Nach mehr ausreichenden Entwicklungszeit hat das Devuan-Team die neue Version Devuan 6 „Excalibur“ offiziell freigegeben. Die auf Debian 13 „Trixie“ basierende Distribution bleibt ihrem Grundprinzip treu, ein vollständig systemd-freies Linux-System anzubieten. Devuan 6 verwendet den Linux-Kernel 6.12 LTS und setzt erstmals auf den neuen Paketmanager APT 3, der für mehr Leistung und Zuverlässigkeit sorgen soll. Eine wichtige technische Neuerung ist […]
Arch Linux erhält mit der Veröffentlichung von Pacman 7.1 mehr Sicherheit beim Paketmanagement. Die Sandbox-Steuerung wurde verfeinert und Systemaufrufe durch neue Flags eingeschränkt.
Ein E-Mail-Umzug von einem Server auf einen anderen gehört zu den Aufgaben, die oft unterschätzt werden. Wer schon einmal versucht hat, ein E-Mail-Konto auf einen neuen Mailserver zu übertragen, kennt die typischen Probleme: unterschiedliche IMAP-Server, abweichende Login-Methoden, große Postfächer oder das Risiko, E-Mails doppelt oder gar nicht zu übertragen.
Für eine saubere und zuverlässige E-Mail-Migration gibt es jedoch ein bewährtes Open-Source-Tool: imapsync. Mit imapsync lassen sich komplette IMAP-Konten effizient und sicher von einem Server auf einen anderen synchronisieren – ohne Datenverlust und mit minimaler Ausfallzeit. Ob beim Providerwechsel, beim Umzug auf einen eigenen Mailserver oder beim Zusammenführen mehrerer Postfächer: imapsync bietet eine stabile und flexible Lösung für jede Art von Mailserver-Migration.
In diesem Artikel zeige ich Schritt für Schritt, wie imapsync funktioniert, welche Parameter in der Praxis wichtig sind und wie du deinen E-Mail-Umzug stressfrei und automatisiert durchführen kannst.
Die Open Source Software Imapsync vorgestellt
So einem Umzug von einem E-Mail-Server zu einem anderen mit einem Terminal-Programm zu machen, klingt etwas verrückt. In Wirklichkeit ist das aber eine große Stärke, da imapsync während der Übertragung bereits wertvolle Statusmeldungen ausgibt und man die Statistik im Blick behält.
Theoretisch lässt sich das Programm via Eingabe verschiedener Flags bedienen. Für mich hat sich aber bewährt, dass man es mit einem einfachen Skript ausführt. In aller Regel zieht man ja kein einzelnes Postfach um, sondern mehrere E-Mail-Konten. Motivation könnte zum Beispiel eine Änderung der Domain oder der Wechsel des Hosters sein. Aber selbst bei Einzelkonten empfehle ich die Benutzung des Skripts, weil sich hier die Zugangsdaten übersichtlich verwalten lassen.
Was imapsync jetzt macht, ist ziemlich straight-forward: Es meldet sich auf dem ersten Host („alter Server“) an, checkt erstmal die Ordnerstruktur, zählt die E-Mails und verschafft sich so einen Überblick. Hat man bereits die Zugangsdaten für den zweiten Host („neuer Server“), tut er das gleiche dort. Danach überträgt die Software die E-Mails von Host 1 auf Host 2. Bereits übertragene Mails werden dabei berücksichtigt. Man kann den Umzug also mehrfach starten, es werden nur die noch nicht übertragenen Mails berücksichtigt.
Die Webseite von imapsync ist auf den ersten Blick etwas ungewöhnlich, worauf der Entwickler auch stolz ist. Wenn man aber genauer hinsieht, merkt man die gute Dokumentation. Es werden auch Spezialfälle wie Office 365 von Microsoft oder Gmail behandelt.
Die Statistik von imapsync gibt bereits einen guten Überblick, wie gut der Umzug geklappt hat
Installation von imapsync
Die Software gibt es für Windows, Mac und Linux. Die Installation unter Ubuntu ist für geübte Benutzer recht einfach, auch wenn die Software nicht in den Paketquellen vorkommt. Github sei Dank.
Die Installation ist nun fertig und systemweit verfügbar.
E-Mail-Postfach von einem Server zum anderen umziehen
Für den Umzug von einem Server zum anderen braucht man – wenig überraschend – jeweils die Zugangsdaten. Diese beinhalten IMAP-Server, Benutzername und Passwort. Das wars. Es empfiehlt sich, mit einem echten Host 1 zu starten, als Host 2 aber erstmal einen Testaccount zu verwenden.
Ich orientiere mich an den Empfehlungen des Programmierers und erstelle zunächst eine Datei mit den jeweiligen Zugangsdaten. Genau wie im Beispielskript verwende ich eine siebte, unnötige Spalte. Sie endet die Zeilen ordentlich ab, ohne dass man ein Problem mit den Zeilenumbruch zu erwarten hat.
Wir nennen die Datei file.txt. Jeweils die Einträge 1 bis 3 sind die Quelle, Spalten 4 bis 6 sind das Ziel.
Der Linux Coffee Talk ist das entspannte Monatsformat bei fosstopia. Hier fassen wir die spannendsten Ereignisse und Entwicklungen der letzten Wochen für Euch zusammen und ordnen es ein. Also schnappt euch einen Kaffee, Tee oder Euer Lieblingsgetränk, macht es euch gemütlich und lasst uns den Oktober Revue passieren. In dieser Ausgabe blicken wir auf die […]
Mit ein wenig Verspätung ist Fedora 43 fertig. Ich habe in den letzten Monaten schon viel mit der Beta gearbeitet und war schon damit überwiegend zufrieden. Fedora 43 ist das erste weitgehend X-freie Release (X wie X Window System, nicht wie Twitter …), es gibt nur noch XWayland zur Ausführung von X-Programmen unter Wayland. Relativ neu ist das Installationsprogramm, auf das ich gleich näher eingehe. Es ist schon seit Fedora 42 verfügbar, aber diese Version habe ich in meinem Blog übersprungen.
Die folgenden Ausführungen beziehen sich auf Fedora 43 Workstation mit Gnome.
Fedora 43 mit Gnome in einer virtuellen Maschine
Installation
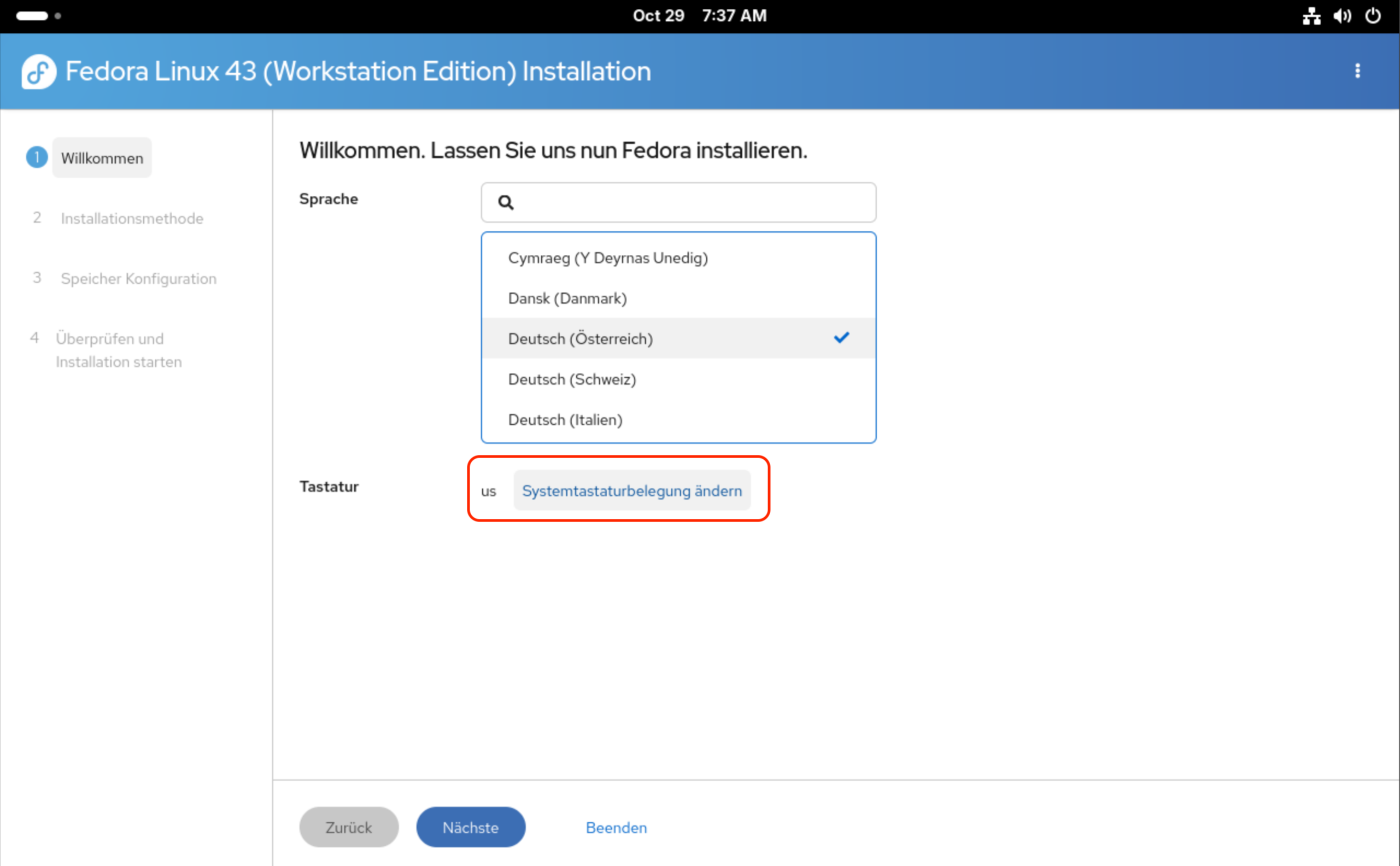
Das Installationsprogramm beginnt aus deutschsprachiger Sicht gleich mit einem Ärgernis: Zwar kann die Sprache mühelos auf Deutsch umgestellt werden, nicht aber das Tastaturlayout. Dazu verweist das Installationsprogramm auf die Systemeinstellungen. Dort müssen Sie nicht nur das gewünschte Layout hinzufügen, sondern auch das vorhandene US-Layout entfernen — vorher ist das Installationsprogramm nicht zufrieden. Das ist einigermaßen umständlich.
Die Einstellung des Tastaturlayouts muss in den Gnome-Systemeinstellungen erfolgen
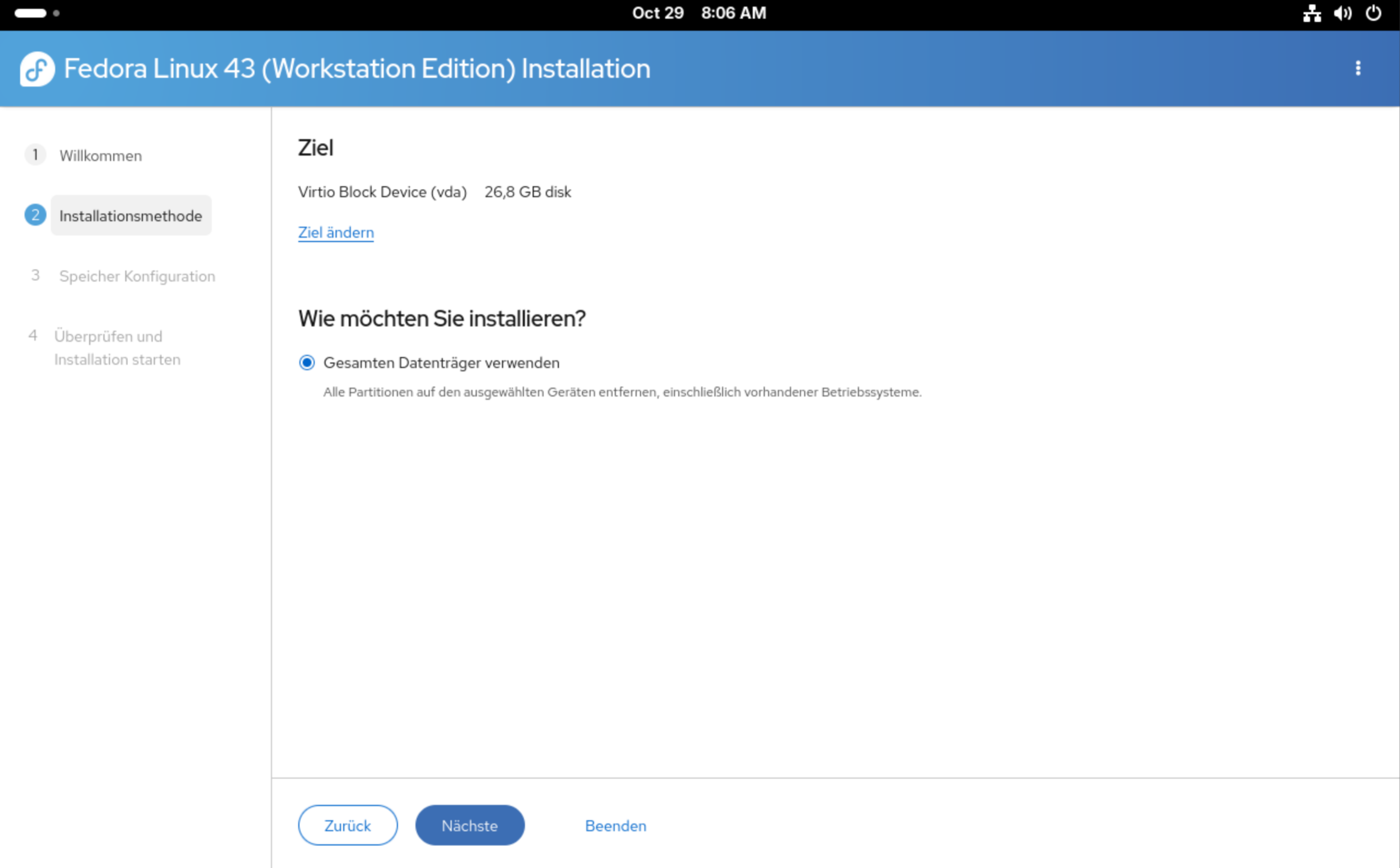
In virtuellen Maschinen wird bei der Installationsmethode (gemeint ist die Partitionierung des Datenträgers und das Einrichten der Dateisysteme) nur eine Option angezeigt: Gesamten Datenträger verwenden. Damit haben Sie weder Einfluss auf die Größe der Partitionen noch auf den Dateisystemtyp oder dessen Optionen. Das Standardlayout lautet: EFI-Partition (vfat), Boot-Partition (ext4) und Systempartition (btrfs mit zwei Subvolumes für / und /home und aktiver Komprimierung). Eine Swap-Partition gibt es nicht, Fedora verwendet schon seit einiger Zeit Swap on ZRAM.
Bei der Installation von Fedora in eine Virtuelle Maschine sind auf den ersten Blick nur wenig Optionen erkennbar …
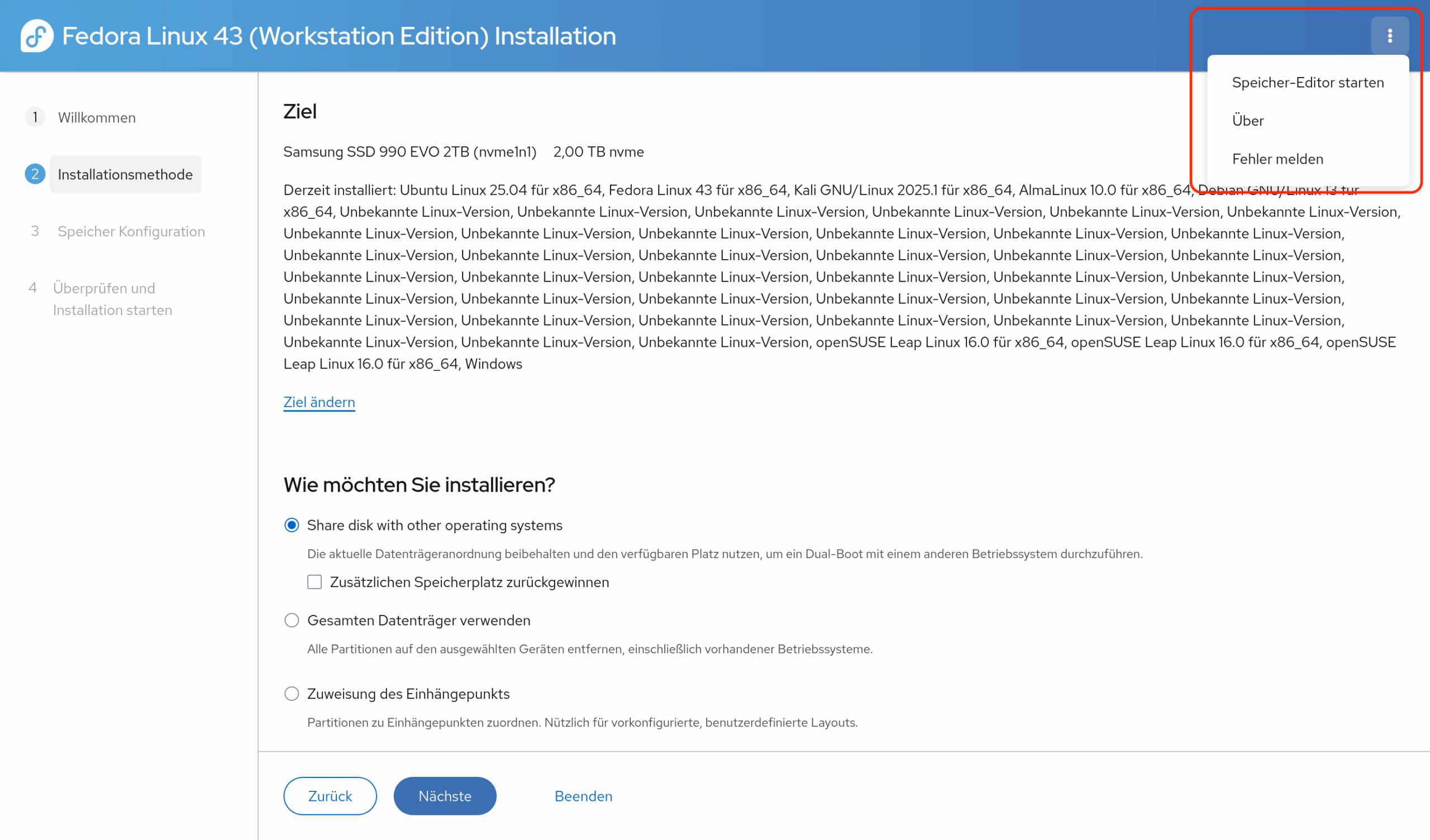
Wenn Sie die Installation auf einem Rechner durchführen, auf dem schon Windows oder andere Linux-Distributionen installiert sind, wird die Auswahl größer:
Die Option Share disk with other operation systems (vielleicht wird der Text bei späteren Versionen noch übersetzt) erscheint, wenn das Setup-Programm Windows oder andere Linux-Distributionen auf der SSD erkennt. In diesem Fall nutzt Fedora den verbleibenden freien Platz auf der SSD und richtet dort eine Boot- und eine Systempartition ein. Wenn es auf der SSD keinen oder zu wenig Platz gibt, sollten Sie zusätzlich die Option Zusätzlichen Speicherplatz zurückgewinnen aktivieren. Sie können dann in einem weiteren Dialog einzelne Partitionen löschen oder verkleinern.
Gesamten Datenträger verwenden löscht alle vorhandene Partitionen und richtet dann wie oben beschreiben EFI-, Boot- und Systempartition ein.
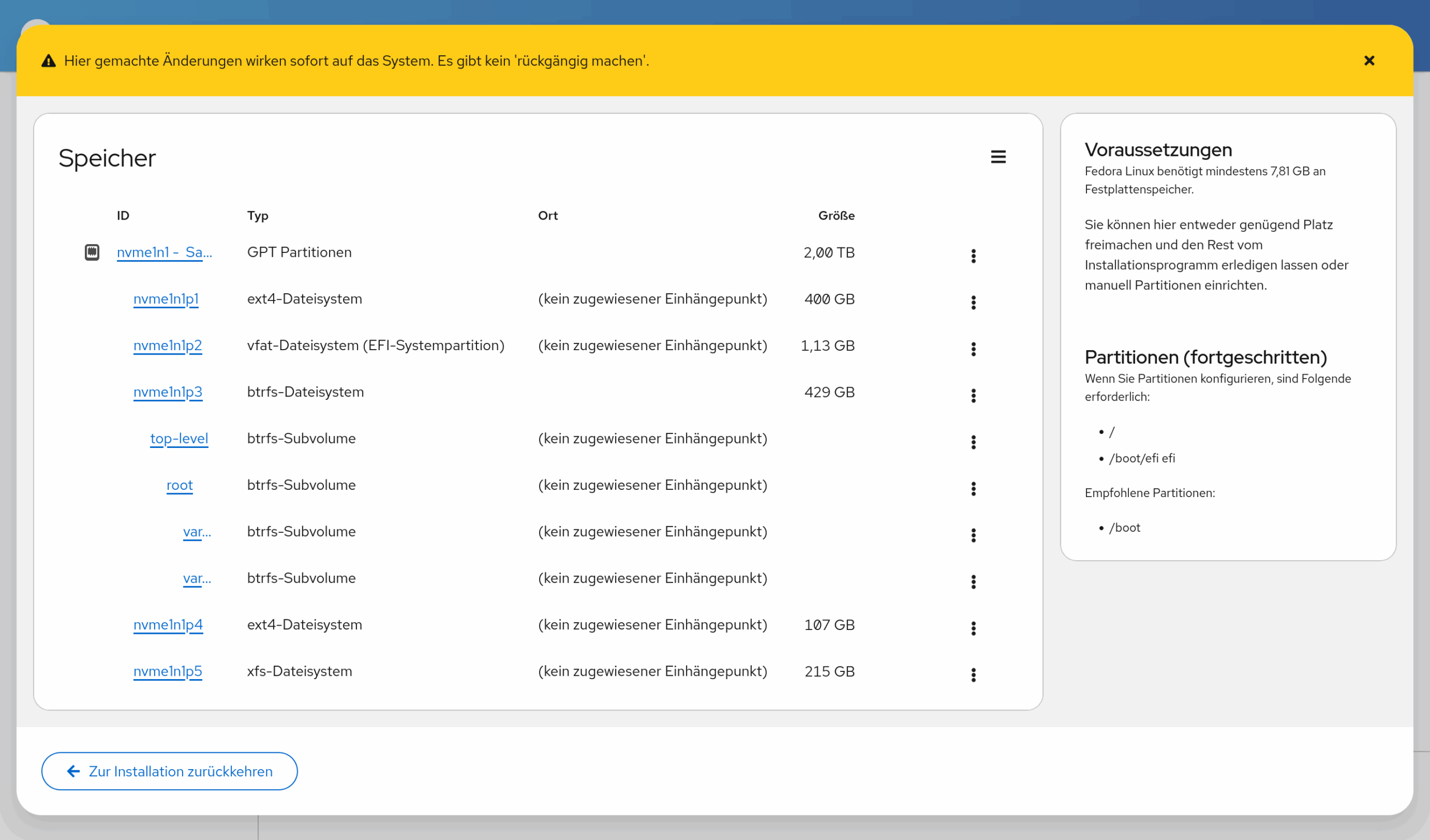
Zuweisung des Einhängepunkts bietet Linux-Profis die Möglichkeit, schon vorhandene Dateisysteme zu nutzen. Es gibt zwei Möglichkeiten, diese Dateisysteme einzurichten. Eine bietet der über den unscheinbaren Menü-Button erreichbare Speicher-Editor. Dort können Sie Partitionen, Logical Volumes, RAID-Setup und Dateisysteme samt Verschlüsselung einrichten. Es mangelt nicht an Funktionen, aber leider ist die Bedienung sehr unübersichtlich. Alle hier initiierten Aktionen werden sofort durchgeführt und können nicht rückgängig gemacht werden. Alternativ können Sie vorweg in einem Terminal mit parted Partitionen einrichten und dann mit mkfs.xxx darin die gewünschten Dateisysteme anlegen. Falls das Dateisystem verschlüsselt werden soll, müssen Sie sich auch darum selbst kümmern (Kommando cryptsetup). Das erfordert ein solides Linux-Vorwissen.
Das Setup-Programm wirkt mit den bereits installierten Distributionen überfordert. (Es sind in Wirklichkeit nur sechs Distributionen, nicht mehrere Dutzend …) Manuelle Partitions-Setups müssen über den »Speichereditor« durchgeführt werden.Der »Speichereditor« zur manuellen Partitionierung listet alle Subvolumes aller btrfs-Dateisysteme auf und ist auch sonst extrem unübersichtlich in seiner Bedienung
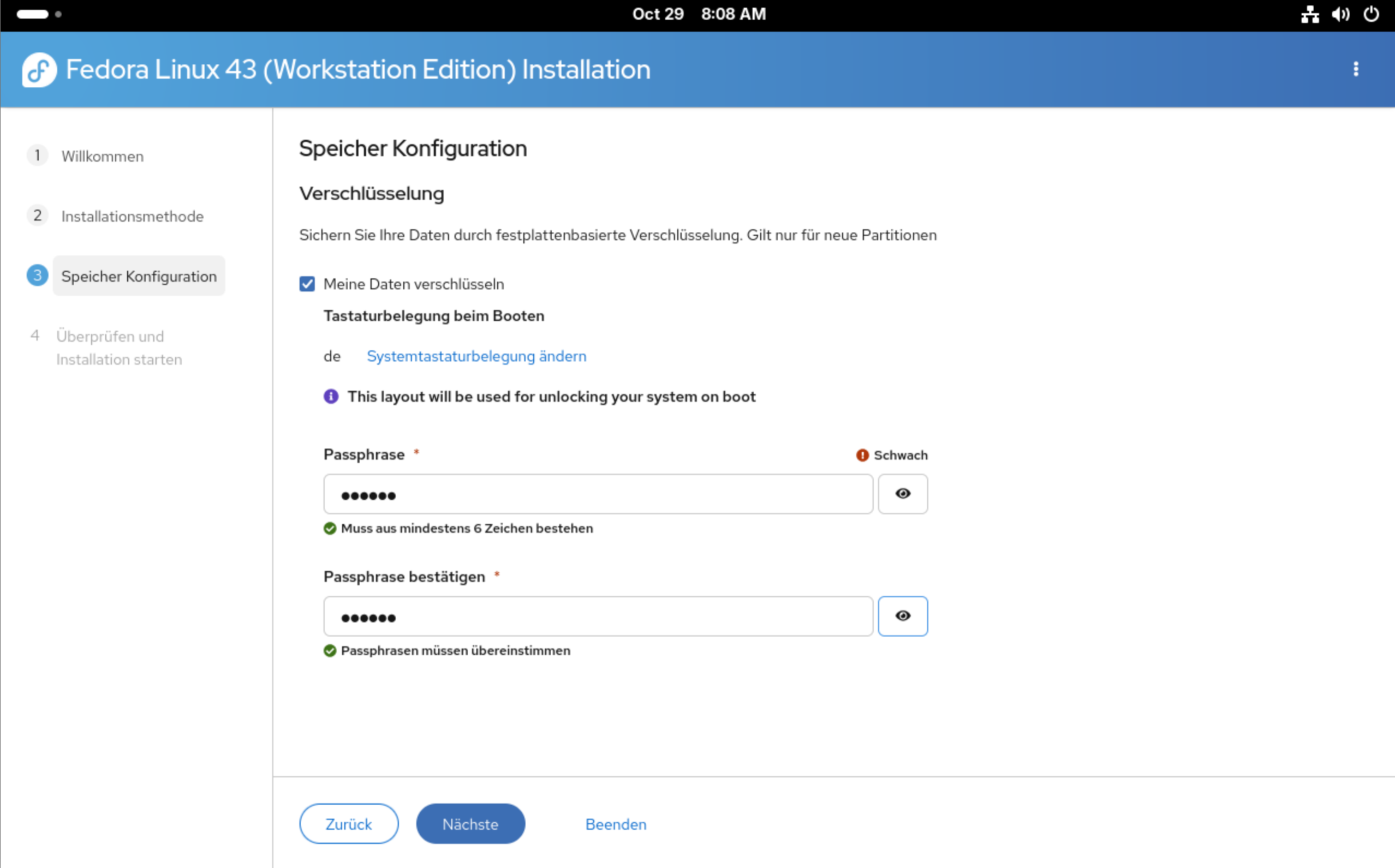
In der Speicher-Konfiguration können Sie das Dateisystem verschlüsseln (außer Sie haben sich im vorigen Schritt für die Zuweisung des Einhängepunkts entschieden). Zur Verschlüsselung geben Sie zweimal das Passwort an und stellen ein, welches Tastaturlayout beim Bootvorgang für die Eingabe dieses Passworts gelten soll.
Die Verschlüsselung des Dateisystems gelingt nur problemlos, sofern Sie im vorigen Schritt keine manuelles Setup eingerichtet haben
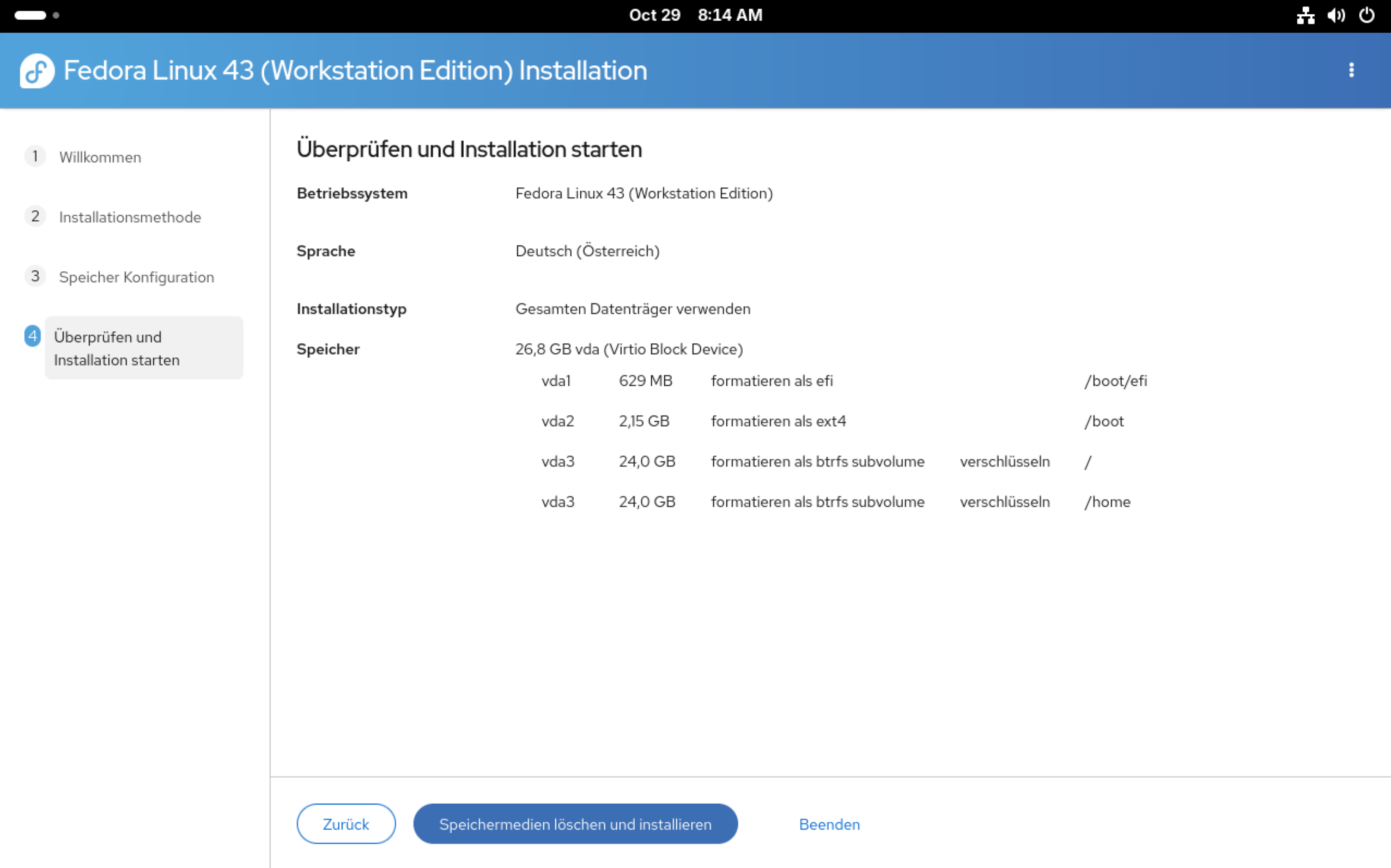
Zuletzt zeigt das Installationsprogramm eine Zusammenfassung der Einstellungen ein. Ein Benutzeraccount samt Passwort wird erst später beim ersten Start von Gnome eingerichtet.
Zusammenfassung des Setups
Alles in allem ist die Bedienung des neuen Programms zwar einfach, sie bietet aber zu wenig Optionen für eine technisch orientierte Distribution. Der aktuelle Trend vieler Distributionen besteht darin, den Installationsprozess auf Web-basierte Tools umzustellen. Die Sinnhaftigkeit erschließt sich für mich nicht, schon gar nicht, wenn dabei auch noch die Funktionalität auf der Strecke bleibt. Muss das Rad wirklich immer wieder neu erfunden werden?
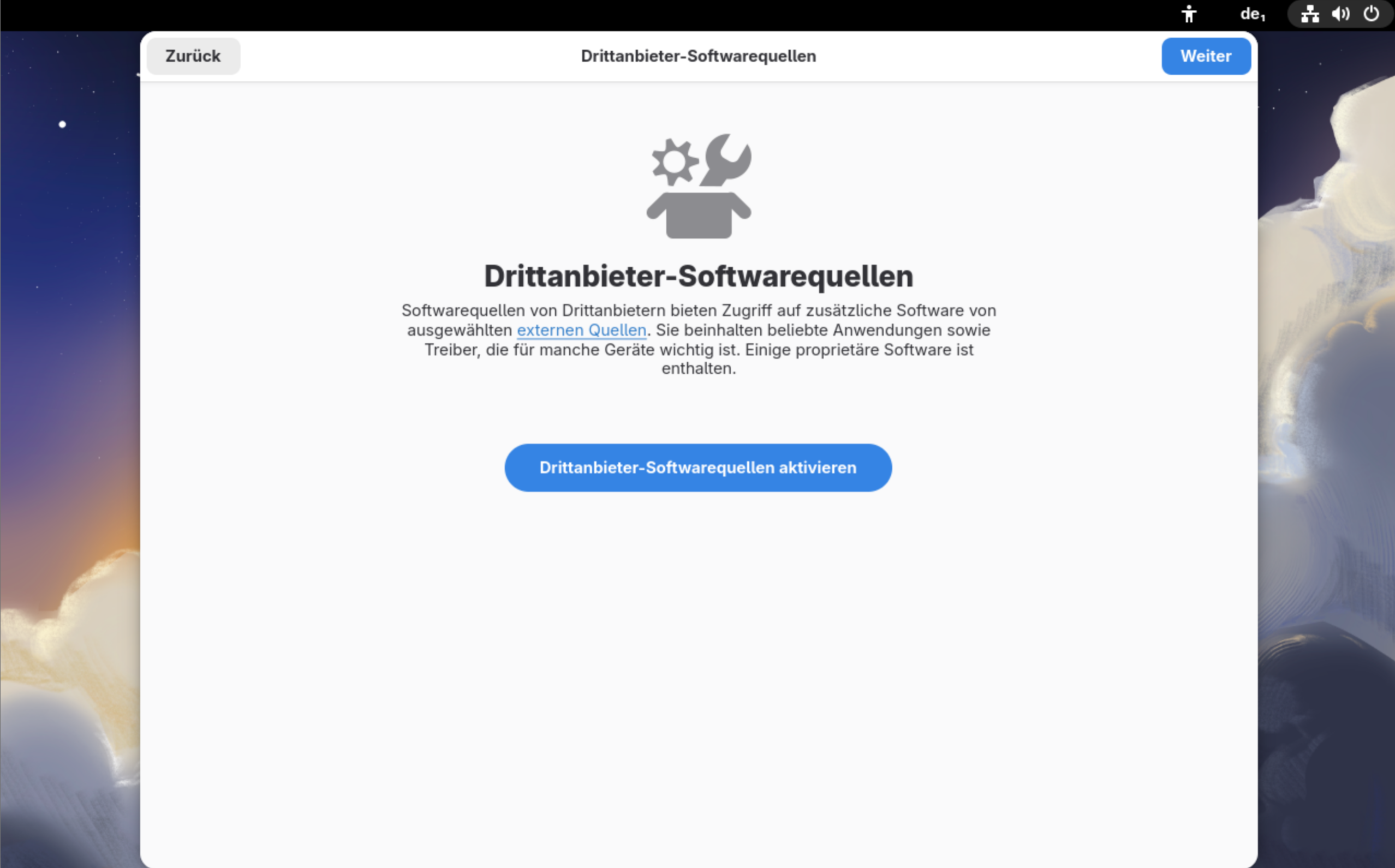
Nach dem Neustart landen Sie in einen Assistenten, der bei der Grundkonfiguration von Gnome hilft: Sprache und Tastaturlayout noch einmal bestätigen, Zeitzone einstellen etc. Vollkommen missglückt ist das Dialogblatt zur Aktivierung von Drittanbieter-Softwarequellen. Gemeint sind damit die RPM-Fusion-Paketquellen mit Paketen und Treibern (z.B. für NVIDIA-Grafikkarten), die nicht dem Open-Source-Modell entsprechen. Im Zentrum des Bildschirms befindet sich ein Toggle-Button mit den Zuständen aktivieren oder deaktivieren. Es ist unmöglich zu erkennen, ob Sie den Button zur Aktivierung drücken müssen oder ob dieser den Zustand »bereits aktiv« ausdrückt. (Auflösung: Sie müssen ihn nicht drücken. Wenn mit blauem Hintergrund »aktivieren« angezeigt wird, werden die zusätzlichen Paketquellen mit Weiter eingerichtet.)
Klicken Sie nicht auf »Drittanbieter-Softwarequellen aktivieren«! Das würde die Option deaktivieren. (Ein Meisterbeispiel für GUI Fails …)
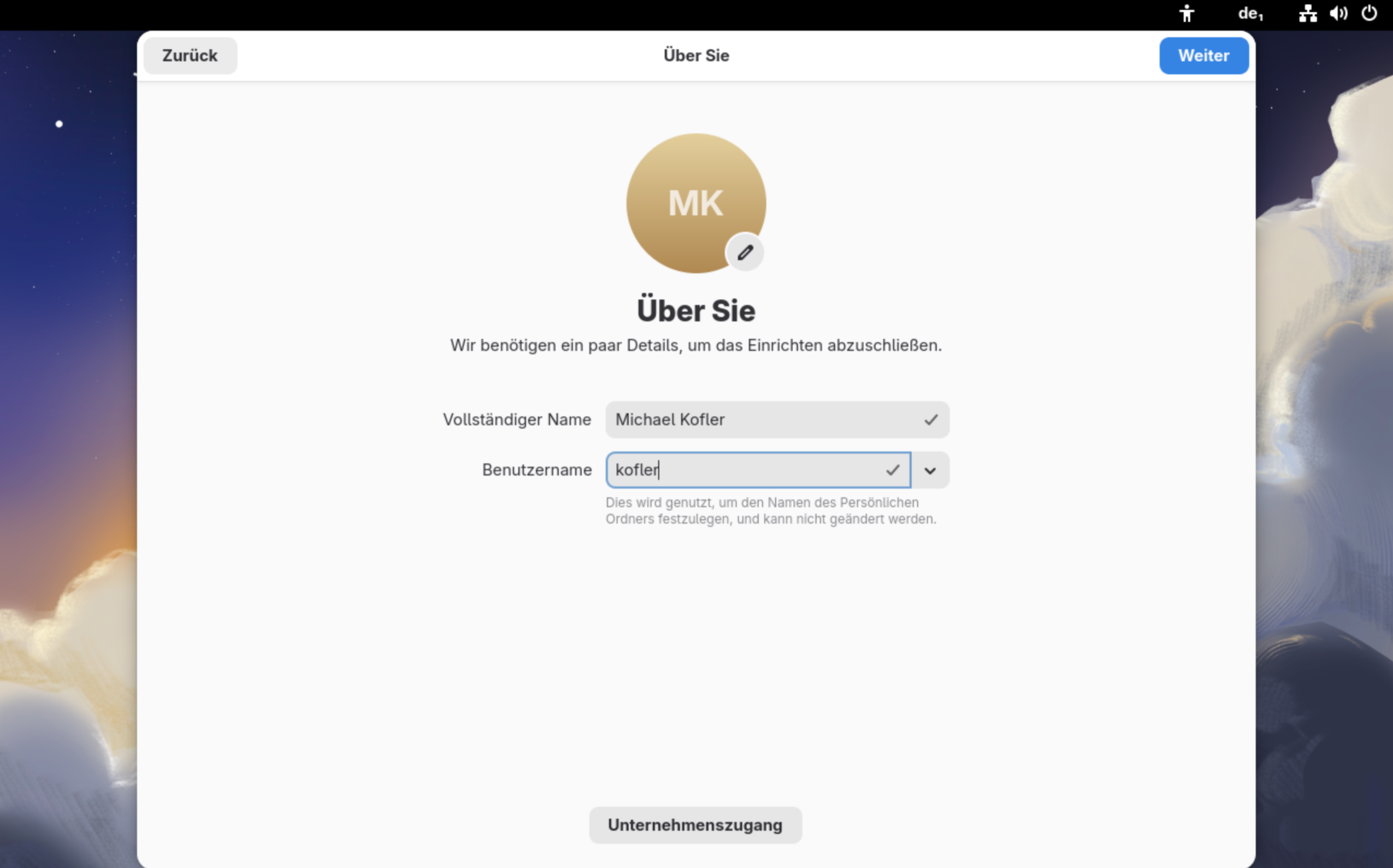
Erst jetzt werden Sie dazu aufgefordert, einen Benutzer einzurichten, der dann auch sudo-Rechte erhält. Sobald Sie alle Daten samt Passwort festgelegt haben, können Sie sich einloggen und mit Fedora loslegen.
Erst ganz zum Schluss richten Sie den Benutzer-Account ein
Um den Hostname hat sich weder das Installationsprogramm noch der Setup-Assistent gekümmert. Außerdem sollten Sie gleich ein erstes Update durchführen:
Die einzige Auffälligkeit ist die komplett veraltete MariaDB-Version. Aktuell ist 12.0, Debian verwendet immerhin 11.8. Die von Fedora eingesetzte Version 10.11 wurde im Februar 2023 (!!) veröffentlicht.
Dafür enthält Fedora mit Version 8.4 eine ganz aktuelle MySQL-Version. Generell steht MySQL erst seit Fedora 41 wieder regulär in Fedora zur Verfügung; ältere Versionen waren MariaDB-only.
Neuerungen
Wenn man von durch Software-Updates verbundenen optischen Änderungen absieht (z.B. in Gnome), gibt es relativ wenig technische Änderungen, und noch weniger davon sind sichtbar.
Gnome und gdm sind seit Version 49 Wayland-only. Darüber wurde in den letzten Wochen schon viel geschrieben. Seit die NVIDIA-Treiber endlich Wayland-kompatibel sind, ist der Abschied von X nicht mehr aufzuhalten. (Persönlich vermisse ich X nicht. Die meisten Linux-Anwender werden keinen Unterschied bemerken bzw. arbeiten ohnedies schon seit zwei, drei Releases mit Wayland, ohne es zu wissen …)
Fedora 43 verwendet erstmals RPM 6.0 als Basis zur Verpackung von Software-Paketen. Daraus ergeben sich neue Möglichkeiten beim Signieren von Paketen, aber an der Anwendung des rpm-Kommandos (das Sie ohnedies selten benötigen werden, es gibt ja dnf) ändert sich nichts.
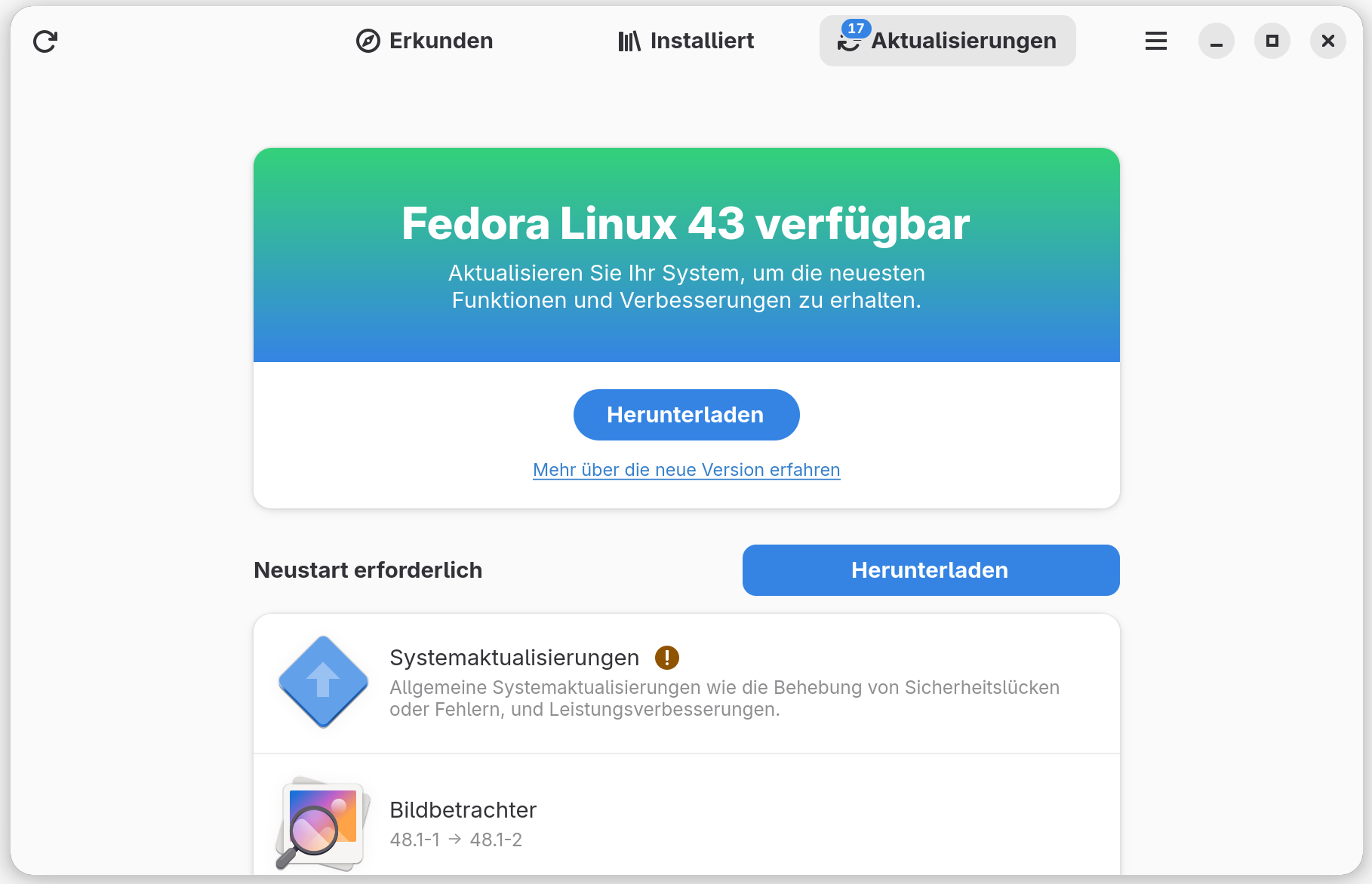
Distributions-Upgrades auf die neue Fedora-Version können Sie jetzt äußerst komfortabel direkt im Gnome-Programm Software starten.
Distributions-Upgrade in Gnome »Software« starten
Wie bisher können Sie natürlich auch auf die folgende Kommandoabfolge zurückgreifen:
Auf UEFI-Systemen setzt das Installationsprogramm nun eine GPT-Partitionierung voraus (nicht MBR).
Die /boot-Partition wird mit 2 GiB großzügiger als bisher dimensioniert, um Platz für zukünftige neue Boot-Systeme zu schaffen.
dnf module gibt es nicht mehr, weil das Modularity-Projekt eingestellt wurde. Bei Fedora ist das weniger schade als bei RHEL, wo ich dieses Feature wirklich vermisse.
dracut, das Tool zum Erzeugen von initramfs-Dateien, verwendet nun zstd statt xz zum Komprimieren der Dateien. Das macht die Boot-Dateien größer, aber den Boot-Vorgang schneller.
Fazit
Ich habe in den letzten Monaten sehr viel unter Fedora gearbeitet. Fedora ist dabei zu meiner zweiten Lieblingsdistribution geworden (neben Arch Linux). Im Betrieb gab es eigentlich nichts auszusetzen. Auch die Distributions-Upgrades haben mehrfach gut funktioniert: Ich habe zuletzt eine physische Installation von Fedora 41 auf 42 und vorgestern auf 43 aktualisiert. Zwischenzeitlich hat sich sogar der Rechner geändert, d.h. ich habe die SSD bei einem Rechner aus- und bei einem anderen Rechner wieder eingebaut. Hat alles klaglos funktioniert.
Das neue Installationsprogramm (neu schon seit der vorigen Version, also Fedora 42) ist aber definitiv ein Rückschritt — und das alte war schon keine Offenbarung. Bevor der Installer in Zukunft unter RHEL 11 zum Einsatz kommen kann, muss Red Hat noch viel nacharbeiten. Wie soll damit ein für den Server-Einsatz übliches RAID- oder LVM-Setup gelingen?
Der oft gehörten Empfehlung, Fedora sei durchaus für Einsteiger geeignet, kann ich deswegen nur teilweise zustimmen. Im Betrieb ist Fedora in der Tat so unkompliziert und stabil wie vergleichbare Distributionen (Debian, Ubuntu etc.). Für die Installation gilt dies aber nur, wenn Sie den gesamten Datenträger — z.B. eine zweite SSD — für Fedora nutzen möchten und mit dem vorgegebenen Default-Layout einverstanden sind. Unkompliziert ist natürlich auch die Installation in eine virtuelle Maschine. Aber jeder Sonderwunsch — ext4 statt btrfs, eine getrennte /home-Partition etc. — wird sofort zum Abenteuer. Schade.
Die Document Foundation hat LibreOffice 25.2.7 veröffentlicht. Die neue Version steht ab sofort für Windows, macOS und Linux bereit und markiert das letzte Wartungsupdate der 25.2-Reihe der bekannten freien Office-Suite. Das Update behebt insgesamt 43 Fehler und verbessert damit Stabilität und Zuverlässigkeit in allen Programmbereichen. Besonders auffällig sind die zahlreichen Korrekturen bei Abstürzen, die beim […]
Canonical will den Einsatz von Künstlicher Intelligenz auf Ubuntu vereinfachen. Das Unternehmen hat neue optimierte Inference Snaps für Intel und ARM Ampere Systeme vorgestellt. Entwickler können damit große Sprachmodelle direkt und effizient auf ihrer Hardware nutzen. Zu den ersten verfügbaren Modellen zählen DeepSeek R1 und Qwen 2.5 VL. Beide sind quelloffen und über den Snap Store als Betaversion […]
System76 hat nun den Veröffentlichungstermin für Pop!_OS 24.04 LTS bekanntgegeben. Nach einer langen Entwicklungsphase rund um den neuen COSMIC-Desktop soll die stabile Version am 11. Dezember 2025 erscheinen. Gleichzeitig wird auch die erste stabile Version des hauseigenen Desktops, COSMIC Epoch 1, veröffentlicht. Firmengründer Carl Richell erklärte auf X, dass zukünftige Versionen von Pop!_OS künftig zeitlich enger an die Ubuntu-LTS-Veröffentlichungen angepasst […]
Das KDE Projekt hat die Version 6.5.1 von KDE Plasma vorgestellt. Sie ist das erste Wartungsupdate der aktuellen Desktop Reihe und behebt zahlreiche Fehler. Außerdem wurden viele Details im Design und in der Bedienung verfeinert. Das Update erscheint nur eine Woche nach der Veröffentlichung von Plasma 6.5. Dennoch bringt es spürbare Verbesserungen. Besonders Nutzer älterer […]
Das Fedora Projekt hat Fedora Linux 43 offiziell freigegeben. Die neue Version der von Red Hat unterstützten Distribution setzt auf moderne Technologien und aktuelle Softwarepakete. Ziel bleibt ein stabiles und zugleich fortschrittliches System für Entwickler und Linux-Enthusiasten. Zu den wichtigsten Neuerungen gehört der Linux Kernel 6.17. Die Workstation Edition nutzt jetzt die Desktop Umgebung GNOME […]
Vielleicht haben einige Ubuntu Nutzer es bereits bemerkt. Die Variante bzw. das Flavour Ubuntu Unity hat keine Version 25.10 veröffentlicht. Der Grund liegt in fehlenden Kapazitäten innerhalb des Entwicklerteams. Nun bittet das Projekt öffentlich um Hilfe aus der Community. Ubuntu 25.10 erschein vor knapp zwei Wochen. Konkret erklärte im o.g. Beitrag ein Teammitglied, dass Projektleiter […]
Solche Aufgaben können notwendig werden, wenn die Dateien aus unterschiedlichen Quellen stammen – so wie im folgenden Beispiel: Ich hatte vier verschiedene Zuarbeiten mit jeweils eigenen Benennungsregeln erhalten. Um die insgesamt 95 Dateien einheitlich in eine bestehende Webseite einzubinden, mussten sie alle nach einem gemeinsamen Schema umbenannt werden.
Umsetzung
Auf einem Ubuntu-System erfolgt die Mehrfachumbenennung ganz einfach: Zunächst wird das Verzeichnis geöffnet, in dem sich alle zu verarbeitenden Bilder befinden.
Dateien – Ansicht Bilder (ungeordnet)
Im Dateimanager „Dateien“ (früher „Nautilus“) werden mit Strg + A alle Dateien markiert.
Dateien – Ansicht Bilder (alle ausgewählt)
Mit einem Rechtsklick lässt sich nun die Option „Umbenennen“ auswählen. Hier wird „[Ursprünglicher Dateiname]“ durch den endgültigen Dateinamen ersetzt und über „+ Hinzufügen“ der neue Suffix ausgewählt.
Die Mehrfachumbenennung unter GNOME ist ein einfaches, aber äußerst praktisches Werkzeug – besonders in Kombination mit einer automatischen Skalierung, wie im zuvor genannten Artikel beschrieben. So lässt sich die Verarbeitung großer Bildmengen deutlich effizienter gestalten und viel Zeit sparen.
In dieser Folge sprechen wir über **Linux Mint** und **LMDE**, die beiden Varianten einer der beliebtesten Linux Distributionen. Beide sehen fast gleich aus und werden vom selben Team entwickelt, unterscheiden sich aber im Kern. Während Linux Mint auf Ubuntu basiert und regelmäßig aktualisiert wird, setzt LMDE auf Debian und legt den Fokus auf Stabilität und Unabhängigkeit. Wir schauen uns an, welche Version sich besser für Einsteiger eignet, wo die technischen Unterschiede liegen und warum LMDE für erfahrene Nutzer eine spannende Alternative ist. Wenn du überlegst, welches Linux System zu dir passt, solltest du diese Folge nicht verpassen.
Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […]
Seit dem 22. Oktober 2025 stehen die ersten lauffähigen täglichen Testversionen von Ubuntu 26.04 LTS zum Download bereit. Canonical richtet sich damit an Tester, Entwickler und neugierige Nutzer. Frühere Builds funktionierten nicht richtig und waren kaum nutzbar im Alltag. Die neuen Images basieren auf Ubuntu 25.10 mit dem Codenamen Questing Quokka, das Anfang Oktober erschienen […]
Das Fedora Council hat eine neue Richtlinie verabschiedet, die erstmals den Einsatz von KI bei Beiträgen zu Fedora Projekten erlaubt. Nach intensiven Diskussionen in der Community wurde nun ein Rahmen geschaffen, der moderne Werkzeuge zulässt, zugleich aber menschliche Verantwortung in den Mittelpunkt stellt. Künftig dürfen Entwickler KI Werkzeuge nutzen, um Code, Dokumentation oder andere Inhalte […]
Das KDE Projekt hat die neue Version 6.5 seiner Desktopumgebung Plasma veröffentlicht. Sie bringt zahlreiche Verbesserungen, neue Funktionen und viele kleine Korrekturen, die den Alltag mit Linux spürbar angenehmer machen. Optisch fällt sofort auf, dass Fenster im Breeze Design nun abgerundete untere Ecken besitzen. Unterstützte Drucker zeigen ihren Tintenstand direkt im System an. Auch HDR […]
In meinem Arbeitsalltag wimmelt es von virtuellen Linux-Maschinen, die ich primär mit zwei Programmen ausführe:
virtual-machine-manager alias virt-manager (KVM/QEMU) unter Linux
UTM (QEMU + Apple Virtualization) unter macOS
Dabei treten regelmäßig zwei Probleme auf:
Bei Neuinstallationen funktioniert der Datenaustausch über die Zwischenablage zwischen Host und VM (= Gast) funktioniert nicht.
Die Uhrzeit in der VM ist falsch, nachdem der Host eine Weile im Ruhestand war.
Diese Ärgernisse lassen sich leicht beheben …
Anmerkung: Ich beziehe mich hier explizit auf die Desktop-Virtualisierung. Ich habe auch VMs im Server-Betrieb — da brauche ich keine Zwischenablage (Text-only, SSH-Administration), und die Uhrzeit macht wegen des dauerhaften Internet-Zugangs auch keine Probleme.
Zwischenablage mit Spice als Grafik-Protokoll
Wenn das Virtualisierungssystem das Grafiksystem mittels Simple Protocol for Independent Computing Environments (SPICE) überträgt (gilt per Default im virtual-machine-manager und in UTM), funktioniert die Zwischenablage nur, wenn in der virtuellen Maschine das Paket spice-vdagent installiert ist. Wenn in der virtuellen Maschine Wayland läuft, was bei immer mehr Distributionen standardmäßig funktioniert, brauchen Sie außerdem wl-clipboard. Also:
Nach der Installation müssen Sie sich in der VM aus- und neu einloggen, damit die Programme auch gestartet werden. Manche, virtualisierungs-affine Distributionen installieren die beiden winzigen Pakete einfach per Default. Deswegen funktioniert die Zwischenablage bei manchen Linux-Gästen sofort, bei anderen aber nicht.
Synchronisierung der Uhrzeit
Grundsätzlich beziehen sowohl die virtuellen Maschine als auch der Virtualisierungs-Host die Uhrzeit via NTP aus dem Internet. Das klappt problemlos.
Probleme treten dann auf, wenn es sich beim Virtualisierungs-Host um ein Notebook oder einen Desktop-Rechner handelt, der hin- und wieder für ein paar Stunden inaktiv im Ruhezustand schläft. Nach der Reaktivierung wird die Zeit im Host automatisch gestellt, in den virtuellen Maschinen aber nicht.
Vielleicht denken Sie sich: Ist ja egal, so wichtig ist die Uhrzeit in den virtuellen Maschinen ja nicht. So einfach ist es aber nicht. Die Überprüfung von Zertifikaten setzt die korrekte Uhrzeit voraus. Ist diese Voraussetzung nicht gegeben, können alle möglichen Problem auftreten (bis hin zu Fehlern bei der Software-Installation bzw. bei Updates).
Für die lokale Uhrzeit in den virtuellen Maschinen ist das Programm chrony zuständig. Eigentlich sollte es in der Lage sein, die Zeit automatisch zu justieren — aber das versagt, wenn die Differenz zwischen lokaler und echter Zeit zu groß ist. Abhilfe: starten Sie chronyd neu:
sudo systemctl restart chronyd
Um die automatische Einstellung der Uhrzeit nach der Wiederherstellung eines Snapshots kümmert sich der qemu-guest-agent (z.B. im Zusammenspiel mit Proxmox). Soweit das Programm nicht automatisch installiert ist:
Im August letzten Jahres habe ich euch gezeigt, was auf meinem Home Server so alles läuft und ich dachte mir, ich liefere euch über ein Jahr später mal einen aktualisierten Einblick. Der Unterbau des...
Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
Seit über 30 Jahren nutze ich Linux, und knapp 25 Jahre davon war die bash meine Shell. Ein eigener Prompt, der das aktuelle Verzeichnis farbig anzeigte, was das Maß der Dinge :-)
Mein Umstieg auf die zsh hatte mit Git zu tun: Die zsh in Kombination mit der Erweiterung Oh my zsh gibt im Prompt direktes Feedback über den Zustand des Repositories (aktiver Zweig, offene Änderungen). Außerdem agiert die zsh in vielen Details »intelligenter« (ein viel strapazierter Begriff, ich weiß) als die bash. Es macht ein wenig Arbeit, bis alles so funktioniert wie es soll, aber ich war glücklich mit meinem Setup.
Seit ein paar Monaten habe ich die Default-Shell meiner wichtigsten Linux-Installationen neuerlich gewechselt. Ich gehöre jetzt zum rasch wachsenden Lager der fish-Fans. fish steht für Friendly Interactive Shell, und die Shell wird diesem Anspruch wirklich gerecht. fish bietet von Grund auf eine Menge Features, die zsh plus diverse Plugins inklusive Oh my zsh erst nach einer relativ mühsamen Konfiguration beherrschen. Die Inbetriebnahme der fish dauert bei den meisten Distributionen weniger als eine Minute — und die Defaultkonfiguration ist so gut, dass weitere Anpassungen oft gar nicht notwendig sind. Und sollte das doch der Fall sein, öffnet fish_config einen komfortablen Konfigurationsdialog im Webbrowser (außer Sie arbeiten in einer SSH-Session).
Die Stärken der fish im Vergleich zu bash und zsh haben aus meiner Sicht wenig mit der Funktionalität zu tun; einige Features der fish lassen sich auch mit bash-Hacks erreichen, fast alle mit zsh-Plugins. Der entscheidende Vorteil ist vielmehr, dass die fish out of the box zufriedenstellend funktioniert. Für mich ist das deswegen entscheidend, weil ich viele Linux-Installationen verwende und keine Zeit dafür habe, mich jedesmal mit dem Shell-Setup zu ärgern. Deswegen hatte ich in der Vergangenheit auf meinen wichtigsten Installationen zsh samt einer maßgeschneiderten Konfiguration, auf allen anderen aber der Einfachheit halber die bash oder eine unkonfigurierte zsh-Installation.
Auf den ersten Blick sieht die »fish« aus wie jede andere Shell
Installation
Die Installation ist schnell erledigt. Alle gängigen Distributionen stellen fish als Paket zur Verfügung. Also apt/dnf install fish, danach:
chsh -s $(which fish)
Aus- und neu einloggen, fertig.
Falls Ihnen die fish doch nicht zusagt, ist die bisherige Shell ebenso schnell mit chsh -s $(which bash) oder chsh -s $(which zsh) reaktiviert.
Features
Im Prinzip verhält sich die fish wie jede andere Shell. Insbesondere gelten die üblichen Mechanismen zum Start von Kommandos, zur Ein- und Ausgabeumleitung mit < und >, zur Bildung von Pipes mit | sowie zur Verarbeitung von Kommandoergebnissen mit $(cmd). Was ist also neu?
Während der Eingabe verwendet die fish Farben, um verschiedene Bestandteile Ihres Kommandos (z.B. Zeichenketten) zu kennzeichnen. Das sieht nett aus, der entscheidende Vorteil ist aber, dass Sie oft Tippfehler erkennen, bevor Sie Return drücken: Kommandos, die es gar nicht gibt, werden rot hervorgehoben, ebenso nicht geschlossene Zeichenketten. (Die Farben sind vom aktiven Farbschema abhängig.)
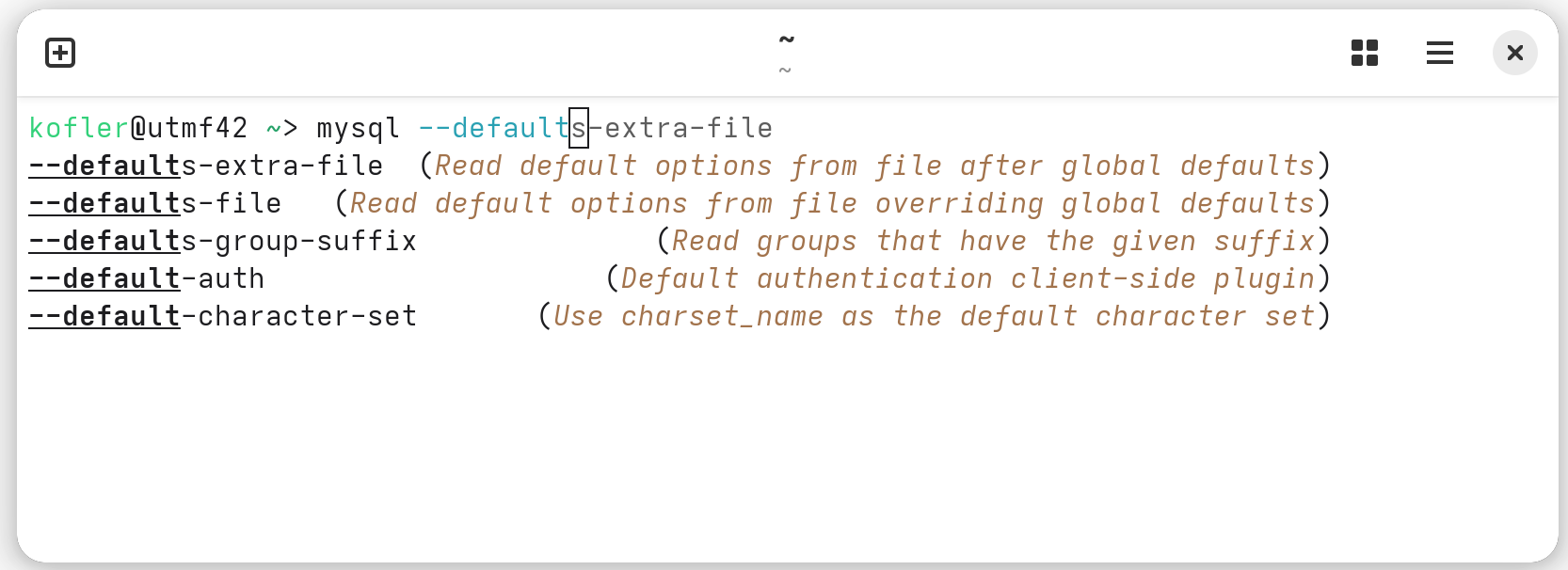
Die Vervollständigung von Kommandos, Optionen, Datei- und Variablennamen mit der Tabulator-Taste ist noch »intelligenter« als bei bash und zsh. fish greift dazu auf über 1000 *.fish-Dateien im Verzeichnis /usr/share/fish/completions zurück, die Regeln für alle erdenklichen Fälle enthalten und mit jeder fish-Version erweitert werden. Die fish zeigt sogar kurze Hilfetexte an (siehe die folgende Abbildung). Wenn es viele mögliche Vervollständigungen gibt, zeigt fish diese in mehreren Spalten an. Sie können mit den Cursortasten das gewünschte Element auswählen.
Bei der Eingabe von Kommandos durchsucht die fish die History, also eine Datei, in der alle zuletzt ausgeführten Kommandos gespeichert wurden. In etwas blasserer Schrift schlägt es das passendste Kommando vor. Die fish berücksichtigt dabei auch den Kontext (welches Verzeichnis ist aktiv, welche Kommandos wurden vorher ausgeführt) und schlägt oft — fast schon ein wenig unheimlich — das richtige Kommando vor. Wenn Sie dieses Kommando ausführen möchten, vervollständigen Sie die Eingabe mit Cursor rechts (nicht Tabulator!) und drücken dann Return. Durch ähnliche Kommandos können Sie mit den Cursortasten blättern.
Alternativ können Sie auch mit Strg+R suchmuster nach früher ausgeführten Kommandos suchen. Die fish sucht nach dem Muster nicht nur in den Anfangsbuchstaben, sondern in den gesamten Zeichenketten der History.
Wenn das aktuelle Verzeichnis Teil eines Git-Repositories ist, zeigt fish den Namen des aktuellen Zweigs in Klammern an. (Wenn Sie mehr Git-Infos sehen wollen, ändern Sie die Prompt-Konfiguration.)
Die »fish« zeigt Hilfetexte zu allen »mysql«-Optionen an, die mit »–default« beginnen.
Globbing-Eigenheiten
In Shells wird die Umwandlung von *.txt in die Liste passender Dateinamen als »Globbing« bezeichnet. Die fish verhält sich dabei fast gleich wie die bash — aber mit einem kleinen Unterschied: Wenn es keine passenden Dateien gibt (z.B. keine einzige Datei mit der Endung .txt), löst die fish einen Fehler aus. Die bash übergibt dagegen das Muster — also *.txt — an das Kommando und überlässt diesem die Auswertung. In der Regel tritt der Fehler dann dort auf. Also kein großer Unterschied?
Es gibt Sonderfälle, in denen das Verhalten der bash günstiger ist. Stellen Sie sich vor, Sie wollen mit scp alle *.png-Dateien von einem externen Rechner auf Ihren lokalen Rechner übertragen:
scp externalhost:*.png .
In der bash funktioniert das wie gewünscht. Die fish kann aber mit externalhost:*.png nichts anfangen und löst einen Fehler aus. Abhilfe: Sie müssen das Globbing-Muster in Anführungszeichen stellen, also:
scp "externalhost:*.png" .
Analoge Probleme können auch beim Aufruf von Paketkommandos auftreten. apt install php8-* funktioniert nicht, wohl aber apt install "php8-*". Hintergründe zum Globbing-Verhalten können Sie hier nachlesen:
Tastenkürzel
Grundsätzlich gelten in der fish dieselben Tastenkürzel wie in der bash. In der fish gibt es darüberhinaus weitere Kürzel, von denen ich die wichtigsten hier zusammengestellt habe. bind oder fish_config (Dialogblatt bindings) liefert eine wesentlich längerer Liste aller Tastenkürzel. Beachten Sie, dass es vom Desktopsystem und vom Terminal abhängt, ob die Alt-Tastenkürzel wirklich funktionieren. Wenn die Kürzel vom Terminal oder dem Desktopsystem verarbeitet werden, erreichen Sie die fish nicht.
Kürzel Bedeutung
------------------ -------------------------------------------------------
Alt+Cursor links führt zurück ins vorige Verzeichnis (prevd)
Alt+Cursor rechts macht die obige Aktion rückgängig (nextd)
Alt+E öffnet den Dateinamen mit $EDITOR
Alt+H oder F1 zeigt die man-Seite zum eingegebenen Kommando an (Help)
Alt+L führt ls aus
Alt+P fügt der Eingabe &| less hinzu (Pager)
Alt+S fügt sudo am Beginn der Eingabe ein
Alt+W zeigt Aliasse und eine Beschreibung des Kommandos (What is?)
Noch eine Anmerkung zu Alt+S: In meiner Praxis kommt es ständig vor, dass ich sudo vergesse. Ich führen also dnf install xy aus und erhalte die Fehlermeldung, dass meine Rechte nicht ausreichen. Jetzt drücke ich einfach Alt+S und Return. Die fish stellt sudo dem vorigen, fehlgeschlagenen Kommando voran und führt es aus.
Konfiguration
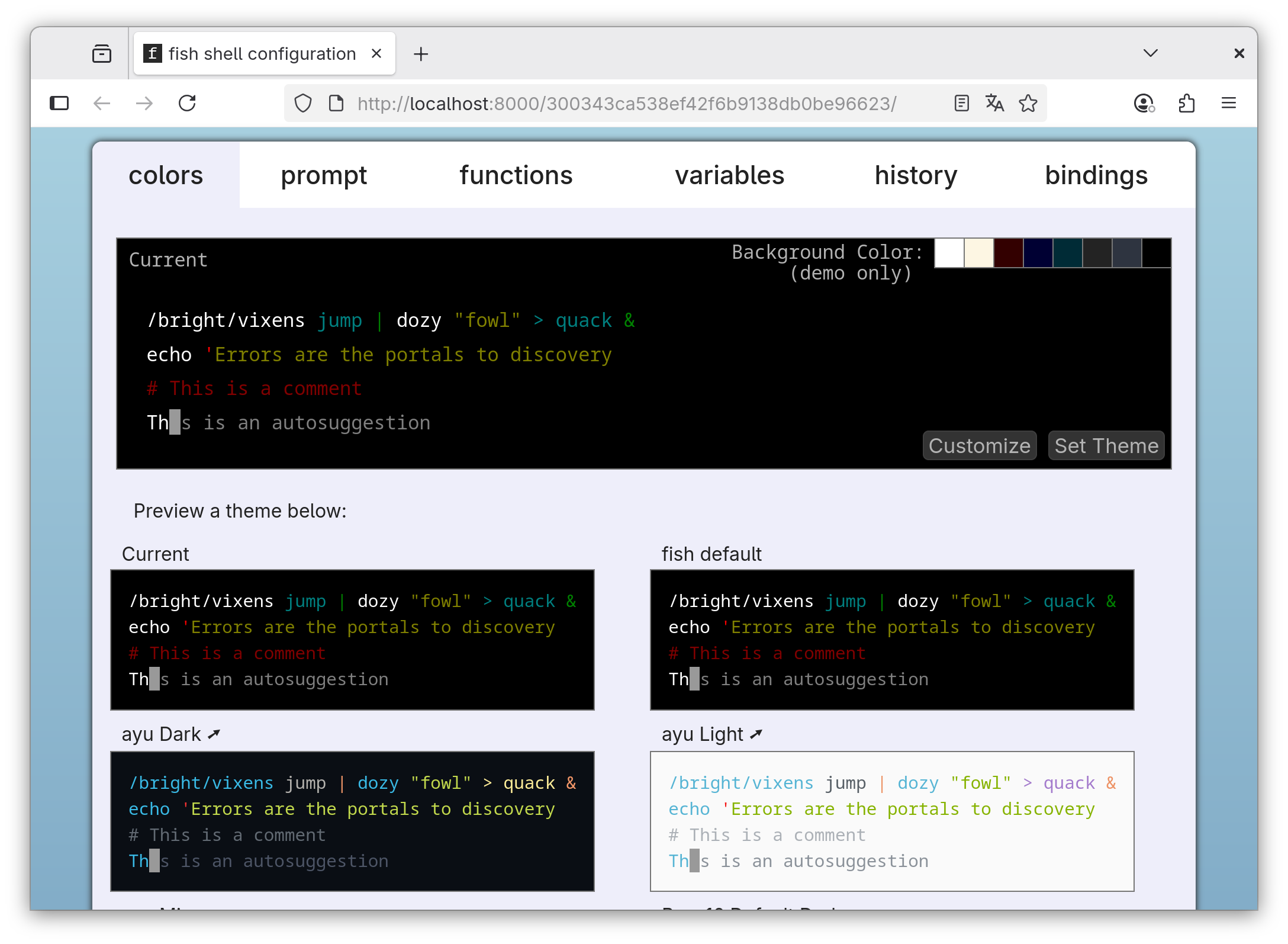
Das Kommando fish_config öffnet einen Konfigurationsdialog im Webbrowser. Falls Ihr Webbrowser gerade minimiert ist, müssen Sie das Fenster selbst in den Vordergrund bringen. Im Browser können Sie nun ein Farbenschema auswählen, noch mehr Informationen in den Prompt integrieren, die Tastenkürzel nachlesen etc.
In SSH-Sessions scheitert der Start eines Webbrowsers. In diesem Fall können Sie mit fish_config prompt bzw. fish_config theme das Promptaussehen und das Farbschema direkt im Textmodus verändern.
fish-Konfiguration im Webbrowser
Wenn Sie Änderungen durchführen, werden diese im Terminal mit set -U fish_xxx newvalue ausgeführt und in Konfigurationsdateien in .config/fish gespeichert, insbesondere in:
Das Gegenstück zu .bashrc oder .zshrc ist die Datei .config/fish/config.fish. Das ist der richtige Ort, um eigene Abkürzungen zu definieren, den PATH zu erweitern etc. config.fish enthält einen vordefinierten if-Block für Einstellungen, die nur für interaktive fish-Sessions relevant sind. Alle anderen Einstellungen, die z.B. in Scripts gelten sollen, führen Sie außerhalb durch. Das folgende Listing zeigt ein paar typische Einstellungen:
# Datei .config/fish/config.fish
...
# PATH ändern
fish_add_path ~/bin
fish_add_path ~/.local/bin
# keine fish-Welcome-Nachricht
set -U fish_greeting ""
# Einstellungen nur für die interaktive Nutzung
if status is-interactive
# abr statt alias
abbr -a ls eza
abbr -a ll 'eza -la'
abbr -a gc 'git commit'
# Lieblingseditor
set -gx EDITOR /usr/bin/jmacs
end
Das obige Listing zeigt schon, das die fish gängige Einstellungen anders handhabt als bash und zsh:
Abkürzungen: Anstelle von alias sieht die fish das Kommando abbr vor. alias steht auch zur Verfügung, von seinem Einsatz wird aber abgeraten. abbr unterscheidet sich durch ein paar Details von alias: Die Expansion in das Kommando erfolgt bereits, wenn Sie Return drücken. Sie sehen daher, welches Kommando wirklich ausgeführt wird, und dieses Kommando (nicht die Abkürzung) wird in der History gespeichert.
PATH-Änderungen: Sie müssen die PATH-Variable nicht direkt verändern, sondern können stattdessen fish_add_path aufrufen. Ihr Pfad wird am Ende hinzugefügt, wobei die Funktion sicherstellt, dass es keine Doppelgänger gibt.
Variablen (set): Die Optionen des set-Kommandos zur Einstellung von Variablen funktionieren anders als in der bash:
-g: Die Variable ist in der gesamten fish-Session zugänglich (Global Scope), nicht nur in einer Funktion oder einem Block.
-x: Die Variable wird an Subprozesse weitergegeben (Export).
-U: Die Variable wird dauerhaft in .config/fish/fish_variables gespeichert und gilt daher auch für künftige fish-Sessions (Universal). Sie wird aber nicht exportiert, es sei denn, Sie verwenden -Ux.
-l: Definiert eine lokale Variable, z.B. innerhalb einer Funktion.
Zusätzliche eingebaute Kommandos
Jede Shell hat eine Menge integrierter Kommandos wie cd, if oder set. In der fish können Sie mit builtin -n alle derartigen Kommandos auflisten. Die meisten Kommandos entsprechen exakt den bash- und zsh-Vorgaben. In der fish gibt es aber einige originelle Erweiterungen: math führt einfache Berechnungen aus, random produziert ganzzahlige Zufallszahlen, string manupuliert Zeichenketten ohne die umständliche Parametersubstitution, path extrahiert Komponenten aus einem zusammengesetzten Dateinamen, count zählt Objekte (vergleichbar mit wc -l etc. Das folgende Listing zeigt die Anwendung dieser Kommandos:
math "2.5 * 3.8"
9.5
string split " " "lorem ipsum dolor est"
lorem
ipsum
dolor
est
string replace ".png" ".jpg" file1.png file2.png file3.png
file1.jpg
file2.jpg
file3.jpg
string sub -s 4 -e 8 "abcdefghijkl" # Start und Ende inklusive
defgh
path basename /home/kofler/images/img_234.png
img_234.png
path dirname /home/kofler/images/img_234.png
/home/kofler/images
path extension /home/kofler/images/img_234.png
.png
random 1 100
13
random choice a b c
c
count * # das aktuelle Verzeichnis hat
# 32 Dateien/Verzeichnisse
32
ps ax | count # gerade laufen 264 Prozesse
264
Programmierung
Die Bezeichnung Friendly Interactive Shell weist schon darauf hin: Die fish ist für die interaktive Nutzung optimiert, nicht für die Programmierung. Die fish unterstützt aber sehr wohl auch die Script-Programmierung. Diese ist insofern attraktiv, weil die fish-Entwickler auf maximale Kompatibilität verzichtet haben und die schlimmsten Syntaxungereimtheiten der bash behoben haben. fish-Scripts sind daher ungleich leichter zu verstehen als bash-Scripts. Umgekehrt heißt das leider: fish-Scripts sind inkompatibel zu bash und zsh und können nur ausgeführt werden, wo die fish zur Verfügung steht. Für mich ist das zumeist ein Ausschlusskriterium.
Anstelle einer systematischen Einführung will ich Ihnen hier anhand eines Beispiels die Vorteile der fish beim Programmieren nahebringen. Das Script ermittelt die Anzahl der Zeilen für alle *.txt-Dateien im aktuellen Verzeichnis. (Ich weiß, wc -l *.txt wäre einfacher; es geht hier nur darum, diverse Syntaxeigenheiten in wenig Zeilen Code zu verpacken.) Die bash-Variante könnte so aussehen:
#!/bin/bash
files=(*.txt)
if [ ${#files[@]} -eq 0 ]; then
echo "No .txt files found"
exit 1
fi
for file in "${files[@]}"; do
if [ -f "$file" ]; then
lines=$(wc -l < "$file")
echo "$file: $lines lines"
fi
done
Das äquivalente fish-Script ist deutlich besser lesbar:
#!/usr/bin/env fish
set files *.txt
if not count $files > /dev/null
echo "No .txt files found"
exit 1
end
for file in $files
if test -f $file
echo "$file: "(count < $file)" lines"
end
end
Auf ein paar Details möchte ich hinweisen:
Kontrollstrukturen werden generell mit end abgeschlossen, nicht mit fi für if oder mit esac für case.
Bedingungen für if, for etc. müssen weder in eckige Klammern gestellt noch mit einem Strichpunkt abgeschlossen werden.
Die fish verarbeitet Variablen korrekt selbst wenn sie Dateinamen mit Leerzeichen enthalten. Es ist nicht notwendig, sie in Anführungszeichen zu stellen (wie bei "$file" im bash-Script).
Wenn Sie in eigenen Scripts Optionen und andere Parameter verarbeiten möchten, hilft Ihnen dabei das Builtin-Kommando argparse. Eine gute Zusammenstellung aller Syntaxunterschiede zwischen bash und fish gibt die fish-Dokumentation.
Paketmanager fisher
Das Versprechen von fish ist ja, dass fast alles out-of-the-box funktioniert, dass die Installation von Zusatzfunktionen und deren Konfiguration ein Thema der Vergangenheit ist. Aber in der Praxis tauchen trotzdem immer Zusatzwünsche auf. Mit dem Paketmanager fisher können Zusatzmodule installiert werden. Eine Sammlung geeigneter Plugins finden Sie hier.
Die Geschichte von fish
Die fish ist erst in den letzten Jahren so richtig populär geworden. Das zeigt, dass es auch in der Linux-Welt Modetrends gibt. fish ist nämlich alles andere als neu. Die erste Version erschien bereits 2005.
fish wurde ursprünglich in C entwickelt, dann nach C++ und schließlich nach Rust portiert. Erst seit Version 4.0 (erschienen im Februar 2025) besteht fish ausschließlich aus Rust-Code sowie in fish selbst geschriebenen Erweiterungen.
Fazit
Die fish punktet durch die gut durchdachte Grundkonfiguration und die leichte Zugänglichkeit (Konfiguration und Hilfe im Webbrowser). Es gibt nicht das eine Feature, mit dem sich die fish von anderen Shells abhebt, es ist vielmehr die Summe vieler, gut durchdachter Kleinigkeiten und Detailverbesserungen. Das Arbeiten in der fish ist intuitiver als bei anderen Shells und macht mehr Spaß. Probieren Sie es aus!
Bei der Programmierung ist die fish inkompatibel zu anderen Shells und insofern kein Ersatz (auch wenn die fish-eigenen Features durchaus spannend sind). Zur Ausführung traditioneller Shell-Scripts brauchen Sie weiterhin eine traditionelle Shell, am besten die bash.
Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […]
Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […]
Die Document Foundation hat mit LibreOffice 25.8.2 das zweite Wartungsupdate der aktuellen Version veröffentlicht. Die neue Ausgabe behebt viele Probleme, die Nutzer seit der letzten Version gemeldet hatten. Ziel des Updates ist es, Stabilität und Zuverlässigkeit der beliebten Bürosoftware weiter zu verbessern. Besonders auffällig sind Korrekturen in den Anwendungen Writer, Calc und Impress. Abstürze beim […]
 Nach mehr ausreichenden Entwicklungszeit hat das Devuan-Team die neue Version Devuan 6 „Excalibur“ offiziell freigegeben. Die auf Debian 13 „Trixie“ basierende Distribution bleibt ihrem Grundprinzip treu, ein vollständig systemd-freies Linux-System anzubieten. Devuan 6 verwendet den Linux-Kernel 6.12 LTS und setzt erstmals auf den neuen Paketmanager APT 3, der für mehr Leistung und Zuverlässigkeit sorgen soll. Eine wichtige technische Neuerung ist […]
Nach mehr ausreichenden Entwicklungszeit hat das Devuan-Team die neue Version Devuan 6 „Excalibur“ offiziell freigegeben. Die auf Debian 13 „Trixie“ basierende Distribution bleibt ihrem Grundprinzip treu, ein vollständig systemd-freies Linux-System anzubieten. Devuan 6 verwendet den Linux-Kernel 6.12 LTS und setzt erstmals auf den neuen Paketmanager APT 3, der für mehr Leistung und Zuverlässigkeit sorgen soll. Eine wichtige technische Neuerung ist […]
 Der Linux Coffee Talk ist das entspannte Monatsformat bei fosstopia. Hier fassen wir die spannendsten Ereignisse und Entwicklungen der letzten Wochen für Euch zusammen und ordnen es ein. Also schnappt euch einen Kaffee, Tee oder Euer Lieblingsgetränk, macht es euch gemütlich und lasst uns den Oktober Revue passieren. In dieser Ausgabe blicken wir auf die […]
Der Linux Coffee Talk ist das entspannte Monatsformat bei fosstopia. Hier fassen wir die spannendsten Ereignisse und Entwicklungen der letzten Wochen für Euch zusammen und ordnen es ein. Also schnappt euch einen Kaffee, Tee oder Euer Lieblingsgetränk, macht es euch gemütlich und lasst uns den Oktober Revue passieren. In dieser Ausgabe blicken wir auf die […]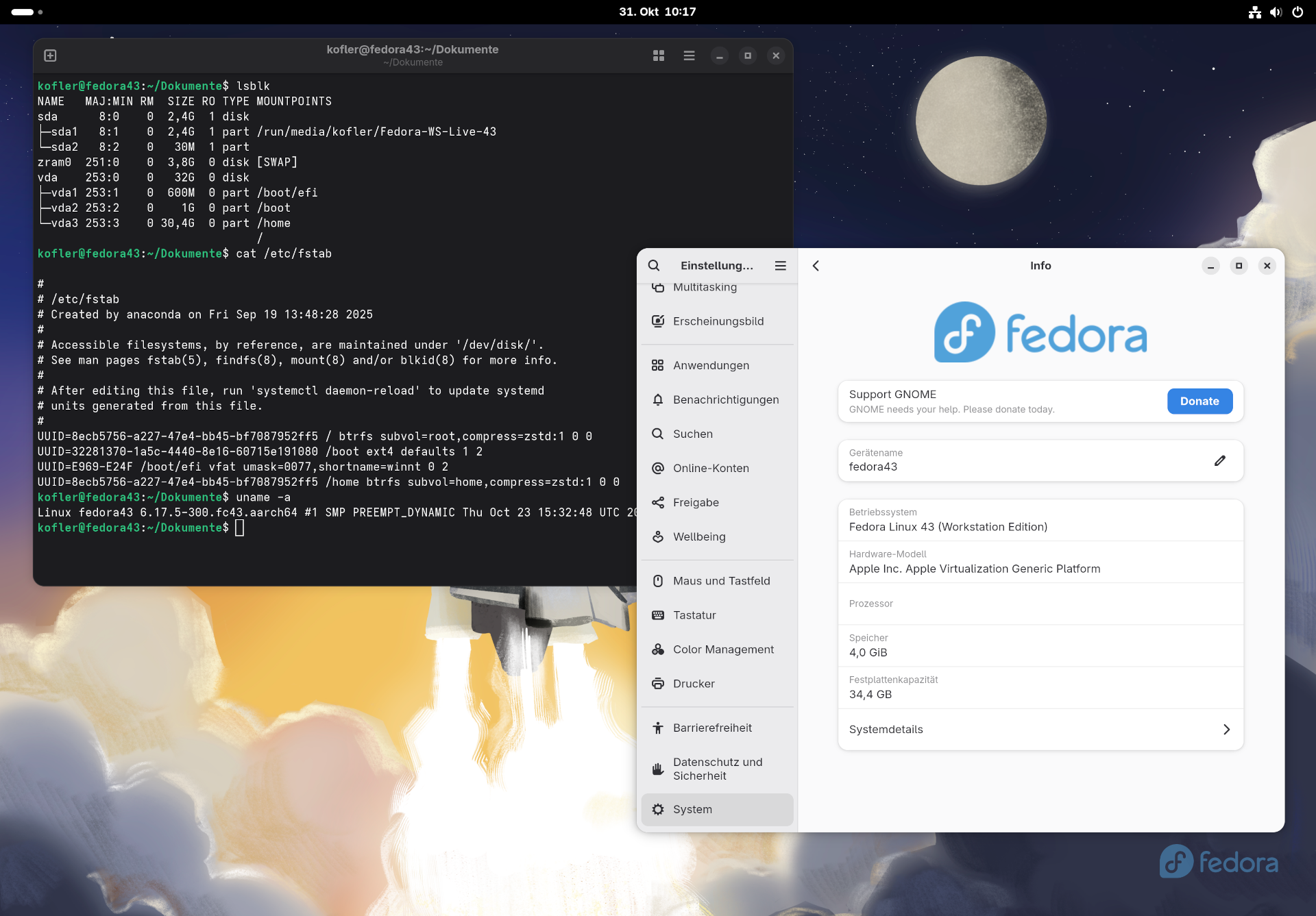
 Die Document Foundation hat LibreOffice 25.2.7 veröffentlicht. Die neue Version steht ab sofort für Windows, macOS und Linux bereit und markiert das letzte Wartungsupdate der 25.2-Reihe der bekannten freien Office-Suite. Das Update behebt insgesamt 43 Fehler und verbessert damit Stabilität und Zuverlässigkeit in allen Programmbereichen. Besonders auffällig sind die zahlreichen Korrekturen bei Abstürzen, die beim […]
Die Document Foundation hat LibreOffice 25.2.7 veröffentlicht. Die neue Version steht ab sofort für Windows, macOS und Linux bereit und markiert das letzte Wartungsupdate der 25.2-Reihe der bekannten freien Office-Suite. Das Update behebt insgesamt 43 Fehler und verbessert damit Stabilität und Zuverlässigkeit in allen Programmbereichen. Besonders auffällig sind die zahlreichen Korrekturen bei Abstürzen, die beim […] Canonical will den Einsatz von Künstlicher Intelligenz auf Ubuntu vereinfachen. Das Unternehmen hat neue optimierte Inference Snaps für Intel und ARM Ampere Systeme vorgestellt. Entwickler können damit große Sprachmodelle direkt und effizient auf ihrer Hardware nutzen. Zu den ersten verfügbaren Modellen zählen DeepSeek R1 und Qwen 2.5 VL. Beide sind quelloffen und über den Snap Store als Betaversion […]
Canonical will den Einsatz von Künstlicher Intelligenz auf Ubuntu vereinfachen. Das Unternehmen hat neue optimierte Inference Snaps für Intel und ARM Ampere Systeme vorgestellt. Entwickler können damit große Sprachmodelle direkt und effizient auf ihrer Hardware nutzen. Zu den ersten verfügbaren Modellen zählen DeepSeek R1 und Qwen 2.5 VL. Beide sind quelloffen und über den Snap Store als Betaversion […] System76 hat nun den Veröffentlichungstermin für Pop!_OS 24.04 LTS bekanntgegeben. Nach einer langen Entwicklungsphase rund um den neuen COSMIC-Desktop soll die stabile Version am 11. Dezember 2025 erscheinen. Gleichzeitig wird auch die erste stabile Version des hauseigenen Desktops, COSMIC Epoch 1, veröffentlicht. Firmengründer Carl Richell erklärte auf X, dass zukünftige Versionen von Pop!_OS künftig zeitlich enger an die Ubuntu-LTS-Veröffentlichungen angepasst […]
System76 hat nun den Veröffentlichungstermin für Pop!_OS 24.04 LTS bekanntgegeben. Nach einer langen Entwicklungsphase rund um den neuen COSMIC-Desktop soll die stabile Version am 11. Dezember 2025 erscheinen. Gleichzeitig wird auch die erste stabile Version des hauseigenen Desktops, COSMIC Epoch 1, veröffentlicht. Firmengründer Carl Richell erklärte auf X, dass zukünftige Versionen von Pop!_OS künftig zeitlich enger an die Ubuntu-LTS-Veröffentlichungen angepasst […] Das KDE Projekt hat die Version 6.5.1 von KDE Plasma vorgestellt. Sie ist das erste Wartungsupdate der aktuellen Desktop Reihe und behebt zahlreiche Fehler. Außerdem wurden viele Details im Design und in der Bedienung verfeinert. Das Update erscheint nur eine Woche nach der Veröffentlichung von Plasma 6.5. Dennoch bringt es spürbare Verbesserungen. Besonders Nutzer älterer […]
Das KDE Projekt hat die Version 6.5.1 von KDE Plasma vorgestellt. Sie ist das erste Wartungsupdate der aktuellen Desktop Reihe und behebt zahlreiche Fehler. Außerdem wurden viele Details im Design und in der Bedienung verfeinert. Das Update erscheint nur eine Woche nach der Veröffentlichung von Plasma 6.5. Dennoch bringt es spürbare Verbesserungen. Besonders Nutzer älterer […] Das Fedora Projekt hat Fedora Linux 43 offiziell freigegeben. Die neue Version der von Red Hat unterstützten Distribution setzt auf moderne Technologien und aktuelle Softwarepakete. Ziel bleibt ein stabiles und zugleich fortschrittliches System für Entwickler und Linux-Enthusiasten. Zu den wichtigsten Neuerungen gehört der Linux Kernel 6.17. Die Workstation Edition nutzt jetzt die Desktop Umgebung GNOME […]
Das Fedora Projekt hat Fedora Linux 43 offiziell freigegeben. Die neue Version der von Red Hat unterstützten Distribution setzt auf moderne Technologien und aktuelle Softwarepakete. Ziel bleibt ein stabiles und zugleich fortschrittliches System für Entwickler und Linux-Enthusiasten. Zu den wichtigsten Neuerungen gehört der Linux Kernel 6.17. Die Workstation Edition nutzt jetzt die Desktop Umgebung GNOME […] Vielleicht haben einige Ubuntu Nutzer es bereits bemerkt. Die Variante bzw. das Flavour Ubuntu Unity hat keine Version 25.10 veröffentlicht. Der Grund liegt in fehlenden Kapazitäten innerhalb des Entwicklerteams. Nun bittet das Projekt öffentlich um Hilfe aus der Community. Ubuntu 25.10 erschein vor knapp zwei Wochen. Konkret erklärte im o.g. Beitrag ein Teammitglied, dass Projektleiter […]
Vielleicht haben einige Ubuntu Nutzer es bereits bemerkt. Die Variante bzw. das Flavour Ubuntu Unity hat keine Version 25.10 veröffentlicht. Der Grund liegt in fehlenden Kapazitäten innerhalb des Entwicklerteams. Nun bittet das Projekt öffentlich um Hilfe aus der Community. Ubuntu 25.10 erschein vor knapp zwei Wochen. Konkret erklärte im o.g. Beitrag ein Teammitglied, dass Projektleiter […]





 Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […]
Linux Mint gehört seit Jahren zu den beliebtesten Desktop Distributionen im Linux Universum. Doch neben der bekannten Ubuntu Variante gibt es mit LMDE (Linux Mint Debian Edition) eine Alternative, die etwas im Schatten steht, aber viele interessante Vorteile bietet. Beide Systeme stammen vom selben Entwicklerteam und sehen auf den ersten Blick fast identisch aus. Der Unterschied liegt […]
 Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
Ein Monat nach dem Start von Version 49 hat das GNOME Projekt nun das erste Wartungsupdate veröffentlicht. GNOME 49.1 konzentriert sich vor allem auf Fehlerbehebungen und Leistungsverbesserungen, die den Alltag am Desktop spürbar angenehmer machen sollen. Im Mittelpunkt stehen dabei GNOME Shell und der Fenstermanager Mutter. Beide Komponenten erhalten zahlreiche Korrekturen, die die Reaktionsgeschwindigkeit verbessern. […]
 Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […]
Mozilla hat die neue Version 144 seines bekannten E Mail Programms Thunderbird veröffentlicht. Die kostenlose und quelloffene Anwendung steht ab sofort zum Download bereit und bringt zahlreiche Korrekturen sowie Verbesserungen bei Leistung und Sicherheit. Eine der auffälligsten Änderungen betrifft die Zuverlässigkeit im Alltag. Texte aus Fehlermeldungen lassen sich nun korrekt kopieren, und ein Problem mit […] Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […]
Mit dem heutigen Tag endet die Unterstützung für Windows 10 in vielen Ländern. Millionen Rechner erfüllen nicht die hohen Hardwareanforderungen von Windows 11 und verlieren damit den offiziellen Support. Für viele Betroffene stellt sich nun die Frage: Neues Gerät kaufen oder auf ein modernes System umsteigen? Genau hier setzt das frisch veröffentlichte Zorin OS 18 […]