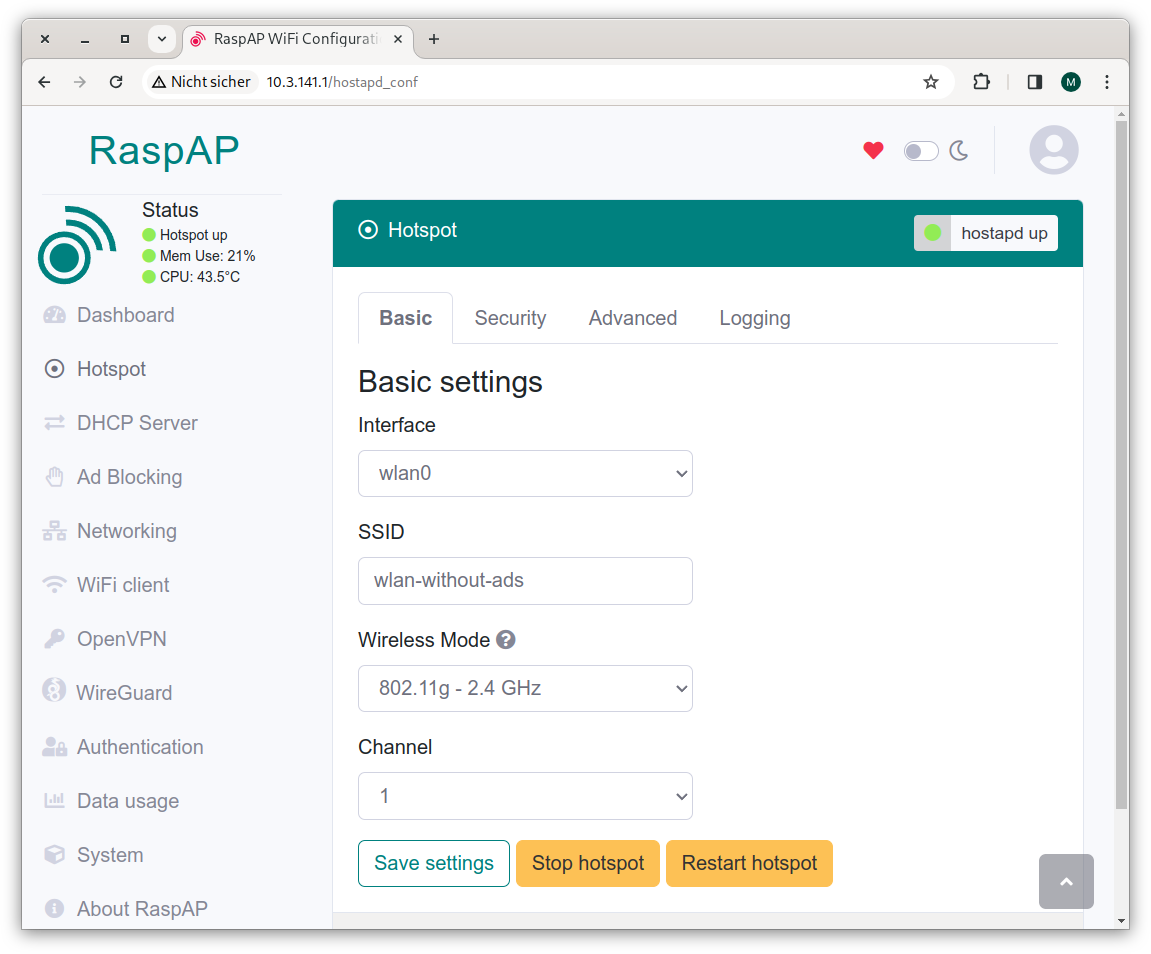
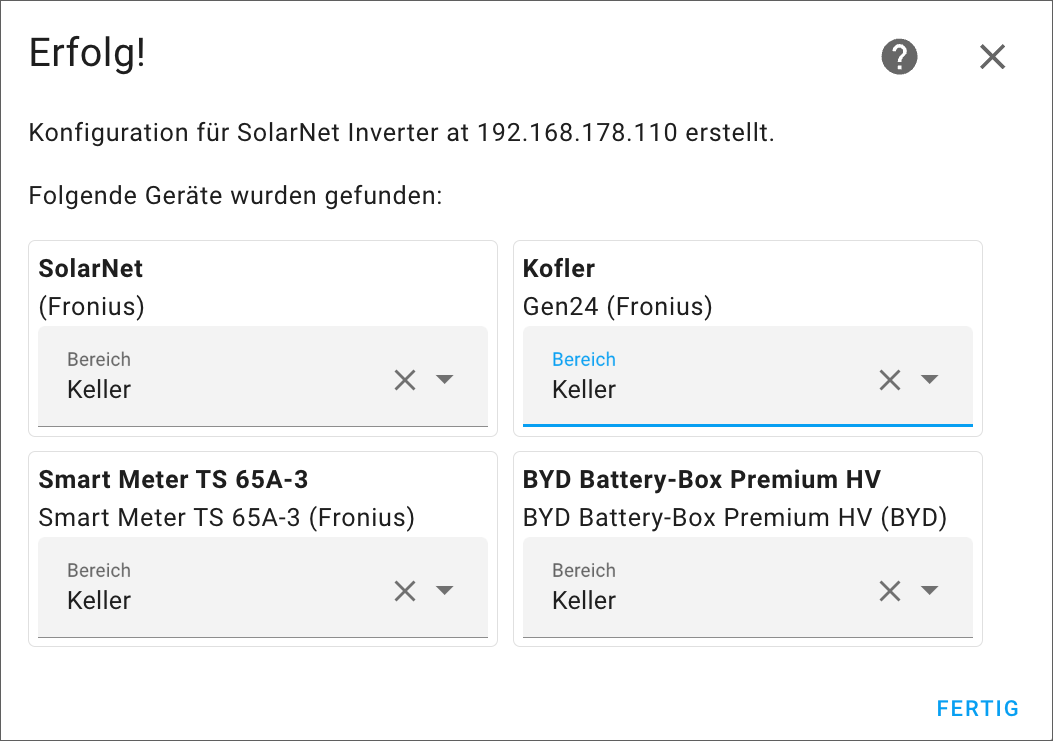
Unser Buch Coding mit KI wird gerade übersetzt. Heute musste ich diverse Fragen zur Übersetzung beantworten und habe bei der Gelegenheit ein paar Beispiele aus unserem Buch mit aktuellen Versionen von ChatGPT und Claude noch einmal ausprobiert. Dabei ging es um die Frage, ob KI-Tools technische Diagramme (z.B. UML-Diagramme) zeichnen können. Die Ergebnisse sind niederschmetternd, aber durchaus unterhaltsam :-)
UML-Diagramme
Vor einem halben Jahr habe ich ChatGPT gebeten, zu zwei einfachen Java-Klassen ein UML-Diagram zu zeichnen. Das Ergebnis sah so aus (inklusive der falschen Einrückungen):
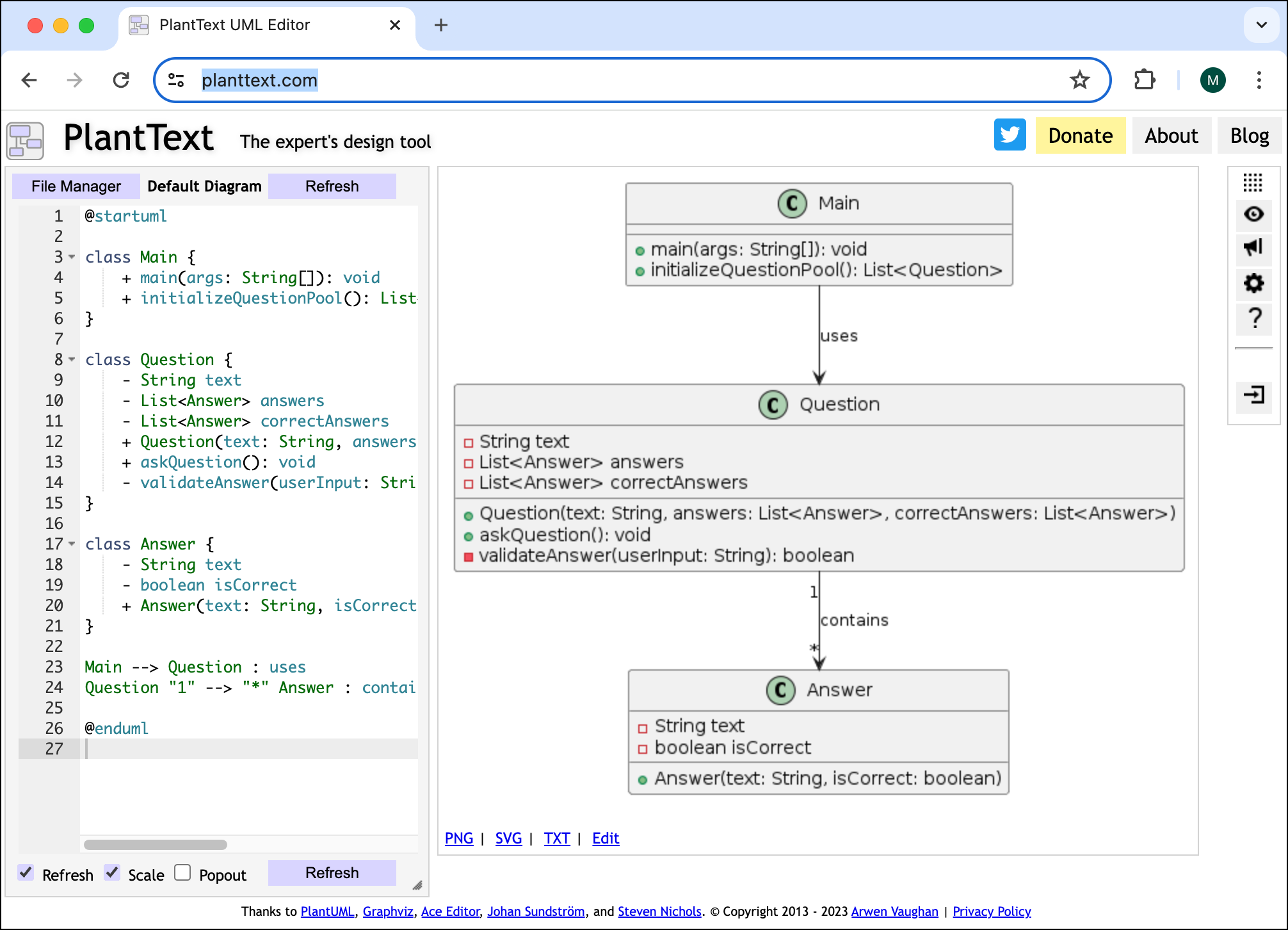
Dabei war ChatGPT schon damals in der Lage, PlantUML- oder Mermaid-Code zu liefern. Der Prompt Please generate PlantUML code instead liefert brauchbaren Code, der dann in https://www.planttext.com/ visualisiert werden kann. Das sieht dann so aus:
ChatGPT lieferte den Code für das UML-Diagramm, planttext.com visualisiert ihn
Heute habe ich das ganze Beispiel noch einmal ausprobiert. Ich habe also den Java-Code für zwei Klassen an ChatGPT übergeben und um ein UML-Diagramm gebeten. Vorbei sind die ASCII-Zeiten. Das Ergebnis sieht jetzt so aus:
ChatGPT nennt diesen von DALL-E produzierten Irrsinn ein »UML-Diagramm«Etwas mehr Kontext zum obigen Diagramm
Leider kann ich hier keinen Link zum ganzen Chat-Verlauf angeben, weil ChatGPT anscheinend nur reine Text-Chat-Verläufe teilen kann.
Visualisierung eines Docker-Setups
Beispiel zwei ergibt sich aus zwei Prompts:
Prompt: I want to build a REST application using Python and Django. The application will run in a Docker container. Do I need a proxy server in this case to make my application visible to the internet?
Prompt: Can you visualize the setup in a diagram?
In der Vergangenheit (Mitte 2024) lieferte ChatGPT das Diagramm als ASCII-Art.
Erst auf die explizite Bitte liefert es auch Mermaid-Code, der dann unter https://mermaid.live/ gezeichnet werden kann.
Heute (Dez. 2024) gibt sich ChatGPT nicht mehr mit ASCII-Art ab sondern leitet den Diagrammwunsch an DALL-E weiter. Das Ergebnis ist eine Katastrophe.
ChatGPT’s jämmerlicher Versuch, ein einfaches Docker-Setup zu visualisieren
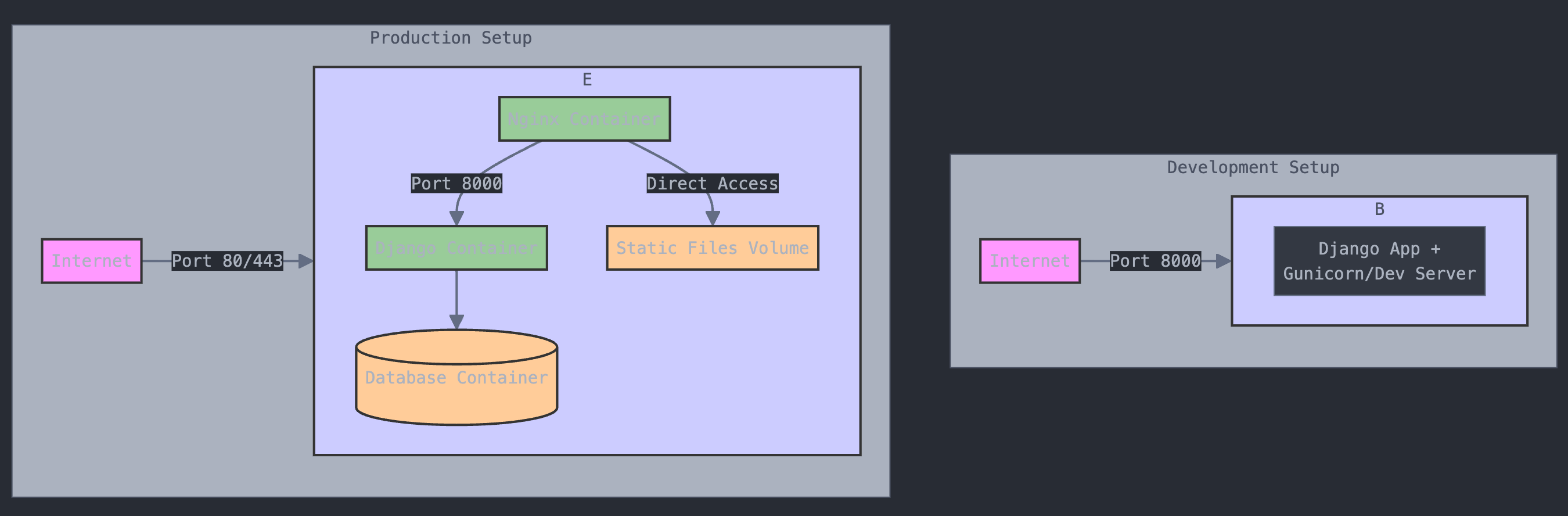
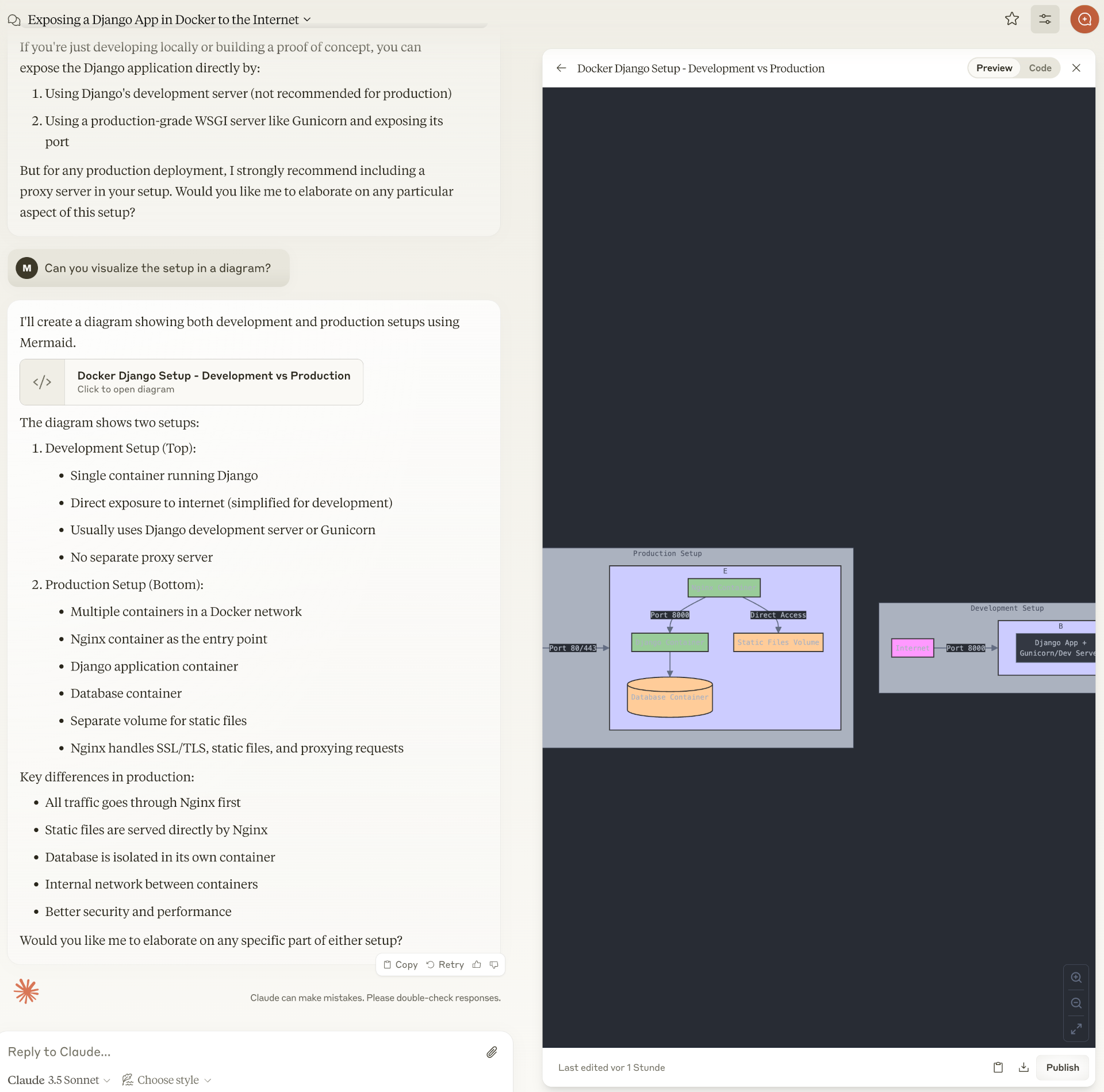
Auch Claude.ai zeichnet selbstbewusst ein Diagramm des Docker-Setups. Dabei wird intern Mermaid verwendet.
Claude leidet offensichtlich unter bedrohlichen Farbstörungen, aber inhaltlich ist das Ergebnis besser als bei ChatGPTHier der relevante Teil des Chat-Verlaufs mit Claude
Fazit
Die Diagramme haben durchaus einen hohen Unterhaltungswert. Aber offensichtlich wird es noch ein wenig dauern, bis KI-Tools brauchbare technische Diagramme zeichnen können. Der Ansatz von Claude wirkt dabei erfolgsversprechender. Technische Diagramme mit DALL-E zu erstellen wollen ist doch eine sehr gewagte Idee von OpenAI.
Die besten Ergebnisse erzielen Sie weiterhin, wenn Sie ChatGPT, Claude oder das KI-Tool Ihrer Wahl explizit um Code in PlantUML oder Mermaid bitten. Den Code können Sie dann selbst visualisieren und bei Bedarf auch weiter optimieren.
Als ich vor 40 Jahren zu schreiben begann, war klar, was ein IT-Fachbuch liefern musste: Korrekte Information zu einem Thema, zu einer Programmiersprache, zu Linux etc. … Je mehr Information, desto besser. Ein dickes Buch war also im Regelfall wertvoller als ein dünnes.
Das IT-Buch war damals nahezu konkurrenzlos: Zu kommerziellen Software-Produkten gab es im Idealfall ein gedrucktes Handbuch (oft lieblos gestaltet und von dürftiger Qualität), dazu eventuell noch ein paar Readme-Dateien; ansonsten waren Administratorinnen und Programmierer weitgehend auf sich selbst gestellt. Mit etwas Glück veröffentlichte eine der damals noch viel zahlreicheren Zeitschriften einen Artikel mit Lösungsideen für ein spezifisches Problem. Aber ansonsten galt: Learning by doing.
Mit dem Siegeszug des Internets änderte sich der IT-Buchmarkt zum ersten Mal radikal: Der Vorteil des Buchs lag nun darin, dass die dort zusammengestellten Informationen (hoffentlich!) besser recherchiert und besser strukturiert waren als die über das Internet und in Videos verstreuten Informationsschnipsel, Tipps und Tricks. Ein gutes Buch konnte ganz einfach Zeit sparen.
Das IT-Buch stand plötzlich in Konkurrenz zur Informationsfülle des Internets. Es liegt in der Natur der Sache, dass ein Buch nie so aktuell sein kann wie das Internet, nie so allumfassend bei der Themenauswahl. Im Internet finden sich selbst für exotische Funktionen Anleitungen, selbst zu selten auftretenden Fehlern Tipps oder zumindest Leidensberichte anderer Personen. Es hilft ja schon zu wissen, dass ein Problem nicht nur auf dem eigenen Rechner oder Server auftritt.
Natürlich habe auch ich als Autor von der einfachen Zugänglichkeit der Informationen profitiert. Während früher Ausprobieren der einzige Weg war, um bestimmte Techniken verlässlich zu dokumentieren, konnte ich jetzt auf den Erfahrungsschatz der riesigen Internet-Community zurückgreifen. Gleichzeitig sank aber der Bedarf nach IT-Büchern — und zwar in einem dramatischen Ausmaß. Viele Verlage, für die ich im Laufe der letzten Jahrzehnte geschrieben habe, existieren heute nicht mehr.
Mit der freien Verfügbarkeit von KI-Tools wie ChatGPT stehen wir heute vor einem weiteren Umbruch: Wozu noch nach einem Buch, einem StackOverflow-Artikel oder einem Blog-Beitrag suchen, wenn KI-Werkzeuge in Sekunden den Code für scheinbar jedes Problem, eine strukturierte Anleitung für jede Aufgabe liefern?
Möglichkeiten und Grenzen von KI-Tools
Seit die erste Version von ChatGPT online war, habe ich mich intensiv mit diesem und vielen anderen KI-Tools auseinandergesetzt. Natürlich habe ich darüber auch geschrieben, sowohl in diesem Blog als auch in Buchform: In Coding mit KI fassen Bernd Öggl, Sebastian Springer und ich zusammen, wie weit KI-Tools heute beim Coding und bei Administrationsaufgaben helfen — und wo ihre Grenzen liegen. Kurz gefasst: Claude, Copilot, Ollama etc. bieten bereits heute eine großartige Unterstüzung bei vielen Aufgaben. Sie machen Coding und Administration effizienter, schneller.
Ja, die Tools machen Fehler, aber sie sind dennoch nützlich, und sie werden jedes Monat besser. Ja, es gibt Datenschutzbedenken, aber die lassen sich lösen (am einfachsten, indem Sprachmodelle lokal ausgeführt werden). Ja, KI-Tools stellen mit ihrem exorbitaten Stromverbrauch vor allem in der Trainings-Phase eine massive ökologische Belastung dar; aber ich glaube/hoffe, dass sich KI-Tools mit bessere Hard- und Software in naher Zukunft ohne ein allzugroßes schlechtes Öko-Gewissen nutzen lassen.
Es ist für mich offensichtlich, dass viele IT-Arbeiten in Zukunft ohne KI-Unterstützung undenkbar sein werden. KI-Tools können bei der Lösung vieler Probleme die Effizienz steigern. Keine Firma, kein Admin, keine Entwicklerin wird es sich auf Dauer leisten können, darauf zu verzichten.
Die Zukunft des IT-Buchs
Ist »Coding mit KI« also das letzte IT-Buch, das Sie lesen müssen/sollen? Vermutlich nicht. (Aus meiner Sicht als Autor: Hoffentlich nicht!)
Auf jeden Fall ändern KI-Tools die Erwartungshaltung an IT-Bücher. Aktuell arbeite ich an einer Neuauflage meines Swift-Buchs. Weil sich inhaltlich viel ändert und ich bei vielen Teilen sowieso quasi bei Null anfangen muss, ist es das erste Buch, das ich von Grund auf im Hinblick auf das KI-Zeitalter neu konzipiere. In der vorigen Auflage habe ich über 1300 Seiten geschrieben und versucht, Swift und die App-Programmierung so allumfassend wie möglich darzustellen.
Dieses Mal bemühe ich mich im Gegenteil, die Seitenanzahl grob auf die Hälfte zu reduzieren. Warum? Weil ich glaube, dass sich das IT-Buch der Zukunft auf die Vermittlung der Grundlagen konzentriert. Es richtet den Blick auf das Wesentliche. Es erklärt die Konzepte. Es gibt Beispiele (durchaus auch komplexe). Aber es verzichtet darauf, endlose Details aufzulisten.
Was sind Ihre Erwartungen?
Ich weiß schon, immer mehr angehende und tatsächliche IT-Profis kommen ohne Bücher aus. Eigenes Ausprobieren in Kombination mit Videos, Blog-Artikeln und KI-Hilfe reichen aus, um neue Konzepte zu erlernen oder ganz pragmatisch ein Problem zu lösen (oft ohne es wirklich zu verstehen). Bleibt nur die Frage, warum Sie überhaupt auf meiner Website gelandet sind :-)
Persönlich lese ich mich in ein neues Thema aber weiterhin gerne ein, lasse mich von einem Autor oder einer Autorin von neuen Denkweisen überzeugen (zuletzt: Prometheus: Up & Running von Julien Pivotto und Brian Brazil). Bevorzugt mache ich das weit weg vom Computer. Wenn ich später ein Detail nochmals nachsehen will, ist mir ein E-Book willkommen. Aber beim ersten Lesen bevorzuge ich den analogen Zugang, ungestört und werbefrei.
Falls also auch Sie noch gelegentlich ein Buch zur Hand nehmen, dann interessiert mich Ihrer Meinung: Was erwarten Sie heute von einem IT-Buch? Was sind Ihre Wünsche an mich als Autor? Was ist aus Ihrer Sicht ein gutes IT-Buch, was ist ein schlechtes? Ich sage es sicherheitshalber gleich: Alle Wünsche kann ich nie erfüllen … Aber ich freue mich auf jeden Fall über Ihr Feedback!
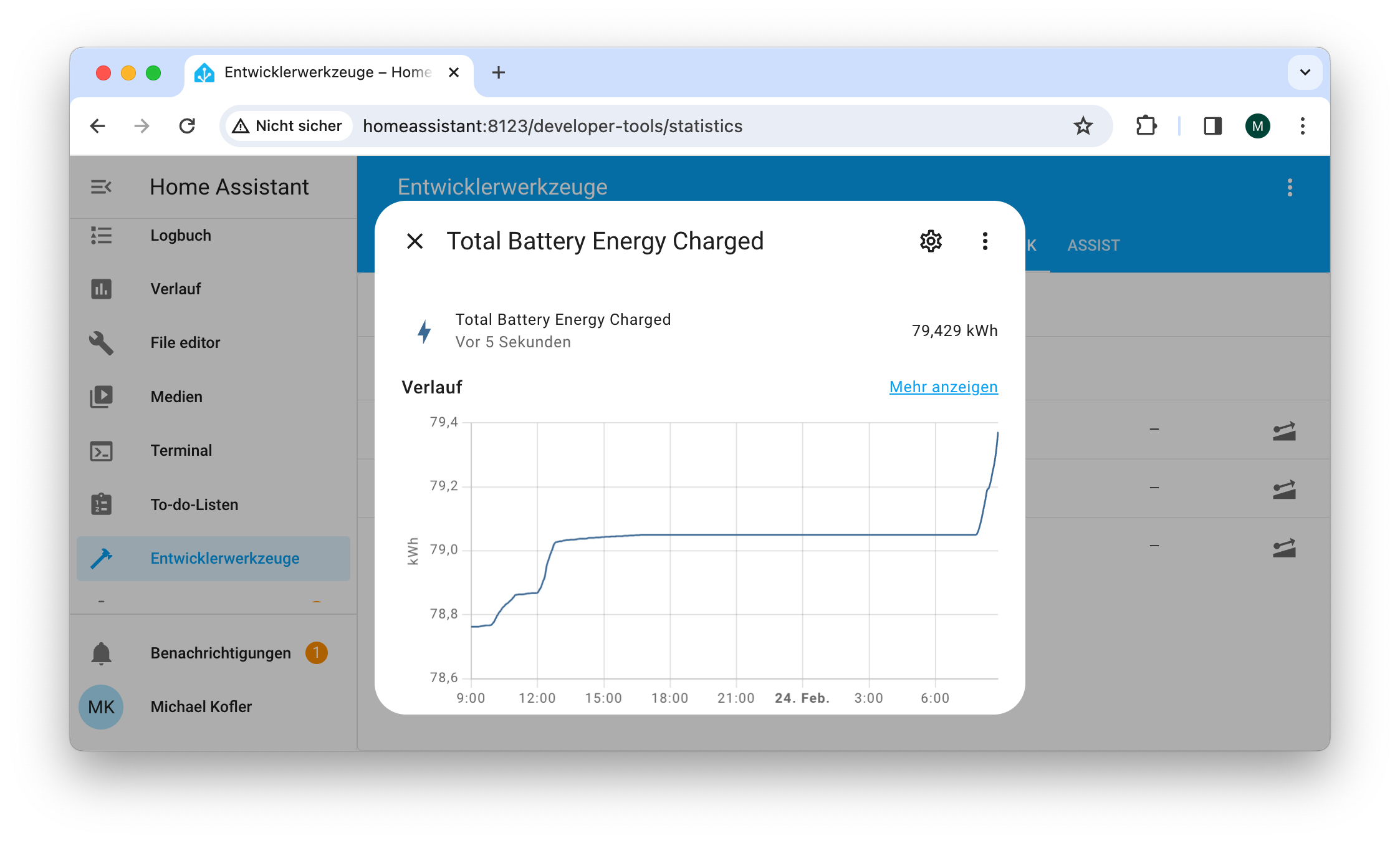
Meine Website kofler.info läuft in einer virtuellen Maschine. Und diese VM läuft wiederum auf einem Root-Server bei Hetzner. Seit ca. 4 Jahren, störungsfrei. Als Virtualisierungssystem verwende ich KVM. Auf dem Root-Server laufen auch andere VMs, die ich für die Arbeit an meinen Büchern sowie für den Unterricht an der Fachhochschule brauche.
Das Setup hat sich in den letzten 15 Jahren immer wieder gewandelt, dennoch ich bin Hetzner treu geblieben (auch in anderen beruflichen Projekten). Dass ich mich vor 15 Jahren gerade für Hetzner entschieden habe, war Zufall. Danach sah ich keinen Grund für einen Wechsel. Bis vor einer Woche. Und das ist eine etwas längere Geschichte.
Vorgeschichte: Ein Lob auf Hetzner
Ich bin seit ca. 15 Jahren Kunde der Firma Hetzner. Ich betreibe dort privat den oben erwähnten Root-Server. Auf Hetzner läuft auch ein Server, den ich und ein Freund für eine gemeinsame Firma administrieren und auf dem diverse Kunden täglich arbeiten. Bei Hetzner laufen schließlich diverse Websites, die ich für Freunde und Verwandte betreue. Auch meine Domains (z.B. kofler.info) werden via Hetzner administriert und abgerechnet.
In meinem Linux-Buch verwende ich Hetzner neben amazon/AWS als Beispiel für die Ausführung von eigenen Servern bzw. Cloud-Instanzen. (Das ist keine Empfehlung, weder für die eine noch für die andere Firma! Und natürlich bekomme ich von beiden Firmen nichts dafür, dass ich sie als Beispiel verwende. Aber irgendwelche Firmen muss ich für Beispiel-Setups verwenden. Ich brauche Firmen, die im europäischen Raum und international Stellenwert haben. Ich habe im Buch keinen Platz für fünf oder zehn Beispiele/Hoster/Cloud-Anbieter. Also habe ich mich für diese beiden entschieden.)
Seit 15 Jahren bin ich zufriedener Kunde bei Hetzner. Ja, meine Server hatten in dieser Zeit auch Probleme, z.B. einen Harddisk-Ausfall, der dank RAID ohne Datenverlust blieb und wo die Disk mit minimaler Downtime ausgetauscht wurde. Ein Server, der nach knapp 4 Jahren Dauereinsatz allmählich instabil wurde und den ich deswegen ein paar Monate vor dem schon geplanten Upgrade austauschen musste. Aber prinzipiell hat immer alles bestens funktioniert, sowohl was die langjährige Stabilität meiner Server betrifft, als auch was den selten benötigten Support betrifft.
Im Vergleich zu großen Cloud-Anbietern (und insbesondere im Vergleich zu AWS) ist ein Root-Server bei Hetzner viel preisgünstiger. Und in der Abrechnung beinahe unendlich viel einfacher. Ein Fixpreis mit 20 TB Traffic (die ich noch nie gebraucht habe), keine komplizierte Zusammensetzung aus einem halben Dutzend im Voraus schwer kalkulierbarer Preiskomponenten. Alles in allem: Für mich hat das Preis/Leistungsverhältnis gepasst, und ich war mit der Leistung zufrieden.
Ein neuer Server mit nur vier Monaten Lebenszeit
Im letzten Satz bin ich plötzlich ins Imperfekt gerutscht. Ich war zufrieden, ja, aber seit einer Woche bin ich massiv verunsichert. Ist Hetzner noch preisgünstig, oder ist das Angebot mittlerweile billig? Billig im Sinne, dass zwar der Preis stimmt, aber die Leistung nicht mehr? Seit ich Kunde bei Hetzner bin, ist die Firma zu einem riesigen Unternehmen geworden, das international auftritt. Geht Quantität vor Qualität?
Die Verunsicherung stammt von einem Server-Upgrade, das ich im April 2024 vorgenommen habe. Als Dedicated Root Server kommt nun ein AX52-Server zum Einsatz (AMD Ryzen 7700, 64 GB RAM, 4xPCIe-SSD mit je 1 TB). Die erste Unstimmigkeit trat schon vor der Installation auf: Im Live-System machte ich einen raschen SMART-Test für die vier SSDs:
for disk in /dev/nvme?n1; do echo $disk; smartctl -A $disk | grep -E 'Power On Hours|Data Units'; done
/dev/nvme0n1
Data Units Read: 220,843,669 [113 TB]
Data Units Written: 51,845,317 [26.5 TB]
Power On Hours: 3,675
/dev/nvme1n1
Data Units Read: 715,250,594 [366 TB]
Data Units Written: 411,316,958 [210 TB]
Power On Hours: 12,078
/dev/nvme2n1
Data Units Read: 3,680,708 [1.88 TB]
Data Units Written: 3,083,051 [1.57 TB]
Power On Hours: 2
/dev/nvme3n1
Data Units Read: 3,673,898 [1.88 TB]
Data Units Written: 3,082,770 [1.57 TB]
Power On Hours: 2
Ergebnis: Zwei fabriksneue SSDs, zwei weitere SSDs, die schon eine Weile im Einsatz waren. Mir ist klar, dass ich mit einem neuen Server nicht automatisch neue SSDs bekomme, aber 12.078 Betriebsstunden = 1 1/2 Jahre ist schon ordentlich. 210 TB written bedeutet außerdem ca. 1/3 der garantierten Endurance für 1 TB-SSDs (siehe z.B. hier). Mein Plan war, den Server wieder ein paar Jahre laufen zu lassen. Insofern habe mich die SMART-Ergebnisse unglücklich gemacht. Ich habe Hetzner kontaktiert, die fragliche SSD wurde auf Kulanz durch eine andere SSD ersetzt, deren Nutzungsdaten etwas geringer waren. OK.
Der neue Server lief in der Folge drei Monate ohne eine Störung. Dann begannen plötzliche Abstürze/Reboots, zuerst ein Reboot alle zwei bis drei Stunden, aber schon einen halben Tag später Reboots innerhalb weniger Minute. (Vielleicht noch ein wenig Background: Dieser Server läuft die meiste Zeit komplett im Leerlauf. Klassisches LAMP-System, viele Datenbanken, Mail-Server etc., aber geringe Nutzung.)
Ich habe den Hetzner-Support kontaktiert, dieser schlug vor, den Server auszutauschen und die vier SSDs in einen neuen Server zu stecken. Nach meiner Zustimmung war der Server eine Stunde später wieder stabil online. Zwar war der vorangegangene 1/2 Tag mit Ausfällen verbunden, aber immerhin nicht mit einem Datenverlust.
Faszinierend: Nach dem Austausch mussten ich nichts an der Konfiguration ändern. Auf meinen Wunsch blieben die IPv4- und IPv6-Adressen unverändert. Die Netzwerkkonfiguration mit Netplan (Ubuntu) funktionierte daher out of the box. Was mich mehr verblüffte: Auch der Boot-Prozess via EFI/GRUB funktionierte auf Anhieb. Ein Lob an den Hetzner-Support und an die Qualität des Setup-Generators für Neuinstallationen!
Unbeantwortet blieb allerdings meine Frage, was denn die Ursache des raschen Server-Tods sein könnte. Die Stromversorgung? Ein instabiler Prozessor? Ein schadhaftes Mainboard? Keine Antwort von Hetzner heißt wohl: Offenbar hatte ich eben Pech mit der Hardware. Sollte nicht passieren, lässt sich aber vielleicht nicht ganz ausschließen.
Einmal ist keinmal, zweimal ist einmal zu viel
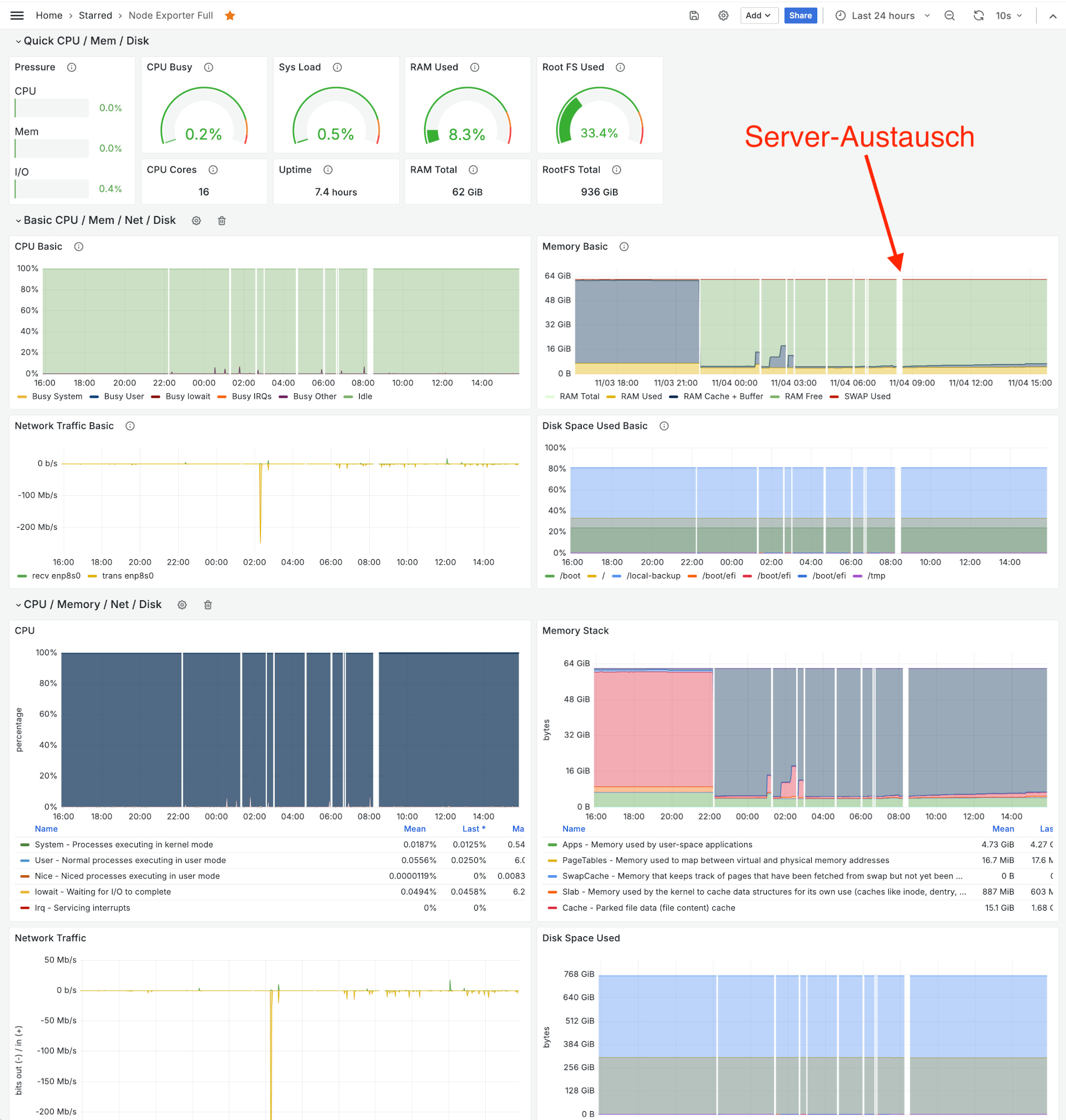
Vor einer Woche hat sich das Spiel wiederholt. Mitten in der Nacht begannen wieder plötzliche Reboots, in der Früh lagen zwischen den Reboots nur noch Minuten.
Server-Monitoring mit Prometheus und Grafana
Erster unerwarteter Reboot am 3.11. um 22:13, dann 12 weitere Reboots innerhalb von 8 Stunden.
last | grep reboot
reboot system boot 6.8.0-48-generic Mon Nov 4 08:28 still running
reboot system boot 6.8.0-48-generic Mon Nov 4 08:01 - 08:12 (00:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:53 - 08:12 (01:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:44 - 08:12 (01:27)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:38 - 08:12 (01:33)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:02 - 08:12 (02:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:00 - 08:12 (02:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 05:53 - 08:12 (02:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 04:40 - 08:12 (03:32)
reboot system boot 6.8.0-48-generic Mon Nov 4 03:01 - 08:12 (05:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 02:36 - 08:12 (05:35)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:35 - 08:12 (06:36)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:17 - 08:12 (06:54)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:16 - 08:12 (06:55)
reboot system boot 6.8.0-48-generic Sun Nov 3 22:13 - 08:12 (09:58)
Genau das gleiche Verhalten wie vor vier Monaten! Etwas verzweifelt habe ich neuerlich Hetzner kontaktiert, die den Server ebenso schnell wie beim ersten Mal austauschten. Seither ist der Server (Stand: heute, 11.11.2024) seit einer Woche störungsfrei.
Diesmal war ich hartnäckiger, was die Ursachenergründung anging. Ich habe bei Hetzner dreimal nachgefragt, was die Fehlerursache sein und wie weitere Ausfälle vermieden werden können. Ich habe explizit gefragt, ob es Problem mit der Stromversorgung des Racks gibt, in dem der Server löuft, oder ob die AX52-Serie instabil ist. In diesem Fall wäre ein Austausch des Servers gegen ein Modell einer andere Serie eine Option für mich.
Alleine, alle Fragen blieben unbeantwortet. Und das ist wirklich ärgerlich!
Update 13.11.: Heute ist doch noch eine Antwort eingetroffen. Die fraglichen Server werden untersucht, aber es ist bisher keine Ursache bekannt.
Jetzt frage ich Sie!
Die wenigen Server, die ich bei Hetzner betreibe, lassen naturgemäß keine statistisch wertvollen Aussagen zu. Ja, es kann tatsächlich sein, dass ich ZWEIMAL Pech hatte. Aber die Wahrscheinlichkeit dafür ist gering. Es wird also vermutlich eine plausible Begründung geben — aber ich kenne sie nicht. Auf jeden Fall hat mein Vertrauen in den langjährigen Betrieb von Servern bei Hetzner einen massiven Dämpfer erfahren.
Unter den Lesern meiner Bücher, meines Blogs, meines mastodon-Auftritts gibt es sicher Admins, die Erfahrungen mit Hetzner haben. Ich würde mich über Rückmeldungen, egal ob privat per Mail, im Forum meiner Website oder auf mastodon, sehr freuen.
Sind Sie mit Hetzner so zufrieden, wie ich es bis vor kurzem war?
Haben Sie negative Erfahrungen gemacht?
Hat sich in den letzten Jahren etwas geändert?
Wie lange lassen Sie einen Root-Server laufen, wenn alles funktioniert? (Mein Zielwert war immer vier Jahre.)
Ist der Root-Server für Sie tot? D.h., ist die Cloud die Alternative? (Cloud-Angebote mit großen Disks sind allerdings ausgesprochen teuer.)
Und, vielleicht am interessantesten: Können Sie europäische Alternativen empfehlen? (Aus Datenschutzgründen ist ein US-Rechenzentrum keine wünschenswerte Alternative.)
Ich bedanke mich schon jetzt für jede Rückmeldung.
PS: Der eigene Betrieb von Servern ist für mich als Privatperson keine Option.
Raspberry Pi OS »Bookworm« verwendet bekanntlich auf den Modellen 4* und 5 standardmäßig Wayland. Dabei kam als sogenannter »Compositor« das Programm Wayfire zum Einsatz. (Der Compositor ist unter anderem dafür zuständig, Fenster am Bildschirm anzuzeigen und mit einem geeigneten Fensterrahmen zu dekorieren.)
Mit dem neuesten Update von Raspberry Pi OS ändern sich nun zwei Dinge:
Anstelle von Wayfire kommt ein anderer Compositor zum Einsatz, und zwar labwc (GitHub).
Wayland kommt auf allen Raspberry Pis zum Einsatz, auch auf älteren Modellen.
Wenn Sie auf Ihrem Raspberry Pi das nächste Update durchführen, werden Sie bei nächster Gelegenheit gefragt, ob Sie auf labwc umstellen möchten. Aktuell werden Sie keinen großen Unterschied feststellen — labwc sollte genau wie wayfire funktionieren (vielleicht ein klein wenig effizienter). Langfristig haben Sie keine große Wahl: Die Raspberry Pi Foundation hat angekündigt, dass sie sich in Zukunft auf labwc konzentrieren und wayfire nicht weiter pflegen wird. Nach der Auswahl wird Ihr Raspberry Pi sofort neu gestartet.
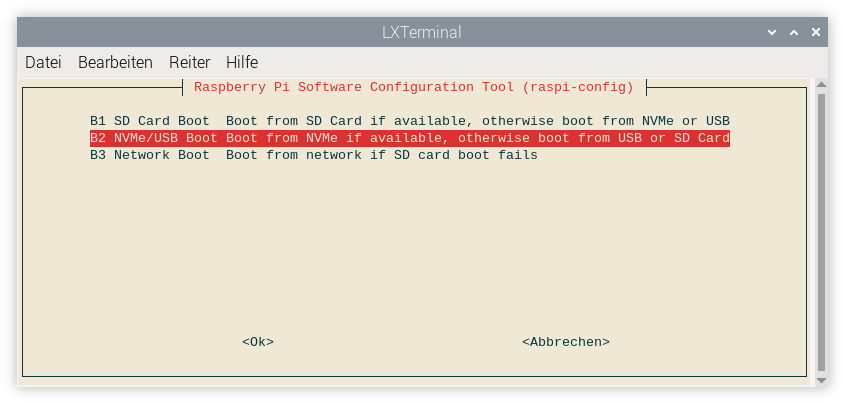
Sie haben die Wahl: Wollen Sie X verwenden oder Wayland mit labwc
Alternativ können Sie die Einstellung auch mit sudo raspi-config durchführen. Unter Advanced Options / Wayland haben Sie die Wahl zwischen allen drei Optionen.
Einstellung des Grafiksystems in raspi-config
Bei meinen Tests stand nach dem Umstieg auf labwc nur noch das US-Tastatur-Layout zur Verfügung. Eine Neueinstellung in Raspberry Pi Configuration löste dieses Problem. Auch die Monitor-Konfiguration musste ich wiederholen. Dabei kommt auch ein neues Tool zum Einsatz(raindrop statt bisher arandr), das optisch aber nicht von seinem Vorgänger zu unterscheiden ist.
Ansonsten habe ich bei meinen Tests keinen großen Unterschied festgestellt. Alles funktioniert wie bisher.
Ein halbes Jahr lang haben wir zu dritt intensiv getestet:
Was ist möglich?
Was ist sinnvoll?
Welche Anwendungsfälle gibt es, die über das reine Erstellen von Code hinausgehen?
Wo liegen die Grenzen?
Was sind die Risken?
Ist der KI-Einsatz ethisch vertretbar?
Wir haben mit ChatGPT und Claude gearbeitet und deren Ergebnisse mit lokalen Sprachmodellen (via Ollama, GPT4All, Continue, Tabby) verglichen. Wir haben Llama, Mistral/Mixtral, CodeLlama, Starcoder, Gemma und andere »freie« Sprachmodelle ausprobiert. Wir haben nicht nur Pair Programming getestet, sondern haben die KI-Werkzeuge auch zum Debugging, Refactoring, Erstellen von Unit-Tests, Design von Datenbanken, Scripting sowie zur Administration eingesetzt. Dabei haben wir mit verschiedenen Prompt-Formulierungen experimentiert und geben dazu eine Menge Tipps.
Der nächste Schritt beim Coding mit KI sind semi-selbstständige Level-3-Tools. Also haben wir uns OpenHands und Aider angesehen und waren von letzterem ziemlich angetan. Wir haben die Grenzen aktueller Sprachmodelle mit Retrieval Augmented Generation (RAG) und Text-to-SQL verschoben. Wir haben Scripts entwickelt, die mit KI-APIs kommunizieren und automatisiert dutzende oder auch hunderte von Code-Dateien verarbeiten.
Kurz und gut: Wir haben uns das Thema »Coding mit KI« so gesamtheitlich wie möglich angesehen und teilen mit Ihnen unsere Erfahrungen. Die Quintessenz ist vielleicht ein wenig banal: Es kommt darauf an. In vielen Fällen haben wir sehr gute Ergebnisse erzielt. Oft sind wir aber auch an die Grenzen gestoßen — umso eher, je spezieller die Probleme, je exotischer die Programmiersprachen und je neuer die genutzten Sprach-Features/Frameworks/Bibliotheken sind.
Was bleibt, ist die Überzeugung, dass an KI-Tools in der Software-Entwicklung kein Weg vorbei geht. Wer KI-Tools richtig einsetzt, spart Zeit, kürzer lässt es sich nicht zusammenfassen. Aber wer sie falsch einsetzt, agiert unverantwortlich und produziert fehlerhaften und unwartbaren Code!
Mehr Details zum (Vorwort, Leseprobe) finden Sie hier.
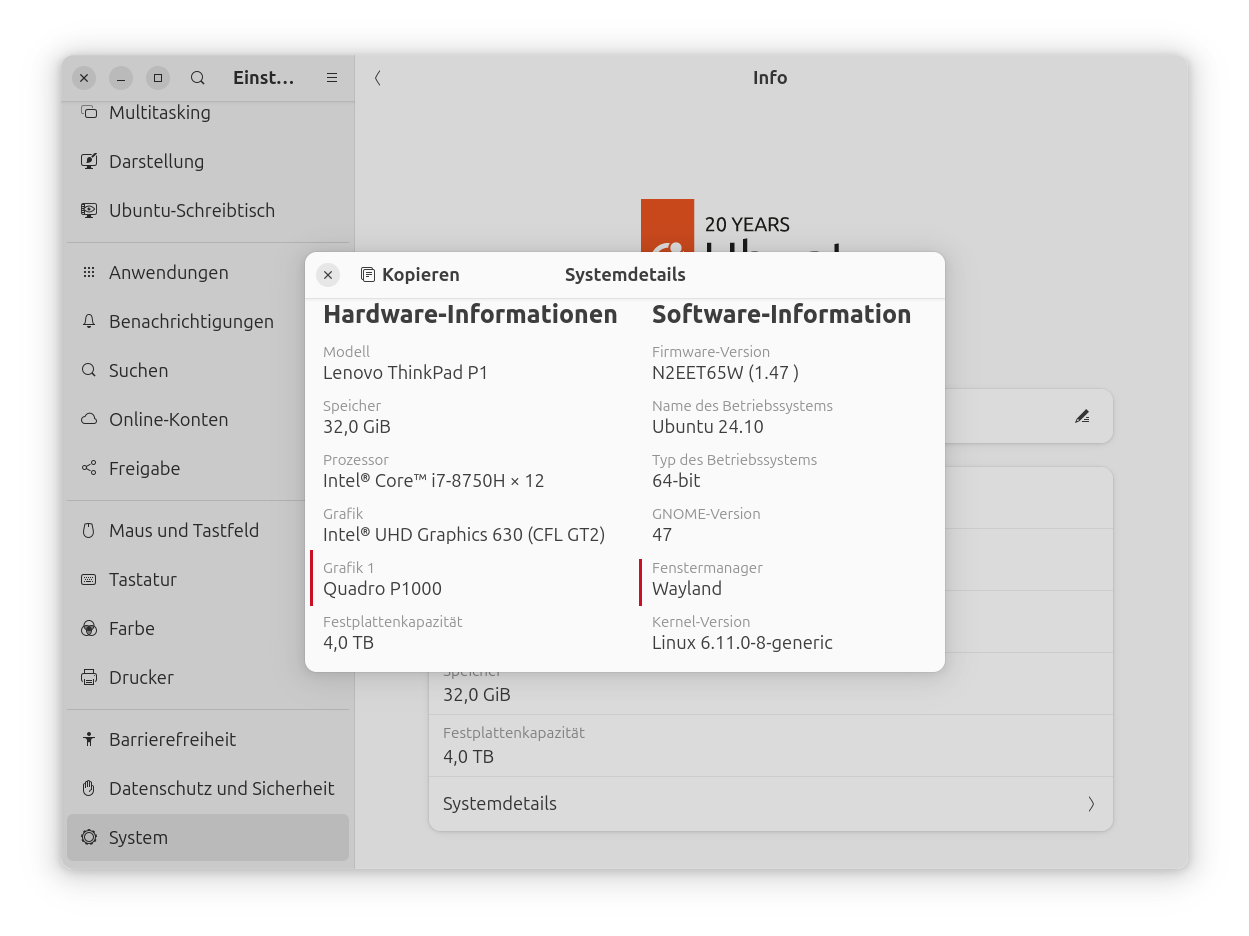
Eigentlich hatte ich nicht vorgehabt, über Ubuntu 24.10 zu schreiben. Es ist kein LTS-Release, dramatische Neuerungen gibt es auch nicht. Aber dann ergab sich überraschend die Notwendigkeit, eine native Ubuntu-Installation auf meinem Notebook (Lenovo P1 gen1) durchzuführen. Außerdem feiert Ubuntu den 20. Geburtstag.
Also habe ich doch ein paar Worte (gar nicht so wenige) zum neuesten Release geschrieben. Der Text ist launiger geworden als beabsichtigt. Er konzentriert sich ausschließlich auf die Desktop-Nutzung, also auf Ubuntu für Büro-, Admin- oder Entwicklerrechner. Der Artikel bringt auch ein wenig meinen Frust zum Ausdruck, den ich mit Linux am Desktop zunehmend verspüre.
Installation
Ich lebe normalerweise in einer weitgehend virtuellen Linux-Welt. Auf meinem Arbeits-Notebook läuft zwar Arch Linux, aber neue Distributionen teste ich meistens in virtuellen Maschinen, viele meiner Server-Installationen befinden sich in Cloud-Instanzen, die Software-Entwicklung erfolgt in Docker-Containern. Überall Linux, aber eben meist eine (oder zwei) virtuelle Schichten entfernt.
Insofern ist es wichtig, hin und wieder auch eine »echte« Installation durchzuführen. Testkandidat war in diesem Fall ein fünf Jahre altes Lenovo P1 Notebook mit Intel-CPU und NVIDIA-GPU. Ich wollte Ubuntu auf eine noch leere 2-TB-SSD installieren, dabei aber nur 400 GiB nutzen. (Auch ein paar andere Distributionen verdienen im nächsten Jahr ihre Chance in der realen Welt …)
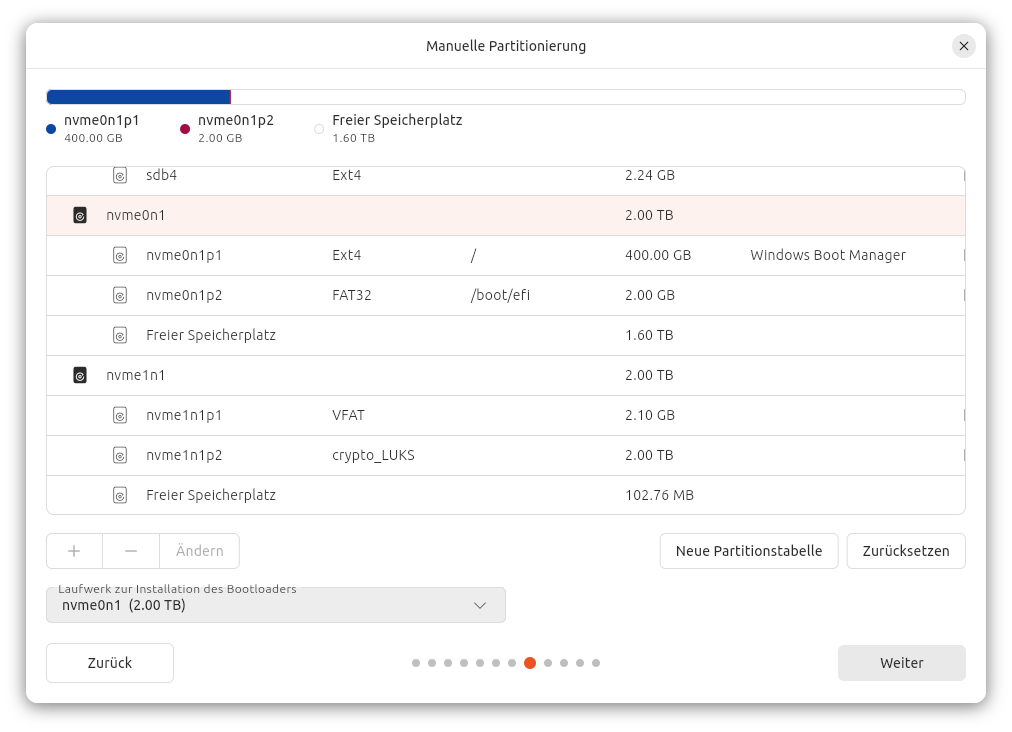
Weil ich nicht die ganze SSD nutzen möchte, werde ich zur manuellen Partitionierung gezwungen. So weit, so gut, allerdings fehlen dort die LVM-Funktionen. Somit ist es für Laien unmöglich, Ubuntu verschlüsselt in ein Logical Volume zu installieren. (Profis können sich Ihr Setup mit parted, pvxxx, vgxxx, lvxxx und cryptsetup selbst zusammenbasteln. Ich habe das aber nicht getestet.)
Bei der manuellen Partitionierung ist es unmöglich, die EI-Partition an den Beginn der Partitionstabelle zu stellen. Die /-Partition wird mit ‚Windows Boot Manager‘ beschriftet, warum auch immer. Die zweite SSD enthält eine schon vorhandene Arch-Linux-Installation.
Noch ein Ärgernis der manuellen Partitionierung: Das Setup-Programm kümmert sich selbst darum, eine EFI-Partition einzurichten. Gut! Aber auf einer aktuell leeren Disk wird diese kleine Partition immer NACH den anderen Partitionen platziert. Mir wäre lieber gewesen, zuerst 2 GiB EFI, dann 400 GiB für /. Solange es keine weiteren Partitionen gibt, hätte ich so die Chance, die Größe von / nachträglich zu ändern. Fehlanzeige. Im Übrigen hat das Setup-Programm auch die von mir gewählte Größe für die EFI-Partition ignoriert. Ich wollte 2 GiB und habe diese Größe auch eingestellt (siehe Screenshot). Das Setup-Programm fand 1 GiB ausreichend und hat sich durchgesetzt.
Zusammenfassung der Installationseinstellungen
Für die meisten Linux-Anwender sind die obigen Anmerkungen nicht relevant. Wenn Sie Ubuntu einfach auf die ganze Disk installieren wollen (real oder in einer virtuellen Maschine), oder in den freien Platz, der neben Windows noch zur Verfügung steht, dann klappt ja alles bestens. Nur Sonderwünsche werden nicht erfüllt.
Letzte Anmerkung: Ich wollte auf dem gleichen Rechner kürzlich Windows 11 neu installieren. (Fragen Sie jetzt nicht, warum …) Um es kurz zu machen — ich bin gescheitert. Das Windows-11-Setup-Programm aus dem aktuellsten ISO-Image glänzt in moderner Windows-7-Optik. Es braucht anscheinend zusätzliche Treiber, damit es auf einem fünf Jahre alten Notebook auf die SSDs zugreifen kann. (?!) Mit der Hilfe von Google habe ich entdeckt, dass er wohl die Intel-RST-Treiber für die Intel-CPU des Rechners haben will. Die habe ich mir runtergeladen, auf einem anderen Windows-Rechner (wird selbstverständlich vorausgesetzt) ausgepackt, auf einen zweiten USB-Stick gegeben und dem Windows-Installer zum Fraß vorgeworfen. Aber es half nichts. Die Treiber wären angeblich inkompatibel zu meiner Hardware. Ich habe fünf Stunden alles Mögliche probiert, das Internet und KI-Tools befragt, diverse Treiber von allen möglichen Seiten heruntergeladen. Aussichtslos. Ich habe mir dann von Lenovo ein Recovery-Image (Windows 10, aber egal) für mein Notebook besorgt. Es bleibt bei der Partitionierung in einem Endlos-Reboot hängen. Vielleicht, weil vor fünf Jahren 2-TB-SSDs unüblich waren? Also: Wer immer (mich selbst eingeschlossen) darüber jammert, wie schwierig eine Linux-Installation doch sei, hat noch nie versucht, Windows auf realer Hardware zu installieren. (Ich weiß, in virtuellen Maschinen klappt es besser.) Jammern über Einschränkungen bei der Ubuntu-Installation ist Jammern auf hohen Niveau. Der Ubuntu-Installer funktioniert ca. 100 Mal besser als der von Windows 11!
Das App Center
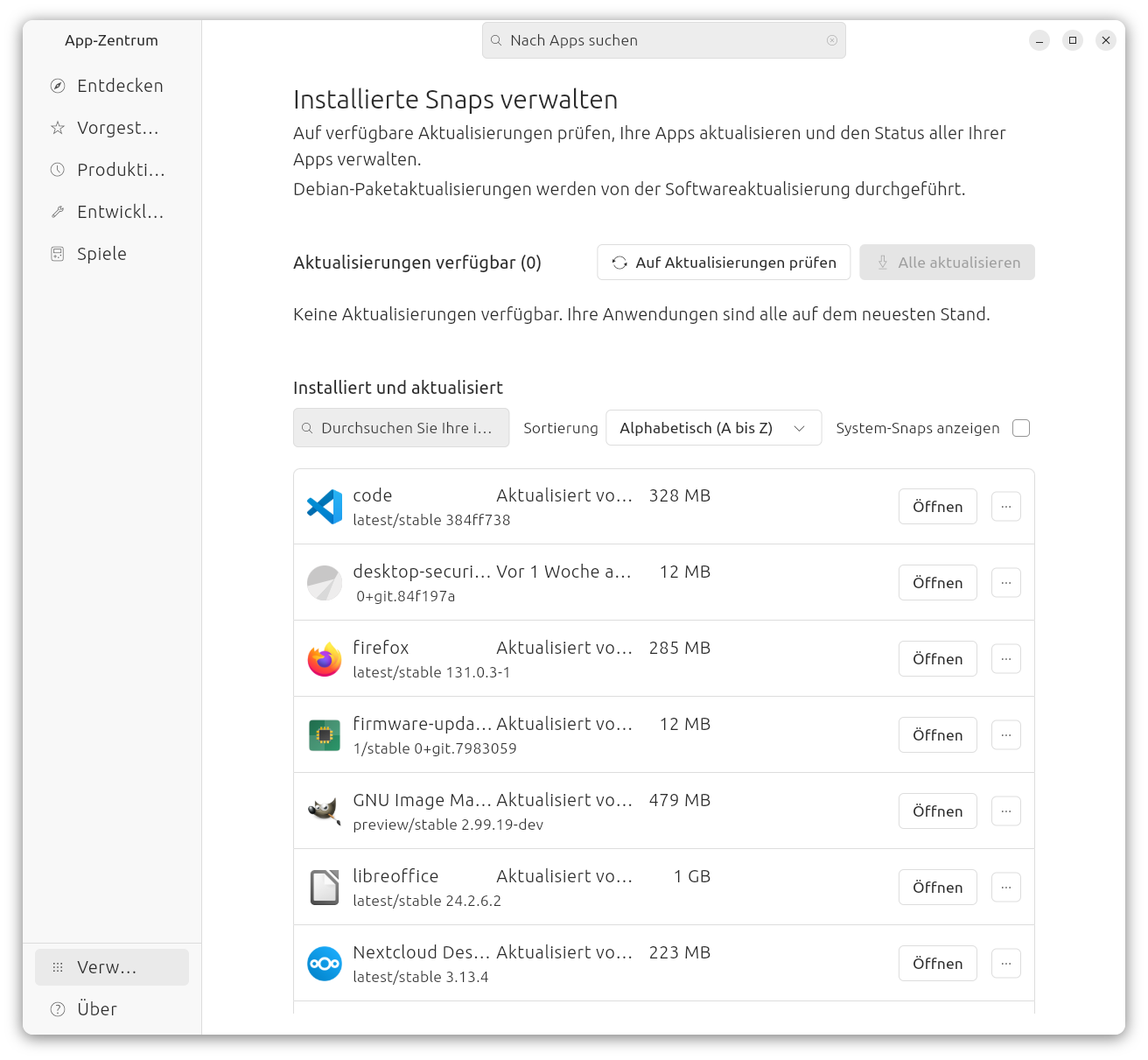
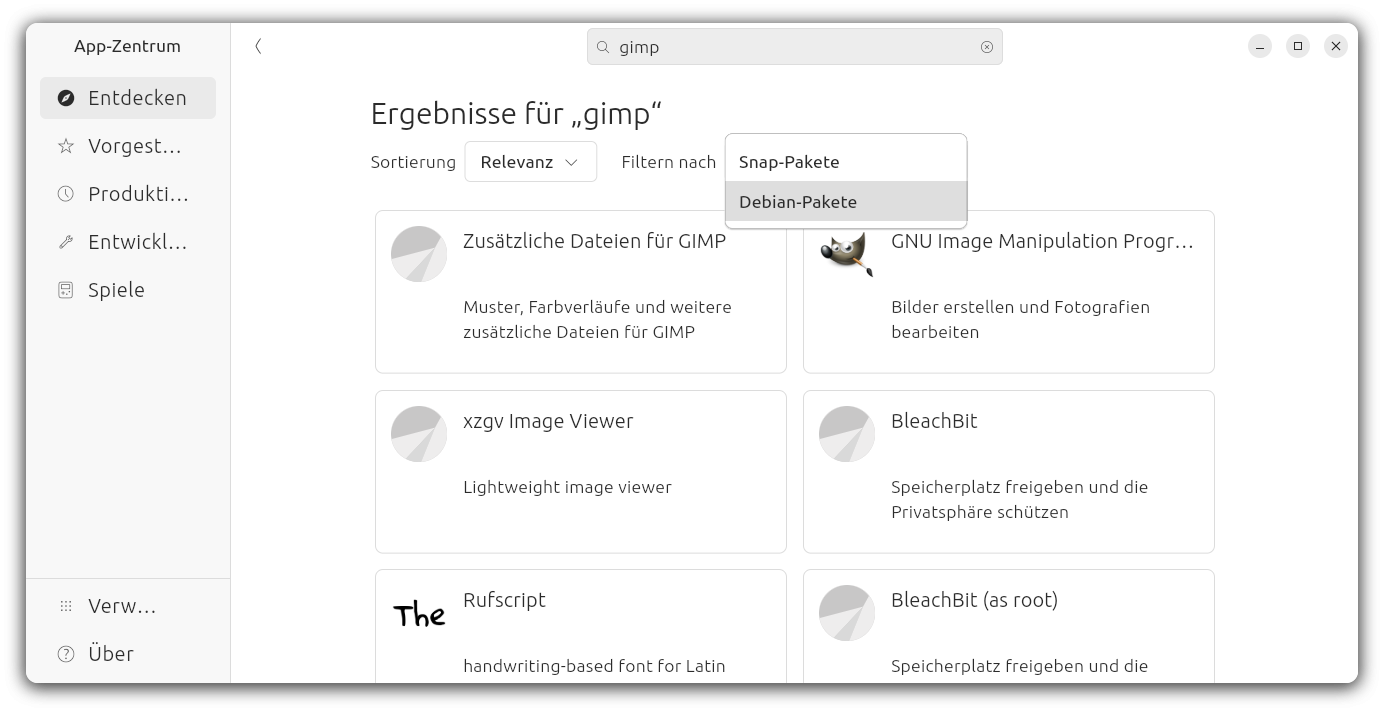
Obwohl ich bekanntermaßen kein großer Snap-Fan bin, habe ich mich entschieden, Ubuntu zur Abwechslung einmal so zu verwenden, wie es von seinen Entwicklern vorgesehen ist. Ich habe daher einige für mich relevante Desktop-Programme aus dem App Center in Form von Snap-Paketen installiert (unter anderem eine Vorabversion von Gimp 3.0, VS Code, den Nextcloud Client und LibreOffice). Auf den Speicherverbrauch habe ich nicht geschaut, Platz auf der SSD und im RAM ist ja genug.
Das Ubuntu App Center stellt ausschließlich Snap-Pakete von snapcraft.io zur Auswahl
Grundsätzlich hat vieles funktioniert, aber gemessen daran, wie lange es nun schon Snaps gibt, stören immer noch erstaunlich viele Kleinigkeiten:
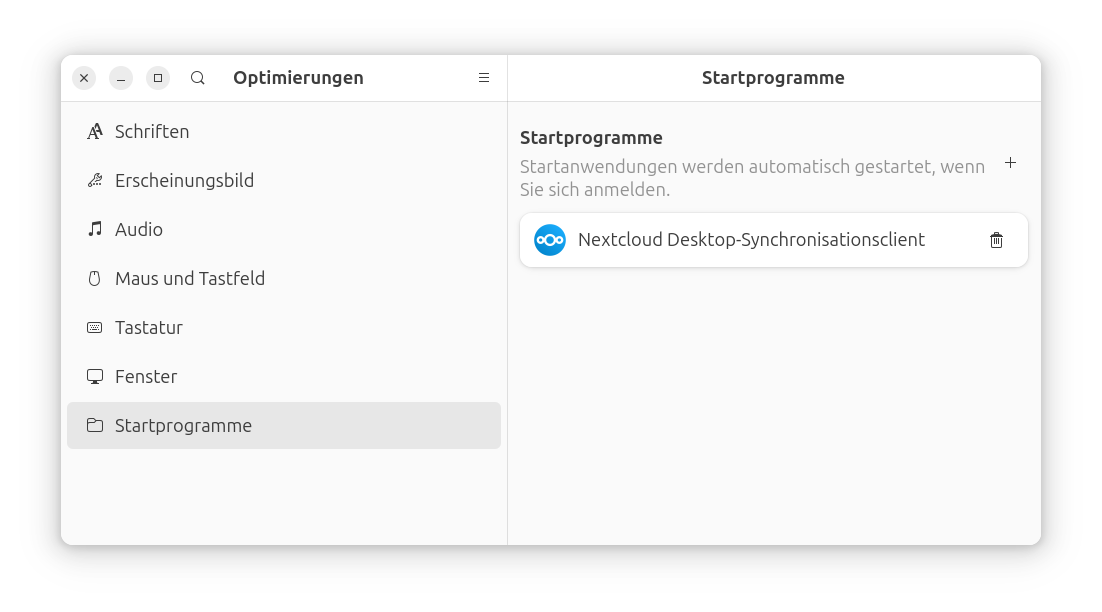
Im Nextcloud-Client hatte ich im ersten Versuch Probleme bei der Verzeichnisauswahl. Diese folgte relativ zum Snap-Installationsverzeichnis statt relativ zu meinem Home-Verzeichnis. In der Folge scheiterte die Synchronisation wegen fehlender Schreibrechte. Das ließ sich relativ schnell beheben, hätte bei Einsteigern aber sicher einiges an Verwirrung verursacht. Noch ein Problem: Der Nextcloud wird NICHT automatisch beim Login gestartet, obwohl die entsprechende Option in den Nextcloud-Einstellungen gesetzt ist. Das muss manuell behoben werden (am einfachsten in gnome-tweaks alias Optimierungen im Tab Startprogramme).
Damit der Nextcloud-Client automatisch startet, nehmen Sie am besten »gnome-tweaks« (Optimierungen) zu Hilfe
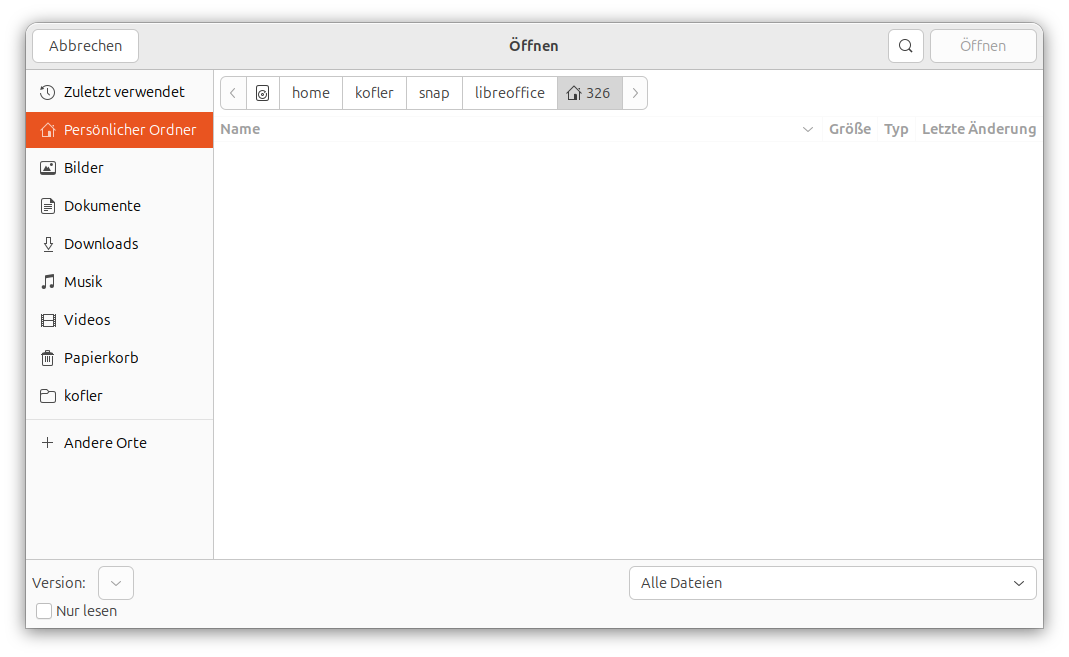
Der Versuch, LibreOffice nach der Installation aus dem Ubuntu Store zu starten (Button Öffnen), führt direkt in den LibreOffice-Datenbank-Assistenten?! Weil ich keine Datenbank einrichten will, breche ich ab — damit endet LibreOffice wieder. Ich habe LibreOffice dann über das Startmenü (ehemals ‚Anwendungen‘) gestartet — funktioniert. Warum nicht gleich? Das nächste Problem tritt auf, sobald ich eine Datei öffnen möchte. Im Dateiauswahldialog drücke ich auf Persönlicher Ordner — aber der ist leer! Warum? Weil wieder alle Verzeichnisse (inkl. des Home-Verzeichnisses) relativ zum Snap-Installationsordner gelten. Meine Güte! Ja, ich kann mit etwas Mühe zu meinem wirklichen Home-Verzeichnis navigieren, aber so treibt man doch jeden Einsteiger zum Wahnsinn. Ab dem zweiten Start funktioniert es dann, d.h. LibreOffice nutzt standardmäßig mein ‚richtiges‘ Home-Verzeichnis.
Snap-Programme wissen nicht immer, wo ‚Home‘ ist.
Zwischendurch ist der App Center abgestürzt. Es kommt auch vor, dass das Programm plötzlich ohne ersichtlichen Grund einen CPU-Core zu 100 % nutzt. Das Programm beenden hilft.
Updates des App Center (selbst ein Snap-Paket), während dieser läuft, sind weiter unmöglich.
Es gibt auch gute Nachrichten: Ein Klick auf ein heruntergeladenes Debian-Paket öffnet das App Center, und dieses kann nun tatsächlich das Debian-Paket installieren. (Es warnt langatmig, wie unsicher die Installation von Paketen unbekannter Herkunft ist, aber gut. In gewisser Weise stimmt das ja.)
Nicht nur dass, wenn Sie den Suchfilter korrekt einstellen, können Sie im App Center sogar nach Debian-Paketen suchen und direkt installieren. Ganz intuitiv ist das nicht, aber es ist ein Fortschritt.
Sie können im App Center nun auch nach Debian-Paketen suchen
NVIDIA und Wayland
Ubuntu 24.10 ist die erste Ubuntu-Version, bei der meine NVIDIA-Grafikkarte out of the box nahezu ohne Einschränkungen funktioniert. Ich habe während der Installation darum gebeten, auch proprietäre Treiber zu installieren. Beim ersten Start werden dementsprechend die NVIDIA-Treiber geladen. Ab dem ersten Login ist tatsächlich Wayland aktiv und nicht wie (bei meiner Hardware in der Vergangenheit) X.org.
Die Installation proprietärer Treiber (inkl. NVIDIA) während der Installation ist ein Kinderspiel.NVIDIA und Wayland kooperieren
Ich habe eine Weile in mit den Anzeige-Einstellungen gespielt: Zwei Monitore in unterschiedlichen Varianten, fraktionelle Skalierung (unscharf, aber prinzipiell OK) usw. Obwohl ich mir Mühe gegeben habe, das Gegenteil zu erreichen: Es hat wirklich jedes Monitor-Setup funktioniert. Ich würde das durchaus als Meilenstein bezeichnen. (Your milage may vary, wie es im Englischen so schön heißt. Alte Hardware ist beim Zusammenspiel mit Linux oft ein Vorteil.)
Na ja, fast alles: Ich war dann so übermütig und habe das System in den Bereitschaftsmodus versetzt. Am nächsten Tag wollte ich mich wieder anmelden. Soweit ich erkennen konnte, ist der Rechner gelaufen (die ganze Nacht??), er reagierte auf jeden Fall auf ping. (Ich war so leichtsinnig und hatte noch keinen SSH-Server installiert. Großer Fehler!) Auf jeden Fall blieben sowohl das Notebook-Display als auch der angeschlossene Monitor schwarz. Ich konnte drücken, wohin ich wollte, den Display-Deckel auf und zu machen, das HDMI-Kabel lösen und wieder anstecken — aussichtslos. Einzige Lösung: brutaler Neustart (Power-Knopf fünf Sekunden lang drücken). Und ich hatte schon gedacht, es wäre ein Wunder passiert …
Und noch ein kleines Detail: Drag&Drop-Operationen zicken (z.B. von Nautilus nach Chrome, Bilder in die WordPress-Mediathek oder Dateien in die Weboberfläche von Nextcloud oder Moodle hochladen). Das ist seit fünf Jahren ein Wayland-Problem. Es funktioniert oft, aber eben nicht immer.
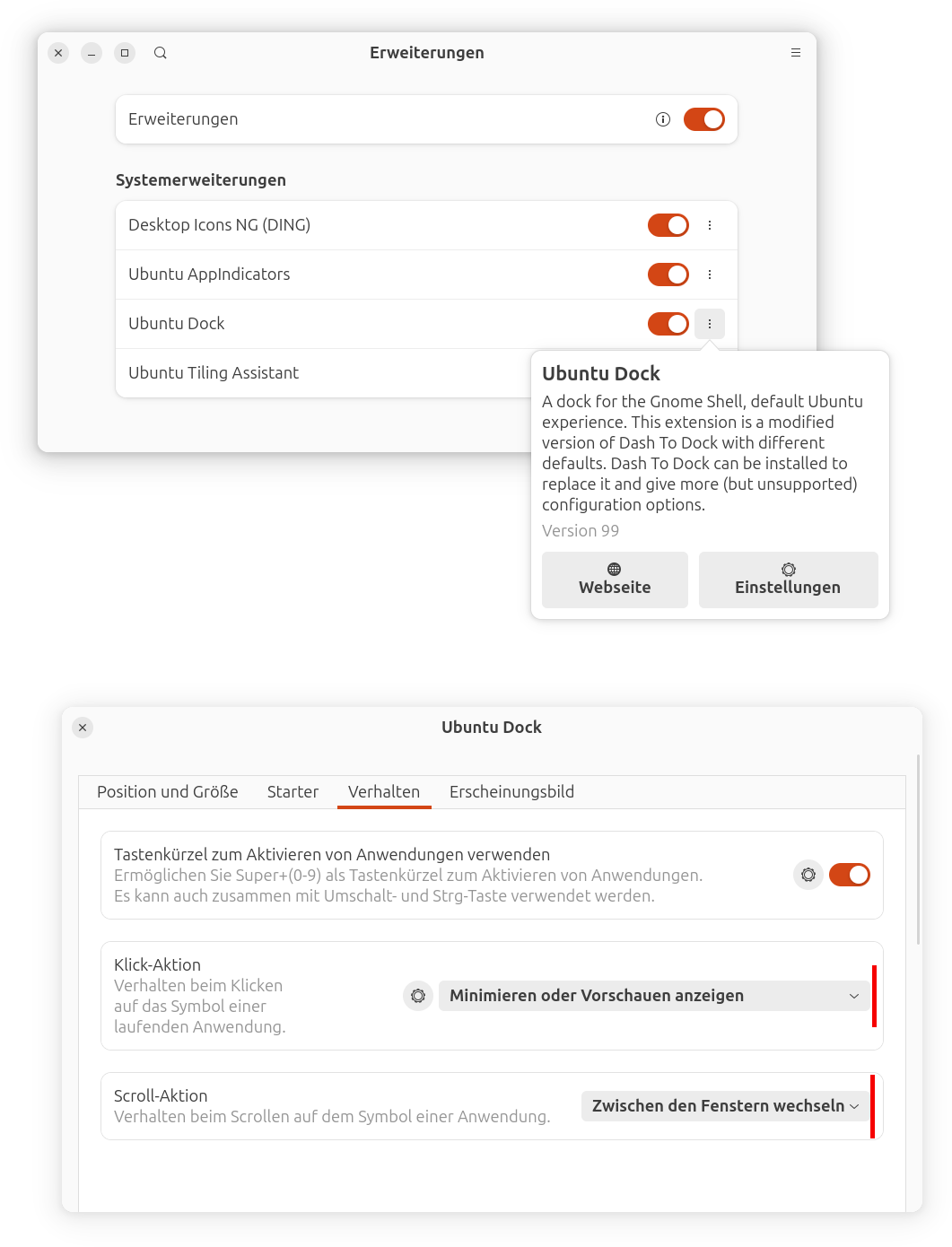
Ubuntu Dock
Das Ubuntu-Dock wird durch eine Ubuntu-eigene Gnome Shell Extension realisiert, die im Wesentlichen Dash to Dock entspricht. (Tatsächlich handelt es sich um einen Klon/Fork dieser Erweiterung.)
In den Gnome-Einstellungen unter Ubuntu-Schreibtisch können allerdings nur rudimentäre Einstellungen dieser Erweiterung verändert werden. Das ist schade, weil es ja viel mehr Funktionen gibt. Einige davon (per Mausrad durch die Fenster wechseln, per Mausklick Fenster ein- und wieder ausblenden) sind aus meiner Sicht essentiell.
Um an die restlichen Einstellungen heranzukommen, müssen Sie das vorinstallierten Programm Erweiterungen starten. Von dort gelangen Sie in den vollständigen Einstellungsdialog der Erweiterung.
Der Weg in den erweiterten Einstellungsdialog für das Ubuntu Dock
20 Jahre Ubuntu
Ubuntu hat den Linux-Desktop nicht zum erhofften Durchbruch verholfen, aber Ubuntu und Canonical haben den Linux-Desktop auf jeden Fall deutlich besser gemacht. Geld ist mit dem Linux-Desktop wohl keines zu verdienen, das hat auch Canonical erkannt. Umso höher muss man es der Firma anrechnen, dass sie sich nicht ausschließlich den Themen Server, Cloud und IoT zuwendet, sondern weiter Geld in die Desktop-Entwicklung steckt.
Die Linux-Community hat Ubuntu und Canonical viel zu verdanken. Und so schließe ich mich diversen Glückwünschen aus dem Netz an und gratuliere Ubuntu ganz herzlich zum 20-jährigen Jubiläum. »Wir hätten dich sonst sehr vermisst«, heißt es in manchen Geburtstagsliedern. Wie sehr trifft das auf Ubuntu zu!
Fazit
Linux im Allgemeinen, Ubuntu im Speziellen funktioniert als Desktop-System gut, zu 90%, vielleicht sogar zu 95%. Seit Jahren, eigentlich schon seit Jahrzehnten. Na ja, zumindest seit einem Jahrzehnt.
Aber die fehlenden paar Prozent — an denen scheint sich nichts zu ändern. Und das ist schade, weil es ja so dringend eine Alternative zum goldenen Käfig (macOS) bzw. dem heillosen Chaos (Windows, bloatware included TM) bräuchte.
Profis können sich mit Linux als Desktop-System arrangieren und profitieren von den vielen Freiheiten, die damit verbunden sind. Aber es fällt mir seit Jahren immer schwerer, Linux außerhalb dieses Segments zu empfehlen.
Linux hält unsere (IT-)Welt server-seitig am Laufen. Praktisch jeder Mensch, der einen Computer oder ein Smartphone verwendet, nutzt täglich Dienste, die Linux-Server zur Verfügung stellen. Warum ist der kleine Schritt, um Linux am Desktop zum Durchbruch zu verhelfen, offenbar zu groß für die Menschheit (oder die Linux-Entwicklergemeinde)?
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
Teil II: mit VirtualBox (Windows mit Intel/AMD-CPU)
Teil III (dieser Text): mit UTM (macOS ARM)
In diesem Artikel gehe ich davon aus, dass Sie einen Mac mit ARM-CPU (M1, M2 usw.) verwenden. Für ältere Modelle mit Intel-CPUs gelten z.T. andere Details, auf die ich hier nicht eingehe. Insbesondere müssen Sie dann eine ISO-Datei für x86-kompatible CPUs verwenden, anstatt, wie hier beschrieben, eine ARM-ISO-Datei!
Virtualisierungssysteme für macOS ARM
Sie haben die Wahl:
Parallels Desktop: gut, aber wegen jährlicher Update-Pflicht sehr teuer
VMWare Fusion: kostenlos (for personal use), aber gut versteckter Download (erfordert vorher Registrierung bei Broadcom, danach lange Suche), verwirrende Bedienung, unklare Zukunft
UTM: Open-Source-Programm, kostenloser Download oder 10 EUR über App Store (einziger Unterschied: automatische Updates)
VirtualBox: kostenlos, aber aktuell erst als Beta-Version verfügbar und extrem langsam
Ich konzentriere mich hier auf UTM, der aus meiner Sicht überzeugendsten Lösung.
UTM
UTM ist ein Open-Source-Programm, das nur als Schnittstelle zu zwei Virtualisierungssystemen dient: dem aus der Linux-Welt bekannten QEMU-System sowie dem Apple Hypervisor Virtualization Framework (integraler Bestandteil von macOS seit Version 13, also seit Herbst 2022). UTM ist also lediglich eine grafische Oberfläche und delegiert die eigentliche Virtualisierung an etablierte Frameworks.
Sie können UTM um ca. 10 EUR im App Store kaufen und so die UTM-Entwickler ein wenig unterstützen, oder das Programm kostenlos von https://mac.getutm.app/ herunterladen und (vollkommen unkompliziert!) selbst installieren.
Sodann können Sie mit UTM virtuelle Maschinen mit Linux, Windows und macOS ausführen. Ich behandle hier ausschließlich Linux.
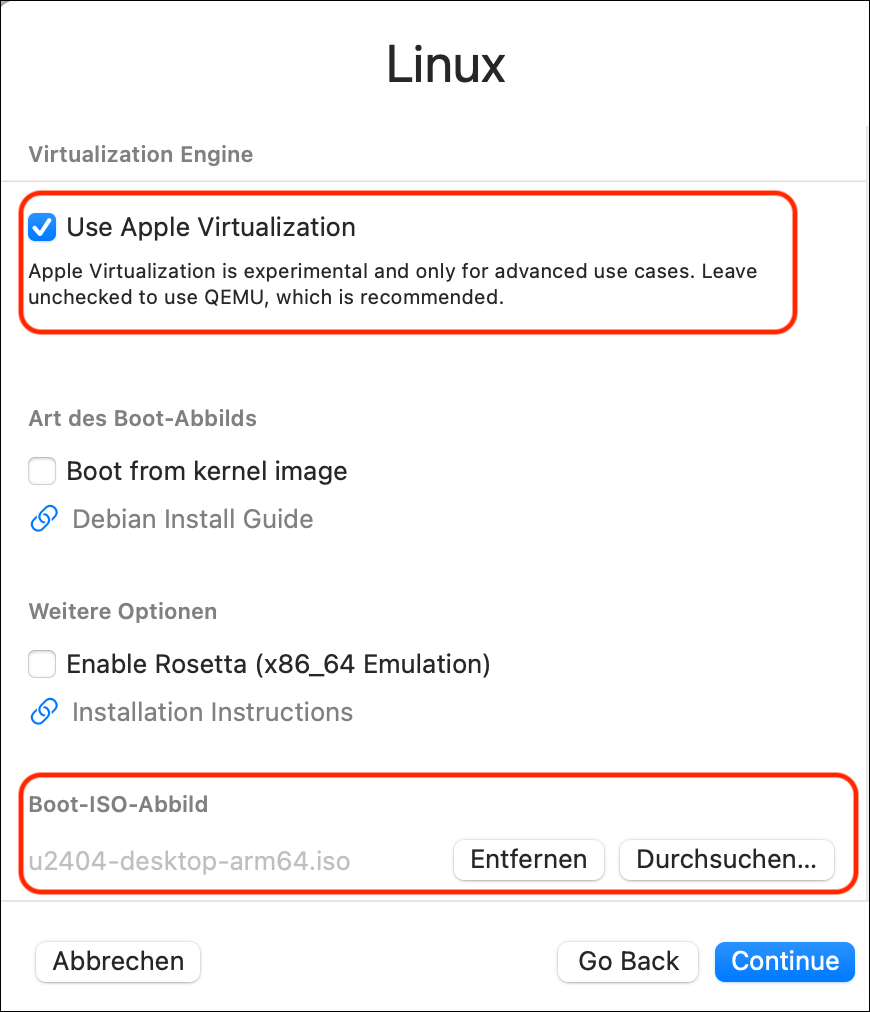
QEMU oder Apple Virtualization?
Wenn Sie in UTM eine neue virtuelle Maschine für Linux einrichten, haben Sie die Wahl zwischen zwei Virtualisierungssystemen: QEMU und Apple Virtualization. Welches ist besser?
Die QEMU-Variante bietet viel mehr Konfigurationsmöglichkeiten rund um die Netzwerkeinbindung und das Grafiksystem. Allerdings braucht die virtuelle Maschine doppelt so viel RAM wie vorgesehen: Wenn Sie eine VM mit 4 GB RAM einrichten, gehen beim Betrieb 8 GB RAM im macOS-Arbeitsspeicher verloren! macOS ist gut dabei, ungenutzte RAM-Teile zu komprimieren oder auszulagern, dennoch ist diese RAM-Verschwendung Wahnsinn. (Das gleiche Problem habe ich übrigens auch bei Tests mit VMWare Fusion festgestellt.)
Bei Apple Virtualization funktioniert die Speicherverwaltung, d.h. eine virtuelle Maschine mit 4 GB RAM braucht tatsächlich nur 4 GB RAM. (Das sollte ja eigentlich selbstverständlich sein …) Dafür haben Sie bei der Netzwerkkonfiguration kaum Wahlmöglichkeiten. Die VMs werden immer über eine Netzwerkbrücke in das lokale Netzwerk integriert. Es gibt zwar zwei Optionen, Gemeinsames Netzwerk und Bridge-Modus. Soweit ich es nachvollziehen kann, reduziert Gemeinsames Netzwerk nur die Optionen für den Bridge-Modus, ändert aber daran nichts. Das Apple Virtualization Framework würde auch NAT unterstützen, aber UTM stellt diese Option nicht zur Wahl.
In der Oberfläche von UTM wird die Verwendung von Apple Virtualization als experimentell bezeichnet. Ich habe bei meinen Tests leider mit beiden Frameworks gelegentliche Abstürze von virtuellen Maschinen erlebt. Ich würde beide Frameworks als gleichermaßen stabil betrachten (oder auch instabil, je nach Sichtweise; unter Linux mit QEMU/KVM sind mir Abstürze unbekannt). Persönlich verwende ich, vor allem um RAM zu sparen, für neue VMs nur mehr die Apple Virtualization. Glücklicherweise passt der Bridge Modus gut zu meinen Netzwerkanforderungen.
Wenn Sie VMs mit macOS oder Windows erstellen, entfällt die Wahlmöglichkeit. Windows VMs können nur durch QEMU ausgeführt werden, macOS VMs nur mit dem Apple Virtualization Framework.
Ubuntu installieren
Die erste Hürde hin zur Ubuntu-Installation besteht darin, ein ARM-ISO-Image zu finden. Auf den üblichen Download-Seiten finden Sie nur die x86-Variante von Ubuntu Desktop. Es gibt aber sehr wohl ein ARM-Image! Es ist auf der Website cdimage.ubuntu.com versteckt (noble-desktop-arm64.iso):
In UTM klicken Sie auf den Plus-Button, um eine neue virtuelle Maschine einzurichten. Danach wählen Sie die folgenden Optionen:
Virtualisieren
Linux
Option Use Apple Virtualiuation, Button Durchsuchen, um die ISO-Datei (das Boot-ISO-Abbild) auszuwählen
Speicher: 4 GB ist zumeist eine sinnvolle Einstellung
Prozessorkerne: ich verwende zumeist 2, die Einstellung Standard ist auch OK
Datenspeicher (Größe des Disk-Images): nach Bedarf, 25 GB sind in meiner Erfahrung das Minimum
Freigegebener Ordner: sollte die Nutzung eines macOS-Verzeichnisses innerhalb der virtuellen Maschine ermöglichen, funktioniert meines Wissens aber nur, wenn die virtuelle Maschine selbst macOS ist
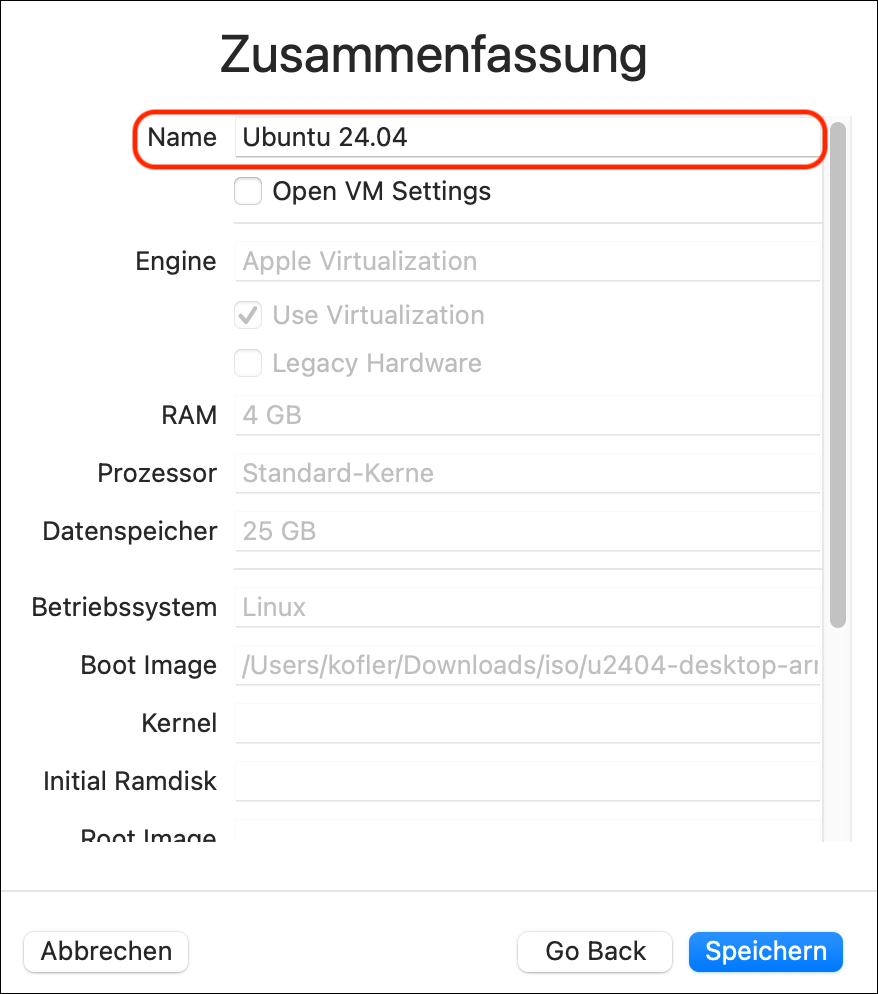
Zusammenfassung: hier geben Sie der virtuellen Maschine einen Namen
Setup der neuen virtuellen Maschine in UTMEinstellung des Namens der virtuellen Maschine
Nachdem Sie alle Einstellungen gespeichert haben, starten Sie die virtuelle Maschine. Nach ca. 30 Sekunden sollte der Desktop mit dem Installationsprogramm erscheinen (erster Dialog: Welcome to Ubuntu). Falls das Installationsprogramm je nach Monitor auf einem riesigen Desktop winzig dargestellt wird, öffnen Sie rechts oben über das Panel-Menü die Einstellungen (Zahnrad-Icon), suchen das Dialogblatt Displays und wählen eine kleinere Bildschirmauflösung aus.
Im Installationsprogramm stellen Sie nun die gewünschte Sprache ein. Bei der Einstellung des Tastaturlayouts wählen Sie Deutsch und die Tastaturvariante Deutsch Macintosh, damit die Mac-Tastatur unter Ubuntu richtig funktioniert. Alle weiteren Einstellungen erfolgen wie bei einer Installation unter VirtualBox, siehe Ubuntu 24.04 in VirtualBox ausführen. Sie brauchen keine Software von Drittanbietern, können aber die Option Unterstützung für zusätzliche Medieformate aktivieren.
Ausführung des Ubuntu-Installationsprogramms
Nach Abschluss aller Setup-Dialoge dauert die Installation ca. fünf Minuten. Da während der Installation manche Pakete aus dem Internet heruntergeladen werden, ist die Dauer der Installation auch von der Geschwindigkeit Ihres Internetzugangs abhängig.
Ubuntu nutzen
Nach dem ersten Neustart erscheint der Ubuntu-Desktop. Wieder kann es je nach Monitor passieren, dass die Grafikauflösung in der virtuellen Maschine zu groß ist. Öffnen Sie das Programm Einstellungen, dort das Dialogblatt Anzeigegeräte und stellen Sie eine passende Auflösung ein. Im Unterschied zu anderen Virtualisierungsprogramme ändert sich die Auflösung nicht automatisch, wenn Sie das UTM-Fenster verändern. Stattdessen wird der im Fenster angezeigte Inhalt skaliert.
Damit sich die Maus in der virtuellen Maschine wie unter macOS verhält, aktivieren Sie in Einstellungen/Maus und Tastfeld die Option Natürliche Rollrichtung.
Um Text zwischen macOS und Ubuntu auszutauschen, können Sie die Zwischenablage verwenden. Dazu muss weder zusätzliche Software installiert noch irgendeine Konfiguration verändert werden.
Zum Austausch von Dateien verwenden Sie am einfachsten scp.
Ubuntu 24.04 (ARM) läuft unter macOS
Speicherort der virtuellen Maschinen
UTM speichert die virtuellen Maschinen im Verzeichnis Library/Containers/com.utmapp.UTM. In der Regel ist es nicht zweckmäßig, die riesigen Image-Dateien in das TimeMachine-Backup mit aufzunehmen. Fügen Sie daher bei den TimeMachine-Einstellungen eine entsprechende Regel hinzu.
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
VirtualBox war lange Zeit das dominierende Virtualisierungsprogramm für Privatanwender: kostenlos (wenn auch nicht vollständig Open Source), funktionell, relativ einfach zu bedienen und für alle drei relevanten Betriebssysteme verfügbar (Windows, macOS, Linux).
Diese Rolle ist zuletzt stark ins Wanken gekommen. Aus meiner Sicht gibt es drei gravierende Probleme:
VirtualBox unter Windows (mit x86-kompatiblen CPUs) litt in den vergangenen Jahren immer wieder unter massiven Stabilitätsproblemen. Möglicherweise wurde diese durch Inkompatibilitäten mit dem Microsoft-Hypervisor (Hyper-V) ausgelöst — wirklich schlüssig war es für mich nie. Wenn VirtualBox auf zehn Studenten-Notebooks mit Windows funktioniert, kann dieselbe Version auf dem elften Notebook Probleme bereiten, die nur schwer nachzuvollziehen sind.
Das zweite Problem besteht darin, dass VirtualBox Intel/AMD-CPUs voraussetzt. Zwar gibt es eine Beta-Version von VirtualBox für Macs mit M1/M2/…-CPU, diese ist aber noch unerträglich langsam. Für Windows oder Linux auf ARM-Hardware gibt es gar keine Angebote.
Schließlich hatte ich zuletzt immer wieder Schwierigkeiten mit den unzähligen Zusatzfunktionen von VirtualBox. Die Installation der Guest Tools hakt, das Grafiksystem zeigt Darstellungsfehler, die geteilten Verzeichnisse haben in der VM die falschen Zugriffsrechte usw. Weniger wäre mehr.
Aktuell gibt es mit dem ganz frischen Release von VirtualBox 7.1.0) noch ein Problem: Die Netzwerkgeschwindigkeit in den virtuellen Maschinen ist unerträglich langsam. Das Problem ist bekannt und wird hoffentlich demnächst behoben. Bis dahin empfehle ich Ihnen, mit Version 7.0.20 zu arbeiten. Ich habe die in diesem Artikel beschriebene Installation mit 7.1.0 durchgeführt (und damit auch die Screenshots erstellt), bin aber im Anschluss zurück auf die alte Version umgestiegen. Das Format der virtuellen Maschinen hat sich zum Glück nicht geändert. Ältere VirtualBox-Downloads finden Sie hier.
Wenn ich Sie bis jetzt nicht abgeschreckt habe, erläutere ich Ihnen im Folgenden die Installation von Ubuntu 24.04 in einer virtuellen Maschine, die in VirtualBox 7.0 unter Windows 11 (für Intel/AMD) läuft.
Ubuntu installieren
Zuerst müssen Sie VirtualBox installieren. Danach brauchen Sie zur Installation von Ubuntu das ISO-Image von Ubuntu, das Sie von der Ubuntu-Download-Seite herunterladen.
Als nächstes richten Sie in VirtualBox mit dem Button Neu eine neue virtuelle Maschine ein. Im ersten Blatt des Setup-Dialogs geben Sie der virtuellen Maschine einen Namen und wählen die ISO-Datei aus. VirtualBox erkennt selbst, dass die ISO-Datei Ubuntu enthält, und stellt Typ, Subtyp und Version selbst ein.
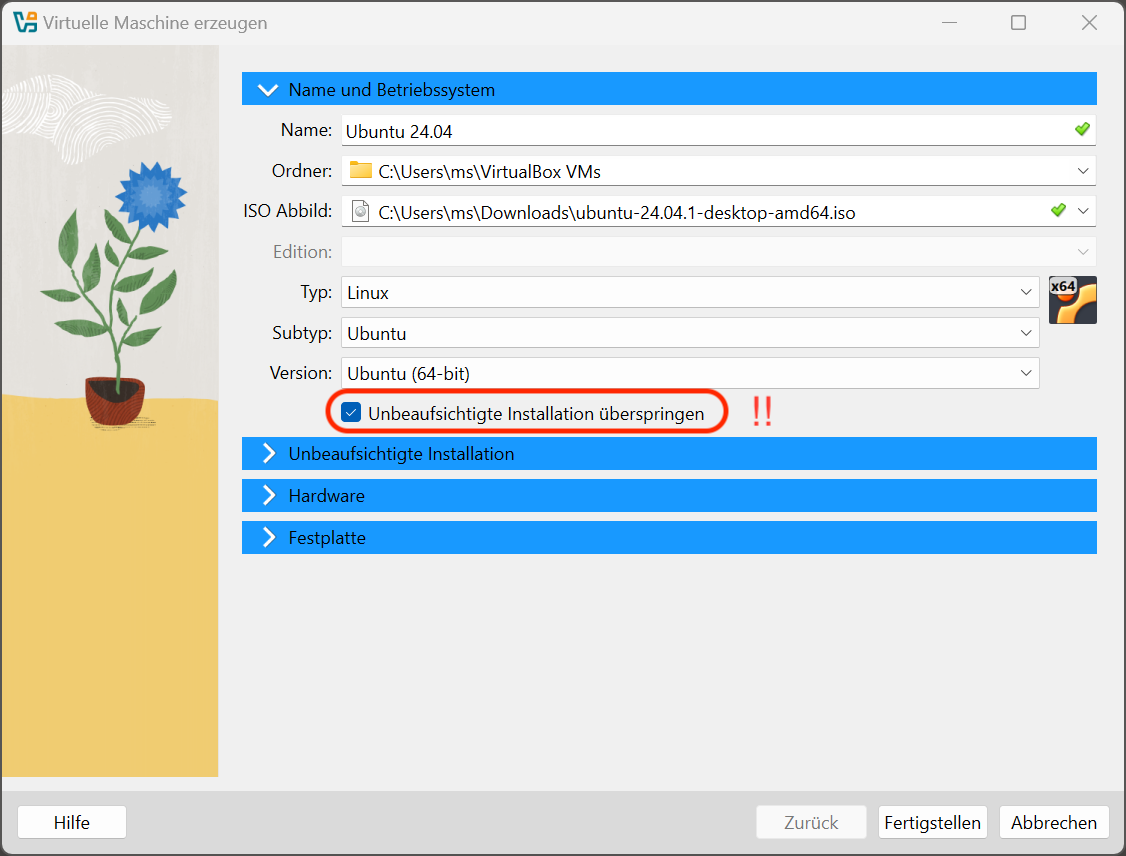
VirtualBox kann bei Ubuntu eine Unbeaufsichtigte Installation durchführen. Dazu geben Sie im folgenden Dialogblatt den Benutzernamen, das Passwort und den gewünschten Hostnamen an. Sie ersparen sich mit einer unbeaufsichtigten Installation die Bedienung des Ubuntu-Installationsprogramms. Allerdings hat diese Installationsvariante den Nachteil, dass Ubuntu nach der Installation englische Menüs anzeigt und ein englisches Tastaturlayout verwendet. Deswegen ist es aus meiner Sicht sinnvoll, die Option Unbeaufsichtigte Installation überspringen zu aktivieren.
Die unbeaufsichtigte Installation hat mehr Nach- als Vorteile
Im Dialogblatt Hardware sollten Sie der virtuellen Maschine zumindest 4 GB RAM und zwei CPU-Cores zuweisen. Die vorgeschlagenen 2 GB RAM sind definitiv zu wenig und führen dazu, dass nicht einmal der Start der virtuellen Maschine möglich ist!
Im Dialogblatt Festplatte stellen Sie ein, wie groß die virtuelle Disk sein soll. 25 GB ist aus meiner Sicht das Minimum, um Ubuntu ein wenig auszuprobieren. Je nach Verwendungszweck brauchen Sie aber natürlich mehr Speicherplatz.
Fertigstellen beendet den Dialog. Bevor Sie mit der Installation starten, sollten Sie nun mit Ändern noch zwei Einstellungen der virtuellen Maschine anpassen:
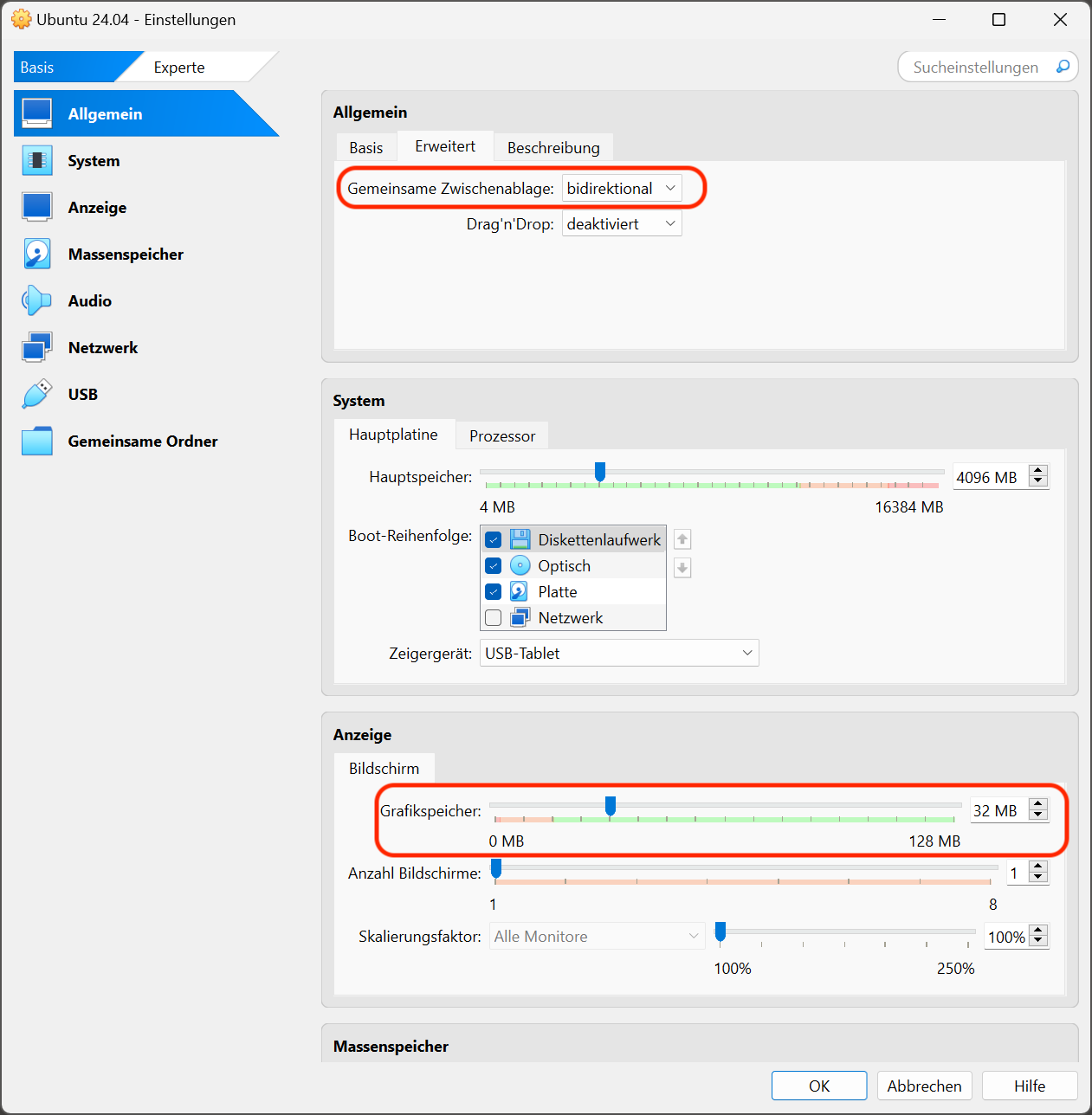
Anzeige/Bildschirm/Grafikspeicher = mindestens 32 MB, ich empfehle das Maximum von 128 MB
Optionale Einstellungen für die virtuelle Maschine. Dem Grafiksystem sollten zumindest 32 MB RAM zur Verfügung stehen.
Ein Doppelklick auf das VM-Icon startet die virtuelle Maschine. Nach ca. einer halben Minute erscheint der Ubuntu-Desktop mit dem Installationsprogramm. Unter Umständen wird vorher im Textmodus die beunruhigende Fehlermeldung * vmwgfx seems to be running on an unsupported hypervisor* angezeigt. Zumindest bei meinen Tests startet das Grafiksystem wenig später dennoch fehlerfrei.
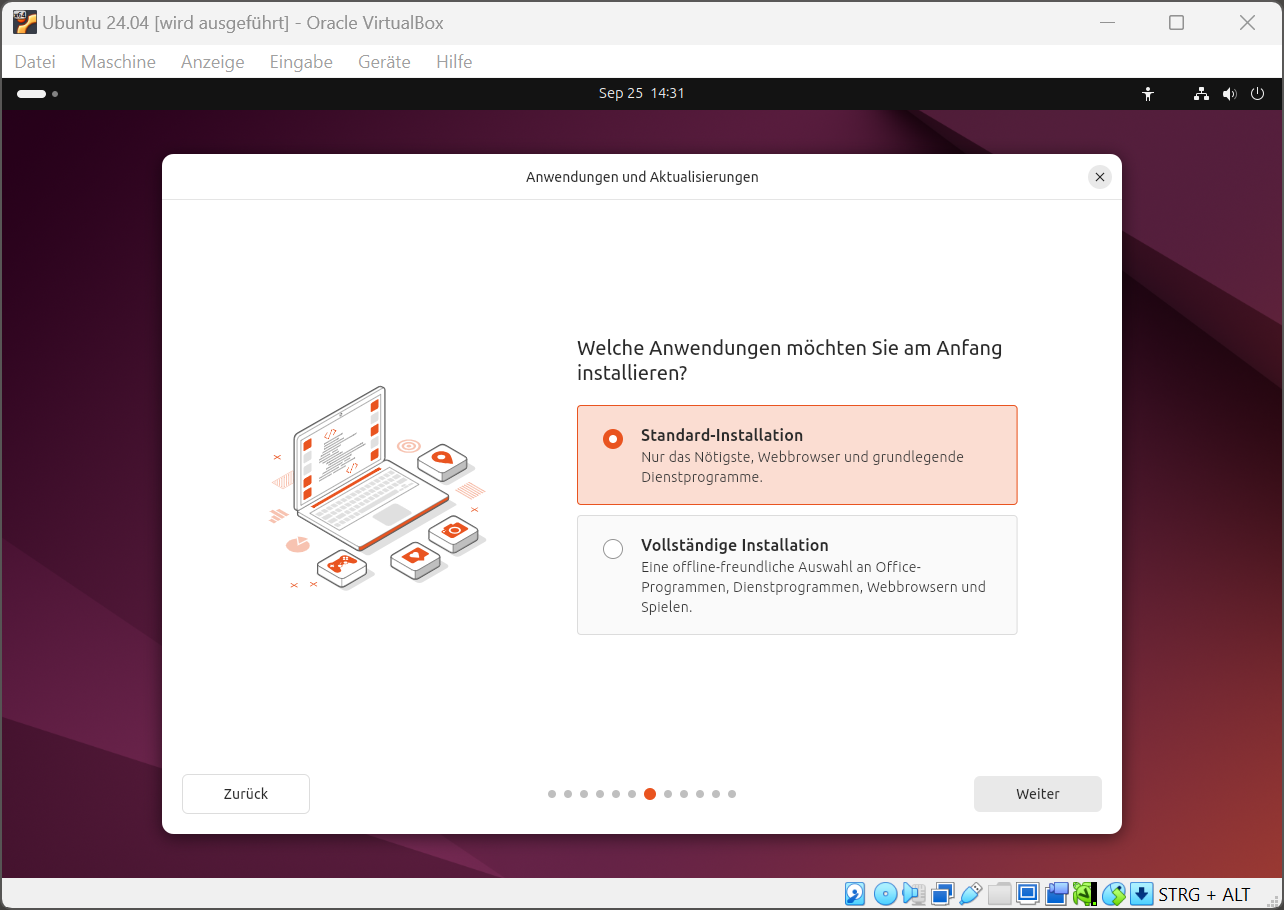
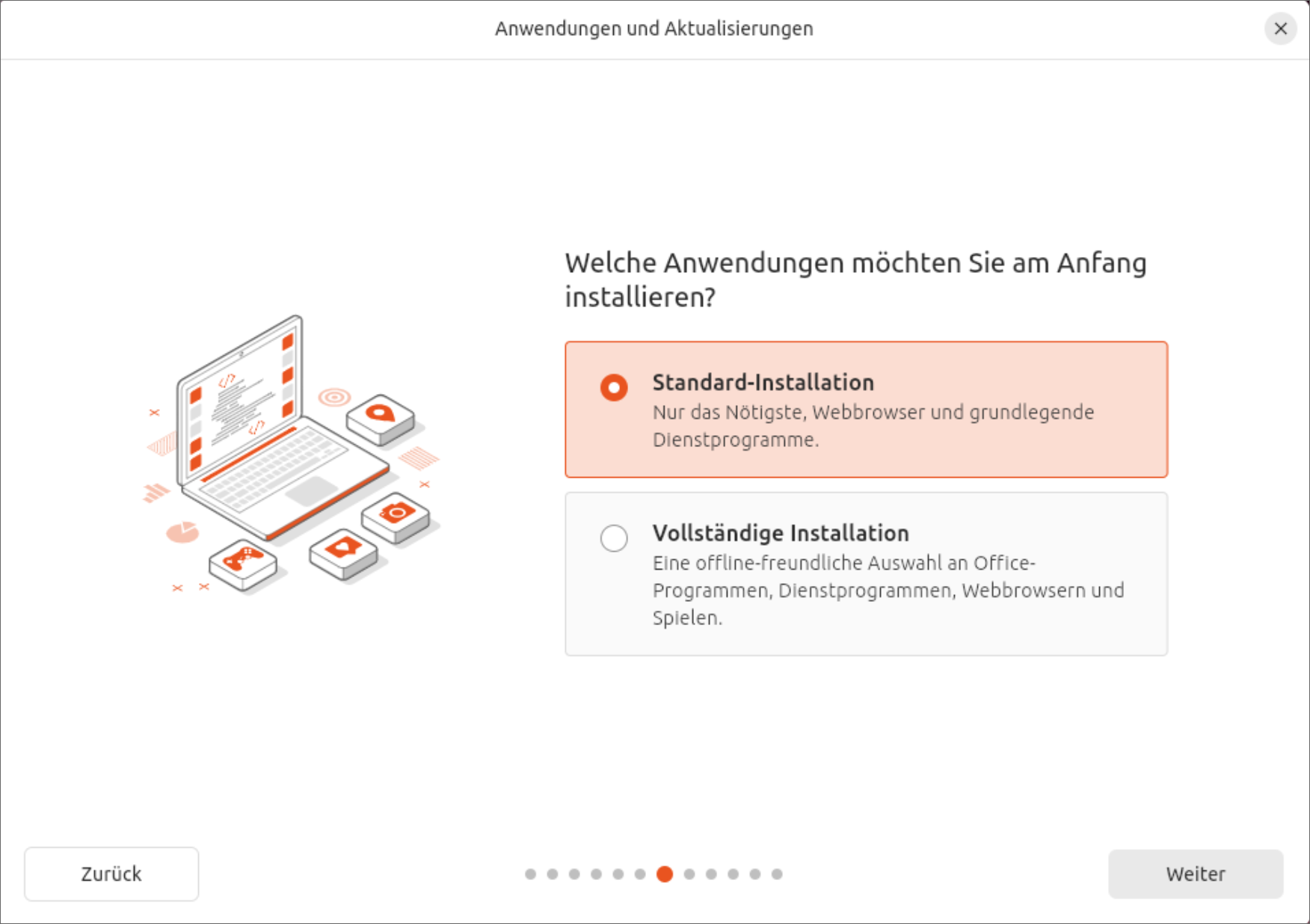
Im Installationsprogramm stellen Sie in den ersten Schritten die gewünschte Sprache und das Tastaturlayout ein. Sie geben an, dass Sie Ubuntu installieren (und nicht nur ausprobieren) möchten, und entscheiden sich für die interaktive Standard-Installation. (Wenn Sie gleich auch Gimp, LibreOffice usw. haben möchten, ist Vollständige Installation die bessere Wahl.)
Mit der »Standard-Installation« werden nur die wichtigsten Programme installiert. Weitere Software können Sie später installieren.
Im nächsten Dialogblatt haben Sie die Option, zusätzliche Treiber sowie Audio- und Video-Codecs zu installieren. Treiber brauchen Sie in der virtuellen Maschine keine, und die fehlenden Codecs können Sie gegebenenfalls später immer noch installieren (sudo apt install ubuntu-restricted-extras).
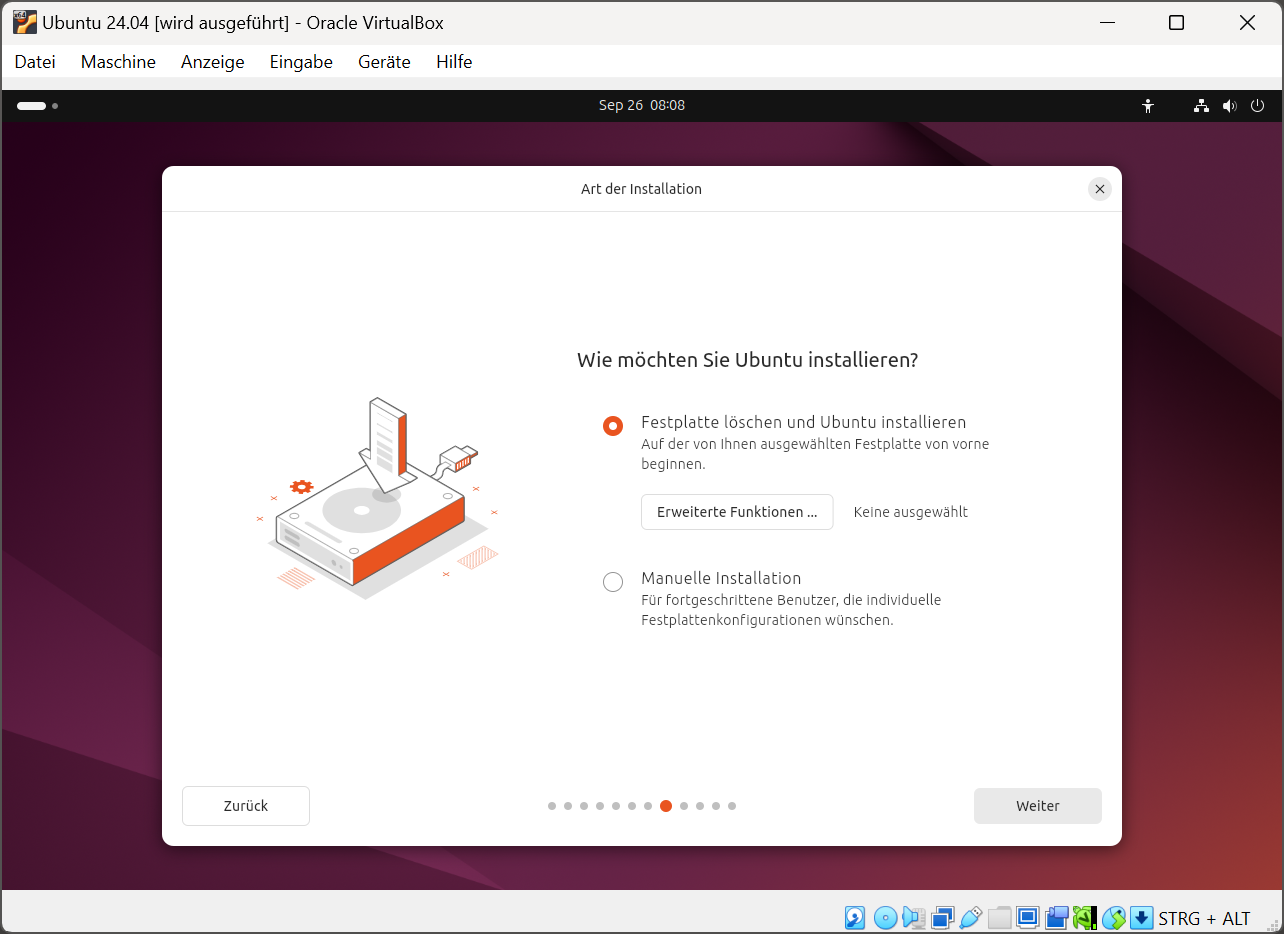
Im Dialogblatt Art der Installation geht es um die Partitionierung der virtuellen Disk sowie um das Einrichten der Dateisysteme für Ubuntu. Weil Sie Ubuntu in eine virtuelle Maschine installieren, müssen Sie keinerlei Rücksicht auf andere Betriebssysteme nehmen und können sich einfach für die Option Festplatte löschen und Ubuntu installieren entscheiden.
In virtuellen Maschinen ist eine manuelle Partitionierung des Datenträgers glücklicherweise überflüssig
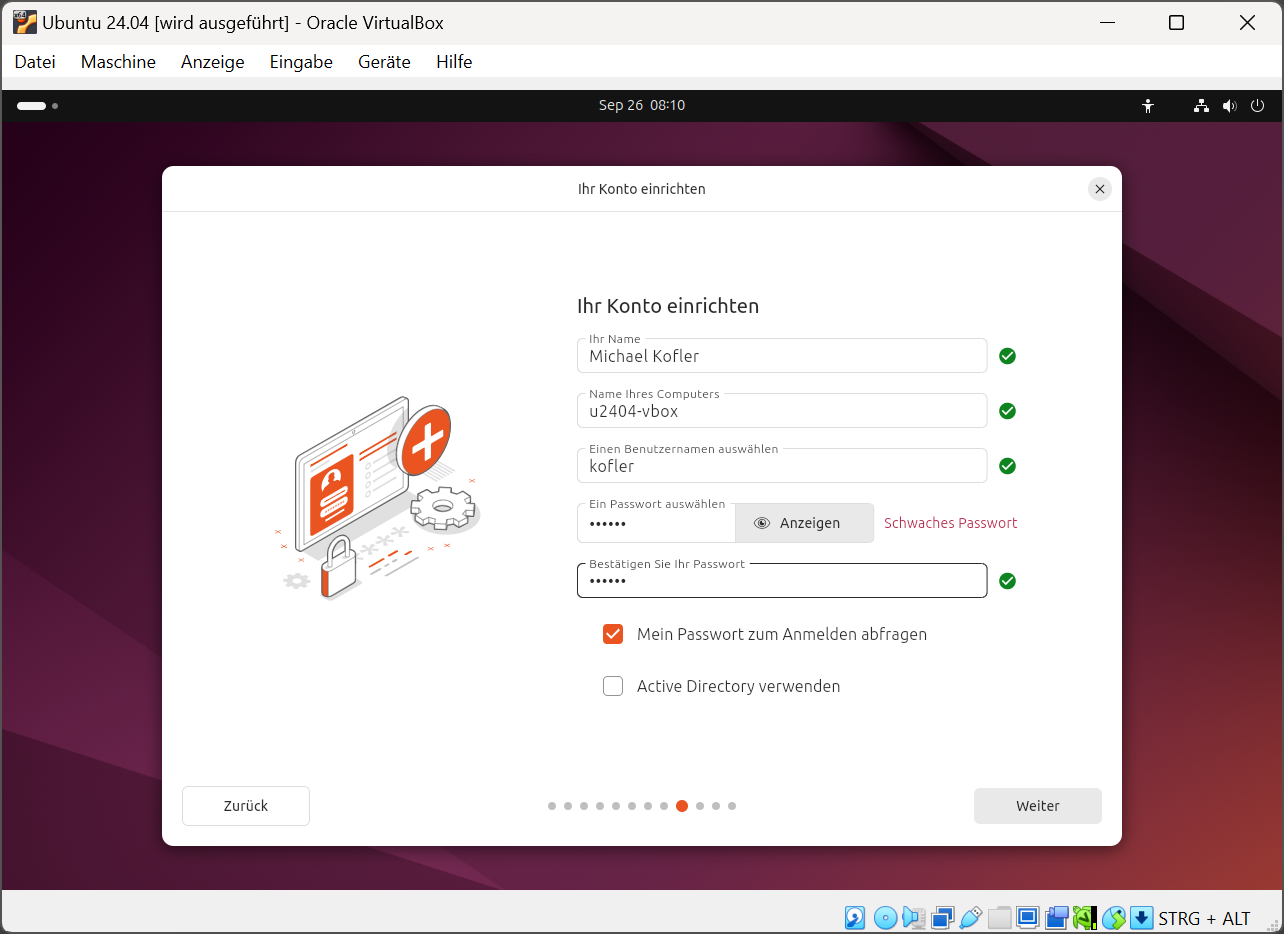
Auf der nächsten Seite geben Sie Ihren Namen, den Hostname, den Account-Namen sowie das gewünschte Passwort an. Das nächste Dialogblatt betrifft die Zeitzone, die normalerweise automatisch korrekt eingestellt wird. Zuletzt werden die wichtigsten Einstellungen nochmals zusammengefasst. Installieren startet den Installations-Prozess, der je nach Rechnergeschwindigkeit einige Minuten dauert.
Personalisierung der Installation
Ubuntu nutzen
Nach Abschluss der Installation starten Sie die virtuelle Maschine neu und können Ubuntu dann beinahe wie bei einer realen Installation nutzen. Die Auflösung der virtuellen Maschine ändern Sie unkompliziert innerhalb von Ubuntu im Programm Einstellungen, Modul Anzeigegeräte. Wenn Sie einen hochauflösenden Bildschirm verwenden, kann es außerdem zweckmäßig sein, den skalierten Modus zu aktivieren (Anzeige / Skalierter Modus im Menü des Fensters der virtuellen Maschine).
Die virtuelle Maschine verwendet Wayland als Grafiksystem
Installation der VirtualBox-Gasterweiterungen
Um den Datenaustausch zwischen Windows und Ubuntu zu erleichtern, können Sie die VirtualBox-Gasterweiterungen installieren. Dazu sind zwei Schritte erforderlich:
Zuerst führen Sie im Fenster der virtuellen Maschine Geräte / Gasterweiterungen einlegen aus.
Anschließend geben Sie in einem Terminalfenster die folgenden Kommandos ein:
Die Auflösung des Grafiksystems von Ubuntu wird automatisch an die Größe des Fensters der virtuellen Maschine angepasst.
Sie können über die Zwischenablage Text zwischen Windows und Ubuntu austauschen. (Dazu muss außerdem der bidirektionale Modus der Zwischenablage aktiviert werden: im VM-Fenster mit Geräte / Gemeinsame Zwischenablage / Bidirektional.
Sie können über ein gemeinsames Verzeichnis Dateien zwischen Ubuntu und Windows austauschen (Konfiguration siehe unten).
Gemeinsames Verzeichnis zum Dateiaustausch einrichten
Um Dateien zwischen Ubuntu und Windows auszutauschen, richten Sie am besten ein gemeinsames Verzeichnis ein. Drei Schritte sind erforderlich:
Die VirtualBox-Gasterweiterungen sind erforderlich.
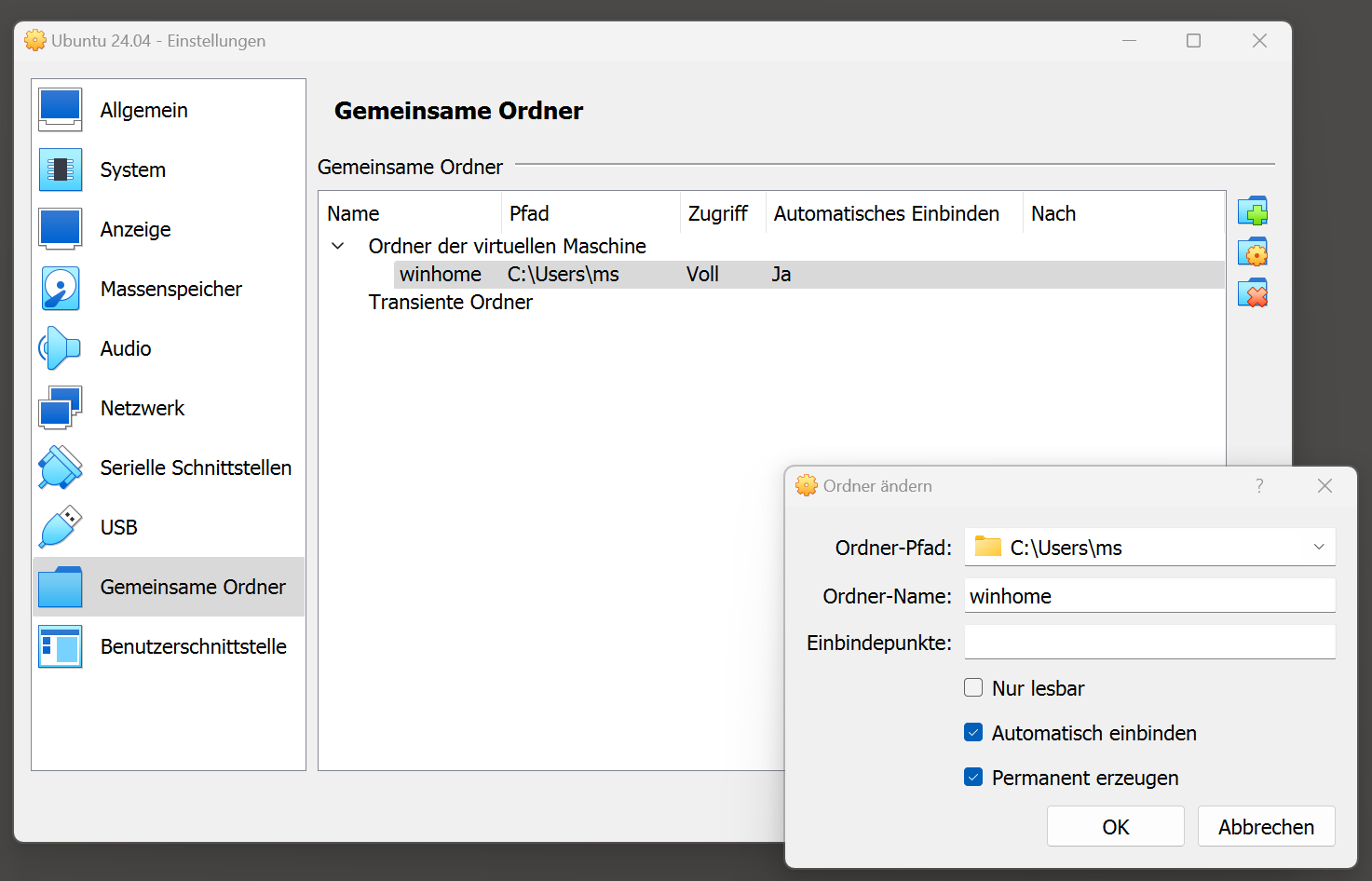
Im Menü des Fensters der virtuellen Maschine führen Sie Geräte / Gemeinsame Ordner / Gemeinsame Ordner aus und wählen ein Windows-Verzeichnis (es kann auch Ihr persönliches Verzeichnis sein). Aktivieren Sie die Optionen Automatisch einbinden und Permanent erzeugen.
Zuletzt müssen Sie in einem Terminal-Fenster in Ubuntu Ihren Account der vboxsf-Gruppe zuordnen:
sudo usermod -a -G vboxsf $USER
Damit das usermod-Kommando wirksam wird, müssen Sie die virtuelle Maschine neustarten. Sie finden das gemeinsame Verzeichnis danach direkt im Datei-Manager.
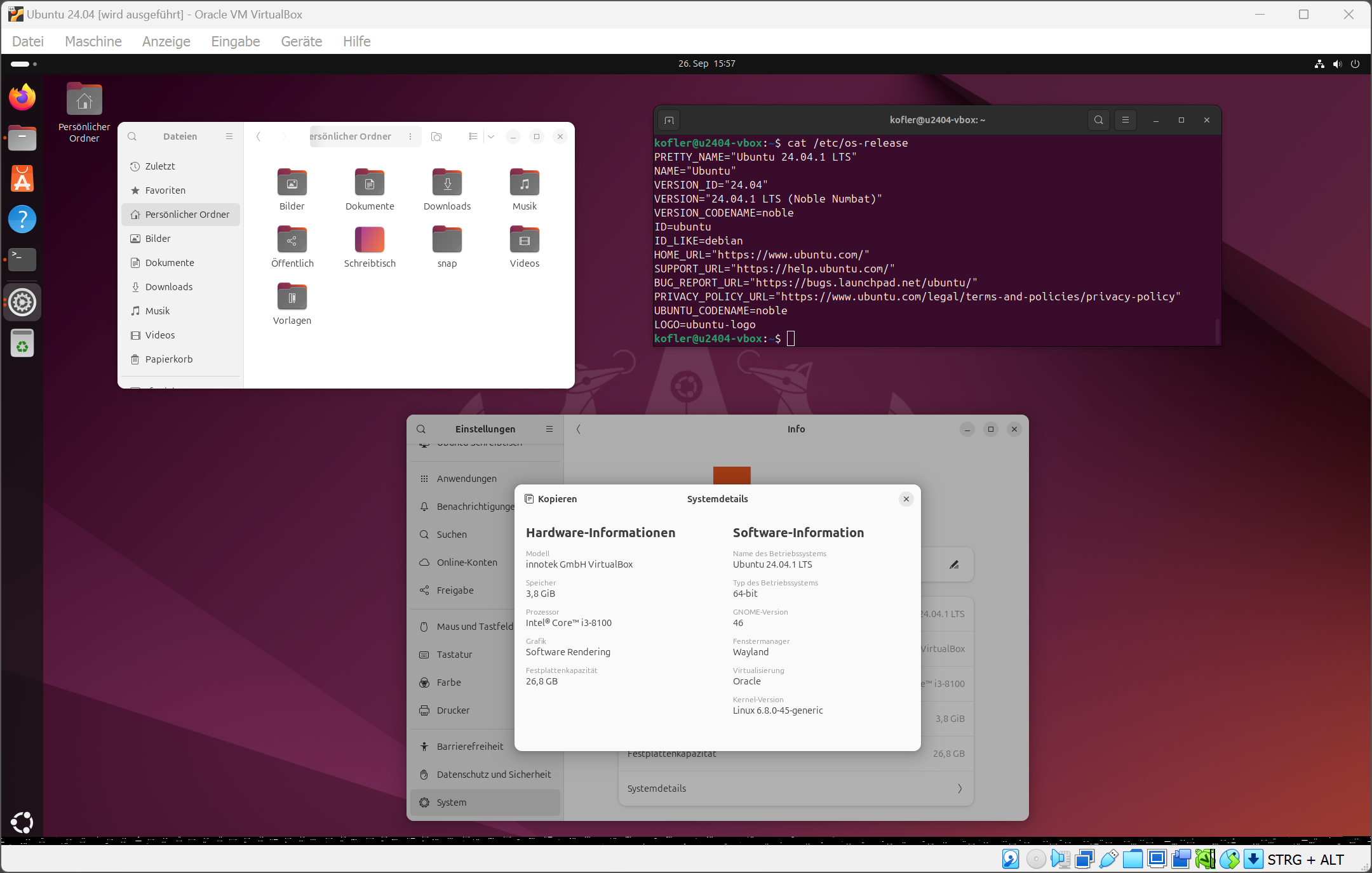
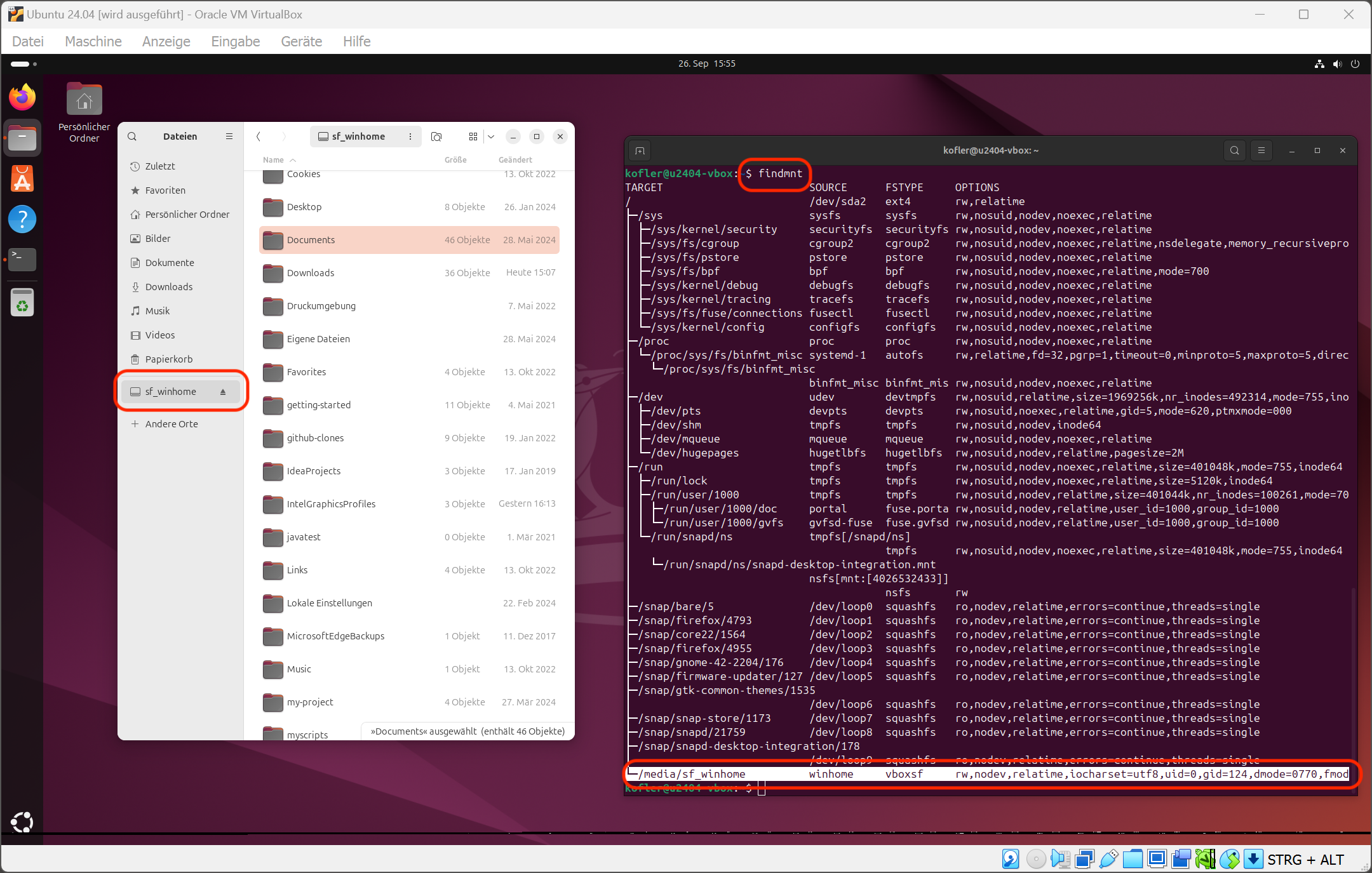
Gemeinsamen Ordner zum Dateiaustausch zwischen Windows und der virtuellen Maschine einrichtenDer gemeinsame Ordner wird im Dateimanager angezeigt. Wenn Sie darauf nicht zugreifen können, haben Sie »usermod« vergessen. Für Experten zeigt »findmnt« die Details des Mount-Verzeichnisses.
Netzwerkkonfiguration und SSH-Zugriff
Wenn ich auf Kommandoebene arbeite, bediene ich meine virtuellen Maschinen gerne über SSH. Unter Ubuntu muss dazu der SSH-Server installiert werden, was mit sudo apt install openssh-server rasch gelingt.
Das reicht aber noch nicht: VirtualBox gibt der virtuellen Maschine standardmäßig mittels Network Address Translation Zugriff auf die Netzwerkverbindung des Host-Computers. Die virtuelle Maschine ist aber im Netzwerk des Hosts unsichtbar, eine SSH-Verbindung ist unmöglich.
Es gibt zwei Auswege. Einer besteht darin, in den Netzwerkeinstellungen der virtuellen Maschine die Option Netzwerkbrücke zu aktivieren. Damit wird die virtuelle Maschine einfach zu einem Mitglied im lokalen Netzwerk. Zuhause funktioniert das gut (einfach ssh name@<ubuntu_hostname> ausführen), in öffentlichen WLANs dagegen leider nicht.
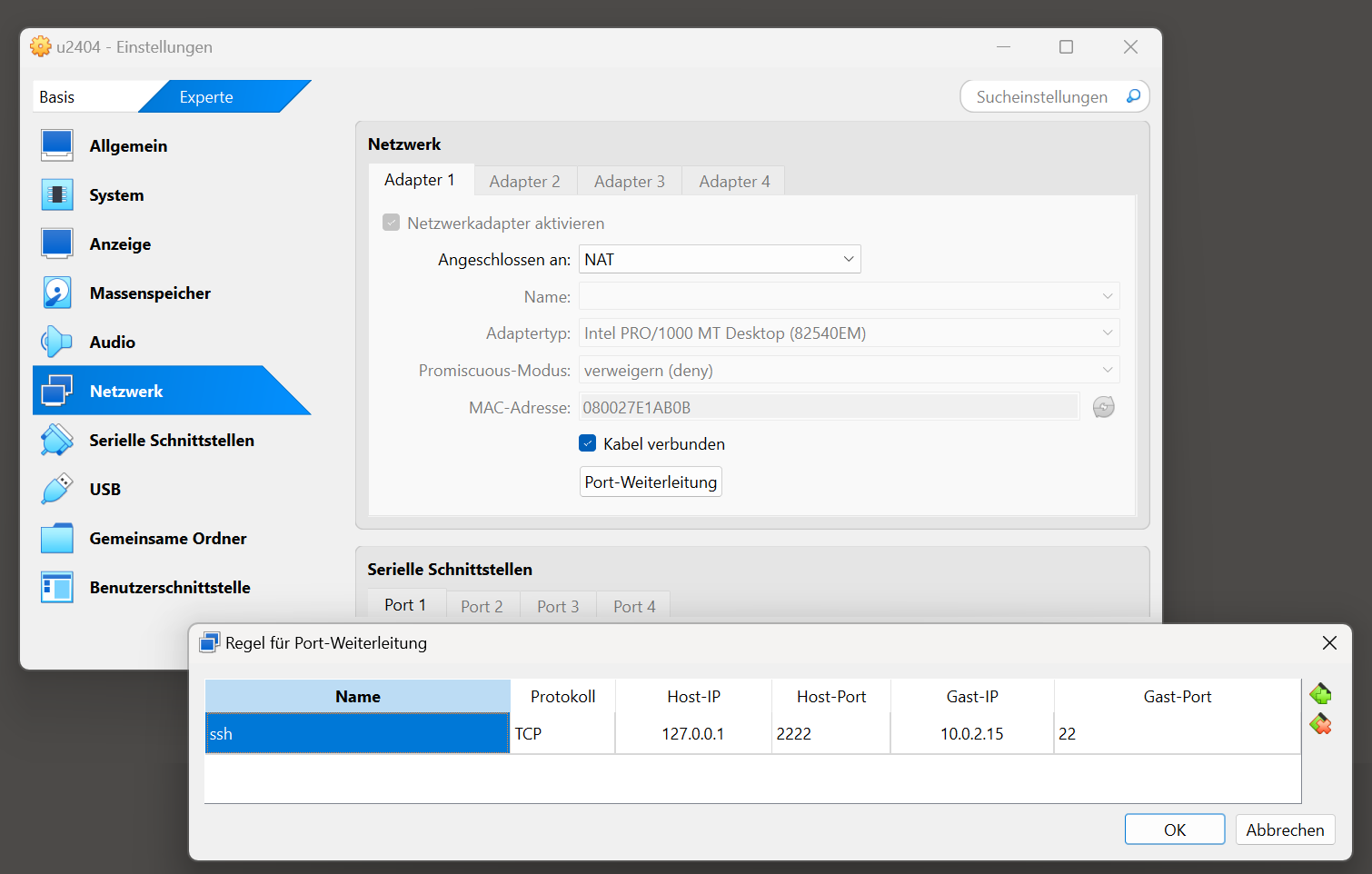
Die Alternative heißt Port-Weiterleitung. Dazu führen Sie im Fenster der virtuellen Maschine Geräte / Netzwerk / Netzwerk-Einstellungen aus, aktivieren das Tab Experte und klappen bei Adapter 1 den Bereich Erweitert aus und klicken auf Port-Weiterleitung. Nun richten Sie eine neue Regel ein, die Port 2222 des Hosts (127.0.0.1) mit Port 22 der virtuellen Maschine (10.0.2.15) verbindet.
Port-Weiterleitung zwischen Port 22 der virtuellen Maschine und Port 2222 des eigenen Rechners einrichten
Nachdem Sie die Einstellungen gespeichert haben (ein Neustart der virtuellen Maschine ist nicht notwendig), können Sie im Terminal von Windows mit dem folgenden Kommando eine SSH-Verbindung zur virtuelle Maschine herstellen:
ssh -p 2222 name@localhost
Wichtig ist dabei die Option -p 2222. ssh soll nicht wie üblich Port 22 verwenden, sondern eben Port 2222. Wichtig ist auch, dass Sie als Zieladresse localhost angeben. Aufgrund der Port-Weiterleitung landen Sie wunschgemäß in der virtuellen Maschine. Anstelle von name geben Sie Ihren Ubuntu-Account-Namen an.
Vielleicht wollen oder können Sie Ubuntu nicht direkt auf Ihr Notebook oder Ihren PC installieren. Dennoch interessieren Sie sich für Linux oder brauchen eine Installation für Schule, Studium oder Software-Entwicklung. Diese Artikelserie fasst drei Wege zusammen, Ubuntu 24.04 virtuell zu nutzen:
Teil I (dieser Text): im Windows Subsystem for Linux (WSL)
Teil III: mit UTM (macOS ARM): mit UTM (macOS ARM)
Windows Subsystem für Linux
Mit WSL hat Microsoft einen Weg geschaffen, Linux im Textmodus unkompliziert unter Windows auszuführen. Diese Variante ist dann empfehlenswert, wenn Sie unter Windows typische Linux-Werkzeuge (die Shell bash, Kommandos wie find und grep usw.) nutzen möchten oder wenn Sie ohne Docker oder virtuelle Maschinen Server-Dienste wie Apache, nginx etc. ausprobieren möchten.
Als erstes müssen Sie sicherstellen, dass im Konfigurationsprogramm Windows-Features aktivieren oder deaktivieren die Optionen Hyper-V und Windows-Subsystem für Linux aktiviert sind. Alternativ können Sie WSL auch im Microsoft Store installieren.
WSL aktivieren
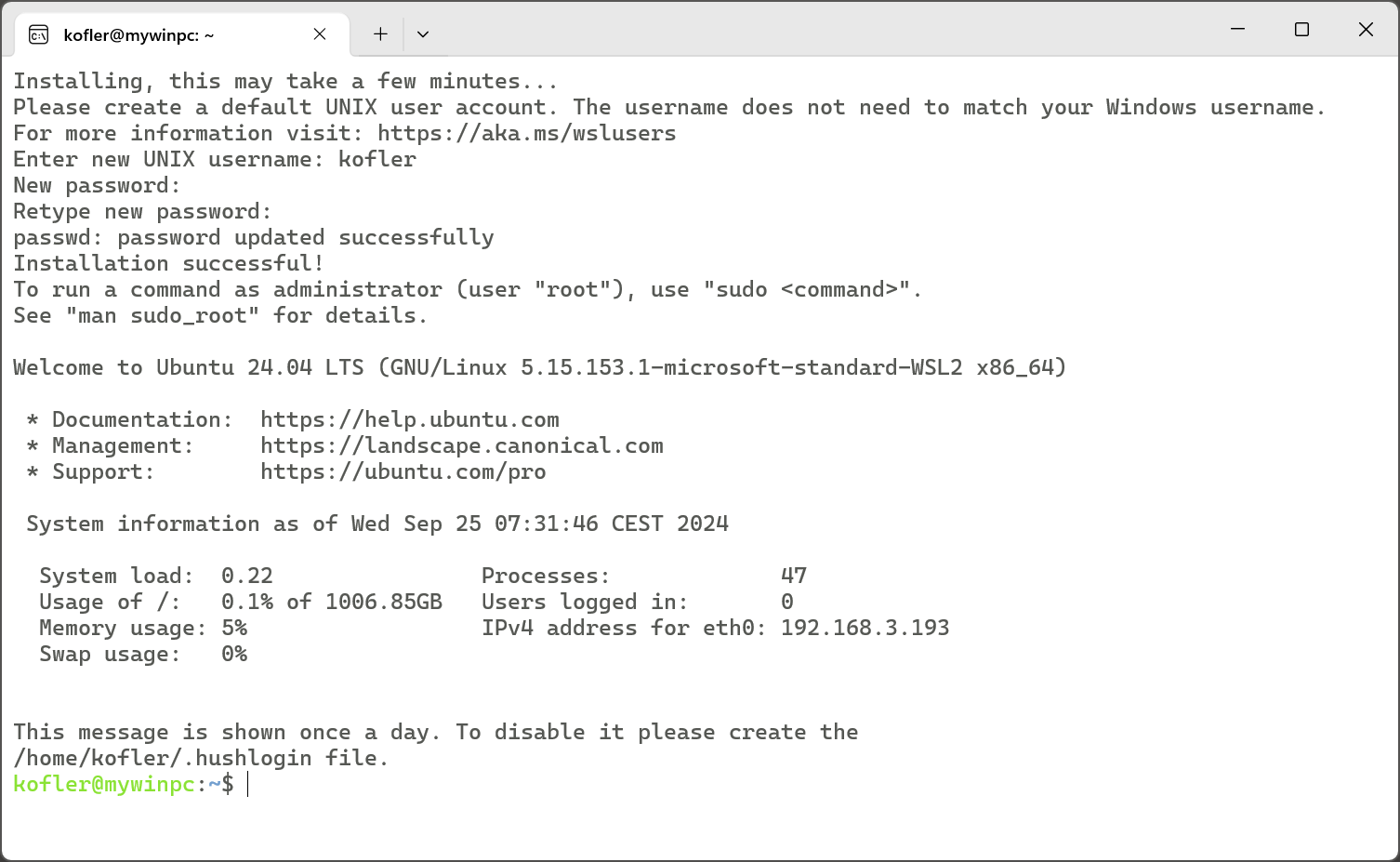
Im zweiten Schritt gehen Sie in den Microsoft Store und suchen nach Ubuntu 24.04. (Passen Sie auf, dass Sie keine alte Version verwenden, die vorher gereiht ist.) Ubuntu 24.04 ist kostenlos. Der Installationsumfang ist mit 350 MByte für eine Linux-Distribution relativ klein. Sobald Sie Öffnen anklicken, erscheint ein Terminal-Fenster. Nach ein paar Sekunden müssen Sie einen Benutzernamen und ein Passwort angeben. Dieses Passwort brauchen Sie später, um administrative Arbeiten zu erledigen (z.B. sudo apt install xxx).
Erster Start von Ubuntu 24.04 unter WSL
In Zukunft können Sie Ubuntu 24.04 im Startmenü oder in der Auswahlliste des Terminal-Programms starten. Als ersten Schritt in der neuen Shell-Umgebung sollten Sie ein Update durchführen (also die Kommandos sudo apt update und sudo apt full-upgrade).
Innerhalb von Ubuntu können Sie über den Pfad /mnt/c auf das Windows-Dateisystem zugreifen. Umgekehrt finden Sie das Linux-Dateisystem im Explorer unter dem Eintrag Linux.
Zugriff auf das Linux-Dateisystem im Explorer
WSL ist für den Betrieb von Linux im Textmodus optimiert. Seit 2021 besteht mit WSLg aber prinzipiell die Möglichkeit, einzelne Programme im Grafikmodus zu installieren und auszuführen:
Meine Erfahrungen mit diesem Feature waren aber nicht überragend. Wenn Sie Ubuntu als Desktop-System im Grafikmodus nutzen möchten, verwenden Sie dazu besser VirtualBox oder ein anderes Virtualisierungssystem.
WSL1, wenn Windows in einer virtuellen Maschine läuft
Aus technischer Sicht gibt es zwei ganz unterschiedliche Varianten von WSL. Standardmäßig kommt WSL2 zum Einsatz. Dabei wird der Linux-Kernel durch das Virtualisierungssystem Hyper-V ausgeführt. In manchen Situationen steht Hyper-V aber nicht zur Verfügung — z.B. wenn Windows selbst in einer virtuellen Maschine läuft (unter Linux oder macOS). In solchen Fällen ist WSL1 ein attraktiver Ausweg. Bei WSL1 kümmert sich ein ganzes Framework von Funktionen um die Kompatibilität zwischen Windows und Linux. WSL1 ist der technisch kompliziertere Weg, weil (fast) alle Linux-Grundfunktionen ohne Virtualisierung nachgebildet wurden.
Um Ubuntu 24.04 unter WSL1 auszuführen, führen Sie die folgenden Kommandos im Terminal aus:
WSL1 hat im Vergleich zu WSL2 einige Nachteile: langsameres I/O, älterer Kernel, keine Grafikfunktionen. Für viele Aufgaben — etwas zum Erlernen grundlegender Linux-Kommandos oder zur bash-Programmierung — funktioniert WSL1 aber genauso gut wie WSL2.
Der aus meiner Sicht größte Nachteil von WSL1 besteht darin, dass systemd nicht funktioniert. Hintergrunddienste wie cron stehen nicht zur Verfügung und können gar nicht oder nur über komplizierte Umwege genutzt werden. Ein wichtiger Teil dessen, was ein komplettes Linux-System ausmacht, fehlt.
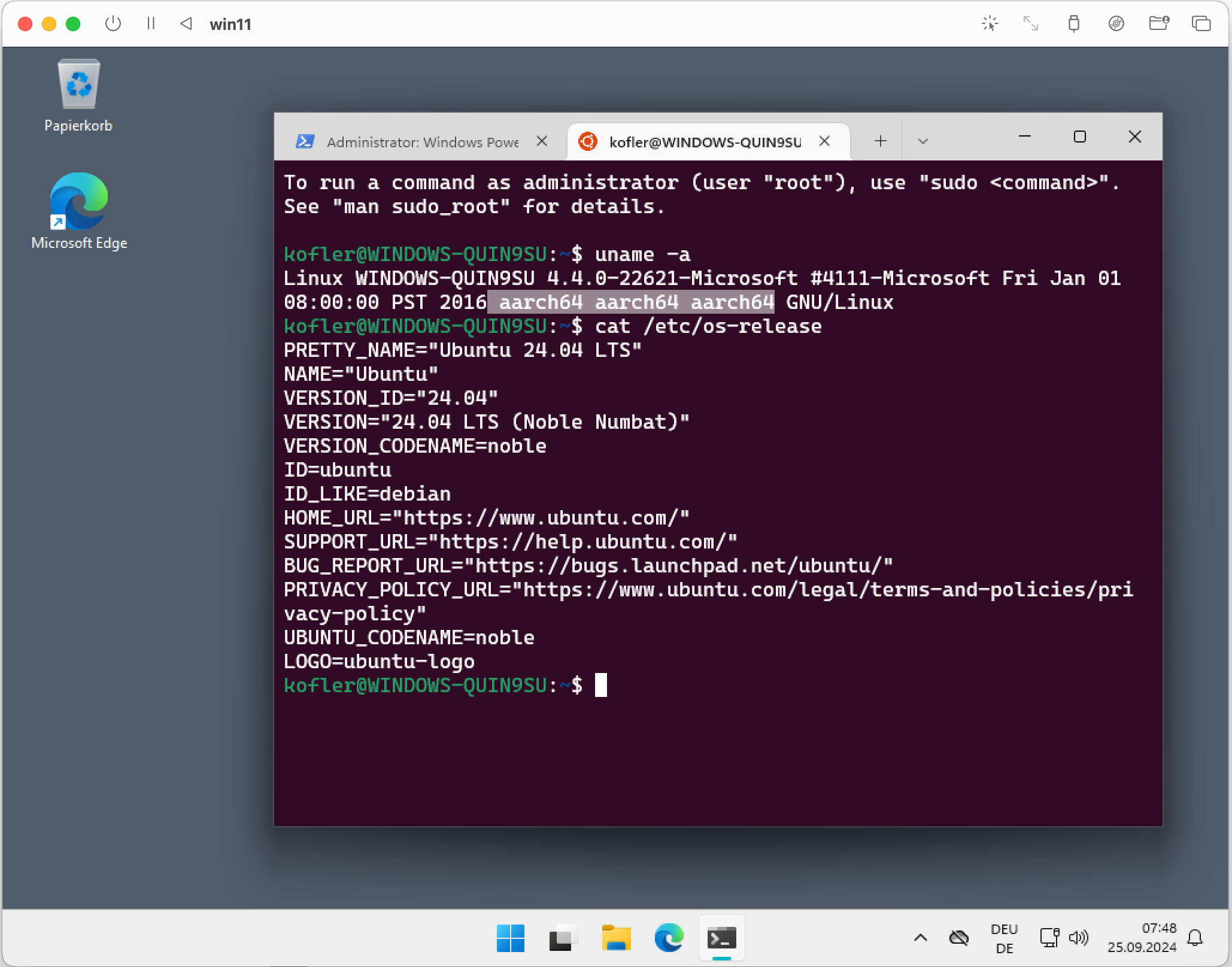
Hier läuft Windows für ARM im Virtualisierungssystem UTM unter macOS. In der virtuellen Maschine ist wiederum Ubuntu 24.04 (auch für ARM) per WSL1 installiert.
(Aktualisiert 13.9.2024) Mit der Auslieferung des Raspberry Pi 5 im Herbst 2024 hat sich bei einigen Low-Level-Tools der GPIO-Zugriff geändert: Für die Modelle bis einschließlich Raspberry Pi 4 erfolgt der GPIO-Zugriff über chip0 bzw. /dev/gpiochip0. Beim Raspberry Pi musste dagegen chip4 bzw. /dev/gpiochip4 verwendet werden. Scripts, die universell auf alten und neuen Geräten laufen sollten, brauchten eine entsprechende Fallunterscheidung.
Mit Kernel 6.6.47, der mittlerweile standardmäßig als Update unter Raspberry Pi OS installiert wird, ändert sich wieder alles! Auch beim Raspberry Pi 5 muss nun /dev/gpiochip0 verwendet werden. Eine Referenz aller internen GPIO-Nummern gibt cat /sys/kernel/debug/gpio.
Die Änderung betrifft unter anderem:
Python: gpiozero, lgpio, gpiod
Bash: gpioset, gpioget
C: lgpio, libgpiod, wiringpi
Scripts, die mit diesen Modulen bzw. Bibliotheken verfasst wurden, müssen geändert werden (Umstellung von GPIO-Chip 4 auf GPIO-Chip 0). Im Folgenden habe ich diesbezüglich Anleitungen für diverse Fälle zusammengefasst.
13.9.2024: Mit dem neuesten Update von Raspberry Pi OS wird ein Link von /dev/gpiochip4 auf /dev/gpiochip0 eingerichtet, wodurch die Auswirkungen des veränderten Kernels in den meisten Fällen nicht mehr spürbar sind.
Von gpiozero gibt es mittlerweile eine aktualisierte Version, die das richtige Chip-Device erkennt.
Python-Scripts mit gpiozero
Beim Start derartiger Scripts auf dem Raspberry Pi 5 mit dem aktuellen Kernel (>= 6.6.47) tritt die Fehlermeldung can not open gpiochip auf. Das Script bricht ab. Der Fehler ist bekannt, es wird demnächst eine neue Version des Python-Modules geben. Bis dahin ist es am einfachsten, das Script wie folgt zu starten:
RPI_LGPIO_CHIP=0 ./gpiozero-led.py
Alternativ führen Sie export RPI_LGPIO_CHIP=0 aus und fügen diese Anweisung auch in /home/your-account/.bashrc ein. Eine weitere Möglichkeit ohne die externe Definition von Umgebungsvariablen besteht darin, am Beginn Ihres Python-Scripts die folgende Zeile einzubauen:
import os
os.environ['RPI_LGPIO_CHIP']='0'
Im gpiozero-Issue ist auch von PWM-Problemen zu lesen, die sich selbst mit RPI_LGPIO_CHIP=0 nicht lösen lassen. Das kann ich nicht bestätigen. Mein PWM-Test-Script gibt zwar eine Warnung aus, funktioniert aber.
Python-Scripts mit lgpio
Wenn Sie in Ihrem Python-Script das lgpio-Modul verwenden, müssen Sie den Handle nun IMMER mit gpiochip_open(0) öffnen, also:
# alle Raspberry-Pi-Modelle mit aktuellen Kernel >= 6.6.45
handle = lgpio.gpiochip_open(0)
# Raspberry Pi 5 mit Kernel < 6.6.45
# handle = lgpio.gpiochip_open(4)
Python-Scripts mit gpiod
Wenn Sie in Ihrem Python-Script das gpiod-Modul verwenden, müssen Sie die Initialisierung nun IMMER mit 'gpiochip0' durchführen, also:
chip = gpiod.Chip('gpiochip0') # alle Modelle mit Kernel >= 6.6.45
# chip = gpiod.Chip('gpiochip4') # Raspberry Pi 5 mit Kernel < 6.6.45
pinout-Kommando
Auch das Kommando pinout liefert zur Zeit Fehlermeldungen (can’t connect to pigpio at localhost sowie Unable to initialize GPIO Zero). Hinter den Kulissen handelt es sich bei dem Kommando um ein Python-Script, das gpiozero verwendet. Bis dieses Modul aktualisiert wird, hilft der oben schon erwähnte Trick mit RPI_LGPIO_CHIP=0 weiter, also:
RPI_LGPIO_CHIP=0 pinout
bash-Scripts mit gpioset, gpioget und gpiomon
Bei den genannten Kommandos übergeben Sie als ersten Parameter die Chip-Nummer. Ab Kernel 6.6.45 lautet diese IMMER 0, also z.B.:
Hier ändert sich nichts. pinctrl war schon in der Vergangenheit in der Lage, die richtige Chip-Nummer selbst zu erkennen, und das funktioniert weiterhin. Großartig!
pinctrl set 7 op dh # LED an Pin 26 ein
pinctrl set 7 op dl # LED an Pin 26 aus
C-Programme mit lgpio
Ab Kernel 6.6.45 müssen Sie IMMER die Chip-Nummer 0 verwenden, also:
#define CHIP 0
...
h = lgGpiochipOpen(CHIP); // open connection to I/O chip
C-Programme mit gpiod
Ab Kernel 6.6.45 müssen Sie IMMER "gpiochip0" verwenden, also:
Die von Gordon Drogon entwickelte wiringpi-Bibliothek ist seit vielen Jahren veraltet (gilt bis Version 2.5).
2024 hat der Grazer Computer Club die Wartung der Bibliothek übernommen. Damit ist diese Bibliothek (jetzt in Version 3.0) wieder verwendbar! Weitere Informationen sowie Installationshinweise gibt es auf der GitHub-Projektseite:
Diese ganze Angelegenheit ist ein einziges Trauerspiel. Dass beim Raspberry Pi 5 anfänglich /dev/gpiochip4 als interne GPIO-Schnittstelle verwendet wurde (und nicht von Anfang an /dev/gpiochip0 wie bei früheren Raspberry-Pi-Modellen), war schon eine äußerst fragwürdige Entscheidung. Aber die Schnittstelle jetzt, fast ein Jahr nach dem Release des Raspberry Pi 5 und Raspberry Pi OS Bookworm, zu ändern, ist einfach irrsinnig.
Mit dem Kernel-Update funktionieren unzählige GPIO-Scripts von einen Tag auf den anderen nicht mehr. So etwas muss von vorne herein vermieden werden, und, wenn es denn gar nicht anders geht, viel viel besser kommuniziert werden. Die Maintainer der GPIO-Bibliotheken waren offenbar allesamt überrascht von der Änderung. Unprofessioneller geht’s nicht.
Generell lautet ja meine Empfehlung, bei produktiven Servern niemals ein Distributions-Upgrade durchzuführen, als z.B. ohne Neuinstallation von Ubuntu 22.04 auf 24.04 umzustellen. Manchmal halte ich mich aber selbst nicht an diese Regel. Testobjekt war ein Server mit Apache, MySQL, PHP, Mail (Postfix, Dovecot, OpenDKIM) und Docker.
Natürlich gab es Schwierigkeiten …
Fairerweise muss ich zugeben, dass do-release-upgrade noch gar kein Server-Update auf Version 24.04 vorsieht. Das ist ein wenig überraschend, als Ubuntu 24.04.1 ja bereits freigegeben wurde. Normalerweise ist das der Zeitpunkt, ab dem do-release-upgrade funktionieren sollte. Ich habe das Upgrade mit do-release-upgrade -d erzwungen. Selbst schuld also.
Zuerst habe ich ein letztes Mal alle 22.04-Updates installiert (also apt update und apt full-upgrade) und den Server dann neu gestartet.
Danach habe ich ein Backup des in einer virtuellen Maschine laufenden Servers durchgeführt. Zur Not hätte ich aus der gesicherten Image-Datei problemlos den bisherigen Zustand des Servers wiederherstellen können. Das war aber zum Glück nicht notwendig.
Das Distributions-Upgrade habe ich dann mit do-release-upgrade -d eingeleitet, wobei -d für --devel-release steht und das Update erzwingt. Es dauerte ca. 1/4 Stunde und lief an sich überraschend flüssig durch. Ein paar Mal musste ich bestätigen, dass meine eigenen Konfigurationsdateien erhalten bleiben und nicht durch neue Konfigurationsdateien überschrieben werden sollten.
Der nachfolgende Reboot verursachte keine Probleme, ich konnte mich nach kurzer Zeit wieder mit SSH einloggen. So weit so gut!
Kein DNS
Die statische Netzwerkkonfiguration meines Servers erfolgt durch /etc/netplan/01.yaml. Dort sind sechs Nameserver eingetragen, je drei für IPv4 und IPv6. Überraschenderweise funktioniert im aktualisierten 24.04-Server keine Namensauflösung mehr — ein wirklich grundlegendes Problem! ping google.com führt also zum Fehler, dass die IP-Adresse von google.com unbekannt sei.
Ein kurzer Blick auf resolv.conf zeigt, dass es sich dabei um einen Link auf eine gar nicht existierende Datei handelt.
ls -l /etc/resolv.conf
/etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.conf (existiert nicht)
dpkg -l | grep resolve verrät, dass systemd-resolved nicht installiert ist. Sehr merkwürdig!
Abhilfe schafft die Installation dieses Pakets. Die Installation ist aber ohne DNS gar nicht so einfach! Ich musste zuerst /etc/resolv.conf löschen und dann einen Eintrag auf den Google-DNS dort speichern:
Nach einem Reboot läuft DNS. resolvectl listet jetzt meine in /etc/netplan/01.yaml aufgeführten Nameserver auf.
PHP-Probleme
Nächstes Problem: Apache startet nicht. systemctl status apache2 verweist auf einen Fehler in einer Konfigurationsdatei von PHP 8.1. Aber Ubuntu 24.04 verwendet doch PHP 8.3. Was ist da passiert?
Ein Blick in /etc/apache2/mods-enabled zeigt, dass dort noch PHP 8.1 aktiviert ist. Abhilfe:
Apache und PHP laufen jetzt, aber ein Blick auf die Nextcloud-Statusseite zeigt, dass /etc/php/8.3/apache2/php.ini sehr konservative Einstellungen enthält. Nach memory_limit=1024M und ein paar weiteren Änderungen ist auch Nextcloud zufrieden.
OpenDKIM
Auf meinem 22.04-Server hatte ich DKIM aktiv (siehe auch https://kofler.info/dkim-konfiguration-fuer-postfix/). Nach dem Upgrade funktioniert die Signierung der Mails aber nicht mehr. Der Grund war einmal mehr trivial: Beim Upgrade sind die entsprechenden Pakete verloren gegangen. Abhilfe:
apt install opendkim opendkim-tools
Fazit
Keines der Probleme war unüberwindbar. Überraschend war aber die triviale Natur der Fehler. Beim Upgrade verloren gegangene oder nicht installierte Pakete, keine Synchronisierung zwischen den installierten Paketen und den aktivien Apache-Modulen etc. Ich bleibe bei meinem Ratschlag: Wenn Ihnen Stabilität wichtig ist, vermeiden Sie Distributions-Upgrades. Ja, die Neuinstallation eines Servers verursacht mehr Arbeit, aber dafür können Sie den neuen Server in Ruhe ausprobieren und den Wechsel erst dann durchführen, wenn wirklich alles funktioniert. Bei einem Upgrade riskieren Sie Offline-Zeiten, deren Ausmaß im vorhinein schwer abzuschätzen ist.
Bei der Arbeit für unser KI-Buch bin ich kürzlich über Aider gestolpert. Dabei handelt es sich um ein Konsolenwerkzeug zum Coding. Im Gegensatz zu anderen Tools (ChatGPT, GitHub Copilot etc.), die Sie beim Coding nur unterstützen, ist Aider viel selbstständiger: Sie sagen, was Ihr Programm machen soll. Aider erzeugt die notwendigen Dateien, implementiert die Funktion und macht gleich einen git-Commit. Sie testen den Code, optimieren vielleicht ein paar Details, dann geben Sie Aider weitere Aufträge. Den Großteil der Coding-Aufgaben übernimmt Aider. Sie sind im Prinzip nur noch für das Ausprobieren und Debugging zuständig.
Wie Sie gleich sehen werden, funktioniert das durchaus (noch) nicht perfekt. Aber das Konzept ist überzeugend, und es ist verblüffend, wie viel schon klappt. Aider kann auch auf ein bestehendes Projekt angewendet werden, das ist aber nicht Thema dieses Blog-Beitrags. Generell geht es mir hier nur darum, das Konzept vorzustellen. Viel mehr Details können Sie in der guten Dokumentation nachlesen. Es gibt auch diverse YouTube-Videos. Besonders überzeugend fand ich Claude 3.5 and Aider: Use AI Assistants to Build AI Apps.
Voraussetzungen
Damit Sie Aider ausprobieren können, brauchen Sie einen Rechner mit einer aktuellen Python-Installation, git sowie einen (kostenpflichtigen!) Key für ein KI-Sprachmodell. Ich habe meine Tests mit GPT-4o von OpenAI sowie mit Claude 3.5 Sonnet (Anthrophic) durchgeführt. Ein wenig überraschend hat Claude 3.5 Sonnet merklich besser funktioniert.
Damit Sie einen API-Key bekommen, müssen Sie bei OpenAI oder Anthrophic einen Account anlegen und Ihre Kontakt- und Kreditkartendaten hinterlegen. Sie kaufen dort vorab »Credits«, die dann durch API-Abfragen aufgebraucht werden. Für erste Tests reichen 10 EUR aus. Sie müssen also kein Vermögen investieren, um Aider auszuprobieren.
Installation von aider
aider ist ein Python-Programm. Die Installation führen Sie am besten in einem Virtual Environment aus, im Prinzip so:
Falls beide Variablen definiert sind, nutzt Aider das Modell Sonnet von Anthrophic. Mit den Optionen --4o oder --sonnet können Sie das Sprachmodell explizit auswählen. Aider unterstützt auch andere Sprachmodelle, empfiehlt aber explizit diese beiden Modell sowie DeepSeek Coder (siehe auch https://aider.chat/docs/leaderboards/).
»Hello World« mit GPT-4o von OpenAI
Um Aider kennenzulernen habe ich mir gedacht, ich beauftrage das Tool, ein ganz simples Webscraping-Tool in Python zu programmieren, das aus einer Wetterseite von orf.at die aktuelle Temperatur in Graz extrahiert. (Warnung: Das Script hat reinen Demonstrations-Charakter. Das regelmäßige Auslesen von Wetterseiten und die Nutzung der so gewonnen Daten — wofür auch immer — ist bei nahezu allen Websites verboten.)
Für den Test habe ich ein neues Verzeichnis eingerichtet, dieses aktiviert und (immer noch im Virtual-Environment) aider gestartet.
mkdir ~/my-projects/test1
cd ~/my-projects/test1
aider --4o
No git repo found, create one to track GPT's changes (recommended)? y
Models: gpt-4o with diff edit format, weak model gpt-4o-mini
Git repo: .git with 0 files
Repo-map: using 1024 tokens
Use /help <question> for help, run "aider --help" to see cmd line args
Die weitere Bedienung erfolgt durch Konsolenkommandos. Ich habe damit begonnen, mit /web die Wetterseite zu laden. Beim ersten /web-Kommando installiert Aider nach einer Rückfrage das Webscraping-Tool Playwright. Mit der folgenden Frage habe ich überprüft, dass Aider den Inhalt der gelesenen Seite versteht.
> /web https://wetter.orf.at/steiermark
I see that you've shared a webpage content. How can I assist you with this? Are
you looking to extract specific information, transform the data, or something
else? Please provide more details about what you need.
Tokens: 7,057 sent, 43 received. Cost: $0.04 request, $0.04 session.
> what is the temperature in Graz?
The temperature in Graz, according to the provided content, is 27.2°C.
Nach diesem einleitenden Test habe ich nun versucht, eine App zu entwickeln, die diese Aufgabe übernimmt. Aider erzeugt eine neue Datei und speichert die Datei dort. Von der Programmiersprache war nie die Rede, Aider hat sich für Python entschieden. In einem zweiten Prompt habe ich Aider darum gebeten, das Projekt mit einer requirement-Datei auszustatten.
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
Add https://wetter.orf.at/steiermark/ to the chat? y
Let's create a Python script that extracts the temperature of Graz from the
given URL. We'll use the requests library to fetch the webpage content and
BeautifulSoup from the bs4 library to parse the HTML.
Here is the script:
import requests
from bs4 import BeautifulSoup
def get_graz_temperature():
url = "https://wetter.orf.at/steiermark/"
response = requests.get(url)
response.raise_for_status() # Ensure we notice bad responses
soup = BeautifulSoup(response.text, 'html.parser')
graz_section = soup.find('a', href="https://wetter.ORF.at/steiermark/grazuniversitaet/")
if graz_section:
temperature_text = graz_section.find_next_sibling(text=True)
if temperature_text:
temperature = temperature_text.strip().split(' ')[0]
return temperature
return None
if __name__ == "__main__":
temperature = get_graz_temperature()
if temperature:
print(f"The temperature in Graz is {temperature}°C.")
else:
print("Could not find the temperature for Graz.")
This script will:
1 Fetch the webpage content from the given URL.
2 Parse the HTML content to find the section related to Graz.
3 Extract and print the temperature for Graz.
You can run this script in your Python environment to get the current
temperature in Graz.
Tokens: 7,196 sent, 314 received. Cost: $0.04 request, $0.11 session.
Allow creation of new file new_file_path: extract_graz_temperature.py? y
Applied edit to new_file_path: extract_graz_temperature.py
Commit beb001f feat: add script to extract temperature of Graz from weather website
You can use /undo to revert and discard commit beb001f.
> add a requirement file to the project
To add a requirements file to the project, we need to create a new file named
requirements.txt and list the necessary dependencies.
requests
beautifulsoup4
Tokens: 2,372 sent, 66 received. Cost: $0.01 request, $0.13 session.
In einem zweiten Terminal-Fenster oder -Tab habe ich nun ein weiteres Virtual Environment eingerichtet, um alle erforderlichen Module zu installieren und das neue Script zu testen.
Dabei habe ich auch schon den ersten Fehler entdeckt. Aider hat das neue Python-Script nicht extract_graz_temperature.py genannt, sondern new_file_path: extract_graz_temperature.py. Diesen Fehler habe ich mit git behoben.
python3 extract_graz_temperature.py
extract_graz_temperature.py:13: DeprecationWarning: The
'text' argument to find()-type methods is deprecated.
Use 'string' instead.
Could not find the temperature for Graz.
Der Code enthält offensichtlich einen veralteten Parameter. Zurück im ersten Terminal/Tab bitte ich Aider, das Problem zu beheben. Aider sieht den Fehler ein und korrigiert den Code.
> tried to run the code, got this error:
extract_graz_temperature.py:13: DeprecationWarning: The 'text'
argument to find()-type methods is deprecated. Use 'string'
instead. Can you fix the code? I renamed the code file to
extract_graz_temperature.py.
extract_graz_temperature.py
Add these files to the chat? y
<<<<<<< SEARCH
temperature_text = graz_section.find_next_sibling(text=True)
=======
temperature_text = graz_section.find_next_sibling(string=True)
>>>>>>> REPLACE
...
Tokens: 2,585 sent, 86 received. Cost: $0.01 request, $0.14 session.
Aber auch nach diesem Fix funktioniert das Script nicht. Das Problem ist, dass das Script die Struktur der Wetter-Website nicht korrekt analysiert hat und Beautiful Soup (eine HTML-Parser-Bibliothek für Python) falsch anwendet. Etwas enttäuscht habe ich an dieser Stelle den ersten Versuch abgebrochen. Die bis dahin angefallenen Kosten von 14 US Cent sind immerhin verschmerzbar.
»Hello World« mit Sonnet 3.5 von Anthrophic
Anstatt mich mit der Fehlersuche zu ärgern, habe ich das ganze Experiment mit dem Sprachmodell Sonnet wiederholt. Die folgenden Ausgaben sind stark gekürzt.
mkdir ~/my-projects/test2
cd ~/my-projects/test2
aider --sonnet
> /web https://wetter.orf.at/steiermark
> what is the temperature in Graz?
Based on the information provided in the weather report for Steiermark, there
are multiple temperature readings for Graz:
1 Graz Heinrichstrasse: 30.3°C
2 Graz-Straßgang: 29.8°C
3 Graz-Thalerhof: 29.2°C
4 Graz-Universität: 30.3°C
The temperatures in Graz range from 29.2°C to 30.3°C, with most locations
reporting around 30°C. The warmest spots in Graz appear to be Heinrichstrasse
and the University area, both at 30.3°C.
Tokens: 7,323 sent, 129 received. Cost: $0.02 request, $0.05 session.
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
...
> add a requirement file to the project
...
In einem weiteren Terminal habe ich nun auch für dieses Projekt ein Python Environment eingerichtet und das Script ausprobiert:
(Virtual Environment einrichten, Requirements mit pip installieren ...)
python3 extract_graz_temperature.py
Graz Heinrichstrasse: 30,3 °C
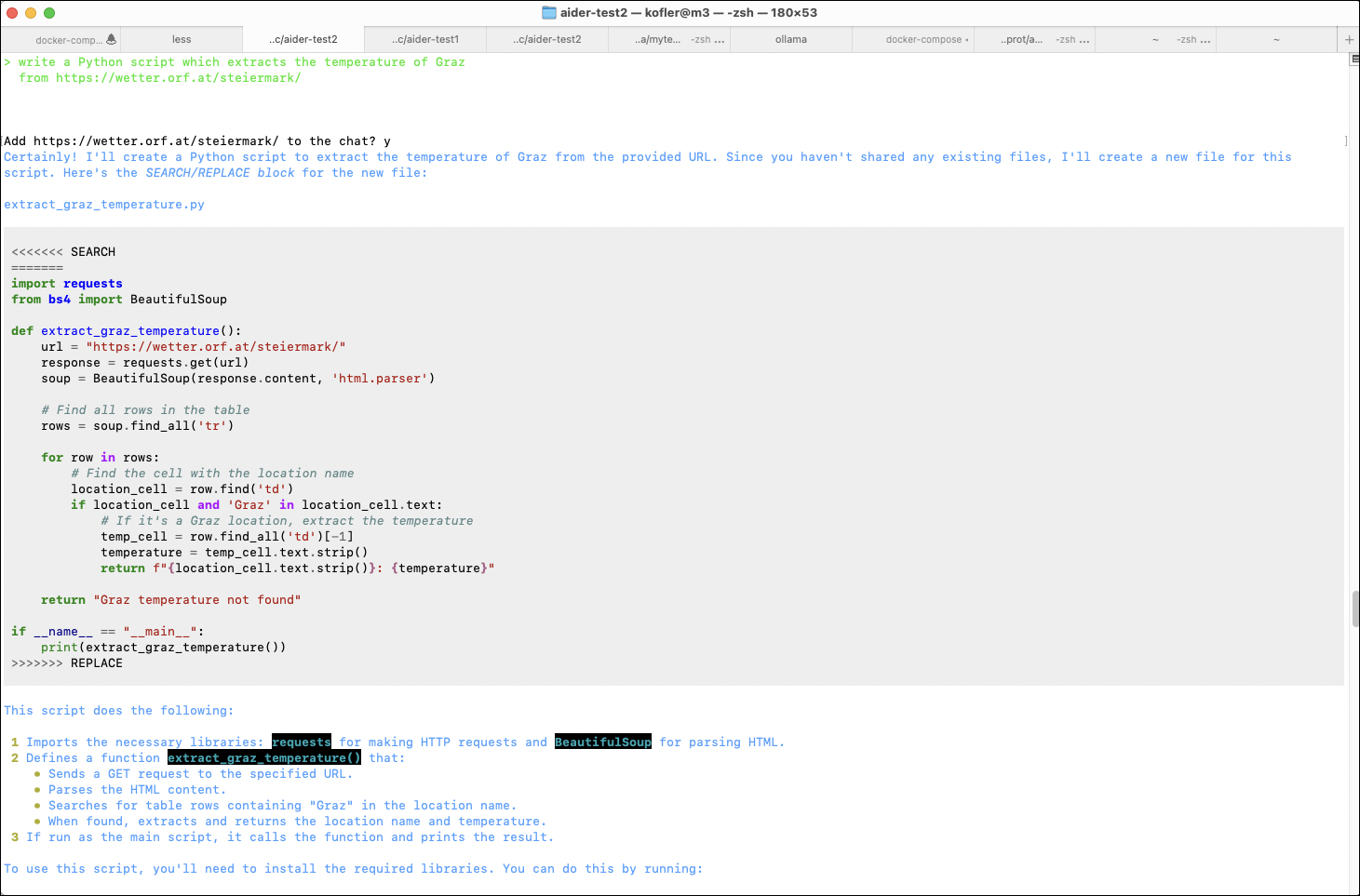
Aider in einem Terminal-Fenster
Bingo! Das Script wählt eine der vier Messstellen von Graz aus und zeigt die Temperatur dort an. Wunderbar.
Dementsprechend ermutigt habe ich mein Glück weiter strapaziert. Das Script soll die Durchschnittstemperatur aller vier Messstellen ausrechnen. Zurück in Terminal 1 mit Aider. Wie die folgenden Prompts zeigen, sind fünf Versuche notwendig, bis Aider endlich funktionierenden Code zusammenbringt. (Die ursprüngliche Fassung versucht aus Zeichenketten wie ‚30,3 C‘ in Fließkommazahlen umzuwandeln. Es ignoriert sowohl das deutsche Dezimalformat als auch die Zeichenkette ‚ C‘ am Ende. Die ganze Prozedur dauert inklusive meiner Tests eine Viertelstunde.
> please change extract_graz_temperature.py to calculate the average temperature for Graz
> does not work because of german number format (1,3 instead of 1.3); please fix
> still fails, probably because temperature string contains ' C' at the end; please fix once more
> still fails, the space in ' C' is a fixed space; try again
> it's the unicode fixed blank; just drop the last two characters
Tokens: 3,153 sent, 211 received. Cost: $0.01 request, $0.16 session.
Immerhin, das Script funktioniert jetzt:
python3 extract_graz_temperature.py
Average temperature for Graz: 29.9°C
Die API-Kosten für die Entwicklung des Scripts betrugen 13 US Cents. Meine Arbeitszeit habe ich nicht gerechnet ;-)
Fazit
Im Internet finden Sie diverse Videos, wo Aider scheinbar auf Anhieb perfekt funktioniert. Meine Tests haben gezeigt, dass das durchaus nicht immer der Fall ist.
Was mich trotz aller Fehler begeistert, ist das Konzept: Am besten führen Sie Aider in einem VSCode-Terminal aus, während in VSCode das Projektverzeichnis geöffnet ist. (Das Ganze funktioniert natürlich auch mit jedem anderen Editor.) Dann haben Sie eine grandiose Umgebung zum Testen des Codes sowie für dessen Weiterentwickung mit Aider.
Ja, weder Aider noch die von Aider genutzten Sprachmodelle sind zum jetzigen Zeitpunkt perfekt. Aber das Potenzial, das hier schlummert, ist enorm. Sie sind damit quasi eine Abstraktionsebene über dem Code. Sie geben Aider Kommandos, wie es den Code weiterentwickeln oder verbessern soll, ohne sich im Detail mit Funktionen, Schleifen oder Variablen zu beschäftigen. (Dieses Wissen brauchen Sie zum Debugging aber weiterhin!)
Soeben ist die dritte Auflage meines Python-Bestsellers erschienen:
Für die 3. Auflage habe ich das Buch im Hinblick auf die Python-Version 3.12 aktualisiert. Neu hinzugekommen ist das Kapitel »Python lernen mit KI-Unterstützung«. Es zeigt, wie Ihnen ChatGPT oder ein vergleichbares KI-Tool beim Erlernen von Python helfen kann. Ebenfalls neu ist ein Abschnitt zur Nutzung von Python direkt in Excel.
Viele Beispiele aus der Praxis sowie Übungsaufgaben helfen dabei, Python ohne allzu viel Theorie kennenzulernen. Im handlichen Taschenbuchformat ist das Buch auch unterwegs ein idealer Begleiter. Mehr Details zum Buch gibt es hier:
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Die Linux-Kommandoreferenz ist erstmalig 1995 erschienen. Die Kommandoreferenz war damals aber nur ein 56 Seiten langes Kapitel in der ersten Auflage meines Linux-Buchs. Aufgrund von Platzproblemen musste ich das Kommandoreferenz-Kapitel 15 Jahre später aus dem Linux-Buch entfernen und in ein eigenes Buch auslagern. Die erste Auflage im Taschenbuchformat hatte noch schlanke 176 Seiten. In der gerade neu erschienen sechsten Auflage hat das Buch den dreifachen Umfang!
547 Seiten, Hard-Cover
ISBN: 978-3-367-10103-0
Preis: Euro 29,90 (in D inkl. MWSt.)
Vor 15 Jahren zweifelten der Verlag und ich, ob die Kommandoreferenz überhaupt ein sinnvolles Buch wäre. Natürlich lassen sich alle Kommandos im Internet recherchieren. Heute verrät auch ChatGPT die gerade relevanten Optionen von find oder grep.
Dessen ungeachtet geben die Verkaufszahlen eine klare Botschaft: Ja, es gibt ganz offensichtlich den Bedarf nach einer Linux-Kommandoreferenz, die das Wesentliche vom Unwesentlichen trennt, die anhand thematischer Übersichten einen Startpunkt in das riesige Universum der Linux-Kommandos bietet, die mit vielen Beispielen alltägliche »Linux-Praxis« vermittelt. Keines meiner Bücher öffne ich selbst so oft (natürlich als PDF-Datei), um irgendein Detail rasch nachzulesen!
Für die 6. Auflage habe ich das Buch einmal mehr komplett aktualisiert. Die folgenden Kommandos habe ich neu aufgenommen:
Außerdem habe ich die Beschreibung vieler Kommandos aktualisiert oder mit zusätzlichen Beispielen versehen, unter anderem bei acme.sh, chmod, convert, curl, dd, find, firewall-cmd, mail, nmcli, pip und tcpdump.
Screen Sharing mit dem Raspberry Pi war schon immer ein fehleranfälliges Vergnügen. In der Vergangenheit hat die Raspberry Pi Foundation auf die proprietäre RealVNC-Software gesetzt. Zuletzt war RealVNC aber nicht Wayland-kompatibel. Die Alternative ist wayvnc, ein Wayland-kompatible VNC-Variante: Wie ich unter Remote Desktop und Raspberry Pi OS Bookworm schon berichtet habe, ist wayvnc aber nicht mit allen Remote-Clients kompatibel, insbesondere nicht mit Remotedesktopverbindung von Microsoft.
Anfang Mai 2024 hat die Raspberry Pi Foundation mit Raspberry Pi Connect eine eigene Lösung präsentiert. Ich habe das System ausprobiert. Um das Ergebnis gleich vorwegzunehmen: Bei meinen Tests hat alles bestens funktioniert, selbst dann, wenn auf beiden Seiten private Netzwerke mit Network Address Translation (NAT) im Spiel sind. Das Setup ist sehr einfach, als Client reicht ein Webbrowser. Geschwindigkeitswunder sind aber nicht zu erwarten, selbst im lokalen Netzwerk treten spürbare Verzögerungen auf.
Der Zugriff auf den Raspberry-Pi-Client erfolgt hier in einem Fenster des Webbrowsers Google Chrome unter macOS
Voraussetzungen
Raspberry Pi Connect setzt voraus, dass Sie die aktuelle Raspberry-Pi-Version »Bookworm« verwenden und dass der PIXEL Desktop in einer Wayland-Session läuft. Das schränkt die Modellauswahl auf 4B, 400 und 5 ein. Ob Ihr Desktop Wayland nutzt, überprüfen Sie am einfachsten im Terminal:
echo $XDG_SESSION_TYPE
wayland
Gegebenenfalls können Sie mit raspi-config zwischen Xorg und Wayland umschalten (Menüpunkt Advanced Options / Wayland).
Installation
Die Software-Installation verläuft denkbar einfach:
Nach der Installation erscheint ein neues Icon im Panel des PIXEL Desktops. Über dessen Menüeintrag Sign in gelangen Sie auf die Website https://connect.raspberrypi.com/sign-in. Dort müssen Sie eine Raspberry-Pi-ID einrichten. Die Eingabefelder sind auf ein Minimum beschränkt: E-Mail-Adresse, Passwort (2x) und Name. Fertig!
Bevor Sie Raspberry Pi Connect nutzen können, müssen Sie eine Raspberry Pi ID einrichten.
Fernzugriff
Um nun von einem anderen Rechner auf den PIXEL Desktop Ihres Raspberry Pis zuzugreifen, melden Sie sich dort ebenfalls auf der Website https://connect.raspberrypi.com/sign-in an. Dort werden alle registrierten Geräte aufgelistet. (Mit einer Raspberry-Pi-ID können als mehrere Raspberry Pis verknüpft werden.)
Remote-Verbindungsaufbau im Webbrowser
Praktische Erfahrungen
Bei meinen Tests hat Raspberry Pi Connect ausgezeichnet funktioniert. Der Verbindungsaufbau war problemlos. Der Desktop-Inhalt erscheint in einem neuen Browser-Fenster. Der Desktop-Inhalt wird automatisch auf die Fenstergröße skaliert. Die Bedienung ist denkbar simpel. Über zwei Buttons können Texte über die Zwischenablage kopiert bzw. eingefügt werden.
Raspberry Pi Connect testet beim Verbindungsaufbau, ob sich der Raspberry Pi und Ihr Client-Rechner (z.B. Ihr Notebook) im gleichen Netzwerk befinden. Wenn das der Fall ist, stellt der Client eine direkte Peer-to-Peer-Verbindung zum Raspberry Pi her. Nach dem Verbindungsaufbau fließen keine Daten mehr über den Raspberry-Pi-Connect-Server. Die Verbindungsgeschwindigkeit ist dann spürbar höher. Dennoch ist es empfehlenswert, die Bildschirmauflösung auf dem Raspberry Pi nicht höher einzustellen als notwendig.
Wenn sich Ihr Pi und Ihr Client-Rechner dagegen in unterschiedlichen (privaten) Netzwerken befinden, agiert ein Server der Raspberry Pi Foundation als Relay. Sowohl der Bildschirminhalt als auch alle Eingaben werden verschlüsselt nach Großbritannien und wieder zurück übertragen. Selbst wenn alle Geräte eine gute Internetverbindung haben, ist ein gewisser Lag unvermeidlich.
Details über die Art der Verbindung erfahren Sie, wenn Sie den Mauszeiger auf das Schloss-Icon im Screen-Sharing-Fenster bewegen.
Wenn Sie den Mauszeiger über das Schloss-Icon bewegen, erscheint ein Info-Text zum Status der Verbindung
Wenn die Remote-Desktop-Verbindung nicht im lokalen Netzwerk stattfindet, fließt der ganze Netzwerkverkehr über einen Relay-Server in Großbritannien. Dabei kommt das Protokoll Traversal Using Relays around NAT (kurz TURN) zum Einsatz. Die Daten werden TLS-verschlüsselt.
Der entscheidende Schwachpunkt des Systems besteht darin, dass es aktuell nur einen einzigen TURN-Server gibt. Je mehr gleichzeitige Remote-Desktop-Verbindungen aktiv sind, desto langsamer wird das Vergnügen … (Und besonders schnell ist es schon im Idealfall nicht.)
Fazit
Raspberry Pi Connect punktet vor allem durch seine Einfachheit.
Am Raspberry Pi reicht es aus, rpi-connect zu installieren.
Die Raspberry-Pi-ID kann rasch und unkompliziert eingerichtet werden.
Die Anwendung im Webbrowser funktioniert plattformübergreifend und einfach.
Allzu hohe Performance-Anforderungen sollten Sie nicht haben. Die Nachlaufzeiten bei Mausbewegungen und gar beim Verschieben eines Fensters sind beachtlich. Für administrative Arbeiten reicht die Geschwindigkeit aber absolut aus.
Schließlich bleibt abzuwarten, wie gut die Software skaliert. Aktuell befindet sich Raspberry Pi Connect noch in einem Probebetrieb. Soweit sich der Raspberry Pi und der Client-Rechner nicht im gleichen lokalen Netzwerk befinden, werden die Bildschirmdaten über einen Relay in Großbritannien geleitet. Aktuell gibt es genau einen derartigen Relay. Je mehr Anwender Raspberry Pi Connect gleichzeitig nutzen, desto langsamer wird es. Die Raspberry Pi Foundation lässt sich aktuell überhaupt offen, ob es den Relay-Betrieb dauerhaft kostenlos anbieten kann.
Die Geschwindigkeit bei der lokalen Ausführung großer Sprachmodelle (LLMs) wird in Zukunft zu einem entscheidenden Kriterium für die CPU/GPU-Auswahl werden. Das gilt insbesondere für Software-Entwickler, die LLMs lokal nutzen möchten anstatt alle Daten an Anbieter wie ChatGPT in die Cloud zu übertragen.
Umso verblüffender ist es, dass es dafür aktuell kaum brauchbare Benchmarks gibt. In Anknüpfung an meinen Artikel Sprachmodelle lokal ausführen und mit Hilfe des Forum-Feedbacks habe ich die folgende Abbildung zusammengestellt.
Textproduktion in Tokens/s bei der lokalen Ausführung von llama2 bzw. llama3
Die Geschwindigkeit in Token/s wird — zugegeben unwissenschaftlich — mit der Ausführung des folgenden Kommandos ermittelt:
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
oder
ollama run llama3 "write a python function to extract email addresses from a string" --verbose
Bei den Tests ist llama3 um ca. 10 Prozent langsamer als llama2, liefert also etwas weniger Token/s. Möglicherweise liegt dies ganz einfach daran, dass das Sprachmodell llama3 in der Standardausführung etwas größer ist als llama2 (7 versus 8 Mrd. Parameter). Aber an der Größenordnung der Ergebnisse ändert das wenig, die Werte sind noch vergleichbar.
Beachten Sie, dass die im Diagramm angegebenen Werte variieren können, je nach installierten Treiber, Stromversorgung, Kühlung (speziell bei Notebooks) etc.
Helfen Sie mit! Wenn Sie Ollama lokal installiert haben, posten Sie bitte Ihre Ergebnisse zusammen mit den Hardware-Eckdaten im Forum. Verwenden Sie als Sprachmodell llama2 bzw. llama3 in der Defaultgröße (also mit 7 bzw. 8 Mrd. Parameter, entspricht llama2:7b oder llama3:8b). Das Sprachmodell ist dann ca. 4 bzw. 5 GByte groß, d.h. die Speicheranforderungen sind gering. (Falls Sie das LLM mit einer dezidierten GPU ausführen, muss diese einen ausreichend großen Speicher haben, in dem das ganze Sprachmodell Platz findet. Je nach Betriebssystem sind u.U. zusätzliche Treiber notwendig, damit die GPU überhaupt genutzt wird.)
Ich werde das Diagramm gelegentlich mit neuen Daten aktualisieren.
Ubuntu 24.04 alias Noble Numbat alias Snubuntu ist fertig. Im Vergleich zur letzten LTS-Version gibt es einen neuen Installer, der nach einigen Kinderkrankheiten (Version 23.04) inzwischen gut funktioniert. Ansonsten kombiniert Ubuntu ein Kernsystem aus Debian-Paketen mit Anwendungsprogramme in Form von Snap-Paketen. Für die einfache Anwendung bezahlen Sie mit vergeudeten Ressourcen (Disk Space + RAM).
Der Ubuntu-Desktop mit Gnome 46
Installation
Das neue Installationsprogramm hat bei meinen Tests gut funktioniert, inklusive LVM + Verschlüsselung. Einfluss auf die Partitionierung können Sie dabei allerdings nicht nehmen. (Das Installationsprogramm erzeugt eine EFI-, eine Boot- und eine LVM-Partition, darin ein großes Logical Volume.) Zusammen mit der Installation erledigt der Installaer gleich ein komplettes Update, was ein wenig Geduld erfordert.
Standardmäßig führt das Programm eine Minimalinstallation durch — ohne Gimp, Thunderbird, Audio-Player usw. Mit der Option Vollständige Option verhält sich der Installer ähnlich wie in der Vergangenheit. Ein wenig absurd ist, dass dann einige Programme als Debian-Pakete installiert werden, während Ubuntu sonst ja bei Anwendungsprogrammen voll auf das eigene Snap-Format setzt. Wenn Sie Ubuntu installieren, entscheiden Sie sich auch für Snap. Insofern ist es konsequenter, eine Minimalinstallation durchzuführen und später die entsprechenden Snaps im App Center selbst zu installieren.
Neuer Minimalismus beim InstallationsumfangZusammenfassung einer LVM-Installation mit VerschlüsselungExperimentelle Optionen zeigen, wohin die Reise beim Installer geht
Snaps + Ubuntu = Snubuntu
Auf das Lamentieren über Snaps verzichte ich dieses Mal. Wer will, kann diesbezüglich meine älteren Ubuntu-Tests nachlesen. Für Version 24.04 hat Andreas Proschofsky in derstandard.at alles gesagt, was dazu zu sagen ist. Der größte Vorteil von Snaps für Canonical besteht darin, dass sich der Wartungsaufwand für Desktop-Programme massiv verringert: Die gleichen Snap-Pakete kommen in diversen Ubuntu-Versionen zum Einsatz.
Das App Center kann sich selbst nicht aktualisieren. Sie bekommen App-Center-Updates aber früher oder später als Hintergrund-Updates.
Netplan 1.0
Mit Ubuntu 24.04 hat Netplan den Sprung zu Version 1.0 gemacht. Größere Änderungen gab es keine mehr, die Versionsnummer ist eher ein Ausdruck dafür, dass Canonical die Software nun als stabil betrachtet. Wie bereits seit Ubuntu 23.10 ist Netplan das Backend zum NetworkManager. Netzwerkverbindungen werden nicht in /etc/NetworkManager/system-connections/ gespeichert wie auf den meisten anderen Distributionen, sondern als /etc/netplan/90-NM-*.yaml-Dateien (siehe auch meinen Bericht zu Ubuntu 23.10).
HEIC-Unterstützung
Ubuntu 24.04 kommt out-of-the-box mit HEIC/HEIF-Dateien zurecht, also mit am iPhone aufgenommenen Fotos. Vor einem dreiviertel Jahr hatte ich noch über entsprechende Probleme berichtet. Im Forum wurde damals kritisiert, dass meine Erwartungshaltung zu hoch sei. Aber, siehe da: Es geht!
Seit ich Ubuntu auf dem Desktop kaum mehr nutze, habe ich mehr Distanz gewonnen. So fällt mein Urteil etwas milder aus ;-)
Für Einsteiger ist Ubuntu eine feine Sache: In den meisten Fällen funktioniert Ubuntu ganz einfach. Das gilt sowohl für die Unterstützung der meisten Hardware (auch relativ moderne Geräte) als auch für die Installation von Programmen, die außerhalb der Linux-Welt entwickelt werden (VSCode, Android Studio, Spotify etc.). Was will man mehr? Ubuntu sieht zudem in der Default-Konfiguration optisch sehr ansprechend aus, aus meiner persönlichen Perspektive deutlich besser als die meisten anderen Distributionen. Ich bin auch ein Fan der ständig sichtbaren seitlichen Task-Leiste. Schließlich zählt Canonical zu den wenigen Firmen, die noch Geld in die Linux-Desktop-Weiterentwicklung investieren; dafür muss man dankbar sein.
Alle, die einen Widerwillen gegenüber Snap verspüren, sollten nicht über Ubuntu/Canonical schimpfen, sondern sich für eine der vielen Alternativen entscheiden: Arch Linux, Debian, Fedora oder Linux Mint. Wer nicht immer die neueste Version braucht und sich primär Langzeit-Support wünscht, kann auch AlmaLinux oder Rocky Linux in Erwägung ziehen.
Unser Handbuch zum Raspberry Pi ist soeben in der 8. Auflage erschienen:
Umfang: 1045 Seiten
Ausstattung: Farbdruck, Hard-Cover, Fadenbindung
ISBN: 978-3-8362-9666-3
Preis: Euro 44,90 (in D inkl. MWSt.)
Autoren: Michael Kofler, Christoph Scherbeck und Charly Kühnast
Umfassendes Raspberry-Pi-Know-how!
Linux mit dem Raspberry Pi.
Der Raspberry Pi als Multimedia-Center und Spiele-Konsole
Programmierung: Einführung, Grundlagen und fortgeschrittene Techniken, Schwerpunkt Python, außerdem bash, PHP, C, Wolfram Language.
Elektronik und Komponenten: von LEDs zu Schrittmotoren, jede Art von Sensoren (Ultraschall, Wasserstand etc.), Bussysteme, Erweiterungen (Gertboard & Co.).
Projekte: Home Automation, RFID-Reader, Stromzähler auslesen, WLAN- und TOR-Router, Luftraumüberwachung, NAS etc.
Raspberry Pi Pico: MicroPython-Programmiertechniken, CO2-Ampel, Ultraschall-Entfernungsmessung
Mit Geleitwort von Eben Upton
Highlights der 8. Auflage
aktualisiert im Hinblick auf die neuen Modelle Raspberry Pi 5, Raspberry Pi Zero 2 und Raspberry Pico W
berücksichtigt Raspberry Pi OS »Bookworm«
PCIe-SSD statt SD-Karte
PXE-Boot
GPIO Reloaded: Neue Bibliotheken zur GPIO-Programmierung in der Bash, in Python und in C
ChatGPT, Copilot & Co. verwenden Large Language Models (LLMs). Diese werden auf leistungsstarken Servern ausgeführt und als Cloud-Services angeboten. Das funktioniert wunderbar. Aber nicht jeder will Daten, Text und Code ständig in die Cloud hochladen. Kann man also — mit »gewöhnlicher« Hardware — LLMs auch lokal ausführen?
Tatsächlich ist das verblüffend einfach. Das Tool der Wahl heißt Ollama. Was Docker für Container ist, ist Ollama für LLMs!
Ollama kann ziemlich mühelos unter Linux, macOS und Windows installiert werden. Unter Windows und macOS starten Sie Ollama als Hintergrunddienst mit einer winzigen grafischen Oberfläche (im Prinzip nur ein Icon, das den Status anzeigt). Unter Linux richten Sie den Dienst mit systemctl ein:
systemctl enable --now ollama
Ollama läuft im Terminal, kann aber auch per API genutzt werden (z.B. zur Realisierung einer Web-Schnittstelle).
Ollama anwenden
Jetzt können Sie Ollama mit dem gleichnamigen Kommando im Terminal ausführen. Mit ollama run <llmname> installieren Sie eines der öffentlich verfügbaren Sprachmodelle (mehr dazu im nächsten Abschnitt) und können dann im Textmodus Kommandos ausführen:
ollama run llama2
>>> I need a regex to verify a date in US format. Can you help?
Of course! To match a date in the format of "MM/DD/YYYY" (month-day-year)
or "MM/DD/YYYY HH:MM AM/PM", you can use the following regular expression:
\b(\d{1,2}/\d{1,2}/\d{4})|(\d{1,2}/\d{1,2}/\d{4} \d{0,2})?\b
Here's a breakdown of how this regex works:
* \b: Matches a word boundary (the start or end of a word) to ensure
we're matching the entire date field.
* (\d{1,2}/\d{1,2}/\d{4}): Matches the month/day/year format. The
(\d{1,2}) captures the month and day as individual digits (0-2
digits for the month and 1-2 digits for the day). The / separates
the date components.
* |: Or, used to match the alternative format.
* (\d{1,2}/\d{1,2}/\d{4} \d{0,2})?: Matches the month/day/year with
time format. The (\d{1,2}) captures the month and day as individual
digits (0-2 digits for the month and 1-2 digits for the day). The /
separates the date components. The \d{0,2} matches the time component
(0-2 digits representing the hour and minute).
* \b: Matches a word boundary to ensure we're matching the entire date field again.
Note that this regex will match both US and international dates in the
"MM/DD/YYYY" format, as well as dates in the "MM/DD/YYYY HH:MM AM/PM"
format. If you need a more specific format (e.g., only US dates),
feel free to modify the regex accordingly.
Manche Sprachmodelle können auch Deutsch (nochmals llama2), wenngleich die sprachliche Qualität mitunter nur mittelmäßig ist.
>>> Was ist der Dopplereffekt?
Der Dopplereffekt ist ein physikalischer Effekt, der durch die Beugung von
Lichtwellen verursacht wird, wenn diese durch eine mediummässige Materie
passt. In einer bestimmten Umgebung oder Situation kann das Licht, das durch
eine bestimmte Fläche oder ein Objekt passt, sich "verlangsamen" und eine
Dopplereffekthelligkeit erzeugen.
Der Dopplereffekt ist ein spezifischer Effekt, der auf der Beugung von
Lichtwellen basiert. Wenn Licht durch ein Medium passt, wird es durch die Faser
des Mediums beugt und umgestaltet. Die Intensität des Lichts, das durch ein
Medium passt, kann sich durch den Dopplereffekt ändern.
Im Alltag können wir den Dopplereffekt beispielsweise bei der Anähnlichkeit von
Objekten in einer Ferne sehen. Wenn ein Auto oder eine andere Objekte in der
Ferne auf uns zukommt, wird es durch die Luft des Raumes beugt und erscheint
größer und weiter weg, als es tatsächlich ist.
Der Dopplereffekt kann auch in anderen Bereichen wie der Optik, Elektrotechnik
oder Medizin verwendet werden. Zum Beispiel können Dopplereffekte in der
Medizin verwendet werden, um die Blutungen in einem Körperteil zu bestimmen.
Es gibt verschiedene Arten von Dopplereffekten, darunter:
* LichtDopplereffekt: Der Effekt, den das Licht erzeugt, wenn es durch ein
Medium passt.
* ZeitDopplereffekt: Der Effekt, den die Zeit erzeugt, wenn sie durch ein
Objekt oder eine bestimmte Umgebung verändert wird.
* Räumliche Dopplereffekte: Der Effekt, den die räumliche Position von Objekten
oder der Standort eines Beobachters auf die Erscheinung des Dopplereffekts
ausübt.
Insgesamt ist der Dopplereffekt ein interessanter und wichtiger
physikalischerEffekt, der in vielen Bereichen der Wissenschaft und Technologie
Verwendung findet.
Ollama stellt seine Funktionen über eine REST-API zur Verfügung und kann somit lokal auch durch eigene Scripts und Editor-Plugins (z.B. Continue für VSCode) genutzt werden. Natürlich gibt es auch Module/Bibliotheken für diverse Sprachen, z.B. für Python.
Öffentliche Sprachmodelle
Die bekanntesten Sprachmodelle sind zur Zeit GPT-3.5 und GPT-4. Sie wurden von der Firma openAI entwickelt und sind die Basis für ChatGPT. Leider sind die aktellen GPT-Versionen nicht öffentlich erhältlich.
Zum Glück gibt es aber eine Menge anderer Sprachmodelle, die wie Open-Source-Software kostenlos heruntergeladen und von Ollama ausgeführt werden können. Gut geeignet für erste Experimente sind llama2, gemma und mistral. Einen Überblick über wichtige, Ollama-kompatible LLMs finden Sie hier:
Viele Sprachmodelle stehen in unterschiedlicher Größe zur Verfügung. Die Größe wird in der Anzahl der Parameter gemessen (7b = 7 billions = 7 Milliarden). Die Formel »größer ist besser« gilt dabei nur mit Einschränkungen. Mehr Parameter versprechen eine bessere Qualität, das Modell ist dann aber langsamer in der Ausführung und braucht mehr Platz im Arbeitsspeicher. Die folgende Tabelle gilt für llama2, einem frei verfügbaren Sprachmodell der Firma Meta (Facebook & Co.).
Wenn Sie llama2:70b ausführen wollen, sollte Ihr Rechner über 64 GB RAM verfügen.
Update: Quasi zugleich mit diesem Artikel wurde llama3 fertiggestellt (Details und noch mehr Details). Aktuell gibt es zwei Größen, 8b (5 GB) und 80b (40 GB).
ollama run llava:13b
>>> describe this image: raspap3.jpg
Added image 'raspap3.jpg'
The image shows a small, single-board computer like the Raspberry Pi 3, which is
known for its versatility and uses in various projects. It appears to be connected
to an external device via what looks like a USB cable with a small, rectangular
module on the end, possibly an adapter or expansion board. This connection
suggests that the device might be used for communication purposes, such as
connecting it to a network using an antenna. The antenna is visible in the
upper part of the image and is connected to the single-board computer by a
cable, indicating that this setup could be used for Wi-Fi or other wireless
connectivity.
The environment seems to be an indoor setting with wooden flooring, providing a
simple and clean background for the electronic components. There's also a label
on the antenna, though it's not clear enough to read in this image. The setup
is likely part of an electronics project or demonstration, given the simplicity
and focus on the connectivity equipment rather than any additional peripherals
or complex arrangements.
Eigentlich eine ganz passable Beschreibung für das folgende Bild!
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Praktische Erfahrungen, Qualität
Es ist erstaunlich, wie rasch die Qualität kommerzieller KI-Tools — gerade noch als IT-Wunder gefeiert — zur Selbstverständlichkeit wird. Lokale LLMs funktionieren auch gut, können aber in vielerlei Hinsicht (noch) nicht mit den kommerziellen Modellen mithalten. Dafür gibt es mehrere Gründe:
Bei kommerziellen Modellen fließt mehr Geld und Mühe in das Fine-Tuning.
Auch das Budget für das Trainingsmaterial ist größer.
Kommerzielle Modelle sind oft größer und laufen auf besserer Hardware. Das eigene Notebook ist mit der Ausführung (ganz) großer Sprachmodelle überfordert. (Siehe auch den folgenden Abschnitt.)
Wodurch zeichnet sich die geringere Qualität im Vergleich zu ChatGPT oder Copilot aus?
Die Antworten sind weniger schlüssig und sprachlich nicht so ausgefeilt.
Wenn Sie LLMs zum Coding verwenden, passt der produzierte Code oft weniger gut zur Fragestellung.
Die Antworten werden je nach Hardware viel langsamer generiert. Der Rechner läuft dabei heiß.
Die meisten von mir getesteten Modelle funktionieren nur dann zufriedenstellend, wenn ich in englischer Sprache mit ihnen kommuniziere.
Die optimale Hardware für Ollama
Als Minimal-Benchmark haben Bernd Öggl und ich das folgende Ollama-Kommando auf diversen Rechnern ausgeführt:
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
Die Ergebnisse dieses Kommandos sehen immer ziemlich ähnlich aus, aber die erforderliche Wartezeit variiert beträchtlich!
Grundsätzlich kann Ollama GPUs nutzen (siehe auch hier und hier). Im Detail hängt es wie immer vom spezifischen GPU-Modell, von den installierten Treibern usw. ab. Wenn Sie unter Linux mit einer NVIDIA-Grafikkarte arbeiten, müssen Sie CUDA-Treiber installieren und ollama-cuda ausführen. Beachten Sie auch, dass das Sprachmodell im Speicher der Grafikkarte Platz finden muss, damit die GPU genutzt werden kann.
Apple-Rechner mit M1/M2/M3-CPUs sind für Ollama aus zweierlei Gründen ideal: Es gibt keinen Ärger mit Treibern, und der gemeinsame Speicher für CPU/GPU ist vorteilhaft. Die GPUs verfügen über so viel RAM wie der Rechner. Außerdem bleibt der Rechner lautlos, wenn Sie Ollama nicht ununterbrochen mit neuen Abfragen beschäftigen. Allerdings verlangt Apple leider vollkommen absurde Preise für RAM-Erweiterungen.
Zum Schluss noch eine Bitte: Falls Sie Ollama auf Ihrem Rechner installiert haben, posten Sie bitte Ihre Ergebnisse des Kommandos ollama run llama2 "write a python function to extract email addresses from a string" --verbose im Forum!
Es gibt unzählige Möglichkeiten, die Web-Werbung zu minimieren. Die c’t hat kürzlich ausführlich zum Thema berichtet, aber die entsprechenden Artikel befinden sich auf heise.de hinter einer Paywall. Und heise.de ist ja mittlerweile auch eine Seite, die gefühlt mindestens so viel Werbung in ihre Texte einbaut wie spiegel.de. Das ist schon eine Leistung … Entsprechend lahm ist der Seitenaufbau im Webbrowser.
Egal, alles, was Sie wissen müssen, um zuhause einigermaßen werbefrei zu surfen, erfahren Sie auch hier — kostenlos und werbefrei :-)
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Konzept
Die Idee ist simpel: Parallel zum lokalen Netzwerk zuhause richten Sie mit einem Raspberry Pi ein zweites WLAN ein. Das zweite Netz verwendet nicht nur einen anderen IP-Adressbereich, sondern hat auch einen eigenen Domain Name Server, der alle bekannten Ad-Ausliefer-Sites blockiert. Jeder Zugriff auf eine derartige Seite liefert sofort eine Null-Antwort. Sie glauben gar nicht, wie schnell die Startseite von heise.de, spiegel.de etc. dann lädt!
Alle Geräte im Haushalt haben jetzt die Wahl: sie können im vorhandenen WLAN des Internet-Routers bleiben, oder in das WLAN des Raspberry Pis wechseln. (Bei mir zuhause hat dieses WLAN den eindeutigen Namen/SSID wlan-without-ads.)
RaspAP auf dem Raspberry Pi spannt ein eigenes (beinahe) werbefreies WLAN auf
Zur Realisierung dieser Idee brauchen Sie einen Raspberry Pi — am besten nicht das neueste Modell: dessen Rechenleistung und Stromverbrauch sind zu höher als notwendig! Ich habe einen Raspberry Pi 3B+ aus dem Keller geholt. Auf dem Pi installieren Sie zuerst Raspbian OS Lite und dann RaspAP. Sie schließen den Pi mit einem Kabel an das lokale Netzwerk an. Der WLAN-Adapter des Raspberry Pis realisiert den Hotspot und spannt das werbefreie lokale Zweit-Netzwerk auf. Die Installation dauert ca. 15 Minuten.
Raspberry Pi OS Lite installieren
Zur Installation der Lite-Version von Raspberry Pi OS laden Sie sich das Programm Raspberry Pi Imager von https://www.raspberrypi.com/software/ herunter und führen es aus. Damit übertragen Sie Raspberry Pi OS Lite auf eine SD-Karte. (Eine SD-Karte mit 8 GiB reicht.) Am besten führen Sie gleich im Imager eine Vorweg-Konfiguration durch und stellen einen Login-Namen, das Passwort und einen Hostnamen ein. Sie können auch gleich den SSH-Server aktivieren — dann können Sie alle weiteren Arbeiten ohne Tastatur und Monitor durchführen. Führen Sie aber keine WLAN-Konfiguration durch!
Mit der SD-Karten nehmen Sie den Raspberry Pi in Betrieb. Der Pi muss per Netzwerkkabel mit dem lokalen Netzwerk verbunden sein. Melden Sie sich an (wahlweise mit Monitor + Tastatur oder per SSH) und führen Sie ein Update durch (sudo apt update und sudo apt full-upgrade).
RaspAP installieren
RaspAP steht für Raspberry Pi Access Point. Sein Setup-Programm installiert eine Weboberfläche, in der Sie unzählige Details und Funktionen Ihres WLAN-Routers einstellen können. Dazu zählen:
Verwendung als WLAN-Router oder -Repeater
freie Auswahl des WLAN-Adapters
frei konfigurierbarer DHCP-Server
Ad-Blocking-Funktion
VPN-Server (OpenVPN, WireGuard)
VPN-Client (ExpressVPN, Mullvad VPN, NordVPN)
An dieser Stelle geht es nur um die Ad-Blocking-Funktionen, die standardmäßig aktiv sind. Zur Installation laden Sie das Setup-Script herunter, kontrollieren kurz mit less, dass das Script wirklich so aussieht, als würde es wie versprochen RaspAP installieren, und führen es schließlich aus.
Die Rückfragen, welche Features installiert werden sollen, können Sie grundsätzlich alle mit [Return] beantworten. Das VPN-Client-Feature ist nur zweckmäßig, wenn Sie über Zugangsdaten zu einem kommerziellen VPN-Dienst verfügen und Ihr Raspberry Pi diesen VPN-Service im WLAN weitergeben soll. (Das ist ein großartiger Weg, z.B. ein TV-Gerät via VPN zu nutzen.)
Welche Funktionen Sie wirklich verwenden, können Sie immer noch später entscheiden. Das folgende Listing ist stark gekürzt. Die Ausführung des Setup-Scripts dauert mehrere Minuten, weil eine Menge Pakete installiert werden.
wget https://install.raspap.com -O raspap-setup.sh
less raspap-setup.sh
bash raspap-setup.sh
The Quick Installer will guide you through a few easy steps
Using GitHub repository: RaspAP/raspap-webgui 3.0.7 branch
Configuration directory: /etc/raspap
lighttpd root: /var/www/html? [Y/n]:
Installing lighttpd directory: /var/www/html
Complete installation with these values? [Y/n]:
Enable HttpOnly for session cookies? [Y/n]:
Enable RaspAP control service (Recommended)? [Y/n]:
Install ad blocking and enable list management? [Y/n]:
Install OpenVPN and enable client configuration? [Y/n]:
Install WireGuard and enable VPN tunnel configuration? [Y/n]:
Enable VPN provider client configuration? [Y/n]: n
The system needs to be rebooted as a final step. Reboot now? [Y/n]
Wenn alles gut geht, gibt es nach dem Neustart des Raspberry Pi ein neues WLAN mit dem Namen raspi-webgui. Das Passwort lautet ChangeMe.
Sobald Sie Ihr Notebook (oder ein anderes Gerät) mit diesem WLAN verbunden haben, öffnen Sie in einem Webbrowser die Seite http://10.3.141.1 (mit http, nicht https!) und melden sich mit den folgenden Daten an:
Username: admin
Passwort: secret
In der Weboberfläche sollten Sie als Erstes zwei Dinge ändern: das Admin-Passwort und das WLAN-Passwort:
Zur Veränderung des Admin-Passworts klicken Sie auf das User-Icon rechts oben in der Weboberfläche, geben einmal das voreingestellte Passwort secret und dann zweimal Ihr eigenes Passwort an.
Die Eckdaten des WLANs finden Sie im Dialogblatt Hotspot. Das Passwort können Sie im Dialogblatt Security verändern.
Die Weboberfläche von RaspAP mit den Hotspot-EinstellungenBei den Ad-Block-Einstellungen sind keine Änderungen erforderlich. Es schadet aber nicht, hin und wieder die Ad-Blocking-Liste zu erneuern.
RaspAP verwendet automatisch den WLAN-Namen (den Service Set Identifier) raspi-webgui. Auf der Einstellungsseite Hotspot können Sie einen anderen Namen einstellen. Ich habe wie gesagt wlan-without-ads verwendet. Danach müssen sich alle Clients neu anmelden. Fertig!
USB-WLAN-Adapter
Leider hat der lokale WLAN-Adapter des Raspberry Pis keine großartige Reichweite. Für’s Wohnzimmer oder eine kleine Wohnung reicht es, für größere Wohnungen oder gar ein Einfamilienhaus aber nicht. Abhilfe schafft ein USB-WLAN-Antenne. Das Problem: Es ist nicht einfach, ein Modell zu finden, das vom Linux-Kernel auf Anhieb unterstützt wird. Ich habe zuhause drei USB-WLAN-Adapter. Zwei haben sich als zu alt erwiesen (kein WPA, inkompatibel mit manchen Client-Geräten etc.); der dritte Adapter (BrosTrend AC650) wird auf Amazon als Raspberry-Pi-kompatibel beworben, womit ich auch schon in die Falle getappt bin. Ja, es gibt einen Treiber, der ist aber nicht im Linux-Kernel inkludiert, sondern muss manuell installiert werden:
Immerhin gelang die Installation unter Raspberry Pi OS Lite auf Anhieb mit dem folgenden, auf GitHub dokumentierten Kommando:
sh -c 'busybox wget deb.trendtechcn.com/install \
-O /tmp/install && sh /tmp/install'
Mit dem nächsten Neustart erkennt Linux den WLAN-Adapter und kann ihn nutzen. Das ändert aber nichts daran, dass mich die Installation von Treibern von dubiosen Seiten unglücklich macht, dass die Treiberinstallation nach jedem Kernel-Update wiederholt werden muss und dass die manuelle Treiberinstallationen bei manchen Linux-Distributionen gar nicht möglich ist (LibreELEC, Home Assistant etc.).
Wenn Sie gute Erfahrungen mit einem USB-WLAN-Adapter gemacht haben, hinterlassen Sie bitte einen kurzen Kommentar!
Sobald RaspAP den WLAN-Adapter kennt, bedarf es nur weniger Mausklicks in der RaspAP-Weboberfläche, um diesen Adapter für den Hotspot zu verwenden.
Alternativ können Sie den internen WLAN-Adapter auch ganz deaktivieren. Dazu bauen Sie in config.txt die folgende Zeile ein und starten den Raspberry Pi dann neu.
Danach kennt Raspberry Pi OS nur noch den USB-WLAN-Adapter, eine Verwechslung ist ausgeschlossen.
Vorteile
Der größte Vorteil von RaspAP als Ad-Blocker ist aus meiner Sicht seine Einfachheit: Der Werbeblocker kann mit minimalem Konfigurationsaufwand von jedem Gerät im Haushalt genutzt werden (Opt-In-Modell). Sollte RaspAP für eine Website zu restriktiv sein, dauert es nur wenige Sekunden, um zurück in das normale WLAN zu wechseln. Bei mir zuhause waren alle Familienmitglieder schnell überzeugt.
Nachteile
Der Raspberry Pi muss per Ethernet-Kabel mit dem lokalen Netzwerk verbunden werden.
Manche Seiten sind so schlau, dass sie das Fehlen der Werbung bemerken und dann nicht funktionieren. Es ist prinzipbedingt unmöglich, für solche Seiten eine Ausnahmeregel zu definieren. Sie müssen in das normale WLAN wechseln, damit die Seite funktioniert.
youtube-Werbung kann nicht geblockt werden, weil Google so schlau ist, die Werbefilme vom eigenen Server und nicht von einem anderen Server zuzuspielen. youtube.com selbst zu blocken würde natürlich helfen und außerdem eine Menge Zeit sparen, schießt aber vielleicht doch über das Ziel hinaus.
Mit RaspAP sind Sie in einem eigenen privaten Netz, NICHT im lokalen Netz Ihres Internet-Routers. Sie können daher mit Geräten, die sich im wlan-without-ads befinden, nicht auf andere Geräte zugreifen, die mit Ihrem lokalen Router (FritzBox etc.) verbunden sind. Das betrifft NAS-Geräte, Raspberry Pis mit Home Assistant oder anderen Anwendungen etc.
Keine Werbeeinnahmen mehr für Seitenbetreiber?
Mir ist klar, dass sich viele Seiten zumindest teilweise über Werbung finanzieren. Das wäre aus meiner Sicht voll OK. Aber das Ausmaß ist unerträglich geworden: Mittlerweile blinkt beinahe zwischen jedem Absatz irgendein sinnloses Inserat. Werbefilme vervielfachen das Download-Volumen der Seiten, der Lüfter heult, ich kann mich nicht mehr auf den Text konzentrieren, den ich lese. Es geht einfach nicht mehr.
Viele Seiten bieten mir Pur-Abos an (also Werbeverzicht gegen Bezahlung). Diesbezüglich war https://derstandard.at ein Pionier, und tatsächlich habe ich genau dort schon vor vielen Jahren mein einziges Pur-Abo abgeschlossen. In diesem Fall ist es auch ein Ausdruck meiner Dankbarkeit für gute Berichterstattung. Früher habe ich für die gedruckte Zeitung bezahlt, jetzt eben für die Online-Nutzung.
Mein Budget reicht aber nicht aus, dass ich solche Abos für alle Seiten abschließen kann, die ich gelegentlich besuche: heise.de, golem.de, phoronix, zeit.de, theguardian.com usw. Ganz abgesehen davon, dass das nicht nur teuer wäre, sondern auch administrativ mühsam. Ich verwende diverse Geräte, alle paar Wochen muss ich mich neu anmelden, damit die Seiten wissen, dass ich zahlender Kunde bin. Das ist bei derstandard.at schon mühsam genug. Wenn ich zehn derartige Abos hätte, würde ich alleine an dieser Stelle schon verzweifeln.
Wenn sich Zeitungs- und Online-News-Herausgeber aber zu einem Site-übergreifenden Abrechnungsmodell zusammenschließen könnten (Aufteilung der monatlichen Abo-Gebühr nach Seitenzugriffen), würde ich mir das vielleicht überlegen. Das ist aber sowieso nur ein Wunschtraum.
Aber so, wie es aktuell aussieht, funktioniert nur alles oder nichts. Mit RaspAP kann ich die Werbung nicht für manche Seiten freischalten. Eine Reduktion des Werbeaufkommens auf ein vernünftiges Maß funktioniert auch nicht. Gut, dann schalte ich die Werbung — soweit technisch möglich — eben ganz ab.
Mein Lehrbuch Datenbanksysteme ist gerade in der 2. Auflage erschienen. Es richtet sich an Studierende, Entwickler und Datenbankanwender. Es erklärt, wie moderne Datenbankmanagementsysteme funktionieren. Es zeigt Ihnen, wie Sie Datenbanken korrekt und effizient entwerfen. Es erläutert den Umgang mit der Structured Query Language (SQL) und gibt einen Überblick über die Administration und Programmierung von Datenbanksystemen.
Unzählige Übungsaufgaben (mit Lösungen!) helfen Ihnen, das erlernte Wissen zu verfestigen und anzuwenden. Zusammen mit dem Buch erhalten Sie den Online-Zugriff auf mehrere Beispieldatenbanken, sodass Sie SQL-Kommandos ohne die langwierige Installation eines eigenen Datenbank-Servers ausprobieren können. Alternativ können Sie die zum Download angebotenen Beispieldatenbanken natürlich auch lokal installieren.
In das Buch fließt meine bald 30-jährige Erfahrung im Entwurf von Datenbanken, bei der Entwicklung von Datenbankanwendungen, bei der Administration von Datenbankmanagementsystemen (DBMS) sowie aus dem Unterricht ein. Ein besonderer Fokus des Buchs liegt im korrekten Datenbankdesign. Fehler, die in dieser Phase passieren, sind später praktisch nicht mehr zu korrigieren. Das Buch berücksichtigt auch neue Entwicklungen, von NoSQL bis hin zu modernen SQL-Features (Rekursion, Common Table Expressions, Window-Funktionen etc.).
Für die 2. Auflage habe ich den NoSQL-Teil des Buchs ausgebaut und um ein MongoDB-Kapitel ergänzt. Außerdem habe ich diverse Fehler korrigiert und da und dort kleine Ergänzungen und Verbesserungen vorgenommen.
Wenn Sie auf der Fachhochschule oder Universität eine Datenbank-Vorlesung oder -Übung abhalten: Kontaktieren Sie dozenten@rheinwerk-verlag.de und fordern Sie ein kostenloses Belegexemplar an!
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
Nachdem ich mich vor ein paar Wochen ausführlich mit der Installation von Fedora Asahi Linux auseinandergesetzt habe, geht es jetzt um die praktischen Erfahrungen. Der Artikel ist ein wenig lang geworden und geht primär auf Tools ein, die ich in meinem beruflichen Umfeld oft brauche.
Ich habe mich für die Gnome-Variante von Fedora Asahi Linux entschieden, die grundsätzlich ausgezeichnet funktioniert. Dazu aber gleich eine Einschränkung: Der Asahi-Entwickler Hector Martin ist KDE-Fan; insofern ist die KDE-Variante besser getestet und sollte im Zweifelsfall als Desktop-System vorgezogen werden.
Gnome Systemeinstellungen
Hardware-Unterstützung
Asahi Linux unterstützt aktuell noch keine Macs mit M3-CPUs. Außerdem hapert es noch bei USB-C-Displays (HDMI funktioniert), einigen Thunderbolt-/USB4-Features und der Mikrofon-Unterstützung. (Die Audio-Ausgabe funktioniert, bei den Notebooks anscheinend sogar in sehr hoher Qualität. Aus eigener Erfahrung kann ich da beim Mac Mini nicht mitreden, dessen Lautsprecher ist ja nicht der Rede wert.) Auf die Authentifizierung mit TouchId müssen Sie auch verzichten. Einen guten Überblick über die Hardware-Unterstützung finden Sie am Ende der folgenden Seite:
Ich habe Fedora Asahi Linux nur auf einem Mac Mini M1 getestet (16 GB RAM). Damit habe ich sehr gute Erfahrungen gemacht. Das System ist genauso leise wie unter macOS (sprich: lautlos, auch wenn der Lüfter sich immer minimal dreht). Aber ich kann keine Aussagen zur Akku-Laufzeit machen, weil ich aktuell kein MacBook besitze. Wie gut Linux die Last zwischen Performance- und Efficiency-Cores verteilt, kann ich ebenfalls nicht sagen.
Der Ruhezustand funktioniert, auch das Aufwachen ;-) Dazu muss allerdings kurz die Power-Taste gedrückt werden. Ein Tastendruck oder ein Mausklick reicht nicht.
Tastatur
An meinem Mac Mini ist eine alte Apple-Alu-Tastatur angeschlossen. Grundsätzlich funktioniert sie auf Anhieb. Ein paar kleinere Optimierungen habe ich vor einiger Zeit hier beschrieben.
Konfiguration bei der Linux-Installation
Ich habe ja schon in meinem Blog-Beitrag zur Installation festgehalten: Während der Installation von Fedora gibt es praktisch keine Konfigurationsmöglichkeiten. Insbesondere können Sie weder die Partitionierung noch das Dateisystem beeinflussen (es gibt eine Partition für alles, das darin enthaltene Dateisystem verwendet btrfs ohne Verschlüsselung).
Wenn Sie davon abweichende Vorstellungen haben und technisch versiert sind, können Sie anfänglich nur einen Teil des freien Disk-Speichers für das Root-System von Fedora nutzen und später eine weitere Partition (z.B. für /home) nach eigenen Vorstellungen hinzuzufügen.
Swap-File
Während der Installation wurde auf meinem System die Swap-Datei /var/swap/swapfile in der Größe von 8 GiB eingerichtet (halbe RAM-Größe?). Außerdem verwendet Fedora standardmäßig Swap on ZRAM. Damit kann Fedora gerade ungenutzte Speicherseite in ein im RAM befindliches Device auslagern. Der Clou: Die Speicherseiten werden dabei komprimiert.
Beim meiner Konfiguration (16 GiB RAM, 8 GiB Swap-File, 8 GiB ZRAM-Swap) glaubt das System, dass es über fast 32 GiB Speicherplatz verfügen kann. (Etwas RAM wird für das Grafiksystem abgezwackt.) Ganz geht sich diese Rechnung natürlich nicht aus, weil ja das ZRAM-Swap selbst wieder Arbeitsspeicher kostet. Aber sagen wir 4 GB ZRAM entspricht mit Komprimierung 8 GB Speicherplatz + 11 GB restliches RAM + 8 GB Swapfile: das würde 27 GB Speicherplatz ergeben. Wenn nicht alle Programme zugleich aktiv sind, kann man damit schon arbeiten.
cat /proc/swaps
Filename Type Size Used Priority
/var/swap/swapfile file 8388576 0 -2
/dev/zram0 partition 8388592 0 100
free -m
total used free shared buff/cache available
Mem: 15444 8063 2842 1521 7112 7381
Swap: 16383 0 16383
Weil ich beim Einsatz virtueller Maschinen gescheitert bin (siehe unten), kann ich nicht beurteilen, ob diese Konfiguration mit der Arbeitsspeicherverwaltung von macOS mithalten kann. Die funktioniert nämlich richtig gut. Auch macOS komprimiert Teile des gerade nicht genutzten Speichers und kompensiert so (ein wenig) den unendlichen Apple-Geiz, was die Ausstattung mit RAM betrifft (oder die Geldgier, wenn mehr RAM gewünscht wird).
Gnome Systemüberwachung
Gnome + Fractional Scaling: mühsam wie vor 10 Jahren
Ein altes Problem: Auf meinem 4k-Monitor (27 Zoll) ist der Bildschirminhalt bei einer Skalierung von 100 % arg klein, bei 200 % sinnlos groß. Seit Jahren wird gepredigt, wie toll Gnome + Wayland ist, aber Fractional Scaling funktioniert immer noch nicht standardmäßig?
Dieses Problem lässt sich zum Glück lösen:
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
Aus Gnome ausloggen, neu einloggen. Jetzt können in den Systemeinstellungen 125 % eingestellt, optimal für mich.
Die fraktionelle Skalierung funktioniert für Wayland-Programme gut, sie muss aber umständlich aktiviert werden
Die meisten Programme, die ich üblicherweise verwende, kommen mit 125 % gut zurecht. Wichtigste Ausnahme (für mich): Emacs. Die Textdarstellung ist ziemlich verschwommen. Angeblich gibt es eine Wayland-Version von Emacs (siehe hier), aber ich habe noch nicht versucht, sie zu installieren.
Webbrowser: kein Google Chrome
Als Webbrowser ist standardmäßig Firefox installiert und funktioniert ausgezeichnet. Chromium steht alternativ auch zur Verfügung (dnf install chromium). Ich bin allerdings, was den Webbrowser betrifft, in der Google-Welt zuhause. Ich habe mich vor über 10 Jahren für Google Chrome entschieden. Lesezeichen, Passwörter usw. — alles bei Google. (Bitte die Kommentare nicht für einen Browser-Glaubenskrieg nutzen, ich werde keine entsprechenden Kommentare freischalten.)
Insofern trifft es mich hart, dass es aktuell keine Linux-Version von Google Chrome für arm64 gibt. Ich habe also die Bookmarks + Passwörter nach Firefox importiert. Bookmarks sind easy, Passwörter müssen in Chrome in eine CSV-Datei exportiert und in Firefox wieder importiert werden. Mit etwas Webrecherche auch nicht schwierig, aber definitiv umständlich. Und natürlich ohne Synchronisation. (Für alle Firefox-Fans: Ja, auch Firefox funktioniert großartig, ich habe überhaupt keine Einwände. Wenn ich die Entscheidung heute treffen würde, wäre vielleicht Firefox der Gewinner. Google bekommt auch so genug von meinen Daten …)
Drag&Drop von Nautilus nach Firefox funktionierte bei meinen Tests nicht immer zuverlässig. Ich glaube, dass es sich dabei um ein Wayland-Problem handelt. Ähnliche Schwierigkeiten hatte ich auf meinen »normalen« Linux-Systemen (also x86) mit Google Chrome auch schon, wenn Wayland im Spiel war.
Nextcloud: perfekt
Zum Austausch meiner wichtigsten Dateien zwischen diversen Rechnern verwende ich Nextcloud. Ich habe nextcloud-client-nautilus installiert und eingerichtet, funktioniert wunderbar. Damit im Panel das Nextcloud-Icon angezeigt wird, ist die Gnome-Erweiterung AppIndicator and KStatusNotifierItem Support erforderlich.
Spotify + Firefox: gescheitert
Ich höre beim Arbeiten gerne Musik. Die Spotify-App gibt es nicht für arm64. Kein Problem, ich habe mich schon lange daran gewöhnt, Spotify im Webbrowser auszuführen. Aber Spotify hält nichts von Firefox: Wiedergabe von geschützten Inhalten ist nicht aktiviert.
Spotify und Firefox vertragen sich nicht
Das Problem ist bekannt und gilt eigentlich als gelöst. Es muss das Widevine-Plugin installiert werden. Asahi greift dabei auf ein Paket der ChromeBooks zurück. Es kann mit widevine-installer installiert werden. (widevine-installer befindet sich im gleichnamigen Paket und ist standardmäßig installiert.) Gesagt, getan:
sudo widevine-installer
This script will download, adapt, and install a copy of the Widevine
Content Decryption Module for aarch64 systems.
Widevine is a proprietary DRM technology developed by Google.
This script uses ARM64 builds intended for ChromeOS images and is
not supported nor endorsed by Google. The Asahi Linux community
also cannot provide direct support for using this proprietary
software, nor any guarantees about its security, quality,
functionality, nor privacy. You assume all responsibility for
usage of this script and of the installed CDM.
This installer will only adapt the binary file format of the CDM
for interoperability purposes, to make it function on vanilla
ARM64 systems (instead of just ChromeOS). The CDM software
itself will not be modified in any way.
Widevine version to be installed: 4.10.2662.3
...
Installing...
Setting up plugin for Firefox and Chromium-based browsers...
Cleaning up...
Installation complete!
Please restart your browser for the changes to take effect.
Nach einem Firefox-Neustart ändert sich: nichts. Ein weiterer Blick in discussion.fedoraproject.org verrät: Es muss auch der User Agent geändert werden, d.h. Firefox muss als Betriebssystem ChromeOS angeben:
Es gibt zwei Möglichkeiten, den User Agent zu ändern. Die eine besteht darin, die Seite about:config zu öffnen, die Option general.useragent.override zu suchen und zu ändern. Das gilt dann aber für alle Webseiten, was mich nicht wirklich glücklich macht.
Die Alternative besteht darin, ein UserAgent-Plugin zu installieren. Ich habe mich für den User-Agent Switcher and Manager entschieden.
Langer Rede kurzer Sinn: Mit beiden Varianten ist es mir nicht gelungen, Spotify zur Zusammenarbeit zu überreden. An dieser Stelle habe ich nach rund einer Stunde Frickelei aufgegeben. Es gibt im Internet Berichte, wonach es funktionieren müsste. Vermutlich bin ich einfach zu blöd.
Spotify + Chromium: geht
Da wollte ich Firefox eine zweite Chance geben … Stattdessen Chromium installiert, damit funktioniert Spotify (widevine-installer vorausgesetzt) auf Anhieb. Sei’s drum.
Chromium läuft übrigens standardmäßig als X-Programm (nicht Wayland), aber nachdem ich den Browser aktuell nur als Spotify-Player benutze, habe ich mir nicht die Mühe gemacht, das zu ändern.
Wie Emacs und Chromium läuft auch Code vorerst als X-Programm. Entsprechend unscharf ist die Schrift bei 125% Scaling. Das ArchWiki verrät, dass beim Programmstart die Option --ozone-platform-hint=auto übergeben werden muss. Das funktioniert tatsächlich: Plötzlich gestochen scharfe Schrift auch in Code.
Ich habe mir eine Kopie von code.desktop erstellt und die gerade erwähnte Option in die Exec-Zeile eingebaut. Bingo!
qemu/libvirt/virt-manager: keine Grafik, keine Maus, keine Tastatur, kein Glück
Meine Arbeit spielt sich viel in virtuellen Maschinen und Containern ab. QEMU und die libvirt-Bibliotheken sind standardmäßig installiert, die grafische VM-Verwaltung gibt es mit dnf install virt-manager dazu.
Als nächstes habe ich mir ein Daily-ISO-Image für Arm64 von Ubuntu 24.04 heruntergeladen und versucht, es in einer virtuellen Maschine zu installieren. Kurz nach dem Start stürzt der virt-manager ab. Die virtuelle Maschine läuft weiter, allerdings nur im Textmodus. Später bleibt die die Installation in einer snap-Endlosschleife hängen. Nun gut, es ist eine Entwicklerversion, die noch nicht einmal offiziellen Beta-Status hat.
Eine gescheiterte Installation von Ubuntu 24.04 daily
Nächster Versuch mit 23.10. Allerdings gibt es auf cdimage.ubuntu.com kein Desktop-Image für arm64!? Gut, ich nehme das Server-Image und baue dieses nach einer Minimalinstallation mit apt install ubuntu-desktop in ein Desktop-System um. Allerdings stellt sich heraus, dass aptsehr lange braucht (Größenordnung: eine Stunde, bei nur sporadischer CPU-Belastung; ich weiß nicht, was da schief läuft). Die Textkonsole im Viewer von virt-manager ist zudem ziemlich unbrauchbar. Installation fertig, Neustart der virtuellen Maschine. Es gelingt nicht, den Grafikmodus zu aktivieren.
Dritter Versuch, Debian 12 für arm64. Obwohl ich mich für eine Installation im Grafikmodus entscheide, erscheinen die Setup-Dialoge in einem recht trostlosen Textmodus (so, als würde die Konsole keine Farben unterstützen).
Super-minimalistischer Textmodus in der VM
Schön langsam dämmert mir, dass mit dem Grafiksystem etwas nicht stimmt. Tatsächlich hat keine der virtuellen Maschinen ein Grafiksystem! (virt-manager unter x86 richtet das Grafiksystem automatisch ein, und es funktioniert — aber offenbar ist das unter arm64 anders.) Ich füge also das Grafiksystem manuell hinzu, aber wieder treten diverse Probleme auf: der VGA-Modus funktioniert nicht, beim Start der VM gibt es die Fehlermeldung failed to find romfile vgabios-stdvga.bin. QXL lässt sich nicht aktivieren: domain configuration does not support video model qxl. RAMfb führt zu einem EFI-Fehler während des Startups. Zuletzt habe ich mit virtio Glück. Allerdings funktioniert jetzt die Textkonsole nicht mehr, der Bootvorgang erfolgt im Blindflug.
Der Grafikmodus erscheint, aber die Maus bewegt sich nicht. Klar, weil der virt-manager auch das Mauseingabe-Modul nicht aktiviert hat. Ich füge auch diese Hardware-Komponente hinzu. Tatsächlich lässt sich der Mauscursor nach dem nächsten Neustart nutzen — aber die Tastatur geht nicht. Ja, die fehlt auch. Wieder ‚Gerät hinzufügen‘, ‚Eingabe/USB-Tastatur‘ führt zum Ziel. Vorübergehend habe ich jetzt ein Erfolgserlebnis, für ein paar Minuten kann ich Ubuntu 23.10 tatsächlich im Grafikmodus verwenden. Ich kann sogar eine angemessene Auflösung einstellen. Aber beim nächsten Neustart bleibt der Monitor schwarz: Display output is not active.
An dieser Stelle habe ich aufgegeben. Die nächste Auflage meines Linux-Buchs (die steht zum Glück erst 2025 an) könnte ich in dieser Umgebung nicht schreiben. Dazu brauche ich definitiv eine Linux-Installation auf x86-Hardware.
Docker, pardon, Podman: voll OK
Red Hat und Fedora meiden Docker wie der Teufel das Weihwasser. Dafür ist die Eigenentwicklung Podman standardmäßig installiert (Version 4.9). Das Programm ist weitestgehend kompatibel zu Docker und in der Regel ein guter Ersatz.
Ich setze in Docker normalerweise stark auf docker compose. Dieses Subkommando ist in Podman noch nicht integriert. Abhilfe schafft das (einigermaßen kompatible) Python-Script podman-compose, das mit dnf installiert wird und aktuell in Version 1.0.6 vorliegt.
Mein Versuch, mit Podman mein aus LaTeX und Pandoc bestehendes Build-System für meine Bücher zusammenzubauen, gelang damit überraschend problemlos. In compose.yaml musste ich die Services mit privileged: true kennzeichnen, um diversen Permission-denied-Fehlern aus dem Weg zu gehen. Auf jeden Fall sind hier keine unlösbaren Hürden aufgetreten.
Fazit
Soweit Asahi Linux mit Ihrem Mac kompatibel ist und Sie keine Features nutzen möchten, die noch nicht unterstützt werden (aus meiner Sicht am schmerzhaftesten: USB-C-Monitor, Mikrofon), funktioniert es großartig. Einerseits die Apple-Kombination aus hoher Performance und Stille, andererseits Linux mit all seinen Konfigurationsmöglichkeiten. Was will man mehr?
Leider sind die arm64-Plattform (genaugenommen aarch64) und Wayland noch immer nicht restlos Linux-Mainstream. Alle hier beschriebenen Ärgernisse hatten irgendwie damit zu tun — und nicht mit Asahi Linux! Der größte Stolperstein für mich: Mit virt-manager lässt sich nicht vernünftig arbeiten. Mag sein, dass sich diese Probleme umgehen lassen (Gnome Boxes?; Cockpit), aber ich befürchte, dass die Probleme tiefer gehen.
Eine gewisse Ironie an der Geschichte besteht darin, dass ich gerade am Raspberry-Pi-Buch arbeite: Raspberry Pi OS ist mittlerweile ebenfalls für die arm64-Architektur optimiert, es verwendet ebenfalls Wayland. Aber Fractional Scaling ist für den PIXEL Desktop sowieso nicht vorgesehen, damit entfallen alle damit verbundenen Probleme. So fällt es nicht auf, dass diverse Programme via XWayland laufen. Und um die arm64-Optimierungen hat sich die Raspberry Pi Foundation in den letzten Monaten gekümmert — zumindest, soweit es für den Raspberry Pi relevante Programme betrifft. Ich arbeite also momentan sowie schon in einer arm64-Welt, und es funktioniert verblüffend gut!
Wenn es also außer dem Raspberry Pi und den MacBooks noch ein paar »normale« Notebooks mit arm64-CPUs gäbe, würde das sowohl dem Markt als auch der Stabilität von Linux auf dieser Plattform gut tun.
Bleibt noch die Frage, ob Asahi Linux besser als macOS ist. Schwer zu sagen. Für hart-gesottene Linux-Fans sicher. Für meine alltägliche Arbeit ist der größte Linux-Pluspunkt absurderweise ein ganz winziges Detail: Ich verwende ununterbrochen die Linux-Funktion, dass ich Text mit der Maus markieren und dann sofort mit der mittleren Maustaste wieder einfügen kann. macOS kann das nicht. Für macOS spricht hingegen die naturgemäß bessere Unterstützung der Apple-Hardware.
Losgelöst davon funktionieren fast alle gängigen Open-Source-Tools auch unter macOS. Über den Desktop von macOS kann man denken, wie man will; ich kann damit leben. Hundertprozentig glücklich machen mich auch Gnome oder KDE nicht. In jedem Fall ist es unter macOS wie unter Linux mit etwas Arbeit verbunden, den Desktop so zu gestalten, wie ich ihn haben will.
PS: Ein persönliches Nachwort
Seit zwei Monaten verwende ich versuchsweise macOS auf einem Mac Mini (wie beschrieben, M1-CPU + 16 GB RAM) als Hauptdesktop. Ich schreibe/überarbeite dort meine Bücher, bereite den Unterricht vor, administriere Linux-Server, entwickle Code. Virtuelle Maschinen laufen mit UTM. Docker funktioniert gut, allerdings stört, dass der Speicher für Docker fix alloziert wird. (Docker unterstützt sogar Rosetta. Ich habe eine Docker-Umgebung, die ein x86-Binary enthält, zu dem es kein arm64-Äquivalent gibt. Und es läuft einfach, es ist schwer zu glauben …)
Ich verwende Chrome als Webbrowser, Thunderbird als E-Mail-Programm, LibreOffice für Office-Aufgaben, Gimp als Bitmap-Editor, draw.io als Zeichenprogramm, Emacs + Code als Editoren, Skim als PDF-Viewer. Im Terminal sind diverse SSH-Sessions aktiv, so dass ich den Raspberry Pi, meine Linux-Server usw. administrieren kann. Zusatzsoftware installiere ich mit brew so unkompliziert wie mit dnf oder apt. Im Prinzip bin ich auf keine unüberwindbaren Hindernisse gestoßen, um meine alltägliche Arbeit auszuführen.
Es gibt nur ganz wenige originale macOS-Programme, die ich regelmäßig ausführe: das Terminal, Preview + Fotos. Außerdem finde ich es praktisch, dass ich M$ Office nativ verwenden kann. Ich hasse Word zwar abgrundtief, muss aber beruflich doch hin und wieder damit arbeiten. Das habe ich bisher auf einem Windows-Rechner erledigt.
Letzten Endes ist der Grund für dieses Experiment banal: Mich nervt der Lüfter meines Linux-Notebooks (ein fünf Jahre alter Lenovo P1) immer mehr. Wenn ich die meiste Zeit Ruhe haben will, muss ich den Turbo-Modus der CPU deaktivieren. Ist es für Intel/AMD wirklich unmöglich, eine CPU zu bauen, die so energieeffizient ist wie die CPUs von Apple? Kann keiner der Mainstream-Notebook-Hersteller (Lenovo, Dell etc.) ein Notebook bauen, das ganz gezielt für den leisen Betrieb gedacht ist, OHNE die Performance gleich komplett auf 0 zu reduzieren?
Im Unterschied zum Lenovo P1 läuft mein Mac komplett lautlos und ist gleichzeitig um ein Mehrfaches schneller. Es ist nicht auszuschließen, dass mein nächstes Notebook keine CPU von Intel oder AMD haben wird, sondern eine M3- oder M4-CPU von Apple. Die Option, auf diesem zukünftigen MacBook evt. auch Linux ausführen zu können, ist ein Pluspunkt und der Grund, weswegen ich mich so intensiv mit Asahi Linux auseinandersetze.
Ich habe es nicht ausprobiert, aber Sie können auch Ubuntu auf M1/M2-Macs installieren. Canonical überlegt anscheinend sogar, das irgendwann offiziell zu unterstützen.
Der neue Raspberry Pi 5 verfügt erstmals über eine PCIe-Schnittstelle. Leider hat man sich bei der Raspberry Pi Foundation nicht dazu aufraffen können, gleich auch einen Slot für eine PCIe-SSD vorzusehen. Gut möglich, dass es auch einfach an Platzgründen gescheitert ist. Oder wird dieser Slot das Kaufargument für den Raspberry Pi 6 sein? Egal.
Mittlerweile gibt es diverse Aufsteckplatinen für den Raspberry Pi, die den Anschluss einer PCIe-SSD ermöglichen. Sie unterscheiden sich darin, ob sie über oder unter der Hauptplatine des Raspberry Pis montiert werden, ob sie kompatibel zum Lüfter sind und in welchen Größen sie SSDs aufnehmen können. (Kleinere Aufsteckplatinen sind mit den langen 2280-er SSDs überfordert.)
Für diesen Artikel habe ich die NVMe Base der britischen Firma Pimoroni ausprobiert (Link). Inklusive Versand kostet das Teil ca. 24 €, der Zoll kommt gegebenenfalls hinzu. Die Platine wird mit einem winzigen Kabel und einer Menge Schrauben geliefert.
Die PCIe-Platine von Pimoroni mit einem Kabel und diversen Schrauben
Der Zusammenbau ist fummelig, aber nicht besonders schwierig. Auf YouTube gibt es eine ausgezeichnete Anleitung. Achten Sie darauf, dass Sie wirklich eine PCIe-SSD verwenden und nicht eine alte M2-SATA-SSD, die Sie vielleicht noch im Keller liegen haben!
Raspberry Pi 5 + Pimoroni PCIe-Platine mit SSD
Nachdem Sie alles zusammengeschraubt haben, starten Sie Ihren Raspberry Pi neu (immer noch von der SD-Karte). Vergewissern Sie sich mit lsblk im Terminal, dass die SSD erkannt wurde! Entscheidend ist, dass die Ausgabe eine oder mehrere Zeilen mit dem Devicenamen nmve0n1* enthält.
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
mmcblk0 179:0 0 29,7G 0 disk
├─mmcblk0p1 179:1 0 512M 0 part /boot/firmware
└─mmcblk0p2 179:2 0 29,2G 0 part
nvme0n1 259:0 0 476,9G 0 disk
Nach der Sandwich-Montage
Raspberry-Pi-OS klonen und von der SSD booten
Jetzt müssen Sie Ihre Raspberry-Pi-OS-Installation von der SD-Karte auf die SSD übertragen. Dazu starten Sie das Programm Zubehör/SD Card Copier, wählen als Datenquelle die SD-Karte und als Ziel die SSD aus.
Inhalt der SD-Karte auf die SSD übertragen
SD Card Copier kopiert das Dateisystem im laufenden Betrieb, was ein wenig heikel ist und im ungünstigen Fall zu Fehlern führen kann. Der Prozess dauert ein paar Minuten. Während dieser Zeit sollten Sie auf dem Raspberry Pi nicht arbeiten! Das Kopier-Tool passt die Größe der Partitionen und Dateisysteme automatisch an die Größe der SSD an.
Als letzten Schritt müssen Sie nun noch den Boot-Modus ändern, damit Ihr Raspberry Pi in Zukunft die SSD als Bootmedium verwendet, nicht mehr die SD-Karte. Dazu führen Sie im Terminal sudo raspi-config aus und wählen Advanced Options -> Boot Order -> NVMe/USB Boot.
Mit »raspi-config« stellen Sie den Boot-Modus um
Selbst wenn alles klappt, verläuft der nächste Boot-Vorgang enttäuschend. Der Raspberry Pi lässt sich mit der Erkennung der SSD so viel Zeit, dass die Zeit bis zum Erscheinen des Desktops sich nicht verkürzt, sondern im Gegenteil ein paar Sekunden verlängert (bei meinen Tests ca. 26 Sekunden, mit SD-Karte nur 20 Sekunden). Falls Sie sich unsicher sind, ob die SSD überhaupt verwendet wird, führen Sie noch einmal lsblk aus. Der Mountpoint / muss jetzt bei einem nvme-Device stehen:
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme0n1 259:0 0 476,9G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/firmware
└─nvme0n1p2 259:2 0 476,4G 0 part /
Wie viel die SSD an Geschwindigkeit bringt, merken Sie am ehesten beim Start großer Programme (Firefox, Chromium, Gimp, Mathematica usw.), der jetzt spürbar schneller erfolgt. Auch größere Update (sudo apt full-upgrade) gehen viel schneller vonstatten.
Benchmark-Tests
Ist die höhere Geschwindigkeit nur Einbildung, oder läuft der Raspberry Pi wirklich schneller? Diese Frage beantworten I/O-Benchmarktests. (I/O steht für Input/Output und bezeichnet den Transfer von Daten zu/von einem Datenträger.)
Ich habe den Pi Benchmark verwendet. Werfen Sie immer einen Blick in heruntergeladene Scripts, bevor Sie sie mit sudo ausführen!
wget https://raw.githubusercontent.com/TheRemote/ \
PiBenchmarks/master/Storage.sh
less Storage.sh
sudo bash Storage.sh
SSD-Benchmarktest
Ich habe den Test viermal ausgeführt:
Mit einer gewöhnlichen SD-Karte.
Mit einer SATA-SSD (Samsung 840) via USB3.
Mit einer PCIe-SSD (Hynix 512 GB PCIe Gen 3 HFS512GD9TNG-62A0A)
Mit einer PCIe-SSD (wie oben) plus PCIe Gen 3 (Details folgen gleich).
Die Unterschiede sind wirklich dramatisch:
Modell Pi 5 + SD Pi 5 + USB Pi 5 + PCIe Pi 5 + PCIe 3
----------------- ----------- ------------- ------------- ---------------
Disk Read 73 MB/s 184 MB/s 348 MB/s 378 MB/s
Cached Disk Read 85 MB/s 186 MB/s 358 MB/s 556 MB/s
Disk Write 14 MB/s 121 MB/s 146 MB/s 135 MB/s
4k random read 3550 IOPS 32926 IOPS 96.150 IOPS 173.559 IOPS
4k random write 918 IOPS 27270 IOPS 81.920 IOPS 83.934 IOPS
4k read 15112 KB/s 28559 KB/s 175.220 KB/s 227.388 KB/s
4k write 4070 KB/s 28032 KB/s 140.384 KB/s 172.500 KB/s
4k random read 13213 KB/s 17153 KB/s 50.767 KB/s 54.682 KB/s
4k random write 2862 KB/s 27507 KB/s 160.041 KB/s 203.630 KB/s
Score 1385 9285 34.723 43.266
Beachten Sie aber, dass das synthetische Tests sind! Im realen Betrieb fühlt sich Ihr Raspberry Pi natürlich schneller an, aber keineswegs in dem Ausmaß, den die obigen Tests vermuten lassen.
PCIe Gen 3
Standardmäßig verwendet der Raspberry Pi PCI Gen 2. Mit dem Einbau von zwei Zeilen Code in /boot/firmware/config.txt können Sie den erheblich schnelleren Modus PCI Gen 3 aktivieren. (Der Tipp stammt vom PCIe-Experten Jeff Geerling.)
# in /boot/firmware/config.txt
dtparam=pciex1
dtparam=pciex1_gen=3
Die obigen Benchmarktests beweisen, dass die Einstellung tatsächlich einiges an Zusatz-Performance bringt. Ehrlicherweise muss ich sagen, dass Sie davon im normalen Betrieb aber wenig spüren.
Bleibt noch die Frage, ob die Einstellung gefährlich ist. Die Raspberry Pi Foundation muss ja einen Grund gehabt haben, warum sie PCI Gen 3 nicht standardmäßig aktiviert hat. Zumindest bei meinen Tests sind keine Probleme aufgetreten. Auch dmesg hat keine beunruhigenden Kernel-Messages geliefert.
Fazit
Es ist natürlich cool, den Raspberry Pi mit einer schnellen SSD zu verwenden. Für Bastelprojekte ist dies nicht notwendig, aber wenn Sie vor haben, Ihren Pi als Server, NAS etc. einzusetzen, beschleunigt die SSD I/O-Vorgänge enorm.
Schön wäre, wenn der Raspberry Pi in Zukunft einen PCIe-Slot erhält, um (zumindest kurze) SSDs ohne Zusatzplatine zu nutzen. Bis dahin sind die Erweiterungsplatinen eine Übergangslösung.
In der Community ist zuletzt die Frage aufgetaucht, ob der Raspberry Pi überhaupt noch preiswert ist. Diese Frage ist nicht unberechtigt: Die Kosten für einen neuen Pi 5 + Netzteil + Lüfter + SSD-Platine + SSD + Gehäuse gehen in Richtung 150 €. Sofern Sie ein Gehäuse finden, in dem der Pi samt SSD-Platine Platz findet … Um dieses Geld bekommen Sie auch schon komplette Mini-PCs (z.B. die Chuwi Larkbox X). Je nach Anwendung muss man fairerweise zugeben, dass ein derartiger Mini-PC tatsächlich ein besserer Deal ist.