Zahlreiche Apps umgehen Sexbilder-Verbote
In der letzten Zeit erregte Elon Musk mit seinem Grok-Chatbot Aufsehen, weil der dazu benutzt werden konnte, Bilder von angezogenen Frauen und Kindern in Nacktdarstellungen zu verwandeln.
In der letzten Zeit erregte Elon Musk mit seinem Grok-Chatbot Aufsehen, weil der dazu benutzt werden konnte, Bilder von angezogenen Frauen und Kindern in Nacktdarstellungen zu verwandeln.
Vishal Sikka, der ehemalige CTO von SAP und heutiger Chef seines Start-ups VianAI Systems, hat zusammen mit seinem Sohn, Varin Sikka (Stanford University) eine Studie herausgegeben, die…
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt hatte ich mit Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Unter Fedora funktioniert es wie folgt:
sudo dnf install fuse-libs # FUSE-Bibliothek installieren
chmod +x Downloads/*.AppImage # execute-Bit setzen
Downloads/LM-Studio-<n.n>.AppImage # LM Studio ausführen
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
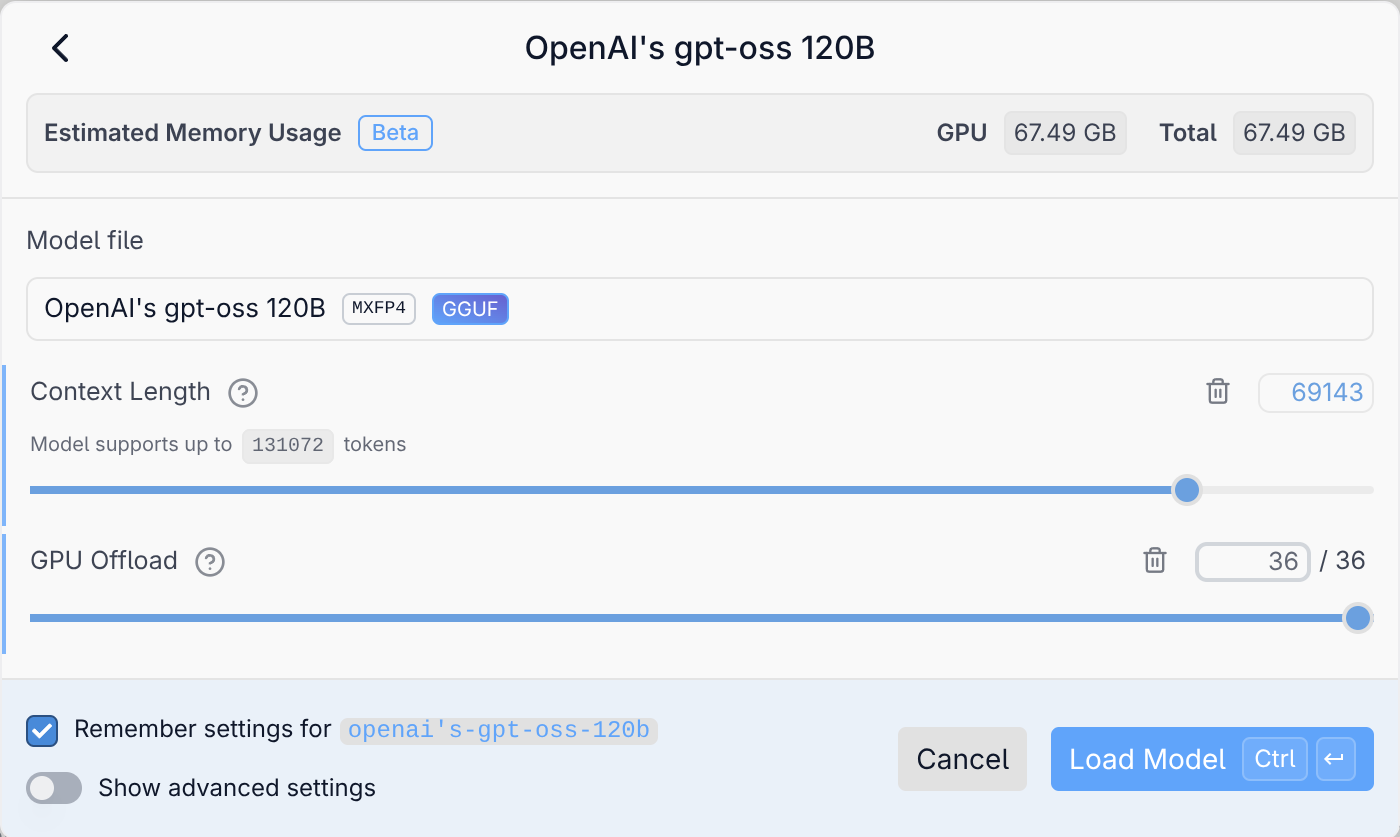
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
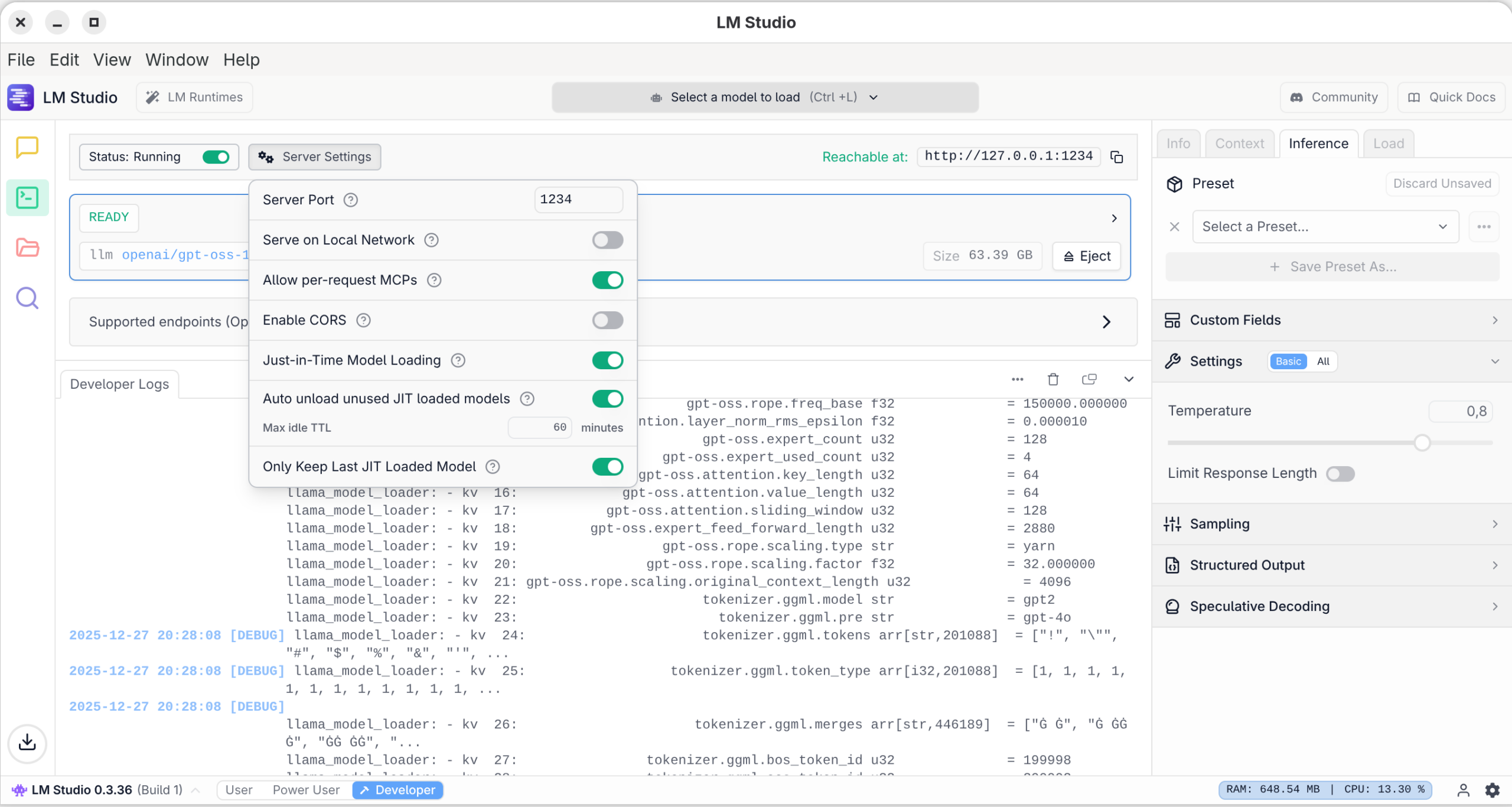
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Sprachmodell MoE Parameter Quant. Token/s
------------- ----- ---------- --------- --------
deepseek-r1-distill-qwen-14b nein 14 Mrd. Q4_K_S 22
devstral-small-2-2512 nein 25 Mrd. Q4_K_M 13
glm-4.5-air ja 110 Mrd. Q3_K_L 25
gpt-oss-20b ja 20 Mrd. MXFP4 65
gpt-oss-120b ja 120 Mrd. MXFP4 48
nouscoder-14b nein 14 Mrd. Q4_K_S 22
qwen3-30b-a3b ja 30 Mrd. Q4_K_M 70
qwen3-next-80b-83b ja 80 Mrd. Q4_K_XL 40
seed-oss-36b nein 36 Mrd. Q4_K_M 10
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Eine Veröffentlichung des Science Policy Forum, an der auch die Direktorin des Max-Planck-Instituts für Sicherheit und Privatsphäre, Prof.
Die amerikanische Science Fiction and Fantasy Writers Association (SFWA) hat bekanntgegeben, dass Werke, die ganz oder teilweise von LLMs verfasst wurden, nicht für ihren Preis, die Nebula…
Tests der britischen Tageszeitung The Guardian haben ergeben, dass ChatGPT bei diversen Anfragen Elon Musks umstrittene Online-Enzyklopedie Grokipedia als Quelle zitiert.
D4RT, ein neues KI-Modell von Google, revolutioniert die Art und Weise, wie Computer Bewegung in der Zeit verstehen.
AMD hat seinen ROCm-Stack aktualisiert.
AMD hat seinen ROCm-Stack aktualisiert.
Eleven Labs hat mit „Das Eleven Album“ eine Sammlung von KI-generierter Musik veröffentlicht, das den Stil prominenter Künstler radiotauglich imitiert.
Einer Umfrage des Beratungsunternehmens PwC unter 4454 CEOs aus 95 Ländern im Oktober/November letzten Jahres hat ergeben, dass global nur sehr wenige Unternehmen von KI profitieren und in…
Der Kreditversicherer Allianz Trade hat Zahlen aus seiner aktuellen Schadensstatistik veröffentlicht und warnt vor immer mehr Fällen und höheren Schäden.
ChatGPT führt ein Age-Prediction-System ein, mit dem es versucht, auf das Alter seiner Nutzer zu schließen und so für Anwender unter 18 besondere Jugendschutzmaßnahmen zu etablieren.
Während multimodale LLMs heute Textaufgaben auf Doktorandenniveau lösen können, versagen sie bei visuellen Aufgaben, die Kleinkinder im Alter von drei bis fünf Jahren beherrschen.
 Viele KI Dienste wie ChatGPT oder Gemini verlangen blinde Vertrauensbereitschaft. Nutzer senden ihre Gedanken und Anliegen im Klartext und hoffen nebst qualititiv guter Antwort auch auf verantwortungsvollen Umgang. Betreiber speichern jedoch oft alles und nutzen die Daten für Training oder Analyse. Die Kontrolle liegt selten bei den Menschen, die diese Systeme verwenden. Confer verfolgt einen […]
Viele KI Dienste wie ChatGPT oder Gemini verlangen blinde Vertrauensbereitschaft. Nutzer senden ihre Gedanken und Anliegen im Klartext und hoffen nebst qualititiv guter Antwort auch auf verantwortungsvollen Umgang. Betreiber speichern jedoch oft alles und nutzen die Daten für Training oder Analyse. Die Kontrolle liegt selten bei den Menschen, die diese Systeme verwenden. Confer verfolgt einen […]
Der Beitrag Confer zeigt neuen Weg für private KI Nutzung erschien zuerst auf fosstopia.
Mit Open Responses gibt es nun erstmals einen Vorschlag für einen Open-Source-Standard für ein herstellerunabhängiges JSON-API, über das Clients mit LLMs kommunizieren können.
In Memphis (Tennessee) geht mit Colossus 2 das erste Gigawatt-Rechenzentrum der Welt in Betrieb. Es dient vor allem dem Training von xAIs Sprachmodell Grok.
Open-Source-Entwickler werden zunehmend durch KI-Müll überlastet. Daniel Stenberg,Gründer und Hauptentwickler des weitverbreiteten Netzwerktools Curl, zieht nun die Konsequenz und beendet sein Bug-Bounty-Programm.
OpenAI hat bekanntgegeben, dass es künftig, beginnend in den USA, allen Nutzern, die die kostenlose Version oder das günstige Go-Abo nutzen, Werbung einblenden will.
Google launcht eine neue Kollektion spezialisierter Sprachmodelle unter dem Namen TranslateGemma, die aus und in 55 Sprachen übersetzt und auf Gemma 3 aufbaut.
Das deutsche KI-Start-up Black Forest Labs veröffentlicht mit Flux.2[klein] sein bisher schnellstes Modell, das hochwertige Bilder in weniger als einer Sekunde erzeugt oder bearbeitet.
Eine neue Zusatzplatine (HAT) rüstet auf dem Raspberry Pi 5 einen KI-Beschleuniger nach, der endlich auch einige generative KI-Modelle ausführen kann.
Eine neue Zusatzplatine (HAT) rüstet auf dem Raspberry Pi 5 einen KI-Beschleuniger nach, der endlich auch einige generative KI-Modelle ausführen kann.
Google schafft eine Möglichkeit, seinen Chatbot Gemini mit anderen Apps wie Gmail, Google Photos, Youtube und der Websuche zu verbinden, die bei Fragen an den Bot persönliche Informationen…
Die britische Marktforschungsagentur Coleman Parkes hat im Auftrag von Camunda, einem Hersteller von Lösungen im Bereich der agentenbasierten Automatisierung, eine Umfrage unter 1150 Personen aus…