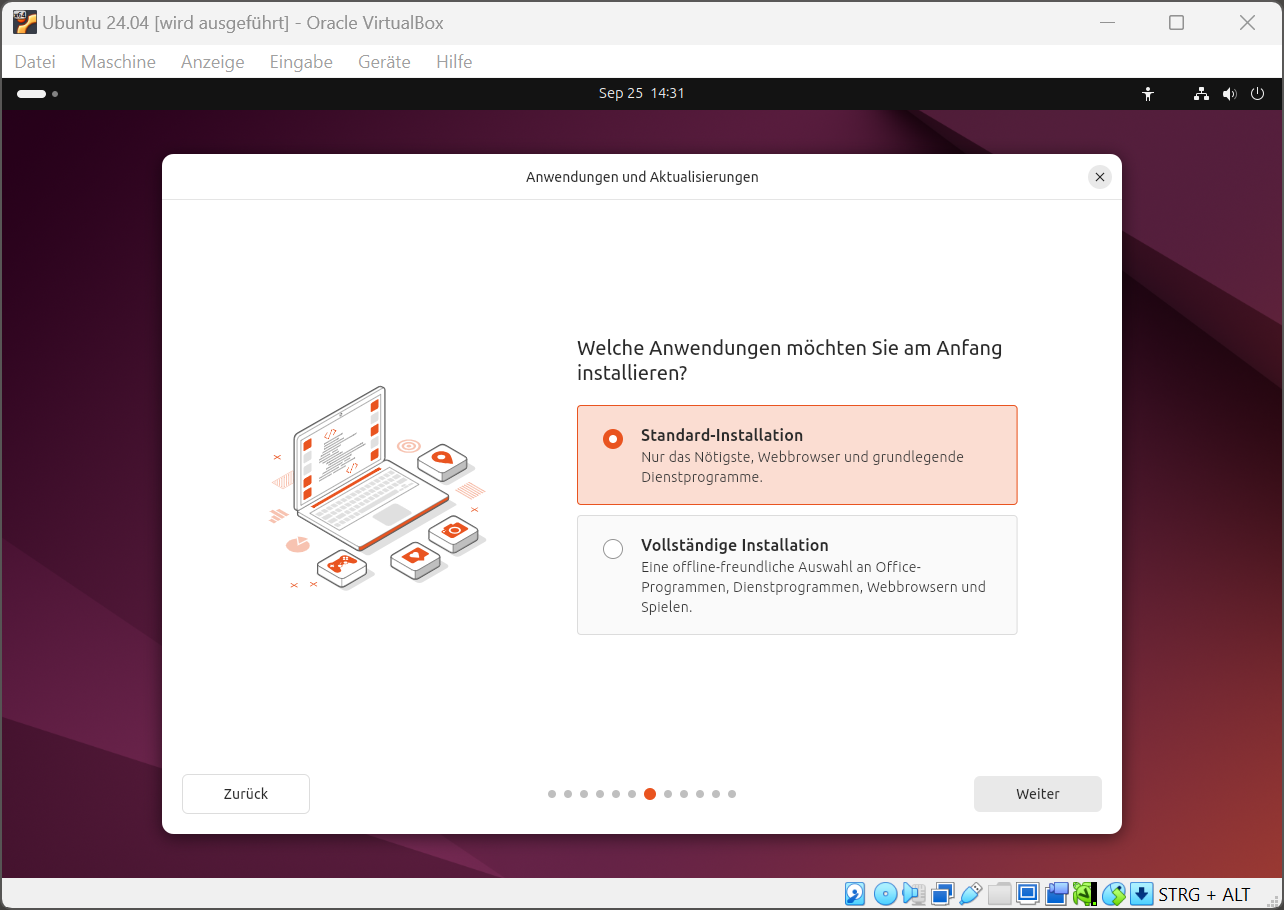
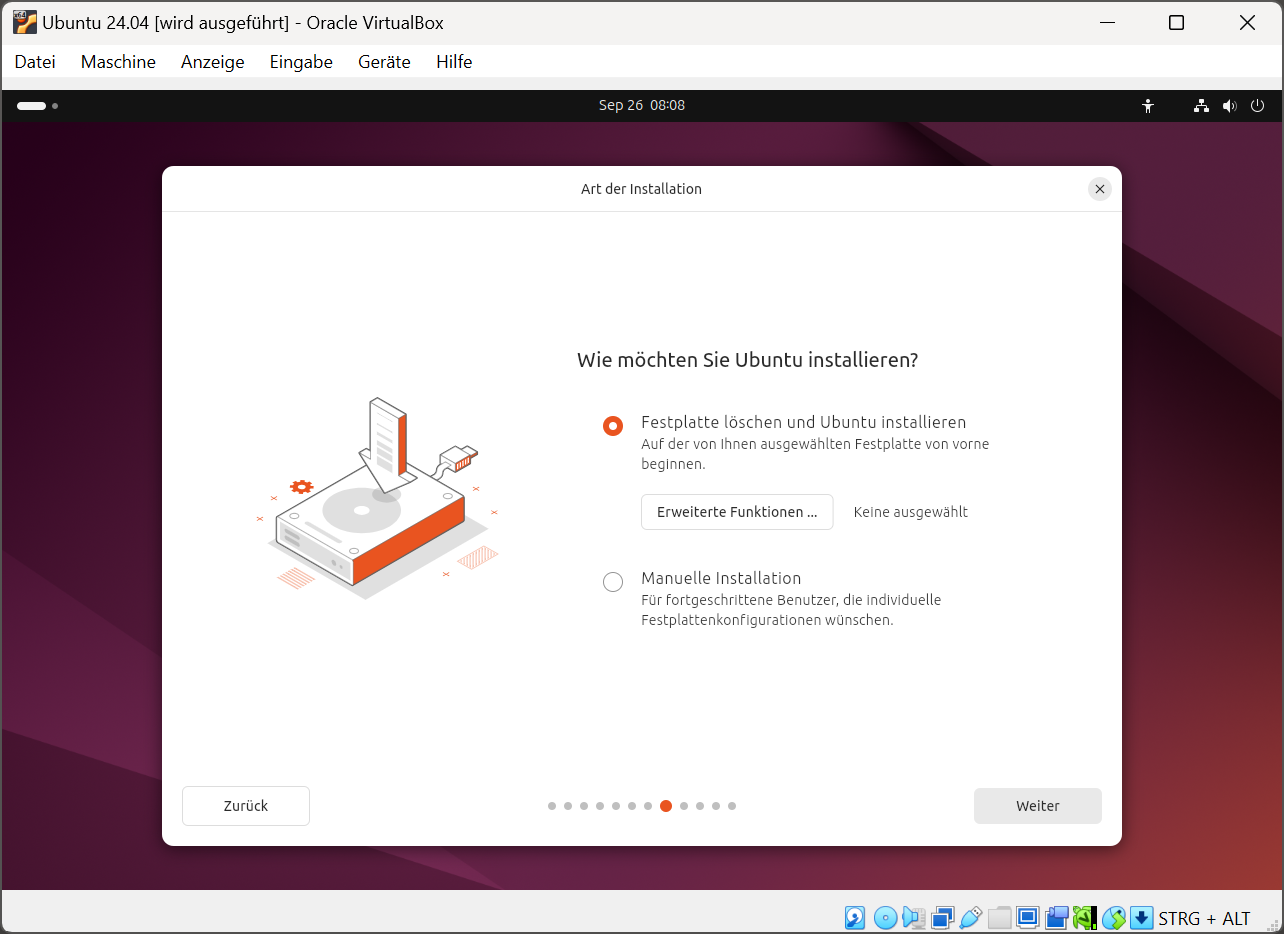
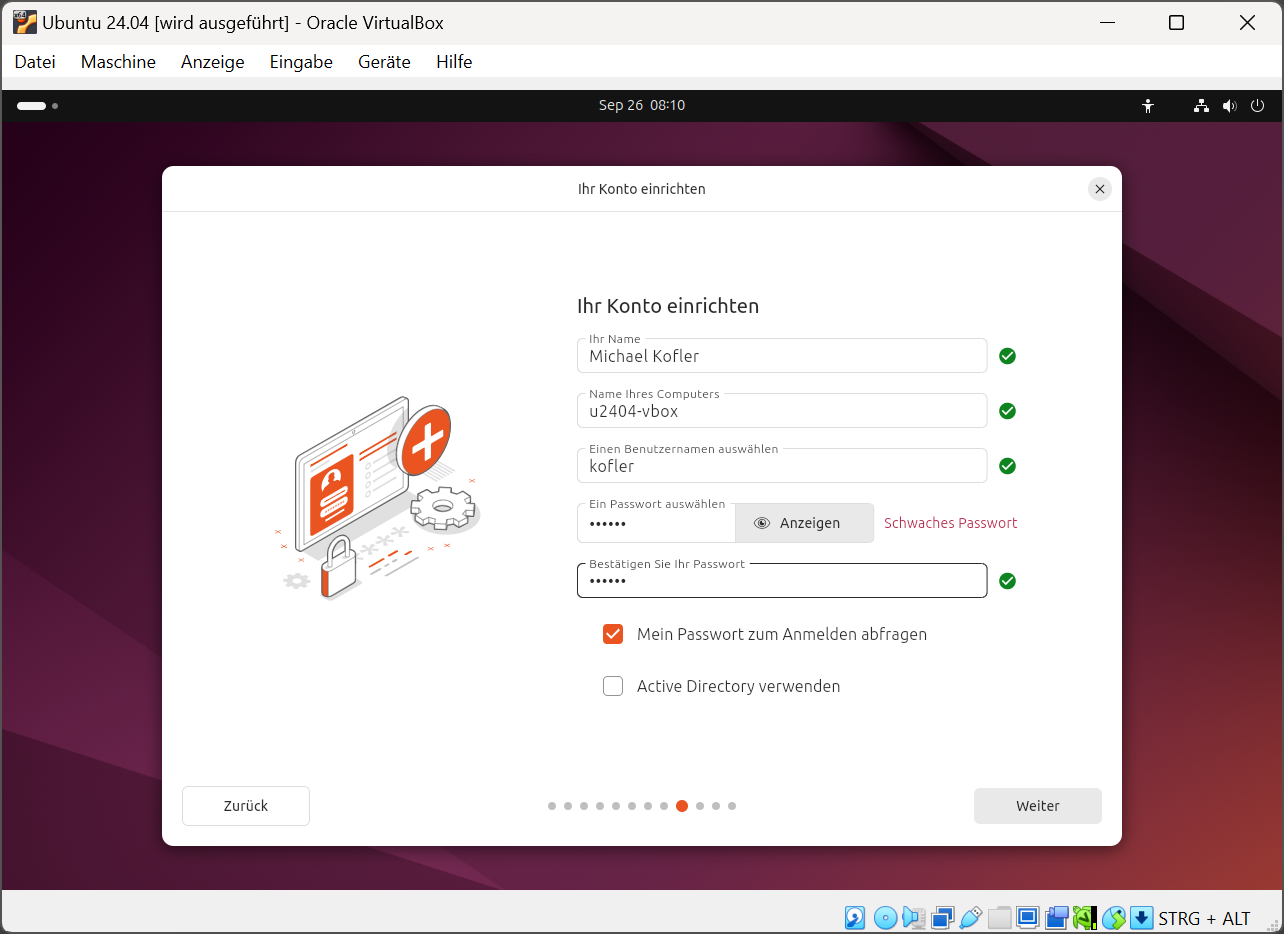
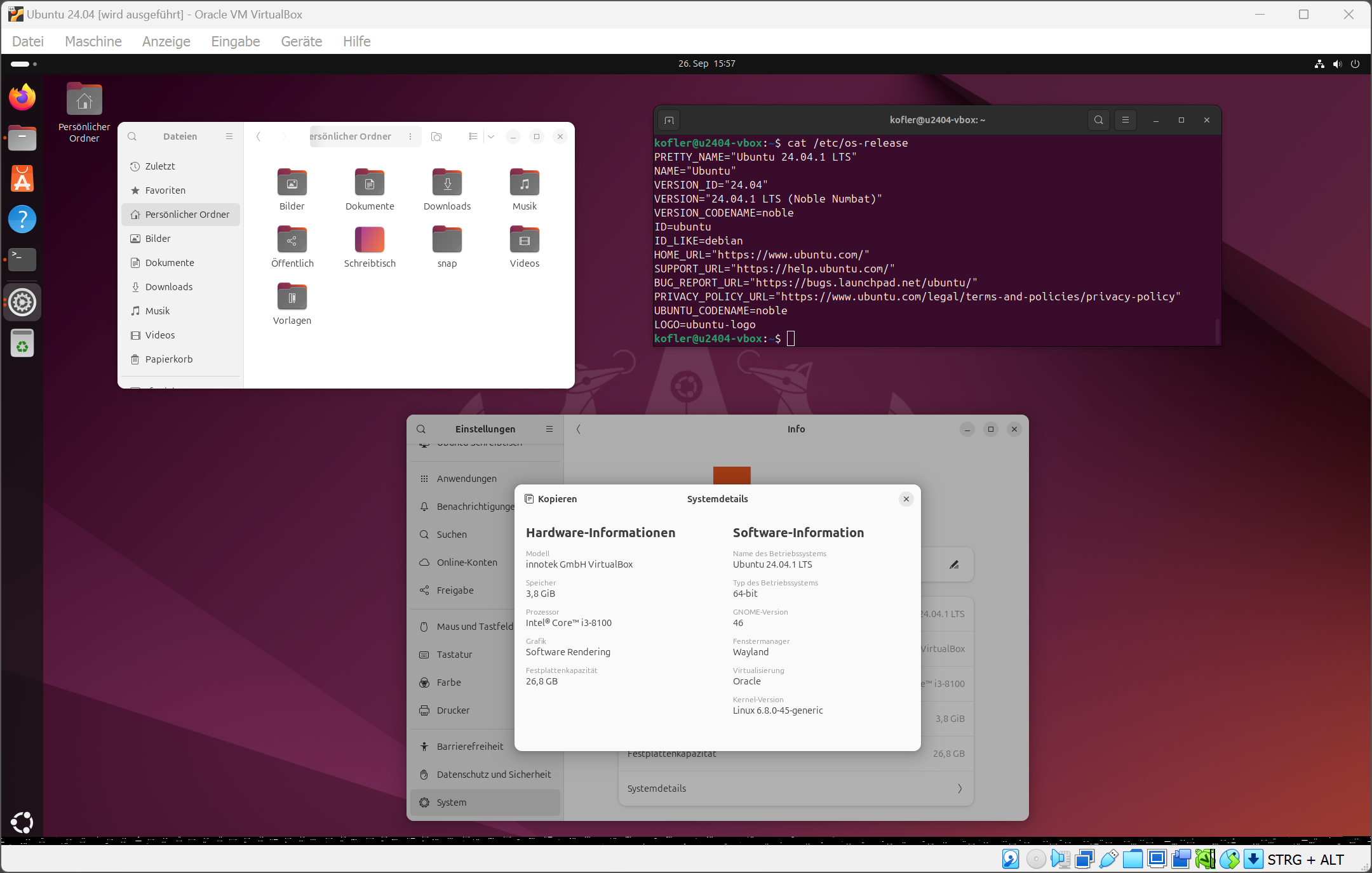
Wie der Titel andeutet, geht es in diesem Text um Release-Zyklen von Betriebssystemen und Zeiträume, in denen diese unterstützt werden. Ich möchte meine großartige Idee mit euch teilen und bin daran interessiert, zu erfahren, wie ihr darüber denkt.
Transparenzhinweis 1: Ich arbeite als Technical Account Manager bei Red Hat. Zuvor habe ich mehrere Jahre als Systemadministrator mit Red Hat Enterprise Linux (RHEL) gearbeitet. Dieser Text spiegelt ausschließlich meine persönliche Meinung wieder.
Transparenzhinweis 2: „Großartige Idee“ ist Code für eine Idee, die andere als Spinnerei, Wahnsinn, verrückt oder anderweitig dispektierlich bezeichnen würden. Mein bester Freund und ich hatten in unserem Leben schon viele großartige Ideen. Wir haben sie bisher alle überlebt. ;-) Nehmt das hier Geschriebene daher vielleicht nicht bierernst und mit einer Prise Ironie und Humor.
Wann? Wie oft? Wie lang?
Ca. alle 2-5 Jahre ist bei den bekannten Linux-Distributionen mit einem neuen Major-Release zu rechnen. Für jedes Major-Release bekommt man bis zu 10 Jahre und länger Unterstützung. Der Umfang der Unterstützung schwankt dabei je nach Support-Phase deutlich.
Die folgenden Abbildungen geben einen kleinen Überblick.
Betrachtet man diese Release-Zyklen und Unterstützungszeiträume, ist es problemlos möglich, ein Release zu überspringen, während sich die Unterstützungszeiträume für das alte und neue Release überschneiden.
Was sagen verschiedene Teams zu neuen Releases?
Die folgende Liste gibt eine Auswahl von Aussagen und Kommentaren wieder, die ich während der letzten 15 Jahre immer wieder in ähnlicher Form gehört habe.
„Schon wieder ein neues Major-Release. Jetzt müssen wir schon wieder testen, ob unsere Prozesse und Automations-/Konfigurations-Skripte noch funktionieren.“
„Hoffentlich müssen wir das Betriebskonzept nicht anpassen.“
„Endlich, wir warten schon lange auf neue Versionen wichtiger Bibliotheken, Laufzeitumgebungen und Datenbankmanagementsysteme.“
„Wir würden ja gern auf Version B deployen, die IT gibt uns aber nur Version A.“
„Mit jedem Major-Release ändert sich irgendwas und wir müssen uns schon wieder anpassen.“
„Unsere Anwendung läuft gut auf Version A. Wir möchten skalieren, aber die IT gibt uns jetzt nur noch Version B. Wir wissen nicht, ob und wie unsere Anwendung darauf läuft.“
„Wir testen gerade noch die letzte Patch-Version unserer Anwendung auf Version A. Der Test der folgenden Patch-Version drängt schon. Wir haben keine Zeit und keine Leute, um die Anwendung auch noch auf Version B zu testen.“
„Kaum sind wir mit der Migration unserer Anwendung von Version A auf Version B fertig, drängt uns der IT-Betrieb schon wieder, wir müssten auf Version C migrieren.“
„Vor lauter Betriebssystemwechseln kommen wir kaum dazu, unsere Anwendung weiterzuentwickeln.“
„Es dauert so lange, bis alle Anwendungen von Version A auf Version B migriert wurden, dass Version B schon fast wieder End-of-Life ist.“
„Es erzeugt enorme Aufwände mehrere Betriebssystemversionen parallel zu betreiben.“
Ihr habt hoffentlich erkannt, dass Version A und Version B hier stellvertretend für ein Release einer beliebigen Linux-Distribution stehen. Nimmt man die Aussagen zusammen, kann man den Eindruck gewinnen, dass ein neues Major-Release nicht bei allen Menschen in einer IT-Organisation Freude auslöst.
Und wenn wir nun ein Release auslassen?
Das Betriebskonzept muss seltener überprüft und ggf. angepasst werden
Die Anwendungsteams müssen ihre Anwendung seltener migrieren
Automations-/Konfigurations-Skripte müssen seltener angepasst werden
Die Anzahl von Migrations- und Veränderungs-Projekten kann reduziert werden
Geringerer Aufwand senkt die Kosten
Lassen wir außer Acht, dass ich einen Punkt bewusst unterschlage, sind die Vorteile offenbar deutlich und überwiegen alle potenziellen Nachteile mit Leichtigkeit. Oder nicht? Also warum wollt ihr unbedingt jedes Major-Release mitnehmen? Bitte schreibt mir eure Gründe dafür gern in die Kommentare.
Aber Jörg, du weißt doch, wie das so ist…
Ja, natürlich ist mir bewusst, dass es sich bei großen Unternehmen um komplexe Systeme handelt, in denen aus verschiedenen Bereichen sehr unterschiedliche Anforderungen an Anwendungen und IT-Dienste gestellt werden.
So reicht das Spannungsfeld regelmäßig von „Never touch a running system (even when it’s 20 years old)“ bis hin zu „We need the latest and greatest to be successful in our business“.
Manche Anwendungen sind nur für den Betrieb auf ausgewählten Betriebssystemversionen zertifiziert, Abhängigkeiten zu Bibliotheken und Laufzeitumgebungen müssen eingehalten werden.
Doch habt ihr wirklich mal zusammen mit allen Beteiligten bewusst überlegt, ob es ohne einschneidende Nachteile möglich ist, ein Major-Release zu überspringen, um die oben skizzierten Vorteile zu nutzen? Oder nehmt ihr jedes Release mit, weil das schon immer so gemacht wurde?
Dies ist wirklich _____ großartige Idee
Also, was haltet ihr von dieser Idee? Machbar? Gut? Oder doch nur eine Schnapsidee? Was spricht dagegen?
Bitte nutzt die Kommentare unter diesem Text, um mich und alle Leserinnen und Leser wissen zu lassen, ob dieser Ansatz Vorteile hat oder welche zwingenden Gründe ihn unrealistisch erscheinen lassen.
Und wenn ihr euch nur mal den Frust von der Seele schreiben wollt, warum es überall klemmt und hakt und wie es besser sein könnte, ist das natürlich auch in Ordnung.
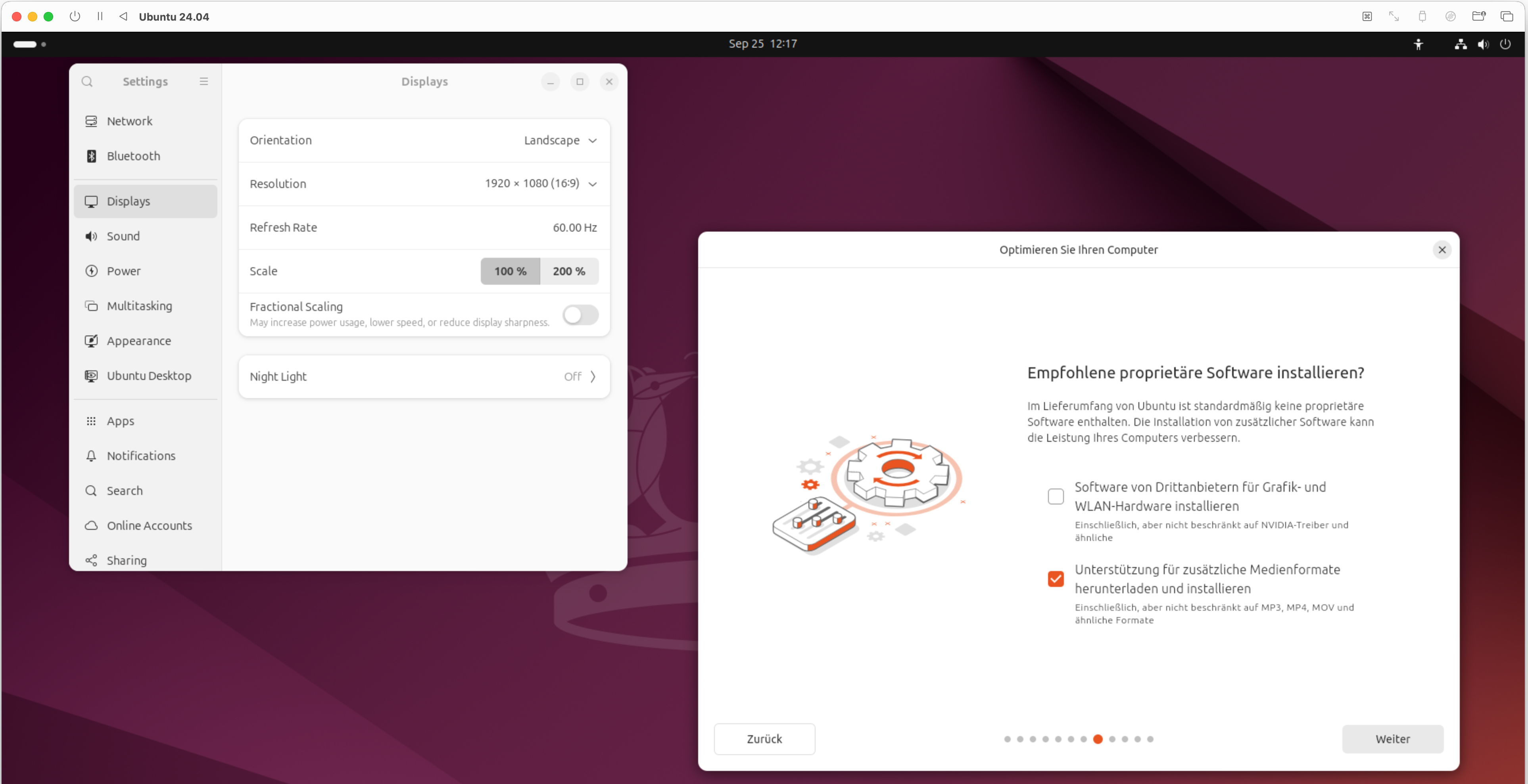
Nach der Installation von Ubuntu wird man feststellen, dass einige Mediendateien die Wiedergabe verweigern. Betroffen sind u. a. Formate wie AVI, MPEG und MP3. Der Grund hierfür liegt in den Lizenzbeschränkungen der einzelnen Formate, weshalb die benötigten Codecs nicht mit dem Betriebssystem ausgeliefert werden dürfen.
Wer hier Abhilfe sucht, kann das Metapaket ubuntu-restricted-extras nachinstallieren. Dieses enthält nicht nur die zuvor erwähnten Codecs, sondern auch die typischen Microsoft-Schriftarten.
Installation
Das Metapaket wird über das Terminal dem System hinzugefügt.
Ende letzten Jahres habe ich euch gezeigt, wie ihr die OpenThread RCP Firmware auf dem SMLIGHT SLZB-07 installiert. Neben den SLZB-07 Modellen gibt es von SMLIGHT noch die SLZB-06 Modelle, welche die im Home...
Es gibt ein paar Stellschrauben, an denen man drehen kann, um das Betriebssystem Ubuntu zu beschleunigen. Heute stelle ich das Tool Preload vor.
Bei Preload handelt es sich um einen Hintergrunddienst, der die Systemleistung verbessert, indem er häufig genutzte Anwendungen vorab lädt. Preload basiert auf der Idee des „predictive loading“, bei dem das System analysiert, welche Programme der Benutzer häufig verwendet, und diese Programme oder Teile davon im Voraus in den Speicher lädt. Dadurch können Programme oder Teile davon, die bereits im RAM vorhanden sind, schneller starten.
Installation
sudo apt install preload
Die Konfiguration kann angepasst werden, wobei die Standardeinstellung völlig ausreicht. Wer dennoch einige Werte anpassen möchte, schaut bitte hier.
Fotobücher lassen sich heutzutage recht leicht über Computer oder Smartphones erstellen. Hierzu gibt es einige Anbieter, die sich darauf spezialisiert haben. Ich möchte heute erklären, wie man die Software CEWE Fotowelt auf Ubuntu 24.04 LTS installiert.
Quelle: YouTube
Installation
Um CEWE Fotowelt zu installieren, wird die Seite cewe.de aufgerufen und die Software über Software & App -> CEWE Fotowelt Software -> Kostenfrei herunterladen und unter Downloads auf dem eigenen Rechner abgelegt. Anschließend wird die Datei setup_CEWE_Fotowelt.tgz im Downloads-Ordner entpackt. Nun wechselt man in das Terminal und führt folgenden Befehl aus:
Hierbei muss noch der Benutzer (in meinem Fall intux) an die eigenen Gegebenheiten angepasst werden.
Man folgt nun der Anleitung durch Bestätigen mit Enter. Es öffnet sich die Endbenutzer-Lizenzvereinbarung (EULA) zu „CEWE FOTOWELT“. Diese wird durch das Drücken von q (nach dem Lesen) verlassen. Danach wird man aufgefordert, die EULA zu akzeptieren. Dies geschieht über die Eingabe von ja und der Bestätigung via Enter.
Die Frage:
Wo soll ‚CEWE Fotowelt 8.0.2‘ installiert werden? [/opt/CEWE/CEWE Fotowelt]
wird ebenfalls mit Enter akzeptiert.
Durch erneutes Bestätigen mit Enter wird das noch nicht existierende Verzeichnis angelegt. Im Anschluss werden durch die neuerliche Eingabe von Enter die Daten aus dem Internet geladen und die Software installiert.
Ein kurzer Refresher, worum es in der Thematik überhaupt geht: Als Git entwickelt wurde, musste ein Weg gefunden werden, wie man die Referenzen auf Commits, die Dateien und die Dateibäume realisiert. In vielen Systemen wie z. B. Issue-Trackern werden aufsteigende Indizes verwendet. In einem verteilten System wie Git ist das aus verschiedenen Gründen der Synchronisation nicht so einfach möglich, da sonst Kollisionen, also gleiche IDs für unterschiedliche Objekte entstehen könnten. Eine Alternative wäre UUIDs, da die IDs einen randomisierten Anteil haben und die Wahrscheinlichkeit für Kollisionen gesenkt wird.
Noch besser als UUIDs ist allerdings Content-adressable Storage, bei dem Inhalte einzig durch ihren Inhalt adressiert werden. Das ist so, als würde man den gesamten Inhalt der Datei nochmal in den Dateinamen schreiben. Der Clou dabei ist jedoch, dass der gesamten Dateiinhalt gar nicht in den Dateinamen geschrieben werden muss, um die Datei durch ihren Inhalt identifizierbar zu machen.
Mit kryptographischen Hashfunktionen wie SHA-1 oder SHA-256 existiert ein Mittel, um einen beliebig langen Dateiinhalt zu einem immer gleich langen Wert, dem Hash, umzuwandeln. Dabei sind kryptographische Hashfunktionen so konstruiert, dass die Wahrscheinlichkeit für Kollisionen durch verschiedene Mechanismen stark minimiert wird. Ein SHA-1-Hash für den Dateiinhalt "Hallo Welt" wäre z. B. 28cbbc72d6a52617a7abbfff6756d04bbad0106a. Ein netter Nebeneffekt ist, dass Dateien mit gleichem Inhalt im Content-adressable Storage auch nur einmal abgespeichert werden, wodurch sogar Deduplikation ermöglicht wird.
Git nutzt dieses Verfahren, um die eingechekten Dateien abzuspeichern. Diese Dateien werden dann in Trees zusammengebunden und in Commits mit den jeweiligen Vorgänger-Commits (parents) in einem sog. Merkle-Tree verheiratet.
Commits werden somit auch durch einen SHA-1-Hash identifiziert, der im hexadezimalen Format 40 Zeichen lang ist.
Das Problem
Das Problem bei dem Verfahren liegt jetzt darin, dass dieser Hash üblicherweise noch weiter abgekürzt wird, um ihn benutzerfreundlicher in Oberflächen oder E-Mails darzustellen. Damit wird natürlich die Wahrscheinlichkeit für Kollisionen erhöht.
Habe ich einen Hash 28cbbc72d6a52617a7abbfff6756d04bbad0106a und nutze nur 28cbbc zur Referenz, reicht das in den meisten kleinen Repositories aus, um einen Commit eindeutig zu referenzieren. In großen Repositories mit vielen Dateien und Commits kann es auf einmal passieren, dass ein weiterer Commit 28cbbcc00aa8ef4e80596c16ecfdb4bc92656cd3 auftaucht, sodass 28cbbc nicht mehr eindeutig einen Commit beschreibt.
Um das Risiko zu verringern, sollte die Mindestanzahl der Zeichen für einen abgekürzten Commit erhöht werden.
Das Kernel-Repository
Genau darum geht es in der aktuellen Diskussion. Aktuell nutzen die Linux-Entwickler zur Referenz von Commits in ihren E-Mails 12 Zeichen lange Hashes. Die Diskussion dreht sich um die Frage, ob die Zahl weiter erhöht werden sollte. Linus Torvalds ist bisher dagegen, weil er das Risiko für Kollisionen gering sieht und er die Position vertritt, dass ein Commit immer mit dem Commit Message Title angegeben werden sollte, was ungewollte Kollisionen ausreichend verhindere.
Gestern veröffentlichte Kees Cook einen Blogpost, indem er eine Commit-Kollision mit dem Werkzeug lucky-commit bewusst herbeiführte, um darauf aufmerksam zu machen, dass die Git- und Kernel-Entwicklungstools mit solchen Situationen klarkommen sollten. Es ist unwahrscheinlich, dass solche Kollisionen bei 12 Zeichen versehentlich entstehen, aber ein Angreifer könnte dies ausnutzen.
Dies sollte ein Apell an alle Entwickler sein, deren Tooling auf abgekürzte Commit-Hashes setzt. Schauen wir mal, wie sich das weiterentwickelt.
Ein Kommentar zu SHA-1
Abschließend ein Kommentar noch zu SHA-1. Wie viele von euch wissen, ist SHA-1 selbst nicht mehr vertretbar kollisionssicher. Das bedeutet, es kann passieren, dass auf einmal zwei Dateiinhalte sich doch den gleichen Hash teilen könnten, wenn ein Angreifer es drauf anlegt.
Da dies natürlich Git massiv stören könnte, gibt es schon Bestrebungen, das Verfahren auf SHA-2 zu aktualisieren, wodurch sich die Hashlänge auch vergrößert. Das ist aber gar nicht so einfach, da SHA-1 an vielen Stellen in die Struktur eines Git-Repos hartkodiert wurde.
Hier geht es aber nicht um das unsichere SHA-1. Durch die Abkürzung des Hashes von 40 auf 12 Zeichen wird die Kollisionssicherheit bewusst und massiv zugunsten der Benutzerfreundlichkeit geschwächt. Und das erfordert immer eine regelmäßige Evaluation, welches Niveau noch vertretbar ist.
Mit diesem Artikel möchte ich meine Nextcloud-Serie schließen. Um die installierte Cloud nun noch mit einer Videokonferenz-Funktion zu erweitern, möchte ich heute zeigen, wie man einen TURN-Server auf das bestehende System aufsetzt. Dies hatte ich im Mai diesen Jahres im Artikel „Coturn TURN-Server für Nextcloud Talk“ zwar schon erklärt, aber es gehört aus meiner Sicht einfach in diese Artikelserie hinein.
Installation
Ein TURN-Server wird von Nextcloud Talk benötigt, um Videokonferenzen zu ermöglichen. Der TURN-Server bringt die Teilnehmer, welche sich in verschiedenen Netzwerken befinden, zusammen. Nur so ist eine reibungslose Verbindung unter den Gesprächspartnern in Nextcloud Talk möglich.
Wer bisher meinen Anleitungen zur Installation von Nextcloud auf dem Raspberry Pi gefolgt ist, kann nun die eigene Cloud für Videokonferenzen fit machen. Zu bedenken gilt aber, dass ein eigener TURN-Server nur bis maximal 6 Teilnehmer Sinn macht. Wer Konferenzen mit mehr Teilnehmern plant, muss zusätzlich einen Signaling-Server integrieren.
Nun zur Installation des TURN-Servers. Zuerst installiert man den Server mit
sudo apt install coturn
und kommentiert folgende Zeile, wie nachfolgend zu sehen in /etc/default/coturn aus.
sudo nano /etc/default/coturn
Dabei wird der Server im System aktiviert.
#
# Uncomment it if you want to have the turnserver running as
# an automatic system service daemon
#
TURNSERVER_ENABLED=1
Nun legt man die Konfigurationsdatei zum TURN-Server mit folgendem Inhalt an.
Hier werden u.a. der Port und das Passwort des Servers sowie die Domain der Cloud eingetragen. Natürlich muss hier noch der Port im Router freigegeben werden. Ein starkes Passwort wird nach belieben vergeben.
Hierbei kann das Terminal hilfreich sein. Der folgende Befehl generiert z.B. ein Passwort mit 24 Zeichen.
gpg --gen-random --armor 1 24
Jetzt wird der Server in den Verwaltungseinstellungen als STUN- und TURN-Server inkl. Listening-Port sowie Passwort eingetragen.
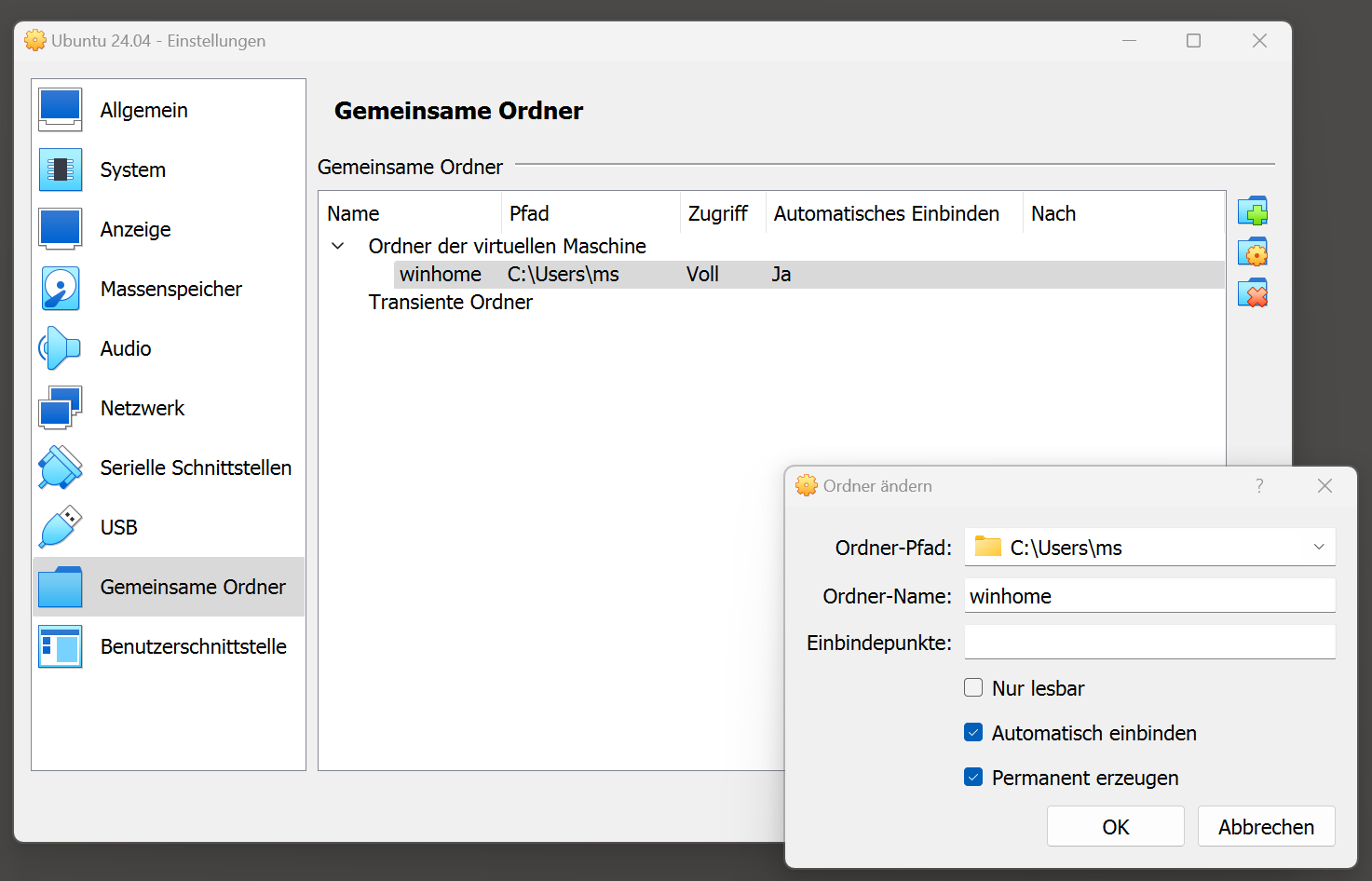
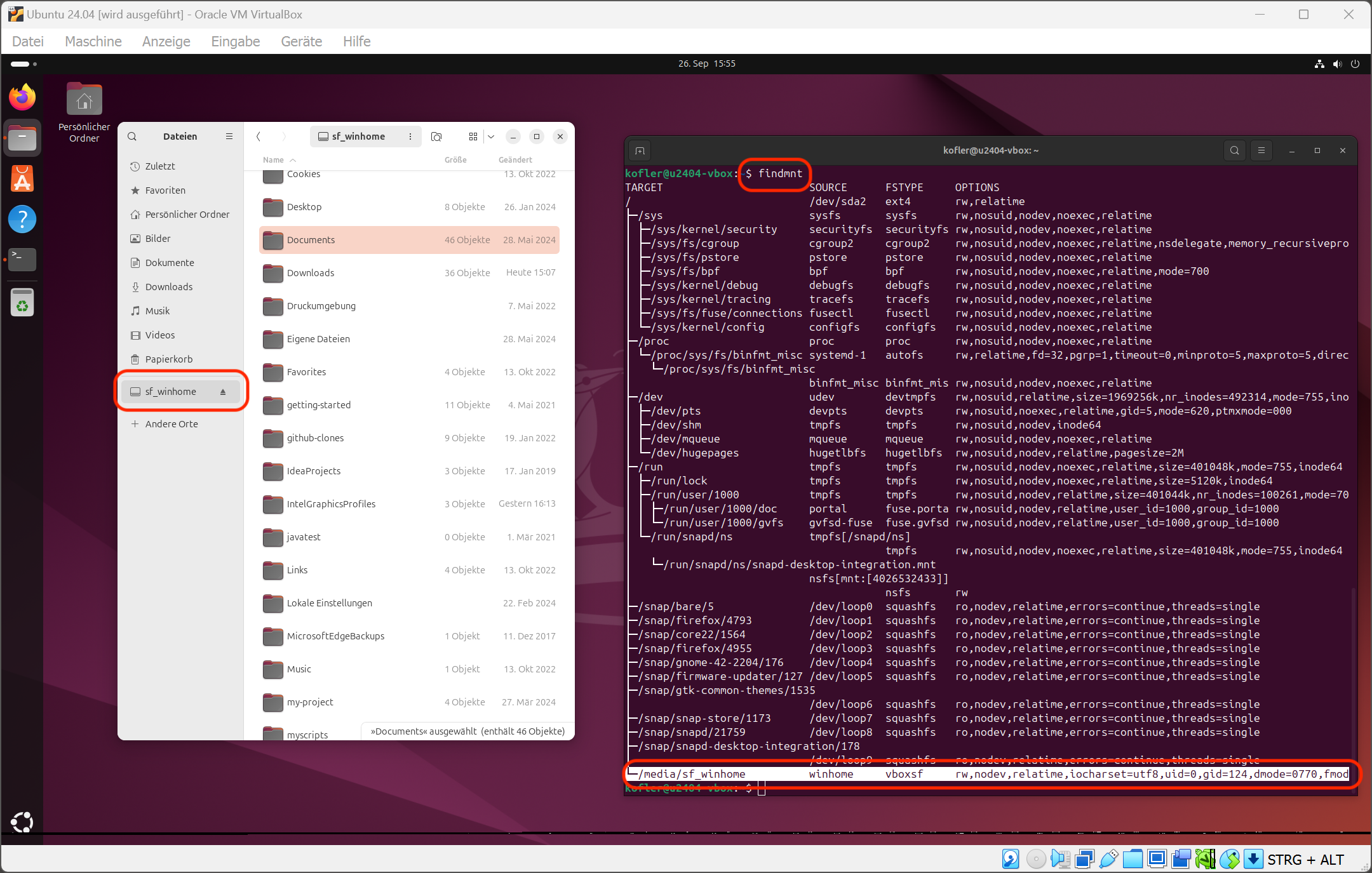
Nextcloud – Verwaltungseinstellungen – TalkEintrag der Domain für STUN- und TURN-Server (sowie Passwort)
Damit der TURN-Server nach einem Reboot auch zuverlässig startet, müssen ein paar Einstellungen am Service vorgenommen werden. Mit
sudo systemctl edit coturn.service
wird der Service des Servers editiert. Folgender Eintrag wird zwischen die Kommentare gesetzt:
### Editing /etc/systemd/system/coturn.service.d/override.conf
### Anything between here and the comment below will become the new contents of the file
[Service]
ExecStartPre=/bin/sleep 30
### Lines below this comment will be discarded
### /lib/systemd/system/coturn.service
Dies ermöglicht den TURN-Server (auch nach einem Upgrade) mit einer Verzögerung von 30 Sekunden zu starten.
Zum Schluss wird der Service neu gestartet.
sudo service coturn restart
Ein Check zeigt, ob der TURN-Server funktioniert. Hierzu klickt man auf das Symbol neben dem Papierkorb in der Rubrik TURN-Server der Nextcloud. Wenn alles perfekt läuft ist, wird im Screenshot, ein grünes Häkchen sichtbar.
Check TURN-ServerCheck bestanden
Damit endet die Artikelserie Nextcloud auf dem RasPi. Viel Spaß beim Nachbauen!
Im Beitrag „SMLIGHT SLZB-07: OpenThread RCP Firmware flashen“ habe ich euch gezeigt, wie ihr die Openthread RCP Firmware auf den SMLIGHT SLZB-07 flasht. In diesem Beitrag zeige ich euch nun, wie ihr mit dem...
Eigentlich installiert man Programme und Anwendungen unter Linux über die Paketverwaltung des Systems. Es gibt jedoch auch alternative Paketsysteme wie Flatpac, Snap oder AppImages, die in der Regel ohne weitere Abhängigkeiten systemweit auf dem System starten. Der Vorteil liegt in den in sich geschlossenen Systemen der einzelnen Anwendungen. Der Nachteil ist ein etwas höherer Speicherbedarf der einzelnen Programme. Innerhalb der Community werden solche Formate auch kritisch gesehen, da sie einer Blackbox gleichen.
Zugriffsrechte Ubuntu 24.04
Anzeige der fehlenden Abhängigkeiten
AppImages können unter Ubuntu aktiviert werden, indem man nach einem Rechtsklick auf die Datei unter „Zugriffsrechte“ ein Häkchen bei „Datei als Programm ausführen“ setzt. Nun kann die Anwendung über einen Doppelklick auf diese Datei ausgeführt werden. Auf einem frisch installierten Ubuntu kann es jedoch vorkommen, dass sich die genannten AppImages trotz Freigabe zum Start nicht ausführen lassen. Der Grund dafür liegt in fehlenden Abhängigkeiten zum Starten dieser AppImages, die erst durch die Eingabe im Terminal sichtbar werden (siehe Screenshot).
Am Beispiel des Yubikey Manager sieht man, dass das Paket „FUSE“ zum Ausführen fehlt. Dieses kann jedoch ganz einfach mit dem Befehl
sudo apt install libfuse2t64
installiert werden. Anschließend sollte sich das AppImage ausführen lassen.
Ich habe mir kürzlich einen SMLIGHT SLZB-07 und einen SMLIGHT SLZB-07p7 gekauft. Ersteren um mit Thread irgendwann rumspielen zu können und letzteren als Ersatz für meinen Sonoff ZB Dongle-P. Wenn ihr auf’s Veröffentlichungsdatum dieses...
Als ich mit der Artikelserie zur Nextcloud auf dem Raspberry Pi begann, war mein Ziel, ein Tutorial zu erstellen, das es ermöglicht, eine Nextcloud auf dem Einplatinencomputer so zu installieren und zu konfigurieren, dass diese produktiv genutzt werden kann. Nextcloud ist mittlerweile mehr als nur eine Cloud. Nextcloud hat sich zu einem professionellen Büroprodukt entwickelt, das ich selbst täglich nutze.
In diesem Artikel zeige ich, wie man den Datenspeicher von der MicroSD auf eine SSD auslagert, um die Speicherkapazität der Nextcloud zu erweitern. Ich verwende dafür eine SanDisk Extreme mit einer Kapazität von 2TB.
Die Leser, die dieser Artikelreihe bisher gefolgt sind und alles auf dem Raspberry Pi nachgebaut haben, sollten die Version 29 installiert haben. Diejenigen, die etwas mutiger waren, haben bereits ein Upgrade auf Version 30 in den Verwaltungseinstellungen durchgeführt.
Installation
Bevor wir starten, sollte unbedingt ein Backup des gesamten Systems durchgeführt werden, um Datenverlust zu vermeiden, falls etwas schief geht.
Zuerst wird die externe SSD mit dem Raspberry Pi über den USB 3.0-Anschluss verbunden. Anschließend wird die SSD mithilfe des folgenden Befehls identifiziert.
sudo fdisk -l
Das System zeigt nun an, dass die SSD als /dev/sda1 eingehängt wurde. Durch die Eingabe von
sudo mkfs.ext4 /dev/sda1
Identifizierung der SSD im System
kann die SSD in Ext4 formatiert werden. Auf meinem System erschien eine Fehlermeldung, dass die SSD bereits eingehängt ist und daher nicht formatiert werden kann.
Fehlermeldung – /dev/sda1 is mounted
Daher muss die SSD zuerst wieder ausgehängt werden.
sudo umount -fl /dev/sda1
Anschließend wird die SSD, gemäß der bereits erwähnten Methode im Artikel, Ext4-formatiert. Die Abfrage wird durch die Eingabe von „y“ bestätigt.
sudo mkfs.ext4 /dev/sda1
Formatierung der SSD (Ext4)
Nun wird das Verzeichnis /media/ssd erstellt, in dem später das Datenverzeichnis auf der externen SSD liegen wird.
sudo mkdir /media/ssd
Danach wird das Verzeichnis mit dem Inhalt der SSD gemountet.
sudo mount /dev/sda1 /media/ssd
Damit die SSD auch nach einem Neustart korrekt eingebunden wird, trägt man sie mit der richtigen UUID in die /etc/fstab ein. Die benötigte UUID findet man über den Befehl:
sudo blkid /dev/sda1
Auslesen der UUID der SSD
Nun kann die fstab mit der entsprechenden Zeile ergänzt werden. Dieser Eintrag erfolgt direkt unter den beiden Hauptpartitionen (siehe Screenshot).
sudo nano /etc/fstab
Die hier von mir angegebene UUID ist natürlich durch die UUID der eigenen Festplatte zu ersetzen.
Dabei muss man mit größter Sorgfalt vorgehen, da das System bei einer falschen Eingabe möglicherweise nicht mehr starten wird. Ein vorheriges Backup bietet (wie oben schon erwähnt) Sicherheit. Nachdem alles korrekt eingegeben wurde, kann der Raspberry Pi neu gestartet werden.
sudo reboot
Wenn das System fehlerfrei neu gestartet ist, wird das Datenverzeichnis von der MicroSD-Karte auf die SSD verschoben. Dieser Vorgang kann je nach Größe einige Minuten dauern.
sudo mv /var/www/html/nextcloud/data /media/ssd
Nun muss der Nextcloud noch mitgeteilt werden, wo sich das Datenverzeichnis befindet. Dazu gehen wir in die config.php.
Das Data-Verzeichnis befindet sich jetzt auf der externen SSD. Falls ein Upgrade ansteht, kann dieses gleich durchgeführt werden.
Nextcloud – Upgrade auf Version 30.0.2Nextcloud – DashboardFestplatte sda1
Vorschau
Im nächsten und letzten Artikel dieser Reihe möchte ich zeigen, wie man Nextcloud mit einem TURN-Server erweitert, um Videokonferenzen mit Nextcloud Talk nutzen zu können.
Meine Website kofler.info läuft in einer virtuellen Maschine. Und diese VM läuft wiederum auf einem Root-Server bei Hetzner. Seit ca. 4 Jahren, störungsfrei. Als Virtualisierungssystem verwende ich KVM. Auf dem Root-Server laufen auch andere VMs, die ich für die Arbeit an meinen Büchern sowie für den Unterricht an der Fachhochschule brauche.
Das Setup hat sich in den letzten 15 Jahren immer wieder gewandelt, dennoch ich bin Hetzner treu geblieben (auch in anderen beruflichen Projekten). Dass ich mich vor 15 Jahren gerade für Hetzner entschieden habe, war Zufall. Danach sah ich keinen Grund für einen Wechsel. Bis vor einer Woche. Und das ist eine etwas längere Geschichte.
Update 13.1.2025: Hetzner hat in in Zusammenarbeit mit dem Hersteller einen Designfehler des betroffenen Mainboards gefunden und tauscht jetzt alle betroffenen Mainboards aus. Respekt! Weitere Infos:
Ich bin seit ca. 15 Jahren Kunde der Firma Hetzner. Ich betreibe dort privat den oben erwähnten Root-Server. Auf Hetzner läuft auch ein Server, den ich und ein Freund für eine gemeinsame Firma administrieren und auf dem diverse Kunden täglich arbeiten. Bei Hetzner laufen schließlich diverse Websites, die ich für Freunde und Verwandte betreue. Auch meine Domains (z.B. kofler.info) werden via Hetzner administriert und abgerechnet.
In meinem Linux-Buch verwende ich Hetzner neben amazon/AWS als Beispiel für die Ausführung von eigenen Servern bzw. Cloud-Instanzen. (Das ist keine Empfehlung, weder für die eine noch für die andere Firma! Und natürlich bekomme ich von beiden Firmen nichts dafür, dass ich sie als Beispiel verwende. Aber irgendwelche Firmen muss ich für Beispiel-Setups verwenden. Ich brauche Firmen, die im europäischen Raum und international Stellenwert haben. Ich habe im Buch keinen Platz für fünf oder zehn Beispiele/Hoster/Cloud-Anbieter. Also habe ich mich für diese beiden entschieden.)
Seit 15 Jahren bin ich zufriedener Kunde bei Hetzner. Ja, meine Server hatten in dieser Zeit auch Probleme, z.B. einen Harddisk-Ausfall, der dank RAID ohne Datenverlust blieb und wo die Disk mit minimaler Downtime ausgetauscht wurde. Ein Server, der nach knapp 4 Jahren Dauereinsatz allmählich instabil wurde und den ich deswegen ein paar Monate vor dem schon geplanten Upgrade austauschen musste. Aber prinzipiell hat immer alles bestens funktioniert, sowohl was die langjährige Stabilität meiner Server betrifft, als auch was den selten benötigten Support betrifft.
Im Vergleich zu großen Cloud-Anbietern (und insbesondere im Vergleich zu AWS) ist ein Root-Server bei Hetzner viel preisgünstiger. Und in der Abrechnung beinahe unendlich viel einfacher. Ein Fixpreis mit 20 TB Traffic (die ich noch nie gebraucht habe), keine komplizierte Zusammensetzung aus einem halben Dutzend im Voraus schwer kalkulierbarer Preiskomponenten. Alles in allem: Für mich hat das Preis/Leistungsverhältnis gepasst, und ich war mit der Leistung zufrieden.
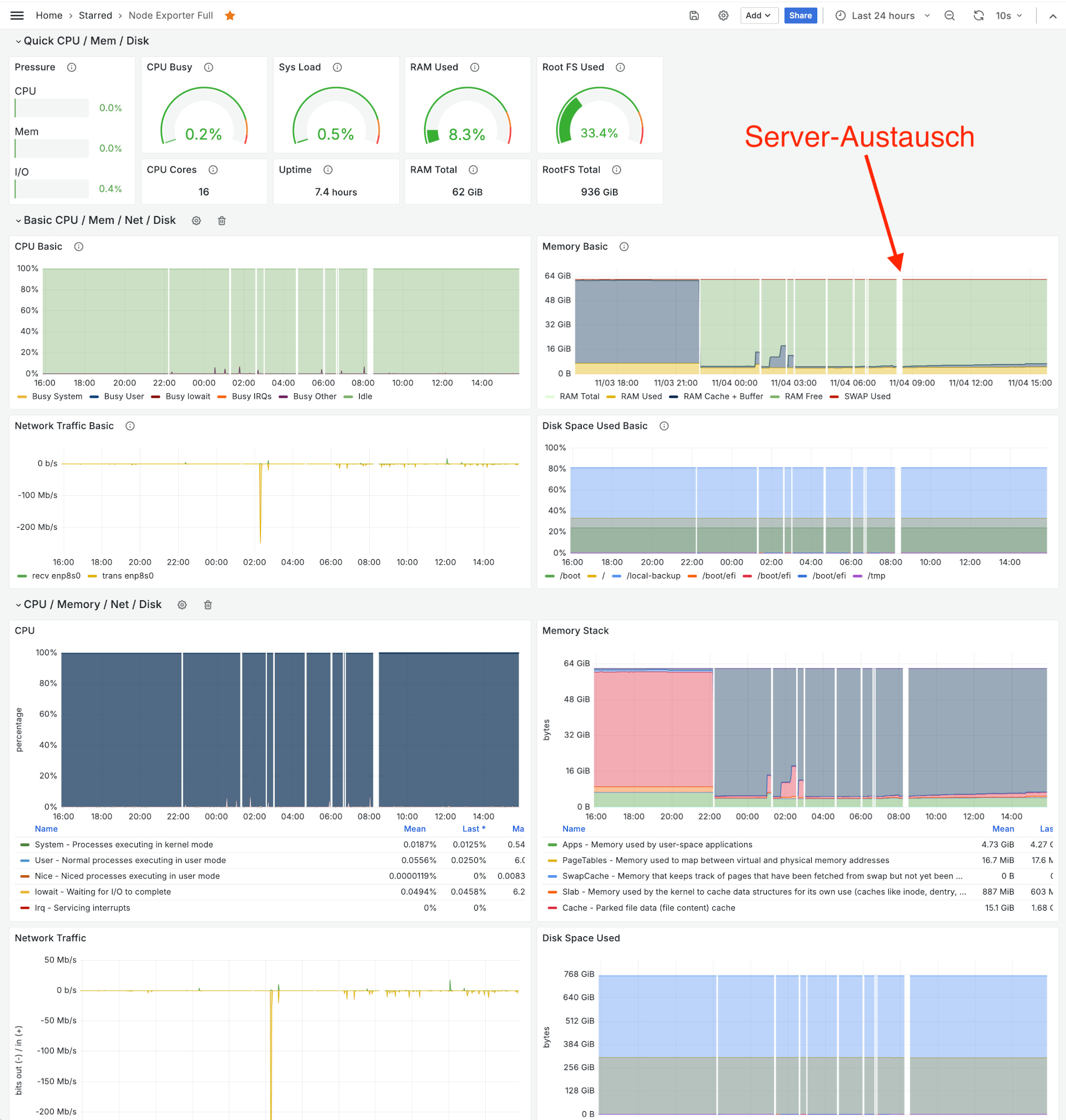
Ein neuer Server mit nur vier Monaten Lebenszeit
Im letzten Satz bin ich plötzlich ins Imperfekt gerutscht. Ich war zufrieden, ja, aber seit einer Woche bin ich massiv verunsichert. Ist Hetzner noch preisgünstig, oder ist das Angebot mittlerweile billig? Billig im Sinne, dass zwar der Preis stimmt, aber die Leistung nicht mehr? Seit ich Kunde bei Hetzner bin, ist die Firma zu einem riesigen Unternehmen geworden, das international auftritt. Geht Quantität vor Qualität?
Die Verunsicherung stammt von einem Server-Upgrade, das ich im April 2024 vorgenommen habe. Zur Ausführung eines großen LAMP-Systems (große Datenmengen, keine Virtualisierung!) habe ich einen AX52-Server in Betrieb genommen: AMD Ryzen 7700, 64 GB RAM, 4xPCIe-SSD mit je 1 TB. Die erste Unstimmigkeit trat schon vor der Installation auf: Im Live-System machte ich einen raschen SMART-Test für die vier SSDs:
for disk in /dev/nvme?n1; do echo $disk; smartctl -A $disk | grep -E 'Power On Hours|Data Units'; done
/dev/nvme0n1
Data Units Read: 220,843,669 [113 TB]
Data Units Written: 51,845,317 [26.5 TB]
Power On Hours: 3,675
/dev/nvme1n1
Data Units Read: 715,250,594 [366 TB]
Data Units Written: 411,316,958 [210 TB]
Power On Hours: 12,078
/dev/nvme2n1
Data Units Read: 3,680,708 [1.88 TB]
Data Units Written: 3,083,051 [1.57 TB]
Power On Hours: 2
/dev/nvme3n1
Data Units Read: 3,673,898 [1.88 TB]
Data Units Written: 3,082,770 [1.57 TB]
Power On Hours: 2
Ergebnis: Zwei fabriksneue SSDs, zwei weitere SSDs, die schon eine Weile im Einsatz waren. Mir ist klar, dass ich mit einem neuen Server nicht automatisch neue SSDs bekomme, aber 12.078 Betriebsstunden = 1 1/2 Jahre ist schon ordentlich. 210 TB written bedeutet außerdem ca. 1/3 der garantierten Endurance für 1 TB-SSDs (siehe z.B. hier). Mein Plan war, den Server wieder ein paar Jahre laufen zu lassen. Insofern habe mich die SMART-Ergebnisse unglücklich gemacht. Ich habe Hetzner kontaktiert, die fragliche SSD wurde auf Kulanz durch eine andere SSD ersetzt, deren Nutzungsdaten etwas geringer waren. OK.
Der neue Server lief in der Folge drei Monate ohne eine Störung. Dann begannen plötzliche Abstürze/Reboots, zuerst ein Reboot alle zwei bis drei Stunden, aber schon einen halben Tag später Reboots innerhalb weniger Minute. (Vielleicht noch ein wenig Background: Dieser Server läuft die meiste Zeit komplett im Leerlauf. Klassisches LAMP-System, viele Datenbanken, Mail-Server etc., aber geringe Nutzung.)
Ich habe den Hetzner-Support kontaktiert, dieser schlug vor, den Server auszutauschen und die vier SSDs in einen neuen Server zu stecken. Nach meiner Zustimmung war der Server eine Stunde später wieder stabil online. Zwar war der vorangegangene 1/2 Tag mit Ausfällen verbunden, aber immerhin nicht mit einem Datenverlust.
Faszinierend: Nach dem Austausch mussten ich nichts an der Konfiguration ändern. Auf meinen Wunsch blieben die IPv4- und IPv6-Adressen unverändert. Die Netzwerkkonfiguration mit Netplan (Ubuntu) funktionierte daher out of the box. Was mich mehr verblüffte: Auch der Boot-Prozess via EFI/GRUB funktionierte auf Anhieb. Ein Lob an den Hetzner-Support und an die Qualität des Setup-Generators für Neuinstallationen!
Unbeantwortet blieb allerdings meine Frage, was denn die Ursache des raschen Server-Tods sein könnte. Die Stromversorgung? Ein instabiler Prozessor? Ein schadhaftes Mainboard? Keine Antwort von Hetzner heißt wohl: Offenbar hatte ich eben Pech mit der Hardware. Sollte nicht passieren, lässt sich aber vielleicht nicht ganz ausschließen.
Einmal ist keinmal, zweimal ist einmal zu viel
Vor einer Woche hat sich das Spiel wiederholt. Mitten in der Nacht begannen wieder plötzliche Reboots, in der Früh lagen zwischen den Reboots nur noch Minuten.
Server-Monitoring mit Prometheus und Grafana
Erster unerwarteter Reboot am 3.11. um 22:13, dann 12 weitere Reboots innerhalb von 8 Stunden.
last | grep reboot
reboot system boot 6.8.0-48-generic Mon Nov 4 08:28 still running
reboot system boot 6.8.0-48-generic Mon Nov 4 08:01 - 08:12 (00:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:53 - 08:12 (01:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:44 - 08:12 (01:27)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:38 - 08:12 (01:33)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:02 - 08:12 (02:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:00 - 08:12 (02:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 05:53 - 08:12 (02:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 04:40 - 08:12 (03:32)
reboot system boot 6.8.0-48-generic Mon Nov 4 03:01 - 08:12 (05:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 02:36 - 08:12 (05:35)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:35 - 08:12 (06:36)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:17 - 08:12 (06:54)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:16 - 08:12 (06:55)
reboot system boot 6.8.0-48-generic Sun Nov 3 22:13 - 08:12 (09:58)
Genau das gleiche Verhalten wie vor vier Monaten! Etwas verzweifelt habe ich neuerlich Hetzner kontaktiert, die den Server ebenso schnell wie beim ersten Mal austauschten. Seither ist der Server (Stand: heute, 11.11.2024) seit einer Woche störungsfrei.
Diesmal war ich hartnäckiger, was die Ursachenergründung anging. Ich habe bei Hetzner dreimal nachgefragt, was die Fehlerursache sein und wie weitere Ausfälle vermieden werden können. Ich habe explizit gefragt, ob es Problem mit der Stromversorgung des Racks gibt, in dem der Server löuft, oder ob die AX52-Serie instabil ist. In diesem Fall wäre ein Austausch des Servers gegen ein Modell einer andere Serie eine Option für mich.
Alleine, alle Fragen blieben unbeantwortet. Und das ist wirklich ärgerlich!
Update 13.11.: Heute ist doch noch eine Antwort eingetroffen. Die fraglichen Server werden untersucht, aber es ist bisher keine Ursache bekannt.
Update 13.1.2025: Hetzner hat in in Zusammenarbeit mit dem Hersteller einen Designfehler des betroffenen Mainboards gefunden und tauscht jetzt alle betroffenen Mainboards aus. Respekt! Weitere Infos:
Die wenigen Server, die ich bei Hetzner betreibe, lassen naturgemäß keine statistisch wertvollen Aussagen zu. Ja, es kann tatsächlich sein, dass ich ZWEIMAL Pech hatte. Aber die Wahrscheinlichkeit dafür ist gering. Es wird also vermutlich eine plausible Begründung geben. Auf jeden Fall hat mein Vertrauen in den langjährigen Betrieb von Servern bei Hetzner einen massiven Dämpfer erfahren.
Unter den Lesern meiner Bücher, meines Blogs, meines mastodon-Auftritts gibt es sicher Admins, die Erfahrungen mit Hetzner haben. Ich würde mich über Rückmeldungen, egal ob privat per Mail, im Forum meiner Website oder auf mastodon, sehr freuen.
Sind Sie mit Hetzner so zufrieden, wie ich es bis vor kurzem war?
Haben Sie negative Erfahrungen gemacht?
Hat sich in den letzten Jahren etwas geändert?
Wie lange lassen Sie einen Root-Server laufen, wenn alles funktioniert? (Mein Zielwert war immer vier Jahre.)
Ist der Root-Server für Sie tot? D.h., ist die Cloud die Alternative? (Cloud-Angebote mit großen Disks sind allerdings ausgesprochen teuer.)
Und, vielleicht am interessantesten: Können Sie europäische Alternativen empfehlen? (Aus Datenschutzgründen ist ein US-Rechenzentrum keine wünschenswerte Alternative.)
Ich bedanke mich schon jetzt für jede Rückmeldung.
PS: Der eigene Betrieb von Servern ist für mich als Privatperson keine Option.
Raspberry Pi OS »Bookworm« verwendet bekanntlich auf den Modellen 4* und 5 standardmäßig Wayland. Dabei kam als sogenannter »Compositor« das Programm Wayfire zum Einsatz. (Der Compositor ist unter anderem dafür zuständig, Fenster am Bildschirm anzuzeigen und mit einem geeigneten Fensterrahmen zu dekorieren.)
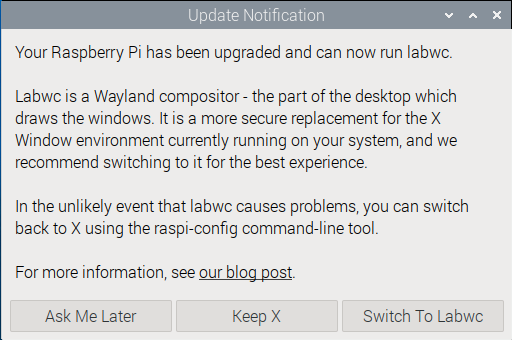
Mit dem neuesten Update von Raspberry Pi OS ändern sich nun zwei Dinge:
Anstelle von Wayfire kommt ein anderer Compositor zum Einsatz, und zwar labwc (GitHub).
Wayland kommt auf allen Raspberry Pis zum Einsatz, auch auf älteren Modellen.
Wenn Sie auf Ihrem Raspberry Pi das nächste Update durchführen, werden Sie bei nächster Gelegenheit gefragt, ob Sie auf labwc umstellen möchten. Aktuell werden Sie keinen großen Unterschied feststellen — labwc sollte genau wie wayfire funktionieren (vielleicht ein klein wenig effizienter). Langfristig haben Sie keine große Wahl: Die Raspberry Pi Foundation hat angekündigt, dass sie sich in Zukunft auf labwc konzentrieren und wayfire nicht weiter pflegen wird. Nach der Auswahl wird Ihr Raspberry Pi sofort neu gestartet.
Sie haben die Wahl: Wollen Sie X verwenden oder Wayland mit labwc
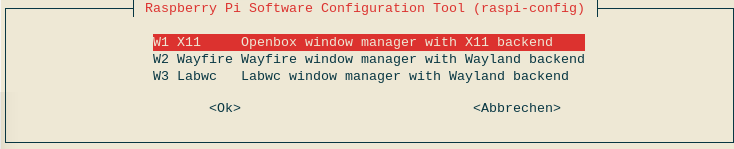
Alternativ können Sie die Einstellung auch mit sudo raspi-config durchführen. Unter Advanced Options / Wayland haben Sie die Wahl zwischen allen drei Optionen.
Einstellung des Grafiksystems in raspi-config
Bei meinen Tests stand nach dem Umstieg auf labwc nur noch das US-Tastatur-Layout zur Verfügung. Eine Neueinstellung in Raspberry Pi Configuration löste dieses Problem. Auch die Monitor-Konfiguration musste ich wiederholen. Dabei kommt auch ein neues Tool zum Einsatz(raindrop statt bisher arandr), das optisch aber nicht von seinem Vorgänger zu unterscheiden ist.
Ansonsten habe ich bei meinen Tests keinen großen Unterschied festgestellt. Alles funktioniert wie bisher.
Heute zeige ich, wie man die aktuelle Version 24.8 von LibreOffice in Ubuntu 24.04 LTS installiert. Alternativ kann dies über das Anwendungszentrum mit Snap im Kanal latest/candidate erfolgen (siehe Screenshot). Da ich jedoch die Paketverwaltung APT bevorzuge, werde ich diesen Weg erläutern.
Anwendungszentrum Ubuntu – LibreOffice
Installation
Mit der Long-Term-Support-Version Ubuntu 24.04 von Canonical wird standardmäßig LibreOffice 24.2 ausgeliefert. Wenn man jedoch die aktuelle Version 24.8 auf seinem System haben möchte, kann man dies einfach über das Repository des Entwicklers nachholen. Dazu fügt man die Paketquelle über das Terminal hinzu
sudo add-apt-repository ppa:libreoffice/ppa
und liest diese neu ein.
sudo apt update
Danach wird LibreOffice über
sudo apt upgrade
auf die Version 24.8 aktualisiert. Klappt das nicht, dann wird das Paket einfach mit
sudo apt install libreoffice
nachinstalliert.
Tipp
Sollte das deutsche Sprachpaket fehlen, kann dieses problemlos mit
Falls ihr meinen Beitrag „Was läuft auf dem Home Server?“ gelesen habt, wisst ihr, dass auf meinem Home Server unter anderem ein LXC mit Stirling PDF vorhanden ist. Ich hatte Stirling PDF aber noch...
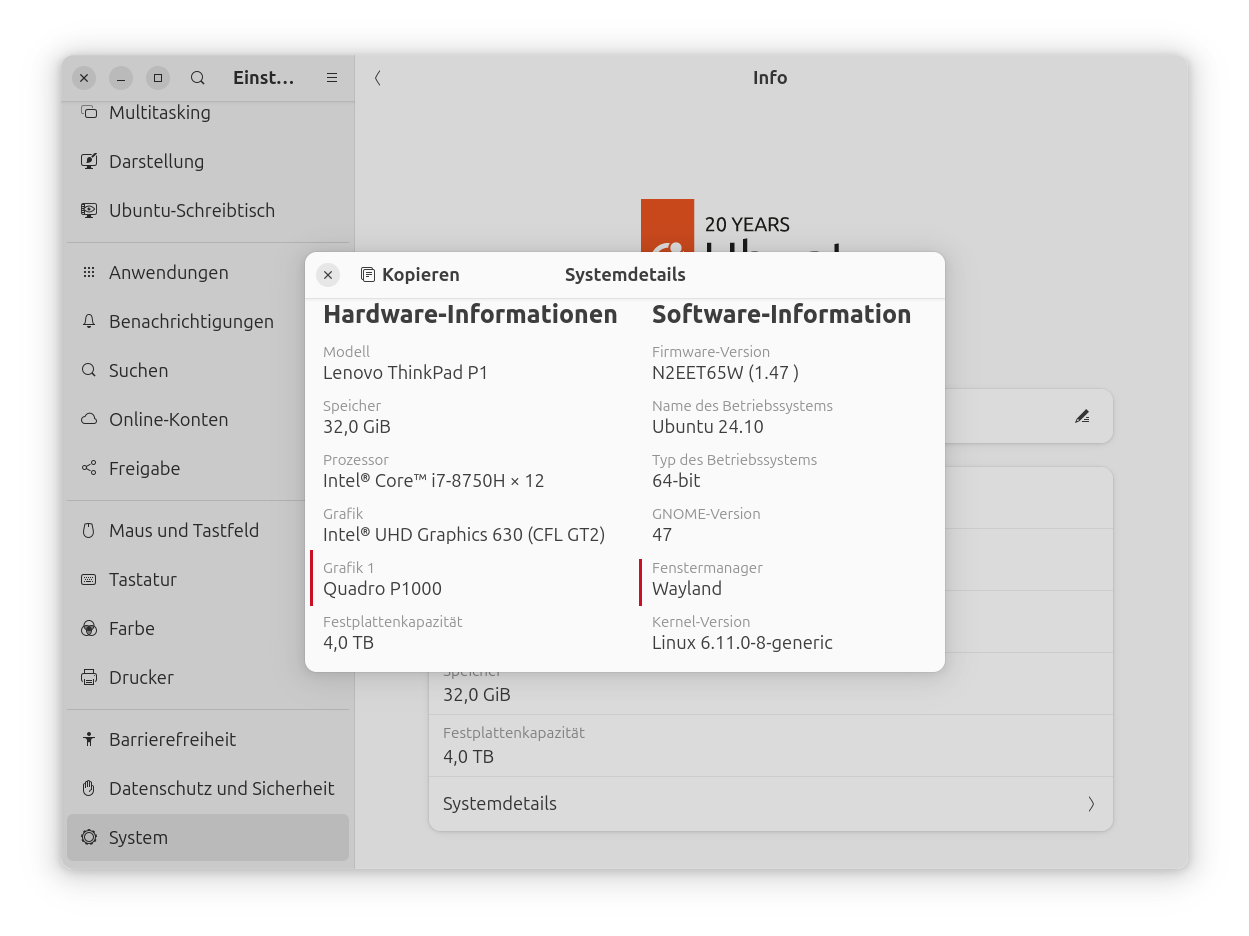
Eigentlich hatte ich nicht vorgehabt, über Ubuntu 24.10 zu schreiben. Es ist kein LTS-Release, dramatische Neuerungen gibt es auch nicht. Aber dann ergab sich überraschend die Notwendigkeit, eine native Ubuntu-Installation auf meinem Notebook (Lenovo P1 gen1) durchzuführen. Außerdem feiert Ubuntu den 20. Geburtstag.
Also habe ich doch ein paar Worte (gar nicht so wenige) zum neuesten Release geschrieben. Der Text ist launiger geworden als beabsichtigt. Er konzentriert sich ausschließlich auf die Desktop-Nutzung, also auf Ubuntu für Büro-, Admin- oder Entwicklerrechner. Der Artikel bringt auch ein wenig meinen Frust zum Ausdruck, den ich mit Linux am Desktop zunehmend verspüre.
Installation
Ich lebe normalerweise in einer weitgehend virtuellen Linux-Welt. Auf meinem Arbeits-Notebook läuft zwar Arch Linux, aber neue Distributionen teste ich meistens in virtuellen Maschinen, viele meiner Server-Installationen befinden sich in Cloud-Instanzen, die Software-Entwicklung erfolgt in Docker-Containern. Überall Linux, aber eben meist eine (oder zwei) virtuelle Schichten entfernt.
Insofern ist es wichtig, hin und wieder auch eine »echte« Installation durchzuführen. Testkandidat war in diesem Fall ein fünf Jahre altes Lenovo P1 Notebook mit Intel-CPU und NVIDIA-GPU. Ich wollte Ubuntu auf eine noch leere 2-TB-SSD installieren, dabei aber nur 400 GiB nutzen. (Auch ein paar andere Distributionen verdienen im nächsten Jahr ihre Chance in der realen Welt …)
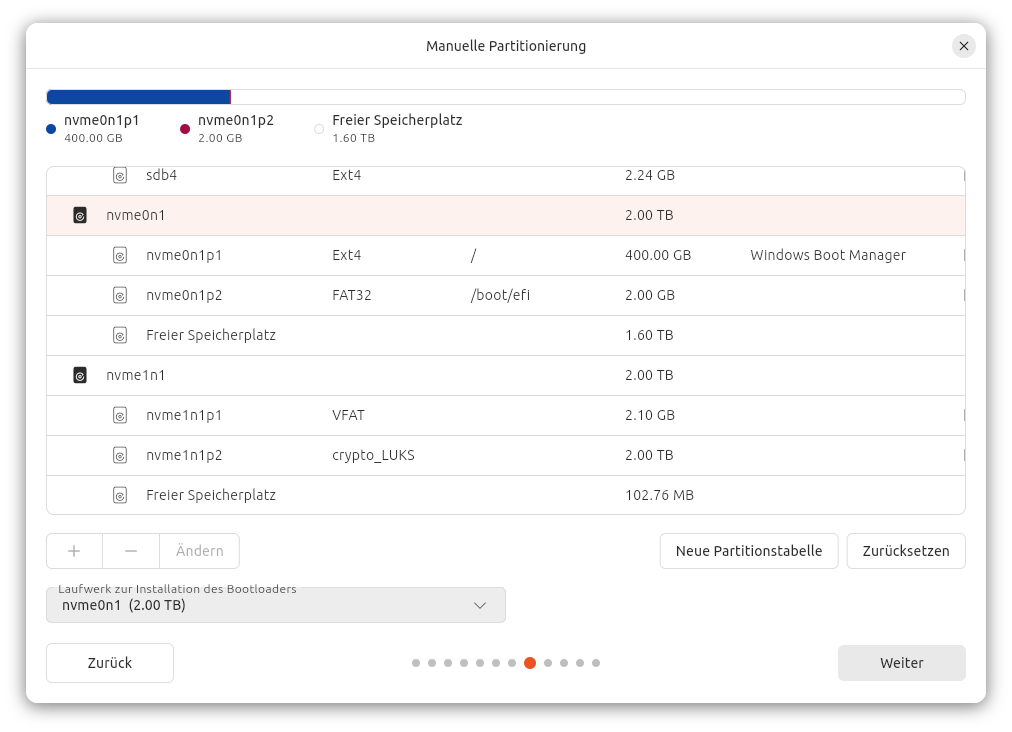
Weil ich nicht die ganze SSD nutzen möchte, werde ich zur manuellen Partitionierung gezwungen. So weit, so gut, allerdings fehlen dort die LVM-Funktionen. Somit ist es für Laien unmöglich, Ubuntu verschlüsselt in ein Logical Volume zu installieren. (Profis können sich Ihr Setup mit parted, pvxxx, vgxxx, lvxxx und cryptsetup selbst zusammenbasteln. Ich habe das aber nicht getestet.)
Bei der manuellen Partitionierung ist es unmöglich, die EI-Partition an den Beginn der Partitionstabelle zu stellen. Die /-Partition wird mit ‚Windows Boot Manager‘ beschriftet, warum auch immer. Die zweite SSD enthält eine schon vorhandene Arch-Linux-Installation.
Noch ein Ärgernis der manuellen Partitionierung: Das Setup-Programm kümmert sich selbst darum, eine EFI-Partition einzurichten. Gut! Aber auf einer aktuell leeren Disk wird diese kleine Partition immer NACH den anderen Partitionen platziert. Mir wäre lieber gewesen, zuerst 2 GiB EFI, dann 400 GiB für /. Solange es keine weiteren Partitionen gibt, hätte ich so die Chance, die Größe von / nachträglich zu ändern. Fehlanzeige. Im Übrigen hat das Setup-Programm auch die von mir gewählte Größe für die EFI-Partition ignoriert. Ich wollte 2 GiB und habe diese Größe auch eingestellt (siehe Screenshot). Das Setup-Programm fand 1 GiB ausreichend und hat sich durchgesetzt.
Zusammenfassung der Installationseinstellungen
Für die meisten Linux-Anwender sind die obigen Anmerkungen nicht relevant. Wenn Sie Ubuntu einfach auf die ganze Disk installieren wollen (real oder in einer virtuellen Maschine), oder in den freien Platz, der neben Windows noch zur Verfügung steht, dann klappt ja alles bestens. Nur Sonderwünsche werden nicht erfüllt.
Letzte Anmerkung: Ich wollte auf dem gleichen Rechner kürzlich Windows 11 neu installieren. (Fragen Sie jetzt nicht, warum …) Um es kurz zu machen — ich bin gescheitert. Das Windows-11-Setup-Programm aus dem aktuellsten ISO-Image glänzt in moderner Windows-7-Optik. Es braucht anscheinend zusätzliche Treiber, damit es auf einem fünf Jahre alten Notebook auf die SSDs zugreifen kann. (?!) Mit der Hilfe von Google habe ich entdeckt, dass er wohl die Intel-RST-Treiber für die Intel-CPU des Rechners haben will. Die habe ich mir runtergeladen, auf einem anderen Windows-Rechner (wird selbstverständlich vorausgesetzt) ausgepackt, auf einen zweiten USB-Stick gegeben und dem Windows-Installer zum Fraß vorgeworfen. Aber es half nichts. Die Treiber wären angeblich inkompatibel zu meiner Hardware. Ich habe fünf Stunden alles Mögliche probiert, das Internet und KI-Tools befragt, diverse Treiber von allen möglichen Seiten heruntergeladen. Aussichtslos. Ich habe mir dann von Lenovo ein Recovery-Image (Windows 10, aber egal) für mein Notebook besorgt. Es bleibt bei der Partitionierung in einem Endlos-Reboot hängen. Vielleicht, weil vor fünf Jahren 2-TB-SSDs unüblich waren? Also: Wer immer (mich selbst eingeschlossen) darüber jammert, wie schwierig eine Linux-Installation doch sei, hat noch nie versucht, Windows auf realer Hardware zu installieren. (Ich weiß, in virtuellen Maschinen klappt es besser.) Jammern über Einschränkungen bei der Ubuntu-Installation ist Jammern auf hohen Niveau. Der Ubuntu-Installer funktioniert ca. 100 Mal besser als der von Windows 11!
Das App Center
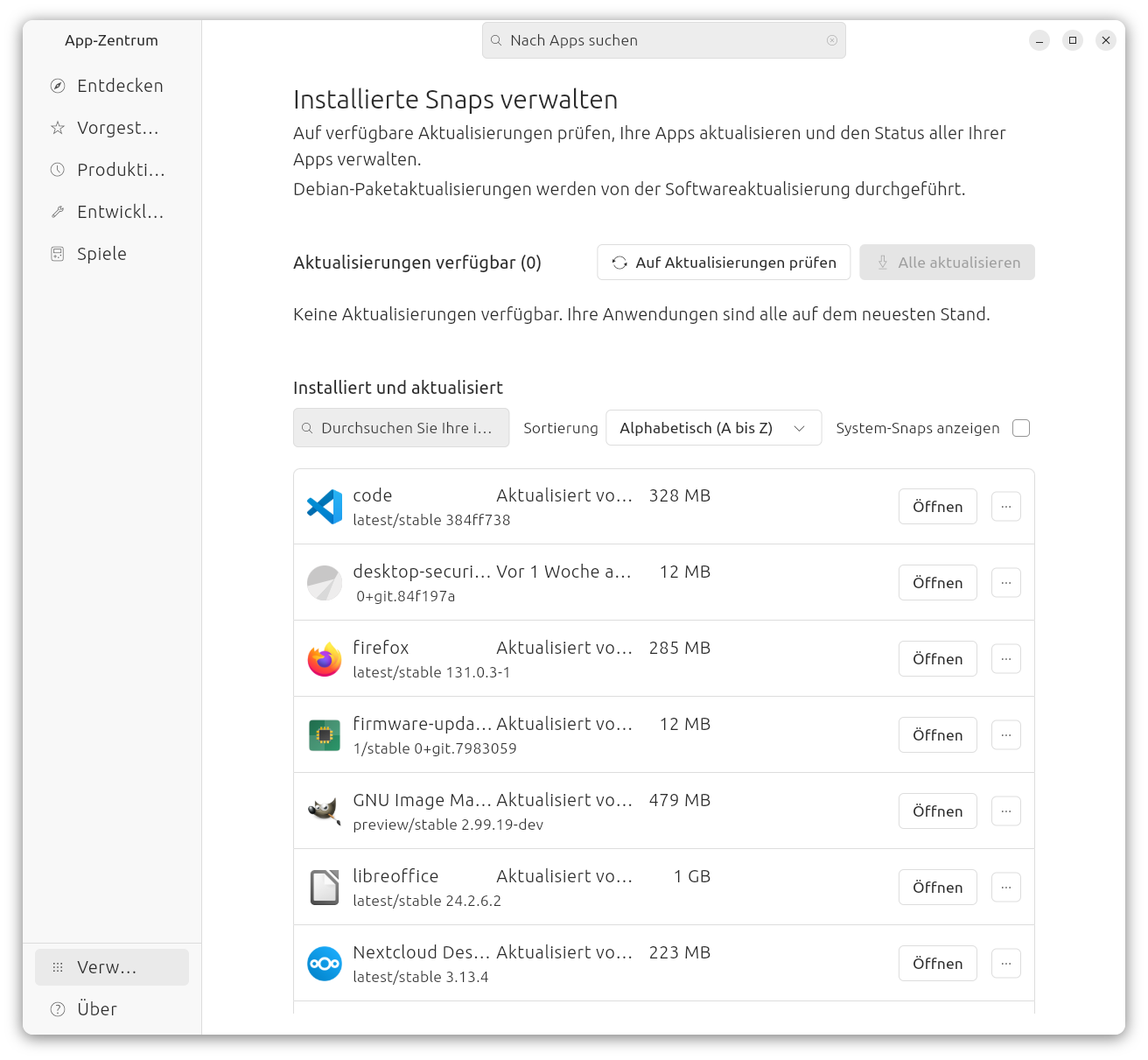
Obwohl ich bekanntermaßen kein großer Snap-Fan bin, habe ich mich entschieden, Ubuntu zur Abwechslung einmal so zu verwenden, wie es von seinen Entwicklern vorgesehen ist. Ich habe daher einige für mich relevante Desktop-Programme aus dem App Center in Form von Snap-Paketen installiert (unter anderem eine Vorabversion von Gimp 3.0, VS Code, den Nextcloud Client und LibreOffice). Auf den Speicherverbrauch habe ich nicht geschaut, Platz auf der SSD und im RAM ist ja genug.
Das Ubuntu App Center stellt ausschließlich Snap-Pakete von snapcraft.io zur Auswahl
Grundsätzlich hat vieles funktioniert, aber gemessen daran, wie lange es nun schon Snaps gibt, stören immer noch erstaunlich viele Kleinigkeiten:
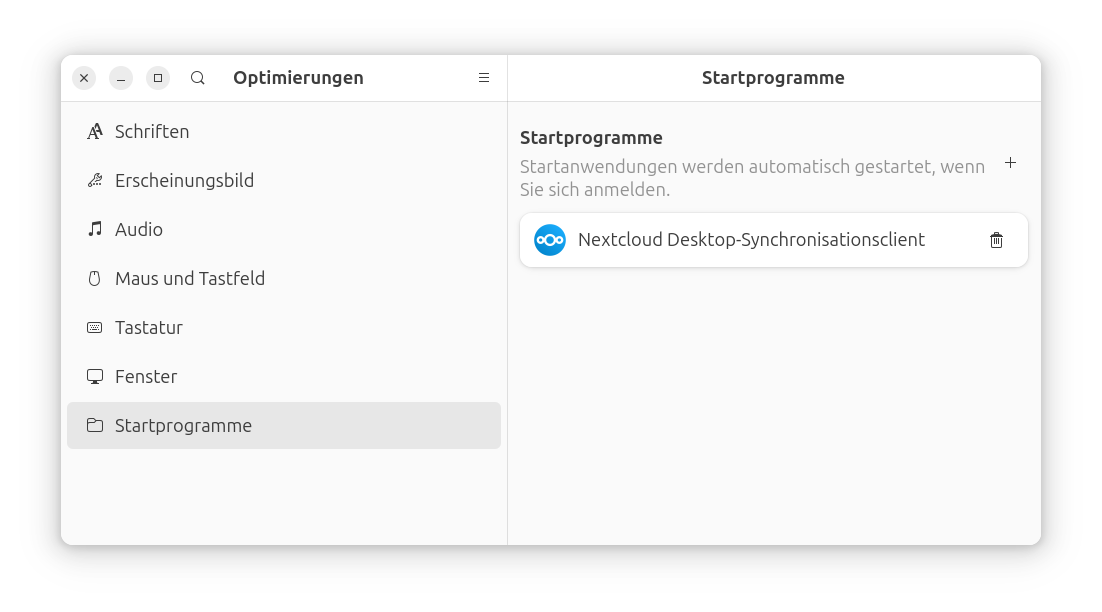
Im Nextcloud-Client hatte ich im ersten Versuch Probleme bei der Verzeichnisauswahl. Diese folgte relativ zum Snap-Installationsverzeichnis statt relativ zu meinem Home-Verzeichnis. In der Folge scheiterte die Synchronisation wegen fehlender Schreibrechte. Das ließ sich relativ schnell beheben, hätte bei Einsteigern aber sicher einiges an Verwirrung verursacht. Noch ein Problem: Der Nextcloud wird NICHT automatisch beim Login gestartet, obwohl die entsprechende Option in den Nextcloud-Einstellungen gesetzt ist. Das muss manuell behoben werden (am einfachsten in gnome-tweaks alias Optimierungen im Tab Startprogramme).
Damit der Nextcloud-Client automatisch startet, nehmen Sie am besten »gnome-tweaks« (Optimierungen) zu Hilfe
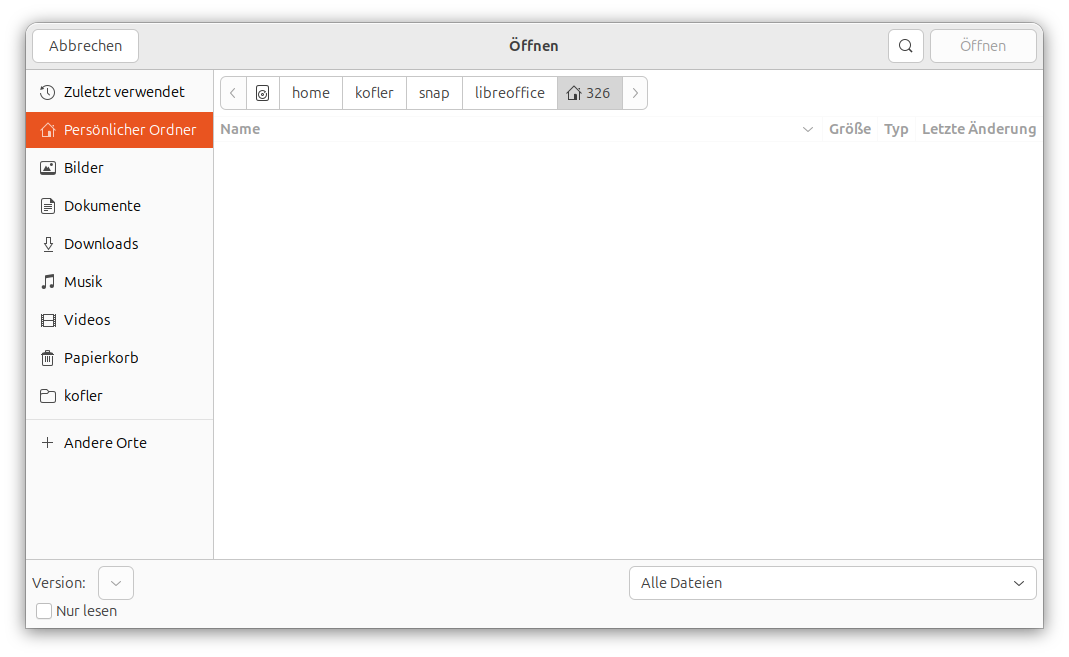
Der Versuch, LibreOffice nach der Installation aus dem Ubuntu Store zu starten (Button Öffnen), führt direkt in den LibreOffice-Datenbank-Assistenten?! Weil ich keine Datenbank einrichten will, breche ich ab — damit endet LibreOffice wieder. Ich habe LibreOffice dann über das Startmenü (ehemals ‚Anwendungen‘) gestartet — funktioniert. Warum nicht gleich? Das nächste Problem tritt auf, sobald ich eine Datei öffnen möchte. Im Dateiauswahldialog drücke ich auf Persönlicher Ordner — aber der ist leer! Warum? Weil wieder alle Verzeichnisse (inkl. des Home-Verzeichnisses) relativ zum Snap-Installationsordner gelten. Meine Güte! Ja, ich kann mit etwas Mühe zu meinem wirklichen Home-Verzeichnis navigieren, aber so treibt man doch jeden Einsteiger zum Wahnsinn. Ab dem zweiten Start funktioniert es dann, d.h. LibreOffice nutzt standardmäßig mein ‚richtiges‘ Home-Verzeichnis.
Snap-Programme wissen nicht immer, wo ‚Home‘ ist.
Zwischendurch ist der App Center abgestürzt. Es kommt auch vor, dass das Programm plötzlich ohne ersichtlichen Grund einen CPU-Core zu 100 % nutzt. Das Programm beenden hilft.
Updates des App Center (selbst ein Snap-Paket), während dieser läuft, sind weiter unmöglich.
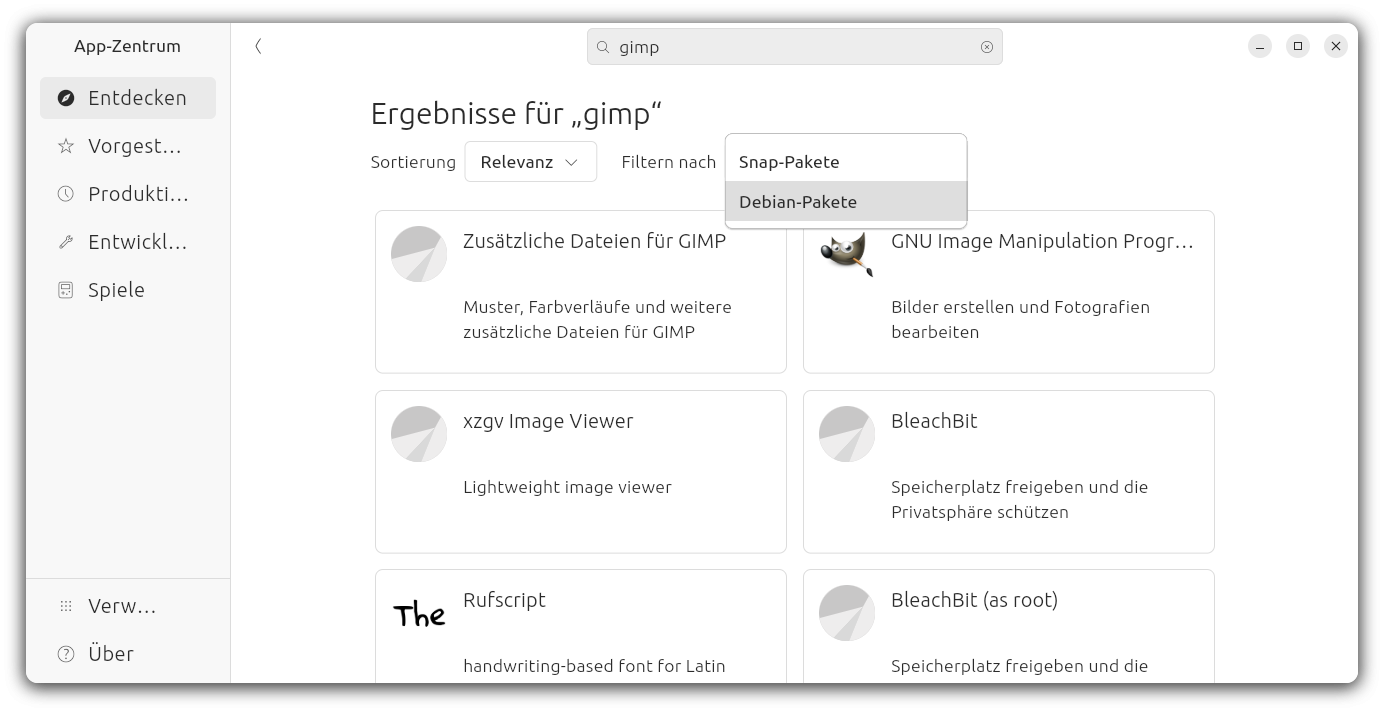
Es gibt auch gute Nachrichten: Ein Klick auf ein heruntergeladenes Debian-Paket öffnet das App Center, und dieses kann nun tatsächlich das Debian-Paket installieren. (Es warnt langatmig, wie unsicher die Installation von Paketen unbekannter Herkunft ist, aber gut. In gewisser Weise stimmt das ja.)
Nicht nur dass, wenn Sie den Suchfilter korrekt einstellen, können Sie im App Center sogar nach Debian-Paketen suchen und direkt installieren. Ganz intuitiv ist das nicht, aber es ist ein Fortschritt.
Sie können im App Center nun auch nach Debian-Paketen suchen
NVIDIA und Wayland
Ubuntu 24.10 ist die erste Ubuntu-Version, bei der meine NVIDIA-Grafikkarte out of the box nahezu ohne Einschränkungen funktioniert. Ich habe während der Installation darum gebeten, auch proprietäre Treiber zu installieren. Beim ersten Start werden dementsprechend die NVIDIA-Treiber geladen. Ab dem ersten Login ist tatsächlich Wayland aktiv und nicht wie (bei meiner Hardware in der Vergangenheit) X.org.
Die Installation proprietärer Treiber (inkl. NVIDIA) während der Installation ist ein Kinderspiel.NVIDIA und Wayland kooperieren
Ich habe eine Weile in mit den Anzeige-Einstellungen gespielt: Zwei Monitore in unterschiedlichen Varianten, fraktionelle Skalierung (unscharf, aber prinzipiell OK) usw. Obwohl ich mir Mühe gegeben habe, das Gegenteil zu erreichen: Es hat wirklich jedes Monitor-Setup funktioniert. Ich würde das durchaus als Meilenstein bezeichnen. (Your milage may vary, wie es im Englischen so schön heißt. Alte Hardware ist beim Zusammenspiel mit Linux oft ein Vorteil.)
Na ja, fast alles: Ich war dann so übermütig und habe das System in den Bereitschaftsmodus versetzt. Am nächsten Tag wollte ich mich wieder anmelden. Soweit ich erkennen konnte, ist der Rechner gelaufen (die ganze Nacht??), er reagierte auf jeden Fall auf ping. (Ich war so leichtsinnig und hatte noch keinen SSH-Server installiert. Großer Fehler!) Auf jeden Fall blieben sowohl das Notebook-Display als auch der angeschlossene Monitor schwarz. Ich konnte drücken, wohin ich wollte, den Display-Deckel auf und zu machen, das HDMI-Kabel lösen und wieder anstecken — aussichtslos. Einzige Lösung: brutaler Neustart (Power-Knopf fünf Sekunden lang drücken). Und ich hatte schon gedacht, es wäre ein Wunder passiert …
Und noch ein kleines Detail: Drag&Drop-Operationen zicken (z.B. von Nautilus nach Chrome, Bilder in die WordPress-Mediathek oder Dateien in die Weboberfläche von Nextcloud oder Moodle hochladen). Das ist seit fünf Jahren ein Wayland-Problem. Es funktioniert oft, aber eben nicht immer.
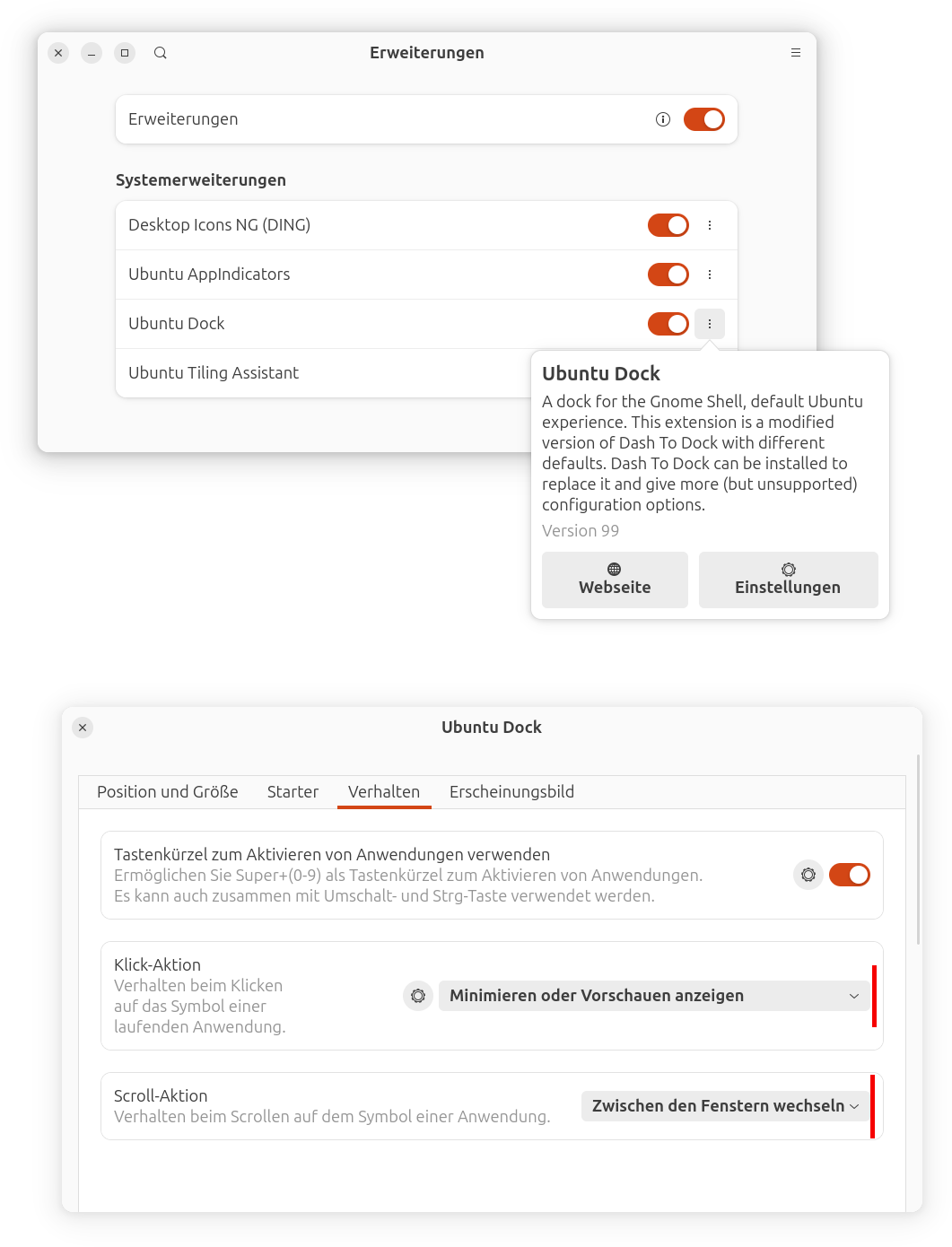
Ubuntu Dock
Das Ubuntu-Dock wird durch eine Ubuntu-eigene Gnome Shell Extension realisiert, die im Wesentlichen Dash to Dock entspricht. (Tatsächlich handelt es sich um einen Klon/Fork dieser Erweiterung.)
In den Gnome-Einstellungen unter Ubuntu-Schreibtisch können allerdings nur rudimentäre Einstellungen dieser Erweiterung verändert werden. Das ist schade, weil es ja viel mehr Funktionen gibt. Einige davon (per Mausrad durch die Fenster wechseln, per Mausklick Fenster ein- und wieder ausblenden) sind aus meiner Sicht essentiell.
Um an die restlichen Einstellungen heranzukommen, müssen Sie das vorinstallierten Programm Erweiterungen starten. Von dort gelangen Sie in den vollständigen Einstellungsdialog der Erweiterung.
Der Weg in den erweiterten Einstellungsdialog für das Ubuntu Dock
20 Jahre Ubuntu
Ubuntu hat den Linux-Desktop nicht zum erhofften Durchbruch verholfen, aber Ubuntu und Canonical haben den Linux-Desktop auf jeden Fall deutlich besser gemacht. Geld ist mit dem Linux-Desktop wohl keines zu verdienen, das hat auch Canonical erkannt. Umso höher muss man es der Firma anrechnen, dass sie sich nicht ausschließlich den Themen Server, Cloud und IoT zuwendet, sondern weiter Geld in die Desktop-Entwicklung steckt.
Die Linux-Community hat Ubuntu und Canonical viel zu verdanken. Und so schließe ich mich diversen Glückwünschen aus dem Netz an und gratuliere Ubuntu ganz herzlich zum 20-jährigen Jubiläum. »Wir hätten dich sonst sehr vermisst«, heißt es in manchen Geburtstagsliedern. Wie sehr trifft das auf Ubuntu zu!
Fazit
Linux im Allgemeinen, Ubuntu im Speziellen funktioniert als Desktop-System gut, zu 90%, vielleicht sogar zu 95%. Seit Jahren, eigentlich schon seit Jahrzehnten. Na ja, zumindest seit einem Jahrzehnt.
Aber die fehlenden paar Prozent — an denen scheint sich nichts zu ändern. Und das ist schade, weil es ja so dringend eine Alternative zum goldenen Käfig (macOS) bzw. dem heillosen Chaos (Windows, bloatware included TM) bräuchte.
Profis können sich mit Linux als Desktop-System arrangieren und profitieren von den vielen Freiheiten, die damit verbunden sind. Aber es fällt mir seit Jahren immer schwerer, Linux außerhalb dieses Segments zu empfehlen.
Linux hält unsere (IT-)Welt server-seitig am Laufen. Praktisch jeder Mensch, der einen Computer oder ein Smartphone verwendet, nutzt täglich Dienste, die Linux-Server zur Verfügung stellen. Warum ist der kleine Schritt, um Linux am Desktop zum Durchbruch zu verhelfen, offenbar zu groß für die Menschheit (oder die Linux-Entwicklergemeinde)?
Da auf meinem Server einige Container laufen, wurde durch mein Rollout des Containers Tubearchivist der Platz langsam eng. Hier habe ich mich entschlossen, den Standardspeicherplatz von Docker auf eine der 6 TB Datenpools zu verschieben. Das Umschreiben des Servicekonfigurationsdatei innerhalb von SystemD wäre hier der falsche Weg. Der richtige Weg ist hier JSON-Konfigurationsdatei des Daemon von ... Weiterlesen
In einer Zeit, in der immer mehr Daten digital gespeichert werden, ist es wichtiger denn je, sich Gedanken über die Sicherheit und den Schutz der eigenen Daten zu machen. Cloudspeicherung bietet eine bequeme Möglichkeit, Daten zu sichern und von überall aus darauf zuzugreifen. Doch viele Nutzer sind besorgt über die Sicherheit ihrer Daten in der Cloud und suchen nach einer Alternative, die ihnen mehr Kontrolle über ihre Daten gibt. Die Nextcloud ist eine solche Alternative, die Sicherheit, Flexibilität und Datenschutz bietet.
Was ist Nextcloud?
Nextcloud ist eine Open-Source-Plattform für die Speicherung und Synchronisierung von Daten. Sie wurde im Jahr 2016 als Abspaltung von OwnCloud ins Leben gerufen und wird von einer Community von Entwicklern und Benutzern ständig weiterentwickelt. Nextcloud bietet ähnliche Funktionen wie andere Cloudspeicherlösungen, darunter die Möglichkeit, Dateien hochzuladen, zu teilen und zu synchronisieren, Kalender und Kontakte zu verwalten und vieles mehr.
Sicherheit und Datenschutz
Einer der Hauptvorteile von Nextcloud ist die Sicherheit, die sie bietet. Da Nextcloud eine Self-Hosted-Lösung ist, haben Benutzer die volle Kontrolle über ihre Daten und können selbst entscheiden, wo sie gespeichert werden. Dies bedeutet, dass Benutzer ihre Daten auf ihren eigenen Servern speichern können, anstatt sie einem Drittanbieter anvertrauen zu müssen. Darüber hinaus bietet Nextcloud Verschlüsselungsoptionen, um die Sicherheit der Daten zu gewährleisten.
Nextcloud legt großen Wert auf Datenschutz. Die Plattform bietet Funktionen wie End-to-End-Verschlüsselung, um sicherzustellen, dass sowohl die Datenübertragung als auch die Speicherung der Daten sicher sind. Nextcloud ermöglicht es Benutzern auch, ihre eigenen Nutzungsbedingungen festzulegen und zu kontrollieren, wer Zugriff auf ihre Daten hat. Dies gibt Benutzern ein hohes Maß an Kontrolle und Privatsphäre über ihre Daten.
Flexibilität und Integration
Nextcloud zeichnet sich auch durch ihre Flexibilität aus. Die Plattform bietet eine Vielzahl von Apps und Erweiterungen, die es Benutzern ermöglichen, die Funktionalität von Nextcloud nach ihren individuellen Bedürfnissen anzupassen. Dies reicht von der Integration mit anderen Diensten und Anwendungen bis hin zur Anpassung des Benutzeroberfläche. Benutzer können auch Nextcloud mit verschiedenen Plugins erweitern, um zusätzliche Funktionen hinzuzufügen.
Nextcloud ist auch in der Lage, mit verschiedenen Geräten und Betriebssystemen zu interagieren. Benutzer können Nextcloud auf verschiedenen Geräten wie Desktop-Computern, Tablets und Smartphones verwenden und von überall aus auf ihre Daten zugreifen. Die Plattform bietet auch Unterstützung für verschiedene Betriebssysteme wie Windows, macOS und Linux.
Fazit
Die Nextcloud ist eine sichere und flexible Alternative zur Cloudspeicherung, die Benutzern mehr Kontrolle über ihre Daten bietet. Mit Funktionen wie Verschlüsselung, Datenschutz und flexiblen Erweiterungsmöglichkeiten ist Nextcloud die ideale Lösung für alle, die ihre Daten sicher und privat speichern möchten. Nextcloud ist eine Open-Source-Lösung, die von einer großen Community von Entwicklern und Benutzern unterstützt wird, so dass Benutzer sicher sein können, dass ihre Daten in guten Händen sind. Wenn man auf der Suche nach einer sicheren und flexiblen Cloudspeicherlösung ist, ist Nextcloud die richtige Wahl.
Wer meiner Artikelreihe „Nextcloud auf dem RasPi“ gefolgt ist und alle Schritte nacheinander umgesetzt hat, sollte erfolgreich eine Nextcloud 29 auf dem Raspberry Pi installiert haben, die über ein SSL-Zertifikat von Let’s Encrypt aus dem Internet erreichbar ist. Obwohl inzwischen Version 30 am 14.09.2024 veröffentlicht wurde, wird diese noch nicht im Stable-Zweig bereitgestellt. Daher werde ich nun auf die Behebung der verbleibenden Fehler in Nextcloud 29 eingehen.
Fehlermeldungen in Nextcloud 29
Es fällt sicherlich auf, dass im installierten System in den Verwaltungseinstellungen zahlreiche Fehlermeldungen aufgelaufen sind. Diese müssen nun behoben und beseitigt werden.
Ihr Datenverzeichnis und Ihre Dateien sind wahrscheinlich vom Internet aus erreichbar. Die .htaccess-Datei funktioniert nicht. Es wird dringend empfohlen, Ihren Webserver dahingehend zu konfigurieren, dass das Datenverzeichnis nicht mehr vom Internet aus erreichbar ist oder dass Sie es aus dem Document-Root-Verzeichnis des Webservers herausverschieben.
Das PHP-Speicherlimit liegt unterhalb des empfohlenen Wertes von 512 MB.
Die PHP-Konfigurationsoption „output_buffering“ muss deaktiviert sein
Ihr Webserver ist nicht ordnungsgemäß für die Auflösung von „/ocm-provider/“ eingerichtet. Dies hängt höchstwahrscheinlich mit einer Webserver-Konfiguration zusammen, die nicht dahingehend aktualisiert wurde, diesen Ordner direkt zu auszuliefern. Bitte vergleichen Sie Ihre Konfiguration mit den mitgelieferten Rewrite-Regeln in „.htaccess“ für Apache oder den in der Nginx-Dokumentation mitgelieferten. Auf Nginx sind das typischerweise die Zeilen, die mit „location ~“ beginnen und ein Update benötigen. Weitere Informationen finden Sie in der Dokumentation .
Ihr Webserver ist nicht ordnungsgemäß für die Auflösung von .well-known-URLs eingerichtet. Fehler bei: /.well-known/webfinger Weitere Informationen finden Sie in der Dokumentation .
4 Fehler in den Protokollen seit 20. September 2024, 10:15:53
Der Server hat keine konfigurierte Startzeit für das Wartungsfenster. Das bedeutet, dass ressourcenintensive tägliche Hintergrundaufgaben auch während Ihrer Hauptnutzungszeit ausgeführt werden. Wir empfehlen, das Wartungsfenster auf eine Zeit mit geringer Nutzung festzulegen, damit Benutzer weniger von der Belastung durch diese umfangreichen Aufgaben beeinträchtigt werden. Weitere Informationen finden Sie in der Dokumentation .
Einige Header sind in Ihrer Instanz nicht richtig eingestellt – Der Strict-Transport-Security-HTTP-Header ist nicht gesetzt (er sollte mindestens 15552000 Sekunden betragen). Für erhöhte Sicherheit wird empfohlen, HSTS zu aktivieren. Weitere Informationen finden Sie in der Dokumentation .
In der Datenbank fehlen einige Indizes. Auf Grund der Tatsache, dass das Hinzufügen von Indizes in großen Tabellen einige Zeit in Anspruch nehmen kann, wurden diese nicht automatisch erzeugt. Durch das Ausführen von „occ db:add-missing-indices“ können die fehlenden Indizes manuell hinzugefügt werden, während die Instanz weiter läuft. Nachdem die Indizes hinzugefügt wurden, sind Anfragen auf die Tabellen normalerweise schneller. Fehlende optionaler Index „mail_messages_strucanalyz_idx“ in der Tabelle „mail_messages“. Fehlende optionaler Index „mail_class_creat_idx“ in der Tabelle „mail_classifiers“. Fehlende optionaler Index „mail_acc_prov_idx“ in der Tabelle „mail_accounts“. Fehlende optionaler Index „mail_alias_accid_idx“ in der Tabelle „mail_aliases“. Fehlende optionaler Index „systag_by_objectid“ in der Tabelle „systemtag_object_mapping“. Fehlende optionaler Index „mail_messages_mb_id_uid_uidx“ in der Tabelle „mail_messages“. Fehlende optionaler Index „mail_smime_certs_uid_email_idx“ in der Tabelle „mail_smime_certificates“. Fehlende optionaler Index „mail_trusted_senders_idx“ in der Tabelle „mail_trusted_senders“. Fehlende optionaler Index „mail_coll_idx“ in der Tabelle „mail_coll_addresses“.
Das PHP OPcache-Modul ist nicht ordnungsgemäß konfiguriert. Der „OPcache interned strings“-Puffer ist fast voll. Um sicherzustellen, dass sich wiederholende Strings effektiv zwischengespeichert werden können, wird empfohlen, „opcache.interned_strings_buffer“ mit einem Wert größer als „8“ in der PHP-Konfiguration zu setzen.. Weitere Informationen finden Sie in der Dokumentation .
Die Datenbank wird für transaktionale Dateisperren verwendet. Um die Leistung zu verbessern, konfigurieren Sie bitte Memcache, falls verfügbar. Weitere Informationen finden Sie in der Dokumentation .
Es wurde kein Speichercache konfiguriert. Um die Leistung zu verbessern, konfigurieren Sie bitte Memcache, sofern verfügbar. Weitere Informationen finden Sie in der Dokumentation .
Für Ihre Installation ist keine Standard-Telefonregion festgelegt. Dies ist erforderlich, um Telefonnummern in den Profileinstellungen ohne Ländervorwahl zu überprüfen. Um Nummern ohne Ländervorwahl zuzulassen, fügen Sie bitte „default_phone_region“ mit dem entsprechenden ISO 3166-1-Code der Region zu Ihrer Konfigurationsdatei hinzu. Weitere Informationen finden Sie in der Dokumentation .
Sie haben Ihre E-Mail-Serverkonfiguration noch nicht festgelegt oder überprüft. Gehen Sie bitte zu den „Grundeinstellungen“, um diese festzulegen. Benutzen Sie anschließend den Button „E-Mail senden“ unterhalb des Formulars, um Ihre Einstellungen zu überprüfen. Weitere Informationen finden Sie in der Dokumentation .
Dieser Instanz fehlen einige empfohlene PHP-Module. Für eine verbesserte Leistung und bessere Kompatibilität wird dringend empfohlen, diese zu installieren: – gmp für WebAuthn passwortlose Anmeldung und SFTP-Speicher Weitere Informationen finden Sie in der Dokumentation .
Fehlerbeseitigung
Der erste Fehler in der Liste (… Datenverzeichnis und Ihre Dateien sind wahrscheinlich vom Internet aus erreichbar …) wird behoben, indem man die Konfigurationsdatei des Webservers mit
sucht. Hier wird „None“ durch „All“ ersetzt. Anschließend wird der Webserver neu gestartet und überprüft, ob die Fehlermeldung tatsächlich verschwunden ist. Diese Vorgehensweise wird nun bei jedem der zu beseitigenden Fehler wiederholt. Auf diese Weise lässt sich gut nachvollziehen, wie die Liste nach und nach abgebaut wird.
sudo service apache2 restart
Beim zweiten Fehler gilt es, das Memory Limit in der php.ini von 128MB auf 512MB anzuheben. Hierzu öffnet man diese mit
sudo nano /etc/php/8.2/apache2/php.ini
und ändert den Wert von
memory_limit = 128M
auf.
memory_limit = 512M
Anschließend wird der Webserver erneut gestartet.
sudo service apache2 restart
Eine weitere Fehlermeldung (… Einige Header sind in Ihrer Instanz nicht richtig eingestellt …) wird behoben, indem wir den Header HSTS aktivieren.
und entfernt das Rautezeichen vor der Zeile. Die Zeile wird also auskommentiert
Header always set Strict-Transport-Security "max-age=31536000"
und der Webserver neu gestartet.
sudo service apache2 restart
Danach wird ein weiterer Fehler (… E-Mail-Serverkonfiguration noch nicht festgelegt …) wie folgt behoben: Hierzu navigiert man in die Verwaltungseinstellungen → Verwaltung → Grundeinstellungen und ermöglicht Nextcloud, eMails zu senden. Dies ist wichtig, damit man bei einem vergessenen Passwort als Nutzer dieses zurücksetzen kann.
Einstellungen des SMTP-Servers (Beispiel)
Diese Daten sind natürlich an die eigene E-Mail-Adresse anzupassen. Die meisten E-Mail-Anbieter geben hier entsprechende Anleitungen.
Die nächste Fehlermeldung (… keine Standard-Telefonregion festgelegt …) verschwindet, indem die Konfigurationsdatei der Nextcloud mit
um folgende Zeile am Ende der Auflistung erweitert wird.
'default_phone_region' => 'DE',
Die Fehlermeldung zum OPcache-Modul (… PHP OPcache-Modul ist nicht ordnungsgemäß konfiguriert …) lässt sich beseitigen, indem das Paket php-apcu installiert und die Erweiterung entsprechend konfiguriert wird.
Abschließend wird der Apache2 wieder neu gestartet.
sudo service apache2 restart
Die Problematik zum Thema (… konfigurieren Sie bitte Memcache …) lässt sich lösen, indem man einen Redis-Server installiert, konfiguriert und diesen einbindet. Dazu werden die Pakete redis-server und php-redis installiert.
Nach einem erneuten Neustart des Webservers sollte nun auch diese Fehlermeldung verschwunden sein.
sudo service apache2 restart
Nun wird noch dafür gesorgt, dass HTTPS bei einer Webserveranfrage erzwungen wird. Dazu wird das Apache2-Modul rewrite installiert
sudo a2enmod rewrite
und via
sudo nano /etc/apache2/sites-available/raspi.conf
ein weiteres Mal der VirtualHost aufgerufen und dieser Block unter der Zeile <VirtualHost *:80> eingefügt.
RewriteEngine On
RewriteCond %{HTTPS} !=on
RewriteRule ^ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
Wieder wird der Webserver gestartet.
sudo service apache2 restart
Die Fehlermeldung zu fehlenden Modulen (… fehlen einige empfohlene PHP-Module …) wird durch die Installation des Pakets php-gmp beseitigt.
sudo apt install php-gmp -y
Nach der Installation wird der Apache2 ein weiteres Mal neu gestartet.
sudo service apache2 restart
Ein anderer Fehler (… Server hat keine konfigurierte Startzeit für das Wartungsfenster …) lässt sich beheben, indem man die Nextcloud-Konfiguration mit
Um OCC-Befehle auszuführen, ist es notwendig, den Alternative PHP Cache (APC) für das Command Line Interface (CLI) zu aktivieren. Dies ist wichtig, um den nächsten Fehler zu beheben. Dazu wird die entsprechende Konfigurationsdatei geöffnet
sudo nano /etc/php/8.2/mods-available/apcu.ini
und folgender Eintrag
apc.enable_cli=1
ans Ende gesetzt und der Webserver neu gestartet.
sudo service apache2 restart
Jetzt kann die Fehlermeldung (… In der Datenbank fehlen einige Indizes …) behoben werden, nachdem das Verzeichnis /var/www/html/nextcloud/ zuvor betreten wurde.
cd /var/www/html/nextcloud/
Hier führt man den entsprechenden OCC-Befehl aus, der fehlende Indizes der Nextcloud-Datenbank hinzufügt.
sudo -u www-data php occ db:add-missing-indices
Abschließend wird die Log-Datei der Nextcloud gelöscht. Danach sollte sich ein grünes Häkchen mit dem Hinweis „Alle Überprüfungen bestanden“ zeigen.
Selbstverständlich ist es von entscheidender Bedeutung, dass die Nextcloud optimal funktioniert. Dieser Artikel soll dazu beitragen. Anfangs mag man durch die Vielzahl der Fehlermeldungen etwas überwältigt sein. Doch wenn alle Schritte nach und nach abgearbeitet werden, wird man am Ende mit dem grünen Häkchen belohnt. Ein regelmäßiger Blick in die Verwaltungseinstellungen gibt Aufschluss über den Fortschritt und erleichtert das Verständnis der durchgeführten Maßnahmen.
Tipp
Nach der Veröffentlichung des ersten Point Releases von Nextcloud 30 wird automatisch ein Upgrade auf diese Version vorgeschlagen. Es wird empfohlen, über den grafischen Updater auf die neuere Version umzusteigen.
Vorschau
Der nächste Artikel dieser Reihe wird sich damit befassen, das System mit „PHP-FPM“ weiter zu optimieren und die Ladezeiten zu verkürzen.
Dieser Artikel gibt meine Motivation für den Bau von Container-Images und die Vorgehensweise wieder und zeigt, wie ich mit Buildah meine OCI-kompatiblen Container-Images erstelle.
Es handelt sich dabei mehr um einen Erfahrungsbericht als ein Tutorial und ich erhebe keinen Anspruch auf Vollständigkeit. Das behandelte Beispiel ist jedoch zum Einstieg und zur Nachahmung für all jene geeignet, die Container ausführen können und diese gerne ohne Verwendung von Containerfiles bauen möchten.
Motivation
Ich möchte die Ansible-Rollen aus meiner Collection tronde.nextcloud mit Molecule und Podman-Containern testen. Als Zielplattform für das Deployment der Nextcloud unterstütze ich zunächst Debian und RHEL.
Die Tests sollen verifizieren, dass Nextcloud im Container in einer rootless-Podman-Umgebung bereitgestellt werden kann. Da der Test unter Verwendung von Podman-Containern durchgeführt werden soll, müssen diese Container eine solche rootless-Podman-Umgebung bereitstellen.
Für RHEL 8 und RHEL 9 habe ich entsprechende Container-Images gefunden. Für Debian bin ich nicht fündig geworden und habe daher beschlossen, diese Container-Images selbst zu erstellen.
Buildah ist das Werkzeug meiner Wahl, da:
Container-Images damit interaktiv erstellt werden können,
die verwendeten Befehle am Ende in einem Bash-Skript gesammelt werden können,
sich damit sogar interaktive Abfragen mit Heredocs beantworten lassen,
man kein containerfile(5) benötigt und
ich das Werkzeug noch nicht kenne und es gerne kennenlernen möchte.
Für mich sind dies ausreichend Gründe, um mich kopfüber in ein neues Container-Projekt zu stürzen. Wer mehr über die Beziehung von Buildah zu Podman erfahren möchte, dem empfehle ich den englischsprachigen Artikel: Buildah and Podman Relationship von Tom Sweeney.
Die folgenden Code-Blöcke zeigen Auszüge aus dem Skript buildah_create_debian_bookworm_with_rootless_podman.sh (Commit 7634ed8). Die enthaltenen Befehle werden unter dem jeweiligen Code-Block erläutert. Alle Befehle werden als normaler Benutzer ohne Root-Rechte ausgeführt.
# Name of target container image
tctri=debian_rootless_podman
# Get a base image
ctr=$(buildah from --pull=newer docker://docker.io/library/debian:bookworm)
Die Variable tctri nimmt den Namen des Container-Images auf, welches ich erzeugen werde
Die Variable ctr nimmt den Namen des Containers auf, welcher durch den buildah-from(1)-Befehl erzeugt wird; mit diesem Container wird im Folgenden gearbeitet
Die Option --pull=newer sorgt dafür, dass das Image nur dann aus der angegebenen Registry heruntergeladen wird, wenn es aktueller als das evtl. lokal gespeicherte Image ist
buildah run -- $ctr apt -y update
buildah run -- $ctr apt -y upgrade
buildah run -- $ctr apt -y install podman fuse-overlayfs libvshadow-utils libcap2-bin ca-certificates
Mit buildah-run(1) werden Befehle innerhalb des Arbeits-Containers ausgeführt
Ich aktualisiere die im Basis-Image enthaltenen Pakte und
installiere die für rootless Podman benötigten Pakete
Das Paket ca-certificates wird benötigt, um später Container-Images aus einer Registry herunterladen zu können
buildah run -- $ctr useradd podman
buildah run -- $ctr sh -c "echo podman:1:999 > /etc/subuid"
buildah run -- $ctr sh -c "echo podman:1001:64535 >> /etc/subuid"
buildah run -- $ctr sh -c "echo podman:1:999 > /etc/subgid"
buildah run -- $ctr sh -c "echo podman:1001:64535 >> /etc/subgid"
buildah run -- $ctr setcap cap_setuid+epi /usr/bin/newuidmap
buildah run -- $ctr setcap cap_setgid+epi /usr/bin/newgidmap
Mit den hier dargestellten Befehlen wird der nicht-privilegierte Benutzer podman erstellt
Die IDs für /etc/sub[g,u]id habe ich mir aus dem ubi9/podman-Image abgeschaut
Die setcap-Befehle sind notwendig, um rootless Podman ausführen zu können; ich habe sie durch Internetrecherche und Trial-and-Error zusammengestellt
Ich erstelle die Verzeichnisse, die ich im Artikel [7] gefunden habe
Ich erstelle die Environment-Variable, die ich ebenfalls in genanntem Artikel [7] gefunden habe
buildah run -- $ctr apt -y reinstall uidmap
buildah run -- $ctr apt -y clean
buildah run -- $ctr rm -rf /var/lib/apt/lists/*
Aus mir nicht bekannter Ursache muss das Paket uidmap neu installiert werden, um ein UID/GID-Mapping sicherzustellen; dies scheint analog zur Neuinstallation der shadow-utils in Artikel [7] notwendig zu sein
Die beiden folgenden Befehle sollen den Paket-Cache aufräumen, um die Größe des resultierenden Images zu verkleinern, zeigen jedoch keinen sichtbaren Effekt
# Commit to an image
buildah commit --rm $ctr $tctri
# Alternative: Use this and add GPG fingerprint for image signing
# buildah commit --sign-by <fingerprint> --rm $ctr $tctri
# Tag the image just created
buildah tag $tctri $tctri:bookworm-$(date --iso)
Mit buildah-commit(1) wird der Inhalt des Arbeits-Containers $ctr in ein Container-Image namens $tctri geschrieben
Durch Angabe der Option --rm wird der Arbeits-Container entfernt
Die Kommentarzeile lässt erkennen, dass ich zukünftig beabsichtige, meine Images digital zu signieren
Der Befehl buildah-commit(1) fügt dem neuen Image übrigens nur einen weiteren Layer hinzu, egal wie viele Befehle zuvor im Arbeits-Container ausgeführt wurden. Das erzeugte Image umfasst also die Layer des Basis-Image plus einen weiteren.
Zwischenfazit
An diesem Punkt habe ich ein Basis-Image ausgewählt, mithilfe von buildah zusätzliche Software installiert, einen Benutzer hinzugefügt und ein neues Image erzeugt.
Die fertigen Images halte ich in der Registry https://quay.io/repository/rhn-support-jkastnin/debian_rootless_podman vor. Fühlt euch frei, diese für eigene Experimente zu benutzen, doch verwendet sie nur mit Vorsicht in Produktion. Ich erzeuge diese Images nur nach Bedarf neu, so dass die veröffentlichen Versionen veraltet und voller Sicherheitslücken sein können.
Validierung
Jetzt, wo die Images fertig sind, kann ich prüfen, ob sich rootless Podman darin auch wie gewünscht ausführen lässt.
Die Prozesse innerhalb des von meinem Container-Image instanziierten Containers laufen als Benutzer root. Um die Prozesse als Benutzer podman auszuführen, ist dies beim Aufruf von podman run explizit mit anzugeben. Der folgende Code-Block verdeutlicht dies und zeigt zugleich den ersten Fehler beim Versuch rootless Podman auszuführen.
]$ podman run --rm localhost/debian_rootless_podman:bookworm-2024-09-21 id
uid=0(root) gid=0(root) groups=0(root)
]$ podman run --rm --user podman localhost/debian_rootless_podman:bookworm-2024-09-21 id
uid=1000(podman) gid=1000(podman) groups=1000(podman)
]$ podman run --rm --security-opt label=disable --user podman --device /dev/fuse localhost/debian_rootless_podman:bookworm-2024-09-21 podman info
time="2024-09-21T18:43:35Z" level=error msg="running `/usr/bin/newuidmap 15 0 1000 1 1 1 999 1000 1001 64535`: newuidmap: write to uid_map failed: Operation not permitted\n"
Error: cannot set up namespace using "/usr/bin/newuidmap": exit status 1
Der Fehler deutet auf fehlende capabilities(7) hin. Um diese Hypothese zu testen, wiederhole ich den letzten Befehl mit der Option --privileged (siehe dazu podman-run(1)):
]$ podman run --rm --security-opt label=disable --user podman --device /dev/fuse --privileged localhost/debian_rootless_podman:bookworm-2024-09-21 podman info
host:
…
Damit funktioniert es. Leider geben sich viele Menschen an dieser Stelle mit dem Ergebnis zufrieden. Doch ich möchte diese Container nicht einfach mit --privileged ausführen. Also studiere ich die Manpage capabilities(7) und teste mich Stück für Stück heran, bis ich mit dem folgenden Kommando ebenfalls erfolgreich bin:
]$ podman run --rm --user podman --security-opt label=disable --device /dev/fuse --cap-add=setuid,setgid,sys_admin,chown localhost/debian_rootless_podman:bookworm-2024-09-21 podman info
host:
…
Dies ist schon deutlich besser, da dem Container hiermit deutlich weniger Privilegien eingeräumt werden müssen. Das Thema Container-Privilegien und capabilities(7) werde ich noch genauer untersuchen. Eventuell folgt dazu dann auch ein weiterer Artikel. Für den Moment ist das Ergebnis gut genug.
Die letzten wichtigen verbleibenden Bausteine für den Realtime-Support für Linux wurden in den Mainline-Zweig aufgenommen. Das bedeutet, dass Linux 6.12 voraussichtlich in einem echtzeitfähigen Modus betrieben werden kann, wenn der Kernel entsprechend kompiliert wird.
Echtzeitfähigkeit wird insbesondere in Embedded-Szenarien benötigt, wenn auf eine Eingabe innerhalb einer vorhersagbaren Zeit eine Antwort erwartet wird. Speziell in der Robotik, aber auch in der Multimediaproduktion gibt es solche Anforderungen. Dabei kommt es nicht darauf an, dass eine Aufgabe schnell abgearbeitet wird, sondern, dass sie in einer deterministischen Zeit begonnen wird.
Ein Beispiel für Echtzeit
An dieser Stelle mag sich die Frage stellen, was diese Echtzeitfähigkeit, von der hier geredet wird, überhaupt ist. Das lässt sich gut am Beispiel eines Line-following Robot klären. Was ein solcher Roboter tut, kann man sich z. B. in diesem YouTube-Video ansehen. Technisch besteht so ein Roboter aus zwei (oder mehr) Kameras als Sensoren, zwei Motoren für jeweils ein Rad als Aktoren und einem Controller zur Steuerung. Die Kameras sollen den Kontrast ermitteln, damit festgestellt werden kann, ob sie noch auf die schwarze Linie zeigen. Bemerkt eine der Kameras beim Fahren, dass sie den Sichtkontakt zur Linie aufgrund z. B. einer Kurve verliert, müssen die Motoren durch eine leichte Drehung nachsteuern, um auf der Linie zu bleiben.
Diese Kameras lösen üblicherweise entsprechend ihrer Abtastfrequenz auf dem Controller für die Steuerung einen Interrupt aus. Das führt zur Abarbeitung der Steuerungsroutine, die für beide Motoren die Geschwindigkeit berechnet, mit der sie sich drehen sollen.
Entscheidend ist, dass nicht beide Kameras den Sichtkontakt verlieren, damit der Roboter weiterhin weiß, in welche Richtung er nachsteuern muss. Üblicherweise wird das beim Testen funktionieren, aber es kann in bestimmten Randbedingungen bei normalen Betriebssystemen, wenn der Controller z. B. mit vielen anderen Aufgaben zufälligerweise beschäftigt ist, passieren, dass auf einmal nicht schnell genug die Routine aufgerufen wird. Der Roboter verliert dann den Sichtkontakt.
Der Entwickler eines solchen Roboters kann nun eine Echtzeitanforderung formulieren, dass z. B. auf ein Interrupt von den Kameras innerhalb von 1 Millisekunde reagiert werden muss. Er kann mit dieser Anforderung jetzt die maximale Geschwindigkeit des Roboters so wählen, dass der Roboter langsam genug fährt, um nicht die Linie – trotz der Latenz von im worst-case 1 Millisekunde – nicht zu verlieren.
Diese 1 Millisekunde muss aber auch vom Controller, seinem Betriebssystem und schließlich seinem Kernel garantiert werden. Der Kernel muss also in jeder Situation in der Lage sein, auf eine Anforderung innerhalb einer vorbestimmten Zeit zu reagieren. Unabhängig von der zwingenden Fähigkeit, präemptiv zu arbeiten, also jederzeit anderer Prozesse unterbrechen zu können, darf der Kernel auch nicht mit sich selber unvorhersehbar lange beschäftigt sein, wenn z. B. eine Synchronisation hängt.
20 Jahre Arbeit
Und genau hierum geht es beim grob gesagt beim PREEMPT_RT-Patch. Der Kernel muss so nachgebessert werden, dass keine Komponente sich unnötig lange aufhängt und somit die Abarbeitung von Aufgaben behindert, für die eine garantierte Ausführungszeit festgelegt wurde.
Die ursprüngliche Arbeit begann bereits im Jahr 2004 auf einem getrennten Zweig und hatte viele Verbesserungen in den Kernel gebracht, zuletzt an der printk()-Infrastruktur. Jetzt sollten die Arbeiten so weit sein, dass Realtime nicht mehr auf einem getrennten Zweig, sondern im Hauptzweig entwickelt werden kann.
Die Echtzeitfähigkeit gab es somit in speziell präparierten Kernels schon lange. Neu ist, dass der Code im Hauptzweig gepflegt wird und somit besser mit Änderungen anderer Maintainer abgestimmt werden kann. Denn eine Änderung an einer anderen Komponente reicht schon aus, um die Echtzeitfähigkeit zu unterminieren.
Linux echtzeitfähig zu machen, ist somit ein großer Aufwand gewesen, weil man solche Fähigkeiten oft nur in spezialisierten Betriebssystemen (sogenannten Real-time operating systems, RTOS) vorfindet. Insbesondere Thomas Gleixner und John Ogness haben hier große Anstrengungen unternommen. Jetzt, nach knapp 20 Jahren Arbeit, dürfte das Vorhaben einen wichtigen Meilenstein erreichen.
Wer sich für einen tieferen Einblick in die Linux-RT-Welt interessiert, kann einerseits den Artikel von Thomas Leemhuis auf Heise Online von letzter Woche lesen oder sich auf LWN durch das Artikelarchiv zu der Thematik arbeiten.
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
Teil II: mit VirtualBox (Windows mit Intel/AMD-CPU)
Teil III (dieser Text): mit UTM (macOS ARM)
In diesem Artikel gehe ich davon aus, dass Sie einen Mac mit ARM-CPU (M1, M2 usw.) verwenden. Für ältere Modelle mit Intel-CPUs gelten z.T. andere Details, auf die ich hier nicht eingehe. Insbesondere müssen Sie dann eine ISO-Datei für x86-kompatible CPUs verwenden, anstatt, wie hier beschrieben, eine ARM-ISO-Datei!
Virtualisierungssysteme für macOS ARM
Sie haben die Wahl:
Parallels Desktop: gut, aber wegen jährlicher Update-Pflicht sehr teuer
VMWare Fusion: kostenlos (for personal use), aber gut versteckter Download (erfordert vorher Registrierung bei Broadcom, danach lange Suche), verwirrende Bedienung, unklare Zukunft
UTM: Open-Source-Programm, kostenloser Download oder 10 EUR über App Store (einziger Unterschied: automatische Updates)
VirtualBox: kostenlos, aber aktuell erst als Beta-Version verfügbar und extrem langsam
Ich konzentriere mich hier auf UTM, der aus meiner Sicht überzeugendsten Lösung.
UTM
UTM ist ein Open-Source-Programm, das nur als Schnittstelle zu zwei Virtualisierungssystemen dient: dem aus der Linux-Welt bekannten QEMU-System sowie dem Apple Hypervisor Virtualization Framework (integraler Bestandteil von macOS seit Version 13, also seit Herbst 2022). UTM ist also lediglich eine grafische Oberfläche und delegiert die eigentliche Virtualisierung an etablierte Frameworks.
Sie können UTM um ca. 10 EUR im App Store kaufen und so die UTM-Entwickler ein wenig unterstützen, oder das Programm kostenlos von https://mac.getutm.app/ herunterladen und (vollkommen unkompliziert!) selbst installieren.
Sodann können Sie mit UTM virtuelle Maschinen mit Linux, Windows und macOS ausführen. Ich behandle hier ausschließlich Linux.
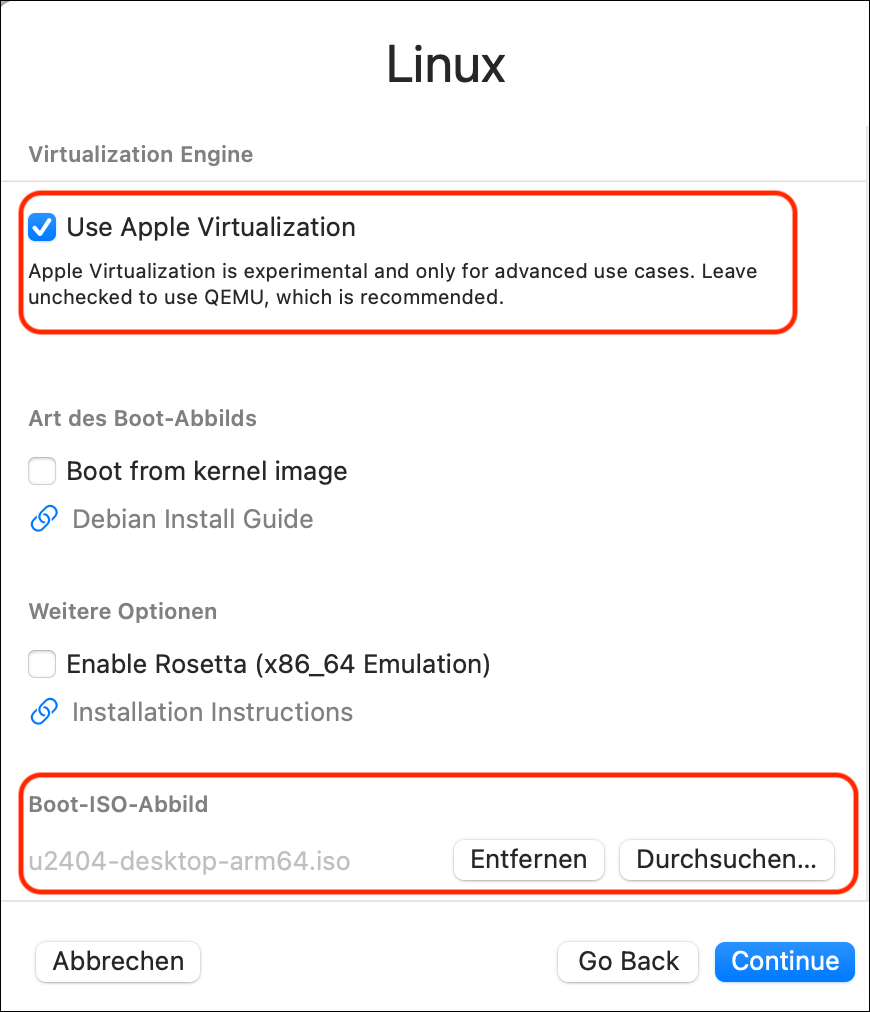
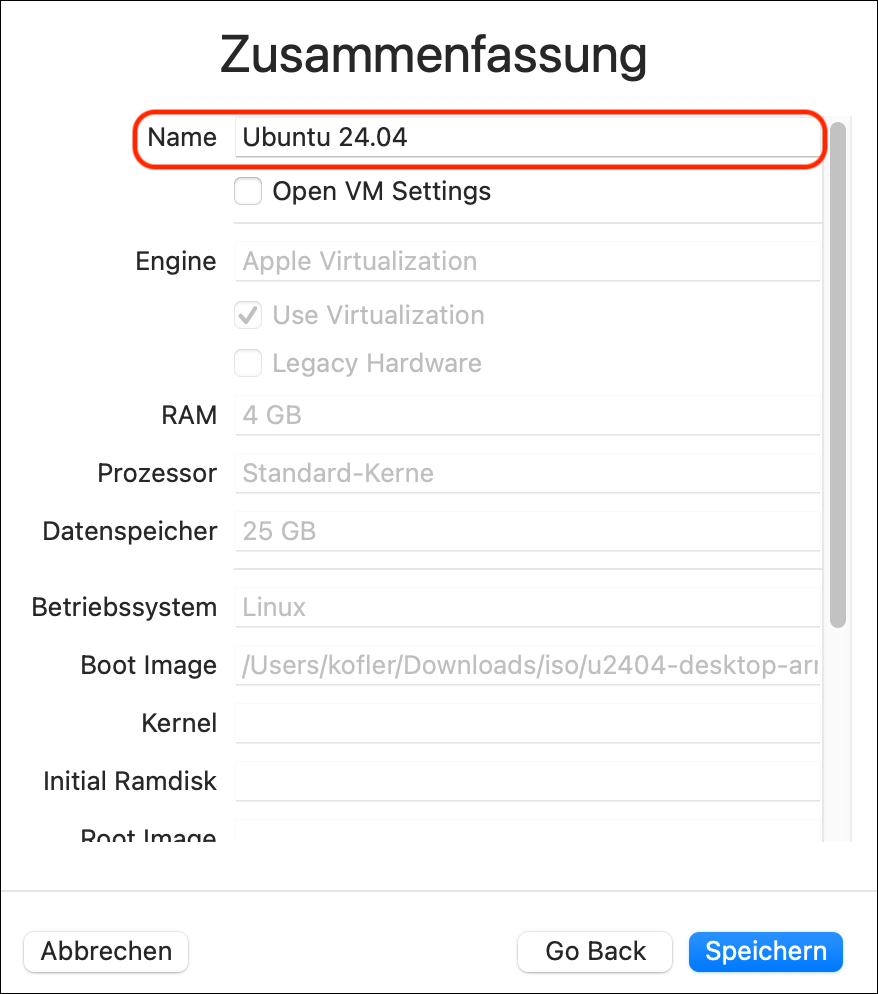
QEMU oder Apple Virtualization?
Wenn Sie in UTM eine neue virtuelle Maschine für Linux einrichten, haben Sie die Wahl zwischen zwei Virtualisierungssystemen: QEMU und Apple Virtualization. Welches ist besser?
Die QEMU-Variante bietet viel mehr Konfigurationsmöglichkeiten rund um die Netzwerkeinbindung und das Grafiksystem. Allerdings braucht die virtuelle Maschine doppelt so viel RAM wie vorgesehen: Wenn Sie eine VM mit 4 GB RAM einrichten, gehen beim Betrieb 8 GB RAM im macOS-Arbeitsspeicher verloren! macOS ist gut dabei, ungenutzte RAM-Teile zu komprimieren oder auszulagern, dennoch ist diese RAM-Verschwendung Wahnsinn. (Das gleiche Problem habe ich übrigens auch bei Tests mit VMWare Fusion festgestellt.)
Bei Apple Virtualization funktioniert die Speicherverwaltung, d.h. eine virtuelle Maschine mit 4 GB RAM braucht tatsächlich nur 4 GB RAM. (Das sollte ja eigentlich selbstverständlich sein …) Dafür haben Sie bei der Netzwerkkonfiguration kaum Wahlmöglichkeiten. Die VMs werden immer über eine Netzwerkbrücke in das lokale Netzwerk integriert. Es gibt zwar zwei Optionen, Gemeinsames Netzwerk und Bridge-Modus. Soweit ich es nachvollziehen kann, reduziert Gemeinsames Netzwerk nur die Optionen für den Bridge-Modus, ändert aber daran nichts. Das Apple Virtualization Framework würde auch NAT unterstützen, aber UTM stellt diese Option nicht zur Wahl.
In der Oberfläche von UTM wird die Verwendung von Apple Virtualization als experimentell bezeichnet. Ich habe bei meinen Tests leider mit beiden Frameworks gelegentliche Abstürze von virtuellen Maschinen erlebt. Ich würde beide Frameworks als gleichermaßen stabil betrachten (oder auch instabil, je nach Sichtweise; unter Linux mit QEMU/KVM sind mir Abstürze unbekannt). Persönlich verwende ich, vor allem um RAM zu sparen, für neue VMs nur mehr die Apple Virtualization. Glücklicherweise passt der Bridge Modus gut zu meinen Netzwerkanforderungen.
Wenn Sie VMs mit macOS oder Windows erstellen, entfällt die Wahlmöglichkeit. Windows VMs können nur durch QEMU ausgeführt werden, macOS VMs nur mit dem Apple Virtualization Framework.
Ubuntu installieren
Die erste Hürde hin zur Ubuntu-Installation besteht darin, ein ARM-ISO-Image zu finden. Auf den üblichen Download-Seiten finden Sie nur die x86-Variante von Ubuntu Desktop. Es gibt aber sehr wohl ein ARM-Image! Es ist auf der Website cdimage.ubuntu.com versteckt (noble-desktop-arm64.iso):
In UTM klicken Sie auf den Plus-Button, um eine neue virtuelle Maschine einzurichten. Danach wählen Sie die folgenden Optionen:
Virtualisieren
Linux
Option Use Apple Virtualiuation, Button Durchsuchen, um die ISO-Datei (das Boot-ISO-Abbild) auszuwählen
Speicher: 4 GB ist zumeist eine sinnvolle Einstellung
Prozessorkerne: ich verwende zumeist 2, die Einstellung Standard ist auch OK
Datenspeicher (Größe des Disk-Images): nach Bedarf, 25 GB sind in meiner Erfahrung das Minimum
Freigegebener Ordner: sollte die Nutzung eines macOS-Verzeichnisses innerhalb der virtuellen Maschine ermöglichen, funktioniert meines Wissens aber nur, wenn die virtuelle Maschine selbst macOS ist
Zusammenfassung: hier geben Sie der virtuellen Maschine einen Namen
Setup der neuen virtuellen Maschine in UTMEinstellung des Namens der virtuellen Maschine
Nachdem Sie alle Einstellungen gespeichert haben, starten Sie die virtuelle Maschine. Nach ca. 30 Sekunden sollte der Desktop mit dem Installationsprogramm erscheinen (erster Dialog: Welcome to Ubuntu). Falls das Installationsprogramm je nach Monitor auf einem riesigen Desktop winzig dargestellt wird, öffnen Sie rechts oben über das Panel-Menü die Einstellungen (Zahnrad-Icon), suchen das Dialogblatt Displays und wählen eine kleinere Bildschirmauflösung aus.
Im Installationsprogramm stellen Sie nun die gewünschte Sprache ein. Bei der Einstellung des Tastaturlayouts wählen Sie Deutsch und die Tastaturvariante Deutsch Macintosh, damit die Mac-Tastatur unter Ubuntu richtig funktioniert. Alle weiteren Einstellungen erfolgen wie bei einer Installation unter VirtualBox, siehe Ubuntu 24.04 in VirtualBox ausführen. Sie brauchen keine Software von Drittanbietern, können aber die Option Unterstützung für zusätzliche Medieformate aktivieren.
Ausführung des Ubuntu-Installationsprogramms
Nach Abschluss aller Setup-Dialoge dauert die Installation ca. fünf Minuten. Da während der Installation manche Pakete aus dem Internet heruntergeladen werden, ist die Dauer der Installation auch von der Geschwindigkeit Ihres Internetzugangs abhängig.
Ubuntu nutzen
Nach dem ersten Neustart erscheint der Ubuntu-Desktop. Wieder kann es je nach Monitor passieren, dass die Grafikauflösung in der virtuellen Maschine zu groß ist. Öffnen Sie das Programm Einstellungen, dort das Dialogblatt Anzeigegeräte und stellen Sie eine passende Auflösung ein. Im Unterschied zu anderen Virtualisierungsprogramme ändert sich die Auflösung nicht automatisch, wenn Sie das UTM-Fenster verändern. Stattdessen wird der im Fenster angezeigte Inhalt skaliert.
Damit sich die Maus in der virtuellen Maschine wie unter macOS verhält, aktivieren Sie in Einstellungen/Maus und Tastfeld die Option Natürliche Rollrichtung.
Um Text zwischen macOS und Ubuntu auszutauschen, können Sie die Zwischenablage verwenden. Dazu muss weder zusätzliche Software installiert noch irgendeine Konfiguration verändert werden.
Zum Austausch von Dateien verwenden Sie am einfachsten scp.
Ubuntu 24.04 (ARM) läuft unter macOS
Speicherort der virtuellen Maschinen
UTM speichert die virtuellen Maschinen im Verzeichnis Library/Containers/com.utmapp.UTM. In der Regel ist es nicht zweckmäßig, die riesigen Image-Dateien in das TimeMachine-Backup mit aufzunehmen. Fügen Sie daher bei den TimeMachine-Einstellungen eine entsprechende Regel hinzu.
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
VirtualBox war lange Zeit das dominierende Virtualisierungsprogramm für Privatanwender: kostenlos (wenn auch nicht vollständig Open Source), funktionell, relativ einfach zu bedienen und für alle drei relevanten Betriebssysteme verfügbar (Windows, macOS, Linux).
Diese Rolle ist zuletzt stark ins Wanken gekommen. Aus meiner Sicht gibt es drei gravierende Probleme:
VirtualBox unter Windows (mit x86-kompatiblen CPUs) litt in den vergangenen Jahren immer wieder unter massiven Stabilitätsproblemen. Möglicherweise wurde diese durch Inkompatibilitäten mit dem Microsoft-Hypervisor (Hyper-V) ausgelöst — wirklich schlüssig war es für mich nie. Wenn VirtualBox auf zehn Studenten-Notebooks mit Windows funktioniert, kann dieselbe Version auf dem elften Notebook Probleme bereiten, die nur schwer nachzuvollziehen sind.
Das zweite Problem besteht darin, dass VirtualBox Intel/AMD-CPUs voraussetzt. Zwar gibt es eine Beta-Version von VirtualBox für Macs mit M1/M2/…-CPU, diese ist aber noch unerträglich langsam. Für Windows oder Linux auf ARM-Hardware gibt es gar keine Angebote.
Schließlich hatte ich zuletzt immer wieder Schwierigkeiten mit den unzähligen Zusatzfunktionen von VirtualBox. Die Installation der Guest Tools hakt, das Grafiksystem zeigt Darstellungsfehler, die geteilten Verzeichnisse haben in der VM die falschen Zugriffsrechte usw. Weniger wäre mehr.
Aktuell gibt es mit dem ganz frischen Release von VirtualBox 7.1.0) noch ein Problem: Die Netzwerkgeschwindigkeit in den virtuellen Maschinen ist unerträglich langsam. Das Problem ist bekannt und wird hoffentlich demnächst behoben. Bis dahin empfehle ich Ihnen, mit Version 7.0.20 zu arbeiten. Ich habe die in diesem Artikel beschriebene Installation mit 7.1.0 durchgeführt (und damit auch die Screenshots erstellt), bin aber im Anschluss zurück auf die alte Version umgestiegen. Das Format der virtuellen Maschinen hat sich zum Glück nicht geändert. Ältere VirtualBox-Downloads finden Sie hier.
Wenn ich Sie bis jetzt nicht abgeschreckt habe, erläutere ich Ihnen im Folgenden die Installation von Ubuntu 24.04 in einer virtuellen Maschine, die in VirtualBox 7.0 unter Windows 11 (für Intel/AMD) läuft.
Ubuntu installieren
Zuerst müssen Sie VirtualBox installieren. Danach brauchen Sie zur Installation von Ubuntu das ISO-Image von Ubuntu, das Sie von der Ubuntu-Download-Seite herunterladen.
Als nächstes richten Sie in VirtualBox mit dem Button Neu eine neue virtuelle Maschine ein. Im ersten Blatt des Setup-Dialogs geben Sie der virtuellen Maschine einen Namen und wählen die ISO-Datei aus. VirtualBox erkennt selbst, dass die ISO-Datei Ubuntu enthält, und stellt Typ, Subtyp und Version selbst ein.
VirtualBox kann bei Ubuntu eine Unbeaufsichtigte Installation durchführen. Dazu geben Sie im folgenden Dialogblatt den Benutzernamen, das Passwort und den gewünschten Hostnamen an. Sie ersparen sich mit einer unbeaufsichtigten Installation die Bedienung des Ubuntu-Installationsprogramms. Allerdings hat diese Installationsvariante den Nachteil, dass Ubuntu nach der Installation englische Menüs anzeigt und ein englisches Tastaturlayout verwendet. Deswegen ist es aus meiner Sicht sinnvoll, die Option Unbeaufsichtigte Installation überspringen zu aktivieren.
Die unbeaufsichtigte Installation hat mehr Nach- als Vorteile
Im Dialogblatt Hardware sollten Sie der virtuellen Maschine zumindest 4 GB RAM und zwei CPU-Cores zuweisen. Die vorgeschlagenen 2 GB RAM sind definitiv zu wenig und führen dazu, dass nicht einmal der Start der virtuellen Maschine möglich ist!
Im Dialogblatt Festplatte stellen Sie ein, wie groß die virtuelle Disk sein soll. 25 GB ist aus meiner Sicht das Minimum, um Ubuntu ein wenig auszuprobieren. Je nach Verwendungszweck brauchen Sie aber natürlich mehr Speicherplatz.
Fertigstellen beendet den Dialog. Bevor Sie mit der Installation starten, sollten Sie nun mit Ändern noch zwei Einstellungen der virtuellen Maschine anpassen:
Anzeige/Bildschirm/Grafikspeicher = mindestens 32 MB, ich empfehle das Maximum von 128 MB
Optionale Einstellungen für die virtuelle Maschine. Dem Grafiksystem sollten zumindest 32 MB RAM zur Verfügung stehen.
Ein Doppelklick auf das VM-Icon startet die virtuelle Maschine. Nach ca. einer halben Minute erscheint der Ubuntu-Desktop mit dem Installationsprogramm. Unter Umständen wird vorher im Textmodus die beunruhigende Fehlermeldung * vmwgfx seems to be running on an unsupported hypervisor* angezeigt. Zumindest bei meinen Tests startet das Grafiksystem wenig später dennoch fehlerfrei.
Im Installationsprogramm stellen Sie in den ersten Schritten die gewünschte Sprache und das Tastaturlayout ein. Sie geben an, dass Sie Ubuntu installieren (und nicht nur ausprobieren) möchten, und entscheiden sich für die interaktive Standard-Installation. (Wenn Sie gleich auch Gimp, LibreOffice usw. haben möchten, ist Vollständige Installation die bessere Wahl.)
Mit der »Standard-Installation« werden nur die wichtigsten Programme installiert. Weitere Software können Sie später installieren.
Im nächsten Dialogblatt haben Sie die Option, zusätzliche Treiber sowie Audio- und Video-Codecs zu installieren. Treiber brauchen Sie in der virtuellen Maschine keine, und die fehlenden Codecs können Sie gegebenenfalls später immer noch installieren (sudo apt install ubuntu-restricted-extras).
Im Dialogblatt Art der Installation geht es um die Partitionierung der virtuellen Disk sowie um das Einrichten der Dateisysteme für Ubuntu. Weil Sie Ubuntu in eine virtuelle Maschine installieren, müssen Sie keinerlei Rücksicht auf andere Betriebssysteme nehmen und können sich einfach für die Option Festplatte löschen und Ubuntu installieren entscheiden.
In virtuellen Maschinen ist eine manuelle Partitionierung des Datenträgers glücklicherweise überflüssig
Auf der nächsten Seite geben Sie Ihren Namen, den Hostname, den Account-Namen sowie das gewünschte Passwort an. Das nächste Dialogblatt betrifft die Zeitzone, die normalerweise automatisch korrekt eingestellt wird. Zuletzt werden die wichtigsten Einstellungen nochmals zusammengefasst. Installieren startet den Installations-Prozess, der je nach Rechnergeschwindigkeit einige Minuten dauert.
Personalisierung der Installation
Ubuntu nutzen
Nach Abschluss der Installation starten Sie die virtuelle Maschine neu und können Ubuntu dann beinahe wie bei einer realen Installation nutzen. Die Auflösung der virtuellen Maschine ändern Sie unkompliziert innerhalb von Ubuntu im Programm Einstellungen, Modul Anzeigegeräte. Wenn Sie einen hochauflösenden Bildschirm verwenden, kann es außerdem zweckmäßig sein, den skalierten Modus zu aktivieren (Anzeige / Skalierter Modus im Menü des Fensters der virtuellen Maschine).
Die virtuelle Maschine verwendet Wayland als Grafiksystem
Installation der VirtualBox-Gasterweiterungen
Um den Datenaustausch zwischen Windows und Ubuntu zu erleichtern, können Sie die VirtualBox-Gasterweiterungen installieren. Dazu sind zwei Schritte erforderlich:
Zuerst führen Sie im Fenster der virtuellen Maschine Geräte / Gasterweiterungen einlegen aus.
Anschließend geben Sie in einem Terminalfenster die folgenden Kommandos ein:
Die Auflösung des Grafiksystems von Ubuntu wird automatisch an die Größe des Fensters der virtuellen Maschine angepasst.
Sie können über die Zwischenablage Text zwischen Windows und Ubuntu austauschen. (Dazu muss außerdem der bidirektionale Modus der Zwischenablage aktiviert werden: im VM-Fenster mit Geräte / Gemeinsame Zwischenablage / Bidirektional.
Sie können über ein gemeinsames Verzeichnis Dateien zwischen Ubuntu und Windows austauschen (Konfiguration siehe unten).
Gemeinsames Verzeichnis zum Dateiaustausch einrichten
Um Dateien zwischen Ubuntu und Windows auszutauschen, richten Sie am besten ein gemeinsames Verzeichnis ein. Drei Schritte sind erforderlich:
Die VirtualBox-Gasterweiterungen sind erforderlich.
Im Menü des Fensters der virtuellen Maschine führen Sie Geräte / Gemeinsame Ordner / Gemeinsame Ordner aus und wählen ein Windows-Verzeichnis (es kann auch Ihr persönliches Verzeichnis sein). Aktivieren Sie die Optionen Automatisch einbinden und Permanent erzeugen.
Zuletzt müssen Sie in einem Terminal-Fenster in Ubuntu Ihren Account der vboxsf-Gruppe zuordnen:
sudo usermod -a -G vboxsf $USER
Damit das usermod-Kommando wirksam wird, müssen Sie die virtuelle Maschine neustarten. Sie finden das gemeinsame Verzeichnis danach direkt im Datei-Manager.
Gemeinsamen Ordner zum Dateiaustausch zwischen Windows und der virtuellen Maschine einrichtenDer gemeinsame Ordner wird im Dateimanager angezeigt. Wenn Sie darauf nicht zugreifen können, haben Sie »usermod« vergessen. Für Experten zeigt »findmnt« die Details des Mount-Verzeichnisses.
Netzwerkkonfiguration und SSH-Zugriff
Wenn ich auf Kommandoebene arbeite, bediene ich meine virtuellen Maschinen gerne über SSH. Unter Ubuntu muss dazu der SSH-Server installiert werden, was mit sudo apt install openssh-server rasch gelingt.
Das reicht aber noch nicht: VirtualBox gibt der virtuellen Maschine standardmäßig mittels Network Address Translation Zugriff auf die Netzwerkverbindung des Host-Computers. Die virtuelle Maschine ist aber im Netzwerk des Hosts unsichtbar, eine SSH-Verbindung ist unmöglich.
Es gibt zwei Auswege. Einer besteht darin, in den Netzwerkeinstellungen der virtuellen Maschine die Option Netzwerkbrücke zu aktivieren. Damit wird die virtuelle Maschine einfach zu einem Mitglied im lokalen Netzwerk. Zuhause funktioniert das gut (einfach ssh name@<ubuntu_hostname> ausführen), in öffentlichen WLANs dagegen leider nicht.
Die Alternative heißt Port-Weiterleitung. Dazu führen Sie im Fenster der virtuellen Maschine Geräte / Netzwerk / Netzwerk-Einstellungen aus, aktivieren das Tab Experte und klappen bei Adapter 1 den Bereich Erweitert aus und klicken auf Port-Weiterleitung. Nun richten Sie eine neue Regel ein, die Port 2222 des Hosts (127.0.0.1) mit Port 22 der virtuellen Maschine (10.0.2.15) verbindet.
Port-Weiterleitung zwischen Port 22 der virtuellen Maschine und Port 2222 des eigenen Rechners einrichten
Nachdem Sie die Einstellungen gespeichert haben (ein Neustart der virtuellen Maschine ist nicht notwendig), können Sie im Terminal von Windows mit dem folgenden Kommando eine SSH-Verbindung zur virtuelle Maschine herstellen:
ssh -p 2222 name@localhost
Wichtig ist dabei die Option -p 2222. ssh soll nicht wie üblich Port 22 verwenden, sondern eben Port 2222. Wichtig ist auch, dass Sie als Zieladresse localhost angeben. Aufgrund der Port-Weiterleitung landen Sie wunschgemäß in der virtuellen Maschine. Anstelle von name geben Sie Ihren Ubuntu-Account-Namen an.
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
Teil I (dieser Text): im Windows Subsystem for Linux (WSL)
Teil III: mit UTM (macOS ARM): mit UTM (macOS ARM)
Windows Subsystem für Linux
Mit WSL hat Microsoft einen Weg geschaffen, Linux im Textmodus unkompliziert unter Windows auszuführen. Diese Variante ist dann empfehlenswert, wenn Sie unter Windows typische Linux-Werkzeuge (die Shell bash, Kommandos wie find und grep usw.) nutzen möchten oder wenn Sie ohne Docker oder virtuelle Maschinen Server-Dienste wie Apache, nginx etc. ausprobieren möchten.
Als erstes müssen Sie sicherstellen, dass im Konfigurationsprogramm Windows-Features aktivieren oder deaktivieren die Optionen Hyper-V und Windows-Subsystem für Linux aktiviert sind. Alternativ können Sie WSL auch im Microsoft Store installieren.
WSL aktivieren
Im zweiten Schritt gehen Sie in den Microsoft Store und suchen nach Ubuntu 24.04. (Passen Sie auf, dass Sie keine alte Version verwenden, die vorher gereiht ist.) Ubuntu 24.04 ist kostenlos. Der Installationsumfang ist mit 350 MByte für eine Linux-Distribution relativ klein. Sobald Sie Öffnen anklicken, erscheint ein Terminal-Fenster. Nach ein paar Sekunden müssen Sie einen Benutzernamen und ein Passwort angeben. Dieses Passwort brauchen Sie später, um administrative Arbeiten zu erledigen (z.B. sudo apt install xxx).
Erster Start von Ubuntu 24.04 unter WSL
In Zukunft können Sie Ubuntu 24.04 im Startmenü oder in der Auswahlliste des Terminal-Programms starten. Als ersten Schritt in der neuen Shell-Umgebung sollten Sie ein Update durchführen (also die Kommandos sudo apt update und sudo apt full-upgrade).
Innerhalb von Ubuntu können Sie über den Pfad /mnt/c auf das Windows-Dateisystem zugreifen. Umgekehrt finden Sie das Linux-Dateisystem im Explorer unter dem Eintrag Linux.
Zugriff auf das Linux-Dateisystem im Explorer
WSL ist für den Betrieb von Linux im Textmodus optimiert. Seit 2021 besteht mit WSLg aber prinzipiell die Möglichkeit, einzelne Programme im Grafikmodus zu installieren und auszuführen:
Meine Erfahrungen mit diesem Feature waren aber nicht überragend. Wenn Sie Ubuntu als Desktop-System im Grafikmodus nutzen möchten, verwenden Sie dazu besser VirtualBox oder ein anderes Virtualisierungssystem.
WSL1, wenn Windows in einer virtuellen Maschine läuft
Aus technischer Sicht gibt es zwei ganz unterschiedliche Varianten von WSL. Standardmäßig kommt WSL2 zum Einsatz. Dabei wird der Linux-Kernel durch das Virtualisierungssystem Hyper-V ausgeführt. In manchen Situationen steht Hyper-V aber nicht zur Verfügung — z.B. wenn Windows selbst in einer virtuellen Maschine läuft (unter Linux oder macOS). In solchen Fällen ist WSL1 ein attraktiver Ausweg. Bei WSL1 kümmert sich ein ganzes Framework von Funktionen um die Kompatibilität zwischen Windows und Linux. WSL1 ist der technisch kompliziertere Weg, weil (fast) alle Linux-Grundfunktionen ohne Virtualisierung nachgebildet wurden.
Um Ubuntu 24.04 unter WSL1 auszuführen, führen Sie die folgenden Kommandos im Terminal aus:
WSL1 hat im Vergleich zu WSL2 einige Nachteile: langsameres I/O, älterer Kernel, keine Grafikfunktionen. Für viele Aufgaben — etwas zum Erlernen grundlegender Linux-Kommandos oder zur bash-Programmierung — funktioniert WSL1 aber genauso gut wie WSL2.
Der aus meiner Sicht größte Nachteil von WSL1 besteht darin, dass systemd nicht funktioniert. Hintergrunddienste wie cron stehen nicht zur Verfügung und können gar nicht oder nur über komplizierte Umwege genutzt werden. Ein wichtiger Teil dessen, was ein komplettes Linux-System ausmacht, fehlt.
Hier läuft Windows für ARM im Virtualisierungssystem UTM unter macOS. In der virtuellen Maschine ist wiederum Ubuntu 24.04 (auch für ARM) per WSL1 installiert.
Um effektiv und ungestört Content für meinen Blog zu erstellen, nutze ich gerne die Pomodoro-Technik, die mir 25-minütige Zeitfenster bietet, um konzentriert zu arbeiten.
Nachdem ich jedoch auf meinem Notebook Ubuntu 24.04.1 LTS installiert hatte, begann für mich die Neuorientierung bezüglich entsprechender Software. Die meisten Anwendungen waren schnell gefunden und installiert. Einige Programme und Tools fehlten jedoch in der Version „Noble Numbat“ oder waren nicht lauffähig, worunter die Zufriedenheit am neuen System etwas litt. Ein wichtiges Tool wie Time ++, der Gnome Extensons, funktionierte konnte nicht mehr installiert werden. Nun habe ich festgestellt, dass das alte Projekt in Cronomix umbenannt wurde, welches sich ganz einfach über die Extensions installieren und aktivieren lässt.
Cronomix Pomodoro-Timer
Fazit
Ende gut, alles gut.
Tipp
Mit Cronomix lässt sich auch die Zeit erfassen, in der man an einem Projekt arbeitet.