Mozilla hat Firefox 150.0.2 veröffentlicht und behebt damit mehrere Probleme der Vorgängerversion. Außerdem wurden zahlreiche Sicherheitslücken geschlossen.
Unser Buch Coding mit KI ist gerade erschienen, da taucht schon wieder ein neues Tool auf, das mehr Effizienz verspricht. Graphify erstellt einen sogenannten Knowledge Graph, also eine interne Datenbank über die Verknüpfungen zwischen Komponenten (Text, Code, Bilder, was auch immer) eines Projekts. In der Folge können KI-Tools wie Claude Code auf diese Datenbank zugreifen und sich damit rascher und vor allem Token-sparender im Projekt orientieren. Graphify funktioniert besonders gut für ungeordnete Verzeichnisse, in denen Sie PDFs, Screenshots etc. zu einem Thema ablegen, um diese Informationen später wieder zu nutzen.
Installation
Graphify ist ein Python-Programm (Open Source, MIT-Lizenz), das Sie am besten mit uv tool install auf Ihrem Rechner einrichten. (uv ist ein moderner Python-Modulmanager, über den ich demnächst hier schreiben will.) Beachten Sie, dass der Paketname graphifyy mit Doppel-Y lautet, während das Kommando graphify heißt.
uv tool install graphifyy installiert das Programm. Sofern PATH das Verzeichnis .local/bin enthält, kann graphify anschließend sofort gestartet werden. graphify install richtet Skill-Dateien für die auf Ihrem Rechner gefundenen KI-Tools (in meinem Fall: Claude) ein.
$ uv tool install graphifyy
$ graphify install
skill installed -> /Users/kofler/.claude/skills/graphify/SKILL.md
CLAUDE.md -> created at /Users/kofler/.claude/CLAUDE.md
Done. Open your AI coding assistant and type:
/graphify .
Verwendung
Im Projektverzeichnis starten Sie nun das KI-Tool Ihrer Wahl (in meinem Fall: Claude Code). Dort steht Graphify jetzt als Skill zur Verfügung. Einfach
/graphify .
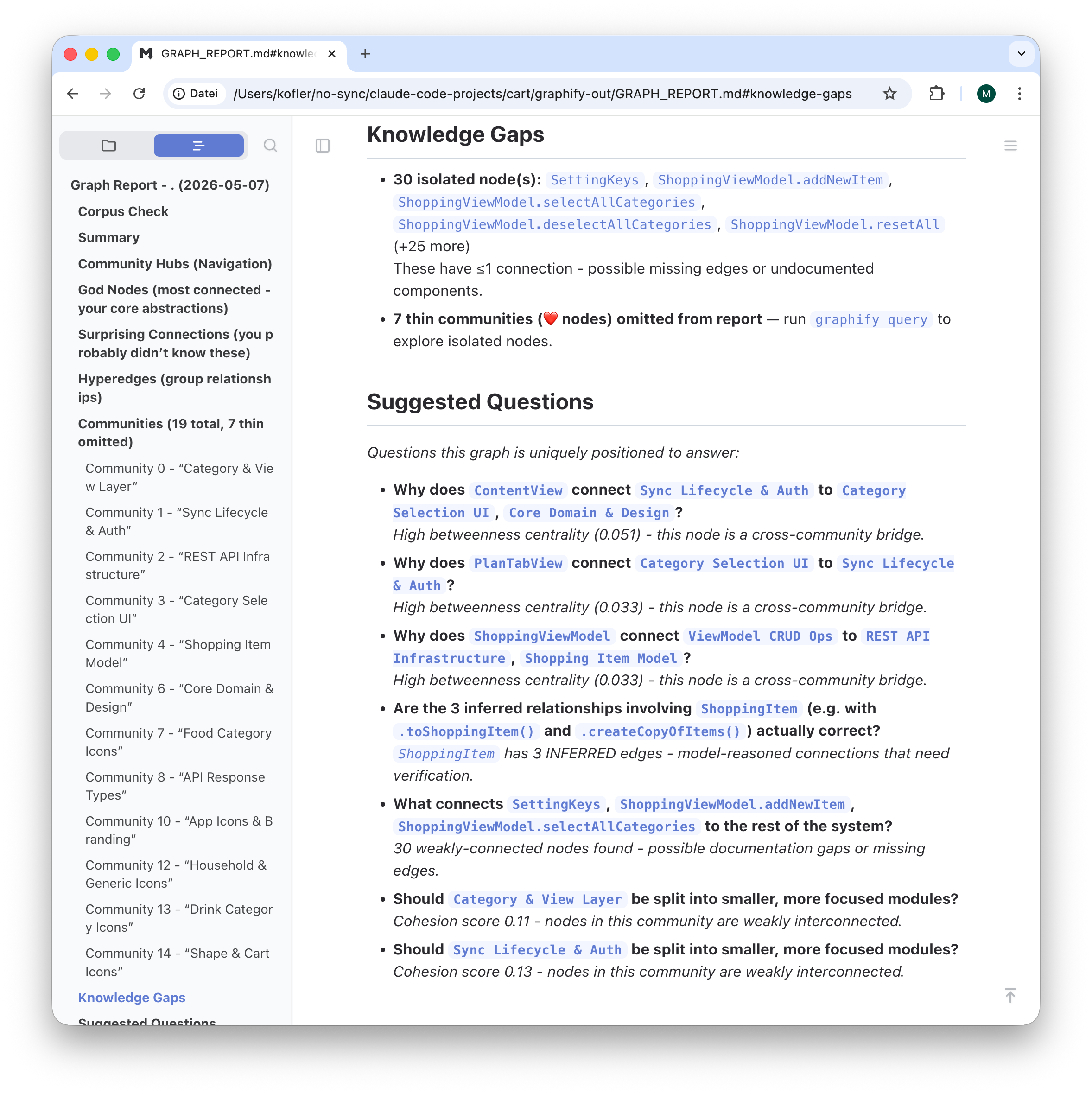
analysiert das Projektverzeichnis und erstellt nach vielen Rückfragen das Verzeichnis graphify_out. Das dauert geraume Zeit und verbrennt etliche Tokens. Das Verzeichnis enthält die folgenden Dateien:
ls -l graphify-out/
drwxr-xr-x 4 kofler staff 128 7 Mai 09:54 cache/
-rw-r--r-- 1 kofler staff 213 7 Mai 10:10 cost.json
-rw-r--r-- 1 kofler staff 8523 7 Mai 10:10 GRAPH_REPORT.md
-rw-r--r-- 1 kofler staff 139973 7 Mai 10:10 graph.html
-rw-r--r-- 1 kofler staff 137091 7 Mai 10:09 graph.json
-rw-r--r-- 1 kofler staff 7912 7 Mai 10:10 manifest.json
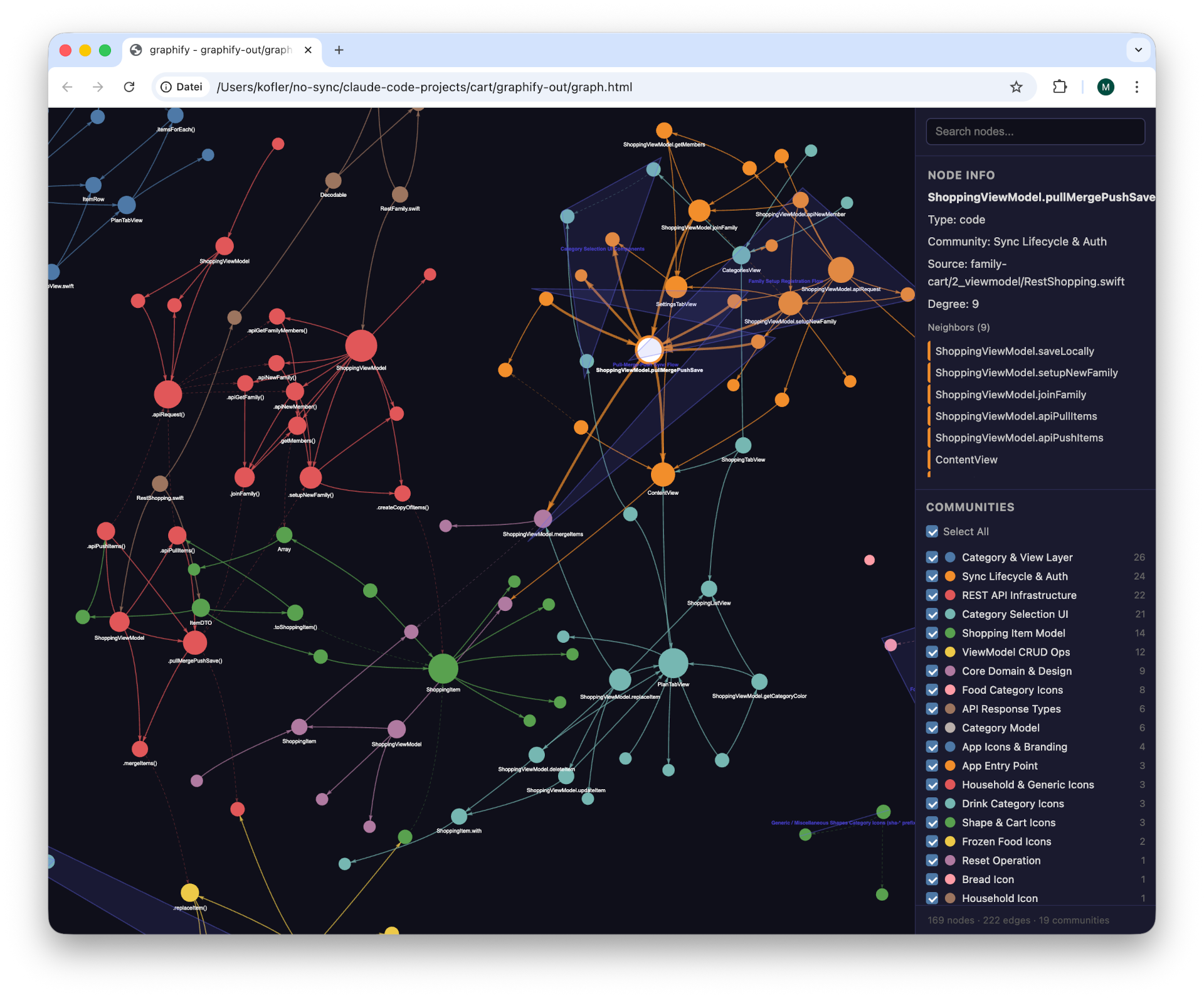
Ich habe meine Tests anhand einer Swift-App mit ca. 2000 Zeilen Code in diversen Dateien durchgeführt. Die Ergebnisse sehen eindrucksvoll aus, der unmittelbare Erkenntnisgewinn war aber — zumindest bei diesem Projekt — überschaubar.
Der anklickbare »Knowledge Graph«Kurzfassung der Projektzusammenhänge im Markdown-Format
Wenn Sie Änderungen in der Code-Basis oder in Ihren Dateien durchführen, aktualisieren Sie den Knowledge Graph:
/graphify . --update # merge changed content into existing graph
Der Knowledge Graph kann jetzt die Grundlage für Analysen mit /graphify explain oder graphiy query sein (Ausgabe etwas gekürzt):
/graphify explain "the sync process"
Here's what the graph tells us about the sync process, grounded in the
extracted edges:
The sync process is orchestrated by ShoppingViewModel.pullMergePushSave
(RestShopping.swift:125-175), which implements the Pull-Merge-Push lifecycle
documented in CLAUDE.md. The graph found 16 nodes directly connected to this
concept.
The three phases (all EXTRACTED edges):
1. Pull — apiPullItems (RestShopping.swift:62-93) fetches items from the
remote REST API since the last sync timestamp.
2. Merge — mergeItems (RestShopping.swift:178-193) resolves conflicts using
Timestamp-Wins: whichever version of an item has the newer updatedAt
wins. Two design rationale nodes connect here:
- Timestamp-Wins Conflict Resolution → mergeItems [EXTRACTED]
- Soft Delete Pattern → ShoppingItem [EXTRACTED] — items are never truly
removed; isDeleted = true propagates deletions to other devices through
the sync
3. Push — apiPushItems (RestShopping.swift:96-120) uploads the merged state
back to the server.
4. Persist — saveLocally (ViewModel.swift:172-178) writes the final state to
the local JSON file. mergeItems then calls replaceItem to update the
ViewModel's live state.
Wire format bridge: ItemDTO (RestShopping.swift:9-53) shares data with
ShoppingItem [EXTRACTED] — it translates between the app's model and the
API's integer-boolean/ISO 8601 wire format.
Trigger points: ContentView and StatusView both connect to pullMergePushSave
in the graph. ContentView runs it via .task, .onChange(scenePhase), and a
40-second timer. StatusView (in Settings) provides a manual
trigger. setupNewFamily and joinFamily also call pullMergePushSave as a final
step after family registration.
The most interesting angle here: the Soft Delete pattern is the load-bearing
coupling between ShoppingItem (the model) and the sync logic — if you ever
changed ShoppingItem to hard-delete, mergeItems would silently stop
propagating deletions. Want me to trace the path from ShoppingItem.isDeleted
through to what happens when a remote device pulls?
/graphify query "Where in code is the Category class used?
Could we drop the @Observable attribute?"
Here's what the graph found — and where its limits are:
Where Category is used (from the graph):
The BFS found 10 nodes. The confirmed connections [EXTRACTED]:
- Category → shares_data_with → ShoppingViewModel (ViewModel.swift:1-181) —
the ViewModel holds the categories: [Category] array
- Category.predefinedCategories (Category.swift:24-37) ↔ ShoppingViewModel —
the ViewModel calls this at init to populate its categories
- .predefinedCategories() → calls → Color — each category has a color
assigned
What the graph is missing: There are no direct edges from Category to the
view layer (CategoriesView, CategoryButton, EditItemView,
CategoryRadioButton). Those views access categories through vm.categories and
mutate category.isSelected/category.isExpanded directly — but the graph
didn't capture these view→Category property access edges since they go
through the ViewModel and aren't explicit call-site imports.
On dropping @Observable:
The graph can't answer this definitively — it would require the actual
property mutation sites. But from the CLAUDE.md rationale node captured in
the graph: "Mutable reference-type state (isSelected, isExpanded) is mutated
directly from views." That design decision is precisely why @Observable is
needed. Without it, those direct mutations on the reference type wouldn't
trigger SwiftUI view updates — CategoriesView and EditItemView would stop
reacting to category selection changes.
Verdict from the graph: @Observable cannot be safely dropped without a larger
refactor (e.g., moving isSelected/isExpanded into the ViewModel as @State or
@Published backing). The graph confirms the coupling exists; reading
Category.swift:4-112 directly would show exactly which properties are var vs
let.
Die Website preist den größten Vorteil von Graphify an, dass derartige Abfragen auf der Basis des lokalen Knowledge Graphs nun wesentlich weniger Token verbrauchen als wenn das KI-Tool mit find und grep die Codebasis durchsucht und (immer wieder neu) analysiert. Bei meinen Tests ließ sich das Ausmaß der Ersparnis schwer messen. Die Grundidee ist aber gut, die Implementierung sieht sehr vielversprechend aus.
Heute Abend klären wieder Hauke und Jean Deine Fragen live!
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
--------------------
Links:
Frage stellen: https://ask.linuxguides.de
Forum: https://forum.linuxguides.de/
Haukes Webseite: https://goos-habermann.de/index.php
Nicht der Weisheit letzter Schluß: youtube.com/@nichtderweisheit
Linux Guides Admin: https://www.youtube.com/@LinuxGuidesAdmin
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Ubuntu Kurs für Anwender*: https://www.linuxguides.de/ubuntu-kurs-fuer-anwender/
Linux für Fortgeschrittene*: https://www.linuxguides.de/linux-kurs-fuer-fortgeschrittene/
Offizielle Webseite: https://www.linuxguides.de
Tux Tage: https://www.tux-tage.de/
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Twitter: https://twitter.com/LinuxGuides
Mastodon: https://mastodon.social/@LinuxGuides
Matrix: https://matrix.to/#/+linuxguides:matrix.org
Discord: https://www.linuxguides.de/discord/
Kontakt: https://www.linuxguides.de/kontakt/
BTC-Spende: 1Lg22tnM7j56cGEKB5AczR4V89sbSXqzwN
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Mit SkySend kannst du Dateien, Notizen, Passwörter, Code und SSH-Keys mit anderen per Link teilen. Deine Daten sind dabei Ende-zu-Ende verschlüsselt und nur für dich und dem Empfänger sichtbar.
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere in unserem Chat mit.
FitTrackee ermöglicht das Hochladen von Tracks aus Outdoor-Aktivitäten und die Anzeige von Statistiken. Workouts können gefiltert und auf einer Karte dargestellt werden.
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere in unserem Chat mit.
Der Enterprise Policy Generator richtet sich an Administratoren von Unternehmen und Organisationen, welche Firefox konfigurieren wollen. Mit dem Enterprise Policy Generator 8.1 wurde nun ein Update veröffentlicht, welches den Fokus auf Fehlerbehebungen und Stabilität legt.
Der Enterprise Policy Generator hilft bei der Erstellung der Datei „policies.json” für die Konfiguration von Firefox. Der Vorteil dieser Konfigurationsdatei gegenüber Group Policy Objects (GPO) ist, dass diese Methode nicht nur auf Windows, sondern plattformübergreifend auf Windows, Apple macOS sowie Linux funktioniert. Dank dieser Erweiterung ist kein tiefergehendes Studium der Dokumentation und aller möglichen Optionen notwendig und Administratoren können sich die gewünschten Richtlinien einfach zusammenklicken.
Neuerungen vom Enterprise Policy Generator 8.1
Mit dem Enterprise Policy Generator 8.0 wurde vor einem Monat das größte Update seit Bestehen der Erweiterung veröffentlicht, in welchem über sechs Monate Entwicklung steckten. Der nun veröffentlichte Enterprise Policy Generator 8.1 behebt sowohl Fehler, die sich im Rahmen der Neuentwicklung eingeschlichen haben, als auch schon länger existierende Sonderfälle, was die Stabilität und Zuverlässigkeit der Erweiterung weiter verbessert.
Fehlerkorrekturen im Enterprise Policy Generator 8.1
Das Importieren von Konfigurationen, welche mit dem Enterprise Policy Generator 8.0 exportiert worden sind, wurde nicht korrekt durchgeführt und verhinderte ein Laden der entsprechenden Konfigurationen.
Der Export von Konfigurationen konnte fehlschlagen, wenn zum Beispiel Emojis in Feldern verwendet worden sind.
Der Wert der Option updates_disabled in der ExtensionSettings-Richtlinie war vertauscht.
Es war nicht möglich, den Wert der OverrideFirstRunPage-Richtlinie sowie der OverridePostUpdatePage-Richtlinie auf einen leeren String zu setzen.
Das Drag and Drop-Verhalten sowie die JSON-Generierung für Lesezeichen-Ordner in der ManagedBookmarks-Richtlinie wurde korrigiert.
Wenn es in der 3rdParty-Richtlinie Eigenschaften mit dem Wert null gab, konnte die Generierung dieser Richtlinie sowie aller nachfolgenden Richtlinien fehlschlagen
Neue Unternehmensrichtlinien
Die Preferences-Richtlinie erlaubt nun auch die Verwendung von Einstellungen, die mit devtools. oder sidebar. beginnen.
Entwicklung unterstützen
Wer die Entwicklung des Add-ons unterstützen möchte, kann dies tun, indem er der Welt vom Enterprise Policy Generator erzählt und die Erweiterung auf addons.mozilla.org bewertet. Auch würde ich mich sehr über eine kleine Spende freuen, welche es mir ermöglicht, weitere Zeit in die Entwicklung des Add-on zu investieren, um zusätzliche Features und neue Richtlinien zu implementieren.
Mozilla hat Firefox Klar 150 (internationaler Name: Firefox Focus 150) für Android veröffentlicht.
Die Neuerungen von Firefox Klar 150 für Android
Bei Firefox Klar 150 handelt es sich um ein Wartungs-Update, bei welchem der Fokus auf Fehlerbehebungen und Verbesserungen unter der Haube lag. Dazu kommen wie immer neue Plattform-Features der aktuellen GeckoView-Engine sowie geschlossene Sicherheitslücken.
In diesem Video zeigt Jean Fedora Workstation in der neuen Version Fedora 44. Was gibt es für Neuerungen und für wen würde ich diese Linux-Distribution empfehlen?
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
- Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
- Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
- Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
- Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
- Offizielle Webseite: https://www.linuxguides.de
- Forum: https://forum.linuxguides.de/
- Unterstützen: http://unterstuetzen.linuxguides.de
- Mastodon: https://mastodon.social/@LinuxGuides
- X: https://twitter.com/LinuxGuides
- Instagram: https://www.instagram.com/linuxguides/
- Kontakt: https://www.linuxguides.de/kontakt/
Inhaltsverzeichnis:
-------------------------------------
00:00 Intro
00:31 Fedora allgemein
05:33 GNOME 50
07:41 Software
13:59 Nix für Fedora
15:56 Installer
20:04 Weitere Features und Funktionen
29:58 Mein Fazit
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Großflächige Linux-Updates sind angesagt: Auch wenn CVE-2026-31431 „nur“ mit CVSS 7.8 eingestuft wird, hat die Lücke aufgrund ihrer Verbreitung es in sich. Forscher von Xint konnten im cryptography-Subsystem einen Logikfehler identifizieren, der es einem einfachen Benutzer ermöglicht, eine 4-Byte-Schreibsequenz im Page Cache jeder lesbaren Datei vorzunehmen.
Der „Copy Fail“ getaufte Angriff funktioniert dabei so ähnlich wie Cache Poisoning. Da Dateien unter Linux im RAM gecached werden, um Mehrfachzugriffe auf die Festplatten zu reduzieren, kann ein Angreifer, der es schafft, diesen RAM-Inhalt zu kontrollieren, Einfluss auf Dateiinhalte nehmen. Normalerweise geht das nicht direkt, da der Kernel prüft, ob auch Schreibrechte vorliegen. In diesem Fall kann das umgangen werden.
Die Gefahr der Rechteausweitung ergibt sich durch die Manipulation von setuid-Binaries wie su oder sudo, die automatisch als root ausgeführt werden, aber deren gehärtete Logik unautorisierten Zugriffen normalerweise standhält. In diesem Fall wird aber der Inhalt der Binary durch den o. g. Cache-Angriff so manipuliert, dass die Angreifer ohne jegliche Zugriffsprüfung Root-Rechte erlangen.
Besondere Gefahr ergibt sich für Container-Umgebungen. Da zwei isolierte Container sich trotzdem denselben Kernel teilen, ermöglicht der Angriff potentiell auch Container-Breakouts.
Ein Fix liegt bereits vor, die betroffenen Kernel-Versionen reichen bis in das Jahr 2017 zurück. Das Xint-Team geht auf seiner Seite auf die genauen Details hinter dem Angriff und dem Fund ein.
Die MZLA Technologies Corporation hat mit Thunderbird 150.0.1 ein Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 150.0.1
Mit Thunderbird 150.0.1 hat die MZLA Technologies Corporation ein Update für seinen Open Source E-Mail-Client veröffentlicht und behebt damit eine mögliche Absturzursache sowie Sicherheitslücken.
Es kommt selten vor, dass ein IT-Buch innerhalb von 18 Monaten eine zweite Auflage erfährt und dabei in großen Teilen neu geschrieben werden muss. Genau das ist uns mit diesem Buch passiert! Wir haben die Gelegenheit genutzt und das Buch komplett aktualisiert und stark erweitert. Der Fokus liegt jetzt bei Agentic Coding, MCP und Skills.
Wir haben in diesem Buch den »State of the Art« im Bereich KI und Agentic Coding abgesteckt. In unzähligen Tests haben wir ausprobiert, wie weit die Versprechen der KI-Hersteller zutreffen, aber auch, wo heutige KI-Tools versagen. Wir haben lokale Modelle und Open-Source-Tools ebenso verwendet wie kommerzielle KI-Tools von Claude, Cursor, Google und OpenAI. Ein eigenes Kapitel behandelt den neuen Trend der CLI-basierten KI-Tools, also z.B. Claude Code oder OpenAI Codex.
Thunderbird steht nicht mehr nur für einen E-Mail-Client. Mit Thunderbird Pro steht ein kostenpflichtiges Zusatzangebot in den Startlöchern. Der Fokus liegt derzeit auf dem neuen E-Mail-Dienst Thundermail. Die ersten Beta-Einladungen sollen bald verschickt werden.
Thunderbird ist vor allem für seinen kostenlosen E-Mail-Client für Windows, macOS und Linux bekannt. Seit November 2024 gibt es Thunderbird auch für Android, Thunderbird für iOS ist in Entwicklung. Doch dabei soll es nicht bleiben: Die MZLA Technologies Corporation möchte ein Ökosystem aus Clients und Diensten als Alternative zu denen der Tech-Giganten wie Google Mail und Microsoft Office 365 etablieren, welches zu 100 Prozent Open Source ist. Im November hatte ich eine erste Vorschau auf den Funktionsumfang der drei neuen Dienste Thundermail, Thunderbird Send sowie Thunderbird Appointment gegeben.
Die Auswertung des Nutzerfeedbacks hat ein klares Bild dahingehend ergeben, dass sich die meisten Nutzer vor allem für den E-Mail-Dienst Thundermail interessieren. Dementsprechend hat MZLA die Entwicklung von Thundermail priorisiert. Auch Thunderbird Send und Thunderbird Appointment werden weiterhin entwickelt, müssen in der Priorisierung derzeit aber etwas hinten anstehen. Fortschritte gibt es aber bei allen drei Diensten, auf die MZLA in seinem Blog näher eingeht.
Auch am anfänglichen Preis möchte man Anpassungen vornehmen, um besser den Erwartungen der Nutzer zu entsprechen, geht in diesem Punkt aber nicht weiter ins Detail. Zuletzt war von 9 USD im Monat zu lesen, aktuell zeigt die Website keinen Preis mehr an. Vermutlich deutet die Aussage auf einen niedrigeren Preis als ursprünglich geplant hin.
Im Mai sollen die ersten Beta-Einladungen für Nutzer verschickt werden, welche sich auf die Warteliste haben setzen lassen.
FediSuite ist eine kostenlose Open-Source-Plattform zum Planen von Beiträgen, automatischen Aufteilen langer Posts in Threads, Verwalten von Benachrichtigungen und dem Handling mehrerer Accounts auf 14 Fediverse-Plattformen — Mastodon, Pixelfed, Vernissage, PeerTube, Misskey und mehr.
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere in unserem Chat mit.
🖌️ Rahmen-Anpassung: Textlabels hinzufügen und den Rahmen um deinen QR-Code gestalten
🛡️ Fehlerkorrekturstufe: Beeinflusst die Größe des QR-Codes und des Logos. Für größere Datenmengen niedrigere Korrekturstufen verwenden, damit der Code lesbar bleibt.
📱 QR-Code-Scanner: Codes mit der Kamera oder per Bild-Upload scannen, mit intelligenter Erkennung für URLs, E-Mails, Telefonnummern, WLAN-Zugangsdaten und mehr
📦 Stapel-Export: CSV-Datei mit mehreren Datensätzen importieren und alle QR-Codes gleichzeitig exportieren. Vorlagen findest du unter public/batch_export_templates/
📲 PWA-Unterstützung: MiniQR als Desktop- oder Mobile-App installieren
📝 Datenvorlagen: Unterstützung für verschiedene Datentypen wie Text, URLs, E-Mails, Telefonnummern, SMS, WLAN-Zugangsdaten, vCards, Standorte und Kalenderereignisse
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere in unserem Chat mit.
Sicherheit für Linux-basierte Mobile-Devices und App-Umgebungen prüfen
Linux bildet die Grundlage für zahlreiche mobile Betriebssysteme und App-Umgebungen, darunter Android und eine wachsende Zahl spezialisierter Embedded-Plattformen. Wer Linux-Sicherheit prüfen möchte, steht vor einer komplexen Aufgabe: Der Kernel selbst, darüber liegende Middleware-Schichten, App-Laufzeitumgebungen und das Mobile-Device-Management greifen ineinander und schaffen ein breites Angriffspotenzial. Schwachstellen entstehen nicht nur im Code, sondern auch durch Fehlkonfigurationen, unsichere Kommunikationskanäle und mangelhafte Berechtigungskonzepte. Gerade in professionellen Umgebungen, in denen mobile Geräte sensible Unternehmensdaten verarbeiten, kann eine unentdeckte Lücke weitreichende Folgen haben. Dieser Artikel erläutert, welche Bereiche bei einer sicherheitstechnischen Prüfung Linux-basierter Mobilgeräte und App-Umgebungen besonders relevant sind, welche Methoden sich bewährt haben und worauf Sicherheitsteams bei der Planung und Durchführung achten sollten.
Die Angriffsfläche Linux-basierter mobiler Systeme verstehen
Kernel und Systemarchitektur als Ausgangspunkt
Der Linux-Kernel ist das Fundament jedes Android-Geräts und vieler spezialisierter mobiler Plattformen. Seine Sicherheitsmerkmale, darunter Mandatory Access Control (MAC) über SELinux oder AppArmor, Namespace-Isolation und Seccomp-Filter, bieten eine solide Basis. Dennoch entstehen Risiken, wenn Geräte mit veralteten Kernel-Versionen betrieben werden oder Hersteller eigene Patches einpflegen, ohne diese ausreichend zu testen.
Besonders kritisch sind Treiber-Schnittstellen: Proprietäre Hardwaretreiber werden häufig ohne denselben Qualitätssicherungsprozess entwickelt wie der mainline Kernel. Angreifer nutzen gezielt Schwachstellen in GPU-, Kamera- oder Modem-Treibern, um Privilegien zu eskalieren. Eine vollständige Sicherheitsprüfung muss daher auch diese Schicht einschließen.
Middleware, Laufzeitumgebungen und App-Isolation
Zwischen Kernel und Anwendung liegen Laufzeitumgebungen wie die Android Runtime (ART) sowie zahlreiche Systemdienste. Fehler in diesen Komponenten können dazu führen, dass Apps auf Ressourcen zugreifen, für die sie keine Berechtigung haben. Inter-Process-Communication-Mechanismen (IPC), etwa über Binder, sind ein klassisches Angriffsziel, da sie Schnittstellen zwischen privilegierten und unprivilegierten Prozessen schaffen.
App-Isolation funktioniert nur dann zuverlässig, wenn das Berechtigungsmodell konsequent umgesetzt wird. In der Praxis finden Sicherheitsteams regelmäßig Apps, die unnötig weitreichende Berechtigungen anfordern oder Systemschnittstellen nutzen, die eigentlich nur für Systemdienste vorgesehen sind.
Methoden zur Prüfung der Linux-Sicherheit in mobilen Umgebungen
Statische Analyse von App-Code und Konfigurationsdateien
Die statische Analyse untersucht App-Binaries, Konfigurationsdateien und Manifest-Dateien, ohne die Anwendung tatsächlich auszuführen. Dabei werden unter anderem folgende Aspekte geprüft:
Hardcodierte Zugangsdaten oder API-Schlüssel im Quellcode
Unsichere kryptografische Algorithmen oder veraltete Bibliotheken
Fehlkonfigurierte Berechtigungen im Android-Manifest
Exportierte Komponenten (Activities, Services, Broadcast Receiver), die ohne Authentifizierung erreichbar sind
Werkzeuge wie MobSF (Mobile Security Framework) automatisieren einen Teil dieser Analyse, ersetzen aber keine manuelle Prüfung durch erfahrene Tester.
Dynamische Analyse und Laufzeitinspektion
Bei der dynamischen Analyse wird die Anwendung in einer kontrollierten Umgebung ausgeführt. Netzwerkverkehr wird mitgeschnitten und auf unsichere Verbindungen, fehlende Zertifikatsprüfungen oder übermäßige Datenweitergabe untersucht. Laufzeitverhalten lässt sich mit Frameworks wie Frida instrumentieren, um Funktionen zu hooken, Verschlüsselungsroutinen zu inspizieren oder Sicherheitsmechanismen wie SSL-Pinning temporär zu umgehen.
Gerade in Linux-basierten Umgebungen ist die dynamische Analyse aufschlussreich, da viele Schwachstellen erst im Zusammenspiel verschiedener Systemkomponenten sichtbar werden. Root-Erkennungsmechanismen, Tamper-Protection und Debugger-Abwehr lassen sich hier ebenfalls auf ihre Wirksamkeit prüfen.
Penetrationstests auf Systemebene
Neben der App-Analyse umfasst eine vollständige Sicherheitsprüfung auch Tests auf Systemebene. Dabei werden Netzwerkdienste gescannt, offene Ports identifiziert und Exploits gegen bekannte Schwachstellen in Systemdiensten geprüft. Für Geräte, die in Unternehmensumgebungen eingesetzt werden, ist die Analyse des Mobile-Device-Managements (MDM) besonders relevant: Fehlkonfigurierte MDM-Profile können Geräterichtlinien aushebeln oder unberechtigten Zugriff auf verwaltete Ressourcen ermöglichen.
Wer den Sicherheitsstatus mobiler Anwendungen systematisch bewerten möchte, kann dafür einen strukturierten mobile App Pentest beauftragen, der App-Analyse, Systemprüfung und MDM-Bewertung kombiniert.
Typische Schwachstellen in Linux-basierten App-Umgebungen
Unsichere Datenspeicherung und Dateirechte
Einer der häufigsten Befunde bei der Prüfung mobiler Linux-Umgebungen ist die unsichere Datenspeicherung. Apps legen sensible Informationen in SharedPreferences, SQLite-Datenbanken oder einfachen Textdateien ab, ohne diese zu verschlüsseln. Auf gerooteten Geräten sind solche Daten für andere Prozesse lesbar. Dateiberechtigungen spielen dabei eine zentrale Rolle: world-readable Dateien oder Verzeichnisse mit zu offenen Rechten sind ein klassisches Einfallstor.
Darüber hinaus hinterlassen Apps häufig Spuren in temporären Dateien, Log-Ausgaben oder Cache-Verzeichnissen, die vertrauliche Daten enthalten. Ein sorgfältiger Test prüft systematisch alle Speicherorte, auf die eine App schreibt.
Schwachstellen in der Netzwerkkommunikation
Fehlende oder fehlerhafte Implementierungen von TLS sind in mobilen App-Umgebungen weit verbreitet. Besonders problematisch sind:
Deaktivierte Zertifikatsprüfungen in Entwicklungsversionen, die versehentlich in Produktionsbuilds übernommen werden
Fehlende Certificate-Pinning-Implementierungen bei sicherheitskritischen Apps
Unverschlüsselte Kommunikation über HTTP für bestimmte Endpunkte
Schwache oder selbst signierte Zertifikate in Unternehmensumgebungen
Linux-basierte Geräte sind hier nicht grundsätzlich unsicherer als andere Plattformen, aber die Vielfalt der eingesetzten Bibliotheken und Frameworks erhöht die Wahrscheinlichkeit inkonsistenter Implementierungen.
Privilege Escalation und Kernel-Exploits
Auf System- und Kernel-Ebene sind Privilege-Escalation-Angriffe besonders folgenreich. Angreifer, die eine App-Sandbox durchbrechen, können über ungepatchte Kernel-Schwachstellen Root-Rechte erlangen und damit sämtliche Sicherheitsmechanismen des Geräts aushebeln. SELinux-Policies, die zu permissiv konfiguriert sind, bieten dann keinen ausreichenden Schutz mehr.
Regelmäßige Kernel-Updates und die Prüfung aktiver SELinux-Kontexte sind grundlegende Maßnahmen, um dieses Risiko zu begrenzen.
Mobile-Device-Management und Linux-Sicherheit prüfen
MDM-Konfigurationen als Sicherheitsschicht
Mobile-Device-Management-Systeme verwalten Geräterichtlinien, App-Verteilung und Zugriffskontrolle in Unternehmensumgebungen. Sicherheitsteams, die Linux-Sicherheit prüfen, dürfen diesen Bereich nicht vernachlässigen: Ein schwach konfiguriertes MDM kann als Einstiegspunkt dienen oder den Schutz korrekt konfigurierter Geräte untergraben.
Typische Prüfpunkte bei MDM-Systemen sind die Durchsetzung von Passwortrichtlinien, die Verschlüsselung verwalteter Daten, die Kontrolle installierbarer Apps sowie die Möglichkeit zur Remote-Wipe-Funktion. Enrollment-Prozesse sollten gegen unbefugte Geräteanmeldungen abgesichert sein.
Geräte-Compliance und Sicherheitsrichtlinien
Neben der technischen Konfiguration ist die Durchsetzung von Compliance-Anforderungen relevant. Kann ein Gerät, das gerootet wurde oder eine veraltete Systemversion verwendet, weiterhin auf Unternehmensressourcen zugreifen? Sind Integritätsprüfungen wie Android Attestation in den Enrollment-Prozess integriert? Diese Fragen lassen sich nur durch eine kombinierte Prüfung aus technischer Analyse und Prozessbewertung beantworten.
Praktische Empfehlungen für Sicherheitsteams
Sicherheitsteams, die Linux-Sicherheit prüfen möchten, profitieren von einem strukturierten Vorgehen:
Zunächst sollte eine vollständige Inventarisierung aller eingesetzten mobilen Geräte, Betriebssysteme und App-Versionen erfolgen. Ohne diesen Überblick lassen sich Priorisierungen nicht sinnvoll treffen. Besonderes Augenmerk gilt dabei Geräten, die nicht mehr mit Sicherheitsupdates versorgt werden.
Im nächsten Schritt empfiehlt sich eine Bedrohungsmodellierung: Welche Daten verarbeiten die eingesetzten Apps? Welche Angreifer sind realistischerweise relevant? Diese Analyse bestimmt, welche Testtiefe und welche Methoden angemessen sind.
Die eigentliche technische Prüfung sollte statische und dynamische Analyse kombinieren und Systemebene sowie Netzwerkkommunikation einschließen. Ergebnisse sollten priorisiert und mit konkreten Maßnahmen verknüpft werden, damit Entwicklungs- und Betriebsteams direkt handeln können.
Schließlich ist Sicherheit kein einmaliges Projekt. Regelmäßige Wiederholungstests, idealerweise nach jedem größeren App-Release oder Systemupdate, stellen sicher, dass neu eingeführte Schwachstellen frühzeitig erkannt werden.
Häufig gestellte Fragen
Was umfasst die Prüfung der Linux-Sicherheit für mobile Geräte?
Die Prüfung der Linux-Sicherheit für mobile Geräte umfasst mehrere Ebenen: den Linux-Kernel und seine Konfiguration, Middleware und Systemdienste, App-Laufzeitumgebungen sowie die Netzwerkkommunikation. Hinzu kommen die Analyse von App-Code, die Bewertung von Datenspeicherpraktiken und die Prüfung des Mobile-Device-Managements. Eine vollständige Prüfung kombiniert statische Analyse, dynamisches Testen und manuelle Expertenprüfung.
Wie unterscheidet sich ein Linux-Sicherheitstest von einem Standard-Android-Pentest?
Android basiert auf Linux, aber ein Linux-fokussierter Sicherheitstest geht tiefer: Er berücksichtigt Kernel-Konfigurationen, SELinux-Policies, Treiber-Schnittstellen und systemnahe Dienste, die bei einem reinen App-Test häufig ausgeblendet bleiben. Besonders bei Embedded-Geräten oder Custom-Android-Builds ist diese erweiterte Perspektive entscheidend, da Hersteller oft eigene Anpassungen vornehmen, die neue Angriffsvektoren einführen.
Wie häufig sollte die Sicherheit Linux-basierter mobiler Systeme geprüft werden?
Eine vollständige Sicherheitsprüfung empfiehlt sich mindestens einmal jährlich sowie nach wesentlichen System- oder App-Updates. Bei sicherheitskritischen Anwendungen, etwa in der Gesundheitsversorgung oder im Finanzbereich, sind häufigere Tests und ein kontinuierliches Monitoring sinnvoll. Patch-Management und die Überwachung neu veröffentlichter Schwachstellen sollten unabhängig davon dauerhaft etabliert sein.
Mozilla hat Firefox 150.0.1 veröffentlicht und behebt damit mehrere Probleme der Vorgängerversion. Außerdem wurden zahlreiche Sicherheitslücken geschlossen.
Mit Firefox 150.0.1 behebt Mozilla zahlreiche Sicherheitslücken. Alleine aus Gründen der Sicherheit ist ein Update daher für alle Nutzer empfohlen.
Diverse Verbesserungen in Zusammenhang mit dem KI-Feature Smart Window wurden vorgenommen, für dessen Beta-Version erste Nutzer von Firefox 150 eingeladen worden sind.
Das Schreiben in die Dateien profiles.ini und installs.ini wurde sicherer gemacht, um Profilverluste durch defekte Einträge zu verhindern.
Tabs konnten nicht zu geschlossenen Tab-Gruppen hinzugefügt werden, wenn diese vor Firefox 149 erstellt worden sind.
Ein Problem wurde behoben, welches für Nutzer der Sicherheits-Software von Bitdefender dafür sorgte, dass Facebook und andere Websites nicht mehr geladen werden konnte.
Es wurde ein Problem behoben, bei dem Firefox den System-Berechtigungsdialog bei einem zweiten Versuch erneut anzeigte, wenn die Abfrage zur Geolokalisierungs-Berechtigung abgelehnt wurde.
Wurden Websites als Web-App geöffnet, konnte die Adressleiste unter Umständen zu kurz dargestellt werden.
Der Abschnitt „Firefox Labs” in den Einstellungen von Firefox zeigte nach dem ersten Start unter Windows möglicherweise keine Einträge an.
Darüber hinaus wurden eine Performance-Regression und mehrere Webkompatibilitäts-Probleme behoben.
Firefox Relay ist ein Dienst von Mozilla, der die persönliche E-Mail-Adresse vor Spam und unerwünschter Offenlegung schützt. Mozilla hat die maximal mögliche Anzahl an E-Mail-Masken für Nutzer der kostenlosen Version von Firefox Relay deutlich erhöht.
Was ist Firefox Relay?
E-Mail-Adressen sind gleichzusetzen mit einer persönlichen Adresse. Sie sind einmalig und viele Nutzer besitzen nur eine einzige E-Mail-Adresse, die sie teilweise auf dutzenden, wenn nicht gar auf hunderten Websites verwenden. Findet auf einer Website, auf der man mit seiner E-Mail-Adresse registriert ist, ein Datendiebstahl statt, wird damit in vielen Fällen auch die persönliche E-Mail-Adresse offengelegt. Und haben Spammer erstmal eine E-Mail-Adresse in ihrem System, darf man sich auf viele unerwünschte E-Mails ohne realistische Hoffnung einstellen, dass der Spam abnehmen wird.
Mit Firefox Relay können sogenannte Masken als Alias-Adressen angelegt werden, die der Nutzer für Newsletter-Anmeldungen und Website-Registrierungen angeben kann. Firefox Relay leitet diese E-Mails dann an die persönliche E-Mail-Adresse weiter. Außerdem kann Firefox Relay bekannte Tracking-Scripts aus E-Mails entfernen.
Firefox Relay ist kostenlos. Es gibt aber auch eine kostenpflichtige Premium-Version, welche unendlich viele Masken sowie eine eigene E-Mail-Domain erlaubt. Außerdem können in Firefox Relay Premium auf weitergeleitete E-Mails geantwortet und Werbe-Mails automatisch blockiert werden. In den USA sowie Kanada können auch Telefonnummern maskiert werden.
Anzahl an möglichen Masken erhöht
Nutzer der kostenlosen Version von Firefox Relay konnten bislang bis zu fünf Masken für die persönliche E-Mail-Adresse anlegen. Ab sofort sind bis zu 50 Masken kostenlos möglich. Nutzer von Firefox Relay Premium können weiterhin unendlich viele Masken anlegen.
Glücklicherweise muss ich nicht allzu oft unter Windows arbeiten. Aber hin und wieder — aktuell für die Überarbeitung meines Scripting-Buchs — lässt es sich nicht vermeiden. Wenn schon Windows, dann wenigstens so komfortabel wie möglich! Und so habe ich in den vergangenen Wochen mein Terminal/PowerShell-Setup optimiert:
Nerdfont installiert
informativen Prompt eingerichtet (Oh My Posh)
bessere Tastaturunterstützung im Terminal (Emacs-Tastenkürzel)
Editor für den Textmodus installiert (je nach Geschmack: Edit, nano, Emacs, NeoVim)
sudo aktiviert
Dieser Artikel liefert dazu ein paar Details. Der Text beweist gleichzeitig, dass man selbst unter Windows mit relativ wenig Mühe ein produktives Setup einrichten kann. Das erforderliche Fundament liefert Microsoft direkt aus: das Windows Terminal mit vielen High-end-Funktionen inklusive GPU-Rendering, die PowerShell sowie das Paketverwaltungskommando winget.
PowerShell in einem Windows Terminal mit den JetBrains Nerd Font und »Oh My Posh«
Nerdfonts
Moderne CLI-Tools stellen im Terminal alle erdenklichen Zeichen und Symbole dar, um auf Dateitypen, den Git-Status oder Fehlerursachen hinzuweisen. In »gewöhnlichen« Fonts fehlen diese Zeichen; im Terminal wird dann ein Rechteck, ein Fragezeichen oder ein anderes Ersatzzeichen angezeigt. Das lässt den Charme moderner Kommandos und Prompt-Frameworks ins Leere laufen. Abhilfe schafft die Installation eines Fonts, der einen Coding-Zeichensatz um Tausende Symbole und Sonderzeichen ergänzt.
Auf der Seite https://nerdfonts.com stehen ca. 100 geeignete Fonts zum freien Download zur Auswahl. Aber welcher Font ist der beste? Wenn Sie sich nicht entscheiden können, ist der beliebte JetBrainsMono Nerd Font eine gute Wahl für erste Experimente. Er basiert auf dem freien Mono-Font der Firma JetBrains (IntelliJ, PyCharm etc.). Dieser Font hat noch einen Vorteil: Er lässt sich im Handumdrehen mit winget installieren. Sie sollten die Installation in einem Terminal mit Admin-Rechten durchführen, damit die Fonts auch dann zur Verfügung stehen, wenn Sie in einem Admin-Terminal arbeiten.
# in einem Admin-Terminal
winget install -e --id DEVCOM.JetBrainsMonoNerdFont
Oh My Posh
Die Fish oder die Zsh mit der Erweiterung »Oh My Zsh« zeigen im Prompt alle erdenklichen Kontextinformationen an: den Hostnamen, den Verzeichnisnamen, den Git-Zweig und -Status etc. Genau das kann auch Oh My Posh, eine Plattform- und Shell-unabhängiges Prompt-Framework. Die Installation gelingt unter Windows am schnellsten mit winget:
winget install JanDeDobbeleer.OhMyPosh -s winget
Damit Oh My Posh in interaktiven PowerShell-Sessions aktiviert wird, bauen Sie die folgenden Anweisungen in die Profile-Datei ein (notepad $Profile, wobei Sie notepad durch Ihren Lieblingseditor ersetzen):
# Datei Documents/PowerShell/Microsoft.PowerShell_profile.ps1
# Oh My Posh nur in interaktiven PowerShell-Sessions verwenden
if (-not [Console]::IsInputRedirected -and
(Get-Module -Name PSReadLine -ErrorAction SilentlyContinue))
{
oh-my-posh init pwsh | Invoke-Expression
}
Wenn Sie jetzt ein neues PowerShell-Tab öffnen, wird Oh My Posh erstmals aktiv. Sie werden von einem informativen und mehrfarbigen Default-Prompt begrüßt. Unter https://ohmyposh.dev/docs/themes stehen über 100 weitere Prompt-Themen zur Wahl. Zur Aktivierung bauen Sie den Themennamen in das oh-my-posh-Init-Kommando in der Profile-Datei ein, z.B. so:
Um die neue Konfiguration zu aktivieren, lesen Sie die Profile-Datei neu ein:
. $PROFILE
Starship Eine Alternative zu Oh My Posh ist das Framework Starship. Es wurde in Rust entwickelt und ist schneller/effizienter als Oh My Posh. Dafür gibt es aber weniger vordefinierte Themen; generell ist die Konfiguration sperriger. Ich habe beide Frameworks ausprobiert, bin dann aber bei Oh My Posh geblieben.
Tastenkürzel in der PowerShell
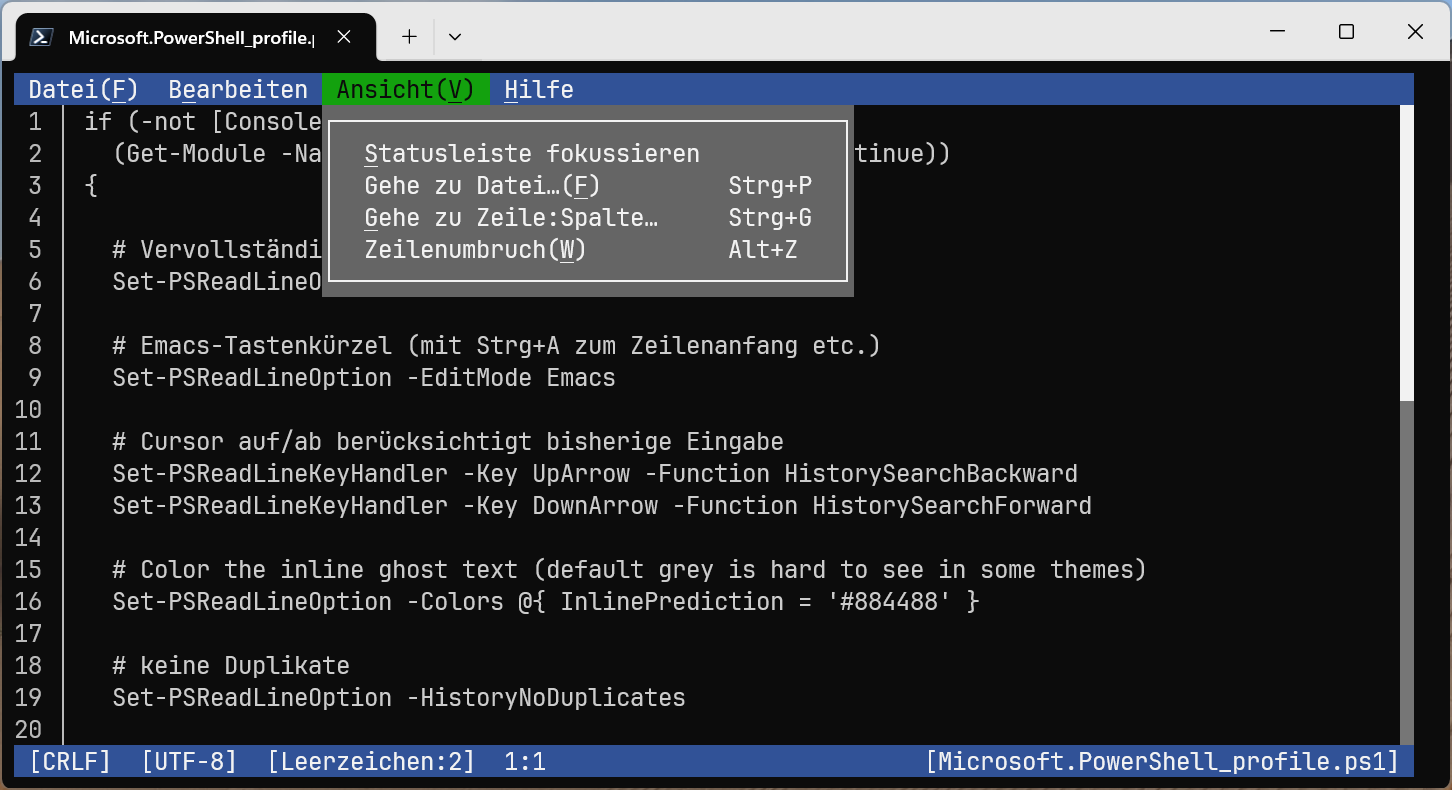
In der PowerShell unterstützt Sie das Modul PSReadLine bei der Kommandoeingabe (siehe auch die Dokumentation zu Set-PSReadLineOption). Standardmäßig schlägt PSReadLine das letzte Kommando mit den selben Anfangsbuchstaben zur Vervollständigung durch Cursor rechts vor. Tab bewirkt, dass begonnenen Dateinamen oder Schlüsselwörter komplettiert werden.
Das Verhalten von PSReadLine kann durch Optionen in der Profile-Datei beeinflusst werden. Diese Datei öffnen Sie am bequemsten mit notepad $Profile, wobei Sie notepad durch Ihren Lieblingseditor ersetzen. Damit die Änderungen wirksam werden, laden Sie die Datei mit . $Profile neu.
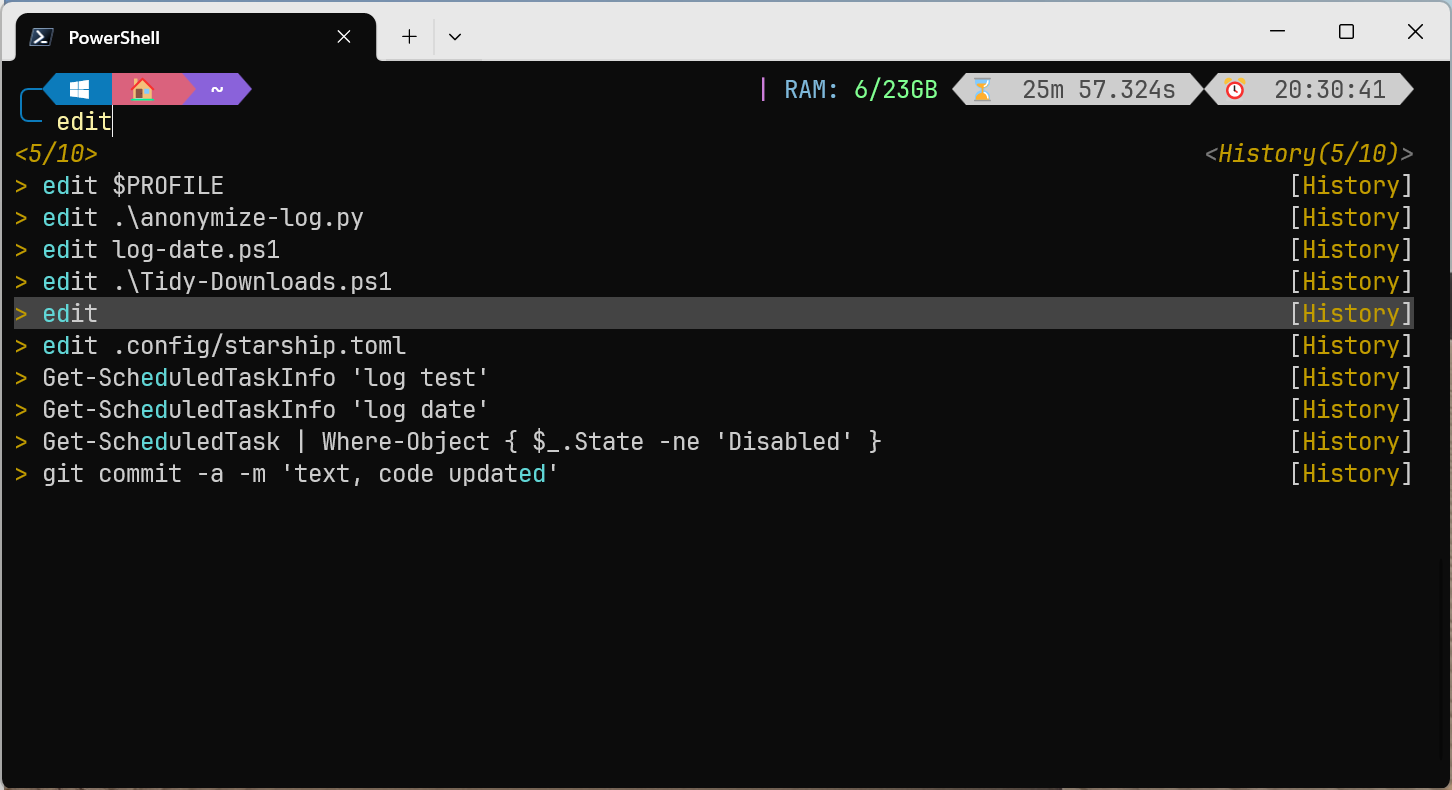
Das folgende Listing schlägt einige Änderungen/Verbesserungen vor. Gleich das erste Kommando bewirkt den größten Unterschied: Nach der Eingabe der ersten Buchstaben haben Sie die Wahl zwischen mehreren ähnlichen zuletzt ausgeführten Kommandos, die Sie mit den Cursortasten aus einer Liste wählen. Mit F2 können Sie zwischen der Listenansicht und dem Defaultverhalten (InlineView) umschalten.
Auswahl aus zuletzt ausgeführten Kommandos, die die Buchstaben »ed« enthalten
Falls Sie bei InlineView bleiben wollen, sollten Sie zumindest die beiden HistorySearch-Kommandos in Erwägung ziehen. Normalerweise blättern Cursor auf und Cursor ab durch alle bisherigen Kommandos. Mit den hier vorgeschlagenen Einstellungen können Sie dagegen git eingeben und dann durch die bisherigen git-Kommandos blättern.
Emacs- und Vi-Fans werden begeistert sein, dass die PowerShell per EditMode die vertrauten Tastenkürzel akzeptiert. Die if-Abfrage im folgenden Listing stellt sicher, dass die Einstellungen nur in interaktiven Sessions gelten, aber z.B. nicht, wenn die PowerShell ein einzelnes Kommando via SSH ausführt.
# Ergänzungen in der Profile-Datei
if (-not [Console]::IsInputRedirected -and
(Get-Module -Name PSReadLine -ErrorAction SilentlyContinue))
{
# zeigt Vervollständigungsliste an, Auswahl per Cursortasten
Set-PSReadLineOption -PredictionViewStyle ListView
# Cursor auf/ab berücksichtigen die bisherige Eingabe
Set-PSReadLineKeyHandler -Key UpArrow `
-Function HistorySearchBackward
Set-PSReadLineKeyHandler -Key DownArrow `
-Function HistorySearchForward
# Emacs- oder Vi-Tastenkürzel (per Default: Windows-Tastenkürzel)
Set-PSReadLineOption -EditMode Emacs
Set-PSReadLineOption -EditMode Vi
# besser sichtbare Farbe für Inline-Vervollständigung
Set-PSReadLineOption -Colors @{ InlinePrediction = '#884488' }
# keine Duplikate in der Kommando-History speichern
Set-PSReadLineOption -HistoryNoDuplicates
}
Terminal-Editoren
An GUI-Editoren herrscht unter Windows kein Mangel — die Palette reicht von notepad.exe über Notepad++ bis hin zu VS Code und anderen KI-tauglichen Programmen/IDEs. Aber oft wollen Sie einfach nur ein paar Zeilen Text ändern, eine Konfigurationsdatei vervollständigen etc. — und zwar, ohne das Terminal zu verlassen. (Das gilt insbesondere, wenn Sie via SSH remote arbeiten!) Dazu brauchen Sie einen Editor, der im Terminal ausgeführt werden kann.
edit: Durchaus nicht die schlechteste Wahl ist edit. Mitte 2025 hat Microsoft diesen Mini-Editor vorgestellt — als GitHub-Projekt in der Programmiersprache Rust! Damit liegt Microsoft voll im Zeitgeist. Zur Installation führen Sie winget install microsoft.edit aus. In der Folge lädt edit <file> die gewünschte Datei.
Bemerkenswert an edit ist die intuitive, einfache Bedienung. Text wird mit den Cursortasten markiert, mit Strg+C und Strg+V kopiert und wieder eingefügt etc. Die Cursorposition kann mit der Maus verändert werden, auch das lokalisierte Menü lässt sich per Maus bedienen und gibt IT-Veteranen ein wenig Turbo-Pascal-Vibes. Fortgeschrittene Funktionen fehlen allerdings: kein Syntaxhighlighting, keine Code-Vervollständigung, keine Einstellungen …
Der relativ neue CLI-Editor »Edit«
nano: In der Linux-Welt ist nano das Gegenstück zu edit. Der Editor hat zwar nur relativ wenige Funktionen, ist dafür aber einfach zu bedienen. Praktischerweise zeigt das Programm alle erforderlichen Tastenkürzel gleich in der Statusleiste an. Die Installation gelingt unkompliziert mit winget install -e --id GNU.Nano.
vi/NeoVim: Die einen lieben ihn, andere hassen ihn — das Editor-Urgestein vi. Vi-Fans verwenden unter Windows am besten die Variante NeoVim (siehe https://neovim.io). NeoVim ist aber nur die Basis: Damit das Programm sein ganzes Potential ausschöpfen kann, brauchen Sie diverse Erweiterungen (Git, LSP, Fuzzy Finding usw.) und Konfigurationseinstellungen. Das Setup gelingt am schnellsten mit Frameworks wie LazyVim oder AstroNvim.
Emacs: Mich hat der Vi nie überzeugen können, ich bin im Emacs-Lager. Unter Windows ist das allerdings ein Abenteuer. Von abgespeckten Emacs-Klonen wie mg, zile oder jmacs gibt es keine Windows-Ports, die im Terminal funktionieren. Also muss es die Vollversion sein: winget install -e --id GNU.Emacs. winget kümmert sich leider nicht darum, das Emacs-Installationsverzeichnis zum Path hinzuzufügen. Sie müssen sich selbst um diesen Schritt kümmern. Die ausführbare Datei befindet sich üblicherweise in C:\Program Files\Emacs\emacs-<n.n>\bin.
Beim Start des Editors müssen Sie an die Option -nw denken (no window), sonst erscheint der Emacs in einem eigenen Fenster statt im Terminal. Noch eine Besonderheit betrifft die Konfigurationsdatei ~/.emacs. Die Windows-Version des Emacs liest diese Datei normalerweise (abhängig von der HOME-Umgebungsvariablen) nicht aus C:\Users\name\.emacs, sondern aus C:\Users\name\AppData\Roaming\.emacs. Wenn Emacs Unicode-Zeichen fehlerhaft anzeigt, bauen Sie die folgenden Anweisungen in .emacs ein:
Um unter Windows ein Kommando mit Administratorrechten auszuführen, müssen Sie zuerst umständlich ein Terminal mit Admin-Rechten öffnen. Unter Linux und macOS klappt das mit sudo viel unkomplizierter.
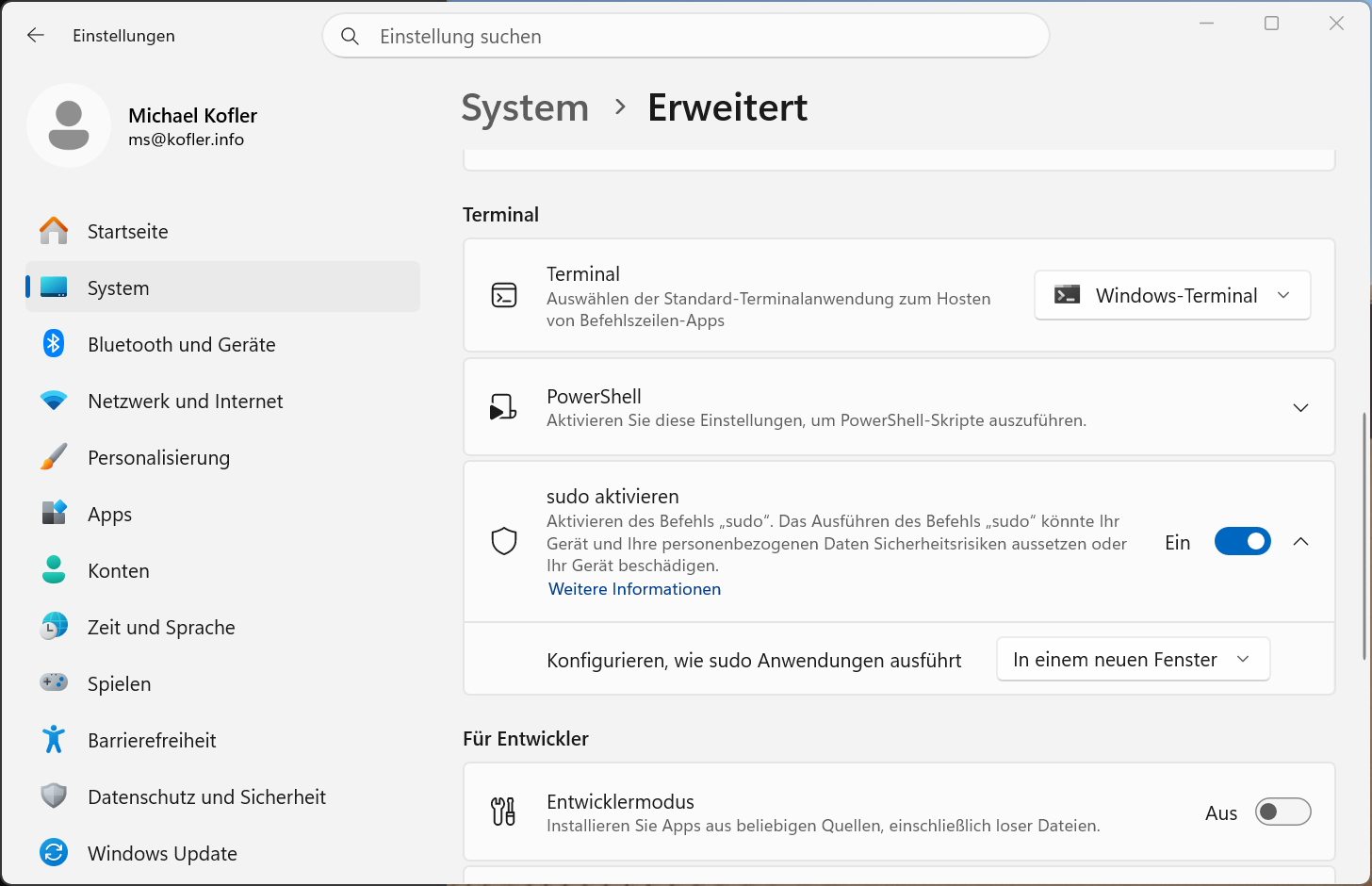
Ab Version 11 / 24H2 gibt es sudo auch unter Windows. Microsoft hat das Kommando komplett neu implementiert und nur den Namen übernommen. Die Funktionsweise und Optionen sind anders als unter Linux oder macOS. Insbesondere gibt es keine (Passwort-)Authentifizierung; stattdessen erscheint vor sudo-Aktivitäten nur der UAC-Bestätigungsdialog (User Account Control).
sudo muss zuerst aktiviert werden. Sie finden die Option in den Einstellungen unter System / Erweitert / Terminal.
sudo unter Windows aktivieren
Es gibt drei Arten, wie sudo-Kommandos ausgeführt werden können: in einem neuen Fenster (gilt per Default, forceNewWindow), mit deaktivierter Eingabe (disableInput, die Standardeingabe wird blockiert) oder inline (normal, also wie unter Linux mit der Möglichkeit, direkt im Terminal mit dem ausgeführten Kommando zu interagieren). Statt in den Einstellungen können Sie sudo auch in einem Terminal mit Admin-Rechten aktivieren:
Sobald sudo zur Verfügung steht, können Sie das Kommando wie in den folgenden Beispielen anwenden. (Das erste Kommando setzt voraus, dass das Programm edit installiert ist.)
Beachten Sie, dass sudo Restart-Service -Name Spoolernicht funktioniert! sudo kann nur »echte« Kommandos (Executables) ausführen, keine CmdLets. Für CmdLets müssen Sie den Umweg über eine neue PowerShell-Instanz nehmen.
Der Windows-Implementierung von sudo fehlt auch die Option -s, um eine neue Shell zu starten. Stattdessen führt sudo pwsh zum Ziel.
Sicherheitsbedenken: Microsoft warnt davor, sudo ohne unmittelbare Notwendigkeit zu aktivieren. Die Warnung bezieht sich insbesondere auf die Inline-Variante. In der sudo-Implementierung von Linux wurden über den Verlauf von Jahrzehnten immer neue Sicherheitsprobleme gefunden und behoben. Vor diesem Hintergrund rate ich dazu, die Warnungen Microsofts ernst zu nehmen. sudo ist eine vergleichsweise neue, bislang eher selten genutzte Funktion.
gsudo: Eine Alternative sudo ist das schon länger verfügbare Kommando gsudo. Dieses Open-Source-Projekt bietet mehr Features als die Microsoft-Implementierung.
Mozilla hat Version 2.36 seiner VPN-Clients für das Mozilla VPN veröffentlicht.
Mit dem Mozilla VPN bietet Mozilla in Zusammenarbeit mit Mullvad sein eigenes Virtual Private Network an und verspricht neben einer sehr einfachen Bedienung eine durch das moderne und schlanke WireGuard-Protokoll schnelle Performance, Sicherheit sowie Privatsphäre: Weder werden Nutzungsdaten geloggt noch mit einer externen Analysefirma zusammengearbeitet, um Nutzungsprofile zu erstellen.
Das Update auf das Mozilla VPN 2.36 bringt in erster Linie Fehlerbehebungen und Verbesserungen unter der Haube. Für Nutzer auf Android gibt es auf GitHub jetzt außerdem eine Variante vom Mozilla VPN zum Download („foss” im Dateinamen), welche nicht von den Google Play Services abhängt.
Mozilla hat Firefox 150 für Apple iOS veröffentlicht. Dieser Artikel beschreibt die Neuerungen von Firefox 150.
Die Neuerungen von Firefox 150 für iOS
Mozilla hat Firefox 150 für das iPhone, iPad sowie iPod touch veröffentlicht. Die neue Version steht im Apple App Store zum Download bereit.
Schütteln zum Zusammenfassen
Seit Firefox 143 ist es für Nutzer eines englischsprachigen Firefox möglich, mit Hilfe Künstlicher Intelligenz (KI) eine Zusammenfassung der aktiven Website zu generieren. Dazu gibt es drei Wege: über ein Blitz-Symbol in der Adressleiste, über das Menü – oder durch ein kurzes Schütteln des Gerätes. Für Nutzer mit einem iPhone 15 Pro oder neuer sowie iOS 26 oder höher findet die Zusammenhang via Apple Intelligence lokal auf dem Gerät des Anwenders statt. Auf anderen Geräten sowie mit früheren Versionen von iOS wird der Inhalt verschlüsselt an Mozillas cloudbasierte KI gesendet und die Zusammenfassung zurück auf das Gerät geschickt. Selbstverständlich lässt sich das Feature in den Einstellungen auch vollständig abschalten.
Firefox 150 bringt dieses Feature auch für Nutzer, die Firefox auf Deutsch, Französisch, Italienisch, Spanisch, Portugiesisch oder Japanisch nutzen.
Sonstige Neuerungen von Firefox 150 für iOS
Ansonsten bringt das Update auf Firefox 150 vor allem Detail-Verbesserungen, Fehlerbehebungen sowie Optimierungen unter der Haube.
Um schneller die passende Option in den Einstellungen von Firefox zu finden, wurde mit Firefox 149 eine Suchfunktion für die Einstellungen integriert. Firefox 150 integriert auch in die sogenannten „Secret Settings”, über welche sich vorab zukünftige Funktionen testen lassen, eine Suchfunktion. Außerdem wurde eine Schaltfläche integriert, um diese alle „Secret Settings” auf ihren Standardwert zurückzusetzen.
Dazu kommen weitere neue Plattform-Features der aktuellen GeckoView-Engine, diverse Fehlerbehebungen, geschlossene Sicherheitslücken sowie Verbesserungen unter der Haube.
Firefox wird mit mehreren Suchmaschinen ausgeliefert. Mit Startpage steht aktuell eine weitere Suchmaschine für einen Teil der europäischen Firefox-Nutzer standardmäßig zur Auswahl.
Firefox-Nutzer können praktisch jede beliebige Suchmaschine zu Firefox hinzufügen. Der Browser besitzt aber auch schon von Haus aus eine Auswahl an Suchmaschinen, die sofort zur Verfügung stehen, ohne dass der Nutzer manuelle Schritte unternehmen muss.
Seit dem 21. April läuft ein Experiment mit einer geplanten Laufzeit von 30 Tagen, in dessen Rahmen ein Teil der Firefox-Nutzer in Deutschland, Österreich, der Schweiz, den Niederlanden sowie Frankreich Startpage als zusätzliche Suchmaschine sieht. Voraussetzung ist die Nutzung von Firefox 150 oder neuer.
Startpage ist eine Suchmaschine aus den Niederlanden, welche einen besonderen Fokus auf Datenschutz legt. Nach Angaben von Mozilla laufen in Firefox bereits über eine Milliarde Suchanfragen pro Jahr über Startpage, nachdem Firefox-Nutzer die Suchmaschine manuell installiert haben. Startpage sei auch die am häufigsten von Firefox-Nutzern angefragte Suchmaschine für eine standardmäßige Integration.
In diesem Video zeigt Jean die neue Ubuntu Long Term Support Version 26.04, das neue Flaggschiff aus dem Hause Canonical. Welche großen Änderungen gibt es seit der letzten LTS-Version und wem würde ich Ubuntu 26.04 empfehlen?
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Inhaltsverzeichnis:
-------------------------------------
00:00 Intro
01:07 Allgemeines zum Desktop (GNOME 50)
04:11 Automatischer Appstart
04:53 Mehrere Monitore
05:41 Benchmarking-Tool
06:35 Neuer Dokument- und Bildbetrachter
08:27 Neues Terminal
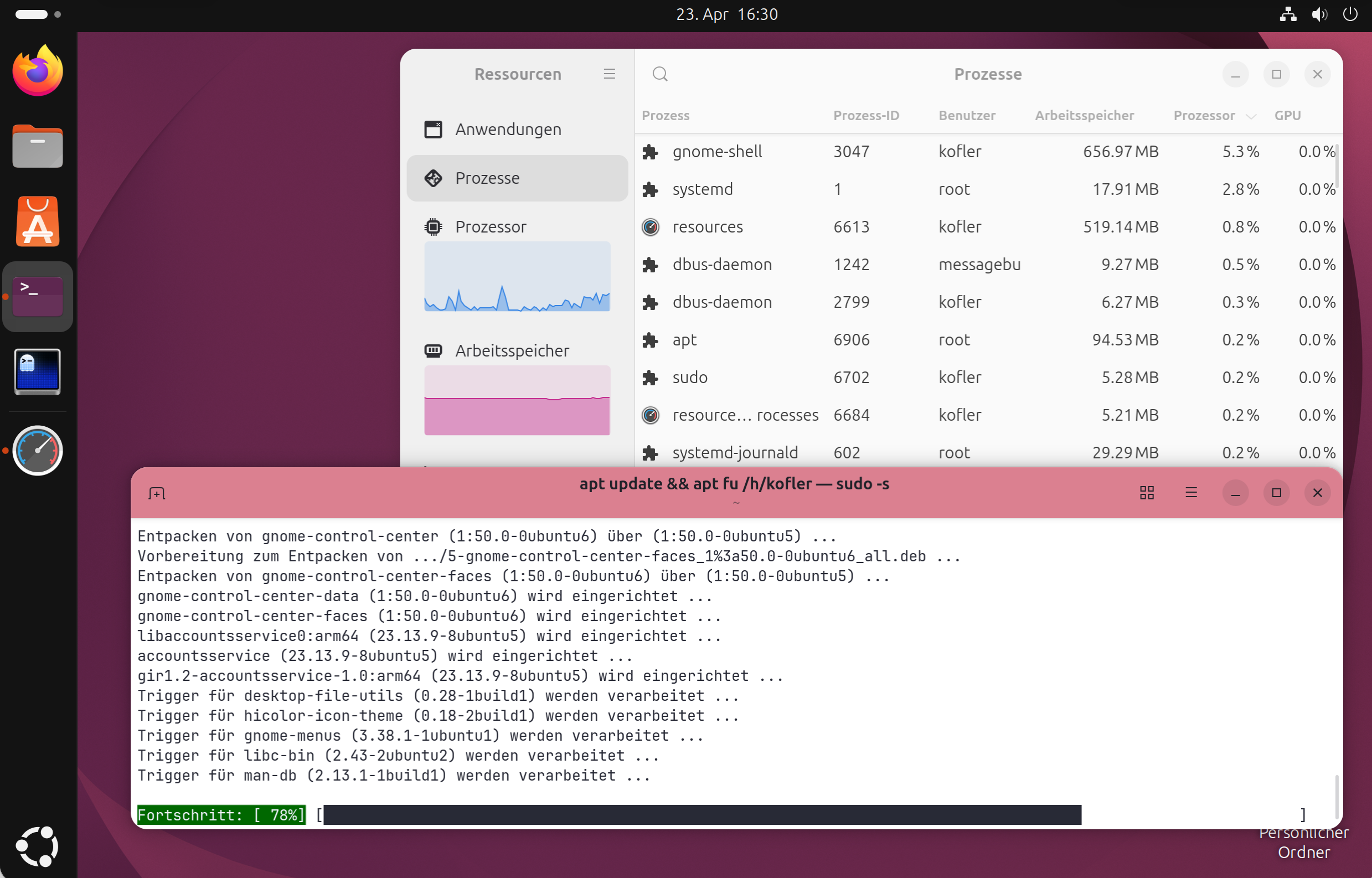
09:15 "Task-Manager" (Ressourcen)
11:12 "Software & Updates"-App entfernt
14:10 App-Zentrum
18:53 Sicherheitszentrum
22:10 Unterstützung für ARM-Architektur
23:17 Keine automatische Erfassung von Daten
25:45 Kritikpunkte an Ubuntu
30:50 Empfehlung zum Update
33:06 Verabschiedung
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Ubuntu 26.04 ist fertig und stellt für die nächsten zwei Jahre die LTS-Messlatte. Im Vergleich zu Version 24.04 hat sich viel geändert. Ich habe mich bemüht, in diesem Blog-Artikel die wichtigsten Details knapp zusammenzufassen.
Noch mehr Lesestoff bieten die Release Notes sowie omgubuntu.co.uk. Einige wesentliche technische Neuerungen waren bereits in Version 25.10 präsent (Rust Core Utilities, Dracut, TPM-Verschlüsselung); diese habe ich im Detail bereits im Blog beschrieben.
Der Ubuntu-Desktop mit dem neuen System-Monitor »Resources«
Software
Die folgende Tabelle fasst die Versionen der Kernkomponenten von Ubuntu 26.04 zusammen:
Ubuntu hat eine ganze Reihe neuer Default-Programme:
Bisher Neu
----------------- -----------
Image-Viewer Eye of Gnome Loupe
PDF-Viewer Evince Paper
System Monitor Gnome System Monitor Resources
Terminal Emulator Gnome Terminal Ptyxis
Video Player Totem Showtime
Apropos Terminal Emulator: Ptyxis ist ein modernes Programm samt GPU-Rendering. Falls Sie noch höhere Ansprüche stellen, steht nun auch Ghostty in den Paketquellen zur Verfügung (Snap-frei mit apt install ghostty).
Standardmäßig nicht mehr installiert wird das Programm Anwendungen & Aktualisierung, mit dem die Paketquellen verändert und proprietäre Treiber installiert werden konnten. Vor allem letztere Funktion war sehr beliebt. Immerhin ist das Programm nur ein apt-Kommando entfernt (apt install software-properties-gtk).
Kein Durchbruch stellt Ubuntu 26.04 bezüglich des Ubuntu-eigenen Snap-Formats dar. Per Default sind überraschend wenige Apps als Snap-Pakete installiert: Firefox, der Firmware Updater, das neue Security Center und die Paketverwaltung App Zentrum alias Snap Store. Das App-Zentrum unterstützt zudem schon seit der vorigen Version auch Debian-Pakete. Die Snap-Revolution bleibt vorerst aus.
Technische Neuerungen
Gnome ist jetzt Wayland-only, X11 wird nicht mehr unterstützt. (XWayland natürlich schon, aber nicht der Betrieb von Gnome unter X.)
Der Kernel hat einen Sprung auf 7.0 gemacht.
Initial-Ramdisk-Dateien werden nun mit Dracut erstellt (schon seit Version 25.10).
Chrony ist der Default-Time-Dämon (ersetzt systemd-timesyncd).
Rust Utilities: Die Rust-Programme/Utilities sudo-rs und rust-coreutils kommen standardmäßig zum Einsatz (schon seit Version 25.10)
Software-Entwicklern hilft das neue Gnome-Programm Sysprof-Programm bei Debugging und Profiling (siehe https://apps.gnome.org/de/Sysprof/).
ROCm: Ubuntu ist stolz darauf, dass die Installation der ROCm-GPU-Bibliotheken von AMD nun ganz einfach mit sudo install rocm gelingt. Praktisch ist das vor allem für KI-Anwendungen und die Ausführung von Sprachmodellen. Phoronix hat das ausprobiert und festgestellt, dass damit die sechs Monate alte Version 7.1 auf der SSD landet. (Aktuell wäre 7.2.2.) Das stiftet wenig Vertrauen in die zukünftige Wartung dieser Pakete …
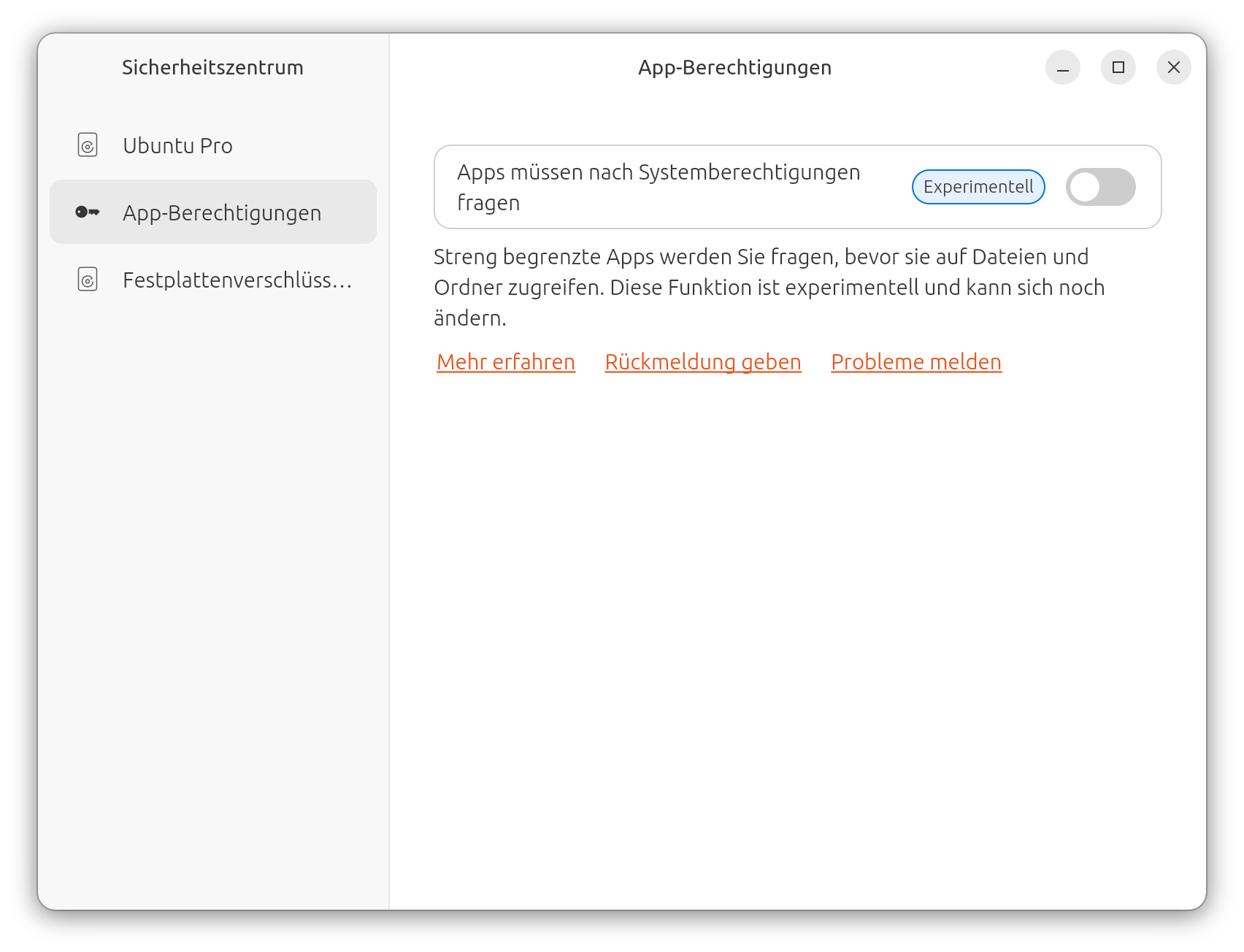
Das neue Sicherheitszentrum (security_center, ein Snap-Paket) hilft bei der Ubuntu-Pro-Aktivierung und der Verwaltung weiterer Sicherheitsfunktionen. Die App hat noch Luft nach oben, würde ich sagen.
Das neue Security Center wirkt noch etwas leer.
Vier GByte RAM sind nicht genug
In der Vergangenheit waren 4 GiB RAM bei den meisten Distributionen zumindest für erste Tests ausreichend. Ubuntu verlangt für Desktop-Installationen nun offiziell 6 GiB. Eine praxisnahe Nutzung unter 8 GiB RAM ist sicher nicht zu empfehlen; das galt auch schon für frühere Versionen. Andererseits waren die 4 GiB lange absolut ausreichend, um Ubuntu zumindest in virtuellen Maschinen einfach schnell mal auszuprobieren. (Und bei vielen anderen Distributionen reicht das noch immer.) Insofern stellt sich die Frage, warum Ubuntu so viel mehr Arbeitsspeicher braucht. (Snap?)
Im Internet gibt es unterschiedliche Angaben, ob der Betrieb nicht doch mit 4 GiB gelingt. Vermutlich. In einer meiner Testinstallationen (6 GiB RAM in einer virtuellen Maschine) sind nach dem Desktop-Login noch 3 GiB verfügbar.
Andererseits blieb eine virtuelle Installation auf einem MacBook mit UTM vor ein paar Tagen hängen (schon während der Installation, nicht im Betrieb). In der Folge habe ich auf weitere 4-GiB-Tests verzichtet. So relevant ist das Limit für mich nun auch wieder nicht. Meine Rechner sind mit ausreichend RAM ausgestattet :-)
Letzte Anmerkung zu diesem Thema: Für Ubuntu Server empfehlen die Release Notes ein Minimum von 1,5 GiB. Zur Einordnung: Im Linux-Unterricht verwende ich dutzendweise Alma-Linux-10-VMs mit 1 GiB RAM, die absolut rund laufen.
Gnome Middle-Click
Ich wechsle berufsbedingt viel zwischen Linux und macOS hin und her. Der für mich auf dem Desktop irritierendste Nachteil von macOS besteht darin, dass das Markieren und Einfügen mit der mittleren Maustaste nicht funktioniert (im Terminal schon, aber nicht mit anderen Programmen). Unter Linux verwende ich diese Funktion ständig, sicher mehrere Male pro Stunde.
Die Gnome-Entwickler sind naturgemäß anderer Meinung und wollen Gnome auch in dieser Hinsicht auf das niedrigere macOS-Niveau angleichen. Die Funktion Einfügen per mittlerer Maustaste ist seit Gnome 50 deaktiviert. Wem fällt so ein Wahnsinn ein? Wer keine Maus bzw. kein Trackpad mit drei Tasten hat, konnte die Funktion schon bisher nicht nutzen. Gut, das ist dann nicht zu ändern. Aber warum muss Gnome alle anderen Anwender ohne jede Not gängeln?
Zum Glück kann der Mittelklick in gnome-tweaks (Optimierungen) oder mit dem folgenden Kommando reaktiviert werden:
gsettings set org.gnome.desktop.interface gtk-enable-primary-paste true
Ubuntu hat die Gnome-Entscheidung einfach nachvollzogen, scheint also irgendwie einverstanden zu sein. Merkwürdig.
Fazit
Bei meinen nicht allzu intensiven Tests hat Ubuntu 26.04 einen runden Eindruck gemacht. Optisch glänzt der Ubuntu-Desktop: Ich kenne keine andere Distribution, die mir out of the box so gut gefällt.
Davon losgelöst klingt mein Fazit schon seit Jahren ziemlich ähnlich: Linux-Einsteiger können mit Ubuntu nicht viel falsch machen. Für mich persönlich ist Ubuntu aber schon eine Weile nicht mehr die erste Wahl.
Die MZLA Technologies Corporation hat mit Thunderbird 150 eine neue Version seines Open Source E-Mail-Clients für Windows, Apple macOS und Linux veröffentlicht.
Neuerungen von Thunderbird 150
Mit Thunderbird 150 hat die MZLA Technologies Corporation ein Update für seinen Open Source E-Mail-Client veröffentlicht.
Der PDF-Betrachter erlaubt nun das Löschen, Kopieren, Verschieben und Exportieren einzelner Seiten einer PDF-Datei.
In den Einstellungen zum Erscheinungsbild gibt es eine neue Option zur Festlegung der Akzentfarbe. Die Ordnerverwaltungsoption „Letzte Ziele” erlaubt jetzt auch eine alphabetische Sortierung.
Die Unterstützung für unaufdringlicher Signaturen (OpenPGP) wurde hinzugefügt. Die Suche im Nachrichtentext wurde für mit OpenPGP und S/MIME verschlüsselte Nachrichten aktiviert.
Karten aus dem Adressbuch können nun als sogenannte vCard in die Zwischenablage kopiert werden.
Beim ersten Start von Thunderbird wird jetzt die Kontoübersicht geöffnet.
Die Monats- und Wochenansicht im Kalender ist jetzt auch über einen Touch-Bildschirm scrollbar.
Ansonsten bringt die neue Version wie immer weitere kleinere Verbesserungen und eine ganze Reihe von Fehlerkorrekturen, welche sich wie immer in den Release Notes (engl.) nachlesen lassen. Auch Sicherheitslücken wurden im neuesten Update wieder behoben.