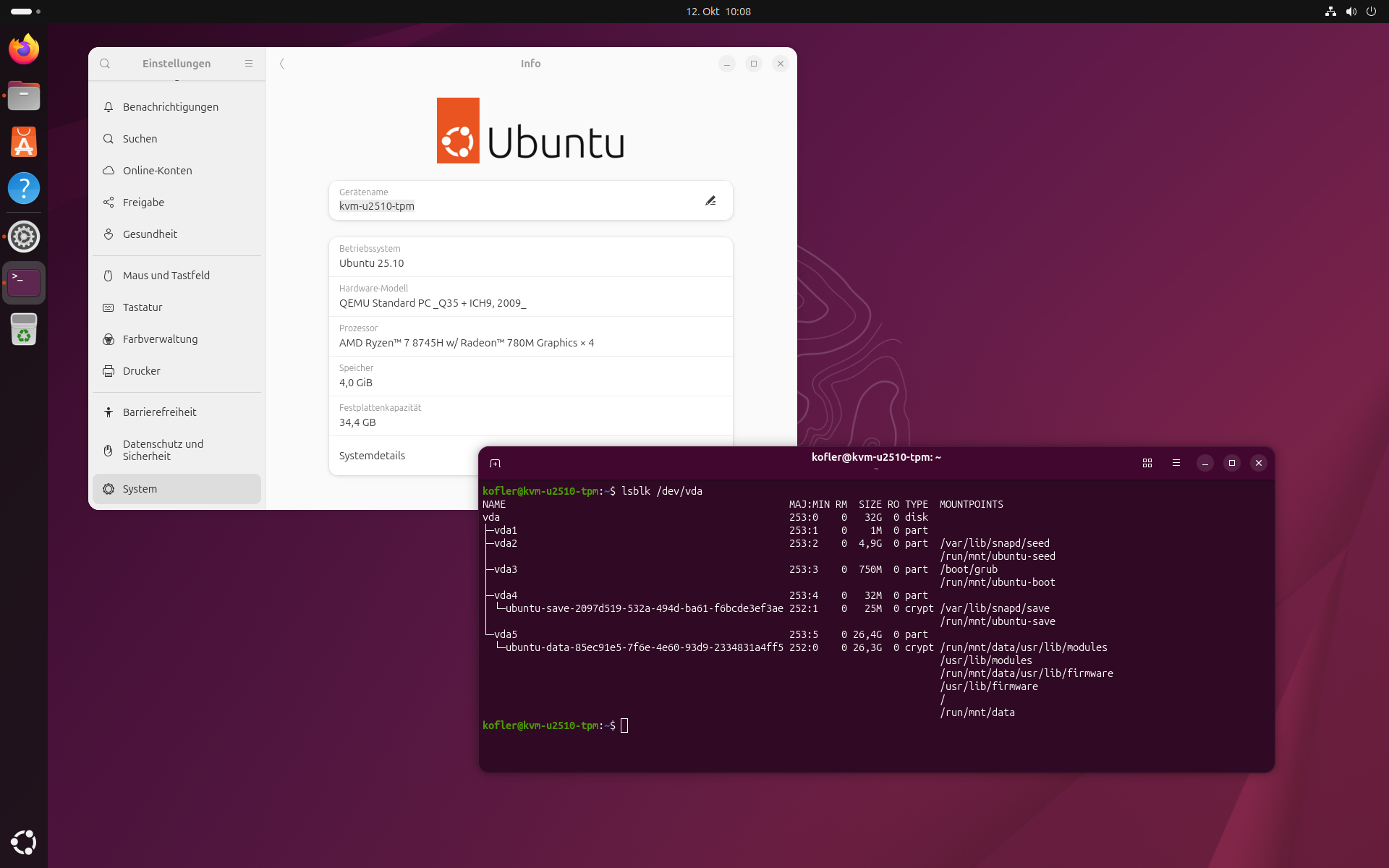
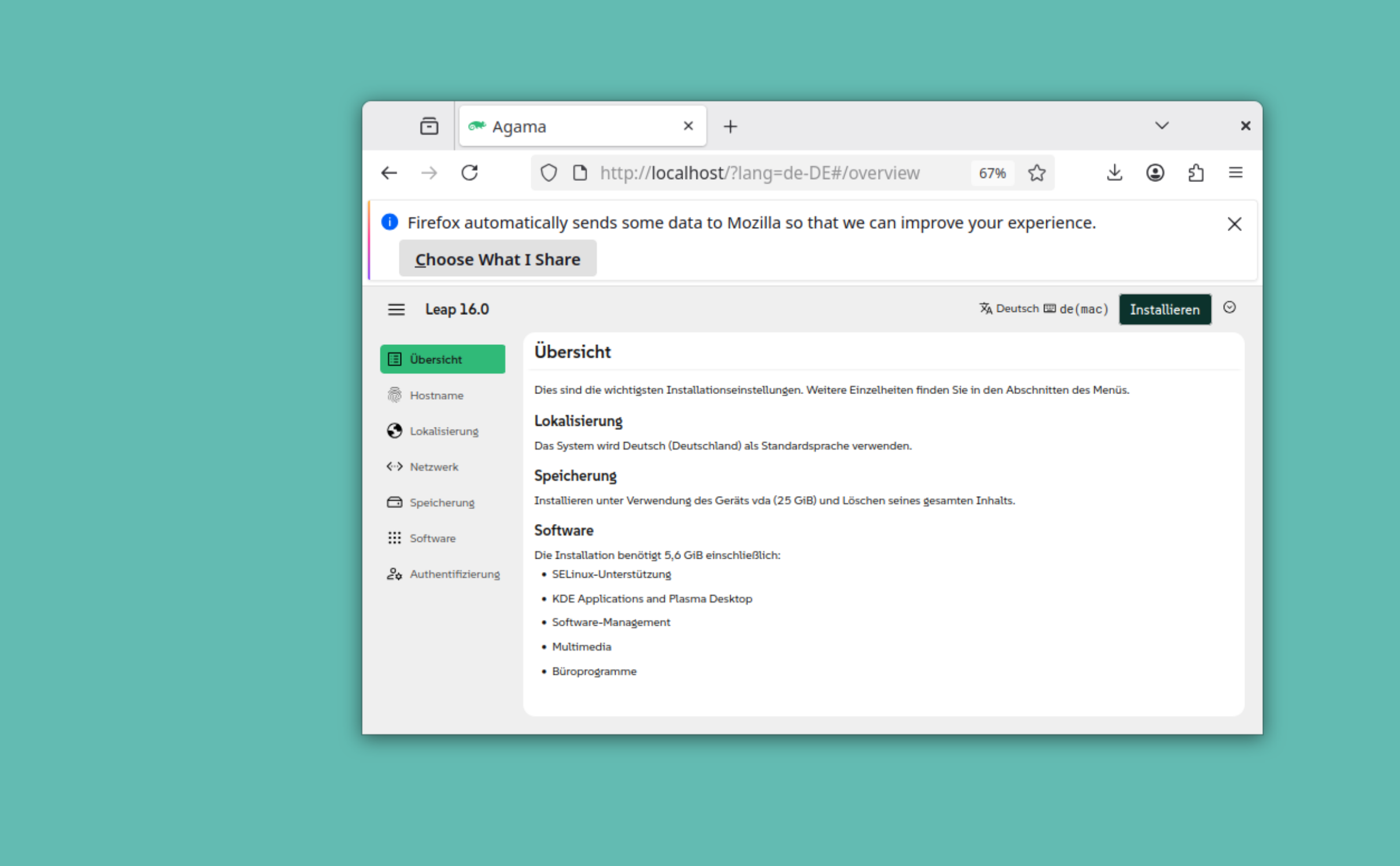
Die im Oktober 2025 erschienene Neuauflage des Raspberry Pi OS, basierend auf Debian 13 „Trixie“, dürfte einige Nutzer überrascht haben. In den Medien wurde darüber nur wenig berichtet – auch an mir war die Veröffentlichung zunächst vorbeigegangen.
Trotzdem habe ich nicht gezögert, das neue System mithilfe des Raspberry Pi Imager auf eine microSD-Karte zu schreiben. Ziel war es wie gewohnt, eine sogenannte headless-Installation vorzubereiten – also ohne Monitor und Tastatur. Die weitere Einrichtung sollte anschließend bequem per SSH (Secure Shell) erfolgen.
Der Vorgang wurde auf einem Notebook mit Ubuntu 24.04 LTS und dem über die Paketverwaltung installierten Raspberry Pi Imager (Version 1.8.5) durchgeführt. Nach dem Flashen wurden die Karte in den Raspberry Pi eingesetzt und das System gestartet. Doch eine Verbindung per SSH war danach nicht möglich.
Ursache und Lösung
Die Ursache für dieses Verhalten war schnell gefunden: Raspberry Pi OS 13 erfordert für die korrekte Vorkonfiguration den Raspberry Pi Imager in Version 2.0 oder höher. Und genau hier beginnt das Problem – zumindest für Linux-Nutzer.
Während Windows-Nutzer den neuen Imager bereits komfortabel nutzen können, hinkt die Linux-Unterstützung deutlich hinterher. Bislang steht weder ein aktuelles .deb-Paket noch eine Snap-Version zur Verfügung. Das sorgt in der Linux-Community verständlicherweise für Kopfschütteln – gerade bei einem Projekt wie dem Raspberry Pi, das tief in der Open-Source-Welt verwurzelt ist.
AppImage als Ausweg
Glücklicherweise bietet der Entwickler ein AppImage des neuen Imagers an. Dieses lässt sich unter Ubuntu und anderen Distributionen unkompliziert starten – ganz ohne Installation. Damit ist es wie gewohnt möglich, WLAN-Zugangsdaten und SSH vor dem ersten Start zu konfigurieren.
Fazit
Wer Raspberry Pi OS 13 „Trixie“ headless nutzen möchte, sollte sicherstellen, dass der Imager in Version 2.0 oder neuer verwendet wird. Für Linux-Nutzer führt der Weg aktuell nur über das bereitgestellte AppImage. Es bleibt zu hoffen, dass die offizielle Paketunterstützung für Linux bald nachgereicht wird.
Beim Experimentieren mit KI-Sprachmodellen bin ich über das Projekt »Toolbx« gestolpert. Damit können Sie unkompliziert gekapselte Software-Umgebungen erzeugen und ausführen.
Toolbx hat große Ähnlichkeiten mit Container-Tools und nutzt deren Infrastruktur, unter Fedora die von Podman. Es gibt aber einen grundlegenden Unterschied zwischen Docker/Podman auf der einen und Toolbx auf der anderen Seite: Docker, Podman & Co. versuchen die ausgeführten Container sicherheitstechnisch möglichst gut vom Host-System zu isolieren. Genau das macht Toolbx nicht! Im Gegenteil, per Toolbx ausgeführte Programme können auf das Heimatverzeichnis des aktiven Benutzers sowie auf das /dev-Verzeichnis zugreifen, Wayland nutzen, Netzwerkschnittstellen bedienen, im Journal protokollieren, die GPU nutzen usw.
Toolbx wurde ursprünglich als Werkzeug zur Software-Installation in Distributionen auf der Basis von OSTree konzipiert (Fedora CoreOS, Siverblue etc.). Dieser Artikel soll als eine Art Crash-Kurs dienen, wobei ich mit explizit auf Fedora als Host-Betriebssystem beziehe. Grundwissen zu Podman/Docker setze ich voraus.
Mehr Details gibt die Projektdokumentation. Beachten Sie, dass die offizielle Bezeichnung des Projekts »Toolbx« ohne »o« in »box« lautet, auch wenn das zentrale Kommando toolbox heißt und wenn die damit erzeugten Umgebungen üblicherweise Toolboxes genannt werden.
Hello, Toolbx!
Das Kommando toolbox aus dem gleichnamigen Paket wird ohne sudo ausgeführt. In der Minimalvariante erzeugen Sie mit toolbox <name> eine neue Toolbox, die als Basis ein Image Ihrer Host-Distribution verwendet. Wenn Sie also wie ich in diesen Beispielen unter Fedora arbeiten, fragt toolbox beim ersten Aufruf, ob es die Fedora-Toolbox herunterladen soll:
toolbox create test1
Image required to create Toolbx container.
Download registry.fedoraproject.org/fedora-toolbox:43 (356.7MB)? [y/N]: y
Created container: test1
Wenn Sie als Basis eine andere Distribution verwenden möchten, geben Sie den Distributionsnamen und die Versionsnummer in zwei Optionen an:
toolbox create --distro rhel --release 9.7 rhel97
Das Kommando toolbox list gibt einen Überblick, welche Images Sie heruntergeladen haben und welche Toolboxes (in der Podman/Docker-Nomenklatur: welche Container) Sie erzeugt haben:
toolbox list
IMAGE ID IMAGE NAME CREATED
f06fdd638830 registry.access.redhat.com/ubi9/toolbox:9.7 3 days ago
b1cc6a02cef9 registry.fedoraproject.org/fedora-toolbox:43 About an hour ago
CONTAINER ID CONTAINER NAME CREATED STATUS IMAGE NAME
695e17331b4a llama-vulkan-radv 2 days ago exited docker.io/kyuz0/amd-strix-halo-toolboxes:vulkan-radv
dc8fd94977a0 rhel97 22 seconds ago created registry.access.redhat.com/ubi9/toolbox:9.7
dd7d51c65852 test1 18 minutes ago created registry.fedoraproject.org/fedora-toolbox:43
Um eine Toolbox aktiv zu nutzen, aktivieren Sie diese mit toolbox enter. Damit starten Sie im Terminal eine neue Session. Sie erkennen nur am veränderten Prompt, dass Sie sich nun in einer anderen Umgebung befinden. Sie haben weiterhin vollen Zugriff auf Ihr Heimatverzeichnis; die restlichen Verzeichnisse stammen aber überwiegend von Toolbox-Container. Hinter den Kulissen setzt sich der in der Toolbox sichtbare Verzeichnisbaum aus einer vollkommen unübersichtlichen Ansammlung von Dateisystem-Mounts zusammen. findmnt liefert eine über 350 Zeilen lange Auflistung!
Innerhalb einer Fedora-Toolbox können Sie wie üblich mit rpm und dnf Pakete verwalten. Standardmäßig ist nur ein relativ kleines Subset an Paketen installiert.
[kofler@toolbx ~]$ rpm -qa | wc -l
340
Innerhalb der Toolbox können Sie mit sudo administrative Aufgaben erledigen, z.B. sudo dnf install <pname>. Dabei ist kein Passwort erforderlich.
ps ax listet alle Prozesse auf, sowohl die der Toolbox als auch alle anderen des Hostsystems!
Mit exit oder Strg+D verlassen Sie die Toolbox. Sie können Sie später mit toolbox enter <name> wieder reaktivieren. Alle zuvor durchgeführten Änderungen gelten weiterhin. (Hinter den Kulissen verwendet das Toolbx-Projekt einen Podman-Container und speichert Toolbox-lokalen Änderungen in einem Overlay-Dateisystem.)
Bei ersten Experimenten mit Toolbx ist mitunter schwer nachzuvollziehen, welche Dateien/Einstellungen Toolbox-lokal sind und welche vom Host übernommen werden. Beispielsweise ist /etc/passwd eine Toolbox-lokale Datei. Allerdings wurden beim Erzeugen dieser Datei die Einstellungen Ihres lokalen Accounts von der Host-weiten Datei /etc/passwd übernommen. Wenn Sie also auf Host-Ebene Fish als Shell verwenden, ist /bin/fish auch in der Toolbox-lokalen passwd-Datei enthalten. Das ist insofern problematisch, als im Standard-Image für Fedora und RHEL zwar die Bash enthalten ist, nicht aber die Fish. In diesem Fall erscheint beim Start der Toolbox eine Fehlermeldung, die Bash wird als Fallback verwendet:
toolbox enter test1
bash: Zeile 1: /bin/fish: Datei oder Verzeichnis nicht gefunden
Error: command /bin/fish not found in container test1
Using /bin/bash instead.
Es spricht aber natürlich nichts dagegen, die Fish zu installieren:
[kofler@toolbx ~]$ sudo dnf install fish
Auf Host-Ebene liefern die Kommandos podman ps -a und podman images sowohl herkömmliche Podman-Container und -Images als auch Toolboxes. Aus Podman-Sicht gibt es keinen Unterschied. Der Unterschied zwischen einem Podman-Container und einer Toolbox ergibt sich erst durch die Ausführung (bei Podman mit sehr strenger Isolierung zwischen Container und Host, bei Toolbox hingegen ohne diese Isolierung).
Eigene Toolboxes erzeugen
Eigene Toolboxes richten Sie ein wie eigene Podman-Images. Die Ausgangsbasis ist ein Containerfile, das die gleiche Syntax wie ein Dockerfile hat:
# Datei my-directory/Containerfile
FROM registry.fedoraproject.org/fedora-toolbox:43
# Add metadata labels
ARG NAME=my-toolbox
ARG VERSION=43
LABEL com.github.containers.toolbox="true" \
name="$NAME" \
version="$VERSION" \
usage="This image is meant to be used with the toolbox(1) command" \
summary="Custom Fedora Toolbx with joe and fish"
# Install your software
RUN dnf --assumeyes install \
fish \
joe
# Clean up
RUN dnf clean all
Mit podman build erzeugen Sie das entsprechende lokale Image:
cd my-directory
podman build --squash --tag localhost/my-dev-toolbox:43 .
Jetzt können Sie auf dieser Basis eine eigene Toolbox einrichten:
toolbox create --image localhost/my-toolbox:43 test2
toolbox enter test2
KI-Sprachmodelle mit Toolbx ausführen
Das Toolbx-Projekt bietet eine großartige Basis, um GPU-Bibliotheken und KI-Programme auszuprobieren, ohne die erforderlichen Bibliotheken auf Systemebene zu installieren. Eine ganze Sammlung von KI-Toolboxes zum Test diverser Software-Umgebungen für llama.cpp finden Sie auf GitHub, beispielsweise hier:
toolbox create erzeugt eine Toolbox mit dem Namen llama-vulkan-radv auf Basis des Images vulkan-radv, das der Entwickler kyuz0 im Docker Hub hinterlegt hat. Das alleinstehende Kürzel -- trennt die toolbox-Optionen von denen für Podman/Docker. Die folgenden drei Optionen sind erforderlich, um der Toolbox direkten Zugriff auf das Device der GPU zu geben.
Mit toolbox enter starten Sie die Toolbox. Innerhalb der Toolbox steht das Kommando llama-cli zur Verfügung. In einem ersten Schritt können Sie testen, ob diese Bibliothek zur Ausführung von Sprachmodellen eine GPU findet.
Wenn Sie auf Ihrem Rechner noch keine Sprachmodelle heruntergeladen haben, finden Sie geeignete Modelle unter https://huggingface.co. Ich habe stattdessen im folgenden Kommando ein Sprachmodell ausgeführt, das ich zuvor in LM Studio heruntergeladen haben. Wie gesagt: In der Toolbox haben Sie vollen Zugriff auf alle Dateien in Ihrem Home-Verzeichnis!
Dabei gibt -c die maximale Kontextgröße an. -ngl bestimmt die Anzahl der Layer, die von der GPU verarbeitet werden sollen (alle). -fa 1 aktiviert Flash Attention. Das ist eine Grundvoraussetzung für eine effiziente Ausführung moderner Modelle. --no-mmap bewirkt, dass das ganze Modell zuerst in den Arbeitsspeicher geladen wird. (Die Alternative wären ein Memory-Mapping der Datei.) Der Server kann auf der Adresse localhost:8080 über eine Weboberfläche bedient werden.
Weboberfläche zu llama.cpp. Dieses Programm wird in einer Toolbox ausgeführt.
Anstatt erste Experimente in der Weboberfläche durchzuführen, können Sie mit dem folgenden Kommando einen einfachen Benchmarktest ausführen. Die pp-Ergebnisse beziehen sich auf das Prompt Processing, also die Verarbeitung des Prompts zu Input Token. tg bezeichnet die Token Generation, also die Produktion der Antwort.
Die Kinder bekommen ihre Weihnachtsgeschenke am 24.12., bei mir war diesmal zufällig schon eine Woche vorher Bescherung. Direkt von Taiwan versendet traf gestern ein Framework Desktop ein (Batch 17). Wobei von »Geschenk« keine Rede ist, ich habe den Rechner ganz regulär bestellt und bezahlt. Über das Preis/Leistungs-Verhältnis darf man gar nicht nachdenken … Aber für die Überarbeitung des Buchs Coding mit KI will ich nun mal moderat große Sprachmodelle (z.B. gpt-oss-120b) selbst lokal ausführen.
Dieser Blog-Beitrag fasst meine ersten Eindrücke zusammen. In den nächsten Wochen werden wohl noch ein paar Artikel rund um Ollama und llama.cpp folgen.
Framework Desktop
Auswahl
Ich war auf der Suche nach einem Rechner mit 128 GByte RAM, das von der GPU genutzt werden kann. Dafür gibt es aktuell drei Plattformen (Intel glänzt durch Abwesenheit):
AMD Ryzen AI Max+ 395 (»Strix Halo«): Dieser Prozessor kombiniert 16 Zen-5-CPU-Cores und 40 GPU-Cores (Radeon 8060S). Die Speicherbandbreite (LPDDR5X) beträgt bis zu 250 GiB/s. Desktop-PCs mit 2 TB SSD kosten zwischen 2.000 und 3.000 €, Notebooks ca. 4.000 €.
Apple Max CPUs: Der Prozessor M4 Max vereint 16 CPU-Cores mit 40 GPU-Cores. Die Speicherbandbreite erreicht beeindruckende 550 GiB/s. Ein entsprechender Mac Studio mit 2 TB SSD kostet ca. 5000 €, ein MacBook mit vergleichbarer Ausstattung ca. 6000 €.
NVIDIA DGX Spark: Diese Plattform besteht aus einer 20-Core ARM-CPU plus NVIDIA Blackwell GPU mit 48 Compute Units. Wegen des LPDDR5X-RAMs ist die Speicherbandbreite wie bei Strix Halo auf ca. 250 GiB/s limitiert. Komplettsysteme kosten ca. 4000 € (Asus, Dell, NVIDIA).
Was die Rechenleistung betrifft, spielen alle drei Plattformen in der gleichen Liga, vielleicht mit kleinen Vorteilen bei Apple, vor allem was Effizienz und Lautstärke betrifft. Gegen die NVIDIA-Lösung spricht, dass diese Rechner dezidiert für KI-Aufgaben gedacht sind; eine »normale« Desktop-Nutzung ist nur mit großen Einschränkungen möglich.
Generell darf man sich von der KI-Geschwindigkeit der aufgezählten Geräten keine Wunder erwarten: GPU-Leistung und Speicherbandbreite sind nur mittelprächtig. Praktisch jede dezidierte Grafikkarte kann kleine Sprachmodelle schneller ausführen — aber nur, solange das Sprachmodell komplett im dezidierten VRAM Platz hat. (Bei Desktop-PCs können Sie mehrere Grafikkarten einbauen und kombinieren, aber das ist teuer und kostet viel Strom.) Die oben aufgezählten CPUs mit integrierter GPU können dagegen das gesamten RAM nutzen. Das ist langsamer als bei dezidierten GPUs, aber es macht immerhin die Ausführung von relativ großen Modellen möglich.
Apple ist wie üblich bei vergleichbarer Ausstattung am teuersten. Umgekehrt muss man anerkennen, dass von allen hier aufgezählten Geräten ein Mac Studio vermutlich der einzige Computer ist, der in drei Jahren noch einen nennenswerten Wiederverkaufswert hat.
Am anderen Ende des Preisspektrums befindet sich die AMD-Variante. Es gibt diverse chinesische Mini-PCs mit der AMD-395-CPU: z.B. Bosgame (aktuell am billigsten), GMKtec EVO-X2, Beelink GTR9 (instabil, Probleme mit Intel-Netzwerkadapter) und Minisforum MS-S1 MAX. HP bietet den Z2 Mini G1a zu einem relativ vernünftigen Preis an, aber das Gerät ist anscheinend sehr laut. Schließlich gibt es den Framework Desktop, der ansprechend aussieht, in Tests gut abgeschnitten hat und die beste/leiseste Kühlung hat (leider ein Irrtum, siehe unten).
Ich habe mich nach wochenlanger Recherche für das Framework-Angebot entschieden. Das Konzept der Framework-Geräte ist sympathisch. Außerdem gibt es eine große Community rund um das Gerät. Zum Zeitpunkt der Bestellung kostete der Rechner mit 128 GByte RAM, ein paar Adaptern, Kacheln und Lüfter knapp 2.500 € (inkl. USt). Eine SSD habe ich anderswo besorgt. (Update 15.1.2026: Der Framework Desktop ist mittlerweile leider noch teurer geworden.)
Lieferung
Der Rechner wurde am 12.12. von Taiwan versendet und kam sechs Tage später bei mir an. Faszinierend. (Ich habe noch nie bei Temu & Co. bestellt, habe diesbezüglich auch keine Ambitionen. Insofern war die Verfolgung des Pakets rund um die halbe Welt für mich Neuland.)
In sechs Tagen um die halbe Welt. Ökologisch ein Alptraum, logistisch ein Wunder.
Bis zum Schluss wusste ich nicht, ob nun Zoll zu zahlen ist oder nicht. Offenbar nicht. Ich kann nicht sagen, ob sich Framework bei EU-Lieferungen um die ganze Abwicklung kümmert oder ob es Zufall/Glück war. (Das Gerät ist weiß Gott auch ohne Zoll teuer genug …)
Der Zusammenbau ist unkompliziert und gelingt in einer halben Stunde. Ich habe dann Fedora 43 installiert (weitere zehn Minuten). Alles funktionierte auf Anhieb, das Gerät lief die erste halbe Stunde praktisch lautlos.
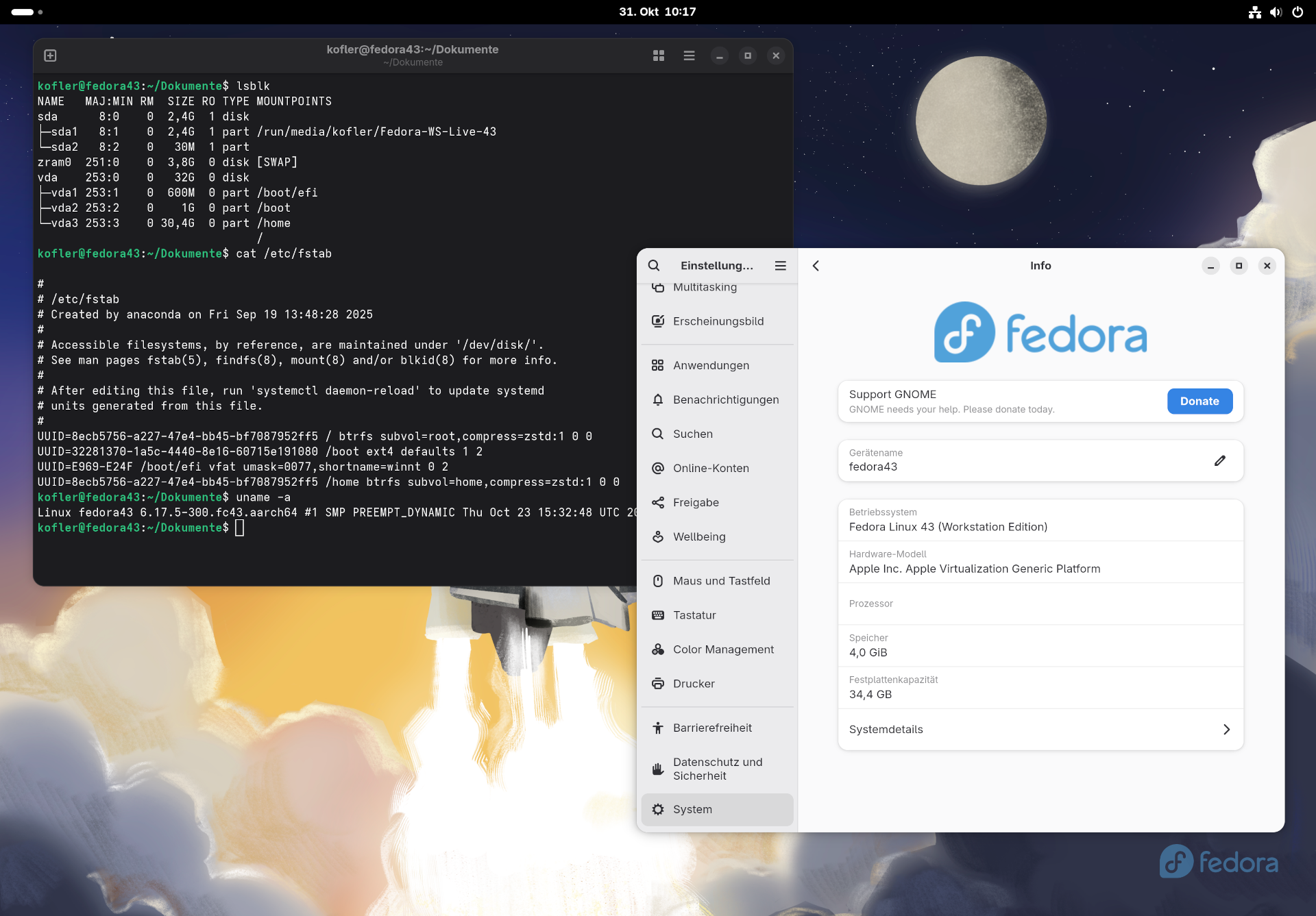
Der Framework Desktop wird als Bastel-Set geliefertSystemzusammenfassung von Gnome
Benchmark-Tests
Ich habe mich nicht lange mit Benchmark-Tests aufgehalten. BIOS in Grundzustand, Fedora 43 mit Gnome im Energiemodus Ausgeglichen.
Geekbench lieferte 2790 Single / 20.700 Multi-Core
Kernel kompilieren (Version 6.18.1): 9:08 Minuten
Systemüberwachung während der Kernel kompiliert wird
BIOS
F2 bzw. je nach Tastatur Fn+F2 führt in die BIOS/EFI-Einstellungen. Dort gibt es eine Menge Optionen zur Steuerung des CPU-Lüfters. Der GPU kann ein fixer Speicher (bis zu 96 GiB) zugewiesen werden. Für die meisten Anwendungen ist das aber nicht sinnvoll. Viele Bibliotheken sind in der Lage, den GPU-Speicher dynamisch anzufordern. Insofern ist es zweckmäßig, den fix reservierten GPU-Speicher möglichst klein einzustellen.
Es gibt keine Optionen, die die CPU/GPU-Leistung beeinflussen.
Achtung: Es gibt ein BIOS-Update von Version 0.03.03 auf 0.03.04. Gnome Software bietet das Update zur Installation an. Allerdings bereitet die neue BIOS-Version Probleme und verlangsamt den Boot-Prozess massiv. Das Update sollte daher nicht installiert werden!
Mit F2 gelangen Sie in die BIOS-Einstellungen
Stromverbrauch
Ich habe den Stromverbrauch am Netzstecker mit einem uralten Haushalts-Strommessgerät gemessen. Dessen Genauigkeit ist sicher nicht großartig, aber die Größenordnung meiner Messwerte klingt plausibel: Demnach beträgt die Leistungsaufnahme im Ruhezustand ca. 12 bis 13 Watt (wieder: Fedora mit Gnome Desktop, Energie-Modus ausgeglichen, keine rechenintensiven Vorgänge, BIOS im Grundzustand). Beim Kompilieren des Kernels steigt die Leistung kurz auf 160 Watt und pendelt sich dann ziemlich stabil rund um 140 Watt ein.
Geräuschentwicklung
Der Rechner hat zwei Lüfter: einen großen für die CPU (kann beim Bestellprozess konfiguriert werden, ich habe mich für das etwas teurere Noctua-Modell entschieden) und einen kleinen, der unsichtbar aber unüberhörbar im Netzteil am Boden des Rechners eingebaut ist.
Der CPU-Lüfter läuft standardmäßig nur unter Last und produziert dann ein gut erträgliches Geräusch (mehr Brummen als Surren). Die Steuerung des CPU-Lüfters kann im BIOS verändert werden. Ich habe probeweise einen Dauerbetrieb mit 25 % eingestellt. Der Lüfter bleibt dann für meine Ohren bei knapp einem Meter Abstand immer noch lautlos, sorgt aber für eine stetige leichte Kühlung.
Das Problem ist das äußerst schmale Netzteil, das sich im unteren Teil des Gehäuses befindet. Framework ist auf das Netzteil ziemlich stolz, aber viele Desktop-Besitzer können diese Begeisterung nicht teilen. Ein schier endloser Forum-Thread dokumentiert den Frust über das Netzteil. Im Prinzip ist es einfach:
Das Netzteil ist komplett gekapselt. Der große CPU-Lüfter kann es daher nicht kühlen.
Die Luftzufuhr wird durch eine enge Röhre und das Gitter des Gehäuses enorm behindert.
Das Netzteil ist mit 80 Plus Silver nur mäßig effizient, was sich vermutlich im Leerlaufbetrieb besonders stark auswirkt.
Im Netzteil steht die Luft. Dieses wird durch die Abwärme immer heißer.
Ca. 1/2 h nach dem Einschalten wird eine kritische Temperatur erreicht. Nun startet unvermittelt der winzige Lüfter. Eine halbe Minute reicht, um das Netzteil mit frischer Luft etwas abzukühlen — aber nach ca. 10 Minuten beginnt das Spiel von neuem. (Unter Last läuft natürlich auch der Netzteillüfter häufiger.)
Das Geräusch des Netzteil-Lüfters ist leider wesentlich unangenehmer als das des CPU-Lüfters. Der kleine Lüfter hat eine unangenehme Frequenz, und das regelmäßige Ein/Aus stört. Eine BIOS-Steuerung ist nicht vorgesehen. Vermutlich wäre es gescheiter, den Netzteil-Lüfter ständig bei niedriger Frequenz laufen zu lassen, um ohne viel Lärm einen andauernden Luftaustausch zu gewährleisten. Aber diese Möglichkeit besteht nicht.
Blick in das Innenleben. Der große Lüfter kühlt die CPU. Das Netzteil ist ganz unten und hat einen weiteren, nicht sichtbaren LüfterDie Luftzufuhr wird durch die Abdeckung weiter behindert
Um es klar zu stellen: Selbst wenn der Netzteillüfter läuft, ist das Gerät nicht wirklich laut — und vermutlich immer noch leiser als Konkurrenzprodukte (die ich aber nicht ausprobiert habe). Und dass der Computer unter Last nicht lautlos ist, war sowieso zu erwarten.
Ärgerlich ist, dass das Gerät trotz seines ausgezeichneten CPU-Kühler-Designs im Leerlauf bzw. bei geringer Belastung nicht leiser ist. Technisch wäre das möglich. Da wurde rund um das Netzteil viel Potenzial verschenkt.
Fazit
Der Framework Desktop wurde offensichtlich mit viel Liebe zum Detail entwickelt. Der Rechner ist optisch ansprechend und liegt preislich im Vergleich zu seinen Konkurrenzprodukten im Mittelfeld. (Generell ist leider zu befürchten, dass die Preise von Computern in den nächsten Monaten steigen werden, weil sowohl RAM als auch SSDs fast täglich teurer werden.)
Die CPU-Kühlung ist vermutlich die beste aller aktuellen Strix-Halo-Angebote. Bei meinen bisherigen Tests lief der Rechner absolut stabil.
Extrem schade, dass das Netzteil so ein Murks ist. Wenn das Netzteil intelligenter gekühlt würde, wäre im Leerlauf bzw. bei moderater Nutzung ein weitgehend lautloser Betrieb möglich. Stattdessen nervt das Gerät mit einem hochfrequenten Gesurre, das alle paar Minuten startet und eine halbe Minute später wieder aufhört. Ärgerlich!
COSMIC, der komplett neue Desktop der Firma system76 ist fertig! COSMIC ist integraler Teil von Pop!_OS. Diese ebenfalls von system76 entwickelte Distribution basiert auf Ubuntu, zeichnet sich aber durch viele Eigenheiten ab. Weil ich mir COSMIC ansehen wollte, habe ich die aktuelle Version von Pop!_OS auf meinen MiniPC installiert. Dieser Artikel fasst ganz kurz meine Beobachtungen zusammen.
Der COSMIC-Desktop im Light Mode und mit Dock auf der linken Seite
Installation
Die Installation erfolgt aus einem Live-System. Der einzig spannende Punkt ist die Partitionierung der SSD. Sofern Sie sich für die manuelle Partitionierung entscheiden, zeigt das Installationsprogramm einen Überblick über die vorhandenen Disks und Partitionen aus. Sie können nun die Partitionen, die Sie einbinden (EFI) oder mit einem Dateisystem ausstatten möchten (zumindest die Systempartition) per Maus aktivieren. Wenn Sie die Partitionierung verändern wollen (Modify Partitions), startet das Installationsprogramm einfach das Programm gparted. Das ist ein pragmatischer Ansatz, mit dem fortgeschrittene Benutzer ans Ziel kommen. Wer verschlüsselte LVM-Setups will, muss selbst Hand anlegen und die erforderlichen Schritte vorweg selbst erledigen.
Auswahl der aktiven Partitionen
COSMIC Desktop
Der COSMIC Desktop besteht aus dem Fenstermanager/Compositor mit den üblichen Desktop-Elementen (Panel, Dock) sowie einigen COSMIC-spezifischen Programmen: Dateimanager, Terminal, Systemeinstellungen, Paketverwaltung, Texteditor und Media-Player. Bei den sonstigen Programmen greift COSMIC auf die üblichen Linux- (Firefox, Thunderbird, LibreOffice, Gimp) oder Gnome-Apps zurück (Systemüberwachung, Laufwerke).
Bei der Fensterverwaltung unterscheidet COSMIC zwischen dem Standardmodus, der im Prinzip wie unter Gnome oder KDE funktioniert, und einem Tiling-Modus mit halbautomatischer Fensteranordnung, wobei stets alle Fenster sichtbar sind. Zwischen den beiden Modi kann über ein Icon im Panel oder mit Super+Y gewechselt werden.
Im Tiling-Modus werden alle Fenster nebeneinander platziert.Die Systemeinstellungen wirken übersichtlicher als bei Gnome oder KDE
Die Bedienung ist intuitiv und funktioniert zumeist problemlos. Aber natürlich (Version 1.0!) gibt es noch kleinere Ungereimtheiten. Um ein paar zu nennen:
Während sich echte COSMIC-Programme perfekt in den Desktop integrieren, wirken KDE- oder Gnome-Programme ein wenig wie Fremdkörper. Dieses Problem haben natürlich auch andere Desktop-Systeme.
Obwohl ich Deutsch als Sprache eingestellt habe, bleibt es im Panel bei Workspaces und Applications, der Dateimanager zeigt das Änderungsdatum der Dateien mit AM/PM an usw. Wiederum: Ähnliche Probleme gibt es auch bei anderen Desktops.
Drag&Drop zwischen Dateimanager und Webbrowser funktioniert unzuverlässig. (Diesem Wayland-Problem bin ich in den vergangenen Jahren auch schon oft begegnet, zuletzt aber immer seltener.)
Das Erstellen von Screenshots in die Zwischenablage funktioniert unzuverlässig.
Beim Verschieben von Icons im Dock hatte ich mehrfach Probleme. Manche Icons werden gar nicht oder mit falschen Symbolen angezeigt (z.B. Google Chrome).
Die Tiling-Steuerung erfordert eine längere Eingewöhnung, erlaubt dann aber eine Bedienung weitgehend ohne Maus. Für Tiling- bzw. COSMIC-Einsteiger wäre hier mehr Dokumentation bzw. ein gutes Video hilfreich.
Die Kennzeichnung des gerade aktiven Fensters durch einen farbigen Rahmen ist funktionell, aber nicht besonders ästhetisch.
Im Dateimanager gibt es keine Funktion, um mehrere Dateien umzubenennen.
Letztlich sind das alles Kleinigkeiten. Meine Tests verliefen absturzfrei, ich konnte mit COSMIC gut und stabil arbeiten. Der Desktop hinterließ dabei einen sehr schnellen, flüssigen Eindruck — aber das ist eine eher subjektive Feststellung, die ich nicht durch Benchmark-Tests untermauern kann.
Meine Lieblingseinstellungen (Dock links, Light Mode, Maus mit Natural Scrolling, 4k-Monitor mit 150%-Skalierung) habe ich mühelos in den gut organisierten Systemeinstellungen gefunden. Anders als unter Gnome musste ich dazu keine Extensions installieren :-)
Paketverwaltung
Pop!_OS basiert auf Ubuntu, verwendet aber eigene Paketquellen und weicht nicht nur beim Desktop vom Original ab (z.B. beim Boot-System, siehe unten). Anstelle von Snap-Paketen setzt Pop!_OS auf Flatpaks. Flathub ist per Default eingerichtet, Flatpaks können mühelos aus dem COSMIC Store installiert werden.
Der COSMIC Store basiert auf FlatpakInstallation von VS Code als Flatpak
Boot-System
Pop!_OS verwendet systemd_boot (nicht GRUB). Die erforderlichen Kernel- und Initrd-Dateien werden direkt in der EFI-Partition gespeichert (Verzeichnis /boot/efi/EFI/Pop-OS-xxx, Platzbedarf ca. 140 MByte). Auf meinem Testrechner erfolgt der Bootvorgang ohne die Anzeige eines Auswahlmenüs blitzschnell. Einige Hintergründe zur Konfiguration inklusive Reparatur-Tipps sind hier in einem Support-Artikel beschrieben.
Fazit
Für ein 1.0-Release funktioniert COSMIC sehr gut. Dafür muss man system76 einfach Respekt zollen! Einen kompletten Desktop neu zu implementieren (in der Programmiersprache Rust, noch ein Pluspunkt!) — das ist einfach bemerkenswert. system76 hat damit ein Fundament geschaffen, aus dem in den nächsten Jahren ein echter Mainstream-Desktop werden könnte, auf einer Stufe mit Gnome oder KDE.
Dessen ungeachtet verspüre ich aktuell keine Versuchung, auf COSMIC umzusteigen. Für meine Zwecke funktioniert Gnome mit ein paar Erweiterungen zufriedenstellend. Auch mit KDE kann ich gut arbeiten. Mein Leidensdruck, einen anderen Desktop zu suchen, ist gering. Meine Linux-Probleme haben selten mit dem Desktop zu tun. Für Linux-Einsteiger betrachte ich weiterhin Gnome als den besten Startpunkt.
system76 sieht hingegen primär Entwickler und fortgeschrittene Entwickler als Zielgruppe. Die Rechnung könnte aufgehen, insbesondere für Tiling-Fans.
Heute auf Pop!_OS 24.04 umzusteigen wirkt wenig attraktiv — in nur vier Monaten wird es mit Ubuntu 26.04 ein von Grund auf modernisiertes Fundament geben, wenig später vermutlich die entsprechende Pop!_OS-Version 26.04 mit sicher schon etwas verbesserten COSMIC-Paketen. Im Übrigen steht COSMIC als echtes Open-Source-Projekt auf für andere Distributionen zur Verfügung, z.B. in Form des durchaus attraktiven Fedora Spins.
„Hacking & Security: Das umfassende Handbuch“ von Michael Kofler, Roland Aigner, Klaus Gebeshuber, Thomas Hackner, Stefan Kania, Frank Neugebauer, Peter Kloep, Tobias Scheible, Aaron Siller, Matthias Wübbeling, Paul Zenker und André Zingsheim ist 2025 in der 4., aktualisierten und erweiterten Auflage im Rheinwerk Verlag erschienen und umfasst 1271 Seiten.
Ein Buchtitel, der bereits im Namen zwei gegensätzliche Extreme vereint: Hacking und Security. Dieser Lesestoff richtet sich nicht an ein breites Publikum, wohl aber an all jene, die Wert auf digitale Sicherheit legen – sei es im Internet, auf Servern, PCs, Notebooks oder mobilen Endgeräten. Gleichzeitig kann dieses umfassende Nachschlagewerk auch als Einstieg in eine Karriere im Bereich Ethical Hacking dienen.
Das Buch ist in drei inhaltlich spannende und klar strukturierte Teile gegliedert.
TEIL I – Einführung und Tools erläutert, warum es unerlässlich ist, sich sowohl mit Hacking als auch mit Security auseinanderzusetzen. Nur wer versteht, wie Angreifer vorgehen, kann seine Systeme gezielt absichern und Sicherheitsmaßnahmen umsetzen, die potenzielle Angriffe wirksam abwehren.
Behandelt werden unter anderem praxisnahe Übungsmöglichkeiten sowie Penetrationstests auf speziell dafür eingerichteten Testsystemen. Ziel ist es, typische Angriffsabläufe nachzuvollziehen und daraus wirksame Schutzkonzepte abzuleiten. Einen zentralen Stellenwert nimmt dabei das speziell für Sicherheitsanalysen entwickelte Betriebssystem Kali Linux ein, das in diesem Zusammenhang ausführlich vorgestellt wird.
Kali Linux – Simulation eines erfolgreichen Angriffs auf SSH
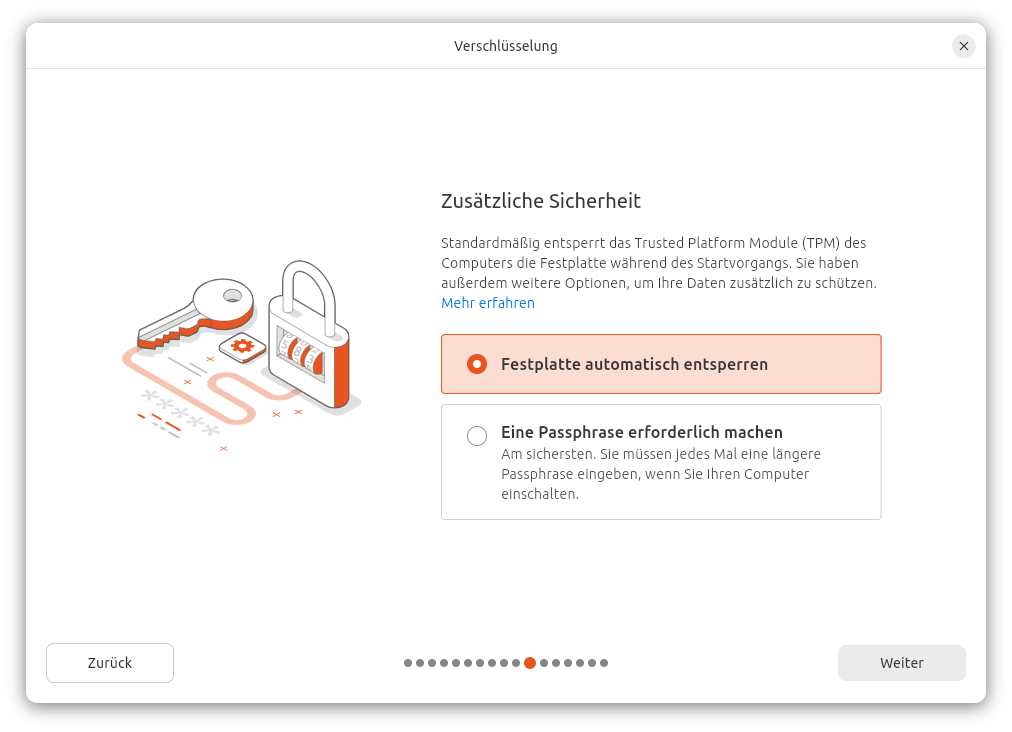
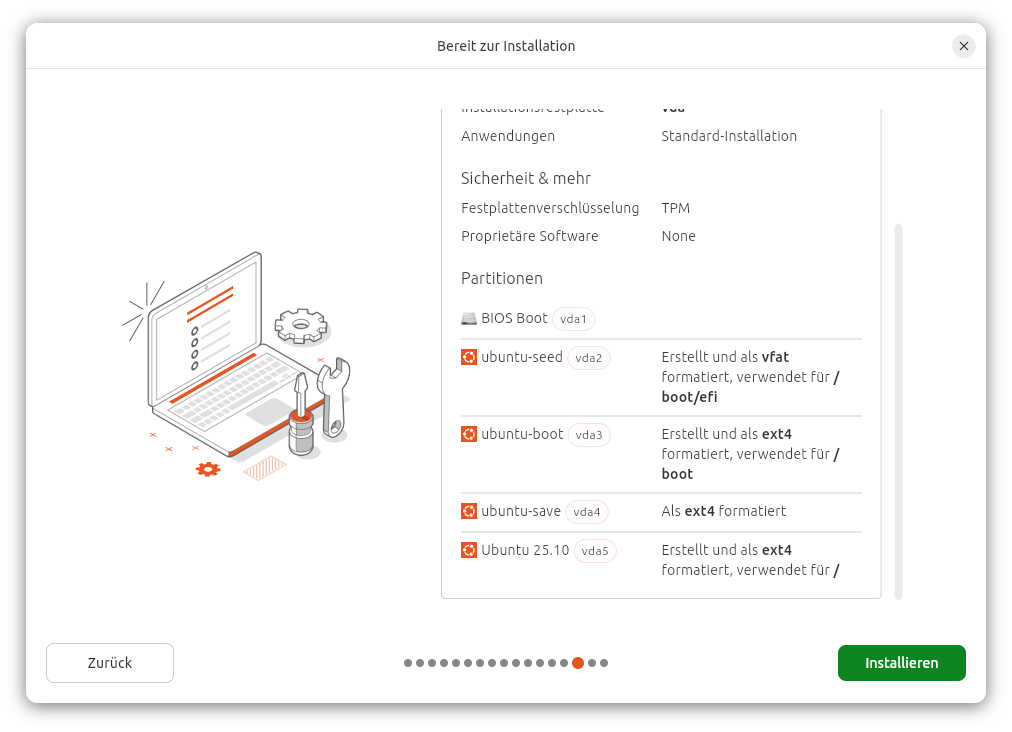
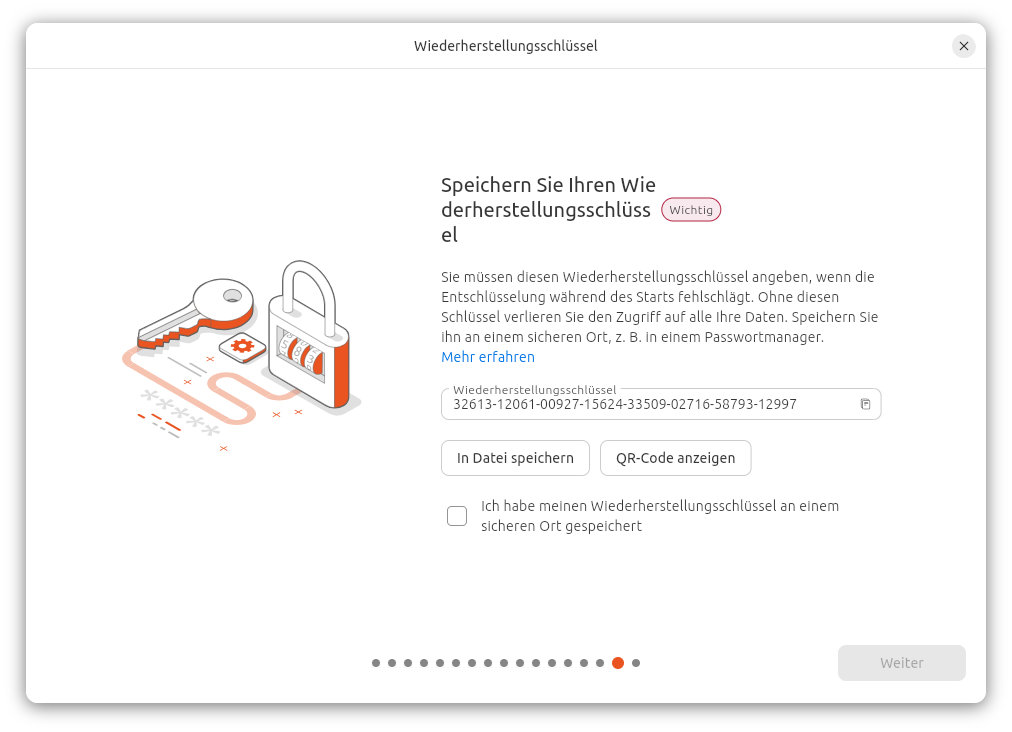
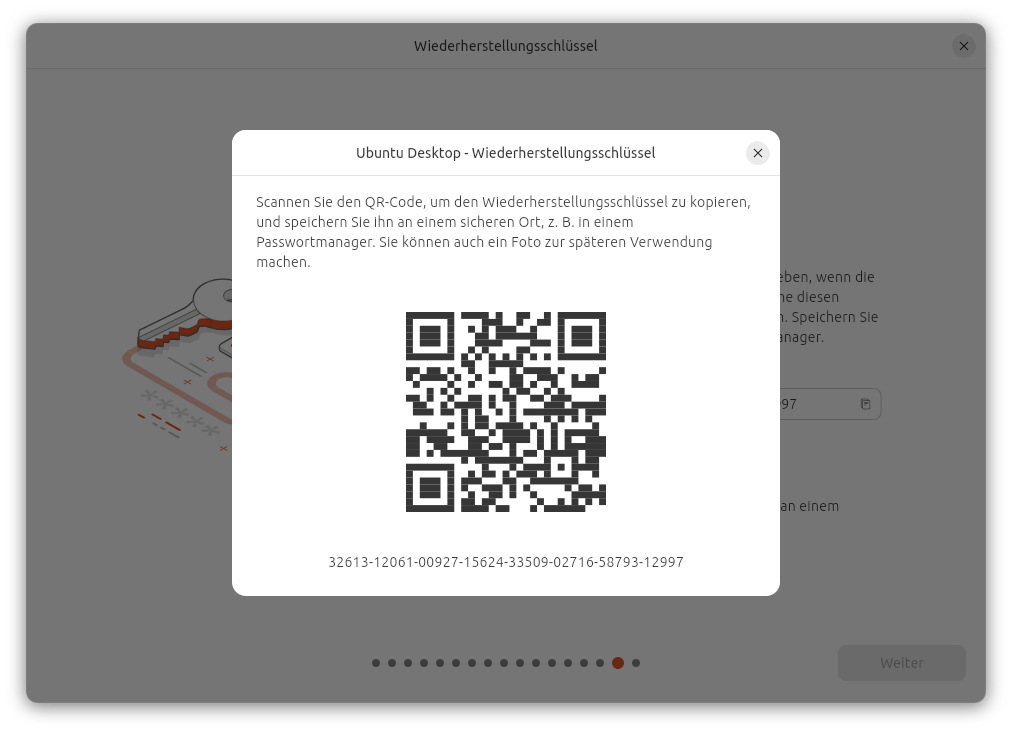
TEIL II – Hacking und Absicherung widmet sich intensiv den beiden zentralen Themenbereichen Hacking und Security. Es werden unterschiedliche Angriffsszenarien analysiert und typische Schwachstellen aufgezeigt. Besonders hervorgehoben wird dabei die Bedeutung der Festplattenverschlüsselung, um den unbefugten Zugriff auf sensible Daten zu verhindern.
Auch der Einsatz starker Passwörter in Kombination mit Zwei-Faktor-Authentifizierung (2FA) gehört heute zum Sicherheitsstandard. Dennoch lauern Gefahren im Alltag: Wird ein Rechner unbeaufsichtigt gelassen oder eine Sitzung nicht ordnungsgemäß beendet, kann etwa ein präparierter USB-Stick mit Schadsoftware gravierende Schäden verursachen.
Server-Betreiber stehen zudem unter permanentem Druck durch neue Bedrohungen aus dem Internet. Das Buch bietet praxisnahe Anleitungen zur Härtung von Windows- und Linux-Servern – beispielsweise durch den Einsatz von Tools wie Fail2Ban, das automatisiert Brute-Force-Angriffe erkennt und unterbindet.
Ein weiteres Kernthema ist die Verschlüsselung von Webverbindungen. Moderne Browser weisen inzwischen deutlich auf unsichere HTTP-Verbindungen hin. Die Übertragung sensibler Daten ohne HTTPS birgt erhebliche Risiken – etwa durch Man-in-the-Middle-Angriffe, bei denen Informationen abgefangen oder manipuliert werden können.
Abgerundet wird das Kapitel durch eine ausführliche Betrachtung von Angriffsmöglichkeiten auf weit verbreitete Content-Management-Systeme (CMS) wie WordPress, inklusive praxisnaher Hinweise zur Absicherung.
TEIL III – Cloud, Smartphones, IoT widmet sich der Sicherheit von Cloud-Systemen, mobilen Endgeräten und dem Internet of Things (IoT). Unter dem Leitsatz „Die Cloud ist der Computer eines anderen“ wird aufgezeigt, wie stark Nutzerinnen und Nutzer bei der Verwendung externer Dienste tatsächlich abhängig sind. Besonders bei Cloud-Angeboten amerikanischer Anbieter werden bestehende geopolitische Risiken oft unterschätzt – obwohl sie spätestens seit den Enthüllungen von Edward Snowden nicht mehr zu ignorieren sind.
Selbst wenn Rechenzentren innerhalb Europas genutzt werden, ist das kein Garant für Datenschutz. Der Zugriff durch Dritte – etwa durch Geheimdienste – bleibt unter bestimmten Umständen möglich. Als datenschutzfreundliche Alternative wird in diesem Kapitel Nextcloud vorgestellt: ein in Deutschland entwickeltes Cloud-System, das sich auf eigenen Servern betreiben lässt. Hinweise zur Installation und Konfiguration unterstützen den Einstieg in die selbstbestimmte Datenverwaltung.
Wer sich für mehr digitale Souveränität entscheidet, übernimmt zugleich Verantwortung – ein Aspekt, dem im Buch besondere Aufmerksamkeit gewidmet wird. Ergänzend werden praxisnahe Empfehlungen zur Absicherung durch Zwei- oder Multi-Faktor-Authentifizierung (2FA/MFA) gegeben.
Ein weiteres Thema sind Sicherheitsrisiken bei mobilen Geräten und IoT-Anwendungen. Besonders kritisch: schlecht gewartete IoT-Server, die oft im Ausland betrieben werden und ein hohes Angriffspotenzial aufweisen. Auch hier werden konkrete Gefahren und Schutzmaßnahmen anschaulich dargestellt.
Das Buch bietet einen fundierten und praxisnahen Einstieg in die Welt von IT-Sicherheit und Hacking. Es richtet sich gleichermaßen an interessierte Einsteiger als auch an fortgeschrittene Anwender, die ihre Kenntnisse vertiefen möchten. Besonders gelungen ist die Verbindung technischer Grundlagen mit konkreten Anwendungsszenarien – vom Einsatz sicherer Tools über das Absichern von Servern bis hin zur datenschutzfreundlichen Cloud-Lösung.
Wer sich ernsthaft mit Sicherheitsaspekten in der digitalen Welt auseinandersetzen möchte, findet in diesem Werk einen gut strukturierten Leitfaden, der nicht nur Wissen vermittelt, sondern auch zum eigenständigen Handeln motiviert. Ein empfehlenswertes Nachschlagewerk für alle, die digitale Souveränität nicht dem Zufall überlassen wollen.
Die Docker Engine 29 unter Linux unterstützt erstmals Firewalls auf nftables-Basis. Die Funktion ist explizit noch experimentell, aber wegen der zunehmenden Probleme mit dem veralteten iptables-Backend geht für Docker langfristig kein Weg daran vorbei. Also habe ich mir gedacht, probiere ich das Feature einfach einmal aus. Mein Testkandidat war Fedora 43 (eine reale Installation auf einem x86-Mini-PC sowie eine virtuelle Maschine unter ARM).
Inbetriebnahme
Das nft-Backend aktivieren Sie mit der folgenden Einstellung in der Datei /etc/docker/daemon.json:
{
"firewall-backend": "nftables"
}
Diese Datei existiert normalerweise nicht, muss also erstellt werden. Die Syntax ist hier zusammengefasst.
Die Docker-Dokumentation weist darauf hin, dass Sie außerdem IP-Forwarding erlauben müssen. Alternativ können Sie Docker anweisen, auf Forwarding zu verzichten ("ip-forward": false in daemon.json) — aber dann funktionieren grundlegende Netzwerkfunktionen nicht.
sysctl --system aktiviert die Änderungen ohne Reboot.
Die Docker-Dokumentation warnt allerdings, dass dieses Forwarding je nach Anwendung zu weitreichend sein und Sicherheitsprobleme verursachen kann. Gegebenenfalls müssen Sie das Forwarding durch weitere Firewall-Regeln wieder einschränken. Die Dokumentation gibt ein Beispiel, um auf Rechnern mit firewalld unerwünschtes Forwarding zwischen eth0 und eth1 zu unterbinden. Alles in allem wirkt der Umgang mit dem Forwarding noch nicht ganz ausgegoren.
Praktische Erfahrungen
Mit diesen Einstellungen lässt sich die Docker Engine prinzipiell starten (systemctl restart docker, Kontrolle mit docker version oder systemctl status docker). Welches Firewall-Backend zum Einsatz kommt, verrät docker info:
docker info | grep 'Firewall Backend'
Firewall Backend: nftables+firewalld
Ich habe dann ein kleines Compose-Setup bestehend aus MariaDB und WordPress gestartet. Soweit problemlos:
Auch wenn ich kein nft-Experte bin, wollte ich mir zumindest einen Überblick verschaffen, wie die Regeln hinter den Kulissen funktionieren und welchen Umfang sie haben:
# ohne Docker (nur firewalld)
nft list tables
table inet firewalld
nft list ruleset | wc -l
374
# nach Start der Docker Engine (keine laufenden Container)
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
nft list ruleset | wc -l
736
Im Prinzip richtet Docker also zwei Regeltabellen docker-bridges ein, je eine für IPv4 und für IPv6. Die zentralen Regeln für IPv4 sehen so aus (hier etwas kompakter als üblich formatiert):
nft list table ip docker-bridges
table ip docker-bridges {
map filter-forward-in-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-in__docker0 }
}
map filter-forward-out-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-out__docker0 }
}
map nat-postrouting-in-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-in__docker0 }
}
map nat-postrouting-out-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-out__docker0 }
}
chain filter-FORWARD {
type filter hook forward priority filter; policy accept;
oifname vmap @filter-forward-in-jumps
iifname vmap @filter-forward-out-jumps
}
chain nat-OUTPUT {
type nat hook output priority dstnat; policy accept;
ip daddr != 127.0.0.0/8 fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-POSTROUTING {
type nat hook postrouting priority srcnat; policy accept;
iifname vmap @nat-postrouting-out-jumps
oifname vmap @nat-postrouting-in-jumps
}
chain nat-PREROUTING {
type nat hook prerouting priority dstnat; policy accept;
fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-prerouting-and-output {
}
chain raw-PREROUTING {
type filter hook prerouting priority raw; policy accept;
}
chain filter-forward-in__docker0 {
ct state established,related counter packets 0 bytes 0 accept
iifname "docker0" counter packets 0 bytes 0 accept comment "ICC"
counter packets 0 bytes 0 drop comment "UNPUBLISHED PORT DROP"
}
chain filter-forward-out__docker0 {
ct state established,related counter packets 0 bytes 0 accept
counter packets 0 bytes 0 accept comment "OUTGOING"
}
chain nat-postrouting-in__docker0 {
}
chain nat-postrouting-out__docker0 {
oifname != "docker0" ip saddr 172.17.0.0/16 counter packets 0 bytes 0 masquerade comment "MASQUERADE"
}
}
Diese Tabelle richtet NAT-Hooks für Pre- und Postrouting ein, die über Verdict-Maps (Datenstrukturen zur Zuordnung von Aktionen) später dynamisch auf bridge-spezifische Chains weiterleiten können. Für das Standard-Docker-Bridge-Netzwerk (docker0, 172.17.0.0/16) sind bereits Filter-Chains vorbereitet, die etablierte Verbindungen akzeptieren, Inter-Container-Kommunikation erlauben würden und nicht veröffentlichte Ports blocken, sowie eine Masquerading-Regel für ausgehenden Traffic von Containern, damit diese über die Host-IP auf das Internet zugreifen können. Die meisten Chains sind vorerst leer oder inaktiv (nat-prerouting-and-output, raw-PREROUTING, nat-postrouting-in__docker0). Wenn Docker Container ausführt, interne Netzwerk bildet etc., kommen weitere Regeln innerhalb von ip docker-bridges hinzu.
Zusammenspiel mit libvirt/virt-manager
Vor ca. einem halben Jahr bin ich das erste Mal über das nicht mehr funktionierende Zusammenspiel von Docker mit iptables und libvirt mit nftables gestolpert (siehe hier). Zumindest bei meinen oberflächlichen Tests klappt das jetzt: libvirt muss nicht auf iptables zurückgestellt werden sondern kann bei der Defaulteinstellung nftables bleiben. Dafür muss Docker wie in diesem Beitrag beschrieben ebenfalls auf nftables umgestellt werden. Nach einem Neustart (erforderlich, damit alte iptables-Docker-Regeln garantiert entfernt werden!) kooperieren Docker und libvirt so wie sie sollen. libvirt erzeugt für seine Netzwerkfunktionen zwei weitere Regeltabellen:
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
table ip libvirt_network
table ip6 libvirt_network
Einschränkungen und Fazit
Die Docker-Dokumentation weist darauf hin, dass das nftables-Backend noch keine Overlay-Regeln erstellt, die für den Betrieb von Docker Swarm notwendig sind. Docker Swarm funktioniert also aktuell nicht, wenn Sie Docker auf nftables umstellen. Für mich ist das kein Problem, weil ich Docker Swarm ohnedies nicht brauche.
Ich habe meine Tests nur unter Fedora durchgeführt. (Meine Zeit ist auch endlich.) Es ist anzunehmen, dass RHEL plus Klone analog funktionieren, aber das bleibt abzuwarten. Debian + Ubuntu wären auch zu testen …
Ich habe nur einfache compose-Setups ausprobiert. Natürlich kein produktiver Einsatz.
Meine nftables- und Firewall-Kenntnisse reichen nicht aus, um eventuelle Sicherheitsimplikationen zu beurteilen, die sich aus der Umstellung von iptables auf nftables ergeben.
Losgelöst von den Docker-spezifischen Problemen zeigt dieser Blog-Beitrag auch, dass das Zusammenspiel mehrerer Programme (firewalld, Docker, libvirt, fail2ban, sonstige Container- und Virtualisierungssysteme), die jeweils ihre eigenen Firewall-Regeln benötigen, alles andere als trivial ist. Es würde mich nicht überraschen, wenn es in naher Zukunft noch mehr unangenehme Überraschungen gäbe, dass also der gleichzeitige Betrieb der Programme A und B zu unerwarteten Sicherheitsproblemen führt. Warten wir es ab …
Insofern ist die Empfehlung, beim produktiven Einsatz von Docker auf dem Host möglichst keine anderen Programme auszuführen, nachvollziehbar. Im Prinzip ist das Konzept ja nicht neu — jeder Dienst (Web, Datenbank, Mail usw.) bekommt möglichst seinen eigenen Server bzw. seine eigene Cloud-Instanz. Für große Firmen mit entsprechender Server-Infrastruktur sollte dies ohnedies selbstverständlich sein. Bei kleineren Server-Installationen ist die Auftrennung aber unbequem und teuer.
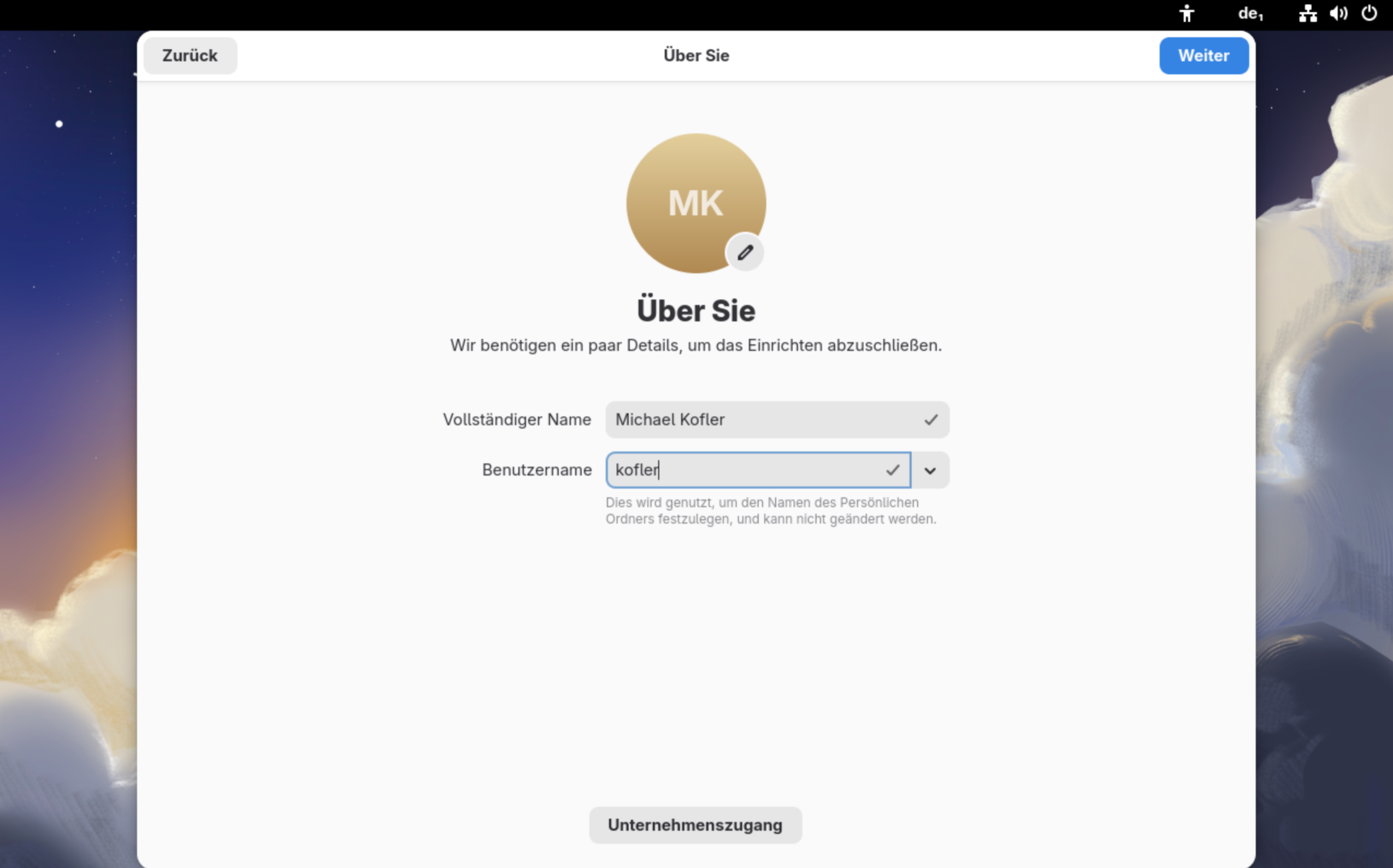
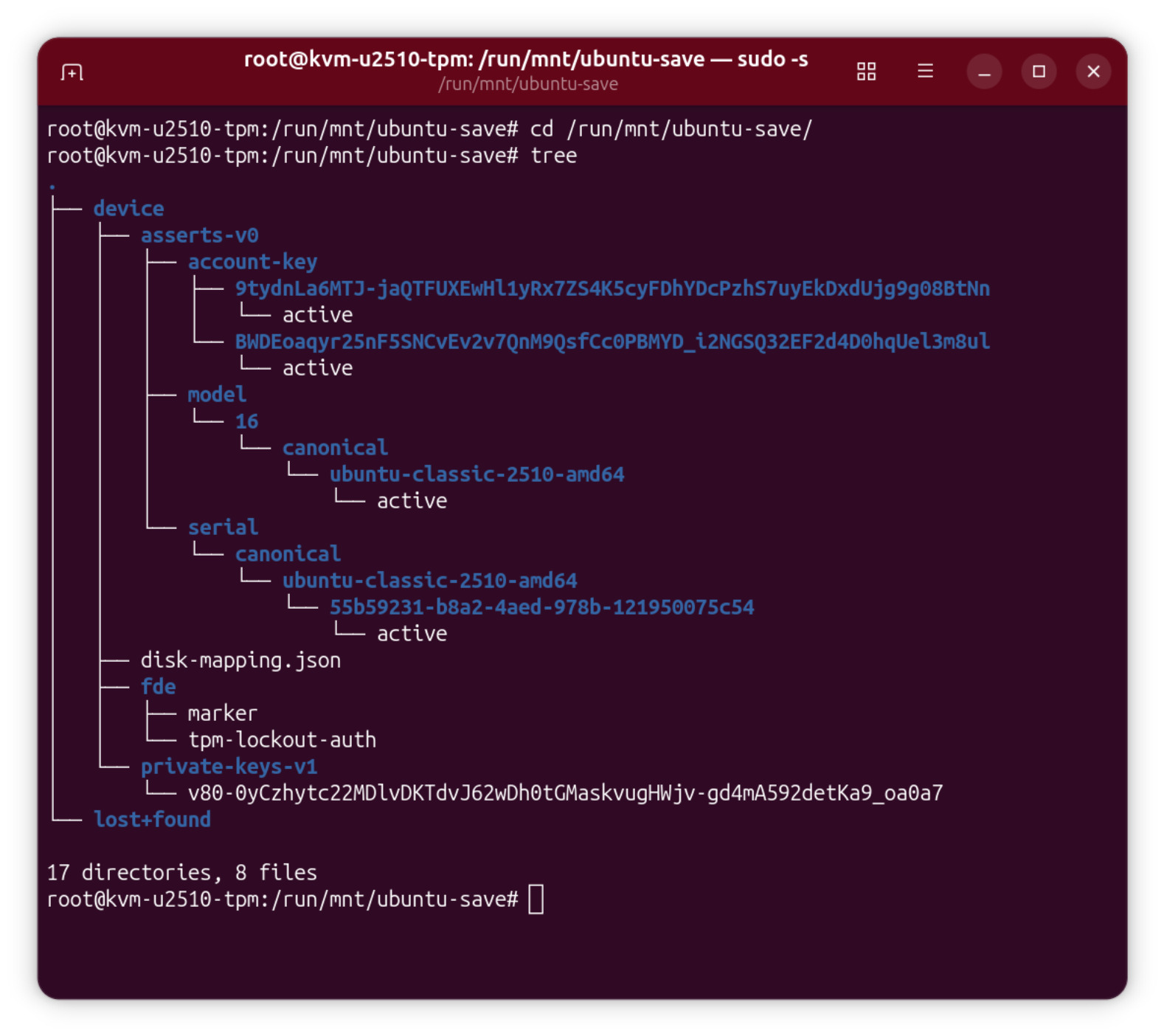
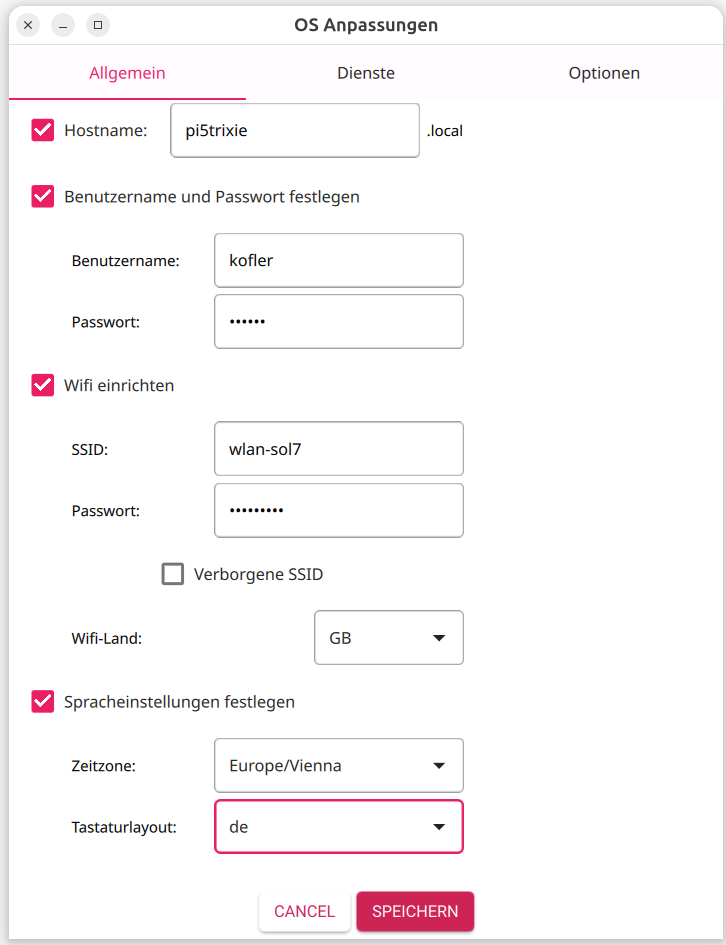
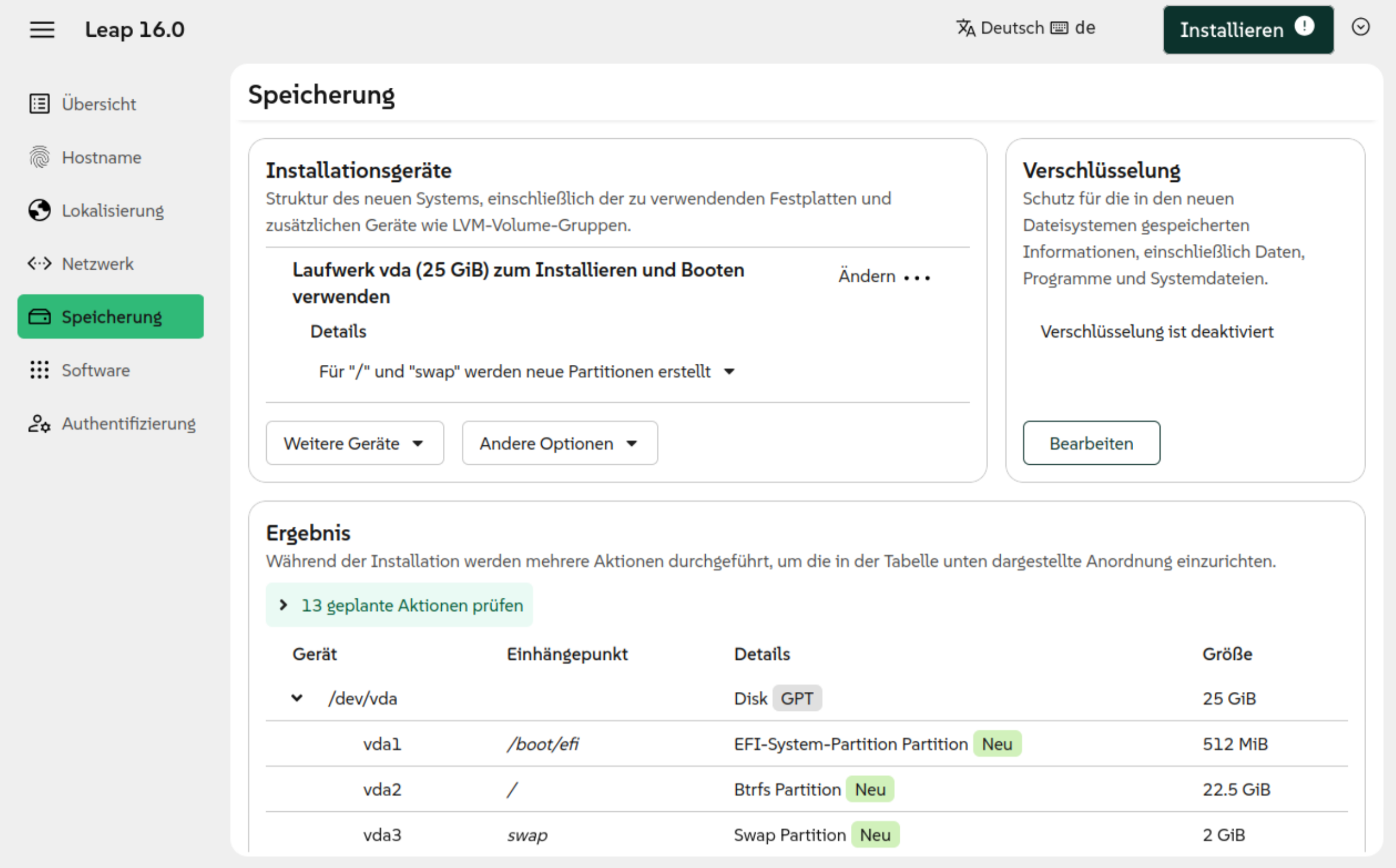
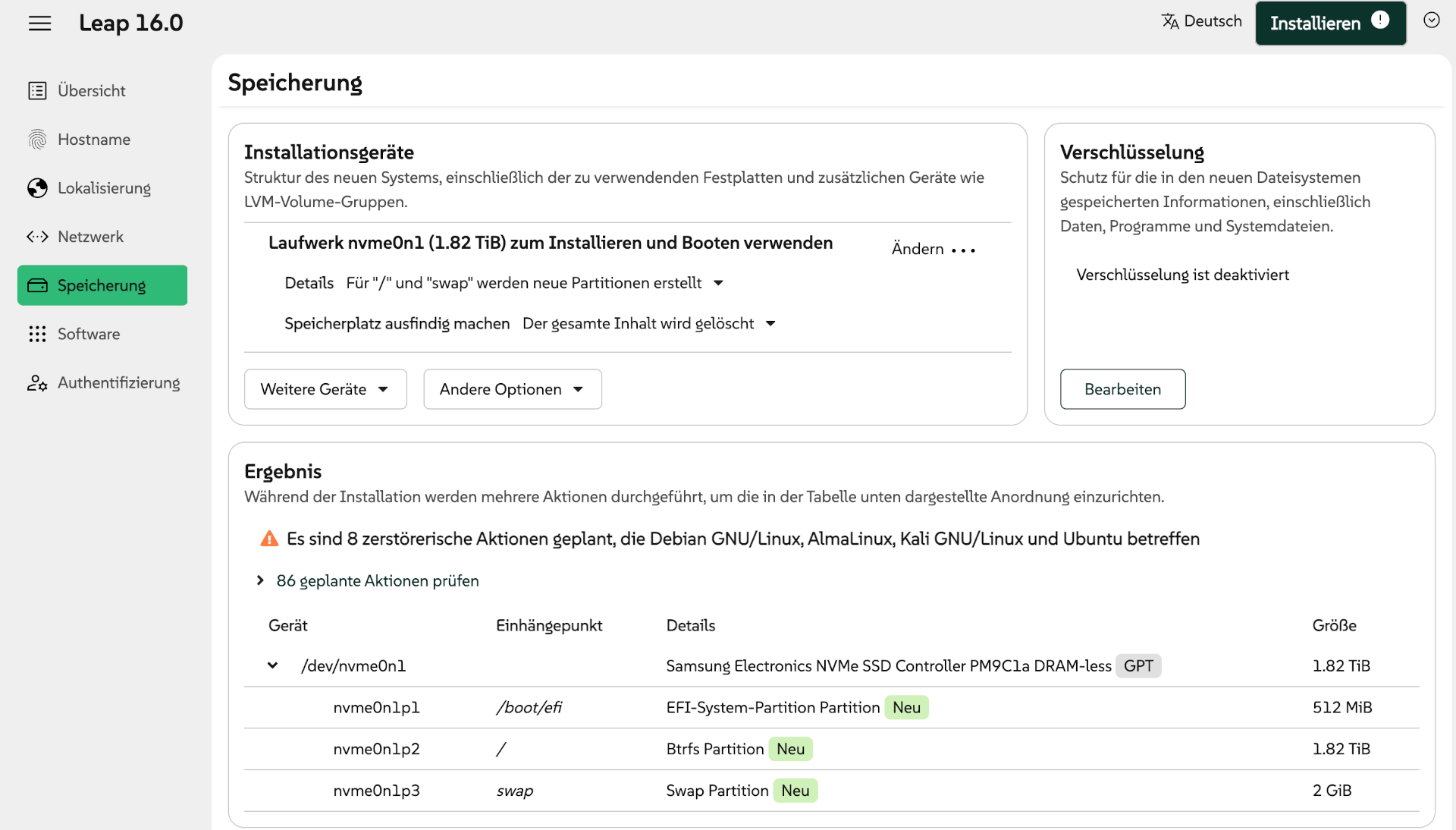
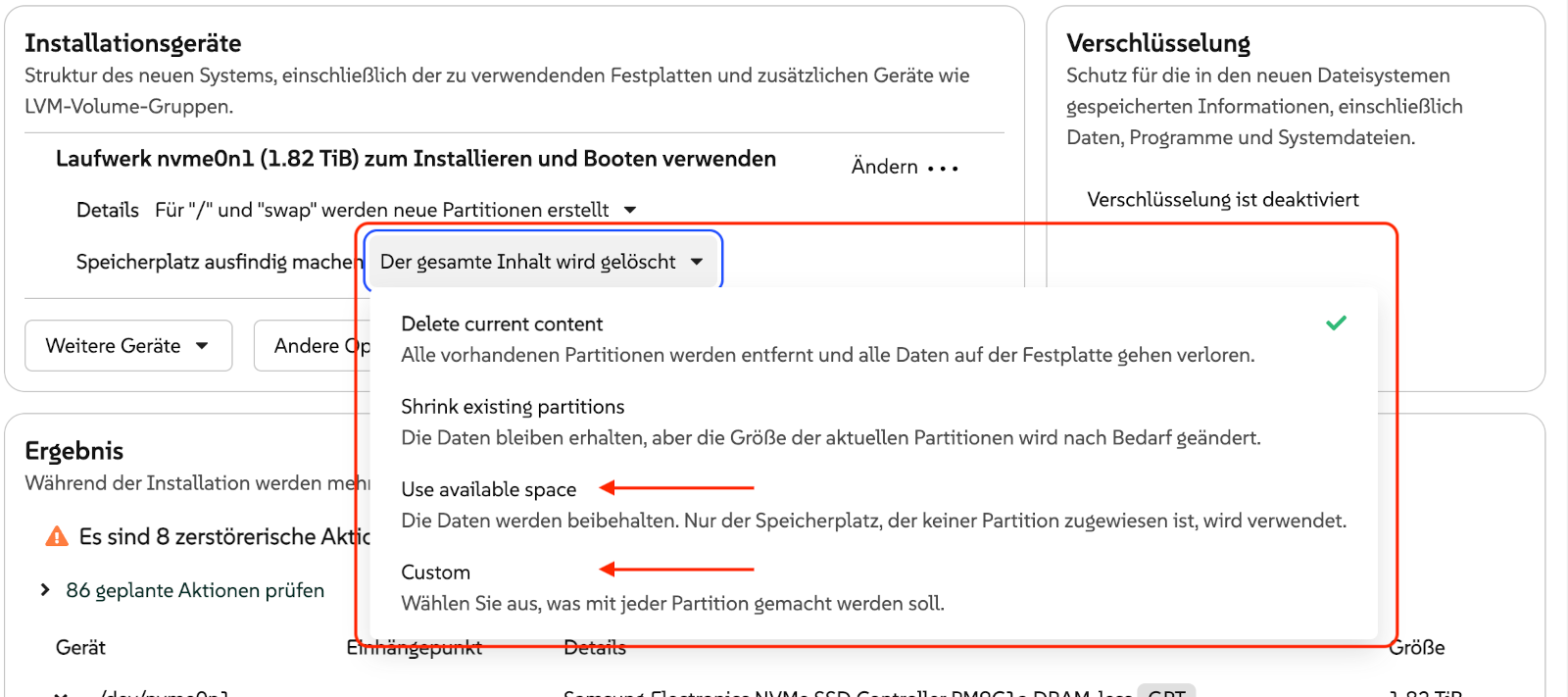
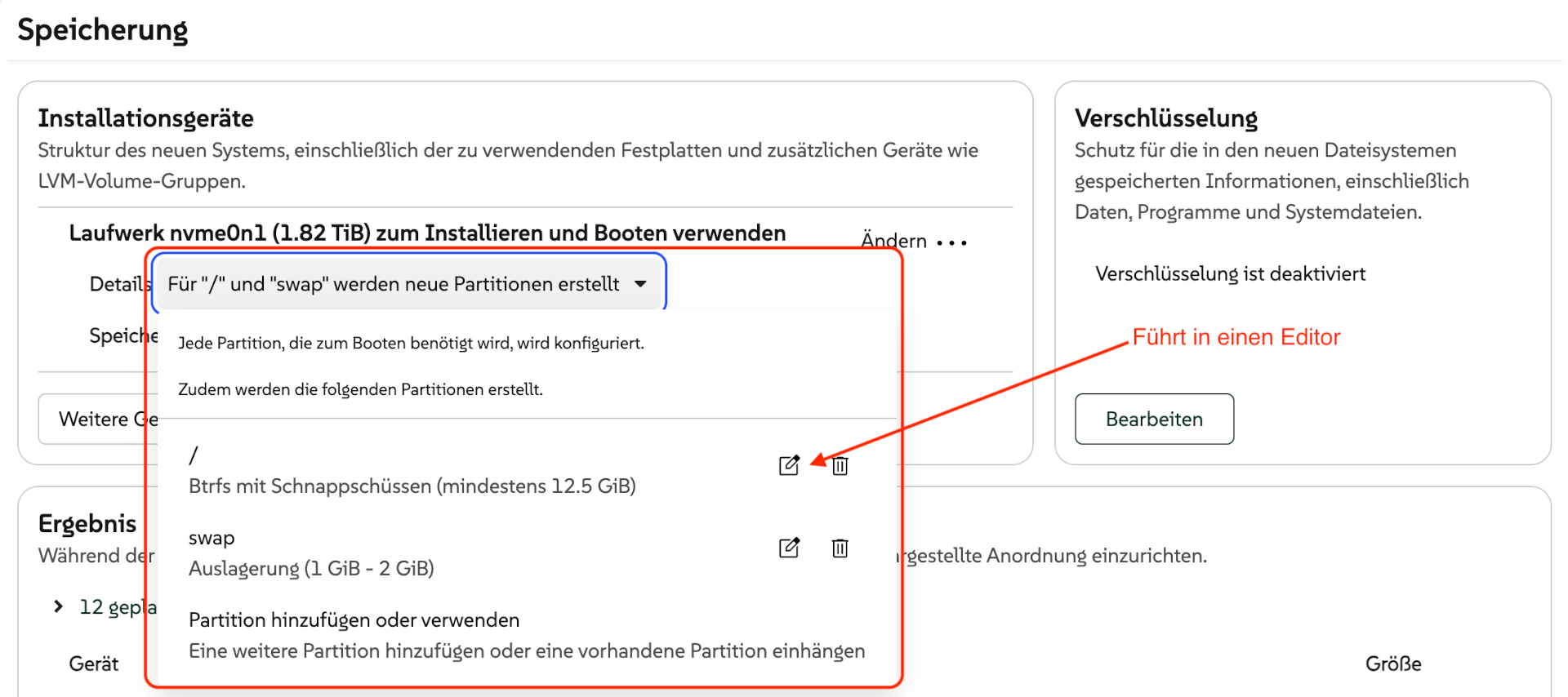
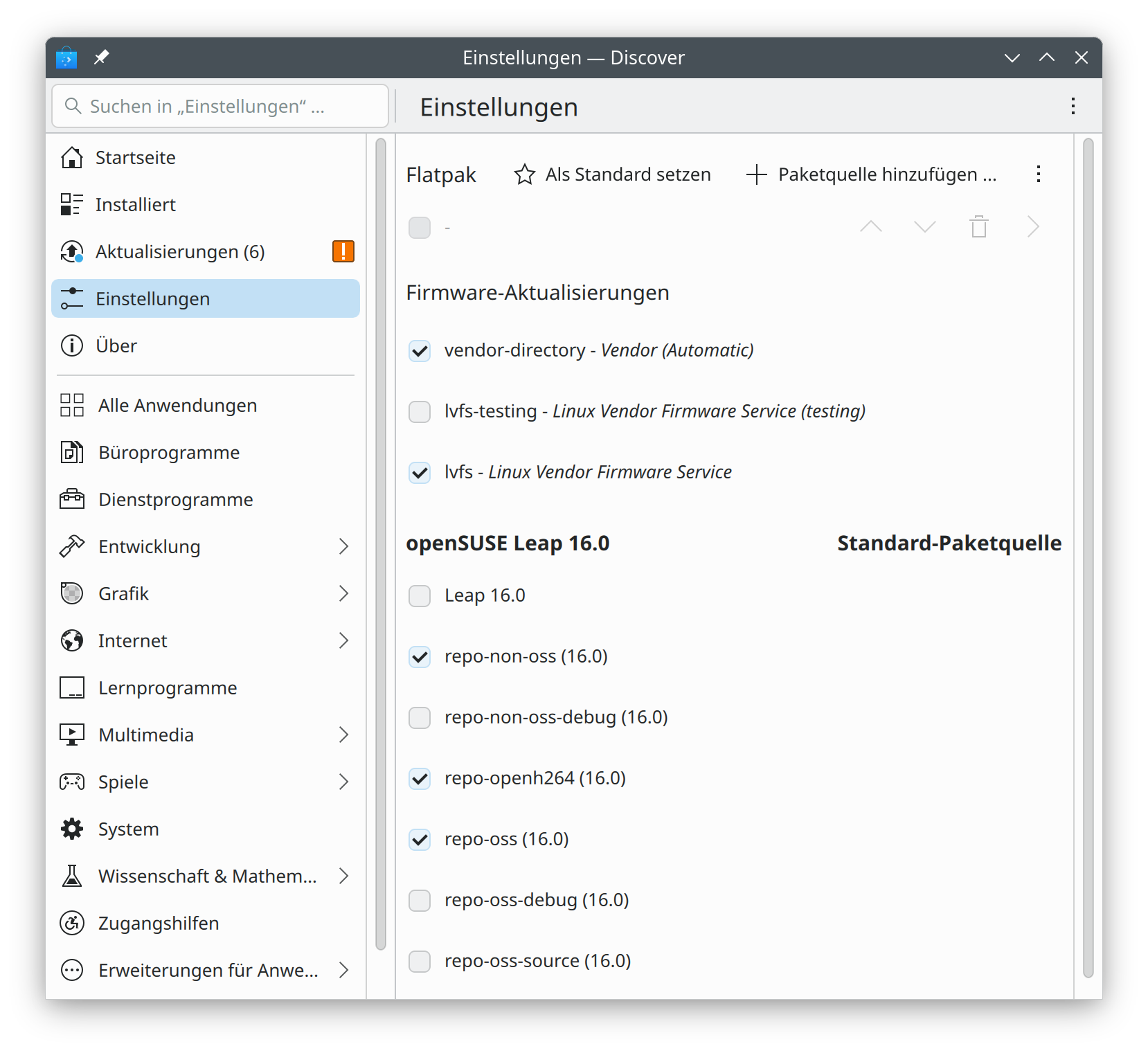
Die Raspberry Pi Foundation hat vor einigen Tagen eine komplett reorganisierte Implementierung Ihres Raspberry Pi OS Imager vorgestellt. Das Programm hilft dabei, Raspberry Pi OS oder andere Distributionen auf SD-Karten für den Raspberry Pi zu schreiben. Mit der vorigen Version hatte ich zuletzt Ärger. Aufgrund einer Unachtsamkeit habe ich Raspberry Pi OS über die Windows-Installation auf der zweite SSD meines Mini-PCs geschrieben. Führt Version 2.0 ebenso leicht in die Irre?
Installation unter Linux
Der Raspberry Pi Imager steht für Windows als EXE-Datei und für macOS als DMG-Image zur Verfügung. Installation und Ausführung gelingen problemlos.
Unter Linux ist die Sache nicht so einfach. Die Raspberry Pi Foundation stellt den Imager als AppImage zur Verfügung. AppImages sind ein ziemlich geniales Format zur Weitergabe von Programmen. Selbst Linux Torvalds war begeistert (und das will was sagen!): »This is just very cool.« Leider setzt Ubuntu auf Snap-Pakete und die Red-Hat-Welt auf Flatpaks. Dementsprechend mau ist die Unterstützung für das AppImage-Format.
Ich habe meine Tests unter Fedora 43 durchgeführt. Der Versuch, den heruntergeladenen Imager einfach zu starten, führt sowohl aus dem Webbrowser als auch im Gnome Dateimanager in das Programm Gnome Disks. Fedora erkennt nicht, dass es sich um eine App handelt und bietet stattdessen Hilfe an, in die Image-Datei hineinzusehen. Abhilfe: Sie müssen zuerst das Execute-Bit setzen:
chmod +x Downloads/imager_2.2.0.amd64.AppImage
Aber auch der nächste Startversuch scheitert. Das Programm verlangt sudo-Rechte.
Der Raspberry Pi Imager muss mit sudo ausgeführt werden
Mit sudo funktioniert es schließlich:
sudo Downloads/imager_2.2.0.amd64.AppImage
Tipp: Beim Start mit sudo müssen Sie imager_n.n.AppImage unbedingt einen Pfad voranstellen! Wenn Sie zuerst mit cd Downloads in das Downloads-Verzeichnis wechseln und dann sudo imager_n.n.AppImage ausführen, lautet die Fehlermeldung Befehl nicht gefunden. Hingegen funktioniert sudo ./imager_n.n.AppImage.
Bedienung
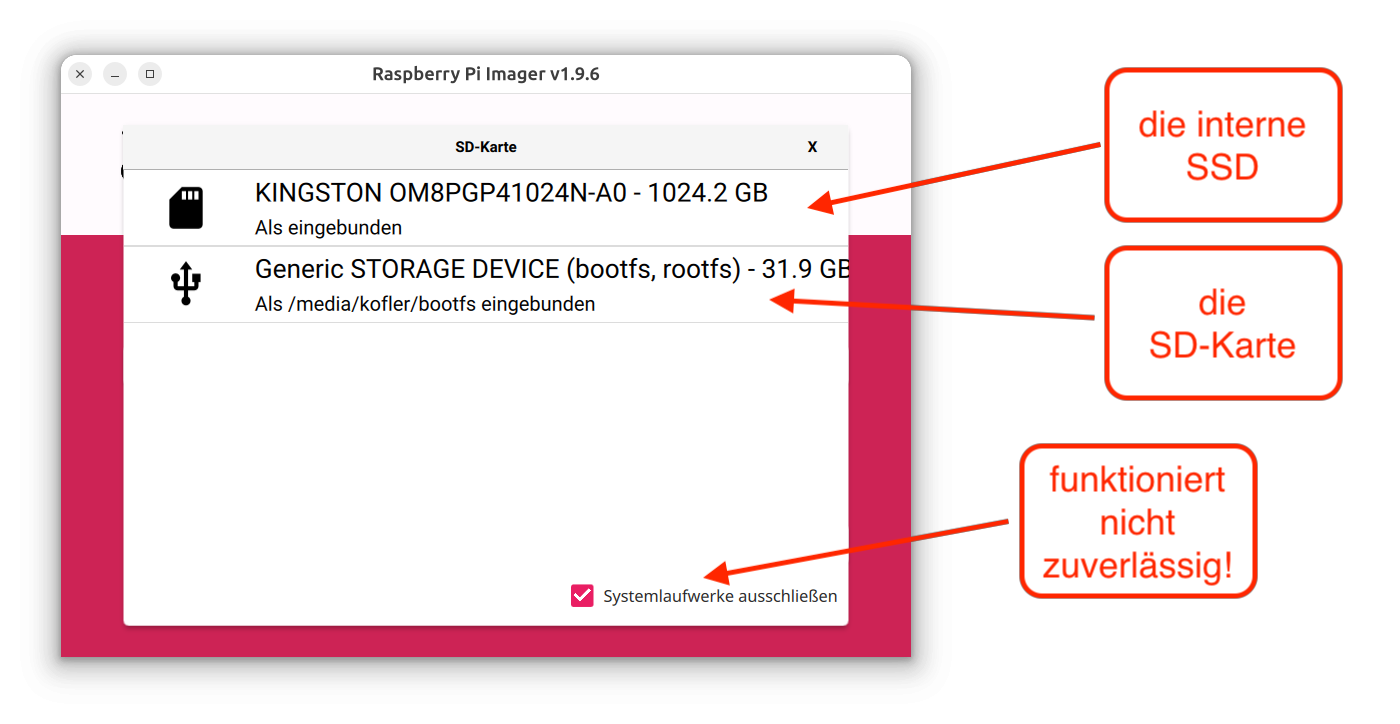
Ist der Start einmal geglückt, lässt sich das Programm einfach bedienen: Sie wählen zuerst Ihr Raspberry-Pi-Modell aus, dann die gewünschte, dazu passende Distribution und schließlich das Device der SD-Karte aus. Vorsicht!! Wie schon bei der alten Version des Programms sind die Icons irreführend. In meinem Fall (PC mit zwei zwei SSDs und einer SD-Karte) wird das SD-Karten-Icon für die zweite SSD verwendet, das USB-Icon dagegen für die SD-Karte. Passen Sie auf, dass Sie nicht das falsche Laufwerk auswählen!! Ich habe ein entsprechendes GitHub-Issue verfasst.
DistributionsauswahlDie Icons zur Auswahl der SD-Karte sind irreführend. Der obere Eintrag ist eine SSD mit meiner Windows-Installation, der untere Eintrag ist die SD-Karte!
In den weiteren Schritten können Sie eine Vorabkonfiguration von Raspberry Pi OS vornehmen, was vor allem dann hilfreich ist, wenn Sie den Raspberry Pi ohne Tastatur und Monitor (»headless«) in Betrieb nehmen und sich direkt per SSH einloggen möchten.
Diverse Parameter können vorkonfiguriert werden
Bei den Zusammenfassungen wäre die Angabe des Device-Namens der SD-Karte eine große Hilfe.
In der Zusammenfassung fehlt der Device-Name der SD-Karte
Fazit
Die Oberfläche des Raspberry Pi Imager wurde überarbeitet und ist ein wenig übersichtlicher geworden. An der Funktionalität hat sich nichts geändert. Leider kann es weiterhin recht leicht passieren, das falsche Device auszuwählen. Bedienen Sie das Programm also mit Vorsicht!
Seit einiger Zeit treten unter Ubuntu 24.04 LTS Probleme beim Ausführen von VirtualBox auf. Diese lassen sich zwar temporär durch das Entladen eines KVM-Moduls beheben, tauchen jedoch nach einem Neustart wieder auf.
KVM steht für Kernel-based Virtual Machine und ist eine Virtualisierungstechnologie für Linux auf x86-Hardware.
Temporäre Lösung
Abhängig vom verwendeten Prozessor kann das jeweilige KVM-Modul aus dem laufenden Kernel mit folgendem Befehl entfernt werden:
sudo modprobe -r kvm_intel
bei AMD-Systemen:
sudo modprobe -r kvm_amd
Diese Methode ist jedoch nicht dauerhaft, da das Modul nach einem Neustart wieder geladen wird.
Bei der Recherche zu diesem Thema bin ich auf zwei Lösungsansätze gestoßen, die das Problem dauerhaft beheben sollten. Zum einen geht es um das Hinzufügen einer Boot-Option in GRUB, zum anderen um die Erstellung einer Blacklist der entsprechenden KVM-Module für VirtualBox.
1. Ansatz – Eingriff in den Bootloader (GRUB)
In der Datei /etc/default/grub wird der Eintrag
GRUB_CMDLINE_LINUX=
um folgenden Parameter (siehe Screenshot) ergänzt:
"kvm.enable_virt_at_load=0"
Anschließend muss die GRUB-Konfiguration aktualisiert werden:
sudo update-grub
Wichtiger Hinweis: Ein fehlerhafter Eintrag in der GRUB-Konfiguration kann dazu führen, dass das System nicht mehr startet. Unerfahrene Nutzer könnten in eine schwierige Situation geraten. Daher ist ein vollständiges System-Backup vor dem Eingriff unbedingt empfehlenswert.
GRUB-Konfiguration
2. Ansatz – Blacklisting des KVM-Moduls
Ein sichererer und eleganterer Weg ist das Blacklisting des Moduls. Dazu wird eine neue Konfigurationsdatei angelegt:
sudo nano /etc/modprobe.d/blacklist-kvm.conf
Dort fügt man folgende Zeilen hinzu:
blacklist kvm
blacklist kvm_intel
Nach einem Neustart des Systems wird das jeweilige KVM-Modul nicht mehr geladen und VirtualBox sollte wie gewohnt funktionieren.
Fazit
Die zweite Methode ist risikoärmer und benutzerfreundlicher. Dennoch empfiehlt es sich, vor jeder Änderung am System ein Backup anzulegen.
Ende November erscheint die 19. Auflage meines Linux-Buchs und markiert damit ein denkwürdiges Jubiläum: Das Buch ist jetzt 30 Jahre alt!
Das Linux-Buch: 1995, 2004, 2010, 2014, 2025
Gleichzeitig ist das Buch so modern wie nie zuvor. Bei der Überarbeitung habe ich das Buch an vielen Stellen gestrafft und von Altlasten befreit. Das hat Platz für neue Inhalte gemacht, z.B. rund um die folgenden Themen:
Die Shell fish (neues Kapitel)
Swap on ZRAM
Geoblocking mit nft (neuer Abschnitt)
Samba im Zusammenspiel mit Windows 11 24H2
Monitoring mit Prometheus und Grafana (neues Kapitel, Docker-Setup mit Traefik)
KI-Sprachmodelle ausführen (neues Kapitel)
Berücksichtigung von CachyOS
Umfang: 1429 Seiten
ISBN: 978-3-367-11069-8
Preis: Euro 49,90 (in D inkl. MWSt.)
Sowohl Linux als auch mein Buch haben sich in den vergangenen 30 Jahren natürlich dramatisch verändert. Die folgenden Absätze stammen aus dem Vorwort. Das gesamte Vorwort befindet sich in der Leseprobe (PDF) zum Buch.
Als ich an der ersten Auflage dieses Buchs schrieb, hatten die meisten Privatanwenderinnen und -anwender noch gar keinen Internetzugang, und wenn doch, dann über ein unzuverlässiges Modem. Das World Wide Web war gerade im Entstehen. In der ersten Auflage des Buchs habe ich Mosaic als Linux-tauglichen Webbrowser empfohlen. Erst in der zweiten Auflage konnte ich auf Netscape eingehen, der damals als erster »richtiger« Browser kostenlos für Linux zur Verfügung stand. (Aus Netscape wurde später Mozilla Firefox.)
Das wichtigste Medium zur Verbreitung von Linux war in den 90er-Jahren die CD. Die ersten Auflagen dieses Buchs enthielten deswegen CDs (später DVDs) mit Linux-Distributionen. Der Siegeszug des Internets veränderte den Charakter dieses Buchs: Es war nicht mehr notwendig, alle Optionen diverser Kommandos bis ins letzte Detail zu beschreiben; jetzt reicht ein Link auf eine Webseite mit vertiefenden Informationen.
In den Vordergrund des Buchs rückte die Vermittlung von Unix/Linux-Grundlagen. Ja, alles steht im Internet, aber Leserinnen und Leser schätzen den geordneten Überblick über Linux, die strukturierte Sammlung von Basiswissen so sehr, dass sich regelmäßige Neuauflagen lohnen. Die altmodische, aber werbefreie Präsentation auf Papier (oder in einem E-Book), frei von blinkenden Bannern und lästigen Werbevideos, ist ein entscheidender Vorteil.
Parallel zur Entwicklung des Internets bekam dieses Buch einen neuen inhaltlichen Fokus. Immer mehr Organisationen und Firmen betreiben selbst Linux-Server, sei es zu Hause, auf gemieteten Root-Servern oder in virtuellen Maschinen (Cloud-Instanzen). Dementsprechend erklärt dieses Buch, wie Sie selbst SSH-, Web-, Mail- und Datenbank-Server einrichten und sicher betreiben.
Ein weiterer Meilenstein der Linux-Geschichte war die Vorstellung des Raspberry Pi vor gut einem Jahrzehnt. Dieser preisgünstige Linux-basierte Mini-Computer bietet viele Anwendungen, von elektronischen Bastelprojekten bis zur Basisstation für die eigene Home Automation.
Seit 2022 zeichnet sich eine weitere IT-Zeitenwende ab: Mit ChatGPT wird der erste brauchbare KI-Chatbot frei verfügbar. Es lässt sich trefflich darüber streiten, wie »intelligent« dieses und konkurrierende Systeme sind. Fest steht, dass KI-Tools eine großartige Hilfe bei Linux-Problemen aller Art sind.
Nachdem ich mich vor zwei Jahrzehnten gefragt habe, ob das Internet IT-Bücher obsolet macht, stellt sich diese Frage jetzt wieder. Und neuerlich glaube ich, dass dies nicht der Fall sein wird. KI-Tools helfen (auch) bei der Lösung von Linux-Problemen. Dennoch brauchen Sie einiges an Grundwissen, um funktionierende Prompts zu formulieren. Und noch mehr Wissen zur Abschätzung, ob die Antworten von ChatGPT & Co. plausibel, veraltet oder frei erfunden sind. Genau dieses Wissen vermittle ich hier — seit 30 Jahren!
Aktuell schreibe ich hier mehr zu Docker als mir lieb ist. Es ist eigentlich absurd: Ich verwende Docker seit Jahren täglich und in der Regel ohne irgendwelche Probleme. Aber in den letzten Wochen prasseln Firewall-Inkompatibilitäten und anderer Ärger förmlich über Docker-Anwender herein.
Konkret geht es in diesem Beitrag um zwei Dinge:
Mit dem Update auf containerd 1.7.28 hat Docker eine Sicherheitslücke durch eine zusätzliche AppArmor-Regel behoben. Das ist eigentlich gut, allerdings führt diese Sicherheitsmaßnahme zu Ärger im Zusammenspiel mit gewissen Containern (z.B. immich) unter Host-Systemen mit AppArmor (Ubuntu, Proxmox etc.)
Docker Engine 29 verlangt die API-Version 1.44 oder neuer. Programme, die eine ältere API-Version verwenden, produzieren dann den Fehler Client Version 1.nnn is too old. Betroffen ist/war unter anderem das im Docker-Umfeld weit verbreitete Programm Traefik.
Im Anfang war der Bug, in diesem Fall CVE-2025-52881. Ein Angreifer kann runc (das wiederum Teil von containerd.io ist) mit Shared Mounts dazu bringen, /proc-Schreibvorgänge auf andere procfs-Dateien umzuleiten. Das ist wiederum sicherheitstechnisch ziemlich ungünstig (Severity ist High). Docker hat das Problem mit containerd 1.7.28-2 behoben — aber jetzt spießt es sich mit AppArmor, das nicht mehr den kompletten Pfad sieht und deswegen eingreift. Der Docker-Security-Fix kann auf Hosts mit AppArmor also dazu führen, dass auch korrekte Zugriffe blockiert werden. Die beste Beschreibung gibt dieser Blog-Beitrag.
Ich kann aus eigener Erfahrung nicht viel zu diesem Problem sagen. Ich betreibe aktuell kein System, das betroffen ist. Besonders oft tritt der Bug in Kombination mit Proxmox oder LXC auf (siehe dieses containerd Issue). Aber auch die weit verbreitete immich.app zum Foto-Management ist betroffen (siehe diese Diskussion).
Die in den verlinkten Beiträgen präsentierten Lösungsvorschläge sind leider allesamt wenig überzeugend: Das Docker-Update nicht durchführen/blockieren, eine alte Docker-Version re-installieren, AppArmor-Regeln ändern etc.
Client Version too old
Vollkommen unabhängig vom ersten Probem, aber fast zeitgleich aufgetreten ist der Fehler Client Version 1.nnn too old. Er resultiert daraus, dass die Docker Engine ab Version 29 für die API-Steuerung zumindest die API-Version 1.44 voraussetzt. (Bis zur Docker Enginge 28 reichte die API-Version 1.24.)
docker version
...
Server: Docker Desktop 4.51.0 (210443)
Engine:
Version: 29.0.0
API version: 1.52 (minimum version 1.44) <------
...
Wenn nun ein Programm eine ältere API-Version nutzt, kommt es zum in der Überschrift genannten Fehler. Betroffen ist davon Traefik. (Das ist ein HTTP-Reverse-Proxy für Microservices und Container-Umgebungen.) Dort ist das Problem bekannt und wurde vorgestern mit Traefik Version 3.6.1 behoben.
Wenn Sie also ein Update auf die neueste Docker-Version durchführen, müssen Sie in compose.yaml für die Traefik-Version 3.6.1 oder einfach 3 oder latest angeben. Denken Sie daran, vor einem Neustart der Container ein Update des Traefek-Images mit docker pull traefik zu erledigen!
sudo apt full-upgrade -y
cd /mein/projekt/verzeichnis
docker pull traefik
docker compose down
docker compose up -d
Ca. seit 2020 kommt nftables (Kommando nft) per Default als Firewall-Backend unter Linux zum Einsatz. Manche Distributionen machten den Schritt noch früher, andere folgten ein, zwei Jahre später. Aber mittlerweile verwenden praktisch alle Linux-Distributionen nftables.
Alte Firewall-Scripts mit iptables funktionieren dank einer Kompatibilitätsschicht zum Glück größtenteils weiterhin. Viele wichtige Firewall-Tools und -Anwendungen (von firewalld über fail2ban bis hin zu den libvirt-Bibliotheken) brauchen diese Komaptibilitätsschicht aber nicht mehr, sondern wurden auf nftables umgestellt.
Welches Programm ist säumig? Docker! Und das wird zunehmend zum Problem.
Update 11.11.2025: In naher Zukunft wird mit Engine Version 29.0 nftables als experimentelles Firewall-Backend ausgeliefert. (Aktuell gibt es den rc3, den ich aber nicht getestet habe. Meine lokalen Installationen verwenden die Engine-Version 28.5.1.) Ich habe den Artikel diesbezüglich erweitert/korrigiert. Sobald die Engine 29 ausgeliefert wird, werde ich das neue Backend ausprobieren und einen neuen Artikel verfassen.
Docker versus libvirt/virt-manager
Auf die bisher massivsten Schwierigkeiten bin ich unter Fedora >=42 und openSUSE >= 16 gestoßen: Wird zuerst Docker installiert und ausgeführt, funktioniert in virtuellen Maschinen, die mit libvirt/virt-manager gestartet werden, das NAT-Networking nicht mehr. Und es bedarf wirklich einiger Mühe, den Zusammenhang mit Docker zu erkennen. Die vorgebliche »Lösung« besteht darin, die libvirt-Firewall-Funktionen von nftables zurück auf iptables zu stellen. Eine echte Lösung wäre es, wenn Docker endlich nftables unterstützen würde.
# in der Datei /etc/libvirt/network.conf
firewall_backend = "iptables"
Weil Docker iptables verwendet, ist es mit nftables oder firewalld nicht möglich, Container mit offenen Ports nach außen hin zu blockieren. Wenn Sie also docker run -p 8080:80 machen oder in compose.yaml eine entsprechende Ports-Zeile einbauen, ist der Port 8080 nicht nur auf dem lokalen Rechner sichtbar, sondern für die ganze Welt! nftables- oder firewalld-Regeln können dagegen nichts tun!
Deswegen ist es wichtig, dass Docker-Container möglichst in internen Netzwerken miteinander kommunizieren bzw. dass offene Ports unbedingt auf localhost limitiert werden:
# Port 8080 ist nur für localhost zugänglich.
docker run -p localhost:8080:80 ...
Ihre Optionen in compose.yaml sehen so aus:
```bash
# compose.yaml
# Ziel: myservice soll mit anderem Container
# in compose.yaml über Port 8888 kommunizieren
services:
myservice:
image: xxx
ports:
# unsicher!
# - "8888:8888"
# besser (Port ist für localhost sichtbar)
# - "127.0.0.1:8888:8888"
# noch besser (Port ist nur Docker-intern offen)
- "8888"
otherservice:
...
Die sicherste Lösung besteht darin, die Container ausschließlich über ein Docker-internes Netzwerk miteinander zu verbinden (siehe backend_network im folgenden schablonenhaften Beispiel). Die Verbindung nach außen für die Ports 80 und 443 erfolgt über ein zweites Netzwerk (frontend_network). Die Angabe des drivers ist optional und verdeutlicht hier nur den Default-Netzwerktyp.
# compose.yaml
# am besten: die beiden Services myservice und
# nginx kommunizieren über das interne Netzwerk
# miteinander
services:
myservice:
build: .
ports:
- "8888:8888"
networks:
- backend_network
nginx:
image: nginx:alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
- /etc/mycerts/fullchain.pem:/etc/nginx/ssl/nginx.crt
- /etc/mycerts/privkey.pem:/etc/nginx/ssl/nginx.key
depends_on:
- myservice
networks:
- frontend_network
- backend_network
networks:
# Verbindung zum Host über eine Bridge
frontend_network:
driver: bridge
# Docker-interne Kommunikation zwischen den Containern
backend_network:
driver: bridge
internal: true
If you use ufw or firewalld to manage firewall settings, be aware that when you expose container ports using Docker, these ports bypass your firewall rules. For more information, refer to Docker and ufw.
Docker is only compatible with iptables-nft and iptables-legacy. Firewall rules created with nft are not supported on a system with Docker installed. Make sure that any firewall rulesets you use are created with iptables or ip6tables, and that you add them to the DOCKER-USER chain, see Packet filtering and firewalls.
Finally, if you run Docker on a server, it is recommended to run exclusively Docker on the server, and move all other services within containers controlled by Docker. Of course, it is fine to keep your favorite admin tools (probably at least an SSH server), as well as existing monitoring/supervision processes, such as NRPE and collectd.
Salopp formuliert: Verwenden Sie für das Docker-Deployment ausschließlich für diesen Zweck dezidierte Server und/oder verwenden Sie bei Bedarf veraltete iptable-Firewalls. Vor fünf Jahren war dieser Standpunkt noch verständlich, aber heute geht das einfach gar nicht mehr. Die Praxis sieht ganz oft so aus, dass auf einem Server diverse »normale« Dienste laufen und zusätzlich ein, zwei Docker-Container Zusatzfunktionen zur Verfügung stellen. Sicherheitstechnisch wird dieser alltägliche Wunsch zum Alptraum.
Land in Sicht?
Bei Docker weiß man natürlich auch, dass iptables keine Zukunft hat. Laut diesem Issue sind 10 von 11 Punkte für die Umstellung von iptables auf nftables erledigt. Aber auch dann ist unklar, wie es weiter gehen soll: Natürlich ist das ein massiver Eingriff in grundlegende Docker-Funktionen. Die sollten vor einem Release ordentlich getestet werden. Einen (offiziellen) Zeitplan für den Umstieg auf nftables habe ich vergeblich gesucht.
Docker ist als Plattform-überschreitende Containerlösung für Software-Entwickler fast konkurrenzlos. Aber sobald man den Sichtwinkel auf Linux reduziert und sich womöglich auf Red-Hat-ähnliche Distributionen fokussiert, sieht die Lage anders aus: Podman ist vielleicht nicht hundertprozentig kompatibel, aber es ist mittlerweile ein sehr ausgereiftes Container-System, das mit Docker in vielerlei Hinsicht mithalten kann. Installationsprobleme entfallen, weil Podman per Default installiert ist. Firewall-Probleme entfallen auch. Und der root-less-Ansatz von Podman ist sicherheitstechnis sowieso ein großer Vorteil (auch wenn er oft zu Netzwerkeinschränkungen und Kompatibilitätsproblemen führt, vor allem bei compose-Setups).
Für mich persönlich war Docker immer die Referenz und Podman die nicht ganz perfekte Alternative. Aber die anhaltenden Firewall-Probleme lassen mich an diesem Standpunkt zweifeln. Die Firewall-Inkompatibilität ist definitiv ein gewichtiger Grund, der gegen den Einsatz der Docker Engine auf Server-Installationen spricht. Docker wäre gut beraten, iptables ENDLICH hinter sich zu lassen!
Update 11.11.2025: Als ich diesen Artikel im Oktober 2025 verfasst und im November veröffentlicht habe, ist mir entgangen, dass die Docker-Engine in der noch nicht ausgelieferten Version 29 tatsächlich bereits ein experimentelles nftables-Backend enthält!
Version 29 liegt aktuell als Release Candidate 3 vor. Ich warte mit meinen Tests, bis die Version tatsächlich ausgeliefert wird. Hier sind die Release Notes, hier die neue Dokumentationsseite. Vermutlich wird es ein, zwei weitere Releases brauchen, bis das nftables-Backend den Sprung von »experimentell« bis »stabil« schafft, aber immerhin ist jetzt ganz konkret ein Ende der Firewall-Misere in Sicht.
Ein E-Mail-Umzug von einem Server auf einen anderen gehört zu den Aufgaben, die oft unterschätzt werden. Wer schon einmal versucht hat, ein E-Mail-Konto auf einen neuen Mailserver zu übertragen, kennt die typischen Probleme: unterschiedliche IMAP-Server, abweichende Login-Methoden, große Postfächer oder das Risiko, E-Mails doppelt oder gar nicht zu übertragen.
Für eine saubere und zuverlässige E-Mail-Migration gibt es jedoch ein bewährtes Open-Source-Tool: imapsync. Mit imapsync lassen sich komplette IMAP-Konten effizient und sicher von einem Server auf einen anderen synchronisieren – ohne Datenverlust und mit minimaler Ausfallzeit. Ob beim Providerwechsel, beim Umzug auf einen eigenen Mailserver oder beim Zusammenführen mehrerer Postfächer: imapsync bietet eine stabile und flexible Lösung für jede Art von Mailserver-Migration.
In diesem Artikel zeige ich Schritt für Schritt, wie imapsync funktioniert, welche Parameter in der Praxis wichtig sind und wie du deinen E-Mail-Umzug stressfrei und automatisiert durchführen kannst.
Die Open Source Software Imapsync vorgestellt
So einem Umzug von einem E-Mail-Server zu einem anderen mit einem Terminal-Programm zu machen, klingt etwas verrückt. In Wirklichkeit ist das aber eine große Stärke, da imapsync während der Übertragung bereits wertvolle Statusmeldungen ausgibt und man die Statistik im Blick behält.
Theoretisch lässt sich das Programm via Eingabe verschiedener Flags bedienen. Für mich hat sich aber bewährt, dass man es mit einem einfachen Skript ausführt. In aller Regel zieht man ja kein einzelnes Postfach um, sondern mehrere E-Mail-Konten. Motivation könnte zum Beispiel eine Änderung der Domain oder der Wechsel des Hosters sein. Aber selbst bei Einzelkonten empfehle ich die Benutzung des Skripts, weil sich hier die Zugangsdaten übersichtlich verwalten lassen.
Was imapsync jetzt macht, ist ziemlich straight-forward: Es meldet sich auf dem ersten Host („alter Server“) an, checkt erstmal die Ordnerstruktur, zählt die E-Mails und verschafft sich so einen Überblick. Hat man bereits die Zugangsdaten für den zweiten Host („neuer Server“), tut er das gleiche dort. Danach überträgt die Software die E-Mails von Host 1 auf Host 2. Bereits übertragene Mails werden dabei berücksichtigt. Man kann den Umzug also mehrfach starten, es werden nur die noch nicht übertragenen Mails berücksichtigt.
Die Webseite von imapsync ist auf den ersten Blick etwas ungewöhnlich, worauf der Entwickler auch stolz ist. Wenn man aber genauer hinsieht, merkt man die gute Dokumentation. Es werden auch Spezialfälle wie Office 365 von Microsoft oder Gmail behandelt.
Die Statistik von imapsync gibt bereits einen guten Überblick, wie gut der Umzug geklappt hat
Installation von imapsync
Die Software gibt es für Windows, Mac und Linux. Die Installation unter Ubuntu ist für geübte Benutzer recht einfach, auch wenn die Software nicht in den Paketquellen vorkommt. Github sei Dank.
Die Installation ist nun fertig und systemweit verfügbar.
E-Mail-Postfach von einem Server zum anderen umziehen
Für den Umzug von einem Server zum anderen braucht man – wenig überraschend – jeweils die Zugangsdaten. Diese beinhalten IMAP-Server, Benutzername und Passwort. Das wars. Es empfiehlt sich, mit einem echten Host 1 zu starten, als Host 2 aber erstmal einen Testaccount zu verwenden.
Ich orientiere mich an den Empfehlungen des Programmierers und erstelle zunächst eine Datei mit den jeweiligen Zugangsdaten. Genau wie im Beispielskript verwende ich eine siebte, unnötige Spalte. Sie endet die Zeilen ordentlich ab, ohne dass man ein Problem mit den Zeilenumbruch zu erwarten hat.
Wir nennen die Datei file.txt. Jeweils die Einträge 1 bis 3 sind die Quelle, Spalten 4 bis 6 sind das Ziel.
Mit ein wenig Verspätung ist Fedora 43 fertig. Ich habe in den letzten Monaten schon viel mit der Beta gearbeitet und war schon damit überwiegend zufrieden. Fedora 43 ist das erste weitgehend X-freie Release (X wie X Window System, nicht wie Twitter …), es gibt nur noch XWayland zur Ausführung von X-Programmen unter Wayland. Relativ neu ist das Installationsprogramm, auf das ich gleich näher eingehe. Es ist schon seit Fedora 42 verfügbar, aber diese Version habe ich in meinem Blog übersprungen.
Die folgenden Ausführungen beziehen sich auf Fedora 43 Workstation mit Gnome.
Fedora 43 mit Gnome in einer virtuellen Maschine
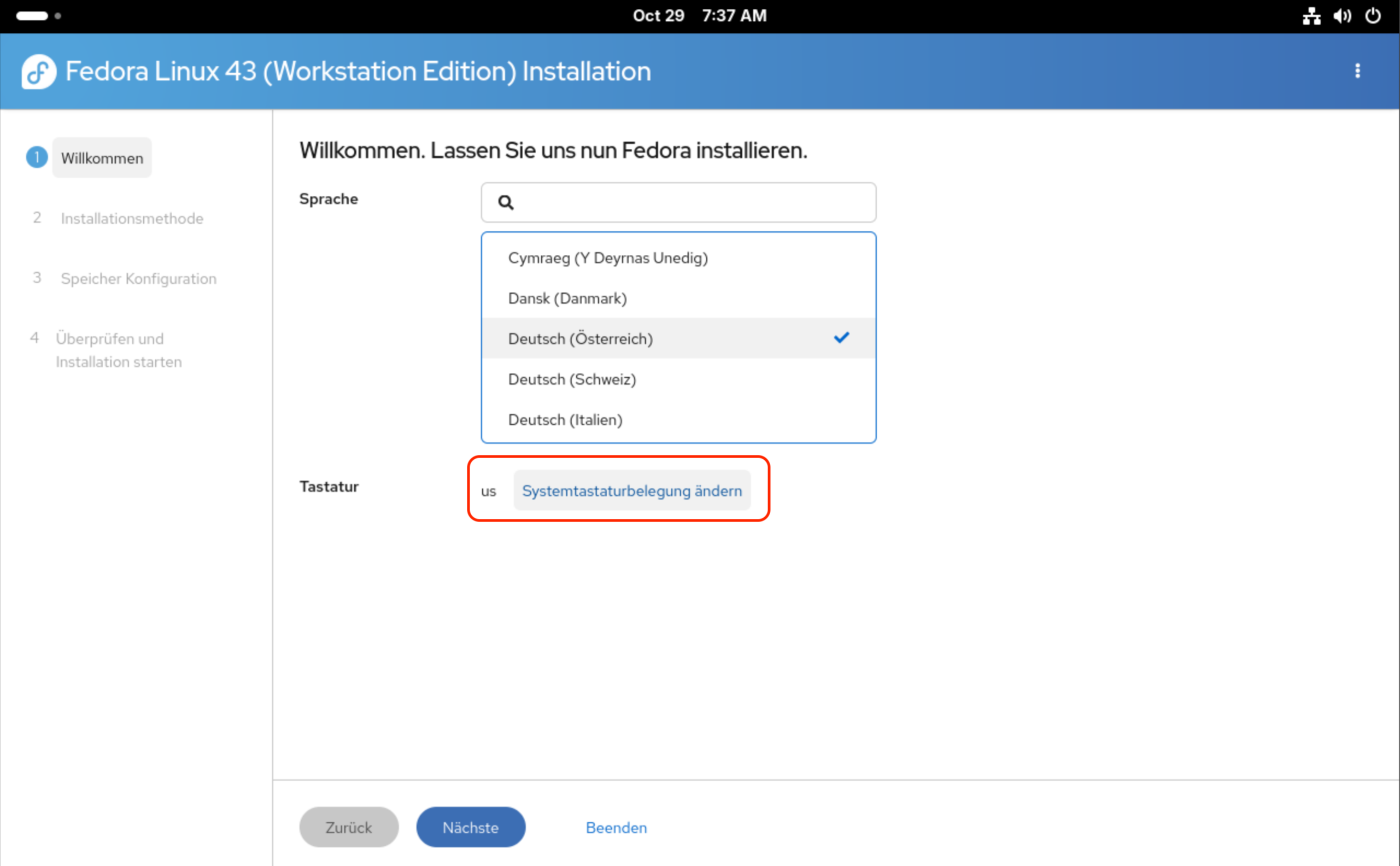
Installation
Das Installationsprogramm beginnt aus deutschsprachiger Sicht gleich mit einem Ärgernis: Zwar kann die Sprache mühelos auf Deutsch umgestellt werden, nicht aber das Tastaturlayout. Dazu verweist das Installationsprogramm auf die Systemeinstellungen. Dort müssen Sie nicht nur das gewünschte Layout hinzufügen, sondern auch das vorhandene US-Layout entfernen — vorher ist das Installationsprogramm nicht zufrieden. Das ist einigermaßen umständlich.
Die Einstellung des Tastaturlayouts muss in den Gnome-Systemeinstellungen erfolgen
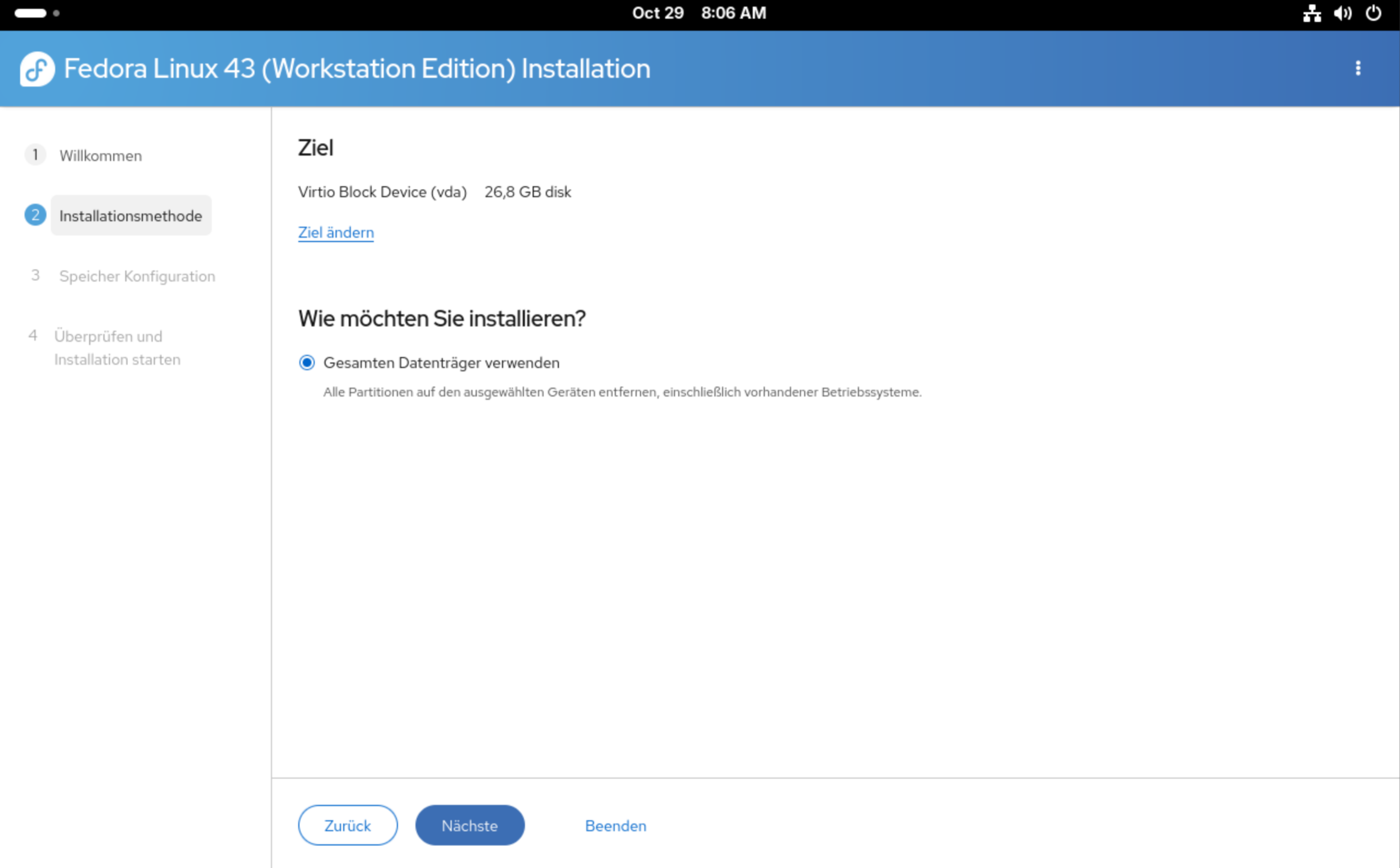
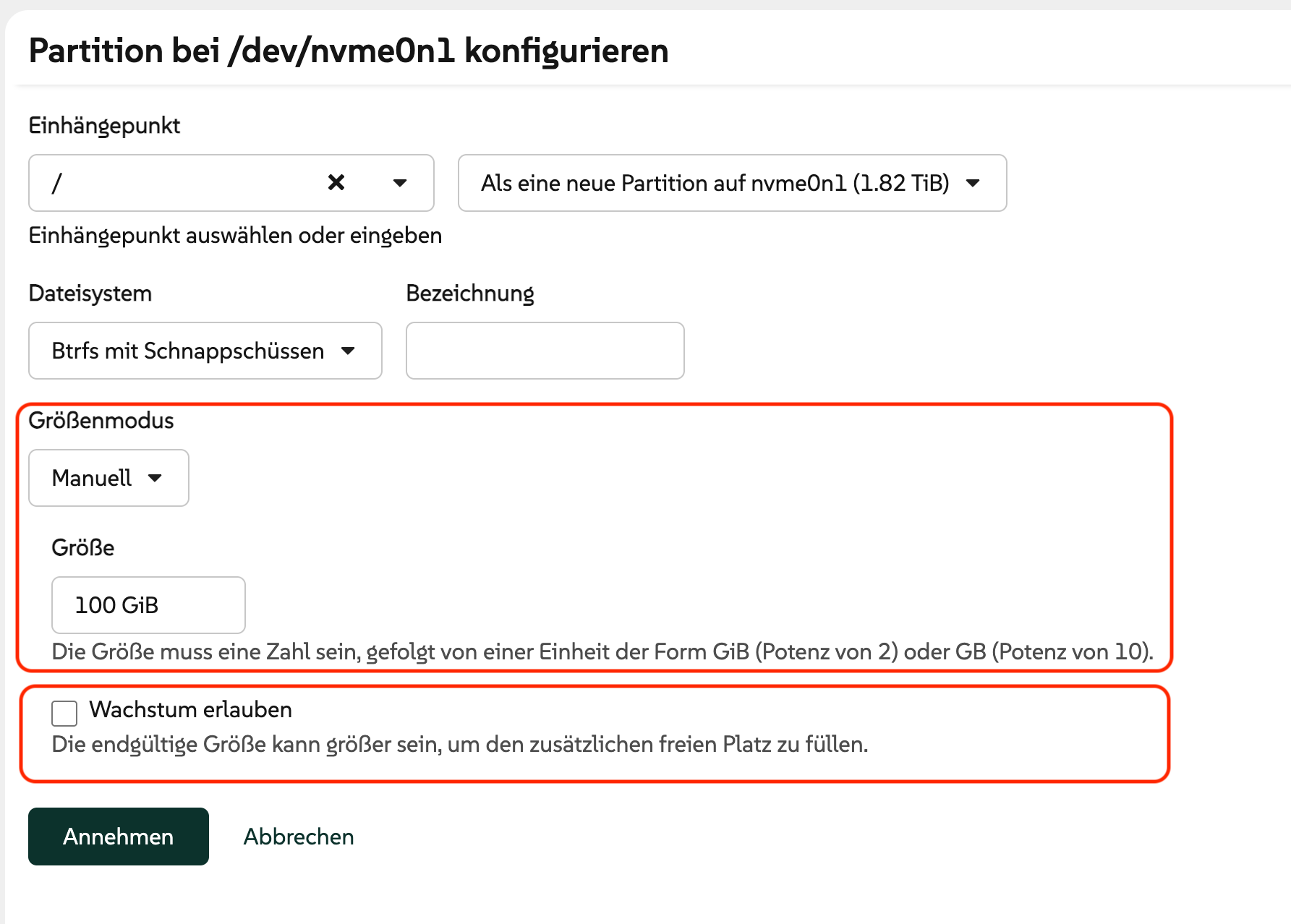
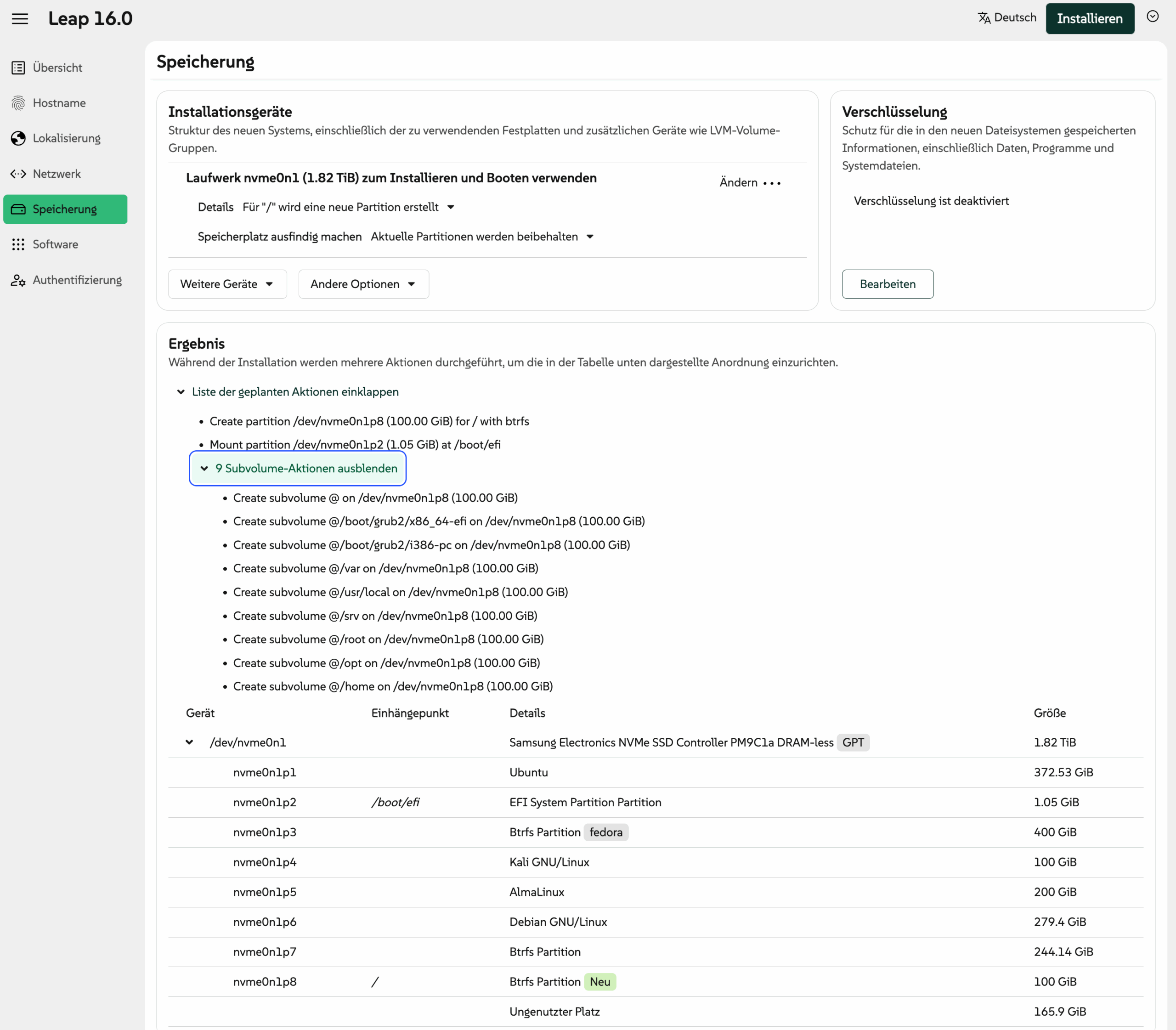
In virtuellen Maschinen wird bei der Installationsmethode (gemeint ist die Partitionierung des Datenträgers und das Einrichten der Dateisysteme) nur eine Option angezeigt: Gesamten Datenträger verwenden. Damit haben Sie weder Einfluss auf die Größe der Partitionen noch auf den Dateisystemtyp oder dessen Optionen. Das Standardlayout lautet: EFI-Partition (vfat), Boot-Partition (ext4) und Systempartition (btrfs mit zwei Subvolumes für / und /home und aktiver Komprimierung). Eine Swap-Partition gibt es nicht, Fedora verwendet schon seit einiger Zeit Swap on ZRAM.
Bei der Installation von Fedora in eine Virtuelle Maschine sind auf den ersten Blick nur wenig Optionen erkennbar …
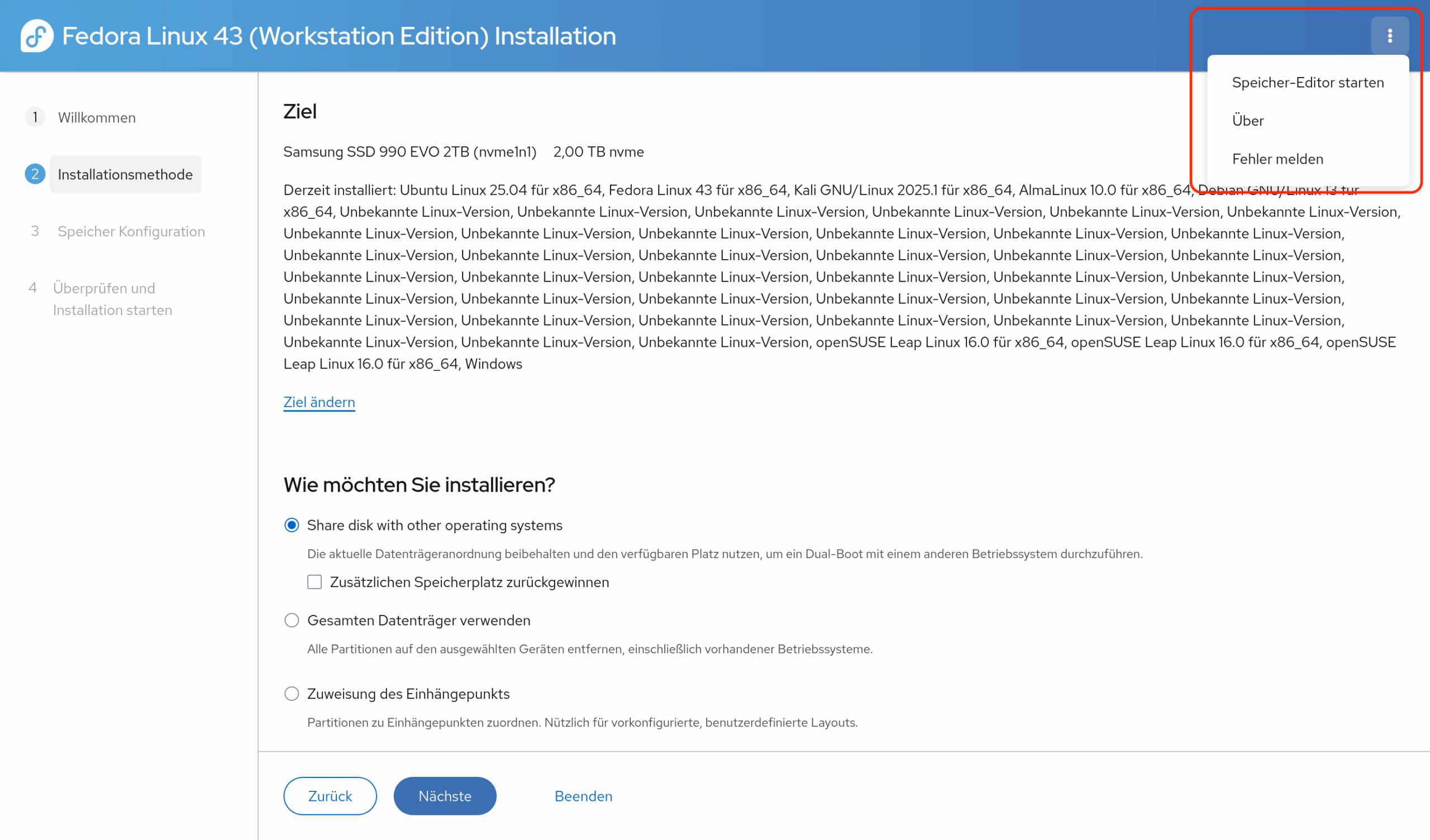
Wenn Sie die Installation auf einem Rechner durchführen, auf dem schon Windows oder andere Linux-Distributionen installiert sind, wird die Auswahl größer:
Die Option Share disk with other operation systems (vielleicht wird der Text bei späteren Versionen noch übersetzt) erscheint, wenn das Setup-Programm Windows oder andere Linux-Distributionen auf der SSD erkennt. In diesem Fall nutzt Fedora den verbleibenden freien Platz auf der SSD und richtet dort eine Boot- und eine Systempartition ein. Wenn es auf der SSD keinen oder zu wenig Platz gibt, sollten Sie zusätzlich die Option Zusätzlichen Speicherplatz zurückgewinnen aktivieren. Sie können dann in einem weiteren Dialog einzelne Partitionen löschen oder verkleinern.
Gesamten Datenträger verwenden löscht alle vorhandene Partitionen und richtet dann wie oben beschreiben EFI-, Boot- und Systempartition ein.
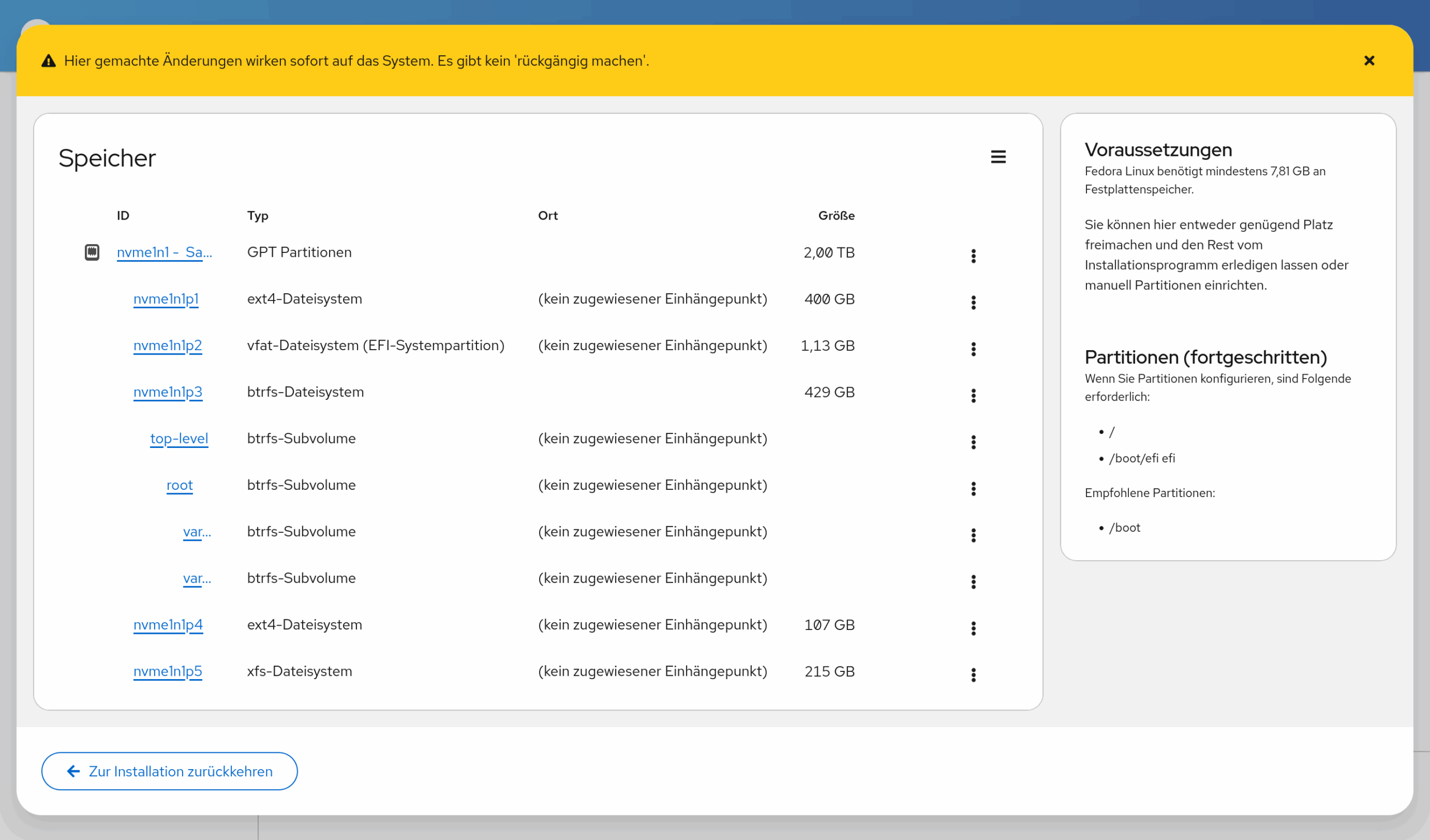
Zuweisung des Einhängepunkts bietet Linux-Profis die Möglichkeit, schon vorhandene Dateisysteme zu nutzen. Es gibt zwei Möglichkeiten, diese Dateisysteme einzurichten. Eine bietet der über den unscheinbaren Menü-Button erreichbare Speicher-Editor. Dort können Sie Partitionen, Logical Volumes, RAID-Setup und Dateisysteme samt Verschlüsselung einrichten. Es mangelt nicht an Funktionen, aber leider ist die Bedienung sehr unübersichtlich. Alle hier initiierten Aktionen werden sofort durchgeführt und können nicht rückgängig gemacht werden. Alternativ können Sie vorweg in einem Terminal mit parted Partitionen einrichten und dann mit mkfs.xxx darin die gewünschten Dateisysteme anlegen. Falls das Dateisystem verschlüsselt werden soll, müssen Sie sich auch darum selbst kümmern (Kommando cryptsetup). Das erfordert ein solides Linux-Vorwissen.
Das Setup-Programm wirkt mit den bereits installierten Distributionen überfordert. (Es sind in Wirklichkeit nur sechs Distributionen, nicht mehrere Dutzend …) Manuelle Partitions-Setups müssen über den »Speichereditor« durchgeführt werden.Der »Speichereditor« zur manuellen Partitionierung listet alle Subvolumes aller btrfs-Dateisysteme auf und ist auch sonst extrem unübersichtlich in seiner Bedienung
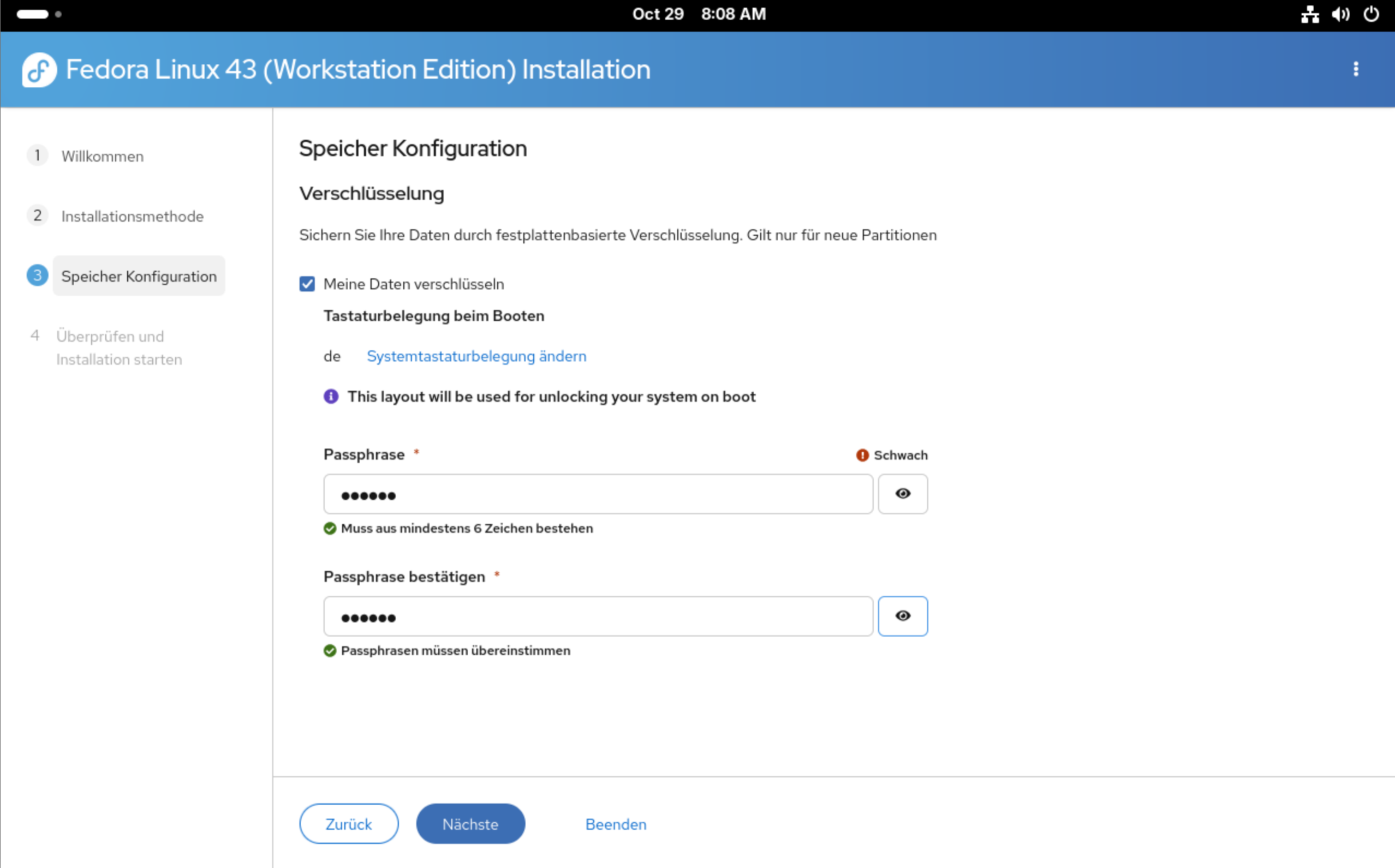
In der Speicher-Konfiguration können Sie das Dateisystem verschlüsseln (außer Sie haben sich im vorigen Schritt für die Zuweisung des Einhängepunkts entschieden). Zur Verschlüsselung geben Sie zweimal das Passwort an und stellen ein, welches Tastaturlayout beim Bootvorgang für die Eingabe dieses Passworts gelten soll.
Die Verschlüsselung des Dateisystems gelingt nur problemlos, sofern Sie im vorigen Schritt keine manuelles Setup eingerichtet haben
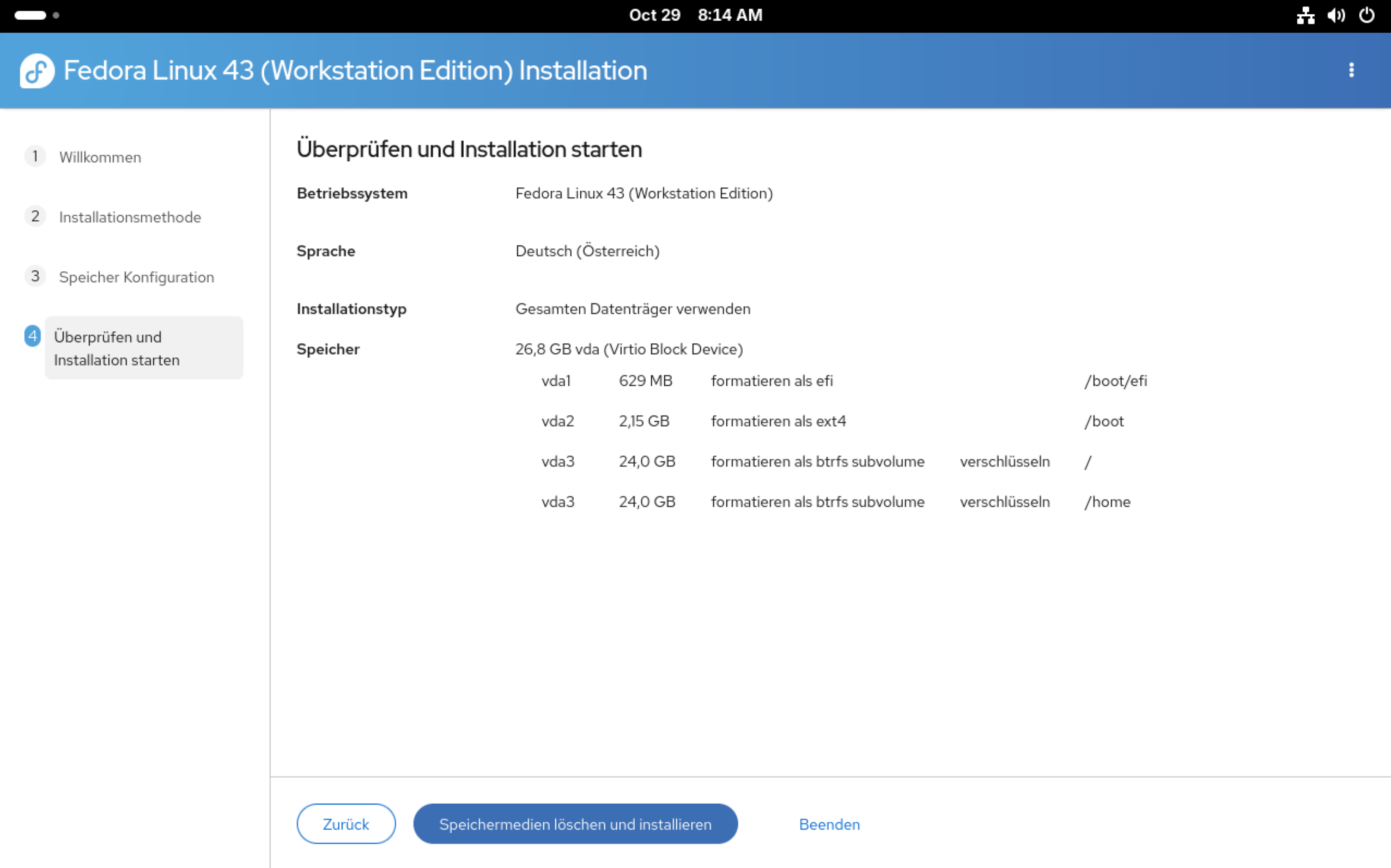
Zuletzt zeigt das Installationsprogramm eine Zusammenfassung der Einstellungen ein. Ein Benutzeraccount samt Passwort wird erst später beim ersten Start von Gnome eingerichtet.
Zusammenfassung des Setups
Alles in allem ist die Bedienung des neuen Programms zwar einfach, sie bietet aber zu wenig Optionen für eine technisch orientierte Distribution. Der aktuelle Trend vieler Distributionen besteht darin, den Installationsprozess auf Web-basierte Tools umzustellen. Die Sinnhaftigkeit erschließt sich für mich nicht, schon gar nicht, wenn dabei auch noch die Funktionalität auf der Strecke bleibt. Muss das Rad wirklich immer wieder neu erfunden werden?
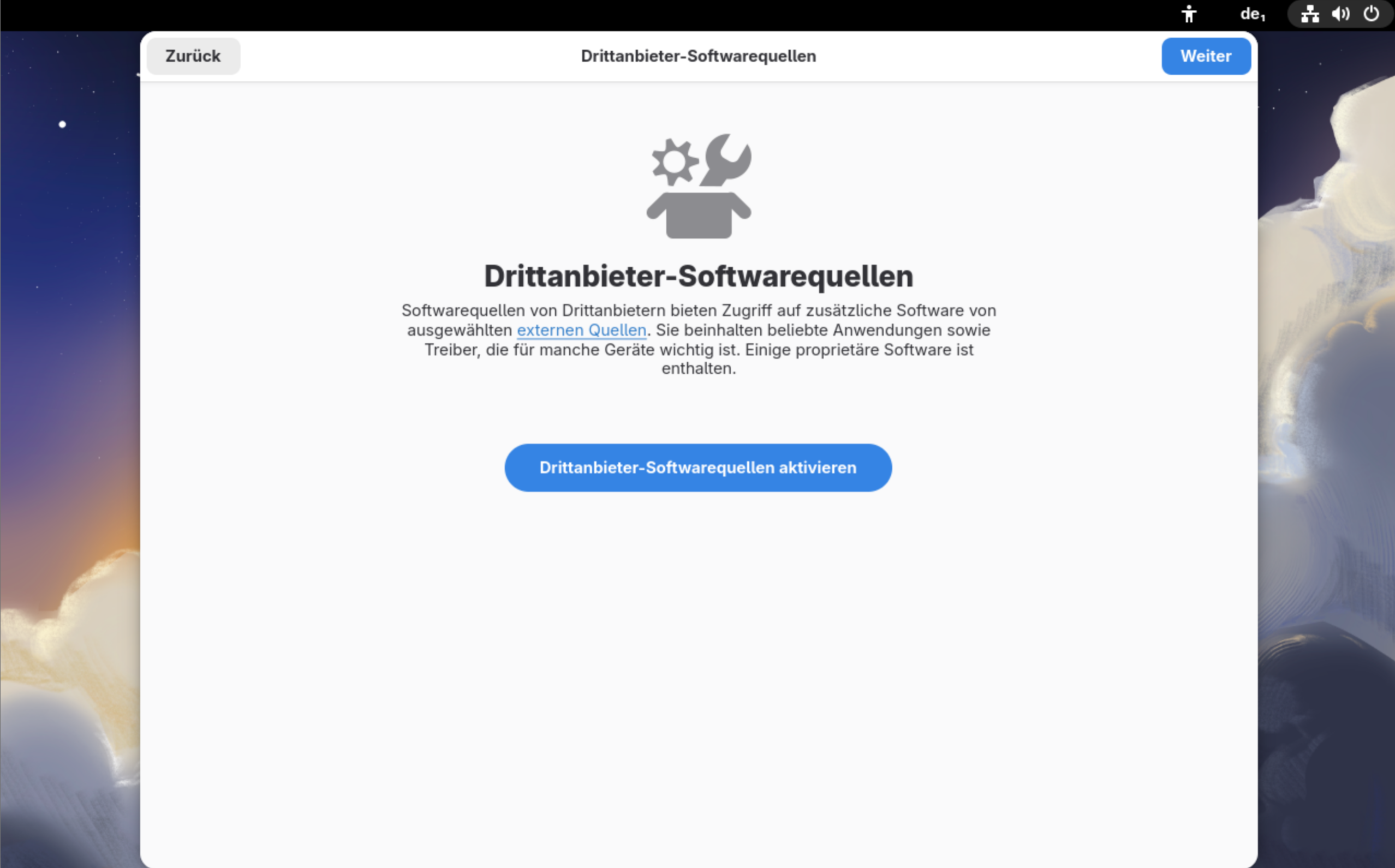
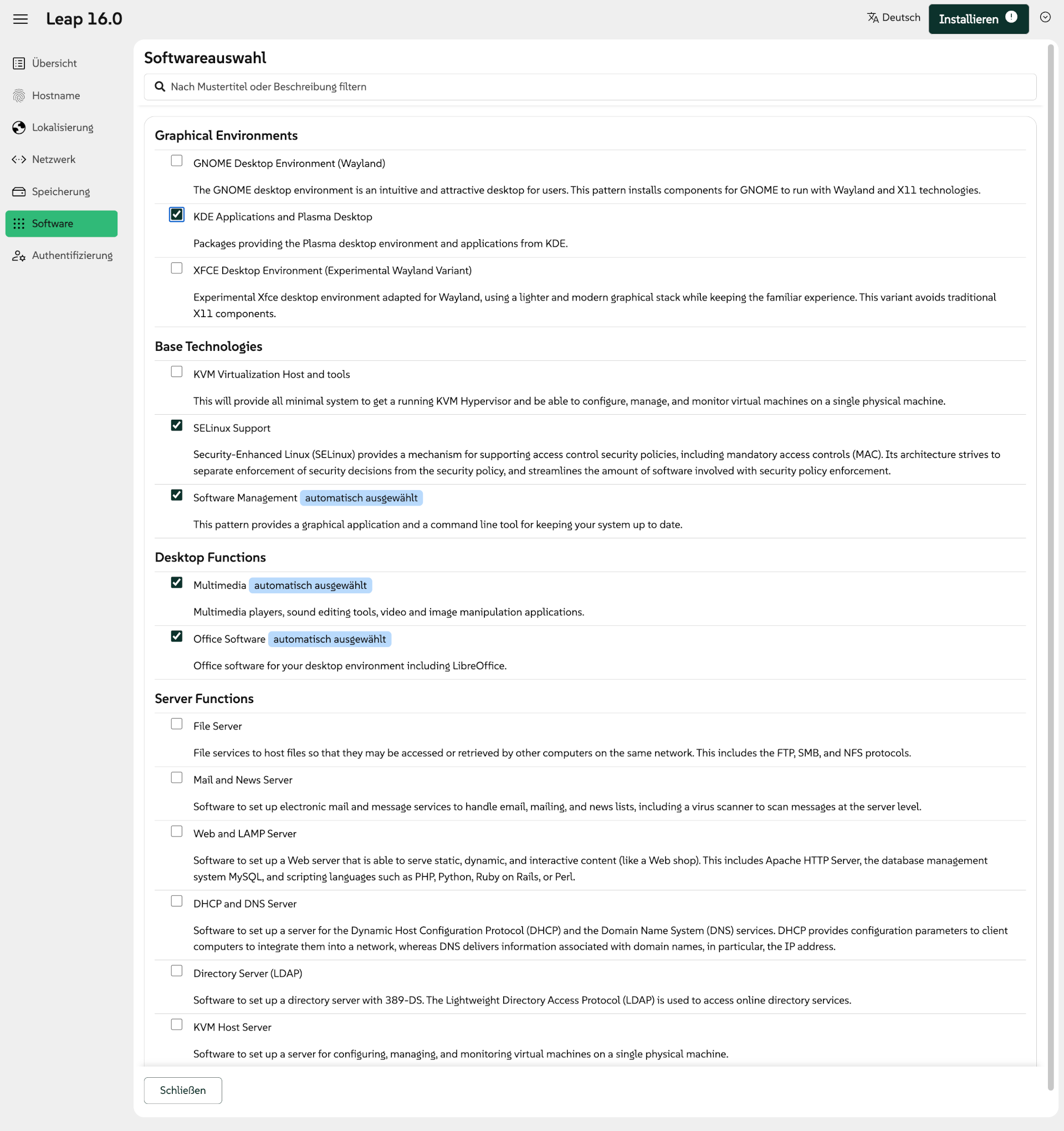
Nach dem Neustart landen Sie in einen Assistenten, der bei der Grundkonfiguration von Gnome hilft: Sprache und Tastaturlayout noch einmal bestätigen, Zeitzone einstellen etc. Vollkommen missglückt ist das Dialogblatt zur Aktivierung von Drittanbieter-Softwarequellen. Gemeint sind damit die RPM-Fusion-Paketquellen mit Paketen und Treibern (z.B. für NVIDIA-Grafikkarten), die nicht dem Open-Source-Modell entsprechen. Im Zentrum des Bildschirms befindet sich ein Toggle-Button mit den Zuständen aktivieren oder deaktivieren. Es ist unmöglich zu erkennen, ob Sie den Button zur Aktivierung drücken müssen oder ob dieser den Zustand »bereits aktiv« ausdrückt. (Auflösung: Sie müssen ihn nicht drücken. Wenn mit blauem Hintergrund »aktivieren« angezeigt wird, werden die zusätzlichen Paketquellen mit Weiter eingerichtet.)
Klicken Sie nicht auf »Drittanbieter-Softwarequellen aktivieren«! Das würde die Option deaktivieren. (Ein Meisterbeispiel für GUI Fails …)
Erst jetzt werden Sie dazu aufgefordert, einen Benutzer einzurichten, der dann auch sudo-Rechte erhält. Sobald Sie alle Daten samt Passwort festgelegt haben, können Sie sich einloggen und mit Fedora loslegen.
Erst ganz zum Schluss richten Sie den Benutzer-Account ein
Um den Hostname hat sich weder das Installationsprogramm noch der Setup-Assistent gekümmert. Außerdem sollten Sie gleich ein erstes Update durchführen:
Die einzige Auffälligkeit ist die komplett veraltete MariaDB-Version. Aktuell ist 12.0, Debian verwendet immerhin 11.8. Die von Fedora eingesetzte Version 10.11 wurde im Februar 2023 (!!) veröffentlicht.
Dafür enthält Fedora mit Version 8.4 eine ganz aktuelle MySQL-Version. Generell steht MySQL erst seit Fedora 41 wieder regulär in Fedora zur Verfügung; ältere Versionen waren MariaDB-only.
Neuerungen
Wenn man von durch Software-Updates verbundenen optischen Änderungen absieht (z.B. in Gnome), gibt es relativ wenig technische Änderungen, und noch weniger davon sind sichtbar.
Gnome und gdm sind seit Version 49 Wayland-only. Darüber wurde in den letzten Wochen schon viel geschrieben. Seit die NVIDIA-Treiber endlich Wayland-kompatibel sind, ist der Abschied von X nicht mehr aufzuhalten. (Persönlich vermisse ich X nicht. Die meisten Linux-Anwender werden keinen Unterschied bemerken bzw. arbeiten ohnedies schon seit zwei, drei Releases mit Wayland, ohne es zu wissen …)
Fedora 43 verwendet erstmals RPM 6.0 als Basis zur Verpackung von Software-Paketen. Daraus ergeben sich neue Möglichkeiten beim Signieren von Paketen, aber an der Anwendung des rpm-Kommandos (das Sie ohnedies selten benötigen werden, es gibt ja dnf) ändert sich nichts.
Distributions-Upgrades auf die neue Fedora-Version können Sie jetzt äußerst komfortabel direkt im Gnome-Programm Software starten.
Distributions-Upgrade in Gnome »Software« starten
Wie bisher können Sie natürlich auch auf die folgende Kommandoabfolge zurückgreifen:
Auf UEFI-Systemen setzt das Installationsprogramm nun eine GPT-Partitionierung voraus (nicht MBR).
Die /boot-Partition wird mit 2 GiB großzügiger als bisher dimensioniert, um Platz für zukünftige neue Boot-Systeme zu schaffen.
dnf module gibt es nicht mehr, weil das Modularity-Projekt eingestellt wurde. Bei Fedora ist das weniger schade als bei RHEL, wo ich dieses Feature wirklich vermisse.
dracut, das Tool zum Erzeugen von initramfs-Dateien, verwendet nun zstd statt xz zum Komprimieren der Dateien. Das macht die Boot-Dateien größer, aber den Boot-Vorgang schneller.
Fazit
Ich habe in den letzten Monaten sehr viel unter Fedora gearbeitet. Fedora ist dabei zu meiner zweiten Lieblingsdistribution geworden (neben Arch Linux). Im Betrieb gab es eigentlich nichts auszusetzen. Auch die Distributions-Upgrades haben mehrfach gut funktioniert: Ich habe zuletzt eine physische Installation von Fedora 41 auf 42 und vorgestern auf 43 aktualisiert. Zwischenzeitlich hat sich sogar der Rechner geändert, d.h. ich habe die SSD bei einem Rechner aus- und bei einem anderen Rechner wieder eingebaut. Hat alles klaglos funktioniert.
Das neue Installationsprogramm (neu schon seit der vorigen Version, also Fedora 42) ist aber definitiv ein Rückschritt — und das alte war schon keine Offenbarung. Bevor der Installer in Zukunft unter RHEL 11 zum Einsatz kommen kann, muss Red Hat noch viel nacharbeiten. Wie soll damit ein für den Server-Einsatz übliches RAID- oder LVM-Setup gelingen?
Der oft gehörten Empfehlung, Fedora sei durchaus für Einsteiger geeignet, kann ich deswegen nur teilweise zustimmen. Im Betrieb ist Fedora in der Tat so unkompliziert und stabil wie vergleichbare Distributionen (Debian, Ubuntu etc.). Für die Installation gilt dies aber nur, wenn Sie den gesamten Datenträger — z.B. eine zweite SSD — für Fedora nutzen möchten und mit dem vorgegebenen Default-Layout einverstanden sind. Unkompliziert ist natürlich auch die Installation in eine virtuelle Maschine. Aber jeder Sonderwunsch — ext4 statt btrfs, eine getrennte /home-Partition etc. — wird sofort zum Abenteuer. Schade.
Solche Aufgaben können notwendig werden, wenn die Dateien aus unterschiedlichen Quellen stammen – so wie im folgenden Beispiel: Ich hatte vier verschiedene Zuarbeiten mit jeweils eigenen Benennungsregeln erhalten. Um die insgesamt 95 Dateien einheitlich in eine bestehende Webseite einzubinden, mussten sie alle nach einem gemeinsamen Schema umbenannt werden.
Umsetzung
Auf einem Ubuntu-System erfolgt die Mehrfachumbenennung ganz einfach: Zunächst wird das Verzeichnis geöffnet, in dem sich alle zu verarbeitenden Bilder befinden.
Dateien – Ansicht Bilder (ungeordnet)
Im Dateimanager „Dateien“ (früher „Nautilus“) werden mit Strg + A alle Dateien markiert.
Dateien – Ansicht Bilder (alle ausgewählt)
Mit einem Rechtsklick lässt sich nun die Option „Umbenennen“ auswählen. Hier wird „[Ursprünglicher Dateiname]“ durch den endgültigen Dateinamen ersetzt und über „+ Hinzufügen“ der neue Suffix ausgewählt.
Die Mehrfachumbenennung unter GNOME ist ein einfaches, aber äußerst praktisches Werkzeug – besonders in Kombination mit einer automatischen Skalierung, wie im zuvor genannten Artikel beschrieben. So lässt sich die Verarbeitung großer Bildmengen deutlich effizienter gestalten und viel Zeit sparen.
In meinem Arbeitsalltag wimmelt es von virtuellen Linux-Maschinen, die ich primär mit zwei Programmen ausführe:
virtual-machine-manager alias virt-manager (KVM/QEMU) unter Linux
UTM (QEMU + Apple Virtualization) unter macOS
Dabei treten regelmäßig zwei Probleme auf:
Bei Neuinstallationen funktioniert der Datenaustausch über die Zwischenablage zwischen Host und VM (= Gast) funktioniert nicht.
Die Uhrzeit in der VM ist falsch, nachdem der Host eine Weile im Ruhestand war.
Diese Ärgernisse lassen sich leicht beheben …
Anmerkung: Ich beziehe mich hier explizit auf die Desktop-Virtualisierung. Ich habe auch VMs im Server-Betrieb — da brauche ich keine Zwischenablage (Text-only, SSH-Administration), und die Uhrzeit macht wegen des dauerhaften Internet-Zugangs auch keine Probleme.
Zwischenablage mit Spice als Grafik-Protokoll
Wenn das Virtualisierungssystem das Grafiksystem mittels Simple Protocol for Independent Computing Environments (SPICE) überträgt (gilt per Default im virtual-machine-manager und in UTM), funktioniert die Zwischenablage nur, wenn in der virtuellen Maschine das Paket spice-vdagent installiert ist. Wenn in der virtuellen Maschine Wayland läuft, was bei immer mehr Distributionen standardmäßig funktioniert, brauchen Sie außerdem wl-clipboard. Also:
Nach der Installation müssen Sie sich in der VM aus- und neu einloggen, damit die Programme auch gestartet werden. Manche, virtualisierungs-affine Distributionen installieren die beiden winzigen Pakete einfach per Default. Deswegen funktioniert die Zwischenablage bei manchen Linux-Gästen sofort, bei anderen aber nicht.
Synchronisierung der Uhrzeit
Grundsätzlich beziehen sowohl die virtuellen Maschine als auch der Virtualisierungs-Host die Uhrzeit via NTP aus dem Internet. Das klappt problemlos.
Probleme treten dann auf, wenn es sich beim Virtualisierungs-Host um ein Notebook oder einen Desktop-Rechner handelt, der hin- und wieder für ein paar Stunden inaktiv im Ruhezustand schläft. Nach der Reaktivierung wird die Zeit im Host automatisch gestellt, in den virtuellen Maschinen aber nicht.
Vielleicht denken Sie sich: Ist ja egal, so wichtig ist die Uhrzeit in den virtuellen Maschinen ja nicht. So einfach ist es aber nicht. Die Überprüfung von Zertifikaten setzt die korrekte Uhrzeit voraus. Ist diese Voraussetzung nicht gegeben, können alle möglichen Problem auftreten (bis hin zu Fehlern bei der Software-Installation bzw. bei Updates).
Für die lokale Uhrzeit in den virtuellen Maschinen ist das Programm chrony zuständig. Eigentlich sollte es in der Lage sein, die Zeit automatisch zu justieren — aber das versagt, wenn die Differenz zwischen lokaler und echter Zeit zu groß ist. Abhilfe: starten Sie chronyd neu:
sudo systemctl restart chronyd
Um die automatische Einstellung der Uhrzeit nach der Wiederherstellung eines Snapshots kümmert sich der qemu-guest-agent (z.B. im Zusammenspiel mit Proxmox). Soweit das Programm nicht automatisch installiert ist:
Im August letzten Jahres habe ich euch gezeigt, was auf meinem Home Server so alles läuft und ich dachte mir, ich liefere euch über ein Jahr später mal einen aktualisierten Einblick. Der Unterbau des...
Seit über 30 Jahren nutze ich Linux, und knapp 25 Jahre davon war die bash meine Shell. Ein eigener Prompt, der das aktuelle Verzeichnis farbig anzeigte, was das Maß der Dinge :-)
Mein Umstieg auf die zsh hatte mit Git zu tun: Die zsh in Kombination mit der Erweiterung Oh my zsh gibt im Prompt direktes Feedback über den Zustand des Repositories (aktiver Zweig, offene Änderungen). Außerdem agiert die zsh in vielen Details »intelligenter« (ein viel strapazierter Begriff, ich weiß) als die bash. Es macht ein wenig Arbeit, bis alles so funktioniert wie es soll, aber ich war glücklich mit meinem Setup.
Seit ein paar Monaten habe ich die Default-Shell meiner wichtigsten Linux-Installationen neuerlich gewechselt. Ich gehöre jetzt zum rasch wachsenden Lager der fish-Fans. fish steht für Friendly Interactive Shell, und die Shell wird diesem Anspruch wirklich gerecht. fish bietet von Grund auf eine Menge Features, die zsh plus diverse Plugins inklusive Oh my zsh erst nach einer relativ mühsamen Konfiguration beherrschen. Die Inbetriebnahme der fish dauert bei den meisten Distributionen weniger als eine Minute — und die Defaultkonfiguration ist so gut, dass weitere Anpassungen oft gar nicht notwendig sind. Und sollte das doch der Fall sein, öffnet fish_config einen komfortablen Konfigurationsdialog im Webbrowser (außer Sie arbeiten in einer SSH-Session).
Die Stärken der fish im Vergleich zu bash und zsh haben aus meiner Sicht wenig mit der Funktionalität zu tun; einige Features der fish lassen sich auch mit bash-Hacks erreichen, fast alle mit zsh-Plugins. Der entscheidende Vorteil ist vielmehr, dass die fish out of the box zufriedenstellend funktioniert. Für mich ist das deswegen entscheidend, weil ich viele Linux-Installationen verwende und keine Zeit dafür habe, mich jedesmal mit dem Shell-Setup zu ärgern. Deswegen hatte ich in der Vergangenheit auf meinen wichtigsten Installationen zsh samt einer maßgeschneiderten Konfiguration, auf allen anderen aber der Einfachheit halber die bash oder eine unkonfigurierte zsh-Installation.
Auf den ersten Blick sieht die »fish« aus wie jede andere Shell
Installation
Die Installation ist schnell erledigt. Alle gängigen Distributionen stellen fish als Paket zur Verfügung. Also apt/dnf install fish, danach:
chsh -s $(which fish)
Aus- und neu einloggen, fertig.
Falls Ihnen die fish doch nicht zusagt, ist die bisherige Shell ebenso schnell mit chsh -s $(which bash) oder chsh -s $(which zsh) reaktiviert.
Features
Im Prinzip verhält sich die fish wie jede andere Shell. Insbesondere gelten die üblichen Mechanismen zum Start von Kommandos, zur Ein- und Ausgabeumleitung mit < und >, zur Bildung von Pipes mit | sowie zur Verarbeitung von Kommandoergebnissen mit $(cmd). Was ist also neu?
Während der Eingabe verwendet die fish Farben, um verschiedene Bestandteile Ihres Kommandos (z.B. Zeichenketten) zu kennzeichnen. Das sieht nett aus, der entscheidende Vorteil ist aber, dass Sie oft Tippfehler erkennen, bevor Sie Return drücken: Kommandos, die es gar nicht gibt, werden rot hervorgehoben, ebenso nicht geschlossene Zeichenketten. (Die Farben sind vom aktiven Farbschema abhängig.)
Die Vervollständigung von Kommandos, Optionen, Datei- und Variablennamen mit der Tabulator-Taste ist noch »intelligenter« als bei bash und zsh. fish greift dazu auf über 1000 *.fish-Dateien im Verzeichnis /usr/share/fish/completions zurück, die Regeln für alle erdenklichen Fälle enthalten und mit jeder fish-Version erweitert werden. Die fish zeigt sogar kurze Hilfetexte an (siehe die folgende Abbildung). Wenn es viele mögliche Vervollständigungen gibt, zeigt fish diese in mehreren Spalten an. Sie können mit den Cursortasten das gewünschte Element auswählen.
Bei der Eingabe von Kommandos durchsucht die fish die History, also eine Datei, in der alle zuletzt ausgeführten Kommandos gespeichert wurden. In etwas blasserer Schrift schlägt es das passendste Kommando vor. Die fish berücksichtigt dabei auch den Kontext (welches Verzeichnis ist aktiv, welche Kommandos wurden vorher ausgeführt) und schlägt oft — fast schon ein wenig unheimlich — das richtige Kommando vor. Wenn Sie dieses Kommando ausführen möchten, vervollständigen Sie die Eingabe mit Cursor rechts (nicht Tabulator!) und drücken dann Return. Durch ähnliche Kommandos können Sie mit den Cursortasten blättern.
Alternativ können Sie auch mit Strg+R suchmuster nach früher ausgeführten Kommandos suchen. Die fish sucht nach dem Muster nicht nur in den Anfangsbuchstaben, sondern in den gesamten Zeichenketten der History.
Wenn das aktuelle Verzeichnis Teil eines Git-Repositories ist, zeigt fish den Namen des aktuellen Zweigs in Klammern an. (Wenn Sie mehr Git-Infos sehen wollen, ändern Sie die Prompt-Konfiguration.)
Die »fish« zeigt Hilfetexte zu allen »mysql«-Optionen an, die mit »–default« beginnen.
Globbing-Eigenheiten
In Shells wird die Umwandlung von *.txt in die Liste passender Dateinamen als »Globbing« bezeichnet. Die fish verhält sich dabei fast gleich wie die bash — aber mit einem kleinen Unterschied: Wenn es keine passenden Dateien gibt (z.B. keine einzige Datei mit der Endung .txt), löst die fish einen Fehler aus. Die bash übergibt dagegen das Muster — also *.txt — an das Kommando und überlässt diesem die Auswertung. In der Regel tritt der Fehler dann dort auf. Also kein großer Unterschied?
Es gibt Sonderfälle, in denen das Verhalten der bash günstiger ist. Stellen Sie sich vor, Sie wollen mit scp alle *.png-Dateien von einem externen Rechner auf Ihren lokalen Rechner übertragen:
scp externalhost:*.png .
In der bash funktioniert das wie gewünscht. Die fish kann aber mit externalhost:*.png nichts anfangen und löst einen Fehler aus. Abhilfe: Sie müssen das Globbing-Muster in Anführungszeichen stellen, also:
scp "externalhost:*.png" .
Analoge Probleme können auch beim Aufruf von Paketkommandos auftreten. apt install php8-* funktioniert nicht, wohl aber apt install "php8-*". Hintergründe zum Globbing-Verhalten können Sie hier nachlesen:
Tastenkürzel
Grundsätzlich gelten in der fish dieselben Tastenkürzel wie in der bash. In der fish gibt es darüberhinaus weitere Kürzel, von denen ich die wichtigsten hier zusammengestellt habe. bind oder fish_config (Dialogblatt bindings) liefert eine wesentlich längerer Liste aller Tastenkürzel. Beachten Sie, dass es vom Desktopsystem und vom Terminal abhängt, ob die Alt-Tastenkürzel wirklich funktionieren. Wenn die Kürzel vom Terminal oder dem Desktopsystem verarbeitet werden, erreichen Sie die fish nicht.
Kürzel Bedeutung
------------------ -------------------------------------------------------
Alt+Cursor links führt zurück ins vorige Verzeichnis (prevd)
Alt+Cursor rechts macht die obige Aktion rückgängig (nextd)
Alt+E öffnet den Dateinamen mit $EDITOR
Alt+H oder F1 zeigt die man-Seite zum eingegebenen Kommando an (Help)
Alt+L führt ls aus
Alt+P fügt der Eingabe &| less hinzu (Pager)
Alt+S fügt sudo am Beginn der Eingabe ein
Alt+W zeigt Aliasse und eine Beschreibung des Kommandos (What is?)
Noch eine Anmerkung zu Alt+S: In meiner Praxis kommt es ständig vor, dass ich sudo vergesse. Ich führen also dnf install xy aus und erhalte die Fehlermeldung, dass meine Rechte nicht ausreichen. Jetzt drücke ich einfach Alt+S und Return. Die fish stellt sudo dem vorigen, fehlgeschlagenen Kommando voran und führt es aus.
Konfiguration
Das Kommando fish_config öffnet einen Konfigurationsdialog im Webbrowser. Falls Ihr Webbrowser gerade minimiert ist, müssen Sie das Fenster selbst in den Vordergrund bringen. Im Browser können Sie nun ein Farbenschema auswählen, noch mehr Informationen in den Prompt integrieren, die Tastenkürzel nachlesen etc.
In SSH-Sessions scheitert der Start eines Webbrowsers. In diesem Fall können Sie mit fish_config prompt bzw. fish_config theme das Promptaussehen und das Farbschema direkt im Textmodus verändern.
fish-Konfiguration im Webbrowser
Wenn Sie Änderungen durchführen, werden diese im Terminal mit set -U fish_xxx newvalue ausgeführt und in Konfigurationsdateien in .config/fish gespeichert, insbesondere in:
Das Gegenstück zu .bashrc oder .zshrc ist die Datei .config/fish/config.fish. Das ist der richtige Ort, um eigene Abkürzungen zu definieren, den PATH zu erweitern etc. config.fish enthält einen vordefinierten if-Block für Einstellungen, die nur für interaktive fish-Sessions relevant sind. Alle anderen Einstellungen, die z.B. in Scripts gelten sollen, führen Sie außerhalb durch. Das folgende Listing zeigt ein paar typische Einstellungen:
# Datei .config/fish/config.fish
...
# PATH ändern
fish_add_path ~/bin
fish_add_path ~/.local/bin
# keine fish-Welcome-Nachricht
set -U fish_greeting ""
# Einstellungen nur für die interaktive Nutzung
if status is-interactive
# abr statt alias
abbr -a ls eza
abbr -a ll 'eza -la'
abbr -a gc 'git commit'
# Lieblingseditor
set -gx EDITOR /usr/bin/jmacs
end
Das obige Listing zeigt schon, das die fish gängige Einstellungen anders handhabt als bash und zsh:
Abkürzungen: Anstelle von alias sieht die fish das Kommando abbr vor. alias steht auch zur Verfügung, von seinem Einsatz wird aber abgeraten. abbr unterscheidet sich durch ein paar Details von alias: Die Expansion in das Kommando erfolgt bereits, wenn Sie Return drücken. Sie sehen daher, welches Kommando wirklich ausgeführt wird, und dieses Kommando (nicht die Abkürzung) wird in der History gespeichert.
PATH-Änderungen: Sie müssen die PATH-Variable nicht direkt verändern, sondern können stattdessen fish_add_path aufrufen. Ihr Pfad wird am Ende hinzugefügt, wobei die Funktion sicherstellt, dass es keine Doppelgänger gibt.
Variablen (set): Die Optionen des set-Kommandos zur Einstellung von Variablen funktionieren anders als in der bash:
-g: Die Variable ist in der gesamten fish-Session zugänglich (Global Scope), nicht nur in einer Funktion oder einem Block.
-x: Die Variable wird an Subprozesse weitergegeben (Export).
-U: Die Variable wird dauerhaft in .config/fish/fish_variables gespeichert und gilt daher auch für künftige fish-Sessions (Universal). Sie wird aber nicht exportiert, es sei denn, Sie verwenden -Ux.
-l: Definiert eine lokale Variable, z.B. innerhalb einer Funktion.
Zusätzliche eingebaute Kommandos
Jede Shell hat eine Menge integrierter Kommandos wie cd, if oder set. In der fish können Sie mit builtin -n alle derartigen Kommandos auflisten. Die meisten Kommandos entsprechen exakt den bash- und zsh-Vorgaben. In der fish gibt es aber einige originelle Erweiterungen: math führt einfache Berechnungen aus, random produziert ganzzahlige Zufallszahlen, string manupuliert Zeichenketten ohne die umständliche Parametersubstitution, path extrahiert Komponenten aus einem zusammengesetzten Dateinamen, count zählt Objekte (vergleichbar mit wc -l etc. Das folgende Listing zeigt die Anwendung dieser Kommandos:
math "2.5 * 3.8"
9.5
string split " " "lorem ipsum dolor est"
lorem
ipsum
dolor
est
string replace ".png" ".jpg" file1.png file2.png file3.png
file1.jpg
file2.jpg
file3.jpg
string sub -s 4 -e 8 "abcdefghijkl" # Start und Ende inklusive
defgh
path basename /home/kofler/images/img_234.png
img_234.png
path dirname /home/kofler/images/img_234.png
/home/kofler/images
path extension /home/kofler/images/img_234.png
.png
random 1 100
13
random choice a b c
c
count * # das aktuelle Verzeichnis hat
# 32 Dateien/Verzeichnisse
32
ps ax | count # gerade laufen 264 Prozesse
264
Programmierung
Die Bezeichnung Friendly Interactive Shell weist schon darauf hin: Die fish ist für die interaktive Nutzung optimiert, nicht für die Programmierung. Die fish unterstützt aber sehr wohl auch die Script-Programmierung. Diese ist insofern attraktiv, weil die fish-Entwickler auf maximale Kompatibilität verzichtet haben und die schlimmsten Syntaxungereimtheiten der bash behoben haben. fish-Scripts sind daher ungleich leichter zu verstehen als bash-Scripts. Umgekehrt heißt das leider: fish-Scripts sind inkompatibel zu bash und zsh und können nur ausgeführt werden, wo die fish zur Verfügung steht. Für mich ist das zumeist ein Ausschlusskriterium.
Anstelle einer systematischen Einführung will ich Ihnen hier anhand eines Beispiels die Vorteile der fish beim Programmieren nahebringen. Das Script ermittelt die Anzahl der Zeilen für alle *.txt-Dateien im aktuellen Verzeichnis. (Ich weiß, wc -l *.txt wäre einfacher; es geht hier nur darum, diverse Syntaxeigenheiten in wenig Zeilen Code zu verpacken.) Die bash-Variante könnte so aussehen:
#!/bin/bash
files=(*.txt)
if [ ${#files[@]} -eq 0 ]; then
echo "No .txt files found"
exit 1
fi
for file in "${files[@]}"; do
if [ -f "$file" ]; then
lines=$(wc -l < "$file")
echo "$file: $lines lines"
fi
done
Das äquivalente fish-Script ist deutlich besser lesbar:
#!/usr/bin/env fish
set files *.txt
if not count $files > /dev/null
echo "No .txt files found"
exit 1
end
for file in $files
if test -f $file
echo "$file: "(count < $file)" lines"
end
end
Auf ein paar Details möchte ich hinweisen:
Kontrollstrukturen werden generell mit end abgeschlossen, nicht mit fi für if oder mit esac für case.
Bedingungen für if, for etc. müssen weder in eckige Klammern gestellt noch mit einem Strichpunkt abgeschlossen werden.
Die fish verarbeitet Variablen korrekt selbst wenn sie Dateinamen mit Leerzeichen enthalten. Es ist nicht notwendig, sie in Anführungszeichen zu stellen (wie bei "$file" im bash-Script).
Wenn Sie in eigenen Scripts Optionen und andere Parameter verarbeiten möchten, hilft Ihnen dabei das Builtin-Kommando argparse. Eine gute Zusammenstellung aller Syntaxunterschiede zwischen bash und fish gibt die fish-Dokumentation.
Paketmanager fisher
Das Versprechen von fish ist ja, dass fast alles out-of-the-box funktioniert, dass die Installation von Zusatzfunktionen und deren Konfiguration ein Thema der Vergangenheit ist. Aber in der Praxis tauchen trotzdem immer Zusatzwünsche auf. Mit dem Paketmanager fisher können Zusatzmodule installiert werden. Eine Sammlung geeigneter Plugins finden Sie hier.
Die Geschichte von fish
Die fish ist erst in den letzten Jahren so richtig populär geworden. Das zeigt, dass es auch in der Linux-Welt Modetrends gibt. fish ist nämlich alles andere als neu. Die erste Version erschien bereits 2005.
fish wurde ursprünglich in C entwickelt, dann nach C++ und schließlich nach Rust portiert. Erst seit Version 4.0 (erschienen im Februar 2025) besteht fish ausschließlich aus Rust-Code sowie in fish selbst geschriebenen Erweiterungen.
Fazit
Die fish punktet durch die gut durchdachte Grundkonfiguration und die leichte Zugänglichkeit (Konfiguration und Hilfe im Webbrowser). Es gibt nicht das eine Feature, mit dem sich die fish von anderen Shells abhebt, es ist vielmehr die Summe vieler, gut durchdachter Kleinigkeiten und Detailverbesserungen. Das Arbeiten in der fish ist intuitiver als bei anderen Shells und macht mehr Spaß. Probieren Sie es aus!
Bei der Programmierung ist die fish inkompatibel zu anderen Shells und insofern kein Ersatz (auch wenn die fish-eigenen Features durchaus spannend sind). Zur Ausführung traditioneller Shell-Scripts brauchen Sie weiterhin eine traditionelle Shell, am besten die bash.
Aktuell komme ich mit den Blog-Artikeln zu neuen Linux-Distributionen kaum mehr hinterher. Ubuntu 25.10 ist gerade fertig geworden, und zur Abwechslung gibt es deutlich mehr technische Neuerungen/Änderungen (und auch mehr Bugs) als sonst. Ich konzentriere mich hier vor allem auf die neue SSD-Verschlüsselung mit Keys im TPM. Generell ist Ubuntu 25.10 als eine Art Preview für die nächste LTS-Version 26.04 zu sehen.
Ubuntu 25.10 mit Gnome 49 und Wayland
Neuerungen
Neben den üblichen Software-Updates, auf die ich diesmal nicht im Detail eingehe (topaktueller Kernel 6.17!) gibt es vier grundlegende Neuerungen:
Gnome unterstützt nur noch Wayland als Grafiksystem. Diese Neuerung hat das Gnome-Projekt vorgegeben, und die Ubuntu-Entwickler mussten mitziehen. Ich kann nicht sagen, ob mit Überzeugung — immerhin ist das ja auch eine Vorentscheidung für Ubuntu 26.04. Die Alternative wäre gewesen, sowohl für dieses als auch für das kommende Release bei Gnome 48 zu bleiben. Persönlich läuft Gnome + Wayland für mich in allen erdenklichen echten und virtuellen Hardware-Umgebungen gut, d.h. ich trauere X nicht nach. (Über XWayland können natürlich weiterhin einzelne X-Programme ausgeführt werden — wichtig für Programme, die noch nicht auf Wayland-kompatible Bibliotheken portiert sind. Aber der Desktop als Ganzes und der Display Manager müssen jetzt Wayland verwenden.)
initramfs-Dateien mit Dracut: Ubuntu verwendet zum Erzeugen der für den Boot-Prozess erforderlichen Initial-RAM-Filesystem (umgangssprachlich der initrd-Dateien) das von Red Hat etablierte Kommando dracut und weicht damit vom Debian-Fundament ab, das weiterhin mkinitramfs verwendet. Das bewährte Kommando update-initramfs bleibt erhalten, aber dieses Script ruft nun eben dracut auf. Die Änderung gilt aktuell nur für Ubuntu Desktop, während Ubuntu Server vorerst bei mkinitramfs bleibt (mehr Details).
Rust Utilities: Nicht nur im Linux-Kernel wächst die Bedeutung der Programmiersprache Rust, auch immer mehr Standard-Utilities von Linux werden aktuell im Rahmen von uutils neu in Rust implementiert. Der entscheidende Vorteil von Rust ist eine bessere interne Speicherverwaltung, die weniger Sicherheitsprobleme verspricht (keine Buffer Overflows, keine Null Pointer). In Ubuntu 25.10 wurde sudo durch die Rust-Implementierung sudo-rs ersetzt. Analog kommen auch die Rust-Core-Utilities zum Einsatz (Paket rust-coreutils, siehe /usr/lib/cargo/bin/coreutils). Das betrifft viele oft benötigte Kommandos, z.B. cat, chmod, chown, cp, date, dd, echo, ln, mv, shaXXXsum etc. Ein Blick in /usr/bin zeigt eine Menge entsprechender Links. Sicherheitstechnisch ist die Umstellung erfreulich, aber die Neuimplementierung hat natürlich auch zu neuen Fehlern geführt. Schon während der Beta-Phase hat Phoronix über größere Probleme berichtet, und ganz ist der Ärger vermutlich noch nicht ausgestanden. Update 27.10.: Ein Fehler in date hat dazu geführt, dass automatische Updates nicht mehr funktionieren, siehe den Bugbericht im Launchpad. Dieser Fehler ist mittlerweile behoben.
TPM-Unterstützung: Bei der Installation können Sie die Keys für die Dateisystemverschlüsselung nun im TPM speichern. Auf die Details gehe ich gleich ausführlich ein.
Flatpak-Probleme
Viel schlechte Presse haben sich die Ubuntu-Entwickler mit einem Flatpak-Bug eingehandelt. Aktuell gibt es ja zwei alternative Formate für (Desktop-)Pakete, Snap (Ubuntu) versus Flatpak (Red Hat und der Rest der Welt). Aufgrund einer AppArmor-Änderung funktionierten Flatpaks unter Ubuntu nicht mehr. Bugbericht, Behebung, fertig?
Und genau hier begann das eigentliche Fiasko. Der Bug-Bericht stammt nämlich vom 5. September. Dennoch wurde Ubuntu 23.10 fünf Wochen später mit eben diesem Bug freigegeben. Und das ist doch ein wenig peinlich, weil es den Eindruck vermitteln könnte, dass es Ubuntu nur wichtig ist, dass das eigene Paketformat funktioniert. (Und auch wenn Ubuntu ein großer Snap-Befürworter ist, gibt es eine Menge Ubuntu-Derivate, die auf Flatpaks setzen.)
Seit ein paar Tagen gibt es einen Fix, dieser wird aber noch nicht ausgeliefert. (Es kann sich nur noch um wenige Tage handeln.) Alternativ kann als Workaround das AppArmor-Profil für fusermount3 deaktiviert werden:
Natürlich ist die ganze Geschichte ein wenig der Sturm im Wasserglas, aber es ist/war definitiv ein vermeidbarer Sturm.
Dateisystem-Verschlüsselung mit Keys im TPM
Zuerst eine Einordnung des Themas: Wenn Sie eine Linux-Installation mit einem verschlüsselten Dateisystem einrichten, müssen Sie während des Boot-Vorgangs zwei Passwörter eingeben: Ganz zu Beginn das Disk-Verschlüsselungspasswort (oft ‚Pass Phrase‘ genannt), und später Ihr Login-Passwort. Die beiden Passwörter sind vollkommen getrennt voneinander, und sie sollten aus Sicherheitsgründen unterschiedlich sein. Elegant ist anders.
Wenn Sie dagegen unter macOS oder Windows das Dateisystem verschlüsseln (FileVault, Bitlocker), gibt es trotzdem nur ein Login-Passwort. Analog gilt das übrigens auch für alle Android- und Apple-Smartphones und -Tablets.
Warum reicht ein Passwort? Weil der Key zur Verschlüsselung des Dateisystems in der Hardware gespeichert wird und während des Boot-Vorgangs von dort ausgelesen wird. Auf x86-Rechnern ist dafür das Trusted Platform Module zuständig. Das TPM kann kryptografische Schlüssel speichern und nur bei Einhaltung bestimmter Boot-Regeln wieder auslesen. Bei aktuellen AMD-CPUs sind die TPM-Funktionen im CPU-Package integriert, bei Intel kümmert sich der Platform Controller Hub (PCH), also ein eigenes Chipset darum. In beiden Fällen ist das TPM sehr Hardware-nah implementiert.
Der Sicherheitsgewinn bei der Verwendung des TPMs ergibt sich daraus, dass das Auslesen des Verschlüsselungs-Keys nur gelingt, solange die Verbindung zwischen Disk und CPU/Chipset besteht (die Disk also nicht in einen anderen Rechner eingebaut wurde) UND eine ganz bestimmte Boot-Sequenz eingehalten wird. Wird die Disk ausgebaut, oder wird der Rechner von einem anderen Betriebssystem gebootet, scheitert das Auslesen des Keys. (Genaugenommen enthält das TPM nicht direkt den Key, sondern den Key zum Key. Deswegen ist es möglich, den Dateisystemverschlüsselungs-Key im Notfall auch durch die Eingabe eines eigenen Codes freizuschalten.)
Die Speicherung des Keys im TPM ermöglicht es also, das Dateisystem zu verschlüsseln, OHNE die Anwender ständig zur Eingabe von zwei Schlüssel zu zwingen. Die TPM-Bindung schützt vor allen Angriffen, bei denen die SSD oder Festplatte ausgebaut wird. Wenn der gesamte Rechner entwendet wird, schützt TPM immer noch vor Angriffen, die durch das Booten von einem fremden System (Linux auf einem USB-Stick) erfolgen. Allerdings kann der Dieb den Rechner ganz normal starten. Das Dateisystem wird dabei ohne Interaktion entschlüsselt, aber ein Zugriff ist mangels Login-Passwort unmöglich. Das System ist also in erster Linie so sicher wie das Login-Passwort. Weiterhin denkbar sind natürlich Angriffe auf die auf dem Rechner laufende Software (z.B. ein Windows/Samba/SSH-Server). Kurzum: TPM macht die Nutzung verschlüsselter Dateisysteme deutlich bequemer, aber (ein bisschen) weniger sicher.
Zum Schluss noch eine Einschränkung: Ich bin kein Kryptografie-Experte und habe die Zusammenhänge hier so gut zusammengefasst (und definitiv vereinfacht), wie ich sie verstehe. Weder kann ich im letzten Detail erklären, warum es bei Windows/Bitlocker unmöglich ist, den Key auch dann auszulesen, wenn der Rechner von einem Linux-System gebootet wird, noch kann ich einschätzen, ob die von Ubuntu durchgeführte Implementierung wirklich wasserdicht und fehlerfrei ist. Aktuell ist sowieso noch Vorsicht angebracht. Die Ubuntu-Entwickler bezeichnen Ihr System nicht umsonst noch als experimentell.
Ubuntu mit TPM-Verschlüsselung einrichten
Ubuntu bezeichnet die Speicherung des Verschlüsselungs-Keys als noch experimentelles Feature. Dementsprechend habe ich meine Tests in einer virtuellen Maschine, nicht auf physischer Hardware ausgeführt. Mein Host-System war Fedora mit QEMU/KVM und virt-manager. Beim Einrichten der virtuellen Maschine sollten Sie UEFI aktivieren. Außerdem müssen Sie unbedingt ein TPM-Device zur virtuellen Maschine hinzufügen.
Virtuelle Maschine mit TPM-Device einrichten
Bei der Installation entscheiden Sie sich für die Hardware-gestützte Verschlüsselung.
Zuerst aktivieren Sie die Verschlüsselung …… und dann die Variante »Hardwaregestützte Verschlüsselung« auswählen
Im nächsten Dialog können Sie den Entschlüsselung des Datenträgers von einem weiteren Passwort abhängig machen. (Der Key für die Verschlüsselung ist dann mit einem TPM-Key und mit Ihrer Passphrase abgesichert.) Sicherheitstechnisch ist das die optimale Variante, aber damit erfordert der Boot-Vorgang doch wieder zwei Passworteingaben. Da können Sie gleich bei der »normalen« Verschlüsselung bleiben, wo Sie das LUKS-Passwort zum Beginn des Boot-Prozesses eingeben. Ich habe mich bei meinen Tests auf jeden Fall gegen die zusätzliche Absicherung entschieden.
Eine zusätzliche Passphrase macht das System noch sicherer, der Bequemlichkeits-Gewinn durch TPM geht aber verloren.
Die Zusammenfassung der Konfiguration macht schon klar, dass das Setup ziemlich komplex ist.
Der Installer richtet vier Partitionen ein: /boot/efi, /boot, / sowie eine zusätzliche Partition mit Seed-Daten
Der Key für die Verschlüsselung wird zufällig generiert. Der Installer zeigt einen Recovery-Key in Textform und als QR-Code an. Diesen Key müssen Sie unbedingt speichern! Er ist erforderlich, wenn Sie den Datenträger in einen anderen Rechner übersiedeln, aber unter Umständen auch nach größeren Ubuntu- oder BIOS/EFI-Updates. Wenn Sie den Recovery-Key dann nicht mehr haben, sind Ihre Daten verloren!
Sie müssen den Recovery-Key unbedingt speichern oder aufschreiben!Dieser QR-Code enthält einfach den darunter dargestellten Zahlencode. (Es handelt sich nicht um einen Link.)
Nach dem Abschluss der Installation merken Sie beim nächsten Reboot nichts von der Verschlüsselung. Der Key zum Entschlüsseln der SSD/Festplatte wird vom TPM geladen und automatisch angewendet. Es bleibt nur der »gewöhnliche« Login.
Als nächstes habe ich mir natürlich das resultierende System näher angesehen. /etc/fstab ist sehr aufgeräumt:
Selbiges kann man von der Mount-Liste leider nicht behaupten. (Diverse Snap-Mounts habe ich weggelassen, außerdem habe ich diverse UUIDs durch xxx bzw. yyy ersetzt.)
Die Partition ubuntu-save (Mount-Punkt /run/mnt/ubuntu-save) enthält lediglich eine JSON-Datei sowie ein paar Key-Dateien (ASCII).
Die Partition »ubuntu-save« enthält lediglich einige Key-Dateien
Ich bin ein großer Anhänger des KISS-Prinzips (Keep it Simple, Stupid!). Sollte bei diesem Setup etwas schief gehen, ist guter Rat teuer!
Mit virtuellen Maschinen kann man schön spielen — und das habe ich nun gemacht. Ich habe eine zweite, neue VM eingerichtet, die 1:1 der ersten entspricht. Diese VM habe ich mit dem virtuellen Datenträger der ersten VM verbunden und versucht zu booten. Erwartungsgemäß ist das gescheitert, weil ja der TPM-Speicher bei der zweiten VM keine Keys enthält. (Das Experiment entspricht also dem Ausbau der Disk aus Rechner A und den Einbau in Rechner B.)
Wichtig: Der Key ist ohne Bindestriche einzugeben. Die Eingabe erfolgt im Blindflug (ich weiß, Sicherheit), was bei 40 Ziffern aber sehr mühsam ist. Wird die Disk ausgebaut bzw. von einer anderen virtuellen Maschine genutzt, muss der Recovery-Key mühsam eingegeben werden.
Immerhin hat der Boot-Vorgang anstandslos funktioniert — allerdings nur einmal. Beim nächsten Reboot muss der Recovery-Key neuerlich eingegeben werden. Ich habe keinen Weg gefunden, die Keys im TPM der zweiten virtuellen Maschine (Rechner B) zu verankern. Wenn sich wirklich die Notwendigkeit ergibt, die SSD in einen neuen Rechner zu migrieren, wäre das eine große Einschränkung.
Danach habe ich wieder VM 1 gebootet. Dort hat alles funktioniert wie bisher. VM 1 hat also nicht bemerkt, dass die Disk vorübergehend in einem anderen Rechner genutzt und auch verändert wurde. Ich bin mir nicht sicher, ob das wünschenswert ist.
Letztlich bleiben zwei Fragen offen:
Wie sicher sind die Daten, wenn das Notebook in falsche Hände gerät?
Wie sicher ist es, dass ich an meine eigenen Daten rankomme, wenn beim Setup etwas schief geht? Aus meiner persönlichen Sichtweise ist dieser zweiter Punkt der wichtigere. Die Vorstellung, dass nach einem Update der Boot-Prozess hängenbleibt und ich keinen Zugriff mehr auf meine eigenen Daten habe, auch keinen Plan B zur manuellen Rettung, ist alptraumhaft. Es ist diese Befürchtung, weswegen ich das System gegenwärtig nie in einem produktivem Setup verwende würde.
Einfacher ist oft besser, und einfacher ist aktuell die »normale« LUKS-Verschlüsselung, auch wenn diese mit einer wenig eleganten Passwort-Eingabe bei jedem Boot-Prozess verbunden ist. Da weiß ich immerhin, wie ich zur Not auch aus einem Live-System heraus meine Daten lesen kann.
Fazit
Ubuntu 25.10 ist aus meiner Sicht ein mutiges, innovatives Release. Ich kann die Kritik daran nur teilweise nachvollziehen. Die Nicht-LTS-Releases haben nun einmal einen gewissen Test-Charakter und sind insofern mit Fedora-Releases zu vergleichen, die auch gelegentlich etwas experimentell sind.
Das interessanteste neue Feature ist aus meiner Sicht definitiv die Speicherung der Crypto-Keys im TPM. Leider bin technisch nicht in der Lage, die Qualität/Sicherheit zu beurteilen. Noch hat das Feature einen experimentellen Status, aber falls TPM-Keys in Ubuntu 26.04 zu einem regulären Feature werden, würde es sich lohnen, das Ganze gründlich zu testen. Allerdings haben sich diese Mühe bisher wohl nur wenige Leute gemacht, was schade ist.
Generell hätte ich beim TPM-Keys-Feature mehr Vertrauen, wenn sich Ubuntu mit Red Hat, Debian etc. auf eine distributionsübergreifende Lösung einigen könnte.
Post Scriptum am 5.11.2025
Ich habe in den letzten Monaten aktuelle Versionen von CachyOS, Debian, Fedora, openSUSE und Ubuntu getestet. Immer wieder taucht die Frage auf, welche Distribution ich Einsteiger(inne)n empfehle. Ubuntu ist schon lange nicht mehr meine persönliche Lieblingsinstallation. Von den genannten fünf Distributionen hat Ubuntu aber definitiv das beste und einfachste Installationsprogramm. Und für den Start mit Linux ist das durchaus entscheidend …
Einige Wochen nach dem Release von Debian 13 »Trixie« hat die Raspberry Pi Foundation auch Raspberry Pi OS aktualisiert. Abseits der Versionsnummern hat sich wenig geändert.
Der Raspberry Pi Desktop »PIXEL« sieht bis auf das Hintergrundbild ziemlich unverändert aus.
Raspberry Pi Imager
Die »Installation« von Raspberry Pi OS funktioniert wie eh und je: Sie laden die für Ihr Betriebssystem passende Version des Raspberry Pi Imagers herunter und wählen in drei Schritten Ihr Raspberry-Pi-Modell, die gewünschte Distribution und schließlich das Device Ihrer SD-Karte aus. Einfacher kann es nicht sein, würde man denken. Dennoch habe ich es geschafft, auf einem Rechner mit zwei SSDs (einmal Linux, diese SSD war aktiv in Verwendung, einmal Windows) die Installationsdaten auf die Windows-SSD statt auf die SD-Karte zu schreiben. Schuld war ich natürlich selbst, weil ich nur auf das Pictogram gesehen und nicht den nebenstehenden Text gelesen habe. Der Imager hat die SSD mit dem SD-Karten-Icon garniert.
Vorsicht bei der Bedienung des Raspberry Pi Imagers!
Wenn Sie möchten, können Sie im Imager eine Vorweg-Konfiguration durchführen. Das ist vor allem für den Headless-Betrieb praktisch, erspart aber auch erste Konfigurationsschritte im Assistenten, der beim ersten Start erscheint.
Die Vorab-Konfiguration ist vor allem für den Headless-Betrieb (also ohne Tastatur und Monitor) praktisch.
Versionsnummern
Raspberry Pi OS Trixie profitiert mit dem Versionssprung vom neueren Software-Angebot in Debian Trixie. Die aktuelleren Versionsnummern sind gleichzeitig das Hauptargument, auf Raspberry Pi OS Trixie umzusteigen.
Die größte Änderung am Desktop »PIXEL« (vom Hintergrundbild abgesehen) betrifft die Konfiguration: Das Control Center umfasst nun auch Desktop-Einstellungen, die Bildschirm-Konfiguration und die Drucker-Konfiguration. Das ist definitiv ein Fortschritt im Vergleich zur bisher recht willkürlichen Aufteilung der Konfiguration über diverse Programme mit recht uneinheitlichem Erscheinungsbild.
Das Konfigurationsprogramm umfasst nun wesentlich mehr Module
gpioset
Die Syntax von gpioset hat sich geändert (vermutlich schon vor einiger Zeit, aber mir ist es erst im Rahmen meiner Tests mit Raspberry Pi OS Trixie aufgefallen):
Der gewünschte Chip (Nummer oder Device) muss mit der Option -c angegeben werden.
Das Kommando läuft per Default endlos, weil es nur so den eingestellten Status der GPIOs garantieren kann. Wenn Sie wie bisher ein sofortiges Ende wünschen, übergeben Sie die Option -t 0. Beachten Sie, dass -t nicht die Zeit einstellt, sondern für ein regelmäßiges Ein- und Ausschalten gedacht ist (toggle). Ich habe die Logik nicht verstanden, aber -t 0 führt auf jeden Fall dazu, dass das Kommando sofort beendet wird.
Alternativ kann das Kommando mit -z im Hintergrund fortgesetzt werden.
Das folgende Kommando gilt für Chip 0 (/dev/gpiochip0) und somit für die »gewöhnlichen« GPIOs. Dank -t 0 wird das Kommando sofort beendet.
Verwenden Sie besser das Kommando pinctrl, wenn Sie GPIOs im Terminal oder in bash-Scripts verändern wollen!
Sonstiges
Raspberry Pi OS verwendet nun per Default Swap on ZRAM. Nicht benötigte Speicherblöcke werden also komprimiert und in einer RAM-Disk gespeichert. Besonders gut funktioniert das bei Raspberry-Pi-Modellen mit viel RAM.
Raspberry Pi OS wird keine Probleme mit dem Jahr 2038 haben. Die zugrundeliegenden Änderungen stammen von Debian und wurden einfach übernommen.
Dank neuer Meta-Pakete ist es einfacher, von Raspberry Pi OS Lite auf die Vollversion umzusteigen. Das ist aus Entwicklersicht sicher erfreulich, der praktische Nutzen hält sich aber in Grenzen.
Mathematica steht aktuell noch nicht zur Verfügung, die Pakete sollen aber bald nachgeliefert werden.
Auch die Software für einige HATs (KI- und TV-Funktionen) müssen erst nachgereicht werden.
Fazit
Alles in allem ist das Raspberry-Pi-OS-Release unspektakulär. Das hat aber auch damit zu tun, dass Raspberry Pi OS bereits in den letztes Releases umfassend modernisiert wurde. Zur Erinnerung: Raspberry Pi OS verwendet Wayland, PipeWire, den NetworkManager etc., verhält sich also mittlerweile ganz ähnlich wie »normale« Linux-Distributionen. Diesmal gab es einfach weniger zu tun :-)
Bei meinen bisherigen Tests sind mir keine Probleme aufgefallen. Umgekehrt gibt es aber auch so wenig Neuerungen, dass ich bei einem vorhandenen Projekt dazu rate, die Vorgängerversion Raspberry Pi OS »Bookworm« einfach weiterlaufen zu lassen. Die Raspberry Pi Foundation rät von Distributions-Updates ab, und der Nutzen einer Neuinstallation steht in keinem Verhältnis zum Aufwand. Und es nicht auszuschließen, dass mit den vielen Versions-Updates doch die eine oder andere Inkompatibilität verbunden ist.
Mein Raspberry Pi 5 ist mit einem SSD-Hat ausgestattet (Pimoroni, siehe Blog). Auf der SSD ist Raspberry Pi OS Bookworm installiert. Jetzt möchte ich aber Raspberry Pi OS Trixie ausprobieren. Das System habe ich mit dem Raspberry Pi Imager auf eine SD-Card geschrieben. Sowohl SSD als auch SD-Karte sind angeschlossen, die Boot-Reihenfolge ist auf SD-Card first eingestellt.
Boot-Reihenfolge einstellen
raspi-config verändert die Variable BOOT_ORDER, die im EEPROM gespeichert wird. Die Variable kann mit `rpi-eeprom-config´ gelesen werden:
0xf461 bedeutet (die Auswertung erfolgt mit den niedrigsten Bits zuerst, also von rechts nach links):
1 - Try SD card
6 - Try NVMe
4 - Try USB mass storage
f - RESTART (loop back to the beginning)
Die Einstellung ist also korrekt, trotzdem bootet der Pi hartnäckig von der SSD und ignoriert die SD-Card. Warum?
Analyse
Schuld sind die Partition-UUIDs! Die SSD habe ich vor eineinhalb Jahren mit dem SD Card Copier geklont. Die Option New Partition UUIDs habe ich nicht verwendet, ich sah keinen Grund dazu. Jetzt liegt folgendes Problem vor: Die SSD und die vom Rasbperry Pi Imager erzeugte SD-Card haben die gleichen Partition-UUIDs!
Solange beide Datenträger verbunden sind, ist nicht vorhersehbar, welche Partitionen tatsächlich genutzt werden. Am einfachsten wäre es natürlich, das Kabel zur SSD vorübergehend zu trennen; das ist aber nicht empfehlenswert, weil es hierfür keinen richtigen Stecker gibt, sondern nur eine sehr filigrane Kabelpressverbindungen, die möglichst nicht anrührt werden sollte.
Lösung
Ich habe den Pi ohne SD-Karte neu gebootet und dann
die Filesystem-UUIDs geändert,
/etc/fstab angepasst und
/boot/firmware/cmdline.txt ebenfalls angepasst.
Im Detail: Da die ursprüngliche Partitionierung der SSD von der SD-Karte übernommen wurde, liegt eine MBR-Partitionstabelle vor. In diesem Fall ergeben sich die Partition-UUIDs aus der Disk-ID plus Partitionsnummer. Die Disk-ID (Hex-Code mit 8 Stellen) kann mit fdisk geändert werden:
fdisk /dev/nvme0n1
Welcome to fdisk (util-linux 2.38.1).
Command (m for help): x. <-- aktiviert den Expertenmodus
Expert command (m for help): i <-- ID ändern
Enter the new disk identifier: 0x1234fedc. <-- neue ID als Hex-Code
Disk identifier changed from 0x8a676486 to 0x1234fedc.
Expert command (m for help): r <-- zurück ins Hauptmenü (return)
Command (m for help): w <-- Änderungen speichern (write)
The partition table has been altered.
Syncing disks.
Mit fdisk -l vergewissern Sie sich, dass die Änderung wirklich funktioniert hat:
fdisk -l /dev/nvme0n1
...
Disk identifier: 0x1234fedc
Weil der Datenträger in Verwendung ist, zeigt fdisk -l /dev/nvme0n1 weiter die alte UUID an. Sie müssen glauben, dass es funktioniert hat :-(
Bevor Sie einen Reboot machen, müssen Sie nun mit einem Editor auch /etc/fstab und /boot/firmware/cmdline.txt anpassen. In meinem Fall sehen die Dateien jetzt so aus:
Jetzt ist ein Reboot fällig, um zu testen, ob alles funktioniert. (Bei mir hat es im ersten Versuch NICHT funktioniert, weil ich bei fdisk das write-Kommando vergessen habe. Dann muss die SSD ausgebaut, ein USB-Gehäuse mit einem Computer verbunden und der Vorgang wiederholt werden.)
Ab jetzt sind die Partitions-UUIDs von SD-Karte und SSD voneinander unterscheidbar. Die Umschaltung des Boot-Systems mit raspi-config funktioniert, wie sie soll.
Mit Version 16 springt openSUSE gewissermaßen in ein neues Zeitalter. Eine Weile war unklar, in welcher Form und auf welcher Basis openSUSE (überhaupt) weitergeführt wird. Letztlich haben sich die Entwickler zu einem pragmatischen Ansatz entschieden: Auch mit Version 16 bleibt openSUSE Leap eine »normale« Distribution mit Paket-Updates (kein Immutable System mit atomaren Updates) — so wie der große Enterprise-Bruder SLES 16. Für diesen Artikel habe ich einen ersten Blick auf die Distribution geworfen.
openSUSE Leap 16 mit KDE Desktop
Installation
openSUSE verwendet das neue, HTML-basiertes Installationsprogramm agama, dessen Minimalismus Parallelen zu Fedora zeigt. Das Programm läuft unter Gnome im Webbrowser Firefox im Full-Screen-Modus. Es ist mir zwar gelungen, den Voll-Screen-Modus zu beenden, ich konnte aber keine anderen Programme starten, d.h. es liegt kein vollwertiges Live-System vor.
Tipp 1: Mit [Strg]+[+] bzw. [Strg]+[-] können Sie den Zoomfaktor verändern. Per Kontextmenüs können Sie Screenshots erstellen. Je nach (erkannter) Bildschirmauflösung wird das seitliche Menü nicht dauerhaft angezeigt, kann aber über den Menü-Button eingeblendet werden.
Tipp 2: Es ist möglich, das Installationsprogramm von einem externen Rechner aus zu bedienen. Dazu wechseln Sie mit Strg+Alt+F1 in eine Konsole. Dort wird die URL (https://agama.local) und das Passwort angezeigt. Jetzt können Sie im Webbrowser die URL oder IP-Adresse angeben, müssen die unsichere Verbindung (selbst signiertes Zertifikat) akzeptieren und sich einloggen. Eigentlich cool!
Die Installation läuft im Webbrowser, der aber normalerweise nicht sichtbar ist (Fullscreen-Modus)Ein Wechseln in die Textkonsole offenbart einen Login-Link zur Weboberfläche des Installers
Im ersten Schritt stellen Sie rechts oben Sprache und Tastaturlayout für das Installationsprogramm ein und entscheiden Sie sich zwischen Leap 16 und Leap Micro 6.2. (Ich habe nur ersteres ausprobiert.)
Einstellung der Sprache des Setup-Programms (rechts oben) und Auswahl des Grundsystems
Jetzt beginnt die eigentliche Installation. Wenn Sie einen statischen Hostnamen wünschen, geben Sie den gewünschten Namen an. Unter Lokalisierung stellen Sie nochmals (!) Sprache, Tastatur und Zeitzone ein — dieses Mal für das zu installierende System. Eleganter wäre, wenn der Installer die bereits durchgeführten Einstellungen einfach übernehmen würde, aber sei’s drum.
Neuerliche Spracheinstellung, jetzt für das Zielsystem
Im Punkt Netzwerk können Sie eine WLAN-Konfiguration durchnehmen. Ethernet-Verbindungen mit DHCP werden automatisch hergestellt.
Damit kommen wir zur Partitionierung und zum Einrichten der Dateisystemeim Punkt Speicherung. Der Installer schlägt vor, drei Partitionen einzurichten: /boot/efi, eine Swap-Partition und eine Systempartition mit btrfs-Dateisystem und neu Subvolumes (/boot, /var, /root, /home usw.). Optional können Sie das Setup auf LVM umstellen (was im Zusammenspiel mit btrfs aber selten große Vorteile mit sich bringt) und eine Verschlüsselung aktivieren. Für Installationen in eine virtuelle Maschine oder auf einen Rechner, wo Sie einfach die gesamte SSD nutzen möchten, ist das Layout OK.
Wenig Auswahl bei der Partitionierung und Einrichtung der Dateisysteme
Auf »echter« Hardware schlägt das Setup-Programm vor, alle vorhandenen Partitionen des Datenträgers zu löschen und dann openSUSE zu installieren. VORSICHT!! Das Setup-Programm bietet die Möglichkeit, auf die Partitionierung Einfluss zu nehmen, die Menüs sind aber nicht ganz leicht zu erkennen (siehe die folgenden fünf Screenshots).
Vorsicht: Per Default löscht der Installer alle vorhandenen BetriebssystemeEine manuelle Partitionierung ist möglich, aber die Optionen sind gut verstecktWenn Sie einzelne Partitionen oder Dateisysteme ändern wollen, ist hier das entscheidende MenüDer Editor für eine Partition / ein DateisystemParallel-Installation von openSUSE zu diversen anderen Linux-Distributionen
Aufpassen müssen Sie auch beim Punkt Software: Standardmäßig wird nur eine Minimalinstallation ohne Desktop-System durchgeführt! Sie müssen die Auswahl ändern und haben dann die Wahl zwischen Gnome, KDE und XFCE.
Bei der Software-Auswahl muss ein Desktop-System ausgewählt werden!
Zuletzt richten Sie einen Benutzer ein, der automatisch sudo-Rechte erhält. Installieren startet nun die Installation.
Jetzt läuft die Installation
Ich habe mehrere Installationen in VMs durchgeführt, eine »echte« auf meinen Mini-PC. Echte Fehler sind keine aufgetreten, aber intuitiv ist die Bedienung des neuen Installers wirklich nicht. Warum muss das Rad ununterbrochen neu erfunden werden, wenn soviele andere Linux-Probleme einer Lösung harren?
Software-Versionen und Paketverwaltung
Die Versionsnummern wichtiger Basispakete stimmen zum größten Teil mit jenen von Debian 13 überein.
Generell ist das Angebot in Leap 16 im Vergleich zu den Vorgängerversionen 15.n aber geschrumpft, worauf LinuxUser hinweist (32.400 Pakete im Vergleich zu 44.700). Für Desktop-Programme ist Flatpak die beste Alternative. Darüberhinaus wird sich weisen, wie groß das Angebot von Paketen sein wird, die in externen Repositories angeboten werden.
Für Multimedia-Pakete war in der Vergangenheit Packman zuständig. Es ist zu erwarten, dass es dort in Zukunft ein Leap-16-Repository geben wird. Aktuell ist das aber noch nicht der Fall.
Am Fundament der Paketverwaltung hat sich wenig geändert — dafür sind weiterhin rpm (Low-Level) und zypper (High-level) zuständig. Desktop-Programme können wahlweise mit Software (Gnome) oder Discover (KDE) installiert werden. Das allumfassende Paketverwaltungs-Modul innerhalb von YaST gibt es nicht mehr.
Standardmäßig sind nur die Repos repo-oss und repo-openh264 aktiv:
zypper repos
Repository priorities are without effect. All enabled repositories share the same priority.
# | Alias | Name | Enabled | GPG Check | Refresh
--+-----------------------------+---------------------------+---------+-----------+--------
1 | Leap | Leap 16.0 | No | ---- | ----
2 | openSUSE:repo-non-oss | repo-non-oss (16.0) | No | ---- | ----
3 | openSUSE:repo-non-oss-debug | repo-non-oss-debug (16.0) | No | ---- | ----
4 | openSUSE:repo-openh264 | repo-openh264 (16.0) | Yes | (r ) Yes | Yes
5 | openSUSE:repo-oss | repo-oss (16.0) | Yes | (r ) Yes | Yes
6 | openSUSE:repo-oss-debug | repo-oss-debug (16.0) | No | ---- | ----
7 | openSUSE:repo-oss-source | repo-oss-source (16.0) | No | ---- | ----
Für Verwirrung — auch in Software und Discover — kann das inaktive Repo Leap 16.0 sorgen. Es bezieht sich aber nur auf das Installationsmedium und wird im weiteren Betrieb tatsächlich nicht mehr gebraucht.
Das non-oss-Repo enthält diverse proprietäre Programme:
Ich habe openSUSE sowohl mit Gnome als auch mit KDE installiert, aber die weiteren Tests dann in einem KDE-System durchgeführt. KDE verwendet sowohl in virtuellen Maschinen als auch auf echter Hardware X11. Das ist ein wenig enttäuschend, Fedora 42 läuft per default mit Wayland (Fedora 43 beta natürlich auch), und meine Erfahrungen damit waren ausgezeichnet.
Der Versuch, die Auflösung meines 4k-Monitors auf 1920×1080 zu reduzieren, scheiterte. Der Bildschirminhalt wird komplett falsch skaliert, oben und unter im Monitor bleibt ein schwarzer Streifen. Bei 2560×1600 kam gar kein Bild zustande. Diese Probleme hatte ich noch nie. Ich bin dann bei der 4k-Auflösung geblieben und habe die Skalierung verändert. Das funktioniert unter KDE glücklicherweise wunderbar.
Zur Paketverwaltung ist Discover vorgesehen. Prinzipiell funktioniert das Programm zufriedenstellend. Irritierend ist auch hier die (korrekt!) inaktive Paketquelle Leap 16.
Paketverwaltung mit Discover. Es irritiert, dass »Leap 16« nicht aktiv ist — aber diese Paketquelle ist nur für die Installation relevant, danach nicht mehr.
Bei der Systemadministration sind Sie auf die Module der KDE-Systemeinstellungen angewiesen. YaST steht nicht mehr zur Verfügung.
Wie schon erwähnt, entscheidet sich der Installer, wenn Sie nicht andere Optionen einstellen, für ein btrfs-Dateisystem mit vielen Subvolumes aber ohne Komprimierung.
Hinter den Kulissen gibt es eine Menge Neuerungen im Vergleich zu Version 15.n (siehe die Release Notes). Ganz kurz die wichtigsten Details:
Wie schon erwähnt: YaST gibt es nicht mehr. openSUSE empfiehlt, Cockpit zur Administration zu verwenden.
Per Default kommt SELinux zum Einsatz, AppArmor ist immerhin noch als Option verfügbar.
openSUSE 16 ist year-2038-safe.
openSUSE 16 soll bis 2031 jährlich mit neuen Versionen gepflegt werden. (Das wäre dann Version 16.6.) openSUSE 17 soll dann 2032 erscheinen. Warten wir ab, ob es dabei bleibt.
openSUSE 16 setzt bei x86-CPUs den V2-Level voraus. Konkret bedeutet das, dass die CPUs nicht älter als gut 15 Jahre sein dürfen (Details). 32-Bit-CPUs werden nicht mehr unterstützt.
Auf Rechnern mit NVIDIA-GPU werden die entsprechenden Paketquellen automatisch aktiviert und die proprietären Treiber installiert. Solche Systeme sollte jetzt out-of-the-box funktionieren. (Habe ich aber nicht getestet, mein Testrechner hat eine AMD-CPU/GPU.)
PulseAudio wurde durch PipeWire ersetzt.
Per Default darf root sich nicht via SSH anmelden. Verwenden Sie einen Account mit sudo-Rechten, oder ändern Sie ggfs. /etc/ssh/sshd_config.
libvirt + Docker: Wenn Sie Docker und libvirt (Qemu/KVM) einsetzen, funktioniert in den virtuellen Maschinen das Networking nicht mehr. Schuld ist Docker, das nicht in der Lage ist, sein Firewall-System auf nft umzustellen :-( Die Lösung ist gleich wie unter Fedora: Sie müssen das libvirt-Firewall-Backend zurück auf iptables setzen (Details).
nmap: Das populäre nmap-Tool hat die Lizenz geändert. openSUSE enthält die letzte Version unter der alten Lizenz.
Migrationstool
Es gibt ein neues Migrationstool, mit dem Sie einerseits openSUSE 15.6 auf Version 16.0 upgraden und andererseits einen Wechsel zwischen verschiedenen SUSE-Varianten (Leap, Tumblewheed, Slowroll, Enterprise) durchführen können. Ich habe das Programm allerdings nicht ausprobiert.
Das neue opensuse-migration-tool
SSH-Server und Firewall
Der SSH-Server wird standardmäßig installiert, läuft aber nicht. Abhilfe:
systemctl enable --now sshd
Als Firewall läuft standardmäßig das von Fedora und RHEL bekannte Programm firewalld. Standardmäßig sind nur die Ports für SSH und den DHCP-Client offen:
firewall-cmd --list-services
dhcpv6-client ssh
Qemu/KVM-Zwischenablage
Wenn Sie openSUSE 16 in einer virtuellen Maschine mit Qemu ausführen, funktioniert die Zwischenablage nicht. Abhilfe: zypper install spice-vdagent, unter Gnome (Wayland!) zusätzlich zypper install wl-clipboard.
Fazit
In openSUSE 16 ist viel Zeit, Mühe und Liebe geflossen — und das Ergebnis kann sich wirklich sehen lassen. Die Frage ist allerdings, ob das reicht. Das Angebot am Distributionsmarkt ist überwältigend groß, und mir fällt es ehrlich schwer, eine klare Zielgruppe für openSUSE zu erkennen.
Den Mainstream decken Debian, Fedora und Ubuntu ab. Meine Empfehlung an Linux-Desktop-Einsteiger geht ganz stark in diese Richtung.
Server-seitig wieder Debian und Ubuntu plus RHEL und Klone.
Wer gerne immer Up-to-date ist: Arch Linux (oder ein Derivat).
CachyOS kitzelt maximale Performance aus dem Rechner, verbunden mit den Arch-Linux-Vorteilen und aktuell einem Hype-Faktor.
Linux Mint vielleicht für Einsteiger. (Ich war allerdings nie ein riesiger Mint-Fan und sehe wenig Vorteile im Vergleich zu Debian/Fedora/Ubuntu.)
Pop!_OS als Distribution für system76-Kunden. Und falls der COSMIC-Desktop je fertig + stabil wird, könnte die Distribution ein interessantes Angebot für technisch orientierte Anwender werden (Entwickler/Admins/Freaks).
Im Vergleich zu Debian/Fedora/Ubuntu ist in Leap 16 das Software-Angebot geringer. Die Aktualität vieler Pakete kann wiederum mit Fedora und Ubuntu nicht mithalten. Als ausgesprochen einsteigerfreundlich empfinde ich Leap auch nicht (schon gar nicht die Installation). YaST als Argument fällt weg. (Das Konfigurations-Tool wurde schon in den letzten Jahren nur noch sehr halbherzig gepflegt.) Der Dateisystem-Editor von openSUSE während der Installation war Weltklasse, aus meiner Sicht besser als bei allen anderen Distributionen. Er ist dem neuen Installationsprogramm zum Opfer gefallen.
Wer sollte sich also für openSUSE entscheiden, und warum? openSUSE 16 ist natürlich eine super Trainings-Umgebung für SLES 16. Aber ist das genug? Selbst innerhalb der SUSE-Welt empfand ich Tumblewheel (oder Slowroll) in den letzten Jahren deutlich spannender als Leap.
Kurz notiert: in den letzten beiden Tagen gab es einige Nachrichten vom Linux-Kernel.
Zuallererst wurde der Kernel in Version 6.17 veröffentlicht. Die Änderungen führen einerseits bessere Steueroption zur Auswahl von Prozessormitigationen, Live-Patching auf 64-Bit Arm sowie einige Verbesserungen an Dateisystemen wie ext4 und Btrfs ein. Die historische Sonderbehandlung von Einprozessorsystemen (ohne SMP) wird rückgebaut. Wer an allen Änderungen im Detail interessiert ist, kann einen Blick in die entsprechendenLWNArtikel oder bei LinuxNews werfen.
Apropos Dateisysteme: das jüngst aufgenommene bcachefs, um das sich vor und während seines Aufenthaltes im Mainline-Zweig viele kontroverse Diskussionen ergaben, wird Mainline im nächsten Release (6.18) voraussichtlich wieder verlassen. Torvalds kündigte im Commit zur Entfernung an, dass es als DKMS-Paket ausgeliefert werden soll.
Damit endet allerdings sicherlich auch die Maßgabe, dass die Module, von denen bcachefs abhängig ist, auf das Dateisystem abgestimmt werden. Hier gab es genau Streit, weil die Änderungen, die Kent Overstreet erwartet hatte, von den zuständigen Maintainern äußerst kritisch aufgenommen wurden. Ob die Änderungen in den anderen Modulen nun wieder zurückgesetzt werden, bleibt abzusehen.
Wer regelmäßig Webprojekte betreut, kennt das Problem: Große Bilddateien können die Ladezeiten einer Website deutlich beeinträchtigen und wirken sich negativ auf die Suchmaschinenoptimierung (SEO) aus. Besonders dann, wenn eine größere Anzahl von Fotos verarbeitet werden muss, ist eine manuelle Bearbeitung mit grafischen Programmen nicht nur zeitraubend, sondern auch ineffizient.
In einem aktuellen Fall erhielt ich rund 120 Fotos eines Fotografen, die für eine Galerie auf einer Webseite vorgesehen waren. Die Bilddateien lagen jedoch in einer Größe vor, die weder performant für das Web war noch den SEO-Richtlinien entsprach.
Da ich für meine Projekte eine maximale Bildbreite von 1024 Pixeln definiert habe, griff ich – wie bereits im Artikel „Bilder per Batch skalieren“ beschrieben – auf ein bewährtes Werkzeug aus dem Open-Source-Bereich zurück: ImageMagick.
Mit einem einfachen Befehl ließ sich die gesamte Bildersammlung direkt über das Terminal verarbeiten:
mogrify -resize 1024x1024 *.jpg
Dieser Befehl skaliert alle .jpg-Dateien im aktuellen Verzeichnis auf eine maximale Kantenlänge von 1024 Pixeln – unter Beibehaltung des Seitenverhältnisses. Innerhalb weniger Sekunden war der gesamte Stapel an Bildern webgerecht optimiert.
Solche kleinen, aber wirkungsvollen Tools aus der Open-Source-Welt sind nicht nur ressourcenschonend, sondern tragen auch dazu bei, Arbeitsabläufe deutlich zu beschleunigen – ganz ohne aufwendige GUI-Programme oder proprietäre Softwarelösungen.
Die Aufgabenstellung ist sehr speziell, und dementsprechend wird dieser Beitrag vermutlich nur wenig Leute interessieren. Aber egal: Ich habe mich drei Tage damit geärgert, vielleicht profitieren ein paar Leser von meinen Erfahrungen …
Die Zielsetzung ist bereits in der Überschrift beschrieben. Ich besitze einen Mini-PC mit AMD 8745H-CPU und 32 GiB RAM. Die CPU enthält auch eine integrierte GPU (Radeon 780M). Auf diesem Rechner wollte ich das momentan sehr beliebte Sprachmodell gpt-oss-20b ausführen. Dieses Sprachmodell ist ca. 11 GiB groß, umfasst 20 Milliarden Parameter in einer etwas exotischen Quantifizierung. (MXFP4 wurde erst 2024 standardisiert und bildet jeden Parameter mit nur 4 Bit ab. Die Besonderheit besteht darin, dass für unterschiedliche Teile des Modells unterschiedliche Skalierungsfaktoren verwendet werden, so dass die Parameter trotz der wenigen möglichen Werte einigermaßen exakt abgebildet werden können.)
Das Sprachmodell wird von der Firma OpenAI kostenlos angeboten. Die Firma gibt an, dass die 20b-Variante ähnlich gute Ergebnisse wie das bis 2024 eingesetzt kommerzielle Modell o3-mini liefert, und auch KI-Experte Simon Willison singt wahre Lobeshymnen auf das Modell.
PS: Ich habe alle Tests unter Fedora 42 durchgeführt.
Warum nicht Ollama?
Für alle, die nicht ganz tief in die lokale Ausführung von Sprachmodellen eintauchen wollen, ist Ollama zumeist die erste Wahl. Egal, ob unter Windows, Linux oder macOS, viele gängige Sprachmodelle können damit unkompliziert ausgeführt werden, in der Regel mit GPU-Unterstützung (macOS, Windows/Linux mit NVIDIA-GPU bzw. mit ausgewählten AMD-GPUs).
Bei meiner Hardware — und ganz allgemein bei Rechnern mit einer AMD-iGPU — ist Ollama aktuell aber NICHT die erste Wahl:
ROCm: Ollama setzt bei NVIDIA-GPUs auf das Framework CUDA (gut), bei AMD-GPUs auf das Framework ROCm (schlecht). Dieses Framework reicht alleine vermutlich als Grund, warum AMD so chancenlos gegen NVIDIA ist. Im konkreten Fall besteht das Problem darin, dass die iGPU 780M (interner ID gfx1103) offiziell nicht unterstützt wird. Die Empfehlung lautet, ROCm per Umgebungsvariable zu überzeugen, dass die eigene GPU kompatibel zu einem anderen Modell ist (HSA_OVERRIDE_GFX_VERSION=11.0.2). Tatsächlich können Sprachmodelle dann ausgeführt werden, aber bei jeder Instabilität (derer es VIELE gibt), stellt sich die Frage, ob nicht genau dieser Hack der Anfang aller Probleme ist.
Speicherverwaltung: Auch mit diesem Hack scheitert Ollama plus ROCm-Framework an der Speicherverwaltung. Bei AMD-iGPUs gibt es zwei Speicherbereiche: fix per BIOS allozierten VRAM sowie dynamisch zwischen CPU + GPU geteiltem GTT-Speicher. (Physikalisch ist der Speicher immer im RAM, den sich CPU und GPU teilen. Es geht hier ausschließlich um die Speicherverwaltung durch den Kernel + Grafiktreiber.)
Ollama alloziert zwar den GTT-Speicher, aber maximal so viel, wie VRAM zur Verfügung steht. Diese (Un)Logik ist am besten anhand von zwei Beispielen zu verstehen. Auf meinem Testrechner habe ich 32 GiB RAM. Standardmäßig reserviert das BIOS 2 GiB VRAM. Der Kernel markiert dann 14 GiB als GTT. (Das kann bei Bedarf mit den Kerneloptionen amdttm.pages_limit und amdttm.page_pool_size verändert werden.) Obwohl mehr als genug Speicher zur Verfügung steht, sieht Ollama eine Grenze von 2 GiB und kann nur winzige LLMs per GPU ausführen.
Nun habe ich im BIOS das VRAM auf 16 GiB erhöht. Ollama verwendet nun 16 GiB als Grenze (gut), nutzt aber nicht das VRAM, sondern den GTT-Speicher (schlecht). Wenn ich nun ein 8 GiB großes LLM mit Ollama ausführen, dann bleiben fast 16 GiB VRAM ungenutzt! Ollama verwendet 8 GiB GTT-Speicher, und für Ihr Linux-System bleiben gerade einmal 8 GiB RAM übrig. Es ist zum aus der Haut fahren! Im Internet gibt es diverse Fehlerberichte zu diesem Problem und sogar einen schon recht alten Pull-Request mit einem Vorschlag zur Behebung des Problems. Eine Lösung ist aber nicht Sicht.
Ich habe mich mehrere Tage mit Ollama geärgert. Schade um die Zeit. (Laut Internet-Berichten gelten die hier beschriebenen Probleme auch für die gehypte Strix-Halo-CPU.)
Next Stop: llama.cpp
Etwas Internet-Recherche liefert den Tipp, anstelle von Ollama das zugrundeliegende Framework llama.cpp eben direkt zu verwenden. Ollama greift zwar selbst auf llama.cpp zurück, aber die direkte Verwendung von llama.cpp bietet andere GPU-Optionen. Dieser Low-Level-Ansatz ist vor allem bei der Modellauswahl etwas umständlicher. Zwei Vorteile können den Zusatzaufwand aber rechtfertigen:
Die neuste Version von llama.cpp unterstützt oft ganz neue Modelle, mit denen Ollama noch nicht zurechtkommt.
llama.cpp kann die GPU auf vielfältigere Weise nutzen als Ollama. Je nach Hardware und Treiber kann so eventuell eine höhere Geschwindigkeit erzielt bzw. der GPU-Speicher besser genutzt werden, um größere Modelle auszuführen.
Die GitHub-Projektseite beschreibt mehrere Installationsvarianten: Sie können llama.cpp selbst kompilieren, den Paketmanager nix verwenden, als Docker-Container ausführen oder fertige Binärpakete herunterladen (https://github.com/ggml-org/llama.cpp/releases). Ich habe den einfachsten Weg beschritten und mich für die letzte Option entschieden. Der Linux-Download enthält genau die llama.cpp-Variante, die für mich am interessantesten war — jene mit Vulkan-Unterstützung. (Vulkan ist eine 3D-Grafikbibliothek, die von den meisten GPU-Treibern unter Linux durch das Mesa-Projekt gut unterstützt wird.) Die Linux-Version von llama.cpp wird anscheinend unter Ubuntu kompiliert und getestet, dementsprechend heißt der Download-Name llama-<version>-bin-ubuntu-vulkan-x86.zip. Trotz dieser Ubuntu-Affinität ließen sich die Dateien bei meinen Tests aber problemlos unter Fedora 42 verwenden.
Nach dem Download packen Sie die ZIP-Datei aus. Die resultierenden Dateien landen im Unterverzeichnis build/bin. Es bleibt Ihnen überlassen, ob Sie die diversen llama-xxx-Kommandos direkt in diesem Verzeichnis ausführen, das Verzeichnis zu PATH hinzufügen oder seinen Inhalt in ein anderes Verzeichnis kopieren (z.B. nach /usr/local/bin).
cd Downloads
unzip llama-b6409-bin-ubuntu-vulkan-x64.zip
cd build/bin
./llama-cli --version
loaded RPC backend from ./build/bin/libggml-rpc.so
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon 780M Graphics (RADV PHOENIX) (radv) ...
loaded Vulkan backend from ./build/bin/libggml-vulkan.so
loaded CPU backend from ./build/bin/libggml-cpu-icelake.so
version: 6409 (d413dca0)
built with cc (Ubuntu 11.4.0-1ubuntu1~22.04.2) for x86_64-linux-gnu
Für die GPU-Unterstützung ist entscheidend, dass auf Ihrem Rechner die Bibliotheken für die 3D-Bibliothek Vulkan installiert sind. Davon überzeugen Sie sich am einfachsten mit vulkaninfo aus dem Paket vulkan-tools. Das Kommando liefert fast 4000 Zeilen Detailinformationen. Mit einem Blick in die ersten Zeilen stellen Sie fest, ob Ihre GPU unterstützt wird.
Um llama.cpp auszuprobieren, brauchen Sie ein Modell. Bereits für Ollama heruntergeladene Modelle sind leider ungeeignet. llama.cpp erwartet Modelle als GGUF-Dateien (GPT-Generated Unified Format). Um die Ergebnisse mit anderen Tools leicht vergleichen zu können, verwende ich als ersten Testkandidat immer Llama 3. Eine llama-taugliche GGUF-Variante von Llama 3.1 mit 8 Milliarden Parametern finden Sie auf der HuggingFace-Website unter dem Namen bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M.
Das folgende Kommando lädt das Modell von HuggingFace herunter (Option -hf), speichert es im Verzeichnis .cache/llama.cpp, lädt es, führt den als Parameter -p angegebenen Prompt aus und beendet die Ausführung dann. In diesem und allen weiteren Beispielen gehe ich davon aus, dass sich die llama-Kommandos in einem PATH-Verzeichnis befinden. Alle Ausgaben sind aus Platzgründen stark gekürzt.
llama-cli -hf bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M \
-p 'bash/Linux: explain the usage of rsync over ssh'
... (diverse Debugging-Ausgaben)
Running in interactive mode.
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
- Not using system message. To change it, set a different value via -sys PROMPT
> bash/Linux: explain the usage of rsync over ssh
rsync is a powerful command-line utility that enables you to
synchronize files and directories between two locations. Here's
a breakdown of how to use rsync over ssh: ...
> <Strg>+<D>
load time = 2231.02 ms
prompt eval time = 922.83 ms / 43 tokens (46.60 tokens per second)
eval time = 31458.46 ms / 525 runs (16.69 tokens per second)
Sie können llama-cli mit diversen Optionen beeinflussen, z.B. um verschiedene Rechenparameter einzustellen, die Länge der Antwort zu limitieren, den Systemprompt zu verändern usw. Eine Referenz gibt llama-cli --help. Deutlich lesefreundlicher ist die folgende Seite:
Mit llama-bench können Sie diverse Benchmark-Tests durchführen. Im einfachsten Fall übergeben Sie nur das Modell in der HuggingFace-Notation — dann ermittelt das Kommando die Token-Geschwindigkeit für das Einlesen des Prompts (Prompt Processing = pp) und die Generierung der Antwort (Token Generation = tg). Allerdings kennt llama-bench die Option -hf nicht; vielmehr müssen Sie mit -m den Pfad zur Modelldatei übergeben:
llama-bench -m ~/.cache/llama.cpp/bartowski_Meta-Llama-3.1-8B-Instruct-GGUF_Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
model size test token/s (Tabelle gekürzt ...)
----------------------- --------- ------- --------
llama 8B Q4_K - Medium 4.58 GiB pp512 204.03
llama 8B Q4_K - Medium 4.58 GiB tg128 17.04
Auf meinem Rechner erreicht llama.cpp mit Vulkan nahezu eine identische Token-Rate wie Ollama mit ROCm (aber ohne die vielen Nachteile dieser AMD-Bibliothek).
AMD-Optimierung
Bei meinen Tests auf dem schon erwähnten Mini-PC mit AMD 8745H-CPU mit der iGPU 780M und 32 GiB RAM funktionierte llama.cpp mit Vulkan viel unkomplizierter als Ollama mit ROCm. Ich habe die VRAM-Zuordnung der GPU wieder zurück auf den Defaultwert von 2 GiB gestellt. Per Default steht llama.cpp auf meinem Rechner dann ca. der halbe Arbeitsspeicher (2 GiB VRAM plus ca. 14 GiB GTT) zur Verfügung. Vulkan kann diesen Speicher ohne merkwürdige Hacks mit Umgebungsvariablen korrekt allozieren. Das reicht ohne jedes Tuning zur Ausführung des Modells gpt-20b aus (siehe den folgenden Abschnitt). So soll es sein!
Wenn Sie noch mehr Speicher für die LLM-Ausführung reservieren wollen, müssen Sie die Kerneloptionen pages_limit und pages_pool_size des AMDGPU-Treibers verändern. Wenn Sie 20 GiB GGT-Speicher nutzen wollen, müssen Sie für beide Optionen den Wert 5242880 angeben (Anzahl der 4-kByte-Blöcke):
Danach aktualisieren Sie die Initrd-Dateien und führen einen Neustart durch:
sudo update-initramfs -u # Debian und Ubuntu
sudo dracut --regenerate-all --force # Fedora, RHEL, SUSE
sudo reboot
sudo dmesg | grep "amdgpu.*memory"
amdgpu: 2048M of VRAM memory ready (<-- laut BIOS-Einstellung)
amdgpu: 20480M of GTT memory ready (<-- laut /etc/modprobe.d/amd.conf)
Modellauswahl
Mit llama.cpp können Sie grundsätzlich jedes Modell im GPT-Generated Unified Format (GGUF) ausführen. Auf der Website von HuggingFace stehen Tausende Modelle zur Wahl:
Die Herausforderung besteht darin, für die eigenen Zwecke relevante Modelle zu finden. Generell ist es eine gute Idee, besonders populäre Modelle vorzuziehen. Außerdem werden Sie rasch feststellen, welche Modellgrößen für Ihre Hardware passen. Die höhere Qualität großer Modelle bringt nichts, wenn die Geschwindigkeit gegen Null sinkt.
gpt-oss-20b
Eine llama.cpp-kompatible Version finden hat ggml-org auf HuggingFace gespeichert. Sofern ca. 15 GiB freier VRAM zur Verfügung stehen (unter AMD: VRAM + GTT), führt llama.cpp das Modell problemlos und beachtlich schnell aus. Beachten Sie, dass es sich hier um ein »Reasoning-Modell« handelt, das zuerst über das Problem nachdenkt und diesen Denkprozess auch darstellt. Danach wird daraus das deutlich kompaktere Ergebnis präsentiert.
Die Kommandos llama-cli und llama-bench dienen in erster Linie zum Testen und Debuggen. Sobald Sie sich einmal überzeugt haben, dass llama.cpp grundsätzlich funktioniert, werden Sie das Programm vermutlich im Server-Betrieb einsetzen. Das entsprechende Kommando lautet llama-server und ist grundsätzlich wie llama-cli aufzurufen. Falls Sie llama-server unter einem anderen Account als llama-cli aufrufen, aber schon heruntergeladene Modelle weiterverwenden wollen, übergeben Sie deren Pfad mit der Option -m:
llama-server -c 0 -fa on --jinja -m /home/kofler/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
Sie können nun unter http://localhost:8080 auf einen Webserver zugreifen und das gestartete Modell komfortabel bedienen. Im Unterschied zu Ollama hält llama.cpp das Modell dauerhaft im Arbeitsspeicher. Das Modell kann immer nur eine Anfrage beantworten. Die Verarbeitung mehrere paralleler Prompts erlaubt --parallel <n>.
Die Web-Oberfläche von llama-server
Es ist unmöglich, mit einem Server mehrere Modelle parallel anzubieten. Vielmehr müssen Sie mehrere Instanzen von llama-server ausführen und jedem Dienst mit --port 8081, --port 8082 usw. eine eigene Port-Nummer zuweisen. (Das setzt voraus, dass Sie genug Video-Speicher für alle Modelle zugleich haben!)
Falls auch andere Rechner Server-Zugang erhalten sollen, übergeben Sie mit --host einen Hostnamen oder eine IP-Nummer im lokalen Netzwerk. Mit --api-key oder --api-key-file können Sie den Server-Zugang mit einem Schlüssel absichern. Mehr Details zu den genannten Optionen sowie eine schier endlose Auflistung weiterer Optionen finden Sie hier:
Jetzt habe ich drei Tage versucht, gpt-oss per GPU auszuführen. Hat sich das gelohnt? Na ja. Mit -ngl 0 kann die Token Generation (also das Erzeugen der Antwort per Sprachmodell) von der GPU auf die CPU verlagert werden. Das ist natürlich langsamer — aber erstaunlicherweise nur um 25%.
Warum ist der Unterschied nicht größer? Weil die 780M keine besonders mächtige GPU ist und weil die Speicherbandbreite der iGPU viel kleiner ist als bei einer dezidierten GPU mit »echtem« VRAM.
Zur Einordnung noch zwei Vergleichszahlen: MacBook Pro M3: 42 Token/s (mit GPU) versus 39 Token/s (nur CPU)
Spätestens seitdem Neobroker mit hohem Werbebudget den Markt auffrischen, ist für viele Menschen das Thema Geldanlage präsent geworden. Noch vor ein paar Jahren war der Erwerb von Wertpapieren mit solchen großen Hürden verbunden, dass sich viele Menschen nicht auf den Kapitalmarkt trauten. Inzwischen ist es auch für nicht-Finanzgurus wie mich möglich, sich unkompliziert Aktien und andere Anlageformen zuzulegen. Die Apps der Banken und Broker sind inzwischen recht benutzerfreundlich, was die Hürde weiter senkt. Wenn man sich der Sache wieder etwas ernster annähern möchte, kommt man mit den Apps aber schnell an seine Grenzen. Um besser den Überblick über meine Finanzen zu behalten, habe ich mich auf die Suche nach einer Software gemacht, die mich dabei unterstützt. Und ich bin in der Open Source Community fündig geworden.
Meine Fragestellung war folgende: Wie diversifiziert ist mein Portfolio eigentlich? In welchen Regionen und Branchen bin ich wie stark präsent? Welches sind meine Top-Firmen? Wie teilt sich mein Vermögen auf Aktien, ETFs und Cash auf? Wie stark bin ich in Small-Caps investiert? Wann und bei welchen Kurswerten habe ich gekauft und verkauft? Wie viele Dividenden habe ich inzwischen erhalten, usw.? Bisher habe ich das mit Excel lösen können. Die Fact-Sheets der ETF sind im Netz zu finden, dort sind die Verteilungen auf Regionen, Branchen usw. nachzulesen. Mit viel Tipparbeit holt man sich die aktuellen Verteilungen in die Datei, gewichtet sie nach aktuellem Wert im Portfolio und lässt es sich als Diagramm anzeigen. Aber: Das ist sehr aufwendig.
Portfolio Performance: Das mächtige Open Source Finanztool
Portfolio Performance ist hier einfacher. Nach der Installation kann man die PDF-Dateien seiner Bank und Broker importieren. Einfach den Kontoauszug und die Kauf- bzw. Verkaufsnachweise, Dividendenausschüttungen usw. in das Programm laden, und schon hat man den perfekten Überblick. Das Programm läuft lokal, was die Frage nach Datensicherheit vollkommen entschärft. Niemand hat Zugriff darauf, niemand kann sich die Daten ansehen. Meine Daten bleiben bei mir.
Neben dem PDF-Import der Bankdaten gibt es noch etliche weitere Importmöglichkeiten. Am gängigsten ist vermutlich das CSV-Format, das sich über einen tollen Assistenten gut importieren lässt.
Historische Kursdaten sind erstmal nicht vorhanden. Man kann sie sich über mehrere Wege ins Programm holen. Für mich am einfachsten ist der Weg über die Datenbank von Portfolio Performance selbst. Dort muss man ein kostenloses Benutzerkonto anlegen, dann kann man auf die historischen Daten dort zugreifen. Etliche andere Finanzportale sind ebenfalls kompatibel. Am Ende geht hier auch wieder CSV.
ETF- und Portfolio-Diversifikation anzeigen lassen
Über die Diagramme „Berichte → Vermögensaufstellung“ kann man sich anzeigen lassen, über welche Anlageklassen man zu welchen Teilen verfügt. Eine der Hauptfragen meinerseits war jedoch: Wie sieht es mit meiner ETF-Diversifikation aus?. Das geht derzeit noch nicht nativ in Portfolio Performance. Hierfür braucht man einen Drittanbieter.
Glücklicherweise gibt es findige Leute in der sehr aktiven Community, die sich die gleichen Fragen gestellt haben und eine Lösung zur Verfügung stellen. Über ein Skript des Users Alfonso1Qto12 kann man sich beispielsweise die Zusammensetzung der ETF über die Morningstar-API direkt in sein Portfolio Performance schreiben lassen.
Hinweis: Dieses Skript ist nach Aussage des Entwicklers experimentell und sollte nur mit einer Kopie der echten Daten benutzt werden! Stand September 2025 muss man den alternativen Branch wechseln, weil main noch auf eine alte API zugreift.
Über die Flag top_holdings 50 lasse ich mir aus den ETF die 50 wertvollsten Firmen ausgeben. Empfohlen wird, auf weniger als 100 Firmen zu gehen, um die Performance des Programms nicht zu gefährden.
Mit diesem Skript werden die Wertpapiere ihren Ländern, Regionen, Holdings usw. anteilsweise zugeordnet. Diese Daten werden direkt in die XML-Datei geschrieben und lassen sich anschließend in Portfolio Performance unter den „Klassifizierungen“ betrachten. Es gibt verschiedene Visualisierungsarten, am übersichtlichsten finde ich die Tabelle, das Kreis- und das Flächendiagramm.
Weitere Schritte und Lehren aus den Daten
Mit Portfolio Performance erhält man eine tolle Übersicht über seine Finanzen. Wie der Name schon verrät, kann man sich hier tolle Dashboards bauen, um die Performance im eigenen Portfolio zu überwachen. Alle gängigen Kriterien sind vorhanden und können in Dashboards oder vielfältige Diagramme eingebaut und visualisiert werden.
Die Daten lassen ein Rebalancing zu, dafür gibt es eigens eingebaute Funktionen. Über eine Smartphone-App lassen sich die Daten sogar auf dem Handy anzeigen. Die Synchronisation muss hier über Cloudanbieter durchgeführt werden, also zum Beispiel über die Nextcloud oder Dropbox. Daten einpflegen lassen sich übers Smartphone allerdings nicht.
Zusammengefasst: Wer eine sehr mächtige Open Source Software sucht, mit der man
sein Portfolio im Blick behalten kann,
das Daten aus vielen Quellen (inkl. PDFs von Banken und Brokern) verarbeiten kann,
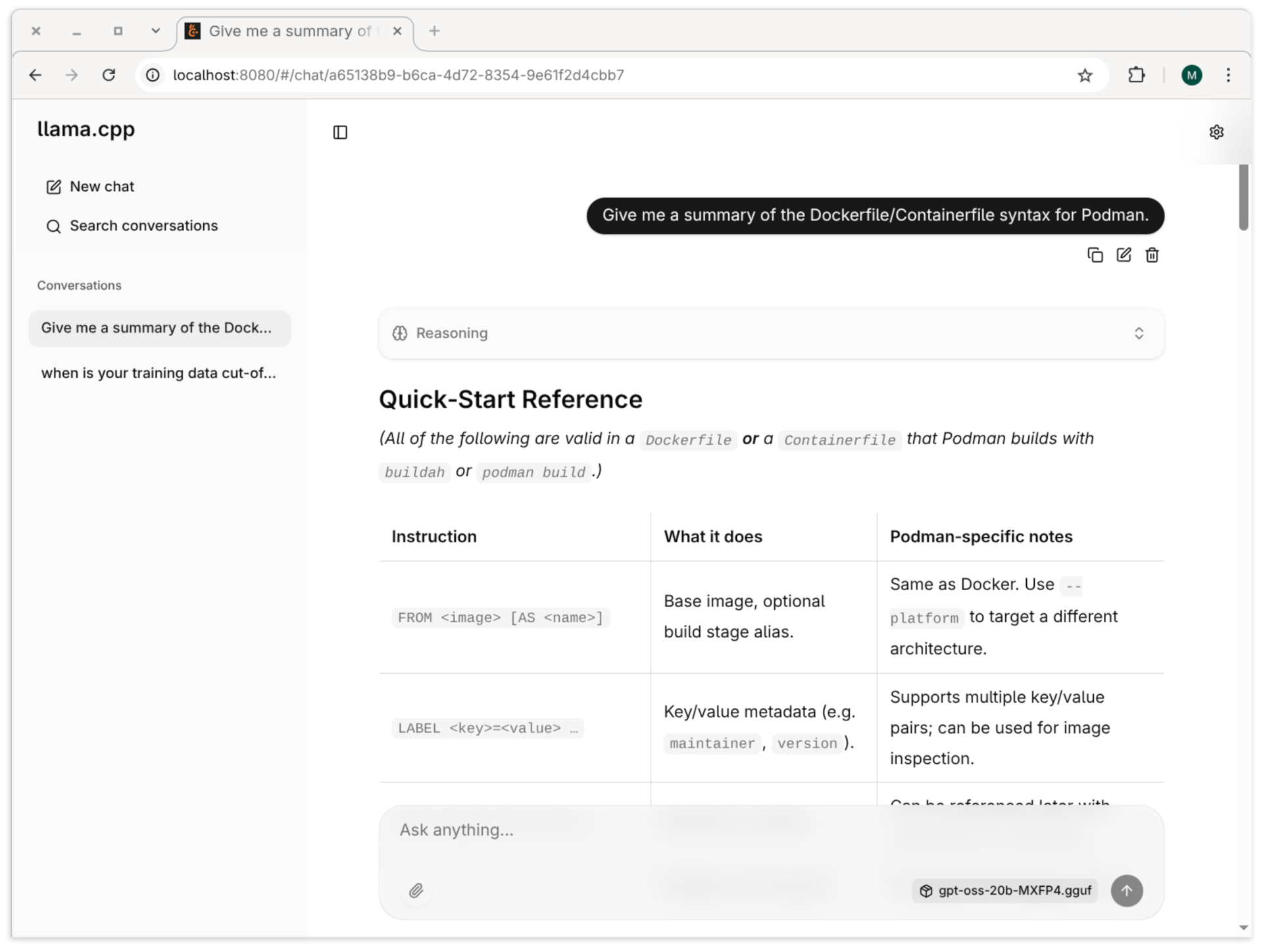

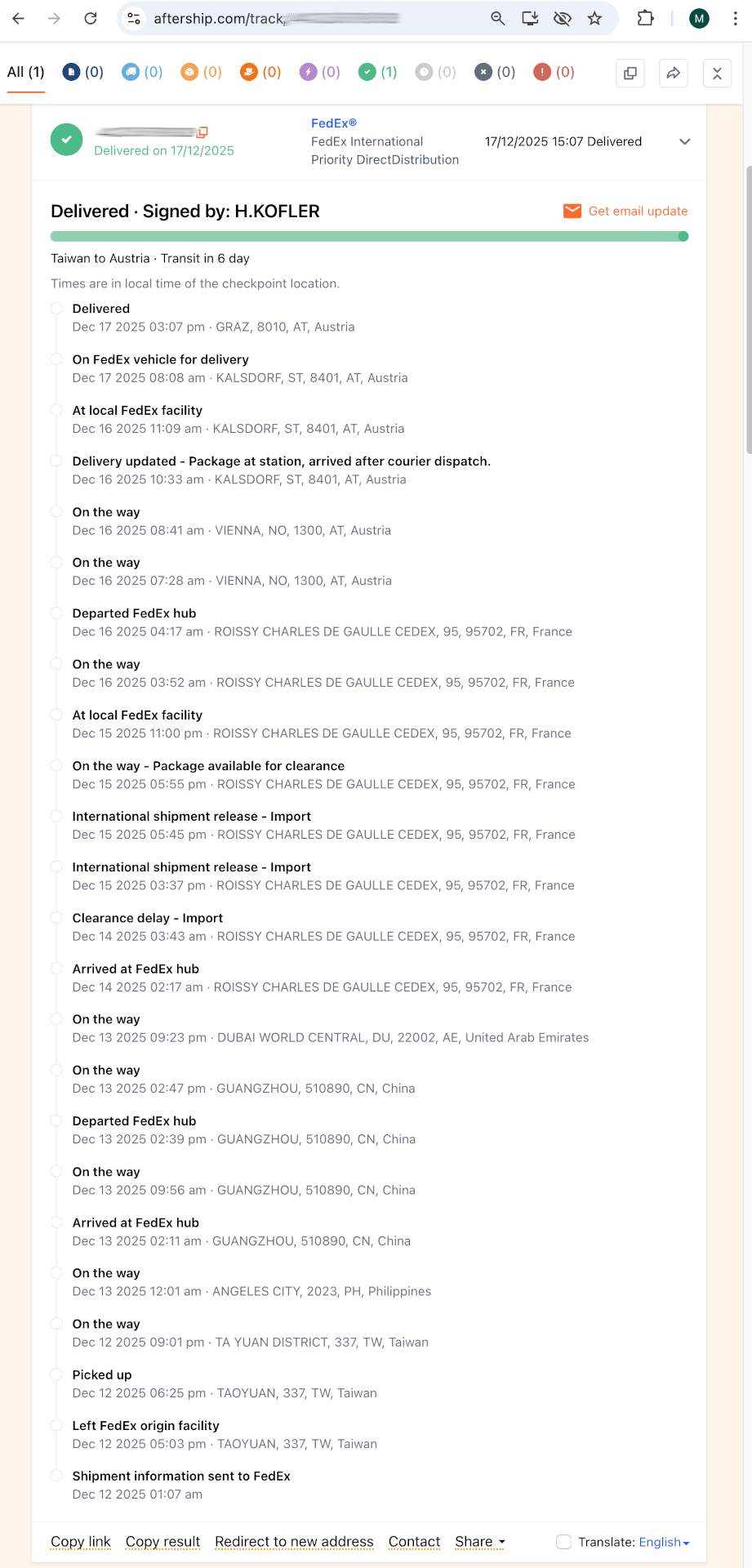

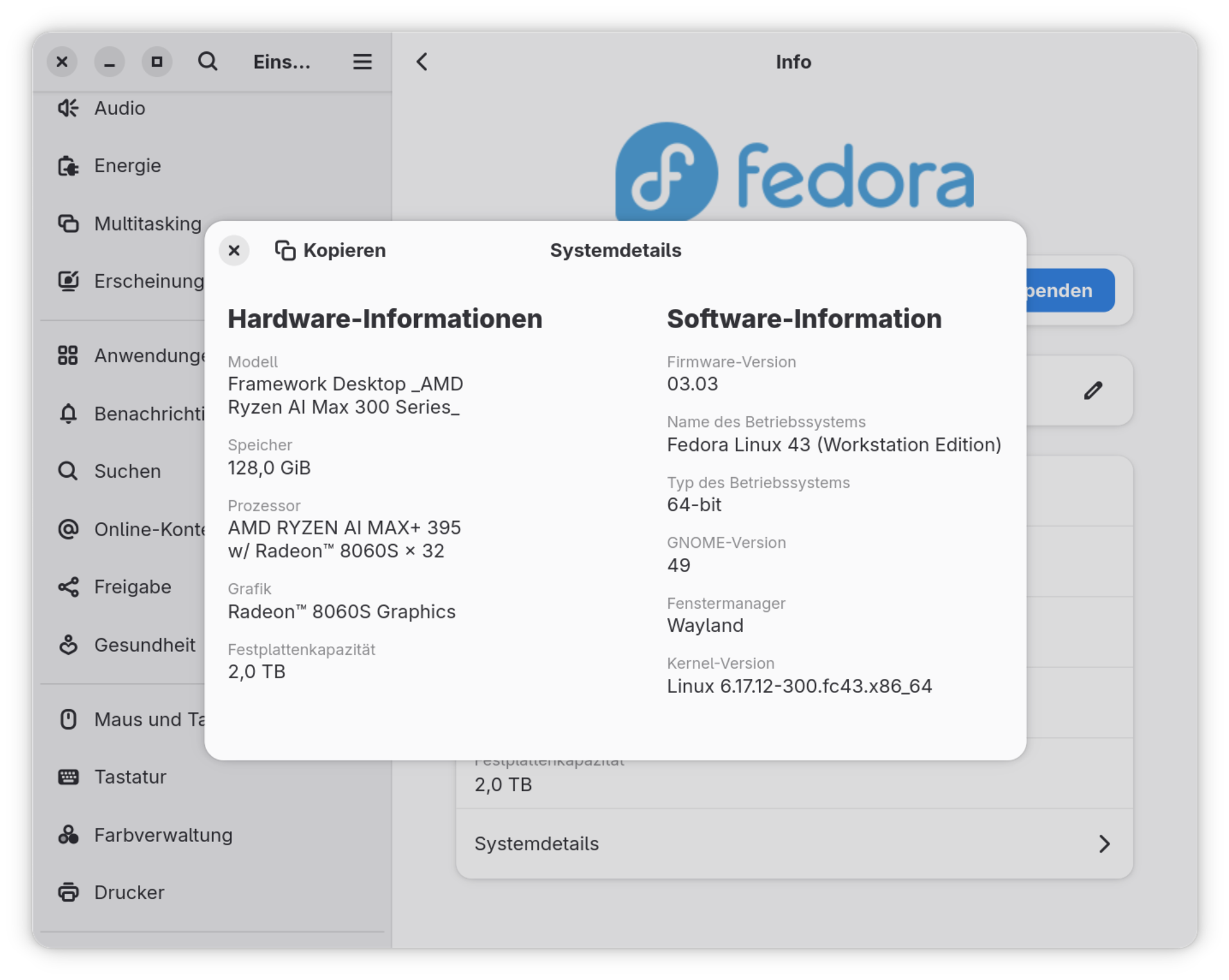
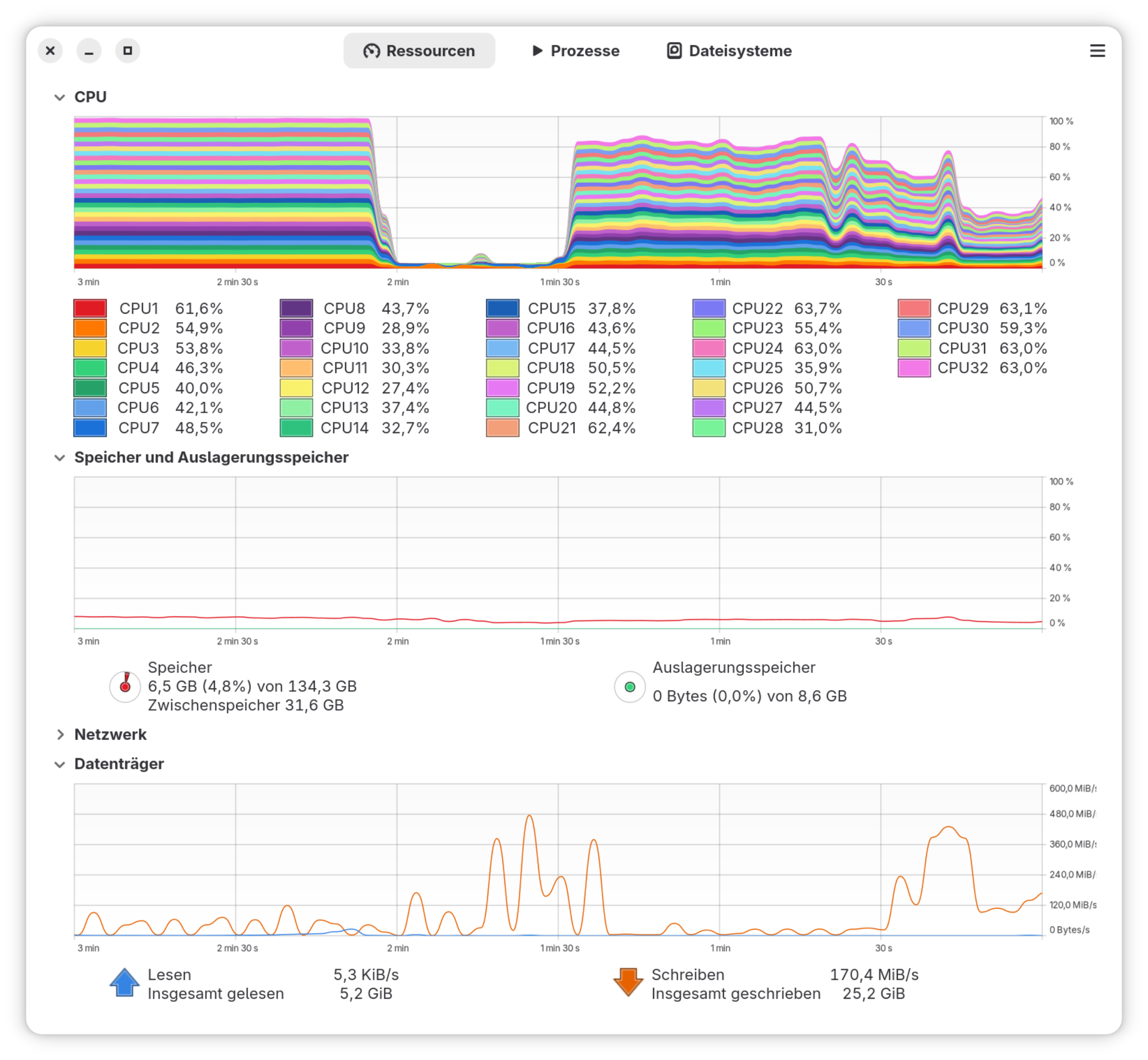
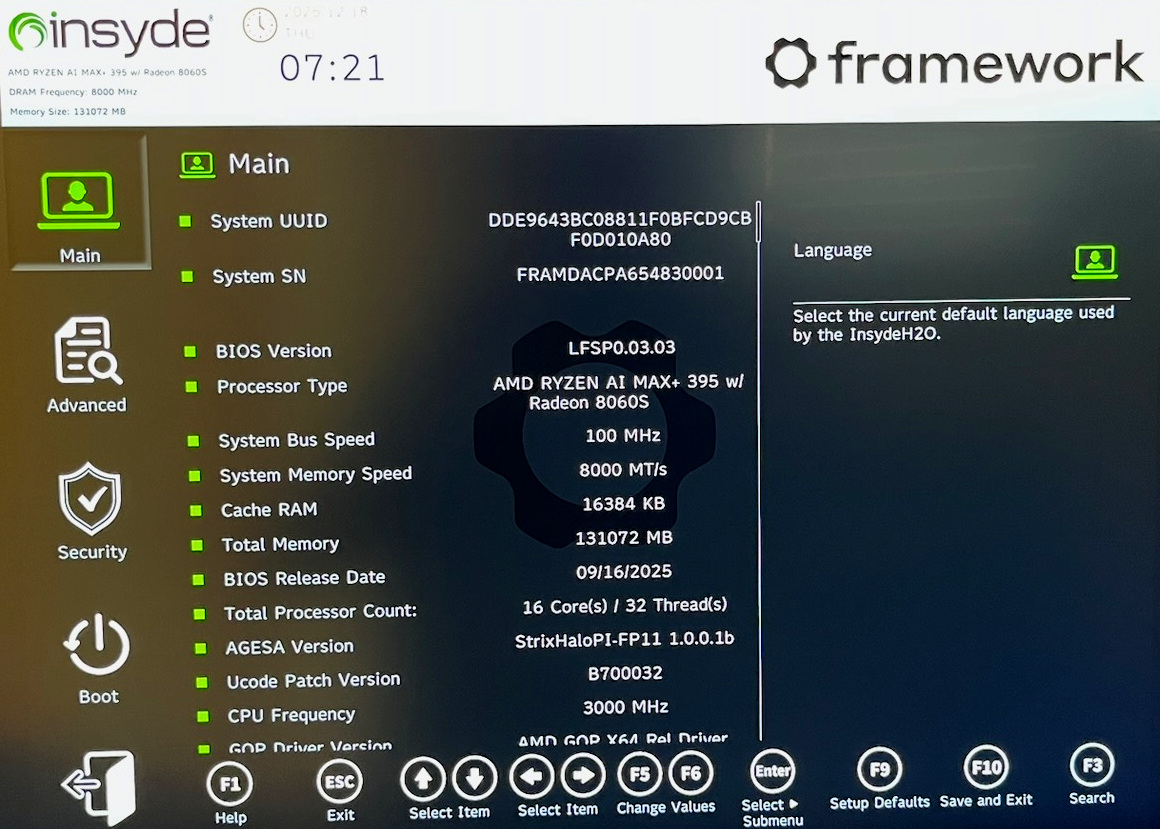










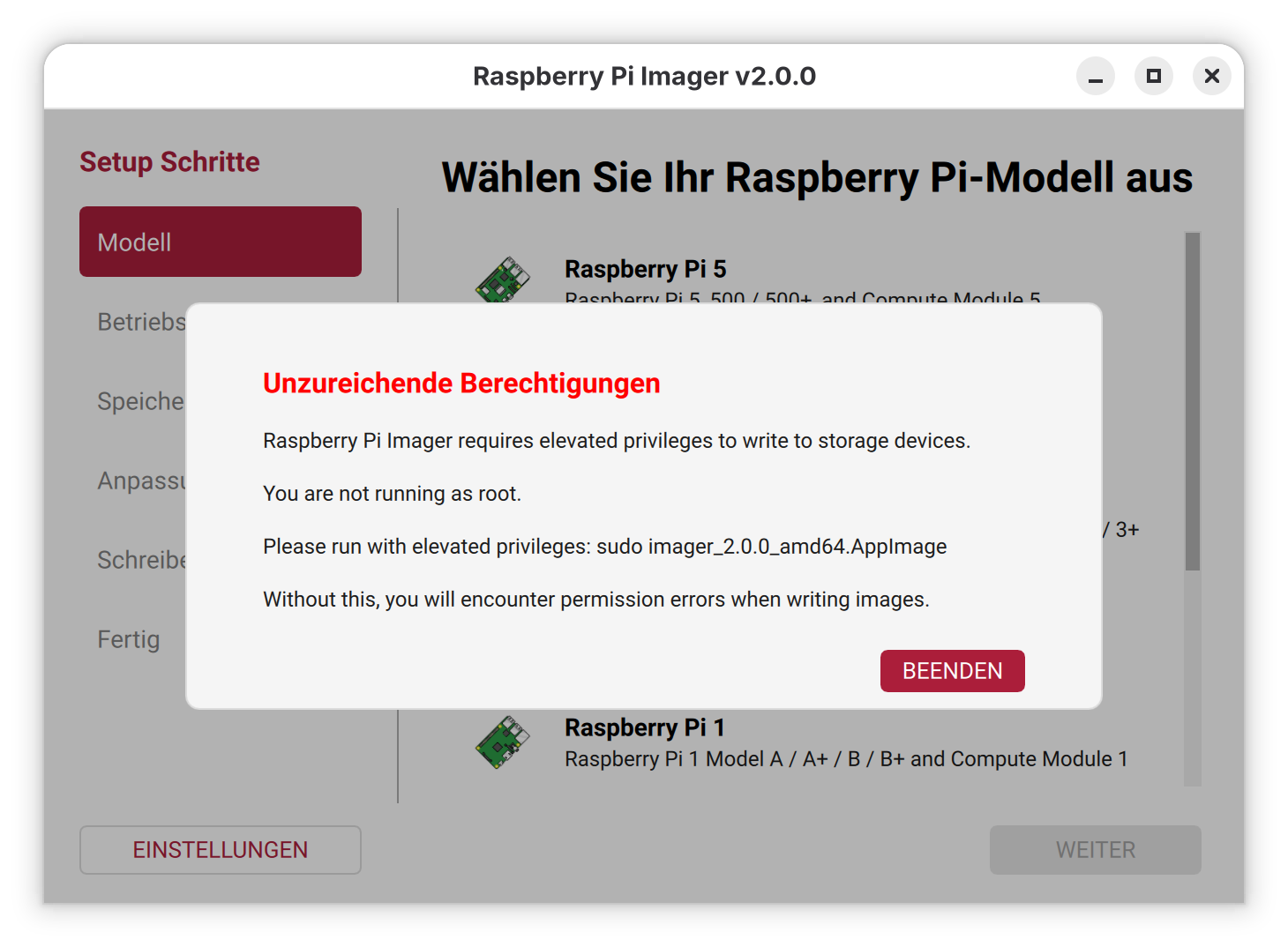
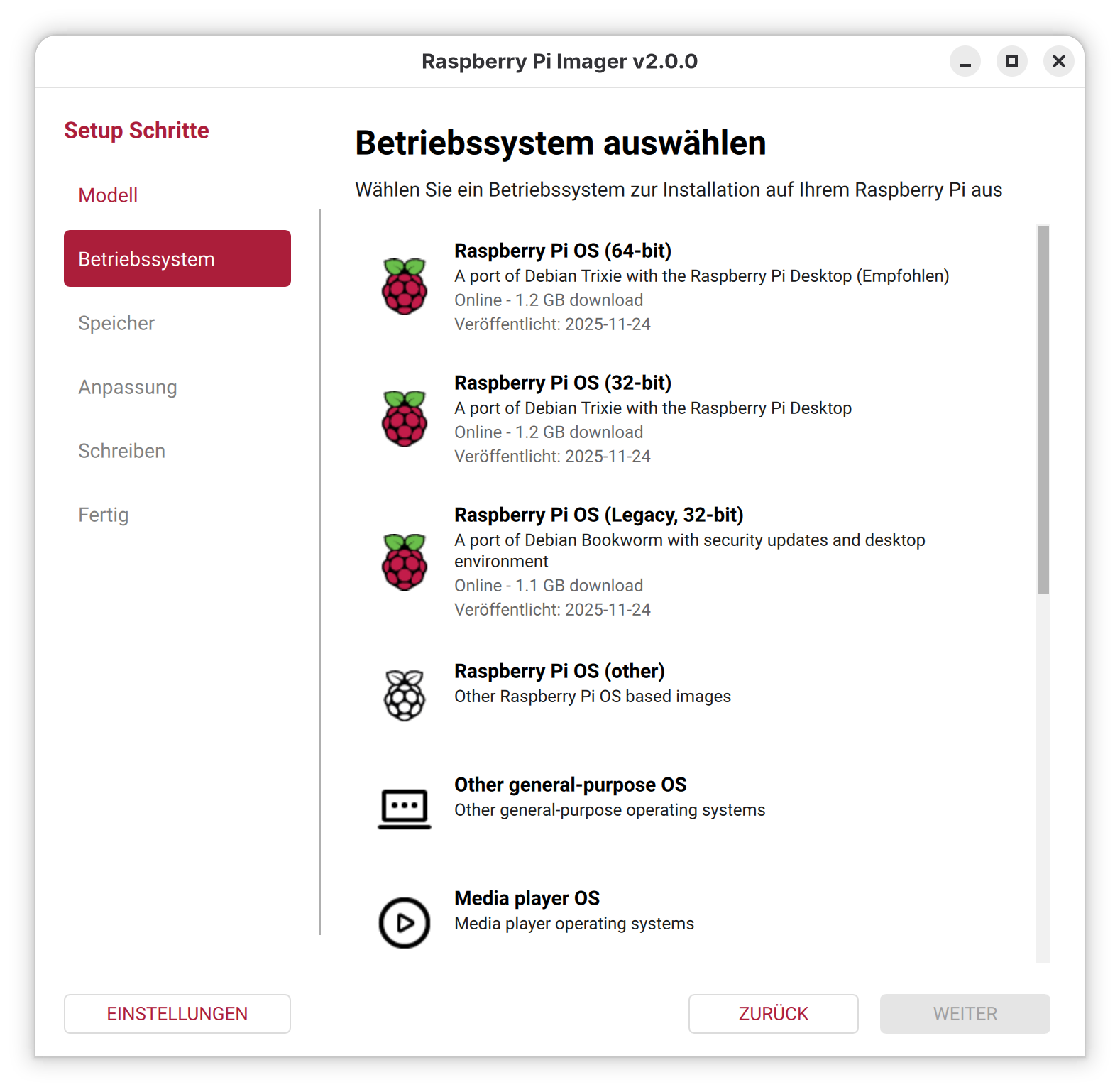
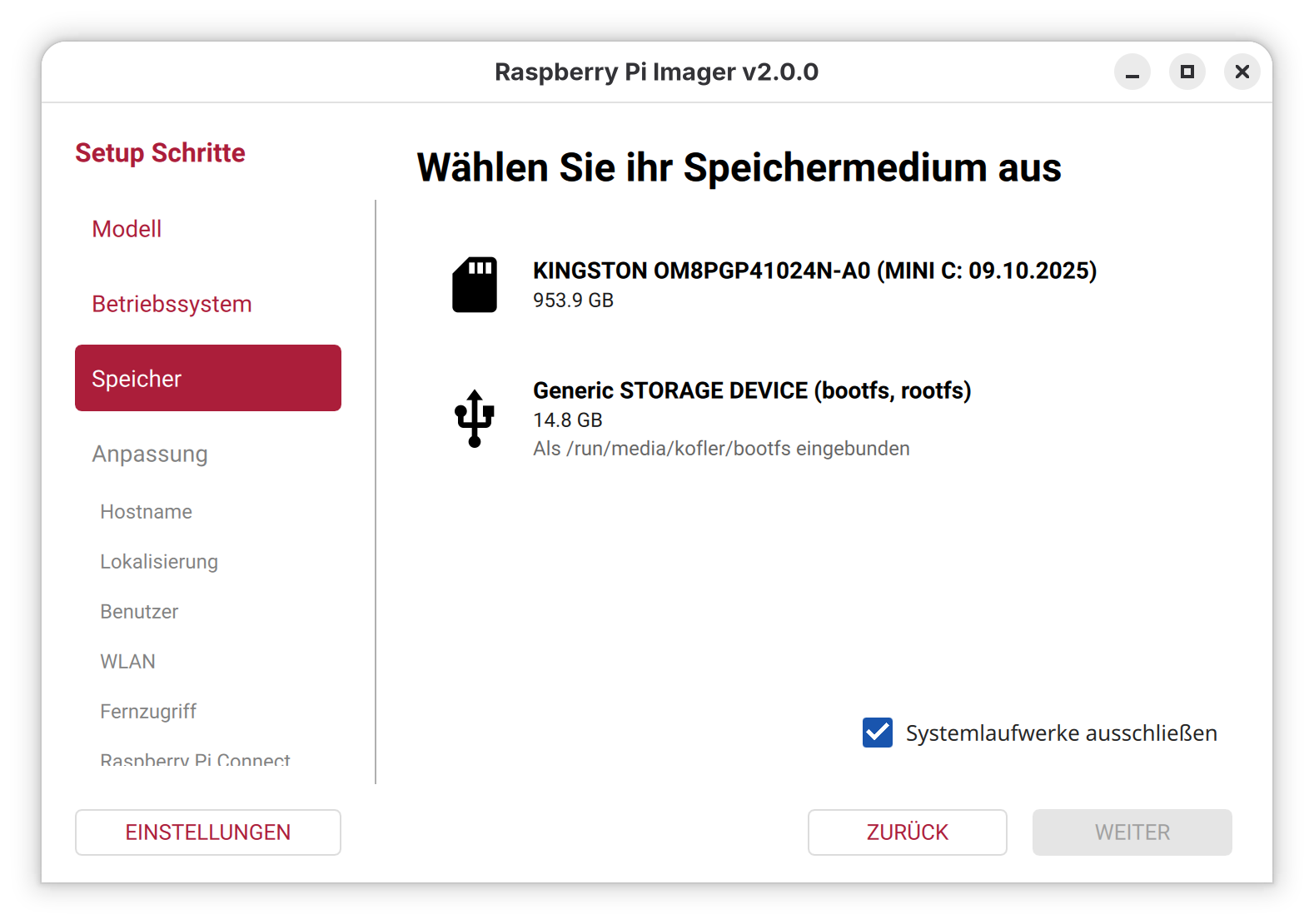
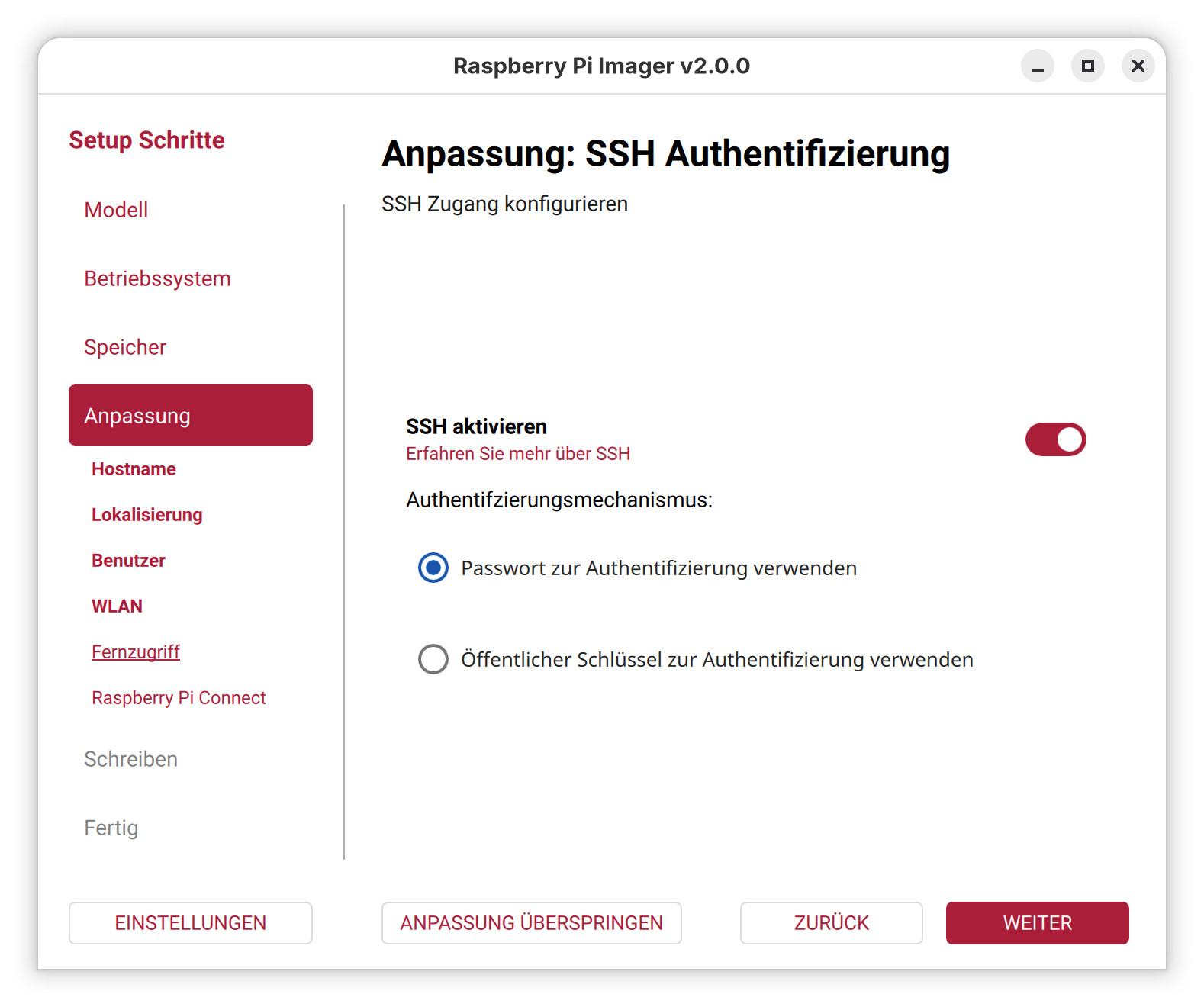
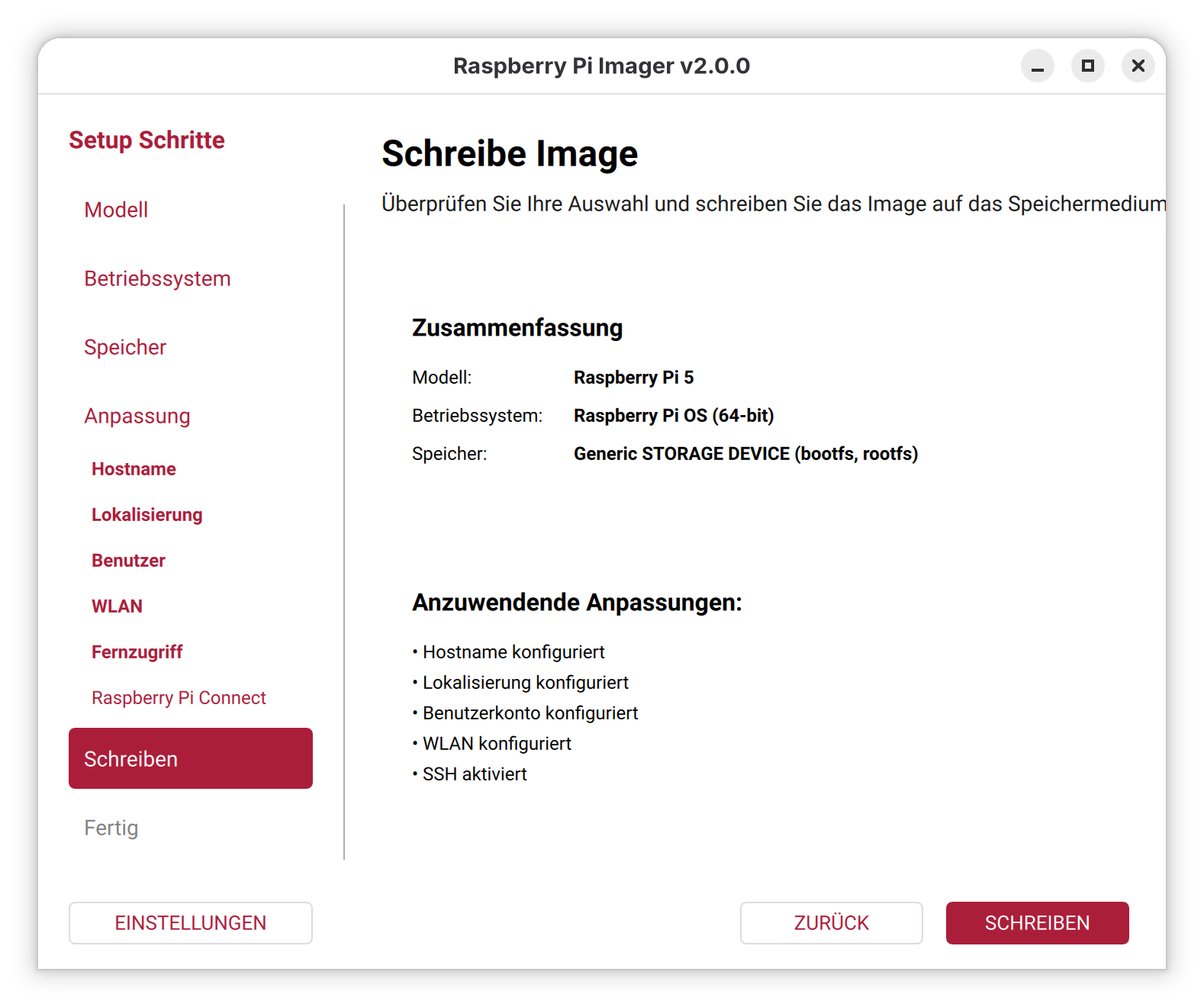
 Wichtiger Hinweis:
Wichtiger Hinweis: