In der Vergangenheit habe ich viele Dokumente, wie z.B. Hausarbeiten, Aufsätze, Briefe, Dokumentationen und Präsentationen mit LaTeX erstellt. In der Vorbereitungsphase für einen Vortrag haben Dirk und ich beschlossen, Typst zu lernen.
Ich habe kein Werkzeug zur automatischen Konvertierung genutzt, da ich zu faul war, ein solches erst zu finden und zu erlernen. Stattdessen habe ich Vim genutzt und die entsprechenden Umgebungen ersetzt. Das war in diesem Fall in Ordnung, kann aber bei komplexeren Dokumenten schnell in Arbeit ausarten. Allerdings werden Automaten bei zunehmend komplexen Projekten ebenfalls an ihre Grenzen kommen.
Im Folgenden findet ihr einen kurzen Vergleich der Syntax-Elemente.
Die Preamble (Vorspann)
Die Preamble ist der Teil des LaTeX-Dokuments, der vor dem eigentlichen Inhalt steht. Hier werden grundlegende Einstellungen und Pakete definiert, die während der Dokumenterstellung verwendet werden. Die Preamble beginnt immer mit dem Befehl \documentclass und endet mit dem Befehl \begin{document}.
Die Referenz ist ständig in einem Browser-Tab geöffnet, wenn ich mit typst arbeite. Dies wird so bleiben, bis ich die am häufigsten verwendeten Funktionen auswendig kenne.
Grundsätzlich halte ich mich an das KISS-Prinzip und den Grundsatz: Form follows function (Deutsch: die Form folgt der Funktion bzw. dem Inhalt). Ich möchte mich so viel wie möglich mit dem Inhalt beschäftigen und möglichst wenig Zeit mit dem Satz bzw. der Formatierung zubringen.
Abbildungen und Tabellen
Zu den häufigsten Umgebungen zählen vermutlich Abbildungen und Tabellen. In der LaTeX-Version habe ich diese wie folgt gesetzt:
\begin{tabular}{ll}
Vertragsnummer & 12345\\
Kundennummer & 98765432\\
Tarif & zuhause100\\
\end{tabular}
\begin{figure}
\centering
\includegraphics[scale=0.3]{bilder/bild.jpg}
\caption{Meine super Bildunterschrift}
\label{fig:bild}
\end{figure}
\begin{figure}
\begin{subfigure}[c]{0.5\textwidth}
\includegraphics[width=0.9\textwidth]{bilder/front.jpg}
\subcaption{Frontansicht}
\end{subfigure}
\begin{subfigure}[c]{0.5\textwidth}
\includegraphics[width=0.9\textwidth]{bilder/rear.jpg}
\subcaption{Rückansicht}
\end{subfigure}
\caption{Das sind zwei tolle Abbildungen.}
\label{fig:bild2}
\end{figure}
Für das LaTeX-Konstrukt subfigure habe ich keinen entsprechenden Ersatz in typst gefunden. Ich setze dies in einzelnen Abbildungen hintereinander um. Die Umgebungen sehen nun wie folgt aus:
Tabellen und Bilder werden beide in einer figure-Umgebung gesetzt. Dies macht in meinen Augen Sinn, da beide Umgebungen in der Regel mit einer Über- bzw. Unterschrift versehen werden, häufig zentriert gesetzt und mit einer Referenz versehen werden.
Ich habe mich noch nicht ganz an die Terminologie gewöhnt. Typst bezeichnet figure und table sowie die meisten anderen Elemente als Funktionen und nicht als Umgebungen.
Aufzählungen, Links und Listen
Für nummerierte und unsortierte Listen in LaTeX siehe Abschnitt 3.18. Listen im KOMA-Script Scrguide. Für typst siehe enum und list.
Für Links steht in LaTeX das mächtige Paket hyperref bereit. In typst gibt es das link-Element.
Fazit
Mir erscheint die typst-Syntax etwas einfacher, dafür weniger flexibel zu sein. Was mir besser gefällt, mag ich noch nicht sagen, da ich noch unentschlossen bin.
Das mit LaTeX erstellte PDF sieht in meinen Augen perfekt aus. Das mit typst erstellte PDF sieht ebenfalls gut aus und ist leserlich. Es reicht in meinen Augen jedoch nicht an die LaTeX-Ausgabe heran.
In typst ist meine Preambel kürzer, die Syntax etwas einfacher. Dafür war es mir nicht so einfach möglich, die Schriftart zu ändern. Diese hätte ich erst in meine typst-Binärdatei mit einkompilieren müssen. Ein Vorgang, der mir entschieden zu aufwendig ist.
Probiert es am besten aus und entscheidet selbst, welches Ergebnis euch besser gefällt. Ich vermag (noch) nicht zu sagen, ob mir LaTeX oder typst insgesamt besser gefallen. Werft ggf. zuerst einen Blick in den Guide for LaTeX Users.
Ich könnte den Spiess ja umdrehen, wieso nutzt Du Keepass und nimmst die Unbequemlichkeit in Kauf?
Aus einem privaten Matrix-Chat mit einer Person im Internet.
Nun gut, ich möchte dieser Person den Artikel nicht schuldig bleiben. ;-)
Warum ich KeePass benutze
Dies hat wie so oft historische Gründe. Die erste Referenz zu KeePass in diesem Blog ist vom 8. Januar 2011. Etwas später, am 20.01.2011, hatte ich dem Thema einen eigenen Artikel gewidmet: Sichere Passwörter und wie man sie verwaltet. Der Artikel hat in meinen Augen nicht an Aktualität verloren, mit zwei kleinen Ausnahmen:
Ich benutze heute keine Windows mehr, sondern KeePassXC unter Linux.
Bei der Wahl der KeePass-Projekte habe ich mich von diesem Artikel von Mike Kuketz beeinflussen lassen.
Ich bin privat dabei geblieben, weil ich die Nutzung gewohnt bin und bisher keinen Grund zu einem Wechsel sehe. Beruflich nutze ich inzwischen Bitwarden, da dies von meinem Arbeitgeber zur Verfügung gestellt wird und ich somit ein offiziell geprüftes und genehmigtes Werkzeug für dienstliche Zwecke verwende. Darüber hinaus finde ich Bitwarden genauso gut wie KeePassXC.
Wie ich KeePass benutze
KeePassXC ist auf allen meinen Geräten des Typs Laptop, Desktop-PC/Heimserver installiert. Auf meinem Tablet und Smartphone nutze ich KeePassDX, welcher auch im F-Droid-Store verfügbar ist.
Die KeePass-Datenbank halte ich mit einer selbstgehosteten Nextcloud auf allen Geräten synchron bzw. stelle sie dort zur Verfügung. Auf PC und Laptop ist dabei permanent eine lokale Kopie der Datenbank verfügbar. Auf dem Smartphone/Tablet steht diese nur zeitlich begrenzt zur Verfügung, nämlich bis der Android-Dateimanager der KeePassDX-App den Zugriff auf die gecachte KeePass-Datenbank-Datei entzieht bzw. diese aus dem Cache entfernt wird. Schaut für weitere Hinweise hierzu bitte in die englischsprachige FAQ des Projekts.
Der Ablauf auf dem Smartphone sieht bei mir so aus:
Nextcloud-App öffnen.
KeePass-Datenbank auswählen und mit KeePassDX öffnen.
Datenbank-Passwort eingeben und mit der üblichen Nutzung fortfahren.
Sollte ich mein Telefon oder Tablet mal verlieren, widerrufe ich den Access-Token in meiner Nextcloud, womit das jeweilige Gerät den Zugriff auf die Nextcloud und damit auf die KeePass-Datenbank verliert. Wichtig: Dies minimiert das Risiko, dass mir eine Kopie der KeePass-Datenbank verloren geht, bietet aber keinen 100%-igen Schutz. Bei der Offline-Funktionalität von Bitwarden schätze ich das Risiko ähnlich ein.
Um die Sicherheit noch etwas zu steigern, kann ich eine Funktion zur Fernlöschung nutzen, mit der die Inhalte von meinem Gerät gelöscht werden. Achtung: Dies funktioniert nur, wenn das Gerät mit dem Internet verbunden ist.
Aktuell entsperre ich die KeePass-Datenbank nur mit einem Passwort. Ich habe mir angesehen, wie man einen YubiKey als zusätzlichen Faktor nutzen kann. Leider wurde mein YubiKey in der Kombination YubiKey 5 NFC, Fedora 43 und KeePassXC nicht erkannt. Ich habe das Troubleshooting nach kurzer Zeit abgebrochen und beschlossen, dass der YubiKey und die dazugehörige Software für Linux aus der Hölle kommen und das Thema in eine Schublade zur E-Mail-Verschlüsselung gesperrt. Falls euch diese Problem bekannt vorkommt und ihr eine einfache Lösung dafür habt, bitte lasst mich wissen, welchen Zauber ihr gewirkt habt.
Browsererweiterung vs. Zwischenablage
Ich nutze die KeePassXC-Browser-Erweiterung, um mir das Leben etwas zu erleichtern und Login-Formulare per Klick ausfüllen zu lassen. Natürlich besteht hierbei das Restrisiko, dass durch eine Schwachstelle im Browser oder der Erweiterung die Login-Informationen abgefangen werden können. Dessen bin ich mir bewusst.
100%-ige Sicherheit gibt es nicht. Wenn sich ein Keylogger auf meinem System befindet oder eine Schadsoftware, welche die Zwischenablage mitschneidet, verliere ich die Informationen ebenfalls.
Da ich dank Passwort-Manager für alle Dienste unterschiedliche Passwörter und wo möglich Mehrfaktor-Authentisierung verwende, hält sich der Schaden selbst dann in Grenzen, wenn einzelne Passwörter kompromittiert werden.
Da ich kein IT-Sicherheitsexperte bin, möchte ich es hiermit aber auch gut sein lassen.
Viele Grüße ins Internet und an die Personen an den heimischen Datensichtgeräten.
Es ist der erste Sonntag im Monat (und des Jahres 2026) und damit Digital Independence Day (di.day). Um kurz zu erklären worum es geht, zitiere ich von der vorstehend verlinkten Seite:
Unser digitales Leben befindet sich in der Hand weniger Superreicher. Mit der Monopolstellung ihrer Unternehmen bestimmen Menschen wie Elon Musk, Jeff Bezos oder Mark Zuckerberg weltweit, wie wir uns online informieren, wie wir diskutieren, kommunizieren oder handeln. Einen solchen unkontrollierten Einfluss sollte kein Mensch und kein Unternehmen besitzen, weil wir dann nicht mehr in Freiheit leben können.
…
Alternativlos erscheinen die Angebote von Big Tech nur durch ihre übergroße Sichtbarkeit. Dabei gibt es zu Social-Media-Plattformen, Online-Einkauf oder Videostreaming eine Vielzahl gesellschaftsschonender Alternativen.
Freie Software und Open Source Software bieten jede Menge Alternativen zu den zentralen Diensten kommerzieller Anbieter. Doch nicht jede/r kann oder möchte diese Dienste selbst hosten. Für diese Menschen möchte ich in diesem Beitrag drei tolle Projekte aus Deutschland vorstellen, welche eine Vielzahl von Diensten (kostenlos) für euch zur Nutzung bereitstellen.
adminForge – Self-hosted Open Source Services & Linux Admin Tutorials
Unter der URL https://www.adminforge.de stellt Stefan Giebel (Stand 2025-12-27) auf 19 Servern insgesamt 72 verschiedene Dienste bereit. Und zwar nach eigenen Angaben frei, ohne Tracking, ohne Logging und ohne Werbung. Die verfügbaren Dienste gliedern sich in die Themenbereiche:
Stefan bietet diese Dienste kostenlos an. Er freut sich, wenn wir seine Arbeit mit einer Spende unterstützen, was ich gerne tue.
Anoxinon e.V. – für ein gemeinschaftliches Internet
Anoxinon e.V. ist ein Verein, der sich der Förderung von Datenschutz und freier Software durch Bereitstellen von Informationen und alternativen Internetdiensten verschrieben hat. Aktuell stellt der Verein 5 Dienste bereit.
Der Verein finanziert sich ausschließlich über Mitgliedsbeiträge, Spenden und ggf. Zuschüsse.
tchncs.de
Seit ca. 2012 betreibt Milan unter tchncs.de Webdienste für die Öffentlichkeit. Das Angebot ist werbefrei und trägt sich durch freiwillige Spenden seiner NutzerInnen.
Am 01.01.2026 habe ich 21 Dienste gezählt, die sich auf die folgenden Kategorien verteilen:
Social
Collaboration
Chat
Blog
Development
Gaming
Aktuell nutze ich keinen der angebotenen Dienste aktiv. Gelegentlich arbeite ich in einem dort gehosteten Cryptpad mit.
Ich finde das großartig und bitte um eure Unterstützung
Privatpersonen und ein Verein stellen hier datensparsame Dienste kostenlos zur Nutzung bereit. Die Dienste, welche ich selbst aus diesem Angebot nutze, empfinde ich als stabil und zuverlässig.
Dafür, dass ich selbst keinen Betriebsaufwand habe, bin ich gerne bereit, diese Projekte durch unregelmäßige Spenden zu unterstützen.
Getreu dem Motto „tue Gutes und rede darüber“ könnt auch ihr den „Digital Independence Day“ und die drei hier vorgestellten Projekte unterstützen, z.B. indem ihr diesen Beitrag in euren Netzwerken teilt. Damit helft ihr, den Bekanntheitsgrad und potenziell die Anzahl der Spenden zu steigern.
Seit Version 137 gibt es im Firefox die Option, einen KI-Chatbot zu etwas zu befragen. Wen diese Option stört, kann diese in den erweiterten Einstellungen wie folgt deaktivieren: Startet euren Firefox, gebt in der...
Im August letzten Jahres habe ich euch gezeigt, was auf meinem Home Server so alles läuft und ich dachte mir, ich liefere euch über ein Jahr später mal einen aktualisierten Einblick. Der Unterbau des...
Das Software-Framework fapolicyd steuert die Ausführung von Anwendungen basierend auf einer benutzerdefinierten Richtlinie. Dies ist eine der effizientesten Methoden, um die Ausführung nicht vertrauenswürdiger und potenziell bösartiger Anwendungen auf dem System zu verhindern.
Dazu möchte ich schreiben, dass fapolicyd nicht als Alternative, sondern eher als Ergänzung zu SELinux zu sehen ist. Es handelt sich dabei also um ein weiteres Werkzeug, mit dem sich steuern lässt, was auf einem System ausgeführt werden darf und was nicht.
Ich kann nachvollziehen, warum man sich solch ein Werkzeug wünscht. Es bietet potenziell eine Antwort auf die Frage: „Wie verhindere ich, dass User beliebige flatpaks aus dem Internet herunterladen und aus ihrem HOME-Verzeichnis ausführen?“
Ob es dafür wirklich gut geeignet ist, habe ich nicht getestet. Es hat jedoch gezeigt, dass es meine Python-Skripte blockieren kann. Allerdings habe ich dabei auch gelernt, dass man diesen Schutz relativ leicht umgehen kann, indem man einfach die Shebang weglässt und das Skript manuell als Argument an einen Python-Interpreter übergibt. Siehe dazu meinen Kommentar auf GitHub.
Auf mich macht dies bisher den Eindruck, dass fapolicyd in der Tat mehr Arbeit und Ärger für Sysadmins bedeutet, jedoch nur einen geringen Zugewinn an Sicherheit bringt.
Was haltet ihr davon? Teilt eure Gedanken gern in den Kommentaren. Ich freue mich, zu lernen, welche Vor- und Nachteile ihr in fapolicyd seht.
…dann können keine Ansible-Playbooks auf dem Zielsystem ausgeführt werden, Sysadmins lassen vom Schreiben der Playbooks ab und wenden sich der Fehleranalyse zu. Genau das mache ich nämlich gerade.
Und damit ihr auch etwas davon habt, halte ich das Ganze in diesen Beitrag fest. Die Gründe dafür sind vielfältig:
Unerfahrene Sysadmins können lernen, wie man bei einer Fehleranalyse vorgehen kann, um nach endlich vielen Schritten zu einem Ergebnis zu kommen
Falls ich meine Arbeit unterbrechen muss, kann ich mich mithilfe dieses Textes besser erinnern, was ich schon getestet habe und meine Arbeit fortsetzen
Falls ich Expertenrat einholen muss, kann ich zeigen, was ich schon alles versucht habe
Die erfahrenen Supporter und Sysadmins unter euch sind gerne eingeladen, in den Kommentaren zu ergänzen, wie ihr bei so einem Problem vorgeht und was ich hätte besser machen können. So lernen wir alle etwas dabei.
Die Methode
Bei einer Fehleranalyse stochert man nicht einfach im Heuhaufen herum, in der Hoffnung eine Nadel zu finden. Ich gehe während der Fehleranalyse in folgender Schleife (Pseudocode) vor:
Solange das Problem besteht:
Sichte und bewerte die vorhandenen Informationen;
Forumuliere eine Hypothese zur Ursache des Problems;
Überprüfe die Hypothese;
Hast du damit das Problem gefunden, stelle es ab und höre auf;
Hast du das Problem damit noch nicht gefunden, nimm die gewonnenen Erkenntnisse und iteriere;
Das Problem
$ ansible -i hosts host.example.com -m ping
host.example.com | FAILED! => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3.9"
},
"changed": false,
"module_stderr": "Shared connection to host.example.com closed.\r\n",
"module_stdout": "/usr/bin/python3.9: can't open file '/home/tronde/.ansible/tmp/ansible-tmp-1757269581.9965136-5304-74956742819711/AnsiballZ_ping.py': [Errno 1] Operation not permitted\r\n",
"msg": "MODULE FAILURE: No start of json char found\nSee stdout/stderr for the exact error",
"rc": 2
}
Der obige Code-Block zeigt das fehlgeschlagene Ansible-Ad-hoc-Kommando. Das Kommando führt das Module ansible.builtin.ping aus, welches prüft, ob eine Verbindung zum Zielsystem hergestellt werden kann und eine nutzbare Python-Umgebung gefunden wird. Wenn dies erfolgreich ist, sieht die Ausgabe wie im folgenden Code-Block aus:
Über host.example.com und host2.example.com ist bekannt, dass es:
sich um Red Hat Enterprise Linux release 9.6 (Plow) handelt
Ich mich mit dem User tronde und SSH-Private-Key einloggen kann
Bei tronde handelt es sich um einen unprivilegierten Benutzer
Dieser darf sudo nutzen, um seine Rechte auszuweiten; dazu muss ein Passwort eingegeben werden
SELinux auf Enforcing steht
Die Fehlermeldung
Und ich habe natürlich eine Fehlermeldung:
"module_stdout": "/usr/bin/python3.9: can't open file '/home/tronde/.ansible/tmp/ansible-tmp-1757269581.9965136-5304-74956742819711/AnsiballZ_ping.py': [Errno 1] Operation not permitted\r\n",
Python meldet, dass die Ausführung von AnsiballZ_ping.py nicht zugelassen ist.
Hypothese 1: Es liegt nicht an AnsiballZ_ping.py
Wenn dieses Python-Skript nicht ausgeführt werden kann, kann ein anderes Python-Skript ebenfalls nicht ausgeführt weden. Um diese Hypothese zur überprüfen, versuche ich, die UID des Benutzers mit dem Modul ansible.builtin.command abzufragen:
$ ansible -i hosts host.example.com -m command -a 'id'
host.example.com | FAILED! => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3.9"
},
"changed": false,
"module_stderr": "Shared connection to host.example.com closed.\r\n",
"module_stdout": "/usr/bin/python3.9: can't open file '/home/tronde/.ansible/tmp/ansible-tmp-1757271016.543905-6189-111082369101490/AnsiballZ_command.py': [Errno 1] Operation not permitted\r\n",
"msg": "MODULE FAILURE: No start of json char found\nSee stdout/stderr for the exact error",
"rc": 2
}
Damit ist bewiesen, dass die Fehlerursache nicht allein im Skript AnsiballZ_ping.py liegt.
Hypothese 2: Es ist ein Problem mit Berechtigungen
Die Meldung [Errno 1] Operation not permitted deutet an, dass fehlende Berechtigungen die Ursache sein können. Also führe ich das Kommando auf dem betroffenen Managed Node einmal als root aus.
Root darf also, was tronde nicht darf, denn mit erweiterten Berechtigungen kann das Kommando erfolgreich ausgeführt werden. Die Python-Skripte, die tronde nicht ausführen darf, liegen im Pfad /home/tronde/.ansible/tmp/<von-Ansible-temporär-erstelltes-Verzeichnis>/AnsiballZ_{command,ping}.py.
Hypothese 3: tronde darf keine Python-Skripte ausführen
Genauer gesagt, tronde darf keine Python-Skripte ausführen, welche unterhalb von /home/tronde/.ansible/tmp/ abgelegt sind. Auch diese These wird direkt geprüft. Dazu logge ich mich per SSH als User tronde auf dem Zielsystem ein, erstelle ein einfaches Python-Skript und versuche dieses auszuführen:
Durch diesen Test habe die Hypothese verifiziert und zusätzlich folgendes gelernt: Meine Ansible-Konfiguration auf meinem Ansible Control Node hat nichts mit dem Problem zu tun, da das Problem auftritt, wenn Ansible gar nicht beteiligt ist.
Hypothese 4: Falsche Datei-Berechigungen verhindern die Ausführung der Datei
Ich schaue mir die Datei-Berechtigungen bis zur Datei hello.py mit dem Programm namei(1) an:
Das sieht auf den ersten Blick nicht verkehrt aus. Ich wechsel in das Verzeichnis und lasse mir die Attribute der Datei mit verschiedenen Programmen anzeigen.
Datei-Berechtigungen und Linux-ACL bescheinigen dem User tronde Lesezugriff auf die Datei hello.py. Das file-Kommando bescheinigt jedoch no read permission.
Hypothese 5: Das chmod u+x verursacht das Problem
Nach der Erstellung des Skripts habe ich dieses mit chmod u+x ausführbar gemacht. Vielleicht verursacht erst dieser Befehl das Problem. Also schaue ich mir die Informationen zum Dateityp vor und nach dem Kommando an. Dazu erstelle ich ein neues Skript.
Damit kann ich chmod ebenfalls als Fehlerquelle ausschließen.
Hypothese 6: Shebang verursacht das Problem
Die Shebang#! sorgt dafür, dass das folgende Kommando mit dem Dateinamen als Argument ausgeführt wird. Gleichzeitig gibt die Shebang auch dem Programm file einen Hinweis darauf, um welchen Dateityp es sich handelt.
Zur Überprüfung dieser Hypothese erhebe ich zuerst die Antworten zu folgenden Fragen.
Kann das Skript ohne Shebang ausgeführt werden?
Bei der Überprüfung von Hypothese 2 habe ich verifiziert, dass root die Dateien wie gewohnt ausführen kann. Nun editiere ich die Datei hello2.py mit root-Rechten und entferne die Shebang. Anschließend versuche ich als User tronde, die Datei mit Hilfe des Python3.9-Interpreters auszuführen.
Hier ist das Verhalten wie erwartet. Damit ist zwar noch nicht sicher bewiesen, dass das Shebang-Problem mit dem Python-Interpreter zusammenhängt, es gibt aber einen ersten Hinweis.
Wie sieht die Ausgabe von file auf einem Referenzsystem aus?
Mit host2 habe ich ja ein System, das Python-Skripte ohne Fehler ausführt. Ich erstelle auch hier das hello.py-Skript inkl. Shebang und lasse mir die Ausgabe von file anzeigen:
Hier findet sich kein Hinweis auf no read permission.
Hypothese 7: Es ist nur der User tronde betroffen
Um diese Hypothese zu prüfen, erstelle ich einen neuen Benutzer test, ein Python-Skript und prüfe, ob das Problem auftritt:
# useradd test
# su - test
$ pwd
/home/test
$ cat <<EOF >hello.py
> #!/usr/bin/env python3
> print("Hello, world.")
> EOF
$ cat hello.py
cat: hello.py: Operation not permitted
Das Problem ist nicht auf den User tronde beschränkt. Es scheint alle nicht privilegierten User zu betreffen.
Zwischenfazit
Das Problem scheint Host-spezifisch zu sein, da es auf einem Referenzsystem nicht auftritt
Das Problem tritt nur auf, wenn nicht privilegierte User ein Python-Skript ausführen, welches eine Shebang enthält
Diese Skripte können jedoch mit root-Rechten ausgeführt werden
Ohne die Shebang können die Skripte mittels /usr/bin/python3 <scriptname> ausgeführt werden
Ist eine Shebang enthalten, die einen Python-Interpreter enthält, verlieren unprivilegierte User den Lesezugriff auf die Datei (cat, less, etc. sind dann ebenfalls betroffen)
Trage ich eine andere Shebang z.B. #!/usr/bin/bash ein, kann ich das Skript als unprivilegierter User mittels `python3 <scriptname>` korrekt ausführen
Für mich bedeutet das leider, dass ich mir nun Hilfe suchen muss, da mir die Ideen ausgehen. Also beginne ich mit einer Internetsuche nach „troubleshooting shebang in python3″… und frage anschließend eine Kollegin um Rat. Vielen lieben Dank Michi für deine Zeit und Ideen!
Die Ursache
Michi und ich haben uns in einer Videokonferenz zusammengefunden und das Problem gemeinsam untersucht. Dabei sind wir nach obigen Muster vorgegangen:
Genau eine Sache überprüfen
Ergebnis auswerten
Eine weitere Vermutung prüfen
Ergebnis auswerten usw.
Dabei haben wir uns SELinux, das Audit-Log, die Linux-ACLs, das Environment, alias, locale und die Ausgabe diverser strace-Kommandos angeschaut. Die Details spare ich an dieser Stelle ein und komme zum Wesentlichen. Michi fand diesen Foreneintrag: Non-root users unable to read perl scripts. Darin wird fapolicyd als Fehlerquelle identifiziert. Und das ist tatsächlich auch in meinem Fall der Übeltäter.
Stoppe ich fapolicyd.service, kann ich die Python-Skripte mit Shebang wieder ausführen. Starte ich den Dienst erneut, ist auch das Problem zurück. Die Ursache ist identifiziert.
Moment, was ist fapolicyd?
Das Software-Framework fapolicyd steuert die Ausführung von Anwendungen basierend auf einer benutzerdefinierten Richtlinie. Dies ist eine der effizientesten Methoden, um die Ausführung nicht vertrauenswürdiger und potenziell bösartiger Anwendungen auf dem System zu verhindern.
Die von Ansible generierten und die von mir zum Test erstellten Python-Skripte wurden in der Ausführung blockiert, da diese als nicht vertrauenswürdig eingestuft wurden.
Allerdings fällt das in diesem Fall in die Kategorie „Gut gemeint ist nicht gleich gut gemacht“. Denn während zwar der Zugriff auf Python-Skripte mit Shebang für nicht-privilegierte User blockiert wird, können Skripte ohne entsprechende Shebang weiterhin ausgeführt werden. Wirkliche Sicherheit bietet dies nicht. Ich mache mir dazu mal eine Notiz, um das beobachtete Verhalten im Nachgang mit den Entwicklern zu diskutieren. Vielleicht habe ich das Design und Konzept von fapolicyd noch nicht ganz verstanden.
Warum ich da nicht früher drauf gekommen bin
Keine Ausgabe gab einen Hinweis darauf, dass fapolicyd die Ausführung blockiert
Ich habe fapolicyd vor langer Zeit zum Test auf diesem Host installiert und vergessen, dass es läuft
Durch fehlende Konfiguration gab es keine Einträge im Audit-Log, die auf die Ursache hätten hinweisen können
Wie findet man die Ursache, wenn man weiß, dass fapolicyd läuft?
Erstmal muss man wissen bzw. sich in meinem Fall daran erinnern, dass fapolicyd läuft. Dann kann man für einen schnellen Test fapolicyd.service stoppen und prüfen, ob das Problem noch besteht.
Um nun herauszufinden, warum fapolicyd die Ausführung von Python-Skripten mit Shebang blockiert, folge ich der Dokumentation in Kapitel 12.6. Troubleshooting problems related to fapolicyd. Ich stoppe fapolicyd.service und starte den Dienst mit dem Befehl fapolicyd --debug-deny. Damit werden nur Einträge ausgegeben, die blockierte Zugriffe zeigen. In diesem Modus führe ich den ursprünglichen Ansible-Ad-hoc-Befehl ansible -i hosts host.example.com -m ping aus, der wie erwartet fehlschlägt. In der Ausgabe auf host.example.com sehe ich nun:
Damit ich host.example.com mit Ansible verwalten kann, muss ich die Ausführung von Python-Skripten unterhalb von /home/tronde/.ansible/tmp/ erlauben. Das dazu erforderliche Vorgehen ist in der Dokumentation in Kapitel 12.4. Adding custom allow and deny rules for fapolicyd beschrieben. Für meinen konkreten Fall sehen die einzelnen Schritte wie folgt aus:
Nach obiger Ausgabe habe ich Regel 11 (rule=11) getriggert. Also schaue ich mir zuerst an, was in Regel 11 steht und anschließend, in welcher Datei unterhalb von /etc/fapolicyd/rules.d diese Regel steht:
~]# fapolicyd-cli --list | grep 11
11. deny_audit perm=any all : ftype=%languages
~]# grep 'deny_audit perm=any all : ftype=%languages' /etc/fapolicyd/rules.d/*
/etc/fapolicyd/rules.d/70-trusted-lang.rules:deny_audit perm=any all : ftype=%languages
Anschließend erstelle ich eine Allow-Regel, in einer neuen Datei. Diese muss lexikalisch vor obiger Datei mit der Deny-Regel liegen:
~]# cat <<EOF >/etc/fapolicyd/rules.d/69-trusted-ansible-scripts.rules
> allow perm=any exe=/usr/bin/python3.9 trust=1 : dir=/home/tronde/.ansible/tmp/ trust=0
> EOF
~]# fagenrules --check
/sbin/fagenrules: Rules have changed and should be updated
~]# fagenrules --load
~]#
Anschließend führe ich zum Test folgende Kommandos aus:
Auf host.example.com: fapolicy --debug-deny
Auf meinem Ansible Control Node: $ ansible -i inventory host.example.com -m ping
Nun beende ich den Debug-Modus und starte fapolicyd.service. Fehleranalyse und Entstörung sind damit beendet.
Für welche Anwendungsfälle diese Lösung funktioniert
Die obige Lösung sorgt dafür, dass Python-Skripte unterhalb des Verzeichnisses /home/tronde/.ansible/tmp/, welche eine Python-Shebang beinhalten, mit dem Python-Interpreter /usr/bin/python3.9 ausgeführt werden können.
Diese Lösung funktioniert nicht
Für andere unprivilegierte User außer tronde
Für andere Python-Interpreter wie z.B. /usr/bin/python3 oder /usr/bin/python3.11
Hinterher ist man immer schlauer
Jetzt, wo ich weiß, wonach ich suchen muss, finde ich auch direkt mehrere Treffer in den Red Hat Solutions:
Dokumentation findet sich neben der Manpage fapolicyd(8) z.B. auch im RHEL 9 Security Hardening Guide ab Kapitel 12. Mit RHELDOCS-20981 – Improve section „Deploying fapolicyd“ in RHEL Security Hardening Guide – habe ich zudem einen Verbesserungsvorschlag eingereicht.
Fazit
Dieser Text hat an einem konkreten Beispiel gezeigt, wie eine strukturierte Fehleranalyse durchgeführt wird. Diese führt über die Problembeschreibung sowie das Formulieren von Hypothesen und deren Falsifizierung/Verifizierung nach endlich vielen Schritten zu einer Lösung.
Die Länge des Textes zeigt, wie aufwändig eine Fehleranalyse werden kann. Wenn man keinen direkten Zugriff auf das betroffene System hat und mit jemandem ausschließlich über ein Ticket-System kommunizieren kann, wird schnell klar, dass sich ein Fall über mehrere Tage und Wochen hinziehen kann.
Ich war irgendwann geistig erschöpft und hatte keine Lust mehr allein weiterzumachen, da mir die Ideen ausgingen. In diesem Fall hilft es, sich einen frischen Geist zur Unterstützung zu holen. Gemeinsam mit meiner Kollegin Michi konnte die Ursache (fapolicyd) identifiziert werden.
Mit Hilfe der Dokumentation war ich dann auch in der Lage, das Problem zu lösen. Ich kann nun Ansible-Playbooks auf dem Zielsystem ausführen.
Der Dienst fapolicyd überzeugt mich nicht. Meine Gedanken dazu werde ich in einem Folgeartikel mit euch teilen.
In einem weiteren Folgeartikel werde ich darüber schreiben, was Hilfesuchende und Supporter tun können, damit beide Seiten eine möglichst gute Support-Erfahrung haben.
Ich freue mich nun über ein gelöstes Problem und schreibe an meinem Ansible-Playbook weiter.
Am 07. August 2025 hat StarFive eine Kickstarter-Kampagne für den VisionFive 2 Lite gestartet. Das Finanzierungsziel wurde in weniger als einer Woche erreicht und läuft noch bis Samstag, den 6. September 2025 um 04:34...
Der Proxmox Backup Server unterstützt ab Version 4, welche sich aktuell in der Beta-Phase befindet, als Technologievorschau das Einbinden von S3-kompatiblen Objektspeichern als Backupspeicher. Hetzner bietet günstig (ab 5,94 EUR/Monat für 1 TB) S3-kompatiblen...
Die folgende Geschichte soll mir zur Erinnerung und euch zur Unterhaltung dienen. Sie handelt von CentOS Stream 10, Containern und der Manpagednf(8). Aber lest selbst.
Es war einmal ein Systemadministrator, der beim Training einige Subkommandos von dnf updateinfo kennenlernte, von deren Existenz er bislang nichts wusste. Und diese Subkommandos heißen list, info und summary. Neugierig schaute er in die Manpage dnf(8), doch zu seinem Erstaunen schwieg sich diese zu diesen Subkommandos aus.
Wut stieg in unserem Sysadmin auf. Wieder einmal haben sich die Entwickler keine Mühe gegeben, die Funktionalität ihrer Anwendung vernünftig zu dokumentieren. Die Qualitätssicherung hat geschlafen. So kann man doch nicht arbeiten. Doch nach dem ersten Wutanfall beschloss der Sysadmin, der Sache in Ruhe auf den Grund zu gehen, bevor er diesen Misstand anprangern würde.
Die Distribution des Sysadmins ist dafür bekannt, dass unter bestimmten Umständen Funktionalität von Upstream zurückportiert wird. Vielleicht hatte sich hier eine Diskrepanz eingeschlichen. Vielleicht war dieser Fehler in einer neueren Version ausgemerzt. Um dies schnell zu überprüfen, wollte unser Sysadmin einen Blick in dnf(8) in Centos 10 Stream werfen. Dazu führte er folgende Befehle in einer Kommandozeile aus:
$ podman run --rm -it centos:stream10
[root@01ede4521839 /]# man 8 dnf
bash: man: command not found
[root@01ede4521839 /]#
Mit einem Augenrollen erinnerte sich unser Sysadmin daran, dass Container-Images nur das absolut Notwendige enthalten, um möglichst wenig Speicherplatz auf der Festplatte zu belegen. Darüber, was absolut notwendig ist, werden seit anbeginn des Containerzeitalters philosophische Streitgespräche geführt. Also prüfte unser Sysadmin, ob es einen vertrauten Paketmanager gab, um die Manpages nachzuinstallieren:
[root@01ede4521839 /]# dnf in man-db man-pages
CentOS Stream 10 - BaseOS 2.6 MB/s | 6.2 MB 00:02
CentOS Stream 10 - AppStream 1.5 MB/s | 2.4 MB 00:01
CentOS Stream 10 - Extras packages 3.3 kB/s | 3.5 kB 00:01
Dependencies resolved.
================================================================================
Package Architecture Version Repository Size
================================================================================
Installing:
man-db x86_64 2.12.0-8.el10 baseos 1.3 M
man-pages noarch 6.06-3.el10 baseos 3.7 M
Installing dependencies:
groff-base x86_64 1.23.0-10.el10 baseos 1.1 M
less x86_64 661-3.el10 baseos 191 k
libpipeline x86_64 1.5.7-7.el10 baseos 53 k
Transaction Summary
================================================================================
Install 5 Packages
Total download size: 6.4 M
Installed size: 9.9 M
Is this ok [y/N]:
…
Installed:
groff-base-1.23.0-10.el10.x86_64 less-661-3.el10.x86_64
libpipeline-1.5.7-7.el10.x86_64 man-db-2.12.0-8.el10.x86_64
man-pages-6.06-3.el10.noarch
Complete!
[root@01ede4521839 /]# mandb
Processing manual pages under /usr/share/man...
Updating index cache for path `/usr/share/man/man7'. Wait...mandb: can't resolve man7/groff_man.7
mandb: warning: /usr/share/man/man7/man.7.gz: bad symlink or ROFF `.so' request
mandb: can't resolve man7/groff_man.7
mandb: warning: /usr/share/man/man7/man.man-pages.7.gz: bad symlink or ROFF `.so' request
Updating index cache for path `/usr/share/man/man3type'. Wait...done.
Checking for stray cats under /usr/share/man...
Checking for stray cats under /var/cache/man...
Processing manual pages under /usr/local/share/man...
Updating index cache for path `/usr/local/share/man/mann'. Wait...done.
Checking for stray cats under /usr/local/share/man...
Checking for stray cats under /var/cache/man/local...
45 man subdirectories contained newer manual pages.
2701 manual pages were added.
0 stray cats were added.
0 old database entries were purged.
[root@01ede4521839 /]# man 8 dnf
No manual entry for dnf in section 8
Resultat: Kein which-Befehl verfügbar. Diese Container-Image-Kuratöre sparten aber wirklich an allem. Doch der obige Codeblock enthüllt noch mehr. Zwar war der Paketmanager dnf installiert, auch die Manpages waren nun vorhanden, nur die Manpage dnf(8) fehlte immer noch. Und so bemühte der Sysadmin wieder die Tastatur, um zu prüfen, ob die entsprechende Datei tatsächlich fehlt, welches Paket sie bereitstellt und um das Problem zu lösen. Sehet und staunet:
[root@01ede4521839 /]# stat /usr/share/man/man8/dnf.8.gz
stat: cannot statx '/usr/share/man/man8/dnf.8.gz': No such file or directory
[root@01ede4521839 /]# dnf provides /usr/share/man/man8/dnf.8.gz
…
dnf-4.20.0-9.el10.noarch : Package manager
Repo : baseos
Matched from:
Filename : /usr/share/man/man8/dnf.8.gz
[root@01ede4521839 /]# dnf reinstall dnf
Last metadata expiration check: 0:01:01 ago on Wed Jan 1 14:31:37 2025.
Dependencies resolved.
================================================================================
Package Architecture Version Repository Size
================================================================================
Reinstalling:
dnf noarch 4.20.0-9.el10 baseos 478 k
Transaction Summary
================================================================================
Total download size: 478 k
Installed size: 2.5 M
Is this ok [y/N]:y
…
Reinstalled:
dnf-4.20.0-9.el10.noarch
Complete!
[root@01ede4521839 /]# stat /usr/share/man/man8/dnf.8.gz
File: /usr/share/man/man8/dnf.8.gz -> dnf4.8.gz
Size: 9 Blocks: 8 IO Block: 4096 symbolic link
Device: 0,111 Inode: 6118189 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-10-28 20:00:00.000000000 -0400
Modify: 2024-10-28 20:00:00.000000000 -0400
Change: 2025-01-01 14:32:59.692356995 -0500
Birth: 2025-01-01 14:32:59.691356987 -0500
Überzeugt, dass der Spuk nun ein Ende habe, versuchte es unser Sysadmin erneut:
[root@01ede4521839 /]# man 8 dnf
No manual entry for dnf in section 8
Moment! Die Datei ist da, die Manpage jedoch nicht? Sind hier dunkle Mächte am Werke? Nein, denn wie die folgenden Befehle offenbarten, lag die Ursache lediglich in kaputten Symlinks und fehlenden Paketen:
[root@01ede4521839 /]# ls -l /usr/share/man/man8/dnf.8.gz
lrwxrwxrwx. 1 root root 9 Oct 28 20:00 /usr/share/man/man8/dnf.8.gz -> dnf4.8.gz
[root@01ede4521839 /]# ls -l /usr/share/man/man8/dnf4.8.gz
ls: cannot access '/usr/share/man/man8/dnf4.8.gz': No such file or directory
[root@01ede4521839 /]# dnf provides /usr/share/man/man8/dnf4.8.gz
Last metadata expiration check: 0:05:59 ago on Wed Jan 1 14:31:37 2025.
…
python3-dnf-4.20.0-9.el10.noarch : Python 3 interface to DNF
Repo : baseos
Matched from:
Filename : /usr/share/man/man8/dnf4.8.gz
[root@01ede4521839 /]# dnf list python3-dnf
Last metadata expiration check: 0:06:16 ago on Wed Jan 1 14:31:37 2025.
Installed Packages
python3-dnf.noarch 4.20.0-9.el10 @System
Getrieben von Ungeduld und etwas Frust installierte unser Sysadmin nun auch das Paket python3-dnf.noarch neu, in einem letzten, verzweifelten Versuch, endlich die lang ersehnte Manpage zu erhalten.
[root@01ede4521839 /]# dnf reinstall python3-dnf.noarch
…
Reinstalled:
python3-dnf-4.20.0-9.el10.noarch
Complete!
[root@01ede4521839 /]# man 8 dnf
DNF4(8) DNF DNF4(8)
NAME
dnf4 - DNF Command Reference
SYNOPSIS
dnf [options] <command> [<args>...]
DESCRIPTION
DNF is the next upcoming major version of YUM, a package manager for
RPM-based Linux distributions. It roughly maintains CLI compatibility
with YUM and defines a strict API for extensions and plugins.
Na endlich! Da war sie, die so lang ersehnte und schmerzlich vermisste Manpage. Und die Mühe unseres Sysadmins wurde mit der Erkenntnis belohnt, dass die gesuchte Information auch in dieser Version von dnf(8) nicht enthalten war. Zufrieden wandte sich der Sysadmin nun dem Ticketsystem zu, um zu erfragen, warum die gesuchten Informationen nicht vorhanden sind und um eine Ergänzung anzuregen.
Und wenn er nicht gestorben ist, wartet er noch immer auf eine Antwort.
Seit einer ganzen Weile läuft nun Paperless-ngx bei mir auf dem Homeserver. In diesem Beitrag möchte ich euch meinen Workflow aufzeigen. Rechnungen per E-Mail Die meisten Rechnungen kommen heutzutage als Anhang per E-Mail. E-Mails...
Wir schreiben das Jahr 2025. Die Frage, ob man Linux-Server mit oder ohne Swap-Partition betreiben sollte, spaltet die Linux-Gemeinschaft in einer Weise, wie wir es seit dem Editor War nicht mehr gesehen haben…
So könnte ein spannender Film für Sysadmins anfangen, oder? Ich möchte aber keinen Streit vom Zaun brechen, sondern bin an euren Erfahrungen und Gedanken interessiert. Daher freue ich mich, wenn ihr euch die Zeit nehmt, folgende Fragen in den Kommentaren zu diesem Beitrag oder in einem eigenen Blogpost zu beantworten.
Stellt ihr Linux-Server mit Swap-Partition bereit und wie begründet ihr eure Entscheidung?
Hat euch die Swap-Partition bei sehr hoher Speicherlast schon mal die Haut bzw. Daten gerettet?
War der Server während des Swapping noch administrierbar? Falls ja, welche Hardware wurde für die Swap-Partition genutzt?
Eine kleine Mastodon-Umfrage lieferte bisher folgendes Bild:
Schaue ich mir meine eigenen Server an, so ergibt sich ein gemischtes Bild:
Debian mit LAMP-Stack und Containern: 16 GB RAM & kein Swap
RHEL-KVM-Hypervisor 1: 32 GB RAM & 4 GB Swap
RHEL-KVM-Hypervisor 2: 128 GB RAM & kein Swap
RHEL-Container-Host (VM): 4 GB RAM & 4 GB Swap
Bis auf den Container-Host handelt es sich um Bare-Metal-Server.
Ich kann mich nicht daran erinnern, dass jemals einem dieser Systeme der Hauptspeicher ausgegangen ist oder der Swapspeicher genutzt worden wäre. Ich erinnere mich, zweimal Swapping auf Kunden-Servern beobachtet zu haben. Die Auswirkungen waren wie folgt.
Im ersten Fall kamen noch SCSI-Festplatten im RAID zum Einsatz. Die Leistung des Gesamtsystems verschlechterte sich durch das Swapping so stark, dass bereitgestellten Dienste praktisch nicht mehr verfügbar waren. Nutzer erhielten Zeitüberschreitungen ihrer Anfragen, Sitzungen brachen ab und das System war nicht mehr administrierbar. Am Ende wurde der Reset-Schalter gedrückt. Das Problem wurde schlussendlich durch eine Vergrößerung des Hauptspeichers gelöst.
Im zweiten Fall, an den ich mich erinnere, führte ein für die Nacht geplanter Task zu einem erhöhten Speicherverbrauch. Hier hat Swapping zunächst geholfen. Tasks liefen zwar länger, wurden aber erfolgreich beendet und verwendeter Hauptspeicher wurde anschließend wieder freigegeben. Hier entstand erst ein Problem, als der Speicherbedarf größer wurde und die Swap-Partition zu klein war. So kam es zum Auftritt des Out-of-Memory-Killer, der mit einer faszinierenden Genauigkeit immer genau den Prozess abgeräumt hat, den man als Sysadmin gern behalten hätte. Auch hier wurde das Problem letztendlich durch eine Erweiterung des Hauptspeichers gelöst.
Ich erinnere mich auch noch an die ein oder andere Anwendung mit einem Speicherleck. Hier hat vorhandener Swap-Speicher das Leid jedoch lediglich kurz verzögert. Das Problem wurde entweder durch einen Bugfix oder den Wechsel der Anwendung behoben.
Nun bin ich auf eure Antworten und Erfahrungsberichte gespannt.
Der Name meines Blogs ist Programm. Es dient mir als digitales Gedächtnis für IT-Themen, die mich mich beschäftigt haben und die nochmal interessant werden können. Es ist eine Art Wissensdatenbank, auf die ich auch gerne zugreifen können möchte, wenn ich mal keine Internetverbindung habe.
Inspiriert durch den heutigen Beitrag von Dirk, möchte ich hier kurz beschreiben, was ich tue, um eine statische Version meines Blogs zu erstellen, welche ich einfach auf dem Laptop, Smartphone oder Tablet mitnehmen kann.
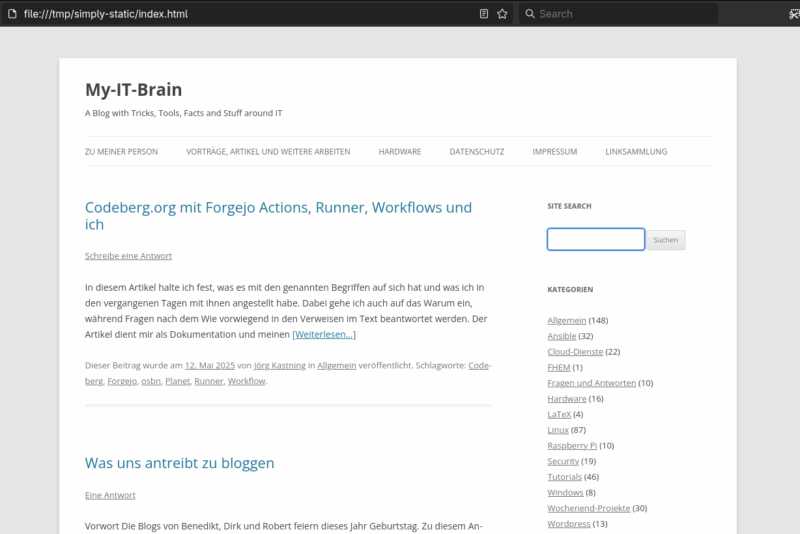
Ich verwende das Plugin Simply Static – The WordPress Static Site Generator, um eine statische Version meines Blogs zu erzeugen und als Zip-Archiv zu speichern. Möchte ich auf die statische Version meines Blogs zugreifen, entpacke ich das Zip-Archiv in ein Verzeichnis wie z.B. /tmp/simply-static/ und öffne anschließend in einem Webbrowser die Datei /tmp/simply-static/index.html.
Bildschirmfoto der statischen Version meines Blogs
So kann ich z.B. auch dann auf meine Artikel und Anleitungen zugreifen, wenn mein Webserver oder Internetzugriff nicht verfügbar ist. Die Suche auf der Seite funktioniert nur sehr eingeschränkt. Hier behelfe ich mir mit einer Dateisystemsuche im Terminal.
Ein paar Zahlen:
Dauer zur Erstellung des Zip-Archivs: ca. 10 Minuten
Größe des Zip-Archivs: 274 MB
Entpackte Größe: 355 MB
Rythmus der Erstellung: Wenn mir danach ist; in der Regel einmal pro Quartal
Mir gefällt an dieser Lösung, dass ich auf meinem mobilen Gerät keinen Container, ja noch nichmal einen Webserver, sondern nur einen Browser benötige. Das ist einfach, sparsam und robust.
Was haltet ihr davon ein Blog auf diese Weise offline verfügbar zu machen? Tragt ihr eure Blogs auch mit euch herum? Welche Werkzeuge nutzt ihr, um sie stets bei euch zu haben? Teilt euch gerne in den Kommentaren oder einem eigenen Blog mit.
Dieser Artikel ist Teil der #BlogWochen2025. Von Mai bis Oktober schreiben (zumindest) Robert, Dirk und ich über unterschiedliche Themen rund ums Bloggen. Du kannst gerne jederzeit einsteigen und mitmachen – die gesammelten Posts aller Teilnehmer:innen findest du auf dieser Seite und kannst sie auch als Feed abonnieren.
In diesem Artikel halte ich fest, was es mit den genannten Begriffen auf sich hat und was ich in den vergangenen Tagen mit ihnen angestellt habe. Dabei gehe ich auch auf das Warum ein, während Fragen nach dem Wie vorwiegend in den Verweisen im Text beantwortet werden.
Der Artikel dient mir als Dokumentation und meinen Leser:innen zur Unterhaltung und zum Wissenstransfer.
Auf Codeberg könnt ihr eure eigenen Freie Software-Projekte entwickeln, zu anderen Projekten beitragen, inspirierende und nützliche Freie Software durchstöbern, euer Wissen teilen oder euren Projekten mit Codeberg Pages ein Zuhause im Web geben, um nur einige Beispiele zu nennen.
Die beiden vorstehenden Abschnitte wurden übersetzt mit DeepL.com (kostenlose Version) und anschließend leicht angepasst und mit Links angereichert.
Mit Codeberg.org werden keine kommerziellen Interessen verfolgt. Man ist hier (nur) Nutzer und/oder Unterstützer, jedoch nicht selbst ein Produkt. Mir gefällt die Mission des Projekts. Daher bin ich dazu übergegangen, einen Teil meiner Repositories hier zu verwalten. Zwar bin ich kein Mitglied des Vereins, unterstütze diesen jedoch durch gelegentliche Spenden.
Actions, Runner und Workflows
Plattformen wie Codeberg.org, GitHub und GitLab unterstützen Softwareentwicklungsprozesse durch CI/CD-Funktionalität.
Ein Forgejo-Runner ist ein Dienst, der Workflows von einer Forgejo-Instanz abruft, sie ausführt, mit den Protokollen zurücksendet und schließlich den Erfolg oder Misserfolg meldet.
Dabei ist ein Workflow in der Forgejo-Terminologie eine YAML-Datei im Verzeichnis .forgejo/workflows eines Repositories. Workflows umfassen einen oder mehrere Jobs, die wiederum aus einem oder mehreren Steps bestehen. Eine Action ist eine Funktion zur Erfüllung häufig benötigter Aufgaben, bspw. Quelltext auschecken, oder sich bei einer Container-Registry einloggen etc. Siehe für weitere Informationen Abschnitt Hierarchy ff. im Forgejo Actions user guide.
Motiviert, meinen eigenen Forgejo-Runner zu installieren, haben mich zwei Blog-Artikel von meinem Arbeitskollegen Jan Wildeboer:
Durch den Betrieb eigener Forgejo-Runner kann ich bereits vorhandene Rechenkapazität nutzen. Es fallen für mich und den Verein Codeberg e.V. dadurch keine zusätzlichen Kosten an. Für die Installation auf RHEL 9 bin ich dem Forgejo Runner installation guide gefolgt, da das in Jans Artikel erwähnte Repository ne0l/forgejo offensichtlich nicht mehr gepflegt wird und nur eine veraltete Version des Runner enthält.
Ein Dankeschön geht raus an Jan für unseren kurzen und produktiven Austausch dazu auf Mastodon.
Wozu das Ganze?
Ich beschäftige mich beruflich seit einiger Zeit mit dem RHEL image mode und möchte demnächst einen meiner KVM-Hypervisor damit betreiben. Bis es soweit ist, arbeite ich eine Weile im „Jugend forscht“-Modus und baue immer wieder neue Versionen meiner Container-Images. Der Ablauf ist dabei stets derselbe:
Um vorstehender Anforderung gerecht zu werden, speichere ich das erzeugte Container-Image in einem privaten Repository auf Quay.io. Sowohl für registry.redhat.io als auch für quay.io ist ein Login erforderlich, bevor es losgehen kann.
Für mich bot sich hier die Gelegenheit, die Nutzung von Forgejo Workflows zu lernen und damit den Ablauf zur Erstellung meines RHEL Bootc Images zu automatisieren.
Forgejo Workflow und Runner-Konfiguration
Im folgenden Codeblock findet ihr meinen Forgejo Workflow aus der Datei .forgejo/workflows/build_image.yaml, gefolgt von einer Beschreibung der einzelnen Schritte. Zur Erklärung der Begriffe name, on, env, jobs, steps, run, etc. siehe Workflow reference guide.
Der Workflow wird jedes Mal ausgeführt, wenn ich einen Commit in den Branch main pushe
Ich definiere einige Umgebungsvariablen, um bei Änderungen nicht alle Schritte im Workflow einzeln auf notwendige Änderungen prüfen zu müssen
Mit `runs-on: podman` bestimme ich, dass der Workflow auf einem Runner mit dem Label podman ausgeführt wird; der entsprechende Runner started dann einen rootless Podman-Container, in dem die folgenden Schritte innerhalb von rootful Podman ausgeführt werden (nested Podman bzw. Podman in Podman)
Git wird installiert
Anmeldung an registry.redhat.io erfolgt
Anmeldung an quay.io erfolgt
Das Git-Repository wird geklont, um es auf dem Runner verfügbar zu haben
Der Runner baut ein Container-Image (Erinnerung an mich selbst: Ersetze den hardcodierten Pfad durch eine Variable)
Das erstellte Image wird in die Registry gepusht
Damit mein Runner den obigen Workflow ausführen kann, existiert auf diesem die Konfigurationsdatei /etc/forgejo-runner/config.yml, welche ich mit dem Kommando forgejo-runner generate-config > config.yml erstellt und anschließend angepasst habe. Der folgende Codeblock zeigt nur die Abschnitte, die ich manuell angepasst habe.
Ich greife mal die Zeile podman:docker://registry.access.redhat.com/ubi9/podman heraus:
podman: am Beginn der Zeile beinhaltet das Label, welches im Worflow mit runs-on verwendet wird
Mit dem Rest der Zeile wird bestimmt, in welchem Container-Image der Workflow ausgeführt wird
Ich habe mich für ubi9/podman entschieden, weil
ich bei Red Hat arbeite und daher
mit den Prozessen zur Erstellung unserer Images vertraut bin,
wodurch sich ein gewisses Vertrauen gebildet hat.
Ich vertraue unseren Images mehr, als jenen, die irgendein Unbekannter gebaut hat und deren Inhalt ich nicht kenne (man kann den Inhalt aber selbstverständlich überprüfen)
und ich so prüfen konnte, ob sich ein Image mit „unseren“ Werkzeugen bauen läst (nicht, dass ich daran gezweifelt hätte).
Die Angabe von privileged: true ist erforderlich, wenn man innerhalb des Containers ebenfalls mit podman oder docker arbeiten möchte.
Entscheidungen
Meinem weiter oben abgebildeten Workflow ist zu entnehmen, dass ich auf die Verwendung von Forgejo Actions verzichtet habe. Das hat folgende Gründe:
Für die Verwendung ist node auf dem Runner erforderlich
node ist im Image ubi9/podman standardmäßig nicht installiert
Node.js ist für mich das Tor zur Hölle und ich vermeide dessen Nutzung wenn möglich
Die Nutzung ist keine Voraussetzung, da ich mein Ziel auch so ohne Mehraufwand erreicht habe
Sobald die Workflows länger und komplexer werden, mag sich meine Einstellung zu Actions ändern.
Zusammenfassung
Ich habe gelernt:
Forgejo Runner zu installieren und zu konfigurieren
Wie Forgejo Workflows funktionieren und auf Codeberg.org genutzt werden können
Wie ich mir damit zukünftig die Arbeit in anderen Projekten erleichtern kann
Suchmaschinen gibt es einige. Google, Bing und DuckDuckGo dürften die bekanntesten sein. Laut statcounter.com führt Google mit 87 Prozent Marktanteil den Suchmaschinenmarkt an. Auf Platz 2 befindet sich Bing mit knapp 6 Prozent Marktanteil....
In diesem Beitrag berichte ich über mein Wochenend-Projekt „Ansible Collection tronde.opencloud“, welche ihr seit dem 4. Mai 2025 in Version 1.0.0 auf Ansible Galaxy sowie bei Codeberg.org findet.
Ich habe die Collection mit den folgenden Zielen erstellt:
Deployment von OpenCloud mittels Ansible in einer rootless Podman-Umgebung
Backup der OpenCloud und Speicherung des Backups auf dem Ansible Control Node
Restore der OpenCloud aus einem zuvor erzeugten Backup
Aktuell läuft eine OpenCloud-Instanz auf einem meiner Server unter Debian Bookworm.
Nicht so schnell! Was sind Ansible, OpenCloud und Podman?
Derjenige, dem diese Begriffe bereits geläufig sind, kann direkt zum Abschnitt Motivation springen. Für alle anderen gibt es hier eine knappe Erklärung mit Verweisen zu weiteren Informationen, um sich mit der Materie vertraut zu machen.
Ansible
Ansible hat sich zu einem beliebten Schweizer Taschenmesser für Automation, Konfigurations-Management, Deployment und Orchestrierung entwickelt. Über folgende Links findet ihr reichlich informationen dazu:
OpenCloud ist die Filesharing & Kollaborations-Lösung der Heinlein Gruppe.
Durch intelligentes Datei-Management und eine starke Open Source-Community werden Dateien zu wertvollen Ressourcen – effektiv strukturiert und langfristig nutzbar.
Ich betreibe und nutze privat eine Nextcloud, um Dateien über mehrere Geräte zu synchronisieren, mit anderen zu teilen und um Backups verschiedener Geräte und Dienste darin abzulegen. Dazu betreibe ich neben dem Reverse Proxy (NGINX) einen Container mit einer MySQL-Datenbank und einen Anwendungscontainer mit Nextcloud selbst. Nextcloud verfügt über ein reichhaltiges Plugin-Ökosystem zur Erweiterung der Funktionalität, welche ich persönlich allerdings nicht benötige.
Mir gefällt, dass OpenCloud ganz ohne Datenbank auskommt und sich auf die Synchronisation und das Teilen von Daten fokussiert. Dies entspricht genau meinem Anwendungsfall. Wenn ich dadurch einen Dienst weniger betreiben kann (MySQL), ist das umso besser.
Nur passt der gewählte Technologie-Stack nicht zu meiner persönlichen Vorliebe. Während OpenCloud auf die Verwendung von Docker Compose mit Traefik als Reverse Proxy setzt, bevorzuge ich, Container mit Podman zu betreiben und verwende (noch) NGINX als Reverse Proxy.
Um OpenCloud etwas kennenzulernen, habe ich beschlossen, analog zu meiner Ansible Collection tronde.nextcloud eine Collection tronde.opencloud zu erstellen, um OpenCloud deployen und verwalten zu können.
Ob sich der Aufwand lohnt, werde ich mit der Zeit sehen. Wenn es mir zuviel wird oder ich den Gefallen daran verliere, werde ich dieses Wochenendprojekt wieder einstellen bzw. gern in die Hände motivierter Menschen geben, die es weiterführen möchten.
Informationen zur Collection
Das Wichtigste zu dieser Collection habe ich bereits zu Beginn dieses Textes geschrieben. Neben den für Ansible Collections und Roles typischen README.md-Dateien habe ich auch ein paar Zeilen Dokumentation erstellt:
Die Collection steht unter einer freien Lizenz und ich gebe keinerlei Garantie oder Gewähr, dass euch deren Verwendung nicht direkt in den Untergang führt. ;-)
Die Collection kann (noch) nicht viel. Das Wenige scheint jedoch robust zu funktionieren. Wenn ihr neugierig seid, probiert sie gerne aus. Auch euer konstruktives Feedback ist mir stets willkommen.
Für mich ist dies ein Wochenend-Projekt, das mit etlichen anderen Themen um meine Zeit konkurriert. Erwartet daher keine schnellen Entwicklungsfortschritte. Wenn ihr gern daran mitwirken möchtet, bin ich dafür offen. Werft einen Blick in den kurzen Contribution Guide und legt los. Falls ihr Fragen habt oder euch mit mir über die Collection austauschen möchtet, könnt ihr
eure Frage als Issue mit dem Label „Question“ im Repository stellen oder
Das noch recht junge Projekt macht einen aufgeräumten Eindruck. Die Benutzeroberfläche ist nicht überladen und ich finde mich schnell darin zurecht. Das Entwicklerteam antwortet bereitwillig auf Fragen und kümmert sich in angemessener Zeit um Issues. Dies ist zumindest mein subjektiver Eindruck.
Einziger Wermudstropfen ist wie so oft die Dokumentation, welche mit der Entwicklung offenbar nicht Schritt halten kann. Diese lässt leider noch viele Fragen offen, welche über GitHub Discussions oder Suche im Quelltext geklärt werden können/müssen. Ich empfinde dies etwas ermüdend und es drückt die Motivation.
Nun werde ich OpenCloud erstmal einige Zeit nutzen und ein paar Versions-Upgrades hinter mich bringen. Anschließend werde ich dann einen Meinungsartikel schreiben, wie es mir gefällt.
In diesem Text dokumentiere ich, wie ein Tang-Server auf Debian installiert werden kann und wie man den Zugriff auf diesen auf eine bestimmte IP-Adresse einschränkt.
Installiert wird der Tang-Server mit folgendem Befehl:
sudo apt install tang
Standardmäßig lauscht der Tang-Server auf Port 80. Da dieser Port auf meinem Server bereits belegt ist, erstelle ich mit dem Befehl sudo systemctl edit tangd.socket eine Override-Datei mit folgendem Inhalt:
Ich möchte den Zugriff auf den Tang-Server auf eine IP-Adresse beschränken, nämlich auf die IP-Adresse des einen Clevis-Clients, der diesen Server verwenden wird. Dazu führe ich die folgenden Schritte durch.
:~# iptables -A INPUT -p tcp -s 203.0.113.1 --dport 7500 -j ACCEPT
:~# iptables -A INPUT -p tcp --dport 7500 -j DROP
:~# mkdir /etc/iptables
:~# iptables-save >/etc/iptables/rules.v4
Damit die in der Datei /etc/iptables/rules.v4 gespeicherten Regeln nach einem Neustart wieder geladen werden, erstelle ich ein Systemd-Service:
Um zu überprüfen, ob der Tang-Server wie gewünscht arbeitet, setze ich auf meinem Clevis-Client den folgenden Befehl ab. Dabei muss nach der Ver- und Entschlüsselung der gleiche Text ‚test‘ ausgegeben werden.
~]$ echo test | clevis encrypt tang '{"url":"tang1.example.com:7500"}' -y | clevis decrypt
test
In der vergangenen Woche ist es einem Kommentar-Spammer gelungen meinen SPAM-Filter zu überwinden und die Kommentarspalte eines älteren Artikels mit SPAM zu füllen.
Eine erste Analyse ergab, dass diese SPAM-Welle von IP-Adressen aus durchgeführt wurde, die in der Russischen Föderation registriert sind. Da der großteil der unerwünschten Zugriffe auf meinen Server aus Russland und China stammen, habe ich eine erste Maßnahme ergriffen: Zugriffe von IP-Adressen aus der Russischen Föderation und China werden blockiert. Damit hatte ich mir zumindest Luft verschafft, um die Lage später etwas genauer zu analysieren.
Erste Erkenntnisse einer oberflächen Analyse
Nachdem die Zugriffe aus Russland und China gesperrt waren, erkannte ich, dass auch von IP-Adressen aus ganz anderen Regionen wie z.B. Vereinigte Arabische Emirate und Niederlande versuchte wurde SPAM in meinem Blog abzuladen; diese Versuche wurden jedoch von Antispam Bee blockiert
Auffällig oft wurde eine E-Mail-Adresse aus der Domain ‚.ru‘ für die Kommentare verwendet
Zwei ältere Artikel aus 2015 und 2022 waren auffällig oft das Ziel der Spammer
In den letzten 6 Tagen sind insgesamt 416 SPAM-Kommentare eingegangen, von denen ich 129 manuell markieren musste
Gegenmaßnahmen
Alle Kommentare, die innerhalb von Inhalt, Autornamen, URL oder E-Mail-Adresse die Zeichenkette ‚.ru‘ enthalten, müssen moderiert werden
Bevor ein Kommentar erscheint, muss der Autor bereits einen freigegebenen Kommentar geschrieben haben; alle anderen werden moderiert
Für die zwei am stärksten betroffenen Artikel habe ich die Kommentarfunktion deaktiviert
Die über Iptables konfigurierte Sperrliste habe ich voerst wieder deaktiviert.
Status um 2025-04-10T20:46+02
Nach der Umsetzung der ersten zwei Gegenmaßnahmen, wurden noch vier Kommentare von Antispam Bee blockiert
Seit der Umsetzung der dritten Gegenmaßnahme ist kein weiterer unerwünschter Kommentar eingegangen
In den letzten Tagen, musste ich hier im Blog leider beobachten, wie sich ein Spammer an den wachsamen Augen der Antispam Bee vorbeigeschlichen hat und einzelne SPAM-Kommentare unter einem älteren Artikel aus dem Jahr 2015 hinterlassen hat.
Was mit einzelnen Kommentaren begann, erweiterte sich dann zu einer kleinen SPAM-Attacke, die in der Nacht vom 10.04.2025 weitere 129 SPAM-Kommentare unter den Artikel spülte. Dabei wurden 30 unterschiedliche IP-Adressen verwendet, die alle in der Russischen Föderation registriert sind.
Nach einer Sichtung weiterer blockierter SPAM-Kommentare stelle ich fest, dass der überwiegende Teil des SPAMs aus der Russischen Föderation und China kommt. IP-Adressen aus diesen Regionen werden auch regelmäßig durch fail2ban blockiert.
Da der letzte Spammer durch den Wechsel der IP-Adressen, bestehende Mechanismen jedoch unterlaufen konnte, baue ich nun eine weitere Verteidigungslinie auf. Zukünftig werden Zugriffe von IP-Adressen aus der Russischen Föderation und China von Iptables blockiert.
Update 2025-04-10T18:40+02: Ich habe die Maßnahme vorerst wieder ausgesetzt und prüfe, ob angepasste Kommentar-Einstellungen ausreichen, um dem Kommentar-SPAM zu begegnen. Ich lasse die folgende Lösung als Dokumentation online. Evtl. muss ich doch wieder darauf zurückfallen.
Hier ist eine iptables-Lösung zum Blockieren von IP-Adressen aus Russland und China:
Hinweis: Den Vorschlag für obige Lösung habe ich mir von perplexity.ai generieren lassen. Dabei musste ich lediglich den Pfad zu /usr/libexec/xtables-addons korrigieren, welcher fälschlicherweise auf /usr/lib/ zeigte.
Fazit
Das Internet ist kaputt. Die Zeiten in denen die Nutzer respektvoll und umsichtig miteinander umgingen, sind lange vorbei.
Mir ist bewusst, dass auch eine Sperrung von IP-Adressen basierend auf Geolokation keine absolute Sicherheit bietet und man mit dieser groben Maßnahme auch mögliche legitime Zugriffe blockiert. Allerdings prasseln aus diesen Teilen der Welt so viele unerwünschte Zugriffsversuche auf meinen kleinen Virtual Private Server ein, dass ich hier nun einen weiteren Riegel vorschiebe.
Welche Maßnahmen ergreift ihr, um unerwünschte Besucher von euren Servern fernzuhalten? Teilt eure Maßnahmen und Erfahrungen gern in den Kommentaren oder verlinkt dort eure Blog-Artikeln, in denen ihr darüber geschrieben habt.
Ich beantworte hier meine eigene Frage, damit ich zukünftig nicht so lange im Internet nach der Anwort suchen muss.
Mein Ziel ist es, eine virtuelle Maschine mit dem Kommando virt-install zu installieren, zu welcher ich mich anschließend mit dem Kommando virsh console <domain> verbinden kann, um z.B. das Netzwerk konfigurieren zu können.
Der entscheidende Teil ist dabei --console pty,target_type=virtio. Der folgende Codeblock zeigt nun noch die erfolgreiche Verbindung zur seriellen Konsole der VM:
$ virsh -c qemu:///system console vm1 --safe
Connected to domain 'vm1'
Escape character is ^] (Ctrl + ])
localhost login:
Das MQTT-Passwort lässt sich auf der Konsole des Home Assistant Systems in der Datei /mnt/data/supervisor/homeassistant/.storage/core.config_entries finden. Der entsprechende Eintrag sieht bei mir wie folgt aus:
Dieses Tutorial führt in den RHEL image mode ein und zeigt, wie ein solches Image in einer virtuellen Maschine (VM) installiert werden kann. Es wird ebenfalls gezeigt, wie ein installiertes Image aktualisiert und bei Bedarf zurückgerollt werden kann.
Während diese Einführung in Deutsch gehalten ist, liegen die Dokumentation und weitere verwendete Quellen ausschließlich in englischer Sprache vor.
Das Tutorial richtet sich in erster Linie an Sysadmins, die bereits Erfahrung mit dem Betrieb von RHEL oder einer verwandten Enterprise Linux Distribution haben. Es bietet keine allgemeine Einführung in die Installation und den Betrieb von Red Hat Enterprise Linux.
Zum Inhalt
Die folgende Liste bietet einen Überblick über den Inhalt:
RHEL image mode ist eine Technology Preview und stellt eine neue Methode dar, um RHEL zu konfigurieren, installieren bzw. deployen und zu verwalten.
Durch Nutzung von Container-Tools wird ein Container-Image erstellt, welches neben dem RHEL-Userland auch den RHEL-Kernel, Boot Loader, Firmware und Treiber umfasst. Dieses RHEL-Container-Image (auch RHEL Bootc Image genannt) kann anschließend genutzt werden, um RHEL im Datacenter oder in der Cloud – auf Bare-Metal-Servern, virtuellen Maschinen oder Edge-Geräten zu deployen. Das RHEL-Container-Image kann direkt als Container ausgeführt werden, um die Funktionalität zu testen. Für das Deployment kann das Container-Image in ein Disk-Image für die entsprechende Zielplattform konvertiert werden. Ein installiertes oder als Disk-Image provisioniertes System läuft anschließend nativ auf der Hardware bzw. in der virtuellen Maschine und wird dort nicht als Container ausgeführt.
Konsolidierung von Bereitstellungsprozessen
In vielen Unternehmen kommen heute neben klassischen virtuellen Maschinen auch Linux-Container zum Einsatz. RHEL image mode bietet die Möglichkeit, Bereitstellungsprozesse zu konsolidieren, indem für die Bereitstellung von RHEL-Images die gleichen Werkzeuge genutzt werden, wie für die Bereitstellung von Container-Images für Anwendungen.
Immutable RHEL
Mit Ausnahme von /etc und /var ist das Wurzel-Dateisystem in RHEL image mode immutable (read-only).
Anwendungen und Updates werden durch aktualisierte RHEL-Container-Images verteilt. Ein provisioniertes System lädt dazu das aktualisierte Image auf die lokale Festplatte und startet dieses nach einem Neustart. Im Fehlerfall kann durch einen weiteren Neustart einfach das vorherige Image gestartet werden. So können fehlgeschlagene Updates einfach zurückgerollt werden.
Dies bietet dem Admin die Sicherheit, bei Bedarf zum vorherigen Zustand zurückkehren zu können, ohne dafür auf VM-/Storage-Snapshots oder andere Mechanismen außerhalb des Betriebssystems zurückgreifen zu müssen.
Deklarative Konfiguration des Betriebssystems
RHEL image mode macht es einfach, zu konfigurieren und zu verfolgen, welche Pakete in einem Basis-Image enthalten sind und wann welche Pakete hinzugefügt wurden.
Red Hat veröffentlicht in der Container-Registry registry.redhat.ioRHEL Bootc Base Images, welche die Basis für eigene Images darstellen. Zu jeder Version wird eine Liste der enthaltenen Pakete veröffentlicht. Diese ist über den Red Hat Ecosystem Catalog einsehbar:
Ansicht der Paketliste eines RHEL 9 Bootc Base Image
Hier ist zu beachten, dass obwohl amd64 als Architektur ausgewählt wurde, die Liste Pakete aller verfügbaren Architekturen zeigt. Natürlich sind im Basis-Image nicht 2302 Pakete enthalten. Die Filtermöglichkeiten und die Ergebnisliste zeigen leider unerwartete Ergebnisse. Ich habe dies bereits intern gemeldet und hoffe, dass sich bald jemand der Sache annimmt.
Das in obiger Abbildung gezeigte Image enthält für die amd64-Architektur 441 Pakete. Vergleiche ich dies mit zwei meiner RHEL 9 Installationen, die auf der Minimalinstallation basieren, so umfassen diese 591 bzw. 510 Pakete. Der Vergleich hinkt allerdings, da ich auf den RHEL package mode Installationen bereits weitere Software nachinstalliert habe. Ich bin jedoch erfreut, dass das Basis-Image nicht mehr Pakete als eine Minimalinstallation enthält.
Pakete, die zusätzlich hinzugefügt werden sollen, werden im Containerfile aufgeführt, welches üblicherweise einer Versionskontrolle unterliegt. Änderungen können so jederzeit nachvollzogen werden.
Meine Laborumgebung besteht aus zwei virtuellen Maschinen, welche auf einem Laptop ausgeführt werden. Beide VMs verfügen über 2 vCPU, 8 GB RAM und 40 GB Speicher.
Auf VM 1 werden folgende Tätigkeiten ausgeführt:
Erstellung und Ausführung einer einfachen Container-Registry
Erstellung und Pflege eines oder mehrerer rhel-bootc-Container-Images
Erstellung von Disk-Images
Anhand von VM 2 werden folgende Dinge demonstriert:
Installation von RHEL image mode
Aktualisierung der Installation
Wechsel des verwendeten Images
Rollback
Die in diesem Tutorial verwendeten Containerfiles, Dateien und Skripte habe ich in einem Git-Repository gesammelt. Fühlt euch frei, die dortigen Dateien auf eigene Gefahr für eigene Versuche zu verwenden. Repository-URL: https://github.com/tronde/image-mode-demo
RHEL Bootc Image erstellen
Dieser Abschnitt wurde aus Kapitel 2 der Dokumentation Using image mode for RHEL to build, deploy, and manage operating systems abgeleitet. In ihm wird das RHEL-Container-Image erstellt, welches im nächsten Schritt für das Deployment in einer VM vorbereitet wird. Dieser Abschnitt behandelt folgende Schritte:
Containerfile(5) erstellen
Container-Image mit podman-build(1) erstellen
Container-Image auf dem Build-System testen
Containerfile
Mit dem folgenden Containerfile(5) wird konfiguriert, wie das RHEL Bootc Base Image ‚rhel-bootc:9.5‚ angepasst werden soll:
Die Dienste httpd und sshd werden aktiviert, damit sie nach dem Boot-Vorgang automatisch starten
Die im Containerfile aufgeführten Pakete sind eine persönliche Auswahl, die ich gern auf meinen Systemen habe. Ihr könnt hier natürlich die Pakete eurer Wahl eintragen.
Für dieses Tutorial installiere ich den Dienst httpd. Das von dem Image provisionierte System wird also einen Webserver hosten. Dass ich die index.html-Datei ebenfalls dem Image hinzufüge, soll mir lediglich den späteren Test in diesem Tutorial vereinfachen. Je nach Aufbau, Inhalt und Änderungsrate der auszuliefernden Webseite bzw. Webanwendung ist es nicht sinnvoll, diese in das Image zu integrieren.
Build
Login registry.redhat.io
Bevor das erste Container-Image erstellt werden kann, ist eine Anmeldung an der Container-Registry registry.redhat.io notwendig:
$ podman login registry.redhat.io
Username: alice
Password:
Login Succeeded!
Mit dem folgenden Befehl kann nun ein Image aus obigen Containerfile erstellt werden:
$ time podman build -t localhost/rhel9.5-bootc:test .
…
Successfully tagged localhost/rhel9.5-bootc:test
c958185aa4c578af37b5bca796c7c5e50a270f7b7de38126c31fa6ab97046f41
real 2m52.574s
user 2m31.787s
sys 0m59.680s
$ podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/rhel9.5-bootc test c958185aa4c5 40 seconds ago 1.68 GB
registry.redhat.io/rhel9/rhel-bootc 9.5 7cf5466a7756 2 days ago 1.56 GB
Das Container-Image wird unter dem Namen localhost/rhel9.5-bootc:test im lokalen Dateisystem gespeichert.
Der Build-Vorgang dauerte insgesamt knapp 3 Minuten. Darin ist die Zeit zum Herunterladen des Basis-Image registry.redhat.io/rhel9/rhel-bootc:9.5 enthalten. Ist dieses Image bereits vorhanden, dauert der Build-Vorgang nur knapp über 1 Minute.
Test
Der nun folgende Code-Block zeigt, wie das soeben erstellte Container-Image mit Podman im interaktiven Modus gestartet werden kann. Es wird geprüft, ob die index.html-Datei vorhanden ist und wie viele Pakete das Image enthält.
$ podman run -it --rm --name mybootc localhost/rhel9.5-bootc:test /bin/bash
bash-5.1# ls -l /var/www/html
total 4
-rw-r--r--. 1 root root 342 Jan 11 11:20 index.html
bash-5.1# rpm -qa | wc -l
465
bash-5.1#
Als nächste teste ich, ob die index.html-Datei auch ausgeliefert wird:
$ podman run -d --rm -p 127.0.0.1:8888:80 --name mybootc localhost/rhel9.5-bootc:test
fa9c1f5110cd58c3f28760fb5a5d69cdc4595a5cba2f29ff67f85eaa076204ab
$ curl http://127.0.0.1:8888
<!DOCTYPE html>
<html lang="de">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Bootc Demo Page</title>
</head>
<body>
<p>Diese Seite wird von einem Webserver ausgeliefert, der mit RHEL Bootc Image Mode bereitgestellt wurde.</p>
</body>
</html>
Test erfolgreich! Die konfigurierte Webseite wird wie erwartet ausgeliefert. Der Container wird mit podman stop mybootc gestoppt und der Test ist beendet.
Zwischenfazit
Bis hier wurde ein Containerfile erstellt, welches das zu verwendende Basis-Image, die zusätzlich zu installierenden Pakete und die auszuführenden Dienste definiert. Mit Hilfe dieses Containerfiles und Podman wurde anschließend das Container-Image localhost/rhel9.5-bootc:test erzeugt. Mit einem einfachen Test konnte auf dem Build-System verifiziert werden, dass die index.html-Datei wie gewünscht ausgeliefert wird.
Das Image enthält keinerlei Passwörter oder SSH-Schlüssel. Es sind somit bisher keinerlei Geheimnisse enthalten, die mit dem Image verloren gehen könnten.
Verglichen mit einer klassischen RHEL-Minimalinstallation, die als Basis für ein Golden-Image dient, konnte der Vorgang deutlich schneller abgeschlossen werden.
ISO-Image mit dem bootc-image-builder erstellen
Der bootc-image-builder ist eine Container-Variante des RHEL Image Builder. Mit diesem wird in den folgenden Schritten ein ISO-Image aus dem zuvor erstellten Container-Image erzeugt. Mit dem ISO-Image wird anschließend eine Installation in einer VM durchgeführt.
Mit dem bootc-image-builder können auch Disk-Images wie AMI, GCE, QCOW2, RAW und VMDK erzeugt werden. Ich habe mich für ISO entschieden, da dies am vielseitigsten verwendbar ist. Man kann damit VMs unter KVM/Qemu und VMware genauso installieren, wie Bare-Metal-Server.
Benutzer, Passwort und SSH-Schlüssel hinzufügen
Um sich nach der Installation interaktiv am System anmelden zu können, werden dem ISO-Image ein Benutzer mit Passwort und SSH-Schlüssel hinzugefügt. Dafür wird die folgende Datei toml.config genutzt:
$ cat config.toml
[[customizations.user]]
name = "alice"
password = "changeme"
key = "ssh-ed25519 AAAAC3NzaC…cr alice@example.com"
groups = ["wheel"]
Durch Hinzufügen des Benutzers zur Gruppe wheel darf dieser privilegierte Kommandos mittels sudo ausführen.
Das Container-Image in den passenden Benutzerkontext kopieren
Das Image localhost/rhel9.5-bootc:test wurde mit einem rootless-Benutzer erstellt. Der Befehl im folgenden Abschnitt muss jedoch mit root-Rechten ausgeführt werden. Rootful-Podman kann jedoch nicht auf das Image zugreifen, welches wir mit rootless-Podman erstellt haben. Der Vorgang würde fehlschlagen mit der Meldung: Error: localhost/rhel9.5-bootc:test: image not known.
Um dies zu verhindern, gibt es zwei Möglichkeiten. Möglichkeit 1 bietet sich an, wenn man das ISO-Image auf dem gleichen System wie das Container-Image erzeugen möchte. Hierbei wird das Container-Image einfach in den passenden Benutzerkontext kopiert. Die zweite Möglichkeit besteht darin, das Container-Image in eine Container-Registry zu pushen, aus der es dann im nächsten Schritt wieder gepullt werden kann.
Möglichkeit 1
Das Container-Image wird mit folgendem Befehl aus dem Kontext des Benutzers ‚alice‘ in den Kontext des Benutzers ‚root‘ kopiert.
$ podman image scp alice@localhost::rhel9.5-bootc:test
…
$ sudo podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/rhel9.5-bootc test fb6237fff684 21 minutes ago 1.68 GB
Selbstverständlich kann das Container-Image auch in einer Container-Registry gespeichert und im root-Kontext von dort wieder heruntergeladen werden. Für die spätere Aktualisierung eines installierten RHEL image mode Systems ist die Nutzung einer Container-Registry von Vorteil.
How to implement a simple personal/private Linux container image registry for internal use beschreibt die Einrichtung einer einfachen Registry. Ich habe die auszuführenden Schritte in dem Skript create_simple_container_registry.sh zusammengefasst. Die zur Ausführung notwendigen Parameter werden in der Datei registry.vars konfiguriert. Diese Datei ist bereits mit Standardwerten gefüllt, die direkt verwendet werden können. Installiert und konfiguriert wird die Registry mit dem Kommando:
$ sudo bash create_simple_container_registry.sh
Ich trage die IP-Adresse und den Hostnamen meiner VM 1 in die Datei /etc/hosts ein, damit die Namensauflösung funktioniert. Der folgende Code-Block zeigt, wie das Image localhost/rhel9.5-bootc in die Registry gepusht wird.
Die Option --tls-verfiy=false ist notwendig, da ein selbstsigniertes TLS-Zertifikat verwendet wird. Mit dem folgenden Befehl kann überprüft werden, ob sich das Image in der Registry befindet.
Der folgende Code-Block zeigt, wie mit dem bootc-image-builder eine ISO-Datei erzeugt wird, die sich für eine RHEL-Installation in einer Offline-Umgebung eignet. Der Befehl muss mit sudo ausgeführt werden, da erweiterte Benutzerrechte erforderlich sind.
Da das Container-Image des bootc-image-builder noch nicht lokal vorliegt, muss zuerst ein Login bei registry.redhat.io erfolgen. Dies wurde weiter oben bereits für den rootless-Benutzer durchgeführt, muss für den rootful-Benutzer jedoch wiederholt werden, da Logins nicht zwischen verschiedenen Benutzerkontexten geteilt werden.
Achtung: Der folgende Befehl funktioniert nur, wenn das Image localhost/rhel9.5-bootc:test für root verfügbar ist. Dies kann durch eine der Methoden, die im vorherigen Abschnitt beschrieben wurden, sichergestellt werden. Ich habe in diesem konkreten Fall Möglichkeit 1 verwendet.
$ sudo podman login registry.redhat.io
Username: alice
Password:
Login Succeeded!
$ mkdir output
$ time sudo podman run \
> --rm \
> -it \
> --privileged \
> --pull=newer \
> --security-opt label=type:unconfined_t \
> -v /var/lib/containers/storage:/var/lib/containers/storage \
> -v $(pwd)/config.toml:/config.toml \
> -v $(pwd)/output:/output \
> registry.redhat.io/rhel9/bootc-image-builder:latest \
> --type iso \
> --config /config.toml \
> --local \
> localhost/rhel9.5-bootc:test
…
real 22m31.407s
user 0m1.997s
sys 0m2.049s
$ ls -lh output/bootiso/
total 2.4G
-rw-r--r--. 1 root root 2.4G Jan 11 14:26 install.iso
Nun zur Erklärung des Ganzen:
Der Login erfolgt, um das bootc-image-builder-Image herunterladen zu können
Im Projektverzeichnis wird das Verzeichnis output erstellt, welches die ISO-Datei enthalten wird
Nun folgt ein ziemlich langer Aufruf von podman run
Falls in registry.redhat.io eine neuere Version des bootc-image-builder gefunden wird, wird diese heruntergeladen und genutzt
bootc-image-builder muss mit erhöhten Rechten ausgeführt werden, weshalb die Ausführung mittels sudo und die Option --privileged erforderlich sind
Ort der config.toml und Verzeichnis für das ISO werden dem Container als Volume zugänglich gemacht
Mit --type iso wird festgelegt, dass eine ISO-Datei erstellt werden soll
Die Option --local gibt an, dass das lokal existierende Image localhost/rhel9.5-bootc.test verwendet und dies nicht aus einer Registry geholt werden soll
Dass der Vorgang ganze 22 Minuten dauerte, ist den 2 vCPU-Kernen und den 8 GB RAM meiner VM geschuldet. Während der Arbeitsspeicher gerade ausreichend war, dürften weitere CPU-Kerne den Vorgang deutlich beschleunigen.
Das nun erstellte ISO kann zur Installation in VM 2 verwendet werden.
Offline-Installation mit dem RHEL image mode
Das im vorherigen Abschnitt erstellte Disk-Image install.iso wird nun verwendet, um VM 2 zu installieren. Die Installation läuft wie eine normale unbeaufsichtigte Anaconda-Installation ab.
In der Datei toml.config wurde ein Benutzer mit einem SSH-Schlüssel spezifiziert, der nun zum Login in das neue System verwendet werden kann.
$ ssh -o StrictHostKeyChecking=no alice@vm2.example.com
Warning: Permanently added 'vm2.example.com' (ED25519) to the list of known hosts.
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 7.1M 1 loop
sr0 11:0 1 2.4G 0 rom
zram0 251:0 0 7.8G 0 disk [SWAP]
vda 252:0 0 30G 0 disk
├─vda1 252:1 0 1G 0 part /boot
├─vda2 252:2 0 1G 0 part [SWAP]
└─vda3 252:3 0 28G 0 part /var
/sysroot/ostree/deploy/default/var
/etc
/sysroot
$ $ mount | grep -E '"/"|var|sysroot|etc'
/dev/vda3 on /sysroot type ext4 (ro,relatime,seclabel)
composefs on / type overlay (ro,relatime,seclabel,lowerdir=/run/ostree/.private/cfsroot-lower::/sysroot/ostree/repo/objects,redirect_dir=on,metacopy=on)
/dev/vda3 on /etc type ext4 (rw,relatime,seclabel)
/dev/vda3 on /sysroot/ostree/deploy/default/var type ext4 (rw,relatime,seclabel)
/dev/vda3 on /var type ext4 (rw,relatime,seclabel)
$ less /usr/lib/systemd/system/bootc-fetch-apply-updates.service
[jkastnin@localhost ~]$ systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; preset: disabled)
Active: active (running) since Tue 2025-01-14 15:29:07 UTC; 28min ago
Docs: man:httpd.service(8)
Main PID: 829 (httpd)
…
Da ich im Vorfeld keine genaueren Angaben gemacht habe, wurde der Datenträger automatisch partitioniert. Die Installation lässt sich durch Kickstart-Dateien steuern. Dazu wird der Inhalt der Kickstart-Datei in die Datei config.toml eingefügt. Siehe hierzu Kapitel 4.9. Using bootc-image-builder to build ISO images with a Kickstart file in der RHEL-Dokumentation.
Fazit nach der Installation von RHEL image mode
Mit rootless podman wurde ein rhel9.5-bootc:test Image erstellt
Mit dem bootc-image-builder wurde ein ISO-Image erstellt, welchem ein Benutzer mit Passwort und öffentlichem SSH-Schlüssel hinzugefügt wurde und welches sich für die Installation von Offline-Systemen eignet
Das ISO-Image wurde genutzt, um RHEL image mode in einer VM zu installieren
Test von Login und einiger weniger Kommandos
Der konfigurierte Webserver wird ausgeführt und liefert die kleine Beispielwebseite aus
Auf dem Weg hier her wurde erklärt, wie Container-Images mittels podman-image-scp(1) ohne Container-Registry zwischen Benutzerkontexten und Hosts kopiert werden können. Es wurde gezeigt, wie eine einfache Container-Registry betrieben und genutzt werden kann.
Zu den Aufgaben des IT-Betriebs gehört es, Betriebssysteme zu aktualisieren, ihre Konfiguration neuen Anforderungen anzupassen und im Fehlerfall die letzten Änderungen schnell rückgängig machen zu können. Diesen Aufgaben widmen sich die beiden folgenden Abschnitte.
Bootc Image Installation aktualisieren bzw. Konfiguration ändern
Während RHEL package mode Systeme zur Laufzeit mit DNF bzw. YUM aktualisiert werden und mit diesen Werkzeugen Software (de-)installiert wird, ist der Ablauf bei RHEL image mode Systemen anders:
Das RHEL Bootc Image wird aktualisiert
Das aktualisierte Container-Image wird in einer Registry verfügbar gemacht
Das aktualisierte Image wird in den Staging-Bereich des laufenden RHEL image mode Systems geladen
Durch einen Neustart wird das aktualisierte Image geladen
Bei Bedarf, z.B. bei auftretenden Problemen, kann das vorherige Image geladen werden
Aktualisierung des RHEL Bootc Image
Ich möchte die Pakete lsof, strace und tcpdump doch nicht in meiner Standardinstallation haben und sie aus der existierenden Installation entfernen. Deshalb kommentiere die entsprechenden Zeilen aus:
Als Nächstes wird ein neues Image erstellt und in die Registry gepusht. Diesmal verwende ich den Tag 0.0.1, um für den Verlauf dieses Tutorials leichter den Überblick zu behalten:
Das zu verwendende Image aus dem System heraus wechseln
Der nun folgende Schritt wird in dem laufenden RHEL image mode System in VM 2 ausgeführt. In der RHEL-Dokumentation ist dieser Schritt in Abschnitt 8.1. Switching the container image reference beschrieben.
Für diesen Schritt ist eine funktionierende Namensauflösung zwischen VM 1 und VM 2 erforderlich. In der Laborumgebung kann dies mithilfe der Datei /etc/hosts erfolgen. Da in der Registry ein selbstsigniertes Zertifikat verwendet wird und das Kommando bootc keine Option --tls-verify besitzt, muss eine insecure registry in VM 2 konfiguriert werden. Der folgende Codeblock zeigt den Inhalt der Datei, mit der die insecure registry konfiguriert wird:
Da bootc auch nicht über ein Login-Kommando verfügt und keinen Zugriff auf die Login-Informationen von Podman hat, wird in VM 2 ein Pull-Secret für bootc konfiguriert. Dazu wird eine Zeichenkette bestehend aus Benutzername:Passwort in Base-64 kodiert und zusammen mit der Registry-URL in die Datei /etc/ostree/auth.json geschrieben. Der folgende Code-Block zeigt dies mit den Beispielwerten aus diesem Tutorial:
Nach dem Wechsel befindet sich das ab nun zu verwendende Image zunächst im Staging-Bereich des lokalen Systems und wird beim nächsten Neustart aktiviert. Der Befehl bootc status gibt dazu übersichtlich Informationen aus, welches Image gestaged ist und welches aktuell verwendet wird:
~]# bootc status
Current staged image: vm1.example.com:5000/rhel9.5-bootc:0.0.1
Image version: 9.20250109.0 (2025-01-14 19:58:27.484294313 UTC)
Image digest: sha256:c3925bc5d9618e803a3164f8f87a16333e4bf274469e72075d5cb50cf8ac51d9
Current booted image: localhost/rhel9.5-bootc:test
Image version: 9.20250109.0 (2025-01-11 12:40:29.172146867 UTC)
Image digest: sha256:eee2c8ea204615a9341f3747a6156c5b7bc208bbcf60f0a5bb28f142f6b0aa54
No rollback image present
Nach einem Neustart wird der Status mit bootc status erneut kontrolliert und wir sehen, dass nun das Image aus der Registry verwendet wird und das vorherige Image für ein Rollback vorgehalten wird:
~]$ sudo bootc status
No staged image present
Current booted image: jkastnin-tpp1-rhel9-podman-1:5000/rhel9.5-bootc:0.0.1
Image version: 9.20250109.0 (2025-01-14 19:58:27.484294313 UTC)
Image digest: sha256:c3925bc5d9618e803a3164f8f87a16333e4bf274469e72075d5cb50cf8ac51d9
Current rollback image: localhost/rhel9.5-bootc:test
Image version: 9.20250109.0 (2025-01-11 12:40:29.172146867 UTC)
Image digest: sha256:eee2c8ea204615a9341f3747a6156c5b7bc208bbcf60f0a5bb28f142f6b0aa54
Automatische Aktualisierungen und wie man sie deaktivieren kann
Auf RHEL image mode Systemen existiert ein systemd.timer(5), welcher automatische Updates anstößt. Folgender Code-Block zeigt die Timer- und Service-Unit in VM 2:
$ systemctl status --no-pager bootc-fetch-apply-updates.{timer,service}
● bootc-fetch-apply-updates.timer - Apply bootc updates
Loaded: loaded (/usr/lib/systemd/system/bootc-fetch-apply-updates.timer; disabled; preset: disabled)
Active: active (waiting) since Wed 2025-01-15 08:29:37 UTC; 1h 1min ago
Until: Wed 2025-01-15 08:29:37 UTC; 1h 1min ago
Trigger: Wed 2025-01-15 10:28:13 UTC; 57min left
Triggers: ● bootc-fetch-apply-updates.service
Docs: man:bootc(8)
Jan 15 08:29:37 localhost systemd[1]: Started Apply bootc updates.
○ bootc-fetch-apply-updates.service - Apply bootc updates
Loaded: loaded (/usr/lib/systemd/system/bootc-fetch-apply-updates.service; static)
Active: inactive (dead)
TriggeredBy: ● bootc-fetch-apply-updates.timer
Docs: man:bootc(8)
Ein Blick in die Service-Unit verrät, was passiert, wenn diese getriggert wird:
Prüft, ob ein neues Image in der Container-Registry verfügbar ist (Prüfung efolgt auf Digest nicht auf Tag)
Falls ein neues Image verfügbar ist, wird dieses gestaged
Der Host wird automatisch neugestartet, um das neue Image zu laden
Möchte man Aktualisierungen durch andere Verfahren steuern, kann die automatische Aktualisierung wie folgt gestoppt werden:
$ systemctl mask bootc-fetch-apply-updates.timer
Rollback
Angenommen, das System soll auf das zuvor verwendete Conatiner-Image zurückgerollt werden. So kann man sich zuvor mit bootc status einen Überblick verschaffen, welches Image als Rollback-Image eingetragen ist:
Euch fällt evtl. auf, dass zwei Images den gleichen Tag, aber unterschiedliche SHA-256-Prüfsummen haben, und zwei Tags die gleiche Prüfsumme und unterschiedliche Tags. Lasst euch davon bitte nicht irritieren; dies ist nur meiner Spielerei geschuldet.
Bei einem Rollback wird das Image hinter dem Eintrag Current rollback image als Boot-Image verwendet. Ein Rollback wird mit folgendem Kommando ausgeführt:
$ sudo bootc rollback
Next boot: rollback deployment
Nur den Neustart muss man noch selbst durchführen. Nach dem Neustart sieht der Status wie folgt aus:
$ sudo bootc status
[sudo] password for jkastnin:
No staged image present
Current booted image: jkastnin-tpp1-rhel9-podman-1:5000/rhel9.5-bootc:0.0.1
Image version: 9.20250109.0 (2025-01-14 19:58:27.484294313 UTC)
Image digest: sha256:c3925bc5d9618e803a3164f8f87a16333e4bf274469e72075d5cb50cf8ac51d9
Current rollback image: jkastnin-tpp1-rhel9-podman-1:5000/rhel9.5-bootc:0.0.1
Image version: 9.20250109.0 (2025-01-15 09:36:38.866194063 UTC)
Image digest: sha256:e68453dd17a45ad9243139b5cbb0565bbd97aa2bcd5a230c41e44d295281f9a7
Anhand der SHA-256-Prüfsumme ist zu erkennen, dass das vorherige rollback image nun den Platz mit dem vorherigen booted image gewechselt hat. Ein weiterer Aufruf von bootc rollback führt zu einem weiteren Image-Wechsel.
Hinweis: Wenn nach einem Update ein Rollback durchgeführt wird und der Systemd-Timer für automatische Updates nicht deaktiviert wurde, führt dieser Timer bei Ablauf zu einem erneuten Update des Systems.
Ende
Hier endet die Einführung in RHEL image mode. Wer dem Tutorial aufmerksam gefolgt ist, sollte an dieser Stelle in der Lage sein:
RHEL Bootc Images zu erstellen
Eine einfache Container-Registry mit Podman zu betreiben
Mit bootc-image-builder Disk-Images zu erstellen
Ein System im RHEL image mode zu installieren
Das installierte System zu aktualisieren
Zu einem anderen Image zu wechseln
Ein Rollback auf das vorherige Image durchzuführen
Wenn euch diese Einführung gefallen hat, freue ich mich, wenn ihr sie mit euren Netzwerken teilt. Nutzt gern die Kommentarfunktion, um mich wissen zu lassen, wie euch diese Einführung gefallen hat.
Falls ihr euch weitere Artikel rund um den RHEL image mode wünscht, teilt mir dies gern ebenfalls über die Kommentarfunktion mit.
SMLIGHT hat am Montagabend das Core Firmware Update 2.7.0 für die SLZB-06x Modelle mit folgenden Neuerungen veröffentlicht: Aktive Sockets Multithreading-Verwaltung: Standardmäßig ist 1 aktiver Socket aktiviert (empfohlene Einstellung). Der Benutzer kann dies auf der...
Ende letzten Jahres habe ich euch gezeigt, wie ihr die OpenThread RCP Firmware auf dem SMLIGHT SLZB-07 installiert. Neben den SLZB-07 Modellen gibt es von SMLIGHT noch die SLZB-06 Modelle, welche die im Home...
Thematisch haben sich fast alle Artikel mit Freier Software und Open Source beschäftigt oder waren daran angelehnt. Wie auch in den vorangegangenen Jahren habe ich keine bewussten Themenschwerpunkte gesetzt, sonder über die Themen geschrieben, dich mich in der jeweiligen Zeit interessierten und mich beschäftigt haben.
Zu Beginn des Jahres hatte es mir das Thema IPv6 angetan, wozu vier Beiträge erschienen sind:
Das Thema begleitet mich auch weiterhin, jedoch gibt es bisher keine spannenden Neuigkeiten, die ich für berichtenswert halte. Ich fürchte, IPv6 wird sobald nicht die Weltherrschaft an sich reißen.
Ein Thema, welches mir sehr wichtig war und ist, ist die Dokumentation für den Notfall bzw. das digitale Erbe. Wie die Kommentare zu diesem Artikel bezeugen, bin ich nicht der Einzige, der sich darum Gedanken macht. Leider bin ich 2024 kaum damit vorangekommen und schiebe es weiter vor mir her. Dies ärgert mich etwas, da ich mir wünsche, mich für ein so wichtiges Thema besser aufraffen zu können.
In 2024 wurden wir auf allen Kanälen mit Künstlicher Intelligenz, Maschinellem Lernen und großen Sprachmodellen überflutet. Es fällt schon fast schwer noch irgendeine Anwendung oder ein Produkt ohne AI kaufen zu können. Abseits des Hypes habe ich mich ebenfalls mit dem Thema beschäftigt und zwei Beiträge ( [1] und [2]) dazu geschrieben. Ich bin überzeugt, dass die verschiedenen Spielarten der künstlichen Intelligenz unser Leben und unsere Art zu Arbeiten stark beeinflussen und verändern werden. Daher werde auch ich hier am Ball zu bleiben, um nicht von der laufenden Entwicklung abgehängt zu werden.
Fazit
Damit sind 2024 insgesamt 26 Artikel erschinen. Das sind 19 weniger als in 2023. Mein selbst gestecktes Ziel, jeden Monat mindestens zwei Artikel zu veröffentlichen habe ich ebenfalls nicht erreicht. Da dies mein Hobby ist und mir primär Freude bereiten soll, setze ich mich durch diese Zielverfehlung nicht unter Druck.
Das Jahr 2025 lasse ich ohne große Ziele und Bestrebungen auf diesen Blog zukommen. Nur eines ist sicher, ich werde meine Texte weiterhin selbst und ohne KI-Unterstützung schreiben. Denn damit würde ich mir nur selbst die Freude am Bloggen nehmen.
Ich freue mich, wenn ich auch 2025 wieder interessantes Wissen in meinen Texten mit euch teilen kann. Ich wünsche euch einen guten Rutsch ins Jahr 2025!