Das Training auf einer virtuellen Maschine mit Fedora 40 Server, 10 CPU-Threads und 32 GB RAM dauerte 180 Std. 44 Min. 7 Sek. Ich halte an dieser Stelle fest, ohne GPU-Beschleunigung fehlt es mir persönlich an Geduld. So macht das Training keinen Spaß.
Nach dem Training mit ilab train findet man ein brandneues LLM auf dem eigenen System:
(venv) tronde@instructlab:~/src/instructlab$ ls -ltrh models
total 18G
-rw-r--r--. 1 tronde tronde 4.1G May 28 20:34 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r--. 1 tronde tronde 14G Jun 6 12:07 ggml-model-f16.gguf
Test des neuen Modells
Den Chat mit dem LLM starte ich mit dem Befehl ilab chat -m models/ggml-model-f16.gguf. Das folgende Bild zeigt zwei Chats mit jeweils unterschiedlichem Ergebnis:
Zwei Chats mit dem frisch trainierten LLM. Beide Male erhalte ich nicht die erhoffte Antwort.
Fazit
Schade, das hat nicht so funktioniert, wie ich mir das vorgestellt habe. Es kommt weiterhin zu KI-Halluzinationen und nur gelegentlich gesteht das LLM seine Unkenntnis bzw. seine Unsicherheit ein.
Für mich sind damit 180 Stunden Rechenzeit verschwendet. Ich werde bis auf Weiteres keine Trainings ohne Beschleuniger-Karten mehr durchführen. Jedoch werde ich mir von Zeit zu Zeit aktualisierte Releases der verfügbaren Modelle herunterladen und diesen Fragen stellen, deren Antworten ich bereits kenne.
Wenn sich mir die Gelegenheit bietet, diesen Versuch auf einem Rechner mit entsprechender GPU-Hardware zu wiederholen, werde ich die Erkenntnisse hier im Blog teilen.
Die Document Foundation hat die allgemeine Verfügbarkeit von LibreOffice 24.2.4 angekündigt. Dies ist die vierte Punktveröffentlichung der neuesten LibreOffice 24.2 Bürosoftware-Serie und behebt mehr als 70 Fehler. LibreOffice 24.2.4 erscheint etwas mehr als einen Monat nach dem LibreOffice 24.2.3 Update und behebt weitere lästige Fehler, Abstürze und andere Unannehmlichkeiten, die von den Nutzern in der...
Mich erreichen in letzter Zeit des Öfteren Klagen, dass man Linux Mint nicht ohne Flatpak betreiben oder nutzen kann. Sobald man Flatpak löscht, startet die Anwendungsverwaltung also der App Store nicht mehr. Betroffen sind Linux Mint und LMDE. Das habe ich mir mal angeschaut und hier ist mein Vorschlag, wie Ihr das Problem lösen könnt....
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Wer ein GitHub Account hat, kann sich sehr einfach über neue Releases (Veröffentlichungen) von Projekten per E-Mail informieren lassen. Es benutzen aber nicht alle Projekte das „Releases“ Feature, sondern setzen stattdessen auf Git Tags....
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
Was ist InstructLab?
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
Hugging Face. The AI community building the future. The platform where the machine learning community collaborates on models, datasets, and applications. URL: https://huggingface.co/
Meine Einstellung gegenüber KI-ChatBots
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Der lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
Screencast eines Chats mit merlinite-7b-lab-Q4_K_M
Wie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
KI-Halluzinationen
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Frage an das LLM: „Who is the chancellor of the Bielefeld University?“
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
ChatBot wird auf Falschaussage hingewiesen
Die Antworten des LLM enthalten folgende Fehler:
Professor Dr. Ulrich Heidt ist nicht der Kanzler der Universität Bielefeld
Die URL ‚https://www.uni-bielefeld.de/english/staff/‘ existiert nicht
Die URL ‚http://www.universitaet-bielefeld.de/en/‘ existiert ebenfalls nicht
Die Universität hieß niemals „Technische Universitaet Braunschweig“
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Wissen und Fähigkeiten hinzufügen und das Modell anlernen
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Wissen erschaffen
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
Konvertiere den Wikipedia-Artikel Bielefeld University ohne Bilder und Tabellen in eine Markdown-Datei und füge sie dem in Schritt 1 erstellten Repository unter dem Namen unibi.md hinzu
Füge dem lokalen Taxonomy-Repository neue Verzeichnisse hinzu: mkdir -p university/germany/bielefeld_university
Erstelle in dem neuen Verzeichnis eine qna.yaml und eine attribution.txt Datei
Führe ilab diff aus, um die Daten zu validieren
Der folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$
Synthetische Daten generieren
Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
Zur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Das Training beginnt
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Fazit
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.
Willkommen in der Welt von Linux, wo Innovation keine Grenzen kennt. Entdeckt das ungenutzte Potenzial von Linux durch seine vielfältigen Merkmale, Anwendungen und Vorteile. Von Servern bis hin zu Desktops, eingebetteten Systemen und Cloud-Computing steht Linux für Vielseitigkeit und Zuverlässigkeit. Nach diesem Video kennt Ihr die vielen Einsatzbereiche von Linux und seine Vorteile. Erfahrt, warum Linux das bevorzugte Betriebssystem für Millionen von Menschen weltweit ist. Viel Spaß!
Debian hat eine neue, abgespeckte Version des KeePassXC-Pakets eingeführt, die sich auf die Kernfunktionen konzentriert und erweiterte Funktionen weglässt, wie die KeePassXC Entwickler berichten. Ziel ist es die Angriffsfläche zu minimieren und die Sicherheit zu erhöhen. Der Paketbetreuer von KeePassXC bei Debian hat kürzlich beschlossen, eine abgespeckte Version des Passwortmanagers bereitzustellen. Dieses neue Paket, das...
Linux ist für seine Vielfalt an Distributionen bekannt, die unterschiedliche Schwerpunkte, Philosophien und Zielgruppen haben. Zwei der bekanntesten Distros passen zusammen wie Ying und Yang: Debian und Arch Linux. Trotz Gemeinsamkeiten könnten sie nicht unterschiedlicher sein. Doch es ist nicht alles so, wie es zunächst scheint. Debian: Die Stabilität und Zuverlässigkeit Debian ist eine der...
Linus Torvalds kündigte die Veröffentlichung und allgemeine Verfügbarkeit des Linux-Kernels 6.9 an, der neuesten stabilen Version des Linux-Kernels, die mehrere neue Funktionen und eine verbesserte Hardwareunterstützung einführt. Zu den Höhepunkten des Linux-Kernels 6.9 gehören Rust-Unterstützung auf AArch64 (ARM64) Architekturen, Unterstützung für den Intel FRED (Flexible Return and Event Delivery) Mechanismus zur verbesserten Ereignisübermittlung auf niedriger...
Die Document Foundation hat die allgemeine Verfügbarkeit von LibreOffice 7.6.7 bekannt gegeben, dem siebten und letzten Wartungsupdate der LibreOffice 7.6 Bürosuite für produktive Umgebungen. Obwohl LibreOffice 24.2 bereits mit seinen neuen Funktionen und Verbesserungen verfügbar ist, pflegt die Document Foundation weiterhin den LibreOffice 7.6-Zweig, der bis zum 12. Juni 2024 unterstützt wird. LibreOffice 7.6.7 ist...
Arch Linux gilt vielen als zu kompliziert und anspruchsvoll. Dies zeigt sich schon zu Beginn bei der Installation. Es gibt keinen grafischen Installer. Die Schritte müssen selbst durchgeführt werden. Doch mittlerweile gibt es ein offizielles Script, das die Installation etwas erleichtert. Genau um dieses Script geht es in diesem Beitrag. Viel Spaß. Dies ist ein...
KeePassXC 2.7.8 wurde als neues Wartungsupdate der KeePassXC 2.7-Serie der beliebten, kostenlosen und plattformübergreifenden Passwort-Manager-Anwendung auf Open-Source Basis veröffentlicht. Für viele ist KeePassXC als der beste Passwort-Manager aufgrund der Vielzahl an Funktionen, die er in einem vergleichsweise kompakten Paket bietet. Insbesondere unter datenschutzorientierten Nutzern, die keine cloud-basierte Lösung wie Bitwarden bevorzugen, erfreut sich KeePassXC großer...
Red Hat hat die allgemeine Verfügbarkeit von Red Hat Enterprise Linux 9.4 bekannt gegeben, das als viertes Update der neuesten Betriebssystemserie von Red Hat Enterprise Linux 9 neue und verbesserte Funktionen einführt. Zu den Highlights von Red Hat Enterprise Linux 9.4 gehören die Möglichkeit, benutzerdefinierte Dateien für das SCAP-Sicherheitsprofil einem Blueprint hinzuzufügen, die Unterstützung für...
Der Wechsel von Windows auf Linux will wohl überlegt und durchdacht sein. Diese Podcast Folge soll auf dem Weg von Windows zu Linux helfen. Vielleicht gruselt es Dir auch vor der neuen von Microsoft vorgestellten "Recall" Funktion in Windows. Dann könnte ein Umstieg zu Linux genau die passende Lösung für das Problem sein.
Mit Alpine Linux 3.20.0 veröffentlicht das Projekt die erste Version der stabilen v3.20-Serie. Unterstützung für 64-Bit-RISC-V zählt zu den Highlights.
Debian hat eine neue, abgespeckte Version des KeePassXC-Pakets eingeführt, die sich auf die Kernfunktionen konzentriert und erweiterte Funktionen weglässt, wie die KeePassXC Entwickler berichten. Ziel ist es die Angriffsfläche zu minimieren und die Sicherheit zu erhöhen. Der Paketbetreuer von KeePassXC bei Debian hat kürzlich beschlossen, eine abgespeckte Version des Passwortmanagers bereitzustellen. Dieses neue Paket, das...
Linux ist für seine Vielfalt an Distributionen bekannt, die unterschiedliche Schwerpunkte, Philosophien und Zielgruppen haben. Zwei der bekanntesten Distros passen zusammen wie Ying und Yang: Debian und Arch Linux. Trotz Gemeinsamkeiten könnten sie nicht unterschiedlicher sein. Doch es ist nicht alles so, wie es zunächst scheint. Debian: Die Stabilität und Zuverlässigkeit Debian ist eine der...
Die auf Arch Linux basierende Distribution CachyOS bietet gleich drei interessante Neuerungen: Der Installationsassistent kann mit dem Bcachefs-Dateisystem umgehen, es gibt ein SDK für…
Linus Torvalds kündigte die Veröffentlichung und allgemeine Verfügbarkeit des Linux-Kernels 6.9 an, der neuesten stabilen Version des Linux-Kernels, die mehrere neue Funktionen und eine verbesserte Hardwareunterstützung einführt. Zu den Höhepunkten des Linux-Kernels 6.9 gehören Rust-Unterstützung auf AArch64 (ARM64) Architekturen, Unterstützung für den Intel FRED (Flexible Return and Event Delivery) Mechanismus zur verbesserten Ereignisübermittlung auf niedriger...
Die Document Foundation hat die allgemeine Verfügbarkeit von LibreOffice 7.6.7 bekannt gegeben, dem siebten und letzten Wartungsupdate der LibreOffice 7.6 Bürosuite für produktive Umgebungen. Obwohl LibreOffice 24.2 bereits mit seinen neuen Funktionen und Verbesserungen verfügbar ist, pflegt die Document Foundation weiterhin den LibreOffice 7.6-Zweig, der bis zum 12. Juni 2024 unterstützt wird. LibreOffice 7.6.7 ist...
Screen Sharing mit dem Raspberry Pi war schon immer ein fehleranfälliges Vergnügen. In der Vergangenheit hat die Raspberry Pi Foundation auf die proprietäre RealVNC-Software gesetzt. Zuletzt war RealVNC aber nicht Wayland-kompatibel. Die Alternative ist wayvnc, ein Wayland-kompatible VNC-Variante: Wie ich unter Remote Desktop und Raspberry Pi OS Bookworm schon berichtet habe, ist wayvnc aber nicht mit allen Remote-Clients kompatibel, insbesondere nicht mit Remotedesktopverbindung von Microsoft.
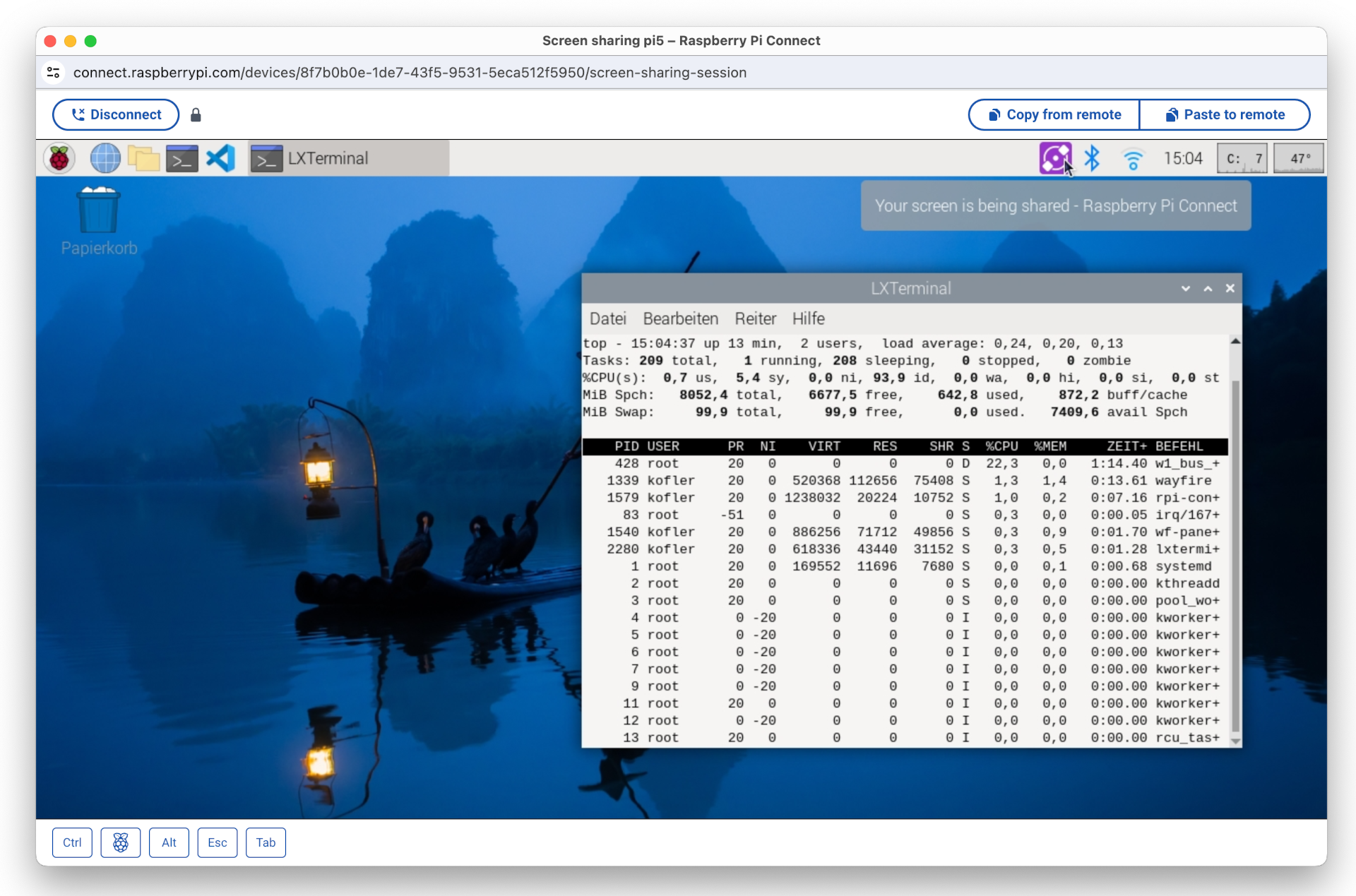
Anfang Mai 2024 hat die Raspberry Pi Foundation mit Raspberry Pi Connect eine eigene Lösung präsentiert. Ich habe das System ausprobiert. Um das Ergebnis gleich vorwegzunehmen: Bei meinen Tests hat alles bestens funktioniert, selbst dann, wenn auf beiden Seiten private Netzwerke mit Network Address Translation (NAT) im Spiel sind. Das Setup ist sehr einfach, als Client reicht ein Webbrowser. Geschwindigkeitswunder sind aber nicht zu erwarten, selbst im lokalen Netzwerk treten spürbare Verzögerungen auf.
Der Zugriff auf den Raspberry-Pi-Client erfolgt hier in einem Fenster des Webbrowsers Google Chrome unter macOS
Voraussetzungen
Raspberry Pi Connect setzt voraus, dass Sie die aktuelle Raspberry-Pi-Version »Bookworm« verwenden und dass der PIXEL Desktop in einer Wayland-Session läuft. Das schränkt die Modellauswahl auf 4B, 400 und 5 ein. Ob Ihr Desktop Wayland nutzt, überprüfen Sie am einfachsten im Terminal:
echo $XDG_SESSION_TYPE
wayland
Gegebenenfalls können Sie mit raspi-config zwischen Xorg und Wayland umschalten (Menüpunkt Advanced Options / Wayland).
Installation
Die Software-Installation verläuft denkbar einfach:
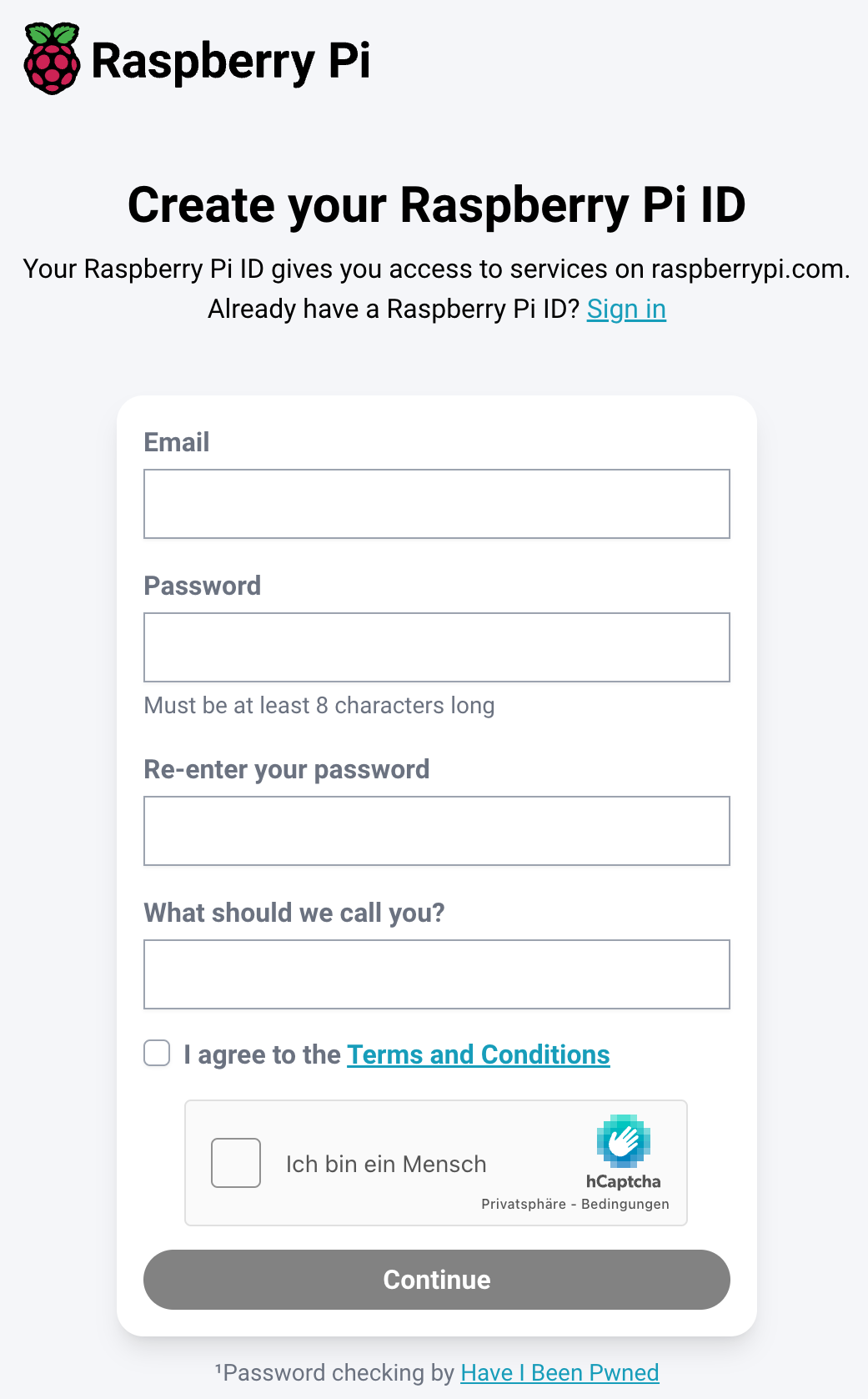
Nach der Installation erscheint ein neues Icon im Panel des PIXEL Desktops. Über dessen Menüeintrag Sign in gelangen Sie auf die Website https://connect.raspberrypi.com/sign-in. Dort müssen Sie eine Raspberry-Pi-ID einrichten. Die Eingabefelder sind auf ein Minimum beschränkt: E-Mail-Adresse, Passwort (2x) und Name. Fertig!
Bevor Sie Raspberry Pi Connect nutzen können, müssen Sie eine Raspberry Pi ID einrichten.
Fernzugriff
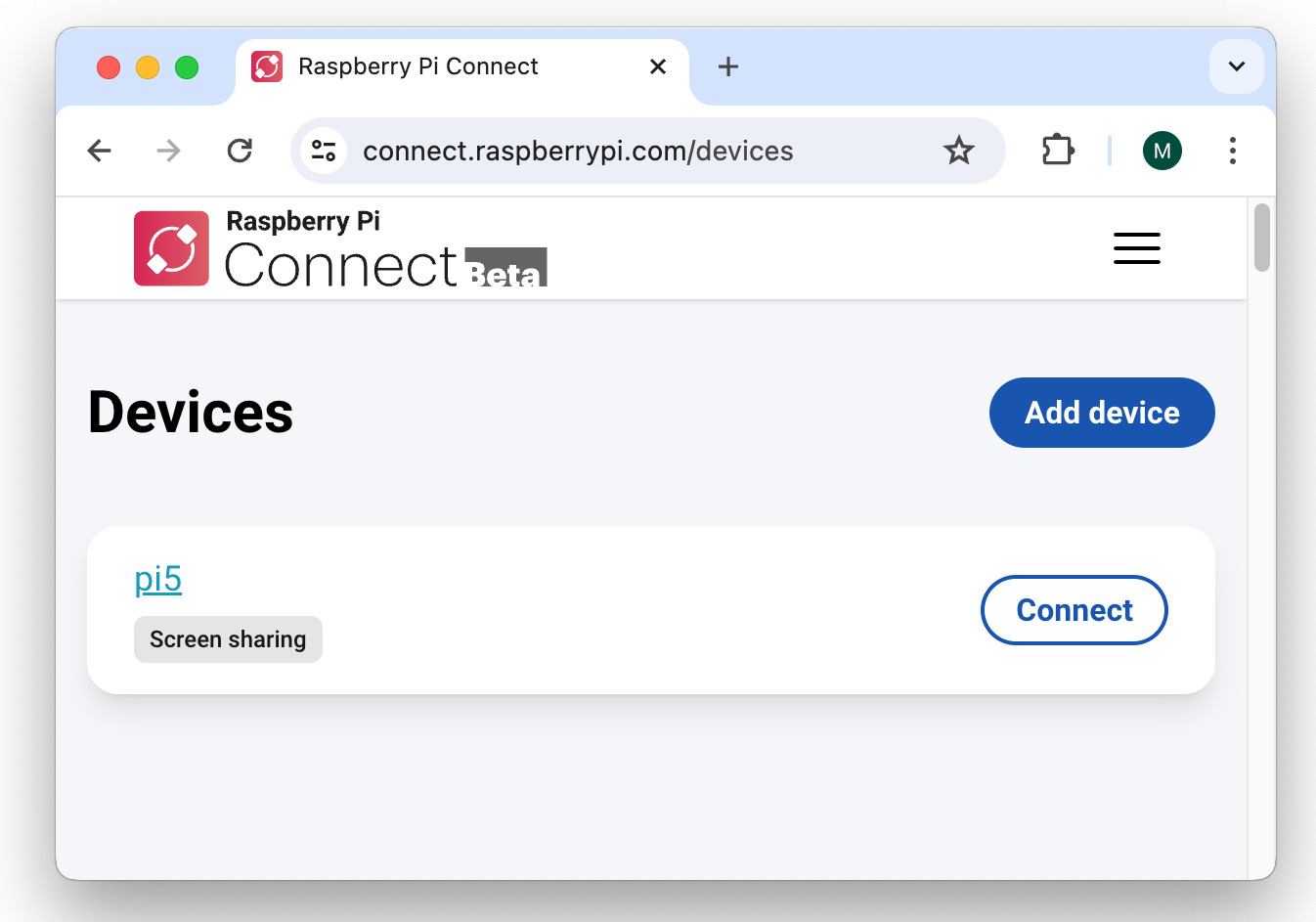
Um nun von einem anderen Rechner auf den PIXEL Desktop Ihres Raspberry Pis zuzugreifen, melden Sie sich dort ebenfalls auf der Website https://connect.raspberrypi.com/sign-in an. Dort werden alle registrierten Geräte aufgelistet. (Mit einer Raspberry-Pi-ID können als mehrere Raspberry Pis verknüpft werden.)
Remote-Verbindungsaufbau im Webbrowser
Praktische Erfahrungen
Bei meinen Tests hat Raspberry Pi Connect ausgezeichnet funktioniert. Der Verbindungsaufbau war problemlos. Der Desktop-Inhalt erscheint in einem neuen Browser-Fenster. Der Desktop-Inhalt wird automatisch auf die Fenstergröße skaliert. Die Bedienung ist denkbar simpel. Über zwei Buttons können Texte über die Zwischenablage kopiert bzw. eingefügt werden.
Raspberry Pi Connect testet beim Verbindungsaufbau, ob sich der Raspberry Pi und Ihr Client-Rechner (z.B. Ihr Notebook) im gleichen Netzwerk befinden. Wenn das der Fall ist, stellt der Client eine direkte Peer-to-Peer-Verbindung zum Raspberry Pi her. Nach dem Verbindungsaufbau fließen keine Daten mehr über den Raspberry-Pi-Connect-Server. Die Verbindungsgeschwindigkeit ist dann spürbar höher. Dennoch ist es empfehlenswert, die Bildschirmauflösung auf dem Raspberry Pi nicht höher einzustellen als notwendig.
Wenn sich Ihr Pi und Ihr Client-Rechner dagegen in unterschiedlichen (privaten) Netzwerken befinden, agiert ein Server der Raspberry Pi Foundation als Relay. Sowohl der Bildschirminhalt als auch alle Eingaben werden verschlüsselt nach Großbritannien und wieder zurück übertragen. Selbst wenn alle Geräte eine gute Internetverbindung haben, ist ein gewisser Lag unvermeidlich.
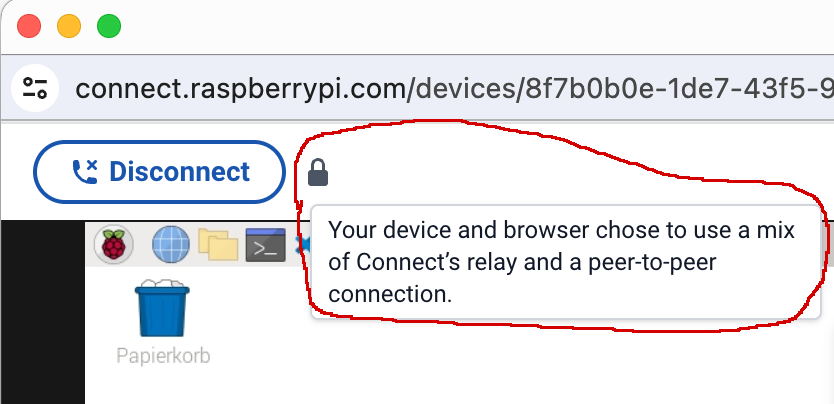
Details über die Art der Verbindung erfahren Sie, wenn Sie den Mauszeiger auf das Schloss-Icon im Screen-Sharing-Fenster bewegen.
Wenn Sie den Mauszeiger über das Schloss-Icon bewegen, erscheint ein Info-Text zum Status der Verbindung
Wenn die Remote-Desktop-Verbindung nicht im lokalen Netzwerk stattfindet, fließt der ganze Netzwerkverkehr über einen Relay-Server in Großbritannien. Dabei kommt das Protokoll Traversal Using Relays around NAT (kurz TURN) zum Einsatz. Die Daten werden TLS-verschlüsselt.
Der entscheidende Schwachpunkt des Systems besteht darin, dass es aktuell nur einen einzigen TURN-Server gibt. Je mehr gleichzeitige Remote-Desktop-Verbindungen aktiv sind, desto langsamer wird das Vergnügen … (Und besonders schnell ist es schon im Idealfall nicht.)
Fazit
Raspberry Pi Connect punktet vor allem durch seine Einfachheit.
Am Raspberry Pi reicht es aus, rpi-connect zu installieren.
Die Raspberry-Pi-ID kann rasch und unkompliziert eingerichtet werden.
Die Anwendung im Webbrowser funktioniert plattformübergreifend und einfach.
Allzu hohe Performance-Anforderungen sollten Sie nicht haben. Die Nachlaufzeiten bei Mausbewegungen und gar beim Verschieben eines Fensters sind beachtlich. Für administrative Arbeiten reicht die Geschwindigkeit aber absolut aus.
Schließlich bleibt abzuwarten, wie gut die Software skaliert. Aktuell befindet sich Raspberry Pi Connect noch in einem Probebetrieb. Soweit sich der Raspberry Pi und der Client-Rechner nicht im gleichen lokalen Netzwerk befinden, werden die Bildschirmdaten über einen Relay in Großbritannien geleitet. Aktuell gibt es genau einen derartigen Relay. Je mehr Anwender Raspberry Pi Connect gleichzeitig nutzen, desto langsamer wird es. Die Raspberry Pi Foundation lässt sich aktuell überhaupt offen, ob es den Relay-Betrieb dauerhaft kostenlos anbieten kann.

 Die Document Foundation hat die allgemeine Verfügbarkeit von LibreOffice 24.2.4 angekündigt. Dies ist die vierte Punktveröffentlichung der neuesten LibreOffice 24.2 Bürosoftware-Serie und behebt mehr als 70 Fehler. LibreOffice 24.2.4 erscheint etwas mehr als einen Monat nach dem LibreOffice 24.2.3 Update und behebt weitere lästige Fehler, Abstürze und andere Unannehmlichkeiten, die von den Nutzern in der...
Die Document Foundation hat die allgemeine Verfügbarkeit von LibreOffice 24.2.4 angekündigt. Dies ist die vierte Punktveröffentlichung der neuesten LibreOffice 24.2 Bürosoftware-Serie und behebt mehr als 70 Fehler. LibreOffice 24.2.4 erscheint etwas mehr als einen Monat nach dem LibreOffice 24.2.3 Update und behebt weitere lästige Fehler, Abstürze und andere Unannehmlichkeiten, die von den Nutzern in der... Mich erreichen in letzter Zeit des Öfteren Klagen, dass man Linux Mint nicht ohne Flatpak betreiben oder nutzen kann. Sobald man Flatpak löscht, startet die Anwendungsverwaltung also der App Store nicht mehr. Betroffen sind Linux Mint und LMDE. Das habe ich mir mal angeschaut und hier ist mein Vorschlag, wie Ihr das Problem lösen könnt....
Mich erreichen in letzter Zeit des Öfteren Klagen, dass man Linux Mint nicht ohne Flatpak betreiben oder nutzen kann. Sobald man Flatpak löscht, startet die Anwendungsverwaltung also der App Store nicht mehr. Betroffen sind Linux Mint und LMDE. Das habe ich mir mal angeschaut und hier ist mein Vorschlag, wie Ihr das Problem lösen könnt....
 InstructLab Project
InstructLab Project Willkommen in der Welt von Linux, wo Innovation keine Grenzen kennt. Entdeckt das ungenutzte Potenzial von Linux durch seine vielfältigen Merkmale, Anwendungen und Vorteile. Von Servern bis hin zu Desktops, eingebetteten Systemen und Cloud-Computing steht Linux für Vielseitigkeit und Zuverlässigkeit. Nach diesem Video kennt Ihr die vielen Einsatzbereiche von Linux und seine Vorteile. Erfahrt, warum Linux das bevorzugte Betriebssystem für Millionen von Menschen weltweit ist. Viel Spaß!
Willkommen in der Welt von Linux, wo Innovation keine Grenzen kennt. Entdeckt das ungenutzte Potenzial von Linux durch seine vielfältigen Merkmale, Anwendungen und Vorteile. Von Servern bis hin zu Desktops, eingebetteten Systemen und Cloud-Computing steht Linux für Vielseitigkeit und Zuverlässigkeit. Nach diesem Video kennt Ihr die vielen Einsatzbereiche von Linux und seine Vorteile. Erfahrt, warum Linux das bevorzugte Betriebssystem für Millionen von Menschen weltweit ist. Viel Spaß! Debian hat eine neue, abgespeckte Version des KeePassXC-Pakets eingeführt, die sich auf die Kernfunktionen konzentriert und erweiterte Funktionen weglässt, wie die KeePassXC Entwickler berichten. Ziel ist es die Angriffsfläche zu minimieren und die Sicherheit zu erhöhen. Der Paketbetreuer von KeePassXC bei Debian hat kürzlich beschlossen, eine abgespeckte Version des Passwortmanagers bereitzustellen. Dieses neue Paket, das...
Debian hat eine neue, abgespeckte Version des KeePassXC-Pakets eingeführt, die sich auf die Kernfunktionen konzentriert und erweiterte Funktionen weglässt, wie die KeePassXC Entwickler berichten. Ziel ist es die Angriffsfläche zu minimieren und die Sicherheit zu erhöhen. Der Paketbetreuer von KeePassXC bei Debian hat kürzlich beschlossen, eine abgespeckte Version des Passwortmanagers bereitzustellen. Dieses neue Paket, das... Linux ist für seine Vielfalt an Distributionen bekannt, die unterschiedliche Schwerpunkte, Philosophien und Zielgruppen haben. Zwei der bekanntesten Distros passen zusammen wie Ying und Yang: Debian und Arch Linux. Trotz Gemeinsamkeiten könnten sie nicht unterschiedlicher sein. Doch es ist nicht alles so, wie es zunächst scheint. Debian: Die Stabilität und Zuverlässigkeit Debian ist eine der...
Linux ist für seine Vielfalt an Distributionen bekannt, die unterschiedliche Schwerpunkte, Philosophien und Zielgruppen haben. Zwei der bekanntesten Distros passen zusammen wie Ying und Yang: Debian und Arch Linux. Trotz Gemeinsamkeiten könnten sie nicht unterschiedlicher sein. Doch es ist nicht alles so, wie es zunächst scheint. Debian: Die Stabilität und Zuverlässigkeit Debian ist eine der... Linus Torvalds kündigte die Veröffentlichung und allgemeine Verfügbarkeit des Linux-Kernels 6.9 an, der neuesten stabilen Version des Linux-Kernels, die mehrere neue Funktionen und eine verbesserte Hardwareunterstützung einführt. Zu den Höhepunkten des Linux-Kernels 6.9 gehören Rust-Unterstützung auf AArch64 (ARM64) Architekturen, Unterstützung für den Intel FRED (Flexible Return and Event Delivery) Mechanismus zur verbesserten Ereignisübermittlung auf niedriger...
Linus Torvalds kündigte die Veröffentlichung und allgemeine Verfügbarkeit des Linux-Kernels 6.9 an, der neuesten stabilen Version des Linux-Kernels, die mehrere neue Funktionen und eine verbesserte Hardwareunterstützung einführt. Zu den Höhepunkten des Linux-Kernels 6.9 gehören Rust-Unterstützung auf AArch64 (ARM64) Architekturen, Unterstützung für den Intel FRED (Flexible Return and Event Delivery) Mechanismus zur verbesserten Ereignisübermittlung auf niedriger... Arch Linux gilt vielen als zu kompliziert und anspruchsvoll. Dies zeigt sich schon zu Beginn bei der Installation. Es gibt keinen grafischen Installer. Die Schritte müssen selbst durchgeführt werden. Doch mittlerweile gibt es ein offizielles Script, das die Installation etwas erleichtert. Genau um dieses Script geht es in diesem Beitrag. Viel Spaß. Dies ist ein...
Arch Linux gilt vielen als zu kompliziert und anspruchsvoll. Dies zeigt sich schon zu Beginn bei der Installation. Es gibt keinen grafischen Installer. Die Schritte müssen selbst durchgeführt werden. Doch mittlerweile gibt es ein offizielles Script, das die Installation etwas erleichtert. Genau um dieses Script geht es in diesem Beitrag. Viel Spaß. Dies ist ein... KeePassXC 2.7.8 wurde als neues Wartungsupdate der KeePassXC 2.7-Serie der beliebten, kostenlosen und plattformübergreifenden Passwort-Manager-Anwendung auf Open-Source Basis veröffentlicht. Für viele ist KeePassXC als der beste Passwort-Manager aufgrund der Vielzahl an Funktionen, die er in einem vergleichsweise kompakten Paket bietet. Insbesondere unter datenschutzorientierten Nutzern, die keine cloud-basierte Lösung wie Bitwarden bevorzugen, erfreut sich KeePassXC großer...
KeePassXC 2.7.8 wurde als neues Wartungsupdate der KeePassXC 2.7-Serie der beliebten, kostenlosen und plattformübergreifenden Passwort-Manager-Anwendung auf Open-Source Basis veröffentlicht. Für viele ist KeePassXC als der beste Passwort-Manager aufgrund der Vielzahl an Funktionen, die er in einem vergleichsweise kompakten Paket bietet. Insbesondere unter datenschutzorientierten Nutzern, die keine cloud-basierte Lösung wie Bitwarden bevorzugen, erfreut sich KeePassXC großer... Red Hat hat die allgemeine Verfügbarkeit von Red Hat Enterprise Linux 9.4 bekannt gegeben, das als viertes Update der neuesten Betriebssystemserie von Red Hat Enterprise Linux 9 neue und verbesserte Funktionen einführt. Zu den Highlights von Red Hat Enterprise Linux 9.4 gehören die Möglichkeit, benutzerdefinierte Dateien für das SCAP-Sicherheitsprofil einem Blueprint hinzuzufügen, die Unterstützung für...
Red Hat hat die allgemeine Verfügbarkeit von Red Hat Enterprise Linux 9.4 bekannt gegeben, das als viertes Update der neuesten Betriebssystemserie von Red Hat Enterprise Linux 9 neue und verbesserte Funktionen einführt. Zu den Highlights von Red Hat Enterprise Linux 9.4 gehören die Möglichkeit, benutzerdefinierte Dateien für das SCAP-Sicherheitsprofil einem Blueprint hinzuzufügen, die Unterstützung für... Der Wechsel von Windows auf Linux will wohl überlegt und durchdacht sein. Diese Podcast Folge soll auf dem Weg von Windows zu Linux helfen. Vielleicht gruselt es Dir auch vor der neuen von Microsoft vorgestellten "Recall" Funktion in Windows. Dann könnte ein Umstieg zu Linux genau die passende Lösung für das Problem sein.
Der Wechsel von Windows auf Linux will wohl überlegt und durchdacht sein. Diese Podcast Folge soll auf dem Weg von Windows zu Linux helfen. Vielleicht gruselt es Dir auch vor der neuen von Microsoft vorgestellten "Recall" Funktion in Windows. Dann könnte ein Umstieg zu Linux genau die passende Lösung für das Problem sein.