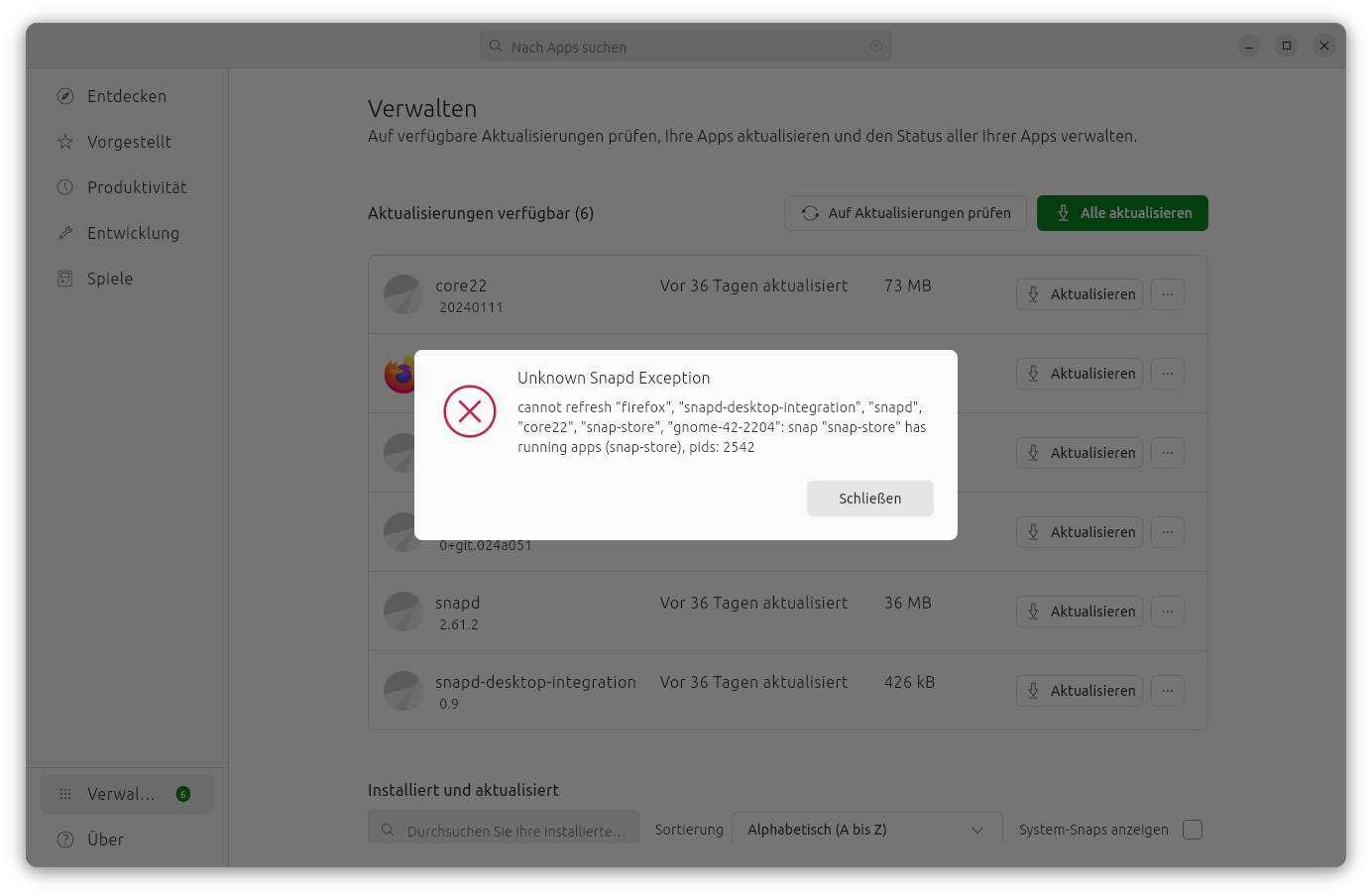
Bei Monitoren kann man üblicherweise über Hardwareknöpfe die Helligkeit ändern. Je nach Monitor kann es jedoch bequemer sein, die Helligkeit über eine grafische Oberfläche zu steuern. Hierfür gibt es eine handvoll Programme. DDCcontrol ist...
Generell lautet ja meine Empfehlung, bei produktiven Servern niemals ein Distributions-Upgrade durchzuführen, als z.B. ohne Neuinstallation von Ubuntu 22.04 auf 24.04 umzustellen. Manchmal halte ich mich aber selbst nicht an diese Regel. Testobjekt war ein Server mit Apache, MySQL, PHP, Mail (Postfix, Dovecot, OpenDKIM) und Docker.
Natürlich gab es Schwierigkeiten …
Fairerweise muss ich zugeben, dass do-release-upgrade noch gar kein Server-Update auf Version 24.04 vorsieht. Das ist ein wenig überraschend, als Ubuntu 24.04.1 ja bereits freigegeben wurde. Normalerweise ist das der Zeitpunkt, ab dem do-release-upgrade funktionieren sollte. Ich habe das Upgrade mit do-release-upgrade -d erzwungen. Selbst schuld also.
Zuerst habe ich ein letztes Mal alle 22.04-Updates installiert (also apt update und apt full-upgrade) und den Server dann neu gestartet.
Danach habe ich ein Backup des in einer virtuellen Maschine laufenden Servers durchgeführt. Zur Not hätte ich aus der gesicherten Image-Datei problemlos den bisherigen Zustand des Servers wiederherstellen können. Das war aber zum Glück nicht notwendig.
Das Distributions-Upgrade habe ich dann mit do-release-upgrade -d eingeleitet, wobei -d für --devel-release steht und das Update erzwingt. Es dauerte ca. 1/4 Stunde und lief an sich überraschend flüssig durch. Ein paar Mal musste ich bestätigen, dass meine eigenen Konfigurationsdateien erhalten bleiben und nicht durch neue Konfigurationsdateien überschrieben werden sollten.
Der nachfolgende Reboot verursachte keine Probleme, ich konnte mich nach kurzer Zeit wieder mit SSH einloggen. So weit so gut!
Kein DNS
Die statische Netzwerkkonfiguration meines Servers erfolgt durch /etc/netplan/01.yaml. Dort sind sechs Nameserver eingetragen, je drei für IPv4 und IPv6. Überraschenderweise funktioniert im aktualisierten 24.04-Server keine Namensauflösung mehr — ein wirklich grundlegendes Problem! ping google.com führt also zum Fehler, dass die IP-Adresse von google.com unbekannt sei.
Ein kurzer Blick auf resolv.conf zeigt, dass es sich dabei um einen Link auf eine gar nicht existierende Datei handelt.
ls -l /etc/resolv.conf
/etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.conf (existiert nicht)
dpkg -l | grep resolve verrät, dass systemd-resolved nicht installiert ist. Sehr merkwürdig!
Abhilfe schafft die Installation dieses Pakets. Die Installation ist aber ohne DNS gar nicht so einfach! Ich musste zuerst /etc/resolv.conf löschen und dann einen Eintrag auf den Google-DNS dort speichern:
Nach einem Reboot läuft DNS. resolvectl listet jetzt meine in /etc/netplan/01.yaml aufgeführten Nameserver auf.
PHP-Probleme
Nächstes Problem: Apache startet nicht. systemctl status apache2 verweist auf einen Fehler in einer Konfigurationsdatei von PHP 8.1. Aber Ubuntu 24.04 verwendet doch PHP 8.3. Was ist da passiert?
Ein Blick in /etc/apache2/mods-enabled zeigt, dass dort noch PHP 8.1 aktiviert ist. Abhilfe:
Apache und PHP laufen jetzt, aber ein Blick auf die Nextcloud-Statusseite zeigt, dass /etc/php/8.3/apache2/php.ini sehr konservative Einstellungen enthält. Nach memory_limit=1024M und ein paar weiteren Änderungen ist auch Nextcloud zufrieden.
OpenDKIM
Auf meinem 22.04-Server hatte ich DKIM aktiv (siehe auch https://kofler.info/dkim-konfiguration-fuer-postfix/). Nach dem Upgrade funktioniert die Signierung der Mails aber nicht mehr. Der Grund war einmal mehr trivial: Beim Upgrade sind die entsprechenden Pakete verloren gegangen. Abhilfe:
apt install opendkim opendkim-tools
Fazit
Keines der Probleme war unüberwindbar. Überraschend war aber die triviale Natur der Fehler. Beim Upgrade verloren gegangene oder nicht installierte Pakete, keine Synchronisierung zwischen den installierten Paketen und den aktivien Apache-Modulen etc. Ich bleibe bei meinem Ratschlag: Wenn Ihnen Stabilität wichtig ist, vermeiden Sie Distributions-Upgrades. Ja, die Neuinstallation eines Servers verursacht mehr Arbeit, aber dafür können Sie den neuen Server in Ruhe ausprobieren und den Wechsel erst dann durchführen, wenn wirklich alles funktioniert. Bei einem Upgrade riskieren Sie Offline-Zeiten, deren Ausmaß im vorhinein schwer abzuschätzen ist.
Ich habe euch bereits in separaten Beiträgen gezeigt, wie ihr Fractional Scaling und VRR unter Gnome aktiviert. Die beiden dort gezeigten Befehle deaktivieren aber die jeweils andere Funktion. Wenn ihr beide Optionen gleichzeitig aktivieren...
Gnome unterstützt seit Version 46 Variable refresh rate (VRR). Ich habe mir kürzlich einen neuen Monitor gekauft, welcher VRR unterstützt. VRR ist standardmäßig nicht unter Gnome aktiviert und muss per Terminal zuerst aktivieren werden....
Der TS101 lässt sich, wie auch der Pinecil v2, mit einem eigenen Bootlogo versehen. Beim TS101 muss das Logo der IronOS Firmwaredatei hinzugefügt werden # Arch Linux sudo pacman -S python-pillow python-intelhex git #...
Heute möchte ich euch wissen lassen, welche Kombination es geworden ist.
Die Hardware
Ich habe mich für ein wiederaufbereitetes Lenovo T570 entschieden, welches für günstige 240 Euro im Onlinehandel verfügbar war. Da war dann auch noch für 30 Euro ein Schutzbrief drin, der Flüssigkeiten und Stürze abdeckt.
Mit dem Intel Core-i5 der 6. Generation, 8 GB RAM und einer 256 GB SSD bietet dieses Gerät mehr als ausreichend Leistung.
Das Gerät weist einige Gebrauchsspuren auf. Den Preis empfinde ich dennoch günstig, da Geräte dieser Klasse nicht unter 1.000 Euro Neupreis zu bekommen sind. Viel wichtiger jedoch ist, dass der Nutzer sich ebenfalls über das Gerät freut.
Linux-Distribution und Desktopumgebung
Wer die Wahl hat, hat die Qual. Um mir einen ersten Eindruck zu verschaffen, habe ich mir einen USB-Stick mit Ventoy und einer Auswahl an verschiedenen Linux-Distributionen erstellt. So konnte ich die verschiedenen Live-Systeme booten und prüfen, ob alles funktioniert und wie es sich in der Oberfläche navigieren lässt.
Schlussendlich habe ich mich für Debian Cinnamon entschieden. Dies machte nach dem ersten kurzen Test insgesamt den besten Eindruck. Firefox, Thunderbird, Bookmarks, Desktop-Verknüpfungen und Zoom-Client waren schnell eingerichtet und das Gerät bereit zur Übergabe.
Die Übergabe ist erfolgt
Mit der Übergabe gab es eine kurze Einweisung in das Gerät:
Wo schließt man das Netzteil an
Wo schaltet man das Gerät ein
Wie meldet man sich an
Wo findet man die Programme inkl. Tests aller wichtigen Dienste
Druck eines Anhangs aus Thunderbird
Wie fährt man das Gerät herunter
So reibungslos hat das bisher noch nie geklappt. Die Nutzungserfahrung ist positiv. Wir freuen uns.
Ende 2021 bin ich von einem Raspberry Pi 4 mit 4 GB auf einen Intel NUC7PJYH mit Proxmox VE umgestiegen. Hauptgrund damals war, dass bei mir das Upgrade von Raspberry Pi OS 10 auf...
Wer sagte noch gleich, dass klassische Release-Distributionen den Rolling Releases überlegen sind, weil sie so stabil seien? Dass es Ausnahmen von der Regel gibt, durfte ich heute erleben. Ich liebe diese Tage, wo auf einmal die normalsten Dinge nicht mehr gehen...
Es galt etwas in einem Softwareprojekt zu testen, das ich hierfür erstmal wieder in Gang bringen musste. Dabei setzt das Projekt auf Vagrant in Kombination mit VirtualBox. Ich habe dazu erstmal das Hostsystem aktualisiert und versucht, mit Vagrant die Maschine aufzusetzen – um dann feststellen zu dürfen, dass Vagrant einen Fehler wirft.
Was ging schief?
Konkret war VirtualBox in die Guru Meditation gefallen. Das tritt dann auf, wenn ein besonders schwerer Fehler auftritt, sodass das Programm nicht ordentlich weiterlaufen kann. Dabei war doch gar nicht viel am Entwicklungssystem verändert worden? Ich halte für solche Entwicklungsprojekte dedizierte Entwicklungsmaschinen vor, auf denen sich das Betriebssystem über die Jahre nicht verändert und die für die tägliche Arbeit auch entsprechend nicht eingesetzt werden. Was ich aber tue: die Zwischenupdates einspielen.
Stellt sich heraus, dass unter Ubuntu 22.04 LTS die Kernelversionen ab 5.15.0-112 den Fehler VERR_VMM_SET_JMP_ABORTED_RESUME wohl verursachen. Der Bug wird schon auf Launchpad, bei ubuntuusers.de und auch im VirtualBox-Forum diskutiert.
Wie kann man das fixen?
Man könnte einereits den Kernel downgraden bzw. einen alten Kernel nutzen, was aber nur kurzfristig Abhilfe schafft. Alternativ gibt es die Flucht nach vorne: entweder Ubuntu auf 24.04 LTS upgraden (habe ich nicht probiert, scheinbar ist der automatische Update-Pfad auch noch gar nicht freigeschaltet) oder VirtualBox auf Version 7.0 updaten. Ich habe mich für letzteren Schritt entschieden und dabei auf die offiziellen VirtualBox-Pakete von Oracle zurückgegriffen, da in den offiziellen Ubuntu-Repos für die Version nur Version 6.1 enthalten ist (was ja bei LTS-Versionen eigentlich auch sinnvoll ist). Das ist natürlich keine schöne Lösung, da man sich fremde Pakete in das System holt – aber sie funktioniert. Man muss allerdings auch bedenken, dass die aktuelle Vagrant-Version, die in den Ubuntu-Repos für 22.04 (jammy) enthalten ist, VirtualBox 7.0 noch gar nicht unterstützt. Folglich muss man dann auch auf die offiziellen Repositories von Hashicorp zurückgreifen – was allerdings angesichts der lizenzrechtlichen Änderungen sowieso bald nötig wird.
Was lernen wir daraus?
Software muss laufend auf Regressionsfehler getestet werden, die durch Updates an anderen Stellen passieren können. Ja, diese Fehler können immer passieren und sind teilweise schwer zu verhindern. Gleichzeitig muss man aber selber auch seine Setups regelmäßig testen, um schnell zu erkennen, dass ggfs. das Kernelupdate schuld war. Mittlerweile vermutet man das aufgrund der Stabilität der Systeme schon fast gar nicht mehr. Ansonsten geht viel Zeit aufgrund der Fehlersuche ins Land. Da ist es auch wenig zuträglich, dass die VirtualBox-Logs scheinbar keine Log Level beinhalten...
Ein Fix seitens Ubuntu steht für diesen Bug im Übrigen noch aus. Theoretisch sollte sich dann das Thema von selbst erledigen, weil die betreffende Änderung im Kernel einfach reverted wird. Ich wollte zwischenzeitlich aber die Workarounds einmal auflisten, sollte jemand ähnliche Probleme haben.
Vor einiger Zeit habe ich beschlossen eine Serie von Artikeln zum Thema Nextcloud auf dem RasPi auf meinem Blog intux.de zu veröffentlichen. Ziel ist es, eine eigene Cloud zu erstellen, die produktiv nutzbar ist. Diese soll später über das Internet erreichbar sein.
Was benötigt man dafür?
Um langfristig sicherzustellen, dass alles funktioniert, empfehle ich, die neueste Hardware zu verwenden, wie den Raspberry Pi 5. Allerdings würde hier auch ein Einplatinencomputer der vorherigen Generation mit 4GB RAM ausreichen.
Hier eine Auflistung der für das Projekt eingesetzten Komponenten:
Raspberry Pi 5
offizielles Gehäuse für den Raspberry PI 5
offizielles Netzteil für den Raspberry PI 5 (8GB RAM)
32GB MicroSD (SanDisk Extreme microSD UHS-I)
Vorbereitung
Diese kleine Anleitung soll helfen, das Projekt Nextcloud auf dem Raspberry Pi nicht nur umzusetzen, sondern auch besser zu verstehen. Der Schwerpunkt liegt dabei auf der Software und der Konfiguration. So können später auftretende Fehler besser lokalisiert und abgestellt werden.
Der Raspberry Pi wird als LAMP-Server (Linux, Apache, MariaDB, PHP) dienen, die Nextcloud zu betreiben. Wie man diese vier Bausteine aufsetzt, zeige ich im folgenden Abschnitt.
LAMP-Server
Installation
Der erste Baustein der installiert wird, ist Linux. Hierbei handelt es sich um das Betriebssystem Raspberry Pi OS. Dieses spielt man ganz einfach mit dem Raspberry Pi Imager auf die MicroSD.
Hier wählt man (siehe Screenshot) das zu installierende Betriebssystem aus. In diesem Fall ist es das Raspberry Pi OS (64-bit). Im Imager können vorab einige Einstellungen vorgenommen werden. Ich werde in dieser Anleitung einfache Bezeichnungen und Passwörter verwenden. Diese können während der Installation entsprechend frei angepasst werden!
Raspberry Pi Imager – OS und SD-Karte auswählenRaspberry Pi Imager – OS-Einstellungen vornehmen
Über das Zahnrad des Imagers lässt sich das Raspberry Pi OS vorkonfigurieren. Hier trägt man für den Anfang die entsprechenden Daten ein:
Danach wählt man am PC/Notebook die MicroSD aus, auf die geschrieben werden soll.
Raspberry Pi Imager – Schreibvorgang
Zum Schluss werden die Daten auf die MicroSD geflasht. Ist dies erledigt, kann die Karte ausgeworfen und in den vorbereiteten Raspbberry Pi (Kühlkörper, Gehäuse, Lüfter) geschoben werden. Dieser wird dann via LAN-Kabel mit dem heimischen Router verbunden und über das Netzteil mit Strom versorgt.
Natürlich könnte der RasPi auch via WLAN mit dem Router kommunizieren. Hiervon rate ich jedoch ab, da über die Funkverbindung oft nicht die volle Geschwindigkeit einer Ethernet-Verbindung genutzt werden kann. Weiterhin kann es zu Verbindungsabbrüchen bzw. -lücken kommen.
Nachdem der Raspberry Pi mit Strom versorgt wird, startet dieser. Ist der Raspberry Pi hochgefahren, kann dieser via arp-scan vom PC/Notebook im Netzwerk lokalisiert werden. In meinem Fall hat er die IP-Adresse 192.168.178.136.
sudo apt install arp-scan
sudo arp-scan -l
Identifizieren des RasPi mit arp-scan
Zugriff auf den Pi erhalte ich nun via zuvor im Imager aktiviertem SSH-Zugang.
ssh Benutzer@IP-Adresse
Zugang via SSH
Ist man eingeloggt, empfiehlt es sich die Lokalisierung über raspi-config auf deutsch (siehe Screenshots) umzustellen. Damit wird Datum und Uhrzeit des Servers an die europäische Zeitzone (Berlin) angepasst.
Nachdem die Installation durchgelaufen ist, kann man zum Testen den Webserver Apache via Browser über die Web-Adresse http://ip erreichen.
Anschließend wird die von der Nextcloud benötigte Datenbank installiert. Zuerst wird jedoch die mysql_secure_installation durchgeführt. Ich empfehle hier das Ganze gemäß meinen Empfehlungen (Enter, n, n, y, y, y, y) zu durchlaufen. Hierbei wird für den MariaDB-Server kein separates Root-Passwort vergeben, der anonyme User wird gelöscht, die Remote-Root-Anmeldung wird verboten, die Test-DB wird gelöscht und die Änderungen ausgeführt.
sudo mysql_secure_installation
If you’ve just installed MariaDB, and you haven’t set the root password yet, the password will be blank, so you should just press enter here. Enter
Switch to unix_socker_authentication [Y/n] n Change the root password? [Y/n] n Remove anonymous users? [Y/n] y Disallow root login remotely? [Y/n] y Remove test database and access to it? [Y/n] y Reload privilege tables now? [Y/n] y
Nachdem dieser Schritt durchgeführt wurde, kann über folgenden Befehl die Datenbank erstellt werden.
sudo mysql -u root -p
In meinem Fall heißen die Datenbank und der Benutzer „nextcloud“. Die Datenbank liegt dann auf dem „localhost“.
> CREATE DATABASE nextcloud;
> CREATE USER 'nextcloud'@'localhost' IDENTIFIED BY 'geheim';
> GRANT ALL ON nextcloud.* TO 'nextcloud'@'localhost';
> FLUSH PRIVILEGES;
> \q
Im Nachgang wechselt man in das Verzeichnis /var/www/html, wo die Nextcloud installiert wird. Die letzte Version wird vom Entwickler herunter geladen und entpackt. Danach wird die nicht mehr benötigte Zip-Datei wieder gelöscht und die Rechte der Dateien an den Benutzer www-data übertragen.
Nun ist die Nextcloud über http://ip/nextcloud (http://102.168.178.136/nextcloud) erreichbar. Man legt den Admin fest und trägt die Daten der zuvor erstellten MariaDB-Datenbank in die Eingabemaske ein. Hat das alles geklappt, dann dauert die Einrichtung ein paar Minuten und die Nextcloud steht bereit zum ersten Login des neuen Administrators.
Administrator-Konto anlegen
Vorschau
Im nächsten Teil zeige ich, wie man die App Collabora Online – Built-in CODE Server (ARM64) in der Nextcloud via Terminal installiert.
Die Entwickler von Immich haben nach der Kritik bzgl. der „Unlicensed“ Meldung nachgebessert und die Meldung heißt nun „Buy Immich“. Wie zuvor wird diese Meldung unten links angezeigt. Nach einem Klick auf die Meldung...
Mit der Veröffentlichung von Immich v1.109.0 haben die Entwickler optionale Lizenzen angekündigt. Man bekommt nun unten links angezeigt, dass man eine unlizenzierte Version einsetzt, sofern man keine Lizenz gekauft hat. Nachfolgend beide Lizenzoptionen und...
Das mit Firefox 128 und der „Privacy Preserving Attribution“ (PPA) Funktion dürften die meisten mitbekommen haben. Ich zeige euch in diesen Beitrag, wie ihr die PPA Funktion unter Linux, Windows, macOS und Android deaktivieren...
Seit Firefox 127 kann man sich das Wetter auf der Startseite anzeigen lassen. Startet euren Firefox, gebt in der Adresszeile about:config ein und bestätigt die Warnung. Sucht nach browser.newtabpage.activity-stream.system.showWeather und stellt den Wert mit...
Das Buch „Nextcloud Schnelleinstieg“ von Herbert Hertramph ist in der 1. Auflage 2023 im mitp-Verlag erschienen. Es trägt den Untertitel „Der leichte Weg zur eigenen Cloud – Daten sicher speichern und teilen“. Das Buch hat insgesamt 224 Seiten und ist für Nutzer konzipiert, die sich für die Verwendung von Nextcloud entschieden haben oder dies planen. Es bietet einen umfassenden Einblick in die Funktionalitäten und die Handhabung dieser besonderen Open-Source-Cloud.
Dieses Buch geht weniger auf Installationsmöglichkeiten der Nextcloud ein, gibt aber wertvolle Tipps, wie der Nutzer an eine eigene Nextcloud gelangt, ob als selbst installiertes Filesharing-System auf einem Einplatinencomputer, wie dem Raspberry Pi, einem angemieteten vServer oder als gemanagte Cloud bei einem Nextcloud-Spezialisten.
In seinem Buch konzentriert sich der Autor ausschließlich auf die Benutzung der Nextcloud. Er erklärt den Aufbau und die Funktionen auf eine klare und verständliche Art. Der Einsatz vieler Grafiken und Screenshots unterstützt diese Erklärungen und macht sie leicht nachvollziehbar.
Im Buch von Herbert Hertramph wird keine spezifische Nextcloud-Version genannt, was aufgrund der häufigen Veröffentlichung neuer Hauptversionen des Open-Source-Projekts in etwa alle sechs Monate auch kaum möglich ist.
Herbert Hertramph zeigt anschaulich die vielfältigen Möglichkeiten, die sich durch die Anwendungen Dateien zur Dateiverwaltung, Kalender und Kontakte ergeben. Er erläutert, wie Daten einfach geteilt werden können und wie kollaboratives Arbeiten in der Cloud funktioniert. Zudem werden spannende Apps wie Aufgaben und Deck genauer betrachtet. Deck ist ein nützliches Kanban System zur Planung und Umsetzung eigener Projekte. Mail und Talk werden ebenfalls ausführlich erklärt: Mail ist ein in die Cloud integrierter eMail-Client und Talk eine eigenständige Anwendung für Videokonferenzen.
Außerdem wird detailliert besprochen, wie arbeitserleichternde Clients für PC und Mobiltelefone genutzt werden können und wie Daten, Kontakte und Kalender mit diesen Geräten synchronisiert werden können.
Nextcloud ist ein hochwertiges, ausgereiftes und kostenfreies System, das in zahlreichen Unternehmen und Bildungseinrichtungen eingesetzt wird. Es wurde in Deutschland entwickelt, ist Open Source und bietet eine transparente Plattform. Anders als herkömmliche Cloud-Lösungen umfasst Nextcloud neben den Grundfunktionen wie Filesharing auch einen E-Mail-Client, Video-Konferenzmöglichkeiten und die Integration eines Online-Office, was es zu einem umfassenden Enterprise-Produkt macht.
Das Buch gliedert sich in folgende Kapitel:
Die Grundlagen
Anmeldung und Rundgang
Dateimanagement
Einstellungssache: Nextcloud anpassen
Geteilte Cloud ist doppelte Cloud: (Mit-)Benutzer einrichten
Terminmanagement: Vom Kalender bis zur Buchungsverwaltung
Ich kann dieses Buch jedem empfehlen, der bereits über die Verwendung von Nextcloud nachdenkt oder bereits ein solches System nutzt. Selbst erfahrene Nutzer werden wahrscheinlich noch nützliche Hinweise darin finden. Insgesamt bin ich der Meinung, dass es sich lohnt, das Buch anzuschaffen.
Liebe Leser*innen, heute seid ihr gefragt. Denn ich möchte von euch wissen, welchen Laptop und welche Linux-Distribution, ihr für ältere, nicht EDV-affine Menschen und Windows-Umsteiger empfehlen könnt.
Hardware
Der Laptop soll über folgende Merkmale verfügen:
Größe: 15-17 Zoll
Webcam
Mikrofon und Lautsprecher
für Videokonferenzen
zum Schauen von Videos in sozialen Netzwerken
Linux- und Windows-Unterstützung
Die Unterstützung von Linux und Windows ist sehr wichtig. Sollte der Feldversuch mit Linux scheitern, möchte auf der gleichen Hardware ein aktuelles Windows-Betriebssystem installieren können.
Mir schwebt etwas in der Richtung der Lenovo IdeaPad oder ein ThinkPad der L-Serie vor, ich bin jedoch auf eure Empfehlungen gespannt.
Desktop-Umgebung
Ich suche nach einer Desktop-Umgebung, die folgende Merkmale bietet:
Ein Startmenü, welches sich in der unteren linken Ecke befindet
Erstellungen von Anwendungsstartern und Verknüpfungen auf der Desktopoberfläche
Dies sind Muss-Kriterien, die unbedingt erfüllt sein müssen. Ich möchte, dass die Desktopoberfläche diese Eigenschaften in der Standardkonfiguration erfüllt und ich diese nicht erst konfigurieren oder drölfzig Plug-ins installieren muss, um diesen Zustand zu erreichen.
Software
Die wichtigsten Anwendungen sind:
Thunderbird für E-Mail
Aktuelle Webbrowser (Chrome/Firefox) für den Rest
Facebook
YouTube
Zoom, MS Teams, Webex und wie sie alle heißen
Ein PDF-Anzeigeprogramm
Libre/Open Office zum Lesen von MS Office-Dokumenten
Linux-Distribution
Die Linux-Distribution muss die oben genannten Anforderungen an die Desktop-Umgebung und die Software erfüllen und dabei stabil allerdings nicht steinalt sein.
Ich möchte nicht vor jeder Videokonferenz mit den Audio-Einstellungen kämpfen müssen, um deutlich zu machen, wo meine Priorität liegt.
Das Training auf einer virtuellen Maschine mit Fedora 40 Server, 10 CPU-Threads und 32 GB RAM dauerte 180 Std. 44 Min. 7 Sek. Ich halte an dieser Stelle fest, ohne GPU-Beschleunigung fehlt es mir persönlich an Geduld. So macht das Training keinen Spaß.
Nach dem Training mit ilab train findet man ein brandneues LLM auf dem eigenen System:
(venv) tronde@instructlab:~/src/instructlab$ ls -ltrh models
total 18G
-rw-r--r--. 1 tronde tronde 4.1G May 28 20:34 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r--. 1 tronde tronde 14G Jun 6 12:07 ggml-model-f16.gguf
Test des neuen Modells
Den Chat mit dem LLM starte ich mit dem Befehl ilab chat -m models/ggml-model-f16.gguf. Das folgende Bild zeigt zwei Chats mit jeweils unterschiedlichem Ergebnis:
Zwei Chats mit dem frisch trainierten LLM. Beide Male erhalte ich nicht die erhoffte Antwort.
Fazit
Schade, das hat nicht so funktioniert, wie ich mir das vorgestellt habe. Es kommt weiterhin zu KI-Halluzinationen und nur gelegentlich gesteht das LLM seine Unkenntnis bzw. seine Unsicherheit ein.
Für mich sind damit 180 Stunden Rechenzeit verschwendet. Ich werde bis auf Weiteres keine Trainings ohne Beschleuniger-Karten mehr durchführen. Jedoch werde ich mir von Zeit zu Zeit aktualisierte Releases der verfügbaren Modelle herunterladen und diesen Fragen stellen, deren Antworten ich bereits kenne.
Wenn sich mir die Gelegenheit bietet, diesen Versuch auf einem Rechner mit entsprechender GPU-Hardware zu wiederholen, werde ich die Erkenntnisse hier im Blog teilen.
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Wer ein GitHub Account hat, kann sich sehr einfach über neue Releases (Veröffentlichungen) von Projekten per E-Mail informieren lassen. Es benutzen aber nicht alle Projekte das „Releases“ Feature, sondern setzen stattdessen auf Git Tags....
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
Was ist InstructLab?
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
Hugging Face. The AI community building the future. The platform where the machine learning community collaborates on models, datasets, and applications. URL: https://huggingface.co/
Meine Einstellung gegenüber KI-ChatBots
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Der lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
Screencast eines Chats mit merlinite-7b-lab-Q4_K_M
Wie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
KI-Halluzinationen
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Frage an das LLM: „Who is the chancellor of the Bielefeld University?“
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
ChatBot wird auf Falschaussage hingewiesen
Die Antworten des LLM enthalten folgende Fehler:
Professor Dr. Ulrich Heidt ist nicht der Kanzler der Universität Bielefeld
Die URL ‚https://www.uni-bielefeld.de/english/staff/‘ existiert nicht
Die URL ‚http://www.universitaet-bielefeld.de/en/‘ existiert ebenfalls nicht
Die Universität hieß niemals „Technische Universitaet Braunschweig“
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Wissen und Fähigkeiten hinzufügen und das Modell anlernen
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Wissen erschaffen
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
Konvertiere den Wikipedia-Artikel Bielefeld University ohne Bilder und Tabellen in eine Markdown-Datei und füge sie dem in Schritt 1 erstellten Repository unter dem Namen unibi.md hinzu
Füge dem lokalen Taxonomy-Repository neue Verzeichnisse hinzu: mkdir -p university/germany/bielefeld_university
Erstelle in dem neuen Verzeichnis eine qna.yaml und eine attribution.txt Datei
Führe ilab diff aus, um die Daten zu validieren
Der folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$
Synthetische Daten generieren
Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
Zur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Das Training beginnt
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Fazit
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.
Screen Sharing mit dem Raspberry Pi war schon immer ein fehleranfälliges Vergnügen. In der Vergangenheit hat die Raspberry Pi Foundation auf die proprietäre RealVNC-Software gesetzt. Zuletzt war RealVNC aber nicht Wayland-kompatibel. Die Alternative ist wayvnc, ein Wayland-kompatible VNC-Variante: Wie ich unter Remote Desktop und Raspberry Pi OS Bookworm schon berichtet habe, ist wayvnc aber nicht mit allen Remote-Clients kompatibel, insbesondere nicht mit Remotedesktopverbindung von Microsoft.
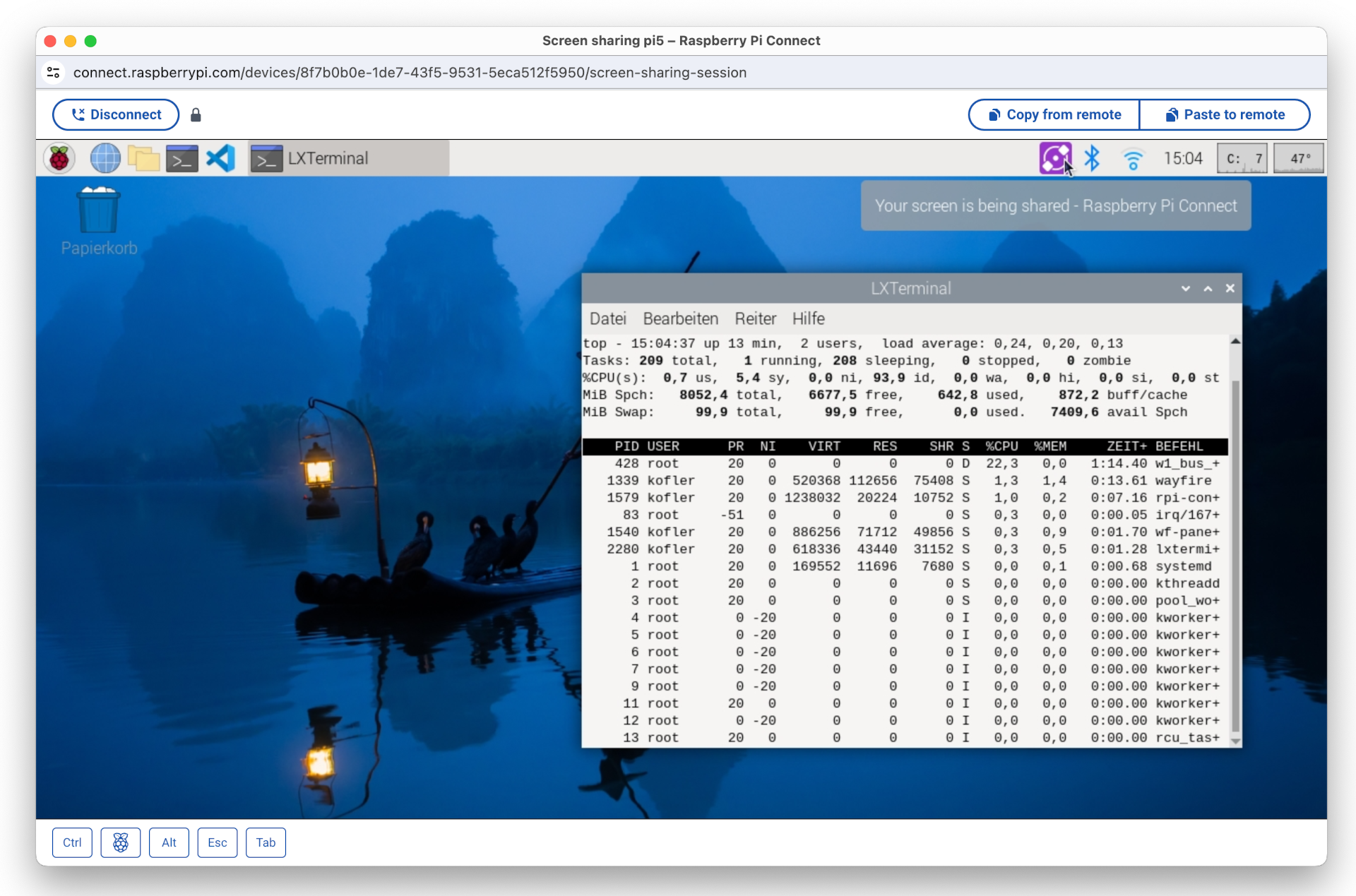
Anfang Mai 2024 hat die Raspberry Pi Foundation mit Raspberry Pi Connect eine eigene Lösung präsentiert. Ich habe das System ausprobiert. Um das Ergebnis gleich vorwegzunehmen: Bei meinen Tests hat alles bestens funktioniert, selbst dann, wenn auf beiden Seiten private Netzwerke mit Network Address Translation (NAT) im Spiel sind. Das Setup ist sehr einfach, als Client reicht ein Webbrowser. Geschwindigkeitswunder sind aber nicht zu erwarten, selbst im lokalen Netzwerk treten spürbare Verzögerungen auf.
Der Zugriff auf den Raspberry-Pi-Client erfolgt hier in einem Fenster des Webbrowsers Google Chrome unter macOS
Voraussetzungen
Raspberry Pi Connect setzt voraus, dass Sie die aktuelle Raspberry-Pi-Version »Bookworm« verwenden und dass der PIXEL Desktop in einer Wayland-Session läuft. Das schränkt die Modellauswahl auf 4B, 400 und 5 ein. Ob Ihr Desktop Wayland nutzt, überprüfen Sie am einfachsten im Terminal:
echo $XDG_SESSION_TYPE
wayland
Gegebenenfalls können Sie mit raspi-config zwischen Xorg und Wayland umschalten (Menüpunkt Advanced Options / Wayland).
Installation
Die Software-Installation verläuft denkbar einfach:
Nach der Installation erscheint ein neues Icon im Panel des PIXEL Desktops. Über dessen Menüeintrag Sign in gelangen Sie auf die Website https://connect.raspberrypi.com/sign-in. Dort müssen Sie eine Raspberry-Pi-ID einrichten. Die Eingabefelder sind auf ein Minimum beschränkt: E-Mail-Adresse, Passwort (2x) und Name. Fertig!
Bevor Sie Raspberry Pi Connect nutzen können, müssen Sie eine Raspberry Pi ID einrichten.
Fernzugriff
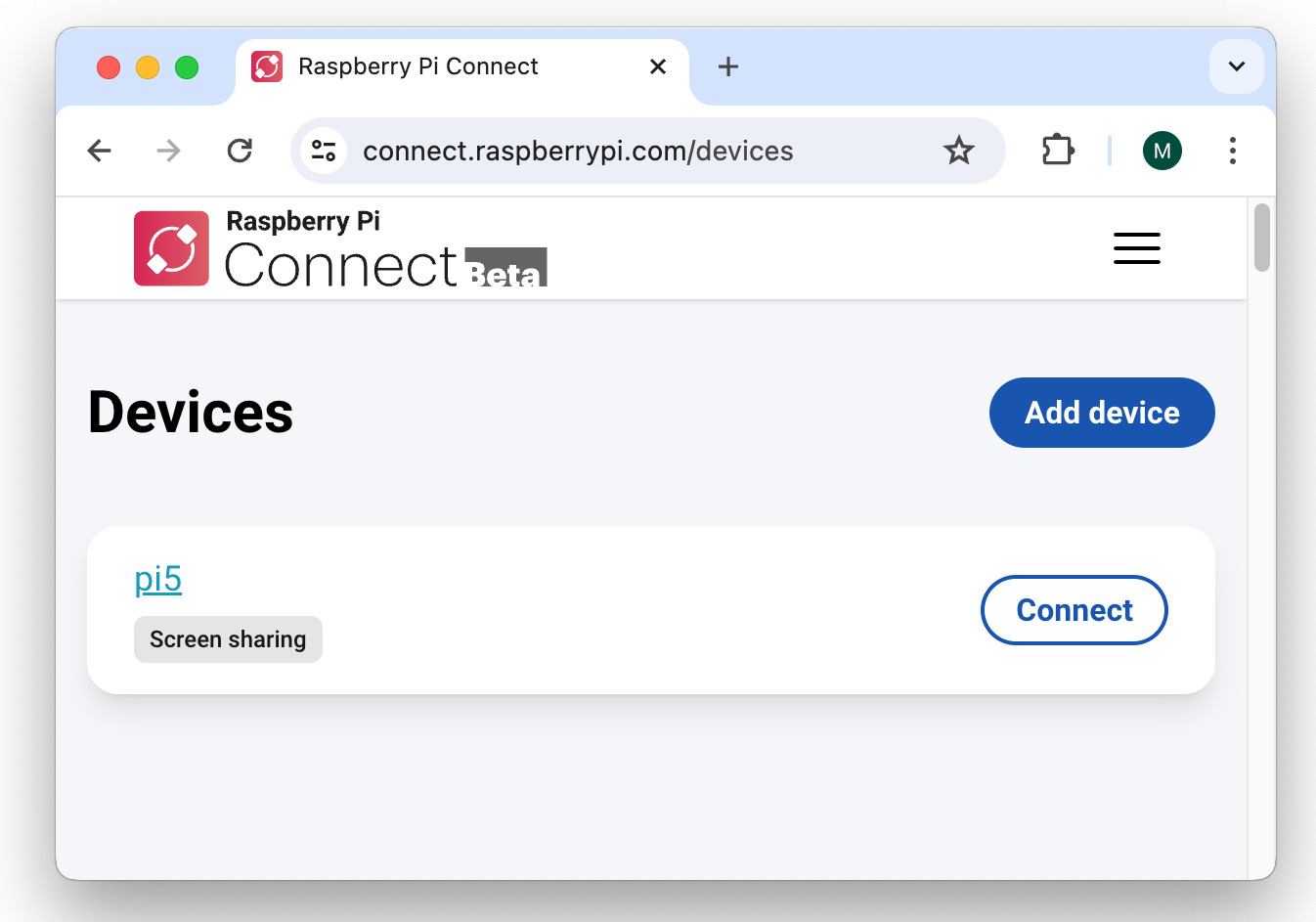
Um nun von einem anderen Rechner auf den PIXEL Desktop Ihres Raspberry Pis zuzugreifen, melden Sie sich dort ebenfalls auf der Website https://connect.raspberrypi.com/sign-in an. Dort werden alle registrierten Geräte aufgelistet. (Mit einer Raspberry-Pi-ID können als mehrere Raspberry Pis verknüpft werden.)
Remote-Verbindungsaufbau im Webbrowser
Praktische Erfahrungen
Bei meinen Tests hat Raspberry Pi Connect ausgezeichnet funktioniert. Der Verbindungsaufbau war problemlos. Der Desktop-Inhalt erscheint in einem neuen Browser-Fenster. Der Desktop-Inhalt wird automatisch auf die Fenstergröße skaliert. Die Bedienung ist denkbar simpel. Über zwei Buttons können Texte über die Zwischenablage kopiert bzw. eingefügt werden.
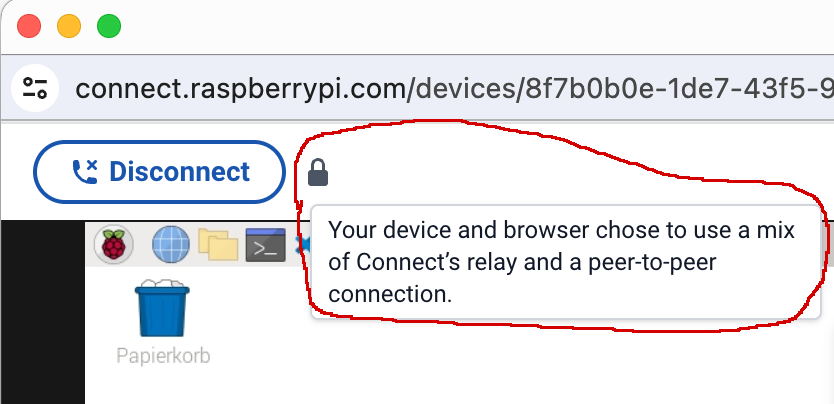
Raspberry Pi Connect testet beim Verbindungsaufbau, ob sich der Raspberry Pi und Ihr Client-Rechner (z.B. Ihr Notebook) im gleichen Netzwerk befinden. Wenn das der Fall ist, stellt der Client eine direkte Peer-to-Peer-Verbindung zum Raspberry Pi her. Nach dem Verbindungsaufbau fließen keine Daten mehr über den Raspberry-Pi-Connect-Server. Die Verbindungsgeschwindigkeit ist dann spürbar höher. Dennoch ist es empfehlenswert, die Bildschirmauflösung auf dem Raspberry Pi nicht höher einzustellen als notwendig.
Wenn sich Ihr Pi und Ihr Client-Rechner dagegen in unterschiedlichen (privaten) Netzwerken befinden, agiert ein Server der Raspberry Pi Foundation als Relay. Sowohl der Bildschirminhalt als auch alle Eingaben werden verschlüsselt nach Großbritannien und wieder zurück übertragen. Selbst wenn alle Geräte eine gute Internetverbindung haben, ist ein gewisser Lag unvermeidlich.
Details über die Art der Verbindung erfahren Sie, wenn Sie den Mauszeiger auf das Schloss-Icon im Screen-Sharing-Fenster bewegen.
Wenn Sie den Mauszeiger über das Schloss-Icon bewegen, erscheint ein Info-Text zum Status der Verbindung
Wenn die Remote-Desktop-Verbindung nicht im lokalen Netzwerk stattfindet, fließt der ganze Netzwerkverkehr über einen Relay-Server in Großbritannien. Dabei kommt das Protokoll Traversal Using Relays around NAT (kurz TURN) zum Einsatz. Die Daten werden TLS-verschlüsselt.
Der entscheidende Schwachpunkt des Systems besteht darin, dass es aktuell nur einen einzigen TURN-Server gibt. Je mehr gleichzeitige Remote-Desktop-Verbindungen aktiv sind, desto langsamer wird das Vergnügen … (Und besonders schnell ist es schon im Idealfall nicht.)
Fazit
Raspberry Pi Connect punktet vor allem durch seine Einfachheit.
Am Raspberry Pi reicht es aus, rpi-connect zu installieren.
Die Raspberry-Pi-ID kann rasch und unkompliziert eingerichtet werden.
Die Anwendung im Webbrowser funktioniert plattformübergreifend und einfach.
Allzu hohe Performance-Anforderungen sollten Sie nicht haben. Die Nachlaufzeiten bei Mausbewegungen und gar beim Verschieben eines Fensters sind beachtlich. Für administrative Arbeiten reicht die Geschwindigkeit aber absolut aus.
Schließlich bleibt abzuwarten, wie gut die Software skaliert. Aktuell befindet sich Raspberry Pi Connect noch in einem Probebetrieb. Soweit sich der Raspberry Pi und der Client-Rechner nicht im gleichen lokalen Netzwerk befinden, werden die Bildschirmdaten über einen Relay in Großbritannien geleitet. Aktuell gibt es genau einen derartigen Relay. Je mehr Anwender Raspberry Pi Connect gleichzeitig nutzen, desto langsamer wird es. Die Raspberry Pi Foundation lässt sich aktuell überhaupt offen, ob es den Relay-Betrieb dauerhaft kostenlos anbieten kann.
Seit Nextcloud Hub 8 (29.0.0) ist ChatGPT nicht mehr über den Picker der Nextcloud zu erreichen. Dieser Umstand kann Nerven kosten, wenn OpenAI’s KI-Dienst hin und wieder genutzt wird und man plötzlich feststellt, dass dieser nicht mehr funktioniert. So ging es mir, als ich den in die Nextcloud integrierten KI-Assistenten einem kleinen Publikum vorstellen wollte. Da das neueste Release 29.0.0 noch recht frisch ist, findet man derzeit wenig Hinweise, wie man ChatGPT weiter nutzen kann.
Einrichtung
Dies hat mich nun dazu bewogen einen kleinen Artikel hierzu zu schreiben. Grundvoraussetzung ist jedoch ein Account beim US-amerikanischen Softwareunternehmen OpenAI bei dem ein API-Key erstellt wird.
Des weiteren müssen in der Nextcloud die Apps OpenAI and LocalAI integration und Nextcloud Assistant hinzugefügt und aktiviert werden.
Nextcloud – OpenAI and LocalAI integration und Nextcloud Assistant
Im Anschluss wird der API-Key, wie im Screenshot zu sehen ist, in der App OpenAI and LocalAI integration hinterlegt.
Nextcloud – OpenAI and LocalAI integration (API Key)
Nun kann man über den neuen Nextcloud-Assistent das KI-Tool nutzen.
Ubuntu 24.04 alias Noble Numbat alias Snubuntu ist fertig. Im Vergleich zur letzten LTS-Version gibt es einen neuen Installer, der nach einigen Kinderkrankheiten (Version 23.04) inzwischen gut funktioniert. Ansonsten kombiniert Ubuntu ein Kernsystem aus Debian-Paketen mit Anwendungsprogramme in Form von Snap-Paketen. Für die einfache Anwendung bezahlen Sie mit vergeudeten Ressourcen (Disk Space + RAM).
Der Ubuntu-Desktop mit Gnome 46
Installation
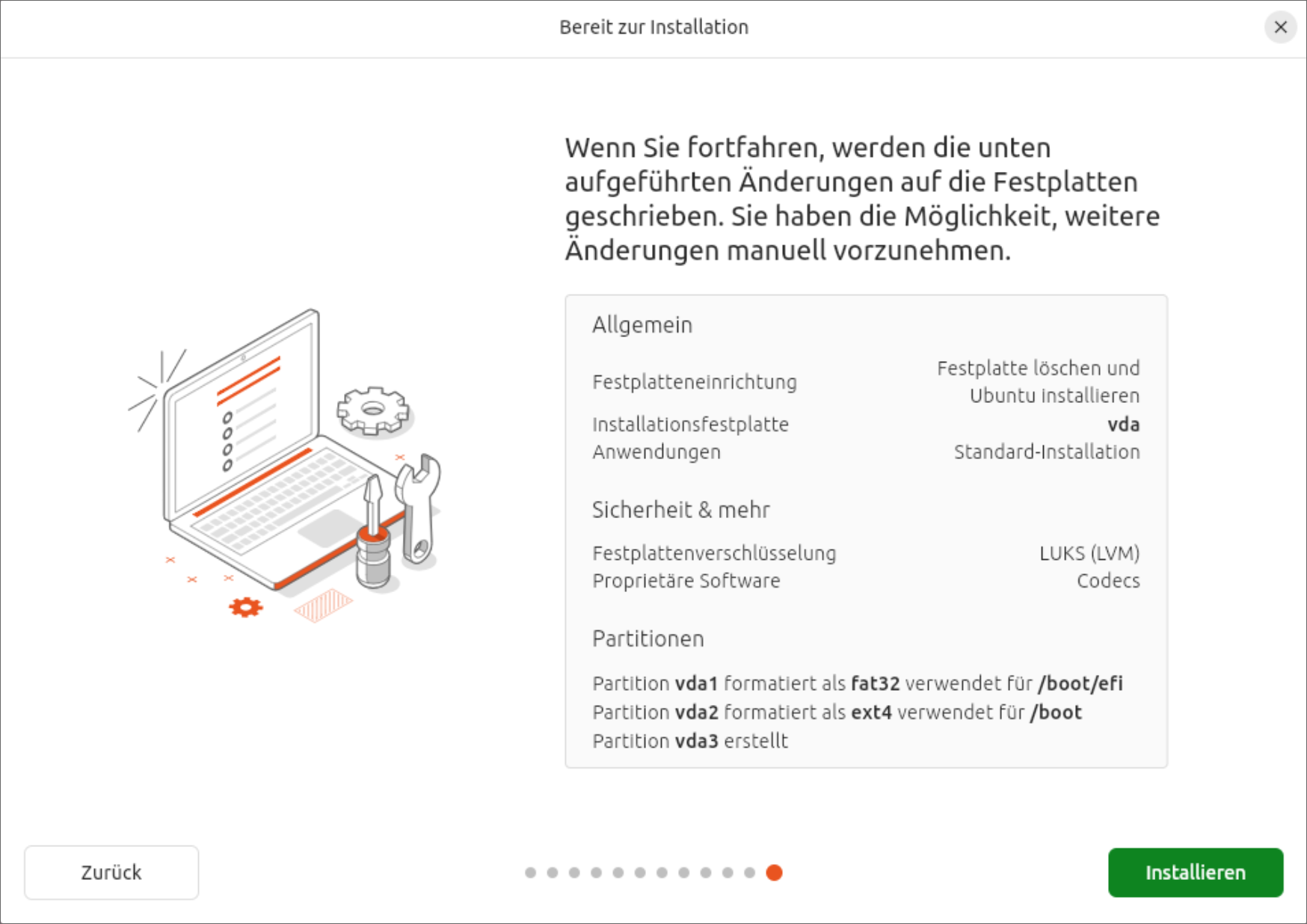
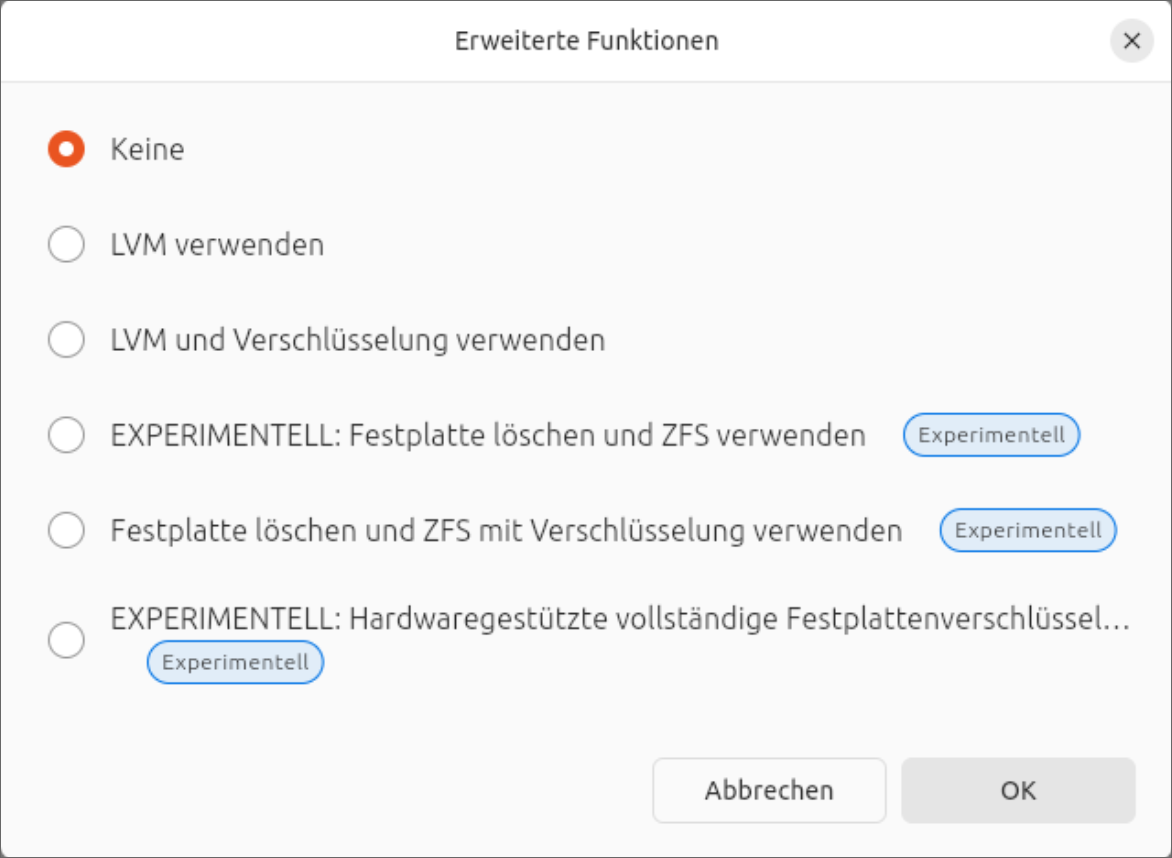
Das neue Installationsprogramm hat bei meinen Tests gut funktioniert, inklusive LVM + Verschlüsselung. Einfluss auf die Partitionierung können Sie dabei allerdings nicht nehmen. (Das Installationsprogramm erzeugt eine EFI-, eine Boot- und eine LVM-Partition, darin ein großes Logical Volume.) Zusammen mit der Installation erledigt der Installaer gleich ein komplettes Update, was ein wenig Geduld erfordert.
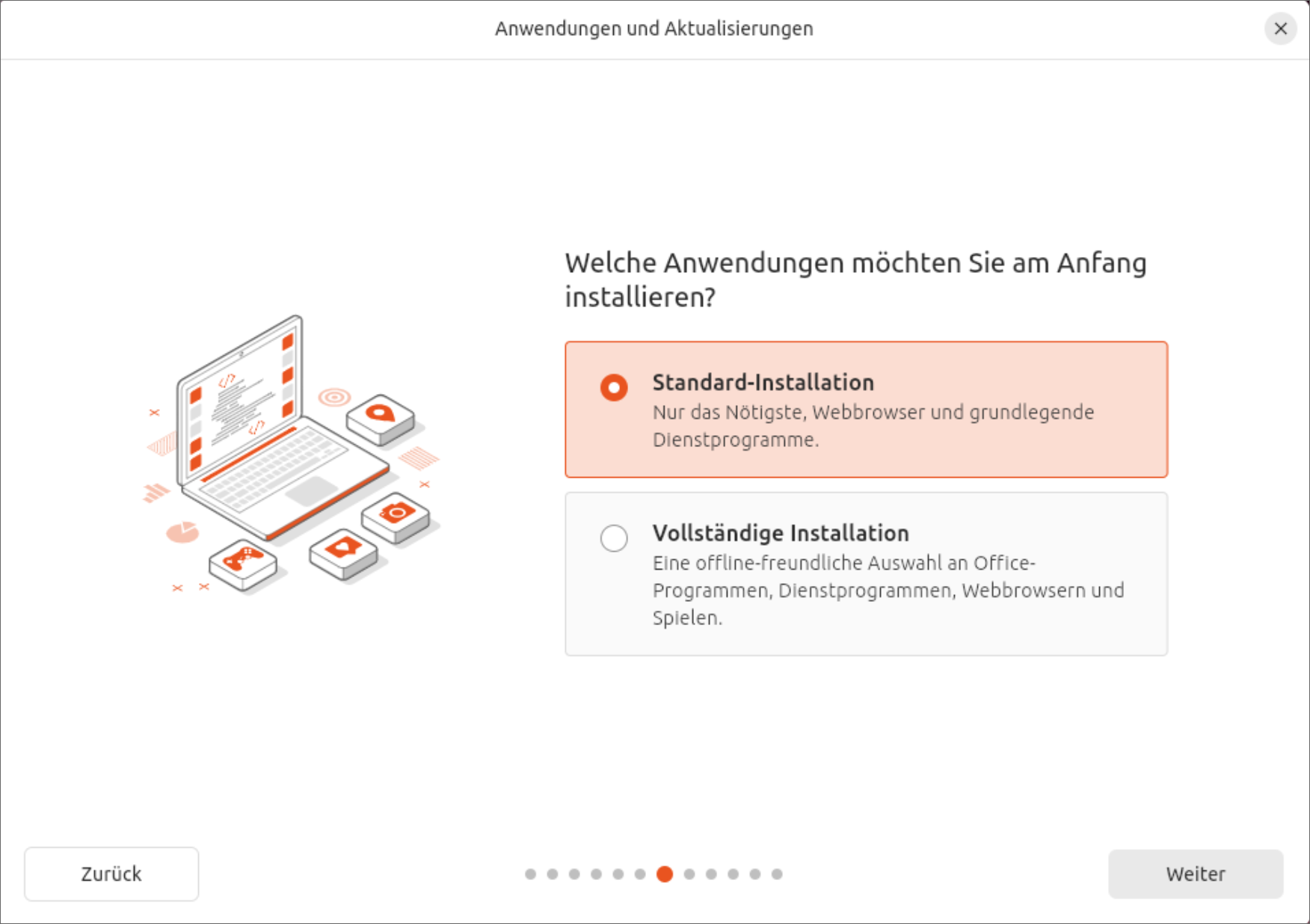
Standardmäßig führt das Programm eine Minimalinstallation durch — ohne Gimp, Thunderbird, Audio-Player usw. Mit der Option Vollständige Option verhält sich der Installer ähnlich wie in der Vergangenheit. Ein wenig absurd ist, dass dann einige Programme als Debian-Pakete installiert werden, während Ubuntu sonst ja bei Anwendungsprogrammen voll auf das eigene Snap-Format setzt. Wenn Sie Ubuntu installieren, entscheiden Sie sich auch für Snap. Insofern ist es konsequenter, eine Minimalinstallation durchzuführen und später die entsprechenden Snaps im App Center selbst zu installieren.
Neuer Minimalismus beim InstallationsumfangZusammenfassung einer LVM-Installation mit VerschlüsselungExperimentelle Optionen zeigen, wohin die Reise beim Installer geht
Snaps + Ubuntu = Snubuntu
Auf das Lamentieren über Snaps verzichte ich dieses Mal. Wer will, kann diesbezüglich meine älteren Ubuntu-Tests nachlesen. Für Version 24.04 hat Andreas Proschofsky in derstandard.at alles gesagt, was dazu zu sagen ist. Der größte Vorteil von Snaps für Canonical besteht darin, dass sich der Wartungsaufwand für Desktop-Programme massiv verringert: Die gleichen Snap-Pakete kommen in diversen Ubuntu-Versionen zum Einsatz.
Das App Center kann sich selbst nicht aktualisieren. Sie bekommen App-Center-Updates aber früher oder später als Hintergrund-Updates.
Netplan 1.0
Mit Ubuntu 24.04 hat Netplan den Sprung zu Version 1.0 gemacht. Größere Änderungen gab es keine mehr, die Versionsnummer ist eher ein Ausdruck dafür, dass Canonical die Software nun als stabil betrachtet. Wie bereits seit Ubuntu 23.10 ist Netplan das Backend zum NetworkManager. Netzwerkverbindungen werden nicht in /etc/NetworkManager/system-connections/ gespeichert wie auf den meisten anderen Distributionen, sondern als /etc/netplan/90-NM-*.yaml-Dateien (siehe auch meinen Bericht zu Ubuntu 23.10).
HEIC-Unterstützung
Ubuntu 24.04 kommt out-of-the-box mit HEIC/HEIF-Dateien zurecht, also mit am iPhone aufgenommenen Fotos. Vor einem dreiviertel Jahr hatte ich noch über entsprechende Probleme berichtet. Im Forum wurde damals kritisiert, dass meine Erwartungshaltung zu hoch sei. Aber, siehe da: Es geht!
Seit ich Ubuntu auf dem Desktop kaum mehr nutze, habe ich mehr Distanz gewonnen. So fällt mein Urteil etwas milder aus ;-)
Für Einsteiger ist Ubuntu eine feine Sache: In den meisten Fällen funktioniert Ubuntu ganz einfach. Das gilt sowohl für die Unterstützung der meisten Hardware (auch relativ moderne Geräte) als auch für die Installation von Programmen, die außerhalb der Linux-Welt entwickelt werden (VSCode, Android Studio, Spotify etc.). Was will man mehr? Ubuntu sieht zudem in der Default-Konfiguration optisch sehr ansprechend aus, aus meiner persönlichen Perspektive deutlich besser als die meisten anderen Distributionen. Ich bin auch ein Fan der ständig sichtbaren seitlichen Task-Leiste. Schließlich zählt Canonical zu den wenigen Firmen, die noch Geld in die Linux-Desktop-Weiterentwicklung investieren; dafür muss man dankbar sein.
Alle, die einen Widerwillen gegenüber Snap verspüren, sollten nicht über Ubuntu/Canonical schimpfen, sondern sich für eine der vielen Alternativen entscheiden: Arch Linux, Debian, Fedora oder Linux Mint. Wer nicht immer die neueste Version braucht und sich primär Langzeit-Support wünscht, kann auch AlmaLinux oder Rocky Linux in Erwägung ziehen.
Da ich einiges an Zeit in meine auf dem Raspberry Pi 4 laufende Nextcloud investiert habe, wäre es schade, für das aktuelle Raspberry Pi OS 12, alles noch einmal aufsetzen und konfigurieren zu müssen. Obwohl die Entwickler des Betriebssystems von einem Upgrade generell abraten, habe ich mich auf die Suche nach einer guten und funktionierenden Anleitung gemacht und bin auf den vielversprechenden Artikel „Raspberry Pi OS – Update von Bullseye (11) auf Bookworm (12)“ von Sascha Syring gestoßen.
Um das Ganze ausgiebig zu testen, habe ich das Upgrade zuerst auf einem Raspberry Pi 4 durchgeführt, auf dem ein Mumble-Server läuft, den unsere Community produktiv zum Erfahrungsaustausch nutzt. Nachdem dies alles problemlos funktioniert hat, habe ich mich an meinen Nextcloud-RasPi gewagt. Was es weiter zu beachten gab, darauf gehe ich am Ende des Artikels noch ein.
Systemupgrade
Bevor es los geht muss das System auf den aktuellsten Stand unter Raspberry Pi OS 11 Bullseye gebracht werden. Hierzu führt man Folgendes aus:
Danach werden die Paketquellen auf das neue System Bookworm angepasst. Hierzu öffnet man die /etc/apt/sources.list
sudo nano /etc/apt/sources.list
und kommentiert alle aktiven Quellen, indem man vor jede aktive Zeile eine Raute „#“ setzt. Danach fügt man die drei Zeilen
deb http://deb.debian.org/debian bookworm main contrib non-free non-free-firmware
deb http://security.debian.org/debian-security bookworm-security main contrib non-free non-free-firmware
deb http://deb.debian.org/debian bookworm-updates main contrib non-free non-free-firmware
am Anfang ein und speichert die Datei mit Ctr + o ab und verlässt dann den Editor mit Ctr + x.
Paketquellen
Das Gleiche Spiel wiederholt man mit den zusätzlichen Paketquellen.
sudo nano /etc/apt/sources.list.d/raspi.list
Hier wird nun folgende Zeile an den Anfang gesetzt:
deb http://archive.raspberrypi.org/debian/ bookworm main
Die Datei wird mit Ctr + o gespeichert und der Editor mit Ctr + x verlassen. Ist dies geschehen, können die Paketquellen neu eingelesen werden.
Zusätzliche Paketquellen
sudo apt update
Bootpartition
Nun kommt der kniffligste Teil. Die Bootpartition muss an die neuen Gegebenheiten angepasst werden. Dazu wird die alte Boot-Partition ausgehängt.
sudo umount /boot
Dann wird das neue Verzeichnis /boot/firmware erstellt.
sudo mkdir /boot/firmware
Jetzt bearbeitet man die Partitionstabelle:
sudo nano /etc/fstab
Hier wird der Eintrag der Bootpartition entsprechend eingetragen. Bei mir sieht das so aus:
Datei zum Einbinden der Datenträger
Die Datei wird wieder mit Ctr + o gespeichert und der Editor mit Ctr + x verlassen. Damit die Änderungen wirksam werden, wird systemd neu geladen
sudo systemctl daemon-reload
und die neue Boot-Partition gemountet.
sudo mount /boot/firmware
Bootloader und Kernel
Im Nachgang werden die aktuelle Firmware und der aktuelle Kernel für das Raspberry Pi OS 12 (Bookworm) installiert
Ist dies geschehen, müssen die Paketquellen nochmalig mit
sudo apt update
eingelesen werden.
Upgrade
Nun kann das eigentlich Upgrade durchgeführt werden. Hierbei stoppt der Vorgang bei den wichtigsten Konfigurationsdateien. Diese werden in der Regel alle beibehalten.
sudo apt full-upgrade
System aufräumen
Nun wird das System noch aufgeräumt.
sudo apt autoremove
sudo apt clean
Neustart
Nach dem Neustart
sudo reboot now
sollte nun das aktuelle Raspberry Pi OS 12 laufen. Das installierte Betriebssystem lässt man sich mit
Abschließend sei darauf hingewiesen, dass das Upgrade einige Gefahren in sich birgt. Bitte vorher unbedingt an ein Backup denken, was im Bedarfsfall wieder eingespielt werden kann!
Noch zu erwähnen
Eingangs des Artikels hatte ich erwähnt, dass es Weiteres zu beachten gibt. Durch das Upgrade wurden die Einstellungen des Dienstes zu meinem Turn-Server zurück gesetzt. Ein funktionierender Turn-Server ist wichtig, um reibungslosen Verlauf in Videokonferenzen zu ermöglichen.
Wer also wie ich eine Nextcloud auf dem Raspberry Pi installiert hat und bisher meinen Anleitungen gefolgt ist, muss den zeitverzögerten Start des Turnservers, wie im Artikel „coTurn zeitverzögert auf Raspberry Pi starten“ beschrieben, wieder neu konfigurieren. Dazu editiert man die Datei /lib/systemd/system/coturn.service:
sudo nano /lib/systemd/system/coturn.service
Nun fügt man den folgenden Eintrag unter [Service] ein und speichert die Änderung mit Ctlr + o.
ExecStartPre=/bin/sleep 30
Den Editor verlässt man dann wieder mit Ctrl + x. Durch den Eintrag wird nun eine Verzögerung von 30 Sekunden erzwungen. Mit
sudo service coturn restart
wird der Turnserver zeitverzögert neu gestartet. jetzt arbeitet coTURN nach dem nächsten Reboot des Raspberry Pi wie gewünscht.
Es gibt eine neue Version der speziellen Linux-Distribution Clonezilla Live. Neben diversen Bugfixes gibt es auch nennenswerte Verbesserungen. Clonezilla Live 3.1.2-22 basiert auf dem Debian Sid Repository mit Stand 8. April 2024. Der Linux-Kernel wurde bei der speziellen Linux-Distribution auf 6.7.9-2 aktualisiert. Mit an Bord ist auch ezio 2.0.11. Zudem gibt es ein neues Format für Meldungen, die an ocsmgrd gesendet werden. Um die Nachrichten zu trennen, benutzt das System ein Komma. Clonezilla-bezogenen Log-Dateien rotiert das Betriebssystem nun und empfängt […]
ChatGPT, Copilot & Co. verwenden Large Language Models (LLMs). Diese werden auf leistungsstarken Servern ausgeführt und als Cloud-Services angeboten. Das funktioniert wunderbar. Aber nicht jeder will Daten, Text und Code ständig in die Cloud hochladen. Kann man also — mit »gewöhnlicher« Hardware — LLMs auch lokal ausführen?
Tatsächlich ist das verblüffend einfach. Das Tool der Wahl heißt Ollama. Was Docker für Container ist, ist Ollama für LLMs!
Ollama kann ziemlich mühelos unter Linux, macOS und Windows installiert werden. Unter Windows und macOS starten Sie Ollama als Hintergrunddienst mit einer winzigen grafischen Oberfläche (im Prinzip nur ein Icon, das den Status anzeigt). Unter Linux richten Sie den Dienst mit systemctl ein:
systemctl enable --now ollama
Ollama läuft im Terminal, kann aber auch per API genutzt werden (z.B. zur Realisierung einer Web-Schnittstelle).
Ollama anwenden
Jetzt können Sie Ollama mit dem gleichnamigen Kommando im Terminal ausführen. Mit ollama run <llmname> installieren Sie eines der öffentlich verfügbaren Sprachmodelle (mehr dazu im nächsten Abschnitt) und können dann im Textmodus Kommandos ausführen:
ollama run llama2
>>> I need a regex to verify a date in US format. Can you help?
Of course! To match a date in the format of "MM/DD/YYYY" (month-day-year)
or "MM/DD/YYYY HH:MM AM/PM", you can use the following regular expression:
\b(\d{1,2}/\d{1,2}/\d{4})|(\d{1,2}/\d{1,2}/\d{4} \d{0,2})?\b
Here's a breakdown of how this regex works:
* \b: Matches a word boundary (the start or end of a word) to ensure
we're matching the entire date field.
* (\d{1,2}/\d{1,2}/\d{4}): Matches the month/day/year format. The
(\d{1,2}) captures the month and day as individual digits (0-2
digits for the month and 1-2 digits for the day). The / separates
the date components.
* |: Or, used to match the alternative format.
* (\d{1,2}/\d{1,2}/\d{4} \d{0,2})?: Matches the month/day/year with
time format. The (\d{1,2}) captures the month and day as individual
digits (0-2 digits for the month and 1-2 digits for the day). The /
separates the date components. The \d{0,2} matches the time component
(0-2 digits representing the hour and minute).
* \b: Matches a word boundary to ensure we're matching the entire date field again.
Note that this regex will match both US and international dates in the
"MM/DD/YYYY" format, as well as dates in the "MM/DD/YYYY HH:MM AM/PM"
format. If you need a more specific format (e.g., only US dates),
feel free to modify the regex accordingly.
Manche Sprachmodelle können auch Deutsch (nochmals llama2), wenngleich die sprachliche Qualität mitunter nur mittelmäßig ist.
>>> Was ist der Dopplereffekt?
Der Dopplereffekt ist ein physikalischer Effekt, der durch die Beugung von
Lichtwellen verursacht wird, wenn diese durch eine mediummässige Materie
passt. In einer bestimmten Umgebung oder Situation kann das Licht, das durch
eine bestimmte Fläche oder ein Objekt passt, sich "verlangsamen" und eine
Dopplereffekthelligkeit erzeugen.
Der Dopplereffekt ist ein spezifischer Effekt, der auf der Beugung von
Lichtwellen basiert. Wenn Licht durch ein Medium passt, wird es durch die Faser
des Mediums beugt und umgestaltet. Die Intensität des Lichts, das durch ein
Medium passt, kann sich durch den Dopplereffekt ändern.
Im Alltag können wir den Dopplereffekt beispielsweise bei der Anähnlichkeit von
Objekten in einer Ferne sehen. Wenn ein Auto oder eine andere Objekte in der
Ferne auf uns zukommt, wird es durch die Luft des Raumes beugt und erscheint
größer und weiter weg, als es tatsächlich ist.
Der Dopplereffekt kann auch in anderen Bereichen wie der Optik, Elektrotechnik
oder Medizin verwendet werden. Zum Beispiel können Dopplereffekte in der
Medizin verwendet werden, um die Blutungen in einem Körperteil zu bestimmen.
Es gibt verschiedene Arten von Dopplereffekten, darunter:
* LichtDopplereffekt: Der Effekt, den das Licht erzeugt, wenn es durch ein
Medium passt.
* ZeitDopplereffekt: Der Effekt, den die Zeit erzeugt, wenn sie durch ein
Objekt oder eine bestimmte Umgebung verändert wird.
* Räumliche Dopplereffekte: Der Effekt, den die räumliche Position von Objekten
oder der Standort eines Beobachters auf die Erscheinung des Dopplereffekts
ausübt.
Insgesamt ist der Dopplereffekt ein interessanter und wichtiger
physikalischerEffekt, der in vielen Bereichen der Wissenschaft und Technologie
Verwendung findet.
Ollama stellt seine Funktionen über eine REST-API zur Verfügung und kann somit lokal auch durch eigene Scripts und Editor-Plugins (z.B. Continue für VSCode) genutzt werden. Natürlich gibt es auch Module/Bibliotheken für diverse Sprachen, z.B. für Python.
Öffentliche Sprachmodelle
Die bekanntesten Sprachmodelle sind zur Zeit GPT-3.5 und GPT-4. Sie wurden von der Firma openAI entwickelt und sind die Basis für ChatGPT. Leider sind die aktellen GPT-Versionen nicht öffentlich erhältlich.
Zum Glück gibt es aber eine Menge anderer Sprachmodelle, die wie Open-Source-Software kostenlos heruntergeladen und von Ollama ausgeführt werden können. Gut geeignet für erste Experimente sind llama2, gemma und mistral. Einen Überblick über wichtige, Ollama-kompatible LLMs finden Sie hier:
Viele Sprachmodelle stehen in unterschiedlicher Größe zur Verfügung. Die Größe wird in der Anzahl der Parameter gemessen (7b = 7 billions = 7 Milliarden). Die Formel »größer ist besser« gilt dabei nur mit Einschränkungen. Mehr Parameter versprechen eine bessere Qualität, das Modell ist dann aber langsamer in der Ausführung und braucht mehr Platz im Arbeitsspeicher. Die folgende Tabelle gilt für llama2, einem frei verfügbaren Sprachmodell der Firma Meta (Facebook & Co.).
Wenn Sie llama2:70b ausführen wollen, sollte Ihr Rechner über 64 GB RAM verfügen.
Update: Quasi zugleich mit diesem Artikel wurde llama3 fertiggestellt (Details und noch mehr Details). Aktuell gibt es zwei Größen, 8b (5 GB) und 80b (40 GB).
ollama run llava:13b
>>> describe this image: raspap3.jpg
Added image 'raspap3.jpg'
The image shows a small, single-board computer like the Raspberry Pi 3, which is
known for its versatility and uses in various projects. It appears to be connected
to an external device via what looks like a USB cable with a small, rectangular
module on the end, possibly an adapter or expansion board. This connection
suggests that the device might be used for communication purposes, such as
connecting it to a network using an antenna. The antenna is visible in the
upper part of the image and is connected to the single-board computer by a
cable, indicating that this setup could be used for Wi-Fi or other wireless
connectivity.
The environment seems to be an indoor setting with wooden flooring, providing a
simple and clean background for the electronic components. There's also a label
on the antenna, though it's not clear enough to read in this image. The setup
is likely part of an electronics project or demonstration, given the simplicity
and focus on the connectivity equipment rather than any additional peripherals
or complex arrangements.
Eigentlich eine ganz passable Beschreibung für das folgende Bild!
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Praktische Erfahrungen, Qualität
Es ist erstaunlich, wie rasch die Qualität kommerzieller KI-Tools — gerade noch als IT-Wunder gefeiert — zur Selbstverständlichkeit wird. Lokale LLMs funktionieren auch gut, können aber in vielerlei Hinsicht (noch) nicht mit den kommerziellen Modellen mithalten. Dafür gibt es mehrere Gründe:
Bei kommerziellen Modellen fließt mehr Geld und Mühe in das Fine-Tuning.
Auch das Budget für das Trainingsmaterial ist größer.
Kommerzielle Modelle sind oft größer und laufen auf besserer Hardware. Das eigene Notebook ist mit der Ausführung (ganz) großer Sprachmodelle überfordert. (Siehe auch den folgenden Abschnitt.)
Wodurch zeichnet sich die geringere Qualität im Vergleich zu ChatGPT oder Copilot aus?
Die Antworten sind weniger schlüssig und sprachlich nicht so ausgefeilt.
Wenn Sie LLMs zum Coding verwenden, passt der produzierte Code oft weniger gut zur Fragestellung.
Die Antworten werden je nach Hardware viel langsamer generiert. Der Rechner läuft dabei heiß.
Die meisten von mir getesteten Modelle funktionieren nur dann zufriedenstellend, wenn ich in englischer Sprache mit ihnen kommuniziere.
Die optimale Hardware für Ollama
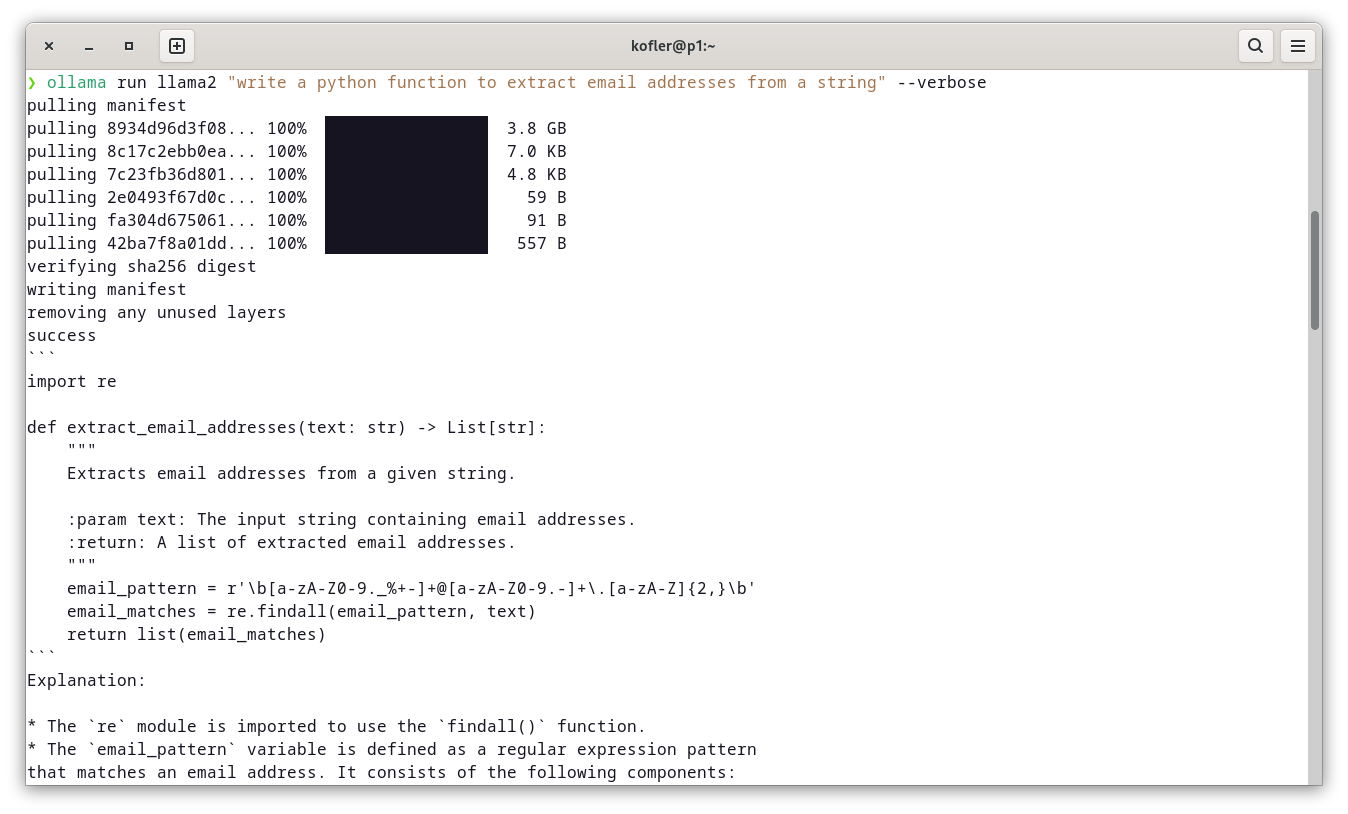
Als Minimal-Benchmark haben Bernd Öggl und ich das folgende Ollama-Kommando auf diversen Rechnern ausgeführt:
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
Die Ergebnisse dieses Kommandos sehen immer ziemlich ähnlich aus, aber die erforderliche Wartezeit variiert beträchtlich!
Grundsätzlich kann Ollama GPUs nutzen (siehe auch hier und hier). Im Detail hängt es wie immer vom spezifischen GPU-Modell, von den installierten Treibern usw. ab. Wenn Sie unter Linux mit einer NVIDIA-Grafikkarte arbeiten, müssen Sie CUDA-Treiber installieren und ollama-cuda ausführen. Beachten Sie auch, dass das Sprachmodell im Speicher der Grafikkarte Platz finden muss, damit die GPU genutzt werden kann.
Apple-Rechner mit M1/M2/M3-CPUs sind für Ollama aus zweierlei Gründen ideal: Es gibt keinen Ärger mit Treibern, und der gemeinsame Speicher für CPU/GPU ist vorteilhaft. Die GPUs verfügen über so viel RAM wie der Rechner. Außerdem bleibt der Rechner lautlos, wenn Sie Ollama nicht ununterbrochen mit neuen Abfragen beschäftigen. Allerdings verlangt Apple leider vollkommen absurde Preise für RAM-Erweiterungen.
Zum Schluss noch eine Bitte: Falls Sie Ollama auf Ihrem Rechner installiert haben, posten Sie bitte Ihre Ergebnisse des Kommandos ollama run llama2 "write a python function to extract email addresses from a string" --verbose im Forum!