AI Act: Online-Tool und Leitfaden zum KI-Einsatz in Unternehmen
12. November 2024 um 10:06
Rechtliche Unsicherheiten sind für 40 Prozent der Unternehmen in Deutschland ein Hemmnis für den KI-Einsatz.
Rechtliche Unsicherheiten sind für 40 Prozent der Unternehmen in Deutschland ein Hemmnis für den KI-Einsatz.
OpenAI hat analysiert, wie ChatGPT auf der Grundlage des Namens eines Benutzers reagiert und ob sich das Modell davon beeinflussen lässt.
Der EU AI Act ist seit Anfang August offiziell in Kraft und muss nun in den EU-Mitgliedsländern umgesetzt werden.
OpenAI hat einen geschlossenen Test für SearchGPT gestartet, einen Prototyp für neue KI-gestützte Suchfunktionen.
OpenAI hat GPT-4o mini angekündigt, den Nachfolger von GPT-3.5 Turbo. Der Anbieter bezeichnet GPT-4o mini als günstiger und schneller.
Dies ist die Fortsetzung von „Mit InstructLab zu Large Language Models beitragen“. Hier beschreibe ich, wie es nach dem Training weitergeht.
Das Training auf einer virtuellen Maschine mit Fedora 40 Server, 10 CPU-Threads und 32 GB RAM dauerte 180 Std. 44 Min. 7 Sek. Ich halte an dieser Stelle fest, ohne GPU-Beschleunigung fehlt es mir persönlich an Geduld. So macht das Training keinen Spaß.
Nach dem Training mit ilab train findet man ein brandneues LLM auf dem eigenen System:
(venv) tronde@instructlab:~/src/instructlab$ ls -ltrh models
total 18G
-rw-r--r--. 1 tronde tronde 4.1G May 28 20:34 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r--. 1 tronde tronde 14G Jun 6 12:07 ggml-model-f16.ggufDen Chat mit dem LLM starte ich mit dem Befehl ilab chat -m models/ggml-model-f16.gguf. Das folgende Bild zeigt zwei Chats mit jeweils unterschiedlichem Ergebnis:
Schade, das hat nicht so funktioniert, wie ich mir das vorgestellt habe. Es kommt weiterhin zu KI-Halluzinationen und nur gelegentlich gesteht das LLM seine Unkenntnis bzw. seine Unsicherheit ein.
Für mich sind damit 180 Stunden Rechenzeit verschwendet. Ich werde bis auf Weiteres keine Trainings ohne Beschleuniger-Karten mehr durchführen. Jedoch werde ich mir von Zeit zu Zeit aktualisierte Releases der verfügbaren Modelle herunterladen und diesen Fragen stellen, deren Antworten ich bereits kenne.
Wenn sich mir die Gelegenheit bietet, diesen Versuch auf einem Rechner mit entsprechender GPU-Hardware zu wiederholen, werde ich die Erkenntnisse hier im Blog teilen.
Der Wandel in der Technologielandschaft erfordere neue Bug Bounty-Programme, um das GenAI-Ökosystem voranzutreiben und Schwachstellen in den Modellen selbst zu beheben, teilt Mozilla mit.
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Die Begriffe Künstliche Intelligenz (KI) oder englisch artificial intelligence (AI) werden in diesem Text synonym verwendet und zumeist einheitlich durch KI abgekürzt.
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
der kann nun teilhaben und ausgewählte LLMs lokal auf seinem Endgerät ausführen, testen und verbessern. Für eine ausführliche Beschreibung siehe:
Informationen zu Open Source LLMs und Basismodellen für InstructLab bieten diese Links:
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Für meine ersten Versuche nutze ich mein Lenovo ThinkPad T14s (AMD) in der Ausstattung von 2021. Aktuell installiert ist Fedora 40 Workstation, welches zu den getesteten Betriebssystemen von InstructLab zählt.
Für die Einrichtung halte ich mich an den Getting Started Guide. Es sind folgende Befehle auszuführen, bis das erste LLM gestartet werden kann:
sudo dnf install gcc-c++ gcc make pip python3 python3-devel python3-GitPython
mkdir instructlab
cd instructlab
python3 -m venv --upgrade-deps venv
source venv/bin/activate
pip cache remove llama_cpp_python
pip install git+https://github.com/instructlab/instructlab.git@stable --extra-index-url=https://download.pytorch.org/whl/cpu
eval "$(_ILAB_COMPLETE=bash_source ilab)"
ilab init
ilab download
ilab serveDer lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
merlinite-7b-lab-Q4_K_MWie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Exkurs: Die Studie Energieverbrauch Index-basierter und KI-basierter Websuchmaschinen gibt einen interessanten Einblick in den Ressourcenverbrauch. Leider war ich nicht in der Lage, diese Studie als PDF aufzutreiben.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Quelle: https://de.wikipedia.org/wiki/Halluzination_(K%C3%BCnstliche_Intelligenz)
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
Die Antworten des LLM enthalten folgende Fehler:
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
README.md, ohne .gitignore und LICENCEunibi.md hinzumkdir -p university/germany/bielefeld_universityqna.yaml und eine attribution.txt Dateiilab diff aus, um die Daten zu validierenDer folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
Dazu wird der Befehl ilab generate aufgerufen, während sich das LLM noch in Ausführung befindet. Dieser endet bei mir erfolgreich mit folgendem Ergebnis:
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonlZur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.
Der OpenAI-Vorstand hat einen Sicherheitsausschuss gebildet. Außerdem lässt der KI-Experte durchblicken, dass er am nächsten Modell arbeitet.
Die Online-Community Reddit und der KI-Experte OpenAI haben eine Partnerschaft angekündigt. Im Zuge der Partnerschaft sollen Reddit-Inhalte in ChatGPT einfließen.
OpenAI hat GPT-4o vorgestellt. Das “o” hinter der 4 steht dabei für “omni”.
Beim Red Hat Summit in Denver hat Red Hat Erweiterungen für OpenShift AI angekündigt, einer offenen hybriden Plattform für Künstliche Intelligenz (KI) und Maschinelles Lernen (ML), die auf Red…
Die in Wien beheimatete Datenschutzorganisation Noyb, gegründet vom Datenschutzaktivisten Max Schrems, fordert die österreichische Datenschutzbehörde (DSB) zu einer Untersuchung der…
Das von Elon Musk gegründete Unternehmen xAI hat die Gewichte des Basismodells und die Netzwerkarchitektur seines KI-Modell Grok-1 unter einer Apache Lizenz veröffentlicht.
Die Entwicklung von KI muss laut Mozilla dezentraler werden. Deshalb investierte Mozilla Ventures kürzlich in das Hamburger KI-Startup Flower Labs.
ChatGPT-Anbieter OpenAI hat mit der Software Sora eine KI zur Erzeugung von Videos aus Textvorgaben vorgestellt.
OpenAI testet derzeit eine Memory-Funktion für ChatGPT.
Im Mai des vergangenen Jahres hatte Mozilla die Übernahme von Fakespot bekannt gegeben, einem Anbieter, der vor gefälschten Bewertungen beim Online-Shopping schützen soll. Firefox 122 wird die Erkennung unglaubwürdiger Produktbewertungen auf amazon.de unterstützen.
Bei Fakespot handelt es sich um einen Anbieter, welcher Künstliche Intelligenz nutzt, um gefälschte Rezensionen auf Shopping-Plattformen wie Amazon zu erkennen. Nach eigenen Angaben nutzen derzeit über eine Million Menschen Fakespot. Anfang Mai hatte Mozilla bekannt gegeben, das Unternehmen Fakespot vollständig und inklusive seiner 13 Mitarbeiter übernommen zu haben.
Seit der Übernahme von Fakespot arbeitet Mozilla an der nativen Integration einer Funktion zur Bewertung von Produkt-Reviews in Firefox. Im August 2023 hatte ich eine erste Vorschau auf das neue Firefox-Feature gegeben.
Wenn Mozilla kommende Woche Firefox 122 veröffentlichen wird, wird die Fakespot-Integration zwar noch nicht standardmäßig aktiviert sein, kann aber über about:config aktiviert werden, indem der Schalter browser.shopping.experience2023.enabled auf true gesetzt wird.
Dies funktioniert zwar bereits im aktuellen Firefox 121, allerdings werden ausschließlich amazon.com, walmart.com sowie bestbuy.com unterstützt. Für Nutzer in Deutschland, Österreich und der Schweiz sehr viel relevanter ist die Version von Amazon für den deutschsprachigen Raum, welche unter amazon.de aufrufbar ist. Diese wird, ebenso wie die französische Version unter amazon.fr, ab Firefox 122 unterstützt.
Der Nutzung dieser Funktion muss zunächst explizit durch den Benutzer zugestimmt werden. Standardmäßig erfolgt keine Anzeige von Review-Bewertungen.
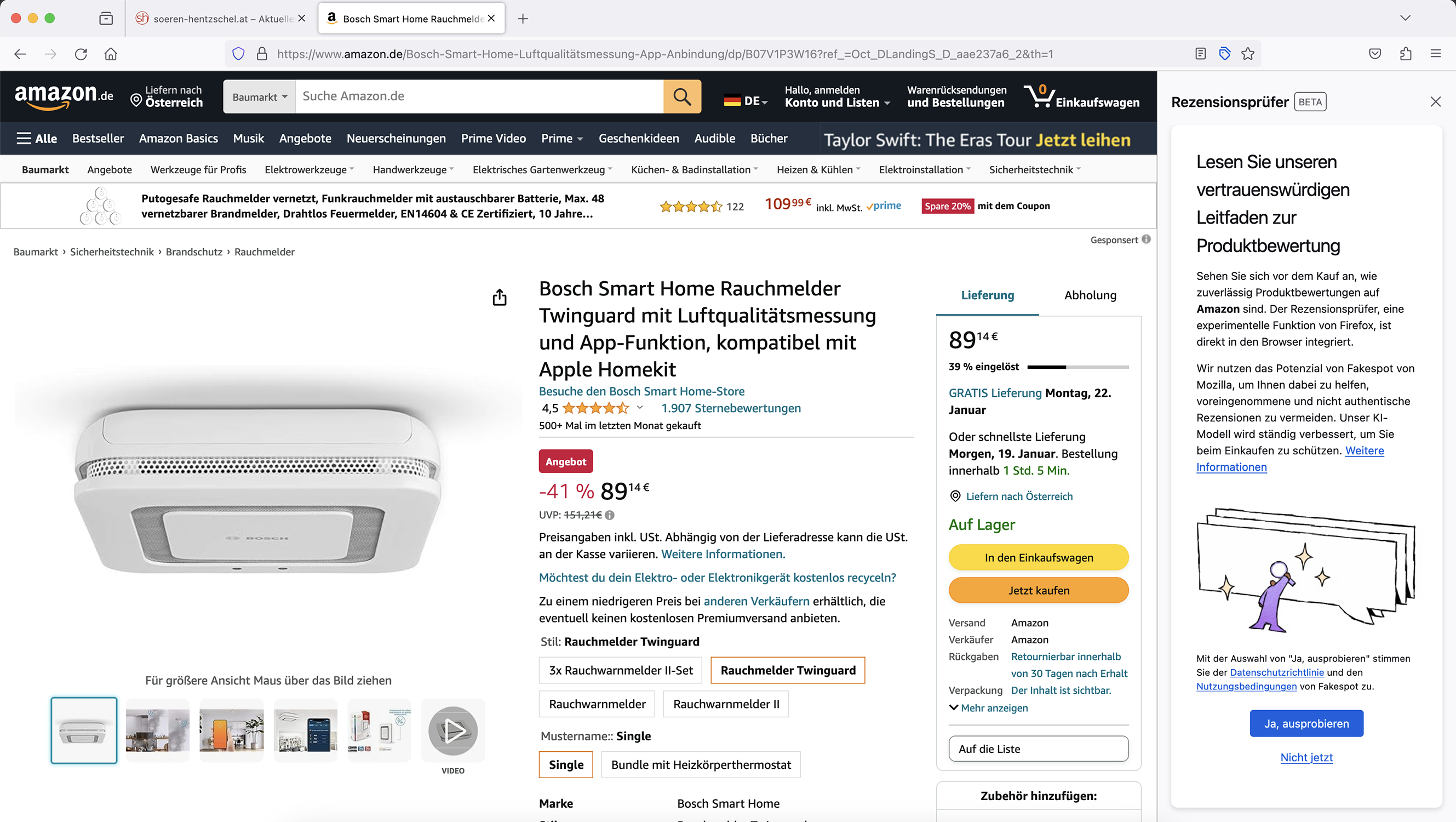
Bei Aufruf der Produktseite zeigt Firefox die Glaubwürdigkeit der abgegebenen Nutzer-Bewertungen in Form einer Schulnote nach amerikanischem System („A“ ist die beste, „F“ die schlechteste Note) an. Darunter wird die bereinigte Durchschnitts-Bewertung des jeweiligen Produkts angezeigt, sprich der Durchschnitt aller Bewertungen abzüglich derer, die nach Einschätzung von Fakespot keine echten Bewertungen sind. Erkennt Fakespot, dass die Bewertung nicht mehr auf dem neuesten Stand ist, bietet Firefox die Möglichkeit an, die Analyse neu durchführen zu lassen.
Schließlich folgt noch eine Anzeige aktueller Highlights aus den Bewertungen, eingeteilt nach Kategorien wie Qualität und Preis. Dabei werden nur die glaubwürdigen Bewertungen der letzten 80 Tage als Grundlage genommen.
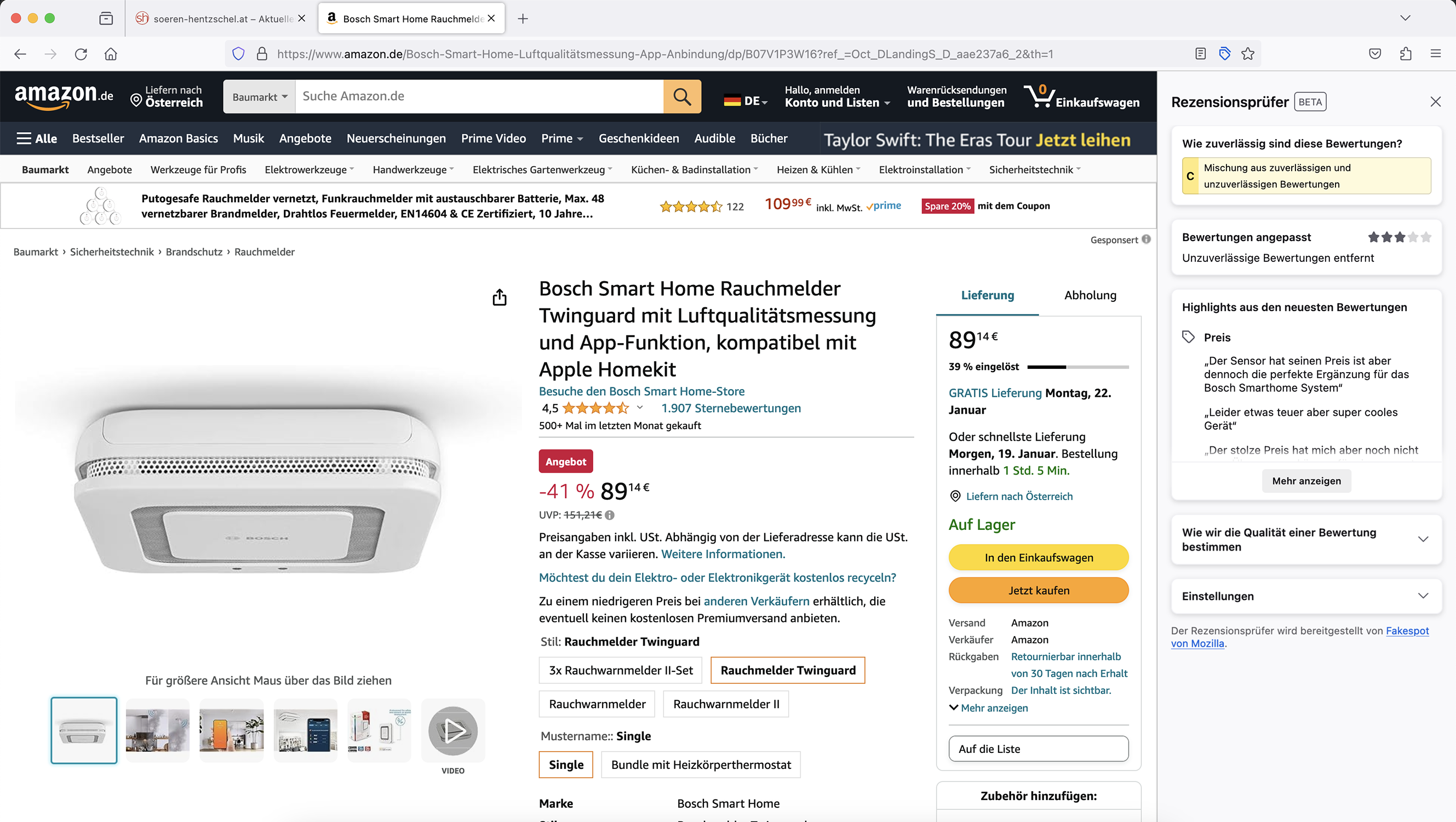
Das Bewerben eines alternativen Produkts aus der gleichen Kategorie, welches eine gute Bewertung für die Glaubwürdigkeit der Produktbewertungen erhalten hat, ist für Deutschland und Frankreich aktuell nicht geplant.
Der Beitrag Firefox 122 unterstützt Erkennung unglaubwürdiger Produktbewertungen auf amazon.de erschien zuerst auf soeren-hentzschel.at.
OpenAI, das Unternehmen hinter ChatGPT hat angekündigt, für die im Jahr 2024 anstehenden Wahlen, Tools und Richtlinien zu veröffentlichen, um Missbrauch ihrer KI-Werkzeuge möglichst zu verhindern…
Es ist der 31.12.2023 und somit wird es wieder Zeit für den traditionellen Jahresrückblick. Dieses Jahr dominierten zwei Buchstaben: KI. Die Veröffentlichung von ChatGPT erfolgte zwar kurz vor 2023, in diesem Jahr wurden allerdings die Auswirkungen sichtbar. Ich muss sagen, dass es lange kein Werkzeug gab, an dem ich so viel Experimentierfreude erleben konnte.
Dabei ist die Mensch-Maschine-Schnittstelle besonders spannend. Die natürlichsprachliche Interaktion verbessert nicht nur die Zugänglichkeit, sondern erhöht auch die Interoperabilität: Das Werkzeug kann nicht nur die Aufgabe verstehen, sondern die Ergebnisse in der gewünschten Form darstellen. Schreibe ich eine Software, erfüllt sie nur einen Zweck. ChatGPT kann besonders einfach an neue Aufgabenbereiche angepasst werden. Man muss nicht einmal im klassischen Sinne "programmieren". Somit wird die Arbeit mit dem Computer auf eine ganz neue Stufe gehoben.
Auf die technische Ebene möchte ich heute gar nicht direkt eingehen, das haben wir das Jahr schon im Detail in diesem Blog ergründet. Diskussionen über Technik und Innovationen stellen nur eine Augenblickaufnahme dar. Im Rückblick auf eine größere Zeitepisode wie ein mindestens Jahr werden allerdings gesellschaftliche Entwicklungen deutlich. Und hier gab es einiges zu beobachten.
ChatGPT hat eine große Nutzerbasis erreicht, die zumindest ein Mal das Werkzeug ausprobiert hat. Im deutschsprachigen Raum, der sonst sich so "datenschutzorientiert" und innovationskritisch gibt, ist das schon bemerkenswert. Diskussionen über Datenschutz waren zweitrangig, die Menschen waren von der Innovation durch das Werkzeug fasziniert. Natürlich kam über das Jahr die Erkenntnis, dass in der aktuellen Form die Technologie je nach Branche noch nicht weit genug ausgereift ist, trotzdem wollte jeder einmal schauen, was es damit auf sich hat und ob es den Alltag erleichtern kann.
Und doch hat OpenAIs Werkzeug in meinen Augen ein wenig den Blick verengt: Durch das schnelle Wachstum wurde ChatGPT zum Sinnbild von "KI" und hat Ängste geschürt. Denn einerseits will jeder, dass KI ihm das Leben einfacher macht, jedoch nicht, dass andere mit KI ihm seine Lebenssituation verschlechtern bzw. ihn zu einem Umdenken zwingen. Ein Zeitungsredakteur möchte gerne KI für die Verbesserung seiner Texte einsetzen, fürchtet jedoch um seine Jobzukunft, wenn andere ihn durch automatische Generierung ganzer Zeitungsbeiträge drohen, überflüssig zu machen.
Dieser Umstand hat die Diskussion rund um den europäischen AI Act noch einmal deutlich angeheizt. An Large Language Models wurden auf einmal hohe Anforderungen gestellt, um subjektiven Ängsten entgegenzutreten. Dann war man sich aufgrund der Innovationsgeschwindigkeit auf einmal nicht sicher, ob es jetzt schon Zeit für eine starre Regulierung ist. Und schlussendlich zeichnet sich eine politische Entwicklung ab, jetzt lieber irgendeinen Kompromiss als später eine gut ausgearbeitete Fassung präsentieren zu können. Wie der AI Act kommt, werden wir dann im nächsten Jahr sehen.
Das alles war aber nicht das, was dieses Jahr in meinen Augen besonders gemacht hat. Es ist etwas anderes: die neue Rolle von Open Source.
Anfang des Jahres sah es so aus, als setzt eine besondere Kommerzialisierung in der Technikwelt ein: die Kommerzialisierung von Basistechnologie. Über die verschiedenen Jahre haben wir gesehen, dass es für verschiedene Produkte in der IT proprietäre und freie Lösungen gibt. Zwar sind erstere gerne technologisch mitunter überlegen, da die Profitorientierung Anreize setzt, für bestimmte Anwendungszwecke besonders passende Lösungen zu entwickeln. Kostet eine Software Geld, kann der Hersteller Programmierer anstellen, die auch die Features entwickeln, die man ungern freiwillig programmiert. Auf diese Weise entstehen runde Produkte für einen Anwendungszweck.
Freie bzw. zumindest quelloffene Software ermöglicht zumindest aber der Öffentlichkeit, einen Blick in die Funktionsweise zu werfen, um zu sehen, wie etwas funktioniert. Das ist die Grundlage, um Technologie zu verbessern.
In der Welt des maschinellen Lernens entstand allerdings durch die benötigte Compute Power eine hohe Eintrittshürde. Es sah so aus, als wären die Large Language Models nur noch großen Konzernen bzw. gut finanzierten Start-ups vorbehalten, die sich die Trainingspower leisten können. Während die Vorgängersysteme wie GPT-2 noch öffentlich zugänglich waren, wurden gerade Systeme wie GPT-3 und GPT-4, bei denen das Produkt endlich richtig nutzbar wurde, zurückgehalten.
Im Laufe des Frühlings habe ich allerdings vermutet, dass freie Modelle die proprietären outperformen können, weil die öffentliche Zugänglichkeit die Chance eröffnet, dass Experten weltweit mit ihren eigenen Erfahrungen, Eindrücken und ihrem Domänenwissen eine Technologie entwickeln können, die verschlossenen Produkten überlegen ist.
Überraschend war, dass es gerade das AI-Team von Facebook war, das den Stein mit LLaMA ins Rollen gebracht hat. Es folgten zahlreiche weitere Abkömmlinge, Weiterentwicklungen oder gänzliche Alternativansätze, die eines gemein hatten: ihr Kern mit den Gewichten war zugänglich.
Wie es aussieht, könnte die Dominanz proprietärer Systeme gebrochen werden, sodass auch die Möglichkeit gewahrt bleibt, einen wissenschaftlichen Diskurs zu führen. Technische Berichte proprietärer Modelle sind zwar nett, aber die Forschungsarbeiten, in denen reproduzierbare Fortschritte aufgezeigt werden, bringen uns tatsächlich eher voran.
Um die rasante Entwicklung im Frühling, als scheinbar jedes KI-Team großer Konzerne und Forschungseinrichtungen alle in der Schublade angesammelten LLM-Projekte zu veröffentlichen versuchte, im Auge zu behalten, habe ich die LLM-Timeline entwickelt. Sie wurde vor einigen Tagen wieder aktualisiert und zeigt besonders, wie sehr LLaMA als eines der ersten praktisch verwertbaren Modelle mit offenen Gewichten die Entwicklung beeinflusst hat.
Ein weiteres Projekt, das ich in der Zusammenarbeit mit der Fachhochschule Kiel realisiert habe, war der Podcast KI & Kultur, der generative Modelle aus der Perspektive Kulturschaffender beleuchtet hat.
Das Jahr hat den 70 Jahre alten Begriff der KI wieder mal in die Massen gebracht. Dabei wird ChatGPT dem Begriff eigentlich gar nicht gerecht, weil es streng genommen relativ dumm ist. Insbesondere beschränkt es die Zustandsfähigkeit nur auf eine Prompt und lernt nicht, während es denkt. Training und Inferenz sind entkoppelt.
Und trotzdem ist es diese natürlichsprachliche Schnittstelle, die es so faszinierend macht. Allerdings ist auch diese Erkenntnis nicht neu und wurde schon vor 55 Jahren mit ELIZA diskutiert.
Erfreulich ist es, dass "Open Source" nicht mehr nur bei Software, sondern in neuen Technologien Anwendung findet. Der Gedanke, dass Technologie zugänglich sein muss, kann so erhalten werden. Und dass es hilft, wenn Wissenschaftler auf der ganzen Welt mit ihrem Wissen beitragen können, sehen wir weiterhin auch in dieser Thematik.
LLMs ermöglichen es, dass wir uns endlich wieder der Mensch-Maschine-Schnittstelle widmen können, die Technologie nutzbar macht. Menschen wollen, dass Technik das Leben einfacher macht. Die bisher begrenzte Rechenleistung hat uns zu Hilfsmitteln wie Displays, Touchscreens oder Tastaturen gezwungen. In den nächsten Jahren können wir schauen, wie wir das überwinden können, um endlich nutzbare Computer zu erhalten, die wirklich was bringen.
Und so ist es schon fast ironisch, dass die naheliegendste Technologie, die in den 2010er-Jahre euphorisch gefeiert wurde, von den LLMs noch wenig profitiert hat: Sprachassistenten. Sie sind überwiegend noch genau so begrenzt und unflexibel wie früher. Hier gibt es einiges zu tun.
Abschließend möchte ich meinen Lesern des Blogs und Zuhörern des Podcasts Risikozone sowie KI & Kultur danken, dass ihr den Blog lest, den Podcast hört und regelmäßig Feedback gebt. Ich wünsche euch einen guten Rutsch in das neue Jahr 2024.
Im nächsten Jahr werden wir wieder gemeinsam neue Technologien ergründen und die aktuellen Nachrichten diskutieren. Es wird auch mehr um Grundlagen und Visualisierungen gehen, hierauf freue ich mich schon besonders!
Viel Glück, Gesundheit und Erfolg!
Der Kampf um Anteile an den sich rasant entwickelnden KI-Entwicklungen ist in vollem Gange. Mozilla möchte dem mit offenen Modellen und lokaler KI entgegenwirken.
Das Interessante an den Open-Source-Modellen ist ja, dass sie das umsetzen, was bei den proprietären Modellen gemunkelt wird, aber nicht nachgewiesen werden kann. Mein aktuelles Highlight: Mixture of Experts (MoE).
Im Sommer kamen Behauptungen auf, dass OpenAIs GPT-4 eigentlich aus acht kleineren Modellen besteht, die zusammengeschaltet werden. Dieses Verfahren nennt man auch Ensemble Learning.
Das klassische Beispiel dafür ist Random Forest, wo mehrere Decision Trees parallel zu so einem Ensemble zusammengeschaltet werden. Soll das Ensemble dann eine Klassifikation vornehmen, nimmt jeder Decision Tree mit seinen eigenen Gewichten die Klassifikation vor. Anschließend entscheidet die Mehrheit der Decision Trees im Ensemble, wie das Gesamtmodell nun klassifizieren soll. Analog würde auch eine Regression umgesetzt werden können, als Aggregierungsfunktion kommt dann statt Mehrheitswahl eben sowas wie Mittelwert o. ä. zum Einsatz. Das besondere ist, dass mit Random Forest üblicherweise bessere Vorhersagen erzielt werden können, als mit einem einfachen Decision Tree.
MoE funktioniert in den groben Zügen ähnlich. Es gibt "Experten" (ähnlich wie die Decision Trees bei Random Forest), die dann gewichtet aggregiert werden (Gating). Die Technik ist eigentlich recht alt und viele waren überrascht, dass OpenAI genau so etwas einsetzen soll.
Umso besser, dass Mistral als das europäische LLM-Startup sich der Sache angenommen hat. Anfang des Wochenendes schwirrte schon ein Torrent durchs Netz, heute gibt es dann auch eine offizielle Pressemitteilung zu Mixtral 8x7B. Hierbei handelt es sich um ein "Sparse Mixture of Experts"-Modell (SMoE). Die Gewichte sind wieder offen und unter der Apache 2.0 lizenziert.
Kurz zu den Eckdaten: 32k Token Kontextlänge können verarbeitet werden. Dabei spricht das Modell Englisch, Französisch, Italienisch, Deutsch und Spanisch und wurde auch auf Codegenerierung optimiert. Fine-tuning ist ebenfalls möglich - so wurde bereits eine instruction-following-Variante trainiert.
Im Vergleich zu Llama 2 70B soll es in einer Vielzahl von Benchmarks bessere Ergebnisse abliefern und dabei schneller arbeiten. Die einzelnen Ergebnisse können der Pressemitteilung entnommen werden.
Einen klassischen Downloadlink konnte ich auf die schnelle nicht finden, das Twitter-Profil verweist nur auf die Torrents. Parallel kündigt das Start-up an, einen eigenen Dienst für API-Endpoints anzubieten, sodass ein Deployment auf eigener Infrastruktur nicht mehr zwangsläufig notwendig ist.
Die Ereignisse um ChatGPT-Erfinder Open-AI vom Wochenende machen eines deutlich: Microsoft ist jetzt mehr als zuvor das Schwergewicht bei der Entwicklung.
Das Wettrennen um die Technologieführerschaft der Large Language Models lief größtenteils bisher auf dem amerikanischen Kontinent ab. OpenAI hat das Produkt populär gemacht und Meta AI veröffentlicht den Konkurrenten mit den freien Gewichten. Mit Falcon 40B und 180B gab es allerdings schon Konkurrenz aus Abu Dhabi, zumal mit der gewählten Apache-2.0-Lizenz ein deutlich offenerer Ansatz gewählt wurde.
Als kurz vor dem Sommer das Start-up Mistral aus Paris 105 Millionen Euro eingesammelt hat, waren die Medienberichte zumindest leicht kritisch, da nicht nur das Start-up mit einer gigantischen Finanzierungssumme aus der Taufe gehoben wurde, sondern das Produkt auch noch gar nicht fertig war. Aus der LLM-Sicht ist dies allerdings verständlich, da solche großen Summen schlicht die Voraussetzung sind, um an den Start zu gehen. Schließlich benötigt Training leistungsfähige GPUs und die sind teuer.
Mit dem veröffentlichten Modell Mistral 7B zeigt das Start-up, was es kann. Dabei handelt es sich um ein LLM, das über 7 Mrd. Parameter verfügt und Llama 2 13B in allen und LLaMa 34B in vielen üblichen Benchmarks überbietet: Commonsense Reasoning, World Knowledge, Reading Comprehension, Math, Code, Popular aggregated results. In Codingaufgaben kann die Leistung von CodeLlama 7B erreicht werden.
Das Beste am LLM ist, dass es unter der Apache-2.0-Lizenz steht. Als klassische Open-Source-Lizenz gibt es nicht nur den Forschern und Entwicklern viele Freiheiten, sondern auch eine gewisse Lizenzsicherheit, dass das Modell in freier Software verwendet werden kann.
Ich hatte bereits vor Wochen geschrieben, dass freie Modelle eine gute Möglichkeit sind, um sich als neuer Player auf dem Markt zu profilieren. Diesen Plan verfolgt nicht nur Falcon, sondern nun auch offenbar Mistral. Es ist trotzdem davon auszugehen, dass die 105 Millionen Euro keine "Forschungsspende" waren und kommerzielle Produkte zeitnah folgen werden.
Für die Forscher und Entwickler von LLMs hat die aktuelle Veröffentlichung nichtsdestotrotz Vorteile. Meta AI hat mit der Lizenzgebung von Llama 2 auf die Open-Source-Bewegung in der LLM-Welt reagiert und sein aktuelles Modell unter eine permissive, aber trotzdem proprietäre Lizenz gestellt. Mistral geht allerdings noch einen Schritt weiter und setzt eine "klassische" Open-Source-Lizenz ein. Das hat nicht nur Signalwirkung, sondern ermöglicht, dass Unternehmen ihre LLM-Lösungen zunehmend privat hosten können, da die Parameteranzahl mit 7 Mrd. so dimensioniert ist, dass auch kleinere Datacenter-GPUs für die Ausführung bzw. Inferenz ausreichen. Es bleibt also weiterhin spannend im Umfeld der LLMs.
Die Mistral-7B-Modelle sind in Version 0.1 auf HuggingFace als normales Modell und als auf Chats spezialisiertes Modell (Instruct) verfügbar.
Auch in der Sommerpause gibt es vereinzelte Neuigkeiten aus der Welt der künstlichen Intelligenz. Heute möchte ich mich dabei wieder einmal den Agenten widmen.
Beim Einsatz von ChatGPT und ähnlichen LLMs stellt sich schnell die Frage, ob da nicht auch mehr geht. Ob das System nicht zur Abbildung alltäglicher Arbeit herangezogen werden kann. Insbesondere mit Anfang des Jahres aus dem Winterschlaf erwachten Konzept der Agenten wurde die Zusammenarbeit unterschiedlicher KI-Instanzen wieder relevant und spannend. Umso interessanter ist es, diese Konzepte zusammenzuführen.
AutoGPT und Co. sind diesem Ziel gefolgt und konnten schon lustige Ergebnisse demonstrieren, wenn man die LLMs sinnbildlich an den eigenen Computer anschließt und z. B. die Ausgaben des LLMs als Eingabe für die eigene Shell verwendet (nicht nachmachen, ist eine dumme Idee). Doch auch hier gab es einige Schwächen, ganz rund lief alles bei weitem noch nicht.
Die Autoren hinter MetaGPT (hier im Bezug auf griechisch meta = über) haben systematisch verschiedene Rollen inkl. ihrer Interaktionen ausgearbeitet und stellen ihre Ergebnisse als Preprint und ihr Framework auf GitHub bereit. Dabei wird eine einzeilige Aufgabe, z. B. die Entwicklung eines Spiels, vom System eingelesen und dann auf ein hierarchisches Team aus Agenten verteilt. Diese Agenten haben verschiedene Rollen, die sich auf die System-Prompts abbilden, d. h. beispielhaft "Du bist ein Entwickler für Python..." oder "Du bist ein Requirements-Engineer...". Am Ende des Tages fällt ein Ergebnis raus, das dann ausprobiert werden kann.
Das Konzept sieht in meinen Augen sehr spannend aus und entwickelt sich stets weiter. Dabei wird deutlich, dass eine simple Prompt für hochwertiges Prompt-Engineering nicht reicht, vielmehr können Effekte ähnlich wie beim Ensemble-Learning genutzt werden, durch die mehrere Instanzen von LLMs, die gemeinsam ein Problem bearbeiten, deutlich effektiver arbeiten.
Irgendwie habe ich die ganzen letzten Monate schon darauf gewartet, dass sich die Autoren klassischer Expertensysteme beim LLM-Thema zu Wort melden. Immerhin prallen hier zwei komplett unterschiedliche Welten aufeinander, die beide versuchen, die Welt zu erklären.
Klassische Expertensysteme versuchen mit Logik die Welt in Regeln zu fassen. Das typische Beispiel ist "Wenn es regnet, dann wird die Straße nass". Eine klare Implikation, die in eine Richtung geht: ist das Kriterium auf der "wenn"-Seite erfüllt, gilt die Aussage auf der "dann"-Seite. Wird das System gefragt, was mit der Straße passiert, wenn es regnet, antwortet es immer, dass sie nass wird. Immer. Dass es nicht zwangsläufig der Regen sein muss, wenn die Straße nass ist, wird ebenfalls durch Logik ermöglicht, da die obige Regel eine Implikation ist und keine Äquivalenz, denn da würde es heißen "Immer wenn es regnet, dann wird die Straße nass".
Problematischer wird es zu modellieren, dass die Straße selbst bei Regen da nicht nass wird, wo gerade ein Auto parkt. Hieran erkennt man, dass es sich um ein schwieriges Unterfangen handelt, wenn Expertensysteme die echte Welt modellieren sollen. Das Cyc-Projekt hat die Mühe aber auf sich genommen und über die letzten knapp 40 Jahre über eine Million solcher Regeln zusammengetragen. Viele einfache Expertensysteme gelten grundsätzlich aber als veraltet und konnten die Erwartungen für "generelle Intelligenz" schon vor 30 Jahren nicht erfüllen.
Anders funktionieren LLMs, die nicht mit klassischer Logik, sondern Wahrscheinlichkeiten arbeiten, um das "am ehesten passende" nächste Wort für die Antwort zu finden. Zusammengefasst sind Expertensysteme für ihre Präzision zulasten der Vielseitigkeit bekannt und LLMs einfach anders herum.
Doug Lenat von Cyc und Gary Marcus von der NYU haben in ihrem Preprint nun 16 Anforderungen zusammengetragen, die eine "vertrauenswürdige KI" haben sollte, darunter Erklärung, Herleitung oder Kontext. Anschließend gehen die Autoren noch ein, wie ihr (kommerzielles) Cyc das umsetzen kann.
Ich bin tatsächlich überzeugt, dass man untersuchen sollte, wie sich diese beiden Ansätze verheiraten lassen. Dabei sprechen auch die Ergebnisse von AutoGPT, MetaGPT & Co. dafür, dass das Vorhaben auf neuronaler Ebene angegangen werden muss, da einfache Varianten wie System-Prompts á la "Du bist LogikGPT. Gib mir die Entscheidungsregeln in Prädikatenlogik aus." immer noch auf Token-/Wortvorhersagen basieren und zu viel Halluzination zulassen.
Dennoch bin ich sicher, dass es auch hier Fortschritte geben wird, die wir dann früher oder später in einem Wochenrückblick diskutieren können. Bis dahin!