Hetzner: Preisgünstig oder billig?
Meine Website kofler.info läuft in einer virtuellen Maschine. Und diese VM läuft wiederum auf einem Root-Server bei Hetzner. Seit ca. 4 Jahren, störungsfrei. Als Virtualisierungssystem verwende ich KVM. Auf dem Root-Server laufen auch andere VMs, die ich für die Arbeit an meinen Büchern sowie für den Unterricht an der Fachhochschule brauche.
Das Setup hat sich in den letzten 15 Jahren immer wieder gewandelt, dennoch ich bin Hetzner treu geblieben (auch in anderen beruflichen Projekten). Dass ich mich vor 15 Jahren gerade für Hetzner entschieden habe, war Zufall. Danach sah ich keinen Grund für einen Wechsel. Bis vor einer Woche. Und das ist eine etwas längere Geschichte.
Vorgeschichte: Ein Lob auf Hetzner
Ich bin seit ca. 15 Jahren Kunde der Firma Hetzner. Ich betreibe dort privat den oben erwähnten Root-Server. Auf Hetzner läuft auch ein Server, den ich und ein Freund für eine gemeinsame Firma administrieren und auf dem diverse Kunden täglich arbeiten. Bei Hetzner laufen schließlich diverse Websites, die ich für Freunde und Verwandte betreue. Auch meine Domains (z.B. kofler.info) werden via Hetzner administriert und abgerechnet.
In meinem Linux-Buch verwende ich Hetzner neben amazon/AWS als Beispiel für die Ausführung von eigenen Servern bzw. Cloud-Instanzen. (Das ist keine Empfehlung, weder für die eine noch für die andere Firma! Und natürlich bekomme ich von beiden Firmen nichts dafür, dass ich sie als Beispiel verwende. Aber irgendwelche Firmen muss ich für Beispiel-Setups verwenden. Ich brauche Firmen, die im europäischen Raum und international Stellenwert haben. Ich habe im Buch keinen Platz für fünf oder zehn Beispiele/Hoster/Cloud-Anbieter. Also habe ich mich für diese beiden entschieden.)
Seit 15 Jahren bin ich zufriedener Kunde bei Hetzner. Ja, meine Server hatten in dieser Zeit auch Probleme, z.B. einen Harddisk-Ausfall, der dank RAID ohne Datenverlust blieb und wo die Disk mit minimaler Downtime ausgetauscht wurde. Ein Server, der nach knapp 4 Jahren Dauereinsatz allmählich instabil wurde und den ich deswegen ein paar Monate vor dem schon geplanten Upgrade austauschen musste. Aber prinzipiell hat immer alles bestens funktioniert, sowohl was die langjährige Stabilität meiner Server betrifft, als auch was den selten benötigten Support betrifft.
Im Vergleich zu großen Cloud-Anbietern (und insbesondere im Vergleich zu AWS) ist ein Root-Server bei Hetzner viel preisgünstiger. Und in der Abrechnung beinahe unendlich viel einfacher. Ein Fixpreis mit 20 TB Traffic (die ich noch nie gebraucht habe), keine komplizierte Zusammensetzung aus einem halben Dutzend im Voraus schwer kalkulierbarer Preiskomponenten. Alles in allem: Für mich hat das Preis/Leistungsverhältnis gepasst, und ich war mit der Leistung zufrieden.
Ein neuer Server mit nur vier Monaten Lebenszeit
Im letzten Satz bin ich plötzlich ins Imperfekt gerutscht. Ich war zufrieden, ja, aber seit einer Woche bin ich massiv verunsichert. Ist Hetzner noch preisgünstig, oder ist das Angebot mittlerweile billig? Billig im Sinne, dass zwar der Preis stimmt, aber die Leistung nicht mehr? Seit ich Kunde bei Hetzner bin, ist die Firma zu einem riesigen Unternehmen geworden, das international auftritt. Geht Quantität vor Qualität?
Die Verunsicherung stammt von einem Server-Upgrade, das ich im April 2024 vorgenommen habe. Als Dedicated Root Server kommt nun ein AX52-Server zum Einsatz (AMD Ryzen 7700, 64 GB RAM, 4xPCIe-SSD mit je 1 TB). Die erste Unstimmigkeit trat schon vor der Installation auf: Im Live-System machte ich einen raschen SMART-Test für die vier SSDs:
for disk in /dev/nvme?n1; do echo $disk; smartctl -A $disk | grep -E 'Power On Hours|Data Units'; done
/dev/nvme0n1
Data Units Read: 220,843,669 [113 TB]
Data Units Written: 51,845,317 [26.5 TB]
Power On Hours: 3,675
/dev/nvme1n1
Data Units Read: 715,250,594 [366 TB]
Data Units Written: 411,316,958 [210 TB]
Power On Hours: 12,078
/dev/nvme2n1
Data Units Read: 3,680,708 [1.88 TB]
Data Units Written: 3,083,051 [1.57 TB]
Power On Hours: 2
/dev/nvme3n1
Data Units Read: 3,673,898 [1.88 TB]
Data Units Written: 3,082,770 [1.57 TB]
Power On Hours: 2
Ergebnis: Zwei fabriksneue SSDs, zwei weitere SSDs, die schon eine Weile im Einsatz waren. Mir ist klar, dass ich mit einem neuen Server nicht automatisch neue SSDs bekomme, aber 12.078 Betriebsstunden = 1 1/2 Jahre ist schon ordentlich. 210 TB written bedeutet außerdem ca. 1/3 der garantierten Endurance für 1 TB-SSDs (siehe z.B. hier). Mein Plan war, den Server wieder ein paar Jahre laufen zu lassen. Insofern habe mich die SMART-Ergebnisse unglücklich gemacht. Ich habe Hetzner kontaktiert, die fragliche SSD wurde auf Kulanz durch eine andere SSD ersetzt, deren Nutzungsdaten etwas geringer waren. OK.
Der neue Server lief in der Folge drei Monate ohne eine Störung. Dann begannen plötzliche Abstürze/Reboots, zuerst ein Reboot alle zwei bis drei Stunden, aber schon einen halben Tag später Reboots innerhalb weniger Minute. (Vielleicht noch ein wenig Background: Dieser Server läuft die meiste Zeit komplett im Leerlauf. Klassisches LAMP-System, viele Datenbanken, Mail-Server etc., aber geringe Nutzung.)
Ich habe den Hetzner-Support kontaktiert, dieser schlug vor, den Server auszutauschen und die vier SSDs in einen neuen Server zu stecken. Nach meiner Zustimmung war der Server eine Stunde später wieder stabil online. Zwar war der vorangegangene 1/2 Tag mit Ausfällen verbunden, aber immerhin nicht mit einem Datenverlust.
Faszinierend: Nach dem Austausch mussten ich nichts an der Konfiguration ändern. Auf meinen Wunsch blieben die IPv4- und IPv6-Adressen unverändert. Die Netzwerkkonfiguration mit Netplan (Ubuntu) funktionierte daher out of the box. Was mich mehr verblüffte: Auch der Boot-Prozess via EFI/GRUB funktionierte auf Anhieb. Ein Lob an den Hetzner-Support und an die Qualität des Setup-Generators für Neuinstallationen!
Unbeantwortet blieb allerdings meine Frage, was denn die Ursache des raschen Server-Tods sein könnte. Die Stromversorgung? Ein instabiler Prozessor? Ein schadhaftes Mainboard? Keine Antwort von Hetzner heißt wohl: Offenbar hatte ich eben Pech mit der Hardware. Sollte nicht passieren, lässt sich aber vielleicht nicht ganz ausschließen.
Einmal ist keinmal, zweimal ist einmal zu viel
Vor einer Woche hat sich das Spiel wiederholt. Mitten in der Nacht begannen wieder plötzliche Reboots, in der Früh lagen zwischen den Reboots nur noch Minuten.
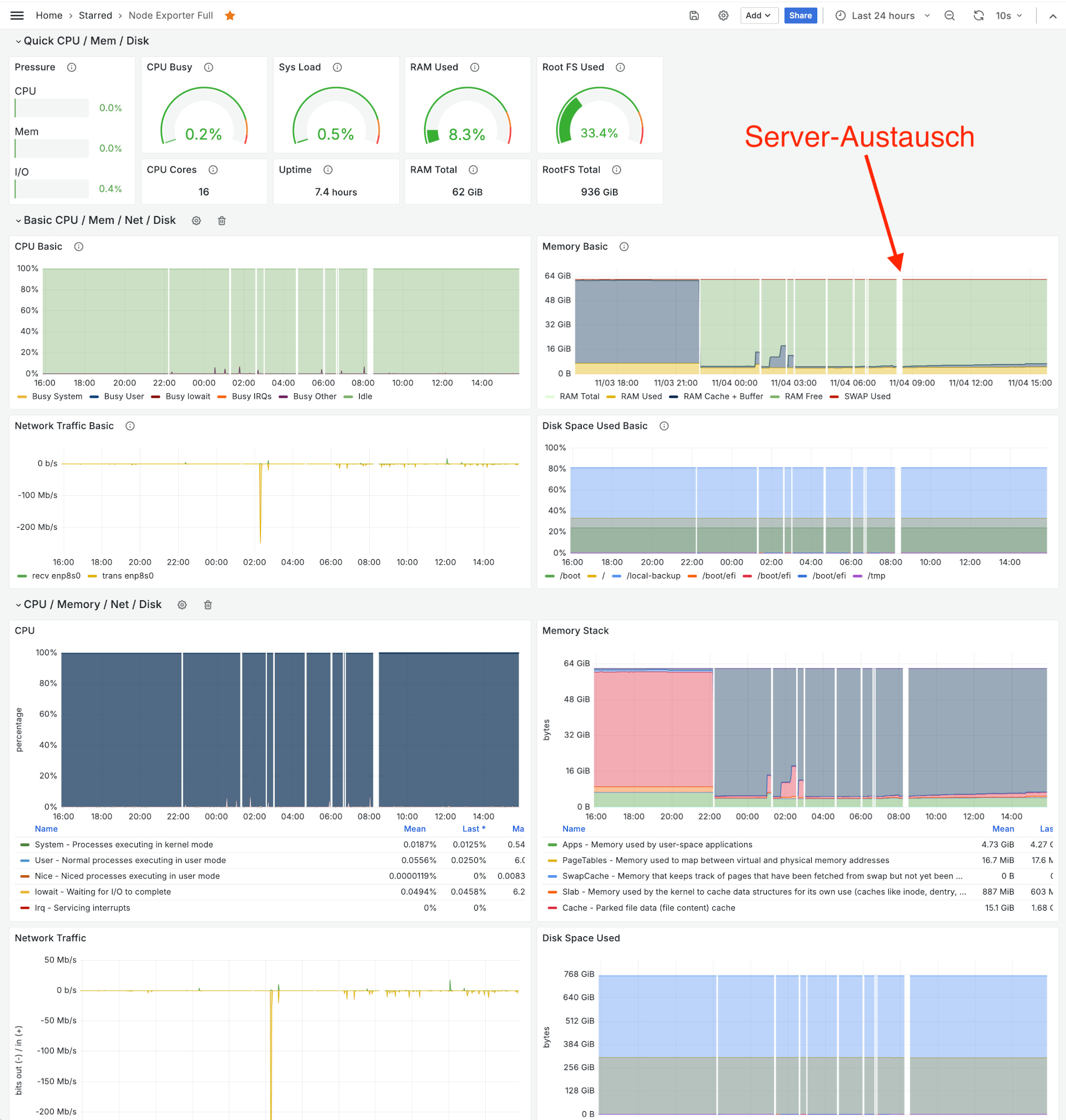
Erster unerwarteter Reboot am 3.11. um 22:13, dann 12 weitere Reboots innerhalb von 8 Stunden.
last | grep reboot
reboot system boot 6.8.0-48-generic Mon Nov 4 08:28 still running
reboot system boot 6.8.0-48-generic Mon Nov 4 08:01 - 08:12 (00:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:53 - 08:12 (01:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:44 - 08:12 (01:27)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:38 - 08:12 (01:33)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:02 - 08:12 (02:10)
reboot system boot 6.8.0-48-generic Mon Nov 4 06:00 - 08:12 (02:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 05:53 - 08:12 (02:18)
reboot system boot 6.8.0-48-generic Mon Nov 4 04:40 - 08:12 (03:32)
reboot system boot 6.8.0-48-generic Mon Nov 4 03:01 - 08:12 (05:11)
reboot system boot 6.8.0-48-generic Mon Nov 4 02:36 - 08:12 (05:35)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:35 - 08:12 (06:36)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:17 - 08:12 (06:54)
reboot system boot 6.8.0-48-generic Mon Nov 4 01:16 - 08:12 (06:55)
reboot system boot 6.8.0-48-generic Sun Nov 3 22:13 - 08:12 (09:58)
Genau das gleiche Verhalten wie vor vier Monaten! Etwas verzweifelt habe ich neuerlich Hetzner kontaktiert, die den Server ebenso schnell wie beim ersten Mal austauschten. Seither ist der Server (Stand: heute, 11.11.2024) seit einer Woche störungsfrei.
Diesmal war ich hartnäckiger, was die Ursachenergründung anging. Ich habe bei Hetzner dreimal nachgefragt, was die Fehlerursache sein und wie weitere Ausfälle vermieden werden können. Ich habe explizit gefragt, ob es Problem mit der Stromversorgung des Racks gibt, in dem der Server löuft, oder ob die AX52-Serie instabil ist. In diesem Fall wäre ein Austausch des Servers gegen ein Modell einer andere Serie eine Option für mich.
Alleine, alle Fragen blieben unbeantwortet. Und das ist wirklich ärgerlich!
Update 13.11.: Heute ist doch noch eine Antwort eingetroffen. Die fraglichen Server werden untersucht, aber es ist bisher keine Ursache bekannt.
Jetzt frage ich Sie!
Die wenigen Server, die ich bei Hetzner betreibe, lassen naturgemäß keine statistisch wertvollen Aussagen zu. Ja, es kann tatsächlich sein, dass ich ZWEIMAL Pech hatte. Aber die Wahrscheinlichkeit dafür ist gering. Es wird also vermutlich eine plausible Begründung geben — aber ich kenne sie nicht. Auf jeden Fall hat mein Vertrauen in den langjährigen Betrieb von Servern bei Hetzner einen massiven Dämpfer erfahren.
Unter den Lesern meiner Bücher, meines Blogs, meines mastodon-Auftritts gibt es sicher Admins, die Erfahrungen mit Hetzner haben. Ich würde mich über Rückmeldungen, egal ob privat per Mail, im Forum meiner Website oder auf mastodon, sehr freuen.
- Sind Sie mit Hetzner so zufrieden, wie ich es bis vor kurzem war?
-
Haben Sie negative Erfahrungen gemacht?
-
Hat sich in den letzten Jahren etwas geändert?
-
Wie lange lassen Sie einen Root-Server laufen, wenn alles funktioniert? (Mein Zielwert war immer vier Jahre.)
-
Ist der Root-Server für Sie tot? D.h., ist die Cloud die Alternative? (Cloud-Angebote mit großen Disks sind allerdings ausgesprochen teuer.)
-
Und, vielleicht am interessantesten: Können Sie europäische Alternativen empfehlen? (Aus Datenschutzgründen ist ein US-Rechenzentrum keine wünschenswerte Alternative.)
Ich bedanke mich schon jetzt für jede Rückmeldung.
PS: Der eigene Betrieb von Servern ist für mich als Privatperson keine Option.