Static Site Generators haben in letzter Zeit stark an Popularität gewonnen. Aus gutem Grund, denn statische Webseiten bieten eine Menge Vorteile gegenüber dynamisch generierten Websites. Statische Seiten sind schnell, erzeugen kaum Last auf dem Server und bieten eine wesentlich geringere Angriffsfläche als PHP-Projekte wie WordPress.
Durch die Verwendung von Static Site Generatoren wird die Erstellung und Wartung statischer Webseiten einfach und komfortabel, ohne dass man sich mit dem HTML-Code der Seite direkt auseinandersetzen muss. Der größte Vorteil der Generatoren ist jedoch, dass man Änderungen an der kompletten Seite vornehmen kann, ohne dutzende HTML-Dateien einzeln zu bearbeiten. Das übernimmt der Generator für einen.
Üblicherweise werden dafür Projekte wie Hugo oder Jekyll verwendet. Diese haben eines gemeinsam, sie werden komplett auf der Kommandozeile bedient und die Formatierung der Texte wird die Auszeichnungssprache Markdown realisiert.
Das mag für technikaffine Menschen sinn- und reizvoll sein. Wenn man aber eine Lösung für weniger technikinteressierte Menschen sucht, scheiden diese Generatoren aus. Hier bietet sich ein Generator mir grafischer Benutzeroberfläche eher an.
Ein solches Projekt ist Publii. Publii bezeichnet sich als Static CMS und bietet im Gegensatz zu den Static Site Generatoren eine grafische Benutzeroberfläche. Das Programm ist Open Source, der Code liegt auf Github. Fertige Builds gibt es für Windows, MacOS und als .Appimage, .rpm und .deb Pakete für Linux. Diese findet man direkt auf der Projektseite getpublii.com.
Wofür eignet sich Publii?
Natürlich haben statische Webseiten auch Nachteile. Da der Content nicht live generiert wird, lässt sich beispielsweise kein Shop realisieren. Aber auch eine Kommentarfunktion bieten statische Seiten nicht. Hier muss man sich mit Drittanbietern behelfen und deren Dienste einbinden. Wenn man den Dienst Disqus verwenden möchte, bietet Publii eine Schnittstelle über welche sich Disqus-Kommentare in den Blogbeitrag einbinden lassen. Möchte man aus Datenschutzgründen einen anderen, evtl. selbstgehosteten Dienst nutzen, so muss man selber Hand am Theme anlegen.
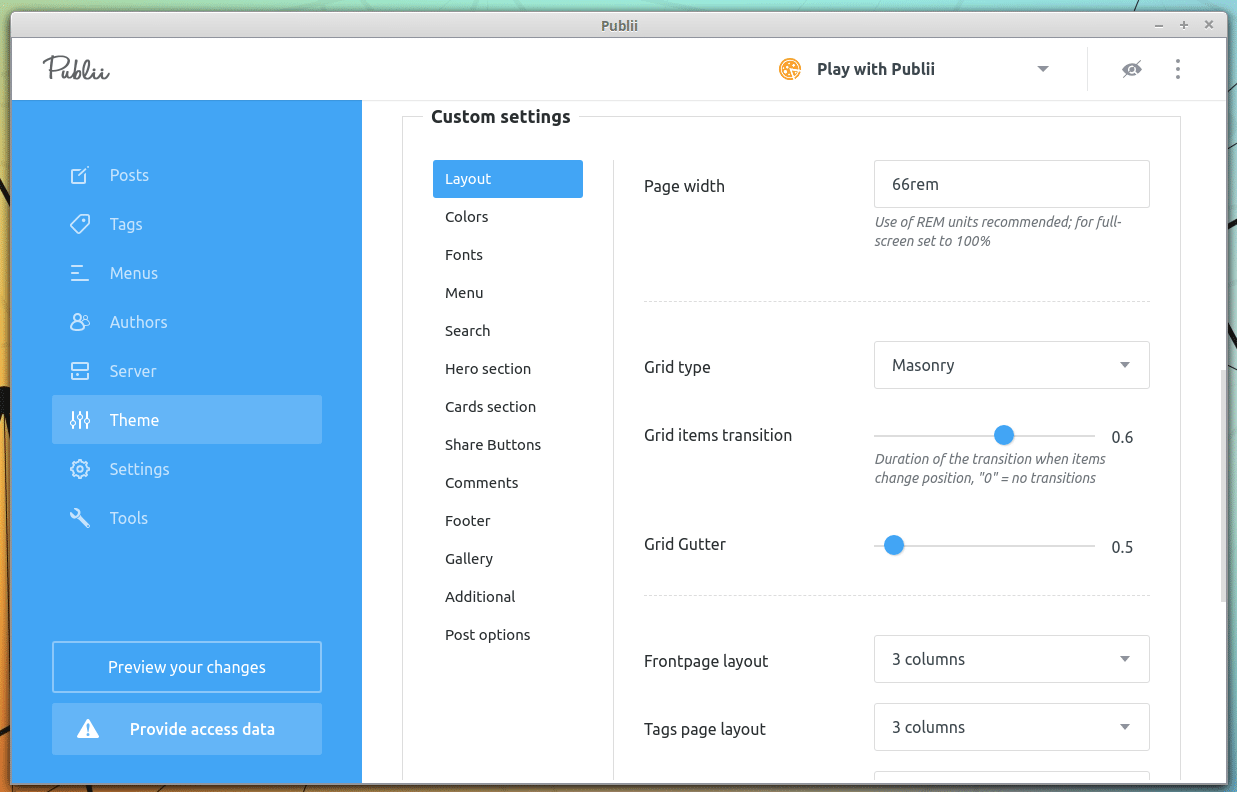
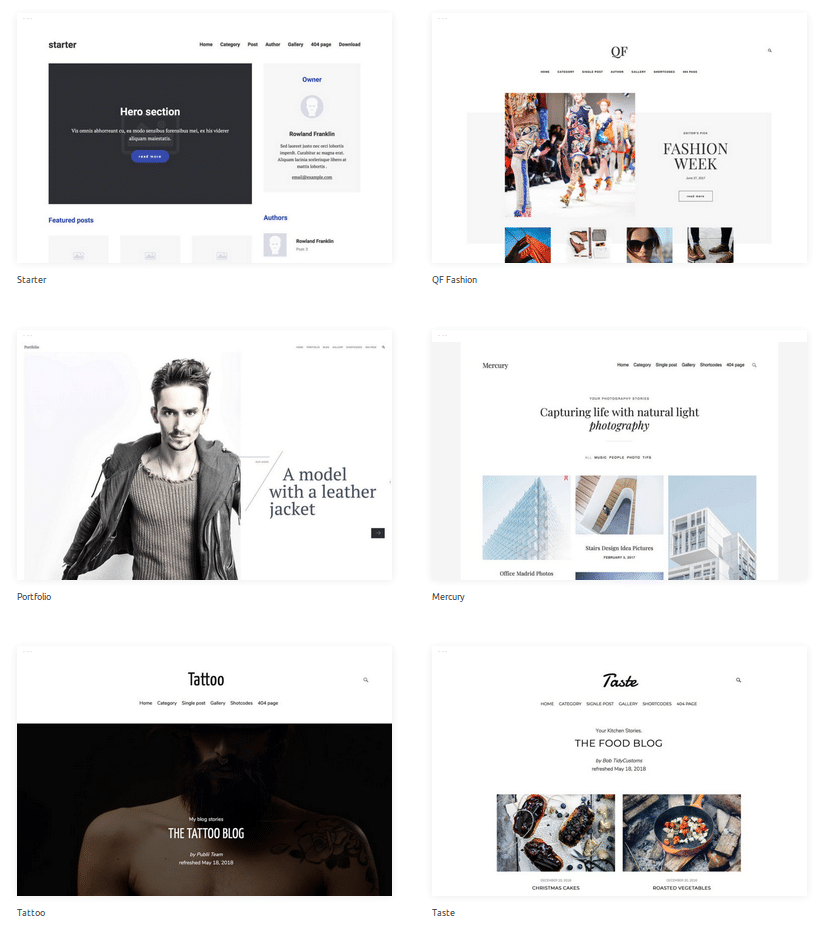
Derzeit stehen für Publii acht Themes zur Verfügung. Die Aufmachung der Webseite lässt darauf schließen, dass zukünfig auch kostenpflichtige Themes angeboten werden sollen. Im Gegensatz zu aufwendigen WordPress Themes ist die Gestaltung der Seiten recht eingeschränkt. So sind alle Themes mehr oder weniger auf das darstellen von Blogbeiträgen spezialisiert. Auf der Startseite werden die einzelnen Beiträge nach Veröffentlichungsdatum mit Anreissertext dargestellt.
Es lässt sich zwar verhinder dass bestimmte Artikel auf der Startseite aufgeführt werden, ein Magazinartiges darstellen von bestimmten, nach Kategorien sortierten Beiträgen auf der Startseite ist jedoch nicht möglich.
Aus meiner Sicht eignet sich Publii also besonders zum Erstellen von Blogs, eben mit Einschränkungen bei der Kommentarfunktion, oder Portfolioseiten. Für Magazine oder eine Wissensdatenbank wie ein Wiki ist es (zumindest bisher) weniger geeignet.
Publii: Oberfläche und Funktionen
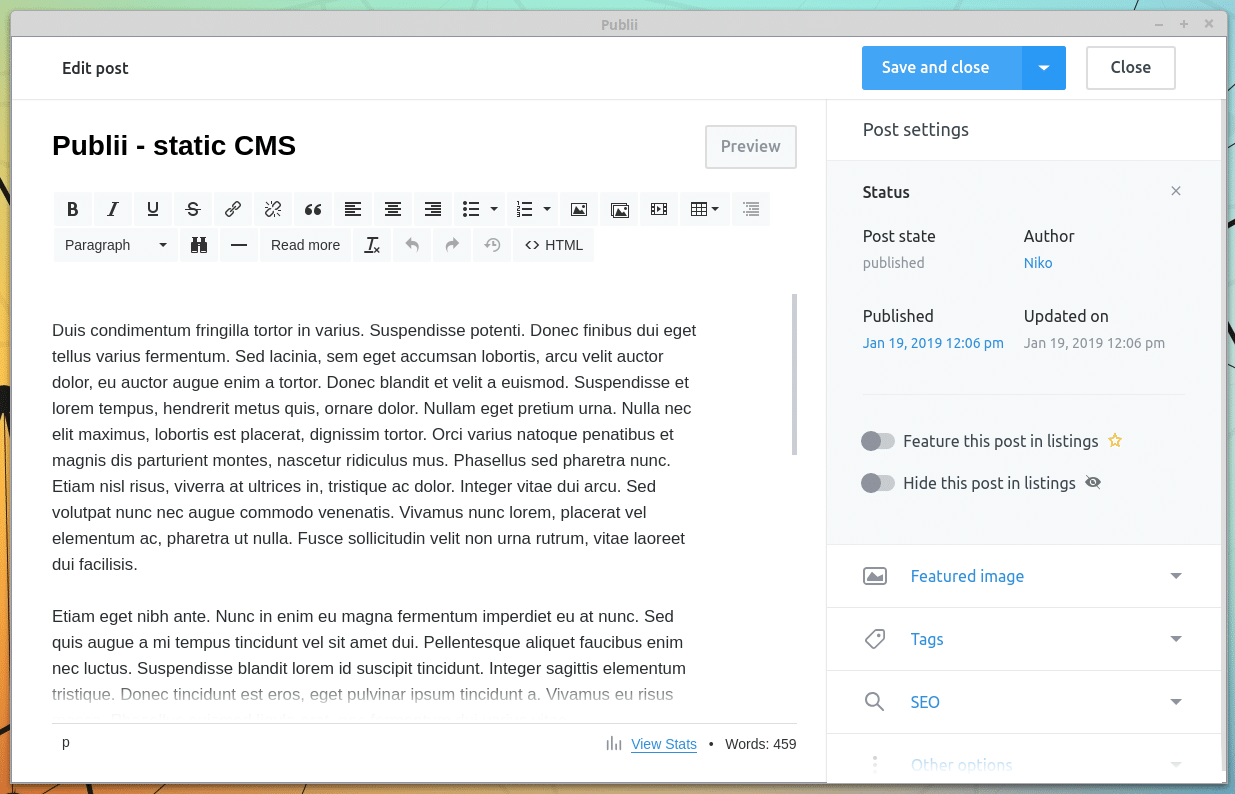
Der Aufbau der Benutzeroberfläche erinnert ein wenig an das Backend von WordPress. So findet man auf der linken Seite eine Menüleiste, über welche sich neue Posts erstellen, das Theme anpassen oder Einstellungen verändern kann. Außerdem lassen sich verschiedene Autoren anlegen, Tags vergeben und Menüs anlegen.
Wer schon mit WordPress gearbeitet hat, der wird sich im Backend von Publii schnell zurecht finden.
Viele Funktionen die man bei WordPress über Plugins realisieren muss, bringt Publii bereits von Haus aus mit. Fehlt hingegen eine Funktion, so wird es mit dem Nachrüsten natürlich schwierig. Beispielsweise bringt Publii bereits eine Funktion mit um die lästigen Cookie-Bars einzublenden. Obwohl sich natürlich gerade eine statische Seite dazu anbietet ohne Cookies eingesetzt zu werden.
Außerdem werden auf Wunsch AMP-Seiten unterstützt, der HTML- und CSS-Code kann komprimiert (also ohne Kommentare, Formatierung usw.) erzeugt werden. Die angebotenen Themes erzeugen alle responsive Webseiten, so dass die Seite sowohl für Desktop-, als auch für Mobilgeräte geeignet sind.
Über den Reiter “Tools” lassen sich Backups der Webseite erstellen. Außerdem kann eigener HTML- und CSS-Code in die Seite eingefügt werden, ohne dass man die Theme-Dateien direkt bearbeiten muss.
Außerdem gibt es ein experimentelles Tool um Beiträge aus WordPress zu importieren.
Über die Vorschaufunktion lässt sich die Seite rendern und im lokalen Webbrowser darstellen, ohne dass die Änderungen direkt veröffentlicht werden.
Hat man eine Webseite erstellt, kann Publii die HTML-Dateien entweder auf der lokalen Festplatte erzeugen, oder diese direkt auf den eigenen Server oder Webspace laden.
Themes binden Google Fonts ein
Mit statischen Seiten lassen sich besonders einfach datenschutzfreundliche Webseiten erstellen. Ohne Kommentarfeld, Kontaktformular, Benutzerlogin usw. werden praktisch keine personenbezogenen Daten verarbeitet.
Daher ist es schade, dass über die Themes Schriftarten von Google Fonts eingebunden werden und damit zumindest die IP-Adresse des Benutzers an Google übermittelt wird. Um dies zu verhindern muss man selbst tätig werden, indem man das Theme anpasst.
Geladen werden die Google Fonts über einen Eintrag in der Header-Datei des Themes. Diese befindet sich unter ~/Dokumente/Publii/themes/THEMENAME/partials/head.hbs
Letzendlich handelt es sich um Textdateien, die man mit einem beliebigen Editor ändern kann. Hier entfernt man die Zeilen
<link rel="preconnect" href="https://fonts.gstatic.com/" crossorigin>
<link href="https://fonts.googleapis.com/css?family= PT+Serif:400,700|Muli:400,600" rel="stylesheet">
Publii bringt standardmäßig acht Themes mit, die bereits im oben genannten Installationsverzeichnis vorliegen. In den Einstellungen der Webseite kann man verschiedene Themes für die gerade bearbeitete Webseite “installieren”. Damit wird das Theme aus oben genanntem Ordner für diese Webseite geladen. Die Anpassung muss daher vor der “Installation” erfolgen.
Damit werden keine Google Fonts mehr geladen, der Browser fällt auf die Standardschriftarten zurück. Möchte man die bisher von Google geladenen Schriftarten vom eigenen Server ausliefern lassen, so hilft einem der google webfonts helper. Damit lassen sich die benötigten Dateien zusammen stellen und der CSS-Code zum laden der Schriftarten erzeugen. Diesen kann man im Backend von Publii über Tools > Custom CSS laden.
Fazit
Ich habe schon länger ein Tool wie Publii gesucht und freue mich endlich etwas gefunden zu haben. Mit Publii lässt sich extrem schnell eine schöne, responsive, schnelle und wartungsarme Webseite erstellen.
Zwar bin ich durchaus ein großer Freund von WordPress, für viele Projekte ist es aber absoluter overkill und verursacht viel Wartungsaufwand. Wenn man eine wartungsarme Webseite erstellen möchte, die eventuell auch nur unregelmäßig aktualisiert wird, ist WordPress völlig ungeeignet. Gerade für Portfolio-Seiten oder Gelegenheitsblogger bietet sich Publii geradezu an.
Durch die grafische Benutzeroberfläche ist Publii außerdem extrem nutzerfreundlich.
Und wenn ich mir überlege wie viele Stunden ich mit der Anpassung dieser WordPress-Installation verbracht habe, damit beispielsweise anonyme Kommentare verfasst werden können, dann fällt das Entfernen der Google Fonts bei Publii nicht wirklich ins Gewicht.
Publii: Static CMS mit grafischer Benutzeroberfläche ist ein Beitrag von techgrube.de.