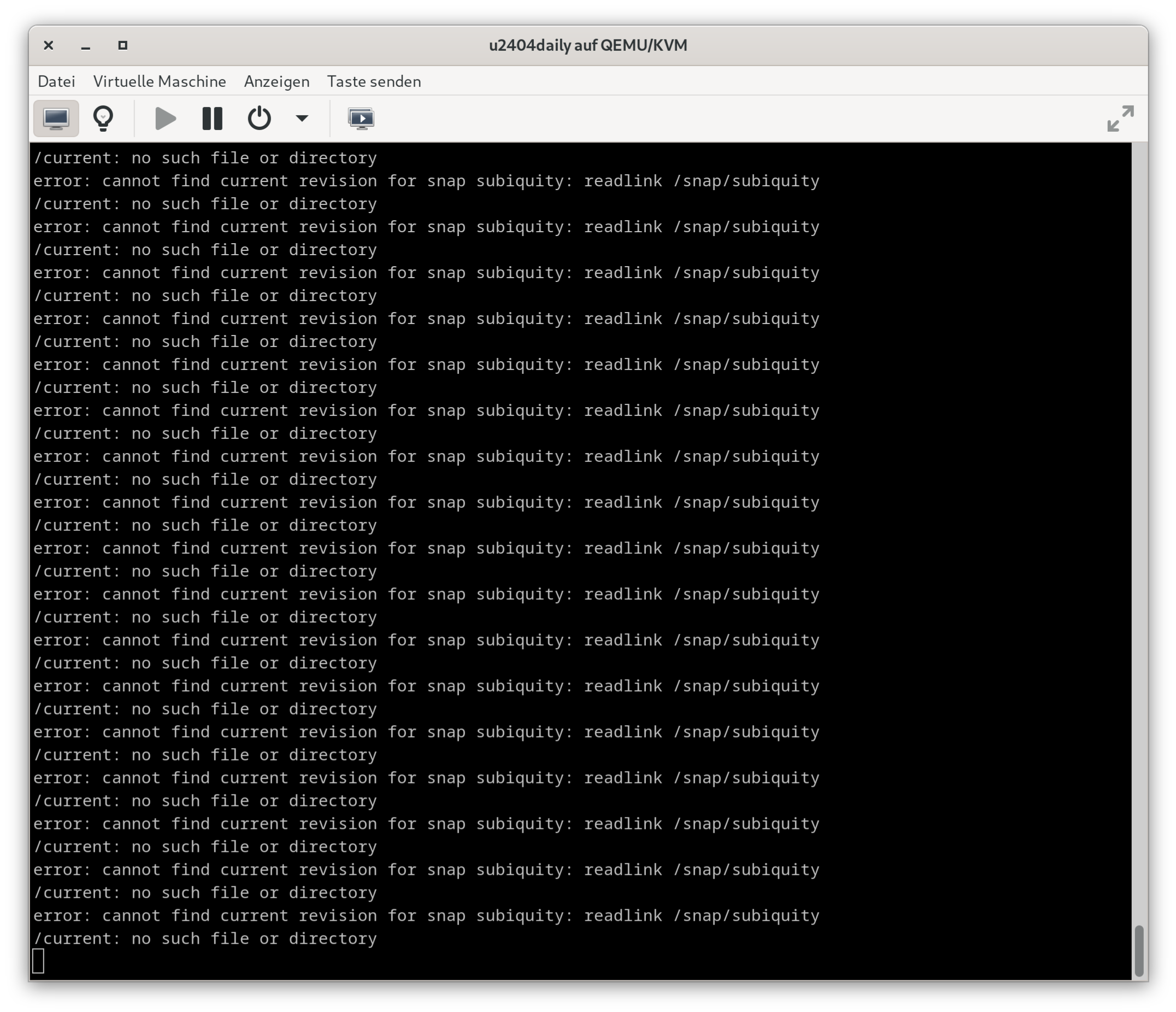
Als nächstes habe ich mir ein Daily-ISO-Image für Arm64 von Ubuntu 24.04 heruntergeladen und versucht, es in einer virtuellen Maschine zu installieren. Kurz nach dem Start stürzt der virt-manager ab. Die virtuelle Maschine läuft weiter, allerdings nur im Textmodus. Später bleibt die die Installation in einer snap-Endlosschleife hängen. Nun gut, es ist eine Entwicklerversion, die noch nicht einmal offiziellen Beta-Status hat.
Eine gescheiterte Installation von Ubuntu 24.04 daily
Nächster Versuch mit 23.10. Allerdings gibt es auf cdimage.ubuntu.com kein Desktop-Image für arm64!? Gut, ich nehme das Server-Image und baue dieses nach einer Minimalinstallation mit apt install ubuntu-desktop in ein Desktop-System um. Allerdings stellt sich heraus, dass aptsehr lange braucht (Größenordnung: eine Stunde, bei nur sporadischer CPU-Belastung; ich weiß nicht, was da schief läuft). Die Textkonsole im Viewer von virt-manager ist zudem ziemlich unbrauchbar. Installation fertig, Neustart der virtuellen Maschine. Es gelingt nicht, den Grafikmodus zu aktivieren.
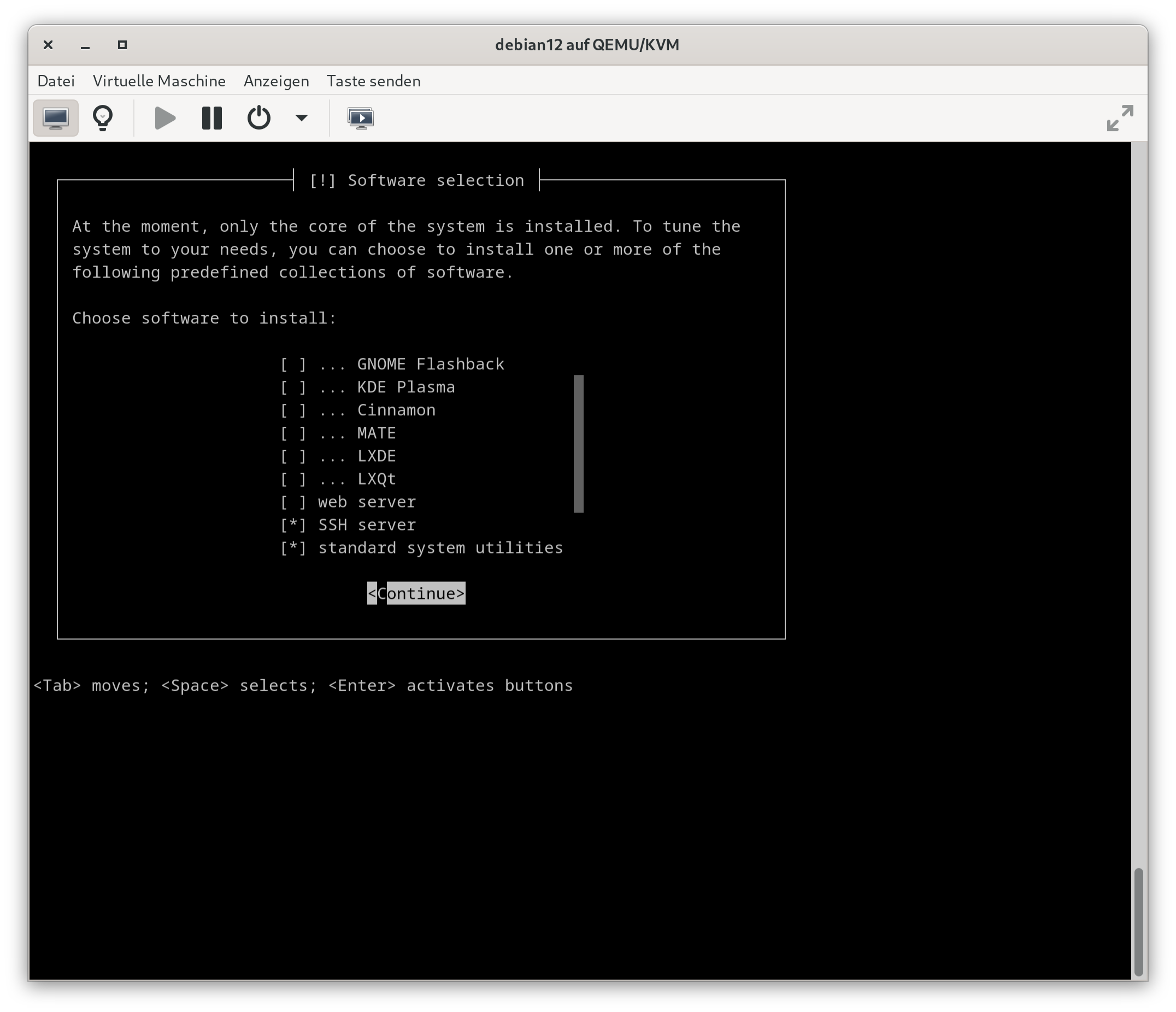
Dritter Versuch, Debian 12 für arm64. Obwohl ich mich für eine Installation im Grafikmodus entscheide, erscheinen die Setup-Dialoge in einem recht trostlosen Textmodus (so, als würde die Konsole keine Farben unterstützen).
Super-minimalistischer Textmodus in der VM
Schön langsam dämmert mir, dass mit dem Grafiksystem etwas nicht stimmt. Tatsächlich hat keine der virtuellen Maschinen ein Grafiksystem! (virt-manager unter x86 richtet das Grafiksystem automatisch ein, und es funktioniert — aber offenbar ist das unter arm64 anders.) Ich füge also das Grafiksystem manuell hinzu, aber wieder treten diverse Probleme auf: der VGA-Modus funktioniert nicht, beim Start der VM gibt es die Fehlermeldung failed to find romfile vgabios-stdvga.bin. QXL lässt sich nicht aktivieren: domain configuration does not support video model qxl. RAMfb führt zu einem EFI-Fehler während des Startups. Zuletzt habe ich mit virtio Glück. Allerdings funktioniert jetzt die Textkonsole nicht mehr, der Bootvorgang erfolgt im Blindflug.
Der Grafikmodus erscheint, aber die Maus bewegt sich nicht. Klar, weil der virt-manager auch das Mauseingabe-Modul nicht aktiviert hat. Ich füge auch diese Hardware-Komponente hinzu. Tatsächlich lässt sich der Mauscursor nach dem nächsten Neustart nutzen — aber die Tastatur geht nicht. Ja, die fehlt auch. Wieder ‚Gerät hinzufügen‘, ‚Eingabe/USB-Tastatur‘ führt zum Ziel. Vorübergehend habe ich jetzt ein Erfolgserlebnis, für ein paar Minuten kann ich Ubuntu 23.10 tatsächlich im Grafikmodus verwenden. Ich kann sogar eine angemessene Auflösung einstellen. Aber beim nächsten Neustart bleibt der Monitor schwarz: Display output is not active.
An dieser Stelle habe ich aufgegeben. Die nächste Auflage meines Linux-Buchs (die steht zum Glück erst 2025 an) könnte ich in dieser Umgebung nicht schreiben. Dazu brauche ich definitiv eine Linux-Installation auf x86-Hardware.
Docker, pardon, Podman: voll OK
Red Hat und Fedora meiden Docker wie der Teufel das Weihwasser. Dafür ist die Eigenentwicklung Podman standardmäßig installiert (Version 4.9). Das Programm ist weitestgehend kompatibel zu Docker und in der Regel ein guter Ersatz.
Ich setze in Docker normalerweise stark auf docker compose. Dieses Subkommando ist in Podman noch nicht integriert. Abhilfe schafft das (einigermaßen kompatible) Python-Script podman-compose, das mit dnf installiert wird und aktuell in Version 1.0.6 vorliegt.
Mein Versuch, mit Podman mein aus LaTeX und Pandoc bestehendes Build-System für meine Bücher zusammenzubauen, gelang damit überraschend problemlos. In compose.yaml musste ich die Services mit privileged: true kennzeichnen, um diversen Permission-denied-Fehlern aus dem Weg zu gehen. Auf jeden Fall sind hier keine unlösbaren Hürden aufgetreten.
Fazit
Soweit Asahi Linux mit Ihrem Mac kompatibel ist und Sie keine Features nutzen möchten, die noch nicht unterstützt werden (aus meiner Sicht am schmerzhaftesten: USB-C-Monitor, Mikrofon), funktioniert es großartig. Einerseits die Apple-Kombination aus hoher Performance und Stille, andererseits Linux mit all seinen Konfigurationsmöglichkeiten. Was will man mehr?
Leider sind die arm64-Plattform (genaugenommen aarch64) und Wayland noch immer nicht restlos Linux-Mainstream. Alle hier beschriebenen Ärgernisse hatten irgendwie damit zu tun — und nicht mit Asahi Linux! Der größte Stolperstein für mich: Mit virt-manager lässt sich nicht vernünftig arbeiten. Mag sein, dass sich diese Probleme umgehen lassen (Gnome Boxes?; Cockpit), aber ich befürchte, dass die Probleme tiefer gehen.
Eine gewisse Ironie an der Geschichte besteht darin, dass ich gerade am Raspberry-Pi-Buch arbeite: Raspberry Pi OS ist mittlerweile ebenfalls für die arm64-Architektur optimiert, es verwendet ebenfalls Wayland. Aber Fractional Scaling ist für den PIXEL Desktop sowieso nicht vorgesehen, damit entfallen alle damit verbundenen Probleme. So fällt es nicht auf, dass diverse Programme via XWayland laufen. Und um die arm64-Optimierungen hat sich die Raspberry Pi Foundation in den letzten Monaten gekümmert — zumindest, soweit es für den Raspberry Pi relevante Programme betrifft. Ich arbeite also momentan sowie schon in einer arm64-Welt, und es funktioniert verblüffend gut!
Wenn es also außer dem Raspberry Pi und den MacBooks noch ein paar »normale« Notebooks mit arm64-CPUs gäbe, würde das sowohl dem Markt als auch der Stabilität von Linux auf dieser Plattform gut tun.
Bleibt noch die Frage, ob Asahi Linux besser als macOS ist. Schwer zu sagen. Für hart-gesottene Linux-Fans sicher. Für meine alltägliche Arbeit ist der größte Linux-Pluspunkt absurderweise ein ganz winziges Detail: Ich verwende ununterbrochen die Linux-Funktion, dass ich Text mit der Maus markieren und dann sofort mit der mittleren Maustaste wieder einfügen kann. macOS kann das nicht. Für macOS spricht hingegen die naturgemäß bessere Unterstützung der Apple-Hardware.
Losgelöst davon funktionieren fast alle gängigen Open-Source-Tools auch unter macOS. Über den Desktop von macOS kann man denken, wie man will; ich kann damit leben. Hundertprozentig glücklich machen mich auch Gnome oder KDE nicht. In jedem Fall ist es unter macOS wie unter Linux mit etwas Arbeit verbunden, den Desktop so zu gestalten, wie ich ihn haben will.
PS: Ein persönliches Nachwort
Seit zwei Monaten verwende ich versuchsweise macOS auf einem Mac Mini (wie beschrieben, M1-CPU + 16 GB RAM) als Hauptdesktop. Ich schreibe/überarbeite dort meine Bücher, bereite den Unterricht vor, administriere Linux-Server, entwickle Code. Virtuelle Maschinen laufen mit UTM. Docker funktioniert gut, allerdings stört, dass der Speicher für Docker fix alloziert wird. (Docker unterstützt sogar Rosetta. Ich habe eine Docker-Umgebung, die ein x86-Binary enthält, zu dem es kein arm64-Äquivalent gibt. Und es läuft einfach, es ist schwer zu glauben …)
Ich verwende Chrome als Webbrowser, Thunderbird als E-Mail-Programm, LibreOffice für Office-Aufgaben, Gimp als Bitmap-Editor, draw.io als Zeichenprogramm, Emacs + Code als Editoren, Skim als PDF-Viewer. Im Terminal sind diverse SSH-Sessions aktiv, so dass ich den Raspberry Pi, meine Linux-Server usw. administrieren kann. Zusatzsoftware installiere ich mit brew so unkompliziert wie mit dnf oder apt. Im Prinzip bin ich auf keine unüberwindbaren Hindernisse gestoßen, um meine alltägliche Arbeit auszuführen.
Es gibt nur ganz wenige originale macOS-Programme, die ich regelmäßig ausführe: das Terminal, Preview + Fotos. Außerdem finde ich es praktisch, dass ich M$ Office nativ verwenden kann. Ich hasse Word zwar abgrundtief, muss aber beruflich doch hin und wieder damit arbeiten. Das habe ich bisher auf einem Windows-Rechner erledigt.
Letzten Endes ist der Grund für dieses Experiment banal: Mich nervt der Lüfter meines Linux-Notebooks (ein fünf Jahre alter Lenovo P1) immer mehr. Wenn ich die meiste Zeit Ruhe haben will, muss ich den Turbo-Modus der CPU deaktivieren. Ist es für Intel/AMD wirklich unmöglich, eine CPU zu bauen, die so energieeffizient ist wie die CPUs von Apple? Kann keiner der Mainstream-Notebook-Hersteller (Lenovo, Dell etc.) ein Notebook bauen, das ganz gezielt für den leisen Betrieb gedacht ist, OHNE die Performance gleich komplett auf 0 zu reduzieren?
Im Unterschied zum Lenovo P1 läuft mein Mac komplett lautlos und ist gleichzeitig um ein Mehrfaches schneller. Es ist nicht auszuschließen, dass mein nächstes Notebook keine CPU von Intel oder AMD haben wird, sondern eine M3- oder M4-CPU von Apple. Die Option, auf diesem zukünftigen MacBook evt. auch Linux ausführen zu können, ist ein Pluspunkt und der Grund, weswegen ich mich so intensiv mit Asahi Linux auseinandersetze.
Ich habe es nicht ausprobiert, aber Sie können auch Ubuntu auf M1/M2-Macs installieren. Canonical überlegt anscheinend sogar, das irgendwann offiziell zu unterstützen.
Ich habe mich nach einer kleinen Testphase gegen GitKraken und für Fork als grafischen Client für Git unter macOS entschieden.Gitkraken mag ein hervorragendes Werkzeug sein, aber das Abomodell hat mich abgeschreckt. Ich möchte noch erwähnen, dass GitKraken ein Studenten- und Universitätspaket anbietet. Ich werde vielleicht GitKraken Kollegen:innen an meinem Arbeitsplatz für einen Test vorschlagen. Dann ... Weiterlesen
Bei meinem letzten Update von Homebrew unter macOS Big Sur hatte ich die Fehlermeldung, dass es eine ungültigen Pfadangabe für die Entwicklerwerkzeuge gäbe. Da ich nur die Kommandozeilenwerkzeuge für macOS nutze wird diese nicht einem Update unterzogen. Bei einer kompletten Installation von Xcode würde dies automatisch geschehen. Um das Update selbst anzustoßen genügt ein:
Ich bin die Tage aus allen Wolken gefallen, als ich sah wie meine Workstation alle 5 Minuten Kontakt zu fedoraproject.org aufnahm. Faszinierend daran war, dass ich sie zu den Uhrzeiten nicht genutzt hatte. Diese Sache hatte für mich zuerst mehr … Weiterlesen →