gpt-oss-20b auf einer iGPU 780M ausführen
Die Aufgabenstellung ist sehr speziell, und dementsprechend wird dieser Beitrag vermutlich nur wenig Leute interessieren. Aber egal: Ich habe mich drei Tage damit geärgert, vielleicht profitieren ein paar Leser von meinen Erfahrungen …
Die Zielsetzung ist bereits in der Überschrift beschrieben. Ich besitze einen Mini-PC mit AMD 8745H-CPU und 32 GiB RAM. Die CPU enthält auch eine integrierte GPU (Radeon 780M). Auf diesem Rechner wollte ich das momentan sehr beliebte Sprachmodell gpt-oss-20b ausführen. Dieses Sprachmodell ist ca. 11 GiB groß, umfasst 20 Milliarden Parameter in einer etwas exotischen Quantifizierung. (MXFP4 wurde erst 2024 standardisiert und bildet jeden Parameter mit nur 4 Bit ab. Die Besonderheit besteht darin, dass für unterschiedliche Teile des Modells unterschiedliche Skalierungsfaktoren verwendet werden, so dass die Parameter trotz der wenigen möglichen Werte einigermaßen exakt abgebildet werden können.)
Das Sprachmodell wird von der Firma OpenAI kostenlos angeboten. Die Firma gibt an, dass die 20b-Variante ähnlich gute Ergebnisse wie das bis 2024 eingesetzt kommerzielle Modell o3-mini liefert, und auch KI-Experte Simon Willison singt wahre Lobeshymnen auf das Modell.
PS: Ich habe alle Tests unter Fedora 42 durchgeführt.
Warum nicht Ollama?
Für alle, die nicht ganz tief in die lokale Ausführung von Sprachmodellen eintauchen wollen, ist Ollama zumeist die erste Wahl. Egal, ob unter Windows, Linux oder macOS, viele gängige Sprachmodelle können damit unkompliziert ausgeführt werden, in der Regel mit GPU-Unterstützung (macOS, Windows/Linux mit NVIDIA-GPU bzw. mit ausgewählten AMD-GPUs).
Bei meiner Hardware — und ganz allgemein bei Rechnern mit einer AMD-iGPU — ist Ollama aktuell aber NICHT die erste Wahl:
ROCm: Ollama setzt bei NVIDIA-GPUs auf das Framework CUDA (gut), bei AMD-GPUs auf das Framework ROCm (schlecht). Dieses Framework reicht alleine vermutlich als Grund, warum AMD so chancenlos gegen NVIDIA ist. Im konkreten Fall besteht das Problem darin, dass die iGPU 780M (interner ID gfx1103) offiziell nicht unterstützt wird. Die Empfehlung lautet, ROCm per Umgebungsvariable zu überzeugen, dass die eigene GPU kompatibel zu einem anderen Modell ist (HSA_OVERRIDE_GFX_VERSION=11.0.2). Tatsächlich können Sprachmodelle dann ausgeführt werden, aber bei jeder Instabilität (derer es VIELE gibt), stellt sich die Frage, ob nicht genau dieser Hack der Anfang aller Probleme ist.
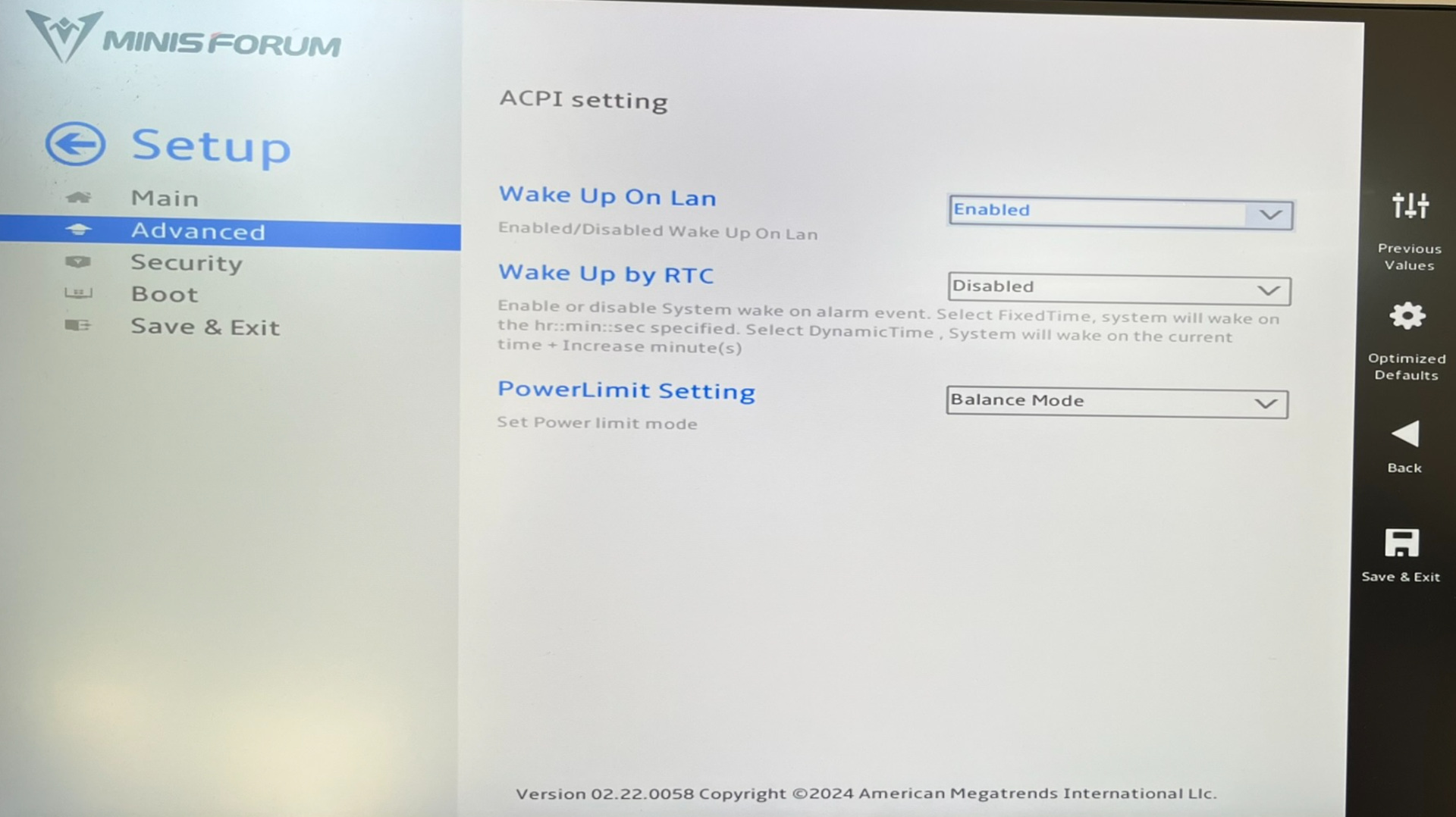
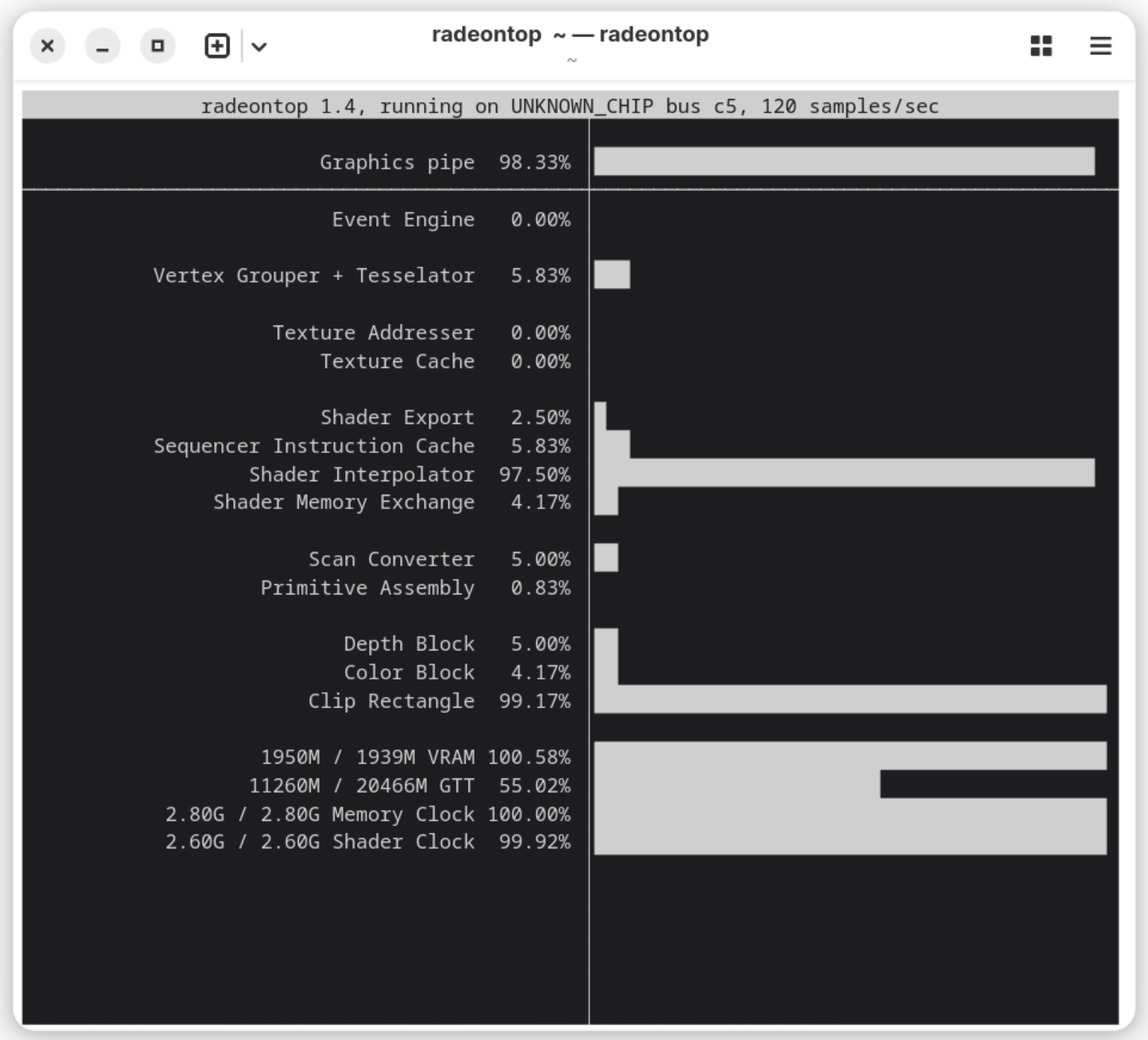
Speicherverwaltung: Auch mit diesem Hack scheitert Ollama plus ROCm-Framework an der Speicherverwaltung. Bei AMD-iGPUs gibt es zwei Speicherbereiche: fix per BIOS allozierten VRAM sowie dynamisch zwischen CPU + GPU geteiltem GTT-Speicher. (Physikalisch ist der Speicher immer im RAM, den sich CPU und GPU teilen. Es geht hier ausschließlich um die Speicherverwaltung durch den Kernel + Grafiktreiber.)
Ollama alloziert zwar den GTT-Speicher, aber maximal so viel, wie VRAM zur Verfügung steht. Diese (Un)Logik ist am besten anhand von zwei Beispielen zu verstehen. Auf meinem Testrechner habe ich 32 GiB RAM. Standardmäßig reserviert das BIOS 2 GiB VRAM. Der Kernel markiert dann 14 GiB als GTT. (Das kann bei Bedarf mit den Kerneloptionen amdttm.pages_limit und amdttm.page_pool_size verändert werden.) Obwohl mehr als genug Speicher zur Verfügung steht, sieht Ollama eine Grenze von 2 GiB und kann nur winzige LLMs per GPU ausführen.
Nun habe ich im BIOS das VRAM auf 16 GiB erhöht. Ollama verwendet nun 16 GiB als Grenze (gut), nutzt aber nicht das VRAM, sondern den GTT-Speicher (schlecht). Wenn ich nun ein 8 GiB großes LLM mit Ollama ausführen, dann bleiben fast 16 GiB VRAM ungenutzt! Ollama verwendet 8 GiB GTT-Speicher, und für Ihr Linux-System bleiben gerade einmal 8 GiB RAM übrig. Es ist zum aus der Haut fahren! Im Internet gibt es diverse Fehlerberichte zu diesem Problem und sogar einen schon recht alten Pull-Request mit einem Vorschlag zur Behebung des Problems. Eine Lösung ist aber nicht Sicht.
Ich habe mich mehrere Tage mit Ollama geärgert. Schade um die Zeit. (Laut Internet-Berichten gelten die hier beschriebenen Probleme auch für die gehypte Strix-Halo-CPU.)
Next Stop: llama.cpp
Etwas Internet-Recherche liefert den Tipp, anstelle von Ollama das zugrundeliegende Framework llama.cpp eben direkt zu verwenden. Ollama greift zwar selbst auf llama.cpp zurück, aber die direkte Verwendung von llama.cpp bietet andere GPU-Optionen. Dieser Low-Level-Ansatz ist vor allem bei der Modellauswahl etwas umständlicher ist. Zwei Vorteile können den Zusatzaufwand aber rechtfertigen:
- Die neuste Version von
llama.cppunterstützt oft ganz neue Modelle, mit denen Ollama noch nicht zurechtkommen. -
llama.cppkann die GPU auf vielfältigere Weise nutzen als Ollama. Je nach Hardware und Treiber kann so eventuell eine höhere Geschwindigkeit erzielt bzw. der GPU-Speicher besser genutzt werden, um größere Modelle auszuführen.
Die GitHub-Projektseite beschreibt mehrere Installationsvarianten: Sie können llama.cpp selbst kompilieren, den Paketmanager nix verwenden, als Docker-Container ausführen oder fertige Binärpakete herunterladen (https://github.com/ggml-org/llama.cpp/releases). Ich habe den einfachsten Weg beschritten und mich für die letzte Option entschieden. Der Linux-Download enthält genau die llama.cpp-Variante, die für mich am interessantesten war — jene mit Vulkan-Unterstützung. (Vulkan ist eine 3D-Grafikbibliothek, die von den meisten GPU-Treibern unter Linux gut unterstützt wird.) Die Linux-Version von llama.cpp wird anscheinend unter Ubuntu kompiliert und getestet, dementsprechend heißt der Download-Name llama-<version>-bin-ubuntu-vulkan-x86.zip. Trotz dieser Ubuntu-Affinität ließen sich die Dateien bei meinen Tests aber problemlos unter Fedora 42 verwenden.
Nach dem Download packen Sie die ZIP-Datei aus. Die resultierenden Dateien landen im Unterverzeichnis build/bin. Es bleibt Ihnen überlassen, ob Sie die diversen llama-xxx-Kommandos direkt in diesem Verzeichnis ausführen, das Verzeichnis zu PATH hinzufügen oder seinen Inhalt in ein anderes Verzeichnis kopieren (z.B. nach /usr/local/bin`).
cd Downloads
unzip llama-b6409-bin-ubuntu-vulkan-x64.zip
cd build/bin
./llama-cli --version
loaded RPC backend from ./build/bin/libggml-rpc.so
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon 780M Graphics (RADV PHOENIX) (radv) ...
loaded Vulkan backend from ./build/bin/libggml-vulkan.so
loaded CPU backend from ./build/bin/libggml-cpu-icelake.so
version: 6409 (d413dca0)
built with cc (Ubuntu 11.4.0-1ubuntu1~22.04.2) for x86_64-linux-gnu
Für die GPU-Unterstützung ist entscheidend, dass auf Ihrem Rechner die Bibliotheken für die 3D-Bibliothek Vulkan installiert sind. Davon überzeugen Sie sich am einfachsten mit vulkaninfo aus dem Paket vulkan-tools. Das Kommando liefert fast 4000 Zeilen Detailinformationen. Mit einem Blick in die ersten Zeilen stellen Sie fest, ob Ihre CPU unterstützt wird.
vulkaninfo | less
Vulkan Instance Version: 1.4.313
Instance Extensions: count = 24
VK_EXT_acquire_drm_display : extension revision 1
VK_EXT_acquire_xlib_display : extension revision 1
...
Layers: count = 1
VK_LAYER_MESA_device_select
Devices: count = 2
GPU id = 0 (AMD Radeon 780M Graphics (RADV PHOENIX))
GPU id = 1 (llvmpipe (LLVM 20.1.8, 256 bits))
...
Erste Tests
Um llama.cpp auszuprobieren, brauchen Sie ein Modell. Bereits für Ollama heruntergeladene Modelle sind leider ungeeignet. llama.cpp erwartet Modelle als GGUF-Dateien. (Details zur Modellauswahl folgen im nächsten Abschnitt.) Um die Ergebnisse mit anderen Tools leicht vergleiche zu können, verwende ich als ersten Testkandidat immer Llama 3. Eine llama-taugliche GGUF-Variante von Llama 3.1 mit 8 Milliarden Parametern finden Sie auf der HuggingFace-Website unter dem Namen bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M.
Das folgende Kommando lädt das Modell von HuggingFace herunter (Option -hf), speichert es im Verzeichnis .cache/llama.cpp, lädt es, führt den als Parameter -p angegebenen Prompt aus und beendet die Ausführung dann. In diesem und allen weiteren Beispielen gehe ich davon aus, dass sich die llama-Kommandos in einem PATH-Verzeichnis befinden. Alle Ausgaben sind aus Platzgründen stark gekürzt.
llama-cli -hf bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M \
-p 'bash/Linux: explain the usage of rsync over ssh'
... (diverse Debugging-Ausgaben)
Running in interactive mode.
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
- Not using system message. To change it, set a different value via -sys PROMPT
> bash/Linux: explain the usage of rsync over ssh
rsync is a powerful command-line utility that enables you to
synchronize files and directories between two locations. Here's
a breakdown of how to use rsync over ssh: ...
> <Strg>+<D>
load time = 2231.02 ms
prompt eval time = 922.83 ms / 43 tokens (46.60 tokens per second)
eval time = 31458.46 ms / 525 runs (16.69 tokens per second)
Sie können llama-cli mit diversen Optionen beeinflussen, z.B. um verschiedene Rechenparameter einzustellen, die Länge der Antwort zu limitieren, den Systemprompt zu verändern usw. Eine Referenz gibt llama-cli --help. Deutlich lesefreundlicher ist die folgende Seite:
https://github.com/ggml-org/llama.cpp/discussions/15709
Mit llama-bench können Sie diverse Benchmark-Tests durchführen. Im einfachsten Fall übergeben Sie nur das Modell in der HuggingFace-Notation — dann ermittelt das Kommando die Token-Geschwindigkeit für das Einlesen des Prompts (Prompt Processing = pp) und die Generierung der Antwort (Token Generation = tg). Allerdings kennt llama-bench die Option -hf nicht; vielmehr müssen Sie mit -m den Pfad zur Modelldatei übergeben:
llama-bench -m ~/.cache/llama.cpp/bartowski_Meta-Llama-3.1-8B-Instruct-GGUF_Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
model size test token/s (Tabelle gekürzt ...)
----------------------- --------- ------- --------
llama 8B Q4_K - Medium 4.58 GiB pp512 204.03
llama 8B Q4_K - Medium 4.58 GiB tg128 17.04
Auf meinem Rechner erreicht llama.cpp mit Vulkan nahezu eine identische Token-Rate wie Ollama mit ROCm (aber ohne die vielen Nachteile dieser AMD-Bibliothek).
AMD-Optimierung
Bei meinen Tests auf dem schon erwähnten Mini-PC mit AMD 8745H-CPU mit der iGPU 780M und 32 GiB RAM funktionierte llama.cpp mit Vulkan viel unkomplizierter als Ollama mit ROCm. Ich habe die VRAM-Zuordnung der GPU wieder zurück auf den Defaultwert von 2 GiB gestellt. Per Default steht llama.cpp auf meinem Rechner dann ca. der halbe Arbeitsspeicher (2 GiB VRAM plus ca. 14 GiB GTT) zur Verfügung. Vulkan kann diesen Speicher ohne merkwürdige Hacks mit Umgebungsvariablen korrekt allozieren. Das reicht ohne jedes Tuning zur Ausführung des Modells gpt-20b aus (siehe den folgenden Abschnitt). So soll es sein!
Wenn Sie noch mehr Speicher für die LLM-Ausführung reservieren wollen, müssen Sie die Kerneloptionen pages_limit und pages_pool_size des AMDGPU-Treibers verändern. Wenn Sie 20 GiB GGT-Speicher nutzen wollen, müssen Sie für beide Optionen den Wert 5242880 angeben (Anzahl der 4-kByte-Blöcke):
# neue Datei /etc/modprobe.d/amd.conf
# 20 * 1024 * 1024 * 1024 / 4096 = 20 * 1024 * 256 = 5242880
options ttm pages_limit=5242880
options ttm page_pool_size=5242880
Danach aktualisieren Sie die Initrd-Dateien und führen einen Neustart durch:
sudo update-initramfs -u # Debian und Ubuntu
sudo dracut --regenerate-all --force # Fedora, RHEL, SUSE
sudo reboot
sudo dmesg | grep "amdgpu.*memory"
amdgpu: 2048M of VRAM memory ready (<-- laut BIOS-Einstellung)
amdgpu: 20480M of GTT memory ready (<-- laut /etc/modprobe.d/amd.conf)
Modellauswahl
Mit llama.cpp können Sie grundsätzlich jedes Modell im GPT-Generated Unified Format (GGUF) ausführen. Auf der Website von HuggingFace stehen Tausende Modelle zur Wahl:
https://huggingface.co/models?pipeline_tag=text-generation&library=gguf
Die Herausforderung besteht darin, für die eigenen Zwecke relevante Modelle zu finden. Generell ist es eine gute Idee, besonders populäre Modelle vorzuziehen. Außerdem werden Sie rasch feststellen, welche Modellgrößen für Ihre Hardware passen. Die höhere Qualität großer Modelle bringt nichts, wenn die Geschwindigkeit gegen Null sinkt.
gpt-oss-20b
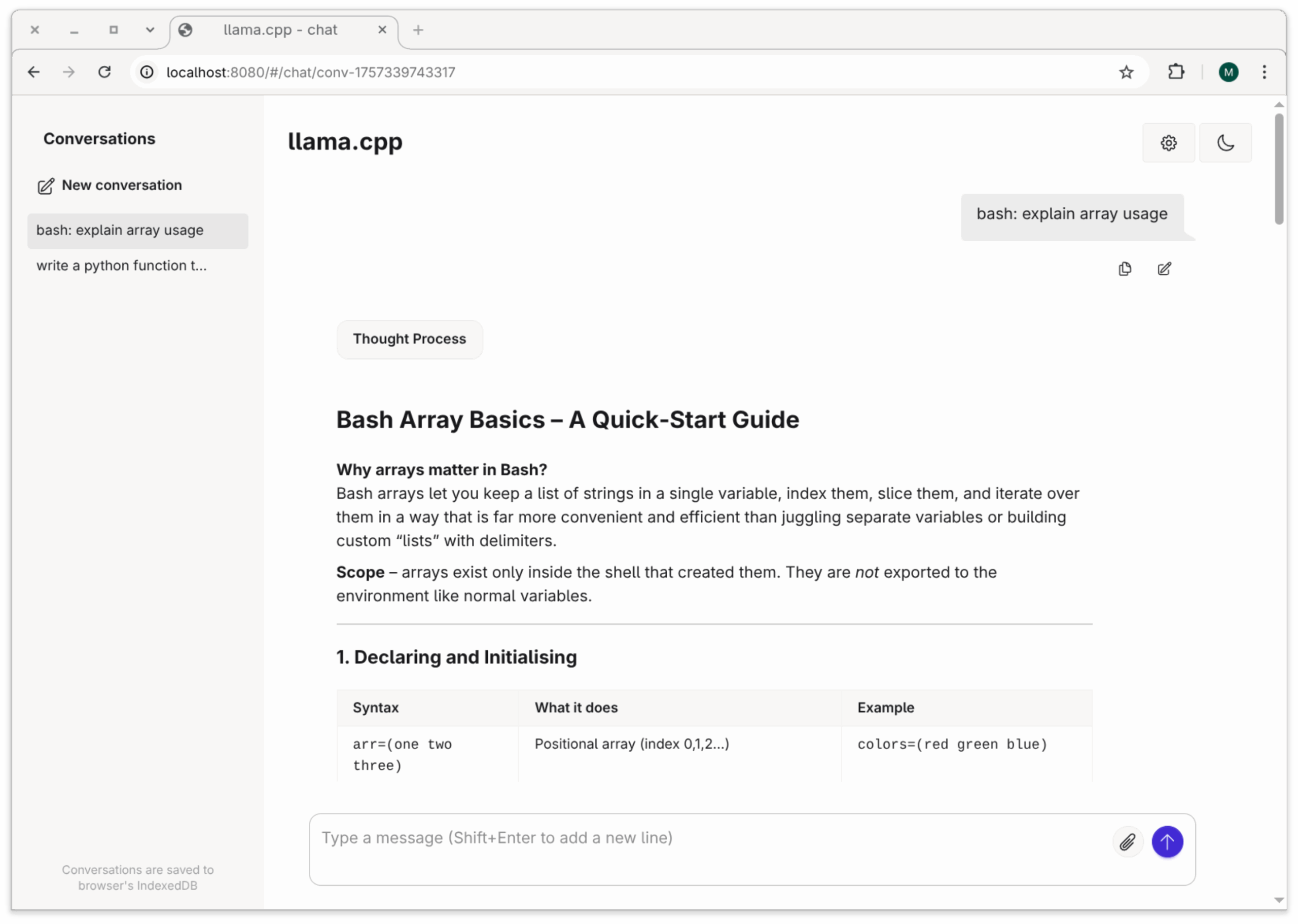
Eine llama.cpp-kompatible Version finden hat ggml-org auf HuggingFace gespeichert. Sofern ca. 15 GiB freier VRAM zur Verfügung stehen (unter AMD: VRAM + GTT), führt llama.cpp das Modell problemlos und beachtlich schnell aus. Beachten Sie, dass es sich hier um ein »Reasoning-Modell« handelt, das zuerst über das Problem nachdenkt und diesen Denkprozess auch darstellt. Danach wird daraus das deutlich kompaktere Ergebnis präsentiert.
llama-cli -hf ggml-org/gpt-oss-20b-GGUF -p 'bash: explain array usage'
...
llama-bench -m ~/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
model size test token/s
----------------------- --------- ------- --------
gpt-oss 20B MXFP4 MoE 11.27 GiB pp512 305.68
gpt-oss 20B MXFP4 MoE 11.27 GiB tg128 27.93
Server-Betrieb
Die Kommandos llama-cli und llama-bench dienen in erster Linie zum Testen und Debuggen. Sobald Sie sich einmal überzeugt haben, dass llama.cpp grundsätzlich funktioniert, werden Sie das Programm vermutlich im Server-Betrieb einsetzen. Das entsprechende Kommando lautet llama-server und ist grundsätzlich wie llama-cli aufzurufen. Falls Sie llama-server unter einem anderen Account als llama-cli aufrufen, aber schon heruntergeladene Modelle weiterverwenden wollen, übergeben Sie deren Pfad mit der Option -m:
llama-server -c 0 -fa on --jinja -m /home/kofler/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
Sie können nun unter http://localhost:8080 auf einen Webserver zugreifen und das gestartete Modell komfortabel bedienen. Im Unterschied zu Ollama hält llama.cpp das Modell dauerhaft im Arbeitsspeicher. Das Modell kann immer nur eine Anfrage beantworten. Die Verarbeitung mehrere paralleler Prompts erlaubt --parallel <n>.
Es ist unmöglich, mit einem Server mehrere Modelle parallel anzubieten. Vielmehr müssen Sie mehrere Instanzen von llama-server ausführen und jedem Dienst mit --port 8081, --port 8082 usw. eine eigene Port-Nummer zuweisen. (Das setzt voraus, dass Sie genug Video-Speicher für alle Modelle zugleich haben!)
Falls auch andere Rechner Server-Zugang erhalten sollen, übergeben Sie mit --host einen Hostnamen oder eine IP-Nummer im lokalen Netzwerk. Mit --api-key oder --api-key-file können Sie den Server-Zugang mit einem Schlüssel absichern. Mehr Details zu den genannten Optionen sowie eine schier endlose Auflistung weiterer Optionen finden Sie hier:
https://github.com/ggml-org/llama.cpp/tree/master/tools/server
Was bringt die GPU? Nicht viel …
Jetzt habe ich drei Tage versucht, gpt-oss per GPU auszuführen. Hat sich das gelohnt? Na ja. Mit -ngl 0 kann die Token Generation (also das Erzeugen der Antwort per Sprachmodell) von der GPU auf die CPU verlagert werden. Das ist natürlich langsamer — aber erstaunlicherweise nur um 25%.
llama-bench -ngl 0 -m ~/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
model size test token/s
----------------------- --------- ------- --------
...
gpt-oss 20B MXFP4 MoE 11.27 GiB tg128 21.15
Warum ist der Unterschied nicht größer? Weil die 780M keine besonders mächtige GPU ist und weil die Speicherbandbreite der iGPU viel kleiner ist als bei einer dezidierten GPU mit »echtem« VRAM.
Zur Einordnung noch zwei Vergleichszahlen: MacBook Pro M3: 42 Token/s (mit GPU) versus 39 Token/s (nur CPU)
Quellen/Links
Sprachmodell gpt-oss
- https://huggingface.co/openai/gpt-oss-20b
- https://huggingface.co/ggml-org/gpt-oss-20b-GGUF
- https://simonwillison.net/2025/Aug/5/gpt-oss
- https://github.com/ggml-org/llama.cpp/discussions/15095
Ollama
- https://ollama.com
- https://github.com/ollama/ollama/blob/main/docs/gpu.md#overrides
- https://github.com/ollama/ollama/issues/12062
- https://github.com/ollama/ollama/pull/6282
llama.cpp
- https://github.com/ggml-org/llama.cpp
- https://github.com/ggml-org/llama.cpp/discussions/15709
- https://huggingface.co/models?pipeline_tag=text-generation&library=gguf
- https://community.frame.work/t/igpu-vram-how-much-can-be-assigned/73081/7
- https://github.com/ggml-org/llama.cpp/tree/master/tools/server