Musks xAI kauft X von Musk
Im Rahmen einer Aktientransaktion hat die KI-Sparte xAI von Elon Musk seine Social-Media-Plattform X übernommen.
Im Rahmen einer Aktientransaktion hat die KI-Sparte xAI von Elon Musk seine Social-Media-Plattform X übernommen.
Laut einer Prognose des US-Marktforschers Gartner werden sich die weltweiten Ausgaben für generative KI (GenAI) im Jahr 2025 auf 644 Milliarden US-Dollar belaufen, was einem Anstieg von 76,4…
Die neueste Version, Red Hat OpenShift AI 2.18, bringt unter anderem End-to-End Model Tuning und distributed Serving.
 SUSE hat auf der diesjährigen SUSECON in Orlando klargestellt, dass es bei der KI-Revolution mitmischen will. Neben einer Reihe von Anwendungsfällen für künstliche Intelligenz gab es auch spannende Neuerungen für Admins im Hinblick auf die verschiedene Linux-Distributionen. Seit 33 Jahren existiert SUSE und brachte im Jahr 2000 mit SUSE Linux Enterprise Server (SLES) seine erste […]
SUSE hat auf der diesjährigen SUSECON in Orlando klargestellt, dass es bei der KI-Revolution mitmischen will. Neben einer Reihe von Anwendungsfällen für künstliche Intelligenz gab es auch spannende Neuerungen für Admins im Hinblick auf die verschiedene Linux-Distributionen. Seit 33 Jahren existiert SUSE und brachte im Jahr 2000 mit SUSE Linux Enterprise Server (SLES) seine erste […]
Der Beitrag SUSECON 2025: SUSE setzt auf KI und erweiterte SLE -Unterstützung erschien zuerst auf fosstopia.
Elon Musk unterliegt mit einem erstem Versuch, die Umwandlung von OpenAI in ein gewinnorientiertes Unternehmen zu blockieren.
In einem Post auf X hat der COO von OpenAI, Brad Lightcap, bekanntgegeben, dass ChatGPT die Marke von 400 Millionen WAU (weekly active users) überschritten hat.
Die KI-Firma von Elon Musk, xAI, hat ihr neues Sprachmodell Grok 3 veröffentlicht und kündigt neue Features für die Web- und iOS-Apps von Grok an.
Das amerikanische Startup PIN AI, gegründet von KI- und Blockchain-Experten der Universitäten Columbia und Stanford sowie des MIT, hat einen KI-Assistenten in Form einer Smartphone-App…
Wir haben in Sachen Open Source „auf der falschen Seite der Geschichte“ gestanden, gab jetzt der CEO von OpenAI, Sam Altman, in einer Reddit-Diskussion unter dem Motto „Ask Me…
 Ein chinesisches Unternehmen sorgt derzeit für Aufsehen in der Tech-Welt. DeepSeek behauptet, ein KI-Modell entwickelt zu haben, das mit ChatGPT mithalten kann. Das ganze zu einem Bruchteil der üblichen Kosten. Statt Hunderte Millionen Dollar habe man lediglich fünf Millionen investiert. Zudem soll das Modell ohne die teuren Nvidia-Chips auskommen. Diese Ankündigung ließ die Nvidia-Aktie einbrechen. […]
Ein chinesisches Unternehmen sorgt derzeit für Aufsehen in der Tech-Welt. DeepSeek behauptet, ein KI-Modell entwickelt zu haben, das mit ChatGPT mithalten kann. Das ganze zu einem Bruchteil der üblichen Kosten. Statt Hunderte Millionen Dollar habe man lediglich fünf Millionen investiert. Zudem soll das Modell ohne die teuren Nvidia-Chips auskommen. Diese Ankündigung ließ die Nvidia-Aktie einbrechen. […]
Der Beitrag DeepSeek kämpft mit schweren Vorwürfen erschien zuerst auf fosstopia.
Elon Musks KI-Firma xAI baute zusammen mit Supermicro und NVIDIA den größten wassergekühlten GPU-Cluster der Welt.
Eine chinesische KI namens Deepseek zieht aktuell weltweite Aufmerksamkeit auf sich. Ihre App stürmte an die Spitze von Apples App Store, was gleichzeitig die Aktienkurse führender US-Tech-Unternehmen ins Wanken brachte. Doch hinter dem Hype steckt mehr – und weniger –, als viele glauben. Die Aufregung dreht sich um die Behauptung, Deepseek habe für nur rund […]
Der Beitrag Deepseek: Chinas Antwort auf ChatGPT. Wo ist Europa? erschien zuerst auf fosstopia.
Linkwarden ist meine bevorzugte App zum Speichern von Links und Webseiten. Die neue Version Linkwarden 2.9 bietet automatisches Tagging mit lokaler KI sowie RSS-Feeds für gespeicherte Links.
Linkwarden ist meine bevorzugte App zum Speichern von Links und Webseiten. Die neue Version Linkwarden 2.9 bietet automatisches Tagging mit lokaler KI sowie RSS-Feeds für gespeicherte Links.

Unser Buch Coding mit KI wird gerade übersetzt. Heute musste ich diverse Fragen zur Übersetzung beantworten und habe bei der Gelegenheit ein paar Beispiele aus unserem Buch mit aktuellen Versionen von ChatGPT und Claude noch einmal ausprobiert. Dabei ging es um die Frage, ob KI-Tools technische Diagramme (z.B. UML-Diagramme) zeichnen können. Die Ergebnisse sind niederschmetternd, aber durchaus unterhaltsam :-)
Vor einem halben Jahr habe ich ChatGPT gebeten, zu zwei einfachen Java-Klassen ein UML-Diagram zu zeichnen. Das Ergebnis sah so aus (inklusive der falschen Einrückungen):
+-------------------------+
| Main |
+-------------------------+
| + main(args: String[]): void |
| + initializeQuestionPool(): List<Question> |
+-------------------------+
+-------------------------+
| Question |
+-------------------------+
| - text: String |
| - answers: List<Answer> |
| - correctAnswers: List<Answer> |
+-------------------------+
| + Question(text: String, answers: List<Answer>,
| correctAnswers: List<Answer>) |
| + askQuestion(): void |
| - validateAnswer(userInput: String): boolean |
+-------------------------+
Dabei war ChatGPT schon damals in der Lage, PlantUML- oder Mermaid-Code zu liefern. Der Prompt Please generate PlantUML code instead liefert brauchbaren Code, der dann in https://www.planttext.com/ visualisiert werden kann. Das sieht dann so aus:
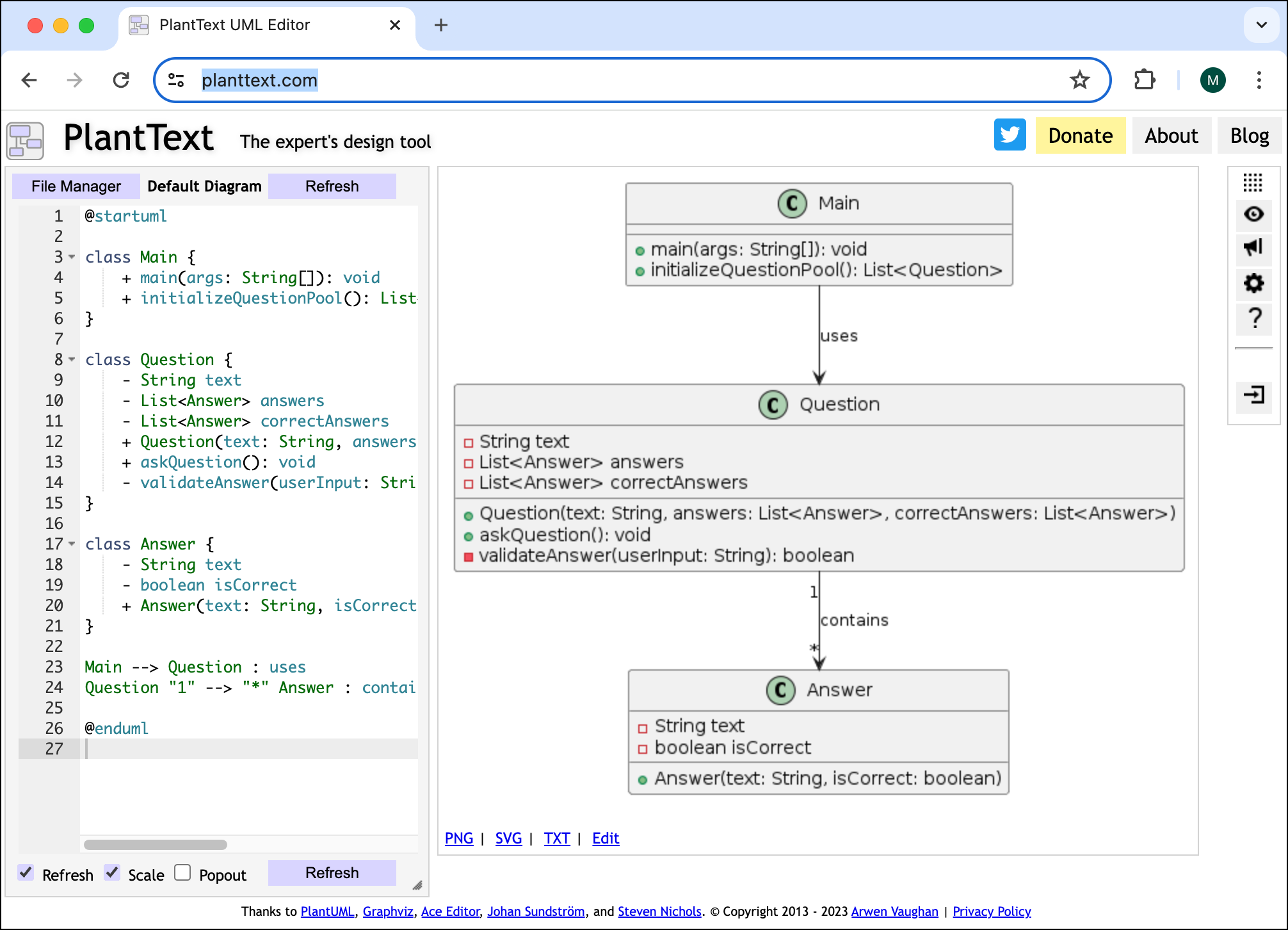
Heute habe ich das ganze Beispiel noch einmal ausprobiert. Ich habe also den Java-Code für zwei Klassen an ChatGPT übergeben und um ein UML-Diagramm gebeten. Vorbei sind die ASCII-Zeiten. Das Ergebnis sieht jetzt so aus:

Leider kann ich hier keinen Link zum ganzen Chat-Verlauf angeben, weil ChatGPT anscheinend nur reine Text-Chat-Verläufe teilen kann.
Beispiel zwei ergibt sich aus zwei Prompts:
Prompt: I want to build a REST application using Python and Django. The application will run in a Docker container. Do I need a proxy server in this case to make my application visible to the internet?
Prompt: Can you visualize the setup in a diagram?
In der Vergangenheit (Mitte 2024) lieferte ChatGPT das Diagramm als ASCII-Art.
+---------------------------+
| Client Browser |
+-----------+---------------+
|
v
+-----------+---------------+
| Nginx Reverse Proxy |
| (Handles SSL, Load |
| Balancing, etc.) |
+-----------+---------------+
|
v
+-----------+----------------+
| Docker Container Network |
| |
| +----------+ +---------+|
| | Web | | DB ||
| | Container| |Container||
| +----------+ +---------+|
| (Django) (Postgres)|
+----------------------------+
Erst auf die explizite Bitte liefert es auch Mermaid-Code, der dann unter https://mermaid.live/ gezeichnet werden kann.
Heute (Dez. 2024) gibt sich ChatGPT nicht mehr mit ASCII-Art ab sondern leitet den Diagrammwunsch an DALL-E weiter. Das Ergebnis ist eine Katastrophe.
Auch Claude.ai zeichnet selbstbewusst ein Diagramm des Docker-Setups. Dabei wird intern Mermaid verwendet.
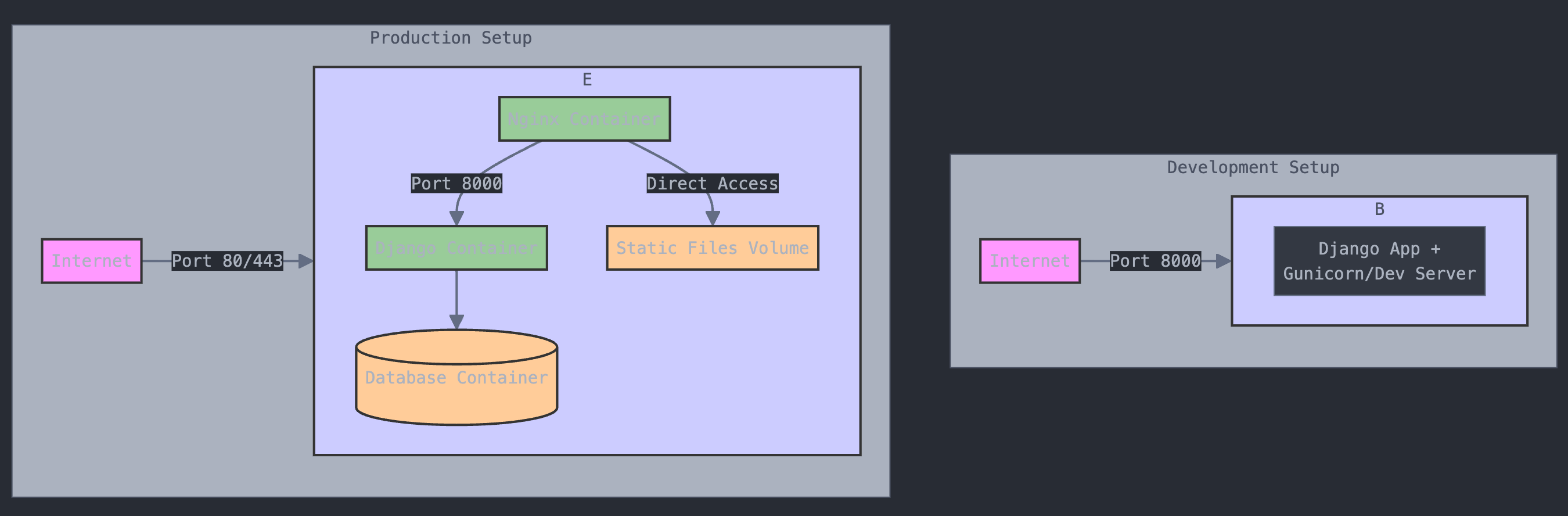
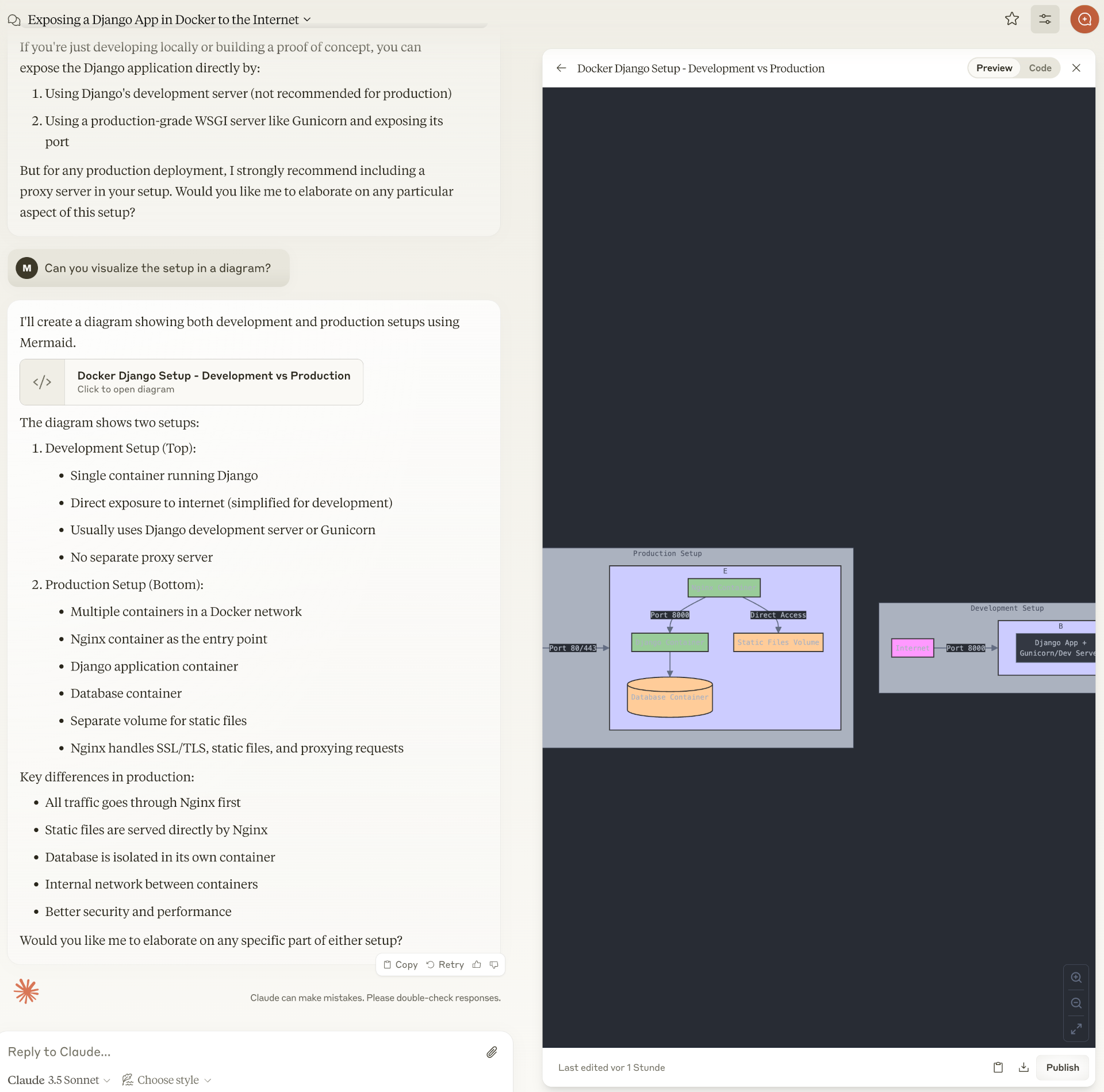
Die Diagramme haben durchaus einen hohen Unterhaltungswert. Aber offensichtlich wird es noch ein wenig dauern, bis KI-Tools brauchbare technische Diagramme zeichnen können. Der Ansatz von Claude wirkt dabei erfolgsversprechender. Technische Diagramme mit DALL-E zu erstellen wollen ist doch eine sehr gewagte Idee von OpenAI.
Die besten Ergebnisse erzielen Sie weiterhin, wenn Sie ChatGPT, Claude oder das KI-Tool Ihrer Wahl explizit um Code in PlantUML oder Mermaid bitten. Den Code können Sie dann selbst visualisieren und bei Bedarf auch weiter optimieren.
Fast 10 Monate nach der ersten Vorstellung hat OpenAI nun eine verbesserte Version seines Videogenerators Sora Turbo veröffentlicht.
Suse hat bei der KubeCon North America 2024 in Salt Lake City Suse AI vorgestellt.
Rechtliche Unsicherheiten sind für 40 Prozent der Unternehmen in Deutschland ein Hemmnis für den KI-Einsatz.
OpenAI hat analysiert, wie ChatGPT auf der Grundlage des Namens eines Benutzers reagiert und ob sich das Modell davon beeinflussen lässt.
Der EU AI Act ist seit Anfang August offiziell in Kraft und muss nun in den EU-Mitgliedsländern umgesetzt werden.
OpenAI hat einen geschlossenen Test für SearchGPT gestartet, einen Prototyp für neue KI-gestützte Suchfunktionen.
OpenAI hat GPT-4o mini angekündigt, den Nachfolger von GPT-3.5 Turbo. Der Anbieter bezeichnet GPT-4o mini als günstiger und schneller.
Dies ist die Fortsetzung von „Mit InstructLab zu Large Language Models beitragen“. Hier beschreibe ich, wie es nach dem Training weitergeht.
Das Training auf einer virtuellen Maschine mit Fedora 40 Server, 10 CPU-Threads und 32 GB RAM dauerte 180 Std. 44 Min. 7 Sek. Ich halte an dieser Stelle fest, ohne GPU-Beschleunigung fehlt es mir persönlich an Geduld. So macht das Training keinen Spaß.
Nach dem Training mit ilab train findet man ein brandneues LLM auf dem eigenen System:
(venv) tronde@instructlab:~/src/instructlab$ ls -ltrh models
total 18G
-rw-r--r--. 1 tronde tronde 4.1G May 28 20:34 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r--. 1 tronde tronde 14G Jun 6 12:07 ggml-model-f16.ggufDen Chat mit dem LLM starte ich mit dem Befehl ilab chat -m models/ggml-model-f16.gguf. Das folgende Bild zeigt zwei Chats mit jeweils unterschiedlichem Ergebnis:

Schade, das hat nicht so funktioniert, wie ich mir das vorgestellt habe. Es kommt weiterhin zu KI-Halluzinationen und nur gelegentlich gesteht das LLM seine Unkenntnis bzw. seine Unsicherheit ein.
Für mich sind damit 180 Stunden Rechenzeit verschwendet. Ich werde bis auf Weiteres keine Trainings ohne Beschleuniger-Karten mehr durchführen. Jedoch werde ich mir von Zeit zu Zeit aktualisierte Releases der verfügbaren Modelle herunterladen und diesen Fragen stellen, deren Antworten ich bereits kenne.
Wenn sich mir die Gelegenheit bietet, diesen Versuch auf einem Rechner mit entsprechender GPU-Hardware zu wiederholen, werde ich die Erkenntnisse hier im Blog teilen.
Der Wandel in der Technologielandschaft erfordere neue Bug Bounty-Programme, um das GenAI-Ökosystem voranzutreiben und Schwachstellen in den Modellen selbst zu beheben, teilt Mozilla mit.
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Die Begriffe Künstliche Intelligenz (KI) oder englisch artificial intelligence (AI) werden in diesem Text synonym verwendet und zumeist einheitlich durch KI abgekürzt.
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
der kann nun teilhaben und ausgewählte LLMs lokal auf seinem Endgerät ausführen, testen und verbessern. Für eine ausführliche Beschreibung siehe:
 InstructLab Project
InstructLab ProjectInformationen zu Open Source LLMs und Basismodellen für InstructLab bieten diese Links:
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Für meine ersten Versuche nutze ich mein Lenovo ThinkPad T14s (AMD) in der Ausstattung von 2021. Aktuell installiert ist Fedora 40 Workstation, welches zu den getesteten Betriebssystemen von InstructLab zählt.
Für die Einrichtung halte ich mich an den Getting Started Guide. Es sind folgende Befehle auszuführen, bis das erste LLM gestartet werden kann:
sudo dnf install gcc-c++ gcc make pip python3 python3-devel python3-GitPython
mkdir instructlab
cd instructlab
python3 -m venv --upgrade-deps venv
source venv/bin/activate
pip cache remove llama_cpp_python
pip install git+https://github.com/instructlab/instructlab.git@stable --extra-index-url=https://download.pytorch.org/whl/cpu
eval "$(_ILAB_COMPLETE=bash_source ilab)"
ilab init
ilab download
ilab serveDer lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
merlinite-7b-lab-Q4_K_MWie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Exkurs: Die Studie Energieverbrauch Index-basierter und KI-basierter Websuchmaschinen gibt einen interessanten Einblick in den Ressourcenverbrauch. Leider war ich nicht in der Lage, diese Studie als PDF aufzutreiben.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Quelle: https://de.wikipedia.org/wiki/Halluzination_(K%C3%BCnstliche_Intelligenz)
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
Die Antworten des LLM enthalten folgende Fehler:
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
README.md, ohne .gitignore und LICENCEunibi.md hinzumkdir -p university/germany/bielefeld_universityqna.yaml und eine attribution.txt Dateiilab diff aus, um die Daten zu validierenDer folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
Dazu wird der Befehl ilab generate aufgerufen, während sich das LLM noch in Ausführung befindet. Dieser endet bei mir erfolgreich mit folgendem Ergebnis:
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonlZur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.