Eine chinesische KI namens Deepseek zieht aktuell weltweite Aufmerksamkeit auf sich. Ihre App stürmte an die Spitze von Apples App Store, was gleichzeitig die Aktienkurse führender US-Tech-Unternehmen ins Wanken brachte. Doch hinter dem Hype steckt mehr – und weniger –, als viele glauben. Die Aufregung dreht sich um die Behauptung, Deepseek habe für nur rund […]
Unser Buch Coding mit KI wird gerade übersetzt. Heute musste ich diverse Fragen zur Übersetzung beantworten und habe bei der Gelegenheit ein paar Beispiele aus unserem Buch mit aktuellen Versionen von ChatGPT und Claude noch einmal ausprobiert. Dabei ging es um die Frage, ob KI-Tools technische Diagramme (z.B. UML-Diagramme) zeichnen können. Die Ergebnisse sind niederschmetternd, aber durchaus unterhaltsam :-)
UML-Diagramme
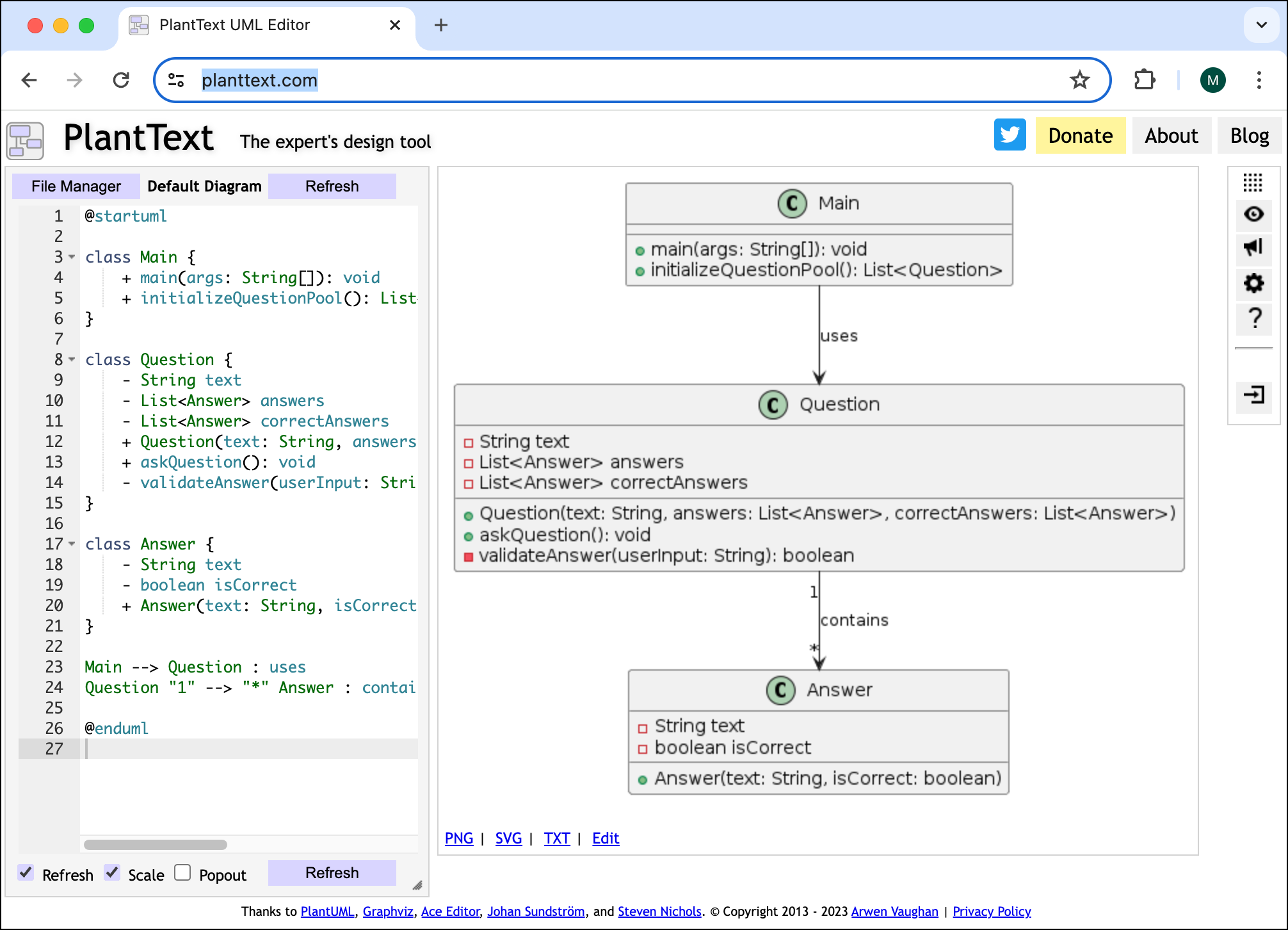
Vor einem halben Jahr habe ich ChatGPT gebeten, zu zwei einfachen Java-Klassen ein UML-Diagram zu zeichnen. Das Ergebnis sah so aus (inklusive der falschen Einrückungen):
Dabei war ChatGPT schon damals in der Lage, PlantUML- oder Mermaid-Code zu liefern. Der Prompt Please generate PlantUML code instead liefert brauchbaren Code, der dann in https://www.planttext.com/ visualisiert werden kann. Das sieht dann so aus:
ChatGPT lieferte den Code für das UML-Diagramm, planttext.com visualisiert ihn
Heute habe ich das ganze Beispiel noch einmal ausprobiert. Ich habe also den Java-Code für zwei Klassen an ChatGPT übergeben und um ein UML-Diagramm gebeten. Vorbei sind die ASCII-Zeiten. Das Ergebnis sieht jetzt so aus:
ChatGPT nennt diesen von DALL-E produzierten Irrsinn ein »UML-Diagramm«Etwas mehr Kontext zum obigen Diagramm
Leider kann ich hier keinen Link zum ganzen Chat-Verlauf angeben, weil ChatGPT anscheinend nur reine Text-Chat-Verläufe teilen kann.
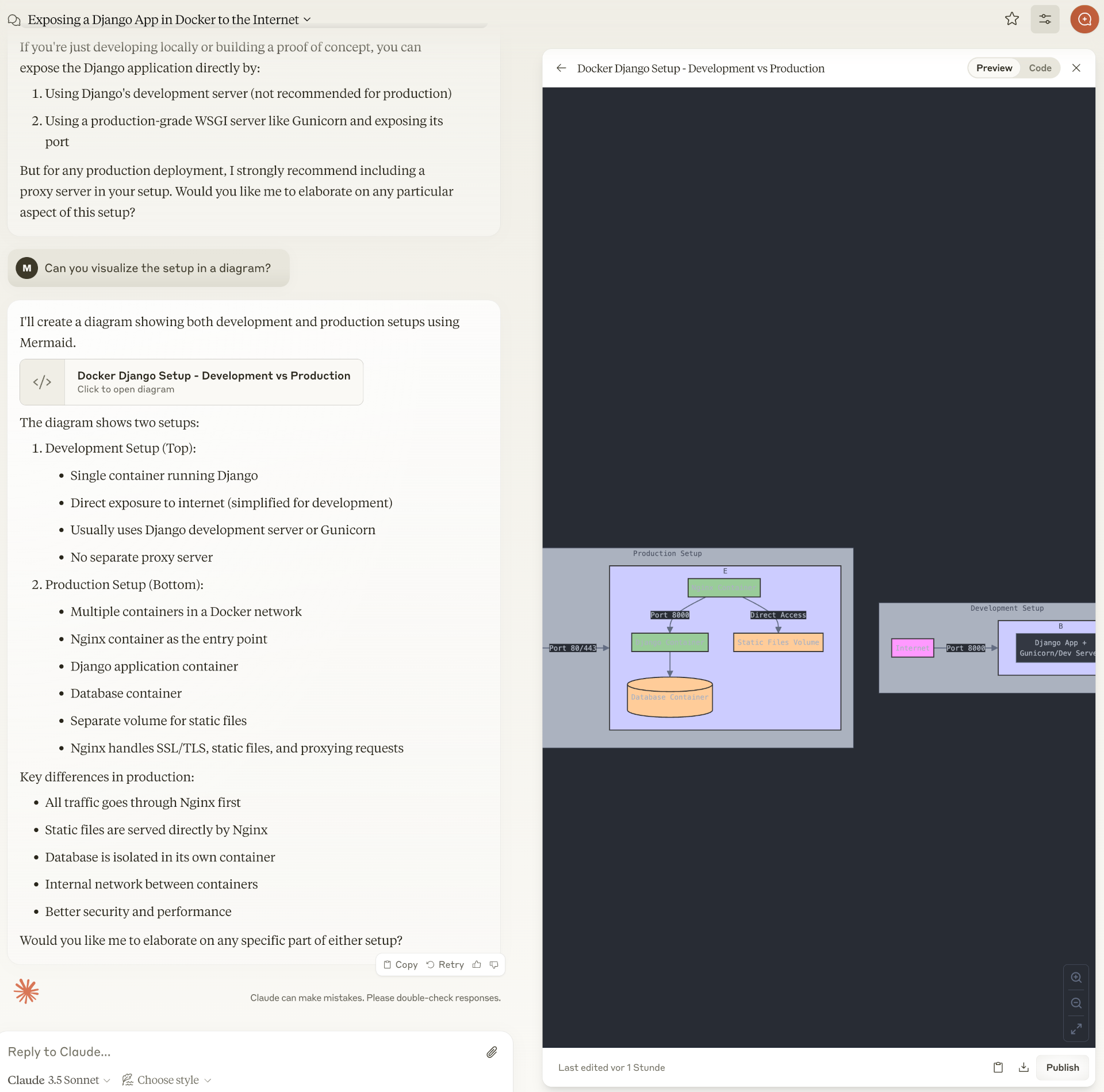
Visualisierung eines Docker-Setups
Beispiel zwei ergibt sich aus zwei Prompts:
Prompt: I want to build a REST application using Python and Django. The application will run in a Docker container. Do I need a proxy server in this case to make my application visible to the internet?
Prompt: Can you visualize the setup in a diagram?
In der Vergangenheit (Mitte 2024) lieferte ChatGPT das Diagramm als ASCII-Art.
Erst auf die explizite Bitte liefert es auch Mermaid-Code, der dann unter https://mermaid.live/ gezeichnet werden kann.
Heute (Dez. 2024) gibt sich ChatGPT nicht mehr mit ASCII-Art ab sondern leitet den Diagrammwunsch an DALL-E weiter. Das Ergebnis ist eine Katastrophe.
ChatGPT’s jämmerlicher Versuch, ein einfaches Docker-Setup zu visualisieren
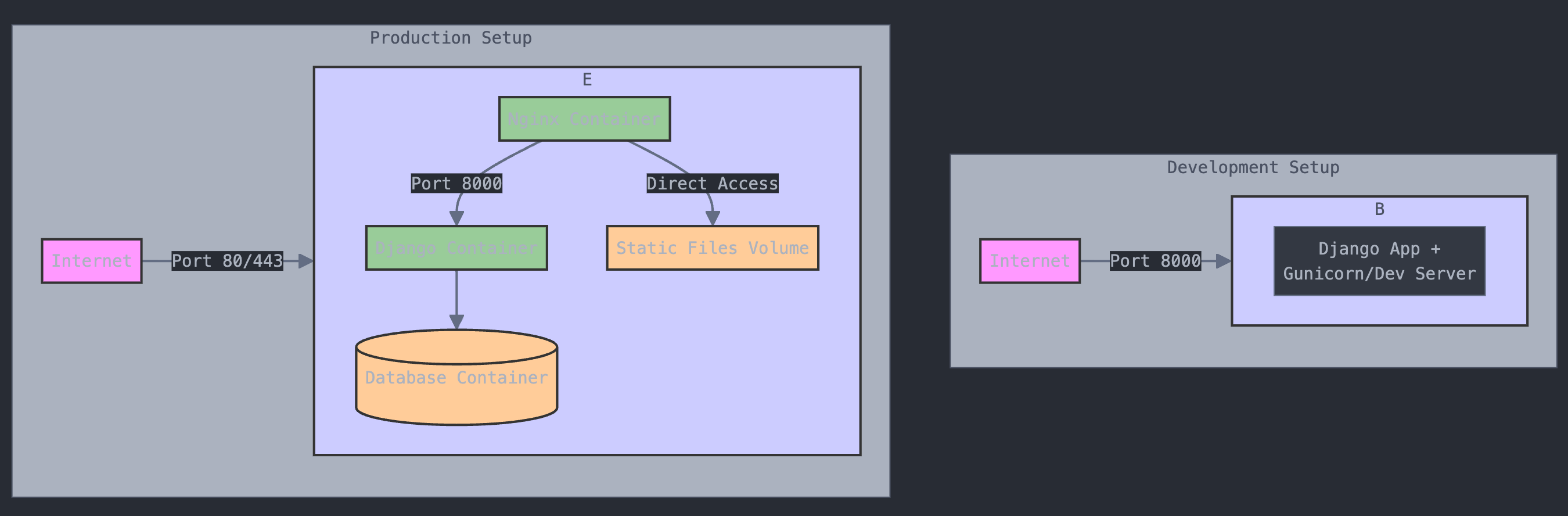
Auch Claude.ai zeichnet selbstbewusst ein Diagramm des Docker-Setups. Dabei wird intern Mermaid verwendet.
Claude leidet offensichtlich unter bedrohlichen Farbstörungen, aber inhaltlich ist das Ergebnis besser als bei ChatGPTHier der relevante Teil des Chat-Verlaufs mit Claude
Fazit
Die Diagramme haben durchaus einen hohen Unterhaltungswert. Aber offensichtlich wird es noch ein wenig dauern, bis KI-Tools brauchbare technische Diagramme zeichnen können. Der Ansatz von Claude wirkt dabei erfolgsversprechender. Technische Diagramme mit DALL-E zu erstellen wollen ist doch eine sehr gewagte Idee von OpenAI.
Die besten Ergebnisse erzielen Sie weiterhin, wenn Sie ChatGPT, Claude oder das KI-Tool Ihrer Wahl explizit um Code in PlantUML oder Mermaid bitten. Den Code können Sie dann selbst visualisieren und bei Bedarf auch weiter optimieren.
Am heutigen 30. November jährt sich die Veröffentlichung von ChatGPT zum zweiten Mal. Die zwei Jahre fühlen sich wie vier an, wenn man bedenkt, was alles passiert ist. Blicken wir auf einige Entwicklungen zurück.
ChatGPT hat die Forschung im Bereich der künstlichen Intelligenz (KI) auf den Kopf gestellt. KI wurde in der Öffentlichkeit bis 2022 mit verschiedenen Teilbereichen wahrgenommen, z. B. Spamfilterung, Bilderkennung, Texterkennung, Klassifikation von Bildern und Texten oder Vorhersagen. Generative Modelle waren eine Nische und vielen eher durch Anwendung des Deepfakes bekannt, bei denen es darum geht, (bewegte) Bilder so gut wie möglich hochrealistisich zu approximieren und nach Belieben anzupassen.
Veränderte Forschungslandschaft
Mittlerweile könnte man annehmen, dass in der Öffentlichkeit KI, ML und LLM synonym betrachtet werden (was zum Glück nicht so gilt). Über diese Vereinfachung könnte man sich jetzt aufregen, sollte es aber differenziert betrachten. Einerseits lernen viel mehr Menschen KI kennen als vorher. Wenn diese Anwender auch nur eine der Technologien, sei es LLM, einsetzen, ist es gewissermaßen eine Bereicherung. Andererseits versuchen viele, bestehende Verfahren und Technologien auf LLMs anzuwenden. Zum Beispiel kann eine Klassifikation (z. B. Spam oder nicht Spam?) entweder mit einem spezialisierten Modell (z. B. Bayes) durchgeführt werden – oder ChatGPT kann einfach nach der Einordnung gefragt werden. Dieser Einsatz ist kritischer zu hinterfragen, weil Nebeneffekte wie Halluzinationen bisher zuverlässige Aufgaben verwässern: wenn ein Klassifikator mit der Softmax-Funktion zwischen 4 Kategorien entscheiden soll, kann er sich nur für eine Kategorie entscheiden. LLMs hingegeben können mit einer neuen Kategorie antworten.
An dieser Stelle sollte erwähnt werden, was ChatGPT eigentlich ist: Es war, ist und bleibt wohl vorerst eine aufgepumpte Textvervollständigungsmaschine. Dabei können die Modelle zum jetzigen Forschungsstand weder das Gesagte konzeptionalisieren, noch einen inneren Sinn anwenden. Die Modelle wurden darauf trainiert, kohärente Texte für Eingaben auszugeben. So kann eine Anfrage wie "Was ist 2+2?" sicherlich durch Training mit 4 beantwortet werden. Das Modell ist jedoch an sich nicht in der Lage, beliebige Rechenaufgaben mit der Präzision eines Taschenrechners zu beantworten.
Das Spannende ist aber der Zusatz "an sich", den ich der Vollständigkeit halber erwähnen muss. Denn die Forscher und Entwickler haben begonnen, diese Schwäche mit Tricks zu kompensieren. Beim Toolformer-Ansatz wird das LLM darauf optimiert, anstatt einer direkten Antwort einen Funktionsaufruf an der passenden Stelle möglichst syntaktisch korrekt auszugeben, z. B. Das Ergebnis von 2+2 ist [Calculator(2+2)]. Die LLM-Ausgabe kann dann anschließend einem Interpreter übergeben werden, der für vorgegebene Funktionen deterministisch korrekt die Berechnung durchführt und das Ergebnis an der Stelle einfügt.
Es lässt sich erahnen, dass LLMs mittlerweile mehr als das reine Modell sind. Die Ausgaben werden technisch durch gezielte Fragestellung, das Prompt Engineering, in eine bestimmte Richtung gelenkt und anschließend angereichert. Diese Schritte können beliebig oft wiederholt werden. Baut man dieses Verfahren so aus, dass in der Antwort bestimmte Aktionen benannt werden, auf die dann wieder Eingaben folgen, kann man Agenten bauen. Das ist ein jahrzenhntealter Ansatz, der jetzt wieder in Mode kommt.
Dieses Ökosystem ist umfangreich und wächst immer weiter. Nur, weil ich ein Large Language Model habe, habe ich noch kein funktionierenden ChatGPT-Klon. Vielmehr gilt es, operative und technische Herausforderungen im Backend zu lösen (Stichwort GPUs und Clustering) und das Modell in eine Pipeline einzubetten. Das Training allein reicht somit nicht mehr aus – bildet aber auch keine Voraussetzung mehr, wie wir später sehen.
Grundsätzlich ist es gut, wenn mehr Aufmerksamkeit der Erforschung künstlicher Intelligenz und maschinellem Lernen gewidmet wird. Die durch die hohen Trainingskosten notwendig gewordene Kommerzialisierung zur Finanzierung hat allerdings auch umfangreiche Auswirkungen gehabt. Die Start-up-Welt verschob sich nicht nur von Blockchain, Metaversum und Fintech hin zu AI, sondern wurde getrieben vom Ziel, das beste Modell zu trainieren. Rückblickend ein Himmelfahrtskommando, wenn man sieht, wie schnell neue Modelle veröffentlicht wurden und wie gering der Return-on-Invest ausfallen kann.
Das Jahr 2023 fühlte sich an, als würde jedes KI-Labor eines jeden größeren Konzerns die Zwischenergebnisse seiner LLM-Leute veröffentlichen. Jede Woche gab es neue Papers, die nicht mehr in jährlichen begutachteten Konferenzen, sondern als Preprint auf arXiv veröffentlicht wurden. LLMs gibt es schon seit über 5 Jahren, aber die Zuverlässigkeit und verbundene Aufmerksamkeit wurde erst mit dem Durchbruch von InstructGPT ermöglicht, was die Basis von ChatGPT in der ersten Version bildete. In 2023 habe ich aktiv eine LLM-Timeline gepflegt und es wurde deutlich, dass "jeder" es einmal versuchen wollte, Beispiel BloombergGPT. Jeder einzelne Beitrag war dabei wertvoll, es war jedoch schwer, den Überblick zu behalten.
Der Gewinner: Open Source
Der Gewinner der letzten zwei Jahre war jedoch nicht nur OpenAI, das letztes Jahr um diese Zeit mit Machtkämpfen (wired.com) beschäftigt war. Vielmehr hat mit Meta (Facebook) ein Unternehmen das Ruder an sich gerissen, von dem man es am wenigsten erwartet hätte, und einen Beitrag geleistet, den man sich noch weniger hätte vorstellen können. Der zeitlich passende Shift von Metaverse zu AI war die Überraschung der letzten Jahre, wie man auch im Aktienkurs sehen konnte.
Die Problematik war, dass die bereits erwähnte Kommerzialisierung zu proprietären Modellen geführt hat, bei denen weder die Gewichte als Basisdaten veröffentlicht noch die Mitbenutzung erlaubt wurde. Durch das aufwändige Training und die hohe Anpassungsfähigkeit an neue Aufgaben hatte auf einmal das Modell an sich einen Wert. Davor war es entweder die Methodik, wie man ein solches Modell trainiert und einsetzt (das - und nur das - ist im Übrigen in der Regel auch nur wissenschaftlich publikationfähig) oder der Datensatz selber, auf dem trainiert wurde. Das Modell konnte man sich früher einfach selber erzeugen und so die Experimente reproduzieren.
Meta AI war nun einer der ersten großen Anbieter, die mit LLaMA im Februar 2023 ein Modell aufwändig trainiert und dann zum Download freigegeben haben. Das geschah allerdings noch unter einer recht restriktiven Lizenz und mit persönlicher Voranmeldung, war aber eines der ersten Modelle, das an die Leistung von OpenAI im entferntesten herankam. Interessanterweise war es auch die ausbleibende Klagewelle, die zur Verbreitung und Weiterentwicklung der Modelle führte, die rechtlich mindestens in einem Graubereich geschah und fast schon an die Einführung der Kartoffel in Deutschland erinnerte.
Spätere Versionen wie Llama 3 wurden unter freizuzügigeren Lizenzen veröffentlicht. Bei diesen lässt sich streiten, ob man sie als Open Source bezeichnen kann. Fest steht, dass für den Einsatz somit Modelle bereitstehen, an denen man lokal testen und sie ggfs. auf eigene Trainingsdaten anpassen kann. Bei der Bilderkennung wurde hierbei üblicherweise der Begriff Transfer Learning verwendet, bei LLMs wurde das Verfahren als Finetuning bekannt. Somit war auch die Bezeichnung von Foundation Models geboren, die die Basis für Finetuning bilden.
Aus Europa stammt ein zwischenzeitlich ähnlich leistungsstarkes Modell mit dem Namen Mistral, das mit der Apache-2.0-Lizenz auch eine echte, anerkannte Open-Source-Lizenz trägt. Der Trend geht somit Richtung Open Source. Zieht man die Parallele zu den Betriebssystemen mit Windows und Linux, ist es schon sehr überraschend, dass in einer solchen Massentechnologie mit technsichen und finanziellen Hürden tatsächlich so schnell der Gedanke der Open-Source-Kultur keimt.
Gesellschaft und Regulierung
Eine weitere Parallele ist die gesellschaftliche Akzeptanz. Diese ist verglichen mit dem Jahr 2000 überraschend hoch. Während Wikipedia als Konkurrenz zur gedruckten Enzyklopädie zu meiner Schulzeit mindestens verachtet wurde, ist ChatGPT als Alternative zur eigenen Arbeitsleistung überraschend salonfähig. Es gilt vielmehr ein "Es geht nicht weg, wir müssen damit klarkommen!" als ein "Wir müssen es unbedingt bekämpfen!".
Bleibt zum Schluss noch der Blick auf die Regulierung. Die Veröffentlichung von ChatGPT kam in dieser Hinsicht zu einem ungünstigen Zeitpunkt. Die Europäische Kommission hat sich in den vergangenen Jahren vorgenommen, den Einsatz in bestimmten Bereichen der künstlichen Intelligenz im Hinblick auf z. B. Scoring-Systemen für Kredite oder Gesichtserkennung zu regulieren. Also typische Einsatzbereiche, die man sich zu der Zeit vorstellte. Ein erster Gesetzesentwurf wurde Anfang 2021, also ein halbes Jahr vor ChatGPT, vorgelegt. Mit ChatGPT kam dann in dem Gesetzgebungsverfahren so richtig Fahrt auf, sodass einerseits die Gegner von KI-Systemen mit einem großen Verbotshebel in der Verhandlung antraten, die Befürworter die Verordnung nicht aus den Augen verloren und die Investitionsträger von KI-Start-ups ihre wirtschaftliche Position bewahren wollten. Das Ergebnis war, dass Foundation Modelle in die Verordnung aufgenommen wurden, aber ab einer Grenze, die scheinbar ihren geistigen Ursprung interessanterweise in der einer zeitgleich entwickelten Executive Order 14110 des US-Präsidenten Joe Biden hat. Zwischenzeitlich ging es darüber hinaus um die strikte Regulierung jeglicher statistischer Methoden. Dies wurde glücklicherweise aber noch abgeschwächt.
Mittlerweile ist der AI Act von der EU in Kraft. So unnötig ich die Regulierung zu einem solch frühen Zeitpunkt halte, so halte ich die Ausnahme großer Teile der Forschung von der Regulierung als wichtige Errungenschaft. Dass man heute aber für Dinge kämpfen muss, die gestern noch selbstverständlich wären (Forschungsfreiheit), ist auch ein Zeichen gesellschaftlicher Umwälzungen.
Interessanterweise gibt es aber mit der TDM-Schranke auch EU-Voragben, die im in dieser Thematik nicht zu unterschätzenden Urheberrecht dem Training von LLMs zuträglich sein können. Ob und inwiefern diese Schranke für Wissenschaft und Wirtschaft anwendbar ist, wird aktuell durch Gerichtsverfahren und Gutachten geklärt.
Fazit
Ich nutze ChatGPT regelmäßig und sehr gerne und finde daher die Veröffentlichung vor zwei Jahren einen wichtigen Meilenstein, zumal es sehr gut bei Übersetzung oder Grammatikoptimierung hilft (dieser Text ist aber menschengeschrieben). Tatsächlich habe ich knapp ein Jahr vorher schon begonnen, mit GPT-3 zu arbeiten, weil es zu der Zeit schon recht populär war, aber noch viel manuelle Arbeit für gute Ergebnisse erforderte. Mit ChatGPT hat sich die Zugänglichkeit und Qualität von LLMs deutlich vereinfacht, weswegen ich den kometenhaften Aufstieg des Produktes gerechtfertigt sehe.
2023 befand sich allerdings die gesamte Techindustrie regelrecht in einem Wahnzustand. Die anfangs hohen Erwartungen, die in die Werkzeuge gesteckt wurden, konnten teilweise erfüllt werden. Wie hoch die Erwartungen allerdings tatsächlich waren, zeigt sich erst, wenn die Investments realisiert werden.
LLMs sind der Hammer, mit dem jedes Problem wie ein Nagel aussieht. Für die Zukunft wünsche ich mir mehr Differenzierung, da es mehr als LLMs in der KI-Welt gibt. Dabei blicke ich gespannt auf die Robotik, weil sich hier ein weiterer großer Anwendungszweck der KI befindet, der auf seinen Durchbruch wartet. Schauen wir, was uns die nächsten Jahre bringen.
Kein Tag vergeht, in dem nicht vom Kampf um die Vorherrschaft bei KI zu lesen ist. Daneben gibt es aber auch eine Entwicklung, die die Stärken von KI erkennt und die Schwächen vermeiden will.
ChatGPT, Copilot & Co. verwenden Large Language Models (LLMs). Diese werden auf leistungsstarken Servern ausgeführt und als Cloud-Services angeboten. Das funktioniert wunderbar. Aber nicht jeder will Daten, Text und Code ständig in die Cloud hochladen. Kann man also — mit »gewöhnlicher« Hardware — LLMs auch lokal ausführen?
Tatsächlich ist das verblüffend einfach. Das Tool der Wahl heißt Ollama. Was Docker für Container ist, ist Ollama für LLMs!
Ollama kann ziemlich mühelos unter Linux, macOS und Windows installiert werden. Unter Windows und macOS starten Sie Ollama als Hintergrunddienst mit einer winzigen grafischen Oberfläche (im Prinzip nur ein Icon, das den Status anzeigt). Unter Linux richten Sie den Dienst mit systemctl ein:
systemctl enable --now ollama
Ollama läuft im Terminal, kann aber auch per API genutzt werden (z.B. zur Realisierung einer Web-Schnittstelle).
Ollama anwenden
Jetzt können Sie Ollama mit dem gleichnamigen Kommando im Terminal ausführen. Mit ollama run <llmname> installieren Sie eines der öffentlich verfügbaren Sprachmodelle (mehr dazu im nächsten Abschnitt) und können dann im Textmodus Kommandos ausführen:
ollama run llama2
>>> I need a regex to verify a date in US format. Can you help?
Of course! To match a date in the format of "MM/DD/YYYY" (month-day-year)
or "MM/DD/YYYY HH:MM AM/PM", you can use the following regular expression:
\b(\d{1,2}/\d{1,2}/\d{4})|(\d{1,2}/\d{1,2}/\d{4} \d{0,2})?\b
Here's a breakdown of how this regex works:
* \b: Matches a word boundary (the start or end of a word) to ensure
we're matching the entire date field.
* (\d{1,2}/\d{1,2}/\d{4}): Matches the month/day/year format. The
(\d{1,2}) captures the month and day as individual digits (0-2
digits for the month and 1-2 digits for the day). The / separates
the date components.
* |: Or, used to match the alternative format.
* (\d{1,2}/\d{1,2}/\d{4} \d{0,2})?: Matches the month/day/year with
time format. The (\d{1,2}) captures the month and day as individual
digits (0-2 digits for the month and 1-2 digits for the day). The /
separates the date components. The \d{0,2} matches the time component
(0-2 digits representing the hour and minute).
* \b: Matches a word boundary to ensure we're matching the entire date field again.
Note that this regex will match both US and international dates in the
"MM/DD/YYYY" format, as well as dates in the "MM/DD/YYYY HH:MM AM/PM"
format. If you need a more specific format (e.g., only US dates),
feel free to modify the regex accordingly.
Manche Sprachmodelle können auch Deutsch (nochmals llama2), wenngleich die sprachliche Qualität mitunter nur mittelmäßig ist.
>>> Was ist der Dopplereffekt?
Der Dopplereffekt ist ein physikalischer Effekt, der durch die Beugung von
Lichtwellen verursacht wird, wenn diese durch eine mediummässige Materie
passt. In einer bestimmten Umgebung oder Situation kann das Licht, das durch
eine bestimmte Fläche oder ein Objekt passt, sich "verlangsamen" und eine
Dopplereffekthelligkeit erzeugen.
Der Dopplereffekt ist ein spezifischer Effekt, der auf der Beugung von
Lichtwellen basiert. Wenn Licht durch ein Medium passt, wird es durch die Faser
des Mediums beugt und umgestaltet. Die Intensität des Lichts, das durch ein
Medium passt, kann sich durch den Dopplereffekt ändern.
Im Alltag können wir den Dopplereffekt beispielsweise bei der Anähnlichkeit von
Objekten in einer Ferne sehen. Wenn ein Auto oder eine andere Objekte in der
Ferne auf uns zukommt, wird es durch die Luft des Raumes beugt und erscheint
größer und weiter weg, als es tatsächlich ist.
Der Dopplereffekt kann auch in anderen Bereichen wie der Optik, Elektrotechnik
oder Medizin verwendet werden. Zum Beispiel können Dopplereffekte in der
Medizin verwendet werden, um die Blutungen in einem Körperteil zu bestimmen.
Es gibt verschiedene Arten von Dopplereffekten, darunter:
* LichtDopplereffekt: Der Effekt, den das Licht erzeugt, wenn es durch ein
Medium passt.
* ZeitDopplereffekt: Der Effekt, den die Zeit erzeugt, wenn sie durch ein
Objekt oder eine bestimmte Umgebung verändert wird.
* Räumliche Dopplereffekte: Der Effekt, den die räumliche Position von Objekten
oder der Standort eines Beobachters auf die Erscheinung des Dopplereffekts
ausübt.
Insgesamt ist der Dopplereffekt ein interessanter und wichtiger
physikalischerEffekt, der in vielen Bereichen der Wissenschaft und Technologie
Verwendung findet.
Ollama stellt seine Funktionen über eine REST-API zur Verfügung und kann somit lokal auch durch eigene Scripts und Editor-Plugins (z.B. Continue für VSCode) genutzt werden. Natürlich gibt es auch Module/Bibliotheken für diverse Sprachen, z.B. für Python.
Öffentliche Sprachmodelle
Die bekanntesten Sprachmodelle sind zur Zeit GPT-3.5 und GPT-4. Sie wurden von der Firma openAI entwickelt und sind die Basis für ChatGPT. Leider sind die aktellen GPT-Versionen nicht öffentlich erhältlich.
Zum Glück gibt es aber eine Menge anderer Sprachmodelle, die wie Open-Source-Software kostenlos heruntergeladen und von Ollama ausgeführt werden können. Gut geeignet für erste Experimente sind llama2, gemma und mistral. Einen Überblick über wichtige, Ollama-kompatible LLMs finden Sie hier:
Viele Sprachmodelle stehen in unterschiedlicher Größe zur Verfügung. Die Größe wird in der Anzahl der Parameter gemessen (7b = 7 billions = 7 Milliarden). Die Formel »größer ist besser« gilt dabei nur mit Einschränkungen. Mehr Parameter versprechen eine bessere Qualität, das Modell ist dann aber langsamer in der Ausführung und braucht mehr Platz im Arbeitsspeicher. Die folgende Tabelle gilt für llama2, einem frei verfügbaren Sprachmodell der Firma Meta (Facebook & Co.).
Wenn Sie llama2:70b ausführen wollen, sollte Ihr Rechner über 64 GB RAM verfügen.
Update: Quasi zugleich mit diesem Artikel wurde llama3 fertiggestellt (Details und noch mehr Details). Aktuell gibt es zwei Größen, 8b (5 GB) und 80b (40 GB).
ollama run llava:13b
>>> describe this image: raspap3.jpg
Added image 'raspap3.jpg'
The image shows a small, single-board computer like the Raspberry Pi 3, which is
known for its versatility and uses in various projects. It appears to be connected
to an external device via what looks like a USB cable with a small, rectangular
module on the end, possibly an adapter or expansion board. This connection
suggests that the device might be used for communication purposes, such as
connecting it to a network using an antenna. The antenna is visible in the
upper part of the image and is connected to the single-board computer by a
cable, indicating that this setup could be used for Wi-Fi or other wireless
connectivity.
The environment seems to be an indoor setting with wooden flooring, providing a
simple and clean background for the electronic components. There's also a label
on the antenna, though it's not clear enough to read in this image. The setup
is likely part of an electronics project or demonstration, given the simplicity
and focus on the connectivity equipment rather than any additional peripherals
or complex arrangements.
Eigentlich eine ganz passable Beschreibung für das folgende Bild!
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Praktische Erfahrungen, Qualität
Es ist erstaunlich, wie rasch die Qualität kommerzieller KI-Tools — gerade noch als IT-Wunder gefeiert — zur Selbstverständlichkeit wird. Lokale LLMs funktionieren auch gut, können aber in vielerlei Hinsicht (noch) nicht mit den kommerziellen Modellen mithalten. Dafür gibt es mehrere Gründe:
Bei kommerziellen Modellen fließt mehr Geld und Mühe in das Fine-Tuning.
Auch das Budget für das Trainingsmaterial ist größer.
Kommerzielle Modelle sind oft größer und laufen auf besserer Hardware. Das eigene Notebook ist mit der Ausführung (ganz) großer Sprachmodelle überfordert. (Siehe auch den folgenden Abschnitt.)
Wodurch zeichnet sich die geringere Qualität im Vergleich zu ChatGPT oder Copilot aus?
Die Antworten sind weniger schlüssig und sprachlich nicht so ausgefeilt.
Wenn Sie LLMs zum Coding verwenden, passt der produzierte Code oft weniger gut zur Fragestellung.
Die Antworten werden je nach Hardware viel langsamer generiert. Der Rechner läuft dabei heiß.
Die meisten von mir getesteten Modelle funktionieren nur dann zufriedenstellend, wenn ich in englischer Sprache mit ihnen kommuniziere.
Die optimale Hardware für Ollama
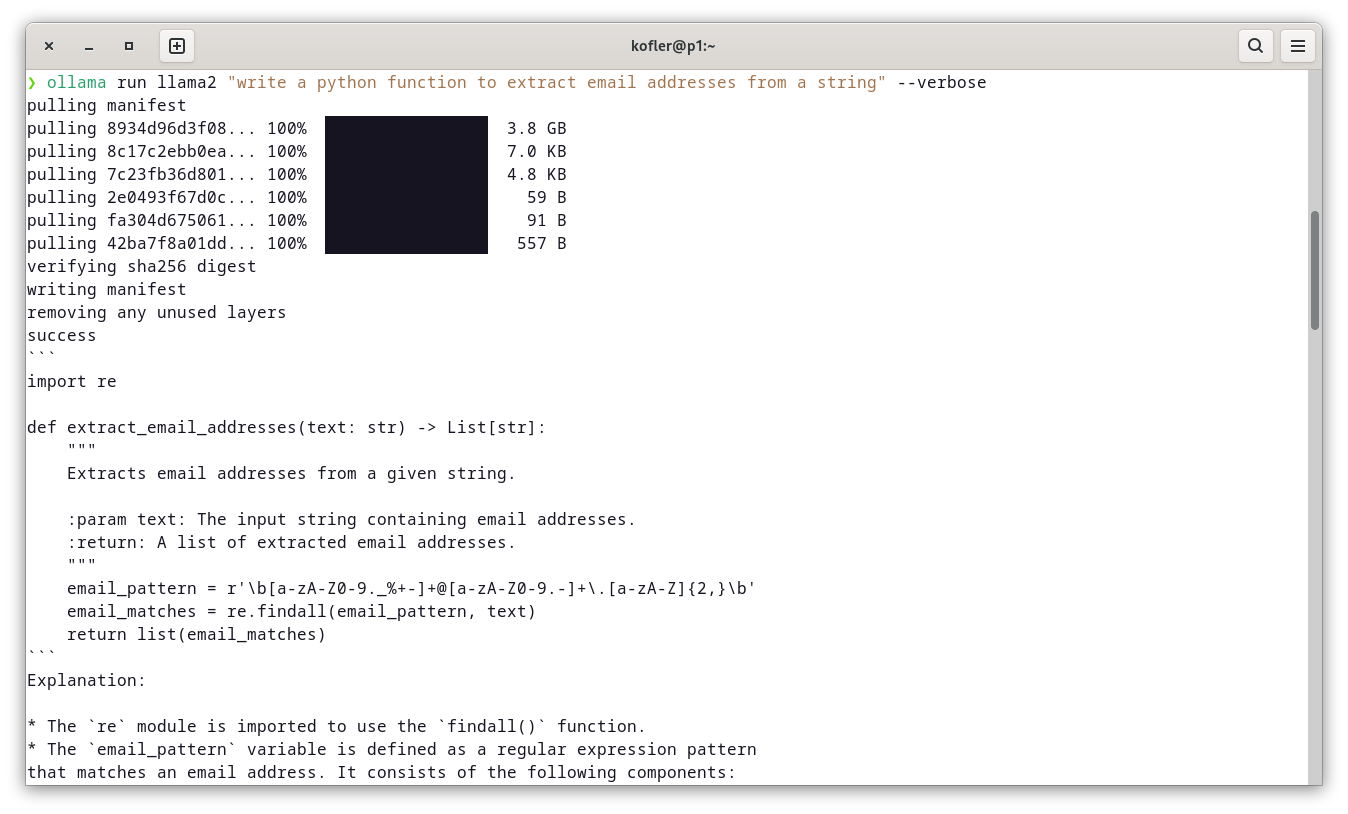
Als Minimal-Benchmark haben Bernd Öggl und ich das folgende Ollama-Kommando auf diversen Rechnern ausgeführt:
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
Die Ergebnisse dieses Kommandos sehen immer ziemlich ähnlich aus, aber die erforderliche Wartezeit variiert beträchtlich!
Grundsätzlich kann Ollama GPUs nutzen (siehe auch hier und hier). Im Detail hängt es wie immer vom spezifischen GPU-Modell, von den installierten Treibern usw. ab. Wenn Sie unter Linux mit einer NVIDIA-Grafikkarte arbeiten, müssen Sie CUDA-Treiber installieren und ollama-cuda ausführen. Beachten Sie auch, dass das Sprachmodell im Speicher der Grafikkarte Platz finden muss, damit die GPU genutzt werden kann.
Apple-Rechner mit M1/M2/M3-CPUs sind für Ollama aus zweierlei Gründen ideal: Es gibt keinen Ärger mit Treibern, und der gemeinsame Speicher für CPU/GPU ist vorteilhaft. Die GPUs verfügen über so viel RAM wie der Rechner. Außerdem bleibt der Rechner lautlos, wenn Sie Ollama nicht ununterbrochen mit neuen Abfragen beschäftigen. Allerdings verlangt Apple leider vollkommen absurde Preise für RAM-Erweiterungen.
Zum Schluss noch eine Bitte: Falls Sie Ollama auf Ihrem Rechner installiert haben, posten Sie bitte Ihre Ergebnisse des Kommandos ollama run llama2 "write a python function to extract email addresses from a string" --verbose im Forum!