Generell lautet ja meine Empfehlung, bei produktiven Servern niemals ein Distributions-Upgrade durchzuführen, als z.B. ohne Neuinstallation von Ubuntu 22.04 auf 24.04 umzustellen. Manchmal halte ich mich aber selbst nicht an diese Regel. Testobjekt war ein Server mit Apache, MySQL, PHP, Mail (Postfix, Dovecot, OpenDKIM) und Docker.
Natürlich gab es Schwierigkeiten …
Fairerweise muss ich zugeben, dass do-release-upgrade noch gar kein Server-Update auf Version 24.04 vorsieht. Das ist ein wenig überraschend, als Ubuntu 24.04.1 ja bereits freigegeben wurde. Normalerweise ist das der Zeitpunkt, ab dem do-release-upgrade funktionieren sollte. Ich habe das Upgrade mit do-release-upgrade -d erzwungen. Selbst schuld also.
Zuerst habe ich ein letztes Mal alle 22.04-Updates installiert (also apt update und apt full-upgrade) und den Server dann neu gestartet.
Danach habe ich ein Backup des in einer virtuellen Maschine laufenden Servers durchgeführt. Zur Not hätte ich aus der gesicherten Image-Datei problemlos den bisherigen Zustand des Servers wiederherstellen können. Das war aber zum Glück nicht notwendig.
Das Distributions-Upgrade habe ich dann mit do-release-upgrade -d eingeleitet, wobei -d für --devel-release steht und das Update erzwingt. Es dauerte ca. 1/4 Stunde und lief an sich überraschend flüssig durch. Ein paar Mal musste ich bestätigen, dass meine eigenen Konfigurationsdateien erhalten bleiben und nicht durch neue Konfigurationsdateien überschrieben werden sollten.
Der nachfolgende Reboot verursachte keine Probleme, ich konnte mich nach kurzer Zeit wieder mit SSH einloggen. So weit so gut!
Kein DNS
Die statische Netzwerkkonfiguration meines Servers erfolgt durch /etc/netplan/01.yaml. Dort sind sechs Nameserver eingetragen, je drei für IPv4 und IPv6. Überraschenderweise funktioniert im aktualisierten 24.04-Server keine Namensauflösung mehr — ein wirklich grundlegendes Problem! ping google.com führt also zum Fehler, dass die IP-Adresse von google.com unbekannt sei.
Ein kurzer Blick auf resolv.conf zeigt, dass es sich dabei um einen Link auf eine gar nicht existierende Datei handelt.
ls -l /etc/resolv.conf
/etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.conf (existiert nicht)
dpkg -l | grep resolve verrät, dass systemd-resolved nicht installiert ist. Sehr merkwürdig!
Abhilfe schafft die Installation dieses Pakets. Die Installation ist aber ohne DNS gar nicht so einfach! Ich musste zuerst /etc/resolv.conf löschen und dann einen Eintrag auf den Google-DNS dort speichern:
Nach einem Reboot läuft DNS. resolvectl listet jetzt meine in /etc/netplan/01.yaml aufgeführten Nameserver auf.
PHP-Probleme
Nächstes Problem: Apache startet nicht. systemctl status apache2 verweist auf einen Fehler in einer Konfigurationsdatei von PHP 8.1. Aber Ubuntu 24.04 verwendet doch PHP 8.3. Was ist da passiert?
Ein Blick in /etc/apache2/mods-enabled zeigt, dass dort noch PHP 8.1 aktiviert ist. Abhilfe:
Apache und PHP laufen jetzt, aber ein Blick auf die Nextcloud-Statusseite zeigt, dass /etc/php/8.3/apache2/php.ini sehr konservative Einstellungen enthält. Nach memory_limit=1024M und ein paar weiteren Änderungen ist auch Nextcloud zufrieden.
OpenDKIM
Auf meinem 22.04-Server hatte ich DKIM aktiv (siehe auch https://kofler.info/dkim-konfiguration-fuer-postfix/). Nach dem Upgrade funktioniert die Signierung der Mails aber nicht mehr. Der Grund war einmal mehr trivial: Beim Upgrade sind die entsprechenden Pakete verloren gegangen. Abhilfe:
apt install opendkim opendkim-tools
Fazit
Keines der Probleme war unüberwindbar. Überraschend war aber die triviale Natur der Fehler. Beim Upgrade verloren gegangene oder nicht installierte Pakete, keine Synchronisierung zwischen den installierten Paketen und den aktivien Apache-Modulen etc. Ich bleibe bei meinem Ratschlag: Wenn Ihnen Stabilität wichtig ist, vermeiden Sie Distributions-Upgrades. Ja, die Neuinstallation eines Servers verursacht mehr Arbeit, aber dafür können Sie den neuen Server in Ruhe ausprobieren und den Wechsel erst dann durchführen, wenn wirklich alles funktioniert. Bei einem Upgrade riskieren Sie Offline-Zeiten, deren Ausmaß im vorhinein schwer abzuschätzen ist.
Bei der Arbeit für unser KI-Buch bin ich kürzlich über Aider gestolpert. Dabei handelt es sich um ein Konsolenwerkzeug zum Coding. Im Gegensatz zu anderen Tools (ChatGPT, GitHub Copilot etc.), die Sie beim Coding nur unterstützen, ist Aider viel selbstständiger: Sie sagen, was Ihr Programm machen soll. Aider erzeugt die notwendigen Dateien, implementiert die Funktion und macht gleich einen git-Commit. Sie testen den Code, optimieren vielleicht ein paar Details, dann geben Sie Aider weitere Aufträge. Den Großteil der Coding-Aufgaben übernimmt Aider. Sie sind im Prinzip nur noch für das Ausprobieren und Debugging zuständig.
Wie Sie gleich sehen werden, funktioniert das durchaus (noch) nicht perfekt. Aber das Konzept ist überzeugend, und es ist verblüffend, wie viel schon klappt. Aider kann auch auf ein bestehendes Projekt angewendet werden, das ist aber nicht Thema dieses Blog-Beitrags. Generell geht es mir hier nur darum, das Konzept vorzustellen. Viel mehr Details können Sie in der guten Dokumentation nachlesen. Es gibt auch diverse YouTube-Videos. Besonders überzeugend fand ich Claude 3.5 and Aider: Use AI Assistants to Build AI Apps.
Voraussetzungen
Damit Sie Aider ausprobieren können, brauchen Sie einen Rechner mit einer aktuellen Python-Installation, git sowie einen (kostenpflichtigen!) Key für ein KI-Sprachmodell. Ich habe meine Tests mit GPT-4o von OpenAI sowie mit Claude 3.5 Sonnet (Anthrophic) durchgeführt. Ein wenig überraschend hat Claude 3.5 Sonnet merklich besser funktioniert.
Damit Sie einen API-Key bekommen, müssen Sie bei OpenAI oder Anthrophic einen Account anlegen und Ihre Kontakt- und Kreditkartendaten hinterlegen. Sie kaufen dort vorab »Credits«, die dann durch API-Abfragen aufgebraucht werden. Für erste Tests reichen 10 EUR aus. Sie müssen also kein Vermögen investieren, um Aider auszuprobieren.
Installation von aider
aider ist ein Python-Programm. Die Installation führen Sie am besten in einem Virtual Environment aus, im Prinzip so:
Falls beide Variablen definiert sind, nutzt Aider das Modell Sonnet von Anthrophic. Mit den Optionen --4o oder --sonnet können Sie das Sprachmodell explizit auswählen. Aider unterstützt auch andere Sprachmodelle, empfiehlt aber explizit diese beiden Modell sowie DeepSeek Coder (siehe auch https://aider.chat/docs/leaderboards/).
»Hello World« mit GPT-4o von OpenAI
Um Aider kennenzulernen habe ich mir gedacht, ich beauftrage das Tool, ein ganz simples Webscraping-Tool in Python zu programmieren, das aus einer Wetterseite von orf.at die aktuelle Temperatur in Graz extrahiert. (Warnung: Das Script hat reinen Demonstrations-Charakter. Das regelmäßige Auslesen von Wetterseiten und die Nutzung der so gewonnen Daten — wofür auch immer — ist bei nahezu allen Websites verboten.)
Für den Test habe ich ein neues Verzeichnis eingerichtet, dieses aktiviert und (immer noch im Virtual-Environment) aider gestartet.
mkdir ~/my-projects/test1
cd ~/my-projects/test1
aider --4o
No git repo found, create one to track GPT's changes (recommended)? y
Models: gpt-4o with diff edit format, weak model gpt-4o-mini
Git repo: .git with 0 files
Repo-map: using 1024 tokens
Use /help <question> for help, run "aider --help" to see cmd line args
Die weitere Bedienung erfolgt durch Konsolenkommandos. Ich habe damit begonnen, mit /web die Wetterseite zu laden. Beim ersten /web-Kommando installiert Aider nach einer Rückfrage das Webscraping-Tool Playwright. Mit der folgenden Frage habe ich überprüft, dass Aider den Inhalt der gelesenen Seite versteht.
> /web https://wetter.orf.at/steiermark
I see that you've shared a webpage content. How can I assist you with this? Are
you looking to extract specific information, transform the data, or something
else? Please provide more details about what you need.
Tokens: 7,057 sent, 43 received. Cost: $0.04 request, $0.04 session.
> what is the temperature in Graz?
The temperature in Graz, according to the provided content, is 27.2°C.
Nach diesem einleitenden Test habe ich nun versucht, eine App zu entwickeln, die diese Aufgabe übernimmt. Aider erzeugt eine neue Datei und speichert die Datei dort. Von der Programmiersprache war nie die Rede, Aider hat sich für Python entschieden. In einem zweiten Prompt habe ich Aider darum gebeten, das Projekt mit einer requirement-Datei auszustatten.
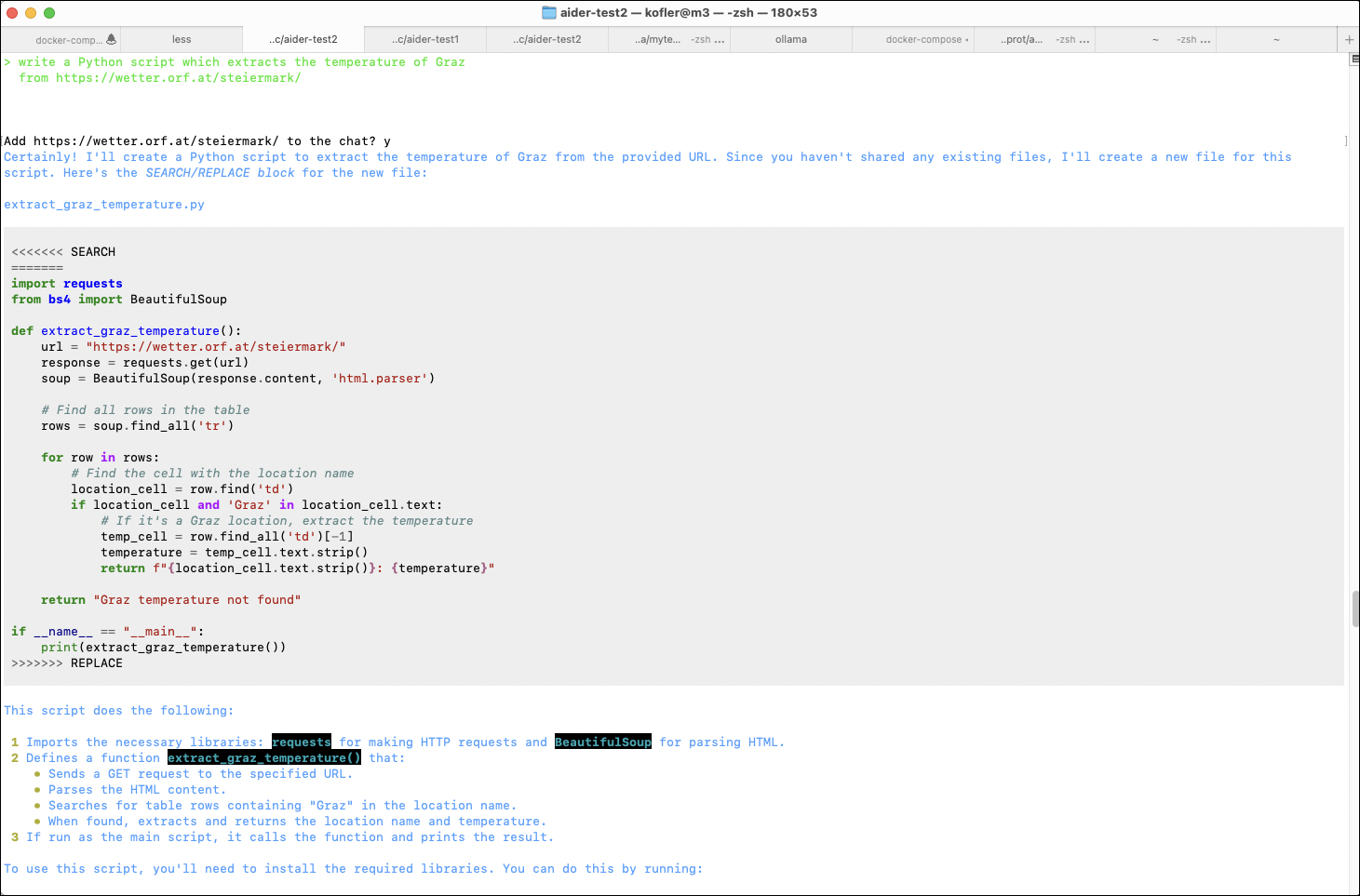
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
Add https://wetter.orf.at/steiermark/ to the chat? y
Let's create a Python script that extracts the temperature of Graz from the
given URL. We'll use the requests library to fetch the webpage content and
BeautifulSoup from the bs4 library to parse the HTML.
Here is the script:
import requests
from bs4 import BeautifulSoup
def get_graz_temperature():
url = "https://wetter.orf.at/steiermark/"
response = requests.get(url)
response.raise_for_status() # Ensure we notice bad responses
soup = BeautifulSoup(response.text, 'html.parser')
graz_section = soup.find('a', href="https://wetter.ORF.at/steiermark/grazuniversitaet/")
if graz_section:
temperature_text = graz_section.find_next_sibling(text=True)
if temperature_text:
temperature = temperature_text.strip().split(' ')[0]
return temperature
return None
if __name__ == "__main__":
temperature = get_graz_temperature()
if temperature:
print(f"The temperature in Graz is {temperature}°C.")
else:
print("Could not find the temperature for Graz.")
This script will:
1 Fetch the webpage content from the given URL.
2 Parse the HTML content to find the section related to Graz.
3 Extract and print the temperature for Graz.
You can run this script in your Python environment to get the current
temperature in Graz.
Tokens: 7,196 sent, 314 received. Cost: $0.04 request, $0.11 session.
Allow creation of new file new_file_path: extract_graz_temperature.py? y
Applied edit to new_file_path: extract_graz_temperature.py
Commit beb001f feat: add script to extract temperature of Graz from weather website
You can use /undo to revert and discard commit beb001f.
> add a requirement file to the project
To add a requirements file to the project, we need to create a new file named
requirements.txt and list the necessary dependencies.
requests
beautifulsoup4
Tokens: 2,372 sent, 66 received. Cost: $0.01 request, $0.13 session.
In einem zweiten Terminal-Fenster oder -Tab habe ich nun ein weiteres Virtual Environment eingerichtet, um alle erforderlichen Module zu installieren und das neue Script zu testen.
Dabei habe ich auch schon den ersten Fehler entdeckt. Aider hat das neue Python-Script nicht extract_graz_temperature.py genannt, sondern new_file_path: extract_graz_temperature.py. Diesen Fehler habe ich mit git behoben.
python3 extract_graz_temperature.py
extract_graz_temperature.py:13: DeprecationWarning: The
'text' argument to find()-type methods is deprecated.
Use 'string' instead.
Could not find the temperature for Graz.
Der Code enthält offensichtlich einen veralteten Parameter. Zurück im ersten Terminal/Tab bitte ich Aider, das Problem zu beheben. Aider sieht den Fehler ein und korrigiert den Code.
> tried to run the code, got this error:
extract_graz_temperature.py:13: DeprecationWarning: The 'text'
argument to find()-type methods is deprecated. Use 'string'
instead. Can you fix the code? I renamed the code file to
extract_graz_temperature.py.
extract_graz_temperature.py
Add these files to the chat? y
<<<<<<< SEARCH
temperature_text = graz_section.find_next_sibling(text=True)
=======
temperature_text = graz_section.find_next_sibling(string=True)
>>>>>>> REPLACE
...
Tokens: 2,585 sent, 86 received. Cost: $0.01 request, $0.14 session.
Aber auch nach diesem Fix funktioniert das Script nicht. Das Problem ist, dass das Script die Struktur der Wetter-Website nicht korrekt analysiert hat und Beautiful Soup (eine HTML-Parser-Bibliothek für Python) falsch anwendet. Etwas enttäuscht habe ich an dieser Stelle den ersten Versuch abgebrochen. Die bis dahin angefallenen Kosten von 14 US Cent sind immerhin verschmerzbar.
»Hello World« mit Sonnet 3.5 von Anthrophic
Anstatt mich mit der Fehlersuche zu ärgern, habe ich das ganze Experiment mit dem Sprachmodell Sonnet wiederholt. Die folgenden Ausgaben sind stark gekürzt.
mkdir ~/my-projects/test2
cd ~/my-projects/test2
aider --sonnet
> /web https://wetter.orf.at/steiermark
> what is the temperature in Graz?
Based on the information provided in the weather report for Steiermark, there
are multiple temperature readings for Graz:
1 Graz Heinrichstrasse: 30.3°C
2 Graz-Straßgang: 29.8°C
3 Graz-Thalerhof: 29.2°C
4 Graz-Universität: 30.3°C
The temperatures in Graz range from 29.2°C to 30.3°C, with most locations
reporting around 30°C. The warmest spots in Graz appear to be Heinrichstrasse
and the University area, both at 30.3°C.
Tokens: 7,323 sent, 129 received. Cost: $0.02 request, $0.05 session.
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
...
> add a requirement file to the project
...
In einem weiteren Terminal habe ich nun auch für dieses Projekt ein Python Environment eingerichtet und das Script ausprobiert:
(Virtual Environment einrichten, Requirements mit pip installieren ...)
python3 extract_graz_temperature.py
Graz Heinrichstrasse: 30,3 °C
Aider in einem Terminal-Fenster
Bingo! Das Script wählt eine der vier Messstellen von Graz aus und zeigt die Temperatur dort an. Wunderbar.
Dementsprechend ermutigt habe ich mein Glück weiter strapaziert. Das Script soll die Durchschnittstemperatur aller vier Messstellen ausrechnen. Zurück in Terminal 1 mit Aider. Wie die folgenden Prompts zeigen, sind fünf Versuche notwendig, bis Aider endlich funktionierenden Code zusammenbringt. (Die ursprüngliche Fassung versucht aus Zeichenketten wie ‚30,3 C‘ in Fließkommazahlen umzuwandeln. Es ignoriert sowohl das deutsche Dezimalformat als auch die Zeichenkette ‚ C‘ am Ende. Die ganze Prozedur dauert inklusive meiner Tests eine Viertelstunde.
> please change extract_graz_temperature.py to calculate the average temperature for Graz
> does not work because of german number format (1,3 instead of 1.3); please fix
> still fails, probably because temperature string contains ' C' at the end; please fix once more
> still fails, the space in ' C' is a fixed space; try again
> it's the unicode fixed blank; just drop the last two characters
Tokens: 3,153 sent, 211 received. Cost: $0.01 request, $0.16 session.
Immerhin, das Script funktioniert jetzt:
python3 extract_graz_temperature.py
Average temperature for Graz: 29.9°C
Die API-Kosten für die Entwicklung des Scripts betrugen 13 US Cents. Meine Arbeitszeit habe ich nicht gerechnet ;-)
Fazit
Im Internet finden Sie diverse Videos, wo Aider scheinbar auf Anhieb perfekt funktioniert. Meine Tests haben gezeigt, dass das durchaus nicht immer der Fall ist.
Was mich trotz aller Fehler begeistert, ist das Konzept: Am besten führen Sie Aider in einem VSCode-Terminal aus, während in VSCode das Projektverzeichnis geöffnet ist. (Das Ganze funktioniert natürlich auch mit jedem anderen Editor.) Dann haben Sie eine grandiose Umgebung zum Testen des Codes sowie für dessen Weiterentwickung mit Aider.
Ja, weder Aider noch die von Aider genutzten Sprachmodelle sind zum jetzigen Zeitpunkt perfekt. Aber das Potenzial, das hier schlummert, ist enorm. Sie sind damit quasi eine Abstraktionsebene über dem Code. Sie geben Aider Kommandos, wie es den Code weiterentwickeln oder verbessern soll, ohne sich im Detail mit Funktionen, Schleifen oder Variablen zu beschäftigen. (Dieses Wissen brauchen Sie zum Debugging aber weiterhin!)
Soeben ist die dritte Auflage meines Python-Bestsellers erschienen:
Für die 3. Auflage habe ich das Buch im Hinblick auf die Python-Version 3.12 aktualisiert. Neu hinzugekommen ist das Kapitel »Python lernen mit KI-Unterstützung«. Es zeigt, wie Ihnen ChatGPT oder ein vergleichbares KI-Tool beim Erlernen von Python helfen kann. Ebenfalls neu ist ein Abschnitt zur Nutzung von Python direkt in Excel.
Viele Beispiele aus der Praxis sowie Übungsaufgaben helfen dabei, Python ohne allzu viel Theorie kennenzulernen. Im handlichen Taschenbuchformat ist das Buch auch unterwegs ein idealer Begleiter. Mehr Details zum Buch gibt es hier:
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Die Linux-Kommandoreferenz ist erstmalig 1995 erschienen. Die Kommandoreferenz war damals aber nur ein 56 Seiten langes Kapitel in der ersten Auflage meines Linux-Buchs. Aufgrund von Platzproblemen musste ich das Kommandoreferenz-Kapitel 15 Jahre später aus dem Linux-Buch entfernen und in ein eigenes Buch auslagern. Die erste Auflage im Taschenbuchformat hatte noch schlanke 176 Seiten. In der gerade neu erschienen sechsten Auflage hat das Buch den dreifachen Umfang!
547 Seiten, Hard-Cover
ISBN: 978-3-367-10103-0
Preis: Euro 29,90 (in D inkl. MWSt.)
Vor 15 Jahren zweifelten der Verlag und ich, ob die Kommandoreferenz überhaupt ein sinnvolles Buch wäre. Natürlich lassen sich alle Kommandos im Internet recherchieren. Heute verrät auch ChatGPT die gerade relevanten Optionen von find oder grep.
Dessen ungeachtet geben die Verkaufszahlen eine klare Botschaft: Ja, es gibt ganz offensichtlich den Bedarf nach einer Linux-Kommandoreferenz, die das Wesentliche vom Unwesentlichen trennt, die anhand thematischer Übersichten einen Startpunkt in das riesige Universum der Linux-Kommandos bietet, die mit vielen Beispielen alltägliche »Linux-Praxis« vermittelt. Keines meiner Bücher öffne ich selbst so oft (natürlich als PDF-Datei), um irgendein Detail rasch nachzulesen!
Für die 6. Auflage habe ich das Buch einmal mehr komplett aktualisiert. Die folgenden Kommandos habe ich neu aufgenommen:
Außerdem habe ich die Beschreibung vieler Kommandos aktualisiert oder mit zusätzlichen Beispielen versehen, unter anderem bei acme.sh, chmod, convert, curl, dd, find, firewall-cmd, mail, nmcli, pip und tcpdump.
Screen Sharing mit dem Raspberry Pi war schon immer ein fehleranfälliges Vergnügen. In der Vergangenheit hat die Raspberry Pi Foundation auf die proprietäre RealVNC-Software gesetzt. Zuletzt war RealVNC aber nicht Wayland-kompatibel. Die Alternative ist wayvnc, ein Wayland-kompatible VNC-Variante: Wie ich unter Remote Desktop und Raspberry Pi OS Bookworm schon berichtet habe, ist wayvnc aber nicht mit allen Remote-Clients kompatibel, insbesondere nicht mit Remotedesktopverbindung von Microsoft.
Anfang Mai 2024 hat die Raspberry Pi Foundation mit Raspberry Pi Connect eine eigene Lösung präsentiert. Ich habe das System ausprobiert. Um das Ergebnis gleich vorwegzunehmen: Bei meinen Tests hat alles bestens funktioniert, selbst dann, wenn auf beiden Seiten private Netzwerke mit Network Address Translation (NAT) im Spiel sind. Das Setup ist sehr einfach, als Client reicht ein Webbrowser. Geschwindigkeitswunder sind aber nicht zu erwarten, selbst im lokalen Netzwerk treten spürbare Verzögerungen auf.
Der Zugriff auf den Raspberry-Pi-Client erfolgt hier in einem Fenster des Webbrowsers Google Chrome unter macOS
Voraussetzungen
Raspberry Pi Connect setzt voraus, dass Sie die aktuelle Raspberry-Pi-Version »Bookworm« verwenden und dass der PIXEL Desktop in einer Wayland-Session läuft. Das schränkt die Modellauswahl auf 4B, 400 und 5 ein. Ob Ihr Desktop Wayland nutzt, überprüfen Sie am einfachsten im Terminal:
echo $XDG_SESSION_TYPE
wayland
Gegebenenfalls können Sie mit raspi-config zwischen Xorg und Wayland umschalten (Menüpunkt Advanced Options / Wayland).
Installation
Die Software-Installation verläuft denkbar einfach:
Nach der Installation erscheint ein neues Icon im Panel des PIXEL Desktops. Über dessen Menüeintrag Sign in gelangen Sie auf die Website https://connect.raspberrypi.com/sign-in. Dort müssen Sie eine Raspberry-Pi-ID einrichten. Die Eingabefelder sind auf ein Minimum beschränkt: E-Mail-Adresse, Passwort (2x) und Name. Fertig!
Bevor Sie Raspberry Pi Connect nutzen können, müssen Sie eine Raspberry Pi ID einrichten.
Fernzugriff
Um nun von einem anderen Rechner auf den PIXEL Desktop Ihres Raspberry Pis zuzugreifen, melden Sie sich dort ebenfalls auf der Website https://connect.raspberrypi.com/sign-in an. Dort werden alle registrierten Geräte aufgelistet. (Mit einer Raspberry-Pi-ID können als mehrere Raspberry Pis verknüpft werden.)
Remote-Verbindungsaufbau im Webbrowser
Praktische Erfahrungen
Bei meinen Tests hat Raspberry Pi Connect ausgezeichnet funktioniert. Der Verbindungsaufbau war problemlos. Der Desktop-Inhalt erscheint in einem neuen Browser-Fenster. Der Desktop-Inhalt wird automatisch auf die Fenstergröße skaliert. Die Bedienung ist denkbar simpel. Über zwei Buttons können Texte über die Zwischenablage kopiert bzw. eingefügt werden.
Raspberry Pi Connect testet beim Verbindungsaufbau, ob sich der Raspberry Pi und Ihr Client-Rechner (z.B. Ihr Notebook) im gleichen Netzwerk befinden. Wenn das der Fall ist, stellt der Client eine direkte Peer-to-Peer-Verbindung zum Raspberry Pi her. Nach dem Verbindungsaufbau fließen keine Daten mehr über den Raspberry-Pi-Connect-Server. Die Verbindungsgeschwindigkeit ist dann spürbar höher. Dennoch ist es empfehlenswert, die Bildschirmauflösung auf dem Raspberry Pi nicht höher einzustellen als notwendig.
Wenn sich Ihr Pi und Ihr Client-Rechner dagegen in unterschiedlichen (privaten) Netzwerken befinden, agiert ein Server der Raspberry Pi Foundation als Relay. Sowohl der Bildschirminhalt als auch alle Eingaben werden verschlüsselt nach Großbritannien und wieder zurück übertragen. Selbst wenn alle Geräte eine gute Internetverbindung haben, ist ein gewisser Lag unvermeidlich.
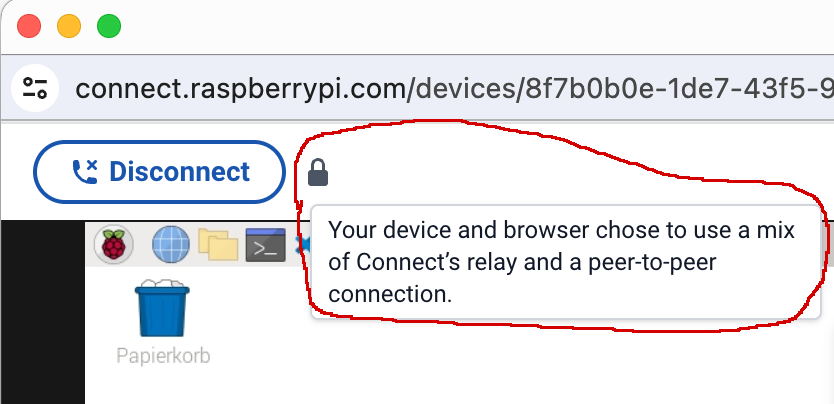
Details über die Art der Verbindung erfahren Sie, wenn Sie den Mauszeiger auf das Schloss-Icon im Screen-Sharing-Fenster bewegen.
Wenn Sie den Mauszeiger über das Schloss-Icon bewegen, erscheint ein Info-Text zum Status der Verbindung
Wenn die Remote-Desktop-Verbindung nicht im lokalen Netzwerk stattfindet, fließt der ganze Netzwerkverkehr über einen Relay-Server in Großbritannien. Dabei kommt das Protokoll Traversal Using Relays around NAT (kurz TURN) zum Einsatz. Die Daten werden TLS-verschlüsselt.
Der entscheidende Schwachpunkt des Systems besteht darin, dass es aktuell nur einen einzigen TURN-Server gibt. Je mehr gleichzeitige Remote-Desktop-Verbindungen aktiv sind, desto langsamer wird das Vergnügen … (Und besonders schnell ist es schon im Idealfall nicht.)
Fazit
Raspberry Pi Connect punktet vor allem durch seine Einfachheit.
Am Raspberry Pi reicht es aus, rpi-connect zu installieren.
Die Raspberry-Pi-ID kann rasch und unkompliziert eingerichtet werden.
Die Anwendung im Webbrowser funktioniert plattformübergreifend und einfach.
Allzu hohe Performance-Anforderungen sollten Sie nicht haben. Die Nachlaufzeiten bei Mausbewegungen und gar beim Verschieben eines Fensters sind beachtlich. Für administrative Arbeiten reicht die Geschwindigkeit aber absolut aus.
Schließlich bleibt abzuwarten, wie gut die Software skaliert. Aktuell befindet sich Raspberry Pi Connect noch in einem Probebetrieb. Soweit sich der Raspberry Pi und der Client-Rechner nicht im gleichen lokalen Netzwerk befinden, werden die Bildschirmdaten über einen Relay in Großbritannien geleitet. Aktuell gibt es genau einen derartigen Relay. Je mehr Anwender Raspberry Pi Connect gleichzeitig nutzen, desto langsamer wird es. Die Raspberry Pi Foundation lässt sich aktuell überhaupt offen, ob es den Relay-Betrieb dauerhaft kostenlos anbieten kann.
Die Geschwindigkeit bei der lokalen Ausführung großer Sprachmodelle (LLMs) wird in Zukunft zu einem entscheidenden Kriterium für die CPU/GPU-Auswahl werden. Das gilt insbesondere für Software-Entwickler, die LLMs lokal nutzen möchten anstatt alle Daten an Anbieter wie ChatGPT in die Cloud zu übertragen.
Umso verblüffender ist es, dass es dafür aktuell kaum brauchbare Benchmarks gibt. In Anknüpfung an meinen Artikel Sprachmodelle lokal ausführen und mit Hilfe des Forum-Feedbacks habe ich die folgende Abbildung zusammengestellt.
Textproduktion in Tokens/s bei der lokalen Ausführung von llama2 bzw. llama3
Die Geschwindigkeit in Token/s wird — zugegeben unwissenschaftlich — mit der Ausführung des folgenden Kommandos ermittelt:
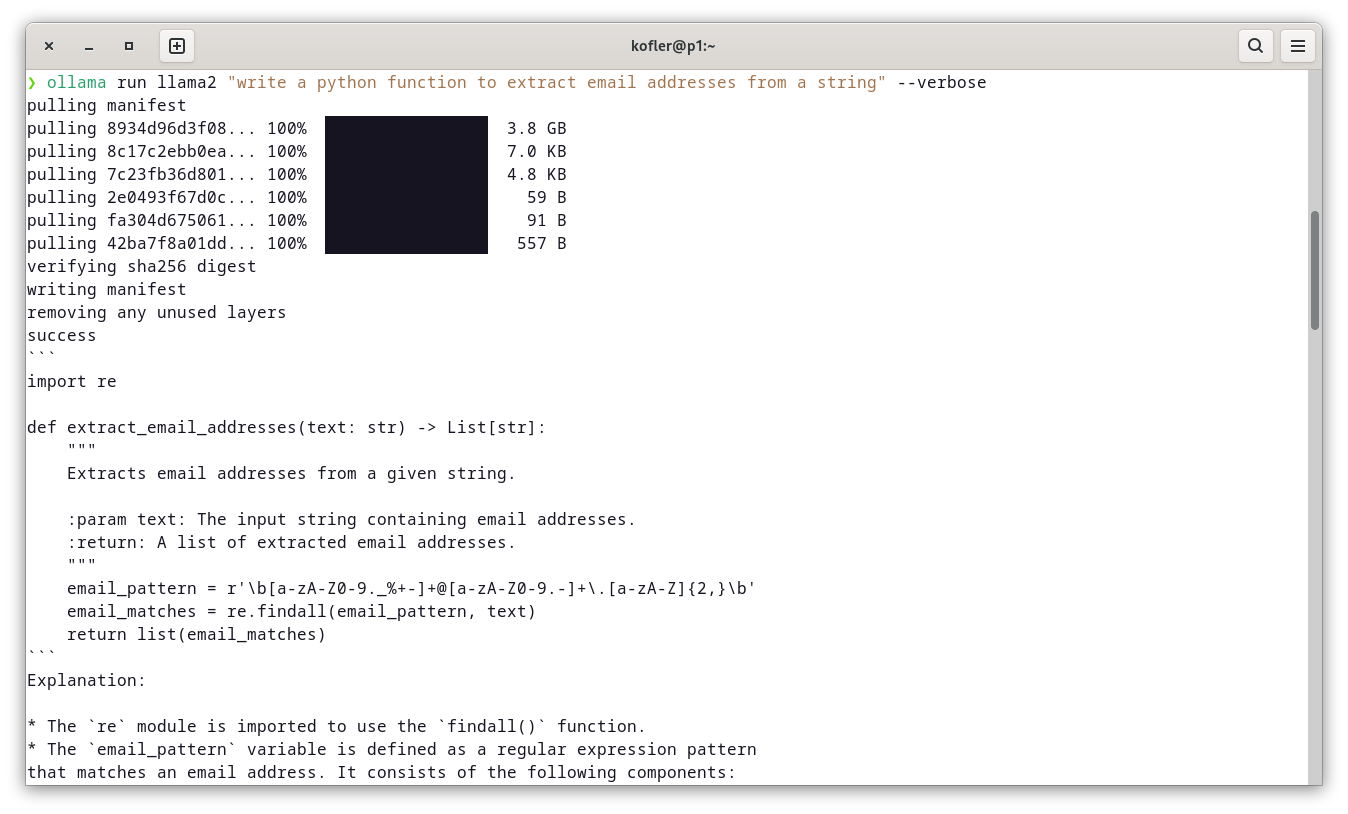
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
oder
ollama run llama3 "write a python function to extract email addresses from a string" --verbose
Bei den Tests ist llama3 um ca. 10 Prozent langsamer als llama2, liefert also etwas weniger Token/s. Möglicherweise liegt dies ganz einfach daran, dass das Sprachmodell llama3 in der Standardausführung etwas größer ist als llama2 (7 versus 8 Mrd. Parameter). Aber an der Größenordnung der Ergebnisse ändert das wenig, die Werte sind noch vergleichbar.
Beachten Sie, dass die im Diagramm angegebenen Werte variieren können, je nach installierten Treiber, Stromversorgung, Kühlung (speziell bei Notebooks) etc.
Helfen Sie mit! Wenn Sie Ollama lokal installiert haben, posten Sie bitte Ihre Ergebnisse zusammen mit den Hardware-Eckdaten im Forum. Verwenden Sie als Sprachmodell llama2 bzw. llama3 in der Defaultgröße (also mit 7 bzw. 8 Mrd. Parameter, entspricht llama2:7b oder llama3:8b). Das Sprachmodell ist dann ca. 4 bzw. 5 GByte groß, d.h. die Speicheranforderungen sind gering. (Falls Sie das LLM mit einer dezidierten GPU ausführen, muss diese einen ausreichend großen Speicher haben, in dem das ganze Sprachmodell Platz findet. Je nach Betriebssystem sind u.U. zusätzliche Treiber notwendig, damit die GPU überhaupt genutzt wird.)
Ich werde das Diagramm gelegentlich mit neuen Daten aktualisieren.
Ubuntu 24.04 alias Noble Numbat alias Snubuntu ist fertig. Im Vergleich zur letzten LTS-Version gibt es einen neuen Installer, der nach einigen Kinderkrankheiten (Version 23.04) inzwischen gut funktioniert. Ansonsten kombiniert Ubuntu ein Kernsystem aus Debian-Paketen mit Anwendungsprogramme in Form von Snap-Paketen. Für die einfache Anwendung bezahlen Sie mit vergeudeten Ressourcen (Disk Space + RAM).
Der Ubuntu-Desktop mit Gnome 46
Installation
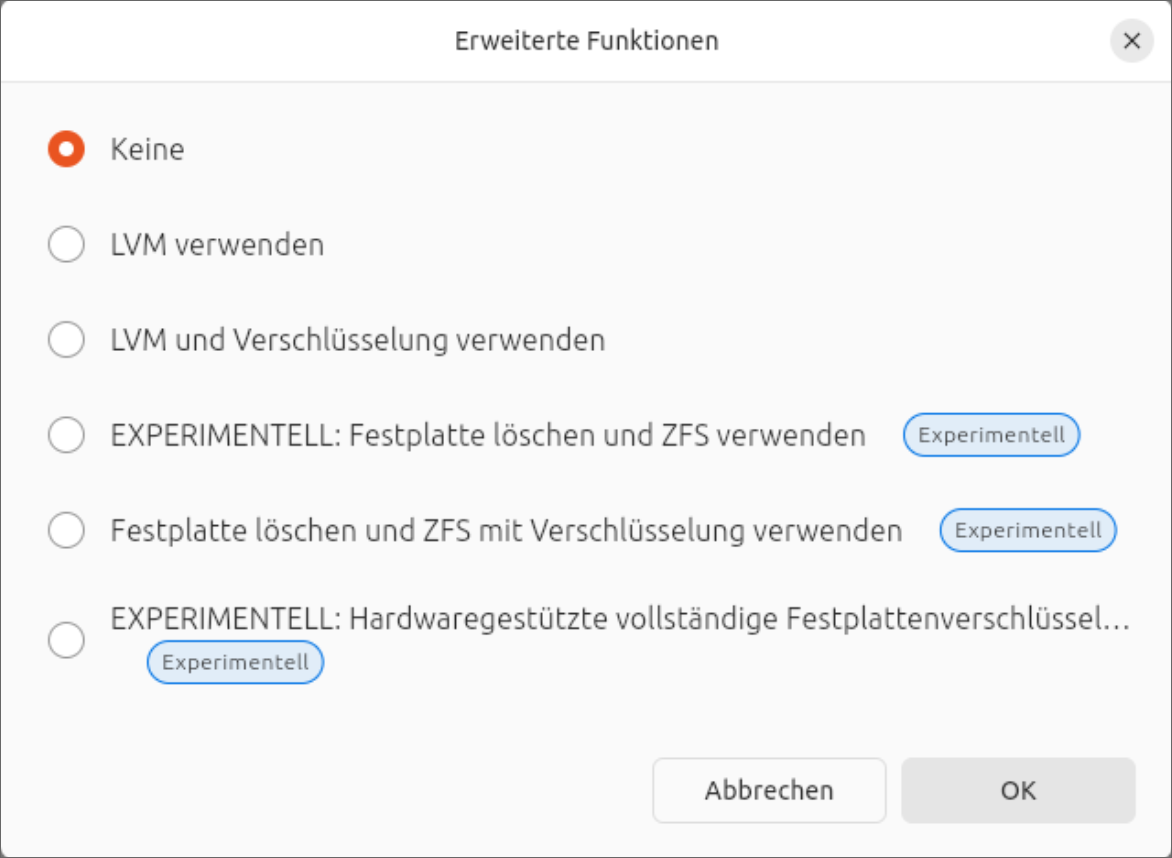
Das neue Installationsprogramm hat bei meinen Tests gut funktioniert, inklusive LVM + Verschlüsselung. Einfluss auf die Partitionierung können Sie dabei allerdings nicht nehmen. (Das Installationsprogramm erzeugt eine EFI-, eine Boot- und eine LVM-Partition, darin ein großes Logical Volume.) Zusammen mit der Installation erledigt der Installaer gleich ein komplettes Update, was ein wenig Geduld erfordert.
Standardmäßig führt das Programm eine Minimalinstallation durch — ohne Gimp, Thunderbird, Audio-Player usw. Mit der Option Vollständige Option verhält sich der Installer ähnlich wie in der Vergangenheit. Ein wenig absurd ist, dass dann einige Programme als Debian-Pakete installiert werden, während Ubuntu sonst ja bei Anwendungsprogrammen voll auf das eigene Snap-Format setzt. Wenn Sie Ubuntu installieren, entscheiden Sie sich auch für Snap. Insofern ist es konsequenter, eine Minimalinstallation durchzuführen und später die entsprechenden Snaps im App Center selbst zu installieren.
Neuer Minimalismus beim InstallationsumfangZusammenfassung einer LVM-Installation mit VerschlüsselungExperimentelle Optionen zeigen, wohin die Reise beim Installer geht
Snaps + Ubuntu = Snubuntu
Auf das Lamentieren über Snaps verzichte ich dieses Mal. Wer will, kann diesbezüglich meine älteren Ubuntu-Tests nachlesen. Für Version 24.04 hat Andreas Proschofsky in derstandard.at alles gesagt, was dazu zu sagen ist. Der größte Vorteil von Snaps für Canonical besteht darin, dass sich der Wartungsaufwand für Desktop-Programme massiv verringert: Die gleichen Snap-Pakete kommen in diversen Ubuntu-Versionen zum Einsatz.
Das App Center kann sich selbst nicht aktualisieren. Sie bekommen App-Center-Updates aber früher oder später als Hintergrund-Updates.
Netplan 1.0
Mit Ubuntu 24.04 hat Netplan den Sprung zu Version 1.0 gemacht. Größere Änderungen gab es keine mehr, die Versionsnummer ist eher ein Ausdruck dafür, dass Canonical die Software nun als stabil betrachtet. Wie bereits seit Ubuntu 23.10 ist Netplan das Backend zum NetworkManager. Netzwerkverbindungen werden nicht in /etc/NetworkManager/system-connections/ gespeichert wie auf den meisten anderen Distributionen, sondern als /etc/netplan/90-NM-*.yaml-Dateien (siehe auch meinen Bericht zu Ubuntu 23.10).
HEIC-Unterstützung
Ubuntu 24.04 kommt out-of-the-box mit HEIC/HEIF-Dateien zurecht, also mit am iPhone aufgenommenen Fotos. Vor einem dreiviertel Jahr hatte ich noch über entsprechende Probleme berichtet. Im Forum wurde damals kritisiert, dass meine Erwartungshaltung zu hoch sei. Aber, siehe da: Es geht!
Seit ich Ubuntu auf dem Desktop kaum mehr nutze, habe ich mehr Distanz gewonnen. So fällt mein Urteil etwas milder aus ;-)
Für Einsteiger ist Ubuntu eine feine Sache: In den meisten Fällen funktioniert Ubuntu ganz einfach. Das gilt sowohl für die Unterstützung der meisten Hardware (auch relativ moderne Geräte) als auch für die Installation von Programmen, die außerhalb der Linux-Welt entwickelt werden (VSCode, Android Studio, Spotify etc.). Was will man mehr? Ubuntu sieht zudem in der Default-Konfiguration optisch sehr ansprechend aus, aus meiner persönlichen Perspektive deutlich besser als die meisten anderen Distributionen. Ich bin auch ein Fan der ständig sichtbaren seitlichen Task-Leiste. Schließlich zählt Canonical zu den wenigen Firmen, die noch Geld in die Linux-Desktop-Weiterentwicklung investieren; dafür muss man dankbar sein.
Alle, die einen Widerwillen gegenüber Snap verspüren, sollten nicht über Ubuntu/Canonical schimpfen, sondern sich für eine der vielen Alternativen entscheiden: Arch Linux, Debian, Fedora oder Linux Mint. Wer nicht immer die neueste Version braucht und sich primär Langzeit-Support wünscht, kann auch AlmaLinux oder Rocky Linux in Erwägung ziehen.
Unser Handbuch zum Raspberry Pi ist soeben in der 8. Auflage erschienen:
Umfang: 1045 Seiten
Ausstattung: Farbdruck, Hard-Cover, Fadenbindung
ISBN: 978-3-8362-9666-3
Preis: Euro 44,90 (in D inkl. MWSt.)
Autoren: Michael Kofler, Christoph Scherbeck und Charly Kühnast
Umfassendes Raspberry-Pi-Know-how!
Linux mit dem Raspberry Pi.
Der Raspberry Pi als Multimedia-Center und Spiele-Konsole
Programmierung: Einführung, Grundlagen und fortgeschrittene Techniken, Schwerpunkt Python, außerdem bash, PHP, C, Wolfram Language.
Elektronik und Komponenten: von LEDs zu Schrittmotoren, jede Art von Sensoren (Ultraschall, Wasserstand etc.), Bussysteme, Erweiterungen (Gertboard & Co.).
Projekte: Home Automation, RFID-Reader, Stromzähler auslesen, WLAN- und TOR-Router, Luftraumüberwachung, NAS etc.
Raspberry Pi Pico: MicroPython-Programmiertechniken, CO2-Ampel, Ultraschall-Entfernungsmessung
Mit Geleitwort von Eben Upton
Highlights der 8. Auflage
aktualisiert im Hinblick auf die neuen Modelle Raspberry Pi 5, Raspberry Pi Zero 2 und Raspberry Pico W
berücksichtigt Raspberry Pi OS »Bookworm«
PCIe-SSD statt SD-Karte
PXE-Boot
GPIO Reloaded: Neue Bibliotheken zur GPIO-Programmierung in der Bash, in Python und in C
ChatGPT, Copilot & Co. verwenden Large Language Models (LLMs). Diese werden auf leistungsstarken Servern ausgeführt und als Cloud-Services angeboten. Das funktioniert wunderbar. Aber nicht jeder will Daten, Text und Code ständig in die Cloud hochladen. Kann man also — mit »gewöhnlicher« Hardware — LLMs auch lokal ausführen?
Tatsächlich ist das verblüffend einfach. Das Tool der Wahl heißt Ollama. Was Docker für Container ist, ist Ollama für LLMs!
Ollama kann ziemlich mühelos unter Linux, macOS und Windows installiert werden. Unter Windows und macOS starten Sie Ollama als Hintergrunddienst mit einer winzigen grafischen Oberfläche (im Prinzip nur ein Icon, das den Status anzeigt). Unter Linux richten Sie den Dienst mit systemctl ein:
systemctl enable --now ollama
Ollama läuft im Terminal, kann aber auch per API genutzt werden (z.B. zur Realisierung einer Web-Schnittstelle).
Ollama anwenden
Jetzt können Sie Ollama mit dem gleichnamigen Kommando im Terminal ausführen. Mit ollama run <llmname> installieren Sie eines der öffentlich verfügbaren Sprachmodelle (mehr dazu im nächsten Abschnitt) und können dann im Textmodus Kommandos ausführen:
ollama run llama2
>>> I need a regex to verify a date in US format. Can you help?
Of course! To match a date in the format of "MM/DD/YYYY" (month-day-year)
or "MM/DD/YYYY HH:MM AM/PM", you can use the following regular expression:
\b(\d{1,2}/\d{1,2}/\d{4})|(\d{1,2}/\d{1,2}/\d{4} \d{0,2})?\b
Here's a breakdown of how this regex works:
* \b: Matches a word boundary (the start or end of a word) to ensure
we're matching the entire date field.
* (\d{1,2}/\d{1,2}/\d{4}): Matches the month/day/year format. The
(\d{1,2}) captures the month and day as individual digits (0-2
digits for the month and 1-2 digits for the day). The / separates
the date components.
* |: Or, used to match the alternative format.
* (\d{1,2}/\d{1,2}/\d{4} \d{0,2})?: Matches the month/day/year with
time format. The (\d{1,2}) captures the month and day as individual
digits (0-2 digits for the month and 1-2 digits for the day). The /
separates the date components. The \d{0,2} matches the time component
(0-2 digits representing the hour and minute).
* \b: Matches a word boundary to ensure we're matching the entire date field again.
Note that this regex will match both US and international dates in the
"MM/DD/YYYY" format, as well as dates in the "MM/DD/YYYY HH:MM AM/PM"
format. If you need a more specific format (e.g., only US dates),
feel free to modify the regex accordingly.
Manche Sprachmodelle können auch Deutsch (nochmals llama2), wenngleich die sprachliche Qualität mitunter nur mittelmäßig ist.
>>> Was ist der Dopplereffekt?
Der Dopplereffekt ist ein physikalischer Effekt, der durch die Beugung von
Lichtwellen verursacht wird, wenn diese durch eine mediummässige Materie
passt. In einer bestimmten Umgebung oder Situation kann das Licht, das durch
eine bestimmte Fläche oder ein Objekt passt, sich "verlangsamen" und eine
Dopplereffekthelligkeit erzeugen.
Der Dopplereffekt ist ein spezifischer Effekt, der auf der Beugung von
Lichtwellen basiert. Wenn Licht durch ein Medium passt, wird es durch die Faser
des Mediums beugt und umgestaltet. Die Intensität des Lichts, das durch ein
Medium passt, kann sich durch den Dopplereffekt ändern.
Im Alltag können wir den Dopplereffekt beispielsweise bei der Anähnlichkeit von
Objekten in einer Ferne sehen. Wenn ein Auto oder eine andere Objekte in der
Ferne auf uns zukommt, wird es durch die Luft des Raumes beugt und erscheint
größer und weiter weg, als es tatsächlich ist.
Der Dopplereffekt kann auch in anderen Bereichen wie der Optik, Elektrotechnik
oder Medizin verwendet werden. Zum Beispiel können Dopplereffekte in der
Medizin verwendet werden, um die Blutungen in einem Körperteil zu bestimmen.
Es gibt verschiedene Arten von Dopplereffekten, darunter:
* LichtDopplereffekt: Der Effekt, den das Licht erzeugt, wenn es durch ein
Medium passt.
* ZeitDopplereffekt: Der Effekt, den die Zeit erzeugt, wenn sie durch ein
Objekt oder eine bestimmte Umgebung verändert wird.
* Räumliche Dopplereffekte: Der Effekt, den die räumliche Position von Objekten
oder der Standort eines Beobachters auf die Erscheinung des Dopplereffekts
ausübt.
Insgesamt ist der Dopplereffekt ein interessanter und wichtiger
physikalischerEffekt, der in vielen Bereichen der Wissenschaft und Technologie
Verwendung findet.
Ollama stellt seine Funktionen über eine REST-API zur Verfügung und kann somit lokal auch durch eigene Scripts und Editor-Plugins (z.B. Continue für VSCode) genutzt werden. Natürlich gibt es auch Module/Bibliotheken für diverse Sprachen, z.B. für Python.
Öffentliche Sprachmodelle
Die bekanntesten Sprachmodelle sind zur Zeit GPT-3.5 und GPT-4. Sie wurden von der Firma openAI entwickelt und sind die Basis für ChatGPT. Leider sind die aktellen GPT-Versionen nicht öffentlich erhältlich.
Zum Glück gibt es aber eine Menge anderer Sprachmodelle, die wie Open-Source-Software kostenlos heruntergeladen und von Ollama ausgeführt werden können. Gut geeignet für erste Experimente sind llama2, gemma und mistral. Einen Überblick über wichtige, Ollama-kompatible LLMs finden Sie hier:
Viele Sprachmodelle stehen in unterschiedlicher Größe zur Verfügung. Die Größe wird in der Anzahl der Parameter gemessen (7b = 7 billions = 7 Milliarden). Die Formel »größer ist besser« gilt dabei nur mit Einschränkungen. Mehr Parameter versprechen eine bessere Qualität, das Modell ist dann aber langsamer in der Ausführung und braucht mehr Platz im Arbeitsspeicher. Die folgende Tabelle gilt für llama2, einem frei verfügbaren Sprachmodell der Firma Meta (Facebook & Co.).
Wenn Sie llama2:70b ausführen wollen, sollte Ihr Rechner über 64 GB RAM verfügen.
Update: Quasi zugleich mit diesem Artikel wurde llama3 fertiggestellt (Details und noch mehr Details). Aktuell gibt es zwei Größen, 8b (5 GB) und 80b (40 GB).
ollama run llava:13b
>>> describe this image: raspap3.jpg
Added image 'raspap3.jpg'
The image shows a small, single-board computer like the Raspberry Pi 3, which is
known for its versatility and uses in various projects. It appears to be connected
to an external device via what looks like a USB cable with a small, rectangular
module on the end, possibly an adapter or expansion board. This connection
suggests that the device might be used for communication purposes, such as
connecting it to a network using an antenna. The antenna is visible in the
upper part of the image and is connected to the single-board computer by a
cable, indicating that this setup could be used for Wi-Fi or other wireless
connectivity.
The environment seems to be an indoor setting with wooden flooring, providing a
simple and clean background for the electronic components. There's also a label
on the antenna, though it's not clear enough to read in this image. The setup
is likely part of an electronics project or demonstration, given the simplicity
and focus on the connectivity equipment rather than any additional peripherals
or complex arrangements.
Eigentlich eine ganz passable Beschreibung für das folgende Bild!
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Praktische Erfahrungen, Qualität
Es ist erstaunlich, wie rasch die Qualität kommerzieller KI-Tools — gerade noch als IT-Wunder gefeiert — zur Selbstverständlichkeit wird. Lokale LLMs funktionieren auch gut, können aber in vielerlei Hinsicht (noch) nicht mit den kommerziellen Modellen mithalten. Dafür gibt es mehrere Gründe:
Bei kommerziellen Modellen fließt mehr Geld und Mühe in das Fine-Tuning.
Auch das Budget für das Trainingsmaterial ist größer.
Kommerzielle Modelle sind oft größer und laufen auf besserer Hardware. Das eigene Notebook ist mit der Ausführung (ganz) großer Sprachmodelle überfordert. (Siehe auch den folgenden Abschnitt.)
Wodurch zeichnet sich die geringere Qualität im Vergleich zu ChatGPT oder Copilot aus?
Die Antworten sind weniger schlüssig und sprachlich nicht so ausgefeilt.
Wenn Sie LLMs zum Coding verwenden, passt der produzierte Code oft weniger gut zur Fragestellung.
Die Antworten werden je nach Hardware viel langsamer generiert. Der Rechner läuft dabei heiß.
Die meisten von mir getesteten Modelle funktionieren nur dann zufriedenstellend, wenn ich in englischer Sprache mit ihnen kommuniziere.
Die optimale Hardware für Ollama
Als Minimal-Benchmark haben Bernd Öggl und ich das folgende Ollama-Kommando auf diversen Rechnern ausgeführt:
ollama run llama2 "write a python function to extract email addresses from a string" --verbose
Die Ergebnisse dieses Kommandos sehen immer ziemlich ähnlich aus, aber die erforderliche Wartezeit variiert beträchtlich!
Grundsätzlich kann Ollama GPUs nutzen (siehe auch hier und hier). Im Detail hängt es wie immer vom spezifischen GPU-Modell, von den installierten Treibern usw. ab. Wenn Sie unter Linux mit einer NVIDIA-Grafikkarte arbeiten, müssen Sie CUDA-Treiber installieren und ollama-cuda ausführen. Beachten Sie auch, dass das Sprachmodell im Speicher der Grafikkarte Platz finden muss, damit die GPU genutzt werden kann.
Apple-Rechner mit M1/M2/M3-CPUs sind für Ollama aus zweierlei Gründen ideal: Es gibt keinen Ärger mit Treibern, und der gemeinsame Speicher für CPU/GPU ist vorteilhaft. Die GPUs verfügen über so viel RAM wie der Rechner. Außerdem bleibt der Rechner lautlos, wenn Sie Ollama nicht ununterbrochen mit neuen Abfragen beschäftigen. Allerdings verlangt Apple leider vollkommen absurde Preise für RAM-Erweiterungen.
Zum Schluss noch eine Bitte: Falls Sie Ollama auf Ihrem Rechner installiert haben, posten Sie bitte Ihre Ergebnisse des Kommandos ollama run llama2 "write a python function to extract email addresses from a string" --verbose im Forum!
Es gibt unzählige Möglichkeiten, die Web-Werbung zu minimieren. Die c’t hat kürzlich ausführlich zum Thema berichtet, aber die entsprechenden Artikel befinden sich auf heise.de hinter einer Paywall. Und heise.de ist ja mittlerweile auch eine Seite, die gefühlt mindestens so viel Werbung in ihre Texte einbaut wie spiegel.de. Das ist schon eine Leistung … Entsprechend lahm ist der Seitenaufbau im Webbrowser.
Egal, alles, was Sie wissen müssen, um zuhause einigermaßen werbefrei zu surfen, erfahren Sie auch hier — kostenlos und werbefrei :-)
Raspberry Pi 3B+ mit USB-WLAN-Adapter
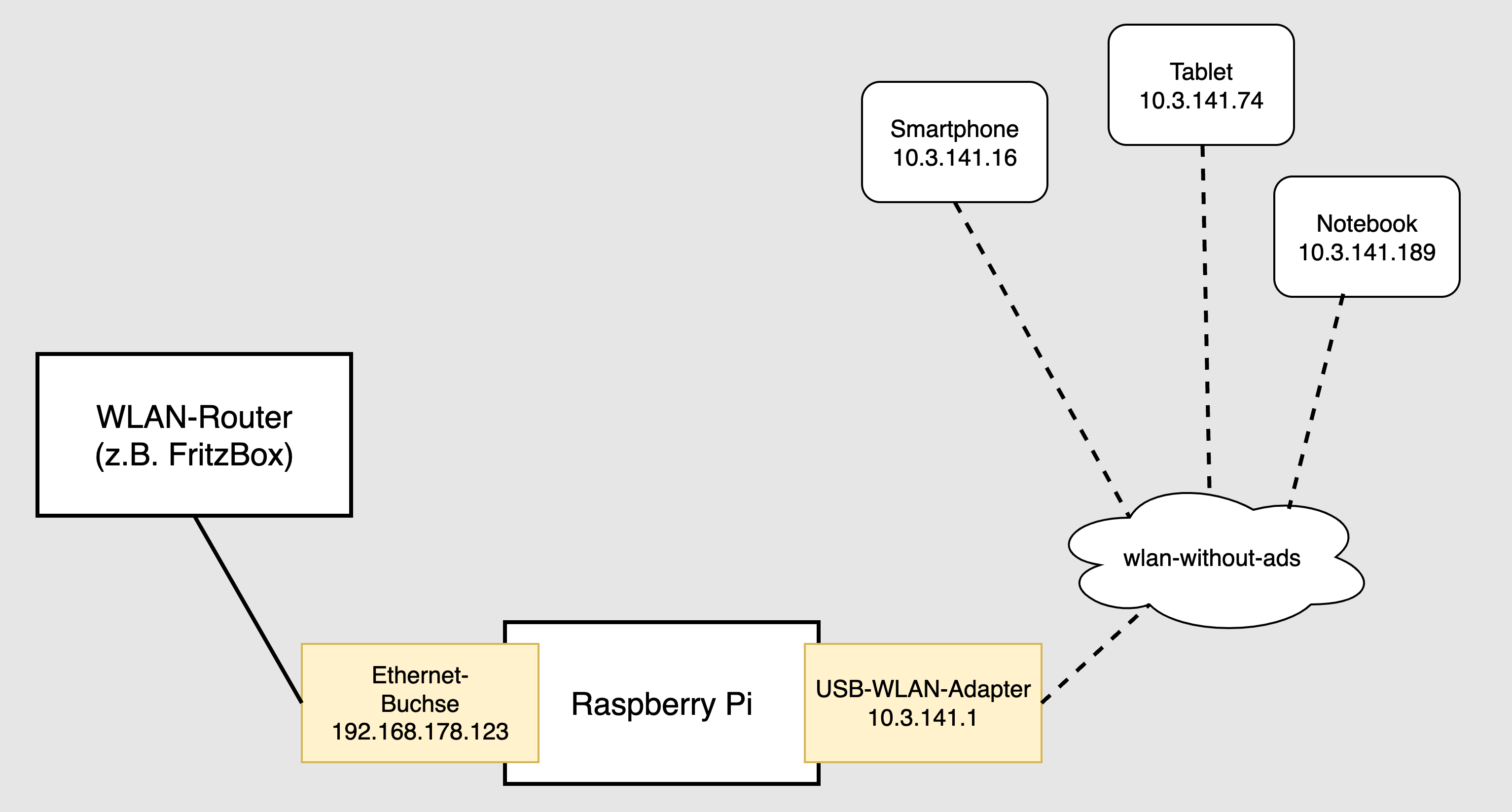
Konzept
Die Idee ist simpel: Parallel zum lokalen Netzwerk zuhause richten Sie mit einem Raspberry Pi ein zweites WLAN ein. Das zweite Netz verwendet nicht nur einen anderen IP-Adressbereich, sondern hat auch einen eigenen Domain Name Server, der alle bekannten Ad-Ausliefer-Sites blockiert. Jeder Zugriff auf eine derartige Seite liefert sofort eine Null-Antwort. Sie glauben gar nicht, wie schnell die Startseite von heise.de, spiegel.de etc. dann lädt!
Alle Geräte im Haushalt haben jetzt die Wahl: sie können im vorhandenen WLAN des Internet-Routers bleiben, oder in das WLAN des Raspberry Pis wechseln. (Bei mir zuhause hat dieses WLAN den eindeutigen Namen/SSID wlan-without-ads.)
RaspAP auf dem Raspberry Pi spannt ein eigenes (beinahe) werbefreies WLAN auf
Zur Realisierung dieser Idee brauchen Sie einen Raspberry Pi — am besten nicht das neueste Modell: dessen Rechenleistung und Stromverbrauch sind zu höher als notwendig! Ich habe einen Raspberry Pi 3B+ aus dem Keller geholt. Auf dem Pi installieren Sie zuerst Raspbian OS Lite und dann RaspAP. Sie schließen den Pi mit einem Kabel an das lokale Netzwerk an. Der WLAN-Adapter des Raspberry Pis realisiert den Hotspot und spannt das werbefreie lokale Zweit-Netzwerk auf. Die Installation dauert ca. 15 Minuten.
Raspberry Pi OS Lite installieren
Zur Installation der Lite-Version von Raspberry Pi OS laden Sie sich das Programm Raspberry Pi Imager von https://www.raspberrypi.com/software/ herunter und führen es aus. Damit übertragen Sie Raspberry Pi OS Lite auf eine SD-Karte. (Eine SD-Karte mit 8 GiB reicht.) Am besten führen Sie gleich im Imager eine Vorweg-Konfiguration durch und stellen einen Login-Namen, das Passwort und einen Hostnamen ein. Sie können auch gleich den SSH-Server aktivieren — dann können Sie alle weiteren Arbeiten ohne Tastatur und Monitor durchführen. Führen Sie aber keine WLAN-Konfiguration durch!
Mit der SD-Karten nehmen Sie den Raspberry Pi in Betrieb. Der Pi muss per Netzwerkkabel mit dem lokalen Netzwerk verbunden sein. Melden Sie sich an (wahlweise mit Monitor + Tastatur oder per SSH) und führen Sie ein Update durch (sudo apt update und sudo apt full-upgrade).
RaspAP installieren
RaspAP steht für Raspberry Pi Access Point. Sein Setup-Programm installiert eine Weboberfläche, in der Sie unzählige Details und Funktionen Ihres WLAN-Routers einstellen können. Dazu zählen:
Verwendung als WLAN-Router oder -Repeater
freie Auswahl des WLAN-Adapters
frei konfigurierbarer DHCP-Server
Ad-Blocking-Funktion
VPN-Server (OpenVPN, WireGuard)
VPN-Client (ExpressVPN, Mullvad VPN, NordVPN)
An dieser Stelle geht es nur um die Ad-Blocking-Funktionen, die standardmäßig aktiv sind. Zur Installation laden Sie das Setup-Script herunter, kontrollieren kurz mit less, dass das Script wirklich so aussieht, als würde es wie versprochen RaspAP installieren, und führen es schließlich aus.
Die Rückfragen, welche Features installiert werden sollen, können Sie grundsätzlich alle mit [Return] beantworten. Das VPN-Client-Feature ist nur zweckmäßig, wenn Sie über Zugangsdaten zu einem kommerziellen VPN-Dienst verfügen und Ihr Raspberry Pi diesen VPN-Service im WLAN weitergeben soll. (Das ist ein großartiger Weg, z.B. ein TV-Gerät via VPN zu nutzen.)
Welche Funktionen Sie wirklich verwenden, können Sie immer noch später entscheiden. Das folgende Listing ist stark gekürzt. Die Ausführung des Setup-Scripts dauert mehrere Minuten, weil eine Menge Pakete installiert werden.
wget https://install.raspap.com -O raspap-setup.sh
less raspap-setup.sh
bash raspap-setup.sh
The Quick Installer will guide you through a few easy steps
Using GitHub repository: RaspAP/raspap-webgui 3.0.7 branch
Configuration directory: /etc/raspap
lighttpd root: /var/www/html? [Y/n]:
Installing lighttpd directory: /var/www/html
Complete installation with these values? [Y/n]:
Enable HttpOnly for session cookies? [Y/n]:
Enable RaspAP control service (Recommended)? [Y/n]:
Install ad blocking and enable list management? [Y/n]:
Install OpenVPN and enable client configuration? [Y/n]:
Install WireGuard and enable VPN tunnel configuration? [Y/n]:
Enable VPN provider client configuration? [Y/n]: n
The system needs to be rebooted as a final step. Reboot now? [Y/n]
Wenn alles gut geht, gibt es nach dem Neustart des Raspberry Pi ein neues WLAN mit dem Namen raspi-webgui. Das Passwort lautet ChangeMe.
Sobald Sie Ihr Notebook (oder ein anderes Gerät) mit diesem WLAN verbunden haben, öffnen Sie in einem Webbrowser die Seite http://10.3.141.1 (mit http, nicht https!) und melden sich mit den folgenden Daten an:
Username: admin
Passwort: secret
In der Weboberfläche sollten Sie als Erstes zwei Dinge ändern: das Admin-Passwort und das WLAN-Passwort:
Zur Veränderung des Admin-Passworts klicken Sie auf das User-Icon rechts oben in der Weboberfläche, geben einmal das voreingestellte Passwort secret und dann zweimal Ihr eigenes Passwort an.
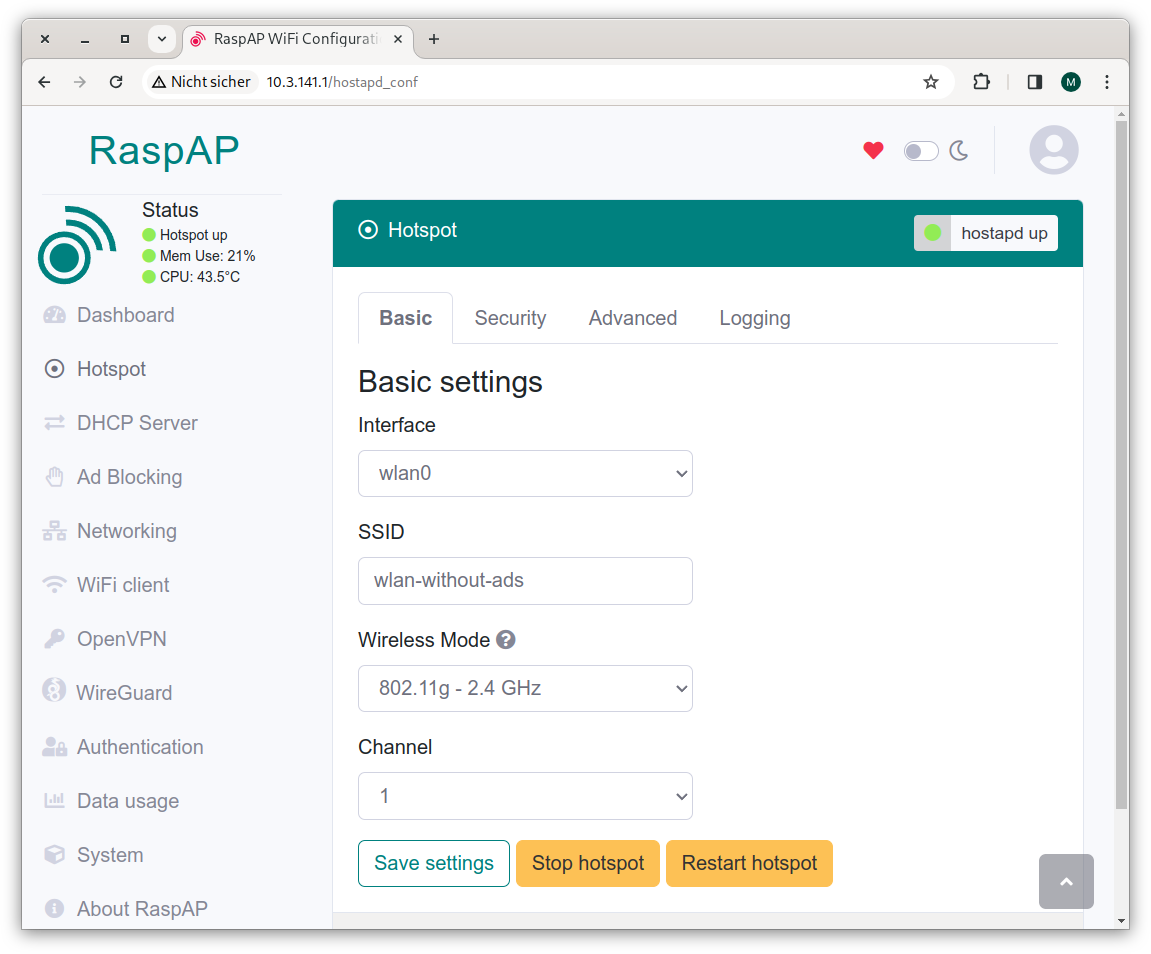
Die Eckdaten des WLANs finden Sie im Dialogblatt Hotspot. Das Passwort können Sie im Dialogblatt Security verändern.
Die Weboberfläche von RaspAP mit den Hotspot-EinstellungenBei den Ad-Block-Einstellungen sind keine Änderungen erforderlich. Es schadet aber nicht, hin und wieder die Ad-Blocking-Liste zu erneuern.
RaspAP verwendet automatisch den WLAN-Namen (den Service Set Identifier) raspi-webgui. Auf der Einstellungsseite Hotspot können Sie einen anderen Namen einstellen. Ich habe wie gesagt wlan-without-ads verwendet. Danach müssen sich alle Clients neu anmelden. Fertig!
USB-WLAN-Adapter
Leider hat der lokale WLAN-Adapter des Raspberry Pis keine großartige Reichweite. Für’s Wohnzimmer oder eine kleine Wohnung reicht es, für größere Wohnungen oder gar ein Einfamilienhaus aber nicht. Abhilfe schafft ein USB-WLAN-Antenne. Das Problem: Es ist nicht einfach, ein Modell zu finden, das vom Linux-Kernel auf Anhieb unterstützt wird. Ich habe zuhause drei USB-WLAN-Adapter. Zwei haben sich als zu alt erwiesen (kein WPA, inkompatibel mit manchen Client-Geräten etc.); der dritte Adapter (BrosTrend AC650) wird auf Amazon als Raspberry-Pi-kompatibel beworben, womit ich auch schon in die Falle getappt bin. Ja, es gibt einen Treiber, der ist aber nicht im Linux-Kernel inkludiert, sondern muss manuell installiert werden:
Immerhin gelang die Installation unter Raspberry Pi OS Lite auf Anhieb mit dem folgenden, auf GitHub dokumentierten Kommando:
sh -c 'busybox wget deb.trendtechcn.com/install \
-O /tmp/install && sh /tmp/install'
Mit dem nächsten Neustart erkennt Linux den WLAN-Adapter und kann ihn nutzen. Das ändert aber nichts daran, dass mich die Installation von Treibern von dubiosen Seiten unglücklich macht, dass die Treiberinstallation nach jedem Kernel-Update wiederholt werden muss und dass die manuelle Treiberinstallationen bei manchen Linux-Distributionen gar nicht möglich ist (LibreELEC, Home Assistant etc.).
Wenn Sie gute Erfahrungen mit einem USB-WLAN-Adapter gemacht haben, hinterlassen Sie bitte einen kurzen Kommentar!
Sobald RaspAP den WLAN-Adapter kennt, bedarf es nur weniger Mausklicks in der RaspAP-Weboberfläche, um diesen Adapter für den Hotspot zu verwenden.
Alternativ können Sie den internen WLAN-Adapter auch ganz deaktivieren. Dazu bauen Sie in config.txt die folgende Zeile ein und starten den Raspberry Pi dann neu.
Danach kennt Raspberry Pi OS nur noch den USB-WLAN-Adapter, eine Verwechslung ist ausgeschlossen.
Vorteile
Der größte Vorteil von RaspAP als Ad-Blocker ist aus meiner Sicht seine Einfachheit: Der Werbeblocker kann mit minimalem Konfigurationsaufwand von jedem Gerät im Haushalt genutzt werden (Opt-In-Modell). Sollte RaspAP für eine Website zu restriktiv sein, dauert es nur wenige Sekunden, um zurück in das normale WLAN zu wechseln. Bei mir zuhause waren alle Familienmitglieder schnell überzeugt.
Nachteile
Der Raspberry Pi muss per Ethernet-Kabel mit dem lokalen Netzwerk verbunden werden.
Manche Seiten sind so schlau, dass sie das Fehlen der Werbung bemerken und dann nicht funktionieren. Es ist prinzipbedingt unmöglich, für solche Seiten eine Ausnahmeregel zu definieren. Sie müssen in das normale WLAN wechseln, damit die Seite funktioniert.
youtube-Werbung kann nicht geblockt werden, weil Google so schlau ist, die Werbefilme vom eigenen Server und nicht von einem anderen Server zuzuspielen. youtube.com selbst zu blocken würde natürlich helfen und außerdem eine Menge Zeit sparen, schießt aber vielleicht doch über das Ziel hinaus.
Mit RaspAP sind Sie in einem eigenen privaten Netz, NICHT im lokalen Netz Ihres Internet-Routers. Sie können daher mit Geräten, die sich im wlan-without-ads befinden, nicht auf andere Geräte zugreifen, die mit Ihrem lokalen Router (FritzBox etc.) verbunden sind. Das betrifft NAS-Geräte, Raspberry Pis mit Home Assistant oder anderen Anwendungen etc.
Keine Werbeeinnahmen mehr für Seitenbetreiber?
Mir ist klar, dass sich viele Seiten zumindest teilweise über Werbung finanzieren. Das wäre aus meiner Sicht voll OK. Aber das Ausmaß ist unerträglich geworden: Mittlerweile blinkt beinahe zwischen jedem Absatz irgendein sinnloses Inserat. Werbefilme vervielfachen das Download-Volumen der Seiten, der Lüfter heult, ich kann mich nicht mehr auf den Text konzentrieren, den ich lese. Es geht einfach nicht mehr.
Viele Seiten bieten mir Pur-Abos an (also Werbeverzicht gegen Bezahlung). Diesbezüglich war https://derstandard.at ein Pionier, und tatsächlich habe ich genau dort schon vor vielen Jahren mein einziges Pur-Abo abgeschlossen. In diesem Fall ist es auch ein Ausdruck meiner Dankbarkeit für gute Berichterstattung. Früher habe ich für die gedruckte Zeitung bezahlt, jetzt eben für die Online-Nutzung.
Mein Budget reicht aber nicht aus, dass ich solche Abos für alle Seiten abschließen kann, die ich gelegentlich besuche: heise.de, golem.de, phoronix, zeit.de, theguardian.com usw. Ganz abgesehen davon, dass das nicht nur teuer wäre, sondern auch administrativ mühsam. Ich verwende diverse Geräte, alle paar Wochen muss ich mich neu anmelden, damit die Seiten wissen, dass ich zahlender Kunde bin. Das ist bei derstandard.at schon mühsam genug. Wenn ich zehn derartige Abos hätte, würde ich alleine an dieser Stelle schon verzweifeln.
Wenn sich Zeitungs- und Online-News-Herausgeber aber zu einem Site-übergreifenden Abrechnungsmodell zusammenschließen könnten (Aufteilung der monatlichen Abo-Gebühr nach Seitenzugriffen), würde ich mir das vielleicht überlegen. Das ist aber sowieso nur ein Wunschtraum.
Aber so, wie es aktuell aussieht, funktioniert nur alles oder nichts. Mit RaspAP kann ich die Werbung nicht für manche Seiten freischalten. Eine Reduktion des Werbeaufkommens auf ein vernünftiges Maß funktioniert auch nicht. Gut, dann schalte ich die Werbung — soweit technisch möglich — eben ganz ab.
Mein Lehrbuch Datenbanksysteme ist gerade in der 2. Auflage erschienen. Es richtet sich an Studierende, Entwickler und Datenbankanwender. Es erklärt, wie moderne Datenbankmanagementsysteme funktionieren. Es zeigt Ihnen, wie Sie Datenbanken korrekt und effizient entwerfen. Es erläutert den Umgang mit der Structured Query Language (SQL) und gibt einen Überblick über die Administration und Programmierung von Datenbanksystemen.
Unzählige Übungsaufgaben (mit Lösungen!) helfen Ihnen, das erlernte Wissen zu verfestigen und anzuwenden. Zusammen mit dem Buch erhalten Sie den Online-Zugriff auf mehrere Beispieldatenbanken, sodass Sie SQL-Kommandos ohne die langwierige Installation eines eigenen Datenbank-Servers ausprobieren können. Alternativ können Sie die zum Download angebotenen Beispieldatenbanken natürlich auch lokal installieren.
In das Buch fließt meine bald 30-jährige Erfahrung im Entwurf von Datenbanken, bei der Entwicklung von Datenbankanwendungen, bei der Administration von Datenbankmanagementsystemen (DBMS) sowie aus dem Unterricht ein. Ein besonderer Fokus des Buchs liegt im korrekten Datenbankdesign. Fehler, die in dieser Phase passieren, sind später praktisch nicht mehr zu korrigieren. Das Buch berücksichtigt auch neue Entwicklungen, von NoSQL bis hin zu modernen SQL-Features (Rekursion, Common Table Expressions, Window-Funktionen etc.).
Für die 2. Auflage habe ich den NoSQL-Teil des Buchs ausgebaut und um ein MongoDB-Kapitel ergänzt. Außerdem habe ich diverse Fehler korrigiert und da und dort kleine Ergänzungen und Verbesserungen vorgenommen.
Wenn Sie auf der Fachhochschule oder Universität eine Datenbank-Vorlesung oder -Übung abhalten: Kontaktieren Sie dozenten@rheinwerk-verlag.de und fordern Sie ein kostenloses Belegexemplar an!