Wer regelmäßig Webprojekte betreut, kennt das Problem: Große Bilddateien können die Ladezeiten einer Website deutlich beeinträchtigen und wirken sich negativ auf die Suchmaschinenoptimierung (SEO) aus. Besonders dann, wenn eine größere Anzahl von Fotos verarbeitet werden muss, ist eine manuelle Bearbeitung mit grafischen Programmen nicht nur zeitraubend, sondern auch ineffizient.
In einem aktuellen Fall erhielt ich rund 120 Fotos eines Fotografen, die für eine Galerie auf einer Webseite vorgesehen waren. Die Bilddateien lagen jedoch in einer Größe vor, die weder performant für das Web war noch den SEO-Richtlinien entsprach.
Da ich für meine Projekte eine maximale Bildbreite von 1024 Pixeln definiert habe, griff ich – wie bereits im Artikel „Bilder per Batch skalieren“ beschrieben – auf ein bewährtes Werkzeug aus dem Open-Source-Bereich zurück: ImageMagick.
Mit einem einfachen Befehl ließ sich die gesamte Bildersammlung direkt über das Terminal verarbeiten:
mogrify -resize 1024x1024 *.jpg
Dieser Befehl skaliert alle .jpg-Dateien im aktuellen Verzeichnis auf eine maximale Kantenlänge von 1024 Pixeln – unter Beibehaltung des Seitenverhältnisses. Innerhalb weniger Sekunden war der gesamte Stapel an Bildern webgerecht optimiert.
Solche kleinen, aber wirkungsvollen Tools aus der Open-Source-Welt sind nicht nur ressourcenschonend, sondern tragen auch dazu bei, Arbeitsabläufe deutlich zu beschleunigen – ganz ohne aufwendige GUI-Programme oder proprietäre Softwarelösungen.
Die Aufgabenstellung ist sehr speziell, und dementsprechend wird dieser Beitrag vermutlich nur wenig Leute interessieren. Aber egal: Ich habe mich drei Tage damit geärgert, vielleicht profitieren ein paar Leser von meinen Erfahrungen …
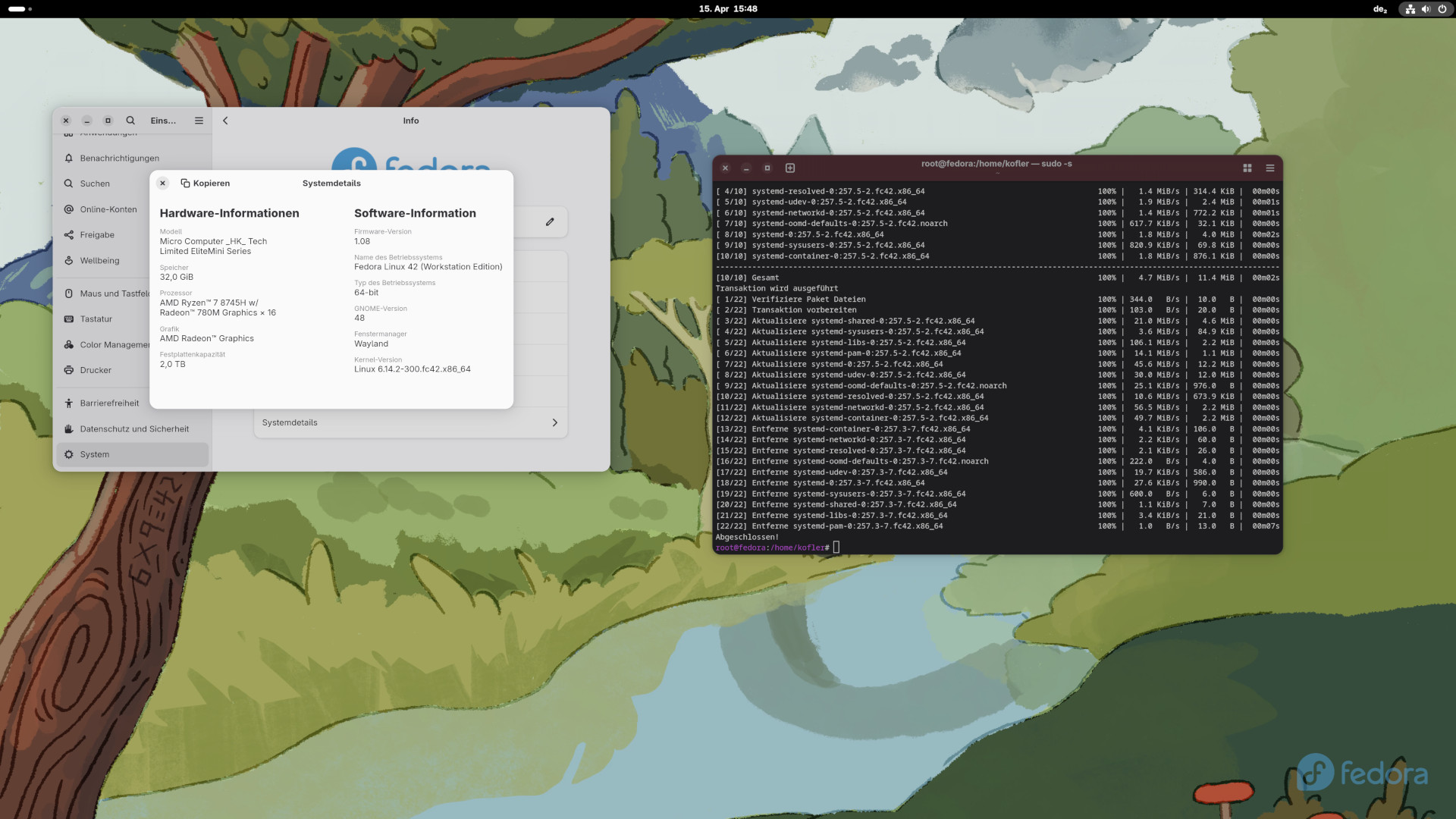
Die Zielsetzung ist bereits in der Überschrift beschrieben. Ich besitze einen Mini-PC mit AMD 8745H-CPU und 32 GiB RAM. Die CPU enthält auch eine integrierte GPU (Radeon 780M). Auf diesem Rechner wollte ich das momentan sehr beliebte Sprachmodell gpt-oss-20b ausführen. Dieses Sprachmodell ist ca. 11 GiB groß, umfasst 20 Milliarden Parameter in einer etwas exotischen Quantifizierung. (MXFP4 wurde erst 2024 standardisiert und bildet jeden Parameter mit nur 4 Bit ab. Die Besonderheit besteht darin, dass für unterschiedliche Teile des Modells unterschiedliche Skalierungsfaktoren verwendet werden, so dass die Parameter trotz der wenigen möglichen Werte einigermaßen exakt abgebildet werden können.)
Das Sprachmodell wird von der Firma OpenAI kostenlos angeboten. Die Firma gibt an, dass die 20b-Variante ähnlich gute Ergebnisse wie das bis 2024 eingesetzt kommerzielle Modell o3-mini liefert, und auch KI-Experte Simon Willison singt wahre Lobeshymnen auf das Modell.
PS: Ich habe alle Tests unter Fedora 42 durchgeführt.
Warum nicht Ollama?
Für alle, die nicht ganz tief in die lokale Ausführung von Sprachmodellen eintauchen wollen, ist Ollama zumeist die erste Wahl. Egal, ob unter Windows, Linux oder macOS, viele gängige Sprachmodelle können damit unkompliziert ausgeführt werden, in der Regel mit GPU-Unterstützung (macOS, Windows/Linux mit NVIDIA-GPU bzw. mit ausgewählten AMD-GPUs).
Bei meiner Hardware — und ganz allgemein bei Rechnern mit einer AMD-iGPU — ist Ollama aktuell aber NICHT die erste Wahl:
ROCm: Ollama setzt bei NVIDIA-GPUs auf das Framework CUDA (gut), bei AMD-GPUs auf das Framework ROCm (schlecht). Dieses Framework reicht alleine vermutlich als Grund, warum AMD so chancenlos gegen NVIDIA ist. Im konkreten Fall besteht das Problem darin, dass die iGPU 780M (interner ID gfx1103) offiziell nicht unterstützt wird. Die Empfehlung lautet, ROCm per Umgebungsvariable zu überzeugen, dass die eigene GPU kompatibel zu einem anderen Modell ist (HSA_OVERRIDE_GFX_VERSION=11.0.2). Tatsächlich können Sprachmodelle dann ausgeführt werden, aber bei jeder Instabilität (derer es VIELE gibt), stellt sich die Frage, ob nicht genau dieser Hack der Anfang aller Probleme ist.
Speicherverwaltung: Auch mit diesem Hack scheitert Ollama plus ROCm-Framework an der Speicherverwaltung. Bei AMD-iGPUs gibt es zwei Speicherbereiche: fix per BIOS allozierten VRAM sowie dynamisch zwischen CPU + GPU geteiltem GTT-Speicher. (Physikalisch ist der Speicher immer im RAM, den sich CPU und GPU teilen. Es geht hier ausschließlich um die Speicherverwaltung durch den Kernel + Grafiktreiber.)
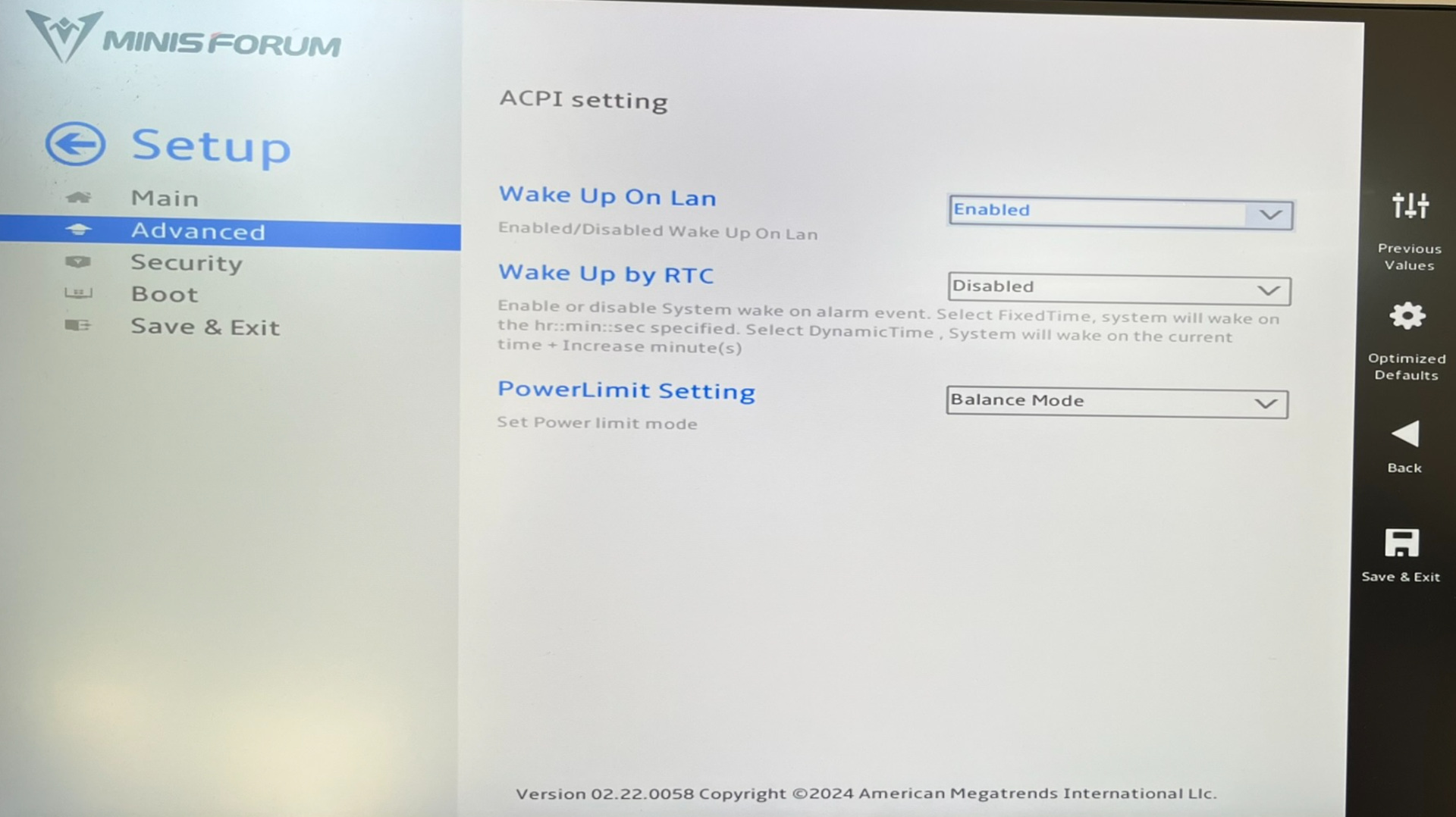
Ollama alloziert zwar den GTT-Speicher, aber maximal so viel, wie VRAM zur Verfügung steht. Diese (Un)Logik ist am besten anhand von zwei Beispielen zu verstehen. Auf meinem Testrechner habe ich 32 GiB RAM. Standardmäßig reserviert das BIOS 2 GiB VRAM. Der Kernel markiert dann 14 GiB als GTT. (Das kann bei Bedarf mit den Kerneloptionen amdttm.pages_limit und amdttm.page_pool_size verändert werden.) Obwohl mehr als genug Speicher zur Verfügung steht, sieht Ollama eine Grenze von 2 GiB und kann nur winzige LLMs per GPU ausführen.
Nun habe ich im BIOS das VRAM auf 16 GiB erhöht. Ollama verwendet nun 16 GiB als Grenze (gut), nutzt aber nicht das VRAM, sondern den GTT-Speicher (schlecht). Wenn ich nun ein 8 GiB großes LLM mit Ollama ausführen, dann bleiben fast 16 GiB VRAM ungenutzt! Ollama verwendet 8 GiB GTT-Speicher, und für Ihr Linux-System bleiben gerade einmal 8 GiB RAM übrig. Es ist zum aus der Haut fahren! Im Internet gibt es diverse Fehlerberichte zu diesem Problem und sogar einen schon recht alten Pull-Request mit einem Vorschlag zur Behebung des Problems. Eine Lösung ist aber nicht Sicht.
Ich habe mich mehrere Tage mit Ollama geärgert. Schade um die Zeit. (Laut Internet-Berichten gelten die hier beschriebenen Probleme auch für die gehypte Strix-Halo-CPU.)
Next Stop: llama.cpp
Etwas Internet-Recherche liefert den Tipp, anstelle von Ollama das zugrundeliegende Framework llama.cpp eben direkt zu verwenden. Ollama greift zwar selbst auf llama.cpp zurück, aber die direkte Verwendung von llama.cpp bietet andere GPU-Optionen. Dieser Low-Level-Ansatz ist vor allem bei der Modellauswahl etwas umständlicher. Zwei Vorteile können den Zusatzaufwand aber rechtfertigen:
Die neuste Version von llama.cpp unterstützt oft ganz neue Modelle, mit denen Ollama noch nicht zurechtkommt.
llama.cpp kann die GPU auf vielfältigere Weise nutzen als Ollama. Je nach Hardware und Treiber kann so eventuell eine höhere Geschwindigkeit erzielt bzw. der GPU-Speicher besser genutzt werden, um größere Modelle auszuführen.
Die GitHub-Projektseite beschreibt mehrere Installationsvarianten: Sie können llama.cpp selbst kompilieren, den Paketmanager nix verwenden, als Docker-Container ausführen oder fertige Binärpakete herunterladen (https://github.com/ggml-org/llama.cpp/releases). Ich habe den einfachsten Weg beschritten und mich für die letzte Option entschieden. Der Linux-Download enthält genau die llama.cpp-Variante, die für mich am interessantesten war — jene mit Vulkan-Unterstützung. (Vulkan ist eine 3D-Grafikbibliothek, die von den meisten GPU-Treibern unter Linux durch das Mesa-Projekt gut unterstützt wird.) Die Linux-Version von llama.cpp wird anscheinend unter Ubuntu kompiliert und getestet, dementsprechend heißt der Download-Name llama-<version>-bin-ubuntu-vulkan-x86.zip. Trotz dieser Ubuntu-Affinität ließen sich die Dateien bei meinen Tests aber problemlos unter Fedora 42 verwenden.
Nach dem Download packen Sie die ZIP-Datei aus. Die resultierenden Dateien landen im Unterverzeichnis build/bin. Es bleibt Ihnen überlassen, ob Sie die diversen llama-xxx-Kommandos direkt in diesem Verzeichnis ausführen, das Verzeichnis zu PATH hinzufügen oder seinen Inhalt in ein anderes Verzeichnis kopieren (z.B. nach /usr/local/bin).
cd Downloads
unzip llama-b6409-bin-ubuntu-vulkan-x64.zip
cd build/bin
./llama-cli --version
loaded RPC backend from ./build/bin/libggml-rpc.so
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = AMD Radeon 780M Graphics (RADV PHOENIX) (radv) ...
loaded Vulkan backend from ./build/bin/libggml-vulkan.so
loaded CPU backend from ./build/bin/libggml-cpu-icelake.so
version: 6409 (d413dca0)
built with cc (Ubuntu 11.4.0-1ubuntu1~22.04.2) for x86_64-linux-gnu
Für die GPU-Unterstützung ist entscheidend, dass auf Ihrem Rechner die Bibliotheken für die 3D-Bibliothek Vulkan installiert sind. Davon überzeugen Sie sich am einfachsten mit vulkaninfo aus dem Paket vulkan-tools. Das Kommando liefert fast 4000 Zeilen Detailinformationen. Mit einem Blick in die ersten Zeilen stellen Sie fest, ob Ihre GPU unterstützt wird.
Um llama.cpp auszuprobieren, brauchen Sie ein Modell. Bereits für Ollama heruntergeladene Modelle sind leider ungeeignet. llama.cpp erwartet Modelle als GGUF-Dateien (GPT-Generated Unified Format). Um die Ergebnisse mit anderen Tools leicht vergleichen zu können, verwende ich als ersten Testkandidat immer Llama 3. Eine llama-taugliche GGUF-Variante von Llama 3.1 mit 8 Milliarden Parametern finden Sie auf der HuggingFace-Website unter dem Namen bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M.
Das folgende Kommando lädt das Modell von HuggingFace herunter (Option -hf), speichert es im Verzeichnis .cache/llama.cpp, lädt es, führt den als Parameter -p angegebenen Prompt aus und beendet die Ausführung dann. In diesem und allen weiteren Beispielen gehe ich davon aus, dass sich die llama-Kommandos in einem PATH-Verzeichnis befinden. Alle Ausgaben sind aus Platzgründen stark gekürzt.
llama-cli -hf bartowski/Meta-Llama-3.1-8B-Instruct-GGUF:Q4_K_M \
-p 'bash/Linux: explain the usage of rsync over ssh'
... (diverse Debugging-Ausgaben)
Running in interactive mode.
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
- Not using system message. To change it, set a different value via -sys PROMPT
> bash/Linux: explain the usage of rsync over ssh
rsync is a powerful command-line utility that enables you to
synchronize files and directories between two locations. Here's
a breakdown of how to use rsync over ssh: ...
> <Strg>+<D>
load time = 2231.02 ms
prompt eval time = 922.83 ms / 43 tokens (46.60 tokens per second)
eval time = 31458.46 ms / 525 runs (16.69 tokens per second)
Sie können llama-cli mit diversen Optionen beeinflussen, z.B. um verschiedene Rechenparameter einzustellen, die Länge der Antwort zu limitieren, den Systemprompt zu verändern usw. Eine Referenz gibt llama-cli --help. Deutlich lesefreundlicher ist die folgende Seite:
Mit llama-bench können Sie diverse Benchmark-Tests durchführen. Im einfachsten Fall übergeben Sie nur das Modell in der HuggingFace-Notation — dann ermittelt das Kommando die Token-Geschwindigkeit für das Einlesen des Prompts (Prompt Processing = pp) und die Generierung der Antwort (Token Generation = tg). Allerdings kennt llama-bench die Option -hf nicht; vielmehr müssen Sie mit -m den Pfad zur Modelldatei übergeben:
llama-bench -m ~/.cache/llama.cpp/bartowski_Meta-Llama-3.1-8B-Instruct-GGUF_Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
model size test token/s (Tabelle gekürzt ...)
----------------------- --------- ------- --------
llama 8B Q4_K - Medium 4.58 GiB pp512 204.03
llama 8B Q4_K - Medium 4.58 GiB tg128 17.04
Auf meinem Rechner erreicht llama.cpp mit Vulkan nahezu eine identische Token-Rate wie Ollama mit ROCm (aber ohne die vielen Nachteile dieser AMD-Bibliothek).
AMD-Optimierung
Bei meinen Tests auf dem schon erwähnten Mini-PC mit AMD 8745H-CPU mit der iGPU 780M und 32 GiB RAM funktionierte llama.cpp mit Vulkan viel unkomplizierter als Ollama mit ROCm. Ich habe die VRAM-Zuordnung der GPU wieder zurück auf den Defaultwert von 2 GiB gestellt. Per Default steht llama.cpp auf meinem Rechner dann ca. der halbe Arbeitsspeicher (2 GiB VRAM plus ca. 14 GiB GTT) zur Verfügung. Vulkan kann diesen Speicher ohne merkwürdige Hacks mit Umgebungsvariablen korrekt allozieren. Das reicht ohne jedes Tuning zur Ausführung des Modells gpt-20b aus (siehe den folgenden Abschnitt). So soll es sein!
Wenn Sie noch mehr Speicher für die LLM-Ausführung reservieren wollen, müssen Sie die Kerneloptionen pages_limit und pages_pool_size des AMDGPU-Treibers verändern. Wenn Sie 20 GiB GGT-Speicher nutzen wollen, müssen Sie für beide Optionen den Wert 5242880 angeben (Anzahl der 4-kByte-Blöcke):
Danach aktualisieren Sie die Initrd-Dateien und führen einen Neustart durch:
sudo update-initramfs -u # Debian und Ubuntu
sudo dracut --regenerate-all --force # Fedora, RHEL, SUSE
sudo reboot
sudo dmesg | grep "amdgpu.*memory"
amdgpu: 2048M of VRAM memory ready (<-- laut BIOS-Einstellung)
amdgpu: 20480M of GTT memory ready (<-- laut /etc/modprobe.d/amd.conf)
Modellauswahl
Mit llama.cpp können Sie grundsätzlich jedes Modell im GPT-Generated Unified Format (GGUF) ausführen. Auf der Website von HuggingFace stehen Tausende Modelle zur Wahl:
Die Herausforderung besteht darin, für die eigenen Zwecke relevante Modelle zu finden. Generell ist es eine gute Idee, besonders populäre Modelle vorzuziehen. Außerdem werden Sie rasch feststellen, welche Modellgrößen für Ihre Hardware passen. Die höhere Qualität großer Modelle bringt nichts, wenn die Geschwindigkeit gegen Null sinkt.
gpt-oss-20b
Eine llama.cpp-kompatible Version finden hat ggml-org auf HuggingFace gespeichert. Sofern ca. 15 GiB freier VRAM zur Verfügung stehen (unter AMD: VRAM + GTT), führt llama.cpp das Modell problemlos und beachtlich schnell aus. Beachten Sie, dass es sich hier um ein »Reasoning-Modell« handelt, das zuerst über das Problem nachdenkt und diesen Denkprozess auch darstellt. Danach wird daraus das deutlich kompaktere Ergebnis präsentiert.
Die Kommandos llama-cli und llama-bench dienen in erster Linie zum Testen und Debuggen. Sobald Sie sich einmal überzeugt haben, dass llama.cpp grundsätzlich funktioniert, werden Sie das Programm vermutlich im Server-Betrieb einsetzen. Das entsprechende Kommando lautet llama-server und ist grundsätzlich wie llama-cli aufzurufen. Falls Sie llama-server unter einem anderen Account als llama-cli aufrufen, aber schon heruntergeladene Modelle weiterverwenden wollen, übergeben Sie deren Pfad mit der Option -m:
llama-server -c 0 -fa on --jinja -m /home/kofler/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
Sie können nun unter http://localhost:8080 auf einen Webserver zugreifen und das gestartete Modell komfortabel bedienen. Im Unterschied zu Ollama hält llama.cpp das Modell dauerhaft im Arbeitsspeicher. Das Modell kann immer nur eine Anfrage beantworten. Die Verarbeitung mehrere paralleler Prompts erlaubt --parallel <n>.
Die Web-Oberfläche von llama-server
Es ist unmöglich, mit einem Server mehrere Modelle parallel anzubieten. Vielmehr müssen Sie mehrere Instanzen von llama-server ausführen und jedem Dienst mit --port 8081, --port 8082 usw. eine eigene Port-Nummer zuweisen. (Das setzt voraus, dass Sie genug Video-Speicher für alle Modelle zugleich haben!)
Falls auch andere Rechner Server-Zugang erhalten sollen, übergeben Sie mit --host einen Hostnamen oder eine IP-Nummer im lokalen Netzwerk. Mit --api-key oder --api-key-file können Sie den Server-Zugang mit einem Schlüssel absichern. Mehr Details zu den genannten Optionen sowie eine schier endlose Auflistung weiterer Optionen finden Sie hier:
Jetzt habe ich drei Tage versucht, gpt-oss per GPU auszuführen. Hat sich das gelohnt? Na ja. Mit -ngl 0 kann die Token Generation (also das Erzeugen der Antwort per Sprachmodell) von der GPU auf die CPU verlagert werden. Das ist natürlich langsamer — aber erstaunlicherweise nur um 25%.
Warum ist der Unterschied nicht größer? Weil die 780M keine besonders mächtige GPU ist und weil die Speicherbandbreite der iGPU viel kleiner ist als bei einer dezidierten GPU mit »echtem« VRAM.
Zur Einordnung noch zwei Vergleichszahlen: MacBook Pro M3: 42 Token/s (mit GPU) versus 39 Token/s (nur CPU)
Spätestens seitdem Neobroker mit hohem Werbebudget den Markt auffrischen, ist für viele Menschen das Thema Geldanlage präsent geworden. Noch vor ein paar Jahren war der Erwerb von Wertpapieren mit solchen großen Hürden verbunden, dass sich viele Menschen nicht auf den Kapitalmarkt trauten. Inzwischen ist es auch für nicht-Finanzgurus wie mich möglich, sich unkompliziert Aktien und andere Anlageformen zuzulegen. Die Apps der Banken und Broker sind inzwischen recht benutzerfreundlich, was die Hürde weiter senkt. Wenn man sich der Sache wieder etwas ernster annähern möchte, kommt man mit den Apps aber schnell an seine Grenzen. Um besser den Überblick über meine Finanzen zu behalten, habe ich mich auf die Suche nach einer Software gemacht, die mich dabei unterstützt. Und ich bin in der Open Source Community fündig geworden.
Meine Fragestellung war folgende: Wie diversifiziert ist mein Portfolio eigentlich? In welchen Regionen und Branchen bin ich wie stark präsent? Welches sind meine Top-Firmen? Wie teilt sich mein Vermögen auf Aktien, ETFs und Cash auf? Wie stark bin ich in Small-Caps investiert? Wann und bei welchen Kurswerten habe ich gekauft und verkauft? Wie viele Dividenden habe ich inzwischen erhalten, usw.? Bisher habe ich das mit Excel lösen können. Die Fact-Sheets der ETF sind im Netz zu finden, dort sind die Verteilungen auf Regionen, Branchen usw. nachzulesen. Mit viel Tipparbeit holt man sich die aktuellen Verteilungen in die Datei, gewichtet sie nach aktuellem Wert im Portfolio und lässt es sich als Diagramm anzeigen. Aber: Das ist sehr aufwendig.
Portfolio Performance: Das mächtige Open Source Finanztool
Portfolio Performance ist hier einfacher. Nach der Installation kann man die PDF-Dateien seiner Bank und Broker importieren. Einfach den Kontoauszug und die Kauf- bzw. Verkaufsnachweise, Dividendenausschüttungen usw. in das Programm laden, und schon hat man den perfekten Überblick. Das Programm läuft lokal, was die Frage nach Datensicherheit vollkommen entschärft. Niemand hat Zugriff darauf, niemand kann sich die Daten ansehen. Meine Daten bleiben bei mir.
Neben dem PDF-Import der Bankdaten gibt es noch etliche weitere Importmöglichkeiten. Am gängigsten ist vermutlich das CSV-Format, das sich über einen tollen Assistenten gut importieren lässt.
Historische Kursdaten sind erstmal nicht vorhanden. Man kann sie sich über mehrere Wege ins Programm holen. Für mich am einfachsten ist der Weg über die Datenbank von Portfolio Performance selbst. Dort muss man ein kostenloses Benutzerkonto anlegen, dann kann man auf die historischen Daten dort zugreifen. Etliche andere Finanzportale sind ebenfalls kompatibel. Am Ende geht hier auch wieder CSV.
ETF- und Portfolio-Diversifikation anzeigen lassen
Über die Diagramme „Berichte → Vermögensaufstellung“ kann man sich anzeigen lassen, über welche Anlageklassen man zu welchen Teilen verfügt. Eine der Hauptfragen meinerseits war jedoch: Wie sieht es mit meiner ETF-Diversifikation aus?. Das geht derzeit noch nicht nativ in Portfolio Performance. Hierfür braucht man einen Drittanbieter.
Glücklicherweise gibt es findige Leute in der sehr aktiven Community, die sich die gleichen Fragen gestellt haben und eine Lösung zur Verfügung stellen. Über ein Skript des Users Alfonso1Qto12 kann man sich beispielsweise die Zusammensetzung der ETF über die Morningstar-API direkt in sein Portfolio Performance schreiben lassen.
Hinweis: Dieses Skript ist nach Aussage des Entwicklers experimentell und sollte nur mit einer Kopie der echten Daten benutzt werden! Stand September 2025 muss man den alternativen Branch wechseln, weil main noch auf eine alte API zugreift.
Über die Flag top_holdings 50 lasse ich mir aus den ETF die 50 wertvollsten Firmen ausgeben. Empfohlen wird, auf weniger als 100 Firmen zu gehen, um die Performance des Programms nicht zu gefährden.
Mit diesem Skript werden die Wertpapiere ihren Ländern, Regionen, Holdings usw. anteilsweise zugeordnet. Diese Daten werden direkt in die XML-Datei geschrieben und lassen sich anschließend in Portfolio Performance unter den „Klassifizierungen“ betrachten. Es gibt verschiedene Visualisierungsarten, am übersichtlichsten finde ich die Tabelle, das Kreis- und das Flächendiagramm.
Weitere Schritte und Lehren aus den Daten
Mit Portfolio Performance erhält man eine tolle Übersicht über seine Finanzen. Wie der Name schon verrät, kann man sich hier tolle Dashboards bauen, um die Performance im eigenen Portfolio zu überwachen. Alle gängigen Kriterien sind vorhanden und können in Dashboards oder vielfältige Diagramme eingebaut und visualisiert werden.
Die Daten lassen ein Rebalancing zu, dafür gibt es eigens eingebaute Funktionen. Über eine Smartphone-App lassen sich die Daten sogar auf dem Handy anzeigen. Die Synchronisation muss hier über Cloudanbieter durchgeführt werden, also zum Beispiel über die Nextcloud oder Dropbox. Daten einpflegen lassen sich übers Smartphone allerdings nicht.
Zusammengefasst: Wer eine sehr mächtige Open Source Software sucht, mit der man
sein Portfolio im Blick behalten kann,
das Daten aus vielen Quellen (inkl. PDFs von Banken und Brokern) verarbeiten kann,
Debian 13 »Trixie« ist fertig. Mehrere RC-Releases sind bei mir schon ein paar Monate im Einsatz — bislang ohne jedes Problem. Insofern sieht es so aus, als würde Debian seinem Ruf für stabile, ausgereifte Releases einmal mehr gerecht. Dieser Artikel fasst in kompakter Form die wichtigsten Neuerungen zusammen.
Debian mit Gnome-Desktop
Plattformen und Versionsnummern
Debian steht für sieben CPU-Plattformen zur Verfügung:
Standard-PCs (x86): nur noch amd64 (i386 nur einzelne Pakete, nicht mehr als vollständige Plattform)
ARM: arm64, armhf, armel
PowerPC: ppc64el
RISC-V: risvc64 (neu!)
IBM System z: s390x
MIPS wird nicht mehr unterstützt, armel mit diesem Release zum letzten Mal.
Die folgende Tabelle fasst die Versionen der Kernkomponenten von Debian 13 zusammen:
Wenn Sie sich bei der Installation für KDE entscheiden, kommen QT 6.8, das KDE-Framework 6.13, Plasma 6.3.6, sowie KDE Gear 25.04 bzw. 24.12 (für die PIM Suite) zur Anwendung.
Bei Dovecot warnen die Release Notes von Debian, dass sich die Syntax von Version 2.3 zu 2.4 inkompatibel geändert hat, was zu Problemen führen wird, wenn eine vorhandene Konfiguration bei einem Update übernommen werden soll. Hier ist der Link in die Dovecot-Dokumentation zu diesem Thema.
Installation
Am Installationsablauf hat sich — zumindest optisch — nichts verändert. Die teilweise seit Jahrzehnten (!) bewährten Dialoge führen durch die Installation. Das ist nicht so elegant und intuitiv wie bei anderen Systemen, dafür können bei der Partitionierung wirklich alle erdenklichen Sonderwünsche realisiert werden. Im Wildwuchs anderer Systeme betrachte ich das Installationssystem zunehmend als Pluspunkt.
Technische Neuerungen
last-Kommando neu implementiert: Unter Linux können Sie mit last die Liste der zuletzt eingeloggten Personen ermitteln. last reboot verrät, wann der Rechner zuletzt neugestartet wurde.
Das alles funktioniert in Debian auch, aber die Implementierung ist neu. last ist jetzt ein symbolischer Link auf wtmpdb. Diese Neuimplementierung der last-Datenbank verwendet SQLite und wird über das Jahr 2038 hinaus funktionieren (was beim herkömmlichen last-Kommando nicht der Fall ist).
Analog wurde lastlog durch lastlog2 ersetzt. Mehr Details geben die Release Notes.
APT-Repository-Format deb822: Debian unterstützt die neuen *.sources-Dateien zur Beschreibung von Paketquellen. Anstelle von einzeiligen Paketbeschreibungen wie
deb http://deb.debian.org/debian/ trixie main
deb-src http://deb.debian.org/debian/ trixie main
können die Paketquellen in einem besser lesbaren, mehrzeiligen Format dargestellt werden:
# Datei /etc/apt/sources.list.d/debian.sources
Types: deb deb-src
URIs: http://deb.debian.org/debian/
Suites: trixie
Components: main
Signed-By: /usr/share/keyrings/debian-archive-keyring.gpg
Anders als ab Ubuntu 24.04 ist das neue Format in Debian 13 nicht per Default aktiv. Alle vorhandenen Paketquellen können aber mit apt modernize-sources umgestellt werden, was bei meinen Tests gut funktioniert hat. Die neuen Repo-Dateien haben die Kennung *.sources anstelle *.list. Wenn gleichnamige Dateien existieren, haben die *.sources-Dateien Vorrang. In die Dateien können auch Signatur-Keys eingebettet werden, was den lästigen Key-Import erspart. Mehr Details liefert man sources.list.
/tmp im RAM: Das /tmp-Verzeichnis wird nun mit dem tmpfs-Dateisystem im RAM abgebildet. Das verspricht höhere Geschwindigkeit beim Umgang mit temporären Dateien, kann aber bei sehr großen Dateien zum Speicherproblemen führen. /tmp darf bis zu 50% des RAMs nutzen. Das Dateisytem wird durch systemd eingerichtet. Der Grenzwert kann mit systemctl edit tmp.mount verändert werden. Dazu bauen Sie im dafür vorgesehen Bereich die folgenden zwei Zeilen ein und verändern die Werte:
Wenn Sie /tmp wie bisher als reguläres Verzeichnis auf der SSD/Festplatte wünschen, führen Sie systemctl mask tmp.mount aus und starten Ihr System neu.
Sicherheit: Debian-Pakete sind gegen ROP- und COP/JOP-Angriffe gehärtet (betrifft die amd64– und arm64-Architektur). Die Pakete sind speziell kompiliert, um Exploits durch Return-Oriented Programming (ROP) bzw. Call/Jump-Oriented Programming (COP/JOP) zu erschweren. Weitere Details und Links finden Sie in den Release Notes.
Geschwindigkeit: Laut einem Test von Phoronix ist Debian 13 rund 13 Prozent schneller als die Vorgängerversion.
Tipps und Tricks
Wenn Sie Debian in einer virtuellen Maschine verwenden und Text und Bilder über die Zwischenablage mit dem Host austauschen wollen, führen Sie apt install spice-vdagent aus und starten die VM neu.
Fazit
Das Debian-Projekt ist 32 Jahre alt (Projektgründung im August 1993, 0.9-Releases 1994 und 1995, Version 1.1 1996). Debian zählt damit zu den ältesten Linux-Distributionen überhaupt — und ist bis heute mehr als nur relevant: Überlegen Sie nur für eine Minute, wie die Linux-Landschaft ohne Debian aussähe! Nicht nur Millionen Debian-Anwender stünden im Regen, auch Ubuntu, Linux Mint, Raspberry Pi OS etc. würde die Basis entzogen.
Für Version 13 gilt: Debian bleibt Debian. Große technische Innovationen finden anderswo statt. Stattdessen gibt es Unterstützung für viele CPU-Plattformen und ein solides, stabiles Fundament für die tägliche Arbeit, sei es am Desktop oder in Server-Anwendungen. Und das alles frei von finanziellen Interessen. Dafür sollte jeder Linux-Fan der Debian-Community unendlich dankbar sein.
CachyOS ist das Kunststück gelungen, die Spitze der distrowatch-Charts zu erklimmen. Über diesen Meilenstein haben zuletzt die meisten IT-Medien berichtet. Das Ranking spiegelt zwar nicht die Anzahl der Installationen wider (diese Zahlen kennt distrowatch nicht), wohl aber das Interesse, das durch Seitenzugriffe gemessen wird. Und das Interesse an CachyOS ist aktuell hoch.
Warum? CachyOS ist eine relativ neue Distribution auf der Basis von Arch Linux. CachyOS verfügt aber über ein verhältnismäßig komfortables grafisches Installationsprogramm, verwendet einen eigenen, auf Geschwindigkeit optimierten Kernel und eigene Paketquellen, deren Programme ebenfalls im Hinblick auf optimale Geschwindigkeit kompiliert sind (mit mehreren Varianten optimiert je nach CPU-Generationen). CachyOS implementiert interessante Features per Default: btrfs-Dateisystem mit komprimierten Subvolumes und Snapper, ufw-Firewall, systemd-boot, fish als Shell etc. Die CachyOS-spezifischen Details sind im Wiki gut dokumentiert.
In Summe ergibt das ein schnelles, modernes und sympathisches Linux, das ganz offensichtlich den Zeitgeist trifft. Höchste Zeit also, dass ich auch in meinem Blog etwas dazu schreibe :-)
CachyOS mit KDE-Desktop
Eckdaten
Rolling Release Modell auf Arch-Linux-Basis (aber mit eigenen Paketquellen)
x86-only, keine ARM-Variante
btrfs als Defaultdateisystem
Snapper als Snapshot-Tool (erfordert btrfs)
systemd-boot als Default-Boot-Loader
fish als Default-Shell
ufw als Firewall
Unzählige Desktops zur Auswahl (mit einer gewissen Präferenz zu KDE)
paru als AUR-Helper
CachyOS-spezifische Zusatzprogramme:CachyOS Hello, CachyOS Package Manager, CachyOS Kernel Manager etc.
Die meisten Details sind frei wählbar. Sie haben bei der Installation die Wahl zwischen diversen Boot-Loadern, können die Dateisysteme frei konfigurieren usw. Ich habe mich bemüht, möglichst nahe an den CachyOS-Vorgaben/Vorlieben zu bleiben, inklusive KDE als Desktop.
Installation
Die Installation von CachyOS erfolgt aus einem Live-System heraus mit dem Programm Calamares. (Dieses distributionsunabhängige Framework wird auch von diversen anderen Distributionen verwendet.) Nach einem ersten Test in einer virtuellen Maschine habe ich diese Installation auf einem Lenovo-P1-Notebook durchgeführt. Die 1-TB-SSD war anfänglich leer, ich wollte aber nur ca. 1/5 der SSD nutzen.
Sie müssen UEFI Secure Boot deaktivieren, falls dieses auf Ihrem Rechner aktiv ist. Es ist möglich, Secure Boot nachträglich zu aktivieren.
Die Installation beginnt — ein wenig absurd! — mit einem Auswahldialog zwischen fünf Boot-Loadern. Willkommen in Nerdistan :-) Hier wäre ein Link in das CachyOS-Wiki hilfreich, wo die Vor- und Nachteile der fünf Programme gut zusammengefasst sind. Die Kurzfassung: GRUB funktioniert immer. Das vorgeschlagene systemd-boot ist klein + schnell und mein persönlicher Favorit. Es unterstützt allerdings nicht die Auswahl eines Snapper-Snapshots während des Bootprozesses. Genau das können GRUB und Limine. GRUB kenne ich von ca. 1000 anderen Linux-Installationen, systemd-boot verwende ich unter Arch Linux, also habe ich mich aus Neugier für Limine entschieden. Bei Limine landen alle Boot-Dateien (sowohl EFI als auch Kernel, Initrd etc.) in einer Partition mit vfat-Dateisystem. Calamares hat das in Verwirrung gebracht (siehe unten).
Auswahl des Boot-Loaders
Erst danach startet das eigentliche Installationsprogramm mit Einstellung von Sprache, Region und Tastatur.
Einstellung der SpracheEinstellung der RegionEinstellung der Tastatur
Wie bei den meisten Distributionen gelingt die Installation am einfachsten und schnellsten, wenn Sie dem Installationsprogramm die Kontrolle über den gesamten Datenträger überlassen und dieses selbst entscheiden kann, welche Partitionen es haben will. Aber wie einleitend erwähnt, wollte ich nur ca. 1/5 der SSD für CachyOS reservieren und habe deswegen eine manuelle Partitionierung durchgeführt. Der Prozess ist in Calamares nur mäßig intuitiv, aber zu schaffen. Ich habe eine 2-GB-Partition für /boot mit FAT32 und eine 180-GB-Partition für / mit btrfs eingerichtet.
Ärgerlicherweise hat Calamares die /-Partitionen vor der /boot-Partition platziert (abweichend von der Darstellung im Partitionseditor und im Zusammenfassungsdialog), was spätere Anpassungen nahezu unmöglich macht :-( Ist das so schwierig?
Beim Verlassen des Partitionseditor beklagt sich Calamares, dass die EFI-Partition fehlt. So wie ich das CachyOS-Wiki und die Limine-Dokumentation verstanden habe, ist diese Partition nicht erforderlich. Ich habe dennoch versucht, in Calamares wie gewünscht eine weitere EFI-Partition einzurichten, bin aber gescheitert. Es gibt nirgendwo die Option, das ESP-Flag zu setzen. Zuletzt habe ich entschieden, mich auf die Dokumentation zu verlassen und die Calamares-Empfehlung zu ignorieren und habe die Installation ohne EFI-Partition fortgesetzt. (Spoiler: hat funktioniert …)
In den nächsten Schritten wählen Sie zuerst den Desktop und dann eventuell gewünschte Zusatzpakete aus. Ich habe mich für KDE entschieden und keine weiteren Paket-Änderungen durchgeführt.
Auswahl des DesktopsAuswahl von zusätzlichen Paketen
Im Dialog »Users« müssen Sie entweder einen eigenen root-User einrichten oder die Option »Nutze das gleiche Passwort auf für das Administratorkonto« verwenden. Ich will weder noch: sudo reicht mir, root braucht kein Passwort (wie unter Ubuntu und macOS). Aber es hilft nichts, diesen Fall sieht Calamares nicht vor.
Benutzer einrichten
Calamares zeigt nun eine Zusammenfassung an. Danach beginnt die Installation, die (zumindest bei meinem lahmen Internet) recht lange braucht. Alle erforderlichen Pakete werden frisch heruntergeladen.
Zusammenfassung der Installationseinstellungen
Alles in allem ist die Installation mit etwas Linux-Erfahrung zu schaffen. Wenn Arch Linux die Messlatte ist, gibt es nichts zu meckern. Fedora, openSUSE oder Ubuntu zeigen aber, dass es deutlich intuitiver geht.
Erste Schritte
Immerhin: Nach einem Neustart bootet CachyOS korrekt. Die Distribution ist auf Platz 1 in der EFI-Bootliste, Limine funktioniert wie es soll.
Nach dem Login erscheint das Programm »CachyOS Hello« und hilft bei den ersten Schritten, z.B. bei der Installation weiterer Pakete. Google Chrome ist in der Auswahl nicht enthalten, aber paru -S google-chrome führt zum Ziel.
»CachyOS Hello« hilft bei ersten Schritten und bei der Installation wichtiger Desktop-Programme
In der Folge habe ich ein paar Stunden damit verbracht, CachyOS arbeitstauglich zu machen: Desktop einrichten, Nextcloud installieren, meine wichtigsten git-Repos herunterladen, Emacs und VSCode installieren usw. Merkwürdigerweise lässt sich die Fenstergröße von Emacs nur ganz schwer mit der Maus ändern — wohl ein Problem im Zusammenspiel mit KDE?
Shell
CachyOS verwendet meine Lieblings-Shell fish per Default — großartig. (Zu fish will ich demnächst einen eigenen Blog-Artikel verfassen.) Auch ein paar praktische Tools wie duf und exa sind standardmäßig installiert. Das bringt Farbe und Komfort ins Terminal. Die bash ist ebenso installiert, z.B. um eigene Scripts damit auszuführen.
fish, exa und duf bringen Farbe und Komfort ins Terminal
btrfs und Snapper
CachyOS empfiehlt btrfs als Dateisystem. Wenn Sie sich dafür entscheiden, richtet CachyOS dort einige Subvolumes für /home, /var/cache, /var/tmp etc. ein. In allen Subvolumes ist die Komprimierfunktion aktiv.
compress=zstd bringt im Root-Dateisystem relativ viel. In den restlichen Subvolumes ist der Nutzen — zumindest bei meinen Daten — sehr überschaubar.
sudo compsize -x /
Processed 264495 files, 143727 regular extents (144574 refs), 152617 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 59% 6.5G 11G 11G
none 100% 4.3G 4.3G 4.3G
zstd 33% 2.2G 6.7G 6.7G
prealloc 100% 1.2M 1.2M 15M
sudo compsize -x /home
Processed 16181 files, 18299 regular extents (18888 refs), 6961 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 95% 10G 10G 10G
none 100% 9.9G 9.9G 9.8G
zstd 25% 180M 715M 711M
prealloc 100% 2.5M 2.5M 44M
sudo compsize -x /var/cache/
Processed 2489 files, 1855 regular extents (1855 refs), 1219 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 99% 3.7G 3.7G 3.7G
none 100% 3.7G 3.7G 3.7G
zstd 27% 2.0M 7.5M 7.1M
sudo compsize -x /var/log
Processed 11 files, 99 regular extents (129 refs), 0 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 83% 13M 16M 16M
none 100% 12M 12M 3.0M
zstd 25% 956K 3.7M 3.7M
In CachyOS ist das von SUSE entwickelte Programm Snapper installiert. Es erstellt vor und nach jeder Paketinstallation bzw. jedem Update Snapshots. Sollte etwas schiefgehen, kann das Root-Dateisystem beim Neustart in einen früheren Zustand zurückversetzt werden. (Den folgenden Limine-Screenshot habe ich in einer virtuellen Maschine erstellt.)
Auswahl eines Snapshots in Limine
Eine Liste aller Snapshots erstellen Sie mit sudo snapper list. Noch bequemer gelingt die Snapper-Administration mit dem vorinstallierten btrfs-assistant. Snapper ist so vorkonfiguriert, dass maximal 50 Snapshots gespeichert werden. Danach werden alte Snapshots automatisch gelöscht.
btrfs-assistant hilft bei der btrfs- und Snapper-Administration
Persönlich habe ich Snapper noch nie benötigt. (Ich kenne das Programm schon seit einigen Jahren von openSUSE.) Man kann argumentieren, dass es ein Hilfsmittel für den Notfall ist, mit nur minimalen störenden Nebenwirkungen. Der Speicherbedarf für die Snapshots ist relativ klein. Wenn Sie die mit Snapper einhergehende Komplexität stört, deinstallieren sie einfach das gleichnamige Paket.
Limine
Wie gesagt, Sie haben bei CachyOS die Wahl zwischen vielen Boot-Loadern. Mich hat Limine interessiert, weil ich das Programm bisher noch nie verwendet habe. Kurz die Eckdaten: x86 + ARM, BIOS + EFI, aber kein Secure Boot.
Unter CachyOS landen die Dateien für Limine und EFI normalerweise in einem FAT32-Dateisystem:
Die gesamte Konfiguration befindet sich in der Textdatei /boot/limine.conf. Im folgenden Listing habe ich die vielen dort befindlichen UUIDs durch xxx ersetzt, damit die Struktur der Datei besser erkenntlich ist.
Um die für Snapper erforderlichen Konfigurationsänderungen kümmert sich das Paket limine-snapper-sync. Das Paket stellt einige systemd-Units zur Verfügung. Die Konfiguration übernimmt /etc/limine-snapper-sync.conf.
Geschwindigkeit
CachyOS stellt eine Menge Kernel zur Auswahl und gibt Ihnen unkompliziert die Möglichkeit, den Scheduler zu beeinflussen. (Der Scheduler steuert, wie viel Rechenzeit welcher Prozess bekommt.) Die für CachyOS kompilierten Kernel sind besonders im Hinblick auf die Geschwindigkeit optimiert. Details können Sie hier, hier und hier nachlesen.
Linux-Freaks haben die Wahl zwischen verschiedenen Kerneln und Schedulern
Darüber hinaus betreibt CachyOS mehrere Repositories mit Paketen, die für unterschiedliche CPU-Generationen optimiert sind. Anstatt also ein Paket anzubieten, das auf jeder noch so alten CPU läuft, gibt es mehrere Pakete, die die Features Ihrer CPU optimal nutzt. Installationen auf Rechner mit einer modernen CPU verwenden automatisch die v3-Repos. Details finden Sie wieder im CachyOS-Wiki.
# Datei /etc/pacman.conf
...
[cachyos-v3]
Include = /etc/pacman.d/cachyos-v3-mirrorlist
[cachyos-core-v3]
Include = /etc/pacman.d/cachyos-v3-mirrorlist
[cachyos-extra-v3]
Include = /etc/pacman.d/cachyos-v3-mirrorlist
[cachyos]
Include = /etc/pacman.d/cachyos-mirrorlist
Was bringen all diese Maßnahmen? Subjektiv nicht viel. Mein Notebook fühlt sich mit CachyOS nicht spürbar schneller an als mit anderen Distributionen. (Die meiste Zeit verwende ich mein Notebook unter Arch Linux, insofern ist das meine Referenz. Und die meiste Zeit erledige ich Dinge, die nicht CPU-intensiv sind — Texte verfassen, Code entwickeln etc.) Andererseits: Wenn Sie viele performance-intensive Programme ausführen (Compiler, lokale KI-Tools, Spiele), dann sind die Optimierungen von CachyOS absolut wertvoll.
Phoronix hat im Mai 2025 umfangreiche Benchmarktests durchgeführt, in denen CachyOS hinter Clear Linux (mittlerweile eingestellt) auf Platz 2 landete, knapp vor Debian 13 RC. Aber die Unterschiede zwischen den Testkandidaten waren überwiegend minimal, im einstelligen Prozentbereich. Schneller ist natürlich immer besser, aber Wunder kann auch CachyOS nicht vollbringen.
CachyOS verwendet standardmäßig ZRAM-Swap und benötigt normalerweise keine zusätzliche Swap-Partition oder Datei. ZRAM-Swap verwendet den Arbeitsspeicher als Auslagerungsort und komprimiert die dort gespeicherten Blöcke. Dieses auch bei Fedora übliche Feature funktioniert normalerweise sehr gut (außer Sie haben wirklich deutlich zu wenig RAM). Der Swap-Speicher wird von systemd eingerichtet (siehe auch zram-generator).
zramctl
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 zstd 30,8G 1,2M 84,7K 840K [SWAP]
Auch das Verzeichnis /tmp ist via tmpfs im Arbeitsspeicher abgebildet (siehe /etc/fstab). All diese Maßnahmen führen dazu, dass das (hoffentlich ausreichend verfügbare) RAM unter CachyOS möglichst gut im Sinne einer optimalen Geschwindigkeit genutzt wird.
Hardware-Erkennung und Treiber-Installation
CachyOS hat mit chwd ein eigenes Tool zur Hardware-Erkennung. Es wird bei der Installation verwendet, um alle notwendigen Treiber zu installieren. Im späteren Betrieb liefert chwd --list einen Überblick über die installierten Treiber. chwd --autoconfigure wiederholt die Treiberkonfiguration, z.B. um Treiber für später eingebaute Komponenten zu installieren.
Unter CachyOS läuft per Default die von Ubuntu stammende Firewall ufw. Von außen kommende Verbindungen werden für alle Ports (auch 22/SSH) blockiert. Wenn Sie einen SSH- oder Webserver installieren und von außen sichtbar machen möchten, müssen Sie den entsprechenden Port öffnen, z.B. so:
sudo systemctl enable --now sshd
sudo ufw allow ssh
sudo ufw status
Status: active
To Action From
-- ------ ----
22 ALLOW Anywhere
22 (v6) ALLOW Anywhere (v6)
Fazit
CachyOS ist eine sympathische, in vielen Details originelle, gut funktionierende neue Linux-Distribution. Es macht Spaß damit zu arbeiten, und man merkt, wie viel Mühe in die Entwicklung geflossen ist.
Ich habe schon viele Distributionen kommen und gehen gesehen. Hinter CachyOS steht ein verhältnismäßig kleines Team ohne die finanzielle Unterstützung großer Sponsoren. Wird es CachyOS also nächstes oder übernächstes Jahr noch geben? Ich weiß es nicht. Das Risiko, plötzlich eine nicht mehr gewartete Distribution zu nutzen, ist aber überschaubar: Zur Not sollte durch einen Wechsel der Paketquellen der Umstieg auf das ursprüngliche Arch Linux gelingen.
Es gehört zu meinem Beruf, dass ich viele Linux-Distributionen ausprobiere. Einen Wechsel meiner »Hauptinstallation« auf meinem Arbeits-Notebook mache ich aber nur ganz selten, das ist einfach zu viel Mühe. Dort läuft seit ca. drei Jahren Arch Linux und ich bin damit zufrieden.
CachyOS macht vieles richtig. Wenn ich mein Notebook heute neu aufsetzen bzw. ein neues Notebook einrichten müsste, würde ich vermutlich CachyOS eine Chance geben. Dafür gibt es aktuell aber keine Notwendigkeit, und so werde ich bis auf weiteres Arch Linux treu bleiben. So groß sind die Unterschiede zu CachyOS dann auch wieder nicht.
Auf meinen privaten Linux-Installationen gehe ich Flatpak- und Snap-Paketen meistens aus dem Weg. Aber damit mir keiner vorwirft, ich sei zu altmodisch, mache ich hin und wieder doch die Probe auf Exempel: Wie gut funktionieren die neuen Paketsysteme? Meine Testkandidaten waren diesmal Fedora 42 sowie zwei Ubuntu-Installationen (25.04 und 25.10 daily), jeweils auf x86_64-Rechnern.
Fedora + Flatpak
Red Hat setzt bekanntermaßen auf Flatpak als sekundäres Paketformat für Desktop-Pakete. Es gibt zwei Motiviationsgründe: Einerseits will Red Hat den Aufwand für die Wartung großer Pakete (LibreOffice, Gimp etc.) längerfristig reduzieren; andererseits soll die Software-Installation für Anwender einfacher werden, insbesondere für Programme, die nicht in den klassischen Paketquellen verfügbar sind.
In Fedora 42 sind Flatpaks optional. Per Default ist kein einziges Flatpak-Paket installiert. Die Flatpak-Infrastruktur ist aber vorkonfiguriert, inklusive zweier Paketquellen (flathub und fedora). Mit dem Gnome-Programm Software können Sie nach Desktop-Programmen suchen. Manche Programme stehen in mehreren Paketformaten zur Auswahl (z.B. Gimp wahlweise als RPM- oder Flatpak-Paket) — dann haben Sie die Wahl, welches Format Sie verwenden möchten. Außerhalb des Linux-Universums entwickelte Apps wie Google Chrome, IntelliJ, Postman, Spotify oder VSCode gibt es hingegen nur als Flatpaks.
Mit dem Gnome-Programm »Software« können Desktop-Programme als herkömmliche Pakete oder als Flatpaks installiert werden. Die Kritierien für die »Editor’s Choice« sind aber nur schwer nachzuvollziehen. Nach den populären Programmen müssen Sie selbst suchen.
Bei RHEL 10 ist die Ausgangssituation ähnlich wie bei Fedora: Die Infrastruktur ist da, aber es sind keine Flatpaks installiert. Falls Sie RHEL als Desktop-System verwenden möchten, ist der Druck hin zu Flatpak aber stärker. Beispielsweise bietet Red Hat LibreOffice nicht mehr als RPM-Paket, sondern nur als Flatpak an. (Für Fedora gilt dies noch nicht, d.h., Sie können LibreOffice weiterhin als RPM installieren. Schauen wir, wie lange das noch so bleibt …)
Mein »Referenztest« ist die Installation von Spotify in einem bisher leeren System (also ohne andere vorher installierte Flatpaks bzw. Snaps). Sie können die Installation in Software oder per Kommando durchführen. Ich ziehe zweiteres oft vor, damit ich sehe, was vor sich geht (Listing gekürzt):
sudo flatpak install flathub com.spotify.Client
Required runtime for com.spotify.Client/x86_64/stable found in remote
flathub. Do you want to install it? [Y/n]: y
...
org.freedesktop.Platform.GL.default 24.08 155 MB
org.freedesktop.Platform.GL.default 24.08extra 155 MB
org.freedesktop.Platform.Locale 24.08 382 MB (partial)
org.freedesktop.Platform.openh264 2.5.1 1 MB
org.freedesktop.Platform 24.08 261 MB
com.spotify.Client stable 208 MB
Für die Installation von Spotify ist ein Download von 1,6 GiB und Platz auf dem Datenträger im Umfang von 1,9 GiB erforderlich. Das ist einfach verrückt.
Einen Überblick über alle installierte Flatpaks samt Größenangaben erhalten Sie mit flatpak list -d. Das folgende Listing ist aus Platzgründen stark gekürzt. Irritierend ist, dass die Paketgrößen in keiner Weise mit den Angaben während der Installation übereinstimmen (siehe das vorige Listing).
Flatpak-Installationen landen im Verzeichnis /var/lib/flatpak. Die unzähligen dort angelegten Verzeichnisse und Dateien verwenden UUIDs und hexadezimale Codes als Namen. Für die Installation von Spotify auf einem zuvor leeren Flatpak-System werden mehr als 46.000 Verzeichnisse, Dateien und Links mit einem Platzbedarf von 1,9 GiB eingerichtet. Es ist nicht lange her, da reichte das für eine ganze Linux-Distribution aus!
Immerhin teilen weitere Flatpaks die nun etablierte Infrastruktur von Bibliotheken und Basispakete, so dass der Platzbedarf bei der Installation weitere Flatpaks etwas langsamer steigt.
Beim Start beansprucht Spotify »nur« ca. 400 MiB im Arbeitsspeicher (gemessen mit free -m vor und nach dem Start des Audio-Players). Von den vielen installierten Bibliotheken wird also nur ein Bruchteil tatsächlich genutzt. Wenn Sie mit Ihren Ressourcen sparsamer umgehen wollen/müssen, führen Sie Spotify am einfachsten in einem Webbrowser aus :-)
Ubuntu und Snap
Canonical hat Snap-Pakete bereits tief in der Ubuntu-Infrastruktur verankert. Bei Ubuntu 25.10 (daily 2025-07-31) sind
mehrere wichtige Desktop-Programme als Snap-Pakete vorinstalliert: Firefox, das App-Zentrum, der Firmware-Aktualisierer sowie ein relativ neues Security Center zur Verwaltung von Snap-Zugriffsrechten. Dazu kommen die dafür erforderlichen Basispakete. Immerhin ist der Platzbedarf auf der SSD mit 1,1 GByte spürbar geringer als bei vergleichbaren Flatpaks. Ein wenig frech erscheint mir, dass apt install thunderbird mittlerweile ungefragt zur Installation des entsprechenden Snap-Pakets führt.
Im Unterschied zu Flatpaks, die rein für Desktop-Installationen gedacht sind, bietet Canonical auch eine Menge Snap-Pakete für den Server-Einsatz an: https://snapcraft.io/store?categories=server
Zur Installation von Desktop-Snaps verwenden Sie das App-Zentrum. Als einzige Paketquelle ist https://snapcraft.io/store vorgesehen. Weil schon einige Basispakete vorinstalliert sind, ist die Installation eines weiteren Pakets nicht mit so riesigen Downloads wie beim konkurrierenden Flatpak-System verbunden.
Ubuntus »App-Zentrum« ist einzig zur Installation von Snap-Paketen gedacht.
Im Terminal administrieren Sie Snap durch das gleichnamige Kommando. Mit snap install installieren Sie ein neues Paket. snap list zählt alle installierten Snap-Anwendungen auf. snap run startet eine Anwendung, snap refresh aktualisiert alle Snap-Pakete, snap remove name löscht ein Paket.
Mein Referenztest ist wieder die Spotify-Installation. Zusammen mit spotify werden auch die Pakete core20 und gnome-3-38 heruntergeladen. Der Platzbedarf für alle drei Pakete beträgt ca. 600 MiB. (Der Vergleich hinkt aber, weil ja schon diverse Snap-Basispakete installiert sind.) Nach dem Start von Spotify sind ca. 320 MiB zusätzlich im RAM belegt.
sudo snap install spotify
spotify 1.2.63.394.g126b0d89 from Spotify installed
Die interne Verwaltung von Snaps erfolgt ganz anders als bei Flatpak. Snap-Anwendungen werden in Form von komprimierten *.snap-Dateien in /var/lib/snapd/snaps gespeichert:
Der im Hintergrund laufende Snap-Dämon snapd bindet diese Dateien als squashfs-Dateisysteme an der Stelle /snap/xxx in den Verzeichnisbaum ein und macht die Anwendungen so zugänglich (alle Größenangaben in MiB):
Unzählige squashfs-Dateisysteme machen das findmnt-Ergebnis ziemlich unübersichtlich
Im Vergleich zu Flatpak sparen die komprimierten Flat-Images zwar Platz auf dem Datenträger. Allerdings speichert
Snap standardmäßig von jedem installierten Paket ein Backup mit der vorigen Version. Im Laufe der Zeit verdoppelt das den von Snap beanspruchten Speicherplatz! Um nicht mehr benötigte Pakete zu löschen, verfassen Sie das folgende Mini-Script. export LANG= stellt dabei die Spracheinstellungen zurück, damit die Ausgaben von snap in englischer Sprache erfolgen. Das Script entfernt alle Snap-Pakete, deren Status disabled ist.
#!/bin/bash
# Datei ~/bin/delete-snap-crap.sh
# Idee: https://superuser.com/questions/1310825
export LANG=
snap list --all | awk '/disabled/{print $1, $3}' |
while read snapname revision; do
snap remove "$snapname" --revision="$revision"
done
Dieses Script führen Sie mit root-Rechten aus:
sudo bash delete-snap-crap.sh
Auf einem Testsystem mit diversen Snap-Paketen (Firefox, Gimp, LibreOffice, Nextcloud Client, VSCode) sank mit der Ausführung dieses Scripts der Platzbedarf in /var/lib/snapd/snaps von 7,6 auf 4,0 GiB.
Download: ca. 150 MB
Platzbedarf auf der SSD: ca. 340 MB
RAM-Bedarf: ca. 350 MB
Fazit: RAM-Bedarf ist bei allen drei Varianten ähnlich, aber die RPM-Variante braucht weniger Platz am Datenträger.
Fazit
Ich sehe die Probleme, die herkömmliche Paketformate verursachen.
Ich verstehe auch den Wunsch nach einem universellem Paketformat, das für alle Distributionen funktioniert, das aus Anwendersicht einfach zu nutzen und das für den Software-Anbieter mit überschaubarem Wartungsaufwand verbunden ist.
Aus meiner Sicht bieten allerdings weder Flatpak noch Snap eine optimale Lösung für diese Probleme/Wünsche. Diese Erkenntnis ist nicht neu, ich habe sie in diesem Blog schon mehrfach formuliert. Die Weiterentwicklung beider Formate in den letzten Jahren hat diesbezüglich leider keine spürbaren Verbesserungen mit sich gebracht.
Bei Flatpak sind die Paketgrößen einfach absurd. Bei Snap sind sie auch zu groß, aber es ist nicht ganz so schlimm — zumindest, wenn alle Doppelgänger regelmäßig entfernt werden. Allerdings ist der Snap Store (also die Paketquelle) Closed Source, was die ohnedies schon geringe Akzeptanz nicht verbessert. Das Software-Angebot im Snap Store ist zwar größer als das auf Flathub, aber ich sehe dennoch die Gefahr, dass das Snap-Format eine Insellösung bleibt und Canonical auch mit dieser Eigenentwicklung Schiffbruch erleidet (ich sage nur Upstart Init System, Unity Desktop, Mir Display Server). Während Flatpaks außerhalb der Red-Hat-Welt zumindest als Option genutzt werden, scheint keine Distribution außer Ubuntu etwas mit Snaps zu tun haben wollen.
Letztlich ist meine Meinung natürlich irrelevant. Ubuntu ist aus meiner Sicht nach wie vor eine attraktive Distribution, sowohl am Desktop als auch am Server. Wer Ubuntu verwenden will, muss eben in den Snap-Apfel beißen. Auf einem Rechner mit einer ausreichend großen SSD und genug RAM funktioniert das gut.
Es ist unklar, ob Red Hat sein Flatpak-Format genauso vehement durchsetzen wird. Bis jetzt sieht es nicht so aus, aber es würde mich nicht überraschen, wenn auch Red Hat irgendwann keine Lust mehr hat, eigene RPM-Pakete für Firefox, Thunderbird, Gimp, Libreoffice usw. zu pflegen und parallel für diverse Distributionen (aktuell: RHEL 8/9/10, Fedora 40/41/42/Rawhide etc.) zu warten.
Vielleicht wir man sich / werde ich mic an den verrückten Ressourcenbedarf neuer Paketsysteme gewöhnen. Auf einem Rechner mit 32 GB RAM und 1 TB SSD — keine ungewöhnlichen Eckdaten heutzutage — spielen 10 GB mehr oder weniger für ein paar Flatpaks oder Snap-Pakete ja keine große Rolle … Mir widerspricht es trotzdem: Wenn es möglich ist, ein Auto zu bauen, das mit 5 Liter Treibstoff pro 100 km auskommt, warum dann eines verwenden, das 8 Liter braucht?
Die folgende Geschichte soll mir zur Erinnerung und euch zur Unterhaltung dienen. Sie handelt von CentOS Stream 10, Containern und der Manpagednf(8). Aber lest selbst.
Es war einmal ein Systemadministrator, der beim Training einige Subkommandos von dnf updateinfo kennenlernte, von deren Existenz er bislang nichts wusste. Und diese Subkommandos heißen list, info und summary. Neugierig schaute er in die Manpage dnf(8), doch zu seinem Erstaunen schwieg sich diese zu diesen Subkommandos aus.
Wut stieg in unserem Sysadmin auf. Wieder einmal haben sich die Entwickler keine Mühe gegeben, die Funktionalität ihrer Anwendung vernünftig zu dokumentieren. Die Qualitätssicherung hat geschlafen. So kann man doch nicht arbeiten. Doch nach dem ersten Wutanfall beschloss der Sysadmin, der Sache in Ruhe auf den Grund zu gehen, bevor er diesen Misstand anprangern würde.
Die Distribution des Sysadmins ist dafür bekannt, dass unter bestimmten Umständen Funktionalität von Upstream zurückportiert wird. Vielleicht hatte sich hier eine Diskrepanz eingeschlichen. Vielleicht war dieser Fehler in einer neueren Version ausgemerzt. Um dies schnell zu überprüfen, wollte unser Sysadmin einen Blick in dnf(8) in Centos 10 Stream werfen. Dazu führte er folgende Befehle in einer Kommandozeile aus:
$ podman run --rm -it centos:stream10
[root@01ede4521839 /]# man 8 dnf
bash: man: command not found
[root@01ede4521839 /]#
Mit einem Augenrollen erinnerte sich unser Sysadmin daran, dass Container-Images nur das absolut Notwendige enthalten, um möglichst wenig Speicherplatz auf der Festplatte zu belegen. Darüber, was absolut notwendig ist, werden seit anbeginn des Containerzeitalters philosophische Streitgespräche geführt. Also prüfte unser Sysadmin, ob es einen vertrauten Paketmanager gab, um die Manpages nachzuinstallieren:
[root@01ede4521839 /]# dnf in man-db man-pages
CentOS Stream 10 - BaseOS 2.6 MB/s | 6.2 MB 00:02
CentOS Stream 10 - AppStream 1.5 MB/s | 2.4 MB 00:01
CentOS Stream 10 - Extras packages 3.3 kB/s | 3.5 kB 00:01
Dependencies resolved.
================================================================================
Package Architecture Version Repository Size
================================================================================
Installing:
man-db x86_64 2.12.0-8.el10 baseos 1.3 M
man-pages noarch 6.06-3.el10 baseos 3.7 M
Installing dependencies:
groff-base x86_64 1.23.0-10.el10 baseos 1.1 M
less x86_64 661-3.el10 baseos 191 k
libpipeline x86_64 1.5.7-7.el10 baseos 53 k
Transaction Summary
================================================================================
Install 5 Packages
Total download size: 6.4 M
Installed size: 9.9 M
Is this ok [y/N]:
…
Installed:
groff-base-1.23.0-10.el10.x86_64 less-661-3.el10.x86_64
libpipeline-1.5.7-7.el10.x86_64 man-db-2.12.0-8.el10.x86_64
man-pages-6.06-3.el10.noarch
Complete!
[root@01ede4521839 /]# mandb
Processing manual pages under /usr/share/man...
Updating index cache for path `/usr/share/man/man7'. Wait...mandb: can't resolve man7/groff_man.7
mandb: warning: /usr/share/man/man7/man.7.gz: bad symlink or ROFF `.so' request
mandb: can't resolve man7/groff_man.7
mandb: warning: /usr/share/man/man7/man.man-pages.7.gz: bad symlink or ROFF `.so' request
Updating index cache for path `/usr/share/man/man3type'. Wait...done.
Checking for stray cats under /usr/share/man...
Checking for stray cats under /var/cache/man...
Processing manual pages under /usr/local/share/man...
Updating index cache for path `/usr/local/share/man/mann'. Wait...done.
Checking for stray cats under /usr/local/share/man...
Checking for stray cats under /var/cache/man/local...
45 man subdirectories contained newer manual pages.
2701 manual pages were added.
0 stray cats were added.
0 old database entries were purged.
[root@01ede4521839 /]# man 8 dnf
No manual entry for dnf in section 8
Resultat: Kein which-Befehl verfügbar. Diese Container-Image-Kuratöre sparten aber wirklich an allem. Doch der obige Codeblock enthüllt noch mehr. Zwar war der Paketmanager dnf installiert, auch die Manpages waren nun vorhanden, nur die Manpage dnf(8) fehlte immer noch. Und so bemühte der Sysadmin wieder die Tastatur, um zu prüfen, ob die entsprechende Datei tatsächlich fehlt, welches Paket sie bereitstellt und um das Problem zu lösen. Sehet und staunet:
[root@01ede4521839 /]# stat /usr/share/man/man8/dnf.8.gz
stat: cannot statx '/usr/share/man/man8/dnf.8.gz': No such file or directory
[root@01ede4521839 /]# dnf provides /usr/share/man/man8/dnf.8.gz
…
dnf-4.20.0-9.el10.noarch : Package manager
Repo : baseos
Matched from:
Filename : /usr/share/man/man8/dnf.8.gz
[root@01ede4521839 /]# dnf reinstall dnf
Last metadata expiration check: 0:01:01 ago on Wed Jan 1 14:31:37 2025.
Dependencies resolved.
================================================================================
Package Architecture Version Repository Size
================================================================================
Reinstalling:
dnf noarch 4.20.0-9.el10 baseos 478 k
Transaction Summary
================================================================================
Total download size: 478 k
Installed size: 2.5 M
Is this ok [y/N]:y
…
Reinstalled:
dnf-4.20.0-9.el10.noarch
Complete!
[root@01ede4521839 /]# stat /usr/share/man/man8/dnf.8.gz
File: /usr/share/man/man8/dnf.8.gz -> dnf4.8.gz
Size: 9 Blocks: 8 IO Block: 4096 symbolic link
Device: 0,111 Inode: 6118189 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-10-28 20:00:00.000000000 -0400
Modify: 2024-10-28 20:00:00.000000000 -0400
Change: 2025-01-01 14:32:59.692356995 -0500
Birth: 2025-01-01 14:32:59.691356987 -0500
Überzeugt, dass der Spuk nun ein Ende habe, versuchte es unser Sysadmin erneut:
[root@01ede4521839 /]# man 8 dnf
No manual entry for dnf in section 8
Moment! Die Datei ist da, die Manpage jedoch nicht? Sind hier dunkle Mächte am Werke? Nein, denn wie die folgenden Befehle offenbarten, lag die Ursache lediglich in kaputten Symlinks und fehlenden Paketen:
[root@01ede4521839 /]# ls -l /usr/share/man/man8/dnf.8.gz
lrwxrwxrwx. 1 root root 9 Oct 28 20:00 /usr/share/man/man8/dnf.8.gz -> dnf4.8.gz
[root@01ede4521839 /]# ls -l /usr/share/man/man8/dnf4.8.gz
ls: cannot access '/usr/share/man/man8/dnf4.8.gz': No such file or directory
[root@01ede4521839 /]# dnf provides /usr/share/man/man8/dnf4.8.gz
Last metadata expiration check: 0:05:59 ago on Wed Jan 1 14:31:37 2025.
…
python3-dnf-4.20.0-9.el10.noarch : Python 3 interface to DNF
Repo : baseos
Matched from:
Filename : /usr/share/man/man8/dnf4.8.gz
[root@01ede4521839 /]# dnf list python3-dnf
Last metadata expiration check: 0:06:16 ago on Wed Jan 1 14:31:37 2025.
Installed Packages
python3-dnf.noarch 4.20.0-9.el10 @System
Getrieben von Ungeduld und etwas Frust installierte unser Sysadmin nun auch das Paket python3-dnf.noarch neu, in einem letzten, verzweifelten Versuch, endlich die lang ersehnte Manpage zu erhalten.
[root@01ede4521839 /]# dnf reinstall python3-dnf.noarch
…
Reinstalled:
python3-dnf-4.20.0-9.el10.noarch
Complete!
[root@01ede4521839 /]# man 8 dnf
DNF4(8) DNF DNF4(8)
NAME
dnf4 - DNF Command Reference
SYNOPSIS
dnf [options] <command> [<args>...]
DESCRIPTION
DNF is the next upcoming major version of YUM, a package manager for
RPM-based Linux distributions. It roughly maintains CLI compatibility
with YUM and defines a strict API for extensions and plugins.
Na endlich! Da war sie, die so lang ersehnte und schmerzlich vermisste Manpage. Und die Mühe unseres Sysadmins wurde mit der Erkenntnis belohnt, dass die gesuchte Information auch in dieser Version von dnf(8) nicht enthalten war. Zufrieden wandte sich der Sysadmin nun dem Ticketsystem zu, um zu erfragen, warum die gesuchten Informationen nicht vorhanden sind und um eine Ergänzung anzuregen.
Und wenn er nicht gestorben ist, wartet er noch immer auf eine Antwort.
Im Artikel „Nextcloud-Kalender in Thunderbird einbinden“ habe ich erklärt, wie man seine Nextcloud-Termine im Mail-Client über die CalDAV-Schnittstelle integrieren kann. Das Gleiche funktioniert auch problemlos via CardDAV mit den Kontakten. Wie das geht, beschreibe ich in diesem Artikel.
Vorbereitung in der Nextcloud
Zuerst meldet man sich über die Weboberfläche der Nexcloud an. Dort navigiert man zu den Kontakten und weiter unten links zu den Kontakte-Einstellungen.
Nextcloud – Kontakte-Einstellungen
Von hier wählt man das entsprechende Adressbuch und kopiert den Link.
Im sich öffnenden Fenster Neues CardDAV-Adressbuch gibt man nun den Benutzernamen des Nextcloud-Accounts und den zuvor kopierten Link der CardDAV-Adresse ein.
Thunderbird – Neues CardDAV-Adressbuch
Diesen Vorgang bestätigt man nun mit dem Passwort des Nextcloud-Accounts und OK
Thunderbird – Authentifizierung
und schließt die Einrichtung nach der Auswahl der Verfügbaren Adressbücher mit Weiter ab.
In einer zunehmend digitalisierten Welt gewinnt das Thema Freie Software immer mehr an Bedeutung. Projekte wie Linux, WordPress und Nextcloud zeigen eindrucksvoll, wie leistungsfähig und benutzerfreundlich quelloffene Alternativen zu proprietärer Software sein können. Der Blog intux.de widmet sich seit Jahren genau diesen Themen – praxisnah, verständlich und immer nah an der Community.
Raspberry Pi: Der Einstieg in die Welt der freien Software
Besonders spannend ist der Einsatz eines Raspberry Pi. Der kleine Einplatinenrechner eignet sich hervorragend als Einstieg in die Welt von Open Source. Egal ob als lokaler Webserver für WordPress, als private Cloud mit Nextcloud oder als Linux-Desktop mit Tux als Maskottchen – die Möglichkeiten sind nahezu unbegrenzt.
Mehr Kontrolle dank quelloffener Systeme
Gerade im privaten Bereich bietet freie Software nicht nur Kostenvorteile, sondern auch ein hohes Maß an Selbstbestimmung. Wer Linux nutzt, hat die volle Kontrolle über sein System. Keine versteckten Updates, keine Telemetrie – nur der Code, der sichtbar und nachvollziehbar ist.
intux.de: Erfahrungsberichte und Tipps aus der Community
Der Blog intux.de beleuchtet regelmäßig neue Entwicklungen rund um Linux und andere Open-Source-Projekte. Die Artikel zeichnen sich durch persönliche Erfahrungen, hilfreiche Tipps und einen klaren Fokus auf quelloffene Software aus. So wird die digitale Souveränität für jedermann zugänglich.
Open Source: Eine Bewegung mit Zukunft
Ob als Werkzeug für den Alltag, als Plattform für kreative Projekte oder als Lernobjekt für IT-Interessierte – Open Source ist längst mehr als nur ein Nischenthema. Es ist eine Bewegung, die täglich wächst – und dank Seiten wie intux.de für viele Menschen greifbar und verständlich wird.
Fazit
Freie und quelloffene Software ist längst mehr als nur ein Hobby für Technik-Enthusiasten. Mit Linux, dem Raspberry Pi, WordPress oder Nextcloud stehen leistungsstarke Werkzeuge zur Verfügung, die Unabhängigkeit, Transparenz und Kontrolle über die eigene digitale Umgebung ermöglichen. Projekte wie intux.de zeigen, wie praxisnah und alltagstauglich der Einsatz von Open Source sein kann – ganz ohne Kompromisse bei Funktionalität oder Komfort. Wer bereit ist, sich ein wenig einzuarbeiten, wird mit einem System belohnt, das Freiheit und Technik sinnvoll vereint.
Im digitalen Arbeitsumfeld sind heterogene IT-Strukturen längst zur Realität geworden. Man arbeitet heute in Teams, die Geräte mit unterschiedlichen Betriebssystemen nutzen – Windows, Linux und macOS koexistieren zunehmend selbstverständlich. Dabei stellt sich weniger die Frage, welches System das beste ist, sondern vielmehr, wie man plattformübergreifend sichere Arbeitsbedingungen schafft. Denn jedes Betriebssystem bringt eigene Stärken mit, aber auch spezifische Schwachstellen. Besonders im Kontext verteilter Arbeitsplätze, hybrider Teams und cloudbasierter Prozesse ist es entscheidend, Sicherheitsmaßnahmen nicht isoliert, sondern systemübergreifend zu denken. Nur wenn man versteht, wie die jeweiligen Architekturen funktionieren und wie sie auf technischer wie organisatorischer Ebene zusammenspielen, kann man Risiken minimieren. Der Zugriff auf sensible Daten, Authentifizierungsmethoden oder der Einsatz von Monitoring-Tools – all diese Bereiche müssen strategisch aufeinander abgestimmt werden.
Unterschiedliche Sicherheitsmodelle verstehen – wie man systembedingte Schwächen ausgleicht
Jedes Betriebssystem folgt einer eigenen Sicherheitsphilosophie. Um ein sicheres Zusammenspiel zu gewährleisten, muss man diese zunächst durchdringen. Windows setzt traditionell auf eine zentrale Benutzerverwaltung über Active Directory und nutzt Gruppenrichtlinien zur Durchsetzung von Sicherheitsvorgaben. macOS orientiert sich stark am UNIX-Prinzip der Benutzertrennung und bringt mit Gatekeeper und System Integrity Protection eigene Schutzmechanismen mit. Linux hingegen ist durch seine Offenheit und Modularität geprägt, was eine hohe Anpassbarkeit ermöglicht – aber auch eine größere Verantwortung beim Anwender voraussetzt.
Man darf sich nicht auf die scheinbare „Stärke“ eines Systems verlassen, sondern muss die jeweiligen Lücken kennen. Während Windows anfällig für Malware über unsichere Dienste sein kann, sind bei Linux-Konfigurationen oft Fehlbedienungen ein Einfallstor. macOS wiederum schützt zuverlässig gegen viele Schadprogramme, ist aber nicht gegen Zero-Day-Exploits immun. Die Lösung liegt in der wechselseitigen Kompensation: Man etabliert Prozesse, die die Schwächen eines Systems durch die Stärken eines anderen abfedern. Etwa durch zentrale Netzwerksegmentierung oder rollenbasierte Zugriffskonzepte. Auch einfache Maßnahmen – wie das sichere Hinterlegen und regelmäßige Erneuern eines Windows 11 Keys – tragen ihren Teil dazu bei, potenzielle Angriffsflächen zu minimieren. Wer das Sicherheitsprofil jedes Systems im Detail kennt, kann systemübergreifend robuste Schutzmechanismen implementieren.
Gemeinsame Standards etablieren – wie man durchrichtlinienübergreifende Policies implementiert
In einer Umgebung mit mehreren Betriebssystemen stößt man schnell auf ein Problem: Sicherheitseinstellungen greifen oft nur innerhalb ihrer nativen Plattform. Um dennoch einheitliche Schutzkonzepte umzusetzen, ist es erforderlich, Richtlinienbetrieb systemübergreifend zu denken. Hier kommen sogenannte Cross-Platform-Policies ins Spiel. Diese Sicherheitsrichtlinien sind nicht an ein bestimmtes Betriebssystem gebunden, sondern basieren auf übergeordneten Prinzipien wie Zero Trust, Least Privilege oder Multi-Faktor-Authentifizierung.
Man beginnt mit einer Analyse aller eingesetzten Systeme und deren zentraler Sicherheitsfunktionen. Anschließend definiert man Kernanforderungen – etwa zur Passwortsicherheit, zum Patch-Zyklus oder zur Verschlüsselung von Daten – und setzt diese mithilfe von Tools wie Microsoft Intune, Jamf oder Open Source-Pendants auf allen Plattformen durch. Dabei ist darauf zu achten, dass die Auslegung der Richtlinien nicht zu rigide erfolgt, da gerade bei Linux-Systemen individuelle Konfigurationen notwendig sein können.
Ein praktisches Beispiel ist der Umgang mit Administratorrechten. Unter Windows nutzt man Gruppenrichtlinien, unter Linux sudo-Berechtigungen, unter macOS rollenbasierte Nutzerprofile. Einheitliche Richtlinien sorgen dafür, dass man die Kontrolle über Rechtevergabe und Systemzugriffe auch bei gemischten Umgebungen nicht verliert. Selbst die Lizenzverwaltung, etwa die Zuweisung eines Windows 11 Keys, kann zentral über Plattform-Managementlösungen erfolgen – sicher, nachvollziehbar und auditierbar.
Authentifizierung, Verschlüsselung, Rechtevergabe – worauf man in gemischten Umgebungen achten muss
Die Authentifizierung bildet die erste Sicherheitsbarriere jedes Systems – unabhängig vom Betriebssystem. In einem plattformübergreifenden Setup muss man sicherstellen, dass alle eingesetzten Mechanismen ein gleich hohes Sicherheitsniveau bieten. Single Sign-On (SSO) über Identity Provider wie Azure AD oder Okta hilft, zentrale Identitäten zu verwalten und Systemzugriffe nachvollziehbar zu gestalten. Entscheidend ist, dass man auch Geräte außerhalb der Windows-Welt – etwa unter Linux oder macOS – nahtlos einbindet.
Verschlüsselung ist der zweite Eckpfeiler. Während Windows mit BitLocker arbeitet, setzen viele Linux-Distributionen auf LUKS, und macOS verwendet FileVault. Diese Tools unterscheiden sich in Funktion und Konfiguration, verfolgen jedoch dasselbe Ziel: die Integrität sensibler Daten auf Systemebene zu gewährleisten. Ein ganzheitliches Verschlüsselungskonzept stellt sicher, dass Daten unabhängig vom Endgerät geschützt sind – selbst wenn der physische Zugriff durch Dritte erfolgt.
Rechtevergabe schließlich muss nicht nur sicher, sondern auch nachvollziehbar sein. Unter Windows spielt das Active Directory eine Schlüsselrolle, unter Linux helfen Access Control Lists (ACL), während macOS ebenfalls fein abgestufte Rollenmodelle erlaubt. Die Herausforderung liegt darin, diese Mechanismen so zu verzahnen, dass keine Lücken entstehen.
Endpoint Management und Monitoring – wie man mit zentralen Tools die Kontrolle behält
In modernen Arbeitsumgebungen verlässt man sich nicht mehr auf stationäre IT-Strukturen. Notebooks, Tablets und mobile Geräte bewegen sich außerhalb klassischer Unternehmensnetzwerke. Das macht effektives Endpoint Management zur unverzichtbaren Sicherheitskomponente. Dabei steht man vor der Aufgabe, unterschiedliche Betriebssysteme gleichzeitig zu verwalten – ohne dass die Kontrolle über Konfiguration, Updates oder Zugriffsrechte verloren geht.
Man setzt auf zentrale Managementlösungen wie Microsoft Endpoint Manager, VMware Workspace ONE oder plattformunabhängige Open-Source-Ansätze wie Munki oder Ansible. Diese Tools ermöglichen es, Sicherheitsrichtlinien über Systemgrenzen hinweg auszurollen, Patches zeitnah zu verteilen und Geräte bei Auffälligkeiten sofort zu isolieren. Auch das Monitoring wird damit skalierbar und konsistent. Man erkennt unautorisierte Zugriffe, veraltete Softwarestände oder kritische Konfigurationsabweichungen – unabhängig davon, ob es sich um ein Windows-Notebook, ein Linux-Server-Device oder ein macOS-Arbeitsgerät handelt.
Ein strukturierter Lifecycle-Ansatz gehört ebenfalls dazu. Vom ersten Boot bis zum Offboarding eines Geräts muss nachvollziehbar dokumentiert werden, welche Zugriffe gewährt, welche Daten gespeichert und welche Updates durchgeführt wurden. Selbst administrative Elemente wie das Einpflegen eines Windows 11 Keys lassen sich über diese Plattformen verwalten – revisionssicher, automatisiert und zuverlässig. So wahrt man in komplexen IT-Landschaften jederzeit die Übersicht und bleibt handlungsfähig.
Was bei mir so vor der Eingabe des LUKs Passwortes und dem Starten von Debian vorbeihuschte, hatte mich dann doch einmal interessiert: Kurz und knapp, es ist ein Fehler im BIOS, welcher schon seit 2013 besteht und vom T440 bis an den T460 weitergereicht wurde.Lenovo behebt den Fehler, welcher bekannt ist nicht.Jemand hat den zugehörigen ... Weiterlesen
Wenn es um den Raspberry Pi und DynDNS geht, empfehle ich gerne, wie im Artikel „Nextcloud auf dem RasPi – Teil 4“ beschrieben, als DynDNS-Anbieter den Dienst dnsHome.de. Privatanwender kommen hier in den Genuss, eine kostenlose DynDNS für kleinere Projekte nutzen zu können. Dieser Dienst arbeitet einwandfrei und sorgt dafür, dass u. a. eigene Cloud-Server nach der Zwangstrennung des Internetanbieters stets erreichbar bleiben. Durch den ständigen Abruf der öffentlichen IP und der Übermittlung bei Änderung dieser an den DynDNS-Anbieter wird sichergestellt, dass der Server über eine Subdomain immer erreichbar bleibt.
Darstellung DynDNS. Quelle: Wikipedia
Nun kam es aber bei einer von mir aufgesetzten Installation in einem Telekom-Netz vor, dass die von dnsHome empfohlene Konfiguration
# Configuration file for ddclient generated by debconf
#
# /etc/ddclient.conf
protocol=dyndns2
ssl=yes # Erst ab ddclient Version 3.7 möglich, bitte prüfen
daemon=3600
use=web, web=ip.dnshome.de
server=www.dnshome.de
login=SUBDOMAIN.DOMAIN.TLD
password=PASSWORT
SUBDOMAIN.DOMAIN.TLD
des ddclients nicht funktionierte. Wo lag das Problem? Der Eintrag
web=ip.dnshome.de
ermittelt in diesem Netz nicht wie gewünscht die IPv4-, sondern die IPv6-Adresse und leitet diese an dnsHome weiter. Somit wurde die Verbindung der Subdomain zum Server gestört. Natürlich gibt es auch hierfür eine einfache Lösung. Durch den Austausch des zuvor erwähnten Eintrags durch
Wenn Sie meinen vorigen Blogbeitrag über Hetzner-Cloud-Benchmarks gelesen haben, ist Ihnen vielleicht aufgefallen, dass ich Alma Linux 10 in einer Hetzner-Cloud-Instanz ausgeführt habe, um dort Geekbench-Tests auszuführen. Das war nicht so einfach: Hetzner bietet Alma Linux 10 noch nicht als Installations-Image an. (Update 3.7.2025: mittlerweile schon, sowohl AlmaLinux 10 als auch Rocky Linux 10)
Also habe ich eine neue Instanz zuerst mit Alma Linux 9 eingerichtet und danach mit Elevate ein Update auf Version 10 durchgeführt. Das ist erstaunlich unkompliziert gelungen, obwohl Version-10-Updates eigentlich noch im Beta-Test sind.
Update 10.7.2025: Version-10-Updates werden jetzt offiziell unterstützt (Quelle)
Was ist LEAPP, was ist Elevate?
RHEL und alle Klone durchlaufen über reguläre Updates alle Minor-Releases. Wenn Sie also Alma Linux 9.0 installiert haben, erhalten Sie durch die regelmäßige Installation von Updates nach und nach die Versionen 9.1, 9.2 usw. Ein Update auf die nächste Major-Version ist aber nicht vorgesehen.
Mit LEAPP hat Red Hat ein Framework geschaffen, um Major-Version-Updates für RHEL durchzuführen. LEAPP wurde sehr allgemeingültig konzipiert und kümmert sich um Pre-Upgrade-Kontrollen, Paketabhängigkeiten, den Workflow zwischen verschiedenen Stadien des Upgrades usw.
Elevate ist eine Community-Erweiterung zu LEAPP, die über das eigentliche Upgrade hinaus in manchen Fällen auch einen Wechsel der Paketquellen zwischen Alma Linux, CentOS, Oracle Linux und RockyLinux durchführen kann. Sie können mit Elevate beispielsweise zuerst von CentOS 7 zu RockyLinux 8 migrieren und dann weiter zu Rocky Linux 9 upgraden.
Mögliche Migrationspfade für »Elevate« (Stand: Juni 2026, Bildquelle: https://wiki.almalinux.org/elevate/ELevate-quickstart-guide.html)
Vorbereitungsarbeiten
Bevor Sie Elevate anwenden, müssen Sie ein vollständiges Backup durchführen und Ihren Rechner bzw. Ihre virtuelle Maschine neu starten:
dnf update
reboot
Danach richten Sie eine Paketquelle für Elevate ein und installieren das für Sie relevante Upgrade-Modul (für das Beispiel in diesem Artikel mit der Zieldistribution Alma Linux also leapp-data-almalinux).
dnf install -y http://repo.almalinux.org/elevate/elevate-release-latest-el$(rpm --eval %rhel).noarch.rpm
# für AlmaLinux
dnf install leapp-upgrade leapp-data-almalinux
# alternativ für Rocky Linux (etc.)
dnf install leapp-upgrade leapp-data-rocky
Als nächstes folgt ein Test, ob das gewünschte Upgrade (plus gegebenenfalls eine Migration zu einer anderen Distribution, hier nicht relevant) überhaupt möglich ist:
leapp preupgrade
leapp preupgrade erzeugt zwei Dateien: Einen umfassenden Bericht, der alle möglichen Probleme aufzählt, und eine answer-Datei, in die Sie gegebenenfalls Optionen eintragen müssen (z.B. mit leapp answer --section check_vdo.confirm=True). In meinem Fall — Upgrade einer Minimalinstallation von Alma Linux 9 auf 10, hat leapp preupgrade auf die folgenden Probleme hingewiesen, aber keine answer-Einträge verlangt.
High: veraltete Netzwerkkonfiguration in /etc/sysconfig/network-scripts
High: unbekannte Systemdateien (»Aktoren«)
High: unbekannte Pakete (hc-utils)
Medium: Berkeley DB (libdb) ist installiert, wird in RHEL 10 nicht mehr unterstützt
Low: unbekannten Paket-Repositories
cat /var/log/leapp/leapp-report.txt
Risk Factor: high (inhibitor)
Title: Legacy network configuration found
Summary: Network configuration files in legacy "ifcfg" format are present ...
- /etc/sysconfig/network-scripts/ifcfg-eth0
Related links:
- How to migrate the connection from ifcfg to NetworkManager keyfile plugin?:
https://access.redhat.com/solutions/7083803
- nmcli(1) manual, describes "connection migrate" sub-command.:
https://networkmanager.dev/docs/api/latest/nmcli.html
...
Remediation: [hint] Convert the configuration into NetworkManager native "keyfile" format.
----------------------------------------
Risk Factor: high
Title: Detected custom leapp actors or files.
Summary: We have detected installed custom actors or files on the system.
These can be provided e.g. by third party vendors ... This is allowed
and appreciated. However Red Hat is not responsible for any issues caused
by these custom leapp actors ...
The list of custom leapp actors and files:
- /usr/share/leapp-repository/repositories/system_upgrade/\
common/files/distro/almalinux/rpm-gpg/10/RPM-GPG-KEY-AlmaLinux-10
- /usr/share/leapp-repository/repositories/system_upgrade/\
common/files/rpm-gpg/10/RPM-GPG-KEY-AlmaLinux-10
...
Den vollständigen Report können Sie sich hier durchlesen.
Migration der Netzwerkkonfiguration
Wirklich kritisch war aus meiner Sicht nur die Netzwerkkonfiguration; die restlichen Hinweise und Empfehlungen habe ich ignoriert. Das Paket hc-utils (Hetzner Cloud Utilities) ist nur für Funktionen relevant, die in meinem Fall ohnedies nicht genutzt werden (siehe hier).
Auch die veraltete Netzwerkkonfiguration stammt vom Hetzner-Image für Alma Linux 9. Eine Umstellung auf eine *.nmconnection-Datei für den NetworkManager gelingt erstaunlich unkompliziert mit einem einzigen Kommando:
Mit einem weiteren Reboot habe ich sichergestellt, dass die Umstellung auch funktioniert.
Das Upgrade
leapp upgrade initiiert nun das Upgrade auf Alma Linux 10. Dabei werden seitenweise Logging-Ausgaben produziert (siehe den kompletten Output mit ca. 3150 Zeilen):
leapp upgrade
==> Processing phase `configuration_phase` ...
==> Processing phase `FactsCollection` ...
...
==> Processing phase `TargetTransactionFactsCollection`
Create custom repofile containing information about
repositories found in target OS installation ISO, if used.
Initializes a directory to be populated as a minimal environment
to run binaries from the target system.
AlmaLinux 10.0 - BaseOS 5.9 MB/s | 2.8 MB 00:00
AlmaLinux 10.0 - AppStream 11 MB/s | 5.6 MB 00:00
AlmaLinux 10.0 - CRB 5.0 MB/s | 2.2 MB 00:00
AlmaLinux 10.0 - HighAvailability 161 kB/s | 69 kB 00:00
AlmaLinux 10.0 - Extras 28 kB/s | 12 kB 00:00
AlmaLinux 10.0 - SAP 8.3 kB/s | 3.5 kB 00:00
AlmaLinux 10.0 - SAPHANA 35 kB/s | 15 kB 00:00
AlmaLinux 10.0 - RT 2.8 MB/s | 1.1 MB 00:00
AlmaLinux 10.0 - NFV 2.8 MB/s | 1.1 MB 00:00
Dependencies resolved.
...
Transaction Summary: Install 153 Packages
...
Complete!
==> Processing phase `TargetTransactionCheck`
...
Transaction Summary
Install 63 Packages
Upgrade 389 Packages
Remove 18 Packages
Downgrade 3 Packages
Transaction test succeeded.
Complete!
====> add_upgrade_boot_entry
Add new boot entry for Leapp provided initramfs.
A reboot is required to continue. Please reboot your system.
Debug output written to /var/log/leapp/leapp-upgrade.log
============================================================
REPORT OVERVIEW
============================================================
HIGH and MEDIUM severity reports:
1. Packages not signed by Red Hat found on the system
2. Detected custom leapp actors or files.
3. Berkeley DB (libdb) has been detected on your system
Reports summary:
Errors: 0
Inhibitors: 0
HIGH severity reports: 2
MEDIUM severity reports: 1
LOW severity reports: 2
INFO severity reports: 1
Before continuing, review the full report below for details about discovered
problems and possible remediation instructions:
A report has been generated at /var/log/leapp/leapp-report.txt
A report has been generated at /var/log/leapp/leapp-report.json
============================================================
END OF REPORT OVERVIEW
============================================================
Answerfile has been generated at /var/log/leapp/answerfile
Reboot the system to continue with the upgrade. This might take a while
depending on the system configuration.
Make sure you have console access to view the actual upgrade process.
Jetzt wird es unheimlich: Mit reboot starten Sie die nächste Phase des Upgrade-Prozesses, der im Blindflug erfolgt. Der Rechner bzw. die virtuelle Maschine wird während dieser Phase noch einmal neu gestartet. Wenn Sie nicht vor dem Rechner sitzen, sehen Sie weder, was passiert, noch haben Sie über eine SSH-Verbindung die Möglichkeit, einzugreifen.
reboot
Wenn alles gut geht, können Sie sich nach ein paar Minuten wieder einloggen. Bei mir hat es funktioniert:
Ich habe mit diesem Experiment erreicht, was ich haben wollte: eine funktionierende, minimale Alma-Linux-10-Installation in einer im Internet erreichbaren virtuellen Maschine. Ich kann damit experimentieren. Vermutlich wird Hetzner in ein paar Wochen Alma Linux 10 als reguläres Cloud-Installations-Image anbieten. Dann werde ich diese Installation vermutlich wieder abschalten.
In der Vergangenheit habe ich Elevate auch schon auf lokale virtuelle Maschinen mit (nicht besonders wichtigen) Testumgebungen angewendet, ebenfalls zu meiner Zufriedenheit.
Aber ich würde mich niemals trauen, für ein produktiv wichtiges System auf diese Weise ein Upgrade oder womöglich eine Migration auf eine andere Distribution durchzuführen — und schon gar nicht, wenn ich keinen physischen Zugriff auf die Installation habe. Es kann dabei so viel schief gehen! Es ist unklar, ob danach überhaupt eine Reparatur möglich ist, und wenn ja, wie lange diese dauern würde.
Vergessen Sie zuletzt nicht, dass das Upgrade von Alma Linux 9 auf Version 10 aktuell noch im Beta-Test ist. Bei meinem Minimalsystem hat es funktioniert, aber das ist keine Garantie, dass das bei Ihnen auch klappt!
Kurz und gut: Die Kombination aus LEAPP und Elevate bietet eine großartige Möglichkeit, Major Upgrades für RHEL und seine Klone durchzuführen. Das ist ideal für Entwicklungs- und Testsysteme. Aber wie bei jedem Linux-Distributions-Upgrade kann dabei viel schief gehen. Der sichere Weg für produktiv wichtige Installationen ist immer eine Neuinstallation! Sie können dann in aller Ruhe sämtliche Funktionen testen, zum Schluss die Daten migrieren und mit minimaler Downtime eine Umstellung durchführen.
Die zwei günstigsten Angebote in der Hetzner-Cloud sind Instanzen mit zwei CPU-Cores, 4 GB RAM und 40 GB Diskspace: Einmal mit virtuellen ARM-CPU-Cores (»CAX11«), einmal mit virtuellen x86-Cores (»CX22«). Der Preis ist identisch: 3,95 EUR/Monat inkl. USt (für D) plus ein Aufpreis von 0,50 EUR/Monat für eine IPv4-Adresse. Die naheliegende Frage ist: Welches Angebot gibt mehr Rechenleistung? Dieser Frage bin ich an einem verregneten Pfingstsonntag auf den Grund gegangen.
Ein »virtueller CPU-Core« heißt in diesem Zusammenhang, dass auf einem Server mehrere/viele virtuelle Maschinen laufen. Je nach Auslastung kann es sein, dass die für eine virtuelle Maschine vorgesehen CPU-Cores nicht vollständig verfügbar sind. Es gibt auch virtuelle Maschinen mit dezidierten Cores, die immer zur Verfügung stehen — aber die sind natürlich teurer.
Auswahl verschiedener Cloud-Instanzen
Testbedingungen
Für meine Tests habe ich zwei Cloud-Instanzen mit Alma Linux 9 eingerichtet, einmal mit zwei ARM-CPU-Cores (CAX11), einmal mit zwei x86-CPU-Cores (CX11). Außer tar und Geekbench habe ich keine weitere Software installiert. /proc/cpuinfo lieferte die folgenden Ergebnisse:
cat /proc/cpuinfo # CAX11 / ARM (Ampere)
processor : 0
BogoMIPS : 50.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop asimddp
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x3
CPU part : 0xd0c
CPU revision : 1
processor : 1
...
Geekbench-Ergebnisse
In beiden virtuellen Maschinen habe ich mit wget Geekbench heruntergeladen, mit tar xzf ausgepackt und dann dreimal ausgeführt. Die Ergebnisse:
CX11 / x86 / Alma Linux 9
Single Multi Core
------ -----------
698 1203
692 1207
642 1205
--------------------------
CAX11 / ARM / Alma Linux 9
Single Multi Core
------ -----------
1082 1979
1084 1982
1079 1965
Zuletzt wollte ich noch wissen, ob Alma Linux 10 bei gleicher Hardware mehr Speed liefert (schnellerer Kernel, bessere Optimierung/Kompilierung der Programme etc.). Diese Tests habe ich nur auf der ARM-Instanz durchgeführt.
CAX11 / ARM / Alma Linux 10
Single Multi Core
------ -----------
1078 1971
1069 1963
1077 1974
Zusammenfassung: Bei meinen Tests boten die CAX11-Instanzen bei gleichen Kosten fast 50% mehr Leistung. Alma Linux 9 versus 10 ergibt dagegen keinen messbaren Unterschied.
PS: Geekbench ist noch nicht im IPv6-Zeitalter angekommen. Ist ja auch wirklich eine ganz neue Technologie … Wenn Sie selbst Tests durchführen wollen, müssen Sie die Instanz mit einer IPv4-Adresse konfigurieren. Weder gelingt der Download (das lässt sich umgehen), noch kann ./geekbench6 danach die Ergebnisse hochladen.
Einschränkungen
Bitte überbewerten Sie die Ergebnisse nicht! Die Hetzner-Cloud-Seite gibt keinerlei Informationen darüber, auf welchem Server bzw. auf welcher CPU Ihre virtuellen Maschinen laufen werden. Hetzner hat mehrere Rechenzentren mit unzähligen Server, mit Glück oder Pech landet Ihre virtuelle Maschine auf einem anderen, besser oder schlechter ausgestatteten Server. Das hier präsentierte Ergebnis ist nur eine Momentaufnahme, kein professionell über Wochen durchgeführter Test!
Es erscheint mir unwahrscheinlich, dass zum Testzeitpunkt (Sonntag nachmittag) die Cloud-Server besonders stark ausgelastet waren, aber es ist natürlich denkbar, dass das Ergebnis durch die Aktivität anderer virtueller Maschinen beeinflusst wurde.
Geekbench ist definitiv nicht das Maß der Dinge für Server-Benchmarks. Aber Geekbench lässt sich leicht installieren und ausführen, außerdem sind die Ergebnisse mit Desktop-Hardware vergleichbar. Sagen wir so: Um die CPU-Performance zu vergleichen, sind die Tests aus meiner Sicht gut genug.
Zu guter Letzt habe ich ausschließlich die billigsten Cloud-Angebote verglichen (die bei meinen Anwendungen aber oft ausreichen). Es gibt viele weitere Varianten, z.B. »CPX11« (2 AMD-Cores, nur 2 GB RAM, 40 GB Disk).
Kurz und gut: Dieser Test besagt NICHT, dass ARM immer mehr Leistung als x86 bietet. Zum Zeitpunkt meiner Tests und bei den von mir gewählten Randbedingungen erscheint es aber so, also würden Sie bei preisgünstige Cloud-Instanzen mit ARM-CPUs aktuell mehr Leistung bekommen als bei Instanzen zum gleichen Preis mit x86-Hardware.
Seit einigen Jahren ist CentOS kein produktionstauglicher RHEL-Klon mehr. Wer RHEL produktiv nutzen will, aber nicht dafür bezahlen kann, hat die Qual der Wahl: zwischen AlmaLinux, CentOS Stream (nicht für Langzeitnutzung), Oracle Linux, RHEL via Developer Subscription und Rocky Linux. Ich bin ein wenig zufällig im AlmaLinux-Lager gelandet und habe damit über mehrere Jahre, vor allem im Unterricht, ausgezeichnete Erfahrungen gemacht.
Nach diversen Tests mit der Beta-Version läuft AlmaLinux 10 jetzt nativ auf meinem Mini-PC (AMD 8745H), außerdem die aarch64-Variante in einer virtuellen Maschine auf meinem Mac. Dieser Artikel stellt die neue Version AlmaLinux 10 vor, die am 27. Mai 2025 freigegeben wurde, genau eine Woche nach dem Release von RHEL 10. Die meisten Informationen in diesem Artikel gelten auch für RHEL 10 sowie für die restlichen Klone. Oft beziehe ich mich daher im Text auf RHEL (Red Hat Enterprise Linux), also das zugrundeliegende Original. Es gibt aber auch ein paar feine Unterschiede zwischen dem Original und seinen Klonen.
AlmaLinux 10 mit Gnome Desktop
Ich habe vor, diesen Artikel in den nächsten Wochen zu aktualisieren, wenn ich mehr Erfahrungen mit AlmaLinux 10 gemacht habe und es zu Rocky Linux 10 und Oracle Linux 10 weitere Informationen gibt.
Update 8.6.2025: Der MySQL-Server ist per Default weiterhin offen wie ein Scheunentor.
Update 16.6.2025: Zu Rocky Linux 10 gibt es jetzt auch Release Notes.
Update 16.6.2025: Postfix und BDB vs LMDB
Update 27.6.2025: Oracle Linux 10 ist auch verfügbar, ich habe am Ende des Artikels Links zum Oracle-Blog und zu den Release Notes eingebaut
Update 3.7.2025: Im Hetzner-Cloud-Konfigurator können Sie jetzt auch AlmaLinux 10 und Rocky Linux 10 auswählen. Die Netzwerkkonfiguration erfolgt durch /etc/NetworkManager/system-connections/cloud-init-eth0.nmconnection (nicht mehr durch die veralteten Dateien in /etc/syconfig/network-scripts).
Red Hat hat mit RHEL 10 den X.org-Server aus den Paketquellen entfernt. RHEL setzt damit voll auf Wayland. (Mit XWayland gibt es für X-Client-Programme eine Kompatibilitätsschicht.) Weil RHEL und seine Klone zumeist im Server-Betrieb und ohne grafische Benutzeroberfläche laufen, ist der Abschied von X.org selten ein großes Problem. Einschränkungen können sich aber im Desktop-Betrieb ergeben, vor allem wenn statt Gnome ein anderes Desktop-System eingesetzt werden soll.
Eine Menge wichtiger Desktop-Programme sind aus den regulären Paketquellen verschwunden, unter anderem Gimp und LibreOffice. RHEL empfiehlt, die Programme bei Bedarf aus Flathub zu installieren. Davon abgesehen ist aber kein Wechsel hin zu Flatpaks zu bemerken. flatpak list ist nach einer Desktop-Installation leer.
In der Vergangenheit haben RHEL & Co. von wichtigen Software-Produkten parallel unterschiedliche Versionen ausgeliefert. Dabei setzte RHEL auf das Kommando dnf module. Beispielsweise stellte RHEL 9 Mitte 2025 die PHP-Versionen 8.1, 8.2 und 8.3 zur Auswahl (siehe dnf module list php).
Anscheinend sollen auch in RHEL 10 unterschiedliche Versionen (»AppStreams«) angeboten werden — allerdings nicht mehr in Form von dnf-Modulen. Wie der neue Mechanismus aussieht, habe ich nach dem Studium der Release Notes allerdings nicht verstanden.
Administration und Logging
Wie schon in den vergangenen Versionen setzt RHEL zur Administration auf Cockpit. Die Weboberfläche ist per Default aktiv, nicht durch eine Firewall geschützt und über Port 9090 erreichbar.
Zur Webadministration ist »Cockpit« auf Port 9090 vorgesehen
Bei einer Desktop-Installation sind standardmäßig rsyslog und das Journal installiert. rsyslog protokolliert wie eh und je in Textdateien in /var/log. Das Journal führt dagegen keine persistente Speicherung durch. Die Logging-Dateien landen in einem temporären Dateisystem in /run/log/journal und verschwinden mit jedem Reboot wieder. Wenn Sie ein dauerhaftes Journal wünschen, führen Sie die folgenden Kommandos aus:
Unbegreiflicherweise ist MySQL — jetzt in Version 8.4 — auch in RHEL 10 per Default so konfiguriert, dass jeder Benutzer mit mysql -u root ohne Passwort volle MySQL-Administrationsrechte erhält. Bei Ubuntu erhält per Default nur sudo mysql Admin-Rechte, und bei MariaDB (egal, ob unter Debian, Fedora, RHEL oder Ubuntu) gilt die gleiche Regel. Warum also nicht auch bei RHEL und MySQL?
Wie dem auch sei, das Problem ist nicht neu. Führen Sie also unmittelbar nach der Installation von mysql-server das Kommando mysql_secure_installation aus! Entscheidend ist dabei die Einstellung einen root-Passworts für MySQL.
sudo mysql_secure_installation
Would you like to setup VALIDATE PASSWORD component? y
There are three levels of password validation policy:
LOW Length >= 8
MEDIUM Length >= 8, numeric, mixed case, and special characters
STRONG Length >= 8, numeric, mixed case, special characters,
dictionary file
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 1
Please set the password for root here.
New password: ************
Re-enter new password: ************
Disallow root login remotely? y
Remove test database and access to it? y
Reload privilege tables now? y
Postfix und BDB versus LMDB
RHEL 10 liefert den Mail-Server Postfix in der Version 3.8 aus. Bei früheren RHEL-Versionen hat Postfix Berkeley Datenbanken (BDB) zur Speicherung von Konfigurationstabellen verwendet. Mit RHEL 10 wird allerdings die libdbd-Bibliotheken aufgrund von Lizenzproblemen nicht mehr mitgeliefert. Postfix verwendet jetzt per Default LMDB-Datenbanken:
So weit, so gut. Ich bin beim Versuch, einen Postfix-Server einzurichten, allerdings über die Datei /etc/aliases gestolpert. Bisher was es notwendig, nach jeder Änderung in dieser Datei die entsprechende BDB-Datenbank aliases.db mit dem Kommando newaliases neu zu generieren. Genau dieser Hinweis steht auch in der von RHEL ausgelieferten Beispieldatei /etc/aliases. Und erstaunlicherweise funktioniert das Kommando auch unter RHEL 10. newaliases ist über fünf Links mit /usr/sbin/smtpctl aus dem Paket opensmtpd verbunden und scheint weiterhin BDB-Funktionen zu enthalten, Lizenzsorgen hin oder her.
Das Problem ist allerdings, dass Postfix /etc/aliases.db ignoriert und sich stattdessen darüber beklagt, dass es /etc/aliases.lmdb nicht gibt.
journalctl -u postfix
... postfix/smtpd[56492]: error: open database /etc/aliases.lmdb: No such file or directory
Ich habe eine Weile gebraucht, bis ich einen Weg gefunden habe, aliases.lmdb zu erzeugen. Das richtige Kommando, das newaliases ersetzt, sieht jetzt so aus:
postalias /etc/aliases
Virtualisierung
Red Hat enthält die üblichen qemu/kvm-Pakete als Basis für den Betrieb virtueller Maschinen. Die Steuerung kann wahlweise auf Kommandoebene (virsh) oder mit der Weboberfläche Cockpit erfolgen.
Das wesentlich komfortablere Programm virt-manager hat Red Hat schon vor Jahren als obsolet bezeichnet, und ich hatte Angst, das Programm wäre mit Version 10 endgültig verschwunden. Aber überraschenderweise gibt es das Paket weiterhin im CodeReady-Builder-Repository:
crb enable
dnf install virt-manager
virt-manager ist aus meiner Sicht die einfachste Oberfläche, um virtuelle Maschinen auf der Basis von QEMU/KVM zu verwalten. Red Hat empfiehlt stattdessen Cockpit (dnf install cockpit-machines), aber dieses Zusatzmodul zur Weboberfläche Cockpit hat mich bisher nicht überzeugen können. Für die Enterprise-Virtualisierung gibt es natürlich auch OpenShift und OpenStack, aber für kleine Lösungen schießen diese Angebote über das Ziel hinaus.
Bereits in RHEL 9 hat Red Hat die Unterstützung für Spice (Simple Protocol for Independent Computing Environments) eingestellt (siehe auch dieses Bugzilla-Ticket). Spice wurde/wird von virt-manager als bevorzugtes Protokoll zur Übertragung des grafischen Desktops verwendet. Die Alternative ist VNC.
Abweichend von RHEL wird Spice von AlmaLinux weiter unterstützt (siehe Release Notes).
EPEL (Extra Packages for Enterprise Linux)
Zu den ersten Aktionen in RHEL 10 oder einem Klon gehört die Aktivierung der EPEL-Paketquelle. In AlmaLinux gelingt das einfach mit dnf install epel-release. Es wird empfohlen, zusammen mit EPEL auch die gerade erwähnte CRB-Paketquelle zu aktivieren.
Die EPEL-10-Paketquelle ist mit schon gut gefüllt. dnf repository-packages epel list | wc -l meldet über 17.000 Pakete! Ein paar Pakete habe ich dennoch vermisst:
google-authenticator fehlt noch, ist aber in EPEL 10.1 für Fedora schon enthalten, wird also hoffentlich auch für RHEL10 & Klone bald verfügbar sein.
joe fehlt ebenfalls nicht mehr (Stand 3.7.2025). Ich installiere dieses Editor-Paket gerne, weil es jmacs zur Verfügung stellt, eine minimale Emacs-Variante. Ich bin vorerst auf mg umgestiegen, es entspricht meinen Ansprüchen ebenfalls. (Ich bin kein vi-Fan, und nano ist mir ein bisschen zu minimalistisch. Den »richtigen« Emacs brauche ich aber auch nicht, um zwei Zeilen in /etc/hosts zu ändern.)
AlmaLinux in der Hetzner-Cloud
Hetzner bietet mittlerweile vorkonfigurierte Cloud-Instanzen für AlmaLinux 10 und RockyLinux 10 an. Die einzige wesentliche Neuerung, die mir aufgefallen ist, betrifft die Netzwerkkonfiguration. Während Hetzner bis Version 9 auf die eigentlich dort schon veralteten Dateien in /etc/sysconfig/network-scripts gesetzt hat, kümmert sich jetzt eine NetworkManager-Datei um die Konfiguration. Beispiel:
cat /etc/NetworkManager/system-connections/cloud-init-eth0.nmconnection
# Generated by cloud-init. Changes will be lost.
[connection]
id=cloud-init eth0
uuid=1dd9a779-d327-56e1-8454-c65e2556c12c
autoconnect-priority=120
type=ethernet
[user]
org.freedesktop.NetworkManager.origin=cloud-init
[ethernet]
mac-address=96:00:04:6E:A0:A0
[ipv4]
method=auto
may-fail=false
[ipv6]
method=manual
may-fail=false
address1=2a01:4f8:1c17:53db::1/64
gateway=fe80::1
dns=2a01:4ff:ff00::add:1;2a01:4ff:ff00::add:2;
AlmaLinux versus Original (RHEL)
Im Wesentlichen verwendet AlmaLinux den gleichen Quellcode wie RHEL und ist zu diesem vollständig kompatibel. Es gibt aber ein paar feine Unterschiede:
Seit RHEL den Zugang zum Quellcodes für die Updates erschwert hat (siehe Ärger für Red-Hat-Klone und Red Hat und die Parasiten), greift AlmaLinux auch auf den Upstream-Quellcode einzelner Projekte zu, führt Bugfixes/Sicherheits-Updates zum Teil früher durch als RHEL und besteht nicht mehr auf eine vollständige Bit-für-Bit- und Bug-für-Bug-Kompatibilität. Im Detail ist diese Strategie und das Ausmaß der Kompatibilität hier dokumentiert.
Red Hat hat RHEL 10 für x86_v3 kompiliert, unterstützt damit nur relativ moderne Intel- und AMD-CPUs. Deswegen läuft RHEL 10 auf älteren Computern nicht mehr! Alma Linux macht es ebenso, bietet aber darüber hinaus eine v2-Variante an und unterstützt damit auch ältere Hardware. Die Mikroarchitektur-Unterschiede zwischen v2 und v3 sind z.B. in der Wikipedia sowie auf infotechys.com beschrieben. Das v2-Angebot umfasst auch die EPEL-Paketquelle.
Der Verzicht auf Bit-für-Bit-Kompatibilität gibt AlmaLinux die Möglichkeit, sich in einigen Details vom Original abzuheben. Das betrifft unter anderem die Unterstützung von Frame Pointers als Debugging-Hilfe sowie die fortgesetzte Unterstützung des Protokolls Spice,
AlmaLinux vs RockyLinux und Oracle Linux
In der Vergangenheit waren alle Klone praktisch gleich. Nun gut, Oracle hat immer einen eigenen »unbreakable« Kernel angeboten, aber davon abgesehen war das gesamte Paketangebot Bit für Bit kompatibel zum Original, kompiliert aus den gleichen Quellen. Die Extrapakete aus der EPEL-Quelle sind sowieso für das Original und seine Klone ident.
Seit Red Hat 2023 den Zugriff auf den Source-Code aller Updates eingeschränkt bzw. deutlich weniger unbequemer gemacht hat, haben sich AlmaLinux auf der einen und Rocky Linux und Oracle Linux auf der anderen Seite ein wenig auseinander entwickelt. AlmaLinux hat den Anspruch auf Bit-für-Bit-Kompatibilität aufgegeben (siehe oben). Rocky Linux und Oracle Linux beziehen den Quellcode für Updates hingegen nun aus anderen öffentlichen Quellen, unter anderem aus Cloud- und Container-Systemen (Quelle).
RHEL Developer
Für Entwickler macht Red Hat mit dem Red Hat Developer eigentlich ein attraktives Angebot. Nach einer Registrierung gibt es 16 freie Lizenzen für Tests und Entwicklungsarbeit. Ich habe einen entsprechenden Account, habe RHEL 10 installiert und registriert, bin aber dennoch nicht in der Lage, die Paketquellen zu aktivieren. Vielleicht bin ich zu blöd, vielleicht wird RHEL 10 noch nicht unterstützt (diesbezüglich fehlt klare Dokumentation) — ich weiß es nicht. Ich habe es ein paar Stunden probiert, und ich werde es in ein paar Wochen wieder versuchen. Vorerst fehlt mir dazu aber die Zeit und der Nerv.
Seit vielen Jahren verwende ich Let’s Encrypt-Zertifikate für meine Webserver. Zum Ausstellen der Zertifikate habe ich in den Anfangszeiten das Kommando certbot genutzt. Weil die Installation dieses Python-Scripts aber oft Probleme bereitete, bin ich schon vor vielen Jahren auf das Shell-Script acme.sh umgestiegen (siehe https://github.com/acmesh-official/acme.sh).
Kürzlich bin ich auf einen Sonderfall gestoßen, bei dem acme.sh nicht auf Anhieb funktioniert. Die Kurzfassung: Ich verwende Apache als Proxy für eine REST-API, die in einem Docker-Container läuft. Bei der Zertifikatausstellung/-erneuerung ist Apache (der auf dem Rechner auch als regulärer Webserver läuft) im Weg; die REST-API liefert wiederum keine statischen Dateien aus. Die Domain-Verifizierung scheitert. Abhilfe schafft eine etwas umständliche Apache-Konfiguration.
Ausgangspunkt
Ausgangspunkt ist also ein »gewöhnlicher« Apache-Webserver. Dieser soll nun zusätzlich eine REST-API ausliefern, die in einem Docker-Container läuft (localhost:8880). Die erste Konfiguration sah ziemlich simpel aus:
Das Problem besteht darin, dass acme.sh zwar diverse Domain-Verifizierungsverfahren kennt, aber keines so richtig zu meiner Konfiguration passt:
acme.sh ... --webroot scheitert, weil die API eine reine API ist und keine statischen Dateien ausliefert.
acme.sh ... --standalone scheitert, weil der bereits laufende Webserver Port 80 blockiert.
acme.sh ... --apache scheitert mit could not resolve api.example.com.well-known.
Die Lösung
Die Lösung besteht darin, die Apache-Proxy-Konfiguration dahingehend zu ändern, dass zusätzlich in einem Verzeichnis statische Dateien ausgeliefert werden dürfen. Dazu habe ich das neue Verzeichnis /var/www/acme-challenge eingerichtet:
Danach habe ich die Konfigurationsdatei für Apache umgebaut, so dass Anfragen an api.example.com/.well-known/acme-challenge mit statischen Dateien aus dem Verzeichnis /var/www/acme-challenge/.well-known/acme-challenge bedient werden:
# Apache-Konfiguration wie bisher
<VirtualHost *:443>
ServerName api.example.com
# SSL
SSLEngine on
SSLCertificateFile /etc/acme-letsencrypt/api.example.com.pem
SSLCertificateKeyFile /etc/acme-letsencrypt/api.example.com.key
# Proxy: localhost:8880 <-> api.example.com
ProxyPreserveHost On
ProxyPass / http://localhost:8880/
ProxyPassReverse / http://localhost:8880/
# Logging Konfiguration ...
</VirtualHost>
# geändert: HTTP auf HTTPS umleiten, aber nicht
# für well-known-Verzeichnis
<VirtualHost *:80>
ServerName api.example.com
# Handle ACME challenges locally
Alias /.well-known/acme-challenge /var/www/acme-challenge/.well-known/acme-challenge
<Directory /var/www/acme-challenge/.well-known/acme-challenge>
Require all granted
</Directory>
# Redirect everything EXCEPT ACME challenges to HTTPS
RewriteEngine On
RewriteCond %{REQUEST_URI} !^/.well-known/acme-challenge/
RewriteRule ^(.*)$ https://api.example.com$1 [R=301,L]
</VirtualHost>
Nach diesen Vorbereitungsarbeiten und mit systemctl reload apache2 gelingt nun endlich das Zertifikaterstellen und -erneuern mit dem --webroot-Verfahren. Dabei richtet acme.sh vorübergehend die Datei /var/www/acme-challenge/.well-known/acme-challenge/xxx ein und testet dann via HTTP (Port 80), ob die Datei gelesen werden kann.
Eine noch elegantere Lösung besteht darin, den Docker-Container mit Traefik zu kombinieren (siehe https://traefik.io/traefik/). Bei korrekter Konfiguration kümmert sich Traefik um alles, nicht nur um die Proxy-Funktionen sondern sogar um das Zertifikatsmanagment. Aber diese Lösung kommt nur in Frage, wenn auf dem Host nicht schon (wie in meinem Fall) ein Webserver läuft, der die Ports 80 und 443 blockiert.
Wir schreiben das Jahr 2025. Die Frage, ob man Linux-Server mit oder ohne Swap-Partition betreiben sollte, spaltet die Linux-Gemeinschaft in einer Weise, wie wir es seit dem Editor War nicht mehr gesehen haben…
So könnte ein spannender Film für Sysadmins anfangen, oder? Ich möchte aber keinen Streit vom Zaun brechen, sondern bin an euren Erfahrungen und Gedanken interessiert. Daher freue ich mich, wenn ihr euch die Zeit nehmt, folgende Fragen in den Kommentaren zu diesem Beitrag oder in einem eigenen Blogpost zu beantworten.
Stellt ihr Linux-Server mit Swap-Partition bereit und wie begründet ihr eure Entscheidung?
Hat euch die Swap-Partition bei sehr hoher Speicherlast schon mal die Haut bzw. Daten gerettet?
War der Server während des Swapping noch administrierbar? Falls ja, welche Hardware wurde für die Swap-Partition genutzt?
Eine kleine Mastodon-Umfrage lieferte bisher folgendes Bild:
Schaue ich mir meine eigenen Server an, so ergibt sich ein gemischtes Bild:
Debian mit LAMP-Stack und Containern: 16 GB RAM & kein Swap
RHEL-KVM-Hypervisor 1: 32 GB RAM & 4 GB Swap
RHEL-KVM-Hypervisor 2: 128 GB RAM & kein Swap
RHEL-Container-Host (VM): 4 GB RAM & 4 GB Swap
Bis auf den Container-Host handelt es sich um Bare-Metal-Server.
Ich kann mich nicht daran erinnern, dass jemals einem dieser Systeme der Hauptspeicher ausgegangen ist oder der Swapspeicher genutzt worden wäre. Ich erinnere mich, zweimal Swapping auf Kunden-Servern beobachtet zu haben. Die Auswirkungen waren wie folgt.
Im ersten Fall kamen noch SCSI-Festplatten im RAID zum Einsatz. Die Leistung des Gesamtsystems verschlechterte sich durch das Swapping so stark, dass bereitgestellten Dienste praktisch nicht mehr verfügbar waren. Nutzer erhielten Zeitüberschreitungen ihrer Anfragen, Sitzungen brachen ab und das System war nicht mehr administrierbar. Am Ende wurde der Reset-Schalter gedrückt. Das Problem wurde schlussendlich durch eine Vergrößerung des Hauptspeichers gelöst.
Im zweiten Fall, an den ich mich erinnere, führte ein für die Nacht geplanter Task zu einem erhöhten Speicherverbrauch. Hier hat Swapping zunächst geholfen. Tasks liefen zwar länger, wurden aber erfolgreich beendet und verwendeter Hauptspeicher wurde anschließend wieder freigegeben. Hier entstand erst ein Problem, als der Speicherbedarf größer wurde und die Swap-Partition zu klein war. So kam es zum Auftritt des Out-of-Memory-Killer, der mit einer faszinierenden Genauigkeit immer genau den Prozess abgeräumt hat, den man als Sysadmin gern behalten hätte. Auch hier wurde das Problem letztendlich durch eine Erweiterung des Hauptspeichers gelöst.
Ich erinnere mich auch noch an die ein oder andere Anwendung mit einem Speicherleck. Hier hat vorhandener Swap-Speicher das Leid jedoch lediglich kurz verzögert. Das Problem wurde entweder durch einen Bugfix oder den Wechsel der Anwendung behoben.
Nun bin ich auf eure Antworten und Erfahrungsberichte gespannt.
Seit über zwölf Jahren beschäftige ich mich intensiv mit Linux-Servern. Der Einstieg gelang mir über den Einplatinencomputer Raspberry Pi. Erste Erfahrungen sammelte ich damals mit XBMC – heute besser bekannt als Kodi. Dabei handelt es sich um eine freie, plattformübergreifende Mediaplayer-Software, die dank ihrer Flexibilität und Erweiterbarkeit schnell mein Interesse an quelloffener Software weckte.
Schnell wurde mir klar, dass der Raspberry Pi weit mehr kann. So folgten bald weitere spannende Projekte, darunter auch die ownCloud. Das von Frank Karlitschek gegründete Unternehmen entwickelte eine Cloud-Software, die nicht nur quelloffen war, sondern sich auch problemlos auf Systemen wie Debian oder Ubuntu installieren ließ. Die Möglichkeit, eigene Dateien auf einem selbst betriebenen Server zu speichern und zu synchronisieren, war ein überzeugender Schritt in Richtung digitaler Eigenverantwortung.
Im Jahr 2016 verließ Karlitschek ownCloud, forkte das Projekt und gründete die Firma Nextcloud. Diese erfreut sich bis heute großer Beliebtheit in der Open-Source-Community. Nextcloud bietet neben der klassischen Dateisynchronisation auch zahlreiche Erweiterungen wie Kalender, Kontakte, Videokonferenzen und Aufgabenverwaltung. Damit positioniert sich die Lösung als vollwertige Alternative zu kommerziellen Diensten wie Google Workspace oder Microsoft 365 – mit dem entscheidenden Unterschied, dass die Datenhoheit beim Nutzer selbst bleibt.
Debian vs. Ubuntu
Nextcloud lässt sich auf Debian- und Ubuntu-Systemen relativ unkompliziert auf einem klassischen LAMP-Stack installieren. Doch welches System die bessere Wahl ist, lässt sich pauschal nicht sagen – beide bringen ihre jeweiligen Stärken und Schwächen mit. Debian gilt als besonders stabil und konservativ, was es ideal für Serverumgebungen macht. Ubuntu hingegen punktet mit einem häufig aktuelleren Softwareangebot und einem umfangreicheren Hardware-Support.
Da das Betriebssystem des Raspberry Pi stark an Debian angelehnt ist, läuft die Cloud-Software auch auf dieser Plattform nach wie vor sehr stabil – inzwischen sogar in einer 64-Bit-Variante. Häufiger Flaschenhals ist hier jedoch nicht die Software selbst, sondern die Internetanbindung. Insbesondere der Upstream kann bei vielen DSL-Verbindungen zur Herausforderung werden, wenn größere Datenmengen übertragen werden sollen. Ein Blick in Richtung Virtual Private Server kann sich lohnen.
Virtual Private Server
Wer eine Nextcloud im eigenen Zuhause betreiben möchte, ist mit einem Raspberry Pi gut beraten. Doch Mini-PCs mit Debian oder Ubuntu bieten aufgrund ihrer Bauform – etwa durch die Möglichkeit, mehrere SSDs aufzunehmen – oft eine noch bessere Alternative. Hinzu kommt der Vorteil, dass auch Dienste wie automatische Backups oder RAID-Systeme einfacher umzusetzen sind.
Will man jedoch weitere Dienste auf dem Server betreiben, wie etwa WordPress für die eigene Webseite oder einen Mailserver für den E-Mail-Verkehr, stößt man mit einem Mini-Computer schnell an Grenzen. In solchen Fällen ist ein Virtual Private Server, kurz VPS, die bessere Wahl. Leistungsfähige Angebote wie ein passendes VPS von IONOS, Hetzner oder Netcup machen ein solches Vorhaben inzwischen auch für Privatnutzer bezahlbar. VPS bieten dabei nicht nur mehr Leistung, sondern auch eine höhere Verfügbarkeit, da die Anbindung an das Internet in der Regel professionell realisiert ist.
Fazit
Wer eigene Dienste wie Cloud, Website oder E-Mail in Selbstverwaltung hosten möchte, kann dies mit überschaubarem Aufwand zu Hause mit Open-Source-Software umsetzen. Reicht die Leistung nicht aus, ist ein Virtual Private Server (VPS) eine sinnvolle Alternative.
Der administrative Aufwand sollte dabei nicht unterschätzt werden. Regelmäßige Updates, Backups und Sicherheitskonfigurationen gehören ebenso zum Betrieb wie ein grundlegendes Verständnis für die eingesetzten Komponenten. Doch der entscheidende Vorteil bleibt: Die Kontrolle über die eigenen Daten liegt vollständig in der eigenen Hand – ein wichtiger Schritt hin zur digitalen Souveränität. Open Source baut hier nicht nur funktionale, sondern auch ideelle Brücken.
Viele Anwender haben lange darauf gewartet – GIMP ist nach fast sechs Jahren Entwicklungszeit in Version 3 erschienen. Dieses Release bringt einen komplett überarbeiteten Kern mit sich und setzt nun auf das GTK3-Toolkit. Das Buch „GIMP 3: Das umfassende Handbuch“ bietet – wie der Name schon verrät – ein umfassendes Nachschlagewerk zum GNU Image Manipulation Program, kurz: GIMP.
Das Buch ist in sieben Teile gegliedert.
Teil I – Grundlagen widmet sich, wie der Titel schon sagt, den grundlegenden Funktionen von GIMP. Der Autor erläutert die Oberfläche des Grafikprogramms und stellt dabei heraus, dass sich Nutzer auch in der neuen Version schnell zurechtfinden – ein Hinweis, der mögliche Bedenken beim Umstieg zerstreuen dürfte. Die Aussage „GIMP ist nicht Photoshop“ von Jürgen Wolf ist prägnant und unterstreicht, dass es sich bei GIMP um ein eigenständiges, leistungsfähiges Programm handelt, das keinen direkten Vergleich mit kommerzieller Software scheuen muss – oder sollte. Zahlreiche Workshops mit umfangreichem Zusatzmaterial begleiten die einzelnen Kapitel. Neben der Benutzeroberfläche werden in Teil I auch Werkzeuge und Dialoge ausführlich erklärt. Darüber hinaus wird beschrieben, wie RAW-Aufnahmen in GIMP importiert und weiterverarbeitet werden können. Ebenso finden sich Anleitungen zum Speichern und Exportieren fertiger Ergebnisse sowie Erläuterungen zu den Unterschieden zwischen Pixel- und Vektorgrafiken (siehe Grafik). Auch Themen wie Farben, Farbmodelle und Farbräume werden behandelt – Letzteres wird im dritten Teil des Buches noch einmal vertieft.
Vektorgrafik vs. Pixelgrafik
Teil II – Die Bildkorrektur behandelt schwerpunktmäßig die Anpassung von Helligkeit, Kontrast und anderen grundlegenden Bildeigenschaften. Ein wesentlicher Abschnitt widmet sich der Verarbeitung von RAW-Aufnahmen, wobei das Zusammenspiel von GIMP mit Darktable im Mittelpunkt steht. Zahlreiche Beispiele und praxisnahe Bearbeitungshinweise unterstützen den Leser bei der Umsetzung am eigenen Bildmaterial.
Teil III – Rund um Farbe und Schwarzweiß beschreibt den Umgang mit Farben und erläutert grundlegende Konzepte dieses Themenbereichs. Dabei wird auch der Einsatz von Werkzeugen wie Pinsel, Stift und Sprühpistole behandelt. Darüber hinaus zeigt das Kapitel, wie Farben verfremdet und Schwarzweißbilder erstellt werden können.
Teil IV – Auswahlen und Ebenen führt den Leser in die Arbeit mit Auswahlen und Ebenen ein. Besonders faszinierend ist dabei das Freistellen von Objekten und die anschließende Bildmanipulation – eine Disziplin, die GIMP hervorragend beherrscht. Auch hierzu bietet das Buch eine Schritt-für-Schritt-Anleitung in Form eines Workshops.
Teil V – Kreative Bildgestaltung und Retusche erklärt, was sich hinter Bildgröße und Auflösung verbirgt und wie sich diese gezielt anpassen lassen. Techniken wie der „Goldene Schnitt“ werden vorgestellt und angewendet, um Motive wirkungsvoll in Szene zu setzen. Außerdem zeigt das Kapitel, wie sich Objektivfehler – etwa tonnen- oder kissenförmige Verzeichnungen – sowie schräg aufgenommene Horizonte korrigieren lassen. Die Bildverbesserung und Retusche werden ausführlich behandelt. Vorgestellte Techniken wie die Warptransformation sind unter anderem in der Nachbearbeitung von Werbefotografie unverzichtbar.
Retusche – Warptransformation
Teil VI – Pfade, Text, Filter und Effekte beschäftigt sich mit den vielfältigen Möglichkeiten, die GIMP für die Arbeit mit Pixel- und Vektorgrafiken bietet. So lassen sich beispielsweise Pixelgrafiken nachzeichnen, um daraus Vektoren bzw. Pfade für die weitere Bearbeitung zu erzeugen. Eine weitere Übung, die sich mit der im Handbuch beschriebenen Methode leicht umsetzen lässt, ist der sogenannte Andy-Warhol-Effekt.
Andy-Warhol-Effekt
Teil VII – Ausgabe und Organisation zeigt, wie der Leser kleine Animationen im WebP- oder GIF-Format erstellen kann. Auch worauf beim Drucken und Scannen zu achten ist, wird in diesem Kapitel ausführlich erläutert. Jürgen Wolf geht zudem noch einmal umfassend auf die verschiedenen Einstellungen in GIMP ein. Besonders hilfreich ist die Auflistung sämtlicher Tastaturkürzel, die die Arbeit mit dem Grafikprogramm spürbar erleichtern.
Das Buch umfasst insgesamt 28 Kapitel und deckt damit alle wichtigen Bereiche der Bildbearbeitung mit GIMP 3 ab.
„GIMP 3: Das umfassende Handbuch“ von Jürgen Wolf überzeugt durch eine klare Struktur, verständliche Erklärungen und praxisnahe Workshops. Sowohl Einsteiger als auch fortgeschrittene Anwender finden hier ein zuverlässiges Nachschlagewerk rund um die Bildbearbeitung mit GIMP. Besonders hervorzuheben sind die zahlreichen Beispiele sowie die umfassende Behandlung aller relevanten Themenbereiche. Wer ernsthaft mit GIMP arbeiten möchte, findet in diesem Buch eine uneingeschränkte Kaufempfehlung.
Der SSH-Dienst ist ein natürliches Angriffsziel jedes Servers. Klassische Abwehrmaßnahmen zielen darauf aus, den root-Login zu sperren (das sollte eine Selbstverständlichkeit sein) und mit Fail2ban wiederholte Login-Versuche zu blockieren. Eine weitere Sicherheitsmaßnahme besteht darin, den Passwort-Login mit einer Zwei-Faktor-Authentifizierung (2FA) zu verbinden. Am einfachsten gelingt das server-seitig mit dem Programm google-authenticator. Zusätzlich zum Passwort muss nun ein One-time Password (OTP) angegeben werden, das mit einer entsprechenden App generiert wird. Es gibt mehrere geeignete Apps, unter anderem Google Authenticator und Authy (beide kostenlos und werbefrei).
Es gibt verschiedene Konfigurationsoptionen. Ziel dieser Anleitung ist es, parallel zwei Authentifizierungsvarianten anzubieten:
mit SSH-Schlüssel (ohne 2FA)
mit Passwort und One-time Password (also mit 2FA)
Links die App »Google Authenticator«, rechts »Authy«
Grundlagen: sshd-Konfiguration
Vorweg einige Worte zu Konfiguration des SSH-Servers. Diese erfolgt durch die folgenden Dateien:
Verwechseln Sie sshd_config nicht mit ssh_config (ohne d) für die Konfiguration des SSH-Clients, also für die Programme ssh und scp! opensshserver.config legt fest, welche Verschlüsselungsalgorithmen erlaubt sind.
Beachten Sie, dass bei Optionen, die in den sshd-Konfigurationsdateien mehrfach eingestellt sind, der erste Eintrag gilt (nicht der letzte)! Das gilt auch für Einstellungen, die am Beginn von sshd_config mit Include aus dem Unterverzeichnis /etc/ssh/sshd_config.d/ gelesen werden und die somit Vorrang gegenüber sshd_config haben.
Werfen Sie bei Konfigurationsproblemen unbedingt auch einen Blick in das oft übersehene sshd_config.d-Verzeichnis und vermeiden Sie Mehrfacheinträge für ein Schlüsselwort!
Weil die Dateien aus /etc/ssh/sshd_config.d/ Vorrang gegenüber sshd_config haben, besteht eine Konfigurationsstrategie darin, sshd_config gar nicht anzurühren und stattdessen alle eigenen Einstellungen in einer eigenen Datei (z.B. sshd_config.d/00-myown.conf) zu speichern. 00 am Beginn des Dateinamens stellt sicher, dass die Datei vor allen anderen Konfigurationsdateien gelesen wird.
Überprüfen Sie bei Konfigurationsproblemen mit sshd -T, ob die Konfiguration Fehler enthält. Wenn es keine Konflikte gibt, liefert sshd -T eine Auflistung aller aktuell gültigen Einstellungen. Die Optionen werden dabei in Kleinbuchstaben angezeigt. Mit grep -i können Sie die für Sie relevante Einstellung suchen:
sshd -T | grep -i permitro
permitrootlogin yes
Änderungen an sshd_config werden erst wirksam, wenn der SSH-Server die Konfiguration neu einliest. Dazu führen Sie das folgende Kommando aus:
Google Authenticator bezeichnet zwei unterschiedliche Programme: einerseits die App, die sowohl für iOS als auch für Android verfügbar ist, andererseits ein Linux-Kommando, um die 2FA auf einem Linux-Server einzurichten. Während der Code für die Smartphone-Apps nicht öffentlich ist, handelt es sich bei dem Linux-Kommando um Open-Source-Code. Das resultierende Paket steht für RHEL-Distributionen in der EPEL-Paketquelle zur Verfügung, bei Ubuntu in universe.
Nach der Installation führen Sie für den Account, als der Sie sich später via SSH anmelden möchten (also nicht für root), das Programm google-authenticator aus. Nachdem Sie den im Terminal angezeigten QR-Code gescannt haben, sollten Sie zur Kontrolle sofort das erste OTP eingeben. Sämtliche Rückfragen können Sie mit y beantworten. Die Rückfragen entfallen, wenn Sie das Kommando mit den Optionen -t -d -f -r 3 -R 30 -W ausführen. Das Programm richtet die Datei .google-authenticator im Heimatverzeichnis ein.
user$ google-authenticator
Do you want authentication tokens to be time-based (y/n)
Enter code from app (-1 to skip): nnnnnn
Do you want me to update your .google_authenticator file? (y/n)
Do you want to disallow multiple uses of the same
authentication token? (y/n)
...
Zum Einrichten wird das Kommando »google-authenticator« im Terminal ausgeführt. Den QR-Code scannen Sie dann mit der OTP-App Ihrer Wahl ein. (Keine Angst, der hier sichtbare QR-Code stammt nicht von einem öffentlich zugänglichen Server. Er wurde vielmehr testweise in einer virtuellen Maschine erzeugt.)
SSH-Server-Konfiguration
Das nächste Listing zeigt die erforderlichen sshd-Einstellungen. Mit der Methode keyboard-interactive wird PAM für die Authentifizierung verwendet, wobei auch eine mehrstufige Kommunikation erlaubt ist. Die ebenfalls erforderliche Einstellung UsePAM yes gilt bei den meisten Linux-Distributionen standardmäßig. Am besten speichern Sie die folgenden Zeilen in der neuen Datei /etc/ssh/sshd_config.d/00-2fa.conf. Diese wird am Beginn der sshd-Konfiguration gelesen und hat damit Vorrang gegenüber anderen Einstellungen.
# Datei /etc/ssh/sshd_config.d/00-2fa.conf
UsePAM yes
PasswordAuthentication yes
PubkeyAuthentication yes
ChallengeResponseAuthentication yes
# Authentifizierung wahlweise nur per SSH-Key oder
# mit Passwort + OTP
AuthenticationMethods publickey keyboard-interactive
PAM-Konfiguration
Der zweite Teil der Konfiguration erfolgt in /etc/pam.d/sshd. Am Ende dieser Datei fügen Sie eine Zeile hinzu, die zusätzlich zu allen anderen Regeln, also zusätzlich zur korrekten Angabe des Account-Passworts, die erfolgreiche Authentifizierung durch das Google-Authenticator-Modul verlangt:
# am Ende von /etc/pam.d/sshd (Debian, Ubuntu)
...
# Authenticator-Zifferncode zwingend erforderlich
auth required pam_google_authenticator.so
Alternativ ist auch die folgende Einstellung mit dem zusätzlichen Schlüsselwort nullok denkbar. Damit akzeptieren Sie einen Login ohne 2FA für Accounts, bei denen Google Authenticator noch nicht eingerichtet wurde. Sicherheitstechnisch ist das natürlich nicht optimal — aber es vereinfacht das Einrichten neuer Accounts ganz wesentlich.
# am Ende von /etc/pam.d/sshd (Debian, Ubuntu)
...
# Authenticator-Zifferncode nur erforderlich, wenn
# Google Authenticator für den Account eingerichtet wurde
auth required pam_google_authenticator.so nullok
Wenn Sie RHEL oder einen Klon verwenden, sieht die PAM-Konfiguration ein wenig anders aus. SELinux verbietet dem SSH-Server Zugriff auf Dateien außerhalb des .ssh-Verzeichnisses. Deswegen müssen Sie die Datei .google-authenticator vom Home-Verzeichnis in das Unterverzeichnis .ssh verschieben. restorecon stellt sicher, dass der SELinux-Kontext für alle Dateien im .ssh-Verzeichnis korrekt ist.
user$ mv .google-authenticator .ssh/ (nur unter RHEL!)
user$ restorecon .ssh
In der Zeile auth required übergeben Sie nun als zusätzliche Option den geänderten Ort von .google-authenticator. Falls Sie die nullok-Option verwenden möchten, fügen Sie dieses Schlüsselwort ganz am Ende hinzu.
# am Ende von /etc/pam.d/sshd (RHEL & Co.)
...
auth required pam_google_authenticator.so secret=/home/${USER}/.ssh/.google_authenticator
Test und Fehlersuche
Passen Sie auf, dass Sie sich nicht aus Ihrem Server aussperren! Probieren Sie das Verfahren zuerst in einer virtuellen Maschine aus, nicht auf einem realen Server!
Vergessen Sie nicht, die durchgeführten Änderungen zu aktivieren. Vor ersten Tests ist es zweckmäßig, eine SSH-Verbindung offen zu lassen, damit Sie bei Problemen die Einstellungen korrigieren können.
Bei meinen Tests hat sich die Google-Authenticator-Konfiguration speziell unter RHEL als ziemlich zickig erwiesen. Beim Debugging können Sie client-seitig mit ssh -v, server-seitig mit journalctl -u sshd nach Fehlermeldungen suchen.
Die Anwendung von Google Authenticator setzt voraus, dass die Uhrzeit auf dem Server korrekt eingestellt ist. Die One-Time-Passwords gelten nur in einem 90-Sekunden-Fenster! Das sollten Sie insbesondere bei Tests in virtuellen Maschinen beachten, wo diese Bedingung mitunter nicht erfüllt ist (z.B. wenn die virtuelle Maschine pausiert wurde). Stellen Sie die Zeit anschließend neu ein, oder starten Sie die virtuelle Maschine neu!
Was ist, wenn das Smartphone verlorengeht?
Für den Fall, dass das Smartphone und damit die zweite Authentifizierungsquelle verlorengeht, zeigt das Kommando google-authenticator bei der Ausführung fünf Ziffernfolgen an, die Sie einmalig für einen Login verwendet können. Diese Codes müssen Sie notieren und an einem sicheren Ort aufbewahren — dann gibt es im Notfall einen »Plan B«. (Die Codes sind auch in der Datei .google_authenticator enthalten. Auf diese Datei können Sie aber natürlich nicht mehr zugreifen, wenn Sie keine Login-Möglichkeit mehr haben.)
Die App Google Authenticator synchronisiert die 2FA-Konfiguration automatisch mit Ihrem Google-Konto. Die 2FA-Konfiguration kann daher auf einem neuen Smartphone rasch wieder hergestellt werden. Schon eher bereitet Sorge, dass nur die Kenntnis der Google-Kontodaten ausreichen, um Zugang zur 2FA-Konfiguration zu erhalten. Die Cloud-Synchronisation kann in den Einstellungen gestoppt werden.
Auch Authy kann die 2FA-Konfiguration auf einem Server der Firma Twilio speichern und mit einem weiteren Gerät synchronisieren. Anders als bei Google werden Ihre 2FA-Daten immerhin mit einem von Ihnen zu wählenden Passwort verschlüsselt. Mangels Quellcode lässt sich aber nicht kontrollieren, wie sicher das Verfahren ist und ob es den Authy-Betreibern Zugriff auf Ihre Daten gewährt oder nicht. 2024 gab es eine Sicherheitspanne bei Twilio, bei der zwar anscheinend keine 2FA-Daten kompromittiert wurden, wohl aber die Telefonnummern von 35 Millionen Authy-Benutzern.
Sicherheits- und Privacy-Bedenken
Authenticator-Apps funktionieren prinzipiell rein lokal. Weder der beim Einrichten erforderliche Schlüssel bzw. QR-Code noch die ständig generierten Einmalcodes müssen auf einen Server übertragen werden. Die Apps implementieren den öffentlich standardisierten HMAC-based One-Time Password Algorithmus (OATH-HOTP).
Allerdings bieten einige OTP-Apps die Möglichkeit, die Account-Einträge über ein Cloud-Service zu sichern (siehe oben). Diese Cloud-Speicherung ist eine mögliche Sicherheitsschwachstelle.
Davon losgelöst gilt wie bei jeder App: Sie müssen der Firma vertrauen, die die App entwickelt hat. Der Code der App Google Authenticator war ursprünglich als Open-Source verfügbar, seit 2020 ist das leider nicht mehr der Fall. Wenn Sie weder Google Authenticator noch Authy vertrauen, finden Sie im Arch Linux Wiki Links zu Apps, deren Code frei verfügbar ist.
Heute möchte ich kurz erzählen, welche Schwierigkeiten ich beim Upgrade auf Nextcloud 31 Hub 10 zu bewältigen hatte.
Das Upgrade auf Nextcloud 31 war in meinem Fall mal wieder von einigen Hürden umstellt. Meine ersten Versuche, die Nextcloud auf Version 31.0.0 Stable zu heben, waren zwar von Erfolg gekrönt, jedoch sperrte ich damit meinen WebAuthn-Zugang zu meinen Daten. Weitere Versuche bei den Neuerscheinungen 31.0.1 und 31.0.2 liefen ebenfalls ins Leere.
Nun, mit Version 31.0.3, wurde das WebAuthn-Problem jedoch gefixt. Nach der Reparatur der Datenbank und dem Einspielen fehlender Indizes blieb noch eine zu beseitigende Fehlermeldung übrig. Es handelt sich um ein falsches Zeilenformat in der Datenbank.
Dieser Konflikt kann aber schnell gelöst werden, indem man ein Skript mit folgendem Inhalt erstellt und dieses im Nachgang im Home-Verzeichnis ausführt. Dazu wechselt man in dieses:
cd ~/
Dann öffnet man den Editor:
sudo nano database.sh
fügt folgenden Inhalt ein und speichert mit Ctrl + o:
#!/bin/bash
# Prompt for database credentials
read -p "Enter Database Name: " DB_NAME
read -p "Enter Username: " DB_USER
read -s -p "Enter Password: " DB_PASS
echo
# Generate ALTER TABLE statements and execute them
mysql -u "$DB_USER" -p"$DB_PASS" -e "
SELECT CONCAT('ALTER TABLE `', TABLE_NAME, '` ROW_FORMAT=DYNAMIC;')
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = '$DB_NAME'
AND ENGINE = 'InnoDB';
" -B -N | while read -r sql; do
mysql -u "$DB_USER" -p"$DB_PASS" -e "$sql" "$DB_NAME"
done
Mit Ctrl + x verlässt man den Editor wieder. Nun wird das Skript mit
sudo chmod +x database.sh
ausführbar gemacht und mit
sudo ./database.sh
gestartet. Während der Ausführung werden Datenbankname, Benutzername und Passwort abgefragt. Sind die Eingaben richtig, sind die Datenbank am Ende gefixt und die Fehlermeldung verschwunden.
Hardware-Tests sind eigentlich nicht meine Spezialität, aber wenn ich schon einmal ein neues Gerät kaufe, kann es nicht schaden, ein paar Sätze zur Linux-Kompatibilität zu schreiben. Die Kurzfassung: relativ hohe Leistung fürs Geld, inkl. Windows-Pro-Lizenz, erweiterbar. Leise, aber nie lautlos. Weitestgehend Linux-kompatibel (Ausnahmen: WLAN, Bluetooth).
Kurz die Ausgangslage: Ich besitze zwei Notebooks, ein Lenovo P1 für Linux und ein MacBook. Mein Windows-PC, den ich gelegentlich zum Testen brauche, hat dagegen seine planmäßige Lebensdauer schon lange überschritten — lahm, nur SATA-SSDs, inkompatibel zu aktuellen Windows-Releases. Zielsetzung war, dafür Ersatz zu schaffen. Aus Platzgründen kein drittes Notebook. Ich wollte ein vorinstalliertes Windows-Pro, mit dem ich mich nicht über die Maßen ärgern muss, einen Slot für eine zweite PCIe-SSD, damit ich parallel Linux installieren kann, eine AMD-CPU mit ordentlicher Rechenleistung und ausreichend RAM für Virtualisierung, Docker & Co. Ein zugängliches BIOS (leider nicht ganz selbstverständlich.) Außerdem sollte das Ding einigermaßen leise sein.
Nach etwas Recherche ist es ein Minisforum UM 870 mit AMD 8745H (Ryzen 7) geworden. 32 GB RAM, 1 TB SSD (plus 1 Slot frei), 2,5 GB Ethernet, 1xUSB-C, 4xUSB-A, HDMI, Displayport, WIFI 6, Bluetooth. Preis zum Zeitpunkt des Kaufs: EUR 550
Also im Prinzip ein »typischer« Mini-PC im mittleren Preissegment. Es gibt billigere Modelle, die aber meist eine langsamere CPU und keinen freien PCIe-Slot haben. Es gibt teurere Modelle mit noch mehr Leistung (verbunden mit mehr Lärm). Für meine Anforderungen erschien mir das Modell genau richtig.
Das Gehäuse lässt sich mühelos mit vier Schrauben öffnen. Die Schrauben sind allerdings unter angeklebten Gumminoppen versteckt. Diese Noppen leiden bei der Demontage etwas, bleiben aber verwendbar. (Minisforum liefert zwei Ersatznoppen mit. An sich sehr nett, aber warum nicht gleich vier?) Der Einbau der zweiten SSD gelang mühelos. Die SSD war bisher in meinem Notebook im Einsatz. Dort hatte ich Ubuntu und Fedora installiert. Beim nächsten Reboot tauchten beide Linux-Distributionen im Bootmenü auf und ließen sich anstandslos starten. Das ist Linux wie ich es liebe!
Zum Öffnen des Gehäuses müssen vier Gumminoppen entfernt werdenDas Innenleben mit den ausgelieferten Komponenten: Crucial RAM, Kingston SSD
Betrieb unter Windows
Windows war vorinstalliert, erfreulicherweise ohne jede Bloatware. Ein Lob an den Hersteller!
Ich habe solange Updates durchgeführt, bis ich bei 24H2 gelandet bin. Das dauert stundenlang, meine Güte! Arm ist, wer viel mit Windows arbeiten muss …
Danach Google Chrome, Nextcloud Client, VSCode, WSL, Docker, VirtualBox, Git, PowerShell, Ollama etc.
Alles in allem keine Probleme. Vielleicht sollte ich doch auf Windows umsteigen? (Kleiner Scherz …)
Betrieb unter Linux
Ich habe bisher nur Ubuntu 24.10 und Fedora 41 ausprobiert. Beide Distributionen laufen vollkommen problemlos. Das Grafiksystem verwendet Wayland.
Pech hat, wer WLAN oder Bluetooth verwenden will. Linux erkennt den WLAN/Bluetooth-Adapter (MediaTek MT7902) nicht. Das war mir schon vor dem Kauf bekannt. Eine kurze Suche zeigt, dass Linux-Treiber nicht in Sicht sind. Zum Glück sind beide Funktionen für mich nicht relevant (USB-Tastatur, Kabel-gebundenes Netzwerk). Andernfalls wäre ein USB-Dongle die einfachste Lösung. Theoretisch wäre es wohl auch möglich, den WLAN/Bluetooth-Adapter auszutauschen. Im Internet gibt es entsprechende Video-Anleitungen, die aber darauf hinweisen, dass die Neuverkabelung der Antennen ziemlich schwierig ist.
Die WLAN/Bluetooth-Probleme beweisen, dass fehlende Hardware-Treiber bis heute zum Linux-Alltag gehören. Hardware-Kauf ohne vorherige Recherche kann direkt in die Sackgasse führen.
Update 15.4.: Ich habe mit dnf system-upgrade download --releasever=42 und dnf system-upgrade reboot ein Upgrade auf Fedora 42 durchgeführt. Der Bildschirmhintergrund ist merkwürdig, sonst ist mir kein offensichtlicher Unterschied aufgefallen. Hinter den Kulissen hat sich natürlich wie immer eine Menge getan, siehe What’s new und Change set.
Fedora 42 mit merkwürdigem Default-Hintergrundbild
BIOS/EFI
In das BIOS/EFI bzw. zu den Boot-Einstellungen gelangt man mit Entf oder F7. Nicht unendlich viele Einstellungen, aber ausreichend. Secure Boot kann ausgeschaltet werden. Eine Möglichkeit, die Größe des für die GPU reservierten RAMs zu beeinflussen, habe ich hingegen nicht gefunden. (Wäre interessant für Ollama.)
UEFI-Boot-MenüDas BIOS
Geekbench-Ergebnisse
Alle Tests mit Geekbench 6.4 und mit den Original-BIOS-Einstellungen (Balanced Mode, außerdem stünde ein Performance Mode zur Wahl). Die Lüfterlautstärke ändert sich während der Tests nur minimal. Das Gerät bleibt immer leise, aber es wird nie lautlos (auch nicht, wenn der PC längere Zeit nichts zu tun hat). Rechner, die schnell und lautlos sind, schafft anscheinend nur Apple.
Unter Ubuntu und Fedora habe ich die Gnome-Energiemodi verwendet. Zwischen Ausgeglichen und Leistung gibt es wie unter Windows keinen nennenswerten Unterschied, zumindest nicht, solange die BIOS-Einstellungen nicht verändert werden. Interessanterweise schneidet Windows bei den Geekbench-Tests ein wenig besser ab als Fedora. Noch deutlicher ist der Vorsprung zu Ubuntu.
Unter Windows habe ich auch Ollama ausprobiert. Mein minimalistischer Ollama-Benchmarktest liefert 12 Token/Sekunde (reine CPU-Leistung, die GPU wird nicht benutzt). Traurig, aber mehr war nicht zu erwarten.
Fazit
Die Lebensdauer kann ich noch nicht beurteilen. Die Stabilität war bisher ausgezeichnet, kein einziger Absturz unter Windows/Ubuntu/Fedora/Kali. WLAN und Bluetooth brauche ich nicht, insofern ist mir das Linux-Treiberproblem gleichgültig. Aber ein Notebook mit MT7902 wäre ein totales No-go!
Update 3.5.2025: Theoretisch sollte es möglich sein, den Computer über USB-C mit Strom zu versorgen (siehe auch diesen heise-Test). In Kombination mit meinem Monitor (LG 27UL850-W, 27 Zoll, 4k) funktioniert das aber nicht.
Ich bin ein Fan lautloser Computer. In dieser Liga spielt das Gerät nicht mit. Der Computer ist leise, aber man vergisst keine Minute, dass der PC eingeschaltet ist.
Davon abgesehen bin ich zufrieden. Das Gerät wäre theoretisch auf 64 GB RAM erweiterbar (unwahrscheinlich, dass ich so viel RAM je brauche). Die beiden PCIe-Slots geben auch beim Speicherplatz viel Flexibilität. Eine zweite USB-C-Buchse und eine SD-Karten-Slot wären nett, aber ich kann ohne leben.
Den neuen Apple Mini mit M4-CPU kenne ich nicht aus eigener Erfahrung, ich beziehe mich also auf Infos aus dem Netz. Der Vergleich drängt sich aber auf. Bei etwa gleichem Preis bietet Apples Mini-PC in Minimalausstattung im Geekbench-Test eine deutlich höhere Single-Core-Leistung (ca. 3700), eine unwesentlich höhere Multi-Core-Leistung (ca. 14.700), macht weniger Lärm, ist kleiner, braucht auch kein externes Netzteil, hat aber nur halb so viel RAM und nur 1/4 des Speicherplatzes. Das RAM ist nicht erweiterbar, die SSD nur kompliziert und relativ teuer. (Zur Einordnung: Ein Mac Mini mit 32 GB RAM und 1 TB SSD würde absurde EUR 1500 kosten.) Und natürlich läuft ohne Virtualisierung weder Windows noch Linux. Ich gebe schon zu: Das ist ein Vergleich zwischen Äpfel und Birnen. Beide PC-Varianten haben Ihre Berechtigung. Apple zeigt, was technisch möglich ist, wenn Geld keine Rolle spielt. Aus Linux- oder Windows-Perspektive bieten Mini-PCs wie das hier präsentierte Modell aber viel Leistung für wenig Geld.
Dieser Beitrag stammt ursprünglich aus dem Jahr 2014, wurde 2025 aber nochmal grundsätzlich überarbeitet, vor allem der Imagemagick- und ffmpeg-Abschnitt.
Ich finde, dass es kaum schönere Videos von Landschaften oder Städten gibt als Zeitrafferaufnahmen. Diese haben meistens eine Dynamik, die das gewisse Extra ausmachen.
Jetzt habe ich bei eine recht gute Kamera herumliegen (Canon EOS 550D), die sehr gute Fotos macht. Jetzt hat sich mir die Frage gestellt: Kann man die Kamera in einstellbaren Intervallen auslösen lassen, sodass sie für mich die Zeitraffer-Fotos erstellt? Man kann!
Die Kamera zeitgesteuert auslösen
Leider gibt es für die Canon EOS 550D keine interne Funktion, mit der man massenhaft Bildern in voreingestellten Intervallen machen kann.
Möglicher Aufbau für Zeitrafferaufnahmen mit einer DSLR und Laptop
Externe Hardware
Es gibt aber kommerzielle Systeme, mit denen das geht. Diese kosten etwa 25 Euro. Irgendwann versuche ich mal, mir selbst so ein Teil zu basteln, aber das wird dann ein eigener Artikel hier im Blog
Gphoto2
Die Mühen und das Geld kann man sich aber sparen, wenn man einen Laptop zur Verfügung hat, auf dem z.B. Ubuntu läuft. Denn mit einem kleinen Helferlein kann man diese Aufgabe auch über den PC steuern!
Das Paket nennt sich Gphoto2 und lässt sich in den meisten Distributionen sehr leicht installieren.
sudo apt-get install gphoto2
Nach der Installation kann man seine Kamera über USB anschließen. Vermutlich wird sie automatisch eingehängt, das umgeht man, indem man die Kamera auf PTP stellt oder sie einfach wieder aushängt. Das geht zum Beispiel in Nautilus, indem ihr den Escape-Button anklickt.
Kamera aushängen über Nautilus
Jetzt kann man überprüfen, ob gphoto2 mit der Kamera zusammenarbeitet. Das macht man mit dem folgenden Befehl, der die Typenbezeichnung der angeschlossenen Kamera ausgeben sollte (siehe meine Ausgabe).
$ gphoto2 --auto-detect
Modell Port
----------------------------------------------------------
Canon EOS 550D usb:002,003
Jetzt kann es losgehen. Die Kamera hatte ich im M-Modus (manuell) und habe folgendes manuell eingestellt:
ISO,
Blende,
Verschlusszeit,
Weißabgleich und
Fokus
Ist man im Halbautomatik-Modus (Av oder Tv) können sich die Bilder in der Helligkeit unterscheiden. Den Autofokus kann man am Anfang verwenden, sollte ihn dann aber abschalten. Das sieht auf dem Video sonst nicht schön aus!
Mit dem folgenden Befehl werden die Bilder für das Zeitraffer aufgenommen.
gphoto2 --capture-image-and-download -I 5 -F 600
Die Einstellungen:
–capture-image-and-download → Die Bilder werden geschossen und sofort auf den Computer geladen. Auf der Speicherkarte sind die Bilder nicht mehr! Alternative: –capture-image → Die Bilder werden auf der Speicherkarte abgelegt.
-I 5 → Das Intervall der Aufnahmen beträgt 5 Sekunden
-F 600 → Es werden 600 Aufnahmen gemacht.
Wer noch mehr einstellen möchte, kann sich über den folgenden Befehl all seine Einstellmöglichkeiten auflisten lassen:
gphoto2 --list-config
Aus einer Bilderserie ein Timelapse-Video machen
Der schwierigste Schritt ist gemacht. Den Rest übernimmt für uns mal wieder Imagemagick, das Bildverarbeitungsprogramm aus der Konsole. Das Herrliche daran: mit wenigen Zeilen kann man mit einem Rutsch alle seine Bilder bearbeiten lassen.
Bilder auf Full-HD Auflösung bringen
Da die Kamera die Bilder in einer sehr hohen Auflösung aufnimmt, muss man diese auf Videogröße skalieren.
Wenn man sich mit dem Terminal im Ordner der Bilder befindet, verkleinert man sie mit dem folgenden Einzeiler auf die Auflösung 1920×1280 (das Bildverhältnis zwingt uns zunächst dazu).
x=1; for i in *.jpg; do convert $i -resize 1920x1280 -shave 0x100 `printf "%05d.jpg" $x`; x=$(($x+1)); done
mit -shave schneiden wir oben und unten jeweils 100 Pixel ab, um auf die finale Auflösung von 1920×1080 Pixel (Full-HD) zu gelangen.
Weiteres Beispiel: Bilder zurechtschneiden und drehen (crop und rotate)
Die Bilderserie wurde mit einer Gopro aufgezeichnet. Der Bildausschnitt muss noch zurechtgeschnitten werden und um 90 ° gedreht werden. Das kann man mit folgendem Befehl durchführen.
$ x=1; for i in *.jpg; do convert $i -crop 3380x1900+300+730 +repage -rotate 90 `printf "%05d.jpg" $x`; x=$(($x+1)); done
Die Geometrie-Angaben für imagemagick Breite x Höhe geben die Größe des fertigen Bildes an. Der Offset x und y wird von der oberen linken Ecke gemessen. Ich habe sie mittels Bildbearbeitungssoftware herausgemessen. Mit +repage stellt man sicher, dass Leinwand und Bild richtig zueinander ausgerichtet sind. Am Ende rotiert die Flagge -rotate das Bild um 90° im Uhrzeigersinn.
Einzelbilder zu Video konvertieren
Mit diesem letzten Befehl verbindet man nun alle Einzelbilder zu einem Video. Ich habe hier eine Framerate von 25 fps (Frames per second) gewählt. Man kann auch weniger nehmen, dann dauert das Video etwas länger, ruckelt allerdings.
Zu beachten ist der Punkt -i 0%04d.jpg . Die Dateien müssen z.B. 00001.jpg genannt sein, das haben wir oben mit imagemagick sichergestellt. Mit der genannten Flagge teile ich das ffmpeg mit, dass eine vierstellige Dezimalzahl in den Dateinamen vorkommt, nach der es die Bilder aneinandersetzen soll.
-profile:v high -level 4.0: das stellt die Kompatibilität zu Handys (z.B. mit Android) sicher
-movflags +faststart: Stellt den Metatag „moov“ an den Beginn der Datei, sodass das Video schon starten kann, bevor es vollständig geladen ist. Das ist wichtig für Handykompatibilität
-pix_fmt yuv420p: Das ist das am weitesten verbreitete Pixelformat.
optional: -vf scale=1280:720 für eine niedrigere Auflösung
optional: -b:v 2M für eine niedrigere Bitrate
Einstellungen für 4K-Videos
4K-Videos haben eine Auflösung von 3840×2160 Pixeln und sind nur auf wenigen Geräten in voller Größe abspielbar.
Tipps und Tricks
Zeitraffer planen
Bevor ihr ein Zeitraffer aufnehmt, solltet ihr es planen. Es ist wichtig zu wissen, wie lange das fertige Video dauern wird und wie schnell sich die Objekte darauf bewegen sollen.
Für ein 30-Sekunden-Video sind 30×25= 750 Fotos notwendig. Wenn in diesen 30 Sekunden ein Zeitraum von 60 Minuten abgebildet werden soll, muss man das Intervall auf 4,8 ~ 5 Sekunden stellen.
Spiegelreflex-Kameras vermeiden
Wer professionell oder zumindest häufiger Zeitraffer aufnehmen möchte, sollte sich eine Alternative zu einer Spiegelreflex-Kamera überlegen. Meine Kamera ist laut (dubioser) Foren im Internet auf 50.000 Bilder ausgelegt, danach beginnen die Probleme. Die Kamera hat also starken Wertverlust durch die Zeitraffer, da hier in kurzer Zeit viele Bilder gemacht werden.
Anzahl der Auslösungen der Kamera anzeigen
Die Anzahl der Auslösungen der Kamera kann man ebenfalls mit gphoto2 auslesen. Man startet es im Terminal in einer ncurses-Umgebung und navigiert durch das Menü: Statusinformationen → Auslösezahl
Vor einem dreiviertel Jahr haben Bernd Öggl, Sebastian Springer und ich das Buch Coding mit KI geschrieben und uns während dieser Zeit intensiv mit diversen KI-Tools und Ihrer Anwendung beschäftigt.
Was hat sich seither geändert? Wie sieht die berufliche Praxis mit KI-Tools heute aus? Im folgenden Fragebogen teilen wir drei unsere Erfahrungen, Wünsche und Ärgernisse. Sie sind herzlich eingeladen, in den Kommentaren eigene Anmerkungen hinzuzufügen.
Bei welchen Projekten hast du KI-Tools im letzten Monat eingesetzt? Mit welchem Erfolg?
Bernd: KI-Tools haben in meine tägliche Programmierung Einzug gehalten und sparen mir Zeit. Oft traue ich der Ki zu wenig zu und stelle Fragen, die nicht weit genug gehen. Zum „vibe-coding“ bin ich noch nicht gekommen :-) Ich verwende KI-Tools in diesen Projekten:
ein großes Code Repo mit Angular und C#: Einsatz sowohl in VSCode (Angular) und Visual Studio (C#, die Unterstützung ist überraschend gut).
ein kleines Projekt (HTML, JS, MongoDB (ca. 20.000 MongoDocs)).
zwei verschiedene Flutter Apps für Android
für eine größere PHP/MariaDB Codebase
Sebastian: Ich setze mittlerweile verschiedene KI-Tools flächendeckend in den Projekten ein. Wir haben das mittlerweile auch in unsere Verträge mit aufgenommen, dass das explizit erlaubt ist.
Die letzten Projekte waren in JavaScript/TypeScript im Frontend React, im Backend Node.js, und es waren immer mittelgroße Projekte mit 2 – 4 Personen über mehrere Monate.
Die verschiedenen Tools sind mittlerweile zum Standard geworden und ich möchte nicht mehr darauf verzichten müssen, gerade bei den langweiligen Routineaufgaben helfen sie enorm.
Michael: Ich habe zuletzt einige Swift/SwiftUI-Beispielprogramme entwickelt. Weil Swift und insbesondere SwiftUI ja noch sehr dynamisch in der Weiterentwicklung ist, hatten die KI-Tools die Tendenz, veraltete Programmiertechniken vorzuschlagen. Aber mit entsprechenden Prompts (use modern features, use async/await etc.) waren die Ergebnisse überwiegend gut (wenn auch nicht sehr gut).
Ansonsten habe ich in den letzten Monaten immer wieder kleinere Mengen Code in PHP/MySQL, Python und der bash geschrieben bzw. erweitert. Mein Problem ist zunehmend, dass ich beim ständigen Wechsel die Syntaxeigenheiten der diversen Sprachen durcheinanderbringe. KI-Tools sind da meine Rettung! Der Code ist in der Regel trivial. Mit einem sorgfältig formulierten Prompt funktioniert KI-generierter Code oft im ersten oder zweiten Versuch. Ich kann derartige Routine-Aufgaben mit KI-Unterstützung viel schneller erledigen als früher, und die KI-Leistungen sind diesbezüglich ausgezeichnet (besser als bei Swift).
Welches KI-Tool verwendest du bevorzugt? In welchem Setup?
Michael: Ich habe in den vergangenen Monaten fast ausschließlich Claude Pro verwendet (über die Weboberfläche). Was die Code-Qualität betrifft, bin ich damit sehr zufrieden und empfand diese oft besser als bei ChatGPT.
In VSCode läuft bei mir Cody (Free Tier). Ich verwende es nur für Vervollständigungen. Es ist OK.
Ansonsten habe ich zuletzt den Großteil meiner Arbeitszeit in Xcode verbracht. Xcode ist im Vergleich zu anderen IDEs noch in der KI-Steinzeit, die aktuell ausgelieferten KI-Werkzeuge in Xcode sind unbrauchbar. Eine Integration von Claude in Xcode hätte mir viel Hin und Her zwischen Xcode und dem Webbrowser erspart. (Es gibt ein Github-Copilot-Plugin für Xcode, das ich aber noch nicht getestet habe. Apple hat außerdem vor fast einem Jahr Swift Code angekündigt, das bessere KI-Funktionen verspricht. Leider ist davon nichts zu sehen. Apple = Gute Hardware, schlechte Software, zumindest aus Entwicklerperspektive.)
Für lokale Modelle habe ich aktuell leider keine geeignete Hardware.
Sebastian: Ich habe über längere Zeit verschiedene IDE-Plugins mit lokalen Modellen ausprobiert, nutze aber seit einigen Monaten nur noch GitHub Copilot. Die Qualität und Performance ist deutlich besser als die von lokalen Modellen.
Für Konzeption und Ideenfindung nutze ich ebenfalls größere kommerzielle Werkzeuge. Aktuell stehen die Gemini-Modelle bei mir ganz hoch im Kurs. Die haben mit Abstand den größten Kontext (1 – 2 Millionen Tokens) und die Ergebnisse sind mindestens genauso gut wie bei ChatGPT, Claude & Co.
Lokale Modelle nutze ich eher punktuell oder für die Integration in Applikationen. Gerade wenn es um Übersetzung, RAG und ähnliches geht, wo es entweder um Standardaufgaben oder um Teilaufgaben geht, wo man mit weiteren Tools wie Vektordatenbanken die Qualität steuern kann. Bei den lokalen Modellen hänge ich nach wie vor bei Llama3 wobei sich auch die Ergebnisse von DeepSeek sehen lassen können.
Für eine kleine Applikation habe ich auch europäische Modelle (eurollm und teuken) ausprobiert, wobei ich da nochmal deutlich mehr Zeit investieren muss.
Für die Ausführung lokaler Modelle habe ich auf die Verfügbarkeit der 50er-Serie von NVIDIA gewartet, wobei mir die RTX 5090 deutlich zu teuer ist. Ich habe seit Jahresbeginn ein neues MacBook Pro (M4 Max) das bei der Ausführung lokaler Modelle echt beeindruckend ist. Mittlerweile nutze ich das MacBook deutlich mehr als meinen Windows PC mit der alten 3070er.
Bernd: Ich verwende aus Interesse vor allem lokale Modelle, die auf meinem MacBook Pro (M2/64GB) wunderbar schnell performen (aktuell gemma3:27b und deepseek-r1:32b, aber das ändert sich schnell). Am MacBook laufen die über ollama. Ich muss aber beruflich auch unter Windows arbeiten und arbeite eigentlich (noch) am liebsten unter Linux mit neovim.
Dazu ist das Macbook jetzt immer online und im lokalen Netz erreichbar. Unter Windows verwenden ich in VSCode das Continue Plugin mit dem Zugriff auf die lokalen Modelle am MacBook. In Visual Studio läuft CoPilot (die „Gratis“-Version). Unter Linux verwende ich sehr oft neovim (mit lazyvim) mit dem avante-Plugin. Während ich früher AI nur für code-completion verwendet habe, ist es inzwischen oft so, dass ich Code-Blöcke markiere und der AI dazu Fragen stelle. Avante macht dann wunderbare Antworten mit Code-Blöcken, die ich wie einen git conflict einbauen kann. Sie sagen es ist so wie cursor.ai, aber das habe ich noch nicht verwendet.
Daneben habe ich unter Linux natürlich auch VSCode mit Continue. Und wenn ich gerade einmal nicht im Büro arbeite (also das Macbook nicht im aktuellen Netz erreichbar ist), so wie gerade eben, dann habe ich Credits für Anthropic und verwende Claude (3.5 Sonnet aktuell) für AI support.
Wo haben dich KI-Tools in letzter Zeit überrascht bzw. enttäuscht?
Sebastian: Ich bin nach wie vor enttäuscht wie viel Zeit es braucht, um den Kontext aufzubauen, damit dir ein LLM wirklich bei der Arbeit hilft. Gerade wenn es um neuere Themen wie aktuelle Frameworks geht. Allerdings lohnt es sich bei größeren Projekten, hier Zeit zu investieren. Ich habe in ein Test-Setup für eine Applikation gleich mehrere Tage investiert und konnte am Ende qualitativ gute Tests generieren, indem ich den Testcase mit einem Satz beschrieben habe und alles weitere aus Beispielen und Templates kam.
Ich bin sehr positiv überrascht vom Leistungssprung den Apple bei der Hardware hingelegt hat. Gerade das Ausführen mittelgroßer lokaler LLMs merkt man das extrem. Ein llama3.2-vision, qwq:32b oder teuken-7b funktionieren echt gut.
Bernd: Überrascht hat mich vor allem der Qualitäts-Gewinn bei lokalen Modellen. Im Vergleich zu vor einem Jahr sind da Welten dazwischen. Ich mache nicht ständig Vergleiche, aber was die aktuellen Kauf-Modelle liefern ist nicht mehr so ganz weit weg von gemma3 und vergleichbaren Modellen.
Michael: Ich musste vor ein paar Wochen eine kleine REST-API in Python realisieren. Datenbank und API-Design hab‘ ich selbst gemacht, aber das Coding hat nahezu zu 100 Prozent die KI erledigt (Claude). Ich habe mich nach KI-Beratung für das FastAPI-Framework entschieden, das ich vorher noch nie verwendet habe. Insgesamt ist die (einzige) Python-Datei knapp 400 Zeilen lang. Acht Requests mit den dazugehörigen Datenstrukturen, Absicherung durch ein Time-based-Token, komplette, automatisch generierte OpenAPI-Dokumentation, Wahnsinn! Und ich habe wirklich nur einzelne Zeilen geändert. (Andererseits: Ich wusste wirklich ganz exakt, was ich wollte, und ich habe viel Datenbank- und Python-Basiswissen. Das hilft natürlich schon.)
So richtig enttäuscht haben mich KI-Tools in letzter Zeit selten. In meinem beruflichen Kontext ergeben sich die größten Probleme bei ganz neuen Frameworks, zu denen die KI zu wenig Trainingsmaterial hat. Das ist aber erwartbar und insofern keine Überraschung. Es ist vielmehr eine Bestätigung, dass KI-Tools keineswegs von sich aus ‚intelligent‘ sind, sondern zuerst genug Trainingsmaterial zum Lernen brauchen.
Was wäre dein größter Wunsch an KI-Coding-Tools?
Bernd: Gute Frage. Aktuell nerven mich ein bisschen die verschiedenen Plugins und die Konfigurationen für unterschiedliche Editoren. Wie gesagt, neovim ist für mich wichtig, da hast du, wie in OpenSource üblich, 23 verschiedene Plugins zur Auswahl :-) Zum Glück gibt es ollama, weil da können alle anbinden. Ich glaub M$ versucht das eh mit CoPilot, eine Lösung, die überall funktioniert, nur ich will halt lokale Modelle und nicht Micro$oft….
Sebastian: Im Moment komme ich mit dem Wünschen ehrlich gesagt gar nicht hinterher, so rasant wie sich alles entwickelt. Microsoft hat GitHub Copilot den Agent Mode spendiert, TypeScript wird “mehr copiloty” und bekommt APIs die eine engere Einbindung von LLMs in den Codingprozess erlauben. Wenn das alles in einer ausreichenden Qualität kommt, hab ich erstmal keine weiteren Wünsche.
Michael: Ich bin wie gesagt ein starker Nutzer der webbasierten KI-Tools. Was ich dabei über alles schätze ist die Möglichkeit, mir die gesamte Konversation zu merken (als Bookmark oder indem ich den Link als Kommentar in den Code einbaue). Ich finde es enorm praktisch, wenn ich mir später noch einmal anschauen kann, was meine Prompts waren und welche Antworten das damalige KI-Modell geliefert hat.
Eine vergleichbare Funktion würde ich mir für IDE-integrierte KI-Tools wünschen. Eine KI-Konversation in VSCode mit GitHub Copilot oder einem anderen Tool sowie die nachfolgenden Code-Umbauten sind später nicht mehr reproduzierbar — aus meiner Sicht ein großer Nachteil.
Beeinflusst die lokale Ausführbarkeit von KI-Tools deinen geplanten bzw. zuletzt durchgeführten Hardware-Kauf?
Bernd: zu 100%! Mein MacBook Pro (gebraucht gekauft, M2 Max mit 64GB) wurde ausschließlch aus diesem Grund gekauft und es war ein großer Gewinn.
Ich habe jetzt ein 2.100 EUR Thinkpad und ein 2.200 EUR MacBook. Rate mal was ich öfter verwende :-) . Die Hardware beim Mac (besonders das Touchpad) ist besser und ich habe quasi alle Linux-Tools auch am Mac (fish-shell, neovim, git, Browser, alle anderen UI-Programme). Wenn ich unter Linux arbeite, denke ich mir oft: »Ah, das kann ich jetzt nicht ollama fragen, weil das nur am MacBook läuft«. Natürlich könnte ich Claude verwenden, aber irgend etwas im Kopf ist dann doch so: »Das muss man jetzt nicht über den großen Teich schicken.«
4000 EUR für die Nvidia-Maschine, die ich zusätzlich zum Laptop mitnehmen muss, ist kein Ding für mich. Ich möchte einen Linux Laptop, der die LLMs so schnell wie der Mac auswerten kann (und noch ein gutes Touchpad hat). Das ist der Wunsch ans Christkind …
Michael: Ein ärgerliches Thema! Ich bin bei Hardware eher sparsam. Vor einem Jahr habe ich mir ein Apple-Notebook (M3 Pro mit 36 GB RAM) gegönnt und damit gerade mein Swift-Buch aktualisiert. Leider waren mir zum Zeitpunkt des Kaufs die Hardware-Anforderungen für lokale LLMs zu wenig klar. Das Notebook ist großartig, aber es hat zu wenig RAM. Den Speicher brauche ich für Docker, virtuelle Maschinen, IDEs, Webbrowser etc. weitgehend selbst, da ist kein Platz mehr für große LLMs.
Aus meiner Sicht sind 64 GB RAM aktuell das Minimum für einen Entwickler-PC mit lokalen LLMs. Im Apple-Universum ist das sündhaft teuer. Im Intel/AMD-Lager gibt es wiederum kein einziges Notebook, das — was die Hardware betrifft — auch nur ansatzweise mit Apple mithalten kann. Meine Linux- und Windows-Rechner kann ich zwar billig mit mehr RAM ausstatten, aber die GPU-Leistung + Speicher-Bandbreite sind vollkommen unzureichend. Deprimierend.
Ein externer Nvidia-Mini-PC (kein Notebook, siehe z.B. die diversen Ankündigungen auf notebookcheck.com) mit 128 GB RAM als LLM-Server wäre eine Verlockung, aber ich bin nicht bereit, dafür plus/minus 4000 EUR auszugeben. Da zahle ich lieber ca. 20 EUR/Monat für ein externes kommerzielles Tool. Aber derartige Rechner, wenn sie denn irgendwann lieferbar sind, wären sicher ein spannendes Angebot für Firmen, die einen lokalen LLM-Server einrichten möchten.
Generell bin ich überrascht, dass die LLM-Tauglichkeit bis jetzt kein großes Thema für Firmen-Rechner und -Notebooks zu sein scheint. Dass gerade Apple hier so gut performt, war ja vermutlich auch nicht so geplant, sondern hat sich mit den selbst entwickelten CPUs als eher zufälliger Nebeneffekt ergeben.
Sebastian: Ursprünglich war mein Plan auf die neuen NVIDIA-Karten zu warten. Nachdem ich aber im Moment eher auf kommerzielle Tools setze und sich mein neues MacBook zufällig als richtige KI-Maschine entpuppt, werde ich erstmal warten, wie sich die Preise entwickeln. Ich bin auch enttäuscht, dass NVIDIA den kleineren karten so wenig Speicher spendiert hat. Meine Hoffnung ist, dass nächstes Jahr die 5080 mit 24GB rauskommt, das wär dann genau meins.
Die digitalen Stromzähler (offizielle Bezeichnung: Moderne Messeinrichtung) sind inzwischen weit verbreitet. Viele können in zwei Richtungen zählen, was bei der Benutzung eines Balkonkraftwerks von großer Bedeutung sein kann. Ich habe vor einiger Zeit beschrieben, wie ich mit dem Impulsausgang auf der Vorderseite des Stromzählers den aktuellen Verbrauch ablese. Diese Methode klappt sehr gut, ist sehr einfach und braucht keine weitere Freischaltung des Netzbetreibers. Man kann einfach loslegen. Leider bringt der Impulszähler zwei Nachteile mit sich.
Über den Impulsausgang sieht man ausschließlich den aktuellen Stromverbrauch, nichts Weiteres. Man erfährt nicht den aktuellen Zählerstand oder die Flussrichtung. Außerdem gibt es keine Kontrolle, ob alle Impulse richtig gezählt werden. Summiert man die Leistung auf, erhält man zwar einen Jahresverbrauch, kann sich aber nicht sicher sein, ob er stimmt.
An sonnigen Tagen kommt es vor, dass man mit seinem Balkonkraftwerk mehr Strom erzeugt, als man im Haushalt verbraucht. In diesem Fall wird Strom ins Netz eingespeist. Der Impulszähler kann aber nicht unterscheiden, ob der Strom vom Netz kommt, oder ob er ins Netz geht. Folglich steigt scheinbar der Stromverbrauch im Haus, obwohl in Wirklichkeit ein Stromüberschuss erzeugt wird.
In diesem Artikel möchte ich eine alternative Auslesevariante vorstellen, die robuster und zuverlässiger arbeitet. Aussetzer in der Datenerfassung lassen sich durch späteres Zählerablesen wieder kompensieren, die Bilanz passt immer. Es können nicht nur der aktuelle Verbrauch, sondern auch die Zählerstände „in beide Richtungen“ erfasst werden. Das geschieht über das Auslesen von mehreren OBIS-Kennzahlen über die SML-Schnittstelle.
Die „Moderne Messeinrichtung“ verfügt über zwei optische Schnittstellen. Der Impulsausgang (oben Mitte) gibt den Momentanverbrauch via Impulsen aus. Diese Einbindung dieser Schnittstelle wurde in einem anderen Artikel bereits behandelt. Die SML-Schnittstelle (rechts) gibt mehrere Werte aus, unter anderem den Momentanverbrauch und den Zählerstand.
Die SML Schnittstelle des digitalen Stromzählers
Die digitalen Stromzähler haben eine zweite, wertvolle Schnittstelle: Die SML-Schnittstelle (Smart Meter Language). Über sie kommuniziert der Stromzähler mit einem genormten Protokoll (IEC 62056-6-1) mit uns Anwendern. In ihr werden die Zählerstände, der Momentanverbrauch und gelegentlich noch weitere Informationen bereitgestellt. Die Informationen sind als OBIS-Kennzahlen verfügbar und können leicht zugeordnet werden. Für mich sind die beiden OBIS-Kennzahlen 1.8.0 (Zählerstand, bezogen aus dem Netz) sowie 2.8.0 (Zählerstand, eingespeiste Energie ins Netz) relevant. Der OBIS-Kennwert 16.7.0 gibt mir die momentan bezogene Leistung aus.
Standardmäßig ist diese optische Schnittstelle deaktiviert und mit einer PIN geschützt. Diese PIN erhält man meist kostenlos von seinem Netzbetreiber. Der Netzbetreiber (nicht verwechseln mit dem Stromanbieter!) ist auf dem Stromzähler und der Stromrechnung genannt. In meinem Fall sind es die Stadtwerke. Eine freundliche E-Mail mit der Bitte um Bekanntgabe der PIN unter Nennung meiner Zählernummer hat bereits gereicht.
Diese PIN muss nun mit einer Taschenlampe in die optische Schnittstelle eingeblinkt werden. Schaut euch das kurze Video von Extra 3 dazu an, darin wird der ganze Frust damit gut zusammengefasst.
Bei erfolgreicher Eingabe der PIN muss die Funktion „Inf off“ auf „Inf on“ gestellt werden. Das gelingt, indem man sich durch das Menü des Stromzählers „blinkt“ und beim entsprechenden Eintrag mind. 4 Sekunden mit der Taschenlampe leuchtet. Diese Funktion schaltet die erweiterte Funktion des Stromzählers frei. Man erkennt das später daran, dass nicht nur der Zählerstand im Display angezeigt wird, sondern auch der Momentanverbrauch.
Ist die PIN eingegeben und die erweiterte Informationsvergabe freigeschaltet, kann es endlich losgehen!
DIY Komponenten und Controller ESP8266 vorbereiten
Ich verwende für die optische Schnittstelle einen ESP8266 und das Bauteil TCRT5000. Beides erhält man für weniger als 5 Euro bei Ebay oder anderen Händlern. Der TCRT5000 ist ein optischer LED-Sensor für Infrarot, die sowohl eine LED als auch eine IR-Diode verwendet.
TCRT5000 und seine Bauteile.
Die LED stört uns in diesem Fall, man muss sie vorher entfernen. Entweder zwickt man sie einfach ab, oder man lötet den Vorwiderstand von ihr weg. Ich habe mich für zweiteres entschieden. Der TCRT hat mehrere Vorteile gegenüber anderen Varianten. Manche Leute löten direkt eine IR-Diode an den ESP. Kann man natürlich machen, ich möchte nur auf die Vorteile meiner Variante hinweisen:
die elektrischen Bauteile sind aufgeräumt auf einer Leiterplatte, keine Bauteile fliegen einzeln herum. Außerdem gibt er genügend „Angriffsfläche“, um ihn – zumindest übergangsweise – per Klebeband zu fixieren.
die Schaltung enthält zwei kleine Status-LEDs: eine zeigt die Spannungsversorgung an, die zweite zeigt das Signal an der IR-Diode an. Vor allem die zweite Status-LED ist sehr, sehr hilfreich, wenn man die Bauteile installiert. Man erhält sofort eine Rückmeldung, ob die Diode ein Signal sieht oder nicht. Das ist besonders beim Ausrichten der Diode hilfreich, oder beim dritten Vorteil:
über das eingebaute Potentiometer kann man die Empfindlichkeit der Diode einstellen. Das ist manchmal notwendig, wenn das Signal der Stromzähler-LED zu stark oder zu schwach ist. Dann dreht man am Poti so lange, bis man über die Status-LED ein sinnvolles Signal sieht. Weiter unten im Artikel zeige ich nochmal genauer, was ich damit meine.
Jetzt verkabelt man die Baugruppe mit dem ESP8266. Ich habe die Variante Wemos D1 mini. Dieses hat bereits die UART-Schnittstelle vorbereitet, die wir verwenden wollen. Dadurch ergibt sich folgendes Verkabelungsschema. Ob ihr das nun verlötet oder mit Jumper-Kabeln verdrahtet, bleibt euch überlassen.
ESPHome konfigurieren und aufspielen
Die Installation von ESPHome im Windows Service for Linux habe ich bereits in einem anderen Artikel beschrieben. Wir erzeugen uns eine Textdatei mit dem Dateinamen stromzaehler-sml.yaml und füllen sie mit folgendem Inhalt.
esphome:
name: stromzaehlersml
esp8266:
board: d1_mini
# Enable logging
logger:
level: VERY_VERBOSE # kann spaeter auf DEBUG verringert werden
logs:
sml: DEBUG
text_sensor: DEBUG
# Enable Home Assistant API
api:
password: "<password>"
ota:
password: "<password>"
wifi:
ssid: !secret wifi_ssid
password: !secret wifi_password
manual_ip:
static_ip: <statische IP eintragen>
gateway: <gateway>
subnet: <subnet>
# Enable fallback hotspot (captive portal) in case wifi connection fails
ap:
ssid: "Stromzaehler Sml"
password: "<password>"
captive_portal:
uart:
id: uart_bus
tx_pin: GPIO1
rx_pin: GPIO3 # dieser GPIO ist wichtig, hier ist das Signalkabel angeschlossen
baud_rate: 9600
data_bits: 8
parity: NONE
stop_bits: 1
sml:
id: mysml
uart_id: uart_bus
sensor:
- platform: sml
name: "Total energy SML 180"
sml_id: mysml
server_id: "0123456789abcdef"
obis_code: "1-0:1.8.0"
unit_of_measurement: kWh
accuracy_decimals: 3
device_class: energy
state_class: total_increasing
filters:
- multiply: 0.0001
- platform: sml
name: "Total energy SML 280"
sml_id: mysml
server_id: "0123456789abcdef"
obis_code: "1-0:2.8.0"
unit_of_measurement: kWh
accuracy_decimals: 3
device_class: energy
state_class: total_increasing
filters:
- multiply: 0.0001
- platform: sml
name: "Stromverbrauch SML 1670"
sml_id: mysml
server_id: "0123456789abcdef"
obis_code: "1-0:16.7.0"
unit_of_measurement: W
accuracy_decimals: 0
device_class: energy
filters:
- multiply: 1.0
text_sensor:
- platform: sml
name: "Total energy text"
sml_id: mysml
server_id: "0123456789abcdef"
obis_code: "1-0:1.8.0"
Es müssen folgende Zeilen angepasst werden:
Wifi Zugangsdaten
Feste IP-Adresse (kann auch erst im zweiten Schritt erfolgen)
die server_id passen wir an, sobald wir sie kennen. Sie ist ggf. auf den Stromzähler aufgedruckt. Weiter unten im Artikel finden wir sie aber auch über die SML-Schnittstelle heraus.
Zur Erklärung: Die Kommunikation zwischen unserer IR-Diode und dem ESP erfolgt über ein Protokoll namens UART. Diese Schnittstelle wird in den Zeilen nach uart: konfiguriert. Der GPIO-Pin 3 ist dabei derjenige, der auf dem Wemos D1 Mini mit RX gekennzeichnet ist. Falls ihr einen anderen verwendet, müsst ihr diese Zeile anpassen. Die SML Schnittstelle wird ab Zeile sml: konfiguriert. Die meisten Einstellungen könnt ihr so lassen, wie es oben beschrieben ist. Die wichtigen Zeilen sind die mit server_id. Dort wird die Server-Adresse eingestellt. Vermutlich kennt ihr sie nicht von Anfang an, lasst also erstmal die Voreinstellung. Wir ändern sie später, sobald wir sie erfahren haben.
Speichert die Datei nun und kompiliert sie über den Befehl
esphome run stromzaehler-sml.yaml
Nach ein paar Augenblicken ist der Vorgang abgeschlossen und irgendwo wird eine Datei namens firmware.bin abgelegt. Der Pfad ist in der Textausgabe angegeben, bei mir war es
Nun flashen wir die Datei auf den ESP8266. Dazu benutzen wir den Google Chrome (oder einen anderen kompatiblen Browser) und gehen auf die Webseite https://web.esphome.io Schließt den ESP mit einem USB-Kabel an den PC an. Auf der Webseite sollte ein Popup erscheinen.
Sollte dieser Schritt nicht funktionieren, liegt das sehr wahrscheinlich am USB-Kabel. Tauscht das Kabel gegen ein anderes, nicht alle Kabel sind dafür geeignet! Folgt den Anweisungen auf der Webseite, um die Datei firmware.bin auf den ESP zu flashen.
Kontrolliert nach dem Flashen, ob ihr den ESP in eurem WLAN findet. Falls ja, großartig! Wir binden ihn gleich in Home Assistant ein. Gehe in Home Assistant auf Einstellungen → Geräte und Dienste → Integration hinzufügen → ESPHome
Baut jetzt den ESP in der Nähe eures Stromzählers auf. Versorgt ihn mit Spannung (z.B. über ein Handy-Netzteil) und richtet die IR-Diode richtig aus. Jetzt hilft euch die Status-LED vom TCRT5000. Sollte sie regelmäßig blinken, habt ihr schon viel geschafft. Ich habe mit einem kleinen Schraubendreher das Poti noch so verstellt, bis ein wirklich sauberes Signal angekommen ist.
Sollte die Status-LED gar nicht leuchten, ist vermutlich die Diode noch nicht richtig ausgerichtet oder das Signal ist zu schwach. Ändert mit einem kleinen Schraubendreher die Empfindlichkeit am Poti. Kommen nur kurze Dauersignale, ist die Empfindlichkeit zu hoch. Dreht am Poti so lange, bis in der AN-Phase ein dezentes Flackern zu sehen ist (unteres Diagramm). Dann wird via UART auf diesem Kanal kommuniziert. Die Ausgabe in den Logs müsste nun mit Leben gefüllt sein.
Auslesen der Daten und Einbindung in Home Assistant
Ruft die Logs des Controllers auf. Über Home Assistant gibt es die entsprechende Schnittstelle, über WSL geht das mit dem Befehl
esphome logs stromzaehler-sml.yaml
Wenn alles bis hierher geklappt hat, müsste die Ausgabe sich stetig erweitern. Darin müssten auch Einträge nach dem folgenden Format auftauchen:
Hier findet ihr auch die Server-ID, die wir anfangs noch nicht kannten. Sie steht in runden Klammern und ist im Screenshot rot eingerahmt. Kopiert sie euch und fügt sie in der YAML-Datei in Zeilen, wo die server_id eingetragen werden muss (insgesamt vier mal).
Zur Kontrolle der Validität der Daten, könnt ihr den HEX-Wert mal umrechnen und checken, ob der Stromzählerwert korrekt übertragen wird. Im Beispiel oben:
0x056f8b25 entspricht 91196197. Multipliziert mit 0,0001 ergibt 9119,6 kWh
Ändert nun die YAML-Datei auf die für euch wichtigen Werte (Server-ID und ggf. andere OBIS-Codes) und flasht sie kabellos („Over the air“) auf den ESP
esphome run stromzaehler-sml.yaml
Seht im Home Assistant, ob die Werte dort ankommen. In aller Regel kommen die Werte dort an und können weiter verarbeitet werden. Ich habe mir noch einen Helfer gebaut, der den aktuellen Verbrauch in Kilowatt umrechnet. Das lässt sich mit anderen Energiequellen schöner in Diagrammen darstellen.
Fertig, ihr habt es geschafft! Kommentiert gerne, ob ihr diese Werte für andere Zwecke weiterverwendet. Realisiert ihr damit eine Nulleinspeisung oder beobachtet den Strompreis in Echtzeit?
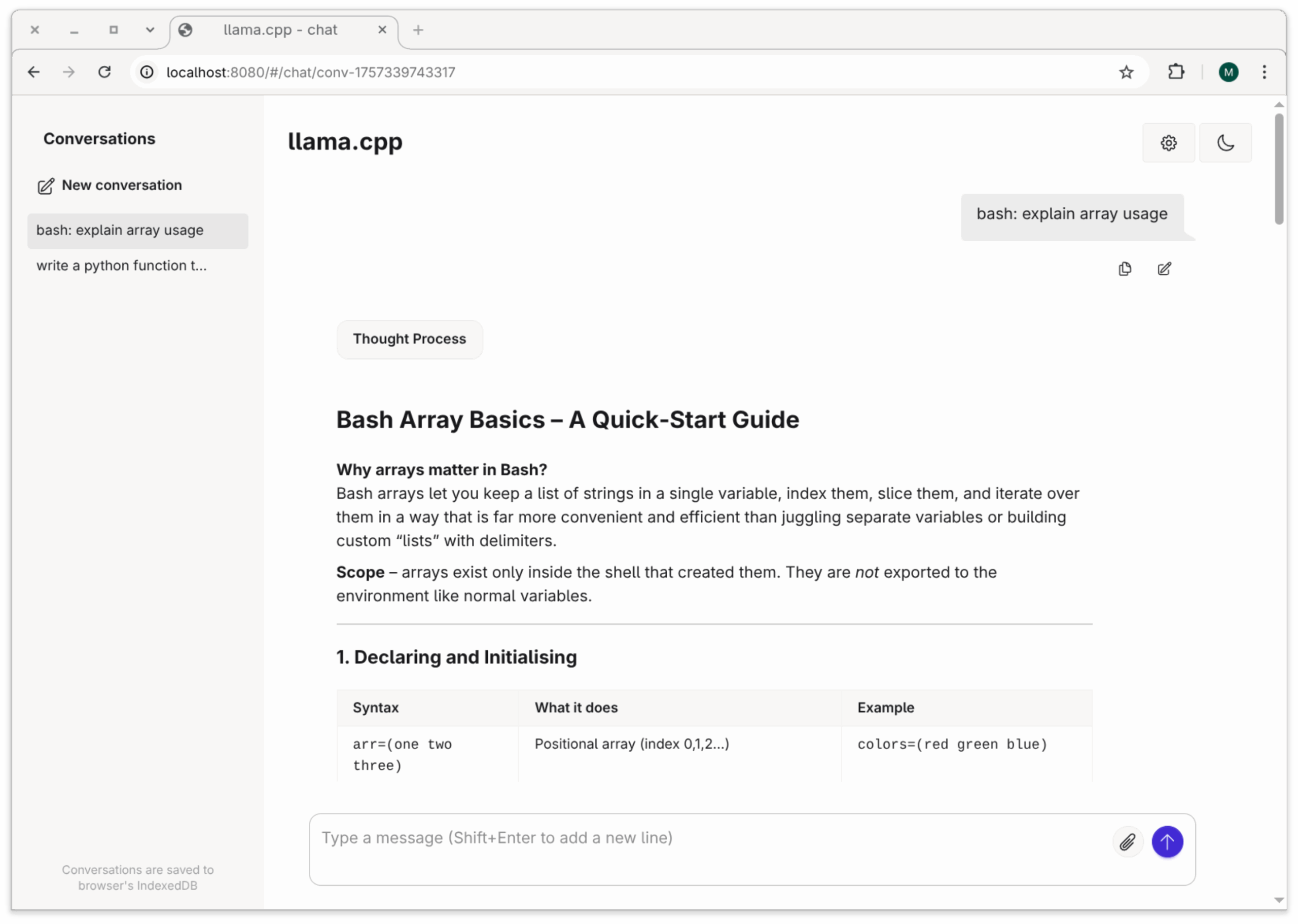

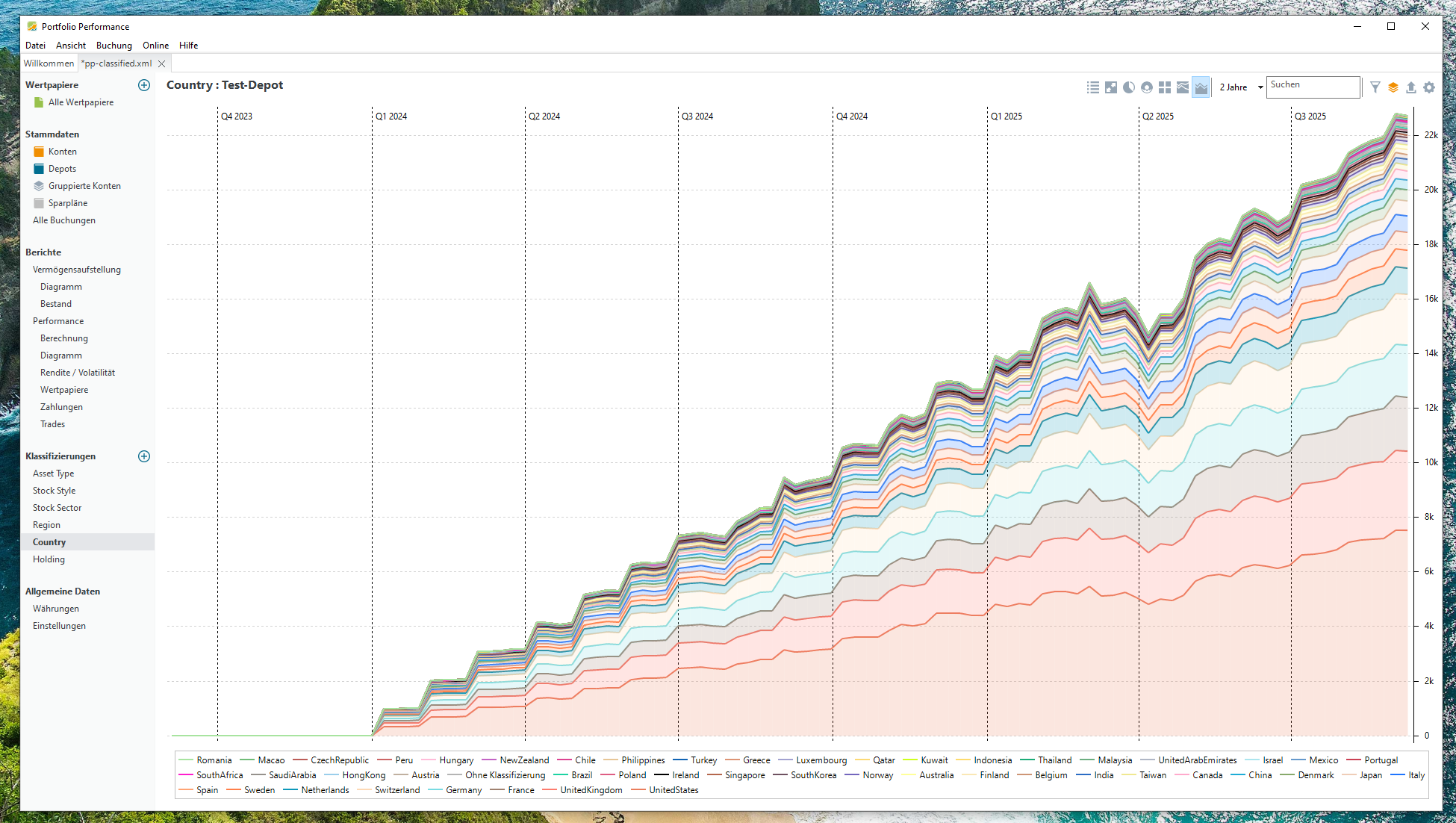
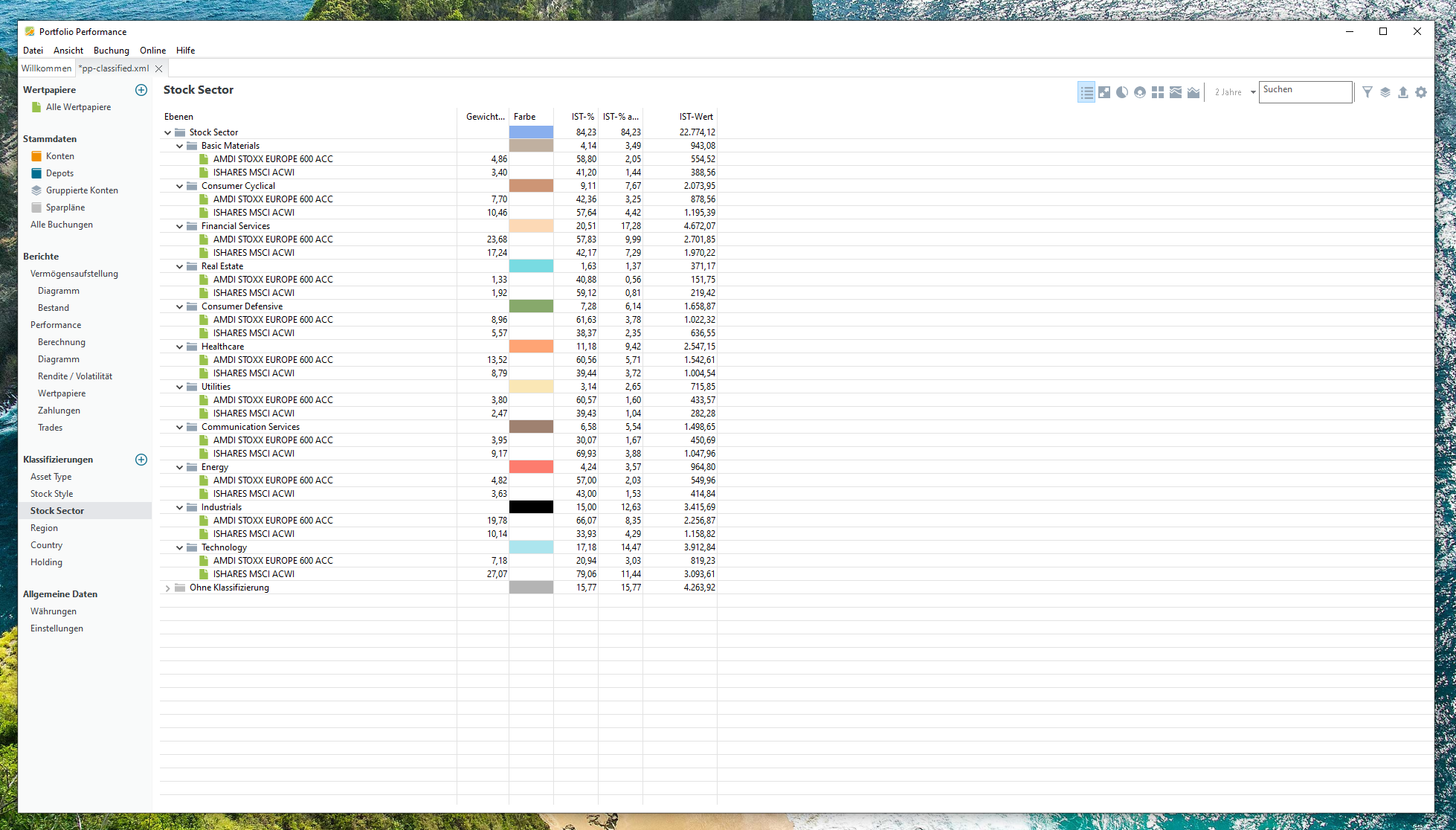
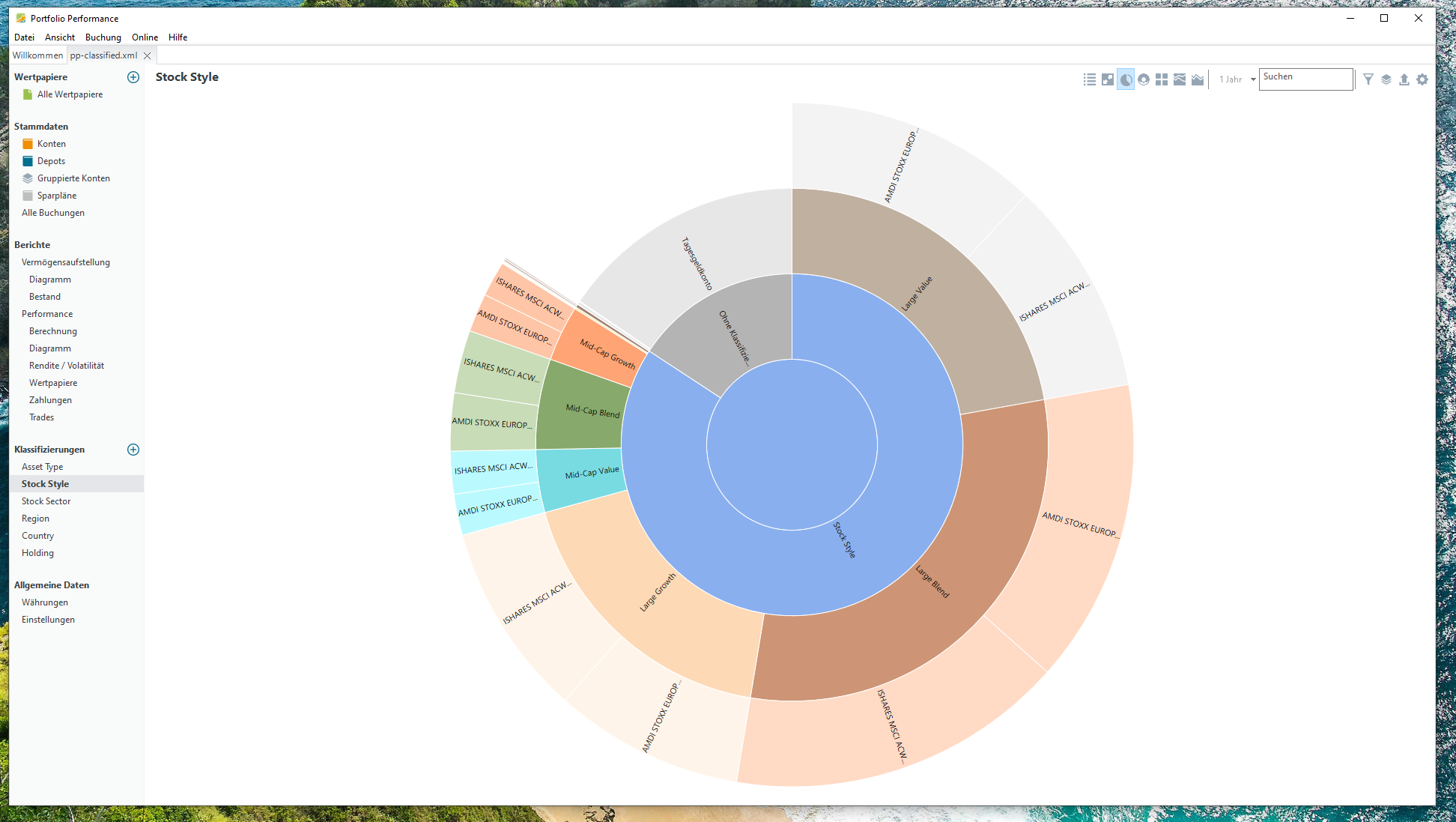
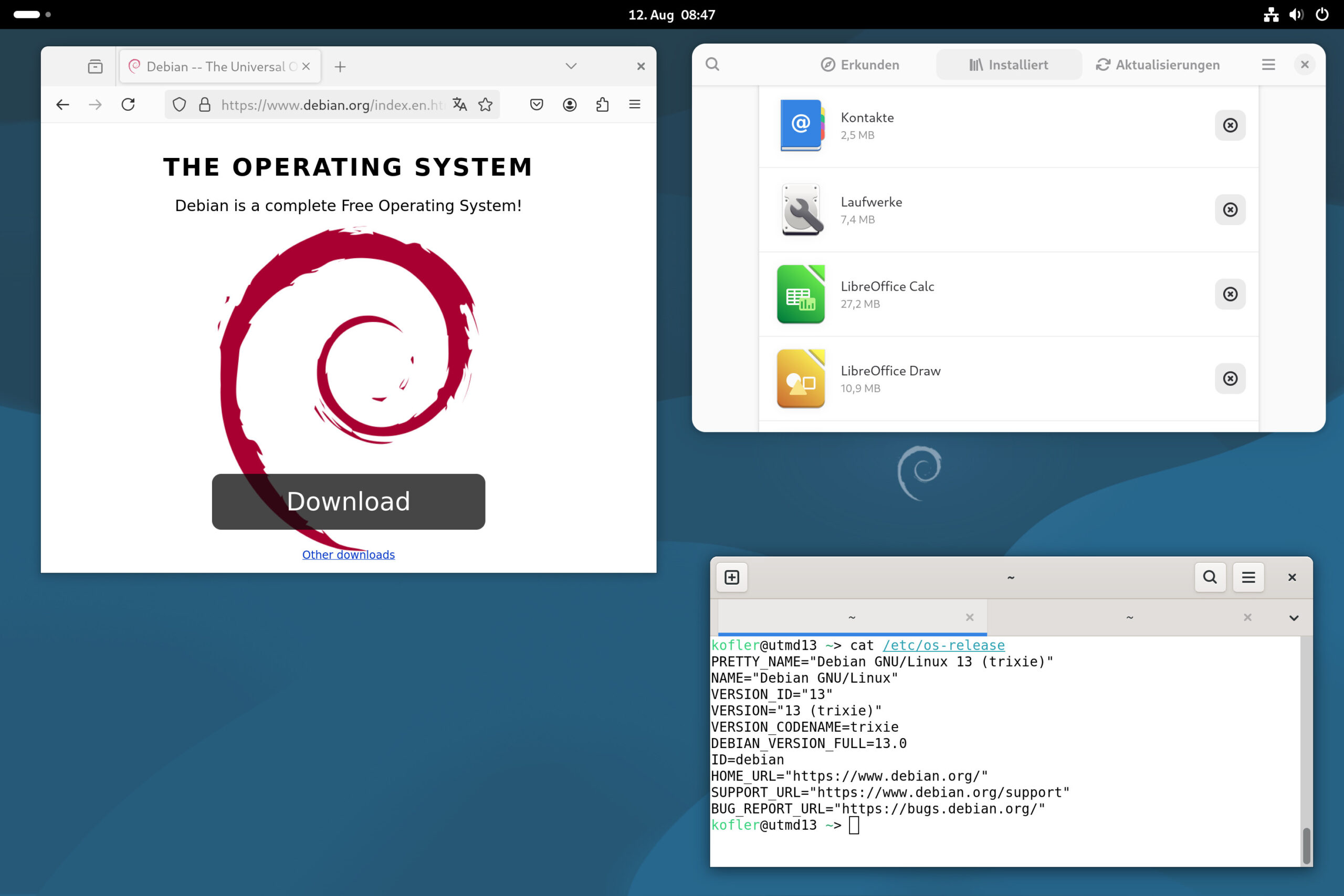
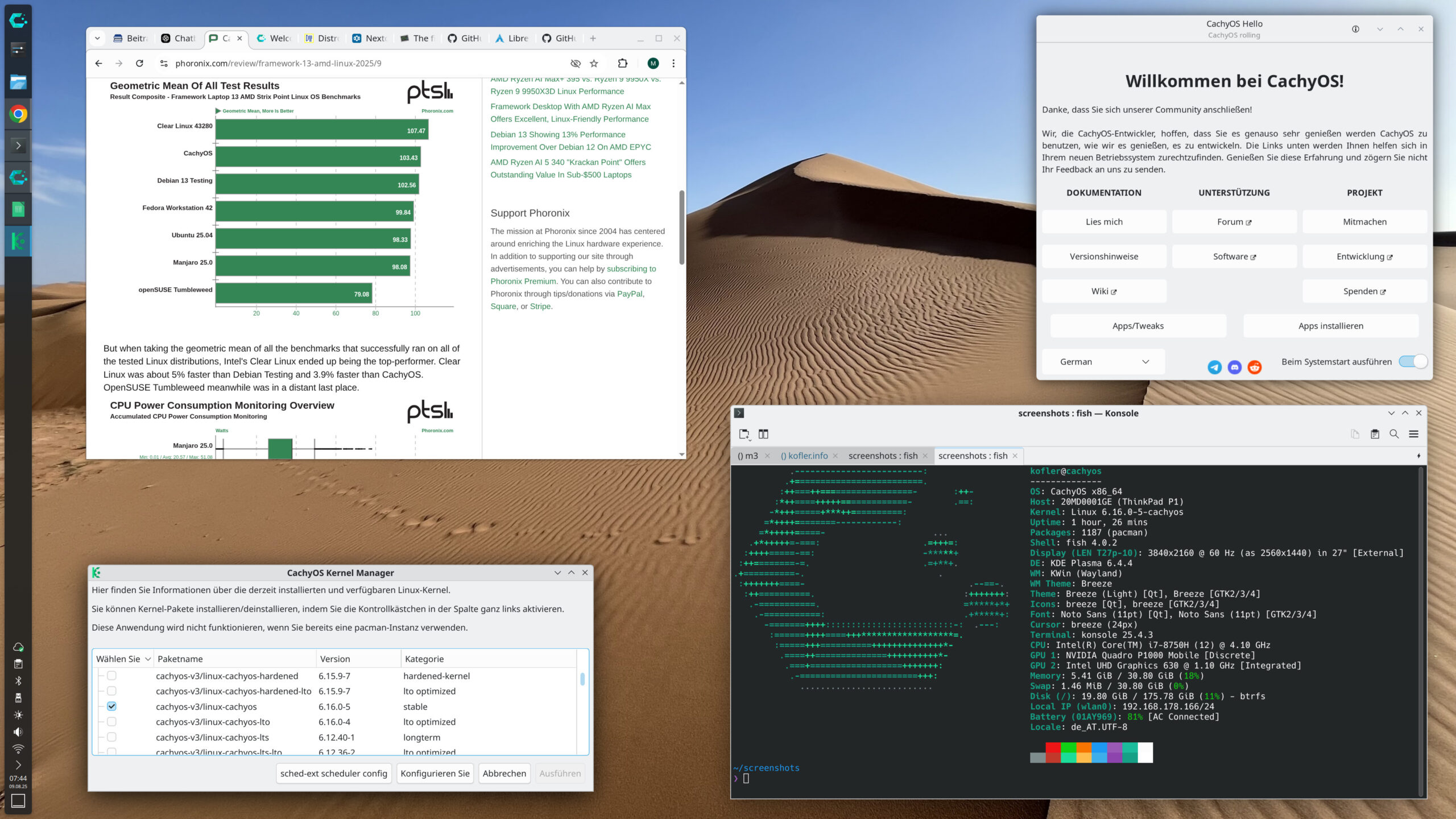
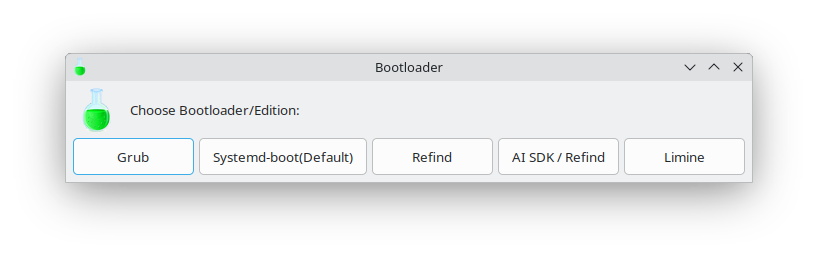
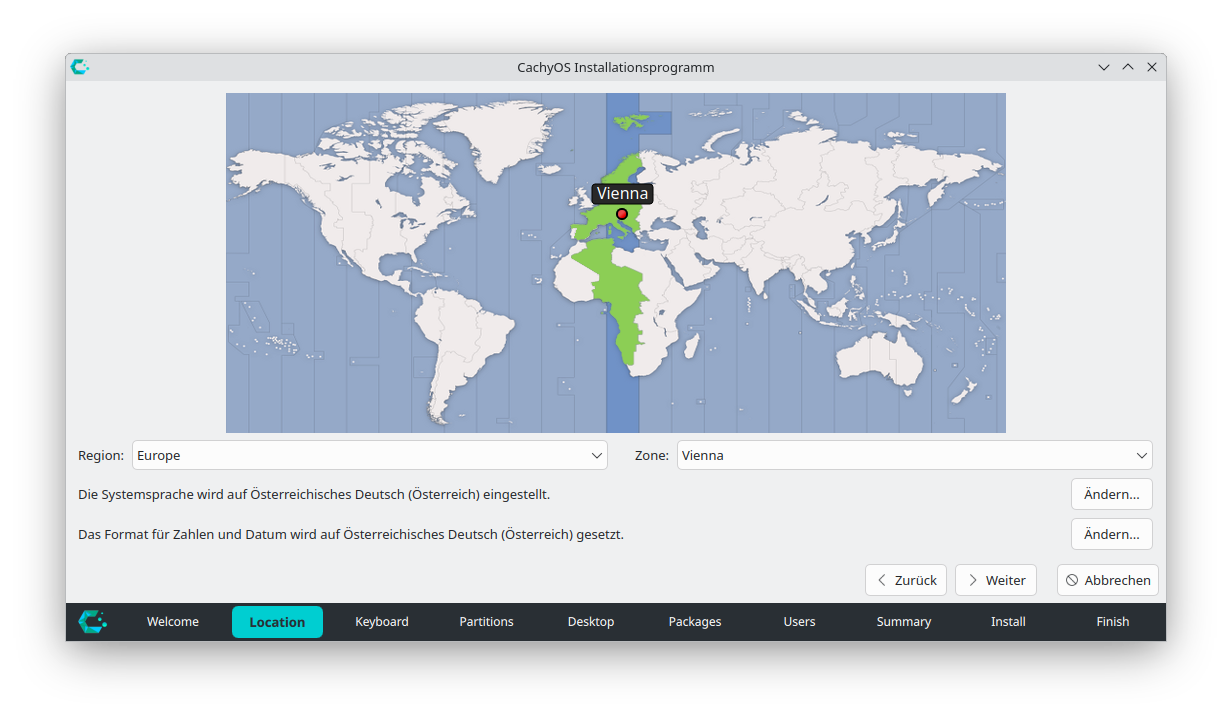
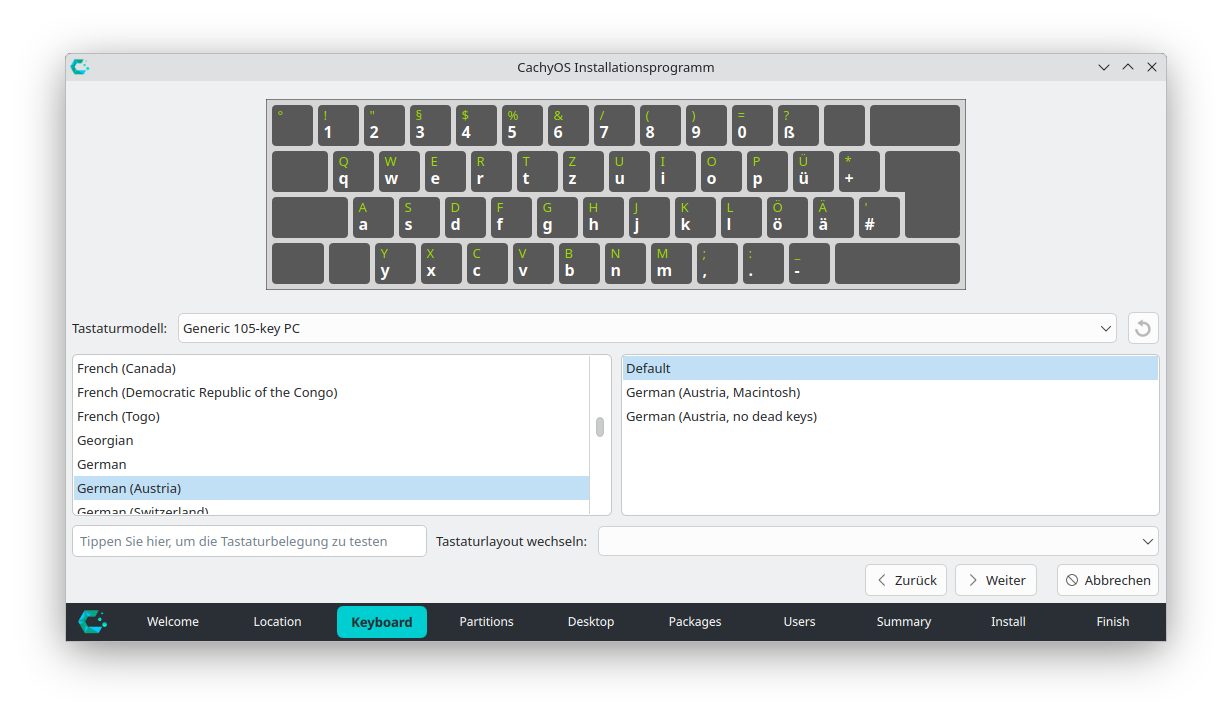
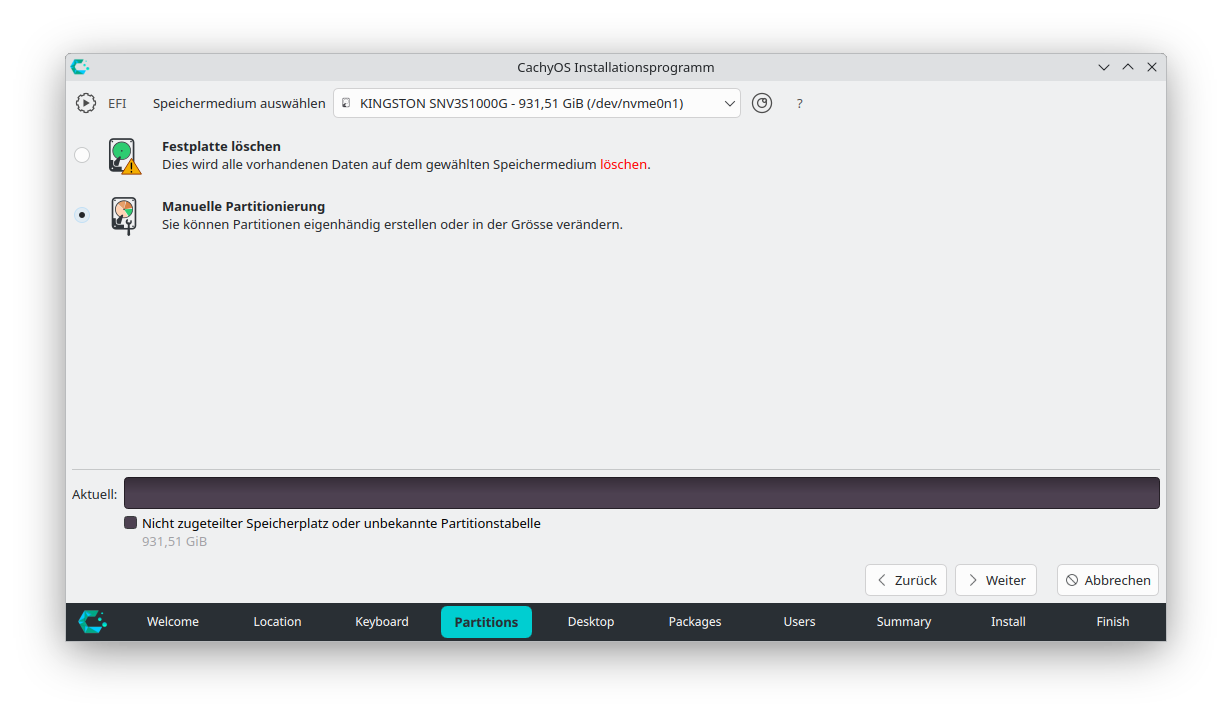
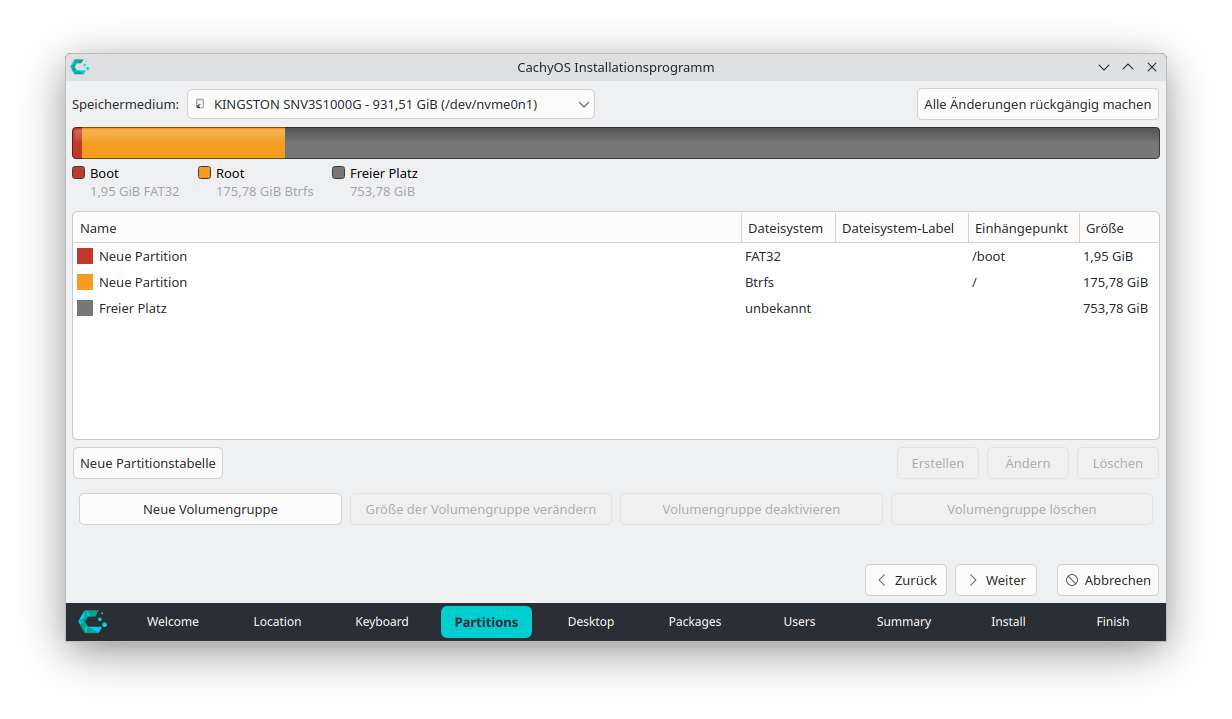
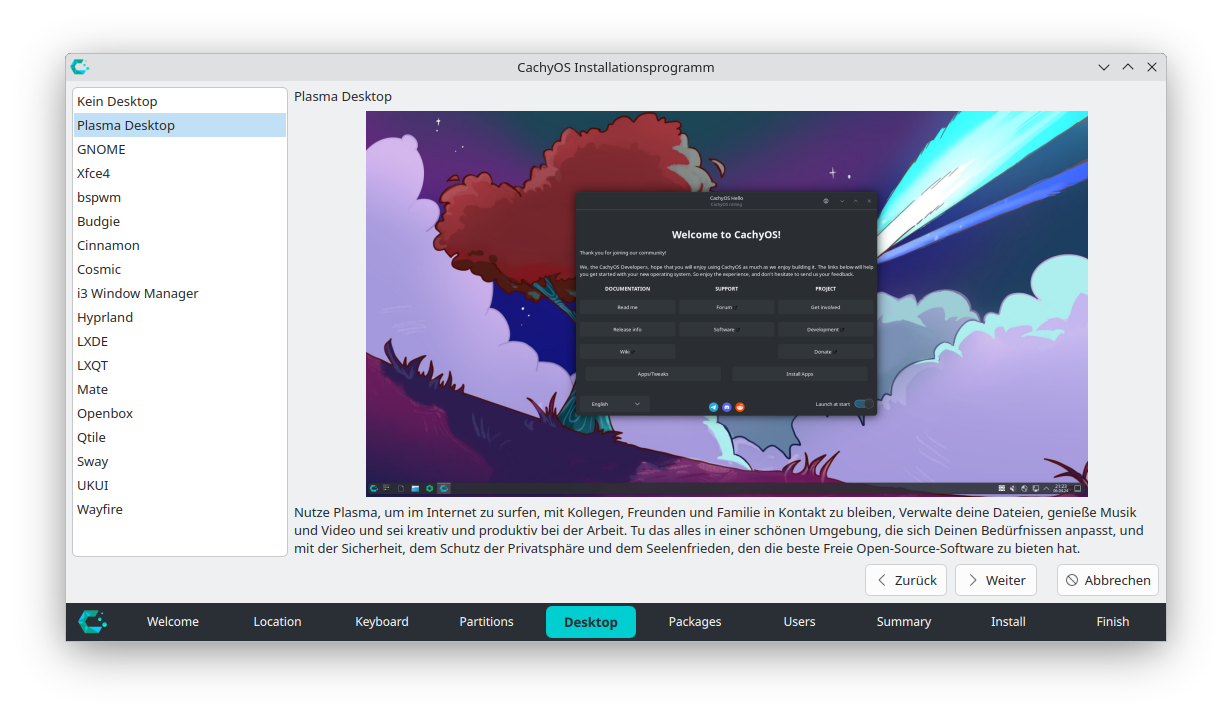
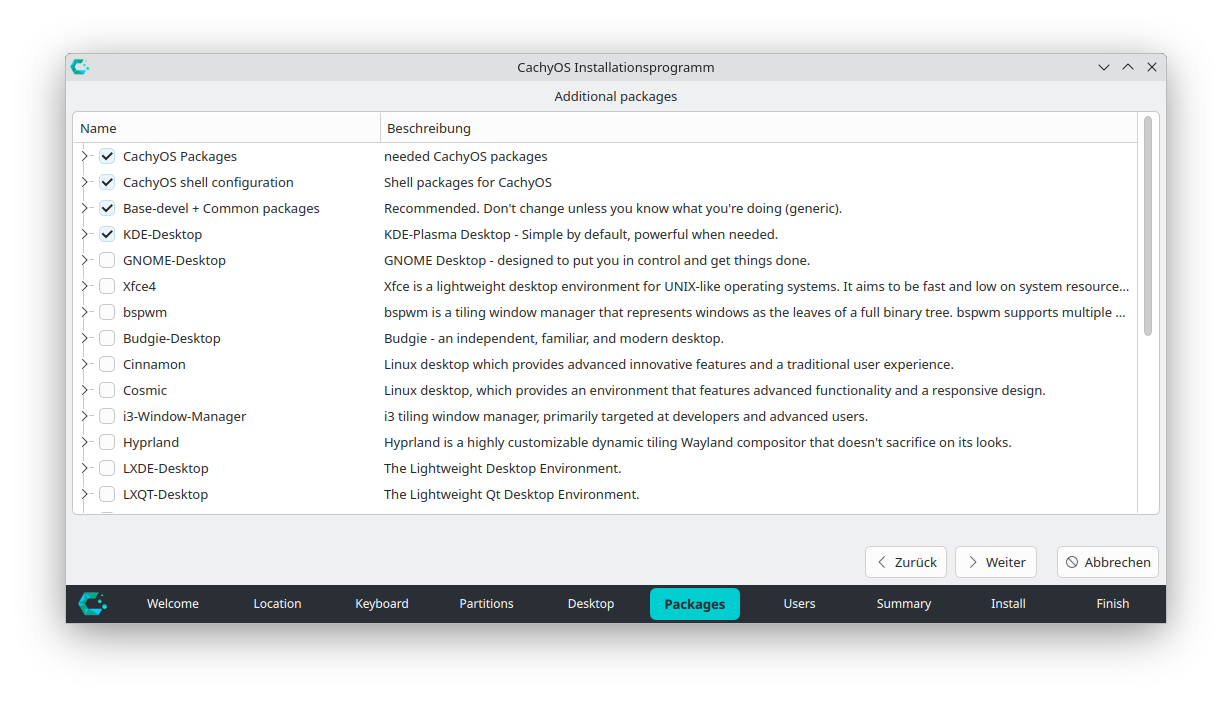
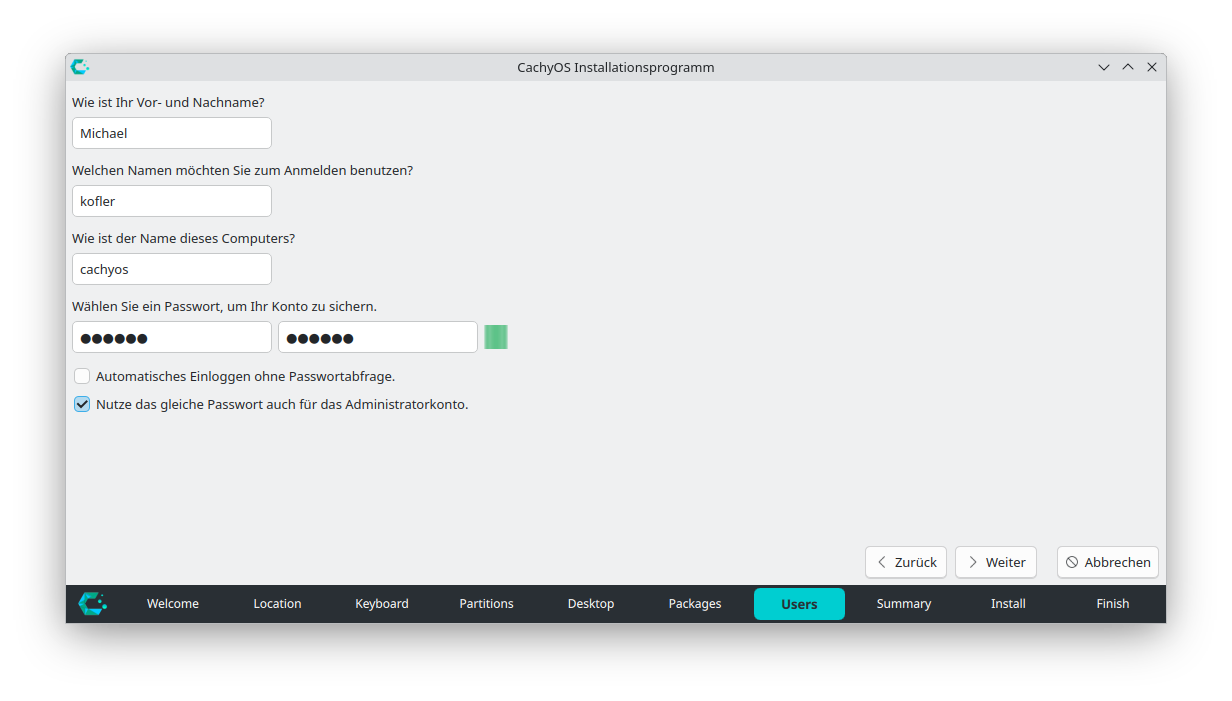
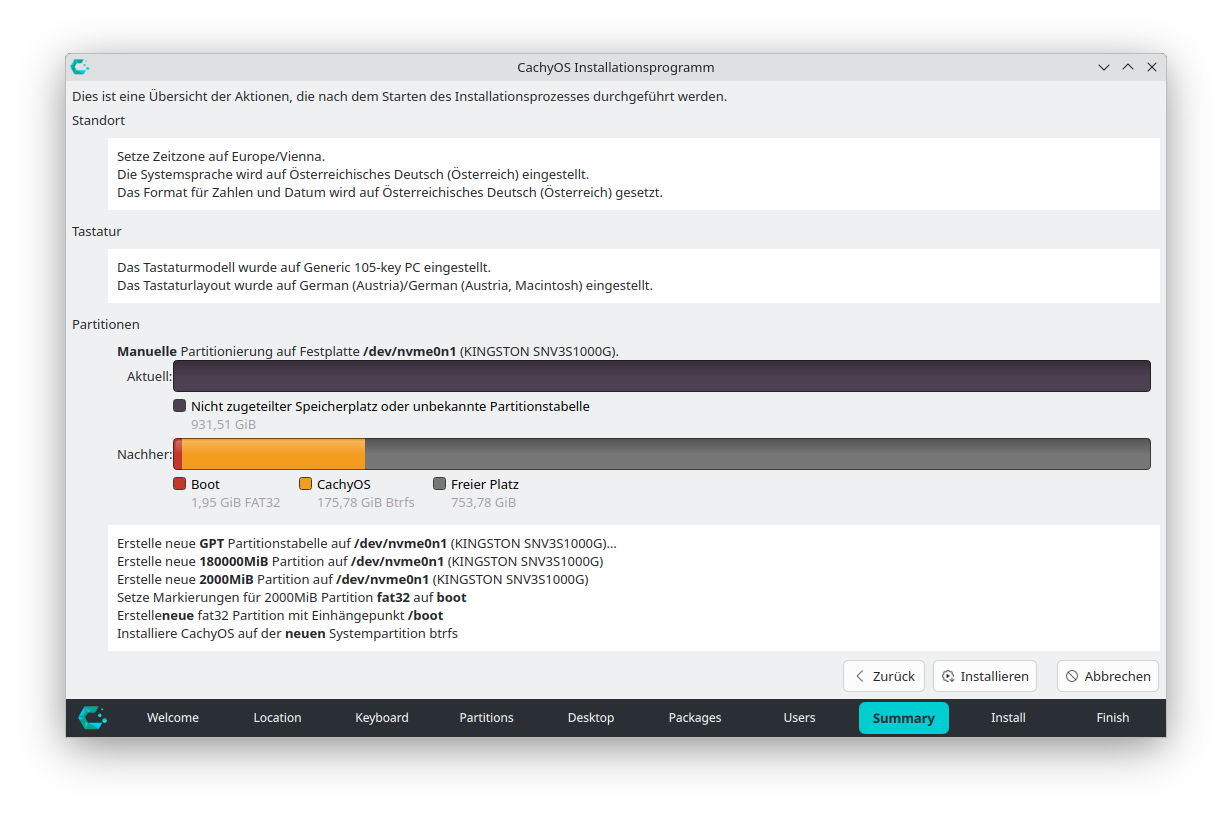
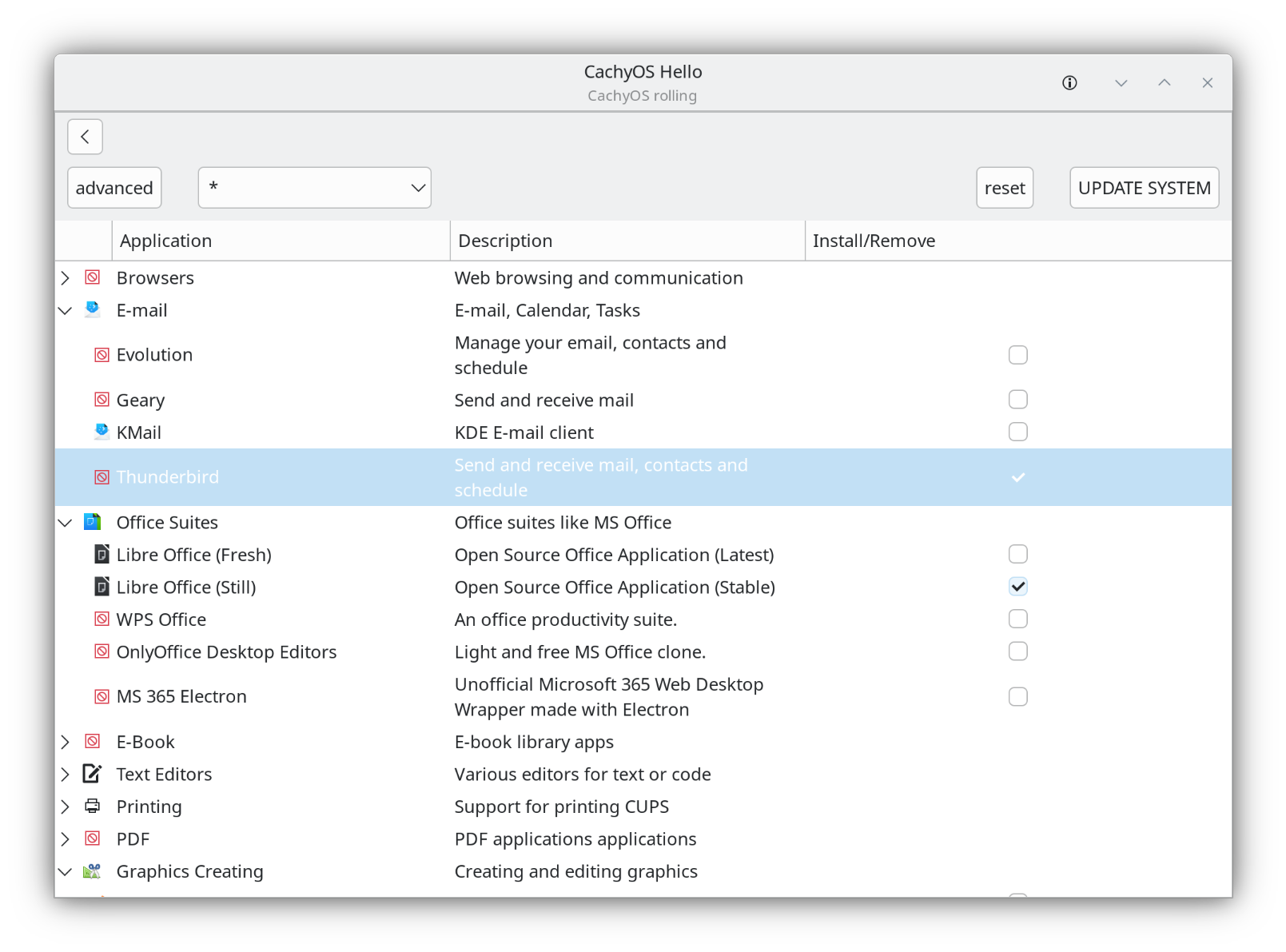
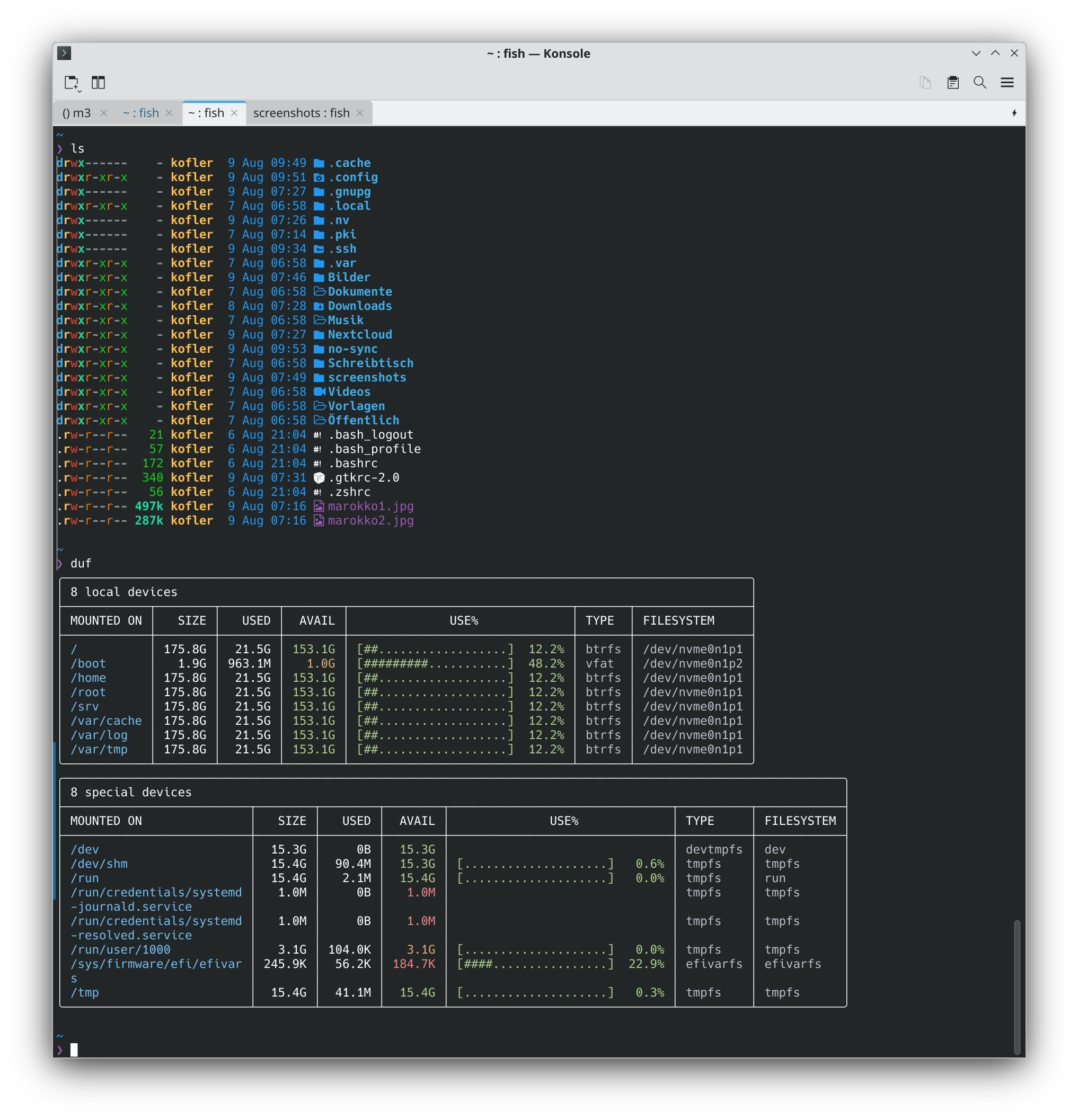
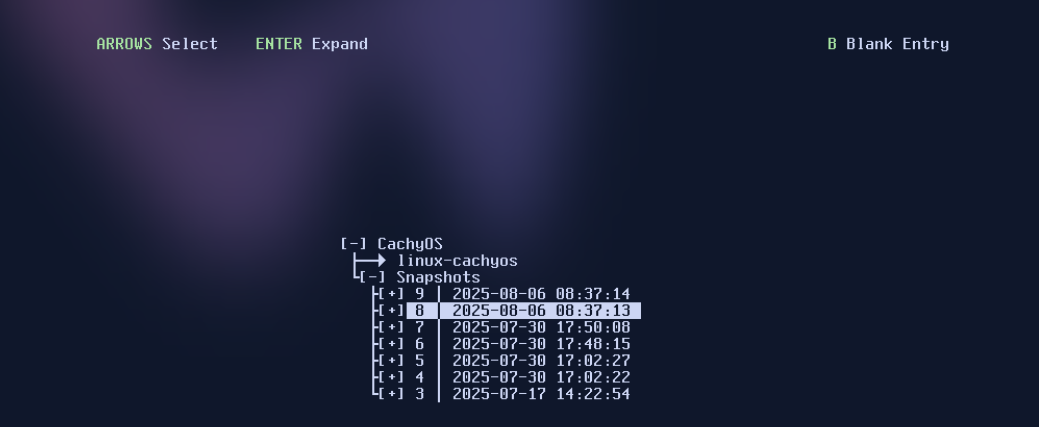
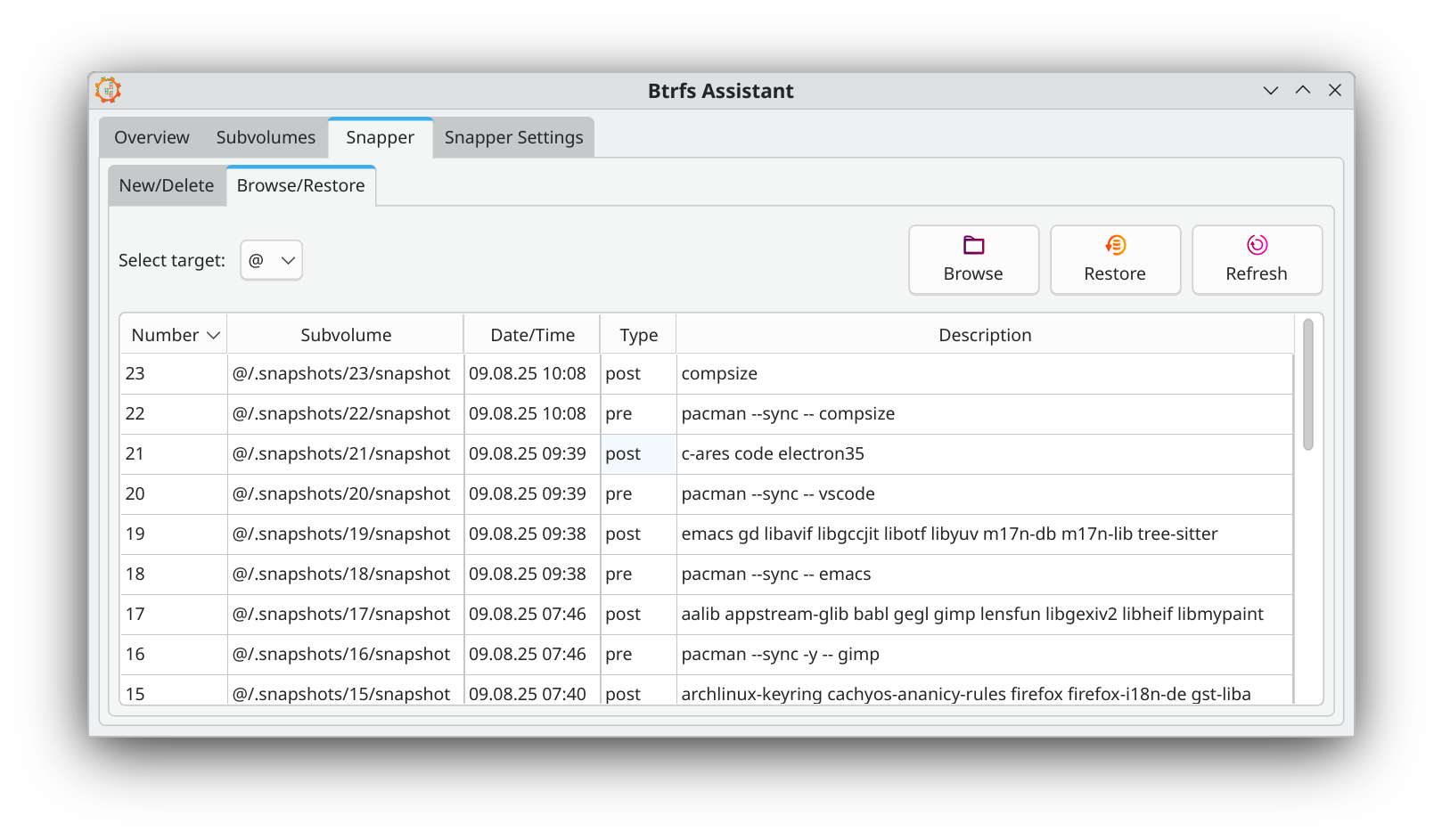
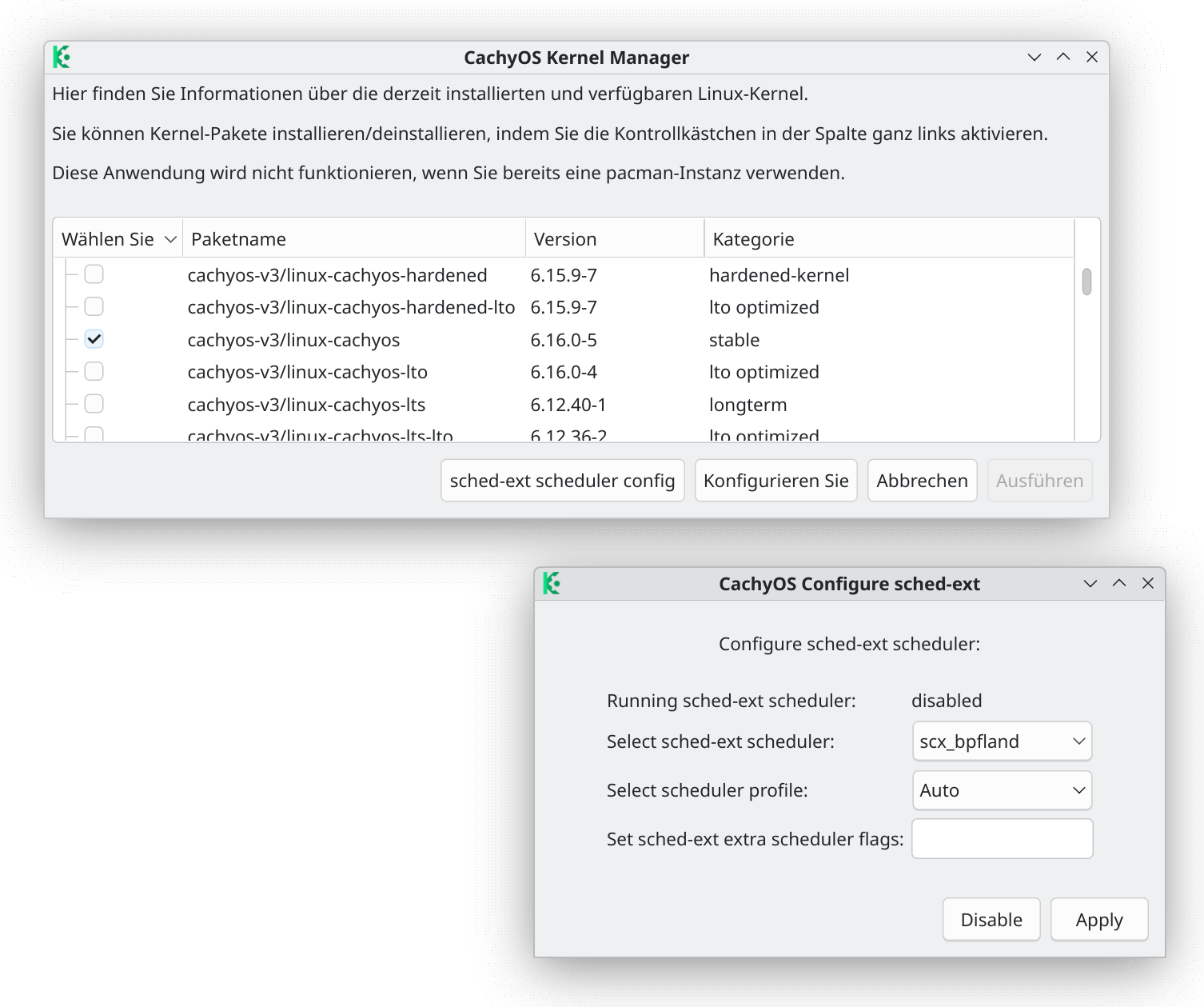













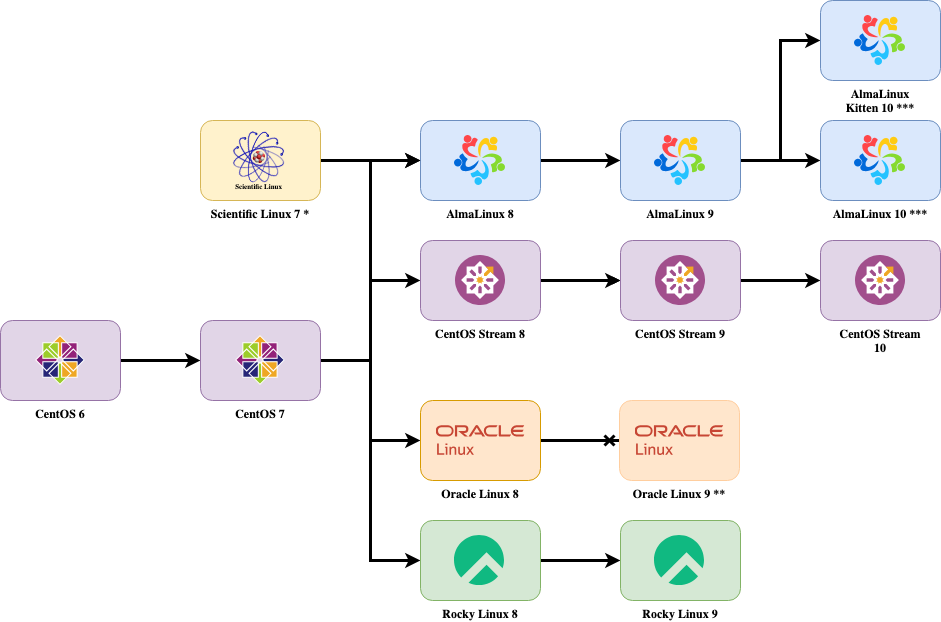
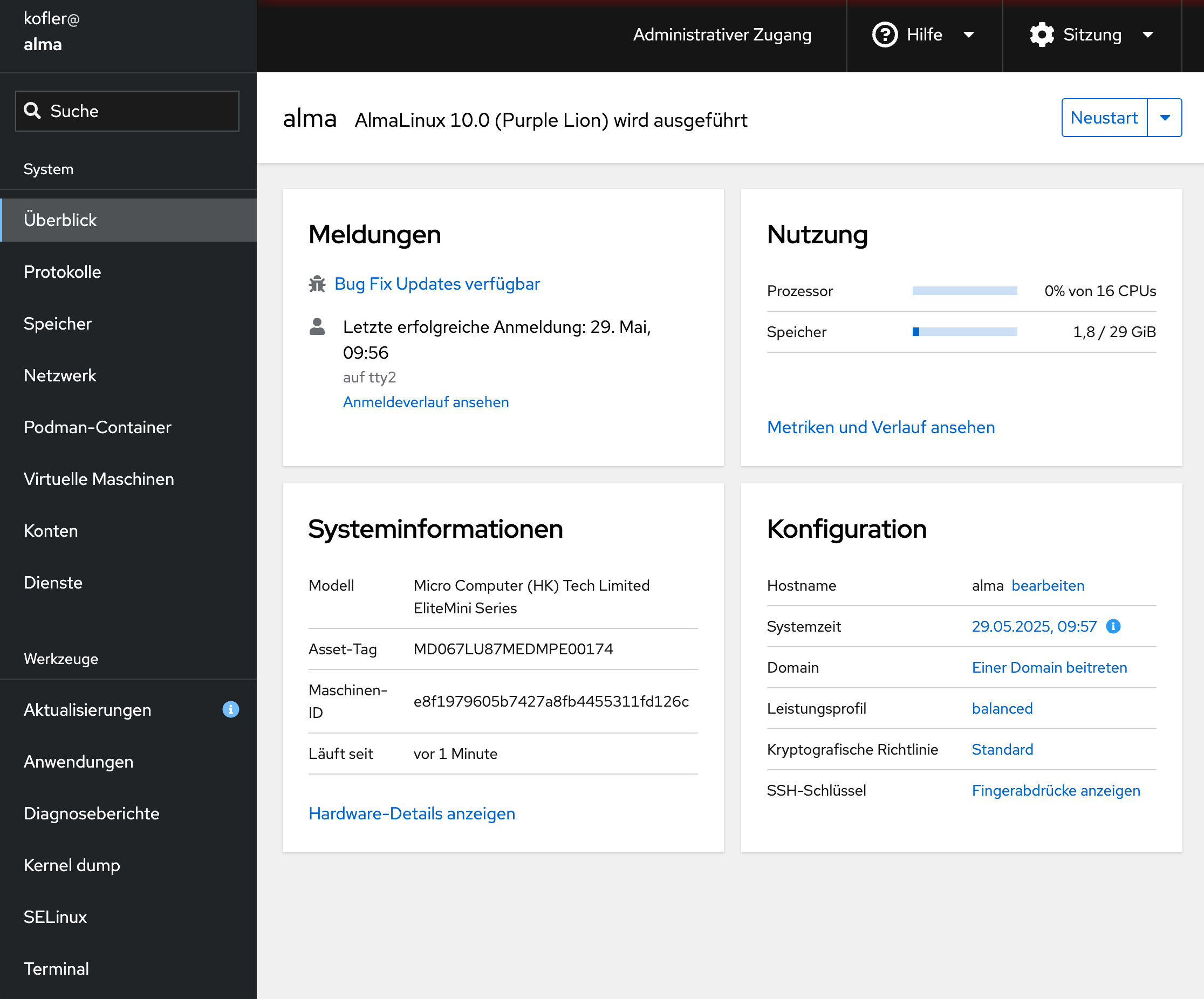





 .
.