In dieser Folge sprechen wir über **Linux Mint** und **LMDE**, die beiden Varianten einer der beliebtesten Linux Distributionen. Beide sehen fast gleich aus und werden vom selben Team entwickelt, unterscheiden sich aber im Kern. Während Linux Mint auf Ubuntu basiert und regelmäßig aktualisiert wird, setzt LMDE auf Debian und legt den Fokus auf Stabilität und Unabhängigkeit. Wir schauen uns an, welche Version sich besser für Einsteiger eignet, wo die technischen Unterschiede liegen und warum LMDE für erfahrene Nutzer eine spannende Alternative ist. Wenn du überlegst, welches Linux System zu dir passt, solltest du diese Folge nicht verpassen.
Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […]
Seit dem 22. Oktober 2025 stehen die ersten lauffähigen täglichen Testversionen von Ubuntu 26.04 LTS zum Download bereit. Canonical richtet sich damit an Tester, Entwickler und neugierige Nutzer. Frühere Builds funktionierten nicht richtig und waren kaum nutzbar im Alltag. Die neuen Images basieren auf Ubuntu 25.10 mit dem Codenamen Questing Quokka, das Anfang Oktober erschienen […]
Das Fedora Council hat eine neue Richtlinie verabschiedet, die erstmals den Einsatz von KI bei Beiträgen zu Fedora Projekten erlaubt. Nach intensiven Diskussionen in der Community wurde nun ein Rahmen geschaffen, der moderne Werkzeuge zulässt, zugleich aber menschliche Verantwortung in den Mittelpunkt stellt. Künftig dürfen Entwickler KI Werkzeuge nutzen, um Code, Dokumentation oder andere Inhalte […]
Das KDE Projekt hat die neue Version 6.5 seiner Desktopumgebung Plasma veröffentlicht. Sie bringt zahlreiche Verbesserungen, neue Funktionen und viele kleine Korrekturen, die den Alltag mit Linux spürbar angenehmer machen. Optisch fällt sofort auf, dass Fenster im Breeze Design nun abgerundete untere Ecken besitzen. Unterstützte Drucker zeigen ihren Tintenstand direkt im System an. Auch HDR […]
In meinem Arbeitsalltag wimmelt es von virtuellen Linux-Maschinen, die ich primär mit zwei Programmen ausführe:
virtual-machine-manager alias virt-manager (KVM/QEMU) unter Linux
UTM (QEMU + Apple Virtualization) unter macOS
Dabei treten regelmäßig zwei Probleme auf:
Bei Neuinstallationen funktioniert der Datenaustausch über die Zwischenablage zwischen Host und VM (= Gast) funktioniert nicht.
Die Uhrzeit in der VM ist falsch, nachdem der Host eine Weile im Ruhestand war.
Diese Ärgernisse lassen sich leicht beheben …
Anmerkung: Ich beziehe mich hier explizit auf die Desktop-Virtualisierung. Ich habe auch VMs im Server-Betrieb — da brauche ich keine Zwischenablage (Text-only, SSH-Administration), und die Uhrzeit macht wegen des dauerhaften Internet-Zugangs auch keine Probleme.
Zwischenablage mit Spice als Grafik-Protokoll
Wenn das Virtualisierungssystem das Grafiksystem mittels Simple Protocol for Independent Computing Environments (SPICE) überträgt (gilt per Default im virtual-machine-manager und in UTM), funktioniert die Zwischenablage nur, wenn in der virtuellen Maschine das Paket spice-vdagent installiert ist. Wenn in der virtuellen Maschine Wayland läuft, was bei immer mehr Distributionen standardmäßig funktioniert, brauchen Sie außerdem wl-clipboard. Also:
Nach der Installation müssen Sie sich in der VM aus- und neu einloggen, damit die Programme auch gestartet werden. Manche, virtualisierungs-affine Distributionen installieren die beiden winzigen Pakete einfach per Default. Deswegen funktioniert die Zwischenablage bei manchen Linux-Gästen sofort, bei anderen aber nicht.
Synchronisierung der Uhrzeit
Grundsätzlich beziehen sowohl die virtuellen Maschine als auch der Virtualisierungs-Host die Uhrzeit via NTP aus dem Internet. Das klappt problemlos.
Probleme treten dann auf, wenn es sich beim Virtualisierungs-Host um ein Notebook oder einen Desktop-Rechner handelt, der hin- und wieder für ein paar Stunden inaktiv im Ruhezustand schläft. Nach der Reaktivierung wird die Zeit im Host automatisch gestellt, in den virtuellen Maschinen aber nicht.
Vielleicht denken Sie sich: Ist ja egal, so wichtig ist die Uhrzeit in den virtuellen Maschinen ja nicht. So einfach ist es aber nicht. Die Überprüfung von Zertifikaten setzt die korrekte Uhrzeit voraus. Ist diese Voraussetzung nicht gegeben, können alle möglichen Problem auftreten (bis hin zu Fehlern bei der Software-Installation bzw. bei Updates).
Für die lokale Uhrzeit in den virtuellen Maschinen ist das Programm chrony zuständig. Eigentlich sollte es in der Lage sein, die Zeit automatisch zu justieren — aber das versagt, wenn die Differenz zwischen lokaler und echter Zeit zu groß ist. Abhilfe: starten Sie chronyd neu:
sudo systemctl restart chronyd
Um die automatische Einstellung der Uhrzeit nach der Wiederherstellung eines Snapshots kümmert sich der qemu-guest-agent (z.B. im Zusammenspiel mit Proxmox). Soweit das Programm nicht automatisch installiert ist:
Im August letzten Jahres habe ich euch gezeigt, was auf meinem Home Server so alles läuft und ich dachte mir, ich liefere euch über ein Jahr später mal einen aktualisierten Einblick. Der Unterbau des...
Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
Seit über 30 Jahren nutze ich Linux, und knapp 25 Jahre davon war die bash meine Shell. Ein eigener Prompt, der das aktuelle Verzeichnis farbig anzeigte, was das Maß der Dinge :-)
Mein Umstieg auf die zsh hatte mit Git zu tun: Die zsh in Kombination mit der Erweiterung Oh my zsh gibt im Prompt direktes Feedback über den Zustand des Repositories (aktiver Zweig, offene Änderungen). Außerdem agiert die zsh in vielen Details »intelligenter« (ein viel strapazierter Begriff, ich weiß) als die bash. Es macht ein wenig Arbeit, bis alles so funktioniert wie es soll, aber ich war glücklich mit meinem Setup.
Seit ein paar Monaten habe ich die Default-Shell meiner wichtigsten Linux-Installationen neuerlich gewechselt. Ich gehöre jetzt zum rasch wachsenden Lager der fish-Fans. fish steht für Friendly Interactive Shell, und die Shell wird diesem Anspruch wirklich gerecht. fish bietet von Grund auf eine Menge Features, die zsh plus diverse Plugins inklusive Oh my zsh erst nach einer relativ mühsamen Konfiguration beherrschen. Die Inbetriebnahme der fish dauert bei den meisten Distributionen weniger als eine Minute — und die Defaultkonfiguration ist so gut, dass weitere Anpassungen oft gar nicht notwendig sind. Und sollte das doch der Fall sein, öffnet fish_config einen komfortablen Konfigurationsdialog im Webbrowser (außer Sie arbeiten in einer SSH-Session).
Die Stärken der fish im Vergleich zu bash und zsh haben aus meiner Sicht wenig mit der Funktionalität zu tun; einige Features der fish lassen sich auch mit bash-Hacks erreichen, fast alle mit zsh-Plugins. Der entscheidende Vorteil ist vielmehr, dass die fish out of the box zufriedenstellend funktioniert. Für mich ist das deswegen entscheidend, weil ich viele Linux-Installationen verwende und keine Zeit dafür habe, mich jedesmal mit dem Shell-Setup zu ärgern. Deswegen hatte ich in der Vergangenheit auf meinen wichtigsten Installationen zsh samt einer maßgeschneiderten Konfiguration, auf allen anderen aber der Einfachheit halber die bash oder eine unkonfigurierte zsh-Installation.
Auf den ersten Blick sieht die »fish« aus wie jede andere Shell
Installation
Die Installation ist schnell erledigt. Alle gängigen Distributionen stellen fish als Paket zur Verfügung. Also apt/dnf install fish, danach:
chsh -s $(which fish)
Aus- und neu einloggen, fertig.
Falls Ihnen die fish doch nicht zusagt, ist die bisherige Shell ebenso schnell mit chsh -s $(which bash) oder chsh -s $(which zsh) reaktiviert.
Features
Im Prinzip verhält sich die fish wie jede andere Shell. Insbesondere gelten die üblichen Mechanismen zum Start von Kommandos, zur Ein- und Ausgabeumleitung mit < und >, zur Bildung von Pipes mit | sowie zur Verarbeitung von Kommandoergebnissen mit $(cmd). Was ist also neu?
Während der Eingabe verwendet die fish Farben, um verschiedene Bestandteile Ihres Kommandos (z.B. Zeichenketten) zu kennzeichnen. Das sieht nett aus, der entscheidende Vorteil ist aber, dass Sie oft Tippfehler erkennen, bevor Sie Return drücken: Kommandos, die es gar nicht gibt, werden rot hervorgehoben, ebenso nicht geschlossene Zeichenketten. (Die Farben sind vom aktiven Farbschema abhängig.)
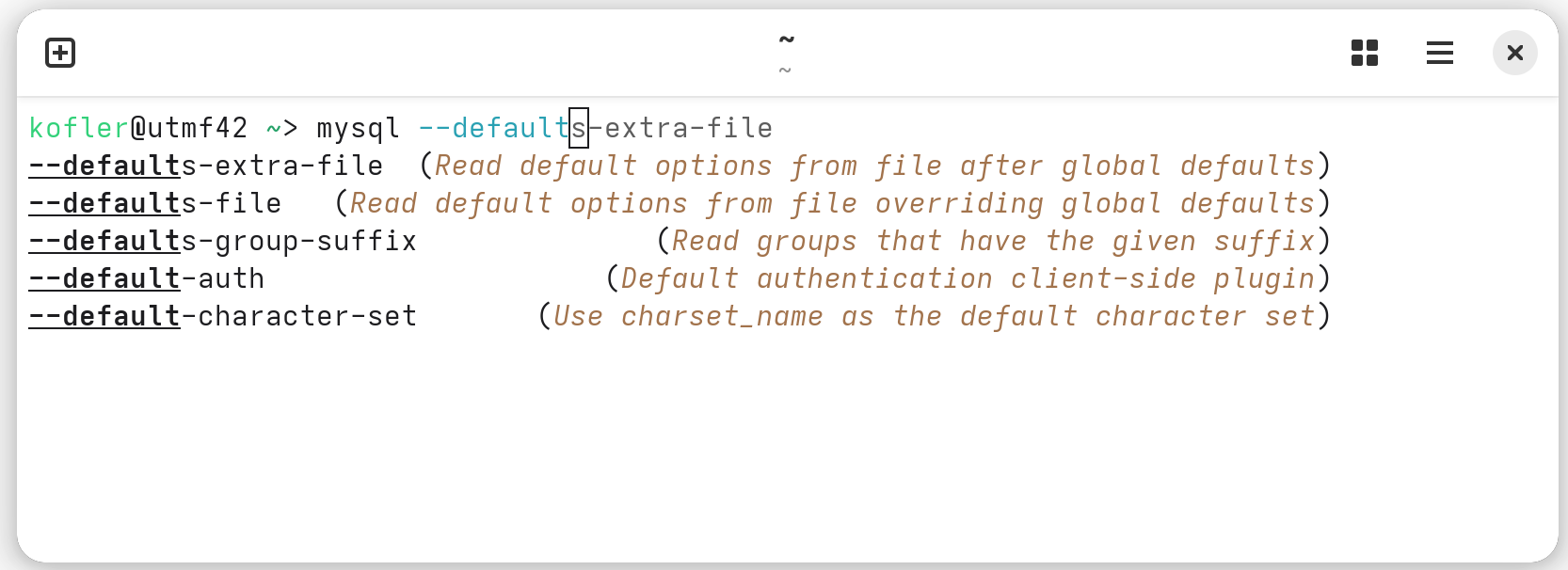
Die Vervollständigung von Kommandos, Optionen, Datei- und Variablennamen mit der Tabulator-Taste ist noch »intelligenter« als bei bash und zsh. fish greift dazu auf über 1000 *.fish-Dateien im Verzeichnis /usr/share/fish/completions zurück, die Regeln für alle erdenklichen Fälle enthalten und mit jeder fish-Version erweitert werden. Die fish zeigt sogar kurze Hilfetexte an (siehe die folgende Abbildung). Wenn es viele mögliche Vervollständigungen gibt, zeigt fish diese in mehreren Spalten an. Sie können mit den Cursortasten das gewünschte Element auswählen.
Bei der Eingabe von Kommandos durchsucht die fish die History, also eine Datei, in der alle zuletzt ausgeführten Kommandos gespeichert wurden. In etwas blasserer Schrift schlägt es das passendste Kommando vor. Die fish berücksichtigt dabei auch den Kontext (welches Verzeichnis ist aktiv, welche Kommandos wurden vorher ausgeführt) und schlägt oft — fast schon ein wenig unheimlich — das richtige Kommando vor. Wenn Sie dieses Kommando ausführen möchten, vervollständigen Sie die Eingabe mit Cursor rechts (nicht Tabulator!) und drücken dann Return. Durch ähnliche Kommandos können Sie mit den Cursortasten blättern.
Alternativ können Sie auch mit Strg+R suchmuster nach früher ausgeführten Kommandos suchen. Die fish sucht nach dem Muster nicht nur in den Anfangsbuchstaben, sondern in den gesamten Zeichenketten der History.
Wenn das aktuelle Verzeichnis Teil eines Git-Repositories ist, zeigt fish den Namen des aktuellen Zweigs in Klammern an. (Wenn Sie mehr Git-Infos sehen wollen, ändern Sie die Prompt-Konfiguration.)
Die »fish« zeigt Hilfetexte zu allen »mysql«-Optionen an, die mit »–default« beginnen.
Globbing-Eigenheiten
In Shells wird die Umwandlung von *.txt in die Liste passender Dateinamen als »Globbing« bezeichnet. Die fish verhält sich dabei fast gleich wie die bash — aber mit einem kleinen Unterschied: Wenn es keine passenden Dateien gibt (z.B. keine einzige Datei mit der Endung .txt), löst die fish einen Fehler aus. Die bash übergibt dagegen das Muster — also *.txt — an das Kommando und überlässt diesem die Auswertung. In der Regel tritt der Fehler dann dort auf. Also kein großer Unterschied?
Es gibt Sonderfälle, in denen das Verhalten der bash günstiger ist. Stellen Sie sich vor, Sie wollen mit scp alle *.png-Dateien von einem externen Rechner auf Ihren lokalen Rechner übertragen:
scp externalhost:*.png .
In der bash funktioniert das wie gewünscht. Die fish kann aber mit externalhost:*.png nichts anfangen und löst einen Fehler aus. Abhilfe: Sie müssen das Globbing-Muster in Anführungszeichen stellen, also:
scp "externalhost:*.png" .
Analoge Probleme können auch beim Aufruf von Paketkommandos auftreten. apt install php8-* funktioniert nicht, wohl aber apt install "php8-*". Hintergründe zum Globbing-Verhalten können Sie hier nachlesen:
Tastenkürzel
Grundsätzlich gelten in der fish dieselben Tastenkürzel wie in der bash. In der fish gibt es darüberhinaus weitere Kürzel, von denen ich die wichtigsten hier zusammengestellt habe. bind oder fish_config (Dialogblatt bindings) liefert eine wesentlich längerer Liste aller Tastenkürzel. Beachten Sie, dass es vom Desktopsystem und vom Terminal abhängt, ob die Alt-Tastenkürzel wirklich funktionieren. Wenn die Kürzel vom Terminal oder dem Desktopsystem verarbeitet werden, erreichen Sie die fish nicht.
Kürzel Bedeutung
------------------ -------------------------------------------------------
Alt+Cursor links führt zurück ins vorige Verzeichnis (prevd)
Alt+Cursor rechts macht die obige Aktion rückgängig (nextd)
Alt+E öffnet den Dateinamen mit $EDITOR
Alt+H oder F1 zeigt die man-Seite zum eingegebenen Kommando an (Help)
Alt+L führt ls aus
Alt+P fügt der Eingabe &| less hinzu (Pager)
Alt+S fügt sudo am Beginn der Eingabe ein
Alt+W zeigt Aliasse und eine Beschreibung des Kommandos (What is?)
Noch eine Anmerkung zu Alt+S: In meiner Praxis kommt es ständig vor, dass ich sudo vergesse. Ich führen also dnf install xy aus und erhalte die Fehlermeldung, dass meine Rechte nicht ausreichen. Jetzt drücke ich einfach Alt+S und Return. Die fish stellt sudo dem vorigen, fehlgeschlagenen Kommando voran und führt es aus.
Konfiguration
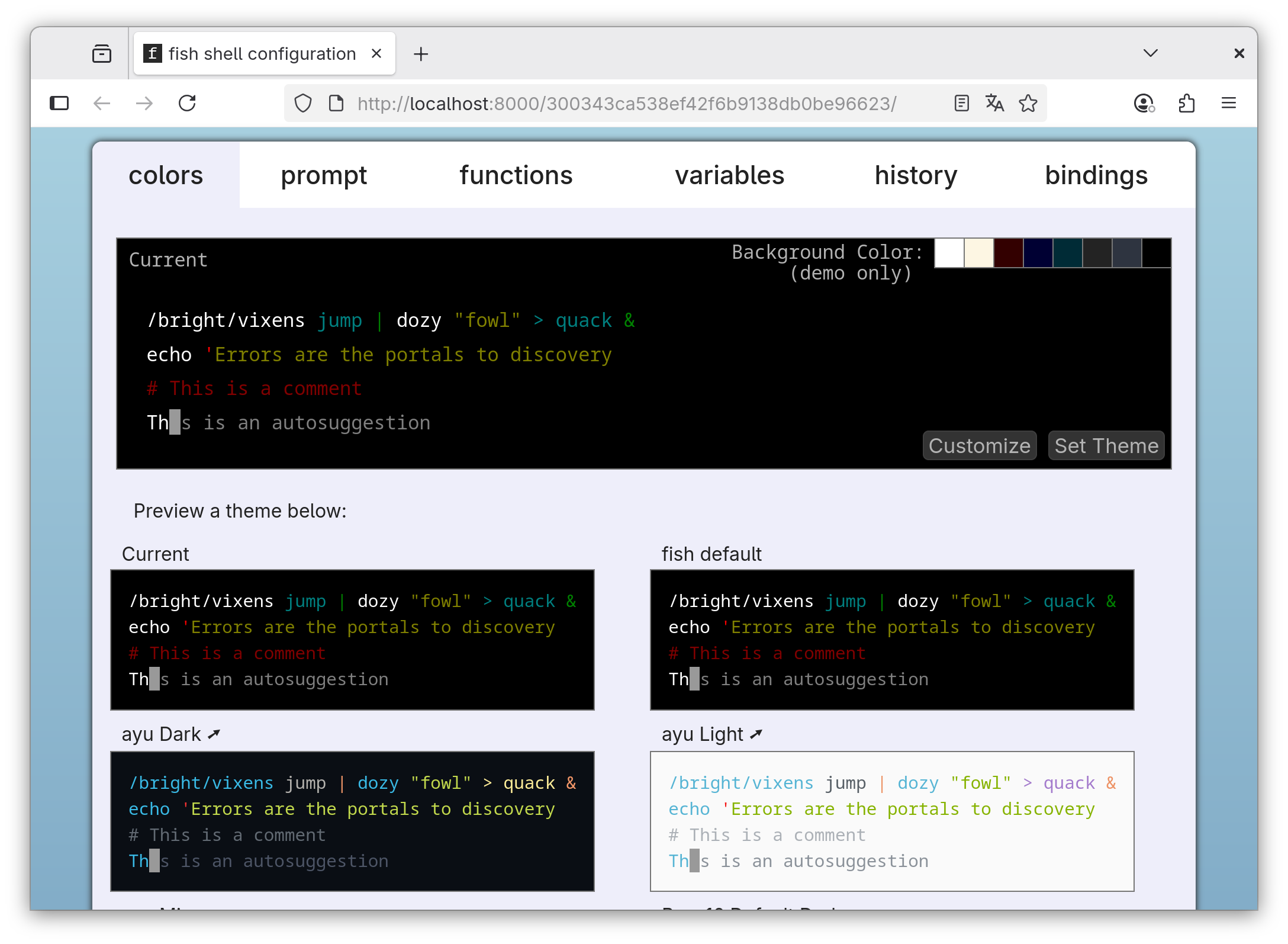
Das Kommando fish_config öffnet einen Konfigurationsdialog im Webbrowser. Falls Ihr Webbrowser gerade minimiert ist, müssen Sie das Fenster selbst in den Vordergrund bringen. Im Browser können Sie nun ein Farbenschema auswählen, noch mehr Informationen in den Prompt integrieren, die Tastenkürzel nachlesen etc.
In SSH-Sessions scheitert der Start eines Webbrowsers. In diesem Fall können Sie mit fish_config prompt bzw. fish_config theme das Promptaussehen und das Farbschema direkt im Textmodus verändern.
fish-Konfiguration im Webbrowser
Wenn Sie Änderungen durchführen, werden diese im Terminal mit set -U fish_xxx newvalue ausgeführt und in Konfigurationsdateien in .config/fish gespeichert, insbesondere in:
Das Gegenstück zu .bashrc oder .zshrc ist die Datei .config/fish/config.fish. Das ist der richtige Ort, um eigene Abkürzungen zu definieren, den PATH zu erweitern etc. config.fish enthält einen vordefinierten if-Block für Einstellungen, die nur für interaktive fish-Sessions relevant sind. Alle anderen Einstellungen, die z.B. in Scripts gelten sollen, führen Sie außerhalb durch. Das folgende Listing zeigt ein paar typische Einstellungen:
# Datei .config/fish/config.fish
...
# PATH ändern
fish_add_path ~/bin
fish_add_path ~/.local/bin
# keine fish-Welcome-Nachricht
set -U fish_greeting ""
# Einstellungen nur für die interaktive Nutzung
if status is-interactive
# abr statt alias
abbr -a ls eza
abbr -a ll 'eza -la'
abbr -a gc 'git commit'
# Lieblingseditor
set -gx EDITOR /usr/bin/jmacs
end
Das obige Listing zeigt schon, das die fish gängige Einstellungen anders handhabt als bash und zsh:
Abkürzungen: Anstelle von alias sieht die fish das Kommando abbr vor. alias steht auch zur Verfügung, von seinem Einsatz wird aber abgeraten. abbr unterscheidet sich durch ein paar Details von alias: Die Expansion in das Kommando erfolgt bereits, wenn Sie Return drücken. Sie sehen daher, welches Kommando wirklich ausgeführt wird, und dieses Kommando (nicht die Abkürzung) wird in der History gespeichert.
PATH-Änderungen: Sie müssen die PATH-Variable nicht direkt verändern, sondern können stattdessen fish_add_path aufrufen. Ihr Pfad wird am Ende hinzugefügt, wobei die Funktion sicherstellt, dass es keine Doppelgänger gibt.
Variablen (set): Die Optionen des set-Kommandos zur Einstellung von Variablen funktionieren anders als in der bash:
-g: Die Variable ist in der gesamten fish-Session zugänglich (Global Scope), nicht nur in einer Funktion oder einem Block.
-x: Die Variable wird an Subprozesse weitergegeben (Export).
-U: Die Variable wird dauerhaft in .config/fish/fish_variables gespeichert und gilt daher auch für künftige fish-Sessions (Universal). Sie wird aber nicht exportiert, es sei denn, Sie verwenden -Ux.
-l: Definiert eine lokale Variable, z.B. innerhalb einer Funktion.
Zusätzliche eingebaute Kommandos
Jede Shell hat eine Menge integrierter Kommandos wie cd, if oder set. In der fish können Sie mit builtin -n alle derartigen Kommandos auflisten. Die meisten Kommandos entsprechen exakt den bash- und zsh-Vorgaben. In der fish gibt es aber einige originelle Erweiterungen: math führt einfache Berechnungen aus, random produziert ganzzahlige Zufallszahlen, string manupuliert Zeichenketten ohne die umständliche Parametersubstitution, path extrahiert Komponenten aus einem zusammengesetzten Dateinamen, count zählt Objekte (vergleichbar mit wc -l etc. Das folgende Listing zeigt die Anwendung dieser Kommandos:
math "2.5 * 3.8"
9.5
string split " " "lorem ipsum dolor est"
lorem
ipsum
dolor
est
string replace ".png" ".jpg" file1.png file2.png file3.png
file1.jpg
file2.jpg
file3.jpg
string sub -s 4 -e 8 "abcdefghijkl" # Start und Ende inklusive
defgh
path basename /home/kofler/images/img_234.png
img_234.png
path dirname /home/kofler/images/img_234.png
/home/kofler/images
path extension /home/kofler/images/img_234.png
.png
random 1 100
13
random choice a b c
c
count * # das aktuelle Verzeichnis hat
# 32 Dateien/Verzeichnisse
32
ps ax | count # gerade laufen 264 Prozesse
264
Programmierung
Die Bezeichnung Friendly Interactive Shell weist schon darauf hin: Die fish ist für die interaktive Nutzung optimiert, nicht für die Programmierung. Die fish unterstützt aber sehr wohl auch die Script-Programmierung. Diese ist insofern attraktiv, weil die fish-Entwickler auf maximale Kompatibilität verzichtet haben und die schlimmsten Syntaxungereimtheiten der bash behoben haben. fish-Scripts sind daher ungleich leichter zu verstehen als bash-Scripts. Umgekehrt heißt das leider: fish-Scripts sind inkompatibel zu bash und zsh und können nur ausgeführt werden, wo die fish zur Verfügung steht. Für mich ist das zumeist ein Ausschlusskriterium.
Anstelle einer systematischen Einführung will ich Ihnen hier anhand eines Beispiels die Vorteile der fish beim Programmieren nahebringen. Das Script ermittelt die Anzahl der Zeilen für alle *.txt-Dateien im aktuellen Verzeichnis. (Ich weiß, wc -l *.txt wäre einfacher; es geht hier nur darum, diverse Syntaxeigenheiten in wenig Zeilen Code zu verpacken.) Die bash-Variante könnte so aussehen:
#!/bin/bash
files=(*.txt)
if [ ${#files[@]} -eq 0 ]; then
echo "No .txt files found"
exit 1
fi
for file in "${files[@]}"; do
if [ -f "$file" ]; then
lines=$(wc -l < "$file")
echo "$file: $lines lines"
fi
done
Das äquivalente fish-Script ist deutlich besser lesbar:
#!/usr/bin/env fish
set files *.txt
if not count $files > /dev/null
echo "No .txt files found"
exit 1
end
for file in $files
if test -f $file
echo "$file: "(count < $file)" lines"
end
end
Auf ein paar Details möchte ich hinweisen:
Kontrollstrukturen werden generell mit end abgeschlossen, nicht mit fi für if oder mit esac für case.
Bedingungen für if, for etc. müssen weder in eckige Klammern gestellt noch mit einem Strichpunkt abgeschlossen werden.
Die fish verarbeitet Variablen korrekt selbst wenn sie Dateinamen mit Leerzeichen enthalten. Es ist nicht notwendig, sie in Anführungszeichen zu stellen (wie bei "$file" im bash-Script).
Wenn Sie in eigenen Scripts Optionen und andere Parameter verarbeiten möchten, hilft Ihnen dabei das Builtin-Kommando argparse. Eine gute Zusammenstellung aller Syntaxunterschiede zwischen bash und fish gibt die fish-Dokumentation.
Paketmanager fisher
Das Versprechen von fish ist ja, dass fast alles out-of-the-box funktioniert, dass die Installation von Zusatzfunktionen und deren Konfiguration ein Thema der Vergangenheit ist. Aber in der Praxis tauchen trotzdem immer Zusatzwünsche auf. Mit dem Paketmanager fisher können Zusatzmodule installiert werden. Eine Sammlung geeigneter Plugins finden Sie hier.
Die Geschichte von fish
Die fish ist erst in den letzten Jahren so richtig populär geworden. Das zeigt, dass es auch in der Linux-Welt Modetrends gibt. fish ist nämlich alles andere als neu. Die erste Version erschien bereits 2005.
fish wurde ursprünglich in C entwickelt, dann nach C++ und schließlich nach Rust portiert. Erst seit Version 4.0 (erschienen im Februar 2025) besteht fish ausschließlich aus Rust-Code sowie in fish selbst geschriebenen Erweiterungen.
Fazit
Die fish punktet durch die gut durchdachte Grundkonfiguration und die leichte Zugänglichkeit (Konfiguration und Hilfe im Webbrowser). Es gibt nicht das eine Feature, mit dem sich die fish von anderen Shells abhebt, es ist vielmehr die Summe vieler, gut durchdachter Kleinigkeiten und Detailverbesserungen. Das Arbeiten in der fish ist intuitiver als bei anderen Shells und macht mehr Spaß. Probieren Sie es aus!
Bei der Programmierung ist die fish inkompatibel zu anderen Shells und insofern kein Ersatz (auch wenn die fish-eigenen Features durchaus spannend sind). Zur Ausführung traditioneller Shell-Scripts brauchen Sie weiterhin eine traditionelle Shell, am besten die bash.
Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […]
Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […]
Die Document Foundation hat mit LibreOffice 25.8.2 das zweite Wartungsupdate der aktuellen Version veröffentlicht. Die neue Ausgabe behebt viele Probleme, die Nutzer seit der letzten Version gemeldet hatten. Ziel des Updates ist es, Stabilität und Zuverlässigkeit der beliebten Bürosoftware weiter zu verbessern. Besonders auffällig sind Korrekturen in den Anwendungen Writer, Calc und Impress. Abstürze beim […]
Am 14. Oktober 2025 endet offiziell der Support für Windows 10. Danach stellt Microsoft keine regulären Sicherheitsupdates mehr bereit. Zwar ist inzwischen angekündigt, dass es noch bis Ende 2026 eine verlängerte Updatephase geben soll, doch die Bedingungen dafür sind noch nicht voll transparent. Millionen funktionstüchtige Computer wären damit theoretisch aus dem Updatezyklus ausgeschlossen, wenn sie […]
Aktuell komme ich mit den Blog-Artikeln zu neuen Linux-Distributionen kaum mehr hinterher. Ubuntu 25.10 ist gerade fertig geworden, und zur Abwechslung gibt es deutlich mehr technische Neuerungen/Änderungen (und auch mehr Bugs) als sonst. Ich konzentriere mich hier vor allem auf die neue SSD-Verschlüsselung mit Keys im TPM. Generell ist Ubuntu 25.10 als eine Art Preview für die nächste LTS-Version 26.04 zu sehen.
Ubuntu 25.10 mit Gnome 49 und Wayland
Neuerungen
Neben den üblichen Software-Updates, auf die ich diesmal nicht im Detail eingehe (topaktueller Kernel 6.17!) gibt es vier grundlegende Neuerungen:
Gnome unterstützt nur noch Wayland als Grafiksystem. Diese Neuerung hat das Gnome-Projekt vorgegeben, und die Ubuntu-Entwickler mussten mitziehen. Ich kann nicht sagen, ob mit Überzeugung — immerhin ist das ja auch eine Vorentscheidung für Ubuntu 26.04. Die Alternative wäre gewesen, sowohl für dieses als auch für das kommende Release bei Gnome 48 zu bleiben. Persönlich läuft Gnome + Wayland für mich in allen erdenklichen echten und virtuellen Hardware-Umgebungen gut, d.h. ich trauere X nicht nach. (Über XWayland können natürlich weiterhin einzelne X-Programme ausgeführt werden — wichtig für Programme, die noch nicht auf Wayland-kompatible Bibliotheken portiert sind. Aber der Desktop als Ganzes und der Display Manager müssen jetzt Wayland verwenden.)
initramfs-Dateien mit Dracut: Ubuntu verwendet zum Erzeugen der für den Boot-Prozess erforderlichen Initial-RAM-Filesystem (umgangssprachlich der initrd-Dateien) das von Red Hat etablierte Kommando dracut und weicht damit vom Debian-Fundament ab, das weiterhin mkinitramfs verwendet. Das bewährte Kommando update-initramfs bleibt erhalten, aber dieses Script ruft nun eben dracut auf. Die Änderung gilt aktuell nur für Ubuntu Desktop, während Ubuntu Server vorerst bei mkinitramfs bleibt (mehr Details).
Rust Utilities: Nicht nur im Linux-Kernel wächst die Bedeutung der Programmiersprache Rust, auch immer mehr Standard-Utilities von Linux werden aktuell im Rahmen von uutils neu in Rust implementiert. Der entscheidende Vorteil von Rust ist eine bessere interne Speicherverwaltung, die weniger Sicherheitsprobleme verspricht (keine Buffer Overflows, keine Null Pointer). In Ubuntu 25.10 wurde sudo durch die Rust-Implementierung sudo-rs ersetzt. Analog kommen auch die Rust-Core-Utilities zum Einsatz (Paket rust-coreutils, siehe /usr/lib/cargo/bin/coreutils). Das betrifft viele oft benötigte Kommandos, z.B. cat, chmod, chown, cp, date, dd, echo, ln, mv, shaXXXsum etc. Ein Blick in /usr/bin zeigt eine Menge entsprechender Links. Sicherheitstechnisch ist die Umstellung erfreulich, aber die Neuimplementierung hat natürlich auch zu neuen Fehlern geführt. Schon während der Beta-Phase hat Phoronix über größere Probleme berichtet, und ganz ist der Ärger vermutlich noch nicht ausgestanden. Update 27.10.: Ein Fehler in date hat dazu geführt, dass automatische Updates nicht mehr funktionieren, siehe den Bugbericht im Launchpad. Dieser Fehler ist mittlerweile behoben.
TPM-Unterstützung: Bei der Installation können Sie die Keys für die Dateisystemverschlüsselung nun im TPM speichern. Auf die Details gehe ich gleich ausführlich ein.
Flatpak-Probleme
Viel schlechte Presse haben sich die Ubuntu-Entwickler mit einem Flatpak-Bug eingehandelt. Aktuell gibt es ja zwei alternative Formate für (Desktop-)Pakete, Snap (Ubuntu) versus Flatpak (Red Hat und der Rest der Welt). Aufgrund einer AppArmor-Änderung funktionierten Flatpaks unter Ubuntu nicht mehr. Bugbericht, Behebung, fertig?
Und genau hier begann das eigentliche Fiasko. Der Bug-Bericht stammt nämlich vom 5. September. Dennoch wurde Ubuntu 23.10 fünf Wochen später mit eben diesem Bug freigegeben. Und das ist doch ein wenig peinlich, weil es den Eindruck vermitteln könnte, dass es Ubuntu nur wichtig ist, dass das eigene Paketformat funktioniert. (Und auch wenn Ubuntu ein großer Snap-Befürworter ist, gibt es eine Menge Ubuntu-Derivate, die auf Flatpaks setzen.)
Seit ein paar Tagen gibt es einen Fix, dieser wird aber noch nicht ausgeliefert. (Es kann sich nur noch um wenige Tage handeln.) Alternativ kann als Workaround das AppArmor-Profil für fusermount3 deaktiviert werden:
Natürlich ist die ganze Geschichte ein wenig der Sturm im Wasserglas, aber es ist/war definitiv ein vermeidbarer Sturm.
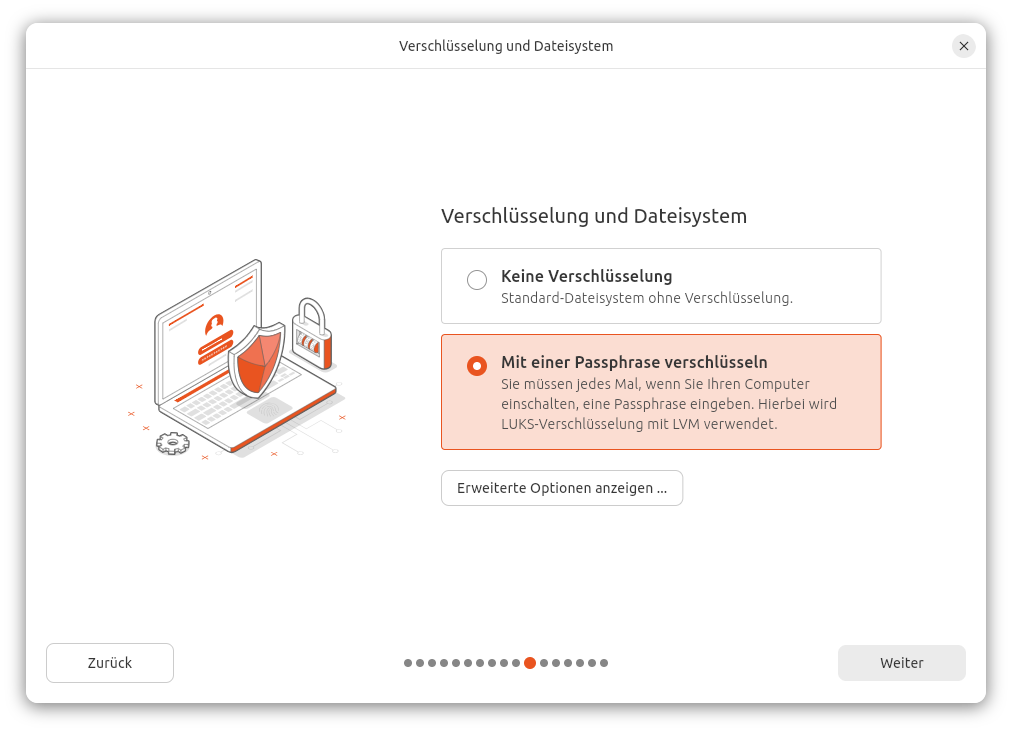
Dateisystem-Verschlüsselung mit Keys im TPM
Zuerst eine Einordnung des Themas: Wenn Sie eine Linux-Installation mit einem verschlüsselten Dateisystem einrichten, müssen Sie während des Boot-Vorgangs zwei Passwörter eingeben: Ganz zu Beginn das Disk-Verschlüsselungspasswort (oft ‚Pass Phrase‘ genannt), und später Ihr Login-Passwort. Die beiden Passwörter sind vollkommen getrennt voneinander, und sie sollten aus Sicherheitsgründen unterschiedlich sein. Elegant ist anders.
Wenn Sie dagegen unter macOS oder Windows das Dateisystem verschlüsseln (FileVault, Bitlocker), gibt es trotzdem nur ein Login-Passwort. Analog gilt das übrigens auch für alle Android- und Apple-Smartphones und -Tablets.
Warum reicht ein Passwort? Weil der Key zur Verschlüsselung des Dateisystems in der Hardware gespeichert wird und während des Boot-Vorgangs von dort ausgelesen wird. Auf x86-Rechnern ist dafür das Trusted Platform Module zuständig. Das TPM kann kryptografische Schlüssel speichern und nur bei Einhaltung bestimmter Boot-Regeln wieder auslesen. Bei aktuellen AMD-CPUs sind die TPM-Funktionen im CPU-Package integriert, bei Intel kümmert sich der Platform Controller Hub (PCH), also ein eigenes Chipset darum. In beiden Fällen ist das TPM sehr Hardware-nah implementiert.
Der Sicherheitsgewinn bei der Verwendung des TPMs ergibt sich daraus, dass das Auslesen des Verschlüsselungs-Keys nur gelingt, solange die Verbindung zwischen Disk und CPU/Chipset besteht (die Disk also nicht in einen anderen Rechner eingebaut wurde) UND eine ganz bestimmte Boot-Sequenz eingehalten wird. Wird die Disk ausgebaut, oder wird der Rechner von einem anderen Betriebssystem gebootet, scheitert das Auslesen des Keys. (Genaugenommen enthält das TPM nicht direkt den Key, sondern den Key zum Key. Deswegen ist es möglich, den Dateisystemverschlüsselungs-Key im Notfall auch durch die Eingabe eines eigenen Codes freizuschalten.)
Die Speicherung des Keys im TPM ermöglicht es also, das Dateisystem zu verschlüsseln, OHNE die Anwender ständig zur Eingabe von zwei Schlüssel zu zwingen. Die TPM-Bindung schützt vor allen Angriffen, bei denen die SSD oder Festplatte ausgebaut wird. Wenn der gesamte Rechner entwendet wird, schützt TPM immer noch vor Angriffen, die durch das Booten von einem fremden System (Linux auf einem USB-Stick) erfolgen. Allerdings kann der Dieb den Rechner ganz normal starten. Das Dateisystem wird dabei ohne Interaktion entschlüsselt, aber ein Zugriff ist mangels Login-Passwort unmöglich. Das System ist also in erster Linie so sicher wie das Login-Passwort. Weiterhin denkbar sind natürlich Angriffe auf die auf dem Rechner laufende Software (z.B. ein Windows/Samba/SSH-Server). Kurzum: TPM macht die Nutzung verschlüsselter Dateisysteme deutlich bequemer, aber (ein bisschen) weniger sicher.
Zum Schluss noch eine Einschränkung: Ich bin kein Kryptografie-Experte und habe die Zusammenhänge hier so gut zusammengefasst (und definitiv vereinfacht), wie ich sie verstehe. Weder kann ich im letzten Detail erklären, warum es bei Windows/Bitlocker unmöglich ist, den Key auch dann auszulesen, wenn der Rechner von einem Linux-System gebootet wird, noch kann ich einschätzen, ob die von Ubuntu durchgeführte Implementierung wirklich wasserdicht und fehlerfrei ist. Aktuell ist sowieso noch Vorsicht angebracht. Die Ubuntu-Entwickler bezeichnen Ihr System nicht umsonst noch als experimentell.
Ubuntu mit TPM-Verschlüsselung einrichten
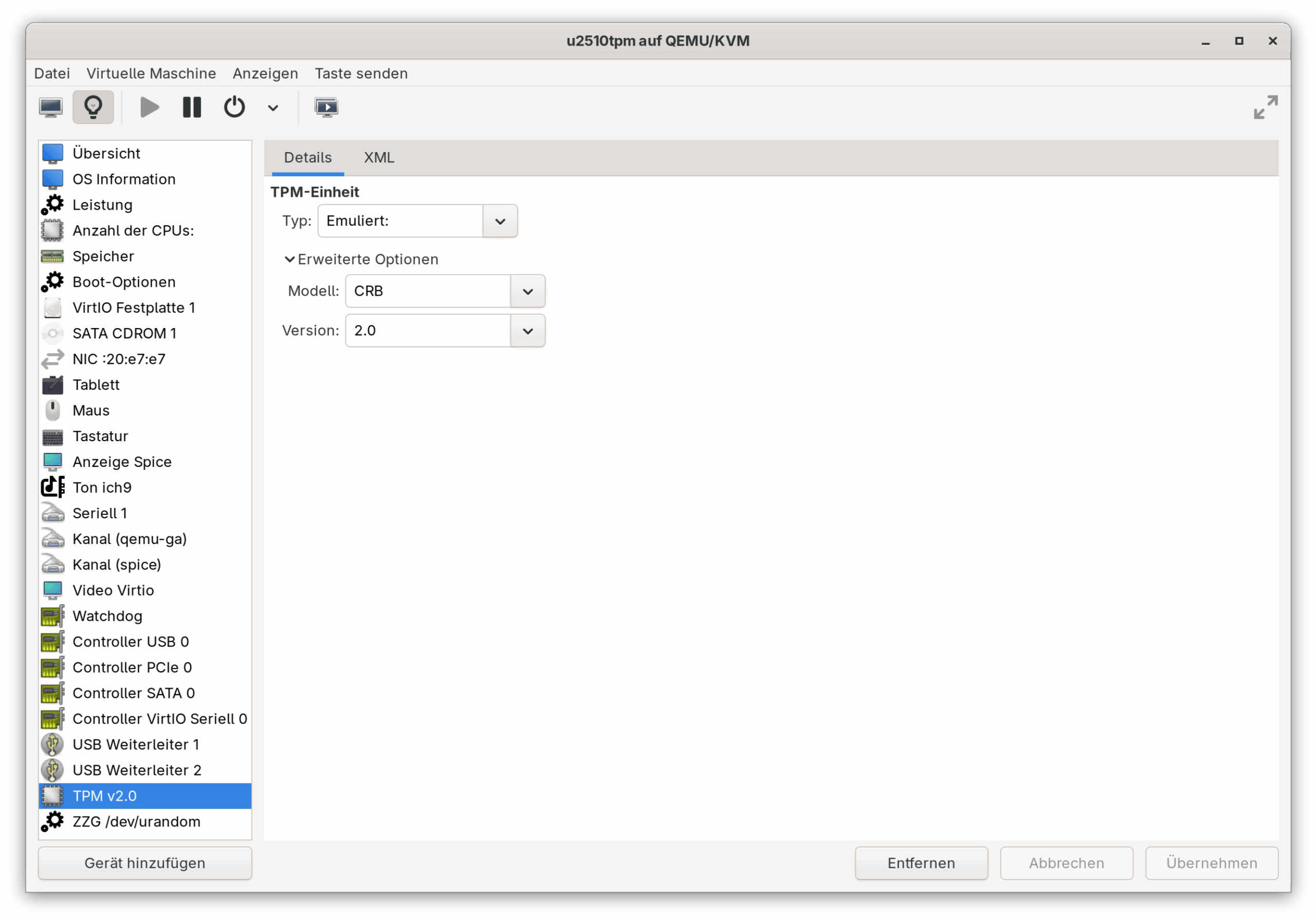
Ubuntu bezeichnet die Speicherung des Verschlüsselungs-Keys als noch experimentelles Feature. Dementsprechend habe ich meine Tests in einer virtuellen Maschine, nicht auf physischer Hardware ausgeführt. Mein Host-System war Fedora mit QEMU/KVM und virt-manager. Beim Einrichten der virtuellen Maschine sollten Sie UEFI aktivieren. Außerdem müssen Sie unbedingt ein TPM-Device zur virtuellen Maschine hinzufügen.
Virtuelle Maschine mit TPM-Device einrichten
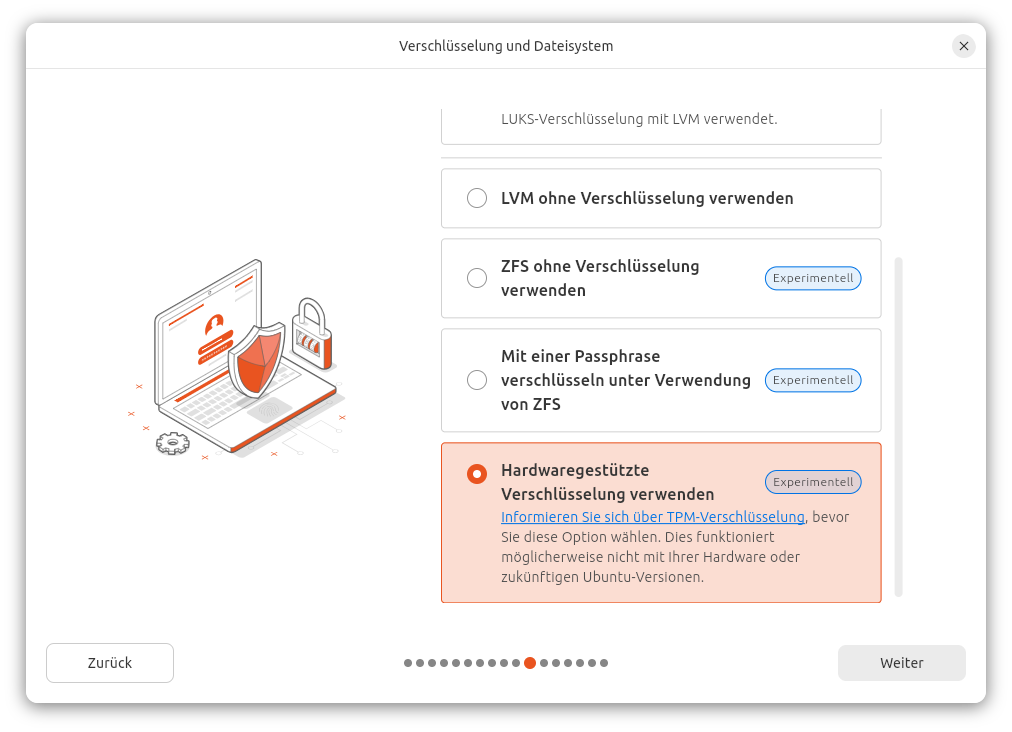
Bei der Installation entscheiden Sie sich für die Hardware-gestützte Verschlüsselung.
Zuerst aktivieren Sie die Verschlüsselung …… und dann die Variante »Hardwaregestützte Verschlüsselung« auswählen
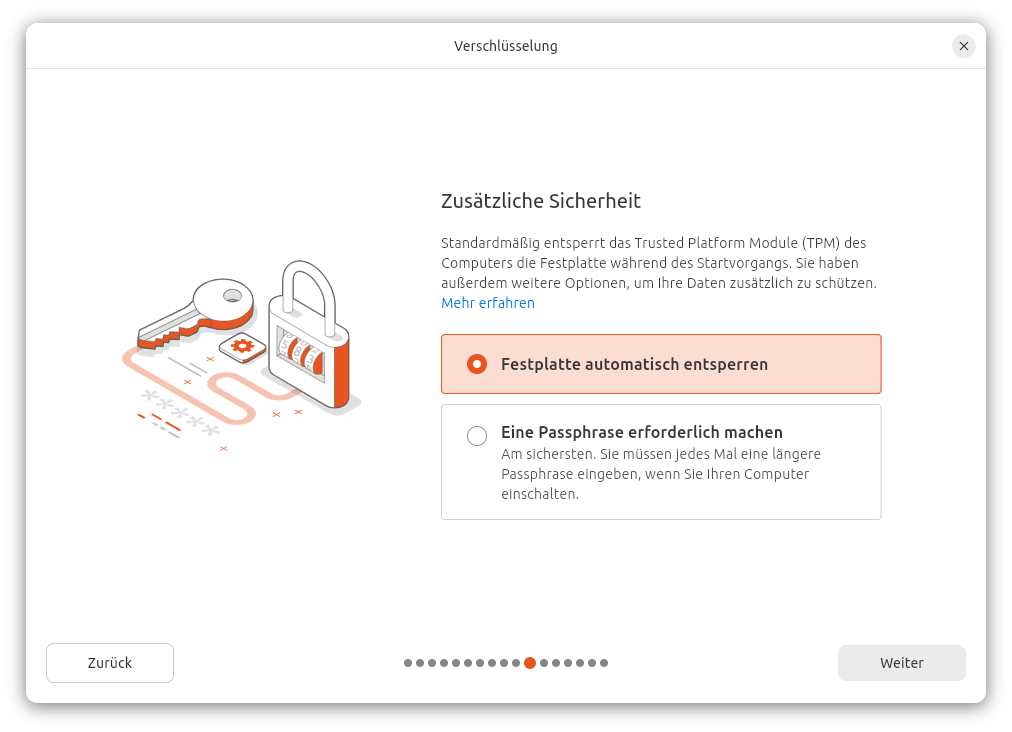
Im nächsten Dialog können Sie den Entschlüsselung des Datenträgers von einem weiteren Passwort abhängig machen. (Der Key für die Verschlüsselung ist dann mit einem TPM-Key und mit Ihrer Passphrase abgesichert.) Sicherheitstechnisch ist das die optimale Variante, aber damit erfordert der Boot-Vorgang doch wieder zwei Passworteingaben. Da können Sie gleich bei der »normalen« Verschlüsselung bleiben, wo Sie das LUKS-Passwort zum Beginn des Boot-Prozesses eingeben. Ich habe mich bei meinen Tests auf jeden Fall gegen die zusätzliche Absicherung entschieden.
Eine zusätzliche Passphrase macht das System noch sicherer, der Bequemlichkeits-Gewinn durch TPM geht aber verloren.
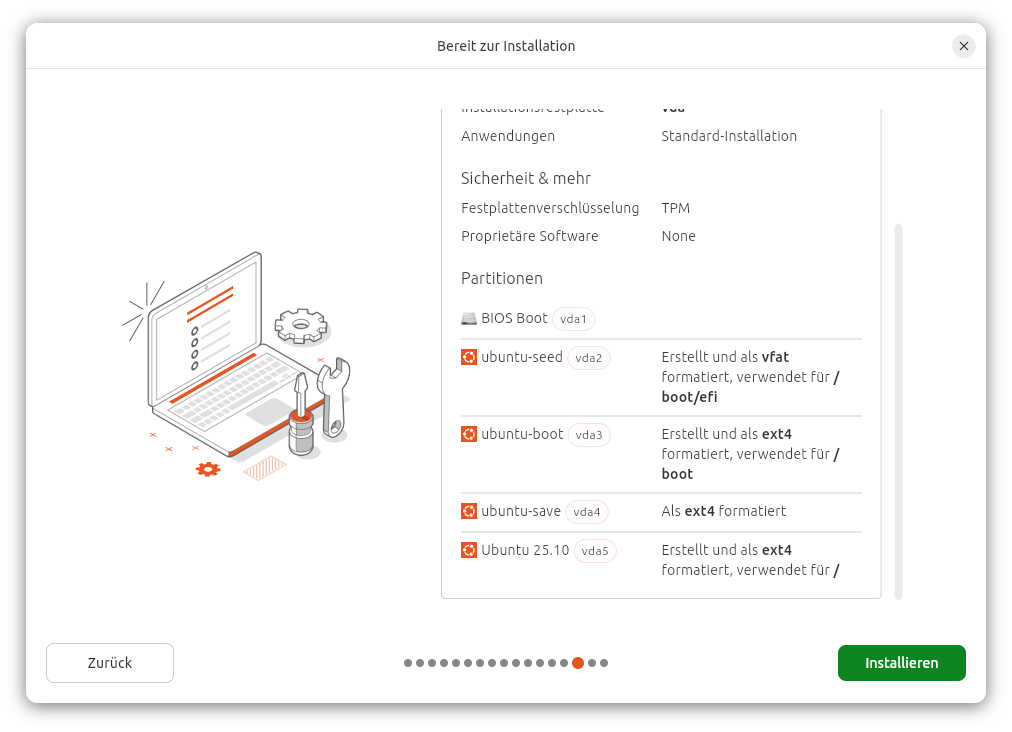
Die Zusammenfassung der Konfiguration macht schon klar, dass das Setup ziemlich komplex ist.
Der Installer richtet vier Partitionen ein: /boot/efi, /boot, / sowie eine zusätzliche Partition mit Seed-Daten
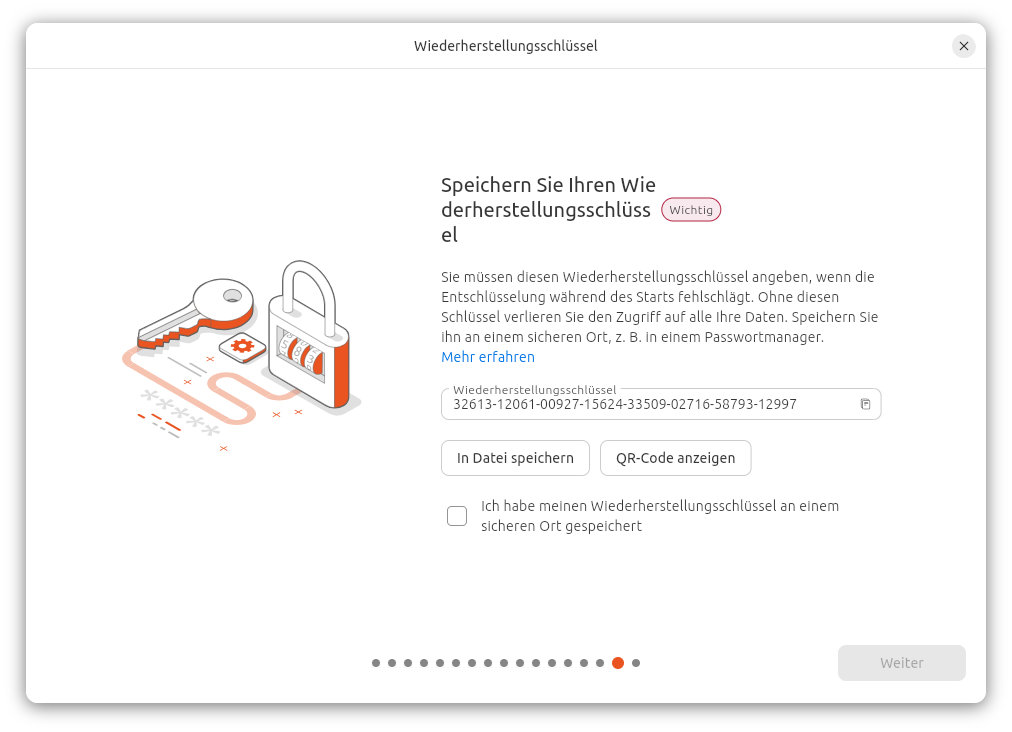
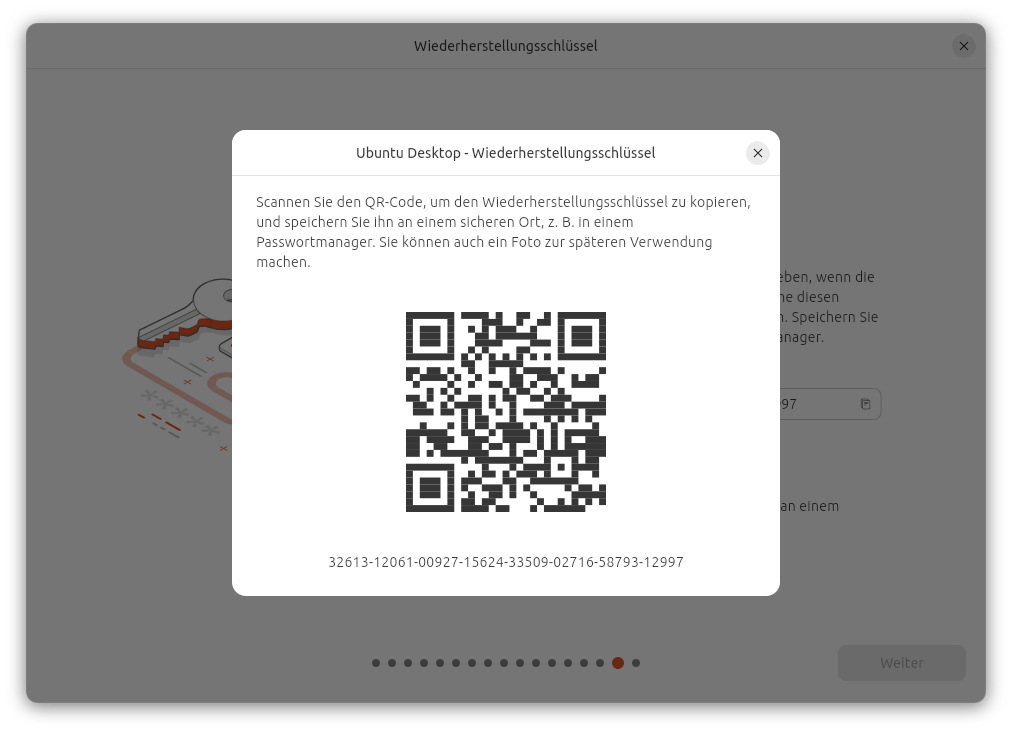
Der Key für die Verschlüsselung wird zufällig generiert. Der Installer zeigt einen Recovery-Key in Textform und als QR-Code an. Diesen Key müssen Sie unbedingt speichern! Er ist erforderlich, wenn Sie den Datenträger in einen anderen Rechner übersiedeln, aber unter Umständen auch nach größeren Ubuntu- oder BIOS/EFI-Updates. Wenn Sie den Recovery-Key dann nicht mehr haben, sind Ihre Daten verloren!
Sie müssen den Recovery-Key unbedingt speichern oder aufschreiben!Dieser QR-Code enthält einfach den darunter dargestellten Zahlencode. (Es handelt sich nicht um einen Link.)
Nach dem Abschluss der Installation merken Sie beim nächsten Reboot nichts von der Verschlüsselung. Der Key zum Entschlüsseln der SSD/Festplatte wird vom TPM geladen und automatisch angewendet. Es bleibt nur der »gewöhnliche« Login.
Als nächstes habe ich mir natürlich das resultierende System näher angesehen. /etc/fstab ist sehr aufgeräumt:
Selbiges kann man von der Mount-Liste leider nicht behaupten. (Diverse Snap-Mounts habe ich weggelassen, außerdem habe ich diverse UUIDs durch xxx bzw. yyy ersetzt.)
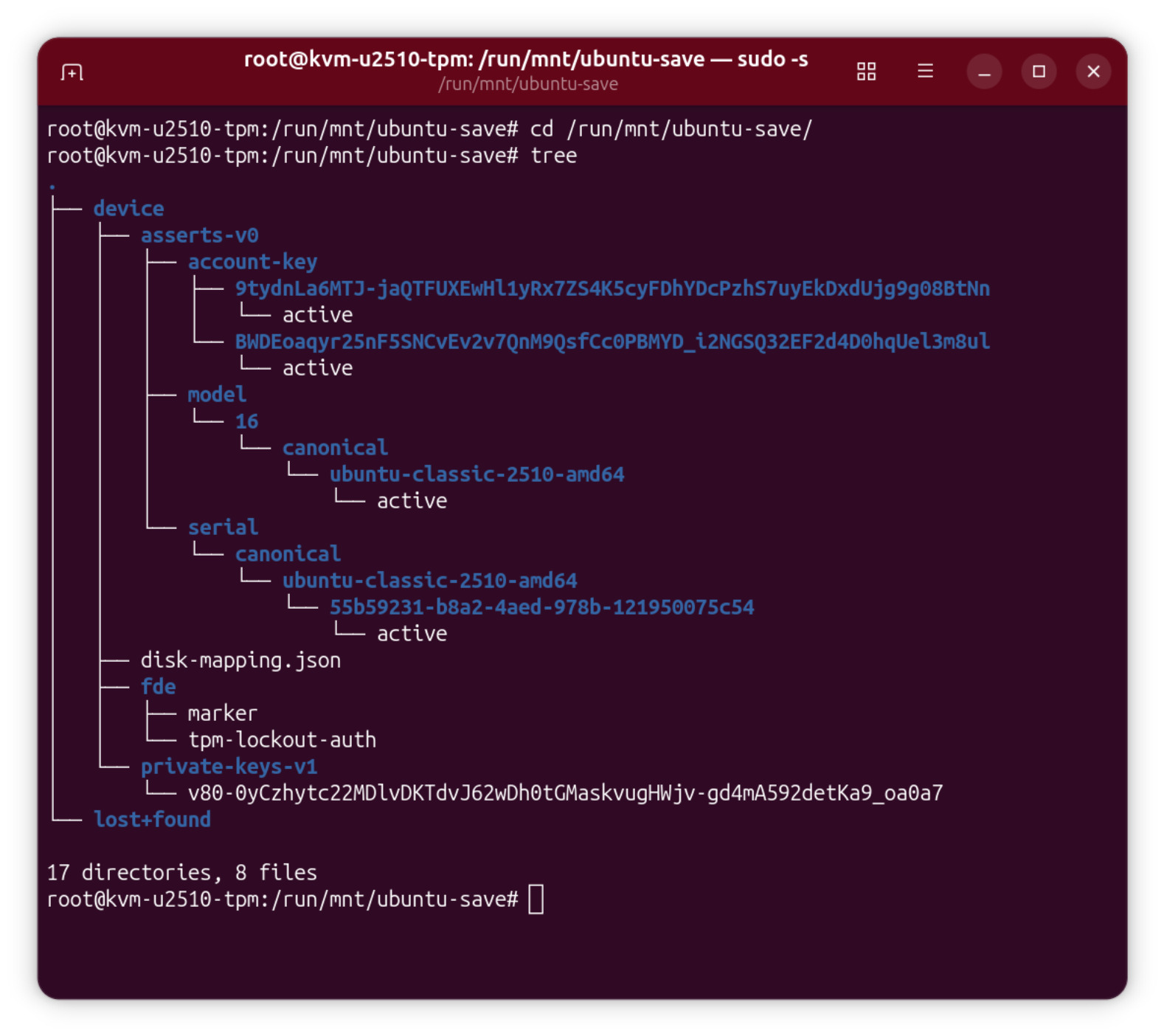
Die Partition ubuntu-save (Mount-Punkt /run/mnt/ubuntu-save) enthält lediglich eine JSON-Datei sowie ein paar Key-Dateien (ASCII).
Die Partition »ubuntu-save« enthält lediglich einige Key-Dateien
Ich bin ein großer Anhänger des KISS-Prinzips (Keep it Simple, Stupid!). Sollte bei diesem Setup etwas schief gehen, ist guter Rat teuer!
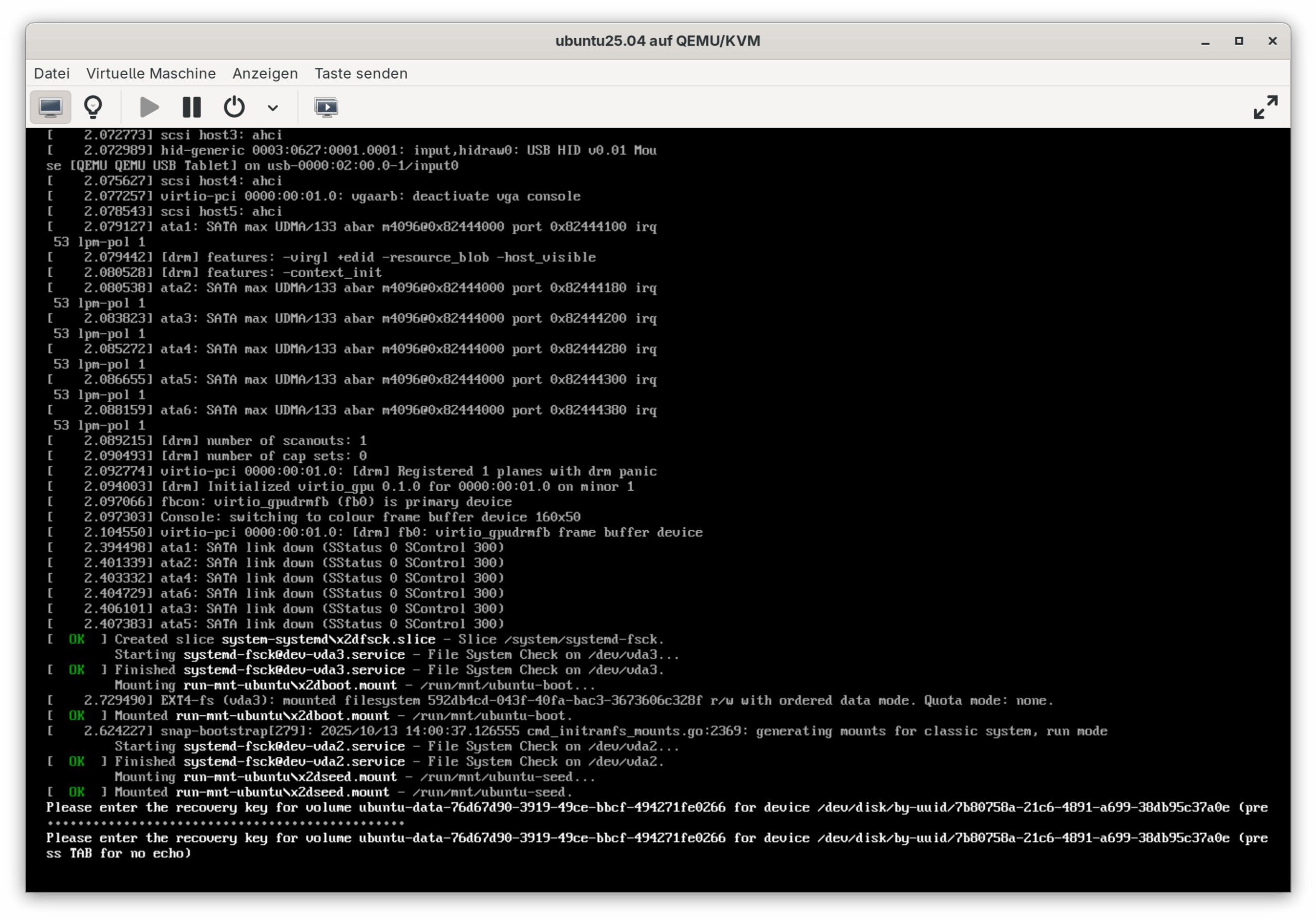
Mit virtuellen Maschinen kann man schön spielen — und das habe ich nun gemacht. Ich habe eine zweite, neue VM eingerichtet, die 1:1 der ersten entspricht. Diese VM habe ich mit dem virtuellen Datenträger der ersten VM verbunden und versucht zu booten. Erwartungsgemäß ist das gescheitert, weil ja der TPM-Speicher bei der zweiten VM keine Keys enthält. (Das Experiment entspricht also dem Ausbau der Disk aus Rechner A und den Einbau in Rechner B.)
Wichtig: Der Key ist ohne Bindestriche einzugeben. Die Eingabe erfolgt im Blindflug (ich weiß, Sicherheit), was bei 40 Ziffern aber sehr mühsam ist. Wird die Disk ausgebaut bzw. von einer anderen virtuellen Maschine genutzt, muss der Recovery-Key mühsam eingegeben werden.
Immerhin hat der Boot-Vorgang anstandslos funktioniert — allerdings nur einmal. Beim nächsten Reboot muss der Recovery-Key neuerlich eingegeben werden. Ich habe keinen Weg gefunden, die Keys im TPM der zweiten virtuellen Maschine (Rechner B) zu verankern. Wenn sich wirklich die Notwendigkeit ergibt, die SSD in einen neuen Rechner zu migrieren, wäre das eine große Einschränkung.
Danach habe ich wieder VM 1 gebootet. Dort hat alles funktioniert wie bisher. VM 1 hat also nicht bemerkt, dass die Disk vorübergehend in einem anderen Rechner genutzt und auch verändert wurde. Ich bin mir nicht sicher, ob das wünschenswert ist.
Letztlich bleiben zwei Fragen offen:
Wie sicher sind die Daten, wenn das Notebook in falsche Hände gerät?
Wie sicher ist es, dass ich an meine eigenen Daten rankomme, wenn beim Setup etwas schief geht? Aus meiner persönlichen Sichtweise ist dieser zweiter Punkt der wichtigere. Die Vorstellung, dass nach einem Update der Boot-Prozess hängenbleibt und ich keinen Zugriff mehr auf meine eigenen Daten habe, auch keinen Plan B zur manuellen Rettung, ist alptraumhaft. Es ist diese Befürchtung, weswegen ich das System gegenwärtig nie in einem produktivem Setup verwende würde.
Einfacher ist oft besser, und einfacher ist aktuell die »normale« LUKS-Verschlüsselung, auch wenn diese mit einer wenig eleganten Passwort-Eingabe bei jedem Boot-Prozess verbunden ist. Da weiß ich immerhin, wie ich zur Not auch aus einem Live-System heraus meine Daten lesen kann.
Fazit
Ubuntu 25.10 ist aus meiner Sicht ein mutiges, innovatives Release. Ich kann die Kritik daran nur teilweise nachvollziehen. Die Nicht-LTS-Releases haben nun einmal einen gewissen Test-Charakter und sind insofern mit Fedora-Releases zu vergleichen, die auch gelegentlich etwas experimentell sind.
Das interessanteste neue Feature ist aus meiner Sicht definitiv die Speicherung der Crypto-Keys im TPM. Leider bin technisch nicht in der Lage, die Qualität/Sicherheit zu beurteilen. Noch hat das Feature einen experimentellen Status, aber falls TPM-Keys in Ubuntu 26.04 zu einem regulären Feature werden, würde es sich lohnen, das Ganze gründlich zu testen. Allerdings haben sich diese Mühe bisher wohl nur wenige Leute gemacht, was schade ist.
Generell hätte ich beim TPM-Keys-Feature mehr Vertrauen, wenn sich Ubuntu mit Red Hat, Debian etc. auf eine distributionsübergreifende Lösung einigen könnte.
Post Scriptum am 5.11.2025
Ich habe in den letzten Monaten aktuelle Versionen von CachyOS, Debian, Fedora, openSUSE und Ubuntu getestet. Immer wieder taucht die Frage auf, welche Distribution ich Einsteiger(inne)n empfehle. Ubuntu ist schon lange nicht mehr meine persönliche Lieblingsinstallation. Von den genannten fünf Distributionen hat Ubuntu aber definitiv das beste und einfachste Installationsprogramm. Und für den Start mit Linux ist das durchaus entscheidend …
Die Linux Mint Entwickler haben die ISO Installer der neuen Version ihrer Debian Edition veröffentlicht. LMDE 7 veröffentlicht. LMDE 7 trägt den Codenamen „Gigi“ und basiert auf dem aktuellen Debian 13 „Trixie“. Die Veröffentlichung bringt zahlreiche Neuerungen mit sich und richtet sich an Nutzer, die auf Ubuntu verzichten möchten. LMDE 7 nutzt den stabilen Linux […]
Bereits seit Jahren arbeitet Schleswig-Holstein an der digitalen Selbstbestimmung des Landes. Erste Erfolge werden sichtbar, aber auch Kritik und Widerstände werden laut.
Einige Wochen nach dem Release von Debian 13 »Trixie« hat die Raspberry Pi Foundation auch Raspberry Pi OS aktualisiert. Abseits der Versionsnummern hat sich wenig geändert.
Der Raspberry Pi Desktop »PIXEL« sieht bis auf das Hintergrundbild ziemlich unverändert aus.
Raspberry Pi Imager
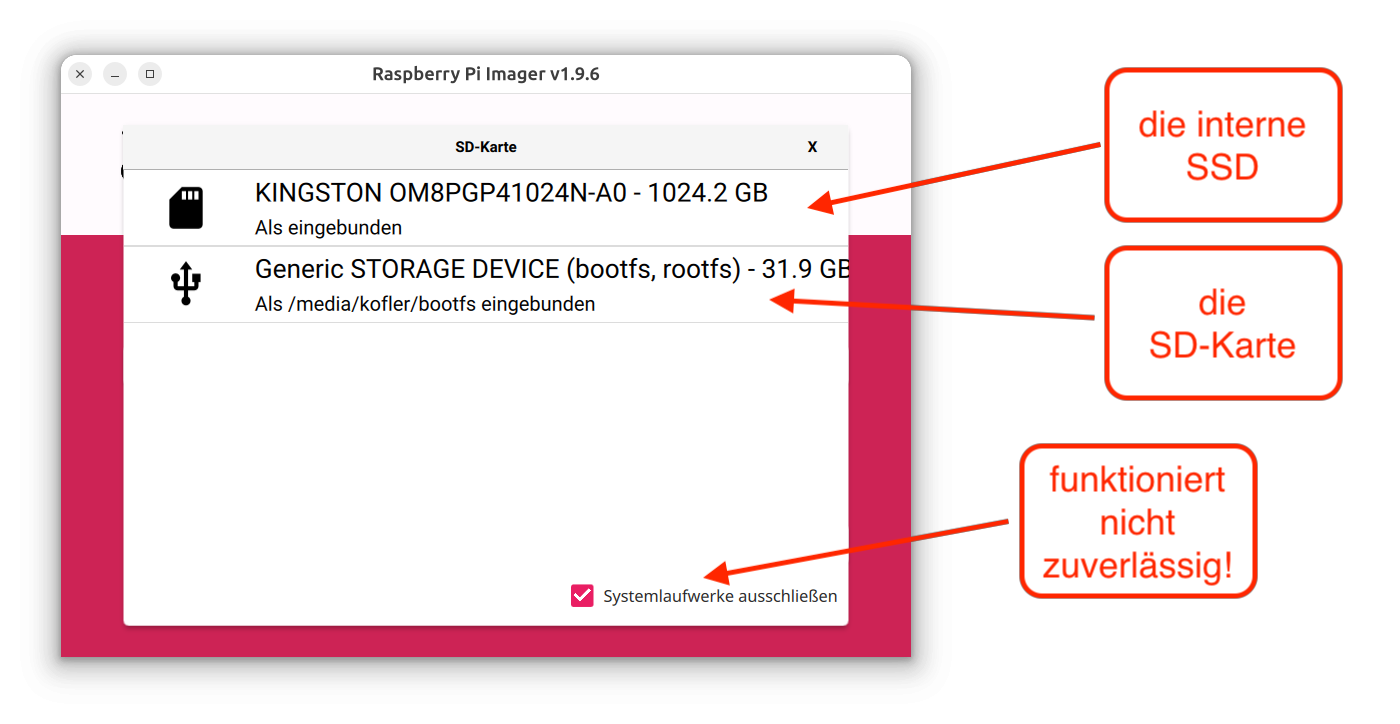
Die »Installation« von Raspberry Pi OS funktioniert wie eh und je: Sie laden die für Ihr Betriebssystem passende Version des Raspberry Pi Imagers herunter und wählen in drei Schritten Ihr Raspberry-Pi-Modell, die gewünschte Distribution und schließlich das Device Ihrer SD-Karte aus. Einfacher kann es nicht sein, würde man denken. Dennoch habe ich es geschafft, auf einem Rechner mit zwei SSDs (einmal Linux, diese SSD war aktiv in Verwendung, einmal Windows) die Installationsdaten auf die Windows-SSD statt auf die SD-Karte zu schreiben. Schuld war ich natürlich selbst, weil ich nur auf das Pictogram gesehen und nicht den nebenstehenden Text gelesen habe. Der Imager hat die SSD mit dem SD-Karten-Icon garniert.
Vorsicht bei der Bedienung des Raspberry Pi Imagers!
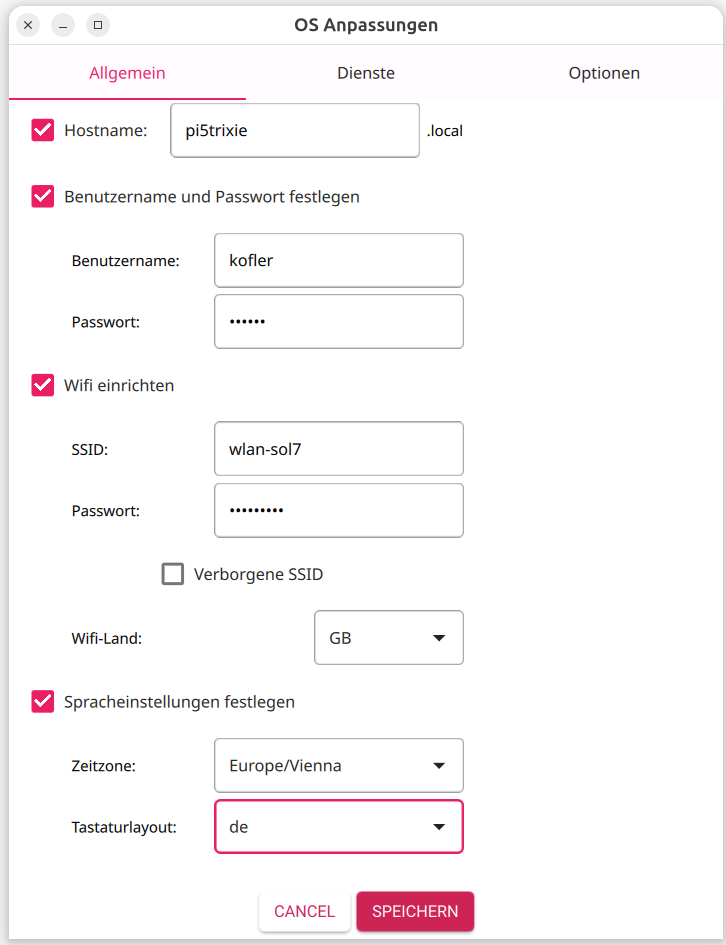
Wenn Sie möchten, können Sie im Imager eine Vorweg-Konfiguration durchführen. Das ist vor allem für den Headless-Betrieb praktisch, erspart aber auch erste Konfigurationsschritte im Assistenten, der beim ersten Start erscheint.
Die Vorab-Konfiguration ist vor allem für den Headless-Betrieb (also ohne Tastatur und Monitor) praktisch.
Versionsnummern
Raspberry Pi OS Trixie profitiert mit dem Versionssprung vom neueren Software-Angebot in Debian Trixie. Die aktuelleren Versionsnummern sind gleichzeitig das Hauptargument, auf Raspberry Pi OS Trixie umzusteigen.
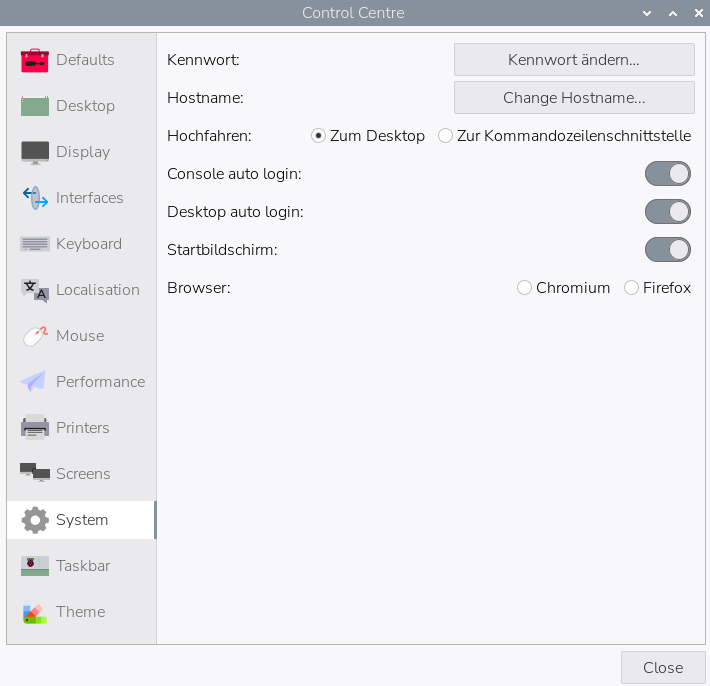
Die größte Änderung am Desktop »PIXEL« (vom Hintergrundbild abgesehen) betrifft die Konfiguration: Das Control Center umfasst nun auch Desktop-Einstellungen, die Bildschirm-Konfiguration und die Drucker-Konfiguration. Das ist definitiv ein Fortschritt im Vergleich zur bisher recht willkürlichen Aufteilung der Konfiguration über diverse Programme mit recht uneinheitlichem Erscheinungsbild.
Das Konfigurationsprogramm umfasst nun wesentlich mehr Module
gpioset
Die Syntax von gpioset hat sich geändert (vermutlich schon vor einiger Zeit, aber mir ist es erst im Rahmen meiner Tests mit Raspberry Pi OS Trixie aufgefallen):
Der gewünschte Chip (Nummer oder Device) muss mit der Option -c angegeben werden.
Das Kommando läuft per Default endlos, weil es nur so den eingestellten Status der GPIOs garantieren kann. Wenn Sie wie bisher ein sofortiges Ende wünschen, übergeben Sie die Option -t 0. Beachten Sie, dass -t nicht die Zeit einstellt, sondern für ein regelmäßiges Ein- und Ausschalten gedacht ist (toggle). Ich habe die Logik nicht verstanden, aber -t 0 führt auf jeden Fall dazu, dass das Kommando sofort beendet wird.
Alternativ kann das Kommando mit -z im Hintergrund fortgesetzt werden.
Das folgende Kommando gilt für Chip 0 (/dev/gpiochip0) und somit für die »gewöhnlichen« GPIOs. Dank -t 0 wird das Kommando sofort beendet.
Verwenden Sie besser das Kommando pinctrl, wenn Sie GPIOs im Terminal oder in bash-Scripts verändern wollen!
Sonstiges
Raspberry Pi OS verwendet nun per Default Swap on ZRAM. Nicht benötigte Speicherblöcke werden also komprimiert und in einer RAM-Disk gespeichert. Besonders gut funktioniert das bei Raspberry-Pi-Modellen mit viel RAM.
Raspberry Pi OS wird keine Probleme mit dem Jahr 2038 haben. Die zugrundeliegenden Änderungen stammen von Debian und wurden einfach übernommen.
Dank neuer Meta-Pakete ist es einfacher, von Raspberry Pi OS Lite auf die Vollversion umzusteigen. Das ist aus Entwicklersicht sicher erfreulich, der praktische Nutzen hält sich aber in Grenzen.
Mathematica steht aktuell noch nicht zur Verfügung, die Pakete sollen aber bald nachgeliefert werden.
Auch die Software für einige HATs (KI- und TV-Funktionen) müssen erst nachgereicht werden.
Fazit
Alles in allem ist das Raspberry-Pi-OS-Release unspektakulär. Das hat aber auch damit zu tun, dass Raspberry Pi OS bereits in den letztes Releases umfassend modernisiert wurde. Zur Erinnerung: Raspberry Pi OS verwendet Wayland, PipeWire, den NetworkManager etc., verhält sich also mittlerweile ganz ähnlich wie »normale« Linux-Distributionen. Diesmal gab es einfach weniger zu tun :-)
Bei meinen bisherigen Tests sind mir keine Probleme aufgefallen. Umgekehrt gibt es aber auch so wenig Neuerungen, dass ich bei einem vorhandenen Projekt dazu rate, die Vorgängerversion Raspberry Pi OS »Bookworm« einfach weiterlaufen zu lassen. Die Raspberry Pi Foundation rät von Distributions-Updates ab, und der Nutzen einer Neuinstallation steht in keinem Verhältnis zum Aufwand. Und es nicht auszuschließen, dass mit den vielen Versions-Updates doch die eine oder andere Inkompatibilität verbunden ist.
Canonical hat die neue Version Ubuntu 25.10 mit dem Codenamen „Questing Quokka“ veröffentlicht. Die Ausgabe ist eine Kurzzeitversion mit neun Monaten Support und erhält Updates bis Juli 2026. Sie richtet sich vor allem an Nutzer, die gerne auf dem neuesten Stand bleiben und aktuelle Technologien im Ubuntu Kosmos testen möchten. Die Distribution basiert auf dem […]
Mit Ubuntu 25.10 »Questing Quokka« hat Canonical das letzte Release vor der nächsten LTS-Version 26.04 freigegeben. Es enthält viele Neuerungen, die nun getestet werden wollen.
Der selbst gehostete RSS-Feed-Aggregator Tiny Tiny RSS (tt-rss) wird zum 1. November 2025 komplett eingestellt und die Infrastruktur dahinter abgeschaltet.
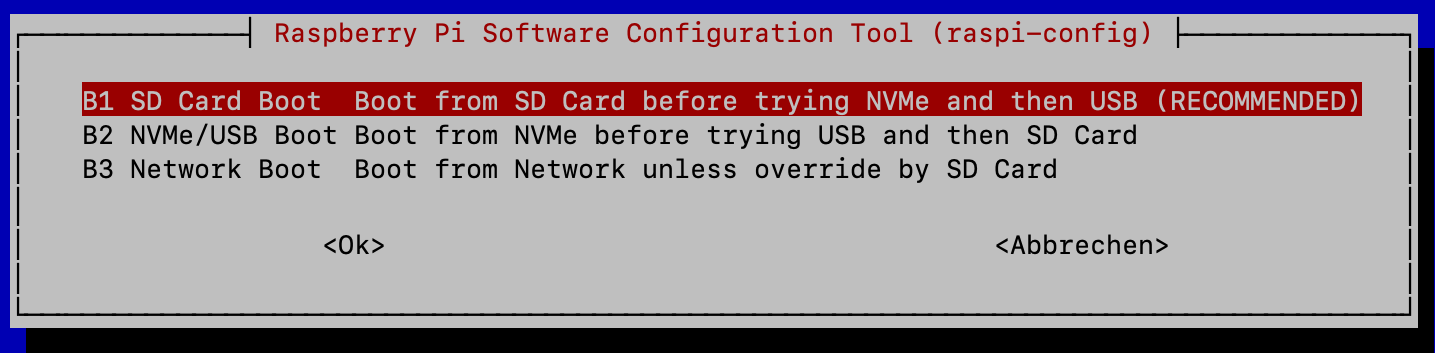
Mein Raspberry Pi 5 ist mit einem SSD-Hat ausgestattet (Pimoroni, siehe Blog). Auf der SSD ist Raspberry Pi OS Bookworm installiert. Jetzt möchte ich aber Raspberry Pi OS Trixie ausprobieren. Das System habe ich mit dem Raspberry Pi Imager auf eine SD-Card geschrieben. Sowohl SSD als auch SD-Karte sind angeschlossen, die Boot-Reihenfolge ist auf SD-Card first eingestellt.
Boot-Reihenfolge einstellen
raspi-config verändert die Variable BOOT_ORDER, die im EEPROM gespeichert wird. Die Variable kann mit `rpi-eeprom-config´ gelesen werden:
0xf461 bedeutet (die Auswertung erfolgt mit den niedrigsten Bits zuerst, also von rechts nach links):
1 - Try SD card
6 - Try NVMe
4 - Try USB mass storage
f - RESTART (loop back to the beginning)
Die Einstellung ist also korrekt, trotzdem bootet der Pi hartnäckig von der SSD und ignoriert die SD-Card. Warum?
Analyse
Schuld sind die Partition-UUIDs! Die SSD habe ich vor eineinhalb Jahren mit dem SD Card Copier geklont. Die Option New Partition UUIDs habe ich nicht verwendet, ich sah keinen Grund dazu. Jetzt liegt folgendes Problem vor: Die SSD und die vom Rasbperry Pi Imager erzeugte SD-Card haben die gleichen Partition-UUIDs!
Solange beide Datenträger verbunden sind, ist nicht vorhersehbar, welche Partitionen tatsächlich genutzt werden. Am einfachsten wäre es natürlich, das Kabel zur SSD vorübergehend zu trennen; das ist aber nicht empfehlenswert, weil es hierfür keinen richtigen Stecker gibt, sondern nur eine sehr filigrane Kabelpressverbindungen, die möglichst nicht anrührt werden sollte.
Lösung
Ich habe den Pi ohne SD-Karte neu gebootet und dann
die Filesystem-UUIDs geändert,
/etc/fstab angepasst und
/boot/firmware/cmdline.txt ebenfalls angepasst.
Im Detail: Da die ursprüngliche Partitionierung der SSD von der SD-Karte übernommen wurde, liegt eine MBR-Partitionstabelle vor. In diesem Fall ergeben sich die Partition-UUIDs aus der Disk-ID plus Partitionsnummer. Die Disk-ID (Hex-Code mit 8 Stellen) kann mit fdisk geändert werden:
fdisk /dev/nvme0n1
Welcome to fdisk (util-linux 2.38.1).
Command (m for help): x. <-- aktiviert den Expertenmodus
Expert command (m for help): i <-- ID ändern
Enter the new disk identifier: 0x1234fedc. <-- neue ID als Hex-Code
Disk identifier changed from 0x8a676486 to 0x1234fedc.
Expert command (m for help): r <-- zurück ins Hauptmenü (return)
Command (m for help): w <-- Änderungen speichern (write)
The partition table has been altered.
Syncing disks.
Mit fdisk -l vergewissern Sie sich, dass die Änderung wirklich funktioniert hat:
fdisk -l /dev/nvme0n1
...
Disk identifier: 0x1234fedc
Weil der Datenträger in Verwendung ist, zeigt fdisk -l /dev/nvme0n1 weiter die alte UUID an. Sie müssen glauben, dass es funktioniert hat :-(
Bevor Sie einen Reboot machen, müssen Sie nun mit einem Editor auch /etc/fstab und /boot/firmware/cmdline.txt anpassen. In meinem Fall sehen die Dateien jetzt so aus:
Jetzt ist ein Reboot fällig, um zu testen, ob alles funktioniert. (Bei mir hat es im ersten Versuch NICHT funktioniert, weil ich bei fdisk das write-Kommando vergessen habe. Dann muss die SSD ausgebaut, ein USB-Gehäuse mit einem Computer verbunden und der Vorgang wiederholt werden.)
Ab jetzt sind die Partitions-UUIDs von SD-Karte und SSD voneinander unterscheidbar. Die Umschaltung des Boot-Systems mit raspi-config funktioniert, wie sie soll.
Ubuntu hat den offiziellen Codenamen seiner nächsten Langzeitversion bekannt gegeben: Resolute Raccoon. Die Version 26.04 LTS erscheint im April 2026 und soll über viele Jahre eine stabile Grundlage für Server und Desktops bieten. Die Namenswahl hat dabei nicht nur symbolischen, sondern auch praktischen Wert. Der Codename wurde von Steve Langasek festgelegt, einem langjährigen Mitarbeiter von Canonical. […]
Bei Intel zeigen sich derzeit deutliche Auswirkungen der jüngsten Konzernumbauten. Nach Entlassungen und dem Weggang mehrerer Entwickler stehen nun auch zahlreiche Softwarepakete des Unternehmens in Debian ohne aktive Betreuung da. Damit sind nicht nur Debian selbst, sondern auch Ubuntu und andere darauf basierende Systeme betroffen. Etwa ein Dutzend Intel Pakete wurden kürzlich offiziell als „verwaist“ […]
 Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […]
Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […] Seit dem 22. Oktober 2025 stehen die ersten lauffähigen täglichen Testversionen von Ubuntu 26.04 LTS zum Download bereit. Canonical richtet sich damit an Tester, Entwickler und neugierige Nutzer. Frühere Builds funktionierten nicht richtig und waren kaum nutzbar im Alltag. Die neuen Images basieren auf Ubuntu 25.10 mit dem Codenamen Questing Quokka, das Anfang Oktober erschienen […]
Seit dem 22. Oktober 2025 stehen die ersten lauffähigen täglichen Testversionen von Ubuntu 26.04 LTS zum Download bereit. Canonical richtet sich damit an Tester, Entwickler und neugierige Nutzer. Frühere Builds funktionierten nicht richtig und waren kaum nutzbar im Alltag. Die neuen Images basieren auf Ubuntu 25.10 mit dem Codenamen Questing Quokka, das Anfang Oktober erschienen […] Das Fedora Council hat eine neue Richtlinie verabschiedet, die erstmals den Einsatz von KI bei Beiträgen zu Fedora Projekten erlaubt. Nach intensiven Diskussionen in der Community wurde nun ein Rahmen geschaffen, der moderne Werkzeuge zulässt, zugleich aber menschliche Verantwortung in den Mittelpunkt stellt. Künftig dürfen Entwickler KI Werkzeuge nutzen, um Code, Dokumentation oder andere Inhalte […]
Das Fedora Council hat eine neue Richtlinie verabschiedet, die erstmals den Einsatz von KI bei Beiträgen zu Fedora Projekten erlaubt. Nach intensiven Diskussionen in der Community wurde nun ein Rahmen geschaffen, der moderne Werkzeuge zulässt, zugleich aber menschliche Verantwortung in den Mittelpunkt stellt. Künftig dürfen Entwickler KI Werkzeuge nutzen, um Code, Dokumentation oder andere Inhalte […] Das KDE Projekt hat die neue Version 6.5 seiner Desktopumgebung Plasma veröffentlicht. Sie bringt zahlreiche Verbesserungen, neue Funktionen und viele kleine Korrekturen, die den Alltag mit Linux spürbar angenehmer machen. Optisch fällt sofort auf, dass Fenster im Breeze Design nun abgerundete untere Ecken besitzen. Unterstützte Drucker zeigen ihren Tintenstand direkt im System an. Auch HDR […]
Das KDE Projekt hat die neue Version 6.5 seiner Desktopumgebung Plasma veröffentlicht. Sie bringt zahlreiche Verbesserungen, neue Funktionen und viele kleine Korrekturen, die den Alltag mit Linux spürbar angenehmer machen. Optisch fällt sofort auf, dass Fenster im Breeze Design nun abgerundete untere Ecken besitzen. Unterstützte Drucker zeigen ihren Tintenstand direkt im System an. Auch HDR […]
 Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
 Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […]
Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […] Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […]
Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […] Die Document Foundation hat mit LibreOffice 25.8.2 das zweite Wartungsupdate der aktuellen Version veröffentlicht. Die neue Ausgabe behebt viele Probleme, die Nutzer seit der letzten Version gemeldet hatten. Ziel des Updates ist es, Stabilität und Zuverlässigkeit der beliebten Bürosoftware weiter zu verbessern. Besonders auffällig sind Korrekturen in den Anwendungen Writer, Calc und Impress. Abstürze beim […]
Die Document Foundation hat mit LibreOffice 25.8.2 das zweite Wartungsupdate der aktuellen Version veröffentlicht. Die neue Ausgabe behebt viele Probleme, die Nutzer seit der letzten Version gemeldet hatten. Ziel des Updates ist es, Stabilität und Zuverlässigkeit der beliebten Bürosoftware weiter zu verbessern. Besonders auffällig sind Korrekturen in den Anwendungen Writer, Calc und Impress. Abstürze beim […] Am 14. Oktober 2025 endet offiziell der Support für Windows 10. Danach stellt Microsoft keine regulären Sicherheitsupdates mehr bereit. Zwar ist inzwischen angekündigt, dass es noch bis Ende 2026 eine verlängerte Updatephase geben soll, doch die Bedingungen dafür sind noch nicht voll transparent. Millionen funktionstüchtige Computer wären damit theoretisch aus dem Updatezyklus ausgeschlossen, wenn sie […]
Am 14. Oktober 2025 endet offiziell der Support für Windows 10. Danach stellt Microsoft keine regulären Sicherheitsupdates mehr bereit. Zwar ist inzwischen angekündigt, dass es noch bis Ende 2026 eine verlängerte Updatephase geben soll, doch die Bedingungen dafür sind noch nicht voll transparent. Millionen funktionstüchtige Computer wären damit theoretisch aus dem Updatezyklus ausgeschlossen, wenn sie […]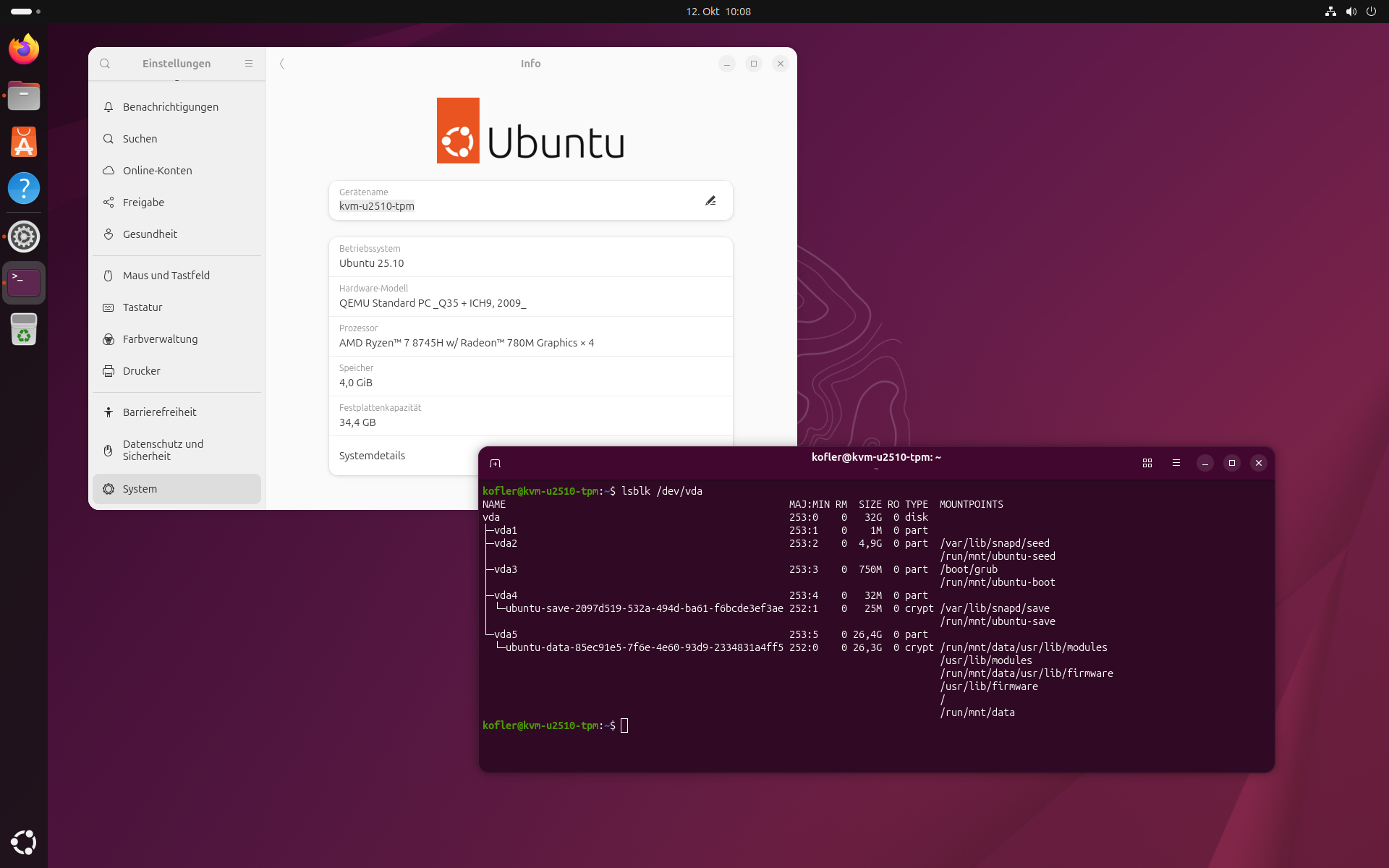
 Die Linux Mint Entwickler haben die ISO Installer der neuen Version ihrer Debian Edition veröffentlicht. LMDE 7 veröffentlicht. LMDE 7 trägt den Codenamen „Gigi“ und basiert auf dem aktuellen Debian 13 „Trixie“. Die Veröffentlichung bringt zahlreiche Neuerungen mit sich und richtet sich an Nutzer, die auf Ubuntu verzichten möchten. LMDE 7 nutzt den stabilen Linux […]
Die Linux Mint Entwickler haben die ISO Installer der neuen Version ihrer Debian Edition veröffentlicht. LMDE 7 veröffentlicht. LMDE 7 trägt den Codenamen „Gigi“ und basiert auf dem aktuellen Debian 13 „Trixie“. Die Veröffentlichung bringt zahlreiche Neuerungen mit sich und richtet sich an Nutzer, die auf Ubuntu verzichten möchten. LMDE 7 nutzt den stabilen Linux […]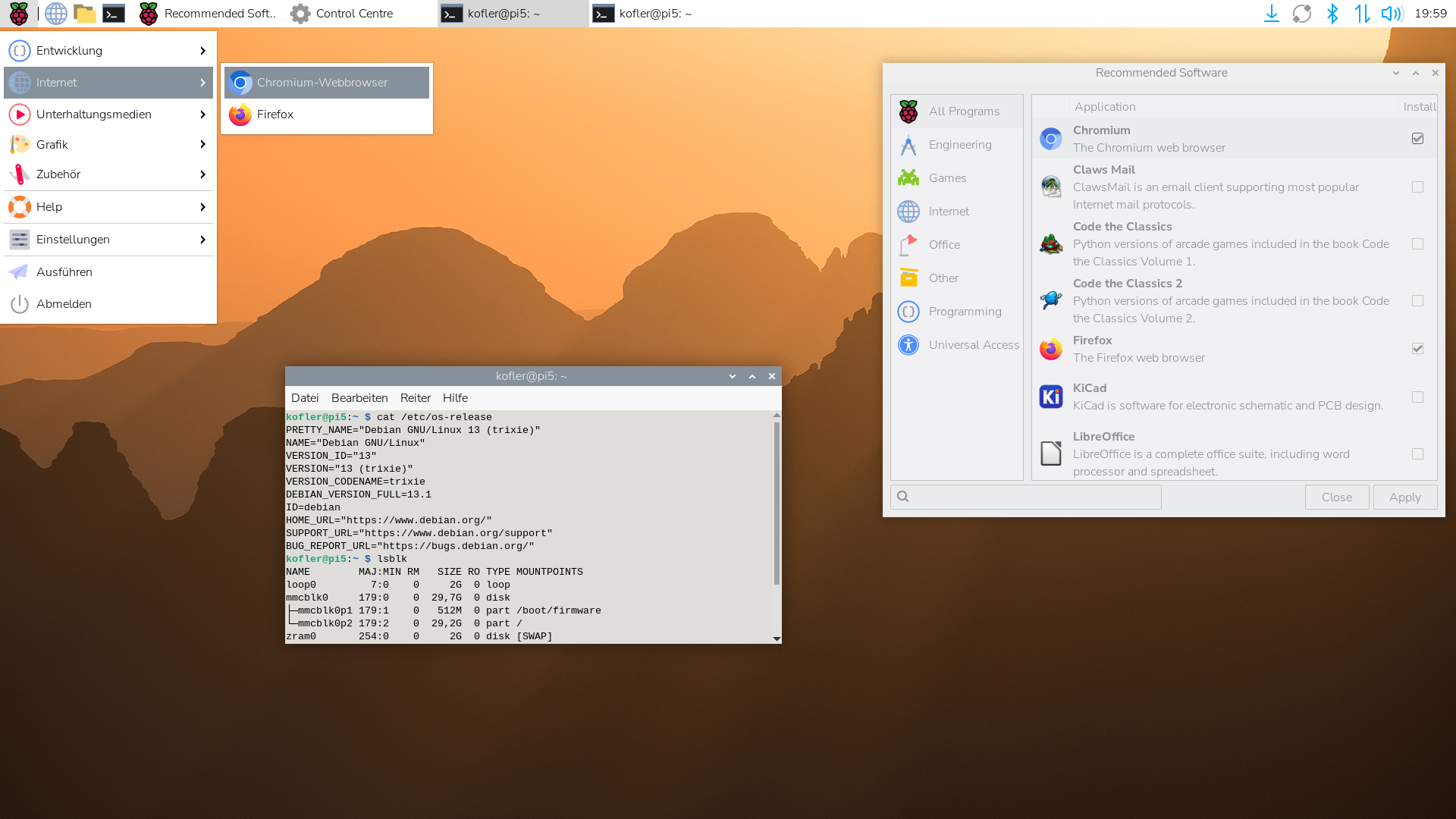
 Bei Intel zeigen sich derzeit deutliche Auswirkungen der jüngsten Konzernumbauten. Nach Entlassungen und dem Weggang mehrerer Entwickler stehen nun auch zahlreiche Softwarepakete des Unternehmens in Debian ohne aktive Betreuung da. Damit sind nicht nur Debian selbst, sondern auch Ubuntu und andere darauf basierende Systeme betroffen. Etwa ein Dutzend Intel Pakete wurden kürzlich offiziell als „verwaist“ […]
Bei Intel zeigen sich derzeit deutliche Auswirkungen der jüngsten Konzernumbauten. Nach Entlassungen und dem Weggang mehrerer Entwickler stehen nun auch zahlreiche Softwarepakete des Unternehmens in Debian ohne aktive Betreuung da. Damit sind nicht nur Debian selbst, sondern auch Ubuntu und andere darauf basierende Systeme betroffen. Etwa ein Dutzend Intel Pakete wurden kürzlich offiziell als „verwaist“ […]