AlmaLinux 10
Seit einigen Jahren ist CentOS kein produktionstauglicher RHEL-Klon mehr. Wer RHEL produktiv nutzen will, aber nicht dafür bezahlen kann, hat seither die Qual der Wahl: zwischen AlmaLinux, CentOS Stream (nicht für Langzeitnutzung), Oracle Linux, RHEL via Developer Subscription und Rocky Linux. Ich bin ein wenig zufällig im AlmaLinux-Lager gelandet und habe damit über mehrere Jahre, vor allem im Unterricht, ausgezeichnete Erfahrungen gemacht.
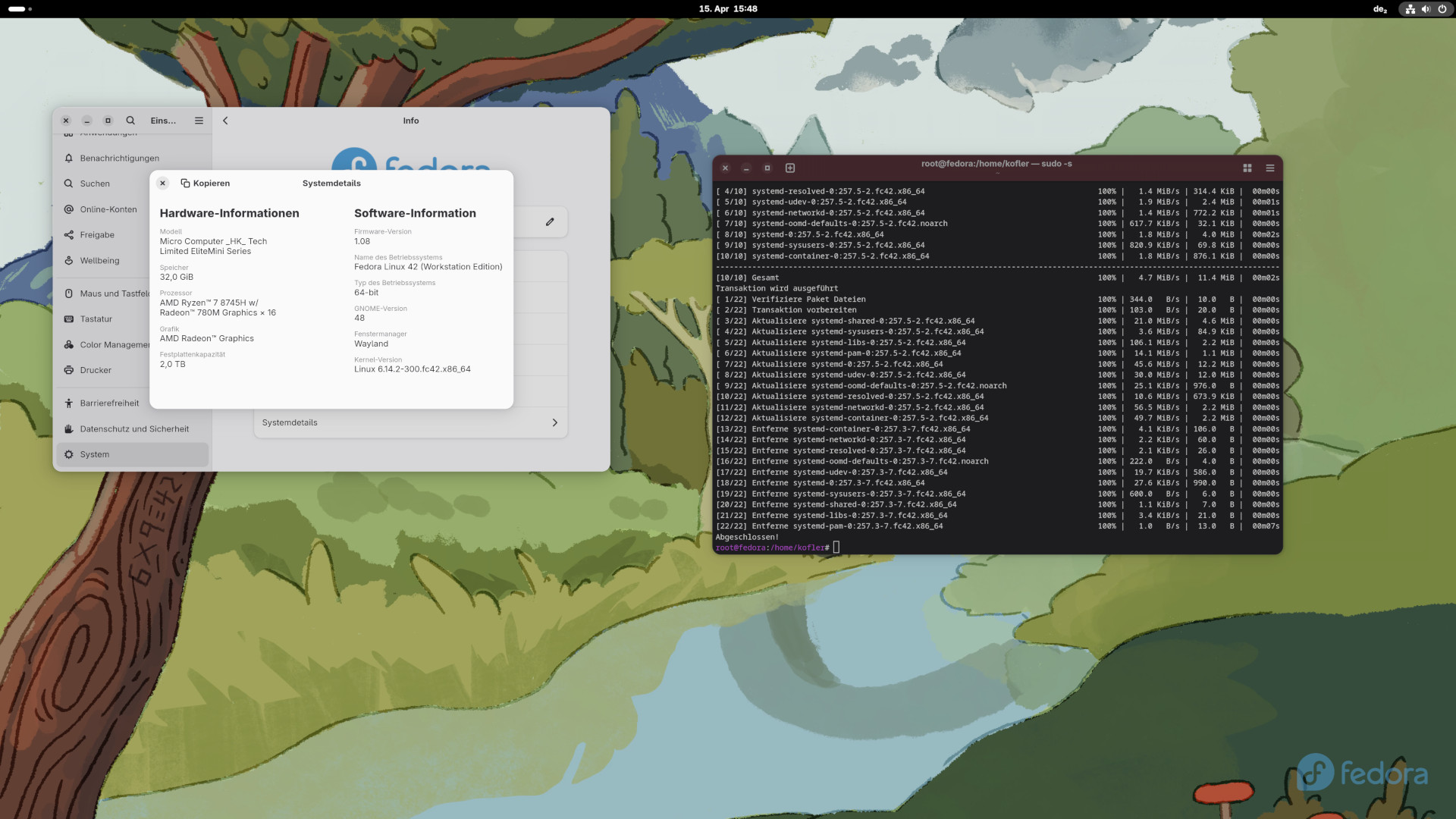
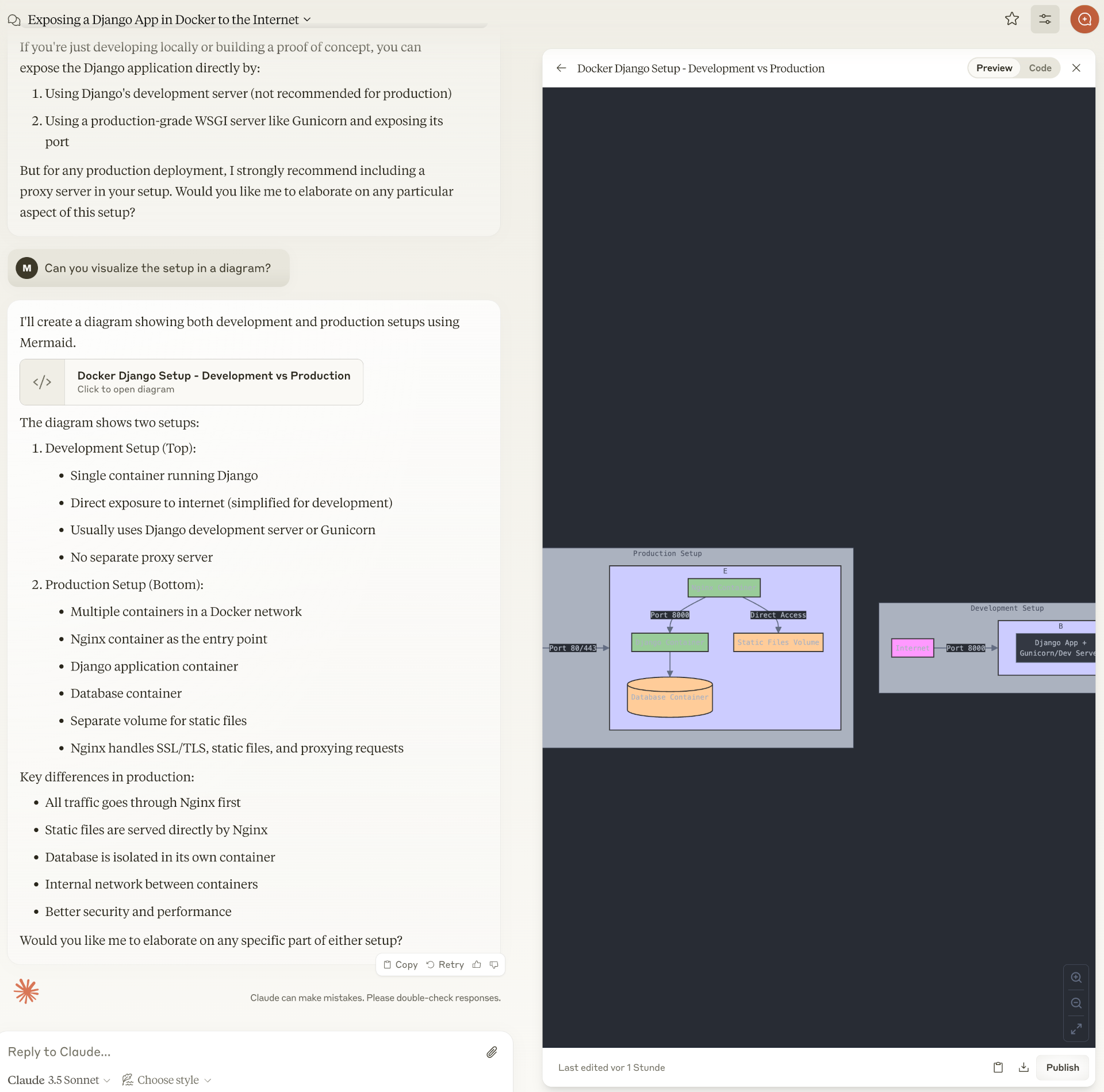
Nach diversen Tests mit der Beta-Version läuft AlmaLinux 10 jetzt nativ auf meinem Mini-PC (AMD 8745H), außerdem die aarch64-Variante in einer virtuellen Maschine auf meinem Mac. Dieser Artikel stellt die neue Version AlmaLinux 10 vor, die am 27. Mai 2025 freigegeben wurde, genau eine Woche nach dem Release von RHEL 10. Die meisten Informationen in diesem Artikel gelten auch für RHEL 10 sowie für die restlichen Klone. Oft beziehe ich mich daher im Text auf RHEL (Red Hat Enterprise Linux), also das zugrundeliegende Original. Es gibt aber auch ein paar feine Unterschiede zwischen dem Original und seinen Klonen.
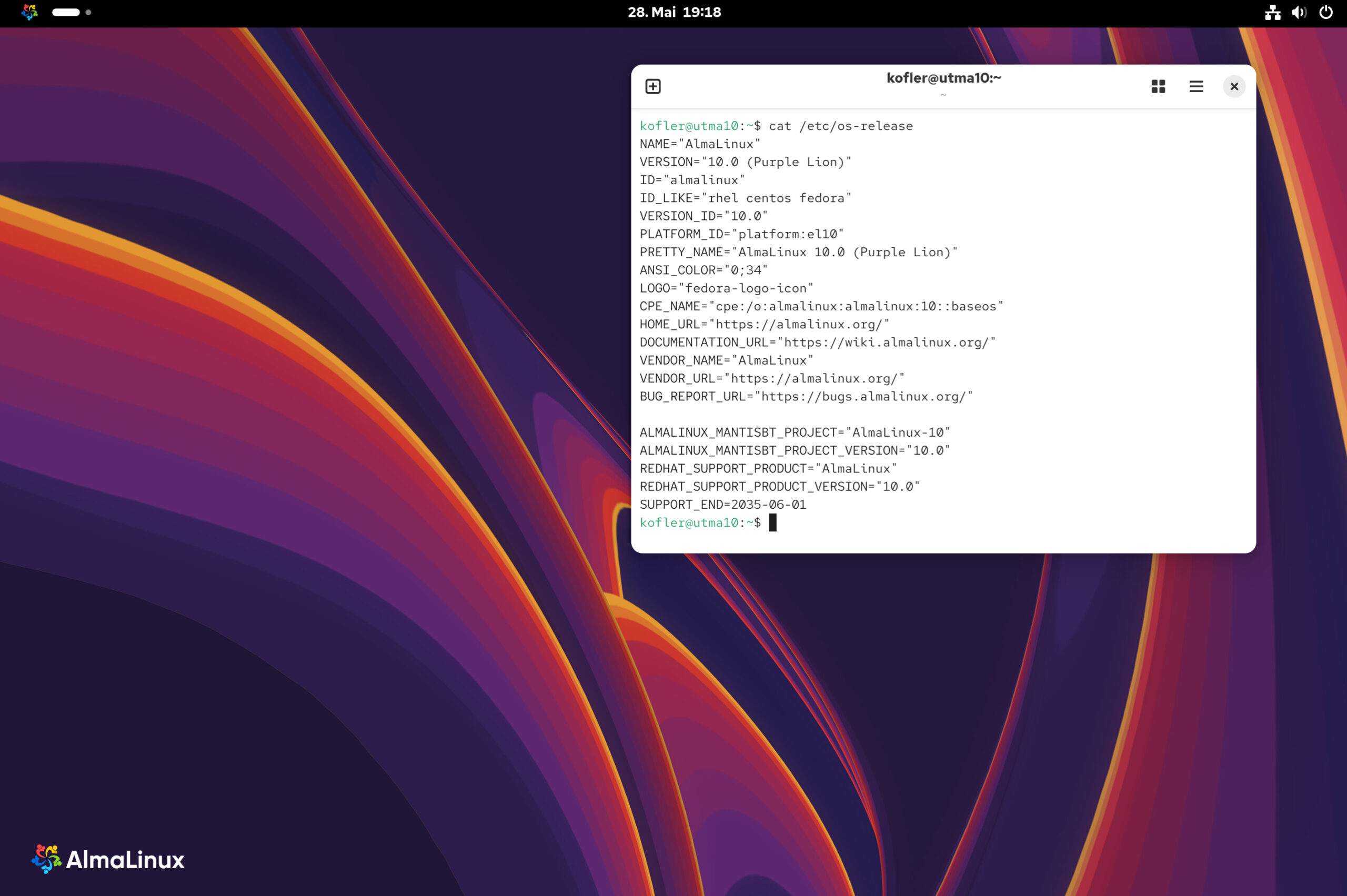
Ich habe vor, diesen Artikel in den nächsten Wochen zu aktualisieren, wenn ich mehr Erfahrungen mit AlmaLinux 10 gemacht habe und es zu Rocky Linux 10 und Oracle Linux 10 weitere Informationen gibt.
Versionsnummern und Paketverwaltung
Basis Programmierung Server
--------------- -------------- ---------------
Kernel 6.12 bash 5.2 Apache 2.4
glibc 2.39 gcc 14.2 CUPS 2.4
Wayland 1.23 git 2.47 MySQL 8.4
Gnome 47 Java 21 MariaDB 11.11
Mesa 24.2 PHP 8.3 OpenSSH 9.9
Systemd 257 Podman 5.4 PostgreSQL 16.8
NetworkMan 1.52 Python 3.12 Postfix 3.8
GRUB 2.12 Node.js 22 qemu/KVM 9.1
Samba 4.21
Red Hat hat mit RHEL 10 den X.org-Server aus den Paketquellen entfernt. RHEL setzt damit voll auf Wayland. (Mit XWayland gibt es für X-Client-Programme eine Kompatibilitätsschicht.) Weil RHEL und seine Klone zumeist im Server-Betrieb und ohne grafische Benutzeroberfläche laufen, ist der Abschied von X.org selten ein großes Problem. Einschränkungen können sich aber im Desktop-Betrieb ergeben, vor allem wenn statt Gnome ein anderes Desktop-System eingesetzt werden soll.
Eine Menge wichtiger Desktop-Programme sind aus den regulären Paketquellen verschwunden, unter anderem Gimp und LibreOffice. RHEL empfiehlt, die Programme bei Bedarf aus Flathub zu installieren. Davon abgesehen ist aber kein Wechsel hin zu Flatpaks zu bemerken. flatpak list ist nach einer Desktop-Installation leer.
In der Vergangenheit haben RHEL & Co. von wichtigen Software-Produkten parallel unterschiedliche Versionen ausgeliefert. Dabei setzte RHEL auf das Kommando dnf module. Beispielsweise stellte RHEL 9 Mitte 2025 die PHP-Versionen 8.1, 8.2 und 8.3 zur Auswahl (siehe dnf module list php).
Anscheinend sollen auch in RHEL 10 unterschiedliche Versionen (»AppStreams«) angeboten werden — allerdings nicht mehr in Form von dnf-Modulen. Wie der neue Mechanismus aussieht, habe ich nach dem Studium der Release Notes allerdings nicht verstanden.
Administration und Logging
Wie schon in den vergangenen Versionen setzt RHEL zur Administration auf Cockpit. Die Weboberfläche ist per Default aktiv, nicht durch eine Firewall geschützt und über Port 9090 erreichbar.
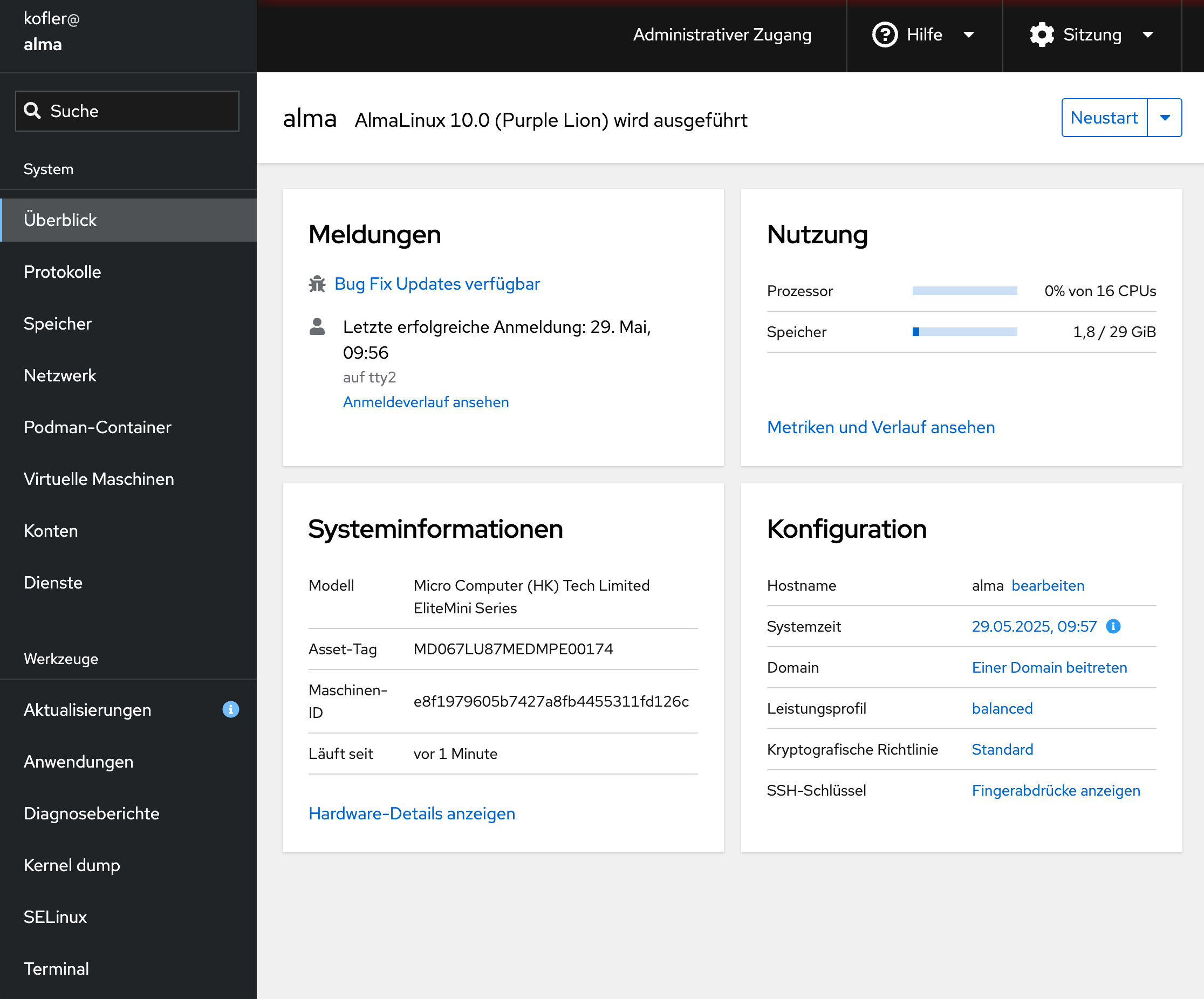
Bei einer Desktop-Installation sind standardmäßig rsyslog und das Journal installiert. rsyslog protokolliert wie eh und je in Textdateien in /var/log. Das Journal führt dagegen keine persistente Speicherung durch. Die Logging-Dateien landen in einem temporären Dateisystem in /run/log/journal und verschwinden mit jedem Reboot wieder. Wenn Sie ein dauerhaftes Journal wünschen, führen Sie die folgenden Kommandos aus:
mkdir /var/log/journal
systemctl restart systemd-journald
systemctl restart systemd-journal-flush
systemctl restart systemd-journald.socket
Virtualisierung
Red Hat enthält die üblichen qemu/kvm-Pakete als Basis für den Betrieb virtueller Maschinen. Die Steuerung kann wahlweise auf Kommandoebene (virsh) oder mit der Weboberfläche Cockpit erfolgen.
Das wesentlich komfortablere Programm virt-manager hat Red Hat schon vor Jahren als obsolet bezeichnet, und ich hatte Angst, das Programm wäre mit Version 10 endgültig verschwunden. Aber überraschenderweise gibt es das Paket weiterhin im CodeReady-Builder-Repository:
crb enable
dnf install virt-manager
virt-manager ist aus meiner Sicht die einfachste Oberfläche, um virtuelle Maschinen auf der Basis von QEMU/KVM zu verwalten. Red Hat empfiehlt stattdessen Cockpit (dnf install cockpit-machines), aber dieses Zusatzmodul zur Weboberfläche Cockpit hat mich bisher nicht überzeugen können. Für die Enterprise-Virtualisierung gibt es natürlich auch OpenShift und OpenStack, aber für kleine Lösungen schießen diese Angebote über das Ziel hinaus.
Bereits in RHEL 9 hat Red Hat die Unterstützung für Spice (Simple Protocol for Independent Computing Environments) eingestellt (siehe auch dieses Bugzilla-Ticket). Spice wurde/wird von virt-manager als bevorzugtes Protokoll zur Übertragung des grafischen Desktops verwendet. Die Alternative ist VNC.
Abweichend von RHEL wird Spice von AlmaLinux weiter unterstützt (siehe Release Notes).
EPEL (Extra Packages for Enterprise Linux)
Zu den ersten Aktionen in RHEL 10 oder einem Klon gehört die Aktivierung der EPEL-Paketquelle. In AlmaLinux gelingt das einfach mit dnf install epel-release. Es wird empfohlen, zusammen mit EPEL auch die gerade erwähnte CRB-Paketquelle zu aktivieren.
Die EPEL-10-Paketquelle ist mit schon gut gefüllt. dnf repository-packages epel list | wc -l meldet über 17.000 Pakete! Ein paar Pakete habe ich dennoch vermisst:
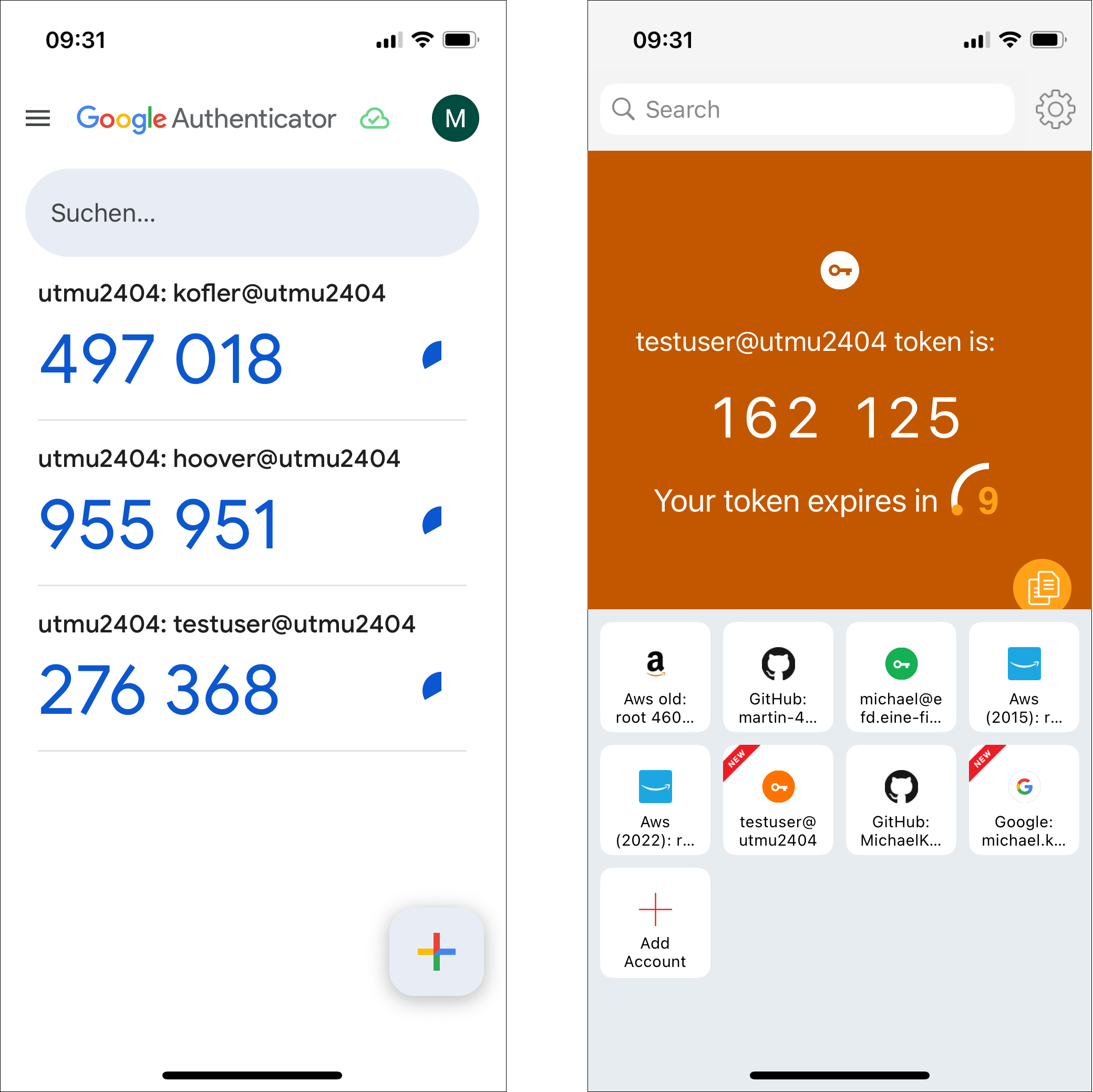
google-authenticatorfehlt noch, ist aber in EPEL 10.1 für Fedora schon enthalten, wird also hoffentlich auch für RHEL10 & Klone bald verfügbar sein.-
joefehlt ebenfalls. Ich installiere dieses Editor-Paket gerne, weil esjmacszur Verfügung stellt, eine minimale Emacs-Variante. Ich bin vorerst aufmgumgestiegen, es entspricht meinen Ansprüchen ebenfalls. (Ich bin keinvi-Fan, undnanoist mir ein bisschen zu minimalistisch. Den »richtigen« Emacs brauche ich aber auch nicht, um zwei Zeilen in/etc/hostszu ändern.)
AlmaLinux versus Original (RHEL)
Im Wesentlichen verwendet AlmaLinux den gleichen Quellcode wie RHEL und ist zu diesem vollständig kompatibel. Es gibt aber ein paar feine Unterschiede:
- Seit RHEL den Zugang zum Quellcodes für die Updates erschwert hat (siehe Ärger für Red-Hat-Klone und Red Hat und die Parasiten), greift AlmaLinux auch auf den Upstream-Quellcode einzelner Projekte zu, führt Bugfixes/Sicherheits-Updates zum Teil früher durch als RHEL und besteht nicht mehr auf eine vollständige Bit-für-Bit- und Bug-für-Bug-Kompatibilität. Im Detail ist diese Strategie und das Ausmaß der Kompatibilität hier dokumentiert.
-
Red Hat hat RHEL 10 für x86_v3 kompiliert, unterstützt damit nur relativ moderne Intel- und AMD-CPUs. Deswegen läuft RHEL 10 auf älteren Computern nicht mehr! Alma Linux macht es ebenso, bietet aber darüber hinaus eine v2-Variante an und unterstützt damit auch ältere Hardware. Die Mikroarchitektur-Unterschiede zwischen v2 und v3 sind z.B. in der Wikipedia sowie auf infotechys.com beschrieben. Das v2-Angebot umfasst auch die EPEL-Paketquelle.
-
Der Verzicht auf Bit-für-Bit-Kompatibilität gibt AlmaLinux die Möglichkeit, sich in einigen Details vom Original abzuheben. Das betrifft unter anderem die Unterstützung von Frame Pointers als Debugging-Hilfe sowie die fortgesetzte Unterstützung des Protokolls Spice,
AlmaLinux vs RockyLinux + Oracle Linux
In der Vergangenheit waren alle Klone praktisch gleich. Nun gut, Oracle hat immer einen eigenen »unbreakable« Kernel angeboten, aber davon abgesehen war das gesamte Paketangebot Bit für Bit kompatibel zum Original, kompiliert aus den gleichen Quellen. Die Extrapakete aus der EPEL-Quelle sind sowieso für das Original und seine Klone ident.
Seit Red Hat 2023 den Zugriff auf den Source-Code aller Updates eingeschränkt bzw. deutlich weniger unbequemer gemacht hat, haben sich AlmaLinux auf der einen und Rocky Linux und Oracle Linux auf der anderen Seite ein wenig auseinander entwickelt. AlmaLinux hat den Anspruch auf Bit-für-Bit-Kompatibilität aufgegeben (siehe oben). Rocky Linux und Oracle Linux beziehen den Quellcode für Updates hingegen nun aus anderen öffentlichen Quellen, unter anderem aus Cloud- und Container-Systemen (Quelle).
RHEL Developer
Für Entwickler macht Red Hat mit dem Red Hat Developer eigentlich ein attraktives Angebot. Nach einer Registrierung gibt es 16 freie Lizenzen für Tests und Entwicklungsarbeit. Ich habe einen entsprechenden Account, habe RHEL 10 installiert und registriert, bin aber dennoch nicht in der Lage, die Paketquellen zu aktivieren. Vielleicht bin ich zu blöd, vielleicht wird RHEL 10 noch nicht unterstützt (diesbezüglich fehlt klare Dokumentation) — ich weiß es nicht. Ich habe es ein paar Stunden probiert, und ich werde es in ein paar Wochen wieder versuchen. Vorerst fehlt mir dazu aber die Zeit und der Nerv.
Quellen und Links
AlmaLinux Release Notes und Dokumentation
- https://almalinux.org/blog/2025-05-27-welcoming-almalinux-10
- https://wiki.almalinux.org/release-notes/10.0.html
- https://almalinux.org/blog/future-of-almalinux/
Red Hat Release Notes und Dokumentation
- https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/10/html/10.0_release_notes/index
- https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/10/html-single/considerations_in_adopting_rhel_10/index
- https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/10/html/configuring_and_managing_windows_virtual_machines/index
- https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/10/html-single/considerations_in_adopting_rhel_10/index
- https://bugzilla.redhat.com/show_bug.cgi?id=2030592
- https://developers.redhat.com/
Andere Test- und News-Berichte
Frühere eigene Blog-Artikel
- https://kofler.info/nachruf-auf-centos/
- https://kofler.info/almalinux-9/
- https://kofler.info/aerger-fuer-red-hat-klone/
- https://kofler.info/kommentar-red-hat-und-die-parasiten/
Sonstiges