Ubuntu 23.10 auf dem Raspberry Pi 5
(Aktualisiert am 15.10.2023, Geekbench-Ergebnisse mit/ohne Lüfter)
Nach Raspberry Pi OS Bookworm habe ich mir heute auch Ubuntu 23.10 auf dem Raspberry Pi angesehen. In aller Kürze: Der Raspberry Pi 5 ist ein großartiger Desktop-Rechner, Ubuntu mit Gnome unter Wayland läuft absolut flüssig.
Systemvoraussetzungen
Die Desktop-Version von Ubuntu 23.10 läuft nur auf den Modellen 4B, 400 und 5 und beansprucht zumindest 4 GiB RAM. Bei meinem Test mit offenem Terminal, Firefox (zwei Tabs mit GitHub und orf.at) sowie dem neuen App Center waren erst gut 2 GiB RAM in Verwendung. Mit offenem Gimp, VS Code und App Center steigt der Speicherbedarf dann auf 4 GiB. Insofern sind für’s ernsthafte Arbeiten 8 GiB RAM sicher kein Schaden.
Installation
Zur Installation habe ich mit dem Raspberry Pi Imager Ubuntu 23.10 auf eine SD-Karte übertragen. Die Spracheinstellung in der Konfigurationsphase beim ersten Starts bleibt wirkungslos und muss später in den Systemeinstellungen nachgeholt werden. Außerdem müssen mit Installierte Sprachen verwalten alle erforderlichen Sprachdateien heruntergeladen werden.
Ein initiales Ubuntu-Desktop-System beansprucht etwa 6 GByte auf der SD-Karte. Mit Schuld am verhältnismäßig großem Speicherbedarf für ein Ubuntu-»Minimalsystem« ohne Anwendungsprogramme ist der unmäßige Speicherbedarf der vorinstallierten Snap-Paketen (App Center, Firefox plus alle dazu erforderlichen Basisbibliotheken).
Gnome
Gnome 45 mit Wayland läuft absolut flüssig. Nur der Start von Snap-Apps führt zu kleinen Verzögerungen — das kennt man ja auch von Ubuntu-Installationen auf hochwertiger Hardware. Bei meinem Testrechner (Pi 5 mit 8 GiB RAM) braucht Firefox beim ersten Start ca. 4 Sekunden, bis es am Bildschirm erscheint. Damit kann man wirklich leben ;-)
Screenshots funktionieren auf Anhieb.
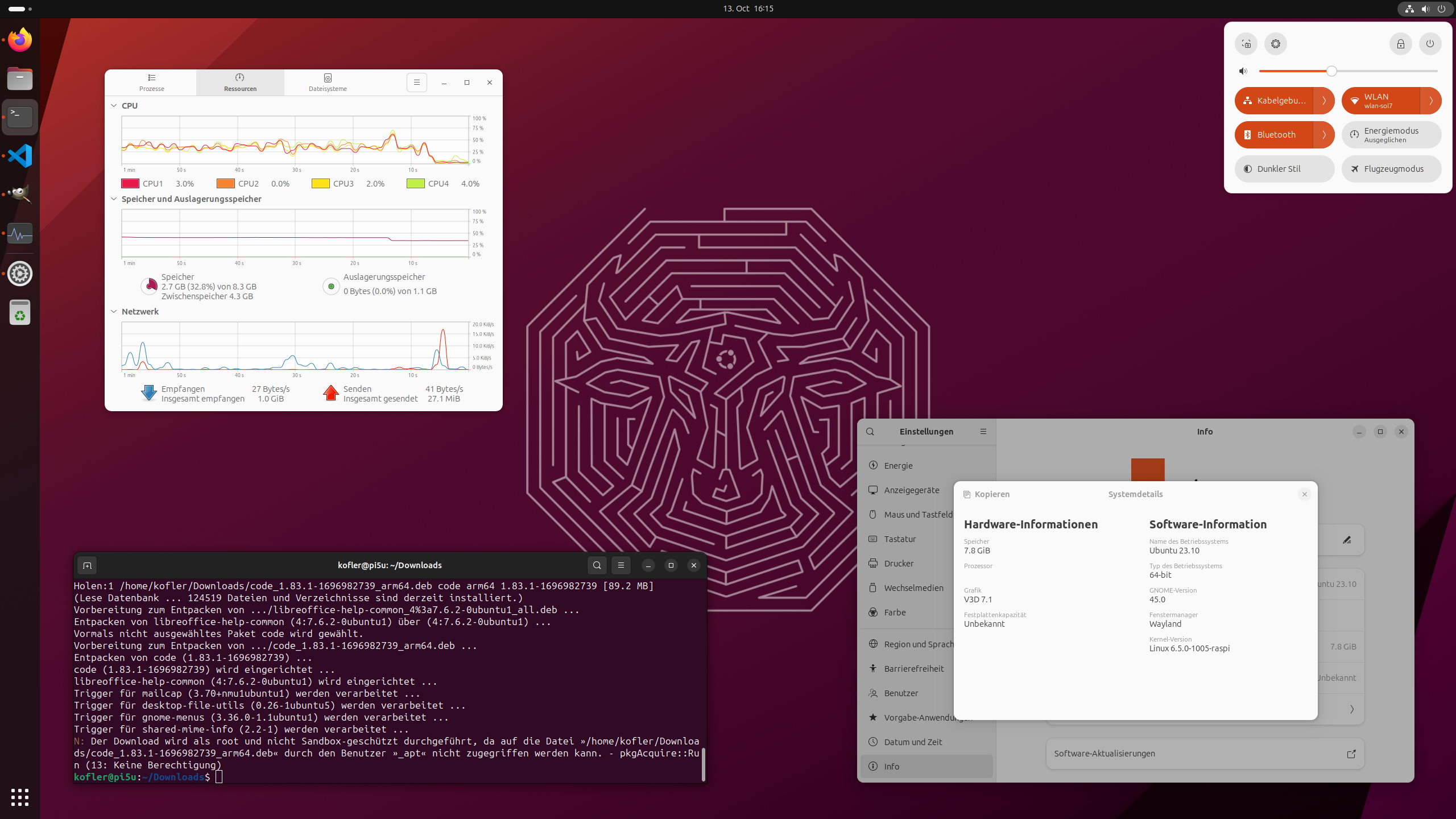
Bei der Erkennung der Systemdaten (also Info/Systemdetails in den Einstellungen) versagt Gnome aber und kann weder die CPU noch die Größe der SD-Karte erkennen (siehe die Abbildung oben). Aber das sind Kleinigkeiten.
Kernel
Ubuntu verwendet mit Version 6.5 einen neueren Kernel als Raspberry Pi OS. Im Gegensatz zu Raspberry Pi OS kommt die »normale« Pagesize von 4 kByte zum Einsatz:
pi5u$ uname -a
Linux pi5u 6.5.0-1005-raspi #7-Ubuntu SMP PREEMPT_DYNAMIC
Sun Oct 8 08:06:18 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
pi5u$ getconf PAGESIZE
4096
Visual Studio Code
Erstaunlicherweise fehlt in der Snap-Bibliothek Visual Studio Code. Ein Debian-Paket für ARM64 kann von https://code.visualstudio.com heruntergeladen werden. Es muss dann mit sudo apt install ./code_xxx.deb installiert werden. Die nachfolgende Fehlermeldung pkgAcquire::Run / Keine Berechtigung können Sie ignorieren. Vergessen Sie aber nicht, ./ bzw. einen gültigen Pfad voranzustellen, sonst glaubt apt, code_xxx.deb wäre der Paketname und verweigert die Installation der lokalen Datei.
Geekbench
Unter https://www.geekbench.com/preview/ gibt es eine AArch64-Version von Geekbench, die ich heruntergeladen, ausgepackt und ausgeführt habe. Die Temperatur des SoC steigt während der Tests auf über 85 °C. Die CPU-Frequenz wird in der Folge auf 1,5 GHz gedrosselt. Ich habe keine Kühlung verwendet (weder aktiv noch passiv). Ergebnisse unter diesen Voraussetzungen: 657
Single-Core Score, 1233 Multi-Core Score. Mehr Details finden Sie hier: https://browser.geekbench.com/v6/cpu/3060411
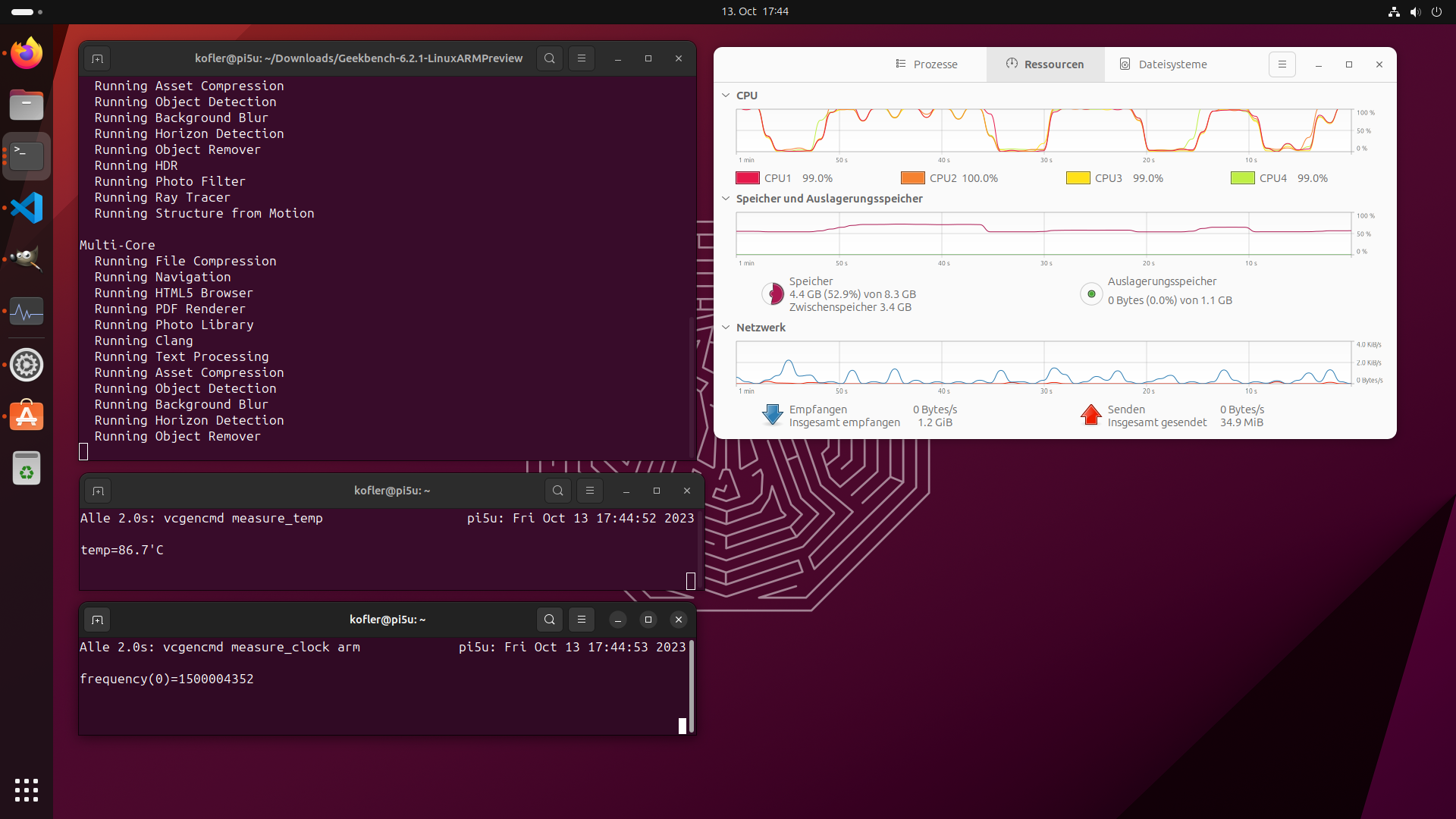
Im Leerlauf unter Ubuntu 23.10 beträgt die CPU-Temperatur übrigens gut 70°C, also auch schon mehr als genug.
Ubuntu fehlt eine dynamische Lüftersteuerung. Sobald ein Lüfter angeschlossen wird, läuft dieser mit maximaler Leistung und produziert ein durchaus störendes Ausmaß an Lärm. Die CPU-Temperatur sinkt dann im Leerlauf auf gut 30°C. Selbst während der Ausführung von Geekbench steigt die Temperatur nur kurzzeitig über 45°C. Gleichzeitig fallen die Werte etwas besser aus (siehe auch https://browser.geekbench.com/v6/cpu/3095791).
Geekbench 6 Single-Core Multi-Core
-------------- ------------ ------------
Ohne Lüfter 657 1233
Mit Lüfter 737 1542
Eine letzte Anmerkung zu Geekbench: Die 64-Bit-Version von Raspberry Pi OS und Geekbench 6.2 sind wegen der 4-kByte-Pagesize inkompatibel zueinander.
Abstürze
Während meiner Tests kam es zweimal zu kapitalen Abstürzen (Bildschirm wurde schwarz, kein Netzwerkzugriff mehr etc.). Möglicherweise war das von mir eingesetzte Netzteil zu schwach. (Unter Raspberry Pi OS hatte ich mit demselben Netzteil allerdings keine Probleme.)
Ich bin dann auf das neue Original-Raspberry-Pi-Netzteil umgestiegen (27 W für einen Minirechner erscheinen wirklich mehr als üppig, aber sei’s drum). Die Komplett-Abstürze haben sich nicht wiederholt.
Allerdings ist in der Folge auch Gimp bei der Verwendung des Dateiauswahldialogs zweimal abgestürzt. Das kenne ich von meinem Notebook überhaupt nicht. Ich kann natürlich nicht sagen, ob dieses Problem ARM-, Ubuntu- oder Raspberry-Pi-spezifisch ist. Aber für zwei Stunden Betrieb waren das für meinen Geschmack recht viele Abstürze …